Verarbeitung natürlicher Sprache - Kurzanleitung
Sprache ist eine Kommunikationsmethode, mit deren Hilfe wir sprechen, lesen und schreiben können. Wir denken zum Beispiel, wir treffen Entscheidungen, Pläne und mehr in natürlicher Sprache. genau in Worten. Die große Frage, mit der wir uns in dieser KI-Ära konfrontiert sehen, ist jedoch, ob wir auf ähnliche Weise mit Computern kommunizieren können. Mit anderen Worten, können Menschen mit Computern in ihrer natürlichen Sprache kommunizieren? Es ist eine Herausforderung für uns, NLP-Anwendungen zu entwickeln, da Computer strukturierte Daten benötigen, die menschliche Sprache jedoch unstrukturiert und häufig mehrdeutig ist.
In diesem Sinne können wir sagen, dass die Verarbeitung natürlicher Sprache (NLP) das Teilgebiet der Informatik ist, insbesondere der künstlichen Intelligenz (KI), in der es darum geht, Computern das Verstehen und Verarbeiten der menschlichen Sprache zu ermöglichen. Technisch gesehen besteht die Hauptaufgabe von NLP darin, Computer für die Analyse und Verarbeitung großer Mengen von Daten in natürlicher Sprache zu programmieren.
Geschichte der NLP
Wir haben die Geschichte der NLP in vier Phasen unterteilt. Die Phasen haben unterschiedliche Anliegen und Stile.
Erste Phase (maschinelle Übersetzungsphase) - Ende der 1940er bis Ende der 1960er Jahre
Die in dieser Phase geleistete Arbeit konzentrierte sich hauptsächlich auf maschinelle Übersetzung (MT). Diese Phase war eine Zeit der Begeisterung und des Optimismus.
Lassen Sie uns jetzt alles sehen, was die erste Phase in sich hatte -
Die Forschung zu NLP begann Anfang der 1950er Jahre nach der Untersuchung von Booth & Richens und dem Memorandum von Weaver über maschinelle Übersetzung im Jahr 1949.
1954 war das Jahr, in dem ein begrenztes Experiment zur automatischen Übersetzung vom Russischen ins Englische im Georgetown-IBM-Experiment demonstriert wurde.
Im selben Jahr begann die Veröffentlichung der Zeitschrift MT (Machine Translation).
Die erste internationale Konferenz über maschinelle Übersetzung (MT) fand 1952 und die zweite 1956 statt.
1961 war die Arbeit, die auf der Teddington International Conference zur maschinellen Übersetzung von Sprachen und zur Analyse angewandter Sprachen vorgestellt wurde, der Höhepunkt dieser Phase.
Zweite Phase (AI-beeinflusste Phase) - Ende der 1960er bis Ende der 1970er Jahre
In dieser Phase bezog sich die geleistete Arbeit hauptsächlich auf das Weltwissen und seine Rolle bei der Konstruktion und Manipulation von Bedeutungsrepräsentationen. Aus diesem Grund wird diese Phase auch als Phase mit AI-Geschmack bezeichnet.
Die Phase hatte Folgendes:
Anfang 1961 begannen die Arbeiten zu den Problemen der Adressierung und Erstellung von Daten oder Wissensdatenbanken. Diese Arbeit wurde von AI beeinflusst.
Im selben Jahr wurde auch ein BASEBALL-Frage-Antwort-System entwickelt. Die Eingabe in dieses System war eingeschränkt und die Sprachverarbeitung war einfach.
Ein weit fortgeschrittenes System wurde in Minsky (1968) beschrieben. Dieses System wurde im Vergleich zum BASEBALL-Frage-Antwort-System erkannt und berücksichtigt, um Rückschlüsse auf die Wissensbasis bei der Interpretation und Beantwortung von Spracheingaben zu erhalten.
Dritte Phase (grammatikalisch-logische Phase) - Ende der 1970er bis Ende der 1980er Jahre
Diese Phase kann als grammatikalisch-logische Phase bezeichnet werden. Aufgrund des Scheiterns des praktischen Systemaufbaus in der letzten Phase wandten sich die Forscher der Verwendung von Logik zur Darstellung und Argumentation von Wissen in der KI zu.
Die dritte Phase hatte Folgendes:
Der grammatikalisch-logische Ansatz gegen Ende des Jahrzehnts half uns mit leistungsstarken Allzweck-Satzprozessoren wie der SRI Core Language Engine und der Discourse Representation Theory, die ein Mittel zur Bewältigung eines erweiterten Diskurses darstellten.
In dieser Phase erhielten wir einige praktische Ressourcen und Tools wie Parser, z. B. Alvey Natural Language Tools, sowie betrieblichere und kommerziellere Systeme, z. B. für Datenbankabfragen.
Die Arbeit am Lexikon in den 1980er Jahren wies auch in Richtung eines grammatikalisch-logischen Ansatzes.
Vierte Phase (Lexical & Corpus Phase) - Die 1990er Jahre
Wir können dies als eine lexikalische & Korpusphase beschreiben. Die Phase hatte eine lexikalisierte Herangehensweise an die Grammatik, die Ende der 1980er Jahre erschien und zunehmend an Einfluss gewann. In diesem Jahrzehnt gab es eine Revolution in der Verarbeitung natürlicher Sprache mit der Einführung von Algorithmen für maschinelles Lernen für die Sprachverarbeitung.
Studium der menschlichen Sprachen
Sprache ist eine entscheidende Komponente für das menschliche Leben und auch der grundlegendste Aspekt unseres Verhaltens. Wir können es hauptsächlich in zwei Formen erleben - schriftlich und mündlich. In schriftlicher Form ist es eine Möglichkeit, unser Wissen von einer Generation zur nächsten weiterzugeben. In der gesprochenen Form ist es das primäre Medium für den Menschen, sich in seinem täglichen Verhalten miteinander zu koordinieren. Die Sprache wird in verschiedenen akademischen Disziplinen studiert. Jede Disziplin hat ihre eigenen Probleme und eine Lösung, um diese anzugehen.
Betrachten Sie die folgende Tabelle, um dies zu verstehen:
| Disziplin | Probleme | Werkzeuge |
|---|---|---|
Sprachwissenschaftler |
Wie können Phrasen und Sätze mit Wörtern gebildet werden? Was schränkt die mögliche Bedeutung eines Satzes ein? |
Intuitionen über Wohlgeformtheit und Bedeutung. Mathematisches Strukturmodell. Zum Beispiel modelltheoretische Semantik, formale Sprachtheorie. |
Psycholinguisten |
Wie können Menschen die Struktur von Sätzen identifizieren? Wie kann die Bedeutung von Wörtern identifiziert werden? Wann findet Verständnis statt? |
Experimentelle Techniken hauptsächlich zur Messung der Leistung von Menschen. Statistische Analyse von Beobachtungen. |
Philosophen |
Wie bekommen Wörter und Sätze die Bedeutung? Wie werden die Objekte durch die Wörter identifiziert? Was ist die Bedeutung? |
Argumentation in natürlicher Sprache unter Verwendung von Intuition. Mathematische Modelle wie Logik und Modelltheorie. |
Computerlinguisten |
Wie können wir die Struktur eines Satzes identifizieren? Wie können Wissen und Argumentation modelliert werden? Wie können wir Sprache verwenden, um bestimmte Aufgaben zu erfüllen? |
Algorithmen Datenstrukturen Formale Repräsentations- und Argumentationsmodelle. KI-Techniken wie Such- und Darstellungsmethoden. |
Mehrdeutigkeit und Unsicherheit in der Sprache
Mehrdeutigkeit, die im Allgemeinen bei der Verarbeitung natürlicher Sprache verwendet wird, kann als die Fähigkeit bezeichnet werden, auf mehr als eine Weise verstanden zu werden. In einfachen Worten können wir sagen, dass Mehrdeutigkeit die Fähigkeit ist, auf mehr als eine Weise verstanden zu werden. Die natürliche Sprache ist sehr vieldeutig. NLP weist die folgenden Arten von Mehrdeutigkeiten auf:
Lexikalische Mehrdeutigkeit
Die Mehrdeutigkeit eines einzelnen Wortes wird als lexikalische Mehrdeutigkeit bezeichnet. Zum Beispiel das Wort behandelnsilver als Substantiv, Adjektiv oder Verb.
Syntaktische Mehrdeutigkeit
Diese Art von Mehrdeutigkeit tritt auf, wenn ein Satz auf unterschiedliche Weise analysiert wird. Zum Beispiel der Satz „Der Mann hat das Mädchen mit dem Teleskop gesehen“. Es ist nicht eindeutig, ob der Mann das Mädchen mit einem Teleskop gesehen hat oder ob er sie durch sein Teleskop gesehen hat.
Semantische Mehrdeutigkeit
Diese Art von Mehrdeutigkeit tritt auf, wenn die Bedeutung der Wörter selbst falsch interpretiert werden kann. Mit anderen Worten, semantische Mehrdeutigkeit tritt auf, wenn ein Satz ein mehrdeutiges Wort oder eine mehrdeutige Phrase enthält. Zum Beispiel ist der Satz „Das Auto hat die Stange getroffen, während es sich bewegte“ semantisch mehrdeutig, da die Interpretationen lauten können: „Das Auto hat während der Bewegung die Stange getroffen“ und „Das Auto hat die Stange getroffen, während sich die Stange bewegt hat“.
Anaphorische Mehrdeutigkeit
Diese Art von Mehrdeutigkeit entsteht durch die Verwendung von Anaphora-Entitäten im Diskurs. Zum Beispiel rannte das Pferd den Hügel hinauf. Es war sehr steil. Es wurde bald müde. Hier verursacht der anaphorische Bezug von „es“ in zwei Situationen Mehrdeutigkeiten.
Pragmatische Mehrdeutigkeit
Eine solche Mehrdeutigkeit bezieht sich auf die Situation, in der der Kontext einer Phrase mehrere Interpretationen ergibt. Mit einfachen Worten können wir sagen, dass pragmatische Mehrdeutigkeit entsteht, wenn die Aussage nicht spezifisch ist. Zum Beispiel kann der Satz „Ich mag dich auch“ mehrere Interpretationen haben, wie ich dich mag (genau wie du mich magst), ich mag dich (genau wie jemand anderes dosiert).
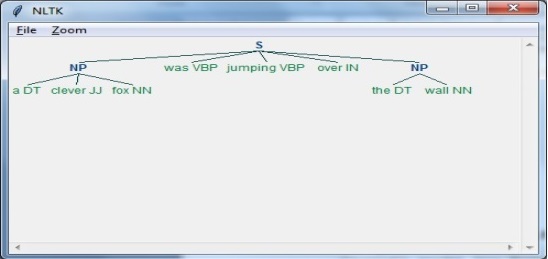
NLP-Phasen
Das folgende Diagramm zeigt die Phasen oder logischen Schritte bei der Verarbeitung natürlicher Sprache -
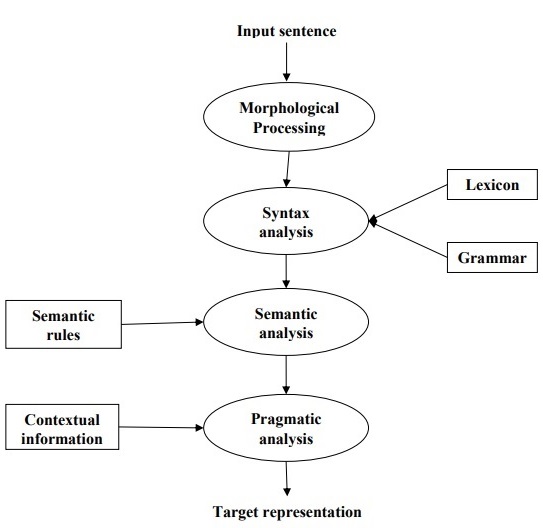
Morphologische Verarbeitung
Es ist die erste Phase von NLP. Der Zweck dieser Phase besteht darin, Teile der Spracheingabe in Sätze von Token aufzuteilen, die Absätzen, Sätzen und Wörtern entsprechen. Zum Beispiel ein Wort wie“uneasy” kann in zwei Unterwort-Token unterteilt werden als “un-easy”.
Syntaxanalyse
Es ist die zweite Phase von NLP. Der Zweck dieser Phase ist zweierlei: zu überprüfen, ob ein Satz gut geformt ist oder nicht, und ihn in eine Struktur aufzuteilen, die die syntaktischen Beziehungen zwischen den verschiedenen Wörtern zeigt. Zum Beispiel mag der Satz“The school goes to the boy” würde vom Syntaxanalysator oder Parser abgelehnt.
Semantische Analyse
Es ist die dritte Phase von NLP. Der Zweck dieser Phase ist es, die genaue Bedeutung zu zeichnen, oder Sie können die Wörterbuchbedeutung aus dem Text sagen. Der Text wird auf Aussagekraft geprüft. Zum Beispiel würde ein semantischer Analysator einen Satz wie „Heißes Eis“ ablehnen.
Pragmatische Analyse
Es ist die vierte Phase der NLP. Die pragmatische Analyse passt einfach die tatsächlichen Objekte / Ereignisse, die in einem bestimmten Kontext existieren, an die in der letzten Phase erhaltenen Objektreferenzen an (semantische Analyse). Zum Beispiel kann der Satz „Legen Sie die Banane in den Korb im Regal“ zwei semantische Interpretationen haben, und der pragmatische Analysator wählt zwischen diesen beiden Möglichkeiten.
In diesem Kapitel lernen wir die sprachlichen Ressourcen in der Verarbeitung natürlicher Sprache kennen.
Korpus
Ein Korpus ist ein großer und strukturierter Satz maschinenlesbarer Texte, die in einer natürlichen kommunikativen Umgebung erstellt wurden. Sein Plural ist Korpora. Sie können auf verschiedene Arten abgeleitet werden, z. B. als ursprünglich elektronischer Text, Transkripte der gesprochenen Sprache und optische Zeichenerkennung usw.
Elemente des Korpusdesigns
Die Sprache ist unendlich, aber ein Korpus muss endlich groß sein. Damit der Korpus endlich groß ist, müssen wir eine Vielzahl von Texttypen abtasten und proportional einbeziehen, um ein gutes Korpusdesign zu gewährleisten.
Lassen Sie uns nun einige wichtige Elemente für das Korpusdesign kennenlernen -
Korpusrepräsentativität
Repräsentativität ist ein bestimmendes Merkmal des Korpusdesigns. Die folgenden Definitionen von zwei großen Forschern - Leech und Biber - helfen uns, die Repräsentativität des Korpus zu verstehen.
According to Leech (1991), "Ein Korpus wird als repräsentativ für die Sprachvielfalt angesehen, die er darstellen soll, wenn die auf seinem Inhalt basierenden Ergebnisse auf diese Sprachvielfalt verallgemeinert werden können."
According to Biber (1993), „Repräsentativität bezieht sich auf das Ausmaß, in dem eine Stichprobe den gesamten Variabilitätsbereich einer Population umfasst.“
Auf diese Weise können wir schließen, dass die Repräsentativität eines Korpus durch die folgenden zwei Faktoren bestimmt wird:
Balance - Das Genre umfasst einen Korpus
Sampling - Wie die Chunks für jedes Genre ausgewählt werden.
Korpusbilanz
Ein weiteres sehr wichtiges Element des Korpusdesigns ist das Korpusgleichgewicht - die Bandbreite der Genres, die in einem Korpus enthalten sind. Wir haben bereits untersucht, dass die Repräsentativität eines allgemeinen Korpus davon abhängt, wie ausgewogen der Korpus ist. Ein ausgewogener Korpus deckt eine Vielzahl von Textkategorien ab, die als Vertreter der Sprache gelten sollen. Wir haben kein verlässliches wissenschaftliches Maß für das Gleichgewicht, aber die beste Schätzung und Intuition funktioniert in diesem Bereich. Mit anderen Worten, wir können sagen, dass der akzeptierte Saldo nur durch den Verwendungszweck bestimmt wird.
Probenahme
Ein weiteres wichtiges Element des Korpusdesigns ist die Probenahme. Korpusrepräsentativität und Gleichgewicht sind sehr eng mit der Stichprobe verbunden. Deshalb können wir sagen, dass die Probenahme im Korpusbau unvermeidlich ist.
Gemäß Biber(1993)„Einige der ersten Überlegungen bei der Erstellung eines Korpus betreffen das Gesamtdesign: Zum Beispiel die Art der enthaltenen Texte, die Anzahl der Texte, die Auswahl bestimmter Texte, die Auswahl der Textbeispiele aus den Texten und die Länge des Textes Proben. Jedes davon beinhaltet eine Stichprobenentscheidung, entweder bewusst oder nicht. “
Um eine repräsentative Stichprobe zu erhalten, müssen wir Folgendes berücksichtigen:
Sampling unit- Es bezieht sich auf das Gerät, für das eine Probe erforderlich ist. Beispielsweise kann eine Stichprobeneinheit für geschriebenen Text eine Zeitung, ein Tagebuch oder ein Buch sein.
Sampling frame - Die Liste aller Stichprobeneinheiten wird als Stichprobenrahmen bezeichnet.
Population- Es kann als Montage aller Probenahmeeinheiten bezeichnet werden. Es wird in Bezug auf Sprachproduktion, Sprachempfang oder Sprache als Produkt definiert.
Korpusgröße
Ein weiteres wichtiges Element des Korpusdesigns ist seine Größe. Wie groß sollte der Korpus sein? Es gibt keine spezifische Antwort auf diese Frage. Die Größe des Korpus hängt von dem Zweck ab, für den er bestimmt ist, sowie von einigen praktischen Überlegungen wie folgt:
Art der vom Benutzer erwarteten Abfrage.
Die Methodik, mit der die Benutzer die Daten untersuchen.
Verfügbarkeit der Datenquelle.
Mit dem technologischen Fortschritt nimmt auch die Korpusgröße zu. Die folgende Vergleichstabelle hilft Ihnen zu verstehen, wie die Korpusgröße funktioniert -
| Jahr | Name des Korpus | Größe (in Worten) |
|---|---|---|
| 1960er - 70er Jahre | Brown und LOB | 1 Million Wörter |
| 1980er Jahre | Die Birmingham Corpora | 20 Millionen Wörter |
| 1990er Jahre | Der britische Nationalkorpus | 100 Millionen Wörter |
| Frühe 21 st Jahrhundert | Das Korpus der Bank of English | 650 Millionen Wörter |
In unseren folgenden Abschnitten werden wir einige Beispiele für Korpus betrachten.
TreeBank Corpus
Es kann als sprachlich analysierter Textkorpus definiert werden, der die syntaktische oder semantische Satzstruktur kommentiert. Geoffrey Leech prägte den Begriff "Baumbank", der darstellt, dass die grammatikalische Analyse am häufigsten über eine Baumstruktur dargestellt wird. Im Allgemeinen werden Treebanks auf einem Korpus erstellt, der bereits mit Teil-der-Sprache-Tags versehen wurde.
Arten von TreeBank Corpus
Semantische und syntaktische Baumbanken sind die beiden häufigsten Arten von Baumbanken in der Linguistik. Lassen Sie uns jetzt mehr über diese Typen erfahren -
Semantische Baumbanken
Diese Baumbanken verwenden eine formale Darstellung der semantischen Struktur des Satzes. Sie variieren in der Tiefe ihrer semantischen Darstellung. Roboterbefehle Treebank, Geoquery, Groningen Meaning Bank und RoboCup Corpus sind einige Beispiele für semantische Baumbanken.
Syntaktische Baumbanken
Im Gegensatz zu den semantischen Treebanks sind Eingaben in die Syntactic Treebank-Systeme Ausdrücke der formalen Sprache, die aus der Konvertierung geparster Treebank-Daten erhalten wird. Die Ausgaben solcher Systeme sind prädikatenbasierte Bedeutungsdarstellungen. Bisher wurden verschiedene syntaktische Treebanks in verschiedenen Sprachen erstellt. Zum Beispiel,Penn Arabic Treebank, Columbia Arabic Treebank sind syntaktische Treebanks, die in arabischer Sprache erstellt wurden. Sininca syntaktische Baumbank in chinesischer Sprache erstellt. Lucy, Susane und BLLIP WSJ syntaktischer Korpus in englischer Sprache erstellt.
Anwendungen von TreeBank Corpus
Im Folgenden sind einige der Anwendungen von TreeBanks aufgeführt:
In der Computerlinguistik
Wenn wir über Computerlinguistik sprechen, besteht die beste Verwendung von TreeBanks darin, hochmoderne Verarbeitungssysteme für natürliche Sprache zu entwickeln, wie z. B. Tagger, Parser, semantische Analysatoren und maschinelle Übersetzungssysteme.
In der Korpuslinguistik
Im Fall der Korpuslinguistik besteht die beste Verwendung von Treebanks darin, syntaktische Phänomene zu untersuchen.
In Theoretischer Linguistik und Psycholinguistik
Die beste Verwendung von Treebanks in der Theorie und Psycholinguistik sind Interaktionsnachweise.
PropBank Corpus
Die PropBank, genauer gesagt "Proposition Bank", ist ein Korpus, der mit verbalen Aussagen und ihren Argumenten versehen ist. Der Korpus ist eine verborientierte Ressource; Die Anmerkungen hier beziehen sich enger auf die syntaktische Ebene. Martha Palmer et al., Institut für Linguistik, Universität von Colorado Boulder, entwickelten es. Wir können den Begriff PropBank als allgemeines Substantiv verwenden, das sich auf jeden Korpus bezieht, der mit Aussagen und ihren Argumenten kommentiert wurde.
In der Verarbeitung natürlicher Sprache (NLP) hat das PropBank-Projekt eine sehr wichtige Rolle gespielt. Es hilft bei der semantischen Rollenbeschriftung.
VerbNet (VN)
VerbNet (VN) ist die hierarchische domänenunabhängige und größte lexikalische Ressource in Englisch, die sowohl semantische als auch syntaktische Informationen zu ihren Inhalten enthält. VN ist ein Verballlexikon mit breiter Abdeckung, das Zuordnungen zu anderen lexikalischen Ressourcen wie WordNet, Xtag und FrameNet enthält. Es ist in Verbklassen organisiert, die Levin-Klassen durch Verfeinerung und Hinzufügung von Unterklassen erweitern, um syntaktische und semantische Kohärenz zwischen Klassenmitgliedern zu erreichen.
Jede VerbNet (VN) -Klasse enthält -
Eine Reihe von syntaktischen Beschreibungen oder syntaktischen Frames
Zur Darstellung der möglichen Oberflächenrealisierungen der Argumentstruktur für Konstruktionen wie transitive, intransitive, präpositionale Phrasen, Resultative und eine große Anzahl von Diathese-Alternativen.
Eine Reihe von semantischen Beschreibungen wie animieren, menschlich, Organisation
Zur Einschränkung können die Arten von thematischen Rollen, die von den Argumenten zugelassen werden, und weitere Einschränkungen auferlegt werden. Dies hilft bei der Angabe der syntaktischen Natur des Bestandteils, der wahrscheinlich mit der thematischen Rolle verbunden ist.
WordNet
WordNet, erstellt von Princeton, ist eine lexikalische Datenbank für die englische Sprache. Es ist der Teil des NLTK-Korpus. In WordNet werden Substantive, Verben, Adjektive und Adverbien in Gruppen von kognitiven Synonymen gruppiert, die als bezeichnet werdenSynsets. Alle Synsets werden mit Hilfe konzeptuell-semantischer und lexikalischer Beziehungen verknüpft. Seine Struktur macht es sehr nützlich für die Verarbeitung natürlicher Sprache (NLP).
In Informationssystemen wird WordNet für verschiedene Zwecke verwendet, z. B. zur Begriffsklärung, zum Abrufen von Informationen, zur automatischen Klassifizierung von Texten und zur maschinellen Übersetzung. Eine der wichtigsten Anwendungen von WordNet besteht darin, die Ähnlichkeit zwischen Wörtern herauszufinden. Für diese Aufgabe wurden verschiedene Algorithmen in verschiedenen Paketen implementiert, wie Ähnlichkeit in Perl, NLTK in Python und ADW in Java.
In diesem Kapitel werden wir die Analyse auf Weltebene in der Verarbeitung natürlicher Sprache verstehen.
Reguläre Ausdrücke
Ein regulärer Ausdruck (RE) ist eine Sprache zum Angeben von Textsuchzeichenfolgen. RE hilft uns dabei, andere Zeichenfolgen oder Sätze von Zeichenfolgen mithilfe einer speziellen Syntax in einem Muster abzugleichen oder zu finden. Reguläre Ausdrücke werden verwendet, um Texte in UNIX und in MS WORD auf identische Weise zu suchen. Wir haben verschiedene Suchmaschinen, die eine Reihe von RE-Funktionen verwenden.
Eigenschaften regulärer Ausdrücke
Das Folgende sind einige der wichtigen Eigenschaften von RE -
Der amerikanische Mathematiker Stephen Cole Kleene formalisierte die Sprache des regulären Ausdrucks.
RE ist eine Formel in einer speziellen Sprache, mit der einfache Klassen von Zeichenfolgen, eine Folge von Symbolen, angegeben werden können. Mit anderen Worten können wir sagen, dass RE eine algebraische Notation zur Charakterisierung einer Reihe von Zeichenfolgen ist.
Regulärer Ausdruck erfordert zwei Dinge: eines ist das Muster, nach dem wir suchen möchten, und das andere ist ein Textkorpus, nach dem wir suchen müssen.
Mathematisch kann ein regulärer Ausdruck wie folgt definiert werden:
ε ist ein regulärer Ausdruck, der angibt, dass die Sprache eine leere Zeichenfolge hat.
φ ist ein regulärer Ausdruck, der angibt, dass es sich um eine leere Sprache handelt.
Wenn X und Y sind dann reguläre Ausdrücke
X, Y
X.Y(Concatenation of XY)
X+Y (Union of X and Y)
X*, Y* (Kleen Closure of X and Y)
sind auch reguläre Ausdrücke.
Wenn eine Zeichenfolge von den obigen Regeln abgeleitet wird, ist dies auch ein regulärer Ausdruck.
Beispiele für reguläre Ausdrücke
Die folgende Tabelle zeigt einige Beispiele für reguläre Ausdrücke -
| Reguläre Ausdrücke | Reguläres Set |
|---|---|
| (0 + 10 *) | {0, 1, 10, 100, 1000, 10000,…} |
| (0 * 10 *) | {1, 01, 10, 010, 0010,…} |
| (0 + & epsi;) (1 + & epsi;) | {ε, 0, 1, 01} |
| (a + b) * | Es würde eine Reihe von Zeichenfolgen von a und b beliebiger Länge sein, die auch die Nullzeichenfolge enthalten, dh {ε, a, b, aa, ab, bb, ba, aaa …….} |
| (a + b) * abb | Es würde aus Strings von a und b bestehen, die mit dem String abb enden, dh {abb, aabb, babb, aaabb, ababb, ………… ..} |
| (11) * | Es würde aus einer geraden Anzahl von Einsen bestehen, die auch eine leere Zeichenfolge enthält, dh {ε, 11, 1111, 111111, ……….} |
| (aa) * (bb) * b | Es würde eine Reihe von Zeichenfolgen sein, die aus einer geraden Anzahl von a bestehen, gefolgt von einer ungeraden Anzahl von b, dh {b, aab, aabbb, aabbbbb, aaaab, aaaabbb, ………… ..} |
| (aa + ab + ba + bb) * | Es wäre eine Zeichenfolge von a und b von gleicher Länge, die durch Verketten einer beliebigen Kombination der Zeichenfolgen aa, ab, ba und bb einschließlich null erhalten werden kann, dh {aa, ab, ba, bb, aaab, aaba, …………. .} |
Reguläre Sets und ihre Eigenschaften
Es kann als die Menge definiert werden, die den Wert des regulären Ausdrucks darstellt und aus bestimmten Eigenschaften besteht.
Eigenschaften regulärer Mengen
Wenn wir zwei reguläre Mengen vereinen, wäre die resultierende Menge auch regula.
Wenn wir den Schnittpunkt zweier regulärer Mengen machen, wäre die resultierende Menge auch regulär.
Wenn wir das Komplement von regulären Mengen machen, dann wäre die resultierende Menge auch regulär.
Wenn wir die Differenz zweier regulärer Mengen machen, wäre die resultierende Menge auch regulär.
Wenn wir reguläre Mengen umkehren, wäre die resultierende Menge auch regulär.
Wenn wir reguläre Mengen schließen, wäre die resultierende Menge auch regulär.
Wenn wir zwei reguläre Mengen verketten, wäre die resultierende Menge auch regulär.
Endliche Zustandsautomaten
Der Begriff Automaten, abgeleitet vom griechischen Wort "αὐτόματα", was "selbsttätig" bedeutet, ist der Plural von Automaten, der als abstraktes selbstfahrendes Rechengerät definiert werden kann, das automatisch einer vorbestimmten Abfolge von Operationen folgt.
Ein Automat mit einer endlichen Anzahl von Zuständen wird als endlicher Automat (FA) oder endlicher Zustandsautomat (FSA) bezeichnet.
Mathematisch kann ein Automat durch ein 5-Tupel (Q, Σ, δ, q0, F) dargestellt werden, wobei -
Q ist eine endliche Menge von Zuständen.
Σ ist eine endliche Menge von Symbolen, die als Alphabet des Automaten bezeichnet wird.
δ ist die Übergangsfunktion
q0 ist der Anfangszustand, von dem aus jede Eingabe verarbeitet wird (q0 ∈ Q).
F ist eine Menge von Endzuständen von Q (F ⊆ Q).
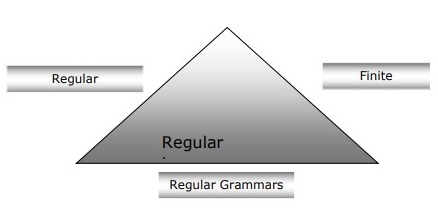
Beziehung zwischen endlichen Automaten, regulären Grammatiken und regulären Ausdrücken
Die folgenden Punkte geben uns einen klaren Überblick über die Beziehung zwischen endlichen Automaten, regulären Grammatiken und regulären Ausdrücken -
Wie wir wissen, sind endliche Zustandsautomaten die theoretische Grundlage der Computerarbeit, und reguläre Ausdrücke sind eine Möglichkeit, sie zu beschreiben.
Wir können sagen, dass jeder reguläre Ausdruck als FSA implementiert werden kann und jeder FSA mit einem regulären Ausdruck beschrieben werden kann.
Andererseits ist regulärer Ausdruck eine Möglichkeit, eine Art Sprache zu charakterisieren, die als reguläre Sprache bezeichnet wird. Daher können wir sagen, dass die reguläre Sprache sowohl mit Hilfe von FSA als auch mit Hilfe des regulären Ausdrucks beschrieben werden kann.
Die reguläre Grammatik, eine formale Grammatik, die rechts oder links regulär sein kann, ist eine weitere Möglichkeit, die reguläre Sprache zu charakterisieren.
Das folgende Diagramm zeigt, dass endliche Automaten, reguläre Ausdrücke und reguläre Grammatiken die äquivalente Art der Beschreibung regulärer Sprachen sind.
Arten der Finite-State-Automatisierung (FSA)
Es gibt zwei Arten der Automatisierung endlicher Zustände. Lassen Sie uns sehen, welche Typen es gibt.
Deterministische endliche Automatisierung (DFA)
Es kann als die Art der endlichen Automatisierung definiert werden, bei der wir für jedes Eingabesymbol den Zustand bestimmen können, in den sich die Maschine bewegt. Es hat eine endliche Anzahl von Zuständen, weshalb die Maschine als deterministischer endlicher Automat (DFA) bezeichnet wird.
Mathematisch kann ein DFA durch ein 5-Tupel (Q, Σ, δ, q0, F) dargestellt werden, wobei -
Q ist eine endliche Menge von Zuständen.
Σ ist eine endliche Menge von Symbolen, die als Alphabet des Automaten bezeichnet wird.
δ ist die Übergangsfunktion, wobei δ: Q × Σ → Q.
q0 ist der Anfangszustand, von dem aus jede Eingabe verarbeitet wird (q0 ∈ Q).
F ist eine Menge von Endzuständen von Q (F ⊆ Q).
Während ein DFA grafisch durch Diagramme dargestellt werden kann, die als Zustandsdiagramme bezeichnet werden, wobei -
Die Staaten werden vertreten durch vertices.
Die Übergänge sind mit beschriftet dargestellt arcs.
Der Ausgangszustand wird durch ein dargestellt empty incoming arc.
Der Endzustand wird dargestellt durch double circle.
Beispiel für DFA
Angenommen, ein DFA ist
Q = {a, b, c},
Σ = {0, 1},
q 0 = {a},
F = {c},
Die Übergangsfunktion δ ist in der Tabelle wie folgt dargestellt:
| Aktuellen Zustand | Nächster Status für Eingang 0 | Nächster Status für Eingabe 1 |
|---|---|---|
| EIN | ein | B. |
| B. | b | EIN |
| C. | c | C. |
Die grafische Darstellung dieses DFA wäre wie folgt:

Nicht deterministische endliche Automatisierung (NDFA)
Es kann als die Art der endlichen Automatisierung definiert werden, bei der wir nicht für jedes Eingabesymbol den Zustand bestimmen können, in den sich die Maschine bewegen wird, dh die Maschine kann sich in eine beliebige Kombination der Zustände bewegen. Es hat eine endliche Anzahl von Zuständen, weshalb die Maschine als nicht deterministische endliche Automatisierung (NDFA) bezeichnet wird.
Mathematisch kann NDFA durch ein 5-Tupel (Q, Σ, δ, q0, F) dargestellt werden, wobei -
Q ist eine endliche Menge von Zuständen.
Σ ist eine endliche Menge von Symbolen, die als Alphabet des Automaten bezeichnet wird.
δ: -ist die Übergangsfunktion in dem δ: Q × Σ → 2 Q .
q0: -ist der Ausgangszustand, von dem aus eine Eingabe verarbeitet wird (q0 ∈ Q).
F: -ist eine Menge von Endzuständen von Q (F ⊆ Q).
Während grafisch (wie DFA) ein NDFA durch Diagramme dargestellt werden kann, die als Zustandsdiagramme bezeichnet werden, wobei -
Die Staaten werden vertreten durch vertices.
Die Übergänge sind mit beschriftet dargestellt arcs.
Der Ausgangszustand wird durch ein dargestellt empty incoming arc.
Der Endzustand wird durch double dargestellt circle.
Beispiel für NDFA
Angenommen, ein NDFA ist
Q = {a, b, c},
Σ = {0, 1},
q 0 = {a},
F = {c},
Die Übergangsfunktion δ ist in der Tabelle wie folgt dargestellt:
| Aktuellen Zustand | Nächster Status für Eingang 0 | Nächster Status für Eingabe 1 |
|---|---|---|
| EIN | a, b | B. |
| B. | C. | a, c |
| C. | b, c | C. |
Die grafische Darstellung dieses NDFA wäre wie folgt:

Morphologische Analyse
Der Begriff morphologische Analyse bezieht sich auf die Analyse von Morphemen. Wir können morphologisches Parsen als das Problem definieren, zu erkennen, dass ein Wort in kleinere bedeutungsvolle Einheiten zerfällt, die als Morpheme bezeichnet werden und eine Art sprachliche Struktur dafür erzeugen. Zum Beispiel können wir das Wort Füchse in zwei Teile teilen , Fuchs und -es . Wir können sehen, dass das Wort Füchse aus zwei Morphemen besteht, eines ist Fuchs und das andere ist -es .
In einem anderen Sinne können wir sagen, dass Morphologie das Studium von - ist
Die Bildung von Wörtern.
Der Ursprung der Wörter.
Grammatische Formen der Wörter.
Verwendung von Präfixen und Suffixen bei der Wortbildung.
Wie Wortarten (PoS) einer Sprache gebildet werden.
Arten von Morphemen
Morpheme, die kleinsten bedeutungstragenden Einheiten, können in zwei Typen unterteilt werden -
Stems
Reihenfolge der Wörter
Stängel
Es ist die zentrale sinnvolle Einheit eines Wortes. Wir können auch sagen, dass es die Wurzel des Wortes ist. Zum Beispiel ist im Wort Füchse der Stamm Fuchs.
Affixes- Wie der Name schon sagt, fügen sie den Wörtern zusätzliche Bedeutung und grammatikalische Funktionen hinzu. Zum Beispiel ist im Wort Füchse der Zusatz - es.
Darüber hinaus können Affixe auch in die folgenden vier Typen unterteilt werden:
Prefixes- Wie der Name schon sagt, stehen Präfixe vor dem Stamm. Zum Beispiel ist un im Wort unbuckle das Präfix.
Suffixes- Wie der Name schon sagt, folgen Suffixe dem Stamm. Zum Beispiel ist im Wort Katzen -s das Suffix.
Infixes- Wie der Name schon sagt, werden Infixe in den Stiel eingefügt. Zum Beispiel kann das Wort cupful durch Verwendung von -s als Infix als cupful pluralisiert werden.
Circumfixes- Sie gehen dem Stamm voraus und folgen ihm. Es gibt sehr wenige Beispiele für Zirkumfixe in englischer Sprache. Ein sehr häufiges Beispiel ist 'A-ing', wo wir -A vorangestellt verwenden können und -ing dem Stamm folgt.
Reihenfolge der Wörter
Die Reihenfolge der Wörter würde durch morphologische Analyse bestimmt. Lassen Sie uns nun die Anforderungen für die Erstellung eines morphologischen Parsers sehen -
Lexikon
Die allererste Voraussetzung für die Erstellung eines morphologischen Parsers ist das Lexikon, das die Liste der Stämme und Anhänge sowie die grundlegenden Informationen dazu enthält. Zum Beispiel die Informationen wie, ob der Stamm Nomenstamm oder Verbstamm usw. ist.
Morphotaktik
Es ist im Grunde das Modell der Morphemordnung. In einem anderen Sinne erklärt das Modell, welche Morphemklassen anderen Morphemklassen innerhalb eines Wortes folgen können. Zum Beispiel ist die morphotaktische Tatsache, dass das englische Pluralmorphem immer dem Substantiv folgt und nicht davor steht.
Orthographische Regeln
Diese Rechtschreibregeln werden verwendet, um die in einem Wort auftretenden Änderungen zu modellieren. Zum Beispiel die Regel der Konvertierung von y in dh in Wort wie Stadt + s = Städte, nicht Städte.
Syntaktische Analyse oder Analyse oder Syntaxanalyse ist die dritte Phase von NLP. Der Zweck dieser Phase ist es, die genaue Bedeutung zu zeichnen, oder Sie können die Wörterbuchbedeutung aus dem Text sagen. Die Syntaxanalyse überprüft den Text im Vergleich zu den Regeln der formalen Grammatik auf Aussagekraft. Zum Beispiel würde der Satz wie "heißes Eis" vom semantischen Analysator abgelehnt.
In diesem Sinne kann syntaktische Analyse oder Analyse als der Prozess der Analyse der Symbolketten in natürlicher Sprache definiert werden, die den Regeln der formalen Grammatik entsprechen. Der Ursprung des Wortes‘parsing’ ist vom lateinischen Wort ‘pars’ was bedeutet ‘part’.
Konzept des Parsers
Es wird verwendet, um die Aufgabe des Parsens zu implementieren. Es kann als die Softwarekomponente definiert werden, die für die Erfassung von Eingabedaten (Text) und die strukturelle Darstellung der Eingabe nach Überprüfung der korrekten Syntax gemäß der formalen Grammatik ausgelegt ist. Außerdem wird eine Datenstruktur im Allgemeinen in Form eines Analysebaums oder eines abstrakten Syntaxbaums oder einer anderen hierarchischen Struktur erstellt.

Die Hauptrollen der Analyse umfassen -
Um einen Syntaxfehler zu melden.
Behebung eines häufig auftretenden Fehlers, damit die Verarbeitung des restlichen Programms fortgesetzt werden kann.
So erstellen Sie einen Analysebaum.
Symboltabelle erstellen.
Zwischenrepräsentationen (IR) erzeugen.
Arten der Analyse
Die Ableitung unterteilt das Parsen in die folgenden zwei Typen:
Top-Down-Analyse
Bottom-up-Analyse
Top-Down-Analyse
Bei dieser Art der Analyse beginnt der Parser mit der Erstellung des Analysebaums aus dem Startsymbol und versucht dann, das Startsymbol in die Eingabe umzuwandeln. Die häufigste Form der Topdown-Analyse verwendet eine rekursive Prozedur, um die Eingabe zu verarbeiten. Der Hauptnachteil der Analyse rekursiver Abstammung ist das Zurückverfolgen.
Bottom-up-Analyse
Bei dieser Art der Analyse beginnt der Parser mit dem Eingabesymbol und versucht, den Parser-Baum bis zum Startsymbol zu erstellen.
Konzept der Ableitung
Um die Eingabezeichenfolge zu erhalten, benötigen wir eine Folge von Produktionsregeln. Die Ableitung besteht aus einer Reihe von Produktionsregeln. Während des Parsens müssen wir das Nicht-Terminal festlegen, das ersetzt werden soll, sowie die Produktionsregel festlegen, mit deren Hilfe das Nicht-Terminal ersetzt werden soll.
Arten der Ableitung
In diesem Abschnitt lernen wir die beiden Arten von Ableitungen kennen, anhand derer entschieden werden kann, welches Nicht-Terminal durch die Produktionsregel ersetzt werden soll.
Ableitung ganz links
Bei der Ableitung ganz links wird die Sententialform einer Eingabe gescannt und von links nach rechts ersetzt. Das sententiale Formular wird in diesem Fall als links-sententiales Formular bezeichnet.
Ableitung ganz rechts
Bei der Ableitung ganz links wird die Sententialform einer Eingabe gescannt und von rechts nach links ersetzt. Das Sentential-Formular wird in diesem Fall als Right-Sentential-Formular bezeichnet.
Konzept des Analysebaums
Es kann als grafische Darstellung einer Ableitung definiert werden. Das Startsymbol der Ableitung dient als Wurzel des Analysebaums. In jedem Analysebaum sind die Blattknoten Terminals und die inneren Knoten sind keine Terminals. Eine Eigenschaft des Analysebaums ist, dass beim Durchlaufen der Reihenfolge die ursprüngliche Eingabezeichenfolge erzeugt wird.
Konzept der Grammatik
Grammatik ist sehr wichtig und wichtig, um die syntaktische Struktur wohlgeformter Programme zu beschreiben. Im literarischen Sinne bezeichnen sie syntaktische Regeln für die Konversation in natürlichen Sprachen. Die Linguistik hat seit Beginn natürlicher Sprachen wie Englisch, Hindi usw. versucht, Grammatiken zu definieren.
Die Theorie der formalen Sprachen ist auch in den Bereichen der Informatik anwendbar, hauptsächlich in Programmiersprachen und Datenstruktur. In der Sprache 'C' geben die genauen Grammatikregeln beispielsweise an, wie Funktionen aus Listen und Anweisungen erstellt werden.
Ein mathematisches Grammatikmodell wurde von gegeben Noam Chomsky im Jahr 1956, die für das Schreiben von Computersprachen wirksam ist.
Mathematisch kann eine Grammatik G formal als 4-Tupel (N, T, S, P) geschrieben werden, wobei -
N oder VN = Satz von nicht-terminalen Symbolen, dh Variablen.
T oder ∑ = Satz von Terminalsymbolen.
S = Startsymbol mit S ∈ N.
Pbezeichnet die Produktionsregeln für Terminals sowie Nicht-Terminals. Es hat die Form α → β, wobei α und β Zeichenfolgen auf V N ∪ ∑ sind und mindestens ein Symbol von α zu V N gehört
Phrasenstruktur oder Konstituentengrammatik
Die von Noam Chomsky eingeführte Grammatik der Phrasenstruktur basiert auf der Wahlkreisbeziehung. Deshalb wird es auch Wahlkreisgrammatik genannt. Es ist entgegengesetzt zur Abhängigkeitsgrammatik.
Beispiel
Bevor wir ein Beispiel für die Wahlkreisgrammatik geben, müssen wir die grundlegenden Punkte der Wahlkreisgrammatik und der Wahlkreisbeziehung kennen.
Alle verwandten Frameworks betrachten die Satzstruktur in Bezug auf die Wahlkreisbeziehung.
Die Wahlkreisbeziehung leitet sich aus der Subjekt-Prädikat-Unterteilung der lateinischen sowie der griechischen Grammatik ab.
Die grundlegende Klauselstruktur wird im Sinne von verstanden noun phrase NP und verb phrase VP.
Wir können den Satz schreiben “This tree is illustrating the constituency relation” wie folgt -

Abhängigkeitsgrammatik
Es ist der Wahlkreisgrammatik entgegengesetzt und basiert auf der Abhängigkeitsbeziehung. Es wurde von Lucien Tesniere eingeführt. Die Abhängigkeitsgrammatik (DG) ist der Konstituentengrammatik entgegengesetzt, da ihr Phrasenknoten fehlen.
Beispiel
Bevor wir ein Beispiel für die Abhängigkeitsgrammatik geben, müssen wir die grundlegenden Punkte der Abhängigkeitsgrammatik und der Abhängigkeitsbeziehung kennen.
In DG sind die sprachlichen Einheiten, dh Wörter, durch gerichtete Verknüpfungen miteinander verbunden.
Das Verb wird zum Zentrum der Klauselstruktur.
Alle anderen syntaktischen Einheiten sind in Bezug auf die gerichtete Verknüpfung mit dem Verb verbunden. Diese syntaktischen Einheiten werden aufgerufendependencies.
Wir können den Satz schreiben “This tree is illustrating the dependency relation” wie folgt;

Der Analysebaum, der die Konstituenz-Grammatik verwendet, wird als Wahlkreis-basierter Analysebaum bezeichnet. und die Analysebäume, die die Abhängigkeitsgrammatik verwenden, werden als abhängigkeitsbasierter Analysebaum bezeichnet.
Kontextfreie Grammatik
Die kontextfreie Grammatik, auch CFG genannt, ist eine Notation zur Beschreibung von Sprachen und eine Obermenge der regulären Grammatik. Es ist in der folgenden Abbildung zu sehen -

Definition von CFG
CFG besteht aus einem endlichen Satz von Grammatikregeln mit den folgenden vier Komponenten:
Satz Nicht-Terminals
Es wird mit V bezeichnet. Die Nicht-Terminals sind syntaktische Variablen, die die Sätze von Zeichenfolgen bezeichnen, die bei der Definition der von der Grammatik erzeugten Sprache weiter helfen.
Satz Terminals
Es wird auch Token genannt und durch Σ definiert. Strings werden mit den Grundsymbolen der Terminals gebildet.
Reihe von Produktionen
Es wird mit P bezeichnet. Das Set definiert, wie die Terminals und Nicht-Terminals kombiniert werden können. Jede Produktion (P) besteht aus Nicht-Terminals, einem Pfeil und Terminals (der Folge von Terminals). Nicht-Terminals werden als linke Seite der Produktion und Terminals als rechte Seite der Produktion bezeichnet.
Symbol starten
Die Produktion beginnt mit dem Startsymbol. Es wird mit dem Symbol S bezeichnet. Das nicht terminale Symbol wird immer als Startsymbol bezeichnet.
Der Zweck der semantischen Analyse besteht darin, die genaue Bedeutung zu zeichnen, oder Sie können die Wörterbuchbedeutung aus dem Text sagen. Die Arbeit des semantischen Analysators besteht darin, den Text auf seine Aussagekraft zu überprüfen.
Wir wissen bereits, dass sich die lexikalische Analyse auch mit der Bedeutung der Wörter befasst. Wie unterscheidet sich die semantische Analyse von der lexikalischen Analyse? Die lexikalische Analyse basiert auf einem kleineren Token, auf der anderen Seite konzentriert sich die semantische Analyse auf größere Blöcke. Aus diesem Grund kann die semantische Analyse in die folgenden zwei Teile unterteilt werden:
Die Bedeutung eines einzelnen Wortes studieren
Es ist der erste Teil der semantischen Analyse, in dem die Bedeutung einzelner Wörter untersucht wird. Dieser Teil heißt lexikalische Semantik.
Die Kombination einzelner Wörter studieren
Im zweiten Teil werden die einzelnen Wörter kombiniert, um in Sätzen Bedeutung zu verleihen.
Die wichtigste Aufgabe der semantischen Analyse ist es, die richtige Bedeutung des Satzes zu erhalten. Analysieren Sie beispielsweise den Satz“Ram is great.”In diesem Satz spricht der Sprecher entweder über Lord Ram oder über eine Person, deren Name Ram ist. Deshalb ist es wichtig, den semantischen Analysator zu verwenden, um die richtige Bedeutung des Satzes zu erhalten.
Elemente der semantischen Analyse
Das Folgende sind einige wichtige Elemente der semantischen Analyse -
Hyponymie
Es kann als die Beziehung zwischen einem Oberbegriff und Instanzen dieses Oberbegriffs definiert werden. Hier wird der Oberbegriff Hypernym genannt und seine Instanzen werden Hyponyme genannt. Zum Beispiel ist das Wort Farbe Hypernym und die Farbe Blau, Gelb usw. sind Hyponyme.
Homonymie
Es kann definiert werden als die Wörter, die dieselbe Schreibweise oder Form haben, aber unterschiedliche und nicht verwandte Bedeutung haben. Zum Beispiel ist das Wort "Fledermaus" ein Homonymie-Wort, weil Fledermaus ein Gerät sein kann, um einen Ball zu schlagen, oder Fledermaus auch ein nachtaktives fliegendes Säugetier ist.
Polysemie
Polysemie ist ein griechisches Wort, das "viele Zeichen" bedeutet. Es ist ein Wort oder eine Phrase mit einem anderen, aber verwandten Sinn. Mit anderen Worten, wir können sagen, dass Polysemie dieselbe Schreibweise hat, aber unterschiedliche und verwandte Bedeutung. Zum Beispiel ist das Wort "Bank" ein Polysemie-Wort mit den folgenden Bedeutungen:
Ein Finanzinstitut.
Das Gebäude, in dem sich eine solche Einrichtung befindet.
Ein Synonym für "sich verlassen".
Unterschied zwischen Polysemie und Homonymie
Sowohl Polysemie- als auch Homonymie-Wörter haben dieselbe Syntax oder Schreibweise. Der Hauptunterschied zwischen ihnen besteht darin, dass in der Polysemie die Bedeutungen der Wörter verwandt sind, in der Homonymie jedoch die Bedeutungen der Wörter nicht verwandt sind. Wenn wir zum Beispiel über dasselbe Wort „Bank“ sprechen, können wir die Bedeutung „ein Finanzinstitut“ oder „ein Flussufer“ schreiben. In diesem Fall wäre es das Beispiel eines Homonyms, da die Bedeutungen nicht miteinander zusammenhängen.
Synonymie
Es ist die Beziehung zwischen zwei lexikalischen Elementen, die unterschiedliche Formen haben, aber dieselbe oder eine nahe Bedeutung ausdrücken. Beispiele sind "Autor / Schriftsteller", "Schicksal / Schicksal".
Antonymie
Es ist die Beziehung zwischen zwei lexikalischen Elementen, die eine Symmetrie zwischen ihren semantischen Komponenten relativ zu einer Achse aufweisen. Der Umfang der Antonymie ist wie folgt:
Application of property or not - Beispiel ist "Leben / Tod", "Gewissheit / Ungewissheit"
Application of scalable property - Beispiel ist "reich / arm", "heiß / kalt"
Application of a usage - Beispiel ist 'Vater / Sohn', 'Mond / Sonne'.
Bedeutung Repräsentation
Die semantische Analyse erzeugt eine Darstellung der Bedeutung eines Satzes. Bevor wir uns jedoch mit dem Konzept und den Ansätzen der Bedeutungsrepräsentation befassen, müssen wir die Bausteine des semantischen Systems verstehen.
Bausteine des semantischen Systems
Bei der Wortdarstellung oder Darstellung der Bedeutung der Wörter spielen die folgenden Bausteine eine wichtige Rolle:
Entities- Es repräsentiert die Person wie eine bestimmte Person, einen bestimmten Ort usw. Zum Beispiel Haryana. Indien, Ram sind alle Einheiten.
Concepts - Es repräsentiert die allgemeine Kategorie der Personen wie eine Person, eine Stadt usw.
Relations- Es repräsentiert die Beziehung zwischen Entitäten und Konzept. Zum Beispiel ist Ram eine Person.
Predicates- Es repräsentiert die Verbstrukturen. Beispielsweise sind semantische Rollen und Fallgrammatik Beispiele für Prädikate.
Jetzt können wir verstehen, dass die Bedeutungsdarstellung zeigt, wie die Bausteine semantischer Systeme zusammengesetzt werden. Mit anderen Worten, es zeigt, wie Entitäten, Konzepte, Beziehungen und Prädikate zusammengestellt werden, um eine Situation zu beschreiben. Es ermöglicht auch das Denken über die semantische Welt.
Ansätze zur Bedeutungsrepräsentation
Die semantische Analyse verwendet die folgenden Ansätze zur Darstellung der Bedeutung -
Prädikatenlogik erster Ordnung (FOPL)
Semantische Netze
Frames
Konzeptionelle Abhängigkeit (CD)
Regelbasierte Architektur
Fallgrammatik
Konzeptgrafiken
Notwendigkeit von Bedeutungsrepräsentationen
Hier stellt sich die Frage, warum wir eine Bedeutungsrepräsentation brauchen. Folgendes sind die Gründe dafür -
Verknüpfung sprachlicher Elemente mit nichtsprachlichen Elementen
Der allererste Grund ist, dass mit Hilfe der Bedeutungsrepräsentation die Verknüpfung von sprachlichen Elementen mit nichtsprachlichen Elementen erfolgen kann.
Darstellung der Vielfalt auf lexikalischer Ebene
Mit Hilfe der Bedeutungsrepräsentation können eindeutige kanonische Formen auf lexikalischer Ebene dargestellt werden.
Kann zum Nachdenken verwendet werden
Bedeutungsrepräsentation kann verwendet werden, um zu begründen, was in der Welt wahr ist, und um das Wissen aus der semantischen Repräsentation abzuleiten.
Lexikalische Semantik
Der erste Teil der semantischen Analyse, der die Bedeutung einzelner Wörter untersucht, wird als lexikalische Semantik bezeichnet. Es enthält auch Wörter, Unterwörter, Anhänge (Untereinheiten), zusammengesetzte Wörter und Phrasen. Alle Wörter, Unterwörter usw. werden zusammen als lexikalische Elemente bezeichnet. Mit anderen Worten, wir können sagen, dass die lexikalische Semantik die Beziehung zwischen lexikalischen Elementen, der Bedeutung von Sätzen und der Syntax von Sätzen ist.
Im Folgenden sind die Schritte der lexikalischen Semantik aufgeführt:
Die Klassifizierung von lexikalischen Elementen wie Wörtern, Unterwörtern, Anhängen usw. erfolgt in lexikalischer Semantik.
Die Zerlegung von lexikalischen Elementen wie Wörtern, Unterwörtern, Anhängen usw. erfolgt in lexikalischer Semantik.
Unterschiede sowie Ähnlichkeiten zwischen verschiedenen lexikalischen semantischen Strukturen werden ebenfalls analysiert.
Wir verstehen, dass Wörter je nach dem Kontext ihrer Verwendung im Satz unterschiedliche Bedeutungen haben. Wenn wir über menschliche Sprachen sprechen, sind sie auch mehrdeutig, da viele Wörter je nach Kontext ihres Auftretens auf verschiedene Arten interpretiert werden können.
Die Wortsinn-Disambiguierung in der Verarbeitung natürlicher Sprache (NLP) kann als die Fähigkeit definiert werden, zu bestimmen, welche Bedeutung des Wortes durch die Verwendung von Wörtern in einem bestimmten Kontext aktiviert wird. Lexikalische Mehrdeutigkeit, syntaktisch oder semantisch, ist eines der allerersten Probleme, mit denen ein NLP-System konfrontiert ist. POS-Tagger (Part-of-Speech) mit hoher Genauigkeit können die syntaktische Mehrdeutigkeit von Word lösen. Andererseits wird das Problem der Auflösung semantischer Ambiguität als WSD (Wortsinn-Disambiguierung) bezeichnet. Das Auflösen semantischer Mehrdeutigkeiten ist schwieriger als das Auflösen syntaktischer Mehrdeutigkeiten.
Betrachten Sie zum Beispiel die beiden Beispiele für den unterschiedlichen Sinn, der für das Wort existiert “bass” - -
Ich kann Bass hören.
Er isst gerne gegrillten Bass.
Das Auftreten des Wortes bassbezeichnet deutlich die eindeutige Bedeutung. Im ersten Satz bedeutet esfrequency und zweitens bedeutet es fish. Wenn es daher durch WSD eindeutig wäre, kann den obigen Sätzen die richtige Bedeutung wie folgt zugewiesen werden:
Ich kann Bass- / Frequenzgeräusche hören.
Er isst gerne gegrillten Bass / Fisch.
Bewertung von WSD
Die Auswertung von WSD erfordert die folgenden zwei Eingaben:
Ein Wörterbuch
Die allererste Eingabe für die Bewertung von WSD ist das Wörterbuch, mit dem die zu unterscheidenden Sinne angegeben werden.
Test Corpus
Eine weitere Eingabe, die von WSD benötigt wird, ist der hoch kommentierte Testkorpus, der das Ziel oder die richtigen Sinne hat. Die Testkorpora können von zwei Arten sein & minsu;
Lexical sample - Diese Art von Korpora wird im System verwendet, wo es erforderlich ist, eine kleine Stichprobe von Wörtern zu disambiguieren.
All-words - Diese Art von Korpora wird im System verwendet, wo erwartet wird, dass alle Wörter in einem laufenden Text eindeutig sind.
Ansätze und Methoden zur Disambiguierung des Wortsinns (WSD)
Ansätze und Methoden für WSD werden nach der Wissensquelle klassifiziert, die bei der Begriffsklärung verwendet wird.
Lassen Sie uns nun die vier konventionellen Methoden für WSD sehen -
Wörterbuchbasierte oder wissensbasierte Methoden
Wie der Name schon sagt, stützen sich diese Methoden zur Begriffsklärung hauptsächlich auf Wörterbücher, Schätze und eine lexikalische Wissensbasis. Sie verwenden keine Korpora-Beweise zur Begriffsklärung. Die Lesk-Methode ist die wegweisende wörterbuchbasierte Methode, die 1986 von Michael Lesk eingeführt wurde. Die Lesk-Definition, auf der der Lesk-Algorithmus basiert, lautet“measure overlap between sense definitions for all words in context”. Im Jahr 2000 gaben Kilgarriff und Rosensweig jedoch die vereinfachte Lesk-Definition als“measure overlap between sense definitions of word and current context”Dies bedeutet ferner, den richtigen Sinn für jeweils ein Wort zu identifizieren. Hier ist der aktuelle Kontext die Menge der Wörter im umgebenden Satz oder Absatz.
Überwachte Methoden
Zur Disambiguierung verwenden maschinelle Lernmethoden sinnlich kommentierte Korpora zum Trainieren. Diese Methoden setzen voraus, dass der Kontext allein genügend Beweise liefern kann, um den Sinn zu disambiguieren. Bei diesen Methoden werden die Wörter Wissen und Argumentation als unnötig erachtet. Der Kontext wird als eine Reihe von „Merkmalen“ der Wörter dargestellt. Es enthält auch die Informationen zu den umgebenden Wörtern. Support Vector Machine und Memory Based Learning sind die erfolgreichsten überwachten Lernansätze für WSD. Diese Methoden beruhen auf einer beträchtlichen Menge manuell korporierter Korpora, deren Erstellung sehr teuer ist.
Halbüberwachte Methoden
Aufgrund des Mangels an Trainingskorpus verwenden die meisten Algorithmen zur Disambiguierung des Wortsinns halbüberwachte Lernmethoden. Dies liegt daran, dass halbüberwachte Methoden sowohl gekennzeichnete als auch nicht gekennzeichnete Daten verwenden. Diese Methoden erfordern eine sehr kleine Menge an kommentiertem Text und eine große Menge an einfachem, nicht kommentiertem Text. Die Technik, die von halbüberwachten Methoden verwendet wird, ist das Bootstrapping von Seed-Daten.
Unüberwachte Methoden
Diese Methoden setzen voraus, dass ähnliche Sinne in einem ähnlichen Kontext auftreten. Aus diesem Grund können die Sinne aus dem Text induziert werden, indem Wortvorkommen unter Verwendung eines gewissen Maßes für die Ähnlichkeit des Kontexts gruppiert werden. Diese Aufgabe wird als Wortsinninduktion oder Diskriminierung bezeichnet. Unüberwachte Methoden haben ein großes Potenzial, um den Engpass beim Wissenserwerb zu überwinden, da sie nicht von manuellen Anstrengungen abhängig sind.
Anwendungen der Word Sense Disambiguation (WSD)
Die Wortsinn-Disambiguierung (WSD) wird in fast jeder Anwendung der Sprachtechnologie angewendet.
Lassen Sie uns nun den Umfang von WSD sehen -
Maschinenübersetzung
Maschinelle Übersetzung oder MT ist die offensichtlichste Anwendung von WSD. In MT wird die lexikalische Auswahl für die Wörter, die unterschiedliche Übersetzungen für unterschiedliche Sinne haben, von WSD vorgenommen. Die Sinne in MT werden als Wörter in der Zielsprache dargestellt. Die meisten maschinellen Übersetzungssysteme verwenden kein explizites WSD-Modul.
Information Retrieval (IR)
Information Retrieval (IR) kann als ein Softwareprogramm definiert werden, das sich mit der Organisation, Speicherung, dem Abruf und der Auswertung von Informationen aus Dokumentenspeichern, insbesondere Textinformationen, befasst. Das System unterstützt Benutzer grundsätzlich beim Auffinden der benötigten Informationen, gibt jedoch die Antworten auf die Fragen nicht explizit zurück. WSD wird verwendet, um die Mehrdeutigkeiten der dem IR-System bereitgestellten Abfragen aufzulösen. Wie bei MT verwenden aktuelle IR-Systeme das WSD-Modul nicht explizit und basieren auf dem Konzept, dass der Benutzer genügend Kontext in die Abfrage eingibt, um nur relevante Dokumente abzurufen.
Text Mining und Informationsextraktion (IE)
In den meisten Anwendungen ist WSD erforderlich, um eine genaue Textanalyse durchzuführen. Beispielsweise hilft WSD dem intelligenten Sammelsystem, die richtigen Wörter zu kennzeichnen. Zum Beispiel könnte ein medizinisch-intelligentes System die Kennzeichnung von „illegalen Drogen“ anstelle von „medizinischen Drogen“ erfordern.
Lexikographie
WSD und Lexikographie können in einer Schleife zusammenarbeiten, da die moderne Lexikographie auf Korpus basiert. Mit der Lexikographie liefert WSD grobe empirische Sinnesgruppierungen sowie statistisch signifikante kontextbezogene Sinnesindikatoren.
Schwierigkeiten bei der Disambiguierung des Wortsinns (WSD)
Das Folgende sind einige Schwierigkeiten, mit denen die Wortsinn-Disambiguierung (WSD) konfrontiert ist -
Unterschiede zwischen Wörterbüchern
Das Hauptproblem von WSD besteht darin, den Sinn des Wortes zu bestimmen, da verschiedene Sinne sehr eng miteinander verbunden sein können. Sogar verschiedene Wörterbücher und Thesauren können unterschiedliche Wortunterteilungen in Sinne ermöglichen.
Unterschiedliche Algorithmen für unterschiedliche Anwendungen
Ein weiteres Problem von WSD besteht darin, dass für verschiedene Anwendungen möglicherweise völlig unterschiedliche Algorithmen erforderlich sind. Bei der maschinellen Übersetzung erfolgt dies beispielsweise in Form einer Zielwortauswahl. und beim Abrufen von Informationen ist kein Sinnesinventar erforderlich.
Varianz zwischen Richtern
Ein weiteres Problem von WSD besteht darin, dass WSD-Systeme im Allgemeinen getestet werden, indem ihre Ergebnisse für eine Aufgabe mit der Aufgabe von Menschen verglichen werden. Dies wird als Problem der Interjudge-Varianz bezeichnet.
Wortsinndiskretion
Eine weitere Schwierigkeit bei WSD besteht darin, dass Wörter nicht einfach in diskrete Bedeutungen unterteilt werden können.
Das schwierigste Problem der KI besteht darin, die natürliche Sprache durch Computer zu verarbeiten, oder mit anderen Worten, die Verarbeitung natürlicher Sprache ist das schwierigste Problem der künstlichen Intelligenz. Wenn wir über die Hauptprobleme in NLP sprechen, dann ist eines der Hauptprobleme in NLP die Diskursverarbeitung - das Erstellen von Theorien und Modellen, wie Äußerungen zusammenhalten, um sich zu bildencoherent discourse. Tatsächlich besteht die Sprache immer aus zusammengestellten, strukturierten und zusammenhängenden Gruppen von Sätzen und nicht aus isolierten und nicht verwandten Sätzen wie Filmen. Diese zusammenhängenden Gruppen von Sätzen werden als Diskurs bezeichnet.
Konzept der Kohärenz
Kohärenz und Diskursstruktur sind auf vielfältige Weise miteinander verbunden. Kohärenz wird zusammen mit der Eigenschaft eines guten Textes verwendet, um die Ausgabequalität des Systems zur Erzeugung natürlicher Sprache zu bewerten. Hier stellt sich die Frage, was es bedeutet, dass ein Text kohärent ist. Angenommen, wir haben einen Satz von jeder Seite der Zeitung gesammelt. Wird es dann ein Diskurs sein? Natürlich nicht. Dies liegt daran, dass diese Sätze keine Kohärenz aufweisen. Der kohärente Diskurs muss folgende Eigenschaften besitzen:
Kohärenzbeziehung zwischen Äußerungen
Der Diskurs wäre kohärent, wenn er sinnvolle Verbindungen zwischen seinen Äußerungen hätte. Diese Eigenschaft wird als Kohärenzbeziehung bezeichnet. Zum Beispiel muss eine Erklärung vorhanden sein, um den Zusammenhang zwischen Äußerungen zu rechtfertigen.
Beziehung zwischen Entitäten
Eine weitere Eigenschaft, die einen Diskurs kohärent macht, ist, dass es eine bestimmte Art von Beziehung zu den Entitäten geben muss. Eine solche Art von Kohärenz wird als entitätsbasierte Kohärenz bezeichnet.
Diskursstruktur
Eine wichtige Frage zum Diskurs ist, welche Struktur der Diskurs haben muss. Die Antwort auf diese Frage hängt von der Segmentierung ab, die wir im Diskurs angewendet haben. Diskurssegmentierungen können definiert werden, um die Arten von Strukturen für einen großen Diskurs zu bestimmen. Es ist ziemlich schwierig, eine Diskurs-Segmentierung zu implementieren, aber es ist sehr wichtig fürinformation retrieval, text summarization and information extraction Art der Anwendungen.
Algorithmen zur Diskurssegmentierung
In diesem Abschnitt lernen wir die Algorithmen für die Diskurs-Segmentierung kennen. Die Algorithmen werden unten beschrieben -
Unüberwachte Diskurssegmentierung
Die Klasse der unbeaufsichtigten Diskurs-Segmentierung wird häufig als lineare Segmentierung dargestellt. Wir können die Aufgabe der linearen Segmentierung anhand eines Beispiels verstehen. In diesem Beispiel besteht die Aufgabe darin, den Text in Einheiten mit mehreren Absätzen zu segmentieren. Die Einheiten repräsentieren die Passage des Originaltextes. Diese Algorithmen hängen von der Kohäsion ab, die als die Verwendung bestimmter Sprachgeräte zum Zusammenbinden der Texteinheiten definiert werden kann. Andererseits ist die Lexikonkohäsion die Kohäsion, die durch die Beziehung zwischen zwei oder mehr Wörtern in zwei Einheiten wie die Verwendung von Synonymen angezeigt wird.
Supervised Discourse Segmentation
Die frühere Methode hat keine handbeschrifteten Segmentgrenzen. Andererseits muss die überwachte Diskurs-Segmentierung über grenzmarkierte Trainingsdaten verfügen. Es ist sehr einfach, dasselbe zu erwerben. Bei der überwachten Diskurs-Segmentierung spielen Diskursmarker oder Stichworte eine wichtige Rolle. Diskursmarker oder Stichwort ist ein Wort oder eine Phrase, die die Diskursstruktur signalisiert. Diese Diskursmarker sind domänenspezifisch.
Textkohärenz
Lexikalische Wiederholungen sind ein Weg, um die Struktur in einem Diskurs zu finden, erfüllen jedoch nicht die Anforderung, ein kohärenter Diskurs zu sein. Um den kohärenten Diskurs zu erreichen, müssen wir uns auf bestimmte Kohärenzbeziehungen konzentrieren. Wie wir wissen, definiert diese Kohärenzbeziehung den möglichen Zusammenhang zwischen Äußerungen in einem Diskurs. Hebb hat folgende Beziehungen vorgeschlagen:
Wir nehmen zwei Begriffe S0 und S1 die Bedeutung der beiden verwandten Sätze darstellen -
Ergebnis
Daraus folgt, dass der Staat durch Begriff behauptet S0 könnte den von behaupteten Zustand verursachen S1. Zum Beispiel zeigen zwei Aussagen das Ergebnis der Beziehung: Ram wurde im Feuer gefangen. Seine Haut brannte.
Erläuterung
Daraus folgt, dass der Staat von behauptet S1 könnte den von behaupteten Zustand verursachen S0. Zum Beispiel zeigen zwei Aussagen die Beziehung - Ram kämpfte mit Shyams Freund. Er war betrunken.
Parallel
Es schließt p (a1, a2,…) aus der Behauptung von S0 und p (b1, b2,…) aus der Behauptung S1. Hier sind ai und bi für alle i ähnlich. Zum Beispiel sind zwei Aussagen parallel - Ram wollte Auto. Shyam wollte Geld.
Ausarbeitung
Es leitet aus beiden Behauptungen den gleichen Satz P ab - S0 und S1Zum Beispiel zeigen zwei Aussagen die Ausarbeitung der Beziehung: Ram war aus Chandigarh. Shyam war aus Kerala.
Gelegenheit
Es passiert, wenn aus der Behauptung von eine Zustandsänderung abgeleitet werden kann S0, deren Endzustand abgeleitet werden kann S1und umgekehrt. Zum Beispiel zeigen die beiden Aussagen den Beziehungsanlass: Ram nahm das Buch auf. Er gab es Shyam.
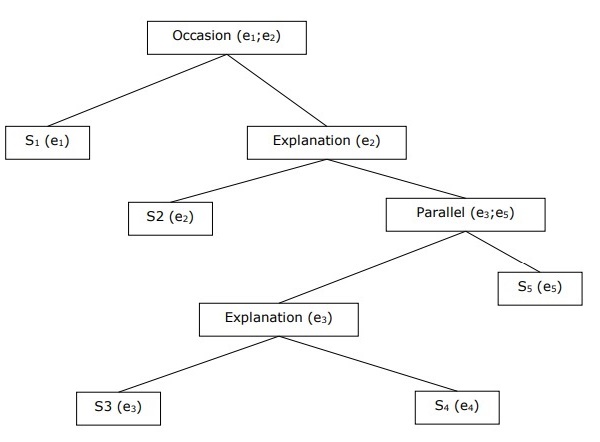
Aufbau einer hierarchischen Diskursstruktur
Die Kohärenz des gesamten Diskurses kann auch durch die hierarchische Struktur zwischen Kohärenzbeziehungen berücksichtigt werden. Zum Beispiel kann die folgende Passage als hierarchische Struktur dargestellt werden -
S1 - Ram ging zur Bank, um Geld einzuzahlen.
S2 - Dann fuhr er mit dem Zug zu Shyams Tuchladen.
S3 - Er wollte ein paar Klamotten kaufen.
S4 - Er hat keine neuen Kleider für die Party.
S5 - Er wollte auch mit Shyam über seine Gesundheit sprechen
Referenzauflösung
Die Interpretation der Sätze aus jedem Diskurs ist eine weitere wichtige Aufgabe. Um dies zu erreichen, müssen wir wissen, über wen oder welche Entität gesprochen wird. Hier ist die Interpretationsreferenz das Schlüsselelement.Referencekann als der sprachliche Ausdruck definiert werden, der eine Entität oder ein Individuum bezeichnet. Zum Beispiel sah Ram , der Manager der ABC Bank , seinen Freund Shyam in einem Geschäft. Er ging ihm entgegen, die sprachlichen Ausdrücke wie Ram, His, Er sind Referenz.
Aus dem gleichen Grund, reference resolution kann als die Aufgabe definiert werden, zu bestimmen, auf welche Entitäten von welchem sprachlichen Ausdruck Bezug genommen wird.
In der Referenzauflösung verwendete Terminologie
Wir verwenden die folgenden Terminologien für die Referenzauflösung:
Referring expression- Der Ausdruck in natürlicher Sprache, der zum Ausführen einer Referenz verwendet wird, wird als verweisender Ausdruck bezeichnet. Zum Beispiel ist die oben verwendete Passage ein verweisender Ausdruck.
Referent- Es ist die Entität, auf die verwiesen wird. Zum Beispiel ist Ram im zuletzt angegebenen Beispiel ein Referent.
Corefer- Wenn zwei Ausdrücke verwendet werden, um auf dieselbe Entität zu verweisen, werden sie als Corefer bezeichnet. Zum Beispiel,Ram und he sind Corefer.
Antecedent- Der Begriff hat die Lizenz, einen anderen Begriff zu verwenden. Zum Beispiel,Ram ist der Vorläufer der Referenz he.
Anaphora & Anaphoric- Es kann als Verweis auf eine Entität definiert werden, die zuvor in den Satz aufgenommen wurde. Und der verweisende Ausdruck heißt anaphorisch.
Discourse model - Das Modell, das die Darstellungen der Entitäten enthält, auf die im Diskurs Bezug genommen wurde, und die Beziehung, in der sie sich befinden.
Arten von verweisenden Ausdrücken
Lassen Sie uns nun die verschiedenen Arten von referenzierenden Ausdrücken sehen. Die fünf Arten von Verweisungsausdrücken werden nachfolgend beschrieben -
Unbestimmte Nominalphrasen
Eine solche Referenz repräsentiert die Entitäten, die für den Hörer neu im Diskurskontext sind. Zum Beispiel - in dem Satz, in dem Ram eines Tages herumgegangen war, um ihm etwas zu essen zu bringen - ist ein unbestimmter Hinweis.
Bestimmte Nominalphrasen
Im Gegensatz zu oben repräsentiert eine solche Referenz die Entitäten, die für den Hörer im Diskurskontext nicht neu oder identifizierbar sind. Zum Beispiel ist in dem Satz - ich habe The Times of India gelesen - The Times of India eine eindeutige Referenz.
Pronomen
Es ist eine Form der eindeutigen Bezugnahme. Zum Beispiel lachte Ram so laut er konnte. Das Worthe repräsentiert das Pronomen, das den Ausdruck bezieht.
Demonstranten
Diese demonstrieren und verhalten sich anders als einfache bestimmte Pronomen. Zum Beispiel sind dies und das Demonstrativpronomen.
Namen
Es ist die einfachste Art, auf einen Ausdruck zu verweisen. Es kann auch der Name einer Person, einer Organisation und eines Ortes sein. In den obigen Beispielen ist beispielsweise Ram der Name-Schiedsrichter-Ausdruck.
Aufgaben zur Referenzauflösung
Die beiden Aufgaben zur Referenzauflösung werden nachfolgend beschrieben.
Koreferenzauflösung
Es ist die Aufgabe, verweisende Ausdrücke in einem Text zu finden, die sich auf dieselbe Entität beziehen. Mit einfachen Worten, es ist die Aufgabe, Corefer-Ausdrücke zu finden. Eine Reihe von Coreferring-Ausdrücken wird als Coreference-Kette bezeichnet. Zum Beispiel - Er, Chief Manager und Sein - beziehen sich diese Ausdrücke auf die erste Passage, die als Beispiel gegeben wurde.
Einschränkung der Koreferenzauflösung
Im Englischen ist das Hauptproblem für die Auflösung von Koreferenzen das Pronomen it. Der Grund dafür ist, dass das Pronomen viele Verwendungszwecke hat. Zum Beispiel kann es sich ähnlich wie er und sie beziehen. Das Pronomen bezieht sich auch auf die Dinge, die sich nicht auf bestimmte Dinge beziehen. Zum Beispiel regnet es. Es ist wirklich gut.
Pronominal Anaphora Resolution
Im Gegensatz zur Koreferenzauflösung kann die Auflösung der pronominalen Anaphora als die Aufgabe definiert werden, den Vorgänger für ein einzelnes Pronomen zu finden. Zum Beispiel ist das Pronomen sein und die Aufgabe der pronominalen Anaphora-Auflösung besteht darin, das Wort Ram zu finden, weil Ram der Vorgänger ist.
Tagging ist eine Art Klassifizierung, die als automatische Zuordnung der Beschreibung zu den Token definiert werden kann. Hier wird der Deskriptor als Tag bezeichnet, das einen Teil der Sprache, semantische Informationen usw. darstellen kann.
Wenn wir nun über PoS-Tagging (Part-of-Speech) sprechen, kann dies als der Prozess definiert werden, bei dem dem angegebenen Wort einer der Wortteile zugewiesen wird. Es wird allgemein als POS-Tagging bezeichnet. In einfachen Worten können wir sagen, dass POS-Tagging eine Aufgabe ist, jedes Wort in einem Satz mit seinem entsprechenden Wortteil zu kennzeichnen. Wir wissen bereits, dass Teile der Sprache Substantive, Verben, Adverbien, Adjektive, Pronomen, Konjunktionen und deren Unterkategorien umfassen.
Der größte Teil des POS-Tagging fällt unter das POS-Tagging auf Regelbasis, das stochastische POS-Tagging und das transformationsbasierte Tagging.
Regelbasiertes POS-Tagging
Eine der ältesten Tagging-Techniken ist das regelbasierte POS-Tagging. Regelbasierte Tagger verwenden Wörterbuch oder Lexikon, um mögliche Tags zum Markieren jedes Wortes zu erhalten. Wenn das Wort mehr als ein mögliches Tag hat, verwenden regelbasierte Tagger handgeschriebene Regeln, um das richtige Tag zu identifizieren. Die Disambiguierung kann auch beim regelbasierten Markieren durchgeführt werden, indem die sprachlichen Merkmale eines Wortes zusammen mit seinen vorhergehenden und folgenden Wörtern analysiert werden. Angenommen, das vorhergehende Wort eines Wortes ist ein Artikel, dann muss das Wort ein Substantiv sein.
Wie der Name schon sagt, werden alle derartigen Informationen beim regelbasierten POS-Tagging in Form von Regeln codiert. Diese Regeln können entweder sein -
Kontextmusterregeln
Oder, als regulärer Ausdruck in Automaten mit endlichen Zuständen kompiliert, mit lexikalisch mehrdeutiger Satzdarstellung geschnitten.
Wir können das regelbasierte POS-Tagging auch an seiner zweistufigen Architektur verstehen -
First stage - In der ersten Phase wird ein Wörterbuch verwendet, um jedem Wort eine Liste potenzieller Wortarten zuzuweisen.
Second stage - In der zweiten Stufe werden große Listen handgeschriebener Disambiguierungsregeln verwendet, um die Liste für jedes Wort in einen einzelnen Wortteil zu sortieren.
Eigenschaften der regelbasierten POS-Kennzeichnung
Regelbasierte POS-Tagger besitzen die folgenden Eigenschaften:
Diese Tagger sind wissensbasierte Tagger.
Die Regeln für das regelbasierte POS-Tagging werden manuell erstellt.
Die Informationen werden in Form von Regeln codiert.
Wir haben eine begrenzte Anzahl von Regeln, ungefähr 1000.
Glättung und Sprachmodellierung werden in regelbasierten Taggern explizit definiert.
Stochastisches POS-Tagging
Eine andere Technik des Markierens ist das stochastische POS-Markieren. Hier stellt sich nun die Frage, welches Modell stochastisch sein kann. Das Modell, das Häufigkeit oder Wahrscheinlichkeit (Statistik) enthält, kann als stochastisch bezeichnet werden. Eine beliebige Anzahl verschiedener Ansätze für das Problem des Teil-der-Sprache-Markierens kann als stochastischer Tagger bezeichnet werden.
Der einfachste stochastische Tagger wendet die folgenden Ansätze für das POS-Tagging an:
Worthäufigkeitsansatz
Bei diesem Ansatz unterscheiden die stochastischen Tagger die Wörter basierend auf der Wahrscheinlichkeit, dass ein Wort mit einem bestimmten Tag auftritt. Wir können auch sagen, dass das Tag, das am häufigsten mit dem Wort im Trainingssatz angetroffen wird, dasjenige ist, das einer mehrdeutigen Instanz dieses Wortes zugewiesen ist. Das Hauptproblem bei diesem Ansatz ist, dass es zu einer unzulässigen Folge von Tags kommen kann.
Tag-Sequenzwahrscheinlichkeiten
Es ist ein weiterer Ansatz des stochastischen Markierens, bei dem der Markierer die Wahrscheinlichkeit des Auftretens einer bestimmten Folge von Markierungen berechnet. Es wird auch als n-Gramm-Ansatz bezeichnet. Es wird so genannt, weil das beste Tag für ein gegebenes Wort durch die Wahrscheinlichkeit bestimmt wird, mit der es bei den n vorherigen Tags auftritt.
Eigenschaften der stochastischen POST-Markierung
Stochastische POS-Tagger besitzen die folgenden Eigenschaften:
Diese POS-Kennzeichnung basiert auf der Wahrscheinlichkeit des Auftretens einer Kennzeichnung.
Es erfordert Trainingskorpus
Es würde keine Wahrscheinlichkeit für die Wörter geben, die nicht im Korpus existieren.
Es werden verschiedene Testkorpus (außer Trainingskorpus) verwendet.
Es ist das einfachste POS-Tagging, da es die häufigsten Tags auswählt, die einem Wort im Trainingskorpus zugeordnet sind.
Transformationsbasiertes Tagging
Transformationsbasiertes Tagging wird auch als Brill-Tagging bezeichnet. Es ist eine Instanz des transformationsbasierten Lernens (TBL), eines regelbasierten Algorithmus zum automatischen Markieren des POS für den angegebenen Text. TBL ermöglicht es uns, Sprachkenntnisse in lesbarer Form zu haben, und transformiert einen Zustand mithilfe von Transformationsregeln in einen anderen Zustand.
Es lässt sich von den beiden zuvor erläuterten Taggern inspirieren - regelbasiert und stochastisch. Wenn wir eine Ähnlichkeit zwischen regelbasiertem und Transformations-Tagger sehen, basiert sie wie regelbasiert auch auf den Regeln, die angeben, welche Tags welchen Wörtern zugewiesen werden müssen. Wenn wir andererseits Ähnlichkeiten zwischen stochastischem und Transformations-Tagger sehen, dann ist es wie bei stochastischen eine maschinelle Lerntechnik, bei der Regeln automatisch aus Daten induziert werden.
Arbeiten des transformationsbasierten Lernens (TBL)
Um die Funktionsweise und das Konzept transformationsbasierter Tagger zu verstehen, müssen wir die Funktionsweise transformationsbasierten Lernens verstehen. Beachten Sie die folgenden Schritte, um die Funktionsweise von TBL zu verstehen:
Start with the solution - Die TBL beginnt normalerweise mit einer Lösung des Problems und arbeitet in Zyklen.
Most beneficial transformation chosen - In jedem Zyklus wählt TBL die vorteilhafteste Transformation.
Apply to the problem - Die im letzten Schritt ausgewählte Transformation wird auf das Problem angewendet.
Der Algorithmus stoppt, wenn die ausgewählte Transformation in Schritt 2 weder mehr Wert hinzufügt noch keine Transformationen mehr ausgewählt werden müssen. Eine solche Art des Lernens eignet sich am besten für Klassifizierungsaufgaben.
Vorteile des transformationsbasierten Lernens (TBL)
Die Vorteile von TBL sind wie folgt:
Wir lernen einen kleinen Satz einfacher Regeln und diese Regeln reichen zum Markieren aus.
Entwicklung und Debugging sind in TBL sehr einfach, da die erlernten Regeln leicht zu verstehen sind.
Die Komplexität beim Markieren wird verringert, da in TBL maschinell erlernte und vom Menschen generierte Regeln miteinander verflochten sind.
Transformationsbasierter Tagger ist viel schneller als Markov-Modell-Tagger.
Nachteile des transformationsbasierten Lernens (TBL)
Die Nachteile von TBL sind wie folgt:
Transformationsbasiertes Lernen (TBL) bietet keine Tag-Wahrscheinlichkeiten.
In TBL ist die Trainingszeit besonders bei großen Korpora sehr lang.
POS-Tagging mit verstecktem Markov-Modell (HMM)
Bevor wir uns eingehend mit dem HMM-POS-Tagging befassen, müssen wir das Konzept des Hidden Markov Model (HMM) verstehen.
Verstecktes Markov-Modell
Ein HMM-Modell kann als doppelt eingebettetes stochastisches Modell definiert werden, bei dem der zugrunde liegende stochastische Prozess verborgen ist. Dieser verborgene stochastische Prozess kann nur durch eine andere Reihe von stochastischen Prozessen beobachtet werden, die die Folge von Beobachtungen erzeugen.
Beispiel
Zum Beispiel wird eine Sequenz von Experimenten zum Werfen versteckter Münzen durchgeführt, und wir sehen nur die Beobachtungssequenz, die aus Kopf und Zahl besteht. Die tatsächlichen Details des Prozesses - wie viele Münzen verwendet wurden, in welcher Reihenfolge sie ausgewählt wurden - sind uns verborgen. Durch Beobachtung dieser Abfolge von Kopf und Zahl können wir mehrere HMMs erstellen, um die Abfolge zu erklären. Es folgt eine Form des Hidden Markov-Modells für dieses Problem:

Wir haben angenommen, dass es im HMM zwei Zustände gibt und jeder der Zustände der Auswahl einer unterschiedlichen vorgespannten Münze entspricht. Die folgende Matrix gibt die Zustandsübergangswahrscheinlichkeiten an -
$$A = \begin{bmatrix}a11 & a12 \\a21 & a22 \end{bmatrix}$$
Hier,
aij = Wahrscheinlichkeit des Übergangs von einem Zustand in einen anderen von i nach j.
a11 + a12= 1 und a 21 + a 22 = 1
P1 = Wahrscheinlichkeit der Köpfe der ersten Münze, dh die Vorspannung der ersten Münze.
P2 = Wahrscheinlichkeit der Köpfe der zweiten Münze, dh die Vorspannung der zweiten Münze.
Wir können auch ein HMM-Modell erstellen, vorausgesetzt, es gibt 3 oder mehr Münzen.
Auf diese Weise können wir HMM anhand der folgenden Elemente charakterisieren:
N die Anzahl der Zustände im Modell (im obigen Beispiel N = 2, nur zwei Zustände).
M, die Anzahl unterschiedlicher Beobachtungen, die mit jedem Zustand im obigen Beispiel auftreten können M = 2, dh H oder T).
A, die Zustandsübergangswahrscheinlichkeitsverteilung - die Matrix A im obigen Beispiel.
P die Wahrscheinlichkeitsverteilung der beobachtbaren Symbole in jedem Zustand (in unserem Beispiel P1 und P2).
Ich, die Ausgangszustandsverteilung.
Verwendung von HMM für die POS-Kennzeichnung
Der POS-Tagging-Prozess ist der Prozess des Findens der Sequenz von Tags, die höchstwahrscheinlich eine bestimmte Wortsequenz erzeugt hat. Wir können diesen POS-Prozess mithilfe eines Hidden Markov-Modells (HMM) modellierentags sind die hidden states das brachte die observable output, dh die words.
Mathematisch gesehen sind wir beim POS-Tagging immer daran interessiert, eine Tag-Sequenz (C) zu finden, die -
P (C|W)
Wo,
C = C 1 , C 2 , C 3 ... C T.
W = W 1 , W 2 , W 3 , W T.
Auf der anderen Seite der Medaille ist die Tatsache, dass wir viele statistische Daten benötigen, um solche Sequenzen vernünftig abzuschätzen. Um das Problem zu vereinfachen, können wir jedoch einige mathematische Transformationen zusammen mit einigen Annahmen anwenden.
Die Verwendung von HMM zur Durchführung eines POS-Tags ist ein Sonderfall der Bayes'schen Interferenz. Daher werden wir das Problem zunächst mit der Bayes-Regel wiederholen, die besagt, dass die oben erwähnte bedingte Wahrscheinlichkeit gleich - ist
(PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT)) / PROB (W1,..., WT)
In all diesen Fällen können wir den Nenner eliminieren, da wir daran interessiert sind, die Sequenz C zu finden, die den obigen Wert maximiert. Dies hat keinen Einfluss auf unsere Antwort. Jetzt reduziert sich unser Problem darauf, die Sequenz C zu finden, die maximiert -
PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT) (1)
Selbst nach dem Reduzieren des Problems im obigen Ausdruck würde es eine große Datenmenge erfordern. Wir können vernünftige Unabhängigkeitsannahmen über die beiden Wahrscheinlichkeiten im obigen Ausdruck treffen, um das Problem zu überwinden.
Erste Annahme
Die Wahrscheinlichkeit eines Tags hängt vom vorherigen (Bigram-Modell) oder den vorherigen zwei (Trigramm-Modell) oder vorherigen n-Tags (n-Gramm-Modell) ab, was mathematisch wie folgt erklärt werden kann:
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-n+1…Ci-1) (n-gram model)
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-1) (bigram model)
Der Beginn eines Satzes kann berücksichtigt werden, indem für jedes Tag eine Anfangswahrscheinlichkeit angenommen wird.
PROB (C1|C0) = PROB initial (C1)
Zweite Annahme
Die zweite Wahrscheinlichkeit in Gleichung (1) oben kann angenähert werden, indem angenommen wird, dass ein Wort in einer Kategorie erscheint, die von den Wörtern in den vorhergehenden oder nachfolgenden Kategorien unabhängig ist, was mathematisch wie folgt erklärt werden kann:
PROB (W1,..., WT | C1,..., CT) = Πi=1..T PROB (Wi|Ci)
Auf der Grundlage der beiden oben genannten Annahmen reduziert sich unser Ziel darauf, eine Sequenz C zu finden, die maximiert
Πi=1...T PROB(Ci|Ci-1) * PROB(Wi|Ci)
Die Frage, die sich hier stellt, ist, ob die Konvertierung des Problems in die obige Form uns wirklich geholfen hat. Die Antwort lautet - ja, das hat es. Wenn wir einen großen markierten Korpus haben, können die beiden Wahrscheinlichkeiten in der obigen Formel wie folgt berechnet werden:
PROB (Ci=VERB|Ci-1=NOUN) = (# of instances where Verb follows Noun) / (# of instances where Noun appears) (2)
PROB (Wi|Ci) = (# of instances where Wi appears in Ci) /(# of instances where Ci appears) (3)
In diesem Kapitel werden wir den Beginn der natürlichen Sprache in der Verarbeitung natürlicher Sprache diskutieren. Lassen Sie uns zunächst verstehen, was Grammatik in natürlicher Sprache ist.
Grammatik der natürlichen Sprache
Für die Linguistik ist Sprache eine Gruppe willkürlicher Stimmzeichen. Wir können sagen, dass Sprache kreativ ist, von Regeln regiert wird, sowohl angeboren als auch universell zugleich. Auf der anderen Seite ist es auch menschlich. Die Art der Sprache ist für verschiedene Menschen unterschiedlich. Es gibt viele Missverständnisse über die Natur der Sprache. Deshalb ist es sehr wichtig, die Bedeutung des mehrdeutigen Begriffs zu verstehen‘grammar’. In der Linguistik kann der Begriff Grammatik als die Regeln oder Prinzipien definiert werden, mit deren Hilfe die Sprache funktioniert. Im weitesten Sinne können wir die Grammatik in zwei Kategorien einteilen -
Beschreibende Grammatik
Das Regelwerk, in dem Linguistik und Grammatiker die Grammatik des Sprechers formulieren, wird als beschreibende Grammatik bezeichnet.
Perspektivische Grammatik
Es ist ein ganz anderer Sinn für Grammatik, der versucht, einen Standard der Korrektheit in der Sprache aufrechtzuerhalten. Diese Kategorie hat wenig mit der tatsächlichen Arbeitsweise der Sprache zu tun.
Komponenten der Sprache
Die Sprache des Studiums ist in die miteinander verbundenen Komponenten unterteilt, die sowohl konventionelle als auch willkürliche Unterteilungen der sprachlichen Untersuchung sind. Die Erklärung dieser Komponenten lautet wie folgt:
Phonologie
Die allererste Komponente der Sprache ist die Phonologie. Es ist das Studium der Sprachlaute einer bestimmten Sprache. Der Ursprung des Wortes kann auf die griechische Sprache zurückgeführt werden, wobei "Telefon" Ton oder Stimme bedeutet. Phonetik, eine Unterteilung der Phonologie, ist das Studium der Sprachlaute der menschlichen Sprache aus der Perspektive ihrer Produktion, Wahrnehmung oder ihrer physikalischen Eigenschaften. IPA (International Phonetic Alphabet) ist ein Werkzeug, das menschliche Klänge während des Studiums der Phonologie regelmäßig darstellt. In IPA repräsentiert jedes geschriebene Symbol einen und nur einen Sprachton und umgekehrt.
Phoneme
Es kann als eine der Toneinheiten definiert werden, die ein Wort in einer Sprache von einem anderen unterscheiden. In der Sprache werden Phoneme zwischen Schrägstrichen geschrieben. Zum Beispiel Phonem/k/ kommt in den Wörtern wie Kit, Sketch vor.
Morphologie
Es ist die zweite Komponente der Sprache. Es ist das Studium der Struktur und Klassifizierung der Wörter in einer bestimmten Sprache. Der Ursprung des Wortes liegt in der griechischen Sprache, wo das Wort "Morphe" "Form" bedeutet. Die Morphologie berücksichtigt die Prinzipien der Wortbildung in einer Sprache. Mit anderen Worten, wie Klänge zu sinnvollen Einheiten wie Präfixen, Suffixen und Wurzeln kombiniert werden. Es wird auch berücksichtigt, wie Wörter in Wortarten gruppiert werden können.
Lexeme
In der Linguistik wird die abstrakte Einheit der morphologischen Analyse, die einer Reihe von Formen eines einzelnen Wortes entspricht, als Lexem bezeichnet. Die Art und Weise, wie ein Lexem in einem Satz verwendet wird, wird durch seine grammatikalische Kategorie bestimmt. Lexem kann ein einzelnes Wort oder ein Mehrwort sein. Zum Beispiel ist das Wort Talk ein Beispiel für ein einzelnes Wortlexem, das viele grammatikalische Varianten wie Talk, Talked und Talking haben kann. Das Mehrwortlexem kann aus mehr als einem orthografischen Wort bestehen. Zum Beispiel sind Sprechen, Durchziehen usw. Beispiele für Mehrwortlexeme.
Syntax
Es ist die dritte Komponente der Sprache. Es ist das Studium der Reihenfolge und Anordnung der Wörter in größeren Einheiten. Das Wort kann auf die griechische Sprache zurückgeführt werden, wo das Wort suntassein "in Ordnung bringen" bedeutet. Es untersucht die Art der Sätze und ihre Struktur, die Klauseln, die Phrasen.
Semantik
Es ist die vierte Komponente der Sprache. Es ist das Studium, wie Bedeutung vermittelt wird. Die Bedeutung kann sich auf die Außenwelt oder auf die Grammatik des Satzes beziehen. Das Wort kann auf die griechische Sprache zurückgeführt werden, wobei das Wort semainein "bedeuten", "zeigen", "signalisieren" bedeutet.
Pragmatik
Es ist die fünfte Komponente der Sprache. Es ist das Studium der Funktionen der Sprache und ihrer Verwendung im Kontext. Der Ursprung des Wortes kann auf die griechische Sprache zurückgeführt werden, wo das Wort "Pragma" "Tat", "Affäre" bedeutet.
Grammatische Kategorien
Eine grammatikalische Kategorie kann als eine Klasse von Einheiten oder Merkmalen innerhalb der Grammatik einer Sprache definiert werden. Diese Einheiten sind die Bausteine der Sprache und haben eine Reihe gemeinsamer Merkmale. Grammatische Kategorien werden auch als grammatikalische Merkmale bezeichnet.
Das Inventar der grammatikalischen Kategorien wird unten beschrieben -
Nummer
Es ist die einfachste grammatikalische Kategorie. Wir haben zwei Begriffe, die sich auf diese Kategorie beziehen - Singular und Plural. Singular ist das Konzept von "Eins", während Plural das Konzept von "Mehr als Eins" ist. Zum Beispiel Hund / Hunde, dies / diese.
Geschlecht
Das grammatikalische Geschlecht wird durch Variation der Personalpronomen und der 3. Person ausgedrückt. Beispiele für grammatikalische Geschlechter sind einzigartig - er, sie, es; die erste und zweite Person bilden sich - ich, wir und du; Die Pluralform der 3. Person ist entweder das gemeinsame Geschlecht oder das neutrale Geschlecht.
Person
Eine andere einfache grammatikalische Kategorie ist Person. Darunter werden folgende drei Begriffe anerkannt:
1st person - Die Person, die spricht, wird als 1. Person anerkannt.
2nd person - Die Person, die der Hörer ist oder mit der gesprochen wird, wird als 2. Person anerkannt.
3rd person - Die Person oder Sache, über die wir sprechen, wird als 3. Person anerkannt.
Fall
Es ist eine der schwierigsten grammatikalischen Kategorien. Es kann als Hinweis auf die Funktion einer Nominalphrase (NP) oder die Beziehung einer Nominalphrase zu einem Verb oder zu den anderen Nominalphrasen im Satz definiert werden. Wir haben die folgenden drei Fälle in Personal- und Interrogativpronomen ausgedrückt:
Nominative case- Es ist die Funktion des Subjekts. Zum Beispiel ich, wir, du, er, sie, es, sie und die nominativ sind.
Genitive case- Es ist die Funktion des Besitzers. Zum Beispiel mein / mein, unser / unser, sein, ihr / ihr, sein, ihr / ihr, dessen Genitiv sind.
Objective case- Es ist die Funktion des Objekts. Zum Beispiel ich, wir, du, er, sie, sie, die objektiv sind.
Grad
Diese grammatikalische Kategorie bezieht sich auf Adjektive und Adverbien. Es hat die folgenden drei Begriffe -
Positive degree- Es drückt eine Qualität aus. Zum Beispiel sind groß, schnell, schön positive Grade.
Comparative degree- Es drückt einen höheren Grad oder eine höhere Intensität der Qualität in einem von zwei Elementen aus. Zum Beispiel sind größere, schnellere und schönere Vergleichsgrade.
Superlative degree- Es drückt den größten Grad oder die größte Intensität der Qualität in einem von drei oder mehr Elementen aus. Zum Beispiel sind die größten, schnellsten und schönsten Abschlüsse der Superlative.
Bestimmtheit und Unbestimmtheit
Beide Konzepte sind sehr einfach. Die uns bekannte Bestimmtheit stellt einen Referenten dar, der dem Sprecher oder Hörer bekannt, vertraut oder identifizierbar ist. Andererseits stellt Unbestimmtheit einen Referenten dar, der nicht bekannt oder unbekannt ist. Das Konzept kann im gleichzeitigen Auftreten eines Artikels mit einem Substantiv verstanden werden -
definite article- die
indefinite article- a / an
Tempus
Diese grammatikalische Kategorie bezieht sich auf das Verb und kann als sprachliche Angabe der Zeit einer Handlung definiert werden. Eine Zeitform stellt eine Beziehung her, weil sie den Zeitpunkt eines Ereignisses in Bezug auf den Moment des Sprechens angibt. Im Allgemeinen handelt es sich um die folgenden drei Typen:
Present tense- Repräsentiert das Auftreten einer Aktion im gegenwärtigen Moment. Zum Beispiel arbeitet Ram hart.
Past tense- Repräsentiert das Auftreten einer Aktion vor dem gegenwärtigen Moment. Zum Beispiel hat es geregnet.
Future tense- Repräsentiert das Auftreten einer Aktion nach dem gegenwärtigen Moment. Zum Beispiel wird es regnen.
Aspekt
Diese grammatikalische Kategorie kann als die Ansicht eines Ereignisses definiert werden. Es kann von den folgenden Typen sein -
Perfective aspect − The view is taken as whole and complete in the aspect. For example, the simple past tense like yesterday I met my friend, in English is perfective in aspect as it views the event as complete and whole.
Imperfective aspect − The view is taken as ongoing and incomplete in the aspect. For example, the present participle tense like I am working on this problem, in English is imperfective in aspect as it views the event as incomplete and ongoing.
Mood
This grammatical category is a bit difficult to define but it can be simply stated as the indication of the speaker’s attitude towards what he/she is talking about. It is also the grammatical feature of verbs. It is distinct from grammatical tenses and grammatical aspect. The examples of moods are indicative, interrogative, imperative, injunctive, subjunctive, potential, optative, gerunds and participles.
Agreement
It is also called concord. It happens when a word changes from depending on the other words to which it relates. In other words, it involves making the value of some grammatical category agree between different words or part of speech. Followings are the agreements based on other grammatical categories −
Agreement based on Person − It is the agreement between subject and the verb. For example, we always use “I am” and “He is” but never “He am” and “I is”.
Agreement based on Number − This agreement is between subject and the verb. In this case, there are specific verb forms for first person singular, second person plural and so on. For example, 1st person singular: I really am, 2nd person plural: We really are, 3rd person singular: The boy sings, 3rd person plural: The boys sing.
Agreement based on Gender − In English, there is agreement in gender between pronouns and antecedents. For example, He reached his destination. The ship reached her destination.
Agreement based on Case − This kind of agreement is not a significant feature of English. For example, who came first − he or his sister?
Spoken Language Syntax
The written English and spoken English grammar have many common features but along with that, they also differ in a number of aspects. The following features distinguish between the spoken and written English grammar −
Disfluencies and Repair
This striking feature makes spoken and written English grammar different from each other. It is individually known as phenomena of disfluencies and collectively as phenomena of repair. Disfluencies include the use of following −
Fillers words − Sometimes in between the sentence, we use some filler words. They are called fillers of filler pause. Examples of such words are uh and um.
Reparandum and repair − The repeated segment of words in between the sentence is called reparandum. In the same segment, the changed word is called repair. Consider the following example to understand this −
Does ABC airlines offer any one-way flights uh one-way fares for 5000 rupees?
In the above sentence, one-way flight is a reparadum and one-way flights is a repair.
Restarts
After the filler pause, restarts occurs. For example, in the above sentence, restarts occur when the speaker starts asking about one-way flights then stops, correct himself by filler pause and then restarting asking about one-way fares.
Word Fragments
Sometimes we speak the sentences with smaller fragments of words. For example, wwha-what is the time? Here the words w-wha are word fragments.
Information retrieval (IR) may be defined as a software program that deals with the organization, storage, retrieval and evaluation of information from document repositories particularly textual information. The system assists users in finding the information they require but it does not explicitly return the answers of the questions. It informs the existence and location of documents that might consist of the required information. The documents that satisfy user’s requirement are called relevant documents. A perfect IR system will retrieve only relevant documents.
With the help of the following diagram, we can understand the process of information retrieval (IR) −

Aus dem obigen Diagramm geht hervor, dass ein Benutzer, der Informationen benötigt, eine Anfrage in Form einer Abfrage in natürlicher Sprache formulieren muss. Anschließend antwortet das IR-System, indem es die relevante Ausgabe in Form von Dokumenten zu den erforderlichen Informationen abruft.
Klassisches Problem im Information Retrieval (IR) System
Das Hauptziel der IR-Forschung ist die Entwicklung eines Modells zum Abrufen von Informationen aus den Repositories von Dokumenten. Hier diskutieren wir ein klassisches Problem namensad-hoc retrieval problem, bezogen auf das IR-System.
Beim Ad-hoc-Abruf muss der Benutzer eine Abfrage in natürlicher Sprache eingeben, die die erforderlichen Informationen beschreibt. Anschließend gibt das IR-System die erforderlichen Dokumente zu den gewünschten Informationen zurück. Angenommen, wir suchen etwas im Internet und es werden einige genaue Seiten angezeigt, die gemäß unserer Anforderung relevant sind, es können jedoch auch einige nicht relevante Seiten vorhanden sein. Dies ist auf das Ad-hoc-Abrufproblem zurückzuführen.
Aspekte des Ad-hoc-Abrufs
Im Folgenden sind einige Aspekte des Ad-hoc-Abrufs aufgeführt, die in der IR-Forschung behandelt werden:
Wie können Benutzer mithilfe von Relevanz-Feedback die ursprüngliche Formulierung einer Abfrage verbessern?
Wie implementiere ich das Zusammenführen von Datenbanken, dh wie können Ergebnisse aus verschiedenen Textdatenbanken zu einer Ergebnismenge zusammengeführt werden?
Wie gehe ich mit teilweise beschädigten Daten um? Welche Modelle eignen sich dafür?
IR-Modell (Information Retrieval)
Mathematisch werden Modelle in vielen wissenschaftlichen Bereichen verwendet, um ein Phänomen in der realen Welt zu verstehen. Ein Modell zum Abrufen von Informationen sagt voraus und erklärt, was ein Benutzer für die gegebene Abfrage relevant findet. Das IR-Modell ist im Grunde ein Muster, das die oben genannten Aspekte des Abrufverfahrens definiert und aus Folgendem besteht:
Ein Modell für Dokumente.
Ein Modell für Abfragen.
Eine Übereinstimmungsfunktion, die Abfragen mit Dokumenten vergleicht.
Mathematisch besteht ein Abrufmodell aus -
D - Vertretung für Dokumente.
R - Darstellung für Anfragen.
F - Das Modellierungsgerüst für D, Q zusammen mit der Beziehung zwischen ihnen.
R (q,di)- Eine Ähnlichkeitsfunktion, die die Dokumente in Bezug auf die Abfrage ordnet. Es wird auch als Ranking bezeichnet.
Arten des Information Retrieval (IR) -Modells
Ein Informationsmodell (IR) kann in die folgenden drei Modelle eingeteilt werden:
Klassisches IR-Modell
Es ist das einfachste und am einfachsten zu implementierende IR-Modell. Dieses Modell basiert auf mathematischen Kenntnissen, die ebenfalls leicht zu erkennen und zu verstehen waren. Boolean, Vector und Probabilistic sind die drei klassischen IR-Modelle.
Nicht klassisches IR-Modell
Es ist völlig entgegengesetzt zum klassischen IR-Modell. Solche IR-Modelle basieren auf anderen Prinzipien als Ähnlichkeit, Wahrscheinlichkeit und Booleschen Operationen. Informationslogikmodell, Situationstheoretisches Modell und Interaktionsmodelle sind Beispiele für nicht klassisches IR-Modell.
Alternatives IR-Modell
Es ist die Verbesserung des klassischen IR-Modells unter Verwendung einiger spezifischer Techniken aus einigen anderen Bereichen. Cluster-Modell, Fuzzy-Modell und LSI-Modelle (Latent Semantic Indexing) sind Beispiele für alternative IR-Modelle.
Konstruktionsmerkmale von Information Retrieval (IR) -Systemen
Lassen Sie uns nun die Konstruktionsmerkmale von IR-Systemen kennenlernen -
Invertierter Index
Die primäre Datenstruktur der meisten IR-Systeme besteht aus einem invertierten Index. Wir können einen invertierten Index als Datenstruktur definieren, die für jedes Wort alle Dokumente auflistet, die ihn enthalten, und die Häufigkeit der Vorkommen im Dokument. Es macht es einfach, nach "Treffern" eines Abfrageworts zu suchen.
Stoppen Sie die Worteliminierung
Stoppwörter sind solche Hochfrequenzwörter, die für die Suche als unwahrscheinlich erachtet werden. Sie haben weniger semantische Gewichte. Alle diese Arten von Wörtern befinden sich in einer Liste, die als Stoppliste bezeichnet wird. Beispielsweise sind Artikel „a“, „an“, „the“ und Präpositionen wie „in“, „of“, „for“, „at“ usw. Beispiele für Stoppwörter. Die Größe des invertierten Index kann durch die Stoppliste erheblich reduziert werden. Gemäß dem Zipf-Gesetz reduziert eine Stoppliste mit einigen Dutzend Wörtern die Größe des invertierten Index um fast die Hälfte. Andererseits kann die Eliminierung von Stoppwörtern manchmal zur Eliminierung des Begriffs führen, der für die Suche nützlich ist. Wenn wir beispielsweise das Alphabet „A“ aus „Vitamin A“ streichen, hat dies keine Bedeutung.
Stemming
Stemming, die vereinfachte Form der morphologischen Analyse, ist der heuristische Prozess des Extrahierens der Grundform von Wörtern durch Abhacken der Wortenden. Zum Beispiel würden die Wörter Lachen, Lachen, Lachen auf das Wurzelwort Lachen zurückgeführt.
In unseren folgenden Abschnitten werden wir einige wichtige und nützliche IR-Modelle diskutieren.
Das Boolesche Modell
Es ist das älteste Information Retrieval (IR) -Modell. Das Modell basiert auf der Mengenlehre und der Booleschen Algebra, wobei Dokumente Mengen von Begriffen und Abfragen Boolesche Ausdrücke von Begriffen sind. Das Boolesche Modell kann definiert werden als -
D- Eine Reihe von Wörtern, dh die in einem Dokument enthaltenen Indexbegriffe. Hier ist jeder Term entweder vorhanden (1) oder nicht vorhanden (0).
Q - Ein boolescher Ausdruck, bei dem Begriffe die Indexbegriffe und Operatoren logische Produkte sind - UND, logische Summe - ODER und logische Differenz - NICHT
F - Boolesche Algebra über Sätze von Begriffen sowie über Sätze von Dokumenten
Wenn wir über das Relevanz-Feedback sprechen, kann die Relevanz-Vorhersage im Booleschen IR-Modell wie folgt definiert werden:
R - Ein Dokument wird genau dann als relevant für den Abfrageausdruck vorhergesagt, wenn es den Abfrageausdruck erfüllt als -
((˅) ˄ ˄ ˜ ˜)
Wir können dieses Modell durch einen Abfragebegriff als eindeutige Definition einer Reihe von Dokumenten erklären.
Zum Beispiel der Abfragebegriff “economic” Definiert die Gruppe von Dokumenten, die mit dem Begriff indiziert sind “economic”.
Was wäre nun das Ergebnis nach der Kombination von Begriffen mit Boolean AND Operator? Es wird ein Dokumentensatz definiert, der kleiner oder gleich den Dokumentensätzen eines der einzelnen Begriffe ist. Zum Beispiel die Abfrage mit Begriffen“social” und “economic”erstellt den Dokumentensatz von Dokumenten, die mit beiden Begriffen indiziert sind. Mit anderen Worten, Dokumentensatz mit dem Schnittpunkt beider Sätze.
Was wäre nun das Ergebnis nach der Kombination von Begriffen mit dem Booleschen ODER-Operator? Es wird ein Dokumentensatz definiert, der größer oder gleich den Dokumentensätzen eines der einzelnen Begriffe ist. Zum Beispiel die Abfrage mit Begriffen“social” oder “economic” erstellt den Dokumentensatz von Dokumenten, die entweder mit dem Begriff indiziert sind “social” oder “economic”. Mit anderen Worten, Dokumentensatz mit der Vereinigung beider Sätze.
Vorteile des Booleschen Modus
Die Vorteile des Booleschen Modells sind folgende:
Das einfachste Modell, das auf Mengen basiert.
Einfach zu verstehen und umzusetzen.
Es werden nur genaue Übereinstimmungen abgerufen
Es gibt dem Benutzer ein Gefühl der Kontrolle über das System.
Nachteile des Booleschen Modells
Die Nachteile des Booleschen Modells sind wie folgt:
Die Ähnlichkeitsfunktion des Modells ist Boolesch. Daher würde es keine Teilübereinstimmungen geben. Dies kann für die Benutzer ärgerlich sein.
In diesem Modell hat die Verwendung des Booleschen Operators viel mehr Einfluss als ein kritisches Wort.
Die Abfragesprache ist ausdrucksstark, aber auch kompliziert.
Kein Ranking für abgerufene Dokumente.
Vektorraummodell
Aufgrund der oben genannten Nachteile des Booleschen Modells schlugen Gerard Salton und seine Kollegen ein Modell vor, das auf Luhns Ähnlichkeitskriterium basiert. Das von Luhn formulierte Ähnlichkeitskriterium besagt: "Je mehr zwei Darstellungen in bestimmten Elementen und ihrer Verteilung vereinbart wurden, desto höher wäre die Wahrscheinlichkeit, dass sie ähnliche Informationen darstellen."
Berücksichtigen Sie die folgenden wichtigen Punkte, um mehr über das Vektorraummodell zu erfahren:
Die Indexdarstellungen (Dokumente) und die Abfragen werden als Vektoren betrachtet, die in einen hochdimensionalen euklidischen Raum eingebettet sind.
Das Ähnlichkeitsmaß eines Dokumentvektors mit einem Abfragevektor ist normalerweise der Kosinus des Winkels zwischen ihnen.
Kosinus-Ähnlichkeitsmaßformel
Cosinus ist ein normalisiertes Punktprodukt, das mit Hilfe der folgenden Formel berechnet werden kann:
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
Vektorraumdarstellung mit Abfrage und Dokument
Die Abfrage und die Dokumente werden durch einen zweidimensionalen Vektorraum dargestellt. Die Bedingungen sindcar und insurance. Es gibt eine Abfrage und drei Dokumente im Vektorraum.

Das Dokument mit dem höchsten Rang als Antwort auf die Bedingungen Auto und Versicherung ist das Dokument d2 weil der Winkel zwischen q und d2ist der kleinste. Der Grund dafür ist, dass sowohl die Konzepte Auto als auch Versicherung in d 2 hervorstechen und daher die hohen Gewichte haben. Auf der anderen Seite,d1 und d3 Erwähnen Sie auch beide Begriffe, aber in jedem Fall ist einer von ihnen kein zentral wichtiger Begriff im Dokument.
Termgewichtung
Termgewichtung bedeutet die Gewichtung der Terme im Vektorraum. Je höher das Gewicht des Begriffs ist, desto größer wäre die Auswirkung des Begriffs auf den Kosinus. Den wichtigeren Begriffen im Modell sollten mehr Gewichte zugewiesen werden. Hier stellt sich nun die Frage, wie wir dies modellieren können.
Eine Möglichkeit, dies zu tun, besteht darin, die Wörter in einem Dokument als Begriffsgewicht zu zählen. Glauben Sie jedoch, dass dies eine effektive Methode wäre?
Eine andere Methode, die effektiver ist, ist die Verwendung term frequency (tfij), document frequency (dfi) und collection frequency (cfi).
Laufzeit (tf ij )
Es kann als die Anzahl der Vorkommen von definiert werden wi im dj. Die Information, die durch die Termhäufigkeit erfasst wird, ist, wie hervorstechend ein Wort innerhalb des gegebenen Dokuments ist, oder mit anderen Worten, wir können sagen, dass je höher die Termhäufigkeit ist, desto mehr ist dieses Wort eine gute Beschreibung des Inhalts dieses Dokuments.
Dokumentenhäufigkeit (df i )
Es kann definiert werden als die Gesamtzahl der Dokumente in der Sammlung, in der w i vorkommt. Es ist ein Indikator für Informativität. Semantisch fokussierte Wörter kommen im Dokument im Gegensatz zu semantisch nicht fokussierten Wörtern mehrmals vor.
Sammelhäufigkeit (vgl. I )
Es kann definiert werden als die Gesamtzahl der Vorkommen von wi in der Sammlung.
Mathematisch, $df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
Formen der Dokumentenfrequenzgewichtung
Lassen Sie uns nun die verschiedenen Formen der Gewichtung von Dokumentenhäufigkeiten kennenlernen. Die Formulare werden unten beschrieben -
Laufzeitfrequenzfaktor
Dies wird auch als Termfrequenzfaktor klassifiziert, was bedeutet, dass wenn ein Term t erscheint oft in einem Dokument dann eine Abfrage mit tsollte dieses Dokument abrufen. Wir können Wörter kombinierenterm frequency (tfij) und document frequency (dfi) in ein einzelnes Gewicht wie folgt -
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
Hier ist N die Gesamtzahl der Dokumente.
Inverse Dokumentfrequenz (idf)
Dies ist eine andere Form der Dokumenthäufigkeitsgewichtung, die häufig als IDF-Gewichtung oder inverse Dokumenthäufigkeitsgewichtung bezeichnet wird. Der wichtige Punkt der IDF-Gewichtung ist, dass die Knappheit des Begriffs in der gesamten Sammlung ein Maß für seine Bedeutung ist und die Bedeutung umgekehrt proportional zur Häufigkeit des Auftretens ist.
Mathematisch,
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
Hier,
N = Dokumente in der Sammlung
n t = Dokumente mit dem Begriff t
Verbesserung der Benutzerabfrage
Das Hauptziel eines Informationsabrufsystems muss die Genauigkeit sein - relevante Dokumente gemäß den Anforderungen des Benutzers zu erstellen. Hier stellt sich jedoch die Frage, wie wir die Ausgabe verbessern können, indem wir den Abfragestil des Benutzers verbessern. Natürlich hängt die Ausgabe eines IR-Systems von der Abfrage des Benutzers ab, und eine gut formatierte Abfrage führt zu genaueren Ergebnissen. Der Benutzer kann seine Abfrage mit Hilfe von verbessernrelevance feedback, ein wichtiger Aspekt jedes IR-Modells.
Relevanz Feedback
Das Relevanz-Feedback übernimmt die Ausgabe, die ursprünglich von der angegebenen Abfrage zurückgegeben wurde. Diese anfängliche Ausgabe kann verwendet werden, um Benutzerinformationen zu sammeln und um festzustellen, ob diese Ausgabe für die Durchführung einer neuen Abfrage relevant ist oder nicht. Die Rückmeldungen können wie folgt klassifiziert werden:
Explizites Feedback
Es kann als das Feedback definiert werden, das von den relevanten Assessoren erhalten wird. Diese Prüfer geben auch die Relevanz eines aus der Abfrage abgerufenen Dokuments an. Um die Leistung beim Abrufen von Abfragen zu verbessern, müssen die Relevanz-Feedback-Informationen mit der ursprünglichen Abfrage interpoliert werden.
Assessoren oder andere Benutzer des Systems können die Relevanz explizit angeben, indem sie die folgenden Relevanzsysteme verwenden:
Binary relevance system - Dieses Relevanz-Feedback-System zeigt an, dass ein Dokument für eine bestimmte Abfrage entweder relevant (1) oder irrelevant (0) ist.
Graded relevance system- Das Bewertungssystem für die Bewertung der Relevanz gibt die Relevanz eines Dokuments für eine bestimmte Abfrage auf der Grundlage der Bewertung anhand von Zahlen, Buchstaben oder Beschreibungen an. Die Beschreibung kann wie "nicht relevant", "etwas relevant", "sehr relevant" oder "relevant" sein.
Implizites Feedback
Es ist das Feedback, das aus dem Benutzerverhalten abgeleitet wird. Das Verhalten umfasst die Zeitdauer, die der Benutzer für das Anzeigen eines Dokuments aufgewendet hat, welches Dokument zum Anzeigen ausgewählt ist und welches nicht, Aktionen zum Durchsuchen und Scrollen von Seiten usw. Eines der besten Beispiele für implizites Feedback istdwell timeDies ist ein Maß dafür, wie viel Zeit ein Benutzer damit verbringt, die in einem Suchergebnis verknüpfte Seite anzuzeigen.
Pseudo-Feedback
Es wird auch als blindes Feedback bezeichnet. Es bietet eine Methode zur automatischen lokalen Analyse. Der manuelle Teil des Relevanz-Feedbacks wird mithilfe des Pseudo-Relevanz-Feedbacks automatisiert, sodass der Benutzer eine verbesserte Abrufleistung ohne erweiterte Interaktion erhält. Der Hauptvorteil dieses Feedback-Systems besteht darin, dass keine Bewerter wie im expliziten Relevanz-Feedback-System erforderlich sind.
Beachten Sie die folgenden Schritte, um dieses Feedback zu implementieren:
Step 1- Zunächst muss das von der ersten Abfrage zurückgegebene Ergebnis als relevantes Ergebnis verwendet werden. Der Bereich der relevanten Ergebnisse muss in den Top 10-50 Ergebnissen liegen.
Step 2 - Wählen Sie nun die besten 20 bis 30 Begriffe aus den Dokumenten aus, indem Sie beispielsweise die Häufigkeit der Termhäufigkeit (tf) und die Häufigkeit der inversen Dokumenthäufigkeit (idf) verwenden.
Step 3- Fügen Sie diese Begriffe zur Abfrage hinzu und stimmen Sie mit den zurückgegebenen Dokumenten überein. Senden Sie dann die relevantesten Dokumente zurück.
Natural Language Processing (NLP) ist eine aufstrebende Technologie, die verschiedene Formen der KI ableitet, die wir in der heutigen Zeit sehen. Ihre Verwendung zur Schaffung einer nahtlosen und interaktiven Schnittstelle zwischen Mensch und Maschine wird für heute und morgen weiterhin oberste Priorität haben zunehmend kognitive Anwendungen. Hier werden wir einige der sehr nützlichen Anwendungen von NLP diskutieren.
Maschinenübersetzung
Die maschinelle Übersetzung (MT), das Übersetzen einer Ausgangssprache oder eines Textes in eine andere Sprache, ist eine der wichtigsten Anwendungen von NLP. Wir können den Prozess der maschinellen Übersetzung anhand des folgenden Flussdiagramms verstehen:
Arten von maschinellen Übersetzungssystemen
Es gibt verschiedene Arten von maschinellen Übersetzungssystemen. Lassen Sie uns sehen, was die verschiedenen Typen sind.
Zweisprachiges MT-System
Zweisprachige MT-Systeme erzeugen Übersetzungen zwischen zwei bestimmten Sprachen.
Mehrsprachiges MT-System
Mehrsprachige MT-Systeme erzeugen Übersetzungen zwischen einem beliebigen Sprachpaar. Sie können entweder unidirektional oder bidirektional sein.
Ansätze zur maschinellen Übersetzung (MT)
Lassen Sie uns nun die wichtigen Ansätze der maschinellen Übersetzung kennenlernen. Die Ansätze für MT sind wie folgt:
Direkter MT-Ansatz
Es ist weniger beliebt, aber der älteste Ansatz von MT. Die Systeme, die diesen Ansatz verwenden, können SL (Ausgangssprache) direkt in TL (Zielsprache) übersetzen. Solche Systeme sind zweisprachig und unidirektional.
Interlingua-Ansatz
Die Systeme, die den Interlingua-Ansatz verwenden, übersetzen SL in eine Zwischensprache namens Interlingua (IL) und übersetzen dann IL in TL. Der Interlingua-Ansatz kann mit Hilfe der folgenden MT-Pyramide verstanden werden:

Transferansatz
Dieser Ansatz umfasst drei Phasen.
In der ersten Phase werden SL-Texte (Source Language) in abstrakte SL-orientierte Darstellungen konvertiert.
In der zweiten Stufe werden SL-orientierte Darstellungen in äquivalente Zielsprachen (TL) -orientierte Darstellungen konvertiert.
In der dritten Stufe wird der endgültige Text generiert.
Empirischer MT-Ansatz
Dies ist ein aufstrebender Ansatz für MT. Grundsätzlich werden große Mengen an Rohdaten in Form von parallelen Korpora verwendet. Die Rohdaten bestehen aus dem Text und ihren Übersetzungen. Analogiebasierte, beispielbasierte, speicherbasierte maschinelle Übersetzungstechniken verwenden empirische MTapproach.
Kampf gegen Spam
Eines der häufigsten Probleme dieser Tage sind unerwünschte E-Mails. Umso wichtiger sind Spam-Filter, da dies die erste Verteidigungslinie gegen dieses Problem ist.
Das Spam-Filtersystem kann mithilfe der NLP-Funktionalität unter Berücksichtigung der wichtigsten falsch-positiven und falsch-negativen Probleme entwickelt werden.
Bestehende NLP-Modelle für die Spam-Filterung
Im Folgenden sind einige vorhandene NLP-Modelle für die Spam-Filterung aufgeführt:
N-Gramm-Modellierung
Ein N-Gramm-Modell ist ein N-Zeichen-Slice einer längeren Zeichenfolge. In diesem Modell werden N-Gramm unterschiedlicher Länge gleichzeitig zur Verarbeitung und Erkennung von Spam-E-Mails verwendet.
Wortstemming
Spammer, Generatoren von Spam-E-Mails, ändern normalerweise ein oder mehrere Zeichen angreifender Wörter in ihren Spam-Mails, sodass sie gegen inhaltsbasierte Spam-Filter verstoßen können. Aus diesem Grund können wir sagen, dass inhaltsbasierte Filter nicht nützlich sind, wenn sie die Bedeutung der Wörter oder Ausdrücke in der E-Mail nicht verstehen können. Um solche Probleme bei der Spam-Filterung zu beseitigen, wurde eine regelbasierte Wortstamming-Technik entwickelt, mit der Wörter übereinstimmen können, die gleich aussehen und gleich klingen.
Bayesianische Klassifikation
Dies ist mittlerweile eine weit verbreitete Technologie für die Spam-Filterung. Die Häufigkeit der Wörter in einer E-Mail wird anhand ihres typischen Vorkommens in einer Datenbank mit unerwünschten (Spam) und legitimen (Ham) E-Mail-Nachrichten in einer statistischen Technik gemessen.
Automatische Zusammenfassung
In diesem digitalen Zeitalter sind Daten oder Informationen das Wertvollste. Werden wir jedoch wirklich nützlich und erhalten die erforderliche Menge an Informationen? Die Antwort lautet "NEIN", da die Informationen überladen sind und unser Zugang zu Wissen und Informationen unsere Fähigkeit, sie zu verstehen, bei weitem übersteigt. Wir brauchen dringend eine automatische Zusammenfassung und Information von Texten, da die Informationsflut über das Internet nicht aufhören wird.
Textzusammenfassung kann als die Technik definiert werden, um eine kurze, genaue Zusammenfassung längerer Textdokumente zu erstellen. Die automatische Zusammenfassung von Texten hilft uns, relevante Informationen in kürzerer Zeit zu erhalten. Die Verarbeitung natürlicher Sprache (NLP) spielt eine wichtige Rolle bei der Entwicklung einer automatischen Textzusammenfassung.
Beantwortung von Fragen
Eine weitere Hauptanwendung der Verarbeitung natürlicher Sprache (NLP) ist die Beantwortung von Fragen. Suchmaschinen haben die Informationen der Welt immer zur Hand, aber es fehlt ihnen immer noch, wenn es darum geht, die Fragen der Menschen in ihrer natürlichen Sprache zu beantworten. Wir haben große Tech-Unternehmen wie Google, die ebenfalls in diese Richtung arbeiten.
Das Beantworten von Fragen ist eine Informatikdisziplin in den Bereichen KI und NLP. Es konzentriert sich auf Gebäudesysteme, die automatisch Fragen beantworten, die von Menschen in ihrer natürlichen Sprache gestellt werden. Ein Computersystem, das die natürliche Sprache versteht, hat die Fähigkeit eines Programmsystems, die vom Menschen geschriebenen Sätze in eine interne Darstellung zu übersetzen, so dass die gültigen Antworten vom System generiert werden können. Die genauen Antworten können durch Syntax und semantische Analyse der Fragen generiert werden. Lexikalische Lücke, Mehrdeutigkeit und Mehrsprachigkeit sind einige der Herausforderungen für NLP beim Aufbau eines guten Systems zur Beantwortung von Fragen.
Stimmungsanalyse
Eine weitere wichtige Anwendung der Verarbeitung natürlicher Sprache (NLP) ist die Stimmungsanalyse. Wie der Name schon sagt, wird die Stimmungsanalyse verwendet, um die Gefühle zwischen mehreren Posts zu identifizieren. Es wird auch verwendet, um das Gefühl zu identifizieren, bei dem die Emotionen nicht explizit ausgedrückt werden. Unternehmen verwenden die Stimmungsanalyse, eine Anwendung der Verarbeitung natürlicher Sprache (NLP), um die Meinung und Stimmung ihrer Kunden online zu ermitteln. Es wird Unternehmen helfen, zu verstehen, was ihre Kunden über die Produkte und Dienstleistungen denken. Unternehmen können anhand von Stimmungsanalysen ihre allgemeine Reputation anhand von Kundenbeiträgen beurteilen. Auf diese Weise können wir sagen, dass die Stimmungsanalyse über die Bestimmung der einfachen Polarität hinaus die Gefühle im Kontext versteht, um besser zu verstehen, was hinter der geäußerten Meinung steckt.
In diesem Kapitel lernen wir die Sprachverarbeitung mit Python kennen.
Die folgenden Funktionen unterscheiden Python von anderen Sprachen:
Python is interpreted - Wir müssen unser Python-Programm nicht kompilieren, bevor wir es ausführen, da der Interpreter Python zur Laufzeit verarbeitet.
Interactive - Wir können direkt mit dem Interpreter interagieren, um unsere Python-Programme zu schreiben.
Object-oriented - Python ist objektorientiert und erleichtert das Schreiben von Programmen in dieser Sprache, da mit Hilfe dieser Programmiertechnik Code in Objekten eingekapselt wird.
Beginner can easily learn - Python wird auch als Anfängersprache bezeichnet, da es sehr leicht zu verstehen ist und die Entwicklung einer Vielzahl von Anwendungen unterstützt.
Voraussetzungen
Die neueste Version von Python 3 ist Python 3.7.1 und ist für Windows, Mac OS und die meisten Varianten von Linux verfügbar.
Für Windows können wir unter dem Link www.python.org/downloads/windows/ Python herunterladen und installieren.
Für MAC OS können wir den Link www.python.org/downloads/mac-osx/ verwenden .
Im Falle von Linux verwenden verschiedene Linux-Varianten unterschiedliche Paketmanager für die Installation neuer Pakete.
Um beispielsweise Python 3 unter Ubuntu Linux zu installieren, können Sie den folgenden Befehl vom Terminal aus verwenden:
$sudo apt-get install python3-minimalUm mehr über die Python-Programmierung zu erfahren, lesen Sie das grundlegende Tutorial zu Python 3 - Python 3
Erste Schritte mit NLTK
Wir werden die Python-Bibliothek NLTK (Natural Language Toolkit) für die Textanalyse in englischer Sprache verwenden. Das Natural Language Toolkit (NLTK) ist eine Sammlung von Python-Bibliotheken, die speziell zum Identifizieren und Kennzeichnen von Wortarten entwickelt wurden, die im Text natürlicher Sprache wie Englisch enthalten sind.
NLTK installieren
Bevor wir NLTK verwenden können, müssen wir es installieren. Mit Hilfe des folgenden Befehls können wir ihn in unserer Python-Umgebung installieren -
pip install nltkWenn wir Anaconda verwenden, kann mit dem folgenden Befehl ein Conda-Paket für NLTK erstellt werden:
conda install -c anaconda nltkHerunterladen der NLTK-Daten
Nach der Installation von NLTK besteht eine weitere wichtige Aufgabe darin, die voreingestellten Textrepositorys herunterzuladen, damit sie problemlos verwendet werden können. Vorher müssen wir jedoch NLTK so importieren, wie wir jedes andere Python-Modul importieren. Der folgende Befehl hilft uns beim Importieren von NLTK -
import nltkLaden Sie jetzt NLTK-Daten mit Hilfe des folgenden Befehls herunter:
nltk.download()Es wird einige Zeit dauern, bis alle verfügbaren NLTK-Pakete installiert sind.
Andere notwendige Pakete
Einige andere Python-Pakete mögen gensim und patternsind auch sehr wichtig für die Textanalyse sowie für die Erstellung von Anwendungen zur Verarbeitung natürlicher Sprache mithilfe von NLTK. Die Pakete können wie unten gezeigt installiert werden -
Gensim
gensim ist eine robuste semantische Modellierungsbibliothek, die für viele Anwendungen verwendet werden kann. Wir können es installieren, indem wir den folgenden Befehl ausführen:
pip install gensimMuster
Es kann verwendet werden, um zu machen gensimPaket funktioniert richtig. Der folgende Befehl hilft bei der Installation von pattern -
pip install patternTokenisierung
Tokenisierung kann als der Prozess des Aufteilens des angegebenen Textes in kleinere Einheiten definiert werden, die als Token bezeichnet werden. Wörter, Zahlen oder Satzzeichen können Token sein. Es kann auch als Wortsegmentierung bezeichnet werden.
Beispiel
Input - Bett und Stuhl sind Arten von Möbeln.

Wir haben verschiedene Pakete für die Tokenisierung, die von NLTK bereitgestellt werden. Wir können diese Pakete basierend auf unseren Anforderungen verwenden. Die Pakete und die Details ihrer Installation sind wie folgt:
Paket sent_tokenize
Mit diesem Paket kann der Eingabetext in Sätze unterteilt werden. Wir können es mit dem folgenden Befehl importieren:
from nltk.tokenize import sent_tokenizeword_tokenize-Paket
Dieses Paket kann verwendet werden, um den eingegebenen Text in Wörter zu unterteilen. Wir können es mit dem folgenden Befehl importieren:
from nltk.tokenize import word_tokenizeWordPunctTokenizer-Paket
Dieses Paket kann verwendet werden, um den eingegebenen Text in Wörter und Satzzeichen zu unterteilen. Wir können es mit dem folgenden Befehl importieren:
from nltk.tokenize import WordPuncttokenizerStemming
Aus grammatikalischen Gründen enthält die Sprache viele Variationen. Variationen in dem Sinne, dass die Sprache, sowohl Englisch als auch andere Sprachen, unterschiedliche Formen eines Wortes haben. Zum Beispiel mögen die Wörterdemocracy, democratic, und democratization. Für maschinelle Lernprojekte ist es sehr wichtig, dass Maschinen verstehen, dass diese verschiedenen Wörter wie oben dieselbe Grundform haben. Deshalb ist es sehr nützlich, die Grundformen der Wörter während der Analyse des Textes zu extrahieren.
Stemming ist ein heuristischer Prozess, der beim Extrahieren der Grundformen der Wörter durch Zerhacken ihrer Enden hilft.
Die verschiedenen Pakete für das Stemming, die vom NLTK-Modul bereitgestellt werden, lauten wie folgt:
PorterStemmer-Paket
Der Porter-Algorithmus wird von diesem Stemming-Paket verwendet, um die Grundform der Wörter zu extrahieren. Mit Hilfe des folgenden Befehls können wir dieses Paket importieren -
from nltk.stem.porter import PorterStemmerZum Beispiel, ‘write’ wäre die Ausgabe des Wortes ‘writing’ als Eingabe für diesen Stemmer angegeben.
LancasterStemmer-Paket
Der Lancaster-Algorithmus wird von diesem Stemming-Paket verwendet, um die Grundform der Wörter zu extrahieren. Mit Hilfe des folgenden Befehls können wir dieses Paket importieren -
from nltk.stem.lancaster import LancasterStemmerZum Beispiel, ‘writ’ wäre die Ausgabe des Wortes ‘writing’ als Eingabe für diesen Stemmer angegeben.
SnowballStemmer-Paket
Der Schneeball-Algorithmus wird von diesem Stemming-Paket verwendet, um die Grundform der Wörter zu extrahieren. Mit Hilfe des folgenden Befehls können wir dieses Paket importieren -
from nltk.stem.snowball import SnowballStemmerZum Beispiel, ‘write’ wäre die Ausgabe des Wortes ‘writing’ als Eingabe für diesen Stemmer angegeben.
Lemmatisierung
Es ist eine andere Möglichkeit, die Grundform von Wörtern zu extrahieren, die normalerweise darauf abzielt, Flexionsenden mithilfe von Vokabeln und morphologischen Analysen zu entfernen. Nach der Lemmatisierung heißt die Grundform eines Wortes Lemma.
Das NLTK-Modul bietet das folgende Paket für die Lemmatisierung:
WordNetLemmatizer-Paket
Dieses Paket extrahiert die Grundform des Wortes, je nachdem, ob es als Substantiv oder als Verb verwendet wird. Der folgende Befehl kann zum Importieren dieses Pakets verwendet werden:
from nltk.stem import WordNetLemmatizerPOS-Tags zählen - Chunking
Die Identifizierung von Wortarten (POS) und kurzen Phrasen kann mit Hilfe von Chunking erfolgen. Es ist einer der wichtigsten Prozesse in der Verarbeitung natürlicher Sprache. Da wir uns des Prozesses der Tokenisierung für die Erstellung von Token bewusst sind, besteht das Chunking tatsächlich darin, diese Token zu kennzeichnen. Mit anderen Worten, wir können sagen, dass wir die Struktur des Satzes mit Hilfe des Chunking-Prozesses erhalten können.
Beispiel
Im folgenden Beispiel implementieren wir das Nunk-Phrase-Chunking, eine Chunking-Kategorie, bei der die Nomen-Phrasen-Chunks im Satz mithilfe des NLTK-Python-Moduls gefunden werden.
Betrachten Sie die folgenden Schritte, um das Chunking von Nominalphrasen zu implementieren:
Step 1: Chunk grammar definition
In diesem Schritt müssen wir die Grammatik für das Chunking definieren. Es würde aus den Regeln bestehen, denen wir folgen müssen.
Step 2: Chunk parser creation
Als nächstes müssen wir einen Chunk-Parser erstellen. Es würde die Grammatik analysieren und die Ausgabe geben.
Step 3: The Output
In diesem Schritt erhalten wir die Ausgabe in einem Baumformat.
Ausführen des NLP-Skripts
Importieren Sie zunächst das NLTK-Paket -
import nltkJetzt müssen wir den Satz definieren.
Hier,
DT ist die Determinante
VBP ist das Verb
JJ ist das Adjektiv
IN ist die Präposition
NN ist das Substantiv
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Als nächstes sollte die Grammatik in Form eines regulären Ausdrucks angegeben werden.
grammar = "NP:{<DT>?<JJ>*<NN>}"Jetzt müssen wir einen Parser zum Parsen der Grammatik definieren.
parser_chunking = nltk.RegexpParser(grammar)Jetzt analysiert der Parser den Satz wie folgt:
parser_chunking.parse(sentence)Als nächstes wird die Ausgabe in der Variablen wie folgt sein: -
Output = parser_chunking.parse(sentence)Der folgende Code hilft Ihnen nun, Ihre Ausgabe in Form eines Baums zu zeichnen.
output.draw()