TensorFlow - Faltungsneurale Netze
Nachdem wir die Konzepte des maschinellen Lernens verstanden haben, können wir uns jetzt auf Konzepte des tiefen Lernens konzentrieren. Deep Learning ist eine Abteilung des maschinellen Lernens und wird von Forschern in den letzten Jahrzehnten als ein entscheidender Schritt angesehen. Die Beispiele für die Implementierung von Deep Learning umfassen Anwendungen wie Bilderkennung und Spracherkennung.
Im Folgenden sind die beiden wichtigen Arten von tiefen neuronalen Netzen aufgeführt:
- Faltungsneurale Netze
- Wiederkehrende neuronale Netze
In diesem Kapitel konzentrieren wir uns auf CNN, Convolutional Neural Networks.
Faltungsneurale Netze
Faltungs-Neuronale Netze dienen zur Verarbeitung von Daten über mehrere Arrays. Diese Art von neuronalen Netzen wird in Anwendungen wie der Bilderkennung oder der Gesichtserkennung verwendet. Der Hauptunterschied zwischen CNN und jedem anderen gewöhnlichen neuronalen Netzwerk besteht darin, dass CNN Eingaben als zweidimensionales Array verwendet und direkt auf die Bilder einwirkt, anstatt sich auf die Merkmalsextraktion zu konzentrieren, auf die sich andere neuronale Netzwerke konzentrieren.
Der vorherrschende Ansatz von CNN umfasst Lösungen für Erkennungsprobleme. Top-Unternehmen wie Google und Facebook haben in Forschung und Entwicklung für Anerkennungsprojekte investiert, um Aktivitäten schneller durchzuführen.
Ein Faltungsnetzwerk verwendet drei Grundideen:
- Lokale entsprechende Felder
- Convolution
- Pooling
Lassen Sie uns diese Ideen im Detail verstehen.
CNN verwendet räumliche Korrelationen, die in den Eingabedaten vorhanden sind. Jede gleichzeitige Schicht eines neuronalen Netzwerks verbindet einige Eingangsneuronen. Diese spezifische Region wird als lokales Empfangsfeld bezeichnet. Das lokale Empfangsfeld konzentriert sich auf die verborgenen Neuronen. Die versteckten Neuronen verarbeiten die Eingabedaten innerhalb des genannten Feldes, ohne die Änderungen außerhalb der spezifischen Grenze zu realisieren.
Es folgt eine Diagrammdarstellung der Erzeugung lokaler entsprechender Felder -
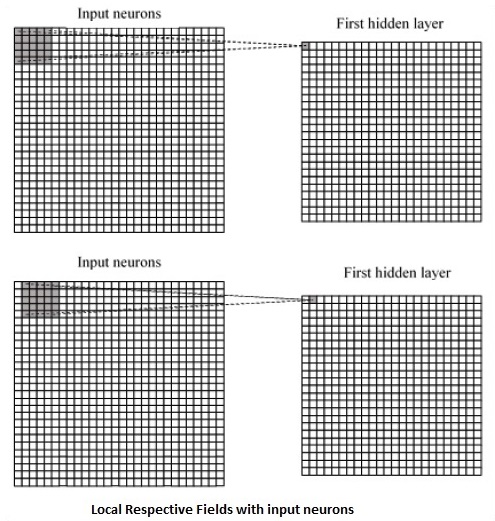
Wenn wir die obige Darstellung beobachten, lernt jede Verbindung ein Gewicht des verborgenen Neurons mit einer damit verbundenen Verbindung mit der Bewegung von einer Schicht zur anderen. Hier führen einzelne Neuronen von Zeit zu Zeit eine Verschiebung durch. Dieser Vorgang wird als "Faltung" bezeichnet.
Die Zuordnung von Verbindungen von der Eingabeebene zur verborgenen Feature-Map wird als "gemeinsame Gewichtung" definiert, und die enthaltene Verzerrung wird als "gemeinsame Verzerrung" bezeichnet.
CNN oder Faltungs-Neuronale Netze verwenden Pooling-Schichten, die die Schichten sind, die unmittelbar nach der CNN-Deklaration positioniert sind. Es nimmt die Eingabe des Benutzers als Feature-Map, die aus Faltungsnetzwerken stammt, und erstellt eine komprimierte Feature-Map. Das Zusammenfassen von Ebenen hilft beim Erstellen von Ebenen mit Neuronen früherer Ebenen.
TensorFlow Implementierung von CNN
In diesem Abschnitt erfahren Sie mehr über die TensorFlow-Implementierung von CNN. Die Schritte, die die Ausführung und die richtige Dimension des gesamten Netzwerks erfordern, sind wie folgt:
Step 1 - Fügen Sie die erforderlichen Module für TensorFlow und die Datensatzmodule hinzu, die zur Berechnung des CNN-Modells benötigt werden.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_dataStep 2 - Deklarieren Sie eine aufgerufene Funktion run_cnn(), die verschiedene Parameter und Optimierungsvariablen mit Deklaration von Datenplatzhaltern enthält. Diese Optimierungsvariablen deklarieren das Trainingsmuster.
def run_cnn():
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
learning_rate = 0.0001
epochs = 10
batch_size = 50Step 3 - In diesem Schritt deklarieren wir die Platzhalter für Trainingsdaten mit Eingabeparametern - für 28 x 28 Pixel = 784. Dies sind die abgeflachten Bilddaten, aus denen gezeichnet wird mnist.train.nextbatch().
Wir können den Tensor gemäß unseren Anforderungen umformen. Der erste Wert (-1) weist die Funktion an, diese Dimension basierend auf der an sie übergebenen Datenmenge dynamisch zu formen. Die beiden mittleren Dimensionen werden auf die Bildgröße eingestellt (dh 28 x 28).
x = tf.placeholder(tf.float32, [None, 784])
x_shaped = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, [None, 10])Step 4 - Jetzt ist es wichtig, einige Faltungsschichten zu erstellen -
layer1 = create_new_conv_layer(x_shaped, 1, 32, [5, 5], [2, 2], name = 'layer1')
layer2 = create_new_conv_layer(layer1, 32, 64, [5, 5], [2, 2], name = 'layer2')Step 5- Lassen Sie uns den Ausgang für die vollständig angeschlossene Ausgangsstufe abflachen - nach zwei Schichten von Schritt 2 mit den Abmessungen 28 x 28 auf die Abmessungen 14 x 14 oder mindestens 7 x 7 x, y-Koordinaten, jedoch mit 64 Ausgangskanäle. Um die vollständig mit "dichter" Ebene verbundene Ebene zu erstellen, muss die neue Form [-1, 7 x 7 x 64] sein. Wir können einige Gewichte und Bias-Werte für diese Ebene festlegen und dann mit ReLU aktivieren.
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev = 0.03), name = 'wd1')
bd1 = tf.Variable(tf.truncated_normal([1000], stddev = 0.01), name = 'bd1')
dense_layer1 = tf.matmul(flattened, wd1) + bd1
dense_layer1 = tf.nn.relu(dense_layer1)Step 6 - Eine weitere Ebene mit spezifischen Softmax-Aktivierungen mit dem erforderlichen Optimierer definiert die Genauigkeitsbewertung, mit der der Initialisierungsoperator eingerichtet wird.
wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev = 0.03), name = 'wd2')
bd2 = tf.Variable(tf.truncated_normal([10], stddev = 0.01), name = 'bd2')
dense_layer2 = tf.matmul(dense_layer1, wd2) + bd2
y_ = tf.nn.softmax(dense_layer2)
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = dense_layer2, labels = y))
optimiser = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_op = tf.global_variables_initializer()Step 7- Wir sollten Aufzeichnungsvariablen einrichten. Dies fügt eine Zusammenfassung hinzu, um die Genauigkeit der Daten zu speichern.
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('E:\TensorFlowProject')
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size = batch_size)
_, c = sess.run([optimiser, cross_entropy], feed_dict = {
x:batch_x, y: batch_y})
avg_cost += c / total_batch
test_acc = sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
summary = sess.run(merged, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
writer.add_summary(summary, epoch)
print("\nTraining complete!")
writer.add_graph(sess.graph)
print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels}))
def create_new_conv_layer(
input_data, num_input_channels, num_filters,filter_shape, pool_shape, name):
conv_filt_shape = [
filter_shape[0], filter_shape[1], num_input_channels, num_filters]
weights = tf.Variable(
tf.truncated_normal(conv_filt_shape, stddev = 0.03), name = name+'_W')
bias = tf.Variable(tf.truncated_normal([num_filters]), name = name+'_b')
#Out layer defines the output
out_layer =
tf.nn.conv2d(input_data, weights, [1, 1, 1, 1], padding = 'SAME')
out_layer += bias
out_layer = tf.nn.relu(out_layer)
ksize = [1, pool_shape[0], pool_shape[1], 1]
strides = [1, 2, 2, 1]
out_layer = tf.nn.max_pool(
out_layer, ksize = ksize, strides = strides, padding = 'SAME')
return out_layer
if __name__ == "__main__":
run_cnn()Es folgt die vom obigen Code erzeugte Ausgabe -
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-19 17:22:58.802268: I
T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2
2018-09-19 17:25:41.522845: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.
2018-09-19 17:25:44.630941: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 501760000 exceeds 10% of system memory.
Epoch: 1 cost = 0.676 test accuracy: 0.940
2018-09-19 17:26:51.987554: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.