Cache-Kohärenz und Synchronisation
In diesem Kapitel werden wir die Cache-Kohärenzprotokolle diskutieren, um die Multicache-Inkonsistenzprobleme zu bewältigen.
Das Cache-Kohärenzproblem
In einem Multiprozessorsystem kann eine Dateninkonsistenz zwischen benachbarten Ebenen oder innerhalb derselben Ebene der Speicherhierarchie auftreten. Beispielsweise können der Cache und der Hauptspeicher inkonsistente Kopien desselben Objekts enthalten.
Da mehrere Prozessoren parallel arbeiten und unabhängig voneinander mehrere Caches unterschiedliche Kopien desselben Speicherblocks besitzen können, entsteht dies cache coherence problem. Cache coherence schemes Um dieses Problem zu vermeiden, behalten Sie einen einheitlichen Status für jeden zwischengespeicherten Datenblock bei.
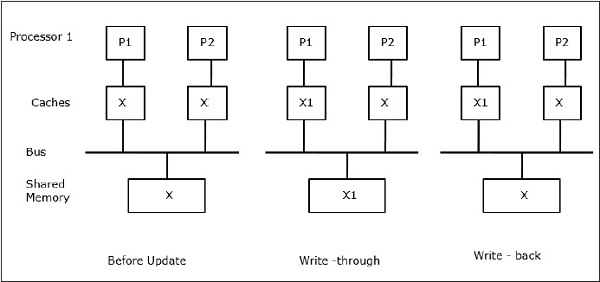
Sei X ein Element gemeinsamer Daten, auf das von zwei Prozessoren, P1 und P2, verwiesen wurde. Am Anfang sind drei Kopien von X konsistent. Wenn der Prozessor P1 neue Daten X1 mithilfe von in den Cache schreibtwrite-through policyDieselbe Kopie wird sofort in den gemeinsam genutzten Speicher geschrieben. In diesem Fall tritt eine Inkonsistenz zwischen dem Cache-Speicher und dem Hauptspeicher auf. Wenn einwrite-back policy verwendet wird, wird der Hauptspeicher aktualisiert, wenn die geänderten Daten im Cache ersetzt oder ungültig gemacht werden.
Im Allgemeinen gibt es drei Ursachen für Inkonsistenzprobleme:
- Weitergabe beschreibbarer Daten
- Prozessmigration
- E / A-Aktivität
Snoopy-Bus-Protokolle
Snoopy-Protokolle erreichen die Datenkonsistenz zwischen dem Cache-Speicher und dem gemeinsam genutzten Speicher über ein busbasiertes Speichersystem. Write-invalidate und write-update Richtlinien werden zur Aufrechterhaltung der Cache-Konsistenz verwendet.
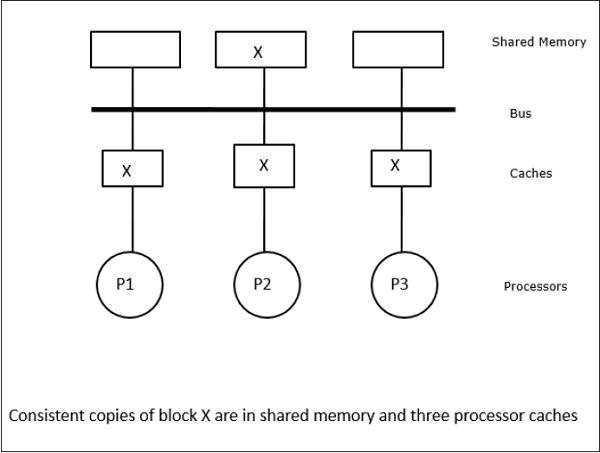
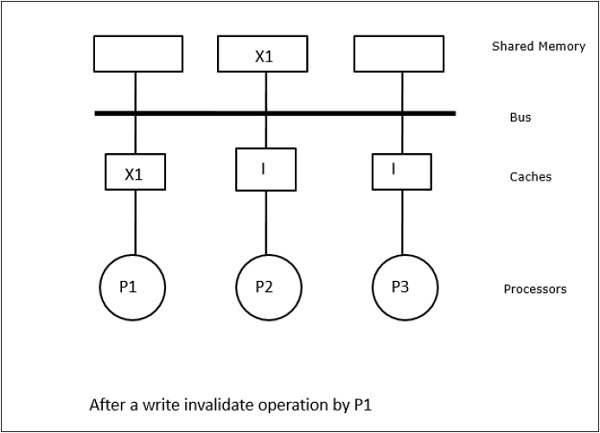
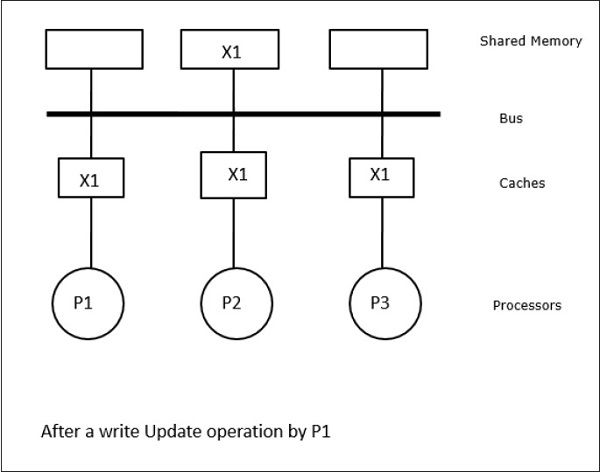
In diesem Fall haben wir drei Prozessoren P1, P2 und P3, die eine konsistente Kopie des Datenelements 'X' in ihrem lokalen Cache-Speicher und im gemeinsam genutzten Speicher haben (Abbildung-a). Der Prozessor P1 schreibt X1 mit in seinen Cache-Speicherwrite-invalidate protocol. Alle anderen Kopien werden also über den Bus ungültig. Es wird mit 'I' bezeichnet (Abbildung-b). Ungültige Blöcke werden auch als bezeichnetdirtydh sie sollten nicht verwendet werden. Daswrite-update protocolaktualisiert alle Cache-Kopien über den Bus. Durch die Nutzungwrite back cachewird auch die Speicherkopie aktualisiert (Abbildung-c).
Cache-Ereignisse und -Aktionen
Folgende Ereignisse und Aktionen treten bei der Ausführung von Speicherzugriffs- und Ungültigkeitsbefehlen auf:
Read-miss- Wenn ein Prozessor einen Block lesen möchte und er sich nicht im Cache befindet, tritt ein Lesefehler auf. Dies initiiert abus-readBetrieb. Wenn keine fehlerhafte Kopie vorhanden ist, liefert der Hauptspeicher mit einer konsistenten Kopie eine Kopie an den anfordernden Cache-Speicher. Wenn eine fehlerhafte Kopie in einem Remote-Cache-Speicher vorhanden ist, beschränkt dieser Cache den Hauptspeicher und sendet eine Kopie an den anfordernden Cache-Speicher. In beiden Fällen wird die Cache-Kopie nach einem Lesefehler in den gültigen Status versetzt.
Write-hit - Wenn die Kopie verschmutzt ist oder reservedZustand, das Schreiben erfolgt lokal und der neue Zustand ist verschmutzt. Wenn der neue Status gültig ist, wird der Befehl write-invalidate an alle Caches gesendet, wodurch deren Kopien ungültig werden. Wenn der gemeinsam genutzte Speicher durchgeschrieben wird, wird der resultierende Status nach diesem ersten Schreibvorgang reserviert.
Write-miss- Wenn ein Prozessor nicht in den lokalen Cache-Speicher schreiben kann, muss die Kopie entweder aus dem Hauptspeicher oder aus einem Remote-Cache-Speicher mit einem verschmutzten Block stammen. Dies erfolgt durch Senden einesread-invalidateBefehl, der alle Cache-Kopien ungültig macht. Dann wird die lokale Kopie mit dem Status "Dirty" aktualisiert.
Read-hit - Read-Hit wird immer im lokalen Cache-Speicher ausgeführt, ohne einen Zustandsübergang zu verursachen oder den Snoopy-Bus zur Ungültigmachung zu verwenden.
Block replacement- Wenn eine Kopie verschmutzt ist, muss sie durch Blockersatzmethode in den Hauptspeicher zurückgeschrieben werden. Wenn sich die Kopie jedoch in einem gültigen oder reservierten oder ungültigen Zustand befindet, erfolgt kein Ersatz.
Verzeichnisbasierte Protokolle
Durch die Verwendung eines mehrstufigen Netzwerks zum Aufbau eines großen Multiprozessors mit Hunderten von Prozessoren müssen die Snoopy-Cache-Protokolle an die Netzwerkfunktionen angepasst werden. Da Broadcasting in einem mehrstufigen Netzwerk sehr teuer ist, werden die Konsistenzbefehle nur an die Caches gesendet, in denen eine Kopie des Blocks gespeichert ist. Dies ist der Grund für die Entwicklung von verzeichnisbasierten Protokollen für netzwerkverbundene Multiprozessoren.
In einem verzeichnisbasierten Protokollsystem werden die gemeinsam genutzten Daten in einem gemeinsamen Verzeichnis abgelegt, das die Kohärenz zwischen den Caches aufrechterhält. Hier fungiert das Verzeichnis als Filter, in dem die Prozessoren um Erlaubnis bitten, einen Eintrag aus dem Primärspeicher in den Cache-Speicher zu laden. Wenn ein Eintrag geändert wird, aktualisiert das Verzeichnis ihn entweder oder macht die anderen Caches mit diesem Eintrag ungültig.
Hardware-Synchronisationsmechanismen
Die Synchronisation ist eine spezielle Form der Kommunikation, bei der anstelle der Datensteuerung Informationen zwischen Kommunikationsprozessen ausgetauscht werden, die sich auf demselben oder verschiedenen Prozessoren befinden.
Multiprozessorsysteme verwenden Hardwaremechanismen, um Synchronisationsoperationen auf niedriger Ebene zu implementieren. Die meisten Multiprozessoren verfügen über Hardwaremechanismen zum Auferlegen atomarer Operationen wie Speicherlese-, Schreib- oder Lese-Änderungs-Schreib-Operationen, um einige Synchronisationsprimitive zu implementieren. Neben atomaren Speicheroperationen werden einige Interprozessor-Interrupts auch zu Synchronisationszwecken verwendet.
Cache-Kohärenz in Shared-Memory-Maschinen
Das Aufrechterhalten der Cache-Kohärenz ist ein Problem im Multiprozessorsystem, wenn die Prozessoren lokalen Cache-Speicher enthalten. In diesem System tritt leicht eine Dateninkonsistenz zwischen verschiedenen Caches auf.
Die Hauptanliegen sind -
- Weitergabe beschreibbarer Daten
- Prozessmigration
- E / A-Aktivität
Weitergabe beschreibbarer Daten
Wenn zwei Prozessoren (P1 und P2) dasselbe Datenelement (X) in ihren lokalen Caches haben und ein Prozess (P1) in das Datenelement (X) schreibt, da die Caches den lokalen Cache von P1 durchschreiben, ist der Hauptspeicher auch aktualisiert. Wenn P2 nun versucht, das Datenelement (X) zu lesen, wird X nicht gefunden, da das Datenelement im Cache von P2 veraltet ist.
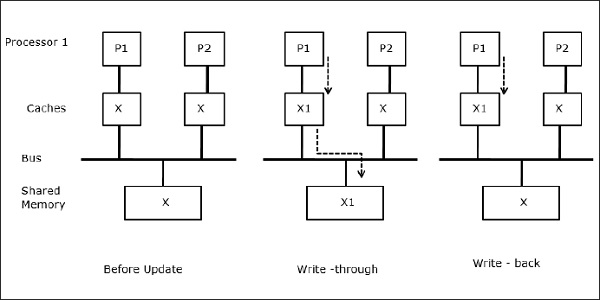
Prozessmigration
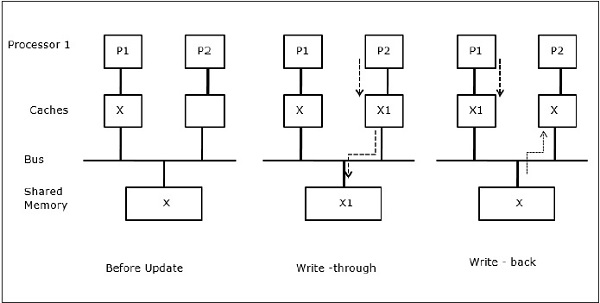
In der ersten Stufe hat der Cache von P1 das Datenelement X, während P2 nichts hat. Ein Prozess auf P2 schreibt zuerst auf X und migriert dann nach P1. Jetzt beginnt der Prozess mit dem Lesen des Datenelements X, aber da der Prozessor P1 veraltete Daten hat, kann der Prozess diese nicht lesen. Ein Prozess auf P1 schreibt also in das Datenelement X und migriert dann nach P2. Nach der Migration beginnt ein Prozess auf P2 mit dem Lesen des Datenelements X, findet jedoch eine veraltete Version von X im Hauptspeicher.
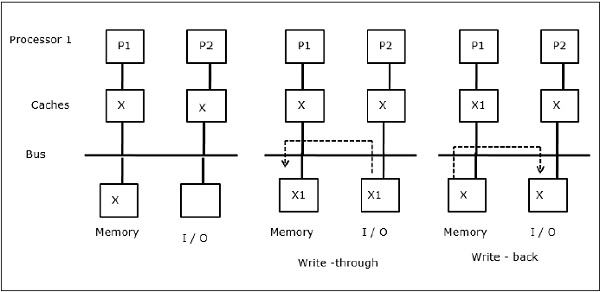
E / A-Aktivität
Wie in der Abbildung dargestellt, wird dem Bus in einer Multiprozessor-Architektur mit zwei Prozessoren ein E / A-Gerät hinzugefügt. Zu Beginn enthalten beide Caches das Datenelement X. Wenn das E / A-Gerät ein neues Element X empfängt, speichert es das neue Element direkt im Hauptspeicher. Wenn nun entweder P1 oder P2 (angenommen P1) versucht, Element X zu lesen, erhält es eine veraltete Kopie. P1 schreibt also in Element X. Wenn das E / A-Gerät nun versucht, X zu übertragen, erhält es eine veraltete Kopie.
Uniform Memory Access (UMA)
Die UMA-Architektur (Uniform Memory Access) bedeutet, dass der gemeinsam genutzte Speicher für alle Prozessoren im System gleich ist. Beliebte Klassen von UMA-Maschinen, die üblicherweise für (Datei-) Server verwendet werden, sind die sogenannten Symmetric Multiprocessors (SMPs). In einem SMP können die Prozessoren auf alle Systemressourcen wie Speicher, Festplatten, andere E / A-Geräte usw. auf einheitliche Weise zugreifen.
Uneinheitlicher Speicherzugriff (NUMA)
In der NUMA-Architektur gibt es mehrere SMP-Cluster mit einem internen indirekten / gemeinsam genutzten Netzwerk, die in einem skalierbaren Netzwerk für die Nachrichtenübermittlung verbunden sind. Die NUMA-Architektur ist also eine logisch gemeinsam genutzte physisch verteilte Speicherarchitektur.
In einer NUMA-Maschine bestimmt der Cache-Controller eines Prozessors, ob eine Speicherreferenz lokal im Speicher des SMP ist oder entfernt. Um die Anzahl der Remote-Speicherzugriffe zu verringern, wenden NUMA-Architekturen normalerweise Caching-Prozessoren an, die die Remote-Daten zwischenspeichern können. Wenn es sich jedoch um Caches handelt, muss die Cache-Kohärenz beibehalten werden. Daher werden diese Systeme auch als CC-NUMA (Cache Coherent NUMA) bezeichnet.
Nur Cache-Speicherarchitektur (COMA)
COMA-Maschinen ähneln NUMA-Maschinen, mit dem einzigen Unterschied, dass die Hauptspeicher von COMA-Maschinen als direkt zugeordnete oder satzassoziative Caches fungieren. Die Datenblöcke werden entsprechend ihrer Adresse an eine Stelle im DRAM-Cache gehasht. Daten, die aus der Ferne abgerufen werden, werden tatsächlich im lokalen Hauptspeicher gespeichert. Darüber hinaus haben Datenblöcke keinen festen Heimatort, sondern können sich im gesamten System frei bewegen.
COMA-Architekturen verfügen meist über ein hierarchisches Netzwerk zur Nachrichtenübermittlung. Ein Switch in einem solchen Baum enthält ein Verzeichnis mit Datenelementen als Unterbaum. Da Daten keinen Heimatort haben, müssen sie explizit gesucht werden. Dies bedeutet, dass für einen Remotezugriff eine Durchquerung der Switches in der Baumstruktur erforderlich ist, um deren Verzeichnisse nach den erforderlichen Daten zu durchsuchen. Wenn ein Switch im Netzwerk mehrere Anforderungen von seinem Teilbaum für dieselben Daten empfängt, kombiniert er diese zu einer einzigen Anforderung, die an das übergeordnete Element des Switch gesendet wird. Wenn die angeforderten Daten zurückgegeben werden, sendet der Switch mehrere Kopien davon in seinem Teilbaum.
COMA gegen CC-NUMA
Nachfolgend sind die Unterschiede zwischen COMA und CC-NUMA aufgeführt.
COMA ist in der Regel flexibler als CC-NUMA, da COMA die Migration und Replikation von Daten ohne das Betriebssystem transparent unterstützt.
COMA-Maschinen sind teuer und komplex zu bauen, da sie nicht standardmäßige Speicherverwaltungshardware benötigen und das Kohärenzprotokoll schwieriger zu implementieren ist.
Fernzugriffe in COMA sind häufig langsamer als in CC-NUMA, da das Baumnetzwerk durchlaufen werden muss, um die Daten zu finden.