Parallele Computerarchitektur - Kurzanleitung
In den letzten 50 Jahren hat sich die Leistung und Leistungsfähigkeit eines Computersystems enorm entwickelt. Dies war mithilfe der VLSI-Technologie (Very Large Scale Integration) möglich. Mit der VLSI-Technologie kann eine große Anzahl von Komponenten auf einem einzigen Chip untergebracht und die Taktraten erhöht werden. Daher können mehrere Operationen gleichzeitig parallel ausgeführt werden.
Die parallele Verarbeitung ist auch mit der Datenlokalität und der Datenkommunikation verbunden. Parallel Computer Architecture ist die Methode zum Organisieren aller Ressourcen, um die Leistung und Programmierbarkeit innerhalb der durch die Technologie und die Kosten jederzeit gegebenen Grenzen zu maximieren.
Warum parallele Architektur?
Die parallele Computerarchitektur erweitert die Entwicklung des Computersystems um eine neue Dimension, indem immer mehr Prozessoren verwendet werden. Im Prinzip ist die Leistung, die durch die Verwendung einer großen Anzahl von Prozessoren erzielt wird, höher als die Leistung eines einzelnen Prozessors zu einem bestimmten Zeitpunkt.
Anwendungstrends
Mit der Weiterentwicklung der Hardwarekapazität stieg auch die Nachfrage nach einer leistungsfähigen Anwendung, was wiederum Anforderungen an die Entwicklung der Computerarchitektur stellte.
Vor der Mikroprozessor-Ära wurde ein leistungsstarkes Computersystem durch exotische Schaltungstechnologie und Maschinenorganisation erhalten, was sie teuer machte. Jetzt wird ein leistungsstarkes Computersystem unter Verwendung mehrerer Prozessoren erhalten, und die wichtigsten und anspruchsvollsten Anwendungen werden als parallele Programme geschrieben. Für eine höhere Leistung müssen daher sowohl parallele Architekturen als auch parallele Anwendungen entwickelt werden.
Um die Leistung einer Anwendung zu steigern, ist die Beschleunigung der zu berücksichtigende Schlüsselfaktor. Speedup on p Prozessoren ist definiert als -
$$Speedup(p \ processors)\equiv\frac{Performance(p \ processors)}{Performance(1 \ processor)}$$Für das einzelne behobene Problem
$$performance \ of \ a \ computer \ system = \frac{1}{Time \ needed \ to \ complete \ the \ problem}$$ $$Speedup \ _{fixed \ problem} (p \ processors) =\frac{Time(1 \ processor)}{Time(p \ processor)}$$Wissenschaftliches und technisches Rechnen
Parallele Architektur ist im wissenschaftlichen Rechnen (wie Physik, Chemie, Biologie, Astronomie usw.) und in technischen Anwendungen (wie Reservoirmodellierung, Luftstromanalyse, Verbrennungseffizienz usw.) unverzichtbar geworden. In fast allen Anwendungen besteht ein großer Bedarf an Visualisierung der Rechenleistung, was zur Entwicklung von Parallelcomputern zur Erhöhung der Rechengeschwindigkeit führt.
Kommerzielles Rechnen
Beim kommerziellen Rechnen (wie Video, Grafik, Datenbanken, OLTP usw.) werden auch Hochgeschwindigkeitscomputer benötigt, um große Datenmengen innerhalb einer bestimmten Zeit zu verarbeiten. Desktop verwendet Multithread-Programme, die fast den parallelen Programmen ähneln. Dies erfordert wiederum die Entwicklung einer parallelen Architektur.
Technologietrends
Mit der Entwicklung von Technologie und Architektur besteht eine starke Nachfrage nach der Entwicklung leistungsfähiger Anwendungen. Experimente zeigen, dass parallele Computer viel schneller arbeiten können als der am weitesten entwickelte Einzelprozessor. Darüber hinaus können parallele Computer im Rahmen der Technologie und der Kosten entwickelt werden.
Die hier verwendete Primärtechnologie ist die VLSI-Technologie. Daher können heutzutage immer mehr Transistoren, Gates und Schaltungen in den gleichen Bereich eingebaut werden. Mit der Reduzierung der grundlegenden VLSI-Merkmalsgröße verbessert sich auch die Taktrate proportional dazu, während die Anzahl der Transistoren mit dem Quadrat zunimmt. Es ist zu erwarten, dass die Verwendung vieler Transistoren gleichzeitig (Parallelität) viel besser funktioniert als durch Erhöhen der Taktrate
Technologietrends deuten darauf hin, dass der grundlegende Einzelchip-Baustein eine immer größere Kapazität bietet. Daher erhöht sich die Möglichkeit, mehrere Prozessoren auf einem einzigen Chip zu platzieren.
Architektonische Trends
Die technologische Entwicklung entscheidet, was machbar ist. Architektur wandelt das Potenzial der Technologie in Leistung und Leistungsfähigkeit um.Parallelism und localitysind zwei Methoden, bei denen größere Ressourcenmengen und mehr Transistoren die Leistung verbessern. Diese beiden Methoden konkurrieren jedoch um dieselben Ressourcen. Wenn mehrere Operationen gleichzeitig ausgeführt werden, wird die Anzahl der zur Ausführung des Programms erforderlichen Zyklen verringert.
Es werden jedoch Ressourcen benötigt, um jede der gleichzeitigen Aktivitäten zu unterstützen. Ressourcen werden auch benötigt, um lokalen Speicher zuzuweisen. Die beste Leistung wird durch einen Zwischenaktionsplan erzielt, bei dem Ressourcen verwendet werden, um ein gewisses Maß an Parallelität und ein gewisses Maß an Lokalität zu nutzen.
Im Allgemeinen wurde die Geschichte der Computerarchitektur in vier Generationen mit folgenden Basistechnologien unterteilt:
- Vakuumröhren
- Transistors
- Integrierte Schaltkreise
- VLSI
Bis 1985 war die Dauer von der Zunahme der Parallelität auf Bitebene geprägt. 4-Bit-Mikroprozessoren, gefolgt von 8-Bit, 16-Bit usw. Um die Anzahl der Zyklen zu verringern, die zur Durchführung einer vollständigen 32-Bit-Operation erforderlich sind, wurde die Breite des Datenpfads verdoppelt. Später wurden 64-Bit-Operationen eingeführt.
Das Wachstum in instruction-level-parallelismdominierte die Mitte der 80er bis Mitte der 90er Jahre. Der RISC-Ansatz zeigte, dass es einfach war, die Schritte der Befehlsverarbeitung so zu leiten, dass im Durchschnitt ein Befehl in fast jedem Zyklus ausgeführt wird. Das Wachstum der Compilertechnologie hat die Produktivität von Anweisungspipelines erhöht.
Mitte der 80er Jahre bestanden mikroprozessorbasierte Computer aus
- Eine Ganzzahl-Verarbeitungseinheit
- Eine Gleitkommaeinheit
- Ein Cache-Controller
- SRAMs für die Cache-Daten
- Tag-Speicher
Mit zunehmender Chipkapazität wurden alle diese Komponenten zu einem einzigen Chip zusammengeführt. Somit bestand ein einzelner Chip aus separater Hardware für Ganzzahlarithmetik, Gleitkommaoperationen, Speicheroperationen und Verzweigungsoperationen. Anders als beim Pipelining einzelner Anweisungen werden mehrere Anweisungen gleichzeitig abgerufen und, wann immer möglich, parallel an verschiedene Funktionseinheiten gesendet. Diese Art der Parallelität auf Befehlsebene wird aufgerufensuperscalar execution.
Parallele Maschinen wurden mit mehreren unterschiedlichen Architekturen entwickelt. In diesem Abschnitt werden wir verschiedene parallele Computerarchitekturen und die Art ihrer Konvergenz diskutieren.
Kommunikationsarchitektur
Die parallele Architektur erweitert die herkömmlichen Konzepte der Computerarchitektur um die Kommunikationsarchitektur. Die Computerarchitektur definiert kritische Abstraktionen (wie Benutzer-System-Grenzen und Hardware-Software-Grenzen) und die Organisationsstruktur, während die Kommunikationsarchitektur die grundlegenden Kommunikations- und Synchronisationsoperationen definiert. Es befasst sich auch mit der Organisationsstruktur.
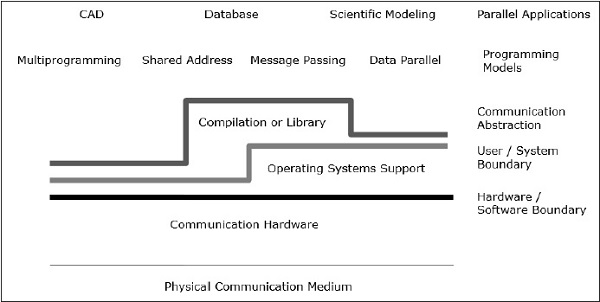
Das Programmiermodell ist die oberste Ebene. Anwendungen werden im Programmiermodell geschrieben. Parallele Programmiermodelle umfassen -
- Gemeinsamer Adressraum
- Nachrichtenübermittlung
- Datenparallele Programmierung
Shared addressDas Programmieren ist wie das Verwenden eines schwarzen Bretts, an dem man mit einer oder mehreren Personen kommunizieren kann, indem man Informationen an einem bestimmten Ort veröffentlicht, die von allen anderen Personen geteilt werden. Die individuelle Aktivität wird koordiniert, indem notiert wird, wer welche Aufgabe erledigt.
Message passing ist wie ein Telefonanruf oder ein Brief, bei dem ein bestimmter Empfänger Informationen von einem bestimmten Absender erhält.
Data parallelProgrammierung ist eine organisierte Form der Zusammenarbeit. Hier führen mehrere Personen gleichzeitig eine Aktion für einzelne Elemente eines Datensatzes aus und tauschen Informationen global aus.
Geteilte Erinnerung
Multiprozessoren mit gemeinsamem Speicher sind eine der wichtigsten Klassen paralleler Maschinen. Es bietet einen besseren Durchsatz bei Workloads mit mehreren Programmen und unterstützt parallele Programme.
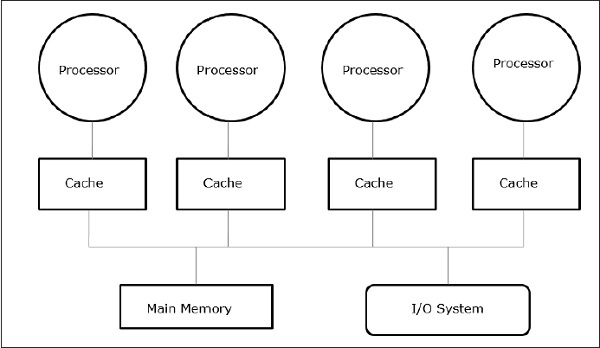
In diesem Fall ermöglichen alle Computersysteme einem Prozessor und einem Satz von E / A-Controllern, über eine Hardwareverbindung auf eine Sammlung von Speichermodulen zuzugreifen. Die Speicherkapazität wird durch Hinzufügen von Speichermodulen erhöht, und die E / A-Kapazität wird durch Hinzufügen von Geräten zum E / A-Controller oder durch Hinzufügen eines zusätzlichen E / A-Controllers erhöht. Die Verarbeitungskapazität kann erhöht werden, indem auf die Verfügbarkeit eines schnelleren Prozessors gewartet wird oder indem weitere Prozessoren hinzugefügt werden.
Alle Ressourcen sind um einen zentralen Speicherbus herum organisiert. Über den Buszugriffsmechanismus kann jeder Prozessor auf jede physikalische Adresse im System zugreifen. Da alle Prozessoren von allen Speicherorten gleich weit entfernt sind, ist die Zugriffszeit oder Latenz aller Prozessoren an einem Speicherort gleich. Das nennt mansymmetric multiprocessor.
Message-Passing-Architektur
Die Nachrichtenübermittlungsarchitektur ist auch eine wichtige Klasse paralleler Maschinen. Es bietet Kommunikation zwischen Prozessoren als explizite E / A-Operationen. In diesem Fall wird die Kommunikation auf E / A-Ebene anstelle des Speichersystems kombiniert.
In der Nachrichtenübermittlungsarchitektur wird die Benutzerkommunikation unter Verwendung von Betriebssystem- oder Bibliotheksaufrufen ausgeführt, die viele Aktionen auf niedrigerer Ebene ausführen, einschließlich der tatsächlichen Kommunikationsoperation. Infolgedessen besteht ein Abstand zwischen dem Programmiermodell und den Kommunikationsoperationen auf der Ebene der physischen Hardware.
Send und receiveist die häufigste Kommunikationsoperation auf Benutzerebene im Nachrichtenübermittlungssystem. Senden gibt einen lokalen Datenpuffer (der übertragen werden soll) und einen empfangenden Remote-Prozessor an. Empfangen gibt einen Sendevorgang und einen lokalen Datenpuffer an, in den die übertragenen Daten gestellt werden. Im Sendevorgang wird einidentifier oder ein tag wird an die Nachricht angehängt und die Empfangsoperation gibt die Übereinstimmungsregel wie ein bestimmtes Tag von einem bestimmten Prozessor oder ein beliebiges Tag von einem beliebigen Prozessor an.
Die Kombination eines Sende- und eines passenden Empfangs vervollständigt eine Speicher-zu-Speicher-Kopie. Jedes Ende gibt seine lokale Datenadresse und ein paarweises Synchronisationsereignis an.
Konvergenz
Die Entwicklung der Hardware und Software hat die klare Grenze zwischen dem gemeinsamen Speicher und den Nachrichtenübermittlungslagern überschritten. Das Weiterleiten von Nachrichten und ein gemeinsamer Adressraum repräsentieren zwei unterschiedliche Programmiermodelle. Jedes bietet ein transparentes Paradigma für das Teilen, Synchronisieren und Kommunizieren. Die grundlegenden Maschinenstrukturen haben sich jedoch zu einer gemeinsamen Organisation zusammengeschlossen.
Datenparallele Verarbeitung
Eine andere wichtige Klasse paralleler Maschinen wird verschiedentlich genannt - Prozessor-Arrays, datenparallele Architektur und Maschinen mit mehreren Anweisungen und mehreren Daten. Das Hauptmerkmal des Programmiermodells besteht darin, dass Operationen für jedes Element einer großen regulären Datenstruktur (wie Array oder Matrix) parallel ausgeführt werden können.
Datenparallele Programmiersprachen werden normalerweise erzwungen, indem der lokale Adressraum einer Gruppe von Prozessen angezeigt wird, einer pro Prozessor, der einen expliziten globalen Raum bildet. Da alle Prozessoren miteinander kommunizieren und eine globale Ansicht aller Vorgänge vorhanden ist, kann entweder ein gemeinsamer Adressraum oder die Nachrichtenübermittlung verwendet werden.
Grundlegende Designprobleme
Die Entwicklung eines Programmiermodells kann weder die Effizienz des Computers noch die Entwicklung von Hardware allein steigern. Die Entwicklung der Computerarchitektur kann jedoch die Leistung des Computers beeinflussen. Wir können das Entwurfsproblem verstehen, indem wir uns darauf konzentrieren, wie Programme eine Maschine verwenden und welche grundlegenden Technologien bereitgestellt werden.
In diesem Abschnitt werden wir die Kommunikationsabstraktion und die grundlegenden Anforderungen des Programmiermodells diskutieren.
Kommunikationsabstraktion
Die Kommunikationsabstraktion ist die Hauptschnittstelle zwischen dem Programmiermodell und der Systemimplementierung. Es ist wie der Befehlssatz, der eine Plattform bereitstellt, damit dasselbe Programm auf vielen Implementierungen korrekt ausgeführt werden kann. Operationen auf dieser Ebene müssen einfach sein.
Kommunikationsabstraktion ist wie ein Vertrag zwischen Hardware und Software, der es einander ermöglicht, sich flexibel zu verbessern, ohne die Arbeit zu beeinträchtigen.
Programmiermodellanforderungen
Ein paralleles Programm hat einen oder mehrere Threads, die mit Daten arbeiten. Ein paralleles Programmiermodell definiert, welche Daten die Threads könnenname, welche operations kann für die genannten Daten ausgeführt werden und in welcher Reihenfolge die Operationen ausgeführt werden.
Um zu bestätigen, dass die Abhängigkeiten zwischen den Programmen erzwungen werden, muss ein paralleles Programm die Aktivität seiner Threads koordinieren.
Die Parallelverarbeitung wurde als effektive Technologie in modernen Computern entwickelt, um die Nachfrage nach höherer Leistung, geringeren Kosten und genauen Ergebnissen in realen Anwendungen zu befriedigen. Gleichzeitige Ereignisse sind in heutigen Computern aufgrund der Praxis des Multiprogrammierens, Multiprozessierens oder Multicomputing häufig.
Moderne Computer verfügen über leistungsstarke und umfangreiche Softwarepakete. Um die Entwicklung der Leistung von Computern zu analysieren, müssen wir zunächst die grundlegende Entwicklung von Hardware und Software verstehen.
Computer Development Milestones - Es gibt zwei Hauptstadien der Computerentwicklung - mechanical oder electromechanicalTeile. Moderne Computer entwickelten sich nach der Einführung elektronischer Komponenten. Elektronen mit hoher Mobilität in elektronischen Computern ersetzten die Betriebsteile in mechanischen Computern. Bei der Informationsübertragung ersetzte ein elektrisches Signal, das sich fast mit Lichtgeschwindigkeit ausbreitet, mechanische Zahnräder oder Hebel.
Elements of Modern computers - Ein modernes Computersystem besteht aus Computerhardware, Befehlssätzen, Anwendungsprogrammen, Systemsoftware und Benutzeroberfläche.

Die Rechenprobleme werden in numerisches Rechnen, logisches Denken und Transaktionsverarbeitung eingeteilt. Einige komplexe Probleme erfordern möglicherweise die Kombination aller drei Verarbeitungsmodi.
Evolution of Computer Architecture- In den letzten vier Jahrzehnten hat die Computerarchitektur revolutionäre Veränderungen erfahren. Wir haben mit der Von Neumann-Architektur begonnen und haben jetzt Multicomputer und Multiprozessoren.
Performance of a computer system- Die Leistung eines Computersystems hängt sowohl von der Maschinenfähigkeit als auch vom Programmverhalten ab. Die Maschinenfähigkeit kann durch bessere Hardwaretechnologie, erweiterte Architekturfunktionen und effizientes Ressourcenmanagement verbessert werden. Das Programmverhalten ist unvorhersehbar, da es von den Anwendungs- und Laufzeitbedingungen abhängt
Multiprozessoren und Multicomputer
In diesem Abschnitt werden zwei Arten von Parallelcomputern erläutert:
- Multiprocessors
- Multicomputers
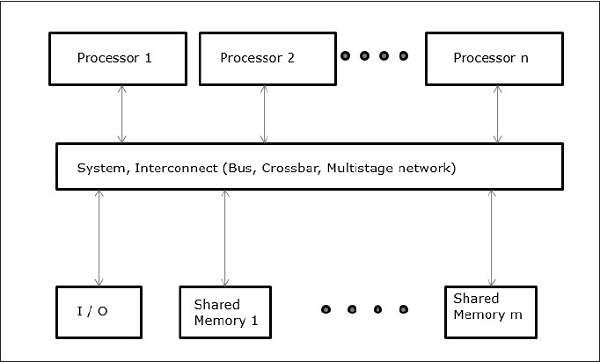
Shared-Memory-Multicomputer
Drei am häufigsten verwendete Multiprozessormodelle für gemeinsam genutzten Speicher sind:
Uniform Memory Access (UMA)
In diesem Modell teilen sich alle Prozessoren den physischen Speicher einheitlich. Alle Prozessoren haben die gleiche Zugriffszeit auf alle Speicherwörter. Jeder Prozessor kann einen privaten Cache-Speicher haben. Die gleiche Regel gilt für Peripheriegeräte.
Wenn alle Prozessoren gleichen Zugriff auf alle Peripheriegeräte haben, wird das System als a bezeichnet symmetric multiprocessor. Wenn nur ein oder wenige Prozessoren auf die Peripheriegeräte zugreifen können, wird das System als bezeichnetasymmetric multiprocessor.
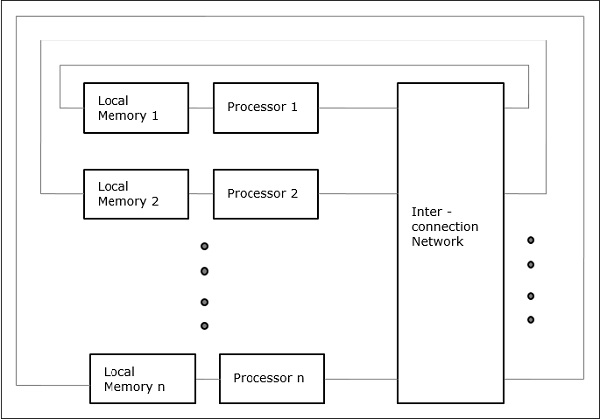
Ungleichmäßiger Speicherzugriff (NUMA)
Im NUMA-Multiprozessormodell variiert die Zugriffszeit mit dem Ort des Speicherworts. Hier wird der gemeinsam genutzte Speicher physisch auf alle Prozessoren verteilt, die als lokale Speicher bezeichnet werden. Die Sammlung aller lokalen Speicher bildet einen globalen Adressraum, auf den alle Prozessoren zugreifen können.
Nur Cache-Speicherarchitektur (COMA)
Das COMA-Modell ist ein Sonderfall des NUMA-Modells. Hier werden alle verteilten Hauptspeicher in Cache-Speicher konvertiert.

Distributed - Memory Multicomputers- Ein Multicomputersystem mit verteiltem Speicher besteht aus mehreren Computern, die als Knoten bezeichnet werden und über ein Nachrichtenübermittlungsnetzwerk miteinander verbunden sind. Jeder Knoten fungiert als autonomer Computer mit einem Prozessor, einem lokalen Speicher und manchmal E / A-Geräten. In diesem Fall sind alle lokalen Speicher privat und nur für die lokalen Prozessoren zugänglich. Deshalb werden die traditionellen Maschinen genanntno-remote-memory-access (NORMA) Maschinen.

Multivektor- und SIMD-Computer
In diesem Abschnitt werden Supercomputer und Parallelprozessoren für die Vektorverarbeitung und Datenparallelität erläutert.
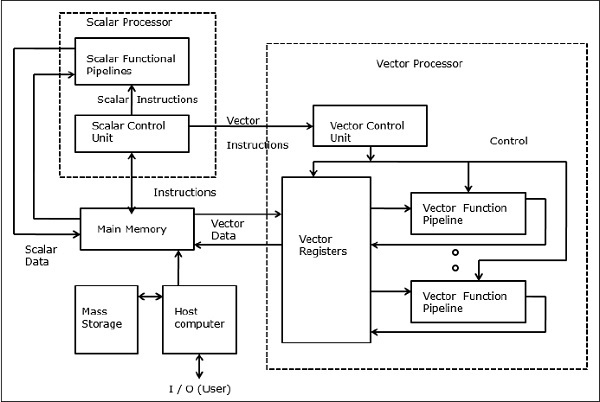
Vektor-Supercomputer
In einem Vektorcomputer ist ein Vektorprozessor als optionales Merkmal an den Skalarprozessor angeschlossen. Der Host-Computer lädt zuerst Programm und Daten in den Hauptspeicher. Dann decodiert die Skalarsteuereinheit alle Anweisungen. Wenn die decodierten Anweisungen Skalaroperationen oder Programmoperationen sind, führt der Skalarprozessor diese Operationen unter Verwendung skalarer Funktionspipelines aus.
Wenn andererseits die decodierten Anweisungen Vektoroperationen sind, werden die Anweisungen an die Vektorsteuereinheit gesendet.
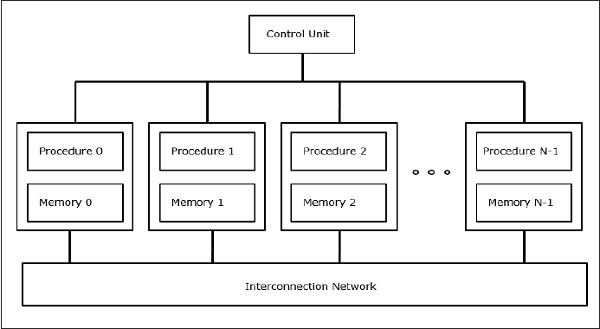
SIMD Supercomputer
In SIMD-Computern sind N Prozessoren an eine Steuereinheit angeschlossen, und alle Prozessoren haben ihre individuellen Speichereinheiten. Alle Prozessoren sind über ein Verbindungsnetzwerk verbunden.
PRAM- und VLSI-Modelle
Das ideale Modell bietet einen geeigneten Rahmen für die Entwicklung paralleler Algorithmen ohne Berücksichtigung der physikalischen Einschränkungen oder Implementierungsdetails.
Die Modelle können erzwungen werden, um theoretische Leistungsgrenzen auf parallelen Computern zu erhalten oder um die VLSI-Komplexität in Bezug auf die Chipfläche und die Betriebszeit vor der Herstellung des Chips zu bewerten.
Parallele Maschinen mit wahlfreiem Zugriff
Sheperdson und Sturgis (1963) modellierten die herkömmlichen Uniprozessor-Computer als Direktzugriffsmaschinen (RAM). Fortune und Wyllie (1978) entwickelten ein PRAM-Modell (Parallel Random-Access-Machine) zur Modellierung eines idealisierten Parallelcomputers ohne Speicherzugriffsaufwand und Synchronisation.

Ein N-Prozessor-PRAM verfügt über eine gemeinsam genutzte Speichereinheit. Dieser gemeinsam genutzte Speicher kann zentralisiert oder auf die Prozessoren verteilt werden. Diese Prozessoren arbeiten mit einem synchronisierten Lese-, Schreib- und Rechenzyklus. Diese Modelle geben also an, wie gleichzeitige Lese- und Schreibvorgänge behandelt werden.
Im Folgenden sind die möglichen Speicheraktualisierungsvorgänge aufgeführt:
Exclusive read (ER) - Bei dieser Methode darf in jedem Zyklus nur ein Prozessor von einem Speicherort lesen.
Exclusive write (EW) - Bei dieser Methode darf jeweils mindestens ein Prozessor in einen Speicherort schreiben.
Concurrent read (CR) - Es ermöglicht mehreren Prozessoren, dieselben Informationen aus demselben Speicherort im selben Zyklus zu lesen.
Concurrent write (CW)- Es ermöglicht gleichzeitige Schreibvorgänge an denselben Speicherort. Um Schreibkonflikte zu vermeiden, werden einige Richtlinien eingerichtet.
VLSI-Komplexitätsmodell
Parallele Computer verwenden VLSI-Chips, um Prozessor-Arrays, Speicher-Arrays und große Switching-Netzwerke herzustellen.
Heutzutage sind VLSI-Technologien zweidimensional. Die Größe eines VLSI-Chips ist proportional zur Menge des in diesem Chip verfügbaren Speicherplatzes (Speicherplatzes).
Wir können die Raumkomplexität eines Algorithmus durch die Chipfläche (A) der VLSI-Chip-Implementierung dieses Algorithmus berechnen. Wenn T die Zeit (Latenz) ist, die zum Ausführen des Algorithmus benötigt wird, gibt AT eine Obergrenze für die Gesamtzahl der durch den Chip (oder E / A) verarbeiteten Bits an. Für bestimmte Berechnungen gibt es eine Untergrenze f (s), so dass
AT 2 > = O (f (s))
Wobei A = Chipfläche und T = Zeit
Architekturentwicklungsspuren
Die Entwicklung paralleler Computer habe ich auf folgenden Spuren verbreitet:
- Mehrere Prozessorspuren
- Multiprozessorspur
- Multicomputer-Spur
- Mehrfachdatenspur
- Vektorspur
- SIMD-Spur
- Spur mit mehreren Threads
- Multithread-Track
- Datenflussspur
Im multiple processor trackEs wird angenommen, dass verschiedene Threads gleichzeitig auf verschiedenen Prozessoren ausgeführt werden und über ein System mit gemeinsamem Speicher (Multiprozessorspur) oder Nachrichtenübermittlung (Multicomputerspur) kommunizieren.
Im multiple data trackEs wird davon ausgegangen, dass derselbe Code für die große Datenmenge ausgeführt wird. Dies erfolgt durch Ausführen derselben Anweisungen auf einer Folge von Datenelementen (Vektorspur) oder durch Ausführen derselben Folge von Befehlen auf einem ähnlichen Datensatz (SIMD-Spur).
Im multiple threads trackEs wird angenommen, dass die verschachtelte Ausführung verschiedener Threads auf demselben Prozessor Synchronisationsverzögerungen zwischen Threads verbirgt, die auf verschiedenen Prozessoren ausgeführt werden. Thread-Interleaving kann grob (Multithread-Spur) oder fein (Datenfluss-Spur) sein.
In den 80er Jahren war ein Spezialprozessor beliebt, um Multicomputer anzurufen Transputer. Ein Transputer bestand aus einem Kernprozessor, einem kleinen SRAM-Speicher, einer DRAM-Hauptspeicherschnittstelle und vier Kommunikationskanälen, alle auf einem einzigen Chip. Um eine parallele Computerkommunikation herzustellen, wurden Kanäle verbunden, um ein Netzwerk von Transputern zu bilden. Es mangelt jedoch an Rechenleistung und konnte daher die steigende Nachfrage nach parallelen Anwendungen nicht befriedigen. Dieses Problem wurde durch die Entwicklung von RISC-Prozessoren gelöst und war auch billig.
Moderne Parallelcomputer verwenden Mikroprozessoren, die Parallelität auf mehreren Ebenen wie Parallelität auf Befehlsebene und Parallelität auf Datenebene verwenden.
Hochleistungsprozessoren
RISC- und RISCy-Prozessoren dominieren den heutigen Markt für Parallelcomputer.
Merkmale des traditionellen RISC sind -
- Hat nur wenige Adressierungsmodi.
- Hat ein festes Format für Anweisungen, normalerweise 32 oder 64 Bit.
- Verfügt über dedizierte Anweisungen zum Laden / Speichern, um Daten aus dem Speicher in das Register zu laden und Daten aus dem Register in den Speicher zu speichern.
- Arithmetische Operationen werden immer an Registern ausgeführt.
- Verwendet Pipelining.
Die meisten Mikroprozessoren sind heutzutage superskalar, dh in einem Parallelcomputer werden mehrere Anweisungspipelines verwendet. Daher können superskalare Prozessoren mehr als einen Befehl gleichzeitig ausführen. Die Wirksamkeit von superskalaren Prozessoren hängt von der Menge der in den Anwendungen verfügbaren Parallelität auf Befehlsebene (ILP) ab. Um die Pipelines gefüllt zu halten, werden die Anweisungen auf Hardwareebene in einer anderen Reihenfolge als der Programmreihenfolge ausgeführt.
Viele moderne Mikroprozessoren verwenden den Super-Pipelining- Ansatz. Beim Super-Pipelining wird zur Erhöhung der Taktfrequenz die in einer Pipeline-Stufe geleistete Arbeit reduziert und die Anzahl der Pipeline-Stufen erhöht.
VLIW-Prozessoren (Very Large Instruction Word)
Diese werden aus der horizontalen Mikroprogrammierung und der superskalaren Verarbeitung abgeleitet. Anweisungen in VLIW-Prozessoren sind sehr umfangreich. Die Operationen innerhalb eines einzelnen Befehls werden parallel ausgeführt und zur Ausführung an die entsprechenden Funktionseinheiten weitergeleitet. Nach dem Abrufen eines VLIW-Befehls werden seine Operationen dekodiert. Anschließend werden die Operationen an die Funktionseinheiten gesendet, in denen sie parallel ausgeführt werden.
Vektorprozessoren
Vektorprozessoren sind Co-Prozessoren zu Allzweck-Mikroprozessoren. Vektorprozessoren sind im Allgemeinen Register-Register oder Speicher-Speicher. Ein Vektorbefehl wird abgerufen und decodiert, und dann wird eine bestimmte Operation für jedes Element der Operandenvektoren ausgeführt, während in einem normalen Prozessor eine Vektoroperation eine Schleifenstruktur im Code benötigt. Um es effizienter zu machen, verketten Vektorprozessoren mehrere Vektoroperationen miteinander, dh das Ergebnis einer Vektoroperation wird als Operand an eine andere weitergeleitet.
Caching
Caches sind ein wichtiges Element von Hochleistungs-Mikroprozessoren. Nach jeweils 18 Monaten wird die Geschwindigkeit von Mikroprozessoren doppelt so hoch, aber DRAM-Chips für den Hauptspeicher können mit dieser Geschwindigkeit nicht mithalten. Daher werden Caches eingeführt, um die Geschwindigkeitslücke zwischen Prozessor und Speicher zu schließen. Ein Cache ist ein schneller und kleiner SRAM-Speicher. In modernen Prozessoren wie TLBs (Translation Look-Side Buffers), Anweisungs- und Datencaches usw. werden viel mehr Caches angewendet.
Direkt zugeordneter Cache
In direkt zugeordneten Caches wird eine Modulo-Funktion für die Eins-zu-Eins-Zuordnung von Adressen im Hauptspeicher zu Cache-Speicherorten verwendet. Da demselben Cache-Eintrag mehrere Hauptspeicherblöcke zugeordnet sein können, muss der Prozessor bestimmen können, ob ein Datenblock im Cache der tatsächlich benötigte Datenblock ist. Diese Identifizierung erfolgt durch Speichern eines Tags zusammen mit einem Cache-Block.
Voll assoziativer Cache
Eine vollständig assoziative Zuordnung ermöglicht das Platzieren eines Cache-Blocks an einer beliebigen Stelle im Cache. Durch die Verwendung einer Ersetzungsrichtlinie bestimmt der Cache einen Cache-Eintrag, in dem er einen Cache-Block speichert. Vollassoziative Caches verfügen über eine flexible Zuordnung, die die Anzahl der Cache-Eintragskonflikte minimiert. Da eine vollständig assoziative Implementierung teuer ist, werden diese niemals in großem Maßstab verwendet.
Set-assoziativer Cache
Eine satzassoziative Zuordnung ist eine Kombination aus einer direkten Zuordnung und einer vollständig assoziativen Zuordnung. In diesem Fall werden die Cache-Einträge in Cache-Sätze unterteilt. Wie bei der direkten Zuordnung gibt es eine feste Zuordnung von Speicherblöcken zu einem Satz im Cache. Innerhalb eines Cache-Sets wird ein Speicherblock jedoch vollständig assoziativ zugeordnet.
Cache-Strategien
Neben dem Mapping-Mechanismus benötigen Caches auch eine Reihe von Strategien, die festlegen, was bei bestimmten Ereignissen geschehen soll. Bei (set-) assoziativen Caches muss der Cache bestimmen, welcher Cache-Block durch einen neuen Block ersetzt werden soll, der in den Cache eintritt.
Einige bekannte Ersatzstrategien sind -
- First-In First Out (FIFO)
- Am wenigsten verwendet (LRU)
In diesem Kapitel werden Multiprozessoren und Multicomputer behandelt.
Multiprozessorsystemverbindungen
Die parallele Verarbeitung erfordert die Verwendung effizienter Systemverbindungen für eine schnelle Kommunikation zwischen den Ein- / Ausgabe- und Peripheriegeräten, Multiprozessoren und dem gemeinsam genutzten Speicher.
Hierarchische Bussysteme
Ein hierarchisches Bussystem besteht aus einer Hierarchie von Bussen, die verschiedene Systeme und Subsysteme / Komponenten in einem Computer verbinden. Jeder Bus besteht aus mehreren Signal-, Steuer- und Stromleitungen. Verschiedene Busse wie lokale Busse, Rückwandbusse und E / A-Busse werden verwendet, um verschiedene Verbindungsfunktionen auszuführen.
Lokale Busse sind die auf den Leiterplatten implementierten Busse. Ein Backplane-Bus ist eine gedruckte Schaltung, an der viele Anschlüsse zum Einstecken von Funktionsplatinen verwendet werden. Busse, die Eingabe- / Ausgabegeräte mit einem Computersystem verbinden, werden als E / A-Busse bezeichnet.
Crossbar-Schalter und Multiport-Speicher
Switched Networks bieten dynamische Verbindungen zwischen den Ein- und Ausgängen. Kleine oder mittlere Systeme verwenden meist Crossbar-Netzwerke. Mehrstufige Netzwerke können auf größere Systeme erweitert werden, wenn das Problem der erhöhten Latenz gelöst werden kann.
Sowohl die Crossbar-Switch- als auch die Multiport-Speicherorganisation sind ein einstufiges Netzwerk. Der Aufbau eines einstufigen Netzwerks ist zwar billiger, es können jedoch mehrere Durchgänge erforderlich sein, um bestimmte Verbindungen herzustellen. Ein mehrstufiges Netzwerk besteht aus mehr als einer Stufe von Schaltkästen. Diese Netzwerke sollten in der Lage sein, jeden Eingang mit jedem Ausgang zu verbinden.
Mehrstufige und kombinierte Netzwerke
Mehrstufige Netzwerke oder mehrstufige Verbindungsnetzwerke sind eine Klasse von Hochgeschwindigkeits-Computernetzwerken, die hauptsächlich aus Verarbeitungselementen an einem Ende des Netzwerks und Speicherelementen am anderen Ende bestehen, die durch Schaltelemente verbunden sind.
Diese Netzwerke werden angewendet, um größere Multiprozessorsysteme aufzubauen. Dazu gehören Omega Network, Butterfly Network und viele mehr.
Multicomputer
Multicomputer sind verteilte Speicher-MIMD-Architekturen. Das folgende Diagramm zeigt ein konzeptionelles Modell eines Multicomputers -
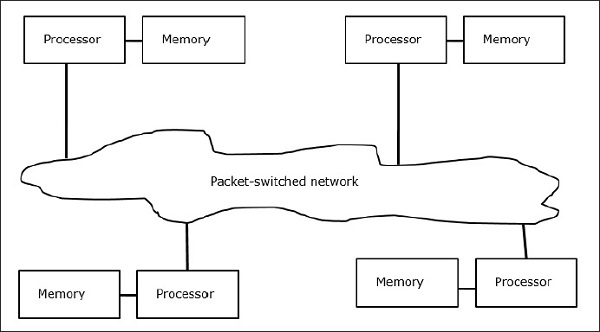
Multicomputer sind Nachrichtenübermittlungsmaschinen, die eine Paketvermittlungsmethode anwenden, um Daten auszutauschen. Hier hat jeder Prozessor einen privaten Speicher, aber keinen globalen Adressraum, da ein Prozessor nur auf seinen eigenen lokalen Speicher zugreifen kann. Kommunikation ist also nicht transparent: Hier müssen Programmierer Kommunikationsprimitive explizit in ihren Code einfügen.
Das Fehlen eines global zugänglichen Speichers ist ein Nachteil von Multicomputern. Dies kann mithilfe der folgenden beiden Schemata gelöst werden:
- Virtueller gemeinsamer Speicher (VSM)
- Gemeinsamer virtueller Speicher (SVM)
In diesen Schemata nimmt der Anwendungsprogrammierer einen großen gemeinsam genutzten Speicher an, der global adressierbar ist. Bei Bedarf werden die von Anwendungen erstellten Speicherreferenzen in das Paradigma der Nachrichtenübermittlung übersetzt.
Virtueller gemeinsamer Speicher (VSM)
VSM ist eine Hardware-Implementierung. Das virtuelle Speichersystem des Betriebssystems wird also transparent auf VSM implementiert. Das Betriebssystem glaubt also, dass es auf einem Computer mit gemeinsam genutztem Speicher ausgeführt wird.
Gemeinsamer virtueller Speicher (SVM)
SVM ist eine Softwareimplementierung auf Betriebssystemebene mit Hardwareunterstützung durch die Memory Management Unit (MMU) des Prozessors. Hier ist die Einheit der Freigabe die Speicherseiten des Betriebssystems.
Wenn ein Prozessor einen bestimmten Speicherort adressiert, bestimmt die MMU, ob sich die dem Speicherzugriff zugeordnete Speicherseite im lokalen Speicher befindet oder nicht. Wenn sich die Seite nicht im Speicher befindet, wird sie in einem normalen Computersystem vom Betriebssystem von der Festplatte eingelagert. In SVM ruft das Betriebssystem die Seite jedoch vom Remote-Knoten ab, dem diese bestimmte Seite gehört.
Drei Generationen von Multicomputern
In diesem Abschnitt werden drei Generationen von Multicomputern behandelt.
Design-Entscheidungen in der Vergangenheit
Bei der Auswahl einer Prozessortechnologie wählt ein Multicomputer-Designer kostengünstige mittelkörnige Prozessoren als Bausteine. Die meisten parallelen Computer sind mit handelsüblichen Mikroprozessoren ausgestattet. Verteilter Speicher wurde für mehrere Computer gewählt, anstatt gemeinsam genutzten Speicher zu verwenden, was die Skalierbarkeit einschränken würde. Jeder Prozessor verfügt über eine eigene lokale Speichereinheit.
Für das Zusammenschaltungsschema verfügen Multicomputer über Punkt-zu-Punkt-Direktnetzwerke zur Nachrichtenübermittlung anstelle von Adressvermittlungsnetzwerken. Für die Steuerungsstrategie wählt der Entwickler mehrerer Computer die asynchronen MIMD-, MPMD- und SMPD-Operationen aus. Caltechs Cosmic Cube (Seitz, 1983) ist der erste Multi-Computer der ersten Generation.
Gegenwärtige und zukünftige Entwicklung
Die Computer der nächsten Generation entwickelten sich von mittelgroßen zu feinkörnigen Multicomputern, die einen global gemeinsam genutzten virtuellen Speicher verwendeten. Multi-Computer der zweiten Generation werden derzeit noch verwendet. Die Verwendung besserer Prozessoren wie i386, i860 usw., Computer der zweiten Generation, hat sich jedoch stark entwickelt.
Computer der dritten Generation sind Computer der nächsten Generation, auf denen von VLSI implementierte Knoten verwendet werden. Jeder Knoten kann einen 14-MIPS-Prozessor, 20-MByte / s-Routingkanäle und 16 KByte RAM auf einem einzelnen Chip haben.
Das Intel Paragon System
Zuvor wurden homogene Knoten verwendet, um Hypercube-Multicomputer herzustellen, da alle Funktionen dem Host zugewiesen wurden. Dies begrenzte also die E / A-Bandbreite. Um große Probleme effizient oder mit hohem Durchsatz zu lösen, konnten diese Computer nicht verwendet werden. Das Intel Paragon-System wurde entwickelt, um diese Schwierigkeit zu überwinden. Der Multicomputer wurde zu einem Anwendungsserver mit Mehrbenutzerzugriff in einer Netzwerkumgebung.
Nachrichtenübermittlungsmechanismen
Nachrichtenübermittlungsmechanismen in einem Multicomputer-Netzwerk erfordern spezielle Hardware- und Softwareunterstützung. In diesem Abschnitt werden wir einige Schemata diskutieren.
Nachrichtenrouting-Schemata
In Multicomputern mit Speicher- und Weiterleitungsroutingschema sind Pakete die kleinste Einheit der Informationsübertragung. In Wurmloch-gerouteten Netzwerken werden Pakete weiter in Flits unterteilt. Die Paketlänge wird durch das Routing-Schema und die Netzwerkimplementierung bestimmt, während die Flit-Länge von der Netzwerkgröße beeinflusst wird.
Im Store and forward routingPakete sind die Grundeinheit der Informationsübertragung. In diesem Fall verwendet jeder Knoten einen Paketpuffer. Ein Paket wird von einem Quellknoten zu einem Zielknoten über eine Folge von Zwischenknoten übertragen. Die Latenz ist direkt proportional zur Entfernung zwischen Quelle und Ziel.
Im wormhole routingDie Übertragung vom Quellknoten zum Zielknoten erfolgt über eine Folge von Routern. Alle Flits desselben Pakets werden in einer untrennbaren Reihenfolge in einer Pipeline-Weise übertragen. In diesem Fall weiß nur der Header-Flit, wohin das Paket geht.
Deadlock und virtuelle Kanäle
Ein virtueller Kanal ist eine logische Verbindung zwischen zwei Knoten. Es wird durch einen Flit-Puffer im Quell- und Empfängerknoten und einen physischen Kanal zwischen ihnen gebildet. Wenn einem Paar ein physischer Kanal zugewiesen wird, wird ein Quellpuffer mit einem Empfängerpuffer gepaart, um einen virtuellen Kanal zu bilden.
Wenn alle Kanäle von Nachrichten belegt sind und keiner der Kanäle im Zyklus freigegeben wird, tritt eine Deadlock-Situation auf. Um dies zu vermeiden, muss ein Deadlock-Vermeidungsschema befolgt werden.
In diesem Kapitel werden wir die Cache-Kohärenzprotokolle diskutieren, um die Multicache-Inkonsistenzprobleme zu bewältigen.
Das Cache-Kohärenzproblem
In einem Multiprozessorsystem kann eine Dateninkonsistenz zwischen benachbarten Ebenen oder innerhalb derselben Ebene der Speicherhierarchie auftreten. Beispielsweise können der Cache und der Hauptspeicher inkonsistente Kopien desselben Objekts enthalten.
Da mehrere Prozessoren parallel arbeiten und unabhängig voneinander mehrere Caches unterschiedliche Kopien desselben Speicherblocks besitzen können, entsteht dies cache coherence problem. Cache coherence schemes Um dieses Problem zu vermeiden, behalten Sie einen einheitlichen Status für jeden zwischengespeicherten Datenblock bei.
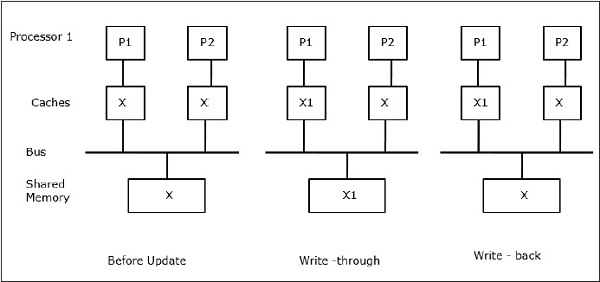
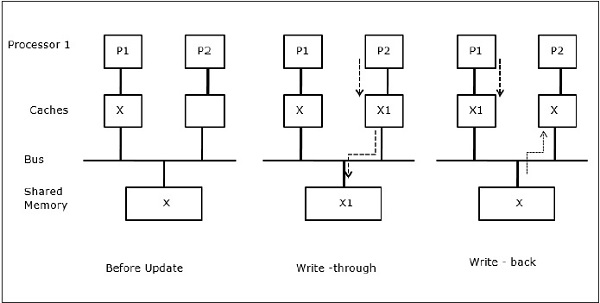
Sei X ein Element gemeinsamer Daten, auf das von zwei Prozessoren, P1 und P2, verwiesen wurde. Am Anfang sind drei Kopien von X konsistent. Wenn der Prozessor P1 neue Daten X1 mithilfe von in den Cache schreibtwrite-through policyDieselbe Kopie wird sofort in den gemeinsam genutzten Speicher geschrieben. In diesem Fall tritt eine Inkonsistenz zwischen dem Cache-Speicher und dem Hauptspeicher auf. Wenn einwrite-back policy verwendet wird, wird der Hauptspeicher aktualisiert, wenn die geänderten Daten im Cache ersetzt oder ungültig gemacht werden.
Im Allgemeinen gibt es drei Ursachen für Inkonsistenzprobleme:
- Weitergabe beschreibbarer Daten
- Prozessmigration
- E / A-Aktivität
Snoopy-Bus-Protokolle
Snoopy-Protokolle erreichen die Datenkonsistenz zwischen dem Cache-Speicher und dem gemeinsam genutzten Speicher über ein busbasiertes Speichersystem. Write-invalidate und write-update Richtlinien werden zur Aufrechterhaltung der Cache-Konsistenz verwendet.
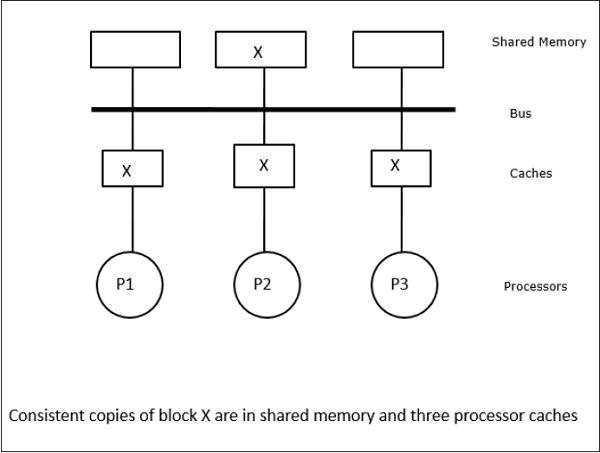
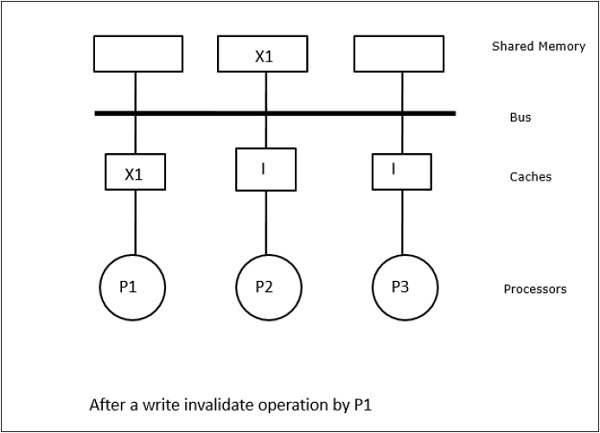
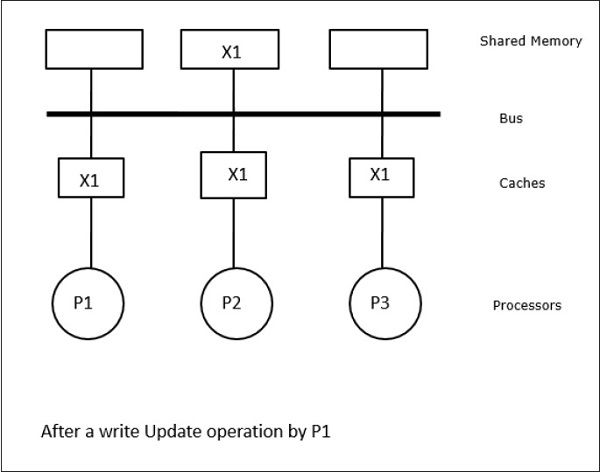
In diesem Fall haben wir drei Prozessoren P1, P2 und P3, die eine konsistente Kopie des Datenelements 'X' in ihrem lokalen Cache-Speicher und im gemeinsam genutzten Speicher haben (Abbildung-a). Der Prozessor P1 schreibt X1 mit in seinen Cache-Speicherwrite-invalidate protocol. Alle anderen Kopien werden also über den Bus ungültig. Es wird mit 'I' bezeichnet (Abbildung-b). Ungültige Blöcke werden auch als bezeichnetdirtydh sie sollten nicht verwendet werden. Daswrite-update protocolaktualisiert alle Cache-Kopien über den Bus. Durch die Nutzungwrite back cachewird auch die Speicherkopie aktualisiert (Abbildung-c).
Cache-Ereignisse und -Aktionen
Folgende Ereignisse und Aktionen treten bei der Ausführung von Speicherzugriffs- und Ungültigkeitsbefehlen auf:
Read-miss- Wenn ein Prozessor einen Block lesen möchte und er sich nicht im Cache befindet, tritt ein Lesefehler auf. Dies initiiert abus-readBetrieb. Wenn keine fehlerhafte Kopie vorhanden ist, liefert der Hauptspeicher mit einer konsistenten Kopie eine Kopie an den anfordernden Cache-Speicher. Wenn eine fehlerhafte Kopie in einem Remote-Cache-Speicher vorhanden ist, beschränkt dieser Cache den Hauptspeicher und sendet eine Kopie an den anfordernden Cache-Speicher. In beiden Fällen wird die Cache-Kopie nach einem Lesefehler in den gültigen Status versetzt.
Write-hit - Wenn die Kopie verschmutzt ist oder reservedZustand, das Schreiben erfolgt lokal und der neue Zustand ist verschmutzt. Wenn der neue Status gültig ist, wird der Befehl write-invalidate an alle Caches gesendet, wodurch deren Kopien ungültig werden. Wenn der gemeinsam genutzte Speicher durchgeschrieben wird, wird der resultierende Status nach diesem ersten Schreibvorgang reserviert.
Write-miss- Wenn ein Prozessor nicht in den lokalen Cache-Speicher schreiben kann, muss die Kopie entweder aus dem Hauptspeicher oder aus einem Remote-Cache-Speicher mit einem verschmutzten Block stammen. Dies erfolgt durch Senden einesread-invalidateBefehl, der alle Cache-Kopien ungültig macht. Dann wird die lokale Kopie mit dem Status "Dirty" aktualisiert.
Read-hit - Read-Hit wird immer im lokalen Cache-Speicher ausgeführt, ohne einen Zustandsübergang zu verursachen oder den Snoopy-Bus zur Ungültigmachung zu verwenden.
Block replacement- Wenn eine Kopie verschmutzt ist, muss sie durch Blockersatzmethode in den Hauptspeicher zurückgeschrieben werden. Wenn sich die Kopie jedoch in einem gültigen oder reservierten oder ungültigen Zustand befindet, erfolgt kein Ersatz.
Verzeichnisbasierte Protokolle
Durch die Verwendung eines mehrstufigen Netzwerks zum Aufbau eines großen Multiprozessors mit Hunderten von Prozessoren müssen die Snoopy-Cache-Protokolle an die Netzwerkfunktionen angepasst werden. Da Broadcasting in einem mehrstufigen Netzwerk sehr teuer ist, werden die Konsistenzbefehle nur an die Caches gesendet, die eine Kopie des Blocks aufbewahren. Dies ist der Grund für die Entwicklung von verzeichnisbasierten Protokollen für netzwerkverbundene Multiprozessoren.
In einem verzeichnisbasierten Protokollsystem werden die gemeinsam genutzten Daten in einem gemeinsamen Verzeichnis abgelegt, das die Kohärenz zwischen den Caches aufrechterhält. Hier fungiert das Verzeichnis als Filter, in dem die Prozessoren um Erlaubnis bitten, einen Eintrag aus dem Primärspeicher in den Cache-Speicher zu laden. Wenn ein Eintrag geändert wird, aktualisiert das Verzeichnis ihn entweder oder macht die anderen Caches mit diesem Eintrag ungültig.
Hardware-Synchronisationsmechanismen
Die Synchronisation ist eine spezielle Form der Kommunikation, bei der anstelle der Datensteuerung Informationen zwischen Kommunikationsprozessen ausgetauscht werden, die sich auf demselben oder verschiedenen Prozessoren befinden.
Multiprozessorsysteme verwenden Hardwaremechanismen, um Synchronisationsoperationen auf niedriger Ebene zu implementieren. Die meisten Multiprozessoren verfügen über Hardwaremechanismen zum Auferlegen atomarer Operationen wie Speicherlese-, Schreib- oder Lese-Änderungs-Schreib-Operationen, um einige Synchronisationsprimitive zu implementieren. Neben atomaren Speicheroperationen werden einige Interprozessor-Interrupts auch zu Synchronisationszwecken verwendet.
Cache-Kohärenz in Shared-Memory-Maschinen
Das Aufrechterhalten der Cache-Kohärenz ist ein Problem im Multiprozessorsystem, wenn die Prozessoren lokalen Cache-Speicher enthalten. In diesem System tritt leicht eine Dateninkonsistenz zwischen verschiedenen Caches auf.
Die Hauptanliegen sind -
- Weitergabe beschreibbarer Daten
- Prozessmigration
- E / A-Aktivität
Weitergabe beschreibbarer Daten
Wenn zwei Prozessoren (P1 und P2) dasselbe Datenelement (X) in ihren lokalen Caches haben und ein Prozess (P1) in das Datenelement (X) schreibt, da die Caches den lokalen Cache von P1 durchschreiben, ist der Hauptspeicher auch aktualisiert. Wenn P2 nun versucht, das Datenelement (X) zu lesen, wird X nicht gefunden, da das Datenelement im Cache von P2 veraltet ist.
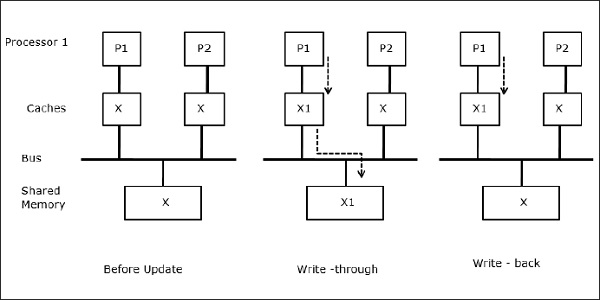
Prozessmigration
In der ersten Stufe hat der Cache von P1 das Datenelement X, während P2 nichts hat. Ein Prozess auf P2 schreibt zuerst auf X und migriert dann nach P1. Jetzt beginnt der Prozess mit dem Lesen des Datenelements X, aber da der Prozessor P1 veraltete Daten hat, kann der Prozess diese nicht lesen. Ein Prozess auf P1 schreibt also in das Datenelement X und migriert dann nach P2. Nach der Migration beginnt ein Prozess auf P2 mit dem Lesen des Datenelements X, findet jedoch eine veraltete Version von X im Hauptspeicher.
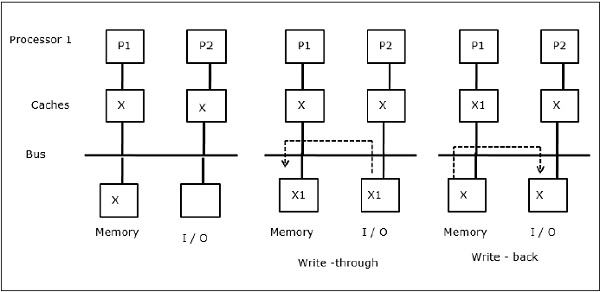
E / A-Aktivität
Wie in der Abbildung dargestellt, wird dem Bus in einer Multiprozessor-Architektur mit zwei Prozessoren ein E / A-Gerät hinzugefügt. Zu Beginn enthalten beide Caches das Datenelement X. Wenn das E / A-Gerät ein neues Element X empfängt, speichert es das neue Element direkt im Hauptspeicher. Wenn nun entweder P1 oder P2 (angenommen P1) versucht, Element X zu lesen, erhält es eine veraltete Kopie. P1 schreibt also in Element X. Wenn das E / A-Gerät nun versucht, X zu übertragen, erhält es eine veraltete Kopie.
Uniform Memory Access (UMA)
Die UMA-Architektur (Uniform Memory Access) bedeutet, dass der gemeinsam genutzte Speicher für alle Prozessoren im System gleich ist. Beliebte Klassen von UMA-Maschinen, die üblicherweise für (Datei-) Server verwendet werden, sind die sogenannten Symmetric Multiprocessors (SMPs). In einem SMP können die Prozessoren auf alle Systemressourcen wie Speicher, Festplatten, andere E / A-Geräte usw. auf einheitliche Weise zugreifen.
Uneinheitlicher Speicherzugriff (NUMA)
In der NUMA-Architektur gibt es mehrere SMP-Cluster mit einem internen indirekten / gemeinsam genutzten Netzwerk, die in einem skalierbaren Netzwerk für die Nachrichtenübermittlung verbunden sind. Die NUMA-Architektur ist also eine logisch gemeinsam genutzte physisch verteilte Speicherarchitektur.
In einer NUMA-Maschine bestimmt der Cache-Controller eines Prozessors, ob eine Speicherreferenz lokal im Speicher des SMP ist oder entfernt. Um die Anzahl der Remotespeicherzugriffe zu verringern, wenden NUMA-Architekturen normalerweise Caching-Prozessoren an, die die Remotedaten zwischenspeichern können. Wenn es sich jedoch um Caches handelt, muss die Cache-Kohärenz beibehalten werden. Daher werden diese Systeme auch als CC-NUMA (Cache Coherent NUMA) bezeichnet.
Nur Cache-Speicherarchitektur (COMA)
COMA-Maschinen ähneln NUMA-Maschinen, mit dem einzigen Unterschied, dass die Hauptspeicher von COMA-Maschinen als direkt zugeordnete oder satzassoziative Caches fungieren. Die Datenblöcke werden entsprechend ihrer Adresse an eine Stelle im DRAM-Cache gehasht. Daten, die remote abgerufen werden, werden tatsächlich im lokalen Hauptspeicher gespeichert. Darüber hinaus haben Datenblöcke keinen festen Heimatort, sondern können sich im gesamten System frei bewegen.
COMA-Architekturen verfügen meist über ein hierarchisches Netzwerk zur Nachrichtenübermittlung. Ein Switch in einem solchen Baum enthält ein Verzeichnis mit Datenelementen als Unterbaum. Da Daten keinen Heimatort haben, müssen sie explizit gesucht werden. Dies bedeutet, dass für einen Remotezugriff eine Durchquerung der Switches in der Baumstruktur erforderlich ist, um deren Verzeichnisse nach den erforderlichen Daten zu durchsuchen. Wenn ein Switch im Netzwerk mehrere Anforderungen von seinem Teilbaum für dieselben Daten empfängt, kombiniert er diese zu einer einzigen Anforderung, die an das übergeordnete Element des Switch gesendet wird. Wenn die angeforderten Daten zurückgegeben werden, sendet der Switch mehrere Kopien davon in seinem Teilbaum.
COMA gegen CC-NUMA
Es folgen die Unterschiede zwischen COMA und CC-NUMA.
COMA ist in der Regel flexibler als CC-NUMA, da COMA die Migration und Replikation von Daten ohne das Betriebssystem transparent unterstützt.
COMA-Maschinen sind teuer und komplex zu bauen, da sie nicht standardmäßige Speicherverwaltungshardware benötigen und das Kohärenzprotokoll schwieriger zu implementieren ist.
Remotezugriffe in COMA sind häufig langsamer als in CC-NUMA, da das Baumnetzwerk durchlaufen werden muss, um die Daten zu finden.
Es gibt viele Methoden, um die Hardwarekosten zu senken. Eine Methode besteht darin, die Kommunikationsunterstützung und das Netzwerk weniger eng in den Verarbeitungsknoten zu integrieren und die Kommunikationslatenz und -belegung zu erhöhen.
Eine andere Methode besteht darin, eine automatische Replikation und Kohärenz in Software und nicht in Hardware bereitzustellen. Die letztere Methode bietet Replikation und Kohärenz im Hauptspeicher und kann mit einer Vielzahl von Granularitäten ausgeführt werden. Es ermöglicht die Verwendung von Standardteilen für die Knoten und die Verbindung, wodurch die Hardwarekosten minimiert werden. Dies setzt den Programmierer unter Druck, eine gute Leistung zu erzielen.
Modelle zur entspannten Speicherkonsistenz
Das Speicherkonsistenzmodell für einen gemeinsam genutzten Adressraum definiert die Einschränkungen in der Reihenfolge, in der die Speicheroperationen an denselben oder an verschiedenen Orten in Bezug aufeinander ausgeführt zu werden scheinen. Tatsächlich muss jede Systemschicht, die ein gemeinsames Adressraum-Namensmodell unterstützt, über ein Speicherkonsistenzmodell verfügen, das die Programmierschnittstelle, die Benutzer-System-Schnittstelle und die Hardware-Software-Schnittstelle umfasst. Software, die mit dieser Schicht interagiert, muss ihr eigenes Speicherkonsistenzmodell kennen.
Systemspezifikationen
Die Systemspezifikation einer Architektur gibt die Reihenfolge und Neuordnung der Speicheroperationen an und wie viel Leistung tatsächlich daraus erzielt werden kann.
Im Folgenden sind die wenigen Spezifikationsmodelle aufgeführt, bei denen die Relaxationen in der Programmreihenfolge verwendet werden.
Relaxing the Write-to-Read Program Order- Mit dieser Modellklasse kann die Hardware die Latenz von Schreibvorgängen unterdrücken, die im Cache-Speicher der ersten Ebene übersehen wurden. Wenn sich der Schreibfehler im Schreibpuffer befindet und für andere Prozessoren nicht sichtbar ist, kann der Prozessor Lesevorgänge ausführen, die in seinem Cache-Speicher getroffen wurden, oder sogar einen einzelnen Lesevorgang, der in seinem Cache-Speicher fehlschlägt.
Relaxing the Write-to-Read and Write-to-Write Program Orders- Wenn Sie zulassen, dass Schreibvorgänge frühere ausstehende Schreibvorgänge an verschiedenen Speicherorten umgehen, können mehrere Schreibvorgänge im Schreibpuffer zusammengeführt werden, bevor der Hauptspeicher aktualisiert wird. Somit überlappen sich mehrere Schreibfehler und werden in unregelmäßiger Reihenfolge sichtbar. Die Motivation besteht darin, den Einfluss der Schreiblatenz auf die Prozessorunterbrechungszeit weiter zu minimieren und die Kommunikationseffizienz zwischen den Prozessoren zu erhöhen, indem neue Datenwerte für andere Prozessoren sichtbar gemacht werden.
Relaxing All Program Orders- Standardmäßig werden keine Programmaufträge außer Daten- und Steuerungsabhängigkeiten innerhalb eines Prozesses sichergestellt. Der Vorteil besteht somit darin, dass die mehreren Leseanforderungen gleichzeitig ausstehen können und in der Programmreihenfolge von späteren Schreibvorgängen umgangen werden können und selbst nicht in der richtigen Reihenfolge ausgeführt werden können, sodass wir die Leselatenz verbergen können. Diese Art von Modellen ist besonders nützlich für dynamisch geplante Prozessoren, die Lesefehler nach anderen Speicherreferenzen fortsetzen können. Sie ermöglichen viele Nachbestellungen, sogar die Eliminierung von Zugriffen, die durch Compiler-Optimierungen vorgenommen werden.
Die Programmierschnittstelle
Die Programmierschnittstellen gehen davon aus, dass Programmreihenfolgen bei Synchronisationsvorgängen überhaupt nicht gepflegt werden müssen. Es wird sichergestellt, dass alle Synchronisationsvorgänge explizit als solche gekennzeichnet oder gekennzeichnet sind. Die Runtime-Bibliothek oder der Compiler übersetzt diese Synchronisationsoperationen in die geeigneten auftragserhaltenden Operationen, die in der Systemspezifikation gefordert werden.
Das System stellt dann sequentiell konsistente Ausführungen sicher, obwohl es Operationen unter den Synchronisationsoperationen auf jede gewünschte Weise neu anordnen kann, ohne die Abhängigkeiten von einem Ort innerhalb eines Prozesses zu stören. Dies ermöglicht dem Compiler eine ausreichende Flexibilität zwischen den Synchronisationspunkten für die gewünschten Neuordnungen und gewährt dem Prozessor außerdem die Möglichkeit, so viele Neuordnungen durchzuführen, wie es sein Speichermodell zulässt. An der Schnittstelle des Programmiergeräts sollte das Konsistenzmodell mindestens so schwach sein wie das der Hardwareschnittstelle, muss jedoch nicht dasselbe sein.
Übersetzungsmechanismen
Bei den meisten Mikroprozessoren bedeutet das Übersetzen von Etiketten in Ordnungserhaltungsmechanismen das Einfügen eines geeigneten Speicherbarrierebefehls vor und / oder nach jeder als Synchronisation gekennzeichneten Operation. Es würde Anweisungen mit einzelnen Ladungen / Speichern speichern, die angeben, welche Anweisungen durchgesetzt werden sollen, und zusätzliche Anweisungen vermeiden. Da die Operationen jedoch normalerweise selten sind, ist dies nicht der Weg, den die meisten Mikroprozessoren bisher eingeschlagen haben.
Kapazitätsbeschränkungen überwinden
Wir haben die Systeme besprochen, die eine automatische Replikation und Kohärenz der Hardware nur im Prozessor-Cache-Speicher bieten. Ein Prozessor-Cache repliziert remote zugewiesene Daten direkt nach der Referenz, ohne dass sie zuerst im lokalen Hauptspeicher repliziert werden.
Ein Problem bei diesen Systemen besteht darin, dass der Bereich für die lokale Replikation auf den Hardware-Cache beschränkt ist. Wenn ein Block aus dem Cache-Speicher ersetzt wird, muss er bei Bedarf erneut aus dem Remote-Speicher abgerufen werden. Der Hauptzweck der in diesem Abschnitt diskutierten Systeme besteht darin, das Problem der Replikationskapazität zu lösen, aber dennoch Kohärenz in der Hardware und bei feiner Granularität der Cache-Blöcke für Effizienz bereitzustellen.
Tertiäre Caches
Um das Problem der Replikationskapazität zu lösen, besteht eine Methode darin, einen großen, aber langsameren RAS-Cache zu verwenden. Dies ist für die Funktionalität erforderlich, wenn die Knoten der Maschine selbst kleine Multiprozessoren sind und für die Leistung einfach vergrößert werden können. Es enthält auch replizierte Remote-Blöcke, die aus dem Cache-Speicher des lokalen Prozessors ersetzt wurden.
Nur-Cache-Speicherarchitekturen (COMA)
In COMA-Maschinen ist jedem Speicherblock im gesamten Hauptspeicher ein Hardware-Tag zugeordnet. Es gibt keinen festen Knoten, bei dem immer sichergestellt ist, dass Platz für einen Speicherblock zugewiesen wird. Daten werden dynamisch zu den Hauptspeichern der Knoten migriert oder in diesen repliziert, die auf sie zugreifen bzw. sie anziehen. Wenn auf einen Remote-Block zugegriffen wird, wird dieser im Attraktionsspeicher repliziert und in den Cache gebracht. Die Hardware hält ihn an beiden Stellen konsistent. Ein Datenblock kann sich in einem beliebigen Anziehungsspeicher befinden und sich leicht von einem zum anderen bewegen.
Reduzierung der Hardwarekosten
Um die Kosten zu senken, müssen einige Funktionen spezialisierter Hardware auf Software übertragen werden, die auf der vorhandenen Hardware ausgeführt wird. Für Software ist es viel einfacher, Replikation und Kohärenz im Hauptspeicher zu verwalten als im Hardware-Cache. Die kostengünstigen Methoden sorgen in der Regel für Replikation und Kohärenz im Hauptspeicher. Damit die Kohärenz effizient gesteuert werden kann, kann jede der anderen Funktionskomponenten des Assistenten von der Hardwarespezialisierung und -integration profitiert werden.
Die Forschungsanstrengungen zielen darauf ab, die Kosten mit verschiedenen Ansätzen zu senken, z. B. indem die Zugriffskontrolle in spezialisierter Hardware durchgeführt wird, aber Software und Standardhardware andere Aktivitäten zugewiesen werden. Ein anderer Ansatz besteht in der Durchführung der Zugriffskontrolle in Software und wurde entwickelt, um eine kohärente Abstraktion des gemeinsam genutzten Adressraums auf Warenknoten und Netzwerken ohne spezielle Hardwareunterstützung zuzuweisen.
Implikationen für parallele Software
Das Modell der entspannten Speicherkonsistenz erfordert, dass parallele Programme die gewünschten widersprüchlichen Zugriffe als Synchronisationspunkte kennzeichnen. Eine Programmiersprache bietet Unterstützung, um einige Variablen als Synchronisation zu kennzeichnen, die dann vom Compiler in die geeignete Anweisung zur Aufrechterhaltung der Reihenfolge übersetzt werden. Um die eigene Neuordnung der Zugriffe auf den gemeinsam genutzten Speicher durch den Compiler einzuschränken, kann der Compiler selbst Beschriftungen verwenden.
Ein interconnection networkIn einer parallelen Maschine werden Informationen von einem beliebigen Quellknoten zu einem beliebigen Zielknoten übertragen. Diese Aufgabe sollte mit möglichst geringer Latenz abgeschlossen werden. Es sollte möglich sein, dass eine große Anzahl solcher Übertragungen gleichzeitig stattfindet. Darüber hinaus sollte es im Vergleich zu den Kosten des Restes der Maschine kostengünstig sein.
Das Netzwerk besteht aus Links und Switches, mit deren Hilfe die Informationen vom Quellknoten zum Zielknoten gesendet werden können. Ein Netzwerk wird durch seine Topologie, seinen Routing-Algorithmus, seine Vermittlungsstrategie und seinen Flusssteuerungsmechanismus spezifiziert.
Organisatorische Struktur
Verbindungsnetzwerke bestehen aus folgenden drei Grundkomponenten:
Links- Eine Verbindung ist ein Kabel aus einer oder mehreren Glasfasern oder elektrischen Drähten mit einem Anschluss an jedem Ende, der an einen Switch oder einen Netzwerkschnittstellenanschluss angeschlossen ist. Dadurch wird ein analoges Signal von einem Ende gesendet und am anderen empfangen, um den ursprünglichen digitalen Informationsstrom zu erhalten.
Switches- Ein Switch besteht aus einer Reihe von Eingangs- und Ausgangsanschlüssen, einer internen „Querleiste“, die alle Eingänge mit allen Ausgängen, der internen Pufferung und der Steuerlogik verbindet, um zu jedem Zeitpunkt die Eingangs- / Ausgangsverbindung herzustellen. Im Allgemeinen entspricht die Anzahl der Eingangsports der Anzahl der Ausgangsports.
Network Interfaces- Die Netzwerkschnittstelle verhält sich ganz anders als Switch-Knoten und kann über spezielle Links verbunden werden. Die Netzwerkschnittstelle formatiert die Pakete und erstellt die Routing- und Steuerinformationen. Es kann im Vergleich zu einem Schalter eine Eingangs- und Ausgangspufferung haben. Es kann eine durchgehende Fehlerprüfung und Flusskontrolle durchführen. Daher werden seine Kosten durch die Verarbeitungskomplexität, die Speicherkapazität und die Anzahl der Ports beeinflusst.
Verbindungsnetz
Verbindungsnetzwerke bestehen aus Vermittlungselementen. Die Topologie ist das Muster zum Verbinden der einzelnen Switches mit anderen Elementen wie Prozessoren, Speichern und anderen Switches. Ein Netzwerk ermöglicht den Datenaustausch zwischen Prozessoren im Parallelsystem.
Direct connection networks- Direkte Netzwerke haben Punkt-zu-Punkt-Verbindungen zwischen benachbarten Knoten. Diese Netzwerke sind statisch, was bedeutet, dass die Punkt-zu-Punkt-Verbindungen fest sind. Einige Beispiele für direkte Netzwerke sind Ringe, Maschen und Würfel.
Indirect connection networks- Indirekte Netzwerke haben keine festen Nachbarn. Die Kommunikationstopologie kann basierend auf den Anwendungsanforderungen dynamisch geändert werden. Indirekte Netzwerke können in drei Teile unterteilt werden: Busnetzwerke, mehrstufige Netzwerke und Crossbar-Switches.
Bus networks- Ein Busnetz besteht aus mehreren Bitleitungen, an die mehrere Ressourcen angeschlossen sind. Wenn Busse dieselben physischen Leitungen für Daten und Adressen verwenden, werden die Daten- und Adressleitungen zeitmultiplexiert. Wenn mehrere Busmaster an den Bus angeschlossen sind, ist ein Arbiter erforderlich.
Multistage networks- Ein mehrstufiges Netzwerk besteht aus mehreren Switch-Stufen. Es besteht aus 'Axb'-Schaltern, die über ein bestimmtes Interstage-Verbindungsmuster (ISC) verbunden sind. Kleine 2x2-Switch-Elemente sind eine häufige Wahl für viele mehrstufige Netzwerke. Die Anzahl der Stufen bestimmt die Verzögerung des Netzwerks. Durch Auswahl verschiedener Verbindungsmuster zwischen den Stufen können verschiedene Arten von mehrstufigen Netzwerken erstellt werden.
Crossbar switches- Ein Crossbar-Schalter enthält eine Matrix einfacher Schalterelemente, die ein- und ausgeschaltet werden können, um eine Verbindung herzustellen oder zu trennen. Durch Einschalten eines Schalterelements in der Matrix kann eine Verbindung zwischen einem Prozessor und einem Speicher hergestellt werden. Crossbar-Switches sind nicht blockierend, dh alle Kommunikationspermutationen können ohne Blockierung durchgeführt werden.
Bewertung von Design-Kompromissen in der Netzwerktopologie
Wenn das Hauptanliegen die Routing-Entfernung ist, muss die Dimension maximiert und ein Hypercube erstellt werden. Beim Store-and-Forward-Routing muss unter der Annahme, dass der Grad des Switches und die Anzahl der Links kein wesentlicher Kostenfaktor waren und die Anzahl der Links oder der Switch-Grad die Hauptkosten sind, die Dimension minimiert und ein Netz erstellt werden gebaut.
Im schlimmsten Fall ist es für jedes Netzwerk bevorzugt, hochdimensionale Netzwerke zu haben, in denen alle Pfade kurz sind. In Mustern, in denen jeder Knoten nur mit einem oder zwei Nachbarn in der Nähe kommuniziert, werden niedrigdimensionale Netzwerke bevorzugt, da nur einige der Dimensionen tatsächlich verwendet werden.
Routing
Der Routing-Algorithmus eines Netzwerks bestimmt, welcher der möglichen Pfade von der Quelle zum Ziel als Routen verwendet wird und wie die Route bestimmt wird, der jedes bestimmte Paket folgt. Das Routing für Dimensionsreihenfolgen begrenzt die Anzahl der zulässigen Pfade, sodass von jeder Quelle zu jedem Ziel genau eine Route vorhanden ist. Diejenige, die erhalten wird, indem zuerst die richtige Strecke in der Dimension höherer Ordnung zurückgelegt wird, dann die nächste Dimension und so weiter.
Routing-Mechanismen
Arithmetik, quellenbasierte Portauswahl und Tabellensuche sind drei Mechanismen, mit denen Hochgeschwindigkeits-Switches den Ausgabekanal aus Informationen im Paket-Header bestimmen. Alle diese Mechanismen sind einfacher als die Art der allgemeinen Routing-Berechnungen, die in herkömmlichen LAN- und WAN-Routern implementiert sind. In parallelen Computernetzwerken muss der Switch die Routing-Entscheidung für alle seine Eingaben in jedem Zyklus treffen, daher muss der Mechanismus einfach und schnell sein.
Deterministisches Routing
Ein Routing-Algorithmus ist deterministisch, wenn die von einer Nachricht genommene Route ausschließlich von ihrer Quelle und ihrem Ziel bestimmt wird und nicht von anderem Verkehr im Netzwerk. Wenn ein Routing-Algorithmus nur kürzeste Pfade zum Ziel auswählt, ist er minimal, andernfalls nicht minimal.
Deadlock-Freiheit
Deadlock kann in verschiedenen Situationen auftreten. Wenn zwei Knoten versuchen, Daten aneinander zu senden, und jeder beginnt zu senden, bevor einer der beiden empfängt, kann ein "frontaler" Deadlock auftreten. Ein weiterer Fall eines Deadlocks tritt auf, wenn mehrere Nachrichten im Netzwerk um Ressourcen konkurrieren.
Die grundlegende Technik zum Nachweis, dass ein Netzwerk frei von Deadlocks ist, besteht darin, die Abhängigkeiten zu beseitigen, die zwischen Kanälen aufgrund von Nachrichten auftreten können, die sich durch die Netzwerke bewegen, und zu zeigen, dass das gesamte Kanalabhängigkeitsdiagramm keine Zyklen enthält. Daher gibt es keine Verkehrsmuster, die zu einem Deadlock führen können. Der übliche Weg, dies zu tun, besteht darin, die Kanalressourcen so zu nummerieren, dass alle Routen einer bestimmten zunehmenden oder abnehmenden Sequenz folgen, so dass keine Abhängigkeitszyklen entstehen.
Schalterdesign
Das Design eines Netzwerks hängt vom Design des Switches und davon ab, wie die Switches miteinander verdrahtet sind. Der Grad des Switches, seine internen Routing-Mechanismen und seine interne Pufferung entscheiden, welche Topologien unterstützt und welche Routing-Algorithmen implementiert werden können. Wie jede andere Hardwarekomponente eines Computersystems enthält ein Netzwerk-Switch Datenpfad, Steuerung und Speicher.
Häfen
Die Gesamtzahl der Pins entspricht der Gesamtzahl der Eingangs- und Ausgangsports multipliziert mit der Kanalbreite. Da der Umfang des Chips im Vergleich zum Bereich langsam wächst, sind die Schalter in der Regel stiftbegrenzt.
Interner Datenpfad
Der Datenpfad ist die Konnektivität zwischen jedem der Eingangsports und jedem Ausgangsport. Es wird allgemein als interne Querstange bezeichnet. Ein nicht blockierender Querbalken ist einer, bei dem jeder Eingangsport in jeder Permutation gleichzeitig mit einem bestimmten Ausgang verbunden werden kann.
Kanalpuffer
Die Organisation des Pufferspeichers innerhalb des Switches hat einen wichtigen Einfluss auf die Switch-Leistung. Herkömmliche Router und Switches verfügen in der Regel über große SRAM- oder DRAM-Puffer außerhalb der Switch-Struktur, während bei VLSI-Switches die Pufferung innerhalb des Switches erfolgt und aus demselben Siliziumbudget wie der Datenpfad und der Steuerabschnitt stammt. Mit zunehmender Chipgröße und -dichte steht mehr Pufferung zur Verfügung und der Netzwerkdesigner hat mehr Optionen. Dennoch ist die Pufferimmobilie die erste Wahl, und ihre Organisation ist wichtig.
Ablaufsteuerung
Wenn mehrere Datenflüsse im Netzwerk versuchen, dieselben gemeinsam genutzten Netzwerkressourcen gleichzeitig zu verwenden, müssen einige Maßnahmen ergriffen werden, um diese Flüsse zu steuern. Wenn wir keine Daten verlieren möchten, müssen einige der Flüsse blockiert werden, während andere fortfahren.
Das Problem der Flusskontrolle tritt in allen Netzwerken und auf vielen Ebenen auf. In parallelen Computernetzwerken ist dies jedoch qualitativ anders als in lokalen und Weitverkehrsnetzen. Bei parallelen Computern muss der Netzwerkverkehr ungefähr so genau wie der Verkehr über einen Bus geliefert werden, und es gibt eine sehr große Anzahl paralleler Flüsse in sehr kleinem Zeitrahmen.
Die Geschwindigkeit von Mikroprozessoren hat sich pro Jahrzehnt um mehr als den Faktor zehn erhöht, aber die Geschwindigkeit von Warenspeichern (DRAMs) hat sich nur verdoppelt, dh die Zugriffszeit wird halbiert. Daher wächst die Latenz des Speicherzugriffs in Bezug auf Prozessortaktzyklen in 10 Jahren um den Faktor sechs. Multiprozessoren verschärften das Problem.
In busbasierten Systemen erhöht die Einrichtung eines Busses mit hoher Bandbreite zwischen dem Prozessor und dem Speicher tendenziell die Latenz beim Abrufen der Daten aus dem Speicher. Wenn der Speicher physisch verteilt ist, wird die Latenz des Netzwerks und der Netzwerkschnittstelle zu der des Zugriffs auf den lokalen Speicher auf dem Knoten addiert.
Die Latenz wächst normalerweise mit der Größe der Maschine, da mehr Knoten mehr Kommunikation im Vergleich zur Berechnung, mehr Sprung im Netzwerk für die allgemeine Kommunikation und wahrscheinlich mehr Konflikte bedeuten. Das Hauptziel des Hardware-Designs besteht darin, die Latenz des Datenzugriffs zu reduzieren und gleichzeitig eine hohe, skalierbare Bandbreite beizubehalten.
Übersicht über die Latenztoleranz
Wie mit Latenztoleranz umgegangen wird, lässt sich am besten anhand der Ressourcen in der Maschine und ihrer Verwendung verstehen. Aus Prozessorsicht kann die Kommunikationsarchitektur von einem Knoten zum anderen als Pipeline betrachtet werden. Die Phasen der Pipeline umfassen Netzwerkschnittstellen an der Quelle und am Ziel sowie in den Netzwerkverbindungen und Switches auf dem Weg. Abhängig davon, wie die Architektur die Kommunikation verwaltet, gibt es auch Stufen in der Kommunikationsunterstützung, im lokalen Speicher- / Cache-System und im Hauptprozessor.
The utilization problem in the baseline communication structure is either the processor or the communication architecture is busy at a given time, and in the communication pipeline only one stage is busy at a time as the single word being transmitted makes its way from source to destination. The aim in latency tolerance is to overlap the use of these resources as much as possible.
Latency Tolerance in Explicit Message Passing
The actual transfer of data in message-passing is typically sender-initiated, using a send operation. A receive operation does not in itself motivate data to be communicated, but rather copies data from an incoming buffer into the application address space. Receiver-initiated communication is done by issuing a request message to the process that is the source of the data. The process then sends the data back via another send.
A synchronous send operation has communication latency equal to the time it takes to communicate all the data in the message to the destination, and the time for receive processing, and the time for an acknowledgment to be returned. The latency of a synchronous receive operation is its processing overhead; which includes copying the data into the application, and the additional latency if the data has not yet arrived. We would like to hide these latencies, including overheads if possible, at both ends.
Latency Tolerance in a Shared Address Space
The baseline communication is through reads and writes in a shared address space. For convenience, it is called read-write communication. Receiver-initiated communication is done with read operations that result in data from another processor’s memory or cache being accessed. If there is no caching of shared data, sender-initiated communication may be done through writes to data that are allocated in remote memories.
With cache coherence, the effect of writes is more complex: either writes leads to sender or receiver-initiated communication depends on the cache coherence protocol. Either receiver-initiated or sender-initiated, the communication in a hardware-supported read writes shared address space is naturally fine-grained, which makes tolerance latency very important.
Block Data Transfer in a Shared Address Space
In a shared address space, either by hardware or software the coalescing of data and the initiation of block transfers can be done explicitly in the user program or transparently by the system. Explicit block transfers are initiated by executing a command similar to a send in the user program. The send command is explained by the communication assist, which transfers the data in a pipelined manner from the source node to the destination. At the destination, the communication assist pulls the data words in from the network interface and stores them in the specified locations.
There are two prime differences from send-receive message passing, both of which arise from the fact that the sending process can directly specify the program data structures where the data is to be placed at the destination, since these locations are in the shared address space.
Proceeding Past Long-latency Events in a Shared Address Space
If the memory operation is made non-blocking, a processor can proceed past a memory operation to other instructions. For writes, this is usually quite simple to implement if the write is put in a write buffer, and the processor goes on while the buffer takes care of issuing the write to the memory system and tracking its completion as required. The difference is that unlike a write, a read is generally followed very soon by an instruction that needs the value returned by the read.
Pre-communication in a Shared Address Space
Pre-communication is a technique that has already been widely adopted in commercial microprocessors, and its importance is likely to increase in the future. A prefetch instruction does not replace the actual read of the data item, and the prefetch instruction itself must be non-blocking, if it is to achieve its goal of hiding latency through overlap.
In this case, as shared data is not cached, the prefetched data is brought into a special hardware structure called a prefetch buffer. When the word is actually read into a register in the next iteration, it is read from the head of the prefetch buffer rather than from memory. If the latency to hide were much bigger than the time to compute single loop iteration, we would prefetch several iterations ahead and there would potentially be several words in the prefetch buffer at a time.
Multithreading in a Shared Address Space
In terms of hiding different types of latency, hardware-supported multithreading is perhaps the versatile technique. It has the following conceptual advantages over other approaches −
It requires no special software analysis or support.
As it is invoked dynamically, it can handle unpredictable situations, like cache conflicts, etc. just as well as predictable ones.
Like prefetching, it does not change the memory consistency model since it does not reorder accesses within a thread.
While the previous techniques are targeted at hiding memory access latency, multithreading can potentially hide the latency of any long-latency event just as easily, as long as the event can be detected at runtime. This includes synchronization and instruction latency as well.
This trend may change in future, as latencies are becoming increasingly longer as compared to processor speeds. Also with more sophisticated microprocessors that already provide methods that can be extended for multithreading, and with new multithreading techniques being developed to combine multithreading with instruction-level parallelism, this trend certainly seems to be undergoing some change in future.