Scikit Learn - Kurzanleitung
In diesem Kapitel werden wir verstehen, was Scikit-Learn oder Sklearn ist, woher Scikit-Learn stammt und einige andere verwandte Themen wie Communitys und Mitwirkende, die für die Entwicklung und Wartung von Scikit-Learn verantwortlich sind, seine Voraussetzungen, Installation und seine Funktionen.
Was ist Scikit-Learn (Sklearn)
Scikit-learn (Sklearn) ist die nützlichste und robusteste Bibliothek für maschinelles Lernen in Python. Es bietet eine Auswahl effizienter Tools für maschinelles Lernen und statistische Modellierung, einschließlich Klassifizierung, Regression, Clustering und Dimensionsreduktion über eine Konsistenzschnittstelle in Python. Diese Bibliothek, die größtenteils in Python geschrieben ist, baut darauf aufNumPy, SciPy und Matplotlib.
Ursprung von Scikit-Learn
Es wurde ursprünglich genannt scikits.learn und wurde ursprünglich von David Cournapeau als Google Summer of Code-Projekt im Jahr 2007 entwickelt. Später, im Jahr 2010, nahmen Fabian Pedregosa, Gael Varoquaux, Alexandre Gramfort und Vincent Michel vom FIRCA (Französisches Institut für Forschung in Informatik und Automatisierung) teil Dieses Projekt wurde auf einer anderen Ebene veröffentlicht und am 1. Februar 2010 erstmals veröffentlicht (v0.1 Beta).
Werfen wir einen Blick auf die Versionsgeschichte -
Mai 2019: scikit-learn 0.21.0
März 2019: scikit-learn 0.20.3
Dezember 2018: scikit-learn 0.20.2
November 2018: scikit-learn 0.20.1
September 2018: scikit-learn 0.20.0
Juli 2018: scikit-learn 0.19.2
Juli 2017: scikit-learn 0.19.0
September 2016. scikit-learn 0.18.0
November 2015. scikit-learn 0.17.0
März 2015. scikit-learn 0.16.0
Juli 2014. scikit-learn 0.15.0
August 2013. scikit-learn 0.14
Community & Mitwirkende
Scikit-Learn ist eine Gemeinschaftsanstrengung und jeder kann dazu beitragen. Dieses Projekt wird am gehostethttps://github.com/scikit-learn/scikit-learn. Die folgenden Personen sind derzeit die Hauptverantwortlichen für die Entwicklung und Wartung von Sklearn -
Joris Van den Bossche (Datenwissenschaftler)
Thomas J Fan (Softwareentwickler)
Alexandre Gramfort (Forscher für maschinelles Lernen)
Olivier Grisel (Experte für maschinelles Lernen)
Nicolas Hug (Associate Research Scientist)
Andreas Mueller (Wissenschaftler für maschinelles Lernen)
Hanmin Qin (Software-Ingenieur)
Adrin Jalali (Open Source Entwickler)
Nelle Varoquaux (Data Science Researcher)
Roman Yurchak (Datenwissenschaftler)
Verschiedene Organisationen wie Booking.com, JP Morgan, Evernote, Inria, AWeber, Spotify und viele mehr verwenden Sklearn.
Voraussetzungen
Bevor wir die neueste Version von scikit-learn verwenden, benötigen wir Folgendes:
Python (> = 3,5)
NumPy (> = 1.11.0)
Scipy (> = 0,17,0) li
Joblib (> = 0,11)
Matplotlib (> = 1.5.1) ist für Sklearn-Plotfunktionen erforderlich.
Pandas (> = 0.18.0) wird für einige der Scikit-Lernbeispiele mit Datenstruktur und Analyse benötigt.
Installation
Wenn Sie NumPy und Scipy bereits installiert haben, sind die beiden einfachsten Möglichkeiten, scikit-learn zu installieren:
Mit pip
Der folgende Befehl kann verwendet werden, um scikit-learn über pip zu installieren -
pip install -U scikit-learnMit conda
Der folgende Befehl kann verwendet werden, um scikit-learn über conda zu installieren -
conda install scikit-learnWenn NumPy und Scipy jedoch noch nicht auf Ihrer Python-Workstation installiert sind, können Sie sie mit beiden installieren pip oder conda.
Eine andere Möglichkeit, scikit-learn zu verwenden, ist die Verwendung von Python-Distributionen wie Canopy und Anaconda weil beide die neueste Version von scikit-learn ausliefern.
Eigenschaften
Anstatt sich auf das Laden, Bearbeiten und Zusammenfassen von Daten zu konzentrieren, konzentriert sich die Scikit-learn-Bibliothek auf das Modellieren der Daten. Einige der beliebtesten Modellgruppen von Sklearn sind:
Supervised Learning algorithms - Fast alle gängigen überwachten Lernalgorithmen wie lineare Regression, Support Vector Machine (SVM), Entscheidungsbaum usw. sind Teil des Scikit-Lernens.
Unsupervised Learning algorithms - Andererseits verfügt es auch über alle gängigen unbeaufsichtigten Lernalgorithmen, von Clustering, Faktoranalyse, PCA (Principal Component Analysis) bis hin zu unbeaufsichtigten neuronalen Netzen.
Clustering - Dieses Modell wird zum Gruppieren unbeschrifteter Daten verwendet.
Cross Validation - Es wird verwendet, um die Genauigkeit von überwachten Modellen auf unsichtbare Daten zu überprüfen.
Dimensionality Reduction - Es wird verwendet, um die Anzahl der Attribute in Daten zu reduzieren, die für die Zusammenfassung, Visualisierung und Funktionsauswahl weiter verwendet werden können.
Ensemble methods - Wie der Name schon sagt, wird es zum Kombinieren der Vorhersagen mehrerer überwachter Modelle verwendet.
Feature extraction - Es wird verwendet, um die Features aus Daten zu extrahieren, um die Attribute in Bild- und Textdaten zu definieren.
Feature selection - Es wird verwendet, um nützliche Attribute zum Erstellen von überwachten Modellen zu identifizieren.
Open Source - Es ist eine Open-Source-Bibliothek und kann auch unter BSD-Lizenz kommerziell verwendet werden.
Dieses Kapitel befasst sich mit dem Modellierungsprozess von Sklearn. Lassen Sie uns dies im Detail verstehen und mit dem Laden des Datensatzes beginnen.
Laden des Datensatzes
Eine Datensammlung wird als Datensatz bezeichnet. Es hat die folgenden zwei Komponenten -
Features- Die Variablen der Daten werden als ihre Merkmale bezeichnet. Sie werden auch als Prädiktoren, Eingaben oder Attribute bezeichnet.
Feature matrix - Es ist die Sammlung von Funktionen, falls es mehr als eine gibt.
Feature Names - Es ist die Liste aller Namen der Funktionen.
Response- Es ist die Ausgabevariable, die im Wesentlichen von den Feature-Variablen abhängt. Sie werden auch als Ziel, Label oder Ausgabe bezeichnet.
Response Vector- Es wird verwendet, um die Antwortspalte darzustellen. Im Allgemeinen haben wir nur eine Antwortspalte.
Target Names - Es stellt die möglichen Werte dar, die von einem Antwortvektor angenommen werden.
Scikit-learn hat nur wenige Beispieldatensätze wie iris und digits für die Klassifizierung und die Boston house prices für die Regression.
Beispiel
Es folgt ein Beispiel zum Laden iris Datensatz -
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print("Feature names:", feature_names)
print("Target names:", target_names)
print("\nFirst 10 rows of X:\n", X[:10])Ausgabe
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Target names: ['setosa' 'versicolor' 'virginica']
First 10 rows of X:
[
[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
]Datensatz aufteilen
Um die Genauigkeit unseres Modells zu überprüfen, können wir den Datensatz in zwei Teile aufteilen.a training set und a testing set. Verwenden Sie das Trainingsset, um das Modell zu trainieren, und das Testset, um das Modell zu testen. Danach können wir bewerten, wie gut unser Modell war.
Beispiel
Im folgenden Beispiel werden die Daten in ein Verhältnis von 70:30 aufgeteilt, dh 70% werden als Trainingsdaten und 30% als Testdaten verwendet. Der Datensatz ist ein Iris-Datensatz wie im obigen Beispiel.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 1
)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)Ausgabe
(105, 4)
(45, 4)
(105,)
(45,)Wie im obigen Beispiel zu sehen, wird es verwendet train_test_split()Funktion von scikit-learn, um den Datensatz zu teilen. Diese Funktion hat die folgenden Argumente:
X, y - Hier, X ist der feature matrix und y ist das response vector, die aufgeteilt werden müssen.
test_size- Dies ist das Verhältnis der Testdaten zu den insgesamt angegebenen Daten. Wie im obigen Beispiel stellen wir eintest_data = 0.3 für 150 Zeilen X. Es werden Testdaten von 150 * 0,3 = 45 Zeilen erzeugt.
random_size- Es wird verwendet, um sicherzustellen, dass die Aufteilung immer gleich ist. Dies ist in Situationen nützlich, in denen Sie reproduzierbare Ergebnisse erzielen möchten.
Trainiere das Modell
Als nächstes können wir unseren Datensatz verwenden, um ein Vorhersagemodell zu trainieren. Wie bereits erwähnt, hat Scikit-Learn eine breite Palette vonMachine Learning (ML) algorithms die eine konsistente Schnittstelle zum Anpassen, Vorhersagen der Genauigkeit, Abrufen usw. haben.
Beispiel
Im folgenden Beispiel verwenden wir den Klassifikator KNN (K nächste Nachbarn). Gehen Sie nicht auf die Details der KNN-Algorithmen ein, da es dafür ein separates Kapitel geben wird. Dieses Beispiel dient nur dazu, den Implementierungsteil zu verstehen.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.4, random_state=1
)
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors = 3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Finding accuracy by comparing actual response values(y_test)with predicted response value(y_pred)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)Ausgabe
Accuracy: 0.9833333333333333
Predictions: ['versicolor', 'virginica']Modellpersistenz
Sobald Sie das Modell trainiert haben, ist es wünschenswert, dass das Modell für die zukünftige Verwendung erhalten bleibt, damit wir es nicht immer wieder neu trainieren müssen. Dies kann mit Hilfe von erfolgendump und load Merkmale joblib Paket.
Betrachten Sie das folgende Beispiel, in dem wir das oben trainierte Modell (classifier_knn) für die zukünftige Verwendung speichern werden -
from sklearn.externals import joblib
joblib.dump(classifier_knn, 'iris_classifier_knn.joblib')Der obige Code speichert das Modell in der Datei iris_classifier_knn.joblib. Jetzt kann das Objekt mit Hilfe des folgenden Codes aus der Datei neu geladen werden:
joblib.load('iris_classifier_knn.joblib')Vorverarbeitung der Daten
Da es sich um viele Daten handelt und diese Daten in Rohform vorliegen, müssen wir sie vor der Eingabe in Algorithmen für maschinelles Lernen in aussagekräftige Daten konvertieren. Dieser Vorgang wird als Vorverarbeitung der Daten bezeichnet. Scikit-learn hat das Paket benanntpreprocessingfür diesen Zweck. Daspreprocessing Paket hat die folgenden Techniken -
Binarisierung
Diese Vorverarbeitungstechnik wird verwendet, wenn wir unsere numerischen Werte in Boolesche Werte konvertieren müssen.
Beispiel
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
data_binarized = preprocessing.Binarizer(threshold=0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)Im obigen Beispiel haben wir verwendet threshold value = 0,5 und deshalb würden alle Werte über 0,5 in 1 und alle Werte unter 0,5 in 0 umgewandelt.
Ausgabe
Binarized data:
[
[ 1. 0. 1.]
[ 0. 1. 1.]
[ 0. 0. 1.]
[ 1. 1. 0.]
]Mittlere Entfernung
Diese Technik wird verwendet, um den Mittelwert aus dem Merkmalsvektor zu eliminieren, so dass jedes Merkmal auf Null zentriert ist.
Beispiel
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
#displaying the mean and the standard deviation of the input data
print("Mean =", input_data.mean(axis=0))
print("Stddeviation = ", input_data.std(axis=0))
#Removing the mean and the standard deviation of the input data
data_scaled = preprocessing.scale(input_data)
print("Mean_removed =", data_scaled.mean(axis=0))
print("Stddeviation_removed =", data_scaled.std(axis=0))Ausgabe
Mean = [ 1.75 -1.275 2.2 ]
Stddeviation = [ 2.71431391 4.20022321 4.69414529]
Mean_removed = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00]
Stddeviation_removed = [ 1. 1. 1.]Skalierung
Wir verwenden diese Vorverarbeitungstechnik zum Skalieren der Merkmalsvektoren. Die Skalierung von Merkmalsvektoren ist wichtig, da die Merkmale nicht synthetisch groß oder klein sein sollten.
Beispiel
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)Ausgabe
Min max scaled data:
[
[ 0.48648649 0.58252427 0.99122807]
[ 0. 1. 0.81578947]
[ 0.27027027 0. 1. ]
[ 1. 0.99029126 0. ]
]Normalisierung
Wir verwenden diese Vorverarbeitungstechnik zum Modifizieren der Merkmalsvektoren. Eine Normalisierung der Merkmalsvektoren ist erforderlich, damit die Merkmalsvektoren im gemeinsamen Maßstab gemessen werden können. Es gibt zwei Arten der Normalisierung:
L1 Normalisierung
Es wird auch als geringste absolute Abweichung bezeichnet. Der Wert wird so geändert, dass die Summe der Absolutwerte in jeder Zeile immer bis zu 1 bleibt. Das folgende Beispiel zeigt die Implementierung der L1-Normalisierung für Eingabedaten.
Beispiel
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l1 = preprocessing.normalize(input_data, norm='l1')
print("\nL1 normalized data:\n", data_normalized_l1)Ausgabe
L1 normalized data:
[
[ 0.22105263 -0.2 0.57894737]
[-0.2027027 0.32432432 0.47297297]
[ 0.03571429 -0.56428571 0.4 ]
[ 0.42142857 0.16428571 -0.41428571]
]L2 Normalisierung
Auch als kleinste Quadrate bezeichnet. Der Wert wird so geändert, dass die Summe der Quadrate in jeder Zeile immer bis zu 1 bleibt. Das folgende Beispiel zeigt die Implementierung der L2-Normalisierung für Eingabedaten.
Beispiel
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l2 = preprocessing.normalize(input_data, norm='l2')
print("\nL1 normalized data:\n", data_normalized_l2)Ausgabe
L2 normalized data:
[
[ 0.33946114 -0.30713151 0.88906489]
[-0.33325106 0.53320169 0.7775858 ]
[ 0.05156558 -0.81473612 0.57753446]
[ 0.68706914 0.26784051 -0.6754239 ]
]Wie wir wissen, wird beim maschinellen Lernen ein Modell aus Daten erstellt. Zu diesem Zweck muss der Computer zuerst die Daten verstehen. Als nächstes werden wir verschiedene Möglichkeiten diskutieren, die Daten darzustellen, um vom Computer verstanden zu werden -
Daten als Tabelle
Die beste Möglichkeit, Daten in Scikit-learn darzustellen, sind Tabellen. Eine Tabelle stellt ein 2D-Datenraster dar, wobei Zeilen die einzelnen Elemente des Datensatzes darstellen und die Spalten die Mengen darstellen, die sich auf diese einzelnen Elemente beziehen.
Beispiel
Mit dem folgenden Beispiel können wir herunterladen iris dataset in Form eines Pandas DataFrame mit Hilfe von Python seaborn Bibliothek.
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()Ausgabe
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaAus der obigen Ausgabe können wir ersehen, dass jede Zeile der Daten eine einzelne beobachtete Blume darstellt und die Anzahl der Zeilen die Gesamtzahl der Blumen im Datensatz darstellt. Im Allgemeinen bezeichnen wir die Zeilen der Matrix als Beispiele.
Andererseits repräsentiert jede Spalte der Daten eine quantitative Information, die jede Probe beschreibt. Im Allgemeinen bezeichnen wir die Spalten der Matrix als Features.
Daten als Feature-Matrix
Die Merkmalsmatrix kann als Tabellenlayout definiert werden, bei dem Informationen als 2D-Matrix betrachtet werden können. Es wird in einer Variablen namens gespeichertXund als zweidimensional mit Form angenommen [n_samples, n_features]. Meistens ist es in einem NumPy-Array oder einem Pandas DataFrame enthalten. Wie bereits erwähnt, stellen die Stichproben immer die einzelnen vom Datensatz beschriebenen Objekte dar, und die Merkmale stellen die unterschiedlichen Beobachtungen dar, die jede Stichprobe quantitativ beschreiben.
Daten als Zielarray
Zusammen mit der mit X bezeichneten Feature-Matrix haben wir auch ein Ziel-Array. Es wird auch Label genannt. Es wird mit y bezeichnet. Die Beschriftung oder das Zielarray ist normalerweise eindimensional mit der Länge n_samples. Es ist im Allgemeinen in NumPy enthaltenarray oder Pandas Series. Das Zielarray kann sowohl Werte als auch kontinuierliche numerische Werte und diskrete Werte aufweisen.
Wie unterscheidet sich das Zielarray von Feature-Spalten?
Wir können beide durch einen Punkt unterscheiden, dass das Zielarray normalerweise die Größe ist, die wir aus den Daten vorhersagen möchten, dh statistisch gesehen ist es die abhängige Variable.
Beispiel
Im folgenden Beispiel prognostizieren wir aus dem Iris-Datensatz die Blütenarten basierend auf den anderen Messungen. In diesem Fall wird die Spalte "Arten" als Feature betrachtet.
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);Ausgabe
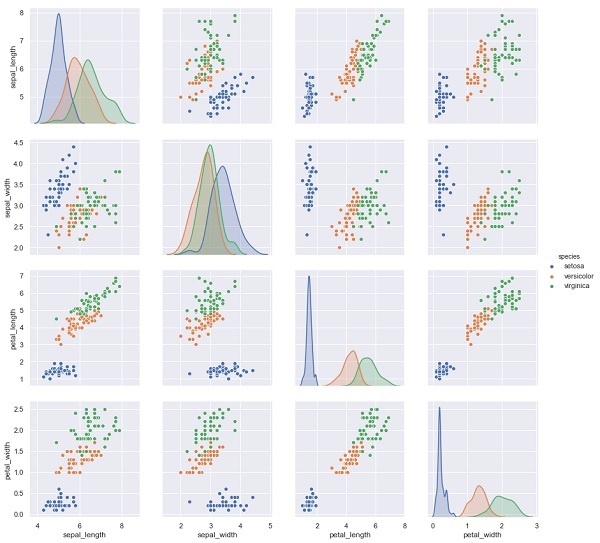
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shapeAusgabe
(150,4)
(150,)In diesem Kapitel erfahren Sie mehr darüber Estimator API(Programmierschnittstelle). Beginnen wir mit dem Verständnis einer Estimator-API.
Was ist die Estimator-API?
Es ist eine der Haupt-APIs, die von Scikit-learn implementiert werden. Es bietet eine konsistente Schnittstelle für eine Vielzahl von ML-Anwendungen, weshalb alle Algorithmen für maschinelles Lernen in Scikit-Learn über die Estimator-API implementiert werden. Das Objekt, das aus den Daten lernt (Anpassung der Daten), ist ein Schätzer. Es kann mit jedem der Algorithmen wie Klassifizierung, Regression, Clustering oder sogar mit einem Transformator verwendet werden, der nützliche Funktionen aus Rohdaten extrahiert.
Zum Anpassen der Daten legen alle Schätzerobjekte eine Anpassungsmethode offen, die einen Datensatz wie folgt verwendet:
estimator.fit(data)Als nächstes können alle Parameter eines Schätzers wie folgt eingestellt werden, wenn er durch das entsprechende Attribut instanziiert wird.
estimator = Estimator (param1=1, param2=2)
estimator.param1Die Ausgabe der obigen wäre 1.
Sobald die Daten mit einem Schätzer ausgestattet sind, werden die Parameter aus den vorliegenden Daten geschätzt. Alle geschätzten Parameter sind nun die Attribute des Schätzobjekts, die wie folgt mit einem Unterstrich enden:
estimator.estimated_param_Verwendung der Estimator-API
Hauptverwendungen von Schätzern sind wie folgt:
Schätzung und Dekodierung eines Modells
Das Schätzobjekt wird zum Schätzen und Decodieren eines Modells verwendet. Darüber hinaus wird das Modell als deterministische Funktion der folgenden geschätzt:
Die Parameter, die bei der Objektkonstruktion bereitgestellt werden.
Der globale Zufallsstatus (numpy.random), wenn der Parameter random_state des Schätzers auf none gesetzt ist.
Alle Daten, die an den letzten Anruf an übergeben wurden fit, fit_transform, or fit_predict.
Alle Daten, die in einer Folge von Aufrufen an übergeben werden partial_fit.
Abbildung einer nicht rechteckigen Datendarstellung auf rechteckige Daten
Es ordnet eine nicht rechteckige Datendarstellung rechteckigen Daten zu. Mit einfachen Worten, es werden Eingaben vorgenommen, bei denen nicht jede Stichprobe als Array-ähnliches Objekt fester Länge dargestellt wird, und es wird für jede Stichprobe ein Array-ähnliches Objekt mit Merkmalen erstellt.
Unterscheidung zwischen Kern- und Außenproben
Es modelliert die Unterscheidung zwischen Kern- und Außenproben mithilfe der folgenden Methoden:
fit
fit_predict wenn transduktiv
vorhersagen, ob induktiv
Leitprinzipien
Beachten Sie beim Entwerfen der Scikit-Learn-API die folgenden Leitprinzipien:
Konsistenz
Dieses Prinzip besagt, dass alle Objekte eine gemeinsame Schnittstelle haben sollten, die aus einer begrenzten Anzahl von Methoden stammt. Die Dokumentation sollte auch konsistent sein.
Begrenzte Objekthierarchie
Dieses Leitprinzip lautet:
Algorithmen sollten durch Python-Klassen dargestellt werden
Datensätze sollten im Standardformat wie NumPy-Arrays, Pandas DataFrames und SciPy-Sparse-Matrix dargestellt werden.
Parameternamen sollten Standard-Python-Zeichenfolgen verwenden.
Komposition
Wie wir wissen, können ML-Algorithmen als die Folge vieler grundlegender Algorithmen ausgedrückt werden. Scikit-learn nutzt diese grundlegenden Algorithmen bei Bedarf.
Sinnvolle Standardeinstellungen
Nach diesem Prinzip definiert die Scikit-Lernbibliothek einen geeigneten Standardwert, wenn ML-Modelle benutzerdefinierte Parameter erfordern.
Inspektion
Gemäß diesem Leitprinzip wird jeder angegebene Parameterwert als Schamattribut angezeigt.
Schritte zur Verwendung der Estimator-API
Im Folgenden finden Sie die Schritte zur Verwendung der Scikit-Learn-Schätzer-API:
Schritt 1: Wählen Sie eine Modellklasse
In diesem ersten Schritt müssen wir eine Modellklasse auswählen. Dies kann durch Importieren der entsprechenden Estimator-Klasse aus Scikit-learn erfolgen.
Schritt 2: Wählen Sie Modellhyperparameter
In diesem Schritt müssen wir Klassenmodell-Hyperparameter auswählen. Dies kann durch Instanziieren der Klasse mit den gewünschten Werten erfolgen.
Schritt 3: Anordnen der Daten
Als nächstes müssen wir die Daten in Merkmalsmatrix (X) und Zielvektor (y) anordnen.
Schritt 4: Modellanpassung
Jetzt müssen wir das Modell an Ihre Daten anpassen. Dies kann durch Aufrufen der fit () -Methode der Modellinstanz erfolgen.
Schritt 5: Anwenden des Modells
Nach dem Anpassen des Modells können wir es auf neue Daten anwenden. Verwenden Sie für überwachtes Lernenpredict()Methode zur Vorhersage der Beschriftungen für unbekannte Daten. Verwenden Sie für unbeaufsichtigtes Lernenpredict() oder transform() Eigenschaften der Daten ableiten.
Beispiel für betreutes Lernen
Als Beispiel für diesen Prozess nehmen wir hier den allgemeinen Fall, dass eine Linie an (x, y) -Daten angepasst wird, d. H. simple linear regression.
Zuerst müssen wir den Datensatz laden, wir verwenden den Iris-Datensatz -
Beispiel
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shapeAusgabe
(150, 4)Beispiel
y_iris = iris['species']
y_iris.shapeAusgabe
(150,)Beispiel
Für dieses Regressionsbeispiel verwenden wir nun die folgenden Beispieldaten:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);Ausgabe
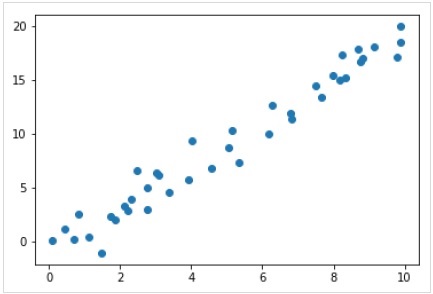
Wir haben also die obigen Daten für unser lineares Regressionsbeispiel.
Mit diesen Daten können wir nun die oben genannten Schritte anwenden.
Wählen Sie eine Modellklasse
Um ein einfaches lineares Regressionsmodell zu berechnen, müssen wir die lineare Regressionsklasse wie folgt importieren:
from sklearn.linear_model import LinearRegressionWählen Sie Modellhyperparameter
Sobald wir eine Modellklasse ausgewählt haben, müssen wir einige wichtige Entscheidungen treffen, die häufig als Hyperparameter dargestellt werden, oder die Parameter, die festgelegt werden müssen, bevor das Modell an Daten angepasst wird. Hier, für dieses Beispiel der linearen Regression, möchten wir den Achsenabschnitt mithilfe von anpassenfit_intercept Hyperparameter wie folgt -
Example
model = LinearRegression(fit_intercept = True)
modelOutput
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)Daten anordnen
Nun, da wir wissen, dass unsere Zielvariable y ist in der richtigen Form, dh eine Länge n_samplesArray von 1-D. Wir müssen jedoch die Feature-Matrix neu gestaltenX um es zu einer Matrix der Größe zu machen [n_samples, n_features]. Dies kann wie folgt erfolgen:
Example
X = x[:, np.newaxis]
X.shapeOutput
(40, 1)Modellbefestigung
Sobald wir die Daten angeordnet haben, ist es Zeit, das Modell anzupassen, dh unser Modell auf Daten anzuwenden. Dies kann mit Hilfe von erfolgenfit() Methode wie folgt -
Example
model.fit(X, y)Output
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)In Scikit-learn wird die fit() Prozess haben einige nachfolgende Unterstriche.
In diesem Beispiel zeigt der folgende Parameter die Steigung der einfachen linearen Anpassung der Daten -
Example
model.coef_Output
array([1.99839352])Der folgende Parameter repräsentiert den Achsenabschnitt der einfachen linearen Anpassung an die Daten -
Example
model.intercept_Output
-0.9895459457775022Anwenden des Modells auf neue Daten
Nach dem Training des Modells können wir es auf neue Daten anwenden. Die Hauptaufgabe des überwachten maschinellen Lernens besteht darin, das Modell anhand neuer Daten zu bewerten, die nicht Teil des Trainingssatzes sind. Dies kann mit Hilfe von erfolgenpredict() Methode wie folgt -
Example
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Output
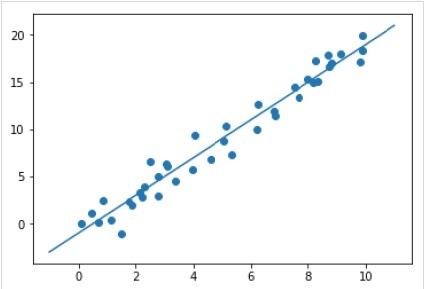
Vollständiges Arbeits- / ausführbares Beispiel
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Beispiel für unbeaufsichtigtes Lernen
Als Beispiel für diesen Prozess wird hier häufig die Dimensionalität des Iris-Datensatzes reduziert, damit wir ihn leichter visualisieren können. In diesem Beispiel verwenden wir die Hauptkomponentenanalyse (PCA), eine schnelle lineare Dimensionsreduktionstechnik.
Wie im obigen Beispiel können wir die Zufallsdaten aus dem Iris-Datensatz laden und zeichnen. Danach können wir die folgenden Schritte ausführen -
Wählen Sie eine Modellklasse
from sklearn.decomposition import PCAWählen Sie Modellhyperparameter
Example
model = PCA(n_components=2)
modelOutput
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Modellbefestigung
Example
model.fit(X_iris)Output
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Transformieren Sie die Daten in zweidimensionale
Example
X_2D = model.transform(X_iris)Jetzt können wir das Ergebnis wie folgt darstellen:
Output
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);Output
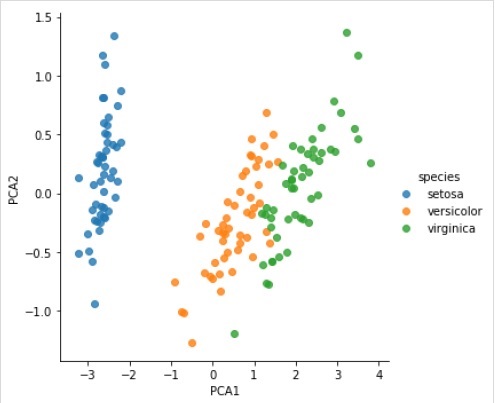
Vollständiges Arbeits- / ausführbares Beispiel
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);Die Objekte von Scikit-learn teilen sich eine einheitliche Basis-API, die aus den folgenden drei komplementären Schnittstellen besteht:
Estimator interface - Es ist für den Bau und die Montage der Modelle.
Predictor interface - Es ist für Vorhersagen.
Transformer interface - Es dient zum Konvertieren von Daten.
Die APIs verwenden einfache Konventionen, und die Entwurfsentscheidungen wurden so gesteuert, dass die Verbreitung von Framework-Code vermieden wird.
Zweck der Konventionen
Mit Konventionen soll sichergestellt werden, dass die API die folgenden allgemeinen Grundsätze einhält:
Consistency - Alle Objekte, unabhängig davon, ob sie einfach oder zusammengesetzt sind, müssen eine konsistente Schnittstelle gemeinsam haben, die sich aus einer begrenzten Anzahl von Methoden zusammensetzt.
Inspection - Konstruktorparameter und Parameterwerte, die vom Lernalgorithmus bestimmt werden, sollten gespeichert und als öffentliche Attribute verfügbar gemacht werden.
Non-proliferation of classes - Datensätze sollten als NumPy-Arrays oder Scipy-Sparse-Matrix dargestellt werden, während Namen und Werte von Hyperparametern als Standard-Python-Zeichenfolgen dargestellt werden sollten, um die Verbreitung von Framework-Code zu vermeiden.
Composition - Die Algorithmen, ob sie als Sequenzen oder Kombinationen von Transformationen zu den Daten ausgedrückt werden können oder natürlich als Metaalgorithmen angesehen werden, die mit anderen Algorithmen parametrisiert sind, sollten implementiert und aus vorhandenen Bausteinen zusammengesetzt werden.
Sensible defaults- In scikit-learn wird immer dann, wenn für eine Operation ein benutzerdefinierter Parameter erforderlich ist, ein geeigneter Standardwert definiert. Dieser Standardwert sollte dazu führen, dass die Operation auf sinnvolle Weise ausgeführt wird, z. B. um eine Basislösung für die jeweilige Aufgabe zu erhalten.
Verschiedene Konventionen
Die in Sklearn verfügbaren Konventionen werden nachfolgend erläutert -
Typ Casting
Es besagt, dass die Eingabe in umgewandelt werden soll float64. Im folgenden Beispiel, in demsklearn.random_projection Modul zur Reduzierung der Dimensionalität der Daten, wird es erklären -
Example
import numpy as np
from sklearn import random_projection
rannge = np.random.RandomState(0)
X = range.rand(10,2000)
X = np.array(X, dtype = 'float32')
X.dtype
Transformer_data = random_projection.GaussianRandomProjection()
X_new = transformer.fit_transform(X)
X_new.dtypeOutput
dtype('float32')
dtype('float64')Im obigen Beispiel können wir sehen, dass X ist float32 welches gegossen wird float64 durch fit_transform(X).
Parameter anpassen und aktualisieren
Hyperparameter eines Schätzers können aktualisiert und angepasst werden, nachdem er über das erstellt wurde set_params()Methode. Sehen wir uns das folgende Beispiel an, um es zu verstehen:
Example
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y = True)
clf = SVC()
clf.set_params(kernel = 'linear').fit(X, y)
clf.predict(X[:5])Output
array([0, 0, 0, 0, 0])Sobald der Schätzer erstellt wurde, ändert der obige Code den Standardkernel rbf linear über SVC.set_params().
Der folgende Code ändert nun den Kernel zurück in rbf, um den Schätzer anzupassen und eine zweite Vorhersage zu treffen.
Example
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y)
clf.predict(X[:5])Output
array([0, 0, 0, 0, 0])Vollständiger Code
Das folgende ist das vollständige ausführbare Programm -
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y = True)
clf = SVC()
clf.set_params(kernel = 'linear').fit(X, y)
clf.predict(X[:5])
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y)
clf.predict(X[:5])Multiclass & Multilabel Fitting
Bei der Anpassung mehrerer Klassen hängen sowohl die Lern- als auch die Vorhersageaufgaben vom Format der angepassten Zieldaten ab. Das verwendete Modul istsklearn.multiclass. Überprüfen Sie das folgende Beispiel, in dem der Klassifikator für mehrere Klassen auf ein 1d-Array passt.
Example
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]]
y = [0, 0, 1, 1, 2]
classif = OneVsRestClassifier(estimator = SVC(gamma = 'scale',random_state = 0))
classif.fit(X, y).predict(X)Output
array([0, 0, 1, 1, 2])Im obigen Beispiel wird der Klassifizierer auf ein eindimensionales Array von Mehrklassenbeschriftungen und die angepasst predict()Das Verfahren liefert daher eine entsprechende Vorhersage für mehrere Klassen. Andererseits ist es aber auch möglich, auf ein zweidimensionales Array von binären Beschriftungsindikatoren wie folgt zu passen:
Example
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]]
y = LabelBinarizer().fit_transform(y)
classif.fit(X, y).predict(X)Output
array(
[
[0, 0, 0],
[0, 0, 0],
[0, 1, 0],
[0, 1, 0],
[0, 0, 0]
]
)In ähnlicher Weise kann einer Instanz im Fall einer Mehrfachetikettenanpassung mehrere Etiketten wie folgt zugewiesen werden:
Example
from sklearn.preprocessing import MultiLabelBinarizer
y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]]
y = MultiLabelBinarizer().fit_transform(y)
classif.fit(X, y).predict(X)Output
array(
[
[1, 0, 1, 0, 0],
[1, 0, 1, 0, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 0, 0]
]
)Im obigen Beispiel ist sklearn.MultiLabelBinarizerwird verwendet, um das zweidimensionale Array von Multilabels zu binarisieren, auf das es passt. Aus diesem Grund gibt die Funktion Predict () ein 2D-Array als Ausgabe mit mehreren Beschriftungen für jede Instanz aus.
Dieses Kapitel hilft Ihnen beim Erlernen der linearen Modellierung in Scikit-Learn. Beginnen wir mit dem Verständnis der linearen Regression in Sklearn.
In der folgenden Tabelle sind verschiedene lineare Modelle aufgeführt, die von Scikit-Learn bereitgestellt werden.
| Sr.Nr. | Modellbeschreibung |
|---|---|
| 1 | Lineare Regression Es ist eines der besten statistischen Modelle, das die Beziehung zwischen einer abhängigen Variablen (Y) und einem bestimmten Satz unabhängiger Variablen (X) untersucht. |
| 2 | Logistische Regression Die logistische Regression ist trotz ihres Namens eher ein Klassifizierungsalgorithmus als ein Regressionsalgorithmus. Basierend auf einem gegebenen Satz unabhängiger Variablen wird es verwendet, um einen diskreten Wert zu schätzen (0 oder 1, ja / nein, wahr / falsch). |
| 3 | Ridge Regression Die Ridge-Regression oder Tikhonov-Regularisierung ist die Regularisierungstechnik, die die L2-Regularisierung durchführt. Es modifiziert die Verlustfunktion durch Addieren der Strafe (Schrumpfungsmenge), die dem Quadrat der Größe der Koeffizienten entspricht. |
| 4 | Bayesian Ridge Regression Die Bayes'sche Regression ermöglicht es einem natürlichen Mechanismus, unzureichende oder schlecht verteilte Daten zu überleben, indem eine lineare Regression unter Verwendung von Wahrscheinlichkeitsverteilern anstelle von Punktschätzungen formuliert wird. |
| 5 | LASSO LASSO ist die Regularisierungstechnik, die die L1-Regularisierung durchführt. Es modifiziert die Verlustfunktion durch Addition der Strafe (Schrumpfungsmenge), die der Summe des Absolutwerts der Koeffizienten entspricht. |
| 6 | Multitasking LASSO Es ermöglicht die gemeinsame Anpassung mehrerer Regressionsprobleme, wodurch die ausgewählten Features für alle Regressionsprobleme, auch als Aufgaben bezeichnet, gleich sind. Sklearn bietet ein lineares Modell namens MultiTaskLasso, das mit einer gemischten L1-, L2-Norm für die Regularisierung trainiert wurde und die spärliche Koeffizienten für mehrere Regressionsprobleme gemeinsam schätzt. |
| 7 | Elastic-Net Das Elastic-Net ist eine regulierte Regressionsmethode, die beide Strafen, dh L1 und L2 der Lasso- und Ridge-Regressionsmethoden, linear kombiniert. Dies ist nützlich, wenn mehrere korrelierte Merkmale vorhanden sind. |
| 8 | Multitasking Elastic-Net Es handelt sich um ein Elastic-Net-Modell, mit dem mehrere Regressionsprobleme gemeinsam angepasst werden können, wobei die ausgewählten Funktionen für alle Regressionsprobleme, auch Aufgaben genannt, gleich bleiben |
Dieses Kapitel konzentriert sich auf die Polynommerkmale und Pipelining-Tools in Sklearn.
Einführung in Polynomfunktionen
Lineare Modelle, die auf nichtlinearen Funktionen von Daten trainiert werden, erhalten im Allgemeinen die schnelle Leistung linearer Methoden. Es ermöglicht ihnen auch, einen viel größeren Datenbereich anzupassen. Aus diesem Grund werden beim maschinellen Lernen solche linearen Modelle verwendet, die auf nichtlinearen Funktionen trainiert werden.
Ein solches Beispiel ist, dass eine einfache lineare Regression erweitert werden kann, indem Polynommerkmale aus den Koeffizienten konstruiert werden.
Angenommen, wir haben ein lineares Standardregressionsmodell, dann würde es für 2D-Daten folgendermaßen aussehen:
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}$$Jetzt können wir die Merkmale in Polynomen zweiter Ordnung kombinieren und unser Modell sieht wie folgt aus:
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}+W_{3}X_{1}X_{2}+W_{4}X_1^2+W_{5}X_2^2$$Das Obige ist immer noch ein lineares Modell. Hier haben wir gesehen, dass die resultierende Polynomregression in derselben Klasse linearer Modelle liegt und auf ähnliche Weise gelöst werden kann.
Zu diesem Zweck stellt scikit-learn ein Modul mit dem Namen bereit PolynomialFeatures. Dieses Modul wandelt eine Eingabedatenmatrix in eine neue Datenmatrix eines bestimmten Grades um.
Parameter
Die folgende Tabelle enthält die von verwendeten Parameter PolynomialFeatures Modul
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | degree - Ganzzahl, Standard = 2 Es repräsentiert den Grad der Polynommerkmale. |
| 2 | interaction_only - Boolean, Standard = false Standardmäßig ist es falsch, aber wenn es auf true gesetzt ist, werden die Features erzeugt, die Produkte mit den meisten Grad unterschiedlicher Eingabe-Features sind. Solche Merkmale werden Interaktionsmerkmale genannt. |
| 3 | include_bias - Boolean, Standard = true Es enthält eine Vorspannungsspalte, dh das Merkmal, in dem alle Polynomkräfte Null sind. |
| 4 | order - str in {'C', 'F'}, Standard = 'C' Dieser Parameter repräsentiert die Reihenfolge des Ausgabearrays im dichten Fall. 'F'-Reihenfolge bedeutet schneller zu berechnen, kann jedoch nachfolgende Schätzer verlangsamen. |
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute PolynomialFeatures Modul
| Sr.Nr. | Attribute & Beschreibung |
|---|---|
| 1 | powers_ - Array, Form (n_output_features, n_input_features) Es zeigt, dass Potenzen_ [i, j] der Exponent des j-ten Eingangs im i-ten Ausgang ist. |
| 2 | n_input_features _ - int Wie der Name schon sagt, gibt es die Gesamtzahl der Eingabefunktionen an. |
| 3 | n_output_features _ - int Wie der Name schon sagt, gibt es die Gesamtzahl der Polynomausgabemerkmale an. |
Implementierungsbeispiel
Das folgende Python-Skript verwendet PolynomialFeatures Transformator zur Umwandlung eines Arrays von 8 in Form (4,2) -
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
Y = np.arange(8).reshape(4, 2)
poly = PolynomialFeatures(degree=2)
poly.fit_transform(Y)Ausgabe
array(
[
[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.],
[ 1., 6., 7., 36., 42., 49.]
]
)Rationalisierung mit Pipeline-Tools
Die obige Art der Vorverarbeitung, dh das Transformieren einer Eingabedatenmatrix in eine neue Datenmatrix eines bestimmten Grades, kann mit dem optimiert werden Pipeline Tools, mit denen grundsätzlich mehrere Schätzer zu einem verkettet werden.
Beispiel
Die folgenden Python-Skripte verwenden die Pipeline-Tools von Scikit-learn, um die Vorverarbeitung zu optimieren (passen zu Polynomdaten der Ordnung 3).
#First, import the necessary packages.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
#Next, create an object of Pipeline tool
Stream_model = Pipeline([('poly', PolynomialFeatures(degree=3)), ('linear', LinearRegression(fit_intercept=False))])
#Provide the size of array and order of polynomial data to fit the model.
x = np.arange(5)
y = 3 - 2 * x + x ** 2 - x ** 3
Stream_model = model.fit(x[:, np.newaxis], y)
#Calculate the input polynomial coefficients.
Stream_model.named_steps['linear'].coef_Ausgabe
array([ 3., -2., 1., -1.])Die obige Ausgabe zeigt, dass das auf Polynommerkmalen trainierte lineare Modell die genauen Eingabepolynomkoeffizienten wiederherstellen kann.
Hier lernen wir einen Optimierungsalgorithmus in Sklearn kennen, der als Stochastic Gradient Descent (SGD) bezeichnet wird.
Stochastic Gradient Descent (SGD) ist ein einfacher, aber effizienter Optimierungsalgorithmus, mit dem die Werte von Parametern / Koeffizienten von Funktionen ermittelt werden, die eine Kostenfunktion minimieren. Mit anderen Worten, es wird zum diskriminativen Lernen von linearen Klassifikatoren unter konvexen Verlustfunktionen wie SVM und logistischer Regression verwendet. Es wurde erfolgreich auf große Datensätze angewendet, da die Aktualisierung der Koeffizienten für jede Trainingsinstanz und nicht am Ende der Instanzen durchgeführt wird.
SGD-Klassifikator
Der SGD-Klassifikator (Stochastic Gradient Descent) implementiert im Wesentlichen eine einfache SGD-Lernroutine, die verschiedene Verlustfunktionen und Strafen für die Klassifizierung unterstützt. Scikit-Learn bietetSGDClassifier Modul zur Implementierung der SGD-Klassifizierung.
Parameter
Die folgende Tabelle enthält die von verwendeten Parameter SGDClassifier Modul -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | loss - str, default = 'Scharnier' Es stellt die Verlustfunktion dar, die während der Implementierung verwendet werden soll. Der Standardwert ist 'Scharnier', wodurch wir eine lineare SVM erhalten. Die anderen Optionen, die verwendet werden können, sind -
|
| 2 | penalty - str, 'keine', 'l2', 'l1', 'elastisches Netz' Dies ist der im Modell verwendete Regularisierungsterm. Standardmäßig ist es L2. Wir können L1 oder 'Elasticnet verwenden; aber auch beide könnten dem Modell Sparsamkeit verleihen, was mit L2 nicht erreichbar ist. |
| 3 | alpha - float, Standard = 0,0001 Alpha, die Konstante, die den Regularisierungsterm multipliziert, ist der Abstimmungsparameter, der entscheidet, wie sehr wir das Modell bestrafen möchten. Der Standardwert ist 0,0001. |
| 4 | l1_ratio - float, Standard = 0,15 Dies wird als ElasticNet-Mischparameter bezeichnet. Sein Bereich ist 0 <= l1_ratio <= 1. Wenn l1_ratio = 1 ist, wäre die Strafe L1 Strafe. Wenn l1_ratio = 0 ist, wäre die Strafe eine L2-Strafe. |
| 5 | fit_intercept - Boolean, Standard = True Dieser Parameter gibt an, dass der Entscheidungsfunktion eine Konstante (Bias oder Intercept) hinzugefügt werden soll. Bei der Berechnung wird kein Achsenabschnitt verwendet, und es wird angenommen, dass die Daten bereits zentriert sind, wenn sie auf false gesetzt werden. |
| 6 | tol - float oder none, optional, Standard = 1.e-3 Dieser Parameter repräsentiert das Stoppkriterium für Iterationen. Der Standardwert ist False. Wenn dieser Wert jedoch auf None gesetzt ist, werden die Iterationen beendet, wennloss > best_loss - tol for n_iter_no_changeaufeinanderfolgende Epochen. |
| 7 | shuffle - Boolean, optional, Standard = True Dieser Parameter gibt an, ob unsere Trainingsdaten nach jeder Epoche gemischt werden sollen oder nicht. |
| 8 | verbose - Ganzzahl, Standard = 0 Es repräsentiert die Ausführlichkeitsstufe. Der Standardwert ist 0. |
| 9 | epsilon - float, Standard = 0.1 Dieser Parameter gibt die Breite des unempfindlichen Bereichs an. Wenn Verlust = "epsilonunempfindlich" ist, wird jeder Unterschied zwischen der aktuellen Vorhersage und der korrekten Bezeichnung, der unter dem Schwellenwert liegt, ignoriert. |
| 10 | max_iter - int, optional, Standard = 1000 Wie der Name schon sagt, repräsentiert es die maximale Anzahl von Durchgängen über die Epochen, dh Trainingsdaten. |
| 11 | warm_start - bool, optional, default = false Wenn dieser Parameter auf True gesetzt ist, können wir die Lösung des vorherigen Aufrufs als Initialisierung wiederverwenden. Wenn wir Standard wählen, dh false, wird die vorherige Lösung gelöscht. |
| 12 | random_state - int, RandomState-Instanz oder None, optional, default = none Dieser Parameter stellt den Startwert der erzeugten Pseudozufallszahl dar, die beim Mischen der Daten verwendet wird. Folgende Optionen stehen zur Verfügung.
|
| 13 | n_jobs - int oder none, optional, Default = None Es gibt die Anzahl der CPUs an, die bei der OVA-Berechnung (One Versus All) für Probleme mit mehreren Klassen verwendet werden sollen. Der Standardwert ist none, was 1 bedeutet. |
| 14 | learning_rate - Zeichenfolge, optional, Standard = 'optimal'
|
| 15 | eta0 - double, default = 0.0 Es stellt die anfängliche Lernrate für die oben genannten Lernratenoptionen dar, dh "konstant", "aufrufend" oder "adaptiv". |
| 16 | power_t - idouble, Standard = 0,5 Es ist der Exponent für die Lernrate. |
| 17 | early_stopping - bool, default = False Dieser Parameter stellt die Verwendung eines frühen Stopps dar, um das Training zu beenden, wenn sich der Validierungswert nicht verbessert. Der Standardwert ist false, aber wenn er auf true gesetzt ist, wird automatisch ein geschichteter Teil der Trainingsdaten als Validierung beiseite gelegt und das Training abgebrochen, wenn sich der Validierungswert nicht verbessert. |
| 18 | validation_fraction - float, Standard = 0.1 Es wird nur verwendet, wenn Early_Stopping wahr ist. Es stellt den Anteil der Trainingsdaten dar, der als Validierungssatz für die vorzeitige Beendigung von Trainingsdaten beiseite gelegt werden soll. |
| 19 | n_iter_no_change - int, Standard = 5 Es stellt die Anzahl der Iterationen ohne Verbesserung dar, sollte der Algorithmus vor dem frühen Stoppen ausgeführt werden. |
| 20 | classs_weight - diktieren, {class_label: weight} oder "ausgeglichen" oder Keine, optional Dieser Parameter repräsentiert die mit Klassen verknüpften Gewichte. Wenn nicht angegeben, sollen die Klassen Gewicht 1 haben. |
| 20 | warm_start - bool, optional, default = false Wenn dieser Parameter auf True gesetzt ist, können wir die Lösung des vorherigen Aufrufs als Initialisierung wiederverwenden. Wenn wir Standard wählen, dh false, wird die vorherige Lösung gelöscht. |
| 21 | average - iBoolean oder int, optional, default = false Es gibt die Anzahl der CPUs an, die bei der OVA-Berechnung (One Versus All) für Probleme mit mehreren Klassen verwendet werden sollen. Der Standardwert ist none, was 1 bedeutet. |
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute SGDClassifier Modul -
| Sr.Nr. | Attribute & Beschreibung |
|---|---|
| 1 | coef_ - Array, Form (1, n_features) wenn n_classes == 2, sonst (n_classes, n_features) Dieses Attribut gibt das den Features zugewiesene Gewicht an. |
| 2 | intercept_ - Array, Form (1,) wenn n_classes == 2, sonst (n_classes,) Es repräsentiert den unabhängigen Begriff in der Entscheidungsfunktion. |
| 3 | n_iter_ - int Es gibt die Anzahl der Iterationen an, um das Stoppkriterium zu erreichen. |
Implementation Example
Wie andere Klassifikatoren muss auch der stochastische Gradientenabstieg (SGD) mit den folgenden zwei Arrays ausgestattet werden:
Ein Array X, das die Trainingsmuster enthält. Es hat die Größe [n_samples, n_features].
Ein Array Y, das die Zielwerte enthält, dh Klassenbezeichnungen für die Trainingsmuster. Es hat die Größe [n_samples].
Example
Das folgende Python-Skript verwendet das lineare Modell SGDClassifier -
import numpy as np
from sklearn import linear_model
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
Y = np.array([1, 1, 2, 2])
SGDClf = linear_model.SGDClassifier(max_iter = 1000, tol=1e-3,penalty = "elasticnet")
SGDClf.fit(X, Y)Output
SGDClassifier(
alpha = 0.0001, average = False, class_weight = None,
early_stopping = False, epsilon = 0.1, eta0 = 0.0, fit_intercept = True,
l1_ratio = 0.15, learning_rate = 'optimal', loss = 'hinge', max_iter = 1000,
n_iter = None, n_iter_no_change = 5, n_jobs = None, penalty = 'elasticnet',
power_t = 0.5, random_state = None, shuffle = True, tol = 0.001,
validation_fraction = 0.1, verbose = 0, warm_start = False
)Example
Nach der Anpassung kann das Modell neue Werte wie folgt vorhersagen:
SGDClf.predict([[2.,2.]])Output
array([2])Example
Für das obige Beispiel können wir den Gewichtsvektor mit Hilfe des folgenden Python-Skripts erhalten -
SGDClf.coef_Output
array([[19.54811198, 9.77200712]])Example
In ähnlicher Weise können wir den Wert des Abfangens mithilfe des folgenden Python-Skripts ermitteln:
SGDClf.intercept_Output
array([10.])Example
Wir können den vorzeichenbehafteten Abstand zur Hyperebene mithilfe von ermitteln SGDClassifier.decision_function wie im folgenden Python-Skript verwendet -
SGDClf.decision_function([[2., 2.]])Output
array([68.6402382])SGD Regressor
Der Stochastic Gradient Descent (SGD) -Regressor implementiert im Wesentlichen eine einfache SGD-Lernroutine, die verschiedene Verlustfunktionen und Strafen unterstützt, um lineare Regressionsmodelle anzupassen. Scikit-Learn bietetSGDRegressor Modul zur Implementierung der SGD-Regression.
Parameter
Von SGDRegressorsind fast die gleichen wie im SGDClassifier-Modul. Der Unterschied liegt im Parameter 'Verlust'. ZumSGDRegressor Verlustparameter der Module Die positiven Werte sind wie folgt:
squared_loss - Es bezieht sich auf die gewöhnliche Anpassung der kleinsten Quadrate.
huber: SGDRegressor- Korrigieren Sie die Ausreißer, indem Sie über eine Entfernung von Epsilon vom quadratischen zum linearen Verlust wechseln. Die Arbeit von 'huber' besteht darin, 'squared_loss' so zu modifizieren, dass sich der Algorithmus weniger auf die Korrektur von Ausreißern konzentriert.
epsilon_insensitive - Tatsächlich werden die Fehler weniger als bei epsilon ignoriert.
squared_epsilon_insensitive- Es ist dasselbe wie epsilon_insensitive. Der einzige Unterschied besteht darin, dass es nach einer Toleranz von Epsilon zu einem quadratischen Verlust wird.
Ein weiterer Unterschied besteht darin, dass der Parameter 'power_t' den Standardwert 0,25 anstelle von 0,5 wie in hat SGDClassifier. Darüber hinaus gibt es keine Parameter 'class_weight' und 'n_jobs'.
Attribute
Die Attribute von SGDRegressor sind auch dieselben wie die des SGDClassifier-Moduls. Vielmehr hat es drei zusätzliche Attribute wie folgt:
average_coef_ - Array, Form (n_features,)
Wie der Name schon sagt, werden die den Features zugewiesenen Durchschnittsgewichte angegeben.
average_intercept_ - Array, Form (1,)
Wie der Name schon sagt, liefert es den gemittelten Intercept-Term.
t_ - int
Es gibt die Anzahl der Gewichtsaktualisierungen an, die während der Trainingsphase durchgeführt wurden.
Note - Die Attribute durchschnittlich_coef_ und durchschnittlich_intercept_ funktionieren, nachdem der Parameter 'Durchschnitt' auf True gesetzt wurde.
Implementation Example
Das folgende Python-Skript verwendet SGDRegressor lineares Modell -
import numpy as np
from sklearn import linear_model
n_samples, n_features = 10, 5
rng = np.random.RandomState(0)
y = rng.randn(n_samples)
X = rng.randn(n_samples, n_features)
SGDReg =linear_model.SGDRegressor(
max_iter = 1000,penalty = "elasticnet",loss = 'huber',tol = 1e-3, average = True
)
SGDReg.fit(X, y)Output
SGDRegressor(
alpha = 0.0001, average = True, early_stopping = False, epsilon = 0.1,
eta0 = 0.01, fit_intercept = True, l1_ratio = 0.15,
learning_rate = 'invscaling', loss = 'huber', max_iter = 1000,
n_iter = None, n_iter_no_change = 5, penalty = 'elasticnet', power_t = 0.25,
random_state = None, shuffle = True, tol = 0.001, validation_fraction = 0.1,
verbose = 0, warm_start = False
)Example
Sobald es angepasst ist, können wir den Gewichtsvektor mithilfe des folgenden Python-Skripts abrufen:
SGDReg.coef_Output
array([-0.00423314, 0.00362922, -0.00380136, 0.00585455, 0.00396787])Example
In ähnlicher Weise können wir den Wert des Abfangens mithilfe des folgenden Python-Skripts ermitteln:
SGReg.intercept_Output
SGReg.intercept_Example
Wir können die Anzahl der Gewichtsaktualisierungen während der Trainingsphase mithilfe des folgenden Python-Skripts ermitteln:
SGDReg.t_Output
61.0Vor- und Nachteile von SGD
Den Profis von SGD folgen -
Der stochastische Gradientenabstieg (SGD) ist sehr effizient.
Die Implementierung ist sehr einfach, da es viele Möglichkeiten zur Code-Optimierung gibt.
Nach den Nachteilen von SGD -
Der stochastische Gradientenabstieg (SGD) erfordert mehrere Hyperparameter wie Regularisierungsparameter.
Es reagiert empfindlich auf die Skalierung von Features.
Dieses Kapitel befasst sich mit einer maschinellen Lernmethode, die als Support Vector Machines (SVMs) bezeichnet wird.
Einführung
Support Vector Machines (SVMs) sind leistungsstarke und dennoch flexible Methoden für überwachtes maschinelles Lernen, die zur Klassifizierung, Regression und Erkennung von Ausreißern verwendet werden. SVMs sind in hochdimensionalen Räumen sehr effizient und werden im Allgemeinen bei Klassifizierungsproblemen verwendet. SVMs sind beliebt und speichereffizient, da sie eine Teilmenge von Trainingspunkten in der Entscheidungsfunktion verwenden.
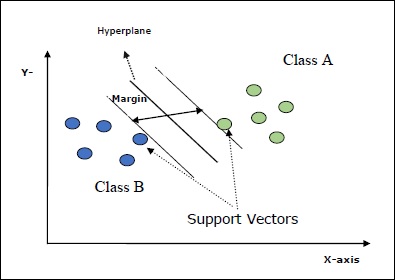
Das Hauptziel von SVMs ist es, die Datensätze in die Anzahl der Klassen zu unterteilen, um a zu finden maximum marginal hyperplane (MMH) Dies kann in den folgenden zwei Schritten erfolgen:
Support Vector Machines generiert zunächst iterativ Hyperebenen, die die Klassen optimal trennen.
Danach wird die Hyperebene ausgewählt, die die Klassen korrekt trennt.
Einige wichtige Konzepte in SVM sind wie folgt:
Support Vectors- Sie können als die Datenpunkte definiert werden, die der Hyperebene am nächsten liegen. Unterstützungsvektoren helfen bei der Entscheidung der Trennlinie.
Hyperplane - Die Entscheidungsebene oder der Raum, der eine Gruppe von Objekten mit unterschiedlichen Klassen teilt.
Margin - Die Lücke zwischen zwei Zeilen auf den Schrankdatenpunkten verschiedener Klassen wird als Rand bezeichnet.
Die folgenden Diagramme geben Ihnen einen Einblick in diese SVM-Konzepte -
SVM in Scikit-learn unterstützt sowohl spärliche als auch dichte Abtastvektoren als Eingabe.
Klassifizierung von SVM
Scikit-learn bietet nämlich drei Klassen SVC, NuSVC und LinearSVC Dies kann eine Klassifizierung in mehreren Klassen durchführen.
SVC
Es ist eine C-Support-Vektorklassifikation, auf deren Implementierung basiert libsvm. Das von scikit-learn verwendete Modul istsklearn.svm.SVC. Diese Klasse behandelt die Unterstützung mehrerer Klassen nach einem Eins-gegen-Eins-Schema.
Parameter
Die folgende Tabelle enthält die von verwendeten Parameter sklearn.svm.SVC Klasse -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | C - float, optional, default = 1.0 Dies ist der Strafparameter des Fehlerterms. |
| 2 | kernel - Zeichenfolge, optional, Standard = 'rbf' Dieser Parameter gibt den Kerneltyp an, der im Algorithmus verwendet werden soll. wir können jeden unter wählen,‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’. Der Standardwert des Kernels wäre‘rbf’. |
| 3 | degree - int, optional, default = 3 Es stellt den Grad der 'Poly'-Kernelfunktion dar und wird von allen anderen Kerneln ignoriert. |
| 4 | gamma - {'scale', 'auto'} oder float, Dies ist der Kernelkoeffizient für die Kernel 'rbf', 'poly' und 'sigmoid'. |
| 5 | optinal default - = 'Skala' Wenn Sie die Standardeinstellung wählen, dh gamma = 'scale', beträgt der von SVC zu verwendende Gamma-Wert 1 / (_ ∗. ()). Wenn andererseits gamma = 'auto' ist, wird 1 / _ verwendet. |
| 6 | coef0 - float, optional, Standard = 0.0 Ein unabhängiger Begriff in der Kernelfunktion, der nur in 'poly' und 'sigmoid' von Bedeutung ist. |
| 7 | tol - float, optional, default = 1.e-3 Dieser Parameter repräsentiert das Stoppkriterium für Iterationen. |
| 8 | shrinking - Boolean, optional, Standard = True Dieser Parameter gibt an, ob die Schrumpfheuristik verwendet werden soll oder nicht. |
| 9 | verbose - Boolescher Wert, Standard: false Es aktiviert oder deaktiviert die ausführliche Ausgabe. Der Standardwert ist false. |
| 10 | probability - boolean, optional, default = true Dieser Parameter aktiviert oder deaktiviert Wahrscheinlichkeitsschätzungen. Der Standardwert ist false, muss jedoch aktiviert werden, bevor wir fit aufrufen. |
| 11 | max_iter - int, optional, default = -1 Wie der Name schon sagt, repräsentiert es die maximale Anzahl von Iterationen innerhalb des Solvers. Der Wert -1 bedeutet, dass die Anzahl der Iterationen unbegrenzt ist. |
| 12 | cache_size - Float, optional Dieser Parameter gibt die Größe des Kernel-Cache an. Der Wert wird in MB (MegaBytes) angegeben. |
| 13 | random_state - int, RandomState-Instanz oder None, optional, default = none Dieser Parameter stellt den Startwert der erzeugten Pseudozufallszahl dar, die beim Mischen der Daten verwendet wird. Folgende sind die Optionen -
|
| 14 | class_weight - {diktieren, 'ausgeglichen'}, optional Dieser Parameter setzt den Parameter C der Klasse j für SVC auf _ℎ [] ∗. Wenn wir die Standardoption verwenden, bedeutet dies, dass alle Klassen das Gewicht eins haben sollen. Auf der anderen Seite, wenn Sie möchtenclass_weight:balancedverwendet die Werte von y, um die Gewichte automatisch anzupassen. |
| 15 | decision_function_shape - ovo ',' ovr ', default =' ovr ' Dieser Parameter entscheidet, ob der Algorithmus zurückkehrt ‘ovr’ (One-vs-Rest) Entscheidungsfunktion der Form wie alle anderen Klassifikatoren oder das Original ovo(Eins-gegen-Eins) Entscheidungsfunktion von libsvm. |
| 16 | break_ties - boolean, optional, default = false True - Die Vorhersage unterbricht die Verbindungen gemäß den Konfidenzwerten von entscheidungsfunktion False - Die Vorhersage gibt die erste Klasse unter den gebundenen Klassen zurück. |
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute sklearn.svm.SVC Klasse -
| Sr.Nr. | Attribute & Beschreibung |
|---|---|
| 1 | support_ - Array-artig, Form = [n_SV] Es gibt die Indizes der Unterstützungsvektoren zurück. |
| 2 | support_vectors_ - Array-artig, Form = [n_SV, n_Features] Es gibt die Unterstützungsvektoren zurück. |
| 3 | n_support_ - Array-ähnlich, dtype = int32, shape = [n_class] Es repräsentiert die Anzahl der Unterstützungsvektoren für jede Klasse. |
| 4 | dual_coef_ - Array, Form = [n_Klasse-1, n_SV] Dies sind die Koeffizienten der Unterstützungsvektoren in der Entscheidungsfunktion. |
| 5 | coef_ - Array, Form = [n_Klasse * (n_Klasse-1) / 2, n_Funktionen] Dieses Attribut, das nur im Fall eines linearen Kernels verfügbar ist, gibt die den Features zugewiesene Gewichtung an. |
| 6 | intercept_ - Array, Form = [n_Klasse * (n_Klasse-1) / 2] Es repräsentiert den unabhängigen Term (Konstante) in der Entscheidungsfunktion. |
| 7 | fit_status_ - int Der Ausgang wäre 0, wenn er richtig sitzt. Der Ausgang wäre 1, wenn er falsch sitzt. |
| 8 | classes_ - Array of Shape = [n_Klassen] Es gibt die Bezeichnungen der Klassen. |
Implementation Example
Wie andere Klassifikatoren muss auch SVC mit den folgenden zwei Arrays ausgestattet werden:
Eine Anordnung XHalten der Trainingsmuster. Es hat die Größe [n_samples, n_features].
Eine Anordnung YHalten der Zielwerte, dh Klassenbezeichnungen für die Trainingsmuster. Es hat die Größe [n_samples].
Das folgende Python-Skript verwendet sklearn.svm.SVC Klasse -
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)Output
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, probability = False, random_state = None, shrinking = False,
tol = 0.001, verbose = False)Example
Sobald es angepasst ist, können wir den Gewichtsvektor mithilfe des folgenden Python-Skripts abrufen:
SVCClf.coef_Output
array([[0.5, 0.5]])Example
In ähnlicher Weise können wir den Wert anderer Attribute wie folgt ermitteln:
SVCClf.predict([[-0.5,-0.8]])Output
array([1])Example
SVCClf.n_support_Output
array([1, 1])Example
SVCClf.support_vectors_Output
array(
[
[-1., -1.],
[ 1., 1.]
]
)Example
SVCClf.support_Output
array([0, 2])Example
SVCClf.intercept_Output
array([-0.])Example
SVCClf.fit_status_Output
0NuSVC
NuSVC ist die Nu Support Vector Classification. Es ist eine weitere Klasse von scikit-learn, die eine Klassifizierung in mehreren Klassen durchführen kann. Es ist wie bei SVC, aber NuSVC akzeptiert leicht unterschiedliche Parametersätze. Der Parameter, der sich von SVC unterscheidet, ist wie folgt:
nu - float, optional, default = 0.5
Es repräsentiert eine Obergrenze für den Anteil der Trainingsfehler und eine Untergrenze für den Anteil der Unterstützungsvektoren. Sein Wert sollte im Intervall von (o, 1] liegen.
Die restlichen Parameter und Attribute sind dieselben wie bei SVC.
Implementierungsbeispiel
Wir können das gleiche Beispiel mit implementieren sklearn.svm.NuSVC Klasse auch.
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import NuSVC
NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
NuSVCClf.fit(X, y)Ausgabe
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, nu = 0.5, probability = False, random_state = None,
shrinking = False, tol = 0.001, verbose = False)Wir können die Ausgaben der restlichen Attribute erhalten, wie dies im Fall von SVC der Fall war.
LinearSVC
Es handelt sich um eine lineare Unterstützungsvektorklassifizierung. Es ist ähnlich wie bei SVC mit Kernel = 'linear'. Der Unterschied zwischen ihnen ist dasLinearSVC implementiert in Bezug auf liblinear, während SVC in implementiert ist libsvm. Das ist der GrundLinearSVChat mehr Flexibilität bei der Auswahl von Strafen und Verlustfunktionen. Es skaliert auch besser auf eine große Anzahl von Proben.
Wenn wir über seine Parameter und Attribute sprechen, wird es nicht unterstützt ‘kernel’ weil angenommen wird, dass es linear ist und es auch einige der Attribute wie fehlt support_, support_vectors_, n_support_, fit_status_ und, dual_coef_.
Es unterstützt jedoch penalty und loss Parameter wie folgt -
penalty − string, L1 or L2(default = ‘L2’)
Dieser Parameter wird verwendet, um die Norm (L1 oder L2) anzugeben, die bei der Bestrafung (Regularisierung) verwendet wird.
loss − string, hinge, squared_hinge (default = squared_hinge)
Es stellt die Verlustfunktion dar, wobei 'Scharnier' der Standard-SVM-Verlust und 'squared_hinge' das Quadrat des Scharnierverlusts ist.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.LinearSVC Klasse -
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 4, random_state = 0)
LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5)
LSVCClf.fit(X, y)Ausgabe
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000,
multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)Beispiel
Nach der Anpassung kann das Modell neue Werte wie folgt vorhersagen:
LSVCClf.predict([[0,0,0,0]])Ausgabe
[1]Beispiel
Für das obige Beispiel können wir den Gewichtsvektor mit Hilfe des folgenden Python-Skripts erhalten -
LSVCClf.coef_Ausgabe
[[0. 0. 0.91214955 0.22630686]]Beispiel
In ähnlicher Weise können wir den Wert des Abfangens mithilfe des folgenden Python-Skripts ermitteln:
LSVCClf.intercept_Ausgabe
[0.26860518]Regression mit SVM
Wie bereits erwähnt, wird SVM sowohl für Klassifizierungs- als auch für Regressionsprobleme verwendet. Die Methode der Support Vector Classification (SVC) von Scikit-learn kann erweitert werden, um auch Regressionsprobleme zu lösen. Diese erweiterte Methode wird als Support Vector Regression (SVR) bezeichnet.
Grundlegende Ähnlichkeit zwischen SVM und SVR
Das von SVC erstellte Modell hängt nur von einer Teilmenge der Trainingsdaten ab. Warum? Da sich die Kostenfunktion für die Erstellung des Modells nicht um Trainingsdatenpunkte kümmert, die außerhalb des Spielraums liegen.
Das von SVR (Support Vector Regression) erstellte Modell hängt auch nur von einer Teilmenge der Trainingsdaten ab. Warum? Weil die Kostenfunktion zum Erstellen des Modells alle Trainingsdatenpunkte ignoriert, die nahe an der Modellvorhersage liegen.
Scikit-learn bietet nämlich drei Klassen SVR, NuSVR and LinearSVR als drei verschiedene Implementierungen von SVR.
SVR
Es ist die Epsilon-unterstützende Vektorregression, auf deren Implementierung basiert libsvm. Im Gegensatz zuSVC Es gibt nämlich zwei freie Parameter im Modell ‘C’ und ‘epsilon’.
epsilon - float, optional, default = 0.1
Es stellt das Epsilon im Epsilon-SVR-Modell dar und gibt die Epsilon-Röhre an, innerhalb derer in der Trainingsverlustfunktion keine Strafe mit Punkten verbunden ist, die innerhalb einer Entfernung von Epsilon vom tatsächlichen Wert vorhergesagt werden.
Die restlichen Parameter und Attribute sind ähnlich wie in SVC.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.SVR Klasse -
from sklearn import svm
X = [[1, 1], [2, 2]]
y = [1, 2]
SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’)
SVRReg.fit(X, y)Ausgabe
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto',
kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)Beispiel
Sobald es angepasst ist, können wir den Gewichtsvektor mithilfe des folgenden Python-Skripts abrufen:
SVRReg.coef_Ausgabe
array([[0.4, 0.4]])Beispiel
In ähnlicher Weise können wir den Wert anderer Attribute wie folgt ermitteln:
SVRReg.predict([[1,1]])Ausgabe
array([1.1])In ähnlicher Weise können wir auch die Werte anderer Attribute abrufen.
NuSVR
NuSVR ist Nu Support Vector Regression. Es ist wie bei NuSVC, aber NuSVR verwendet einen Parameternuum die Anzahl der Unterstützungsvektoren zu steuern. Und im Gegensatz zu NuSVC wonu C-Parameter ersetzt, hier ersetzt epsilon.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.SVR Klasse -
from sklearn.svm import NuSVR
import numpy as np
n_samples, n_features = 20, 15
np.random.seed(0)
y = np.random.randn(n_samples)
X = np.random.randn(n_samples, n_features)
NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M
NuSVRReg.fit(X, y)Ausgabe
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto',
kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001,
verbose = False)Beispiel
Sobald es angepasst ist, können wir den Gewichtsvektor mithilfe des folgenden Python-Skripts abrufen:
NuSVRReg.coef_Ausgabe
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)In ähnlicher Weise können wir auch den Wert anderer Attribute erhalten.
LinearSVR
Es ist eine lineare Unterstützungsvektorregression. Es ist ähnlich wie bei SVR mit Kernel = 'linear'. Der Unterschied zwischen ihnen ist dasLinearSVR implementiert in Bezug auf liblinear, während SVC implementiert in libsvm. Das ist der GrundLinearSVRhat mehr Flexibilität bei der Auswahl von Strafen und Verlustfunktionen. Es skaliert auch besser auf eine große Anzahl von Proben.
Wenn wir über seine Parameter und Attribute sprechen, wird es nicht unterstützt ‘kernel’ weil angenommen wird, dass es linear ist und es auch einige der Attribute wie fehlt support_, support_vectors_, n_support_, fit_status_ und, dual_coef_.
Es unterstützt jedoch 'Verlust'-Parameter wie folgt:
loss - string, optional, default = 'epsilon_insensitive'
Es stellt die Verlustfunktion dar, bei der epsilon_insensitiver Verlust der L1-Verlust und der quadratische epsilonunempfindliche Verlust der L2-Verlust ist.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.LinearSVR Klasse -
from sklearn.svm import LinearSVR
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 4, random_state = 0)
LSVRReg = LinearSVR(dual = False, random_state = 0,
loss = 'squared_epsilon_insensitive',tol = 1e-5)
LSVRReg.fit(X, y)Ausgabe
LinearSVR(
C=1.0, dual=False, epsilon=0.0, fit_intercept=True,
intercept_scaling=1.0, loss='squared_epsilon_insensitive',
max_iter=1000, random_state=0, tol=1e-05, verbose=0
)Beispiel
Nach der Anpassung kann das Modell neue Werte wie folgt vorhersagen:
LSRReg.predict([[0,0,0,0]])Ausgabe
array([-0.01041416])Beispiel
Für das obige Beispiel können wir den Gewichtsvektor mit Hilfe des folgenden Python-Skripts erhalten -
LSRReg.coef_Ausgabe
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])Beispiel
In ähnlicher Weise können wir den Wert des Abfangens mithilfe des folgenden Python-Skripts ermitteln:
LSRReg.intercept_Ausgabe
array([-0.01041416])Hier erfahren wir, was Anomalieerkennung in Sklearn ist und wie sie zur Identifizierung der Datenpunkte verwendet wird.
Die Erkennung von Anomalien ist eine Technik, mit der Datenpunkte im Datensatz identifiziert werden, die nicht gut mit den übrigen Daten übereinstimmen. Es hat viele geschäftliche Anwendungen wie Betrugserkennung, Intrusion Detection, Überwachung des Systemzustands, Überwachung und vorausschauende Wartung. Anomalien, die auch als Ausreißer bezeichnet werden, können in die folgenden drei Kategorien unterteilt werden:
Point anomalies - Es tritt auf, wenn eine einzelne Dateninstanz für den Rest der Daten als anomal angesehen wird.
Contextual anomalies- Eine solche Anomalie ist kontextspezifisch. Es tritt auf, wenn eine Dateninstanz in einem bestimmten Kontext anomal ist.
Collective anomalies - Dies tritt auf, wenn eine Sammlung verwandter Dateninstanzen für den gesamten Datensatz und nicht für einzelne Werte anomal ist.
Methoden
Zwei Methoden nämlich outlier detection und novelty detectionkann zur Erkennung von Anomalien verwendet werden. Es ist notwendig, den Unterschied zwischen ihnen zu sehen.
Ausreißererkennung
Die Trainingsdaten enthalten Ausreißer, die weit vom Rest der Daten entfernt sind. Solche Ausreißer werden als Beobachtungen definiert. Aus diesem Grund versuchen Ausreißererkennungsschätzer immer, die Region mit den konzentriertesten Trainingsdaten anzupassen, während sie die abweichenden Beobachtungen ignorieren. Es ist auch als unbeaufsichtigte Anomalieerkennung bekannt.
Neuheitserkennung
Es geht darum, bei neuen Beobachtungen ein unbeobachtetes Muster zu erkennen, das nicht in den Trainingsdaten enthalten ist. Hier werden die Trainingsdaten nicht durch die Ausreißer verschmutzt. Es ist auch als halbüberwachte Anomalieerkennung bekannt.
Es gibt eine Reihe von ML-Tools, die von scikit-learn bereitgestellt werden und sowohl zur Erkennung von Ausreißern als auch zur Erkennung von Neuheiten verwendet werden können. Diese Tools implementieren zunächst das Lernen von Objekten aus den Daten unbeaufsichtigt mithilfe der fit () -Methode wie folgt:
estimator.fit(X_train)Nun würden die neuen Beobachtungen wie folgt sortiert inliers (labeled 1) oder outliers (labeled -1) unter Verwendung der Predict () -Methode wie folgt:
estimator.fit(X_test)Der Schätzer berechnet zuerst die Rohbewertungsfunktion und dann sagt die Vorhersagemethode den Schwellenwert für diese Rohbewertungsfunktion her. Wir können mit Hilfe von auf diese Rohbewertungsfunktion zugreifenscore_sample Methode und kann den Schwellenwert durch steuern contamination Parameter.
Wir können auch definieren decision_function Methode, die Ausreißer als negativen Wert und Lieferanten als nicht negativen Wert definiert.
estimator.decision_function(X_test)Sklearn-Algorithmen zur Ausreißererkennung
Beginnen wir damit, zu verstehen, was eine elliptische Hülle ist.
Anbringen einer elliptischen Hülle
Dieser Algorithmus geht davon aus, dass reguläre Daten aus einer bekannten Verteilung wie der Gaußschen Verteilung stammen. Zur Erkennung von Ausreißern stellt Scikit-learn ein Objekt mit dem Namen bereitcovariance.EllipticEnvelop.
Dieses Objekt passt eine robuste Kovarianzschätzung an die Daten an und passt somit eine Ellipse an die zentralen Datenpunkte an. Die Punkte außerhalb des zentralen Modus werden ignoriert.
Parameter
Die folgende Tabelle enthält die von sklearn. covariance.EllipticEnvelop Methode -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | store_precision - Boolean, optional, Standard = True Wir können es angeben, wenn die geschätzte Genauigkeit gespeichert ist. |
| 2 | assume_centered - Boolean, optional, Standard = False Wenn wir False setzen, werden der robuste Ort und die Kovarianz mithilfe des FastMCD-Algorithmus direkt berechnet. Wenn andererseits True festgelegt ist, wird die Unterstützung von robustem Standort und Kovarian berechnet. |
| 3 | support_fraction - float in (0., 1.), optional, default = None Dieser Parameter gibt der Methode an, wie viel Prozent der Punkte in die Unterstützung der rohen MCD-Schätzungen einbezogen werden sollen. |
| 4 | contamination - float in (0., 1.), optional, default = 0.1 Es gibt den Anteil der Ausreißer im Datensatz an. |
| 5 | random_state - int, RandomState-Instanz oder None, optional, default = none Dieser Parameter stellt den Startwert der erzeugten Pseudozufallszahl dar, die beim Mischen der Daten verwendet wird. Folgende sind die Optionen -
|
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute sklearn. covariance.EllipticEnvelop Methode -
| Sr.Nr. | Attribute & Beschreibung |
|---|---|
| 1 | support_ - Array-ähnliche Form (n_samples,) Es stellt die Maske der Beobachtungen dar, die zur Berechnung robuster Schätzungen von Ort und Form verwendet werden. |
| 2 | location_ - Array-ähnliche Form (n_Features) Es gibt den geschätzten robusten Standort zurück. |
| 3 | covariance_ - Array-ähnliche Form (n_Features, n_Features) Es gibt die geschätzte robuste Kovarianzmatrix zurück. |
| 4 | precision_ - Array-ähnliche Form (n_Features, n_Features) Es gibt die geschätzte pseudo-inverse Matrix zurück. |
| 5 | offset_ - schweben Es wird verwendet, um die Entscheidungsfunktion aus den Rohwerten zu definieren. decision_function = score_samples -offset_ |
Implementation Example
import numpy as np^M
from sklearn.covariance import EllipticEnvelope^M
true_cov = np.array([[.5, .6],[.6, .4]])
X = np.random.RandomState(0).multivariate_normal(mean = [0, 0], cov=true_cov,size=500)
cov = EllipticEnvelope(random_state = 0).fit(X)^M
# Now we can use predict method. It will return 1 for an inlier and -1 for an outlier.
cov.predict([[0, 0],[2, 2]])Output
array([ 1, -1])Isolationswald
Bei hochdimensionalen Datensätzen besteht eine effiziente Möglichkeit zur Ausreißererkennung darin, zufällige Gesamtstrukturen zu verwenden. Das Scikit-Lernen bietetensemble.IsolationForestMethode, die die Beobachtungen durch zufällige Auswahl eines Merkmals isoliert. Anschließend wird zufällig ein Wert zwischen den Maximal- und Minimalwerten der ausgewählten Features ausgewählt.
Hier entspricht die Anzahl der zum Isolieren einer Stichprobe erforderlichen Aufteilung der Pfadlänge vom Wurzelknoten zum Endknoten.
Parameter
Die folgende Tabelle enthält die von verwendeten Parameter sklearn. ensemble.IsolationForest Methode -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | n_estimators - int, optional, Standard = 100 Es repräsentiert die Anzahl der Basisschätzer im Ensemble. |
| 2 | max_samples - int oder float, optional, default = "auto" Es stellt die Anzahl der Stichproben dar, die aus X gezogen werden müssen, um jeden Basisschätzer zu trainieren. Wenn wir int als Wert wählen, werden max_samples-Samples gezeichnet. Wenn wir float als Wert wählen, werden max_samples ∗ .shape [0] Samples gezeichnet. Und wenn wir auto als Wert wählen, wird max_samples = min (256, n_samples) gezeichnet. |
| 3 | support_fraction - float in (0., 1.), optional, default = None Dieser Parameter gibt der Methode an, wie viel Prozent der Punkte in die Unterstützung der rohen MCD-Schätzungen einbezogen werden sollen. |
| 4 | contamination - auto oder float, optional, default = auto Es gibt den Anteil der Ausreißer im Datensatz an. Wenn wir die Standardeinstellung "Auto" festlegen, wird der Schwellenwert wie im Originalpapier festgelegt. Bei Schwimmen liegt der Verschmutzungsbereich im Bereich von [0,0,5]. |
| 5 | random_state - int, RandomState-Instanz oder None, optional, default = none Dieser Parameter stellt den Startwert der erzeugten Pseudozufallszahl dar, die beim Mischen der Daten verwendet wird. Folgende sind die Optionen -
|
| 6 | max_features - int oder float, optional (Standard = 1.0) Es stellt die Anzahl der Merkmale dar, die aus X gezogen werden müssen, um jeden Basisschätzer zu trainieren. Wenn wir int als Wert auswählen, werden max_features-Features gezeichnet. Wenn wir float als Wert wählen, werden max_features * X.shape [] Samples gezeichnet. |
| 7 | bootstrap - Boolean, optional (Standard = False) Die Standardoption ist False, was bedeutet, dass die Probenahme ersatzlos durchgeführt wird. Wenn andererseits True festgelegt ist, bedeutet dies, dass einzelne Bäume in eine zufällige Teilmenge der Trainingsdaten passen, die durch Ersetzen abgetastet wurden. |
| 8 | n_jobs - int oder None, optional (Standard = None) Es gibt die Anzahl der Jobs an, für die parallel ausgeführt werden soll fit() und predict() Methoden beide. |
| 9 | verbose - int, optional (Standard = 0) Dieser Parameter steuert die Ausführlichkeit des Baumerstellungsprozesses. |
| 10 | warm_start - Bool, optional (Standard = False) Wenn warm_start = true ist, können wir die Lösung für frühere Aufrufe wiederverwenden und dem Ensemble weitere Schätzer hinzufügen. Wenn jedoch false festgelegt ist, müssen wir einen ganz neuen Wald anpassen. |
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute sklearn. ensemble.IsolationForest Methode -
| Sr.Nr. | Attribute & Beschreibung |
|---|---|
| 1 | estimators_ - Liste der DecisionTreeClassifier Bereitstellung der Sammlung aller angepassten Unterschätzer. |
| 2 | max_samples_ - Ganzzahl Es gibt die tatsächliche Anzahl der verwendeten Proben an. |
| 3 | offset_ - schweben Es wird verwendet, um die Entscheidungsfunktion aus den Rohwerten zu definieren. decision_function = score_samples -offset_ |
Implementation Example
Das folgende Python-Skript wird verwendet sklearn. ensemble.IsolationForest Methode zum Anpassen von 10 Bäumen an gegebene Daten
from sklearn.ensemble import IsolationForest
import numpy as np
X = np.array([[-1, -2], [-3, -3], [-3, -4], [0, 0], [-50, 60]])
OUTDClf = IsolationForest(n_estimators = 10)
OUTDclf.fit(X)Output
IsolationForest(
behaviour = 'old', bootstrap = False, contamination='legacy',
max_features = 1.0, max_samples = 'auto', n_estimators = 10, n_jobs=None,
random_state = None, verbose = 0
)Lokaler Ausreißerfaktor
Der LOF-Algorithmus (Local Outlier Factor) ist ein weiterer effizienter Algorithmus zur Durchführung der Ausreißererkennung für hochdimensionale Daten. Das Scikit-Lernen bietetneighbors.LocalOutlierFactorMethode, die eine Punktzahl berechnet, die als lokaler Ausreißerfaktor bezeichnet wird und den Grad der Anomalie der Beobachtungen widerspiegelt. Die Hauptlogik dieses Algorithmus besteht darin, die Proben zu erfassen, die eine wesentlich geringere Dichte als ihre Nachbarn haben. Deshalb wird die lokale Dichteabweichung bestimmter Datenpunkte gegenüber ihren Nachbarn gemessen.
Parameter
Die folgende Tabelle enthält die von verwendeten Parameter sklearn. neighbors.LocalOutlierFactor Methode
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | n_neighbors - int, optional, default = 20 Es gibt die Anzahl der Nachbarn an, die standardmäßig für die Abfrage von Knienachbarn verwendet werden. Alle Proben würden verwendet, wenn. |
| 2 | algorithm - optional Welcher Algorithmus zur Berechnung der nächsten Nachbarn verwendet werden soll.
|
| 3 | leaf_size - int, optional, default = 30 Der Wert dieses Parameters kann die Geschwindigkeit der Erstellung und Abfrage beeinflussen. Dies wirkt sich auch auf den Speicher aus, der zum Speichern des Baums erforderlich ist. Dieser Parameter wird an BallTree- oder KdTree-Algorithmen übergeben. |
| 4 | contamination - auto oder float, optional, default = auto Es gibt den Anteil der Ausreißer im Datensatz an. Wenn wir die Standardeinstellung "Auto" festlegen, wird der Schwellenwert wie im Originalpapier festgelegt. Bei Schwimmen liegt der Verschmutzungsbereich im Bereich von [0,0,5]. |
| 5 | metric - Zeichenfolge oder aufrufbar, Standard Es stellt die Metrik dar, die für die Entfernungsberechnung verwendet wird. |
| 6 | P - int, optional (Standard = 2) Dies ist der Parameter für die Minkowski-Metrik. P = 1 entspricht der Verwendung von manhattan_distance, dh L1, während P = 2 der Verwendung von euclidean_distance, dh L2, entspricht. |
| 7 | novelty - Boolescher Wert (Standard = Falsch) Standardmäßig wird der LOF-Algorithmus für die Ausreißererkennung verwendet, er kann jedoch für die Neuheitserkennung verwendet werden, wenn wir Neuheit = wahr setzen. |
| 8 | n_jobs - int oder None, optional (Standard = None) Es gibt die Anzahl der Jobs an, die parallel für die Methoden fit () und Predict () ausgeführt werden sollen. |
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute sklearn.neighbors.LocalOutlierFactor Methode -
| Sr.Nr. | Attribute & Beschreibung |
|---|---|
| 1 | negative_outlier_factor_ - numpy Array, Form (n_samples,) Bereitstellung des gegenüberliegenden LOF der Trainingsmuster. |
| 2 | n_neighbors_ - Ganzzahl Es gibt die tatsächliche Anzahl der Nachbarn an, die für Nachbarabfragen verwendet werden. |
| 3 | offset_ - schweben Es wird verwendet, um die binären Beschriftungen aus den Rohwerten zu definieren. |
Implementation Example
Das unten angegebene Python-Skript wird verwendet sklearn.neighbors.LocalOutlierFactor Methode zum Erstellen der NeighborsClassifier-Klasse aus einem beliebigen Array, das unserem Datensatz entspricht
from sklearn.neighbors import NearestNeighbors
samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]]
LOFneigh = NearestNeighbors(n_neighbors = 1, algorithm = "ball_tree",p=1)
LOFneigh.fit(samples)Output
NearestNeighbors(
algorithm = 'ball_tree', leaf_size = 30, metric='minkowski',
metric_params = None, n_jobs = None, n_neighbors = 1, p = 1, radius = 1.0
)Example
Nun können wir von diesem konstruierten Klassifikator fragen, ob der Closet-Punkt auf [0.5, 1., 1.5] unter Verwendung des folgenden Python-Skripts lautet:
print(neigh.kneighbors([[.5, 1., 1.5]])Output
(array([[1.7]]), array([[1]], dtype = int64))Ein-Klassen-SVM
Die von Schölkopf et al. Eingeführte One-Class-SVM ist die unbeaufsichtigte Ausreißererkennung. Es ist auch sehr effizient bei hochdimensionalen Daten und schätzt die Unterstützung einer hochdimensionalen Verteilung. Es ist in der implementiertSupport Vector Machines Modul in der Sklearn.svm.OneClassSVMObjekt. Für die Definition einer Grenze sind ein Kernel (meistens RBF) und ein Skalarparameter erforderlich.
Zum besseren Verständnis passen wir unsere Daten an svm.OneClassSVM Objekt -
Beispiel
from sklearn.svm import OneClassSVM
X = [[0], [0.89], [0.90], [0.91], [1]]
OSVMclf = OneClassSVM(gamma = 'scale').fit(X)Jetzt können wir die score_samples für Eingabedaten wie folgt abrufen:
OSVMclf.score_samples(X)Ausgabe
array([1.12218594, 1.58645126, 1.58673086, 1.58645127, 1.55713767])Dieses Kapitel hilft Ihnen beim Verständnis der Methoden für den nächsten Nachbarn in Sklearn.
Nachbarbasierte Lernmethoden sind nämlich von beiden Arten supervised und unsupervised. Überwachtes, auf Nachbarn basierendes Lernen kann sowohl für Klassifizierungs- als auch für Regressionsvorhersageprobleme verwendet werden, wird jedoch hauptsächlich für Klassifizierungsvorhersageprobleme in der Industrie verwendet.
Nachbarbasierte Lernmethoden haben keine spezielle Trainingsphase und verwenden alle Daten für das Training während der Klassifizierung. Es wird auch nichts über die zugrunde liegenden Daten vorausgesetzt. Das ist der Grund, warum sie faul und nicht parametrisch sind.
Das Hauptprinzip hinter den Methoden des nächsten Nachbarn ist -
Um eine vordefinierte Anzahl von Trainingsmustern im Abstand zum neuen Datenpunkt zu finden
Sagen Sie das Etikett anhand dieser Anzahl von Trainingsmustern voraus.
Hier kann die Anzahl der Abtastwerte eine benutzerdefinierte Konstante sein, wie beim Lernen mit K-nächsten Nachbarn, oder basierend auf der lokalen Punktdichte variieren, wie beim Lernen mit Radius-basierten Nachbarn.
sklearn.neighbors Modul
Scikit-lernen haben sklearn.neighborsModul, das Funktionen für unbeaufsichtigte und überwachte nachbarschaftsbasierte Lernmethoden bietet. Als Eingabe können die Klassen in diesem Modul entweder NumPy-Arrays oder verarbeitenscipy.sparse Matrizen.
Arten von Algorithmen
Es gibt verschiedene Arten von Algorithmen, die bei der Implementierung nachbarschaftlicher Methoden verwendet werden können:
Rohe Gewalt
Die Brute-Force-Berechnung der Abstände zwischen allen Punktpaaren im Datensatz bietet die naivste Implementierung für die Nachbarsuche. Mathematisch skaliert für N Proben in D-Dimensionen der Brute-Force-Ansatz als0[DN2]
Für kleine Datenproben kann dieser Algorithmus sehr nützlich sein, aber er wird unmöglich, wenn die Anzahl der Proben zunimmt. Die Brute-Force-Nachbarn-Suche kann durch Schreiben des Schlüsselworts aktiviert werdenalgorithm=’brute’.
KD-Baum
Eine der baumbasierten Datenstrukturen, die erfunden wurden, um die rechnerischen Ineffizienzen des Brute-Force-Ansatzes zu beheben, ist die KD-Baumdatenstruktur. Grundsätzlich ist der KD-Baum eine binäre Baumstruktur, die als K-dimensionaler Baum bezeichnet wird. Der Parameterraum wird rekursiv entlang der Datenachsen partitioniert, indem er in verschachtelte orthografische Bereiche unterteilt wird, in die die Datenpunkte gefüllt werden.
Vorteile
Im Folgenden sind einige Vorteile des KD-Baumalgorithmus aufgeführt:
Construction is fast - Da die Partitionierung nur entlang der Datenachsen durchgeführt wird, ist der Aufbau des KD-Baums sehr schnell.
Less distance computations- Dieser Algorithmus benötigt sehr viel weniger Entfernungsberechnungen, um den nächsten Nachbarn eines Abfragepunkts zu bestimmen. Es dauert nur[ ()] Entfernungsberechnungen.
Nachteile
Fast for only low-dimensional neighbor searches- Es ist sehr schnell für niedrigdimensionale (D <20) Nachbarsuchen, aber wenn D wächst, wird es ineffizient. Da die Partitionierung nur entlang der Datenachsen durchgeführt wird,
Die Suche nach KD-Baumnachbarn kann durch Schreiben des Schlüsselworts aktiviert werden algorithm=’kd_tree’.
Kugelbaum
Da wir wissen, dass KD Tree in höheren Dimensionen ineffizient ist, wurde die Ball Tree-Datenstruktur entwickelt, um diese Ineffizienz von KD Tree zu beheben. Mathematisch unterteilt es die Daten rekursiv in Knoten, die durch einen Schwerpunkt C und einen Radius r definiert sind, so dass jeder Punkt im Knoten innerhalb der durch den Schwerpunkt definierten Hyperkugel liegtC und Radius r. Es wird die unten angegebene Dreiecksungleichung verwendet, wodurch die Anzahl der Kandidatenpunkte für eine Nachbarsuche verringert wird
$$\arrowvert X+Y\arrowvert\leq \arrowvert X\arrowvert+\arrowvert Y\arrowvert$$Vorteile
Im Folgenden sind einige Vorteile des Ball Tree-Algorithmus aufgeführt:
Efficient on highly structured data - Da der Ballbaum die Daten in eine Reihe verschachtelter Hyperkugeln aufteilt, ist er bei stark strukturierten Daten effizient.
Out-performs KD-tree - Der Ballbaum übertrifft den KD-Baum in hohen Dimensionen, da er eine sphärische Geometrie der Ballbaumknoten aufweist.
Nachteile
Costly - Die Aufteilung der Daten in eine Reihe von verschachtelten Hyperkugeln macht ihre Konstruktion sehr kostspielig.
Die Suche nach Ballbaumnachbarn kann durch Schreiben des Schlüsselworts aktiviert werden algorithm=’ball_tree’.
Auswahl des Algorithmus für die nächsten Nachbarn
Die Wahl eines optimalen Algorithmus für einen bestimmten Datensatz hängt von den folgenden Faktoren ab:
Anzahl der Proben (N) und Dimensionalität (D)
Dies sind die wichtigsten Faktoren, die bei der Auswahl des Nearest Neighbor-Algorithmus berücksichtigt werden müssen. Es ist aus den unten angegebenen Gründen -
Die Abfragezeit des Brute-Force-Algorithmus wächst mit O [DN].
Die Abfragezeit des Ballbaumalgorithmus wächst mit O [D log (N)].
Die Abfragezeit des KD-Baumalgorithmus ändert sich mit D auf seltsame Weise, die sehr schwer zu charakterisieren ist. Wenn D <20 ist, sind die Kosten O [D log (N)] und dieser Algorithmus ist sehr effizient. Andererseits ist es in dem Fall ineffizient, wenn D> 20 ist, weil die Kosten auf nahezu O [DN] ansteigen.
Datenstruktur
Ein weiterer Faktor, der die Leistung dieser Algorithmen beeinflusst, ist die intrinsische Dimensionalität der Daten oder die Sparsamkeit der Daten. Dies liegt daran, dass die Abfragezeiten von Ball Tree- und KD Tree-Algorithmen stark davon beeinflusst werden können. Während die Abfragezeit des Brute-Force-Algorithmus durch die Datenstruktur unverändert bleibt. Im Allgemeinen erzeugen Ballbaum- und KD-Baumalgorithmen eine schnellere Abfragezeit, wenn sie in sparser Daten mit geringerer intrinsischer Dimensionalität implantiert werden.
Anzahl der Nachbarn (k)
Die Anzahl der Nachbarn (k), die für einen Abfragepunkt angefordert werden, beeinflusst die Abfragezeit von Ball Tree- und KD Tree-Algorithmen. Ihre Abfragezeit wird langsamer, wenn die Anzahl der Nachbarn (k) zunimmt. Während die Abfragezeit von Brute Force vom Wert von k nicht beeinflusst wird.
Anzahl der Abfragepunkte
Da sie eine Bauphase benötigen, sind sowohl KD-Baum- als auch Kugelbaum-Algorithmen effektiv, wenn eine große Anzahl von Abfragepunkten vorhanden ist. Wenn andererseits eine geringere Anzahl von Abfragepunkten vorhanden ist, ist der Brute-Force-Algorithmus leistungsfähiger als der KD-Baum- und der Ballbaum-Algorithmus.
k-NN (k-Nearest Neighbor), einer der einfachsten Algorithmen für maschinelles Lernen, ist nicht parametrisch und faul. Nicht parametrisch bedeutet, dass für die zugrunde liegende Datenverteilung keine Annahme vorliegt, dh die Modellstruktur wird aus dem Datensatz bestimmt. Faules oder instanzbasiertes Lernen bedeutet, dass für die Modellgenerierung keine Trainingsdatenpunkte erforderlich sind und in der Testphase ganze Trainingsdaten verwendet werden.
Der k-NN-Algorithmus besteht aus den folgenden zwei Schritten:
Schritt 1
In diesem Schritt werden die k nächsten Nachbarn für jede Stichprobe im Trainingssatz berechnet und gespeichert.
Schritt 2
In diesem Schritt werden für eine unbeschriftete Stichprobe die k nächsten Nachbarn aus dem Datensatz abgerufen. Dann sagt es unter diesen k-nächsten Nachbarn die Klasse durch Abstimmung voraus (Klasse mit Stimmenmehrheit gewinnt).
Das Modul, sklearn.neighbors Das implementiert den Algorithmus für k-nächste Nachbarn und bietet die Funktionalität für unsupervised ebenso gut wie supervised nachbarschaftsbasierte Lernmethoden.
Die unbeaufsichtigten nächsten Nachbarn implementieren unterschiedliche Algorithmen (BallTree, KDTree oder Brute Force), um die nächsten Nachbarn für jede Stichprobe zu finden. Diese unbeaufsichtigte Version ist im Grunde nur Schritt 1, der oben diskutiert wurde, und die Grundlage vieler Algorithmen (KNN und K-Mittel sind die berühmten), die die Nachbarsuche erfordern. Mit einfachen Worten, es ist ein unbeaufsichtigter Lernender für die Implementierung von Nachbarsuchen.
Andererseits wird das beaufsichtigte nachbarschaftsbasierte Lernen sowohl zur Klassifizierung als auch zur Regression verwendet.
Unüberwachtes KNN-Lernen
Wie bereits erwähnt, gibt es viele Algorithmen wie KNN und K-Means, die eine Suche nach dem nächsten Nachbarn erfordern. Aus diesem Grund hat Scikit-learn beschlossen, den Teil der Nachbarsuche als eigenen „Lernenden“ zu implementieren. Der Grund für die Suche nach Nachbarn als separater Lernender ist, dass die Berechnung aller paarweisen Entfernungen zum Finden eines nächsten Nachbarn offensichtlich nicht sehr effizient ist. Sehen wir uns das Modul an, das Sklearn verwendet, um unbeaufsichtigtes Lernen für den nächsten Nachbarn zusammen mit einem Beispiel zu implementieren.
Scikit-Lernmodul
sklearn.neighbors.NearestNeighborsist das Modul, mit dem unbeaufsichtigtes Lernen für den nächsten Nachbarn implementiert wird. Es verwendet spezielle Algorithmen für den nächsten Nachbarn mit den Namen BallTree, KDTree oder Brute Force. Mit anderen Worten, es fungiert als einheitliche Schnittstelle zu diesen drei Algorithmen.
Parameter
Die folgende Tabelle enthält die von verwendeten Parameter NearestNeighbors Modul -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | n_neighbors - int, optional Die Anzahl der Nachbarn zu bekommen. Der Standardwert ist 5. |
| 2 | radius - Float, optional Es begrenzt die Entfernung der Nachbarn zur Rückkehr. Der Standardwert ist 1.0. |
| 3 | algorithm - {'auto', 'ball_tree', 'kd_tree', 'brute'}, optional Dieser Parameter verwendet den Algorithmus (BallTree, KDTree oder Brute-Force), mit dem Sie die nächsten Nachbarn berechnen möchten. Wenn Sie 'auto' angeben, wird versucht, den am besten geeigneten Algorithmus basierend auf den an die Anpassungsmethode übergebenen Werten zu bestimmen. |
| 4 | leaf_size - int, optional Dies kann sich auf die Geschwindigkeit der Erstellung und Abfrage sowie auf den zum Speichern des Baums erforderlichen Speicher auswirken. Es wird an BallTree oder KDTree übergeben. Obwohl der optimale Wert von der Art des Problems abhängt, beträgt sein Standardwert 30. |
| 5 | metric - Zeichenfolge oder aufrufbar Dies ist die Metrik, die für die Entfernungsberechnung zwischen Punkten verwendet wird. Wir können es als String oder aufrufbare Funktion übergeben. Bei einer aufrufbaren Funktion wird die Metrik für jedes Zeilenpaar aufgerufen und der resultierende Wert aufgezeichnet. Es ist weniger effizient als die Übergabe des Metriknamens als Zeichenfolge. Wir können zwischen einer Metrik von scikit-learn oder scipy.spatial.distance wählen. Die gültigen Werte lauten wie folgt: Scikit-learn - ['Cosinus', 'Manhattan', 'Euklidisch', 'l1', 'l2', 'Stadtblock'] Scipy.spatial.distance - ['braycurtis', 'canberra', 'chebyshev', 'würfeln', 'hämmern', 'jaccard', 'korrelation', 'kulsinski', 'mahalanobis', 'minkowski', 'rogerstanimoto', 'russellrao', ' sokalmicheme ',' sokalsneath ',' seuclidean ',' sqeuclidean ',' yule ']. Die Standardmetrik ist 'Minkowski'. |
| 6 | P - Ganzzahl, optional Dies ist der Parameter für die Minkowski-Metrik. Der Standardwert ist 2, was der Verwendung von Euclidean_distance (l2) entspricht. |
| 7 | metric_params - diktieren, optional Dies sind die zusätzlichen Schlüsselwortargumente für die Metrikfunktion. Der Standardwert ist Keine. |
| 8 | N_jobs - int oder None, optional Es gibt die Anzahl der parallelen Jobs wieder, die für die Nachbarsuche ausgeführt werden sollen. Der Standardwert ist Keine. |
Implementation Example
Im folgenden Beispiel werden die nächsten Nachbarn zwischen zwei Datensätzen mithilfe von gefunden sklearn.neighbors.NearestNeighbors Modul.
Zuerst müssen wir das erforderliche Modul und die erforderlichen Pakete importieren -
from sklearn.neighbors import NearestNeighbors
import numpy as npDefinieren Sie nun nach dem Importieren der Pakete die Datensätze dazwischen, um die nächsten Nachbarn zu finden.
Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]])Wenden Sie als Nächstes den unbeaufsichtigten Lernalgorithmus wie folgt an:
nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm = 'ball_tree')Passen Sie als Nächstes das Modell mit dem Eingabedatensatz an.
nrst_neigh.fit(Input_data)Suchen Sie nun die K-Nachbarn des Datensatzes. Es werden die Indizes und Abstände der Nachbarn jedes Punktes zurückgegeben.
distances, indices = nbrs.kneighbors(Input_data)
indicesOutput
array(
[
[0, 1, 3],
[1, 2, 0],
[2, 1, 0],
[3, 4, 0],
[4, 5, 3],
[5, 6, 4],
[6, 5, 4]
], dtype = int64
)
distancesOutput
array(
[
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712],
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712]
]
)Die obige Ausgabe zeigt, dass der nächste Nachbar jedes Punktes der Punkt selbst ist, dh bei Null. Dies liegt daran, dass der Abfragesatz mit dem Trainingssatz übereinstimmt.
Example
Wir können auch eine Verbindung zwischen benachbarten Punkten zeigen, indem wir einen spärlichen Graphen wie folgt erzeugen:
nrst_neigh.kneighbors_graph(Input_data).toarray()Output
array(
[
[1., 1., 0., 1., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 0., 0., 1., 1., 0., 0.],
[0., 0., 0., 1., 1., 1., 0.],
[0., 0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 1., 1., 1.]
]
)Sobald wir die unbeaufsichtigten passen NearestNeighbors Modell werden die Daten in einer Datenstruktur basierend auf dem für das Argument festgelegten Wert gespeichert ‘algorithm’. Danach können wir diesen unbeaufsichtigten Lernenden benutzenkneighbors in einem Modell, das Nachbarsuchen erfordert.
Complete working/executable program
from sklearn.neighbors import NearestNeighbors
import numpy as np
Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]])
nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm='ball_tree')
nrst_neigh.fit(Input_data)
distances, indices = nbrs.kneighbors(Input_data)
indices
distances
nrst_neigh.kneighbors_graph(Input_data).toarray()Betreutes KNN-Lernen
Das beaufsichtigte nachbarschaftsbasierte Lernen wird verwendet, um Folgendes zu verfolgen:
- Klassifizierung für die Daten mit diskreten Bezeichnungen
- Regression für die Daten mit fortlaufenden Beschriftungen.
Nächster Nachbar Klassifikator
Wir können die auf Nachbarn basierende Klassifizierung anhand der folgenden zwei Merkmale verstehen:
- Sie wird aus einer einfachen Mehrheit der nächsten Nachbarn jedes Punktes berechnet.
- Es werden einfach Instanzen der Trainingsdaten gespeichert. Deshalb handelt es sich um eine Art nicht verallgemeinerndes Lernen.
Scikit-Lernmodule
Es folgen die zwei verschiedenen Arten von Klassifikatoren für den nächsten Nachbarn, die von scikit-learn verwendet werden:
| S.No. | Klassifikatoren & Beschreibung |
|---|---|
| 1. | KNeighborsClassifier Das K im Namen dieses Klassifikators repräsentiert die k nächsten Nachbarn, wobei k ein vom Benutzer angegebener ganzzahliger Wert ist. Wie der Name schon sagt, implementiert dieser Klassifikator das Lernen basierend auf den k nächsten Nachbarn. Die Wahl des Wertes von k hängt von den Daten ab. |
| 2. | RadiusNeighborsClassifier Der Radius im Namen dieses Klassifikators repräsentiert die nächsten Nachbarn innerhalb eines angegebenen Radius r, wobei r ein vom Benutzer angegebener Gleitkommawert ist. Wie der Name schon sagt, implementiert dieser Klassifikator das Lernen basierend auf der Anzahl der Nachbarn innerhalb eines festen Radius r von jedem Trainingspunkt. |
Nächster Nachbar Regressor
Es wird in Fällen verwendet, in denen Datenbeschriftungen fortlaufender Natur sind. Die zugewiesenen Datenbeschriftungen werden auf der Grundlage des Mittelwerts der Beschriftungen der nächsten Nachbarn berechnet.
Es folgen die zwei verschiedenen Arten von Regressoren für den nächsten Nachbarn, die von scikit-learn verwendet werden:
KNeighborsRegressor
Das K im Namen dieses Regressors repräsentiert die k nächsten Nachbarn, wobei k ist ein integer valuevom Benutzer angegeben. Wie der Name schon sagt, implementiert dieser Regressor das Lernen basierend auf den k nächsten Nachbarn. Die Wahl des Wertes von k hängt von den Daten ab. Lassen Sie es uns anhand eines Implementierungsbeispiels besser verstehen.
Es folgen die zwei verschiedenen Arten von Regressoren für den nächsten Nachbarn, die von scikit-learn verwendet werden:
Implementierungsbeispiel
In diesem Beispiel implementieren wir KNN für einen Datensatz mit dem Namen Iris Flower-Datensatz mithilfe von scikit-learn KNeighborsRegressor.
Importieren Sie zunächst den Iris-Datensatz wie folgt:
from sklearn.datasets import load_iris
iris = load_iris()Jetzt müssen wir die Daten in Trainings- und Testdaten aufteilen. Wir werden Sklearn verwendentrain_test_split Funktion zum Aufteilen der Daten in das Verhältnis von 70 (Trainingsdaten) und 20 (Testdaten) -
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)Als nächstes werden wir die Datenskalierung mit Hilfe des Sklearn-Vorverarbeitungsmoduls wie folgt durchführen:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Als nächstes importieren Sie die KNeighborsRegressor Klasse von Sklearn und geben Sie den Wert der Nachbarn wie folgt an.
Beispiel
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors = 8)
knnr.fit(X_train, y_train)Ausgabe
KNeighborsRegressor(
algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = None, n_neighbors = 8, p = 2,
weights = 'uniform'
)Beispiel
Jetzt können wir den MSE (Mean Squared Error) wie folgt finden:
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))Ausgabe
The MSE is: 4.4333349609375Beispiel
Verwenden Sie es nun, um den Wert wie folgt vorherzusagen:
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors = 3)
knnr.fit(X, y)
print(knnr.predict([[2.5]]))Ausgabe
[0.66666667]Vollständiges Arbeits- / ausführbares Programm
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=8)
knnr.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=3)
knnr.fit(X, y)
print(knnr.predict([[2.5]]))RadiusNeighborsRegressor
Der Radius im Namen dieses Regressors repräsentiert die nächsten Nachbarn innerhalb eines angegebenen Radius r, wobei r ein vom Benutzer angegebener Gleitkommawert ist. Wie der Name schon sagt, implementiert dieser Regressor das Lernen basierend auf der Anzahl der Nachbarn innerhalb eines festen Radius r jedes Trainingspunkts. Lassen Sie es uns mit Hilfe eines Implementierungsbeispiels besser verstehen -
Implementierungsbeispiel
In diesem Beispiel implementieren wir KNN für einen Datensatz mit dem Namen Iris Flower-Datensatz mithilfe von scikit-learn RadiusNeighborsRegressor - -
Importieren Sie zunächst den Iris-Datensatz wie folgt:
from sklearn.datasets import load_iris
iris = load_iris()Jetzt müssen wir die Daten in Trainings- und Testdaten aufteilen. Wir werden die Funktion Sklearn train_test_split verwenden, um die Daten in das Verhältnis von 70 (Trainingsdaten) und 20 (Testdaten) aufzuteilen.
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)Als nächstes werden wir die Datenskalierung mit Hilfe des Sklearn-Vorverarbeitungsmoduls wie folgt durchführen:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Als nächstes importieren Sie die RadiusneighborsRegressor Klasse von Sklearn und geben Sie den Wert des Radius wie folgt an:
import numpy as np
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius=1)
knnr_r.fit(X_train, y_train)Beispiel
Jetzt können wir den MSE (Mean Squared Error) wie folgt finden:
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))Ausgabe
The MSE is: The MSE is: 5.666666666666667Beispiel
Verwenden Sie es nun, um den Wert wie folgt vorherzusagen:
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius=1)
knnr_r.fit(X, y)
print(knnr_r.predict([[2.5]]))Ausgabe
[1.]Vollständiges Arbeits- / ausführbares Programm
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X, y)
print(knnr_r.predict([[2.5]]))Naive Bayes-Methoden sind eine Reihe von überwachten Lernalgorithmen, die auf der Anwendung des Bayes-Theorems basieren, mit der starken Annahme, dass alle Prädiktoren unabhängig voneinander sind, dh das Vorhandensein eines Merkmals in einer Klasse ist unabhängig vom Vorhandensein eines anderen Merkmals in derselben Klasse. Dies ist eine naive Annahme, weshalb diese Methoden als naive Bayes-Methoden bezeichnet werden.
Das Bayes-Theorem gibt die folgende Beziehung an, um die hintere Wahrscheinlichkeit der Klasse zu ermitteln, dh die Wahrscheinlichkeit einer Markierung und einige beobachtete Merkmale: $P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$.
$$P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)=\left(\frac{P\lgroup Y\rgroup P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)}{P\left(\begin{array}{c} features\end{array}\right)}\right)$$Hier, $P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$ ist die hintere Wahrscheinlichkeit der Klasse.
$P\left(\begin{array}{c} Y\end{array}\right)$ ist die vorherige Wahrscheinlichkeit der Klasse.
$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$ ist die Wahrscheinlichkeit, die die Wahrscheinlichkeit eines Prädiktors für eine bestimmte Klasse ist.
$P\left(\begin{array}{c} features\end{array}\right)$ ist die vorherige Wahrscheinlichkeit eines Prädiktors.
Das Scikit-Learn bietet verschiedene naive Bayes-Klassifikatormodelle, nämlich Gauß, Multinomial, Complement und Bernoulli. Alle unterscheiden sich hauptsächlich durch die Annahme, die sie hinsichtlich der Verteilung von machen$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$ dh die Wahrscheinlichkeit eines Prädiktors für eine bestimmte Klasse.
| Sr.Nr. | Modellbeschreibung |
|---|---|
| 1 | Gaußsche naive Bayes Der Gaußsche Naive Bayes-Klassifikator geht davon aus, dass die Daten von jedem Etikett aus einer einfachen Gaußschen Verteilung stammen. |
| 2 | Multinomial Naive Bayes Es wird davon ausgegangen, dass die Features aus einer einfachen Multinomialverteilung stammen. |
| 3 | Bernoulli Naive Bayes Die Annahme in diesem Modell ist, dass die Merkmale binärer Natur (0s und 1s) sind. Eine Anwendung der Bernoulli Naïve Bayes-Klassifikation ist die Textklassifikation mit dem 'Bag of Words'-Modell |
| 4 | Ergänzen Sie naive Bayes Es wurde entwickelt, um die schwerwiegenden Annahmen des Multinomial Bayes-Klassifikators zu korrigieren. Diese Art von NB-Klassifikator eignet sich für unausgeglichene Datensätze |
Gebäude Naive Bayes Classifier
Wir können den Naïve Bayes-Klassifikator auch auf den Scikit-Learn-Datensatz anwenden. Im folgenden Beispiel wenden wir GaussianNB an und passen den Brustkrebs-Datensatz von Scikit-leran an.
Beispiel
Import Sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
data = load_breast_cancer()
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
print(label_names)
print(labels[0])
print(feature_names[0])
print(features[0])
train, test, train_labels, test_labels = train_test_split(
features,labels,test_size = 0.40, random_state = 42
)
from sklearn.naive_bayes import GaussianNB
GNBclf = GaussianNB()
model = GNBclf.fit(train, train_labels)
preds = GNBclf.predict(test)
print(preds)Ausgabe
[
1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1
1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1
1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0
1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0
1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1
0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1
1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0
1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1
1 1 1 1 0 1 0 0 1 1 0 1
]Die obige Ausgabe besteht aus einer Reihe von Nullen und Einsen, die im Wesentlichen die vorhergesagten Werte aus Tumorklassen sind, nämlich bösartig und gutartig.
In diesem Kapitel lernen wir die Lernmethode in Sklearn kennen, die als Entscheidungsbäume bezeichnet wird.
Decisions Tress (DTs) sind die leistungsstärkste nicht parametrische überwachte Lernmethode. Sie können für die Klassifizierungs- und Regressionsaufgaben verwendet werden. Das Hauptziel von DTs besteht darin, ein Modell zu erstellen, das den Wert der Zielvariablen vorhersagt, indem einfache Entscheidungsregeln gelernt werden, die aus den Datenmerkmalen abgeleitet werden. Entscheidungsbäume haben zwei Hauptentitäten; Einer ist der Wurzelknoten, an dem sich die Daten teilen, und der andere sind Entscheidungsknoten oder Blätter, an denen wir die endgültige Ausgabe erhalten haben.
Entscheidungsbaum-Algorithmen
Verschiedene Entscheidungsbaum-Algorithmen werden unten erläutert -
ID3
Es wurde 1986 von Ross Quinlan entwickelt. Es wird auch als Iterativer Dichotomiser 3 bezeichnet. Das Hauptziel dieses Algorithmus besteht darin, für jeden Knoten die kategorialen Merkmale zu finden, die den größten Informationsgewinn für kategoriale Ziele erzielen.
Dadurch kann der Baum auf seine maximale Größe vergrößert werden, und um die Fähigkeit des Baums für unsichtbare Daten zu verbessern, wird ein Bereinigungsschritt ausgeführt. Die Ausgabe dieses Algorithmus wäre ein Mehrwegbaum.
C4.5
Es ist der Nachfolger von ID3 und definiert dynamisch ein diskretes Attribut, das den kontinuierlichen Attributwert in einen diskreten Satz von Intervallen aufteilt. Aus diesem Grund wurde die Einschränkung kategorialer Merkmale aufgehoben. Es konvertiert den ID3-trainierten Baum in Sätze von 'IF-THEN'-Regeln.
Um die Reihenfolge zu bestimmen, in der diese Regeln angewendet werden sollen, wird zuerst die Genauigkeit jeder Regel bewertet.
C5.0
Es funktioniert ähnlich wie C4.5, benötigt jedoch weniger Speicher und erstellt kleinere Regelsätze. Es ist genauer als C4.5.
WAGEN
Es wird als Klassifizierungs- und Regressionsbaum-Algorithmus bezeichnet. Grundsätzlich werden binäre Teilungen unter Verwendung der Merkmale und des Schwellenwerts generiert, die den größten Informationsgewinn an jedem Knoten ergeben (der als Gini-Index bezeichnet wird).
Die Homogenität hängt vom Gini-Index ab. Je höher der Wert des Gini-Index, desto höher wäre die Homogenität. Es ist wie der C4.5-Algorithmus, aber der Unterschied besteht darin, dass er keine Regelsätze berechnet und auch keine numerischen Zielvariablen (Regression) unterstützt.
Klassifizierung mit Entscheidungsbäumen
In diesem Fall sind die Entscheidungsvariablen kategorisch.
Sklearn Module - Die Scikit-Lernbibliothek enthält den Modulnamen DecisionTreeClassifier zum Durchführen einer Klassifizierung mehrerer Klassen für einen Datensatz.
Parameter
Die folgende Tabelle enthält die von sklearn.tree.DecisionTreeClassifier Modul -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | criterion - string, optional default = "gini" Es stellt die Funktion dar, um die Qualität eines Split zu messen. Unterstützte Kriterien sind "Gini" und "Entropie". Die Standardeinstellung ist Gini für Gini-Verunreinigungen, während Entropie für den Informationsgewinn gilt. |
| 2 | splitter - string, optional default = "best" Es teilt dem Modell mit, welche Strategie von "am besten" oder "zufällig" gewählt wird, um die Aufteilung an jedem Knoten zu wählen. |
| 3 | max_depth - int oder None, optionaler Standardwert = None Dieser Parameter bestimmt die maximale Tiefe des Baums. Der Standardwert ist None. Dies bedeutet, dass die Knoten erweitert werden, bis alle Blätter rein sind oder bis alle Blätter weniger als min_smaples_split-Samples enthalten. |
| 4 | min_samples_split - int, float, optionaler Standard = 2 Dieser Parameter gibt die Mindestanzahl von Abtastwerten an, die zum Teilen eines internen Knotens erforderlich sind. |
| 5 | min_samples_leaf - int, float, optionaler Standard = 1 Dieser Parameter gibt die Mindestanzahl von Stichproben an, die erforderlich sind, um sich an einem Blattknoten zu befinden. |
| 6 | min_weight_fraction_leaf - float, optionaler Standard = 0. Mit diesem Parameter erhält das Modell den minimalen gewichteten Bruchteil der Summe der Gewichte, die erforderlich sind, um sich an einem Blattknoten zu befinden. |
| 7 | max_features - int, float, string oder None, optionaler Standardwert = None Es gibt dem Modell die Anzahl der Features, die bei der Suche nach der besten Aufteilung berücksichtigt werden müssen. |
| 8 | random_state - int, RandomState-Instanz oder None, optional, default = none Dieser Parameter stellt den Startwert der erzeugten Pseudozufallszahl dar, die beim Mischen der Daten verwendet wird. Folgende sind die Optionen -
|
| 9 | max_leaf_nodes - int oder None, optionaler Standardwert = None Mit diesem Parameter kann ein Baum mit max_leaf_nodes auf die beste Art und Weise wachsen. Der Standardwert ist none, was bedeutet, dass eine unbegrenzte Anzahl von Blattknoten vorhanden ist. |
| 10 | min_impurity_decrease - float, optionaler Standard = 0. Dieser Wert dient als Kriterium für die Aufteilung eines Knotens, da das Modell einen Knoten aufteilt, wenn diese Aufteilung eine Abnahme der Verunreinigung größer oder gleich bewirkt min_impurity_decrease value. |
| 11 | min_impurity_split - float, Standard = 1e-7 Es stellt die Schwelle für ein frühes Stoppen des Baumwachstums dar. |
| 12 | class_weight - Diktat, Liste der Diktate, "ausgeglichen" oder "Keine", Standard = Keine Es repräsentiert die mit Klassen verbundenen Gewichte. Das Formular lautet {class_label: weight}. Wenn wir die Standardoption verwenden, bedeutet dies, dass alle Klassen das Gewicht eins haben sollen. Auf der anderen Seite, wenn Sie möchtenclass_weight: balancedverwendet die Werte von y, um die Gewichte automatisch anzupassen. |
| 13 | presort - bool, optionaler Standardwert = False Es teilt dem Modell mit, ob die Daten vorsortiert werden sollen, um das Finden der besten Teilungen bei der Anpassung zu beschleunigen. Der Standardwert ist false, aber wenn er auf true gesetzt ist, kann dies den Trainingsprozess verlangsamen. |
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute sklearn.tree.DecisionTreeClassifier Modul -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | feature_importances_ - Array of Shape = [n_Features] Dieses Attribut gibt die Feature-Wichtigkeit zurück. |
| 2 | classes_: - Array of Shape = [n_classes] oder eine Liste solcher Arrays Es stellt die Klassenbeschriftungen dar, dh das Problem mit der einzelnen Ausgabe, oder eine Liste von Arrays mit Klassenbeschriftungen, dh das Problem mit mehreren Ausgaben. |
| 3 | max_features_ - int Es repräsentiert den abgeleiteten Wert des Parameters max_features. |
| 4 | n_classes_ - int oder Liste Es repräsentiert die Anzahl der Klassen, dh das Problem mit einer einzelnen Ausgabe, oder eine Liste der Anzahl von Klassen für jede Ausgabe, dh das Problem mit mehreren Ausgaben. |
| 5 | n_features_ - int Es gibt die Anzahl von features wenn die Methode fit () ausgeführt wird. |
| 6 | n_outputs_ - int Es gibt die Anzahl von outputs wenn die Methode fit () ausgeführt wird. |
Methoden
Die folgende Tabelle enthält die von verwendeten Methoden sklearn.tree.DecisionTreeClassifier Modul -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | apply(self, X [, check_input]) Diese Methode gibt den Index des Blattes zurück. |
| 2 | decision_path(self, X [, check_input]) Wie der Name schon sagt, gibt diese Methode den Entscheidungspfad im Baum zurück |
| 3 | fit(self, X, y [, sample_weight,…]) Die Methode fit () erstellt einen Entscheidungsbaumklassifizierer aus dem angegebenen Trainingssatz (X, y). |
| 4 | get_depth(selbst) Wie der Name schon sagt, gibt diese Methode die Tiefe des Entscheidungsbaums zurück |
| 5 | get_n_leaves(selbst) Wie der Name schon sagt, gibt diese Methode die Anzahl der Blätter des Entscheidungsbaums zurück. |
| 6 | get_params(Selbst [, tief]) Wir können diese Methode verwenden, um die Parameter für den Schätzer zu erhalten. |
| 7 | predict(self, X [, check_input]) Der Klassenwert für X wird vorhergesagt. |
| 8 | predict_log_proba(Selbst, X) Es werden Klassenprotokollwahrscheinlichkeiten der von uns, X, bereitgestellten Eingabestichproben vorhergesagt. |
| 9 | predict_proba(self, X [, check_input]) Es werden Klassenwahrscheinlichkeiten der von uns bereitgestellten Eingabestichproben X vorhergesagt. |
| 10 | score(self, X, y [, sample_weight]) Wie der Name schon sagt, gibt die score () -Methode die mittlere Genauigkeit der angegebenen Testdaten und Labels zurück. |
| 11 | set_params(self, \ * \ * params) Mit dieser Methode können wir die Parameter des Schätzers einstellen. |
Implementierungsbeispiel
Das folgende Python-Skript wird verwendet sklearn.tree.DecisionTreeClassifier Modul zur Erstellung eines Klassifikators zur Vorhersage von Männern oder Frauen aus unserem Datensatz mit 25 Stichproben und zwei Merkmalen, nämlich "Größe" und "Länge der Haare" -
from sklearn import tree
from sklearn.model_selection import train_test_split
X=[[165,19],[175,32],[136,35],[174,65],[141,28],[176,15]
,[131,32],[166,6],[128,32],[179,10],[136,34],[186,2],[12
6,25],[176,28],[112,38],[169,9],[171,36],[116,25],[196,2
5], [196,38], [126,40], [197,20], [150,25], [140,32],[136,35]]
Y=['Man','Woman','Woman','Man','Woman','Man','Woman','Ma
n','Woman','Man','Woman','Man','Woman','Woman','Woman','
Man','Woman','Woman','Man', 'Woman', 'Woman', 'Man', 'Man', 'Woman', 'Woman']
data_feature_names = ['height','length of hair']
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 1)
DTclf = tree.DecisionTreeClassifier()
DTclf = clf.fit(X,Y)
prediction = DTclf.predict([[135,29]])
print(prediction)Ausgabe
['Woman']Wir können die Wahrscheinlichkeit jeder Klasse auch vorhersagen, indem wir die folgende python Predict_proba () -Methode wie folgt verwenden:
Beispiel
prediction = DTclf.predict_proba([[135,29]])
print(prediction)Ausgabe
[[0. 1.]]Regression mit Entscheidungsbäumen
In diesem Fall sind die Entscheidungsvariablen stetig.
Sklearn Module - Die Scikit-Lernbibliothek enthält den Modulnamen DecisionTreeRegressor zum Anwenden von Entscheidungsbäumen auf Regressionsprobleme.
Parameter
Von DecisionTreeRegressor sind fast die gleichen wie die in verwendet wurden DecisionTreeClassifierModul. Der Unterschied liegt im Parameter 'Kriterium'. ZumDecisionTreeRegressor Module ‘criterion: string, optional default = "mse" 'Parameter haben die folgenden Werte -
mse- Es steht für den mittleren quadratischen Fehler. Dies entspricht der Varianzreduzierung als Merkmalauswahlkriterium. Es minimiert den L2-Verlust unter Verwendung des Mittelwerts jedes Endknotens.
freidman_mse - Es wird auch der mittlere quadratische Fehler verwendet, jedoch mit Friedmans Verbesserungswert.
mae- Es steht für den mittleren absoluten Fehler. Es minimiert den L1-Verlust unter Verwendung des Medians jedes Endknotens.
Ein weiterer Unterschied ist, dass es nicht hat ‘class_weight’ Parameter.
Attribute
Attribute von DecisionTreeRegressor sind auch die gleichen wie die von DecisionTreeClassifierModul. Der Unterschied ist, dass es nicht hat‘classes_’ und ‘n_classes_'Attribute.
Methoden
Methoden von DecisionTreeRegressor sind auch die gleichen wie die von DecisionTreeClassifierModul. Der Unterschied ist, dass es nicht hat‘predict_log_proba()’ und ‘predict_proba()’'Attribute.
Implementierungsbeispiel
Die Methode fit () im Regressionsmodell des Entscheidungsbaums verwendet Gleitkommawerte von y. Sehen wir uns ein einfaches Implementierungsbeispiel mit anSklearn.tree.DecisionTreeRegressor - -
from sklearn import tree
X = [[1, 1], [5, 5]]
y = [0.1, 1.5]
DTreg = tree.DecisionTreeRegressor()
DTreg = clf.fit(X, y)Nach der Anpassung können wir dieses Regressionsmodell verwenden, um Vorhersagen wie folgt zu treffen:
DTreg.predict([[4, 5]])Ausgabe
array([1.5])Dieses Kapitel hilft Ihnen beim Verständnis randomisierter Entscheidungsbäume in Sklearn.
Randomisierte Entscheidungsbaumalgorithmen
Da wir wissen, dass ein DT normalerweise durch rekursives Aufteilen der Daten trainiert wird, aber zu Überanpassungen neigt, wurden sie in zufällige Wälder umgewandelt, indem viele Bäume über verschiedene Teilstichproben der Daten trainiert wurden. Dassklearn.ensemble Modul hat folgende zwei Algorithmen basierend auf zufälligen Entscheidungsbäumen -
Der Random Forest-Algorithmus
Für jedes betrachtete Merkmal wird die lokal optimale Kombination aus Merkmal und Teilung berechnet. In Random Forest wird jeder Entscheidungsbaum im Ensemble aus einer Stichprobe erstellt, die mit Ersatz aus dem Trainingssatz gezogen wurde. Anschließend erhält er die Vorhersage von jedem von ihnen und wählt schließlich die beste Lösung durch Abstimmung aus. Es kann sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet werden.
Klassifizierung mit Random Forest
Zum Erstellen eines zufälligen Waldklassifikators bietet das Scikit-Lernmodul sklearn.ensemble.RandomForestClassifier. Beim Erstellen eines zufälligen Gesamtstrukturklassifikators werden von diesem Modul hauptsächlich folgende Parameter verwendet‘max_features’ und ‘n_estimators’.
Hier, ‘max_features’ist die Größe der zufälligen Teilmengen von Features, die beim Teilen eines Knotens berücksichtigt werden müssen. Wenn wir den Wert dieses Parameters auf "Keine" setzen, werden alle Features und keine zufällige Teilmenge berücksichtigt. Andererseits,n_estimatorssind die Anzahl der Bäume im Wald. Je höher die Anzahl der Bäume, desto besser ist das Ergebnis. Die Berechnung wird jedoch auch länger dauern.
Implementierungsbeispiel
Im folgenden Beispiel erstellen wir mithilfe von einen zufälligen Gesamtstrukturklassifizierer sklearn.ensemble.RandomForestClassifier und auch seine Genauigkeit auch mit zu überprüfen cross_val_score Modul.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
X, y = make_blobs(n_samples = 10000, n_features = 10, centers = 100,random_state = 0) RFclf = RandomForestClassifier(n_estimators = 10,max_depth = None,min_samples_split = 2, random_state = 0)
scores = cross_val_score(RFclf, X, y, cv = 5)
scores.mean()Ausgabe
0.9997Beispiel
Wir können auch das sklearn-Dataset verwenden, um einen Random Forest-Klassifikator zu erstellen. Wie im folgenden Beispiel verwenden wir den Iris-Datensatz. Wir werden auch die Genauigkeitsbewertung und die Verwirrungsmatrix finden.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
path = "https://archive.ics.uci.edu/ml/machine-learning-database
s/iris/iris.data"
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
dataset = pd.read_csv(path, names = headernames)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
RFclf = RandomForestClassifier(n_estimators = 50)
RFclf.fit(X_train, y_train)
y_pred = RFclf.predict(X_test)
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)Ausgabe
Confusion Matrix:
[[14 0 0]
[ 0 18 1]
[ 0 0 12]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 1.00 0.95 0.97 19
Iris-virginica 0.92 1.00 0.96 12
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Accuracy: 0.9777777777777777Regression mit Random Forest
Zum Erstellen einer zufälligen Waldregression bietet das Scikit-Lernmodul sklearn.ensemble.RandomForestRegressor. Beim Erstellen eines zufälligen Waldregressors werden dieselben Parameter verwendet, die auch von verwendet werdensklearn.ensemble.RandomForestClassifier.
Implementierungsbeispiel
Im folgenden Beispiel erstellen wir mithilfe von einen zufälligen Gesamtstrukturregressor sklearn.ensemble.RandomForestregressor und auch Vorhersagen für neue Werte unter Verwendung der Predict () - Methode.
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
RFregr = RandomForestRegressor(max_depth = 10,random_state = 0,n_estimators = 100)
RFregr.fit(X, y)Ausgabe
RandomForestRegressor(
bootstrap = True, criterion = 'mse', max_depth = 10,
max_features = 'auto', max_leaf_nodes = None,
min_impurity_decrease = 0.0, min_impurity_split = None,
min_samples_leaf = 1, min_samples_split = 2,
min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None,
oob_score = False, random_state = 0, verbose = 0, warm_start = False
)Einmal angepasst, können wir aus dem Regressionsmodell Folgendes vorhersagen:
print(RFregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Ausgabe
[98.47729198]Extra-Tree-Methoden
Für jedes betrachtete Merkmal wird ein zufälliger Wert für die Aufteilung ausgewählt. Der Vorteil der Verwendung zusätzlicher Baummethoden besteht darin, dass die Varianz des Modells etwas stärker reduziert werden kann. Der Nachteil der Verwendung dieser Verfahren besteht darin, dass die Vorspannung geringfügig erhöht wird.
Klassifizierung mit Extra-Tree-Methode
Zum Erstellen eines Klassifikators mit der Extra-Tree-Methode bietet das Scikit-Lernmodul sklearn.ensemble.ExtraTreesClassifier. Es werden die gleichen Parameter verwendet wie vonsklearn.ensemble.RandomForestClassifier. Der einzige Unterschied besteht in der oben diskutierten Art und Weise, wie sie Bäume bauen.
Implementierungsbeispiel
Im folgenden Beispiel erstellen wir mithilfe von einen zufälligen Gesamtstrukturklassifizierer sklearn.ensemble.ExtraTreeClassifier und auch die Genauigkeit mit zu überprüfen cross_val_score Modul.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import ExtraTreesClassifier
X, y = make_blobs(n_samples = 10000, n_features = 10, centers=100,random_state = 0)
ETclf = ExtraTreesClassifier(n_estimators = 10,max_depth = None,min_samples_split = 10, random_state = 0)
scores = cross_val_score(ETclf, X, y, cv = 5)
scores.mean()Ausgabe
1.0Beispiel
Wir können auch das sklearn-Dataset verwenden, um einen Klassifikator mithilfe der Extra-Tree-Methode zu erstellen. Wie im folgenden Beispiel verwenden wir den Pima-Indian-Datensatz.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import ExtraTreesClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 7
kfold = KFold(n_splits=10, random_state=seed)
num_trees = 150
max_features = 5
ETclf = ExtraTreesClassifier(n_estimators=num_trees, max_features=max_features)
results = cross_val_score(ETclf, X, Y, cv=kfold)
print(results.mean())Ausgabe
0.7551435406698566Regression mit Extra-Tree-Methode
Zum Erstellen eines Extra-Tree Regression bietet das Scikit-Lernmodul sklearn.ensemble.ExtraTreesRegressor. Beim Erstellen eines zufälligen Waldregressors werden dieselben Parameter verwendet, die auch von verwendet werdensklearn.ensemble.ExtraTreesClassifier.
Implementierungsbeispiel
Im folgenden Beispiel bewerben wir uns sklearn.ensemble.ExtraTreesregressorund auf den gleichen Daten, die wir beim Erstellen eines zufälligen Waldregressors verwendet haben. Lassen Sie uns den Unterschied in der Ausgabe sehen
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
ETregr = ExtraTreesRegressor(max_depth = 10,random_state = 0,n_estimators = 100)
ETregr.fit(X, y)Ausgabe
ExtraTreesRegressor(bootstrap = False, criterion = 'mse', max_depth = 10,
max_features = 'auto', max_leaf_nodes = None,
min_impurity_decrease = 0.0, min_impurity_split = None,
min_samples_leaf = 1, min_samples_split = 2,
min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None,
oob_score = False, random_state = 0, verbose = 0, warm_start = False)Beispiel
Einmal angepasst, können wir aus dem Regressionsmodell Folgendes vorhersagen:
print(ETregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Ausgabe
[85.50955817]In diesem Kapitel lernen wir die Boosting-Methoden in Sklearn kennen, mit denen ein Ensemble-Modell erstellt werden kann.
Boosting-Methoden erstellen das Ensemble-Modell inkrementell. Das Hauptprinzip besteht darin, das Modell schrittweise zu erstellen, indem jeder Basismodellschätzer nacheinander trainiert wird. Um ein leistungsfähiges Ensemble aufzubauen, kombinieren diese Methoden im Wesentlichen mehrere Wochenlerner, die nacheinander über mehrere Iterationen von Trainingsdaten trainiert werden. Das Modul sklearn.ensemble verfügt über zwei Boosting-Methoden.
AdaBoost
Es ist eine der erfolgreichsten Boosting-Ensemble-Methoden, deren Hauptschlüssel in der Art und Weise liegt, wie die Instanzen im Datensatz gewichtet werden. Aus diesem Grund muss der Algorithmus beim Erstellen nachfolgender Modelle den Instanzen weniger Aufmerksamkeit schenken.
Klassifizierung mit AdaBoost
Zum Erstellen eines AdaBoost-Klassifikators bietet das Scikit-Lernmodul sklearn.ensemble.AdaBoostClassifier. Während der Erstellung dieses Klassifikators ist der Hauptparameter, den dieses Modul verwendetbase_estimator. Hier ist base_estimator der Wert vonbase estimatoraus dem das verstärkte Ensemble aufgebaut ist. Wenn wir den Wert dieses Parameters auf none setzen, wäre der BasisschätzerDecisionTreeClassifier(max_depth=1).
Implementierungsbeispiel
Im folgenden Beispiel erstellen wir mithilfe von einen AdaBoost-Klassifizierer sklearn.ensemble.AdaBoostClassifier und auch Vorhersage und Überprüfung seiner Punktzahl.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples = 1000, n_features = 10,n_informative = 2, n_redundant = 0,random_state = 0, shuffle = False)
ADBclf = AdaBoostClassifier(n_estimators = 100, random_state = 0)
ADBclf.fit(X, y)Ausgabe
AdaBoostClassifier(algorithm = 'SAMME.R', base_estimator = None,
learning_rate = 1.0, n_estimators = 100, random_state = 0)Beispiel
Einmal angepasst, können wir neue Werte wie folgt vorhersagen:
print(ADBclf.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Ausgabe
[1]Beispiel
Jetzt können wir die Punktzahl wie folgt überprüfen:
ADBclf.score(X, y)Ausgabe
0.995Beispiel
Wir können auch das sklearn-Dataset verwenden, um einen Klassifikator mithilfe der Extra-Tree-Methode zu erstellen. In einem unten angegebenen Beispiel verwenden wir beispielsweise den Pima-Indian-Datensatz.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names = headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 5
kfold = KFold(n_splits = 10, random_state = seed)
num_trees = 100
max_features = 5
ADBclf = AdaBoostClassifier(n_estimators = num_trees, max_features = max_features)
results = cross_val_score(ADBclf, X, Y, cv = kfold)
print(results.mean())Ausgabe
0.7851435406698566Regression mit AdaBoost
Zum Erstellen eines Regressors mit der Ada Boost-Methode bietet die Scikit-Lernbibliothek sklearn.ensemble.AdaBoostRegressor. Beim Erstellen des Regressors werden dieselben Parameter verwendet, die auch von verwendet werdensklearn.ensemble.AdaBoostClassifier.
Implementierungsbeispiel
Im folgenden Beispiel erstellen wir mithilfe von einen AdaBoost-Regressor sklearn.ensemble.AdaBoostregressor und auch Vorhersagen für neue Werte unter Verwendung der Predict () - Methode.
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
ADBregr = RandomForestRegressor(random_state = 0,n_estimators = 100)
ADBregr.fit(X, y)Ausgabe
AdaBoostRegressor(base_estimator = None, learning_rate = 1.0, loss = 'linear',
n_estimators = 100, random_state = 0)Beispiel
Einmal angepasst, können wir aus dem Regressionsmodell Folgendes vorhersagen:
print(ADBregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Ausgabe
[85.50955817]Gradient Tree Boosting
Es wird auch genannt Gradient Boosted Regression Trees(GRBT). Es ist im Grunde eine Verallgemeinerung der Verstärkung auf beliebig differenzierbare Verlustfunktionen. Es wird ein Vorhersagemodell in Form eines Ensembles von Wochenvorhersagemodellen erstellt. Es kann für die Regressions- und Klassifizierungsprobleme verwendet werden. Ihr Hauptvorteil liegt in der Tatsache, dass sie natürlich mit den gemischten Typdaten umgehen.
Klassifizierung mit Gradient Tree Boost
Zum Erstellen eines Gradient Tree Boost-Klassifikators bietet das Scikit-Lernmodul sklearn.ensemble.GradientBoostingClassifier. Während der Erstellung dieses Klassifikators ist der Hauptparameter, den dieses Modul verwendet, "Verlust". Hier ist 'Verlust' der Wert der zu optimierenden Verlustfunktion. Wenn wir Verlust = Abweichung wählen, bezieht sich dies auf Abweichung zur Klassifizierung mit probabilistischen Ergebnissen.
Wenn wir dagegen den Wert dieses Parameters als exponentiell wählen, wird der AdaBoost-Algorithmus wiederhergestellt. Der Parametern_estimatorssteuert die Anzahl der wöchentlichen Lernenden. Ein Hyperparameter mit dem Namenlearning_rate (im Bereich von (0,0, 1,0]) steuert die Überanpassung durch Schrumpfen.
Implementierungsbeispiel
Im folgenden Beispiel erstellen wir mithilfe von einen Gradienten-Boosting-Klassifikator sklearn.ensemble.GradientBoostingClassifier. Wir passen diesen Klassifikator an 50-wöchige Lernende an.
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state = 0)
X_train, X_test = X[:5000], X[5000:]
y_train, y_test = y[:5000], y[5000:]
GDBclf = GradientBoostingClassifier(n_estimators = 50, learning_rate = 1.0,max_depth = 1, random_state = 0).fit(X_train, y_train)
GDBclf.score(X_test, y_test)Ausgabe
0.8724285714285714Beispiel
Wir können auch das sklearn-Dataset verwenden, um einen Klassifikator mit dem Gradient Boosting Classifier zu erstellen. Wie im folgenden Beispiel verwenden wir den Pima-Indian-Datensatz.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names = headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 5
kfold = KFold(n_splits = 10, random_state = seed)
num_trees = 100
max_features = 5
ADBclf = GradientBoostingClassifier(n_estimators = num_trees, max_features = max_features)
results = cross_val_score(ADBclf, X, Y, cv = kfold)
print(results.mean())Ausgabe
0.7946582356674234Regression mit Gradient Tree Boost
Zum Erstellen eines Regressors mit der Gradient Tree Boost-Methode bietet die Scikit-Learn-Bibliothek sklearn.ensemble.GradientBoostingRegressor. Sie kann die Verlustfunktion für die Regression über den Parameternamen Verlust angeben. Der Standardwert für Verlust ist 'ls'.
Implementierungsbeispiel
Im folgenden Beispiel erstellen wir mithilfe von Gradient Boosting einen Regressor sklearn.ensemble.GradientBoostingregressor und auch Finden des mittleren quadratischen Fehlers unter Verwendung der Methode mean_squared_error ().
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples = 2000, random_state = 0, noise = 1.0)
X_train, X_test = X[:1000], X[1000:]
y_train, y_test = y[:1000], y[1000:]
GDBreg = GradientBoostingRegressor(n_estimators = 80, learning_rate=0.1,
max_depth = 1, random_state = 0, loss = 'ls').fit(X_train, y_train)Nach der Anpassung können wir den mittleren quadratischen Fehler wie folgt ermitteln:
mean_squared_error(y_test, GDBreg.predict(X_test))Ausgabe
5.391246106657164Hier werden wir uns mit den Clustering-Methoden in Sklearn befassen, die bei der Identifizierung von Ähnlichkeiten in den Datenproben helfen.
Clustering-Methoden, eine der nützlichsten unbeaufsichtigten ML-Methoden, werden verwendet, um Ähnlichkeits- und Beziehungsmuster zwischen Datenproben zu ermitteln. Danach gruppieren sie diese Stichproben in Gruppen mit Ähnlichkeit basierend auf Merkmalen. Clustering bestimmt die intrinsische Gruppierung unter den vorhandenen unbeschrifteten Daten. Deshalb ist es wichtig.
Die Scikit-Lernbibliothek hat sklearn.clusterClustering von unbeschrifteten Daten durchführen. Unter diesem Modul haben scikit-leran die folgenden Clustering-Methoden:
KMeans
Dieser Algorithmus berechnet die Schwerpunkte und iteriert, bis der optimale Schwerpunkt gefunden ist. Es muss die Anzahl der Cluster angegeben werden, weshalb davon ausgegangen wird, dass sie bereits bekannt sind. Die Hauptlogik dieses Algorithmus besteht darin, die Daten, die Proben trennen, in n Gruppen von Gruppen gleicher Varianz zu gruppieren, indem die als Trägheit bekannten Kriterien minimiert werden. Die Anzahl der durch den Algorithmus identifizierten Cluster wird durch 'K' dargestellt.
Scikit-lernen haben sklearn.cluster.KMeansModul zur Durchführung von K-Means-Clustering. Während der Berechnung der Clusterzentren und des Trägheitswerts wird der Parameter benanntsample_weight erlaubt sklearn.cluster.KMeans Modul, um einigen Proben mehr Gewicht zuzuweisen.
Affinitätsausbreitung
Dieser Algorithmus basiert auf dem Konzept der "Nachrichtenübermittlung" zwischen verschiedenen Stichprobenpaaren bis zur Konvergenz. Es ist nicht erforderlich, dass die Anzahl der Cluster angegeben wird, bevor der Algorithmus ausgeführt wird. Der Algorithmus hat eine zeitliche Komplexität in der Größenordnung (2), was der größte Nachteil ist.
Scikit-lernen haben sklearn.cluster.AffinityPropagation Modul zur Durchführung von Affinity Propagation Clustering.
Mittlere Verschiebung
Dieser Algorithmus entdeckt hauptsächlich blobsin einer glatten Dichte von Proben. Es ordnet die Datenpunkte den Clustern iterativ zu, indem Punkte in Richtung der höchsten Dichte von Datenpunkten verschoben werden. Anstatt sich auf einen Parameter mit dem Namen zu verlassenbandwidth Durch die Festlegung der Größe der zu durchsuchenden Region wird automatisch die Anzahl der Cluster festgelegt.
Scikit-lernen haben sklearn.cluster.MeanShift Modul zur Durchführung von Mean Shift-Clustering.
Spektrale Clusterbildung
Vor dem Clustering verwendet dieser Algorithmus im Wesentlichen die Eigenwerte, dh das Spektrum der Ähnlichkeitsmatrix der Daten, um eine Dimensionsreduktion in weniger Dimensionen durchzuführen. Die Verwendung dieses Algorithmus ist nicht ratsam, wenn eine große Anzahl von Clustern vorhanden ist.
Scikit-lernen haben sklearn.cluster.SpectralClustering Modul zur Durchführung von Spektralclustern.
Hierarchisches Clustering
Dieser Algorithmus erstellt verschachtelte Cluster, indem die Cluster nacheinander zusammengeführt oder aufgeteilt werden. Diese Clusterhierarchie wird als Dendrogramm dargestellt, dh als Baum. Es fällt in folgende zwei Kategorien:
Agglomerative hierarchical algorithms- Bei dieser Art von hierarchischem Algorithmus wird jeder Datenpunkt wie ein einzelner Cluster behandelt. Es agglomeriert dann nacheinander die Clusterpaare. Dies verwendet den Bottom-up-Ansatz.
Divisive hierarchical algorithms- In diesem hierarchischen Algorithmus werden alle Datenpunkte als ein großer Cluster behandelt. Dabei umfasst der Clustering-Prozess die Aufteilung des einen großen Clusters mithilfe eines Top-Down-Ansatzes in verschiedene kleine Cluster.
Scikit-lernen haben sklearn.cluster.AgglomerativeClustering Modul zur Durchführung eines agglomerativen hierarchischen Clusters.
DBSCAN
Es steht für “Density-based spatial clustering of applications with noise”. Dieser Algorithmus basiert auf der intuitiven Vorstellung von "Clustern" und "Rauschen", dass Cluster dichte Bereiche mit niedrigerer Dichte im Datenraum sind, die durch Bereiche mit niedrigerer Dichte von Datenpunkten getrennt sind.
Scikit-lernen haben sklearn.cluster.DBSCANModul zur Durchführung von DBSCAN-Clustering. Es gibt zwei wichtige Parameter, nämlich min_samples und eps, die von diesem Algorithmus zum Definieren der Dichte verwendet werden.
Höherer Parameterwert min_samples oder ein niedrigerer Wert des Parameters eps gibt einen Hinweis auf die höhere Dichte von Datenpunkten, die zur Bildung eines Clusters erforderlich ist.
OPTIK
Es steht für “Ordering points to identify the clustering structure”. Dieser Algorithmus findet auch dichtebasierte Cluster in räumlichen Daten. Die grundlegende Arbeitslogik ist wie bei DBSCAN.
Es behebt eine große Schwäche des DBSCAN-Algorithmus - das Problem der Erkennung aussagekräftiger Cluster in Daten unterschiedlicher Dichte -, indem die Punkte der Datenbank so angeordnet werden, dass räumlich nächstgelegene Punkte zu Nachbarn in der Reihenfolge werden.
Scikit-lernen haben sklearn.cluster.OPTICS Modul zur Durchführung von OPTICS-Clustering.
BIRKE
Es steht für Balanced iterative Reduction und Clustering mithilfe von Hierarchien. Es wird verwendet, um hierarchisches Clustering über große Datenmengen durchzuführen. Es wird ein Baum mit dem Namen erstelltCFT dh Characteristics Feature Treefür die angegebenen Daten.
Der Vorteil von CFT besteht darin, dass die als CF-Knoten (Characteristics Feature) bezeichneten Datenknoten die erforderlichen Informationen für das Clustering enthalten, wodurch die Notwendigkeit, die gesamten Eingabedaten im Speicher zu halten, weiter verhindert wird.
Scikit-lernen haben sklearn.cluster.Birch Modul zur Durchführung von BIRCH-Clustering.
Clustering-Algorithmen vergleichen
Die folgende Tabelle gibt einen Vergleich (basierend auf Parametern, Skalierbarkeit und Metrik) der Clustering-Algorithmen in Scikit-Learn.
| Sr.Nr. | Algorithmusname | Parameter | Skalierbarkeit | Verwendete Metrik |
|---|---|---|---|---|
| 1 | K-Mittel | Anzahl der Cluster | Sehr große n_samples | Der Abstand zwischen Punkten. |
| 2 | Affinitätsausbreitung | Dämpfung | Es ist nicht mit n_samples skalierbar | Diagrammabstand |
| 3 | Mean-Shift | Bandbreite | Es ist nicht mit n_samples skalierbar. | Der Abstand zwischen Punkten. |
| 4 | Spektrale Clusterbildung | Anzahl der Cluster | Mittlere Skalierbarkeit mit n_samples. Geringe Skalierbarkeit mit n_clusters. | Diagrammabstand |
| 5 | Hierarchisches Clustering | Entfernungsschwelle oder Anzahl der Cluster | Große n_samples Große n_cluster | Der Abstand zwischen Punkten. |
| 6 | DBSCAN | Größe der Nachbarschaft | Sehr große n_samples und mittlere n_cluster. | Nächste Punktentfernung |
| 7 | OPTIK | Minimale Clustermitgliedschaft | Sehr große n_samples und große n_cluster. | Der Abstand zwischen Punkten. |
| 8 | BIRKE | Schwelle, Verzweigungsfaktor | Große n_samples Große n_cluster | Der euklidische Abstand zwischen Punkten. |
K-Means Clustering im Scikit-Learn Digit-Datensatz
In diesem Beispiel wenden wir K-Mittel-Clustering auf Ziffern-Dataset an. Dieser Algorithmus identifiziert ähnliche Ziffern ohne Verwendung der ursprünglichen Etiketteninformationen. Die Implementierung erfolgt auf dem Jupyter-Notebook.
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shapeAusgabe
1797, 64)Diese Ausgabe zeigt, dass der Ziffern-Datensatz 1797 Samples mit 64 Funktionen enthält.
Beispiel
Führen Sie nun das K-Means-Clustering wie folgt durch:
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shapeAusgabe
(10, 64)Diese Ausgabe zeigt, dass durch K-means Clustering 10 Cluster mit 64 Funktionen erstellt wurden.
Beispiel
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks = [], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)Ausgabe
Die folgende Ausgabe enthält Bilder, die Clusterzentren zeigen, die durch K-Means Clustering gelernt wurden.

Als Nächstes vergleicht das folgende Python-Skript die gelernten Cluster-Labels (mit K-Means) mit den darin enthaltenen True-Labels.
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]Wir können die Genauigkeit auch mit Hilfe des unten genannten Befehls überprüfen.
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)Ausgabe
0.7935447968836951Vollständiges Implementierungsbeispiel
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)Es gibt verschiedene Funktionen, mit deren Hilfe wir die Leistung von Clustering-Algorithmen bewerten können.
Im Folgenden finden Sie einige wichtige und am häufigsten verwendete Funktionen des Scikit-Learn zur Bewertung der Clusterleistung.
Angepasster Rand-Index
Rand Index ist eine Funktion, die ein Ähnlichkeitsmaß zwischen zwei Clustern berechnet. Für diese Berechnung berücksichtigt der Rand-Index alle Paare von Stichproben und Zählpaaren, die in den vorhergesagten und wahren Clustern in ähnlichen oder unterschiedlichen Clustern zugewiesen sind. Anschließend wird der rohe Rand-Index-Score unter Verwendung der folgenden Formel "zufällig angepasst" in den Adjusted Rand-Index-Score umgewandelt.
$$Adjusted\:RI=\left(RI-Expected_{-}RI\right)/\left(max\left(RI\right)-Expected_{-}RI\right)$$Es hat nämlich zwei Parameter labels_true, das sind Grundwahrheitsklassenbezeichnungen, und labels_pred, die Cluster-Label zu bewerten sind.
Beispiel
from sklearn.metrics.cluster import adjusted_rand_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
adjusted_rand_score(labels_true, labels_pred)Ausgabe
0.4444444444444445Perfekte Kennzeichnung würde mit 1 bewertet und schlechte Kennzeichnung oder unabhängige Kennzeichnung mit 0 oder negativ bewertet.
Auf gegenseitiger Information basierende Punktzahl
Gegenseitige Information ist eine Funktion, die die Übereinstimmung der beiden Zuordnungen berechnet. Es ignoriert die Permutationen. Es stehen folgende Versionen zur Verfügung:
Normalisierte gegenseitige Information (NMI)
Scikit lernen haben sklearn.metrics.normalized_mutual_info_score Modul.
Beispiel
from sklearn.metrics.cluster import normalized_mutual_info_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
normalized_mutual_info_score (labels_true, labels_pred)Ausgabe
0.7611702597222881Angepasste gegenseitige Information (AMI)
Scikit lernen haben sklearn.metrics.adjusted_mutual_info_score Modul.
Beispiel
from sklearn.metrics.cluster import adjusted_mutual_info_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
adjusted_mutual_info_score (labels_true, labels_pred)Ausgabe
0.4444444444444448Fowlkes-Mallows Score
Die Fowlkes-Mallows-Funktion misst die Ähnlichkeit zweier Cluster einer Punktmenge. Es kann als das geometrische Mittel der paarweisen Genauigkeit und des Rückrufs definiert werden.
Mathematisch,
$$FMS=\frac{TP}{\sqrt{\left(TP+FP\right)\left(TP+FN\right)}}$$Hier, TP = True Positive - Anzahl der Punktepaare, die zu denselben Clustern gehören, sowohl in echten als auch in vorhergesagten Bezeichnungen.
FP = False Positive - Anzahl der Punktepaare, die zu denselben Clustern in echten Bezeichnungen gehören, jedoch nicht in den vorhergesagten Bezeichnungen.
FN = False Negative - Anzahl der Punktepaare, die zu denselben Clustern in den vorhergesagten Bezeichnungen gehören, jedoch nicht in den wahren Bezeichnungen.
Das Scikit-Lernen hat das Modul sklearn.metrics.fowlkes_mallows_score -
Beispiel
from sklearn.metrics.cluster import fowlkes_mallows_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
fowlkes_mallows__score (labels_true, labels_pred)Ausgabe
0.6546536707079771Silhouette-Koeffizient
Die Silhouette-Funktion berechnet den mittleren Silhouette-Koeffizienten aller Proben unter Verwendung der mittleren Entfernung innerhalb des Clusters und der mittleren Entfernung zum nächsten Cluster für jede Probe.
Mathematisch,
$$S=\left(b-a\right)/max\left(a,b\right)$$Hier ist a die Entfernung innerhalb des Clusters.
und b ist der mittlere Abstand zum nächsten Cluster.
Die Scikit lernen haben sklearn.metrics.silhouette_score Modul -
Beispiel
from sklearn import metrics.silhouette_score
from sklearn.metrics import pairwise_distances
from sklearn import datasets
import numpy as np
from sklearn.cluster import KMeans
dataset = datasets.load_iris()
X = dataset.data
y = dataset.target
kmeans_model = KMeans(n_clusters = 3, random_state = 1).fit(X)
labels = kmeans_model.labels_
silhouette_score(X, labels, metric = 'euclidean')Ausgabe
0.5528190123564091Kontingenzmatrix
Diese Matrix gibt die Schnittpunktkardinalität für jedes vertrauenswürdige Paar von (wahr, vorhergesagt) an. Die Verwirrungsmatrix für Klassifizierungsprobleme ist eine quadratische Kontingenzmatrix.
Die Scikit lernen haben sklearn.metrics.contingency_matrix Modul.
Beispiel
from sklearn.metrics.cluster import contingency_matrix
x = ["a", "a", "a", "b", "b", "b"]
y = [1, 1, 2, 0, 1, 2]
contingency_matrix(x, y)Ausgabe
array([
[0, 2, 1],
[1, 1, 1]
])Die erste Zeile der obigen Ausgabe zeigt, dass unter drei Stichproben, deren wahrer Cluster "a" ist, keine in 0 ist, zwei in 1 und 1 in 2. Andererseits zeigt die zweite Zeile dies unter drei Stichproben dessen wahrer Cluster "b" ist, 1 ist in 0, 1 ist in 1 und 1 ist in 2.
Bei der Dimensionsreduzierung wird eine unbeaufsichtigte Methode des maschinellen Lernens verwendet, um die Anzahl der Merkmalsvariablen für jede Datenprobe zu reduzieren und einen Satz von Hauptmerkmalen auszuwählen. Die Hauptkomponentenanalyse (PCA) ist einer der beliebtesten Algorithmen zur Dimensionsreduzierung.
Genaue PCA
Principal Component Analysis (PCA) wird zur linearen Dimensionsreduktion mit verwendet Singular Value Decomposition(SVD) der Daten, um sie in einen Raum mit niedrigeren Dimensionen zu projizieren. Während der Zerlegung mit PCA werden die Eingabedaten zentriert, aber nicht für jedes Merkmal skaliert, bevor die SVD angewendet wird.
Die Scikit-Learn ML-Bibliothek bietet sklearn.decomposition.PCAModul, das als Transformatorobjekt implementiert ist und in seiner fit () -Methode n Komponenten lernt. Es kann auch für neue Daten verwendet werden, um sie auf diese Komponenten zu projizieren.
Beispiel
Im folgenden Beispiel wird das Modul sklearn.decomposition.PCA verwendet, um die besten 5 Hauptkomponenten aus dem Pima Indians Diabetes-Datensatz zu finden.
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', ‘class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 5)
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)Ausgabe
Explained Variance: [0.88854663 0.06159078 0.02579012 0.01308614 0.00744094]
[
[-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03]
[-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01]
[-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]
[-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01]
[ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01]
]Inkrementelle PCA
Incremental Principal Component Analysis (IPCA) wird verwendet, um die größte Einschränkung der Hauptkomponentenanalyse (PCA) zu beheben. Das heißt, PCA unterstützt nur die Stapelverarbeitung. Dies bedeutet, dass alle zu verarbeitenden Eingabedaten in den Speicher passen sollten.
Die Scikit-Learn ML-Bibliothek bietet sklearn.decomposition.IPCA Modul, das es ermöglicht, Out-of-Core-PCA entweder mithilfe seines zu implementieren partial_fit Methode zum sequentiellen Abrufen von Datenblöcken oder durch Aktivieren der Verwendung von np.memmap, eine Speicherzuordnungsdatei, ohne die gesamte Datei in den Speicher zu laden.
Wie bei PCA werden bei der Zerlegung mithilfe von IPCA die Eingabedaten zentriert, jedoch nicht für jedes Merkmal skaliert, bevor die SVD angewendet wird.
Beispiel
Das folgende Beispiel wird verwendet sklearn.decomposition.IPCA Modul zum Sklearn-Ziffern-Datensatz.
from sklearn.datasets import load_digits
from sklearn.decomposition import IncrementalPCA
X, _ = load_digits(return_X_y = True)
transformer = IncrementalPCA(n_components = 10, batch_size = 100)
transformer.partial_fit(X[:100, :])
X_transformed = transformer.fit_transform(X)
X_transformed.shapeAusgabe
(1797, 10)Hier können wir teilweise auf kleinere Datenstapel passen (wie bei 100 pro Stapel) oder Sie können das zulassen fit() Funktion zum Aufteilen der Daten in Stapel.
Kernel PCA
Die Kernel-Hauptkomponentenanalyse, eine Erweiterung von PCA, erzielt eine nichtlineare Dimensionsreduktion mithilfe von Kerneln. Es unterstützt beidetransform and inverse_transform.
Die Scikit-Learn ML-Bibliothek bietet sklearn.decomposition.KernelPCA Modul.
Beispiel
Das folgende Beispiel wird verwendet sklearn.decomposition.KernelPCAModul zum Sklearn-Ziffern-Datensatz. Wir verwenden Sigmoid-Kernel.
from sklearn.datasets import load_digits
from sklearn.decomposition import KernelPCA
X, _ = load_digits(return_X_y = True)
transformer = KernelPCA(n_components = 10, kernel = 'sigmoid')
X_transformed = transformer.fit_transform(X)
X_transformed.shapeAusgabe
(1797, 10)PCA mit randomisierter SVD
Die Hauptkomponentenanalyse (PCA) unter Verwendung einer randomisierten SVD wird verwendet, um Daten in einen Raum mit niedrigeren Dimensionen zu projizieren, wobei der größte Teil der Varianz erhalten bleibt, indem der Singularvektor von Komponenten gelöscht wird, die mit niedrigeren Singularwerten assoziiert sind. Hier dassklearn.decomposition.PCA Modul mit dem optionalen Parameter svd_solver=’randomized’ wird sehr nützlich sein.
Beispiel
Das folgende Beispiel wird verwendet sklearn.decomposition.PCA Modul mit dem optionalen Parameter svd_solver = 'randomisiert', um die besten 7 Hauptkomponenten aus dem Pima Indians Diabetes-Datensatz zu finden.
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 7,svd_solver = 'randomized')
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)Ausgabe
Explained Variance: [8.88546635e-01 6.15907837e-02 2.57901189e-02 1.30861374e-027.44093864e-03 3.02614919e-03 5.12444875e-04]
[
[-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03]
[-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01]
[-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]
[-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01]
[ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01]
[-5.04730888e-03 5.07391813e-02 7.56365525e-02 2.21363068e-01-6.13326472e-03 -9.70776708e-01 -2.02903702e-03 -1.51133239e-02]
[ 9.86672995e-01 8.83426114e-04 -1.22975947e-03 -3.76444746e-041.42307394e-03 -2.73046214e-03 -6.34402965e-03 -1.62555343e-01]
]