PyBrain - Présentation
Pybrain est une bibliothèque open-source pour le Machine Learning implémentée à l'aide de python. La bibliothèque vous propose des algorithmes de formation faciles à utiliser pour les réseaux, les ensembles de données, les formateurs pour former et tester le réseau.
La définition de Pybrain telle que présentée par sa documentation officielle est la suivante -
PyBrain est une bibliothèque modulaire d'apprentissage automatique pour Python. Son objectif est de proposer des algorithmes flexibles, faciles à utiliser mais toujours puissants pour les tâches d'apprentissage automatique et une variété d'environnements prédéfinis pour tester et comparer vos algorithmes.
PyBrain est l'abréviation de Python-based Reinforcement Learning, Artificial Intelligence et Neural Network Library. En fait, nous avons trouvé le nom en premier et plus tard, nous avons procédé à une ingénierie inverse de ce "Backronym" assez descriptif.
Caractéristiques de Pybrain
Voici les caractéristiques de Pybrain -
Réseaux
Un réseau est composé de modules et ils sont connectés à l'aide de connexions. Pybrain prend en charge les réseaux de neurones tels que le réseau Feed-Forward, le réseau récurrent, etc.
feed-forward networkest un réseau neuronal, où les informations entre les nœuds se déplacent vers l'avant et ne voyageront jamais vers l'arrière. Le réseau Feed Forward est le premier et le plus simple parmi les réseaux disponibles dans le réseau de neurones artificiels.
Les informations sont transmises à partir des nœuds d'entrée, à côté des nœuds masqués et plus tard au nœud de sortie.
Recurrent Networkssont similaires à Feed Forward Network; la seule différence est qu'il doit se souvenir des données à chaque étape. L'historique de chaque étape doit être sauvegardé.
Ensembles de données
Les jeux de données sont les données à fournir pour tester, valider et former sur les réseaux. Le type de jeu de données à utiliser dépend des tâches que nous allons effectuer avec le Machine Learning. Les ensembles de données les plus couramment utilisés pris en charge par Pybrain sontSupervisedDataSet et ClassificationDataSet.
SupervisedDataSet - Il se compose de champs de input et target. Il s'agit de la forme la plus simple d'un ensemble de données et est principalement utilisé pour les tâches d'apprentissage supervisé.
ClassificationDataSet- Il est principalement utilisé pour traiter les problèmes de classification. Il prend eninput, targetchamp et également un champ supplémentaire appelé "classe" qui est une sauvegarde automatique des cibles données. Par exemple, la sortie sera 1 ou 0 ou la sortie sera regroupée avec des valeurs basées sur l'entrée donnée, c'est-à-dire qu'elle tombera dans une classe particulière.
Entraîneur
Lorsque nous créons un réseau, c'est-à-dire un réseau de neurones, il sera formé en fonction des données d'apprentissage qui lui sont données. Le fait que le réseau soit correctement formé ou non dépendra désormais de la prédiction des données de test testées sur ce réseau. Le concept le plus important dans Pybrain Training est l'utilisation de BackpropTrainer et TrainUntilConvergence.
BackpropTrainer - C'est un formateur qui forme les paramètres d'un module selon un jeu de données supervisé ou ClassificationDataSet (potentiellement séquentiel) en rétropropropageant les erreurs (dans le temps).
TrainUntilConvergence −Il est utilisé pour entraîner le module sur l'ensemble de données jusqu'à ce qu'il converge.
Outils
Pybrain propose des modules d'outils qui peuvent aider à construire un réseau en important des packages: pybrain.tools.shortcuts.buildNetwork
Visualisation
Les données de test ne peuvent pas être visualisées à l'aide de pybrain. Mais Pybrain peut travailler avec d'autres frameworks comme Mathplotlib, pyplot pour visualiser les données.
Avantages de Pybrain
Les avantages de Pybrain sont -
Pybrain est une bibliothèque gratuite open source pour apprendre le Machine Learning. C'est un bon début pour tout nouveau venu intéressé par l'apprentissage automatique.
Pybrain utilise python pour l'implémenter et cela le rend rapide dans le développement par rapport à des langages comme Java / C ++.
Pybrain fonctionne facilement avec d'autres bibliothèques de python pour visualiser les données.
Pybrain offre un support pour les réseaux populaires tels que le réseau Feed-Forward, les réseaux récurrents, les réseaux de neurones, etc.
Travailler avec .csv pour charger des ensembles de données est très facile dans Pybrain. Il permet également d'utiliser des ensembles de données d'une autre bibliothèque.
La formation et le test des données sont faciles à l'aide des entraîneurs Pybrain.
Limitations de Pybrain
Pybrain offre moins d'aide pour les problèmes rencontrés. Il y a des questions sans réponse surstackoverflow et sur Google Group.
Flux de travail de Pybrain
Selon la documentation Pybrain, le flux de l'apprentissage automatique est illustré dans la figure suivante -
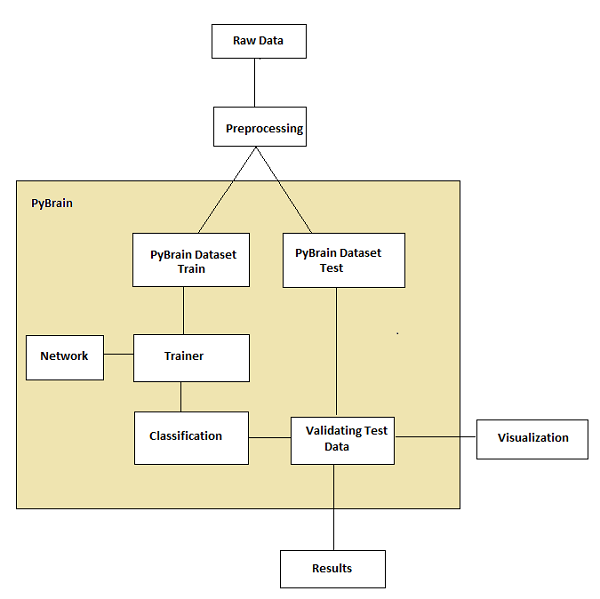
Au départ, nous avons des données brutes qui, après prétraitement, peuvent être utilisées avec Pybrain.
Le flux de Pybrain commence avec des ensembles de données qui sont divisés en données entraînées et de test.
le réseau est créé et le jeu de données et le réseau sont remis au formateur.
le formateur forme les données sur le réseau et classe les sorties comme erreur entraînée et erreur de validation qui peuvent être visualisées.
les données testées peuvent être validées pour voir si la sortie correspond aux données entraînées.
Terminologie
Il y a des termes importants à prendre en compte lors de l'utilisation de Pybrain pour l'apprentissage automatique. Ils sont les suivants -
Total Error- Il fait référence à l'erreur affichée après la formation du réseau. Si l'erreur continue de changer à chaque itération, cela signifie qu'elle a encore besoin de temps pour se régler, jusqu'à ce qu'elle commence à afficher une erreur constante entre les itérations. Une fois qu'il commence à afficher les nombres d'erreur constants, cela signifie que le réseau a convergé et restera le même indépendamment de toute formation supplémentaire appliquée.
Trained data - Ce sont les données utilisées pour entraîner le réseau Pybrain.
Testing data - Ce sont les données utilisées pour tester le réseau Pybrain entraîné.
Trainer- Lorsque nous créons un réseau, c'est-à-dire un réseau de neurones, il sera formé en fonction des données d'apprentissage qui lui sont données. Maintenant, que le réseau soit correctement formé ou non dépendra de la prédiction des données de test testées sur ce réseau. Le concept le plus important dans Pybrain Training est l'utilisation de BackpropTrainer et TrainUntilConvergence.
BackpropTrainer - C'est un formateur qui forme les paramètres d'un module selon un jeu de données supervisé ou ClassificationDataSet (potentiellement séquentiel) en rétropropropageant les erreurs (dans le temps).
TrainUntilConvergence - Il est utilisé pour entraîner le module sur l'ensemble de données jusqu'à ce qu'il converge.
Layers - Les couches sont essentiellement un ensemble de fonctions utilisées sur les couches cachées d'un réseau.
Connections- Une connexion fonctionne comme une couche; une seule différence est qu'il déplace les données d'un nœud à l'autre dans un réseau.
Modules - Les modules sont des réseaux composés de tampons d'entrée et de sortie.
Supervised Learning- Dans ce cas, nous avons une entrée et une sortie, et nous pouvons utiliser un algorithme pour mapper l'entrée avec la sortie. L'algorithme est fait pour apprendre sur les données d'apprentissage données et itérées dessus et le processus d'itération s'arrête lorsque l'algorithme prédit les données correctes.
Unsupervised- Dans ce cas, nous avons une entrée mais ne connaissons pas la sortie. Le rôle de l'apprentissage non supervisé est de se former autant que possible avec les données fournies.