Verarbeitung natürlicher Sprache - Einführung
Sprache ist eine Kommunikationsmethode, mit deren Hilfe wir sprechen, lesen und schreiben können. Wir denken zum Beispiel, wir treffen Entscheidungen, Pläne und mehr in natürlicher Sprache. genau in Worten. Die große Frage, mit der wir uns in dieser KI-Ära konfrontiert sehen, ist jedoch, ob wir auf ähnliche Weise mit Computern kommunizieren können. Mit anderen Worten, können Menschen mit Computern in ihrer natürlichen Sprache kommunizieren? Es ist eine Herausforderung für uns, NLP-Anwendungen zu entwickeln, da Computer strukturierte Daten benötigen, die menschliche Sprache jedoch unstrukturiert und häufig mehrdeutig ist.
In diesem Sinne können wir sagen, dass die Verarbeitung natürlicher Sprache (NLP) das Teilgebiet der Informatik ist, insbesondere der künstlichen Intelligenz (KI), das sich darum bemüht, Computern das Verständnis und die Verarbeitung der menschlichen Sprache zu ermöglichen. Technisch gesehen wäre die Hauptaufgabe von NLP die Programmierung von Computern zur Analyse und Verarbeitung großer Mengen von Daten in natürlicher Sprache.
Geschichte der NLP
Wir haben die Geschichte der NLP in vier Phasen unterteilt. Die Phasen haben unterschiedliche Anliegen und Stile.
Erste Phase (maschinelle Übersetzungsphase) - Ende der 1940er bis Ende der 1960er Jahre
Die in dieser Phase geleistete Arbeit konzentrierte sich hauptsächlich auf maschinelle Übersetzung (MT). Diese Phase war eine Zeit der Begeisterung und des Optimismus.
Lassen Sie uns jetzt alles sehen, was die erste Phase in sich hatte -
Die Forschung zu NLP begann Anfang der 1950er Jahre nach der Untersuchung von Booth & Richens und dem Memorandum von Weaver über maschinelle Übersetzung im Jahr 1949.
1954 war das Jahr, in dem im Georgetown-IBM-Experiment ein begrenztes Experiment zur automatischen Übersetzung vom Russischen ins Englische demonstriert wurde.
Im selben Jahr begann die Veröffentlichung der Zeitschrift MT (Machine Translation).
Die erste internationale Konferenz über maschinelle Übersetzung (MT) fand 1952 und die zweite 1956 statt.
1961 war die auf der Teddington International Conference über maschinelle Übersetzung von Sprachen und angewandte Sprache vorgestellte Arbeit der Höhepunkt dieser Phase.
Zweite Phase (AI-beeinflusste Phase) - Ende der 1960er bis Ende der 1970er Jahre
In dieser Phase bezog sich die geleistete Arbeit hauptsächlich auf das Weltwissen und seine Rolle bei der Konstruktion und Manipulation von Bedeutungsrepräsentationen. Aus diesem Grund wird diese Phase auch als Phase mit AI-Geschmack bezeichnet.
Die Phase hatte Folgendes:
Anfang 1961 begannen die Arbeiten zu den Problemen der Adressierung und Erstellung von Daten oder Wissensdatenbanken. Diese Arbeit wurde von AI beeinflusst.
Im selben Jahr wurde auch ein BASEBALL-Frage-Antwort-System entwickelt. Die Eingabe in dieses System war eingeschränkt und die Sprachverarbeitung war einfach.
Ein weit fortgeschrittenes System wurde in Minsky (1968) beschrieben. Dieses System wurde im Vergleich zum BASEBALL-Frage-Antwort-System erkannt und berücksichtigt, um Rückschlüsse auf die Wissensbasis bei der Interpretation und Beantwortung von Spracheingaben zu erhalten.
Dritte Phase (grammatikalisch-logische Phase) - Ende der 1970er bis Ende der 1980er Jahre
Diese Phase kann als grammatikalisch-logische Phase bezeichnet werden. Aufgrund des Scheiterns des praktischen Systemaufbaus in der letzten Phase wandten sich die Forscher der Verwendung von Logik zur Darstellung und Argumentation von Wissen in der KI zu.
Die dritte Phase hatte Folgendes:
Der grammatikalisch-logische Ansatz gegen Ende des Jahrzehnts half uns mit leistungsstarken Allzweck-Satzprozessoren wie der SRI Core Language Engine und der Discourse Representation Theory, die ein Mittel zur Bewältigung eines erweiterten Diskurses darstellten.
In dieser Phase erhielten wir einige praktische Ressourcen und Tools wie Parser, z. B. Alvey Natural Language Tools, sowie betrieblichere und kommerziellere Systeme, z. B. für Datenbankabfragen.
Die Arbeit am Lexikon in den 1980er Jahren wies auch in Richtung eines grammatikalisch-logischen Ansatzes.
Vierte Phase (Lexical & Corpus Phase) - Die 1990er Jahre
Wir können dies als eine lexikalische & Korpusphase beschreiben. Die Phase hatte eine lexikalisierte Herangehensweise an die Grammatik, die Ende der 1980er Jahre erschien und zunehmend an Einfluss gewann. In diesem Jahrzehnt gab es eine Revolution in der Verarbeitung natürlicher Sprache mit der Einführung von Algorithmen für maschinelles Lernen für die Sprachverarbeitung.
Studium der menschlichen Sprachen
Sprache ist eine entscheidende Komponente für das menschliche Leben und auch der grundlegendste Aspekt unseres Verhaltens. Wir können es hauptsächlich in zwei Formen erleben - schriftlich und mündlich. In schriftlicher Form ist es eine Möglichkeit, unser Wissen von einer Generation zur nächsten weiterzugeben. In der gesprochenen Form ist es das primäre Medium für den Menschen, sich in seinem täglichen Verhalten miteinander zu koordinieren. Die Sprache wird in verschiedenen akademischen Disziplinen studiert. Jede Disziplin hat ihre eigenen Probleme und eine Lösung, um diese anzugehen.
Betrachten Sie die folgende Tabelle, um dies zu verstehen:
| Disziplin | Probleme | Werkzeuge |
|---|---|---|
Sprachwissenschaftler |
Wie können Phrasen und Sätze mit Wörtern gebildet werden? Was schränkt die mögliche Bedeutung eines Satzes ein? |
Intuitionen über Wohlgeformtheit und Bedeutung. Mathematisches Strukturmodell. Zum Beispiel modelltheoretische Semantik, formale Sprachtheorie. |
Psycholinguisten |
Wie können Menschen die Struktur von Sätzen identifizieren? Wie kann die Bedeutung von Wörtern identifiziert werden? Wann findet Verständnis statt? |
Experimentelle Techniken hauptsächlich zur Messung der Leistung von Menschen. Statistische Analyse von Beobachtungen. |
Philosophen |
Wie bekommen Wörter und Sätze die Bedeutung? Wie werden die Objekte durch die Wörter identifiziert? Was ist die Bedeutung? |
Argumentation in natürlicher Sprache unter Verwendung von Intuition. Mathematische Modelle wie Logik und Modelltheorie. |
Computerlinguisten |
Wie können wir die Struktur eines Satzes identifizieren? Wie können Wissen und Argumentation modelliert werden? Wie können wir Sprache verwenden, um bestimmte Aufgaben zu erfüllen? |
Algorithmen Datenstrukturen Formale Repräsentations- und Argumentationsmodelle. KI-Techniken wie Such- und Darstellungsmethoden. |
Mehrdeutigkeit und Unsicherheit in der Sprache
Mehrdeutigkeit, die im Allgemeinen bei der Verarbeitung natürlicher Sprache verwendet wird, kann als die Fähigkeit bezeichnet werden, auf mehr als eine Weise verstanden zu werden. In einfachen Worten können wir sagen, dass Mehrdeutigkeit die Fähigkeit ist, auf mehr als eine Weise verstanden zu werden. Die natürliche Sprache ist sehr vieldeutig. NLP weist die folgenden Arten von Mehrdeutigkeiten auf:
Lexikalische Mehrdeutigkeit
Die Mehrdeutigkeit eines einzelnen Wortes wird als lexikalische Mehrdeutigkeit bezeichnet. Zum Beispiel das Wort behandelnsilver als Substantiv, Adjektiv oder Verb.
Syntaktische Mehrdeutigkeit
Diese Art von Mehrdeutigkeit tritt auf, wenn ein Satz auf unterschiedliche Weise analysiert wird. Zum Beispiel der Satz „Der Mann hat das Mädchen mit dem Teleskop gesehen“. Es ist nicht eindeutig, ob der Mann das Mädchen mit einem Teleskop gesehen hat oder ob er sie durch sein Teleskop gesehen hat.
Semantische Mehrdeutigkeit
Diese Art von Mehrdeutigkeit tritt auf, wenn die Bedeutung der Wörter selbst falsch interpretiert werden kann. Mit anderen Worten, semantische Mehrdeutigkeit tritt auf, wenn ein Satz ein mehrdeutiges Wort oder eine mehrdeutige Phrase enthält. Zum Beispiel ist der Satz „Das Auto hat die Stange getroffen, während es sich bewegte“ semantisch mehrdeutig, da die Interpretationen lauten können: „Das Auto hat während der Bewegung die Stange getroffen“ und „Das Auto hat die Stange getroffen, während sich die Stange bewegt hat“.
Anaphorische Mehrdeutigkeit
Diese Art von Mehrdeutigkeit entsteht durch die Verwendung von Anaphora-Entitäten im Diskurs. Zum Beispiel rannte das Pferd den Hügel hinauf. Es war sehr steil. Es wurde bald müde. Hier verursacht der anaphorische Bezug von „es“ in zwei Situationen Mehrdeutigkeiten.
Pragmatische Mehrdeutigkeit
Eine solche Mehrdeutigkeit bezieht sich auf die Situation, in der der Kontext einer Phrase mehrere Interpretationen ergibt. Mit einfachen Worten können wir sagen, dass pragmatische Mehrdeutigkeit entsteht, wenn die Aussage nicht spezifisch ist. Zum Beispiel kann der Satz „Ich mag dich auch“ mehrere Interpretationen haben, wie ich dich mag (genau wie du mich magst), ich mag dich (genau wie jemand anderes dosiert).
NLP-Phasen
Das folgende Diagramm zeigt die Phasen oder logischen Schritte bei der Verarbeitung natürlicher Sprache -
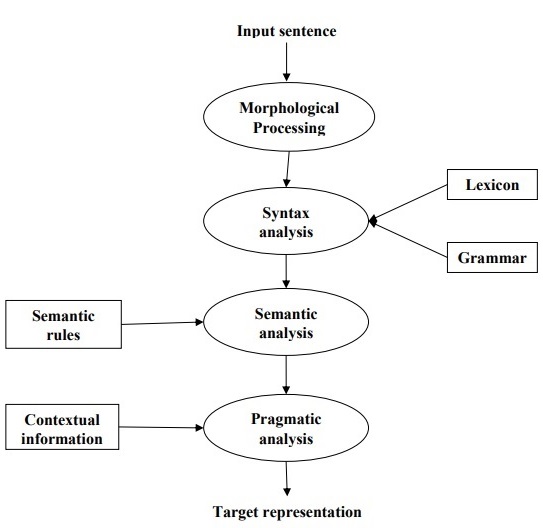
Morphologische Verarbeitung
Es ist die erste Phase von NLP. Der Zweck dieser Phase besteht darin, Teile der Spracheingabe in Sätze von Token aufzuteilen, die Absätzen, Sätzen und Wörtern entsprechen. Zum Beispiel ein Wort wie“uneasy” kann in zwei Unterwort-Token unterteilt werden als “un-easy”.
Syntaxanalyse
Es ist die zweite Phase von NLP. Der Zweck dieser Phase ist zweierlei: zu überprüfen, ob ein Satz gut geformt ist oder nicht, und ihn in eine Struktur aufzuteilen, die die syntaktischen Beziehungen zwischen den verschiedenen Wörtern zeigt. Zum Beispiel mag der Satz“The school goes to the boy” würde vom Syntaxanalysator oder Parser abgelehnt.
Semantische Analyse
Es ist die dritte Phase von NLP. Der Zweck dieser Phase ist es, die genaue Bedeutung zu zeichnen, oder Sie können die Wörterbuchbedeutung aus dem Text sagen. Der Text wird auf Aussagekraft geprüft. Zum Beispiel würde ein semantischer Analysator einen Satz wie „Heißes Eis“ ablehnen.
Pragmatische Analyse
Es ist die vierte Phase der NLP. Die pragmatische Analyse passt einfach die tatsächlichen Objekte / Ereignisse, die in einem bestimmten Kontext existieren, an die in der letzten Phase erhaltenen Objektreferenzen an (semantische Analyse). Zum Beispiel kann der Satz „Legen Sie die Banane in den Korb im Regal“ zwei semantische Interpretationen haben, und der pragmatische Analysator wählt zwischen diesen beiden Möglichkeiten.