Diskursverarbeitung in natürlicher Sprache
Das schwierigste Problem der KI besteht darin, die natürliche Sprache durch Computer zu verarbeiten, oder mit anderen Worten, die Verarbeitung natürlicher Sprache ist das schwierigste Problem der künstlichen Intelligenz. Wenn wir über die Hauptprobleme in NLP sprechen, dann ist eines der Hauptprobleme in NLP die Diskursverarbeitung - das Erstellen von Theorien und Modellen, wie Äußerungen zusammenhalten, um sich zu bildencoherent discourse. Tatsächlich besteht die Sprache immer aus zusammengestellten, strukturierten und zusammenhängenden Gruppen von Sätzen und nicht aus isolierten und nicht verwandten Sätzen wie Filmen. Diese zusammenhängenden Gruppen von Sätzen werden als Diskurs bezeichnet.
Konzept der Kohärenz
Kohärenz und Diskursstruktur sind auf vielfältige Weise miteinander verbunden. Kohärenz wird zusammen mit der Eigenschaft eines guten Textes verwendet, um die Ausgabequalität des Systems zur Erzeugung natürlicher Sprache zu bewerten. Hier stellt sich die Frage, was es bedeutet, dass ein Text kohärent ist. Angenommen, wir haben einen Satz von jeder Seite der Zeitung gesammelt. Wird es dann ein Diskurs sein? Natürlich nicht. Dies liegt daran, dass diese Sätze keine Kohärenz aufweisen. Der kohärente Diskurs muss folgende Eigenschaften besitzen:
Kohärenzbeziehung zwischen Äußerungen
Der Diskurs wäre kohärent, wenn er sinnvolle Verbindungen zwischen seinen Äußerungen hätte. Diese Eigenschaft wird als Kohärenzbeziehung bezeichnet. Zum Beispiel muss eine Erklärung vorhanden sein, um den Zusammenhang zwischen Äußerungen zu rechtfertigen.
Beziehung zwischen Entitäten
Eine weitere Eigenschaft, die einen Diskurs kohärent macht, ist, dass es eine bestimmte Art von Beziehung zu den Entitäten geben muss. Eine solche Art von Kohärenz wird als entitätsbasierte Kohärenz bezeichnet.
Diskursstruktur
Eine wichtige Frage zum Diskurs ist, welche Struktur der Diskurs haben muss. Die Antwort auf diese Frage hängt von der Segmentierung ab, die wir im Diskurs angewendet haben. Diskurssegmentierungen können definiert werden, um die Arten von Strukturen für einen großen Diskurs zu bestimmen. Es ist ziemlich schwierig, eine Diskurs-Segmentierung zu implementieren, aber es ist sehr wichtig fürinformation retrieval, text summarization and information extraction Art der Anwendungen.
Algorithmen zur Diskurssegmentierung
In diesem Abschnitt lernen wir die Algorithmen für die Diskurs-Segmentierung kennen. Die Algorithmen werden unten beschrieben -
Unüberwachte Diskurssegmentierung
Die Klasse der unbeaufsichtigten Diskurs-Segmentierung wird häufig als lineare Segmentierung dargestellt. Wir können die Aufgabe der linearen Segmentierung anhand eines Beispiels verstehen. In diesem Beispiel besteht die Aufgabe darin, den Text in Einheiten mit mehreren Absätzen zu segmentieren. Die Einheiten repräsentieren die Passage des Originaltextes. Diese Algorithmen hängen von der Kohäsion ab, die als die Verwendung bestimmter Sprachgeräte zum Zusammenbinden der Texteinheiten definiert werden kann. Andererseits ist die Lexikonkohäsion die Kohäsion, die durch die Beziehung zwischen zwei oder mehr Wörtern in zwei Einheiten wie die Verwendung von Synonymen angezeigt wird.
Supervised Discourse Segmentation
Die frühere Methode hat keine handbeschrifteten Segmentgrenzen. Andererseits muss die überwachte Diskurs-Segmentierung über grenzmarkierte Trainingsdaten verfügen. Es ist sehr einfach, dasselbe zu erwerben. Bei der überwachten Diskurs-Segmentierung spielen Diskursmarker oder Stichworte eine wichtige Rolle. Diskursmarker oder Stichwort ist ein Wort oder eine Phrase, die die Diskursstruktur signalisiert. Diese Diskursmarker sind domänenspezifisch.
Textkohärenz
Lexikalische Wiederholungen sind ein Weg, um die Struktur in einem Diskurs zu finden, erfüllen jedoch nicht die Anforderung, ein kohärenter Diskurs zu sein. Um den kohärenten Diskurs zu erreichen, müssen wir uns auf bestimmte Kohärenzbeziehungen konzentrieren. Wie wir wissen, definiert diese Kohärenzbeziehung den möglichen Zusammenhang zwischen Äußerungen in einem Diskurs. Hebb hat folgende Beziehungen vorgeschlagen:
Wir nehmen zwei Begriffe S0 und S1 die Bedeutung der beiden verwandten Sätze darstellen -
Ergebnis
Daraus folgt, dass der Staat durch Begriff behauptet S0 könnte den von behaupteten Zustand verursachen S1. Zum Beispiel zeigen zwei Aussagen das Ergebnis der Beziehung: Ram wurde im Feuer gefangen. Seine Haut brannte.
Erläuterung
Daraus folgt, dass der Staat von behauptet S1 könnte den von behaupteten Zustand verursachen S0. Zum Beispiel zeigen zwei Aussagen die Beziehung - Ram kämpfte mit Shyams Freund. Er war betrunken.
Parallel
Es schließt p (a1, a2,…) aus der Behauptung von S0 und p (b1, b2,…) aus der Behauptung S1. Hier sind ai und bi für alle i ähnlich. Zum Beispiel sind zwei Aussagen parallel - Ram wollte Auto. Shyam wollte Geld.
Ausarbeitung
Es leitet aus beiden Behauptungen den gleichen Satz P ab - S0 und S1Zum Beispiel zeigen zwei Aussagen die Ausarbeitung der Beziehung: Ram war aus Chandigarh. Shyam war aus Kerala.
Gelegenheit
Es passiert, wenn aus der Behauptung von eine Zustandsänderung abgeleitet werden kann S0, deren Endzustand abgeleitet werden kann S1und umgekehrt. Zum Beispiel zeigen die beiden Aussagen den Beziehungsanlass: Ram nahm das Buch auf. Er gab es Shyam.
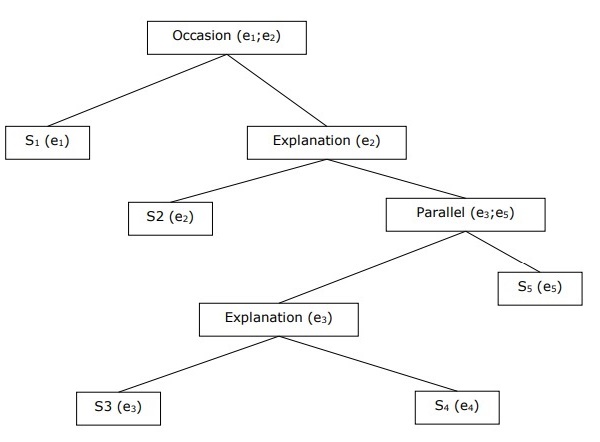
Aufbau einer hierarchischen Diskursstruktur
Die Kohärenz des gesamten Diskurses kann auch durch die hierarchische Struktur zwischen Kohärenzbeziehungen berücksichtigt werden. Zum Beispiel kann die folgende Passage als hierarchische Struktur dargestellt werden -
S1 - Ram ging zur Bank, um Geld einzuzahlen.
S2 - Dann nahm er einen Zug zu Shyams Tuchladen.
S3 - Er wollte ein paar Klamotten kaufen.
S4 - Er hat keine neuen Kleider für die Party.
S5 - Er wollte auch mit Shyam über seine Gesundheit sprechen
Referenzauflösung
Die Interpretation der Sätze aus jedem Diskurs ist eine weitere wichtige Aufgabe. Um dies zu erreichen, müssen wir wissen, über wen oder welche Entität gesprochen wird. Hier ist die Interpretationsreferenz das Schlüsselelement.Referencekann als der sprachliche Ausdruck definiert werden, der eine Entität oder ein Individuum bezeichnet. Zum Beispiel in der Passage, Ram , der Manager von ABC Bank , sah seinen Freund Shyam in einem Laden. Er ging ihm entgegen, die sprachlichen Ausdrücke wie Ram, His, Er sind Referenz.
Aus dem gleichen Grund, reference resolution kann als die Aufgabe definiert werden, zu bestimmen, auf welche Entitäten von welchem sprachlichen Ausdruck Bezug genommen wird.
In der Referenzauflösung verwendete Terminologie
Wir verwenden die folgenden Terminologien für die Referenzauflösung:
Referring expression- Der Ausdruck in natürlicher Sprache, der zum Ausführen einer Referenz verwendet wird, wird als verweisender Ausdruck bezeichnet. Zum Beispiel ist die oben verwendete Passage ein verweisender Ausdruck.
Referent- Es ist die Entität, auf die verwiesen wird. Zum Beispiel ist Ram im zuletzt angegebenen Beispiel ein Referent.
Corefer- Wenn zwei Ausdrücke verwendet werden, um auf dieselbe Entität zu verweisen, werden sie als Corefer bezeichnet. Zum Beispiel,Ram und he sind Corefer.
Antecedent- Der Begriff hat die Lizenz, einen anderen Begriff zu verwenden. Zum Beispiel,Ram ist der Vorläufer der Referenz he.
Anaphora & Anaphoric- Es kann als Verweis auf eine Entität definiert werden, die zuvor in den Satz aufgenommen wurde. Und der verweisende Ausdruck heißt anaphorisch.
Discourse model - Das Modell, das die Darstellungen der Entitäten enthält, auf die im Diskurs Bezug genommen wurde, und die Beziehung, in der sie sich befinden.
Arten von verweisenden Ausdrücken
Lassen Sie uns nun die verschiedenen Arten von referenzierenden Ausdrücken sehen. Die fünf Arten von Verweisungsausdrücken werden nachfolgend beschrieben -
Unbestimmte Nominalphrasen
Eine solche Referenz repräsentiert die Entitäten, die für den Hörer neu im Diskurskontext sind. Zum Beispiel - in dem Satz, in dem Ram eines Tages herumgegangen war, um ihm etwas zu essen zu bringen - ist ein unbestimmter Hinweis.
Bestimmte Nominalphrasen
Im Gegensatz zu oben repräsentiert eine solche Art von Referenz die Entitäten, die für den Hörer im Diskurskontext nicht neu oder identifizierbar sind. Zum Beispiel ist in dem Satz - ich habe The Times of India gelesen - The Times of India eine eindeutige Referenz.
Pronomen
Es ist eine Form der eindeutigen Bezugnahme. Zum Beispiel lachte Ram so laut er konnte. Das Worthe repräsentiert das Pronomen, das sich auf den Ausdruck bezieht.
Demonstranten
Diese demonstrieren und verhalten sich anders als einfache bestimmte Pronomen. Zum Beispiel sind dies und das Demonstrativpronomen.
Namen
Es ist die einfachste Art, auf einen Ausdruck zu verweisen. Es kann auch der Name einer Person, einer Organisation und eines Ortes sein. In den obigen Beispielen ist Ram beispielsweise der Ausdruck für die Namensreferenz.
Aufgaben zur Referenzauflösung
Die beiden Aufgaben zur Referenzauflösung werden nachfolgend beschrieben.
Koreferenzauflösung
Es ist die Aufgabe, verweisende Ausdrücke in einem Text zu finden, die sich auf dieselbe Entität beziehen. Mit einfachen Worten, es ist die Aufgabe, Corefer-Ausdrücke zu finden. Eine Reihe von Coreferring-Ausdrücken wird als Coreference-Kette bezeichnet. Zum Beispiel - Er, Chief Manager und Sein - beziehen sich diese Ausdrücke auf die erste Passage, die als Beispiel gegeben wurde.
Einschränkung der Koreferenzauflösung
Im Englischen ist das Hauptproblem für die Auflösung von Koreferenzen das Pronomen it. Der Grund dafür ist, dass das Pronomen viele Verwendungszwecke hat. Zum Beispiel kann es sich ähnlich wie er und sie beziehen. Das Pronomen bezieht sich auch auf die Dinge, die sich nicht auf bestimmte Dinge beziehen. Zum Beispiel regnet es. Es ist wirklich gut.
Pronominal Anaphora Resolution
Im Gegensatz zur Koreferenzauflösung kann die Auflösung der pronominalen Anaphora als die Aufgabe definiert werden, den Vorgänger für ein einzelnes Pronomen zu finden. Zum Beispiel ist das Pronomen sein und die Aufgabe der pronominalen Anaphora-Auflösung besteht darin, das Wort Ram zu finden, weil Ram der Vorgänger ist.