Scikit Learn - Datendarstellung
Wie wir wissen, wird beim maschinellen Lernen ein Modell aus Daten erstellt. Zu diesem Zweck muss der Computer zuerst die Daten verstehen. Als nächstes werden wir verschiedene Möglichkeiten diskutieren, die Daten darzustellen, um vom Computer verstanden zu werden -
Daten als Tabelle
Die beste Möglichkeit, Daten in Scikit-learn darzustellen, sind Tabellen. Eine Tabelle stellt ein 2D-Datenraster dar, wobei Zeilen die einzelnen Elemente des Datensatzes darstellen und die Spalten die Mengen darstellen, die sich auf diese einzelnen Elemente beziehen.
Beispiel
Mit dem folgenden Beispiel können wir herunterladen iris dataset in Form eines Pandas DataFrame mit Hilfe von Python seaborn Bibliothek.
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()Ausgabe
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaAus der obigen Ausgabe können wir ersehen, dass jede Zeile der Daten eine einzelne beobachtete Blume darstellt und die Anzahl der Zeilen die Gesamtzahl der Blumen im Datensatz darstellt. Im Allgemeinen bezeichnen wir die Zeilen der Matrix als Beispiele.
Andererseits repräsentiert jede Spalte der Daten eine quantitative Information, die jede Probe beschreibt. Im Allgemeinen bezeichnen wir die Spalten der Matrix als Features.
Daten als Feature-Matrix
Die Merkmalsmatrix kann als Tabellenlayout definiert werden, bei dem Informationen als 2D-Matrix betrachtet werden können. Es wird in einer Variablen namens gespeichertXund als zweidimensional mit Form angenommen [n_samples, n_features]. Meistens ist es in einem NumPy-Array oder einem Pandas DataFrame enthalten. Wie bereits erwähnt, stellen die Stichproben immer die einzelnen vom Datensatz beschriebenen Objekte dar, und die Merkmale stellen die unterschiedlichen Beobachtungen dar, die jede Stichprobe quantitativ beschreiben.
Daten als Zielarray
Zusammen mit der mit X bezeichneten Feature-Matrix haben wir auch ein Ziel-Array. Es wird auch Label genannt. Es wird mit y bezeichnet. Die Beschriftung oder das Zielarray ist normalerweise eindimensional mit der Länge n_samples. Es ist im Allgemeinen in NumPy enthaltenarray oder Pandas Series. Das Zielarray kann sowohl Werte als auch kontinuierliche numerische Werte und diskrete Werte aufweisen.
Wie unterscheidet sich das Zielarray von Feature-Spalten?
Wir können beide durch einen Punkt unterscheiden, dass das Zielarray normalerweise die Größe ist, die wir aus den Daten vorhersagen möchten, dh statistisch gesehen ist es die abhängige Variable.
Beispiel
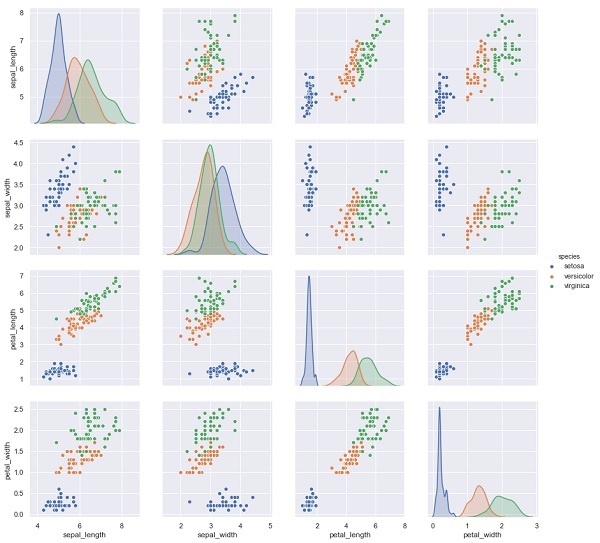
Im folgenden Beispiel prognostizieren wir aus dem Iris-Datensatz die Blütenarten basierend auf den anderen Messungen. In diesem Fall wird die Spalte "Arten" als Feature betrachtet.
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);Ausgabe
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shapeAusgabe
(150,4)
(150,)