PyBrain - Types de jeux de données
Les jeux de données sont des données à fournir pour tester, valider et former sur les réseaux. Le type d'ensemble de données à utiliser dépend des tâches que nous allons effectuer avec l'apprentissage automatique. Nous allons discuter des différents types de jeux de données dans ce chapitre.
Nous pouvons travailler avec l'ensemble de données en ajoutant le package suivant -
pybrain.datasetSupervisedDataSet
SupervisedDataSet se compose de champs de input et target. C'est la forme la plus simple d'un ensemble de données et elle est principalement utilisée pour les tâches d'apprentissage supervisé.
Voici comment vous pouvez l'utiliser dans le code -
from pybrain.datasets import SupervisedDataSetLes méthodes disponibles sur SupervisedDataSet sont les suivantes -
addSample (entrée, cible)
Cette méthode ajoutera un nouvel échantillon d'entrée et de cible.
splitWithProportion (proportion = 0,10)
Cela divisera les ensembles de données en deux parties. La première partie aura le% de l'ensemble de données donné en entrée, c'est-à-dire que si l'entrée est de 0,10, alors c'est 10% de l'ensemble de données et 90% des données. Vous pouvez décider de la proportion selon votre choix. Les ensembles de données divisés peuvent être utilisés pour tester et former votre réseau.
copy() - Renvoie une copie complète de l'ensemble de données.
clear() - Effacez l'ensemble de données.
saveToFile (nom de fichier, format = Aucun, ** kwargs)
Enregistrez l'objet dans un fichier donné par nom de fichier.
Exemple
Voici un exemple de travail utilisant un SupervisedDataset -
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
norgate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))
# Add input and target values to dataset
# Values for NOR truth table
nortrain.addSample((0, 0), (1,))
nortrain.addSample((0, 1), (0,))
nortrain.addSample((1, 0), (0,))
nortrain.addSample((1, 1), (0,))
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=nortrain, verbose = True)Production
La sortie pour le programme ci-dessus est la suivante -
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)ClassificationDataSet
Cet ensemble de données est principalement utilisé pour traiter les problèmes de classification. Il prend en entrée, le champ cible et également un champ supplémentaire appelé "classe" qui est une sauvegarde automatique des cibles données. Par exemple, la sortie sera 1 ou 0 ou la sortie sera regroupée avec des valeurs basées sur l'entrée donnée, c'est-à-dire qu'elle appartiendra à une classe particulière.
Voici comment vous pouvez l'utiliser dans le code -
from pybrain.datasets import ClassificationDataSet
Syntax
// ClassificationDataSet(inp, target=1, nb_classes=0, class_labels=None)Les méthodes disponibles sur ClassificationDataSet sont les suivantes -
addSample(inp, target) - Cette méthode ajoutera un nouvel échantillon d'entrée et de cible.
splitByClass() - Cette méthode donnera deux nouveaux jeux de données, le premier jeu de données aura la classe sélectionnée (0..nClasses-1), le second aura des échantillons restants.
_convertToOneOfMany() - Cette méthode convertira les classes cibles en une représentation 1 sur k, en conservant les anciennes cibles en tant que classe de champ
Voici un exemple de travail de ClassificationDataSet.
Exemple
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample( training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1] )
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(trainer.testOnClassData(dataset=test_data), test_data['class']))L'ensemble de données utilisé dans l'exemple ci-dessus est un ensemble de données numériques et les classes sont comprises entre 0 et 9, il y a donc 10 classes. L'entrée est 64, la cible est 1 et les classes, 10.
Le code entraîne le réseau avec l'ensemble de données et génère le graphique pour l'erreur d'apprentissage et l'erreur de validation. Il donne également le pourcentage d'erreur sur les données de test qui est le suivant -
Production
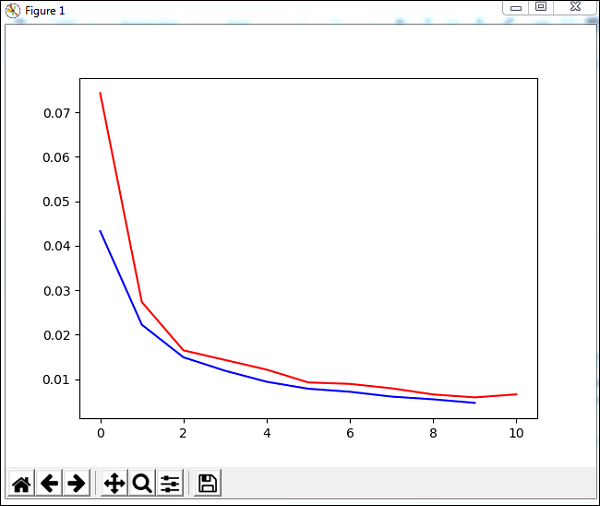
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735