Verarbeitung natürlicher Sprache - Python
In diesem Kapitel lernen wir die Sprachverarbeitung mit Python kennen.
Die folgenden Funktionen unterscheiden Python von anderen Sprachen:
Python is interpreted - Wir müssen unser Python-Programm nicht kompilieren, bevor wir es ausführen, da der Interpreter Python zur Laufzeit verarbeitet.
Interactive - Wir können direkt mit dem Interpreter interagieren, um unsere Python-Programme zu schreiben.
Object-oriented - Python ist objektorientiert und erleichtert das Schreiben von Programmen in dieser Sprache, da mit Hilfe dieser Programmiertechnik Code in Objekten eingekapselt wird.
Beginner can easily learn - Python wird auch als Anfängersprache bezeichnet, da es sehr leicht zu verstehen ist und die Entwicklung einer Vielzahl von Anwendungen unterstützt.
Voraussetzungen
Die neueste Version von Python 3 ist Python 3.7.1 und ist für Windows, Mac OS und die meisten Varianten von Linux verfügbar.
Für Windows können wir unter dem Link www.python.org/downloads/windows/ Python herunterladen und installieren.
Für MAC OS können wir den Link www.python.org/downloads/mac-osx/ verwenden .
Im Falle von Linux verwenden verschiedene Linux-Varianten unterschiedliche Paketmanager für die Installation neuer Pakete.
Um beispielsweise Python 3 unter Ubuntu Linux zu installieren, können Sie den folgenden Befehl vom Terminal aus verwenden:
$sudo apt-get install python3-minimalUm mehr über die Python-Programmierung zu erfahren, lesen Sie das grundlegende Tutorial zu Python 3 - Python 3
Erste Schritte mit NLTK
Wir werden die Python-Bibliothek NLTK (Natural Language Toolkit) für die Textanalyse in englischer Sprache verwenden. Das Natural Language Toolkit (NLTK) ist eine Sammlung von Python-Bibliotheken, die speziell zum Identifizieren und Kennzeichnen von Wortarten entwickelt wurden, die im Text natürlicher Sprache wie Englisch enthalten sind.
NLTK installieren
Bevor wir NLTK verwenden können, müssen wir es installieren. Mit Hilfe des folgenden Befehls können wir ihn in unserer Python-Umgebung installieren -
pip install nltkWenn wir Anaconda verwenden, kann mit dem folgenden Befehl ein Conda-Paket für NLTK erstellt werden:
conda install -c anaconda nltkHerunterladen der NLTK-Daten
Nach der Installation von NLTK besteht eine weitere wichtige Aufgabe darin, die voreingestellten Textrepositorys herunterzuladen, damit sie problemlos verwendet werden können. Vorher müssen wir jedoch NLTK so importieren, wie wir jedes andere Python-Modul importieren. Der folgende Befehl hilft uns beim Importieren von NLTK -
import nltkLaden Sie jetzt NLTK-Daten mit Hilfe des folgenden Befehls herunter:
nltk.download()Es wird einige Zeit dauern, bis alle verfügbaren NLTK-Pakete installiert sind.
Andere notwendige Pakete
Einige andere Python-Pakete mögen gensim und patternsind auch sehr wichtig für die Textanalyse sowie für die Erstellung von Anwendungen zur Verarbeitung natürlicher Sprache mithilfe von NLTK. Die Pakete können wie unten gezeigt installiert werden -
gensim
gensim ist eine robuste semantische Modellierungsbibliothek, die für viele Anwendungen verwendet werden kann. Wir können es installieren, indem wir den folgenden Befehl ausführen:
pip install gensimMuster
Es kann verwendet werden, um zu machen gensimPaket funktioniert richtig. Der folgende Befehl hilft bei der Installation von pattern -
pip install patternTokenisierung
Tokenisierung kann als der Prozess des Aufteilens des angegebenen Textes in kleinere Einheiten definiert werden, die als Token bezeichnet werden. Wörter, Zahlen oder Satzzeichen können Token sein. Es kann auch als Wortsegmentierung bezeichnet werden.
Beispiel
Input - Bett und Stuhl sind Arten von Möbeln.

Wir haben verschiedene Pakete für die Tokenisierung, die von NLTK bereitgestellt werden. Wir können diese Pakete basierend auf unseren Anforderungen verwenden. Die Pakete und die Details ihrer Installation sind wie folgt:
Paket sent_tokenize
Mit diesem Paket kann der Eingabetext in Sätze unterteilt werden. Wir können es mit dem folgenden Befehl importieren:
from nltk.tokenize import sent_tokenizeword_tokenize-Paket
Dieses Paket kann verwendet werden, um den eingegebenen Text in Wörter zu unterteilen. Wir können es mit dem folgenden Befehl importieren:
from nltk.tokenize import word_tokenizeWordPunctTokenizer-Paket
Dieses Paket kann verwendet werden, um den eingegebenen Text in Wörter und Satzzeichen zu unterteilen. Wir können es mit dem folgenden Befehl importieren:
from nltk.tokenize import WordPuncttokenizerStemming
Aus grammatikalischen Gründen enthält die Sprache viele Variationen. Variationen in dem Sinne, dass die Sprache, sowohl Englisch als auch andere Sprachen, unterschiedliche Formen eines Wortes haben. Zum Beispiel mögen die Wörterdemocracy, democratic, und democratization. Für maschinelle Lernprojekte ist es sehr wichtig, dass Maschinen verstehen, dass diese verschiedenen Wörter wie oben dieselbe Grundform haben. Deshalb ist es sehr nützlich, die Grundformen der Wörter während der Analyse des Textes zu extrahieren.
Stemming ist ein heuristischer Prozess, der beim Extrahieren der Grundformen der Wörter durch Zerhacken ihrer Enden hilft.
Die verschiedenen Pakete für das Stemming, die vom NLTK-Modul bereitgestellt werden, lauten wie folgt:
PorterStemmer-Paket
Der Porter-Algorithmus wird von diesem Stemming-Paket verwendet, um die Grundform der Wörter zu extrahieren. Mit Hilfe des folgenden Befehls können wir dieses Paket importieren -
from nltk.stem.porter import PorterStemmerZum Beispiel, ‘write’ wäre die Ausgabe des Wortes ‘writing’ als Eingabe für diesen Stemmer angegeben.
LancasterStemmer-Paket
Der Lancaster-Algorithmus wird von diesem Stemming-Paket verwendet, um die Grundform der Wörter zu extrahieren. Mit Hilfe des folgenden Befehls können wir dieses Paket importieren -
from nltk.stem.lancaster import LancasterStemmerZum Beispiel, ‘writ’ wäre die Ausgabe des Wortes ‘writing’ als Eingabe für diesen Stemmer angegeben.
SnowballStemmer-Paket
Der Schneeball-Algorithmus wird von diesem Stemming-Paket verwendet, um die Grundform der Wörter zu extrahieren. Mit Hilfe des folgenden Befehls können wir dieses Paket importieren -
from nltk.stem.snowball import SnowballStemmerZum Beispiel, ‘write’ wäre die Ausgabe des Wortes ‘writing’ als Eingabe für diesen Stemmer angegeben.
Lemmatisierung
Es ist eine andere Möglichkeit, die Grundform von Wörtern zu extrahieren, die normalerweise darauf abzielt, Flexionsenden mithilfe von Vokabeln und morphologischen Analysen zu entfernen. Nach der Lemmatisierung heißt die Grundform eines Wortes Lemma.
Das NLTK-Modul bietet das folgende Paket für die Lemmatisierung:
WordNetLemmatizer-Paket
Dieses Paket extrahiert die Grundform des Wortes, je nachdem, ob es als Substantiv oder als Verb verwendet wird. Der folgende Befehl kann zum Importieren dieses Pakets verwendet werden:
from nltk.stem import WordNetLemmatizerPOS-Tags zählen - Chunking
Die Identifizierung von Wortarten (POS) und kurzen Phrasen kann mit Hilfe von Chunking erfolgen. Es ist einer der wichtigsten Prozesse in der Verarbeitung natürlicher Sprache. Da wir uns des Prozesses der Tokenisierung für die Erstellung von Token bewusst sind, besteht das Chunking tatsächlich darin, diese Token zu kennzeichnen. Mit anderen Worten, wir können sagen, dass wir die Struktur des Satzes mit Hilfe des Chunking-Prozesses erhalten können.
Beispiel
Im folgenden Beispiel implementieren wir das Nunk-Phrase-Chunking, eine Chunking-Kategorie, bei der die Nomen-Phrasen-Chunks im Satz mithilfe des NLTK-Python-Moduls gefunden werden.
Betrachten Sie die folgenden Schritte, um das Chunking von Nominalphrasen zu implementieren:
Step 1: Chunk grammar definition
In diesem Schritt müssen wir die Grammatik für das Chunking definieren. Es würde aus den Regeln bestehen, denen wir folgen müssen.
Step 2: Chunk parser creation
Als nächstes müssen wir einen Chunk-Parser erstellen. Es würde die Grammatik analysieren und die Ausgabe geben.
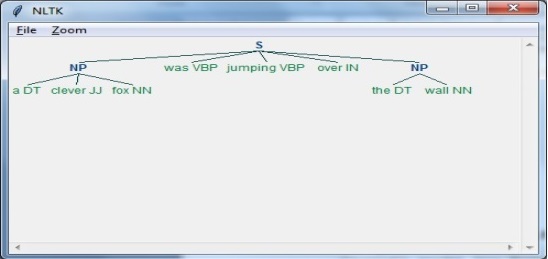
Step 3: The Output
In diesem Schritt erhalten wir die Ausgabe in einem Baumformat.
Ausführen des NLP-Skripts
Importieren Sie zunächst das NLTK-Paket -
import nltkJetzt müssen wir den Satz definieren.
Hier,
DT ist die Determinante
VBP ist das Verb
JJ ist das Adjektiv
IN ist die Präposition
NN ist das Substantiv
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Als nächstes sollte die Grammatik in Form eines regulären Ausdrucks angegeben werden.
grammar = "NP:{<DT>?<JJ>*<NN>}"Jetzt müssen wir einen Parser zum Parsen der Grammatik definieren.
parser_chunking = nltk.RegexpParser(grammar)Jetzt analysiert der Parser den Satz wie folgt:
parser_chunking.parse(sentence)Als nächstes wird die Ausgabe in der Variablen wie folgt sein: -
Output = parser_chunking.parse(sentence)Der folgende Code hilft Ihnen nun, Ihre Ausgabe in Form eines Baums zu zeichnen.
output.draw()