TensorFlow - Kurzanleitung
TensorFlow ist eine Softwarebibliothek oder ein Software-Framework, das vom Google-Team entwickelt wurde, um Konzepte für maschinelles Lernen und tiefes Lernen auf einfachste Weise zu implementieren. Es kombiniert die rechnerische Algebra von Optimierungstechniken zur einfachen Berechnung vieler mathematischer Ausdrücke.
Die offizielle Website von TensorFlow wird unten erwähnt -
www.tensorflow.org
Betrachten wir nun die folgenden wichtigen Funktionen von TensorFlow:
Es enthält eine Funktion, mit der mathematische Ausdrücke mithilfe mehrdimensionaler Arrays, die als Tensoren bezeichnet werden, einfach definiert, optimiert und berechnet werden können.
Es beinhaltet eine Programmierunterstützung für tiefe neuronale Netze und Techniken des maschinellen Lernens.
Es enthält eine hoch skalierbare Berechnungsfunktion mit verschiedenen Datensätzen.
TensorFlow verwendet GPU-Computing und automatisiert das Management. Es enthält auch eine einzigartige Funktion zur Optimierung des gleichen Speichers und der verwendeten Daten.
Warum ist TensorFlow so beliebt?
TensorFlow ist gut dokumentiert und enthält zahlreiche Bibliotheken für maschinelles Lernen. Es bietet einige wichtige Funktionen und Methoden dafür.
TensorFlow wird auch als "Google" -Produkt bezeichnet. Es enthält eine Vielzahl von Algorithmen für maschinelles Lernen und tiefes Lernen. TensorFlow kann tiefe neuronale Netze für die handschriftliche Ziffernklassifizierung, Bilderkennung, Worteinbettung und Erstellung verschiedener Sequenzmodelle trainieren und ausführen.
Um TensorFlow zu installieren, ist es wichtig, dass „Python“ auf Ihrem System installiert ist. Python Version 3.4+ wird als die beste Version für die Installation von TensorFlow angesehen.
Führen Sie die folgenden Schritte aus, um TensorFlow unter Windows zu installieren.
Step 1 - Überprüfen Sie die zu installierende Python-Version.
Step 2- Ein Benutzer kann jeden Mechanismus zur Installation von TensorFlow im System auswählen. Wir empfehlen "pip" und "Anaconda". Pip ist ein Befehl zum Ausführen und Installieren von Modulen in Python.
Bevor wir TensorFlow installieren, müssen wir das Anaconda-Framework in unserem System installieren.
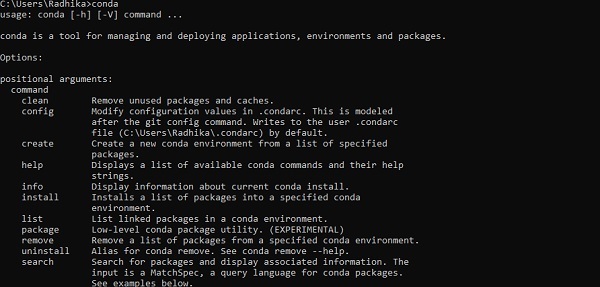
Überprüfen Sie nach erfolgreicher Installation die Eingabeaufforderung über den Befehl "conda". Die Ausführung des Befehls wird unten angezeigt -
Step 3 - Führen Sie den folgenden Befehl aus, um die Installation von TensorFlow zu initialisieren. -
conda create --name tensorflow python = 3.5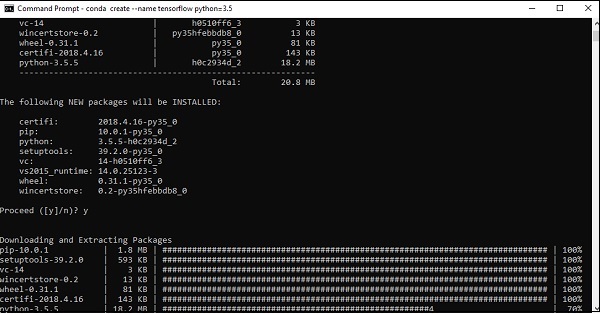
Es werden die erforderlichen Pakete heruntergeladen, die für das TensorFlow-Setup erforderlich sind.
Step 4 - Nach erfolgreicher Einrichtung der Umgebung ist es wichtig, das TensorFlow-Modul zu aktivieren.
activate tensorflow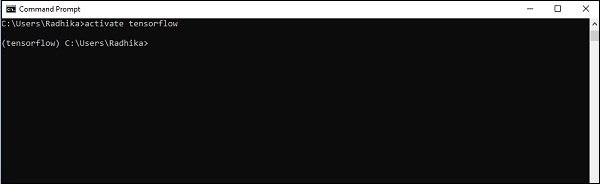
Step 5- Verwenden Sie pip, um „Tensorflow“ im System zu installieren. Der für die Installation verwendete Befehl wird wie folgt erwähnt:
pip install tensorflowUnd,
pip install tensorflow-gpu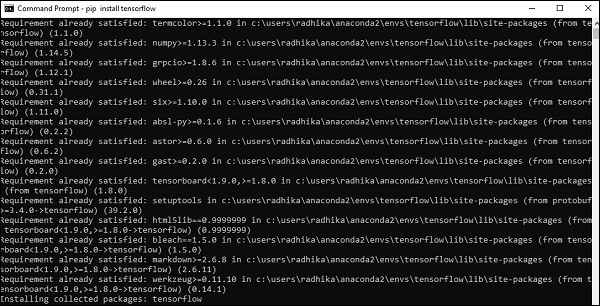
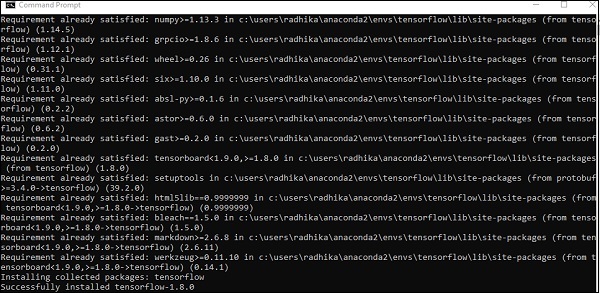
Nach erfolgreicher Installation ist es wichtig, die Beispielprogrammausführung von TensorFlow zu kennen.
Das folgende Beispiel hilft uns, die grundlegende Programmerstellung „Hello World“ in TensorFlow zu verstehen.
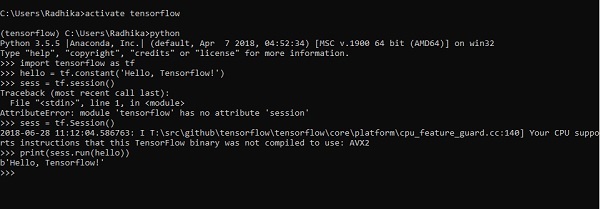
Der Code für die erste Programmimplementierung wird unten erwähnt -
>> activate tensorflow
>> python (activating python shell)
>> import tensorflow as tf
>> hello = tf.constant(‘Hello, Tensorflow!’)
>> sess = tf.Session()
>> print(sess.run(hello))Künstliche Intelligenz umfasst den Simulationsprozess der menschlichen Intelligenz durch Maschinen und spezielle Computersysteme. Beispiele für künstliche Intelligenz sind Lernen, Denken und Selbstkorrektur. Zu den Anwendungen der KI gehören Spracherkennung, Expertensysteme sowie Bilderkennung und Bildverarbeitung.
Maschinelles Lernen ist der Zweig der künstlichen Intelligenz, der sich mit Systemen und Algorithmen befasst, die neue Daten und Datenmuster lernen können.
Konzentrieren wir uns auf das unten erwähnte Venn-Diagramm, um die Konzepte des maschinellen Lernens und des tiefen Lernens zu verstehen.
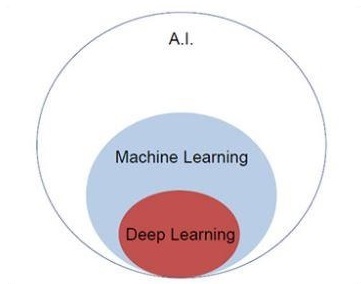
Maschinelles Lernen umfasst einen Abschnitt des maschinellen Lernens und tiefes Lernen ist ein Teil des maschinellen Lernens. Die Fähigkeit eines Programms, das maschinellen Lernkonzepten folgt, besteht darin, die Leistung der beobachteten Daten zu verbessern. Das Hauptmotiv der Datentransformation besteht darin, ihr Wissen zu verbessern, um in Zukunft bessere Ergebnisse zu erzielen und eine Ausgabe bereitzustellen, die näher an der gewünschten Ausgabe für das jeweilige System liegt. Maschinelles Lernen umfasst die „Mustererkennung“, die die Fähigkeit umfasst, die Muster in Daten zu erkennen.
Die Muster sollten trainiert werden, um die Ausgabe auf die gewünschte Weise zu zeigen.
Maschinelles Lernen kann auf zwei verschiedene Arten trainiert werden -
- Betreutes Training
- Unbeaufsichtigtes Training
Überwachtes Lernen
Überwachtes Lernen oder überwachtes Training umfasst ein Verfahren, bei dem der Trainingssatz als Eingabe in das System gegeben wird, wobei jedes Beispiel mit einem gewünschten Ausgabewert gekennzeichnet ist. Das Training in diesem Typ wird unter Verwendung der Minimierung einer bestimmten Verlustfunktion durchgeführt, die den Ausgabefehler in Bezug auf das gewünschte Ausgabesystem darstellt.
Nach Abschluss des Trainings wird die Genauigkeit jedes Modells in Bezug auf disjunkte Beispiele aus dem Trainingssatz gemessen, der auch als Validierungssatz bezeichnet wird.
Das beste Beispiel zur Veranschaulichung des „überwachten Lernens“ sind eine Reihe von Fotos mit Informationen. Hier kann der Benutzer ein Modell trainieren, um neue Fotos zu erkennen.
Unbeaufsichtigtes Lernen
Schließen Sie in unbeaufsichtigtes Lernen oder unbeaufsichtigtes Training Trainingsbeispiele ein, die nicht vom System gekennzeichnet sind, zu welcher Klasse sie gehören. Das System sucht nach Daten, die gemeinsame Merkmale aufweisen, und ändert sie basierend auf internen Wissensmerkmalen. Diese Art von Lernalgorithmen wird im Wesentlichen bei Clustering-Problemen verwendet.
Das beste Beispiel zur Veranschaulichung von „unbeaufsichtigtem Lernen“ sind eine Reihe von Fotos ohne Informationen und ein Benutzertrainingsmodell mit Klassifizierung und Clustering. Diese Art von Trainingsalgorithmus arbeitet mit Annahmen, da keine Informationen angegeben werden.

Es ist wichtig, die für TensorFlow erforderlichen mathematischen Konzepte zu verstehen, bevor Sie die Basisanwendung in TensorFlow erstellen. Mathematik wird als das Herzstück eines jeden Algorithmus für maschinelles Lernen angesehen. Mit Hilfe von Kernkonzepten der Mathematik wird eine Lösung für einen bestimmten Algorithmus für maschinelles Lernen definiert.
Vektor
Ein Array von Zahlen, das entweder stetig oder diskret ist, wird als Vektor definiert. Algorithmen für maschinelles Lernen befassen sich mit Vektoren fester Länge für eine bessere Ausgabeerzeugung.
Algorithmen für maschinelles Lernen verarbeiten mehrdimensionale Daten, sodass Vektoren eine entscheidende Rolle spielen.

Die bildliche Darstellung des Vektormodells ist wie folgt:
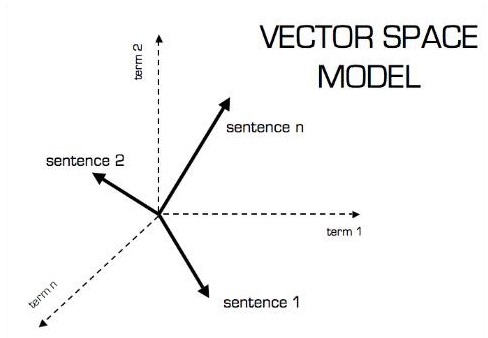
Skalar
Skalar kann als eindimensionaler Vektor definiert werden. Skalare sind solche, die nur Größe und keine Richtung enthalten. Bei Skalaren geht es uns nur um die Größe.
Beispiele für Skalar sind Gewichts- und Größenparameter von Kindern.
Matrix
Matrix kann als mehrdimensionale Arrays definiert werden, die im Format von Zeilen und Spalten angeordnet sind. Die Größe der Matrix wird durch Zeilenlänge und Spaltenlänge definiert. Die folgende Abbildung zeigt die Darstellung einer bestimmten Matrix.
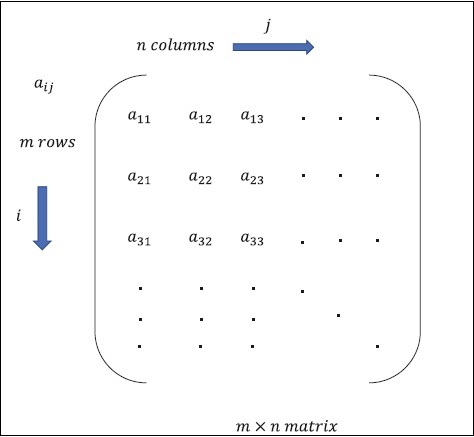
Betrachten Sie die Matrix mit "m" Zeilen und "n" Spalten, wie oben erwähnt. Die Matrixdarstellung wird als "m * n Matrix" angegeben, die auch die Länge der Matrix definiert.
Mathematische Berechnungen
In diesem Abschnitt lernen wir die verschiedenen mathematischen Berechnungen in TensorFlow kennen.
Zugabe von Matrizen
Das Hinzufügen von zwei oder mehr Matrizen ist möglich, wenn die Matrizen dieselbe Dimension haben. Die Addition impliziert die Addition jedes Elements gemäß der angegebenen Position.
Betrachten Sie das folgende Beispiel, um zu verstehen, wie das Hinzufügen von Matrizen funktioniert:
$$ Beispiel: A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} \: dann \: A. + B = \ begin {bmatrix} 1 + 5 & 2 + 6 \\ 3 + 7 & 4 + 8 \ end {bmatrix} = \ begin {bmatrix} 6 & 8 \\ 10 & 12 \ end {bmatrix} $$
Subtraktion von Matrizen
Die Subtraktion von Matrizen funktioniert ähnlich wie die Addition von zwei Matrizen. Der Benutzer kann zwei Matrizen subtrahieren, sofern die Abmessungen gleich sind.
$$ Beispiel: A- \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B- \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} \: then \: AB - \ begin {bmatrix} 1-5 & 2-6 \\ 3-7 & 4-8 \ end {bmatrix} - \ begin {bmatrix} -4 & -4 \\ - 4 & -4 \ end {bmatrix} $$
Multiplikation von Matrizen
Damit zwei Matrizen A m * n und B p * q multiplizierbar sind, n sollte gleich sein p. Die resultierende Matrix ist -
C m * q
$$ A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} $$
$$ c_ {11} = \ begin {bmatrix} 1 & 2 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 1 \ times5 + 2 \ times7 = 19 \: c_ {12} = \ begin {bmatrix} 1 & 2 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 1 \ times6 + 2 \ times8 = 22 $$
$$ c_ {21} = \ begin {bmatrix} 3 & 4 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 3 \ times5 + 4 \ times7 = 43 \: c_ {22} = \ begin {bmatrix} 3 & 4 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 3 \ times6 + 4 \ times8 = 50 $$
$$ C = \ begin {bmatrix} c_ {11} & c_ {12} \\ c_ {21} & c_ {22} \ end {bmatrix} = \ begin {bmatrix} 19 & 22 \\ 43 & 50 \ end {bmatrix} $$
Matrix transponieren
Die Transponierung einer Matrix A, m * n wird im Allgemeinen durch AT (Transponierung) n * m dargestellt und wird durch Transponieren der Spaltenvektoren als Zeilenvektoren erhalten.
$$ Beispiel: A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} \: dann \: A ^ {T} \ begin {bmatrix} 1 & 3 \\ 2 & 4 \ end { bmatrix} $$
Punktprodukt von Vektoren
Jeder Vektor der Dimension n kann als Matrix v = R ^ n * 1 dargestellt werden.
$$ v_ {1} = \ begin {bmatrix} v_ {11} \\ v_ {12} \\\ cdot \\\ cdot \\\ cdot \\ v_ {1n} \ end {bmatrix} v_ {2} = \ begin {bmatrix} v_ {21} \\ v_ {22} \\\ cdot \\\ cdot \\\ cdot \\ v_ {2n} \ end {bmatrix} $$
Das Punktprodukt zweier Vektoren ist die Summe des Produkts der entsprechenden Komponenten - Komponenten entlang derselben Dimension und kann ausgedrückt werden als
$$ v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = v_2 ^ Tv_ {1} = v_ {11} v_ {21} + v_ {12} v_ {22} + \ cdot \ cdot + v_ {1n} v_ {2n} = \ Anzeigestil \ Summe \ Grenzen_ {k = 1} ^ n v_ {1k} v_ {2k} $$
Das Beispiel des Punktprodukts von Vektoren wird unten erwähnt -
$$ Beispiel: v_ {1} = \ begin {bmatrix} 1 \\ 2 \\ 3 \ end {bmatrix} v_ {2} = \ begin {bmatrix} 3 \\ 5 \\ - 1 \ end {bmatrix} v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = 1 \ times3 + 2 \ times5-3 \ times1 = 10 $$
Künstliche Intelligenz ist einer der beliebtesten Trends der letzten Zeit. Maschinelles Lernen und tiefes Lernen bilden künstliche Intelligenz. Das unten gezeigte Venn-Diagramm erklärt die Beziehung zwischen maschinellem Lernen und tiefem Lernen -
Maschinelles Lernen
Maschinelles Lernen ist die Kunst der Wissenschaft, Computer dazu zu bringen, gemäß den entworfenen und programmierten Algorithmen zu handeln. Viele Forscher glauben, dass maschinelles Lernen der beste Weg ist, um Fortschritte in Richtung KI auf menschlicher Ebene zu erzielen. Maschinelles Lernen umfasst die folgenden Arten von Mustern
- Überwachtes Lernmuster
- Unüberwachtes Lernmuster
Tiefes Lernen
Deep Learning ist ein Teilgebiet des maschinellen Lernens, in dem betroffene Algorithmen von der Struktur und Funktion des Gehirns inspiriert sind, die als künstliche neuronale Netze bezeichnet werden.
Der gesamte Wert von Deep Learning liegt heute in überwachtem Lernen oder Lernen aus gekennzeichneten Daten und Algorithmen.
Jeder Algorithmus im Deep Learning durchläuft denselben Prozess. Es enthält eine Hierarchie der nichtlinearen Transformation von Eingaben, mit der ein statistisches Modell als Ausgabe generiert werden kann.
Beachten Sie die folgenden Schritte, die den maschinellen Lernprozess definieren
- Identifiziert relevante Datensätze und bereitet sie für die Analyse vor.
- Wählt den zu verwendenden Algorithmus aus
- Erstellt ein analytisches Modell basierend auf dem verwendeten Algorithmus.
- Trainiert das Modell anhand von Testdatensätzen und überarbeitet es nach Bedarf.
- Führt das Modell aus, um Testergebnisse zu generieren.
Unterschied zwischen maschinellem Lernen und tiefem Lernen
In diesem Abschnitt lernen wir den Unterschied zwischen maschinellem Lernen und tiefem Lernen kennen.
Datenmenge
Maschinelles Lernen funktioniert mit großen Datenmengen. Es ist auch für kleine Datenmengen nützlich. Deep Learning hingegen funktioniert effizient, wenn die Datenmenge schnell zunimmt. Das folgende Diagramm zeigt die Arbeitsweise von maschinellem Lernen und Deep Learning mit der Datenmenge -
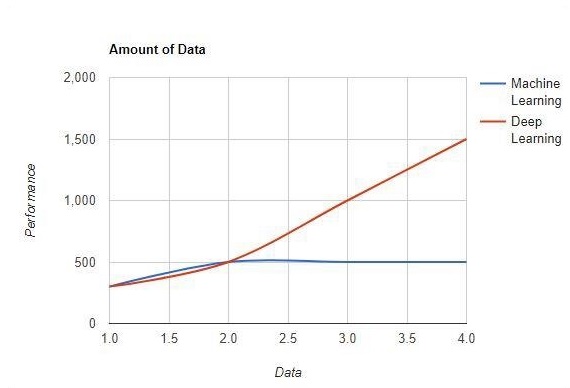
Hardware-Abhängigkeiten
Deep-Learning-Algorithmen sind im Gegensatz zu herkömmlichen Algorithmen für maschinelles Lernen so konzipiert, dass sie stark von High-End-Maschinen abhängen. Deep-Learning-Algorithmen führen eine Reihe von Matrixmultiplikationsoperationen durch, die eine große Menge an Hardwareunterstützung erfordern.
Feature Engineering
Beim Feature-Engineering werden Domänenwissen in bestimmte Features integriert, um die Komplexität der Daten zu verringern und Muster zu erstellen, die für die funktionierenden Lernalgorithmen sichtbar sind.
Beispiel - Herkömmliche Muster für maschinelles Lernen konzentrieren sich auf Pixel und andere Attribute, die für den Feature-Engineering-Prozess benötigt werden. Deep-Learning-Algorithmen konzentrieren sich auf Funktionen auf hoher Ebene aus Daten. Es reduziert die Aufgabe, für jedes neue Problem einen neuen Feature-Extraktor zu entwickeln.
Problemlösungsansatz
Die traditionellen Algorithmen für maschinelles Lernen folgen einem Standardverfahren, um das Problem zu lösen. Es zerlegt das Problem in Teile, löst jedes einzelne und kombiniert sie, um das gewünschte Ergebnis zu erzielen. Deep Learning konzentriert sich darauf, das Problem von Ende zu Ende zu lösen, anstatt es in Abteilungen aufzuteilen.
Ausführungszeit
Die Ausführungszeit ist die Zeit, die zum Trainieren eines Algorithmus erforderlich ist. Deep Learning erfordert viel Zeit zum Trainieren, da es viele Parameter enthält, die länger dauern als gewöhnlich. Der Algorithmus für maschinelles Lernen erfordert vergleichsweise weniger Ausführungszeit.
Interpretierbarkeit
Die Interpretierbarkeit ist der Hauptfaktor für den Vergleich von Algorithmen für maschinelles Lernen und tiefes Lernen. Der Hauptgrund ist, dass Deep Learning vor seiner Verwendung in der Industrie noch einen zweiten Gedanken hat.
Anwendungen des maschinellen Lernens und des tiefen Lernens
In diesem Abschnitt lernen wir die verschiedenen Anwendungen des maschinellen Lernens und des tiefen Lernens kennen.
Computer Vision, das zur Gesichtserkennung und zur Anwesenheitsmarke durch Fingerabdrücke oder zur Fahrzeugidentifikation durch Nummernschild verwendet wird.
Informationsabruf von Suchmaschinen wie der Textsuche für die Bildsuche.
Automatisiertes E-Mail-Marketing mit angegebener Zielidentifikation.
Medizinische Diagnose von Krebstumoren oder Anomalieerkennung einer chronischen Krankheit.
Verarbeitung natürlicher Sprache für Anwendungen wie das Markieren von Fotos. Das beste Beispiel zur Erklärung dieses Szenarios wird in Facebook verwendet.
Onlinewerbung.
Zukunftstrends
Mit dem zunehmenden Trend, Data Science und maschinelles Lernen in der Branche einzusetzen, wird es für jedes Unternehmen wichtig, maschinelles Lernen in seinen Unternehmen zu fördern.
Deep Learning gewinnt an Bedeutung als maschinelles Lernen. Deep Learning erweist sich als eine der besten Techniken für hochmoderne Leistungen.
Maschinelles Lernen und tiefes Lernen werden sich im Bereich Forschung und Wissenschaft als vorteilhaft erweisen.
Fazit
In diesem Artikel hatten wir einen Überblick über maschinelles Lernen und tiefes Lernen mit Abbildungen und Unterschieden, die sich auch auf zukünftige Trends konzentrieren. Viele KI-Anwendungen verwenden Algorithmen für maschinelles Lernen, um in erster Linie Self-Service zu betreiben, die Produktivität der Agenten zu steigern und Arbeitsabläufe zuverlässiger zu gestalten. Algorithmen für maschinelles Lernen und tiefes Lernen bieten für viele Unternehmen und Branchenführer eine aufregende Perspektive.
In diesem Kapitel lernen wir die Grundlagen von TensorFlow kennen. Wir beginnen mit dem Verständnis der Datenstruktur des Tensors.
Tensordatenstruktur
Tensoren werden als grundlegende Datenstrukturen in der TensorFlow-Sprache verwendet. Tensoren repräsentieren die Verbindungskanten in jedem Flussdiagramm, das als Datenflussdiagramm bezeichnet wird. Tensoren werden als mehrdimensionales Array oder Liste definiert.
Tensoren werden durch die folgenden drei Parameter identifiziert:
Rang
Die im Tensor beschriebene Maßeinheit wird als Rang bezeichnet. Es gibt die Anzahl der Dimensionen des Tensors an. Ein Rang eines Tensors kann als die Reihenfolge oder n-Dimensionen eines definierten Tensors beschrieben werden.
Gestalten
Die Anzahl der Zeilen und Spalten zusammen definiert die Form des Tensors.
Art
Typ beschreibt den Datentyp, der den Tensor-Elementen zugewiesen ist.
Ein Benutzer muss die folgenden Aktivitäten zum Erstellen eines Tensors berücksichtigen:
- Erstellen Sie ein n-dimensionales Array
- Konvertieren Sie das n-dimensionale Array.
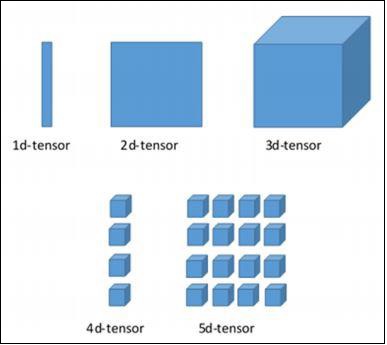
Verschiedene Abmessungen von TensorFlow
TensorFlow enthält verschiedene Dimensionen. Die Abmessungen werden im Folgenden kurz beschrieben -
Eindimensionaler Tensor
Ein eindimensionaler Tensor ist eine normale Array-Struktur, die einen Satz von Werten desselben Datentyps enthält.
Declaration
>>> import numpy as np
>>> tensor_1d = np.array([1.3, 1, 4.0, 23.99])
>>> print tensor_1dDie Implementierung mit der Ausgabe ist im folgenden Screenshot dargestellt -
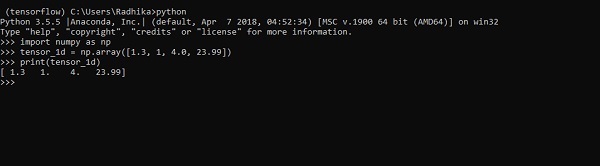
Die Indizierung von Elementen entspricht Python-Listen. Das erste Element beginnt mit dem Index 0; Um die Werte über den Index zu drucken, müssen Sie lediglich die Indexnummer angeben.
>>> print tensor_1d[0]
1.3
>>> print tensor_1d[2]
4.0
Zweidimensionale Tensoren
Die Reihenfolge der Arrays wird zur Erzeugung von "zweidimensionalen Tensoren" verwendet.
Die Erzeugung zweidimensionaler Tensoren wird nachfolgend beschrieben -

Im Folgenden finden Sie die vollständige Syntax zum Erstellen zweidimensionaler Arrays:
>>> import numpy as np
>>> tensor_2d = np.array([(1,2,3,4),(4,5,6,7),(8,9,10,11),(12,13,14,15)])
>>> print(tensor_2d)
[[ 1 2 3 4]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
>>>Die spezifischen Elemente zweidimensionaler Tensoren können mithilfe der als Indexnummern angegebenen Zeilennummer und Spaltennummer verfolgt werden.
>>> tensor_2d[3][2]
14
Tensorhandhabung und Manipulationen
In diesem Abschnitt erfahren Sie mehr über die Handhabung und Manipulation von Tensoren.
Betrachten wir zunächst den folgenden Code:
import tensorflow as tf
import numpy as np
matrix1 = np.array([(2,2,2),(2,2,2),(2,2,2)],dtype = 'int32')
matrix2 = np.array([(1,1,1),(1,1,1),(1,1,1)],dtype = 'int32')
print (matrix1)
print (matrix2)
matrix1 = tf.constant(matrix1)
matrix2 = tf.constant(matrix2)
matrix_product = tf.matmul(matrix1, matrix2)
matrix_sum = tf.add(matrix1,matrix2)
matrix_3 = np.array([(2,7,2),(1,4,2),(9,0,2)],dtype = 'float32')
print (matrix_3)
matrix_det = tf.matrix_determinant(matrix_3)
with tf.Session() as sess:
result1 = sess.run(matrix_product)
result2 = sess.run(matrix_sum)
result3 = sess.run(matrix_det)
print (result1)
print (result2)
print (result3)Output
Der obige Code generiert die folgende Ausgabe:
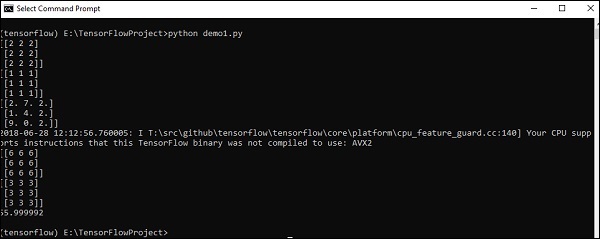
Erläuterung
Wir haben im obigen Quellcode mehrdimensionale Arrays erstellt. Jetzt ist es wichtig zu verstehen, dass wir Diagramme und Sitzungen erstellt haben, die die Tensoren verwalten und die entsprechende Ausgabe generieren. Mit Hilfe des Graphen haben wir die Ausgabe, die die mathematischen Berechnungen zwischen Tensoren spezifiziert.
Nachdem wir die Konzepte des maschinellen Lernens verstanden haben, können wir uns jetzt auf Konzepte des tiefen Lernens konzentrieren. Deep Learning ist eine Abteilung des maschinellen Lernens und wird von Forschern in den letzten Jahrzehnten als ein entscheidender Schritt angesehen. Die Beispiele für die Implementierung von Deep Learning umfassen Anwendungen wie Bilderkennung und Spracherkennung.
Im Folgenden sind die beiden wichtigen Arten von tiefen neuronalen Netzen aufgeführt:
- Faltungsneurale Netze
- Wiederkehrende neuronale Netze
In diesem Kapitel konzentrieren wir uns auf CNN, Convolutional Neural Networks.
Faltungsneurale Netze
Faltungs-Neuronale Netze dienen zur Verarbeitung von Daten über mehrere Arrays. Diese Art von neuronalen Netzen wird in Anwendungen wie der Bilderkennung oder der Gesichtserkennung verwendet. Der Hauptunterschied zwischen CNN und jedem anderen gewöhnlichen neuronalen Netzwerk besteht darin, dass CNN Eingaben als zweidimensionales Array verwendet und direkt auf die Bilder einwirkt, anstatt sich auf die Merkmalsextraktion zu konzentrieren, auf die sich andere neuronale Netzwerke konzentrieren.
Der vorherrschende Ansatz von CNN umfasst Lösungen für Erkennungsprobleme. Top-Unternehmen wie Google und Facebook haben in Forschung und Entwicklung für Anerkennungsprojekte investiert, um Aktivitäten schneller durchzuführen.
Ein Faltungsnetzwerk verwendet drei Grundideen:
- Lokale entsprechende Felder
- Convolution
- Pooling
Lassen Sie uns diese Ideen im Detail verstehen.
CNN verwendet räumliche Korrelationen, die in den Eingabedaten vorhanden sind. Jede gleichzeitige Schicht eines neuronalen Netzwerks verbindet einige Eingangsneuronen. Diese spezifische Region wird als lokales Empfangsfeld bezeichnet. Das lokale Empfangsfeld konzentriert sich auf die verborgenen Neuronen. Die versteckten Neuronen verarbeiten die Eingabedaten innerhalb des genannten Feldes, ohne die Änderungen außerhalb der spezifischen Grenze zu realisieren.
Es folgt eine Diagrammdarstellung der Erzeugung lokaler entsprechender Felder -
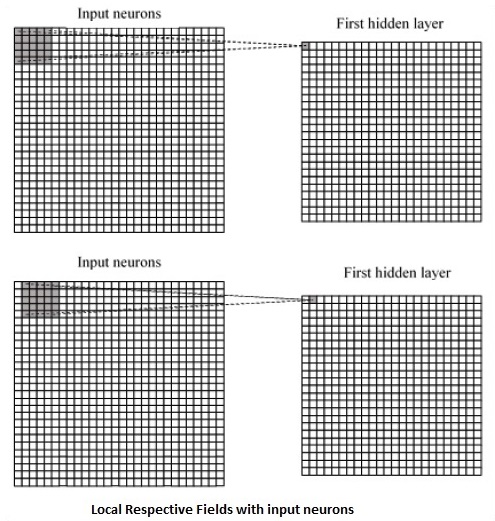
Wenn wir die obige Darstellung beobachten, lernt jede Verbindung ein Gewicht des verborgenen Neurons mit einer damit verbundenen Verbindung mit der Bewegung von einer Schicht zur anderen. Hier führen einzelne Neuronen von Zeit zu Zeit eine Verschiebung durch. Dieser Vorgang wird als "Faltung" bezeichnet.
Die Zuordnung von Verbindungen von der Eingabeebene zur verborgenen Feature-Map wird als "gemeinsame Gewichtung" definiert, und die enthaltene Verzerrung wird als "gemeinsame Verzerrung" bezeichnet.
CNN oder Faltungs-Neuronale Netze verwenden Pooling-Schichten, die die Schichten sind, die unmittelbar nach der CNN-Deklaration positioniert sind. Es nimmt die Eingabe des Benutzers als Feature-Map, die aus Faltungsnetzwerken stammt, und erstellt eine komprimierte Feature-Map. Das Zusammenfassen von Ebenen hilft beim Erstellen von Ebenen mit Neuronen früherer Ebenen.
TensorFlow Implementierung von CNN
In diesem Abschnitt erfahren Sie mehr über die TensorFlow-Implementierung von CNN. Die Schritte, die die Ausführung und die richtige Dimension des gesamten Netzwerks erfordern, sind wie folgt:
Step 1 - Fügen Sie die erforderlichen Module für TensorFlow und die Datensatzmodule hinzu, die zur Berechnung des CNN-Modells benötigt werden.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_dataStep 2 - Deklarieren Sie eine aufgerufene Funktion run_cnn(), die verschiedene Parameter und Optimierungsvariablen mit Deklaration von Datenplatzhaltern enthält. Diese Optimierungsvariablen deklarieren das Trainingsmuster.
def run_cnn():
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
learning_rate = 0.0001
epochs = 10
batch_size = 50Step 3 - In diesem Schritt deklarieren wir die Platzhalter für Trainingsdaten mit Eingabeparametern - für 28 x 28 Pixel = 784. Dies sind die abgeflachten Bilddaten, aus denen gezeichnet wird mnist.train.nextbatch().
Wir können den Tensor gemäß unseren Anforderungen umformen. Der erste Wert (-1) weist die Funktion an, diese Dimension basierend auf der an sie übergebenen Datenmenge dynamisch zu formen. Die beiden mittleren Dimensionen werden auf die Bildgröße eingestellt (dh 28 x 28).
x = tf.placeholder(tf.float32, [None, 784])
x_shaped = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, [None, 10])Step 4 - Jetzt ist es wichtig, einige Faltungsschichten zu erstellen -
layer1 = create_new_conv_layer(x_shaped, 1, 32, [5, 5], [2, 2], name = 'layer1')
layer2 = create_new_conv_layer(layer1, 32, 64, [5, 5], [2, 2], name = 'layer2')Step 5- Lassen Sie uns den Ausgang für die vollständig angeschlossene Ausgangsstufe abflachen - nach zwei Schichten von Schritt 2 mit den Abmessungen 28 x 28 auf die Abmessungen 14 x 14 oder mindestens 7 x 7 x, y-Koordinaten, jedoch mit 64 Ausgangskanäle. Um die vollständig mit "dichter" Ebene verbundene Ebene zu erstellen, muss die neue Form [-1, 7 x 7 x 64] sein. Wir können einige Gewichte und Bias-Werte für diese Ebene festlegen und dann mit ReLU aktivieren.
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev = 0.03), name = 'wd1')
bd1 = tf.Variable(tf.truncated_normal([1000], stddev = 0.01), name = 'bd1')
dense_layer1 = tf.matmul(flattened, wd1) + bd1
dense_layer1 = tf.nn.relu(dense_layer1)Step 6 - Eine weitere Ebene mit spezifischen Softmax-Aktivierungen mit dem erforderlichen Optimierer definiert die Genauigkeitsbewertung, mit der der Initialisierungsoperator eingerichtet wird.
wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev = 0.03), name = 'wd2')
bd2 = tf.Variable(tf.truncated_normal([10], stddev = 0.01), name = 'bd2')
dense_layer2 = tf.matmul(dense_layer1, wd2) + bd2
y_ = tf.nn.softmax(dense_layer2)
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = dense_layer2, labels = y))
optimiser = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_op = tf.global_variables_initializer()Step 7- Wir sollten Aufzeichnungsvariablen einrichten. Dies fügt eine Zusammenfassung hinzu, um die Genauigkeit der Daten zu speichern.
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('E:\TensorFlowProject')
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size = batch_size)
_, c = sess.run([optimiser, cross_entropy], feed_dict = {
x:batch_x, y: batch_y})
avg_cost += c / total_batch
test_acc = sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
summary = sess.run(merged, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
writer.add_summary(summary, epoch)
print("\nTraining complete!")
writer.add_graph(sess.graph)
print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels}))
def create_new_conv_layer(
input_data, num_input_channels, num_filters,filter_shape, pool_shape, name):
conv_filt_shape = [
filter_shape[0], filter_shape[1], num_input_channels, num_filters]
weights = tf.Variable(
tf.truncated_normal(conv_filt_shape, stddev = 0.03), name = name+'_W')
bias = tf.Variable(tf.truncated_normal([num_filters]), name = name+'_b')
#Out layer defines the output
out_layer =
tf.nn.conv2d(input_data, weights, [1, 1, 1, 1], padding = 'SAME')
out_layer += bias
out_layer = tf.nn.relu(out_layer)
ksize = [1, pool_shape[0], pool_shape[1], 1]
strides = [1, 2, 2, 1]
out_layer = tf.nn.max_pool(
out_layer, ksize = ksize, strides = strides, padding = 'SAME')
return out_layer
if __name__ == "__main__":
run_cnn()Es folgt die vom obigen Code erzeugte Ausgabe -
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-19 17:22:58.802268: I
T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2
2018-09-19 17:25:41.522845: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.
2018-09-19 17:25:44.630941: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 501760000 exceeds 10% of system memory.
Epoch: 1 cost = 0.676 test accuracy: 0.940
2018-09-19 17:26:51.987554: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
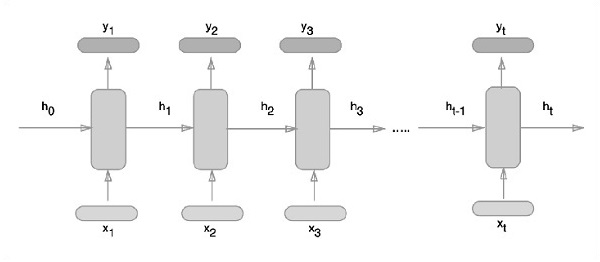
of 1003520000 exceeds 10% of system memory.Wiederkehrende neuronale Netze sind eine Art Deep-Learning-orientierter Algorithmus, der einem sequentiellen Ansatz folgt. In neuronalen Netzen gehen wir immer davon aus, dass jeder Ein- und Ausgang unabhängig von allen anderen Schichten ist. Diese Art von neuronalen Netzen wird als wiederkehrend bezeichnet, da sie sequentielle mathematische Berechnungen durchführen.
Betrachten Sie die folgenden Schritte, um ein wiederkehrendes neuronales Netzwerk zu trainieren:
Step 1 - Geben Sie ein bestimmtes Beispiel aus dem Datensatz ein.
Step 2 - Das Netzwerk nimmt ein Beispiel und berechnet einige Berechnungen mit zufällig initialisierten Variablen.
Step 3 - Ein vorhergesagtes Ergebnis wird dann berechnet.
Step 4 - Der Vergleich des tatsächlich generierten Ergebnisses mit dem erwarteten Wert führt zu einem Fehler.
Step 5 - Um den Fehler zu verfolgen, wird er über denselben Pfad weitergegeben, in dem auch die Variablen angepasst werden.
Step 6 - Die Schritte von 1 bis 5 werden wiederholt, bis wir sicher sind, dass die Variablen, die zum Abrufen der Ausgabe deklariert wurden, richtig definiert sind.
Step 7 - Eine systematische Vorhersage wird durchgeführt, indem diese Variablen angewendet werden, um neue unsichtbare Eingaben zu erhalten.
Der schematische Ansatz zur Darstellung wiederkehrender neuronaler Netze wird nachstehend beschrieben -
Wiederkehrende Implementierung eines neuronalen Netzwerks mit TensorFlow
In diesem Abschnitt erfahren Sie, wie Sie ein wiederkehrendes neuronales Netzwerk mit TensorFlow implementieren.
Step 1 - TensorFlow enthält verschiedene Bibliotheken für die spezifische Implementierung des wiederkehrenden neuronalen Netzwerkmoduls.
#Import necessary modules
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)Wie oben erwähnt, helfen die Bibliotheken bei der Definition der Eingabedaten, die den Hauptteil der wiederkehrenden Implementierung eines neuronalen Netzwerks bilden.
Step 2- Unser Hauptmotiv besteht darin, die Bilder mithilfe eines wiederkehrenden neuronalen Netzwerks zu klassifizieren, wobei wir jede Bildzeile als eine Folge von Pixeln betrachten. Die MNIST-Bildform ist speziell als 28 * 28 px definiert. Jetzt werden wir 28 Sequenzen von 28 Schritten für jede erwähnte Probe behandeln. Wir werden die Eingabeparameter definieren, um das sequentielle Muster fertigzustellen.
n_input = 28 # MNIST data input with img shape 28*28
n_steps = 28
n_hidden = 128
n_classes = 10
# tf Graph input
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes]
weights = {
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([n_classes]))
}Step 3- Berechnen Sie die Ergebnisse mit einer in RNN definierten Funktion, um die besten Ergebnisse zu erzielen. Hier wird jede Datenform mit der aktuellen Eingabeform verglichen und die Ergebnisse werden berechnet, um die Genauigkeitsrate aufrechtzuerhalten.
def RNN(x, weights, biases):
x = tf.unstack(x, n_steps, 1)
# Define a lstm cell with tensorflow
lstm_cell = rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)
# Get lstm cell output
outputs, states = rnn.static_rnn(lstm_cell, x, dtype = tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
pred = RNN(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()Step 4- In diesem Schritt starten wir das Diagramm, um die Berechnungsergebnisse zu erhalten. Dies hilft auch bei der Berechnung der Genauigkeit für Testergebnisse.
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={x: test_data, y: test_label}))Die folgenden Screenshots zeigen die generierte Ausgabe -
TensorFlow enthält ein Visualisierungstool, das als TensorBoard bezeichnet wird. Es wird zur Analyse von Datenflussdiagrammen und zum Verständnis von Modellen für maschinelles Lernen verwendet. Die wichtige Funktion von TensorBoard umfasst die Ansicht verschiedener Arten von Statistiken zu den Parametern und Details eines Diagramms in vertikaler Ausrichtung.
Das tiefe neuronale Netzwerk umfasst bis zu 36.000 Knoten. TensorBoard hilft beim Reduzieren dieser Knoten in übergeordneten Blöcken und beim Hervorheben der identischen Strukturen. Dies ermöglicht eine bessere Analyse des Diagramms, wobei der Schwerpunkt auf den primären Abschnitten des Berechnungsdiagramms liegt. Die TensorBoard-Visualisierung soll sehr interaktiv sein, wobei ein Benutzer die Knoten schwenken, zoomen und erweitern kann, um die Details anzuzeigen.
Die folgende schematische Darstellung zeigt die vollständige Funktionsweise der TensorBoard-Visualisierung -
Die Algorithmen reduzieren Knoten zu Blöcken auf hoher Ebene und markieren die spezifischen Gruppen mit identischen Strukturen, die Knoten mit hohem Grad trennen. Das so erstellte TensorBoard ist nützlich und wird für die Optimierung eines maschinellen Lernmodells gleichermaßen wichtig behandelt. Dieses Visualisierungstool wurde für die Konfigurationsprotokolldatei mit zusammenfassenden Informationen und Details entwickelt, die angezeigt werden müssen.
Konzentrieren wir uns auf das Demo-Beispiel der TensorBoard-Visualisierung mit Hilfe des folgenden Codes:
import tensorflow as tf
# Constants creation for TensorBoard visualization
a = tf.constant(10,name = "a")
b = tf.constant(90,name = "b")
y = tf.Variable(a+b*2,name = 'y')
model = tf.initialize_all_variables() #Creation of model
with tf.Session() as session:
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("/tmp/tensorflowlogs",session.graph)
session.run(model)
print(session.run(y))Die folgende Tabelle zeigt die verschiedenen Symbole der TensorBoard-Visualisierung, die für die Knotendarstellung verwendet werden.

Das Einbetten von Wörtern ist das Konzept der Abbildung von diskreten Objekten wie Wörtern auf Vektoren und reelle Zahlen. Es ist wichtig für die Eingabe für maschinelles Lernen. Das Konzept umfasst Standardfunktionen, die diskrete Eingabeobjekte effektiv in nützliche Vektoren umwandeln.
Die Beispieldarstellung der Eingabe der Worteinbettung ist wie folgt:
blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259)
blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158)
orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213)
oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976)Word2vec
Word2vec ist der am häufigsten verwendete Ansatz für unbeaufsichtigte Worteinbettungstechniken. Es trainiert das Modell so, dass ein bestimmtes Eingabewort den Kontext des Wortes mithilfe von Sprunggramm vorhersagt.
TensorFlow bietet viele Möglichkeiten, diese Art von Modell mit zunehmender Komplexität und Optimierung zu implementieren und Multithreading-Konzepte und Abstraktionen auf höherer Ebene zu verwenden.
import os
import math
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
batch_size = 64
embedding_dimension = 5
negative_samples = 8
LOG_DIR = "logs/word2vec_intro"
digit_to_word_map = {
1: "One",
2: "Two",
3: "Three",
4: "Four",
5: "Five",
6: "Six",
7: "Seven",
8: "Eight",
9: "Nine"}
sentences = []
# Create two kinds of sentences - sequences of odd and even digits.
for i in range(10000):
rand_odd_ints = np.random.choice(range(1, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_odd_ints]))
rand_even_ints = np.random.choice(range(2, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_even_ints]))
# Map words to indices
word2index_map = {}
index = 0
for sent in sentences:
for word in sent.lower().split():
if word not in word2index_map:
word2index_map[word] = index
index += 1
index2word_map = {index: word for word, index in word2index_map.items()}
vocabulary_size = len(index2word_map)
# Generate skip-gram pairs
skip_gram_pairs = []
for sent in sentences:
tokenized_sent = sent.lower().split()
for i in range(1, len(tokenized_sent)-1):
word_context_pair = [[word2index_map[tokenized_sent[i-1]],
word2index_map[tokenized_sent[i+1]]], word2index_map[tokenized_sent[i]]]
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][0]])
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][1]])
def get_skipgram_batch(batch_size):
instance_indices = list(range(len(skip_gram_pairs)))
np.random.shuffle(instance_indices)
batch = instance_indices[:batch_size]
x = [skip_gram_pairs[i][0] for i in batch]
y = [[skip_gram_pairs[i][1]] for i in batch]
return x, y
# batch example
x_batch, y_batch = get_skipgram_batch(8)
x_batch
y_batch
[index2word_map[word] for word in x_batch] [index2word_map[word[0]] for word in y_batch]
# Input data, labels train_inputs = tf.placeholder(tf.int32, shape = [batch_size])
train_labels = tf.placeholder(tf.int32, shape = [batch_size, 1])
# Embedding lookup table currently only implemented in CPU with
tf.name_scope("embeddings"):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_dimension], -1.0, 1.0),
name = 'embedding')
# This is essentialy a lookup table
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Create variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_dimension], stddev = 1.0 /
math.sqrt(embedding_dimension)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(
tf.nn.nce_loss(weights = nce_weights, biases = nce_biases, inputs = embed,
labels = train_labels,num_sampled = negative_samples,
num_classes = vocabulary_size)) tf.summary.scalar("NCE_loss", loss)
# Learning rate decay
global_step = tf.Variable(0, trainable = False)
learningRate = tf.train.exponential_decay(learning_rate = 0.1,
global_step = global_step, decay_steps = 1000, decay_rate = 0.95, staircase = True)
train_step = tf.train.GradientDescentOptimizer(learningRate).minimize(loss)
merged = tf.summary.merge_all()
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(LOG_DIR,
graph = tf.get_default_graph())
saver = tf.train.Saver()
with open(os.path.join(LOG_DIR, 'metadata.tsv'), "w") as metadata:
metadata.write('Name\tClass\n') for k, v in index2word_map.items():
metadata.write('%s\t%d\n' % (v, k))
config = projector.ProjectorConfig()
embedding = config.embeddings.add() embedding.tensor_name = embeddings.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv')
projector.visualize_embeddings(train_writer, config)
tf.global_variables_initializer().run()
for step in range(1000):
x_batch, y_batch = get_skipgram_batch(batch_size) summary, _ = sess.run(
[merged, train_step], feed_dict = {train_inputs: x_batch, train_labels: y_batch})
train_writer.add_summary(summary, step)
if step % 100 == 0:
saver.save(sess, os.path.join(LOG_DIR, "w2v_model.ckpt"), step)
loss_value = sess.run(loss, feed_dict = {
train_inputs: x_batch, train_labels: y_batch})
print("Loss at %d: %.5f" % (step, loss_value))
# Normalize embeddings before using
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims = True))
normalized_embeddings = embeddings /
norm normalized_embeddings_matrix = sess.run(normalized_embeddings)
ref_word = normalized_embeddings_matrix[word2index_map["one"]]
cosine_dists = np.dot(normalized_embeddings_matrix, ref_word)
ff = np.argsort(cosine_dists)[::-1][1:10] for f in ff: print(index2word_map[f])
print(cosine_dists[f])Ausgabe
Der obige Code generiert die folgende Ausgabe:
Für das Verständnis von einschichtigem Perzeptron ist es wichtig, künstliche neuronale Netze (ANN) zu verstehen. Künstliche neuronale Netze sind das Informationsverarbeitungssystem, dessen Mechanismus von der Funktionalität biologischer neuronaler Schaltkreise inspiriert ist. Ein künstliches neuronales Netzwerk besitzt viele miteinander verbundene Verarbeitungseinheiten. Es folgt die schematische Darstellung eines künstlichen neuronalen Netzwerks -
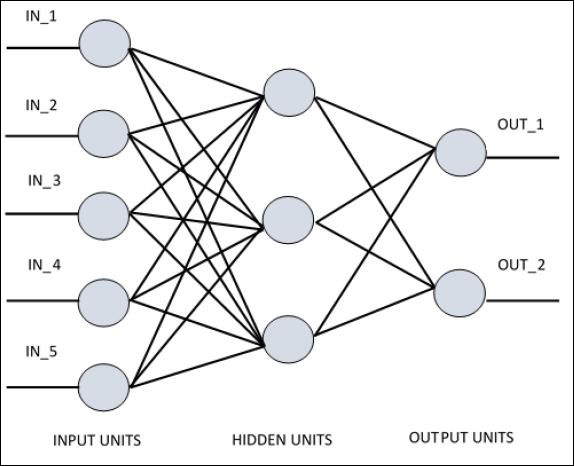
Das Diagramm zeigt, dass die versteckten Einheiten mit der externen Schicht kommunizieren. Während die Eingabe- und Ausgabeeinheiten nur über die verborgene Schicht des Netzwerks kommunizieren.
Das Verbindungsmuster mit Knoten, die Gesamtzahl der Schichten und die Ebene der Knoten zwischen Ein- und Ausgängen mit der Anzahl der Neuronen pro Schicht definieren die Architektur eines neuronalen Netzwerks.
Es gibt zwei Arten von Architektur. Diese Typen konzentrieren sich auf die Funktionalität künstlicher neuronaler Netze wie folgt:
- Einschichtiges Perceptron
- Mehrschichtiges Perzeptron
Einschichtiges Perceptron
Einschichtiges Perzeptron ist das erste vorgeschlagene neuronale Modell, das erstellt wurde. Der Inhalt des lokalen Gedächtnisses des Neurons besteht aus einem Gewichtsvektor. Die Berechnung eines Einzelschicht-Perzeptrons erfolgt über die Berechnung der Summe des Eingabevektors mit jeweils dem Wert multipliziert mit dem entsprechenden Vektorelement der Gewichte. Der Wert, der in der Ausgabe angezeigt wird, ist die Eingabe einer Aktivierungsfunktion.

Konzentrieren wir uns auf die Implementierung eines einschichtigen Perzeptrons für ein Bildklassifizierungsproblem mit TensorFlow. Das beste Beispiel zur Veranschaulichung des einschichtigen Perzeptrons ist die Darstellung der „logistischen Regression“.
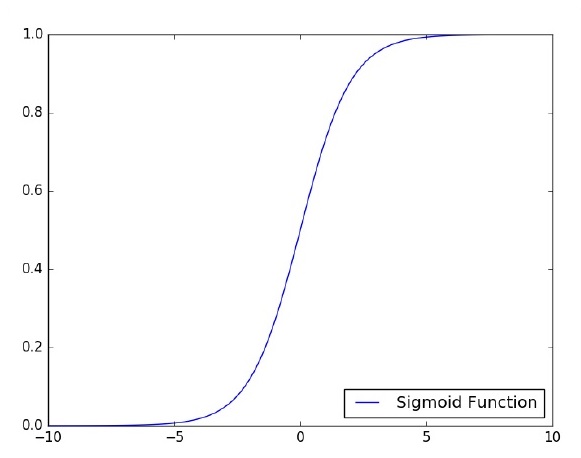
Betrachten wir nun die folgenden grundlegenden Schritte zum Training der logistischen Regression:
Die Gewichte werden zu Beginn des Trainings mit zufälligen Werten initialisiert.
Für jedes Element des Trainingssatzes wird der Fehler mit der Differenz zwischen der gewünschten Ausgabe und der tatsächlichen Ausgabe berechnet. Der berechnete Fehler wird verwendet, um die Gewichte anzupassen.
Der Vorgang wird wiederholt, bis der im gesamten Trainingssatz gemachte Fehler den angegebenen Schwellenwert nicht unterschreitet, bis die maximale Anzahl von Iterationen erreicht ist.
Der vollständige Code zur Bewertung der logistischen Regression ist unten aufgeführt -
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder("float", [None, 784]) # mnist data image of shape 28*28 = 784
y = tf.placeholder("float", [None, 10]) # 0-9 digits recognition => 10 classes
# Create model
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Construct model
activation = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
# Minimize error using cross entropy
cross_entropy = y*tf.log(activation)
cost = tf.reduce_mean\ (-tf.reduce_sum\ (cross_entropy,reduction_indices = 1))
optimizer = tf.train.\ GradientDescentOptimizer(learning_rate).minimize(cost)
#Plot settings
avg_set = []
epoch_set = []
# Initializing the variables init = tf.initialize_all_variables()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = \ mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, \ feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss avg_cost += sess.run(cost, \ feed_dict = {
x: batch_xs, \ y: batch_ys})/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print ("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
avg_set.append(avg_cost) epoch_set.append(epoch+1)
print ("Training phase finished")
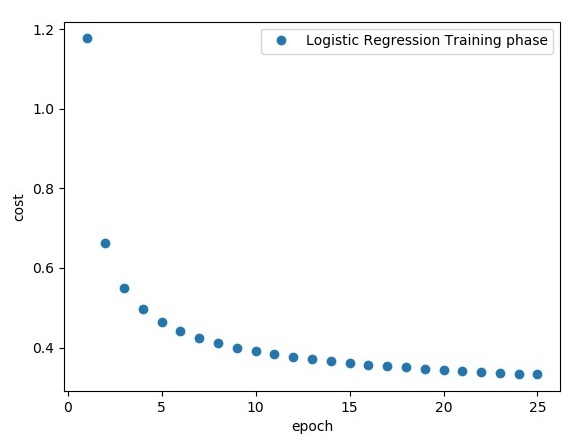
plt.plot(epoch_set,avg_set, 'o', label = 'Logistic Regression Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(activation, 1), tf.argmax(y, 1))
# Calculate accuracy
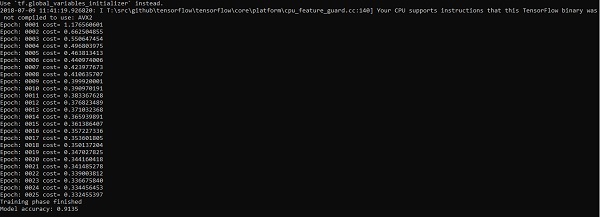
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print
("Model accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))Ausgabe
Der obige Code generiert die folgende Ausgabe:
Die logistische Regression wird als prädiktive Analyse betrachtet. Die logistische Regression wird verwendet, um Daten zu beschreiben und die Beziehung zwischen einer abhängigen binären Variablen und einer oder mehreren nominalen oder unabhängigen Variablen zu erklären.
In diesem Kapitel konzentrieren wir uns auf das grundlegende Beispiel der Implementierung einer linearen Regression mit TensorFlow. Die logistische oder lineare Regression ist ein überwachter Ansatz des maschinellen Lernens zur Klassifizierung diskreter Kategorien. Unser Ziel in diesem Kapitel ist es, ein Modell zu erstellen, mit dem ein Benutzer die Beziehung zwischen Prädiktorvariablen und einer oder mehreren unabhängigen Variablen vorhersagen kann.
Die Beziehung zwischen diesen beiden Variablen wird als linear angesehen. Wenn y die abhängige Variable ist und x als unabhängige Variable betrachtet wird, sieht die lineare Regressionsbeziehung zweier Variablen wie folgt aus:
Y = Ax+bWir werden einen Algorithmus für die lineare Regression entwerfen. Auf diese Weise können wir die folgenden zwei wichtigen Konzepte verstehen:
- Kostenfunktion
- Gradientenabstiegsalgorithmen
Die schematische Darstellung der linearen Regression wird unten erwähnt -

Die grafische Ansicht der Gleichung der linearen Regression wird unten erwähnt -
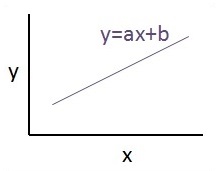
Schritte zum Entwerfen eines Algorithmus für die lineare Regression
Wir werden nun die Schritte kennenlernen, die beim Entwerfen eines Algorithmus für die lineare Regression helfen.
Schritt 1
Es ist wichtig, die erforderlichen Module zum Zeichnen des linearen Regressionsmoduls zu importieren. Wir beginnen mit dem Import der Python-Bibliotheken NumPy und Matplotlib.
import numpy as np
import matplotlib.pyplot as pltSchritt 2
Definieren Sie die Anzahl der Koeffizienten, die für die logistische Regression erforderlich sind.
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78Schritt 3
Iterieren Sie die Variablen zum Generieren von 300 zufälligen Punkten um die Regressionsgleichung -
Y = 0,22x + 0,78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])Schritt 4
Zeigen Sie die generierten Punkte mit Matplotlib an.
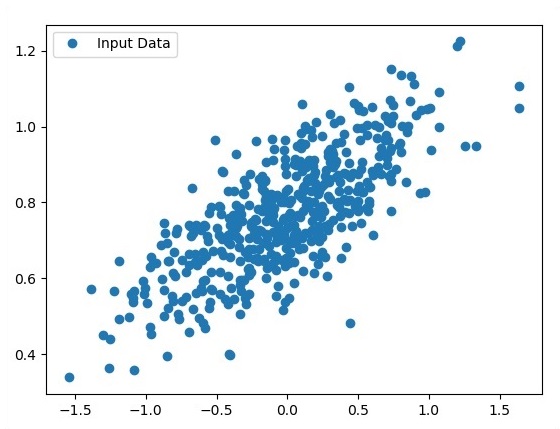
fplt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend() plt.show()Der vollständige Code für die logistische Regression lautet wie folgt:
import numpy as np
import matplotlib.pyplot as plt
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])
plt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend()
plt.show()Die Anzahl der Punkte, die als Eingabe verwendet werden, wird als Eingabedaten betrachtet.
TFLearn kann als modularer und transparenter Deep-Learning-Aspekt definiert werden, der im TensorFlow-Framework verwendet wird. Das Hauptmotiv von TFLearn besteht darin, TensorFlow eine übergeordnete API zur Verfügung zu stellen, um neue Experimente zu ermöglichen und aufzuzeigen.
Berücksichtigen Sie die folgenden wichtigen Funktionen von TFLearn:
TFLearn ist einfach zu bedienen und zu verstehen.
Es enthält einfache Konzepte zum Aufbau hochmodularer Netzwerkschichten, Optimierer und verschiedene darin eingebettete Metriken.
Es beinhaltet vollständige Transparenz mit dem TensorFlow-Arbeitssystem.
Es enthält leistungsstarke Hilfsfunktionen zum Trainieren der eingebauten Tensoren, die mehrere Ein-, Ausgänge und Optimierer akzeptieren.
Es enthält eine einfache und schöne Grafikvisualisierung.
Die Diagrammvisualisierung enthält verschiedene Details zu Gewichten, Verläufen und Aktivierungen.
Installieren Sie TFLearn, indem Sie den folgenden Befehl ausführen:
pip install tflearnBei Ausführung des obigen Codes wird die folgende Ausgabe generiert:
Die folgende Abbildung zeigt die Implementierung von TFLearn mit Random Forest-Klassifikator -
from __future__ import division, print_function, absolute_import
#TFLearn module implementation
import tflearn
from tflearn.estimators import RandomForestClassifier
# Data loading and pre-processing with respect to dataset
import tflearn.datasets.mnist as mnist
X, Y, testX, testY = mnist.load_data(one_hot = False)
m = RandomForestClassifier(n_estimators = 100, max_nodes = 1000)
m.fit(X, Y, batch_size = 10000, display_step = 10)
print("Compute the accuracy on train data:")
print(m.evaluate(X, Y, tflearn.accuracy_op))
print("Compute the accuracy on test set:")
print(m.evaluate(testX, testY, tflearn.accuracy_op))
print("Digits for test images id 0 to 5:")
print(m.predict(testX[:5]))
print("True digits:")
print(testY[:5])In diesem Kapitel konzentrieren wir uns auf den Unterschied zwischen CNN und RNN -
| CNN | RNN |
|---|---|
| Es eignet sich für räumliche Daten wie Bilder. | RNN eignet sich für zeitliche Daten, auch sequentielle Daten genannt. |
| CNN gilt als leistungsfähiger als RNN. | RNN bietet im Vergleich zu CNN eine geringere Funktionskompatibilität. |
| Dieses Netzwerk verwendet Eingaben mit fester Größe und generiert Ausgaben mit fester Größe. | RNN kann beliebige Eingabe- / Ausgabelängen verarbeiten. |
| CNN ist eine Art künstliches neuronales Feed-Forward-Netzwerk mit Variationen von mehrschichtigen Perzeptronen, die so ausgelegt sind, dass nur minimale Vorverarbeitungsmengen verwendet werden. | RNN kann im Gegensatz zu Feed-Forward-Neuronalen Netzen ihren internen Speicher verwenden, um beliebige Sequenzen von Eingaben zu verarbeiten. |
| CNNs verwenden Konnektivitätsmuster zwischen den Neuronen. Dies ist inspiriert von der Organisation des visuellen Kortex des Tieres, dessen einzelne Neuronen so angeordnet sind, dass sie auf überlappende Bereiche reagieren, die das Gesichtsfeld kacheln. | Wiederkehrende neuronale Netze verwenden Zeitreiheninformationen. Was ein Benutzer zuletzt gesprochen hat, wirkt sich auf das aus, was er als Nächstes spricht. |
| CNNs sind ideal für die Bild- und Videoverarbeitung. | RNNs sind ideal für die Text- und Sprachanalyse. |
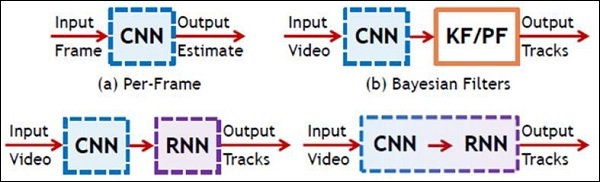
Die folgende Abbildung zeigt die schematische Darstellung von CNN und RNN -
Keras ist eine kompakte, leicht zu erlernende Python-Bibliothek auf hoher Ebene, die auf dem TensorFlow-Framework ausgeführt wird. Es konzentriert sich auf das Verständnis von Deep-Learning-Techniken, z. B. das Erstellen von Schichten für neuronale Netze, wobei die Konzepte von Formen und mathematischen Details beibehalten werden. Es gibt zwei Arten von Rahmenarbeiten:
- Sequentielle API
- Funktionale API
Betrachten Sie die folgenden acht Schritte, um ein Deep-Learning-Modell in Keras zu erstellen:
- Laden der Daten
- Verarbeiten Sie die geladenen Daten vor
- Definition des Modells
- Modell kompilieren
- Passen Sie das angegebene Modell an
- Bewerten Sie es
- Machen Sie die erforderlichen Vorhersagen
- Speichern Sie das Modell
Wir werden das Jupyter-Notizbuch zur Ausführung und Anzeige der Ausgabe verwenden, wie unten gezeigt -
Step 1 - Das Laden der Daten und das Vorverarbeiten der geladenen Daten wird zuerst implementiert, um das Deep-Learning-Modell auszuführen.
import warnings
warnings.filterwarnings('ignore')
import numpy as np
np.random.seed(123) # for reproducibility
from keras.models import Sequential
from keras.layers import Flatten, MaxPool2D, Conv2D, Dense, Reshape, Dropout
from keras.utils import np_utils
Using TensorFlow backend.
from keras.datasets import mnist
# Load pre-shuffled MNIST data into train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)Dieser Schritt kann als "Bibliotheken und Module importieren" definiert werden. Dies bedeutet, dass alle Bibliotheken und Module als erster Schritt importiert werden.
Step 2 - In diesem Schritt definieren wir die Modellarchitektur -
model = Sequential()
model.add(Conv2D(32, 3, 3, activation = 'relu', input_shape = (28,28,1)))
model.add(Conv2D(32, 3, 3, activation = 'relu'))
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Step 3 - Lassen Sie uns nun das angegebene Modell kompilieren -
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])Step 4 - Wir werden das Modell nun anhand von Trainingsdaten anpassen -
model.fit(X_train, Y_train, batch_size = 32, epochs = 10, verbose = 1)Die Ausgabe der erstellten Iterationen lautet wie folgt:
Epoch 1/10 60000/60000 [==============================] - 65s -
loss: 0.2124 -
acc: 0.9345
Epoch 2/10 60000/60000 [==============================] - 62s -
loss: 0.0893 -
acc: 0.9740
Epoch 3/10 60000/60000 [==============================] - 58s -
loss: 0.0665 -
acc: 0.9802
Epoch 4/10 60000/60000 [==============================] - 62s -
loss: 0.0571 -
acc: 0.9830
Epoch 5/10 60000/60000 [==============================] - 62s -
loss: 0.0474 -
acc: 0.9855
Epoch 6/10 60000/60000 [==============================] - 59s -
loss: 0.0416 -
acc: 0.9871
Epoch 7/10 60000/60000 [==============================] - 61s -
loss: 0.0380 -
acc: 0.9877
Epoch 8/10 60000/60000 [==============================] - 63s -
loss: 0.0333 -
acc: 0.9895
Epoch 9/10 60000/60000 [==============================] - 64s -
loss: 0.0325 -
acc: 0.9898
Epoch 10/10 60000/60000 [==============================] - 60s -
loss: 0.0284 -
acc: 0.9910Dieses Kapitel befasst sich mit den ersten Schritten mit verteiltem TensorFlow. Ziel ist es, Entwicklern zu helfen, die grundlegenden wiederkehrenden verteilten TF-Konzepte wie TF-Server zu verstehen. Wir werden das Jupyter-Notizbuch zur Bewertung des verteilten TensorFlow verwenden. Die Implementierung von Distributed Computing mit TensorFlow wird unten erwähnt -
Step 1 - Importieren Sie die für das verteilte Rechnen erforderlichen Module. -
import tensorflow as tfStep 2- Erstellen Sie einen TensorFlow-Cluster mit einem Knoten. Lassen Sie diesen Knoten für einen Job verantwortlich sein, der den Namen "Arbeiter" hat und der einen Take bei localhost ausführt: 2222.
cluster_spec = tf.train.ClusterSpec({'worker' : ['localhost:2222']})
server = tf.train.Server(cluster_spec)
server.targetDie obigen Skripte erzeugen die folgende Ausgabe:
'grpc://localhost:2222'
The server is currently running.Step 3 - Die Serverkonfiguration mit der jeweiligen Sitzung kann durch Ausführen des folgenden Befehls berechnet werden: -
server.server_defDer obige Befehl generiert die folgende Ausgabe:
cluster {
job {
name: "worker"
tasks {
value: "localhost:2222"
}
}
}
job_name: "worker"
protocol: "grpc"Step 4- Starten Sie eine TensorFlow-Sitzung, wobei die Ausführungsengine der Server ist. Verwenden Sie TensorFlow, um einen lokalen Server zu erstellen und zu verwendenlsof um den Standort des Servers herauszufinden.
sess = tf.Session(target = server.target)
server = tf.train.Server.create_local_server()Step 5 - Zeigen Sie die in dieser Sitzung verfügbaren Geräte an und schließen Sie die entsprechende Sitzung.
devices = sess.list_devices()
for d in devices:
print(d.name)
sess.close()Der obige Befehl generiert die folgende Ausgabe:
/job:worker/replica:0/task:0/device:CPU:0Hier konzentrieren wir uns auf die MetaGraph-Bildung in TensorFlow. Dies wird uns helfen, das Exportmodul in TensorFlow zu verstehen. Der MetaGraph enthält die grundlegenden Informationen, die erforderlich sind, um einen zuvor trainierten Graphen zu trainieren, eine Bewertung durchzuführen oder eine Inferenz durchzuführen.
Es folgt das Code-Snippet für dasselbe -
def export_meta_graph(filename = None, collection_list = None, as_text = False):
"""this code writes `MetaGraphDef` to save_path/filename.
Arguments:
filename: Optional meta_graph filename including the path. collection_list:
List of string keys to collect. as_text: If `True`,
writes the meta_graph as an ASCII proto.
Returns:
A `MetaGraphDef` proto. """Eines der typischen Nutzungsmodelle für dasselbe wird unten erwähnt -
# Build the model ...
with tf.Session() as sess:
# Use the model ...
# Export the model to /tmp/my-model.meta.
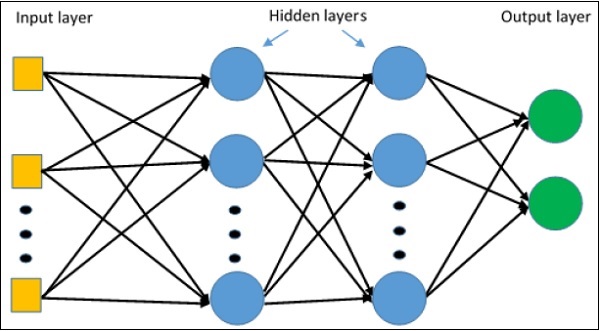
meta_graph_def = tf.train.export_meta_graph(filename = '/tmp/my-model.meta')Multi-Layer-Perzeptron definiert die komplizierteste Architektur künstlicher neuronaler Netze. Es besteht im Wesentlichen aus mehreren Perzeptronschichten.
Die schematische Darstellung des mehrschichtigen Perzeptron-Lernens ist wie folgt:
MLP-Netzwerke werden normalerweise für das überwachte Lernformat verwendet. Ein typischer Lernalgorithmus für MLP-Netzwerke wird auch als Back-Propagation-Algorithmus bezeichnet.
Jetzt konzentrieren wir uns auf die Implementierung mit MLP für ein Bildklassifizierungsproblem.
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.001
training_epochs = 20
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256
# 1st layer num features
n_hidden_2 = 256 # 2nd layer num features
n_input = 784 # MNIST data input (img shape: 28*28) n_classes = 10
# MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
# weights layer 1
h = tf.Variable(tf.random_normal([n_input, n_hidden_1])) # bias layer 1
bias_layer_1 = tf.Variable(tf.random_normal([n_hidden_1]))
# layer 1 layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, h), bias_layer_1))
# weights layer 2
w = tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2]))
# bias layer 2
bias_layer_2 = tf.Variable(tf.random_normal([n_hidden_2]))
# layer 2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, w), bias_layer_2))
# weights output layer
output = tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
# biar output layer
bias_output = tf.Variable(tf.random_normal([n_classes])) # output layer
output_layer = tf.matmul(layer_2, output) + bias_output
# cost function
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = output_layer, labels = y))
#cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(output_layer, y))
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# optimizer = tf.train.GradientDescentOptimizer(
learning_rate = learning_rate).minimize(cost)
# Plot settings
avg_set = []
epoch_set = []
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples / batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss
avg_cost += sess.run(cost, feed_dict = {x: batch_xs, y: batch_ys}) / total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print
Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost)
avg_set.append(avg_cost)
epoch_set.append(epoch + 1)
print
"Training phase finished"
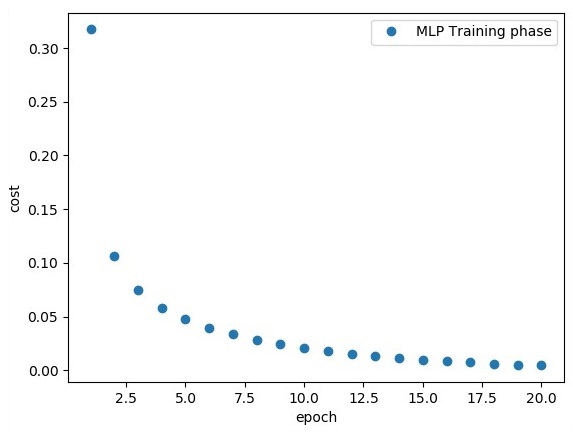
plt.plot(epoch_set, avg_set, 'o', label = 'MLP Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(output_layer, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print
"Model Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels})Die obige Codezeile generiert die folgende Ausgabe:
In diesem Kapitel konzentrieren wir uns auf das Netzwerk, das wir aus bekannten Punkten mit den Namen x und f (x) lernen müssen. Eine einzelne verborgene Schicht wird dieses einfache Netzwerk aufbauen.
Der Code zur Erklärung versteckter Perzeptronschichten lautet wie folgt:
#Importing the necessary modules
import tensorflow as tf
import numpy as np
import math, random
import matplotlib.pyplot as plt
np.random.seed(1000)
function_to_learn = lambda x: np.cos(x) + 0.1*np.random.randn(*x.shape)
layer_1_neurons = 10
NUM_points = 1000
#Training the parameters
batch_size = 100
NUM_EPOCHS = 1500
all_x = np.float32(np.random.uniform(-2*math.pi, 2*math.pi, (1, NUM_points))).T
np.random.shuffle(all_x)
train_size = int(900)
#Training the first 700 points in the given set x_training = all_x[:train_size]
y_training = function_to_learn(x_training)
#Training the last 300 points in the given set x_validation = all_x[train_size:]
y_validation = function_to_learn(x_validation)
plt.figure(1)
plt.scatter(x_training, y_training, c = 'blue', label = 'train')
plt.scatter(x_validation, y_validation, c = 'pink', label = 'validation')
plt.legend()
plt.show()
X = tf.placeholder(tf.float32, [None, 1], name = "X")
Y = tf.placeholder(tf.float32, [None, 1], name = "Y")
#first layer
#Number of neurons = 10
w_h = tf.Variable(
tf.random_uniform([1, layer_1_neurons],\ minval = -1, maxval = 1, dtype = tf.float32))
b_h = tf.Variable(tf.zeros([1, layer_1_neurons], dtype = tf.float32))
h = tf.nn.sigmoid(tf.matmul(X, w_h) + b_h)
#output layer
#Number of neurons = 10
w_o = tf.Variable(
tf.random_uniform([layer_1_neurons, 1],\ minval = -1, maxval = 1, dtype = tf.float32))
b_o = tf.Variable(tf.zeros([1, 1], dtype = tf.float32))
#build the model
model = tf.matmul(h, w_o) + b_o
#minimize the cost function (model - Y)
train_op = tf.train.AdamOptimizer().minimize(tf.nn.l2_loss(model - Y))
#Start the Learning phase
sess = tf.Session() sess.run(tf.initialize_all_variables())
errors = []
for i in range(NUM_EPOCHS):
for start, end in zip(range(0, len(x_training), batch_size),\
range(batch_size, len(x_training), batch_size)):
sess.run(train_op, feed_dict = {X: x_training[start:end],\ Y: y_training[start:end]})
cost = sess.run(tf.nn.l2_loss(model - y_validation),\ feed_dict = {X:x_validation})
errors.append(cost)
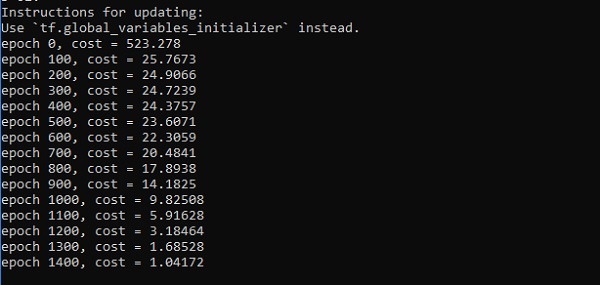
if i%100 == 0:
print("epoch %d, cost = %g" % (i, cost))
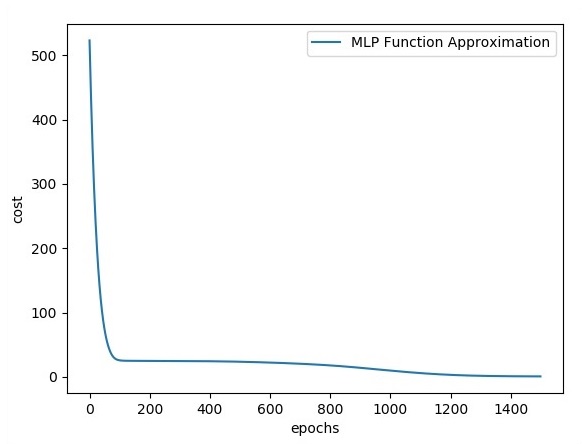
plt.plot(errors,label='MLP Function Approximation') plt.xlabel('epochs')
plt.ylabel('cost')
plt.legend()
plt.show()Ausgabe
Es folgt die Darstellung der Funktionsschichtnäherung -
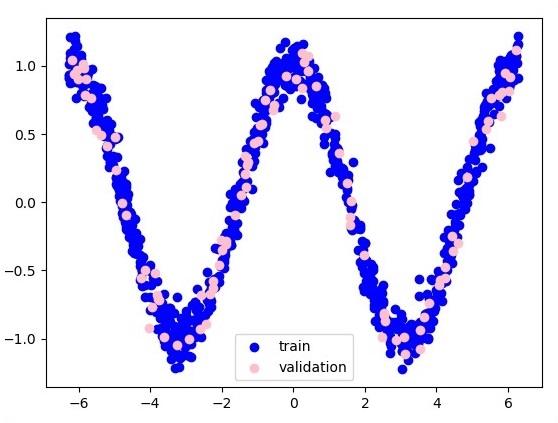
Hier werden zwei Daten in Form von W dargestellt. Die beiden Daten sind: Zug und Validierung, die in unterschiedlichen Farben dargestellt werden, wie im Legendenabschnitt sichtbar.
Optimierer sind die erweiterte Klasse, die zusätzliche Informationen zum Trainieren eines bestimmten Modells enthält. Die Optimierungsklasse wird mit bestimmten Parametern initialisiert, es ist jedoch wichtig zu beachten, dass kein Tensor benötigt wird. Die Optimierer werden zur Verbesserung der Geschwindigkeit und Leistung beim Training eines bestimmten Modells verwendet.
Der grundlegende Optimierer von TensorFlow ist -
tf.train.OptimizerDiese Klasse wird im angegebenen Pfad von tensorflow / python / training / optimizer.py definiert.
Im Folgenden finden Sie einige Optimierer in Tensorflow -
- Stochastischer Gradientenabstieg
- Stochastischer Gradientenabstieg mit Gradientenschnitt
- Momentum
- Nesterov Schwung
- Adagrad
- Adadelta
- RMSProp
- Adam
- Adamax
- SMORMS3
Wir werden uns auf den stochastischen Gradientenabstieg konzentrieren. Die Abbildung zum Erstellen eines Optimierers für dasselbe ist unten aufgeführt -
def sgd(cost, params, lr = np.float32(0.01)):
g_params = tf.gradients(cost, params)
updates = []
for param, g_param in zip(params, g_params):
updates.append(param.assign(param - lr*g_param))
return updatesDie Grundparameter werden innerhalb der jeweiligen Funktion definiert. In unserem folgenden Kapitel konzentrieren wir uns auf die Optimierung des Gradientenabfalls mit der Implementierung von Optimierern.
In diesem Kapitel erfahren Sie mehr über die XOR-Implementierung mit TensorFlow. Bevor Sie mit der XOR-Implementierung in TensorFlow beginnen, sehen wir uns die XOR-Tabellenwerte an. Dies wird uns helfen, den Ver- und Entschlüsselungsprozess zu verstehen.
| EIN | B. | EIN XOR B. |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Die XOR-Verschlüsselungsmethode wird im Wesentlichen zum Verschlüsseln von Daten verwendet, die mit der Brute-Force-Methode nur schwer zu knacken sind, dh durch Generieren zufälliger Verschlüsselungsschlüssel, die mit dem entsprechenden Schlüssel übereinstimmen.
Das Konzept der Implementierung mit XOR Cipher besteht darin, einen XOR-Verschlüsselungsschlüssel zu definieren und dann mit diesem Schlüssel eine XOR-Operation der Zeichen in der angegebenen Zeichenfolge durchzuführen, die ein Benutzer zu verschlüsseln versucht. Jetzt konzentrieren wir uns auf die XOR-Implementierung mit TensorFlow, die unten erwähnt wird -
#Declaring necessary modules
import tensorflow as tf
import numpy as np
"""
A simple numpy implementation of a XOR gate to understand the backpropagation
algorithm
"""
x = tf.placeholder(tf.float64,shape = [4,2],name = "x")
#declaring a place holder for input x
y = tf.placeholder(tf.float64,shape = [4,1],name = "y")
#declaring a place holder for desired output y
m = np.shape(x)[0]#number of training examples
n = np.shape(x)[1]#number of features
hidden_s = 2 #number of nodes in the hidden layer
l_r = 1#learning rate initialization
theta1 = tf.cast(tf.Variable(tf.random_normal([3,hidden_s]),name = "theta1"),tf.float64)
theta2 = tf.cast(tf.Variable(tf.random_normal([hidden_s+1,1]),name = "theta2"),tf.float64)
#conducting forward propagation
a1 = tf.concat([np.c_[np.ones(x.shape[0])],x],1)
#the weights of the first layer are multiplied by the input of the first layer
z1 = tf.matmul(a1,theta1)
#the input of the second layer is the output of the first layer, passed through the
activation function and column of biases is added
a2 = tf.concat([np.c_[np.ones(x.shape[0])],tf.sigmoid(z1)],1)
#the input of the second layer is multiplied by the weights
z3 = tf.matmul(a2,theta2)
#the output is passed through the activation function to obtain the final probability
h3 = tf.sigmoid(z3)
cost_func = -tf.reduce_sum(y*tf.log(h3)+(1-y)*tf.log(1-h3),axis = 1)
#built in tensorflow optimizer that conducts gradient descent using specified
learning rate to obtain theta values
optimiser = tf.train.GradientDescentOptimizer(learning_rate = l_r).minimize(cost_func)
#setting required X and Y values to perform XOR operation
X = [[0,0],[0,1],[1,0],[1,1]]
Y = [[0],[1],[1],[0]]
#initializing all variables, creating a session and running a tensorflow session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
#running gradient descent for each iteration and printing the hypothesis
obtained using the updated theta values
for i in range(100000):
sess.run(optimiser, feed_dict = {x:X,y:Y})#setting place holder values using feed_dict
if i%100==0:
print("Epoch:",i)
print("Hyp:",sess.run(h3,feed_dict = {x:X,y:Y}))Die obige Codezeile generiert eine Ausgabe wie im folgenden Screenshot gezeigt -
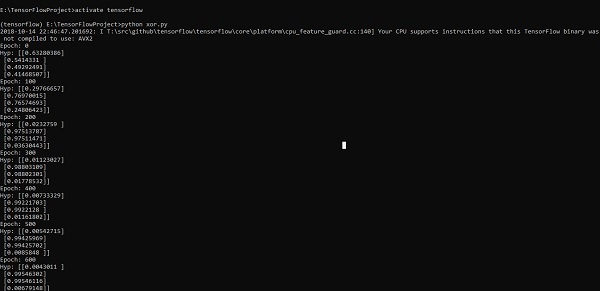
Die Optimierung des Gradientenabstiegs wird als wichtiges Konzept in der Datenwissenschaft angesehen.
Betrachten Sie die unten gezeigten Schritte, um die Implementierung der Gradientenabstiegsoptimierung zu verstehen.
Schritt 1
Fügen Sie die erforderlichen Module und die Deklaration von x- und y-Variablen hinzu, mit denen wir die Optimierung des Gradientenabfalls definieren.
import tensorflow as tf
x = tf.Variable(2, name = 'x', dtype = tf.float32)
log_x = tf.log(x)
log_x_squared = tf.square(log_x)
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(log_x_squared)Schritt 2
Initialisieren Sie die erforderlichen Variablen und rufen Sie die Optimierer auf, um sie mit der entsprechenden Funktion zu definieren und aufzurufen.
init = tf.initialize_all_variables()
def optimize():
with tf.Session() as session:
session.run(init)
print("starting at", "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
for step in range(10):
session.run(train)
print("step", step, "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
optimize()Die obige Codezeile generiert eine Ausgabe wie im folgenden Screenshot gezeigt -
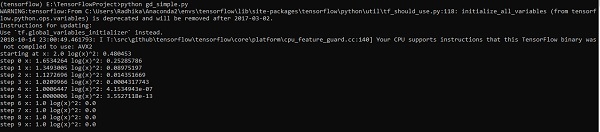
Wir können sehen, dass die erforderlichen Epochen und Iterationen wie in der Ausgabe gezeigt berechnet werden.
Eine partielle Differentialgleichung (PDE) ist eine Differentialgleichung, die partielle Ableitungen mit unbekannter Funktion mehrerer unabhängiger Variablen beinhaltet. In Bezug auf partielle Differentialgleichungen konzentrieren wir uns auf die Erstellung neuer Diagramme.
Nehmen wir an, es gibt einen Teich mit der Größe 500 * 500 Quadrat -
N = 500
Nun werden wir die partielle Differentialgleichung berechnen und daraus den jeweiligen Graphen bilden. Beachten Sie die unten angegebenen Schritte zur Berechnung des Diagramms.
Step 1 - Importieren Sie Bibliotheken für die Simulation.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltStep 2 - Fügen Sie Funktionen zur Transformation eines 2D-Arrays in einen Faltungskern und eine vereinfachte 2D-Faltungsoperation hinzu.
def make_kernel(a):
a = np.asarray(a)
a = a.reshape(list(a.shape) + [1,1])
return tf.constant(a, dtype=1)
def simple_conv(x, k):
"""A simplified 2D convolution operation"""
x = tf.expand_dims(tf.expand_dims(x, 0), -1)
y = tf.nn.depthwise_conv2d(x, k, [1, 1, 1, 1], padding = 'SAME')
return y[0, :, :, 0]
def laplace(x):
"""Compute the 2D laplacian of an array"""
laplace_k = make_kernel([[0.5, 1.0, 0.5], [1.0, -6., 1.0], [0.5, 1.0, 0.5]])
return simple_conv(x, laplace_k)
sess = tf.InteractiveSession()Step 3 - Geben Sie die Anzahl der Iterationen an und berechnen Sie das Diagramm, um die Datensätze entsprechend anzuzeigen.
N = 500
# Initial Conditions -- some rain drops hit a pond
# Set everything to zero
u_init = np.zeros([N, N], dtype = np.float32)
ut_init = np.zeros([N, N], dtype = np.float32)
# Some rain drops hit a pond at random points
for n in range(100):
a,b = np.random.randint(0, N, 2)
u_init[a,b] = np.random.uniform()
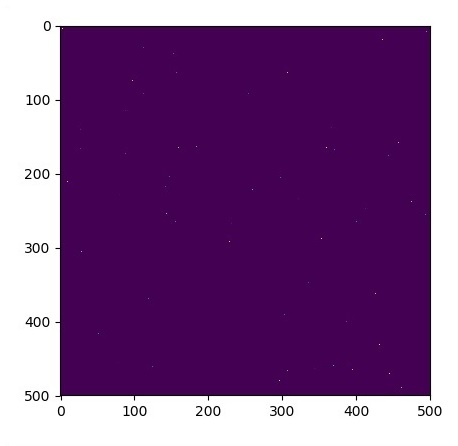
plt.imshow(u_init)
plt.show()
# Parameters:
# eps -- time resolution
# damping -- wave damping
eps = tf.placeholder(tf.float32, shape = ())
damping = tf.placeholder(tf.float32, shape = ())
# Create variables for simulation state
U = tf.Variable(u_init)
Ut = tf.Variable(ut_init)
# Discretized PDE update rules
U_ = U + eps * Ut
Ut_ = Ut + eps * (laplace(U) - damping * Ut)
# Operation to update the state
step = tf.group(U.assign(U_), Ut.assign(Ut_))
# Initialize state to initial conditions
tf.initialize_all_variables().run()
# Run 1000 steps of PDE
for i in range(1000):
# Step simulation
step.run({eps: 0.03, damping: 0.04})
# Visualize every 50 steps
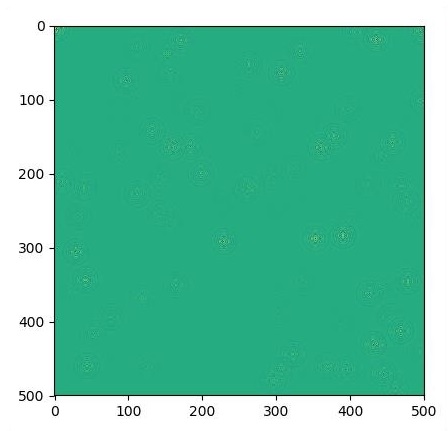
if i % 500 == 0:
plt.imshow(U.eval())
plt.show()Die Grafiken sind wie folgt dargestellt:
TensorFlow enthält eine spezielle Funktion zur Bilderkennung. Diese Bilder werden in einem bestimmten Ordner gespeichert. Mit relativ gleichen Bildern ist es aus Sicherheitsgründen einfach, diese Logik zu implementieren.
Die Ordnerstruktur der Implementierung des Bilderkennungscodes ist wie folgt:
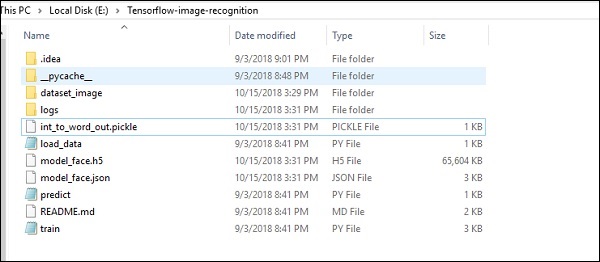
Das Dataset-Bild enthält die zugehörigen Bilder, die geladen werden müssen. Wir konzentrieren uns auf die Bilderkennung mit unserem darin definierten Logo. Die Bilder werden mit dem Skript "load_data.py" geladen, mit dessen Hilfe Sie verschiedene Bilderkennungsmodule in ihnen notieren können.
import pickle
from sklearn.model_selection import train_test_split
from scipy import misc
import numpy as np
import os
label = os.listdir("dataset_image")
label = label[1:]
dataset = []
for image_label in label:
images = os.listdir("dataset_image/"+image_label)
for image in images:
img = misc.imread("dataset_image/"+image_label+"/"+image)
img = misc.imresize(img, (64, 64))
dataset.append((img,image_label))
X = []
Y = []
for input,image_label in dataset:
X.append(input)
Y.append(label.index(image_label))
X = np.array(X)
Y = np.array(Y)
X_train,y_train, = X,Y
data_set = (X_train,y_train)
save_label = open("int_to_word_out.pickle","wb")
pickle.dump(label, save_label)
save_label.close()Das Training von Bildern hilft beim Speichern der erkennbaren Muster in einem bestimmten Ordner.
import numpy
import matplotlib.pyplot as plt
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import SGD
from keras.layers import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
import load_data
from keras.models import Sequential
from keras.layers import Dense
import keras
K.set_image_dim_ordering('tf')
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train,y_train) = load_data.data_set
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
#X_test = X_test.astype('float32')
X_train = X_train / 255.0
#X_test = X_test / 255.0
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
#y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), padding = 'same',
activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation = 'relu', padding = 'same',
kernel_constraint = maxnorm(3)))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Flatten())
model.add(Dense(512, activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation = 'softmax'))
# Compile model
epochs = 10
lrate = 0.01
decay = lrate/epochs
sgd = SGD(lr = lrate, momentum = 0.9, decay = decay, nesterov = False)
model.compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = ['accuracy'])
print(model.summary())
#callbacks = [keras.callbacks.EarlyStopping(
monitor = 'val_loss', min_delta = 0, patience = 0, verbose = 0, mode = 'auto')]
callbacks = [keras.callbacks.TensorBoard(log_dir='./logs',
histogram_freq = 0, batch_size = 32, write_graph = True, write_grads = False,
write_images = True, embeddings_freq = 0, embeddings_layer_names = None,
embeddings_metadata = None)]
# Fit the model
model.fit(X_train, y_train, epochs = epochs,
batch_size = 32,shuffle = True,callbacks = callbacks)
# Final evaluation of the model
scores = model.evaluate(X_train, y_train, verbose = 0)
print("Accuracy: %.2f%%" % (scores[1]*100))
# serialize model to JSONx
model_json = model.to_json()
with open("model_face.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model_face.h5")
print("Saved model to disk")Die obige Codezeile generiert eine Ausgabe wie unten gezeigt -
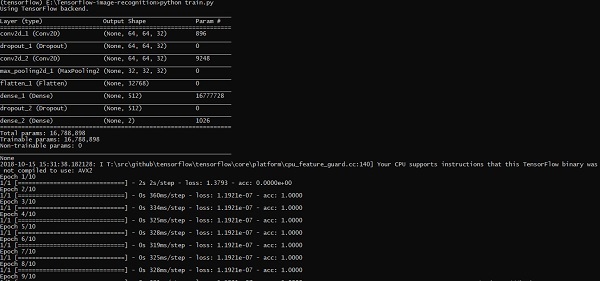
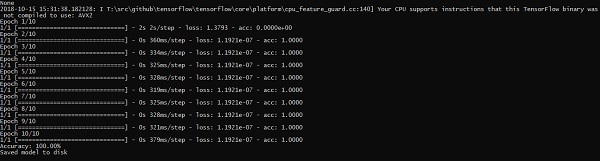
In diesem Kapitel werden wir die verschiedenen Aspekte des neuronalen Netzwerktrainings verstehen, die mit dem TensorFlow-Framework implementiert werden können.
Es folgen die zehn Empfehlungen, die bewertet werden können:
Rückenausbreitung
Die Rückausbreitung ist eine einfache Methode zur Berechnung partieller Ableitungen, die die Grundform der Zusammensetzung enthält, die für neuronale Netze am besten geeignet ist.
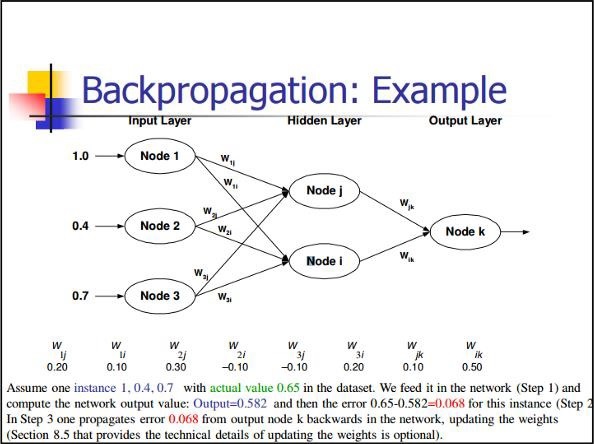
Stochastischer Gradientenabstieg
Bei stochastischem Gefälle, a batchist die Gesamtzahl der Beispiele, anhand derer ein Benutzer den Gradienten in einer einzelnen Iteration berechnet. Bisher wird davon ausgegangen, dass der Stapel der gesamte Datensatz war. Die beste Illustration ist die Arbeit im Google-Maßstab. Datensätze enthalten oft Milliarden oder sogar Hunderte von Milliarden von Beispielen.
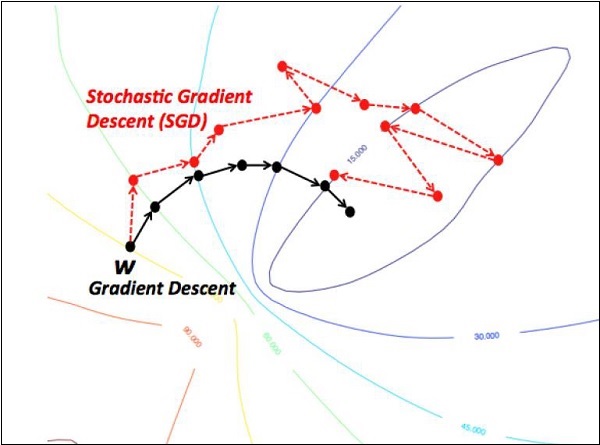
Lernratenabfall
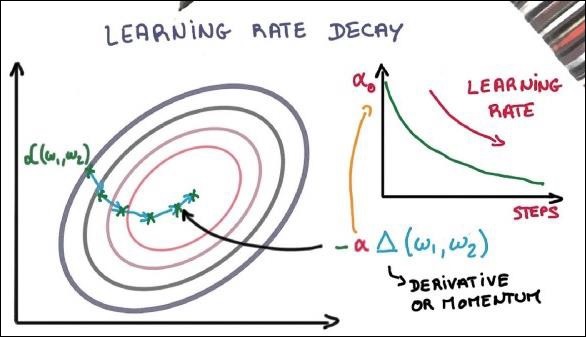
Die Anpassung der Lernrate ist eines der wichtigsten Merkmale der Optimierung des Gradientenabstiegs. Dies ist für die Implementierung von TensorFlow von entscheidender Bedeutung.
Aussteigen
Tiefe neuronale Netze mit einer Vielzahl von Parametern bilden leistungsfähige maschinelle Lernsysteme. Eine Überanpassung ist jedoch in solchen Netzwerken ein ernstes Problem.

Max Pooling
Max Pooling ist ein stichprobenbasierter Diskretisierungsprozess. Das Ziel besteht darin, eine Eingabedarstellung herunterzusampeln, wodurch die Dimensionalität mit den erforderlichen Annahmen reduziert wird.

Langzeit-Kurzzeitgedächtnis (LSTM)
LSTM steuert die Entscheidung darüber, welche Eingaben innerhalb des angegebenen Neurons vorgenommen werden sollen. Es enthält die Kontrolle darüber, was berechnet und welche Ausgabe generiert werden soll.