Parallele Computerarchitektur - Modelle
Die Parallelverarbeitung wurde als effektive Technologie in modernen Computern entwickelt, um die Nachfrage nach höherer Leistung, geringeren Kosten und genauen Ergebnissen in realen Anwendungen zu befriedigen. Gleichzeitige Ereignisse sind in heutigen Computern aufgrund der Praxis des Multiprogrammierens, Multiprozessierens oder Multicomputing häufig.
Moderne Computer verfügen über leistungsstarke und umfangreiche Softwarepakete. Um die Entwicklung der Leistung von Computern zu analysieren, müssen wir zunächst die grundlegende Entwicklung von Hardware und Software verstehen.
Computer Development Milestones - Es gibt zwei Hauptphasen der Computerentwicklung - mechanical oder electromechanicalTeile. Moderne Computer entwickelten sich nach der Einführung elektronischer Komponenten. Elektronen mit hoher Mobilität in elektronischen Computern ersetzten die Betriebsteile in mechanischen Computern. Bei der Informationsübertragung ersetzte ein elektrisches Signal, das sich fast mit Lichtgeschwindigkeit ausbreitet, mechanische Zahnräder oder Hebel.
Elements of Modern computers - Ein modernes Computersystem besteht aus Computerhardware, Befehlssätzen, Anwendungsprogrammen, Systemsoftware und Benutzeroberfläche.

Die Rechenprobleme werden in numerisches Rechnen, logisches Denken und Transaktionsverarbeitung eingeteilt. Einige komplexe Probleme erfordern möglicherweise die Kombination aller drei Verarbeitungsmodi.
Evolution of Computer Architecture- In den letzten vier Jahrzehnten hat die Computerarchitektur revolutionäre Veränderungen erfahren. Wir haben mit der Von Neumann-Architektur begonnen und haben jetzt Multicomputer und Multiprozessoren.
Performance of a computer system- Die Leistung eines Computersystems hängt sowohl von der Maschinenfähigkeit als auch vom Programmverhalten ab. Die Maschinenfähigkeit kann durch bessere Hardwaretechnologie, erweiterte Architekturfunktionen und effizientes Ressourcenmanagement verbessert werden. Das Programmverhalten ist unvorhersehbar, da es von den Anwendungs- und Laufzeitbedingungen abhängt
Multiprozessoren und Multicomputer
In diesem Abschnitt werden zwei Arten von Parallelcomputern erläutert:
- Multiprocessors
- Multicomputers
Shared-Memory-Multicomputer
Drei am häufigsten verwendete Multiprozessormodelle für gemeinsam genutzten Speicher sind:
Uniform Memory Access (UMA)
In diesem Modell teilen sich alle Prozessoren den physischen Speicher einheitlich. Alle Prozessoren haben die gleiche Zugriffszeit auf alle Speicherwörter. Jeder Prozessor kann einen privaten Cache-Speicher haben. Die gleiche Regel gilt für Peripheriegeräte.
Wenn alle Prozessoren gleichen Zugriff auf alle Peripheriegeräte haben, wird das System als a bezeichnet symmetric multiprocessor. Wenn nur ein oder wenige Prozessoren auf die Peripheriegeräte zugreifen können, wird das System als bezeichnetasymmetric multiprocessor.
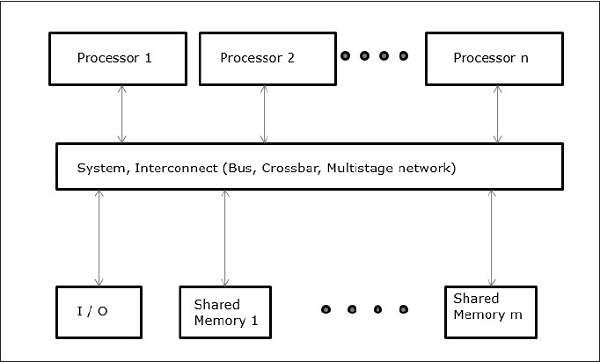
Ungleichmäßiger Speicherzugriff (NUMA)
Im NUMA-Multiprozessormodell variiert die Zugriffszeit mit dem Ort des Speicherworts. Hier wird der gemeinsam genutzte Speicher physisch auf alle Prozessoren verteilt, die als lokale Speicher bezeichnet werden. Die Sammlung aller lokalen Speicher bildet einen globalen Adressraum, auf den alle Prozessoren zugreifen können.
Nur Cache-Speicherarchitektur (COMA)
Das COMA-Modell ist ein Sonderfall des NUMA-Modells. Hier werden alle verteilten Hauptspeicher in Cache-Speicher konvertiert.

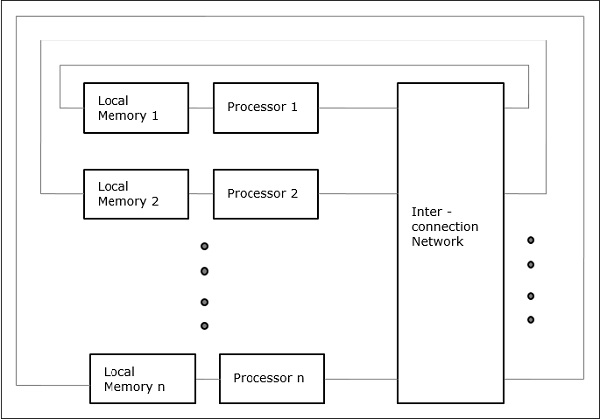
Distributed - Memory Multicomputers- Ein Multicomputersystem mit verteiltem Speicher besteht aus mehreren Computern, die als Knoten bezeichnet werden und über ein Netzwerk zur Nachrichtenübermittlung miteinander verbunden sind. Jeder Knoten fungiert als autonomer Computer mit einem Prozessor, einem lokalen Speicher und manchmal E / A-Geräten. In diesem Fall sind alle lokalen Speicher privat und nur für die lokalen Prozessoren zugänglich. Deshalb werden die traditionellen Maschinen genanntno-remote-memory-access (NORMA) Maschinen.

Multivektor- und SIMD-Computer
In diesem Abschnitt werden Supercomputer und Parallelprozessoren für die Vektorverarbeitung und Datenparallelität erläutert.
Vektor-Supercomputer
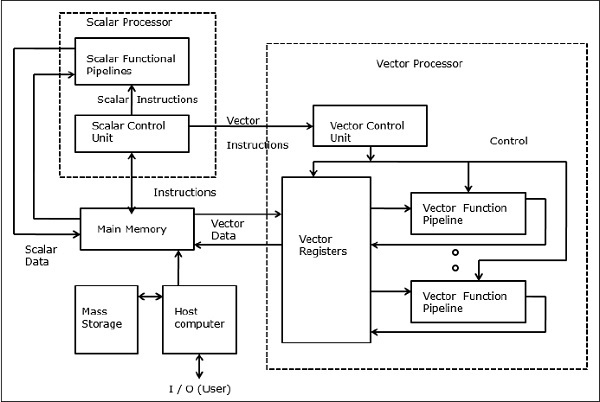
In einem Vektorcomputer ist ein Vektorprozessor als optionales Merkmal an den Skalarprozessor angeschlossen. Der Host-Computer lädt zuerst Programm und Daten in den Hauptspeicher. Dann decodiert die Skalarsteuereinheit alle Anweisungen. Wenn die decodierten Anweisungen Skalaroperationen oder Programmoperationen sind, führt der Skalarprozessor diese Operationen unter Verwendung skalarer Funktionspipelines aus.
Wenn andererseits die decodierten Anweisungen Vektoroperationen sind, werden die Anweisungen an die Vektorsteuereinheit gesendet.
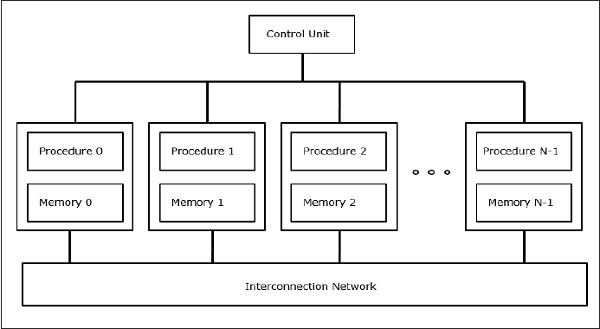
SIMD Supercomputer
In SIMD-Computern sind 'N' Prozessoren mit einer Steuereinheit verbunden, und alle Prozessoren haben ihre individuellen Speichereinheiten. Alle Prozessoren sind über ein Verbindungsnetzwerk verbunden.
PRAM- und VLSI-Modelle
Das ideale Modell bietet einen geeigneten Rahmen für die Entwicklung paralleler Algorithmen ohne Berücksichtigung der physikalischen Einschränkungen oder Implementierungsdetails.
Die Modelle können erzwungen werden, um theoretische Leistungsgrenzen auf parallelen Computern zu erhalten oder um die VLSI-Komplexität in Bezug auf die Chipfläche und die Betriebszeit vor der Herstellung des Chips zu bewerten.
Parallele Maschinen mit wahlfreiem Zugriff
Sheperdson und Sturgis (1963) modellierten die herkömmlichen Uniprozessor-Computer als Direktzugriffsmaschinen (RAM). Fortune und Wyllie (1978) entwickelten ein PRAM-Modell (Parallel Random Access Access Machine) zur Modellierung eines idealisierten Parallelcomputers ohne Speicherzugriffsaufwand und Synchronisation.

Ein N-Prozessor-PRAM verfügt über eine gemeinsam genutzte Speichereinheit. Dieser gemeinsam genutzte Speicher kann zentralisiert oder auf die Prozessoren verteilt werden. Diese Prozessoren arbeiten mit einem synchronisierten Lese-, Schreib- und Rechenzyklus. Diese Modelle geben also an, wie gleichzeitige Lese- und Schreibvorgänge behandelt werden.
Im Folgenden sind die möglichen Speicheraktualisierungsvorgänge aufgeführt:
Exclusive read (ER) - Bei dieser Methode darf in jedem Zyklus nur ein Prozessor von einem Speicherort lesen.
Exclusive write (EW) - Bei dieser Methode darf jeweils mindestens ein Prozessor in einen Speicherort schreiben.
Concurrent read (CR) - Es ermöglicht mehreren Prozessoren, dieselben Informationen aus demselben Speicherort im selben Zyklus zu lesen.
Concurrent write (CW)- Es ermöglicht gleichzeitige Schreibvorgänge an denselben Speicherort. Um Schreibkonflikte zu vermeiden, werden einige Richtlinien eingerichtet.
VLSI-Komplexitätsmodell
Parallele Computer verwenden VLSI-Chips, um Prozessor-Arrays, Speicher-Arrays und große Switching-Netzwerke herzustellen.
Heutzutage sind VLSI-Technologien zweidimensional. Die Größe eines VLSI-Chips ist proportional zur Menge des in diesem Chip verfügbaren Speicherplatzes (Speicherplatzes).
Wir können die Raumkomplexität eines Algorithmus durch die Chipfläche (A) der VLSI-Chip-Implementierung dieses Algorithmus berechnen. Wenn T die Zeit (Latenz) ist, die zum Ausführen des Algorithmus benötigt wird, gibt AT eine Obergrenze für die Gesamtzahl der durch den Chip (oder E / A) verarbeiteten Bits an. Für bestimmte Berechnungen gibt es eine Untergrenze f (s), so dass
AT 2 > = O (f (s))
Wobei A = Chipfläche und T = Zeit
Architekturentwicklungsspuren
Die Entwicklung paralleler Computer habe ich auf folgenden Spuren verbreitet:
- Mehrere Prozessorspuren
- Multiprozessorspur
- Multicomputer-Spur
- Mehrfachdatenspur
- Vektorspur
- SIMD-Spur
- Spur mit mehreren Threads
- Multithread-Track
- Datenflussspur
Im multiple processor trackEs wird angenommen, dass verschiedene Threads gleichzeitig auf verschiedenen Prozessoren ausgeführt werden und über ein System mit gemeinsamem Speicher (Multiprozessorspur) oder Nachrichtenübermittlung (Multicomputerspur) kommunizieren.
Im multiple data trackEs wird davon ausgegangen, dass derselbe Code für die große Datenmenge ausgeführt wird. Dies erfolgt durch Ausführen derselben Befehle auf einer Folge von Datenelementen (Vektorspur) oder durch Ausführen derselben Folge von Befehlen auf einem ähnlichen Datensatz (SIMD-Spur).
Im multiple threads trackEs wird angenommen, dass die verschachtelte Ausführung verschiedener Threads auf demselben Prozessor Synchronisationsverzögerungen zwischen Threads verbirgt, die auf verschiedenen Prozessoren ausgeführt werden. Thread-Interleaving kann grob (Multithread-Spur) oder fein (Datenfluss-Spur) sein.