Scikit Learn - Unterstützt Vektormaschinen
Dieses Kapitel befasst sich mit einer maschinellen Lernmethode, die als Support Vector Machines (SVMs) bezeichnet wird.
Einführung
Support Vector Machines (SVMs) sind leistungsstarke und dennoch flexible Methoden für überwachtes maschinelles Lernen, die zur Klassifizierung, Regression und Erkennung von Ausreißern verwendet werden. SVMs sind in hochdimensionalen Räumen sehr effizient und werden im Allgemeinen bei Klassifizierungsproblemen verwendet. SVMs sind beliebt und speichereffizient, da sie eine Teilmenge von Trainingspunkten in der Entscheidungsfunktion verwenden.
Das Hauptziel von SVMs ist es, die Datensätze in die Anzahl der Klassen zu unterteilen, um a zu finden maximum marginal hyperplane (MMH) Dies kann in den folgenden zwei Schritten erfolgen:
Support Vector Machines generiert zunächst iterativ Hyperebenen, die die Klassen optimal trennen.
Danach wird die Hyperebene ausgewählt, die die Klassen korrekt trennt.
Einige wichtige Konzepte in SVM sind wie folgt:
Support Vectors- Sie können als die Datenpunkte definiert werden, die der Hyperebene am nächsten liegen. Unterstützungsvektoren helfen bei der Entscheidung der Trennlinie.
Hyperplane - Die Entscheidungsebene oder der Raum, der eine Gruppe von Objekten mit unterschiedlichen Klassen teilt.
Margin - Die Lücke zwischen zwei Zeilen auf den Schrankdatenpunkten verschiedener Klassen wird als Rand bezeichnet.
Die folgenden Diagramme geben Ihnen einen Einblick in diese SVM-Konzepte -
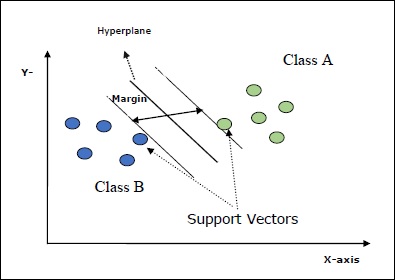
SVM in Scikit-learn unterstützt sowohl spärliche als auch dichte Abtastvektoren als Eingabe.
Klassifizierung von SVM
Scikit-learn bietet nämlich drei Klassen SVC, NuSVC und LinearSVC Dies kann eine Klassifizierung in mehreren Klassen durchführen.
SVC
Es ist eine C-Support-Vektorklassifikation, auf deren Implementierung basiert libsvm. Das von scikit-learn verwendete Modul istsklearn.svm.SVC. Diese Klasse behandelt die Unterstützung mehrerer Klassen nach einem Eins-gegen-Eins-Schema.
Parameter
Die folgende Tabelle enthält die von verwendeten Parameter sklearn.svm.SVC Klasse -
| Sr.Nr. | Parameter & Beschreibung |
|---|---|
| 1 | C - float, optional, default = 1.0 Dies ist der Strafparameter des Fehlerterms. |
| 2 | kernel - Zeichenfolge, optional, Standard = 'rbf' Dieser Parameter gibt den Kerneltyp an, der im Algorithmus verwendet werden soll. wir können jeden unter wählen,‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’. Der Standardwert des Kernels wäre‘rbf’. |
| 3 | degree - int, optional, default = 3 Es stellt den Grad der 'Poly'-Kernelfunktion dar und wird von allen anderen Kerneln ignoriert. |
| 4 | gamma - {'scale', 'auto'} oder float, Dies ist der Kernelkoeffizient für die Kernel 'rbf', 'poly' und 'sigmoid'. |
| 5 | optinal default - = 'Skala' Wenn Sie die Standardeinstellung wählen, dh gamma = 'scale', beträgt der von SVC zu verwendende Gamma-Wert 1 / (_ ∗. ()). Wenn andererseits gamma = 'auto' ist, wird 1 / _ verwendet. |
| 6 | coef0 - float, optional, Standard = 0.0 Ein unabhängiger Begriff in der Kernelfunktion, der nur in 'poly' und 'sigmoid' von Bedeutung ist. |
| 7 | tol - float, optional, default = 1.e-3 Dieser Parameter repräsentiert das Stoppkriterium für Iterationen. |
| 8 | shrinking - Boolean, optional, Standard = True Dieser Parameter gibt an, ob die Schrumpfheuristik verwendet werden soll oder nicht. |
| 9 | verbose - Boolescher Wert, Standard: false Es aktiviert oder deaktiviert die ausführliche Ausgabe. Der Standardwert ist false. |
| 10 | probability - boolean, optional, default = true Dieser Parameter aktiviert oder deaktiviert Wahrscheinlichkeitsschätzungen. Der Standardwert ist false, muss jedoch aktiviert werden, bevor wir fit aufrufen. |
| 11 | max_iter - int, optional, default = -1 Wie der Name schon sagt, repräsentiert es die maximale Anzahl von Iterationen innerhalb des Solvers. Der Wert -1 bedeutet, dass die Anzahl der Iterationen unbegrenzt ist. |
| 12 | cache_size - Float, optional Dieser Parameter gibt die Größe des Kernel-Cache an. Der Wert wird in MB (MegaBytes) angegeben. |
| 13 | random_state - int, RandomState-Instanz oder None, optional, default = none Dieser Parameter stellt den Startwert der erzeugten Pseudozufallszahl dar, die beim Mischen der Daten verwendet wird. Folgende sind die Optionen -
|
| 14 | class_weight - {diktieren, 'ausgeglichen'}, optional Dieser Parameter setzt den Parameter C der Klasse j für SVC auf _ℎ [] ∗. Wenn wir die Standardoption verwenden, bedeutet dies, dass alle Klassen das Gewicht eins haben sollen. Auf der anderen Seite, wenn Sie möchtenclass_weight:balancedverwendet die Werte von y, um die Gewichte automatisch anzupassen. |
| 15 | decision_function_shape - ovo ',' ovr ', default =' ovr ' Dieser Parameter entscheidet, ob der Algorithmus zurückkehrt ‘ovr’ (One-vs-Rest) Entscheidungsfunktion der Form wie alle anderen Klassifikatoren oder das Original ovo(Eins-gegen-Eins) Entscheidungsfunktion von libsvm. |
| 16 | break_ties - boolean, optional, default = false True - Die Vorhersage unterbricht die Verbindungen gemäß den Konfidenzwerten von entscheidungsfunktion False - Die Vorhersage gibt die erste Klasse unter den gebundenen Klassen zurück. |
Attribute
Die folgende Tabelle enthält die von verwendeten Attribute sklearn.svm.SVC Klasse -
| Sr.Nr. | Attribute & Beschreibung |
|---|---|
| 1 | support_ - Array-artig, Form = [n_SV] Es gibt die Indizes der Unterstützungsvektoren zurück. |
| 2 | support_vectors_ - Array-artig, Form = [n_SV, n_Features] Es gibt die Unterstützungsvektoren zurück. |
| 3 | n_support_ - Array-ähnlich, dtype = int32, shape = [n_class] Es repräsentiert die Anzahl der Unterstützungsvektoren für jede Klasse. |
| 4 | dual_coef_ - Array, Form = [n_Klasse-1, n_SV] Dies sind die Koeffizienten der Unterstützungsvektoren in der Entscheidungsfunktion. |
| 5 | coef_ - Array, Form = [n_Klasse * (n_Klasse-1) / 2, n_Funktionen] Dieses Attribut, das nur im Fall eines linearen Kernels verfügbar ist, gibt die den Features zugewiesene Gewichtung an. |
| 6 | intercept_ - Array, Form = [n_Klasse * (n_Klasse-1) / 2] Es repräsentiert den unabhängigen Term (Konstante) in der Entscheidungsfunktion. |
| 7 | fit_status_ - int Der Ausgang wäre 0, wenn er richtig sitzt. Der Ausgang wäre 1, wenn er falsch sitzt. |
| 8 | classes_ - Array of Shape = [n_Klassen] Es gibt die Bezeichnungen der Klassen. |
Implementation Example
Wie andere Klassifikatoren muss auch SVC mit den folgenden zwei Arrays ausgestattet werden:
Eine Anordnung XHalten der Trainingsmuster. Es hat die Größe [n_samples, n_features].
Eine Anordnung YHalten der Zielwerte, dh Klassenbezeichnungen für die Trainingsmuster. Es hat die Größe [n_samples].
Das folgende Python-Skript verwendet sklearn.svm.SVC Klasse -
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)Output
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, probability = False, random_state = None, shrinking = False,
tol = 0.001, verbose = False)Example
Sobald es angepasst ist, können wir den Gewichtsvektor mithilfe des folgenden Python-Skripts abrufen:
SVCClf.coef_Output
array([[0.5, 0.5]])Example
In ähnlicher Weise können wir den Wert anderer Attribute wie folgt ermitteln:
SVCClf.predict([[-0.5,-0.8]])Output
array([1])Example
SVCClf.n_support_Output
array([1, 1])Example
SVCClf.support_vectors_Output
array(
[
[-1., -1.],
[ 1., 1.]
]
)Example
SVCClf.support_Output
array([0, 2])Example
SVCClf.intercept_Output
array([-0.])Example
SVCClf.fit_status_Output
0NuSVC
NuSVC ist die Nu Support Vector Classification. Es ist eine weitere Klasse von scikit-learn, die eine Klassifizierung in mehreren Klassen durchführen kann. Es ist wie bei SVC, aber NuSVC akzeptiert leicht unterschiedliche Parametersätze. Der Parameter, der sich von SVC unterscheidet, ist wie folgt:
nu - float, optional, default = 0.5
Es repräsentiert eine Obergrenze für den Anteil der Trainingsfehler und eine Untergrenze für den Anteil der Unterstützungsvektoren. Sein Wert sollte im Intervall von (o, 1] liegen.
Die restlichen Parameter und Attribute sind dieselben wie bei SVC.
Implementierungsbeispiel
Wir können das gleiche Beispiel mit implementieren sklearn.svm.NuSVC Klasse auch.
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import NuSVC
NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
NuSVCClf.fit(X, y)Ausgabe
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, nu = 0.5, probability = False, random_state = None,
shrinking = False, tol = 0.001, verbose = False)Wir können die Ausgaben der restlichen Attribute erhalten, wie dies im Fall von SVC der Fall war.
LinearSVC
Es handelt sich um eine lineare Unterstützungsvektorklassifizierung. Es ist ähnlich wie bei SVC mit Kernel = 'linear'. Der Unterschied zwischen ihnen ist dasLinearSVC implementiert in Bezug auf liblinear, während SVC in implementiert ist libsvm. Das ist der GrundLinearSVChat mehr Flexibilität bei der Auswahl von Strafen und Verlustfunktionen. Es skaliert auch besser auf eine große Anzahl von Proben.
Wenn wir über seine Parameter und Attribute sprechen, wird es nicht unterstützt ‘kernel’ weil angenommen wird, dass es linear ist und es auch einige der Attribute wie fehlt support_, support_vectors_, n_support_, fit_status_ und, dual_coef_.
Es unterstützt jedoch penalty und loss Parameter wie folgt -
penalty − string, L1 or L2(default = ‘L2’)
Dieser Parameter wird verwendet, um die Norm (L1 oder L2) anzugeben, die bei der Bestrafung (Regularisierung) verwendet wird.
loss − string, hinge, squared_hinge (default = squared_hinge)
Es stellt die Verlustfunktion dar, wobei 'Scharnier' der Standard-SVM-Verlust und 'squared_hinge' das Quadrat des Scharnierverlusts ist.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.LinearSVC Klasse -
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 4, random_state = 0)
LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5)
LSVCClf.fit(X, y)Ausgabe
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000,
multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)Beispiel
Nach der Anpassung kann das Modell neue Werte wie folgt vorhersagen:
LSVCClf.predict([[0,0,0,0]])Ausgabe
[1]Beispiel
Für das obige Beispiel können wir den Gewichtsvektor mit Hilfe des folgenden Python-Skripts erhalten -
LSVCClf.coef_Ausgabe
[[0. 0. 0.91214955 0.22630686]]Beispiel
In ähnlicher Weise können wir den Wert des Abfangens mithilfe des folgenden Python-Skripts ermitteln:
LSVCClf.intercept_Ausgabe
[0.26860518]Regression mit SVM
Wie bereits erwähnt, wird SVM sowohl für Klassifizierungs- als auch für Regressionsprobleme verwendet. Die Methode der Support Vector Classification (SVC) von Scikit-learn kann erweitert werden, um auch Regressionsprobleme zu lösen. Diese erweiterte Methode wird als Support Vector Regression (SVR) bezeichnet.
Grundlegende Ähnlichkeit zwischen SVM und SVR
Das von SVC erstellte Modell hängt nur von einer Teilmenge der Trainingsdaten ab. Warum? Da sich die Kostenfunktion für die Erstellung des Modells nicht um Trainingsdatenpunkte kümmert, die außerhalb des Spielraums liegen.
Das von SVR (Support Vector Regression) erstellte Modell hängt auch nur von einer Teilmenge der Trainingsdaten ab. Warum? Weil die Kostenfunktion zum Erstellen des Modells alle Trainingsdatenpunkte ignoriert, die nahe an der Modellvorhersage liegen.
Scikit-learn bietet nämlich drei Klassen SVR, NuSVR and LinearSVR als drei verschiedene Implementierungen von SVR.
SVR
Es ist die Epsilon-unterstützende Vektorregression, auf deren Implementierung basiert libsvm. Im Gegensatz zuSVC Es gibt nämlich zwei freie Parameter im Modell ‘C’ und ‘epsilon’.
epsilon - float, optional, default = 0.1
Es stellt das Epsilon im Epsilon-SVR-Modell dar und gibt die Epsilon-Röhre an, innerhalb derer in der Trainingsverlustfunktion keine Strafe mit Punkten verbunden ist, die innerhalb einer Entfernung von Epsilon vom tatsächlichen Wert vorhergesagt werden.
Die restlichen Parameter und Attribute sind ähnlich wie in SVC.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.SVR Klasse -
from sklearn import svm
X = [[1, 1], [2, 2]]
y = [1, 2]
SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’)
SVRReg.fit(X, y)Ausgabe
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto',
kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)Beispiel
Sobald es angepasst ist, können wir den Gewichtsvektor mithilfe des folgenden Python-Skripts abrufen:
SVRReg.coef_Ausgabe
array([[0.4, 0.4]])Beispiel
In ähnlicher Weise können wir den Wert anderer Attribute wie folgt ermitteln:
SVRReg.predict([[1,1]])Ausgabe
array([1.1])In ähnlicher Weise können wir auch die Werte anderer Attribute abrufen.
NuSVR
NuSVR ist Nu Support Vector Regression. Es ist wie bei NuSVC, aber NuSVR verwendet einen Parameternuum die Anzahl der Unterstützungsvektoren zu steuern. Und im Gegensatz zu NuSVC wonu C-Parameter ersetzt, hier ersetzt epsilon.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.SVR Klasse -
from sklearn.svm import NuSVR
import numpy as np
n_samples, n_features = 20, 15
np.random.seed(0)
y = np.random.randn(n_samples)
X = np.random.randn(n_samples, n_features)
NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M
NuSVRReg.fit(X, y)Ausgabe
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto',
kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001,
verbose = False)Beispiel
Sobald es angepasst ist, können wir den Gewichtsvektor mithilfe des folgenden Python-Skripts abrufen:
NuSVRReg.coef_Ausgabe
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)In ähnlicher Weise können wir auch den Wert anderer Attribute erhalten.
LinearSVR
Es ist eine lineare Unterstützungsvektorregression. Es ist ähnlich wie bei SVR mit Kernel = 'linear'. Der Unterschied zwischen ihnen ist dasLinearSVR implementiert in Bezug auf liblinear, während SVC implementiert in libsvm. Das ist der GrundLinearSVRhat mehr Flexibilität bei der Auswahl von Strafen und Verlustfunktionen. Es skaliert auch besser auf eine große Anzahl von Proben.
Wenn wir über seine Parameter und Attribute sprechen, wird es nicht unterstützt ‘kernel’ weil angenommen wird, dass es linear ist und es auch einige der Attribute wie fehlt support_, support_vectors_, n_support_, fit_status_ und, dual_coef_.
Es unterstützt jedoch 'Verlust'-Parameter wie folgt:
loss - string, optional, default = 'epsilon_insensitive'
Es stellt die Verlustfunktion dar, bei der epsilon_insensitiver Verlust der L1-Verlust und der quadratische epsilonunempfindliche Verlust der L2-Verlust ist.
Implementierungsbeispiel
Das folgende Python-Skript verwendet sklearn.svm.LinearSVR Klasse -
from sklearn.svm import LinearSVR
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 4, random_state = 0)
LSVRReg = LinearSVR(dual = False, random_state = 0,
loss = 'squared_epsilon_insensitive',tol = 1e-5)
LSVRReg.fit(X, y)Ausgabe
LinearSVR(
C=1.0, dual=False, epsilon=0.0, fit_intercept=True,
intercept_scaling=1.0, loss='squared_epsilon_insensitive',
max_iter=1000, random_state=0, tol=1e-05, verbose=0
)Beispiel
Nach der Anpassung kann das Modell neue Werte wie folgt vorhersagen:
LSRReg.predict([[0,0,0,0]])Ausgabe
array([-0.01041416])Beispiel
Für das obige Beispiel können wir den Gewichtsvektor mit Hilfe des folgenden Python-Skripts erhalten -
LSRReg.coef_Ausgabe
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])Beispiel
In ähnlicher Weise können wir den Wert des Abfangens mithilfe des folgenden Python-Skripts ermitteln:
LSRReg.intercept_Ausgabe
array([-0.01041416])