PyBrain - Guide rapide
Pybrain est une bibliothèque open-source pour le Machine Learning implémentée à l'aide de python. La bibliothèque vous propose des algorithmes de formation faciles à utiliser pour les réseaux, les ensembles de données, les formateurs pour former et tester le réseau.
La définition de Pybrain telle que présentée par sa documentation officielle est la suivante -
PyBrain est une bibliothèque modulaire d'apprentissage automatique pour Python. Son objectif est de proposer des algorithmes flexibles, faciles à utiliser mais toujours puissants pour les tâches d'apprentissage automatique et une variété d'environnements prédéfinis pour tester et comparer vos algorithmes.
PyBrain est l'abréviation de Python-based Reinforcement Learning, Artificial Intelligence et Neural Network Library. En fait, nous avons trouvé le nom en premier et plus tard, nous avons procédé à une ingénierie inverse de ce "Backronym" assez descriptif.
Caractéristiques de Pybrain
Voici les caractéristiques de Pybrain -
Réseaux
Un réseau est composé de modules et ils sont connectés à l'aide de connexions. Pybrain prend en charge les réseaux de neurones tels que le réseau Feed-Forward, le réseau récurrent, etc.
feed-forward networkest un réseau neuronal, où les informations entre les nœuds se déplacent vers l'avant et ne voyageront jamais vers l'arrière. Le réseau Feed Forward est le premier et le plus simple parmi les réseaux disponibles dans le réseau de neurones artificiels.
Les informations sont transmises à partir des nœuds d'entrée, à côté des nœuds masqués et plus tard au nœud de sortie.
Recurrent Networkssont similaires à Feed Forward Network; la seule différence est qu'il doit se souvenir des données à chaque étape. L'historique de chaque étape doit être sauvegardé.
Ensembles de données
Les jeux de données sont les données à fournir pour tester, valider et former sur les réseaux. Le type de jeu de données à utiliser dépend des tâches que nous allons effectuer avec le Machine Learning. Les ensembles de données les plus couramment utilisés pris en charge par Pybrain sontSupervisedDataSet et ClassificationDataSet.
SupervisedDataSet - Il se compose de champs de input et target. Il s'agit de la forme la plus simple d'un ensemble de données et est principalement utilisé pour les tâches d'apprentissage supervisé.
ClassificationDataSet- Il est principalement utilisé pour traiter les problèmes de classification. Il prend eninput, targetchamp et également un champ supplémentaire appelé "classe" qui est une sauvegarde automatique des cibles données. Par exemple, la sortie sera 1 ou 0 ou la sortie sera regroupée avec des valeurs basées sur l'entrée donnée, c'est-à-dire qu'elle tombera dans une classe particulière.
Entraîneur
Lorsque nous créons un réseau, c'est-à-dire un réseau de neurones, il sera formé en fonction des données d'apprentissage qui lui sont données. Le fait que le réseau soit correctement formé ou non dépendra désormais de la prédiction des données de test testées sur ce réseau. Le concept le plus important dans Pybrain Training est l'utilisation de BackpropTrainer et TrainUntilConvergence.
BackpropTrainer - C'est un formateur qui forme les paramètres d'un module selon un jeu de données supervisé ou ClassificationDataSet (potentiellement séquentiel) en rétropropropageant les erreurs (dans le temps).
TrainUntilConvergence −Il est utilisé pour entraîner le module sur l'ensemble de données jusqu'à ce qu'il converge.
Outils
Pybrain propose des modules d'outils qui peuvent aider à construire un réseau en important des packages: pybrain.tools.shortcuts.buildNetwork
Visualisation
Les données de test ne peuvent pas être visualisées à l'aide de pybrain. Mais Pybrain peut travailler avec d'autres frameworks comme Mathplotlib, pyplot pour visualiser les données.
Avantages de Pybrain
Les avantages de Pybrain sont -
Pybrain est une bibliothèque gratuite open source pour apprendre le Machine Learning. C'est un bon début pour tout nouveau venu intéressé par l'apprentissage automatique.
Pybrain utilise python pour l'implémenter et cela le rend rapide dans le développement par rapport à des langages comme Java / C ++.
Pybrain fonctionne facilement avec d'autres bibliothèques de python pour visualiser les données.
Pybrain offre un support pour les réseaux populaires tels que le réseau Feed-Forward, les réseaux récurrents, les réseaux de neurones, etc.
Travailler avec .csv pour charger des ensembles de données est très facile dans Pybrain. Il permet également d'utiliser des ensembles de données d'une autre bibliothèque.
La formation et le test des données sont faciles à l'aide des entraîneurs Pybrain.
Limitations de Pybrain
Pybrain offre moins d'aide pour les problèmes rencontrés. Il y a des questions sans réponse surstackoverflow et sur Google Group.
Flux de travail de Pybrain
Selon la documentation Pybrain, le flux de l'apprentissage automatique est illustré dans la figure suivante -
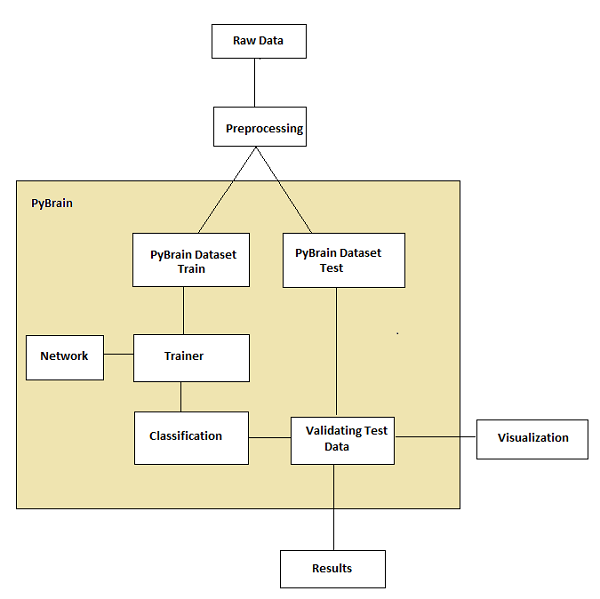
Au départ, nous avons des données brutes qui, après prétraitement, peuvent être utilisées avec Pybrain.
Le flux de Pybrain commence avec des ensembles de données qui sont divisés en données entraînées et de test.
le réseau est créé et le jeu de données et le réseau sont remis au formateur.
le formateur forme les données sur le réseau et classe les sorties comme erreur entraînée et erreur de validation qui peuvent être visualisées.
les données testées peuvent être validées pour voir si la sortie correspond aux données entraînées.
Terminologie
Il y a des termes importants à prendre en compte lors de l'utilisation de Pybrain pour l'apprentissage automatique. Ils sont les suivants -
Total Error- Il fait référence à l'erreur affichée après la formation du réseau. Si l'erreur continue de changer à chaque itération, cela signifie qu'elle a encore besoin de temps pour se régler, jusqu'à ce qu'elle commence à afficher une erreur constante entre les itérations. Une fois qu'il commence à afficher les nombres d'erreur constants, cela signifie que le réseau a convergé et restera le même indépendamment de toute formation supplémentaire appliquée.
Trained data - Ce sont les données utilisées pour entraîner le réseau Pybrain.
Testing data - Ce sont les données utilisées pour tester le réseau Pybrain entraîné.
Trainer- Lorsque nous créons un réseau, c'est-à-dire un réseau de neurones, il sera formé en fonction des données d'apprentissage qui lui sont données. Le fait que le réseau soit correctement formé ou non dépendra désormais de la prédiction des données de test testées sur ce réseau. Le concept le plus important dans Pybrain Training est l'utilisation de BackpropTrainer et TrainUntilConvergence.
BackpropTrainer - C'est un formateur qui forme les paramètres d'un module selon un jeu de données supervisé ou ClassificationDataSet (potentiellement séquentiel) en rétropropropageant les erreurs (dans le temps).
TrainUntilConvergence - Il est utilisé pour entraîner le module sur l'ensemble de données jusqu'à ce qu'il converge.
Layers - Les couches sont essentiellement un ensemble de fonctions utilisées sur les couches cachées d'un réseau.
Connections- Une connexion fonctionne comme une couche; une seule différence est qu'il déplace les données d'un nœud à l'autre dans un réseau.
Modules - Les modules sont des réseaux composés de tampons d'entrée et de sortie.
Supervised Learning- Dans ce cas, nous avons une entrée et une sortie, et nous pouvons utiliser un algorithme pour mapper l'entrée avec la sortie. L'algorithme est fait pour apprendre sur les données d'apprentissage données et itérées dessus et le processus d'itération s'arrête lorsque l'algorithme prédit les données correctes.
Unsupervised- Dans ce cas, nous avons une entrée mais ne connaissons pas la sortie. Le rôle de l'apprentissage non supervisé est de se former autant que possible avec les données fournies.
Dans ce chapitre, nous travaillerons sur l'installation de PyBrain. Pour commencer à travailler avec PyBrain, nous devons d'abord installer Python. Nous allons donc travailler à suivre -
- Installez Python
- Installez PyBrain
Installer Python
Pour installer Python, accédez au site officiel de Python: www.python.org/downloads comme indiqué ci-dessous et cliquez sur la dernière version disponible pour Windows, Linux / Unix et macOS. Téléchargez Python selon votre système d'exploitation 64 ou 32 bits disponible avec vous.

Une fois que vous avez téléchargé, cliquez sur le .exe et suivez les étapes pour installer python sur votre système.
Le gestionnaire de paquets python, c'est-à-dire pip, sera également installé par défaut avec l'installation ci-dessus. Pour le faire fonctionner globalement sur votre système, ajoutez directement l'emplacement de python à la variable PATH, la même chose est affichée au début de l'installation pour ne pas oublier de cocher la case qui dit AJOUTER à PATH. Si vous oubliez de le vérifier, veuillez suivre les étapes ci-dessous pour l'ajouter à PATH.
Ajouter à PATH
Pour ajouter à PATH, suivez les étapes ci-dessous -
Faites un clic droit sur l'icône de votre ordinateur et cliquez sur Propriétés -> Paramètres système avancés.
Il affichera l'écran comme indiqué ci-dessous
Cliquez sur Variables d'environnement comme indiqué ci-dessus. Il affichera l'écran comme indiqué ci-dessous

Sélectionnez Chemin et cliquez sur le bouton Modifier, ajoutez le chemin de localisation de votre python à la fin. Voyons maintenant la version de python.
Vérification de la version Python
Le code ci-dessous nous aide à vérifier la version de Python -
E:\pybrain>python --version
Python 3.7.3Installer PyBrain
Maintenant que nous avons installé Python, nous allons installer Pybrain. Clonez le référentiel pybrain comme indiqué ci-dessous -
git clone git://github.com/pybrain/pybrain.gitC:\pybrain>git clone git://github.com/pybrain/pybrain.git
Cloning into 'pybrain'...
remote: Enumerating objects: 2, done.
remote: Counting objects: 100% (2/2), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 12177 (delta 0), reused 0 (delta 0), pack-reused 12175
Receiving objects: 100% (12177/12177), 13.29 MiB | 510.00 KiB/s, done.
Resolving deltas: 100% (8506/8506), done.Maintenant, effectuez cd pybrain et exécutez la commande suivante -
python setup.py installCette commande installera pybrain sur votre système.
Une fois cela fait, pour vérifier si pybrain est installé ou non, ouvrez l'invite de ligne de commande et démarrez l'interpréteur python comme indiqué ci-dessous -
C:\pybrain\pybrain>python
Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>Nous pouvons ajouter import pybrain en utilisant le code ci-dessous -
>>> import pybrain
>>>Si l'importation pybrain fonctionne sans aucune erreur, cela signifie que pybrain est installé avec succès. Vous pouvez maintenant écrire votre code pour commencer à travailler avec pybrain.
PyBrain est une bibliothèque développée pour le Machine Learning avec Python. Il existe des concepts importants dans le Machine Learning et l'un d'entre eux est les réseaux. Un réseau est composé de modules et ils sont connectés à l'aide de connexions.
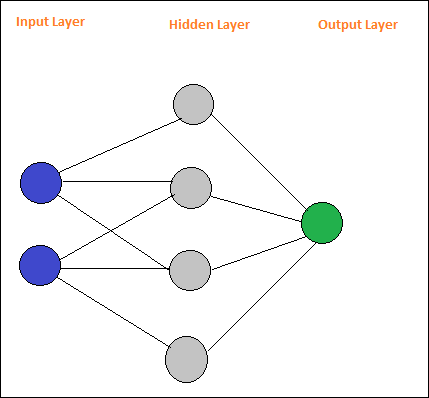
Une disposition d'un réseau de neurones simple est la suivante -
Pybrain prend en charge les réseaux neuronaux tels que le réseau Feed-Forward, le réseau récurrent, etc.
UNE feed-forward networkest un réseau neuronal, où les informations entre les nœuds se déplacent vers l'avant et ne voyageront jamais vers l'arrière. Le réseau Feed Forward est le premier et le plus simple parmi les réseaux disponibles dans le réseau de neurones artificiels. Les informations sont transmises à partir des nœuds d'entrée, à côté des nœuds masqués et plus tard au nœud de sortie.
Voici une disposition de réseau simple à feed forward.
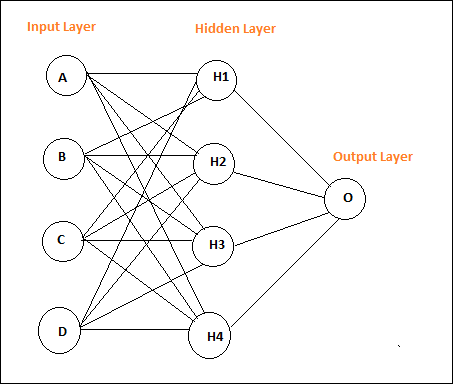
On dit que les cercles sont des modules et les lignes avec des flèches sont des connexions aux modules.
Les nœuds A, B, C et D sont des nœuds d'entrée
H1, H2, H3, H4 sont des nœuds cachés et O est la sortie.
Dans le réseau ci-dessus, nous avons 4 nœuds d'entrée, 4 couches cachées et 1 sortie. Le nombre de lignes affichées dans le diagramme indique les paramètres de poids dans le modèle qui sont ajustés pendant l'entraînement.
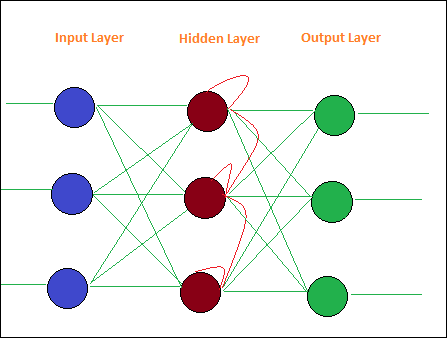
Recurrent Networkssont similaires à Feed Forward Network à la seule différence qu'il doit se souvenir des données à chaque étape. L'historique de chaque étape doit être sauvegardé.
Voici une présentation simple du réseau récurrent -
Un réseau est composé de modules et ils sont connectés à l'aide de connexions. Dans ce chapitre, nous allons apprendre à -
- Créer un réseau
- Analyser le réseau
Créer un réseau
Nous allons utiliser l'interpréteur python pour exécuter notre code. Pour créer un réseau dans pybrain, nous devons utiliserbuildNetwork api comme indiqué ci-dessous -
C:\pybrain\pybrain>python
Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>>
>>> from pybrain.tools.shortcuts import buildNetwork
>>> network = buildNetwork(2, 3, 1)
>>>Nous avons créé un réseau en utilisant buildNetwork () et les paramètres sont 2, 3, 1 ce qui signifie que le réseau est composé de 2 entrées, 3 cachées et une seule sortie.
Vous trouverez ci-dessous les détails du réseau, c'est-à-dire les modules et les connexions -
C:\pybrain\pybrain>python
Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from pybrain.tools.shortcuts import buildNetwork
>>> network = buildNetwork(2,3,1)
>>> print(network)
FeedForwardNetwork-8
Modules:
[<BiasUnit 'bias'>, <LinearLayer 'in'>, <SigmoidLayer 'hidden0'>,
<LinearLay er 'out'>]
Connections:
[<FullConnection 'FullConnection-4': 'hidden0' -> 'out'>, <FullConnection 'F
ullConnection-5': 'in' -> 'hidden0'>, <FullConnection 'FullConnection-6': 'bias'
-< 'out'>, <FullConnection 'FullConnection-7': 'bias' -> 'hidden0'>]
>>>Les modules se composent de couches et la connexion est établie à partir d'objets FullConnection. Ainsi, chacun des modules et la connexion sont nommés comme indiqué ci-dessus.
Analyse du réseau
Vous pouvez accéder individuellement aux couches du module et à la connexion en vous référant à leurs noms comme suit -
>>> network['bias']
<BiasUnit 'bias'>
>>> network['in']
<LinearLayer 'in'>Les jeux de données sont des données d'entrée à fournir pour tester, valider et former les réseaux. Le type de jeu de données à utiliser dépend des tâches que nous allons effectuer avec le Machine Learning. Dans ce chapitre, nous allons examiner ce qui suit -
- Créer un jeu de données
- Ajout de données à l'ensemble de données
Nous allons d'abord apprendre à créer un ensemble de données et à tester l'ensemble de données avec l'entrée donnée.
Créer un jeu de données
Pour créer un ensemble de données, nous devons utiliser le package d'ensemble de données pybrain: pybrain.datasets.
Pybrain prend en charge les classes de jeux de données comme SupervisedDataset, SequentialDataset, ClassificationDataSet. Nous allons utiliserSupervisedDataset , pour créer notre ensemble de données.L'ensemble de données à utiliser dépend de la tâche d'apprentissage automatique que l'utilisateur tente d'implémenter.SupervisedDataset est le plus simple et nous allons utiliser la même chose ici.
UNE SupervisedDataset datasetnécessite une entrée et une cible de paramètres. Considérez une table de vérité XOR, comme indiqué ci-dessous -
| UNE | B | A XOR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Les entrées qui sont données sont comme un tableau à 2 dimensions et nous obtenons 1 sortie. Donc, ici, l'entrée devient la taille et la cible la sortie qui est 1. Ainsi, les entrées qui iront pour notre jeu de données seront 2,1.
createdataset.py
from pybrain.datasets import SupervisedDataSet
sds = SupervisedDataSet(2, 1)
print(sds)C'est ce que nous obtenons lorsque nous exécutons le code ci-dessus python createdataset.py -
C:\pybrain\pybrain\src>python createdataset.py
input: dim(0, 2)
[]
target: dim(0, 1)
[]Il affiche l'entrée de taille 2 et la cible de taille 1 comme indiqué ci-dessus.
Ajout de données à l'ensemble de données
Ajoutons maintenant les exemples de données à l'ensemble de données.
createdataset.py
from pybrain.datasets import SupervisedDataSet
sds = SupervisedDataSet(2, 1)
xorModel = [
[(0,0), (0,)],
[(0,1), (1,)],
[(1,0), (1,)],
[(1,1), (0,)],
]
for input, target in xorModel:
sds.addSample(input, target)
print("Input is:")
print(sds['input'])
print("\nTarget is:")
print(sds['target'])Nous avons créé un tableau XORModel comme indiqué ci-dessous -
xorModel = [
[(0,0), (0,)],
[(0,1), (1,)],
[(1,0), (1,)],
[(1,1), (0,)],
]Pour ajouter des données à l'ensemble de données, nous utilisons la méthode addSample () qui prend en entrée et en cible.
Pour ajouter des données à addSample, nous allons parcourir le tableau xorModel comme indiqué ci-dessous -
for input, target in xorModel:
sds.addSample(input, target)Après l'exécution, voici la sortie que nous obtenons -
python createdataset.py
C:\pybrain\pybrain\src>python createdataset.py
Input is:
[[0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]
Target is:
[[0.]
[1.]
[1.]
[0.]]Vous pouvez obtenir les détails d'entrée et de cible à partir de l'ensemble de données créé en utilisant simplement l'index d'entrée et de cible comme indiqué ci-dessous -
print(sds['input'])
print(sds[‘target’])Les jeux de données sont des données à fournir pour tester, valider et former sur les réseaux. Le type de jeu de données à utiliser dépend des tâches que nous allons effectuer avec l'apprentissage automatique. Nous allons discuter des différents types de jeux de données dans ce chapitre.
Nous pouvons travailler avec l'ensemble de données en ajoutant le package suivant -
pybrain.datasetSupervisedDataSet
SupervisedDataSet se compose de champs de input et target. Il s'agit de la forme la plus simple d'un ensemble de données et est principalement utilisé pour les tâches d'apprentissage supervisé.
Voici comment vous pouvez l'utiliser dans le code -
from pybrain.datasets import SupervisedDataSetLes méthodes disponibles sur SupervisedDataSet sont les suivantes -
addSample (entrée, cible)
Cette méthode ajoutera un nouvel échantillon d'entrée et de cible.
splitWithProportion (proportion = 0,10)
Cela divisera les ensembles de données en deux parties. La première partie aura le% de l'ensemble de données donné en entrée, c'est-à-dire que si l'entrée est de 0,10, alors c'est 10% de l'ensemble de données et 90% des données. Vous pouvez décider de la proportion selon votre choix. Les ensembles de données divisés peuvent être utilisés pour tester et former votre réseau.
copy() - Renvoie une copie complète de l'ensemble de données.
clear() - Effacez l'ensemble de données.
saveToFile (nom de fichier, format = Aucun, ** kwargs)
Enregistrez l'objet dans un fichier donné par nom de fichier.
Exemple
Voici un exemple de travail utilisant un SupervisedDataset -
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
norgate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))
# Add input and target values to dataset
# Values for NOR truth table
nortrain.addSample((0, 0), (1,))
nortrain.addSample((0, 1), (0,))
nortrain.addSample((1, 0), (0,))
nortrain.addSample((1, 1), (0,))
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=nortrain, verbose = True)Production
La sortie pour le programme ci-dessus est la suivante -
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)ClassificationDataSet
Cet ensemble de données est principalement utilisé pour traiter les problèmes de classification. Il prend en entrée, le champ cible et également un champ supplémentaire appelé "classe" qui est une sauvegarde automatique des cibles données. Par exemple, la sortie sera 1 ou 0 ou la sortie sera regroupée avec des valeurs basées sur l'entrée donnée, c'est-à-dire qu'elle tombera dans une classe particulière.
Voici comment vous pouvez l'utiliser dans le code -
from pybrain.datasets import ClassificationDataSet
Syntax
// ClassificationDataSet(inp, target=1, nb_classes=0, class_labels=None)Les méthodes disponibles sur ClassificationDataSet sont les suivantes -
addSample(inp, target) - Cette méthode ajoutera un nouvel échantillon d'entrée et de cible.
splitByClass() - Cette méthode donnera deux nouveaux jeux de données, le premier jeu de données aura la classe sélectionnée (0..nClasses-1), le second aura des échantillons restants.
_convertToOneOfMany() - Cette méthode convertira les classes cibles en une représentation 1 sur k, en conservant les anciennes cibles en tant que classe de champ
Voici un exemple de travail de ClassificationDataSet.
Exemple
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample( training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1] )
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(trainer.testOnClassData(dataset=test_data), test_data['class']))L'ensemble de données utilisé dans l'exemple ci-dessus est un ensemble de données numériques et les classes vont de 0 à 9, il y a donc 10 classes. L'entrée est 64, la cible est 1 et les classes, 10.
Le code entraîne le réseau avec l'ensemble de données et génère le graphique pour l'erreur d'apprentissage et l'erreur de validation. Il donne également le pourcentage d'erreur sur les données de test qui est le suivant -
Production
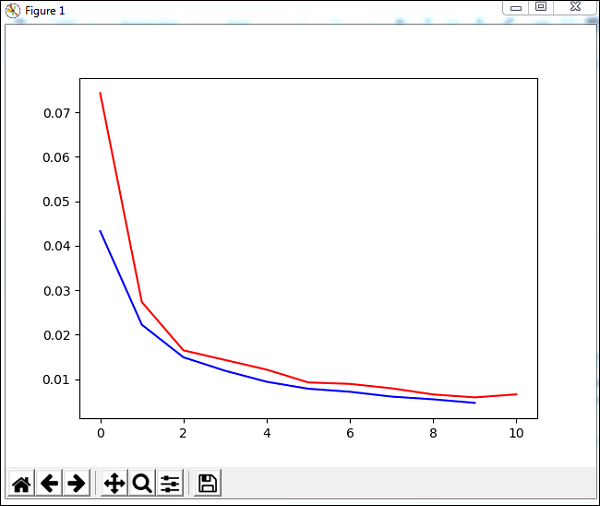
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735Dans ce chapitre, nous allons apprendre comment faire fonctionner les données avec les ensembles de données Pybrain.
Les jeux de données les plus couramment utilisés sont -
- Utiliser sklearn
- À partir d'un fichier CSV
Utiliser sklearn
Utiliser sklearn
Voici le lien qui contient des détails sur les ensembles de données de sklearn:https://scikit-learn.org/stable/datasets/index.html
Voici quelques exemples d'utilisation des ensembles de données de sklearn -
Exemple 1: load_digits ()
from sklearn import datasets
from pybrain.datasets import ClassificationDataSet
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])Exemple 2: load_iris ()
from sklearn import datasets
from pybrain.datasets import ClassificationDataSet
digits = datasets.load_iris()
X, y = digits.data, digits.target
ds = ClassificationDataSet(4, 1, nb_classes=3)
for i in range(len(X)):
ds.addSample(X[i], y[i])À partir d'un fichier CSV
Nous pouvons également utiliser les données du fichier csv comme suit -
Voici des exemples de données pour la table de vérité xor: datasettest.csv
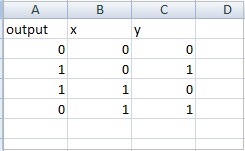
Voici l'exemple de travail pour lire les données du fichier .csv pour l'ensemble de données.
Exemple
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
import pandas as pd
print('Read data...')
df = pd.read_csv('data/datasettest.csv',header=0).head(1000)
data = df.values
train_output = data[:,0]
train_data = data[:,1:]
print(train_output)
print(train_data)
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
_gate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
for i in range(0, len(train_output)) :
_gate.addSample(train_data[i], train_output[i])
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, _gate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=_gate, verbose = True)Panda est utilisé pour lire les données du fichier csv comme indiqué dans l'exemple.
Production
C:\pybrain\pybrain\src>python testcsv.py
Read data...
[0 1 1 0]
[
[0 0]
[0 1]
[1 0]
[1 1]
]
Testing on data:
('out: ', '[0.004 ]')
('correct:', '[0 ]')
error: 0.00000795
('out: ', '[0.997 ]')
('correct:', '[1 ]')
error: 0.00000380
('out: ', '[0.996 ]')
('correct:', '[1 ]')
error: 0.00000826
('out: ', '[0.004 ]')
('correct:', '[0 ]')
error: 0.00000829
('All errors:', [7.94733477723902e-06, 3.798267582566822e-06, 8.260969076585322e
-06, 8.286246525558165e-06])
('Average error:', 7.073204490487332e-06)
('Max error:', 8.286246525558165e-06, 'Median error:', 8.260969076585322e-06)Jusqu'à présent, nous avons vu comment créer un réseau et un jeu de données. Pour travailler ensemble avec des ensembles de données et des réseaux, nous devons le faire avec l'aide de formateurs.
Vous trouverez ci-dessous un exemple de travail pour voir comment ajouter un ensemble de données au réseau créé, puis formé et testé à l'aide de formateurs.
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
norgate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))
# Add input and target values to dataset
# Values for NOR truth table
nortrain.addSample((0, 0), (1,))
nortrain.addSample((0, 1), (0,))
nortrain.addSample((1, 0), (0,))
nortrain.addSample((1, 1), (0,))
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=nortrain, verbose = True)Pour tester le réseau et l'ensemble de données, nous avons besoin de BackpropTrainer. BackpropTrainer est un formateur qui entraîne les paramètres d'un module selon un jeu de données supervisé (potentiellement séquentiel) en rétropropropageant les erreurs (dans le temps).
Nous avons créé 2 ensembles de données de classe - SupervisedDataSet. Nous utilisons le modèle de données NOR qui est le suivant -
| UNE | B | A NOR B |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 0 |
Le modèle de données ci-dessus est utilisé pour former le réseau.
norgate = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))Voici l'ensemble de données utilisé pour tester -
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))Le formateur est utilisé comme suit -
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()Pour tester sur l'ensemble de données, nous pouvons utiliser le code ci-dessous -
trainer.testOnData(dataset=nortrain, verbose = True)Production
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218, 0.005227359234093431
, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)Si vous vérifiez la sortie, les données de test correspondent presque à l'ensemble de données que nous avons fourni et l'erreur est donc de 0,008.
Modifions maintenant les données de test et voyons une erreur moyenne. Nous avons changé la sortie comme indiqué ci-dessous -
Voici l'ensemble de données utilisé pour tester -
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (0,))
norgate.addSample((0, 1), (1,))
norgate.addSample((1, 0), (1,))
norgate.addSample((1, 1), (0,))Testons-le maintenant.
Production
python testnework.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.988 ]')
('correct:', '[0 ]')
error: 0.48842978
('out: ', '[0.027 ]')
('correct:', '[1 ]')
error: 0.47382097
('out: ', '[0.021 ]')
('correct:', '[1 ]')
error: 0.47876379
('out: ', '[-0.04 ]')
('correct:', '[0 ]')
error: 0.00079160
('All errors:', [0.4884297811030845, 0.47382096780393873, 0.47876378995939756, 0
.0007915982149002194])
('Average error:', 0.3604515342703303)
('Max error:', 0.4884297811030845, 'Median error:', 0.47876378995939756)Nous obtenons l'erreur 0,36, ce qui montre que nos données de test ne correspondent pas complètement au réseau formé.
Dans ce chapitre, nous allons voir un exemple où nous allons former les données et tester les erreurs sur les données entraînées.
Nous allons utiliser des formateurs -
BackpropTrainer
BackpropTrainer est un formateur qui entraîne les paramètres d'un module selon un jeu de données supervisé ou ClassificationDataSet (potentiellement séquentiel) en rétropropropageant les erreurs (dans le temps).
TrainJusqu'àConvergence
Il est utilisé pour entraîner le module sur l'ensemble de données jusqu'à ce qu'il converge.
Lorsque nous créons un réseau de neurones, il sera formé en fonction des données d'apprentissage qui lui sont données.Maintenant, si le réseau est formé correctement ou non, cela dépendra de la prédiction des données de test testées sur ce réseau.
Voyons un exemple de travail étape par étape où va construire un réseau neuronal et prédire les erreurs d'entraînement, les erreurs de test et les erreurs de validation.
Tester notre réseau
Voici les étapes que nous suivrons pour tester notre réseau -
- Importation de PyBrain et d'autres packages requis
- Créer un ClassificationDataSet
- Fractionnement des ensembles de données 25% en tant que données de test et 75% en tant que données entraînées
- Conversion des données de test et des données formées en tant que ClassificationDataSet
- Créer un réseau neuronal
- Former le réseau
- Visualisation des données d'erreur et de validation
- Pourcentage d'erreur des données de test
Step 1
Importation de PyBrain et d'autres packages requis.
Les packages dont nous avons besoin sont importés comme indiqué ci-dessous -
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravelStep 2
L'étape suivante consiste à créer ClassificationDataSet.
Pour les ensembles de données, nous allons utiliser les ensembles de données des ensembles de données sklearn comme indiqué ci-dessous -
Reportez-vous aux ensembles de données load_digits de sklearn dans le lien ci-dessous -
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
# we are having inputs are 64 dim array and since the digits are from 0-9 the
classes considered is 10.
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # adding sample to datasetsStep 3
Fractionnement des ensembles de données 25% en tant que données de test et 75% en tant que données entraînées -
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)Donc, ici, nous avons utilisé une méthode sur l'ensemble de données appelée splitWithProportion () avec la valeur 0,25, elle divisera l'ensemble de données en 25% en tant que données de test et 75% en tant que données d'entraînement.
Step 4
Conversion des données de test et des données formées en tant que ClassificationDataSet.
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()L'utilisation de la méthode splitWithProportion () sur l'ensemble de données convertit l'ensemble de données en ensemble de données supervisé, nous allons donc reconvertir l'ensemble de données en ensemble de données de classification comme indiqué à l'étape ci-dessus.
Step 5
La prochaine étape consiste à créer un réseau neuronal.
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)Nous créons un réseau dans lequel l'entrée et la sortie sont utilisées à partir des données d'entraînement.
Step 6
Former le réseau
Maintenant, la partie importante consiste à entraîner le réseau sur l'ensemble de données comme indiqué ci-dessous -
trainer = BackpropTrainer(net, dataset=training_data,
momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01)Nous utilisons la méthode BackpropTrainer () et le jeu de données sur le réseau créé.
Step 7
L'étape suivante consiste à visualiser l'erreur et à valider les données.
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()Nous utiliserons une méthode appelée trainUntilConvergence sur les données d'entraînement qui convergeront pour des époques de 10. Elle renverra une erreur d'apprentissage et une erreur de validation que nous avons tracées comme indiqué ci-dessous. La ligne bleue montre les erreurs d'entraînement et la ligne rouge montre l'erreur de validation.
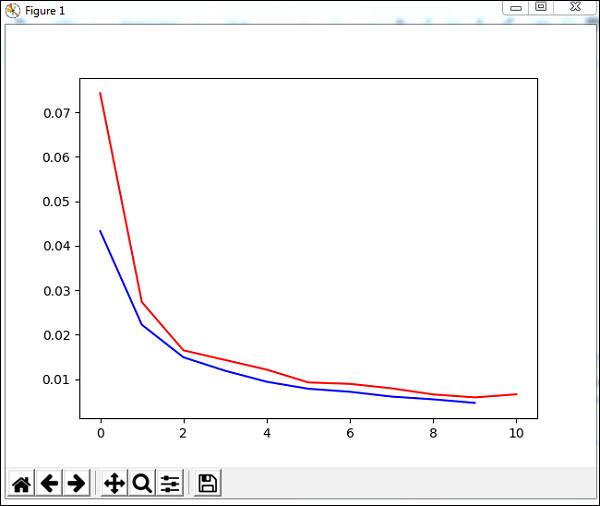
L'erreur totale reçue lors de l'exécution du code ci-dessus est indiquée ci-dessous -
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')L'erreur commence à 0,04 et diminue plus tard pour chaque époque, ce qui signifie que le réseau est formé et s'améliore à chaque époque.
Step 8
Pourcentage d'erreur des données de test
Nous pouvons vérifier le pourcentage d'erreur en utilisant la méthode percentError comme indiqué ci-dessous -
print('Percent Error on
testData:',percentError(trainer.testOnClassData(dataset=test_data),
test_data['class']))Percent Error on testData - 3.34075723830735
Nous obtenons le pourcentage d'erreur, soit 3,34%, ce qui signifie que le réseau neuronal est précis à 97%.
Ci-dessous le code complet -
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,
learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))Un réseau à réaction est un réseau neuronal, où les informations entre les nœuds se déplacent vers l'avant et ne voyageront jamais vers l'arrière. Le réseau Feed Forward est le premier et le plus simple parmi les réseaux disponibles dans le réseau de neurones artificiels. Les informations sont transmises à partir des nœuds d'entrée, à côté des nœuds masqués et plus tard au nœud de sortie.
Dans ce chapitre, nous allons discuter de la façon de -
- Créer des réseaux Feed-Forward
- Ajouter une connexion et des modules à FFN
Créer un réseau Feed Forward
Vous pouvez utiliser l'IDE python de votre choix, c'est-à-dire PyCharm. En cela, nous utilisons Visual Studio Code pour écrire le code et l'exécuterons dans le terminal.
Pour créer un réseau feedforward, nous devons l'importer depuis pybrain.structure comme indiqué ci-dessous -
ffn.py
from pybrain.structure import FeedForwardNetwork
network = FeedForwardNetwork()
print(network)Exécutez ffn.py comme indiqué ci-dessous -
C:\pybrain\pybrain\src>python ffn.py
FeedForwardNetwork-0
Modules:
[]
Connections:
[]Nous n'avons ajouté aucun module ni aucune connexion au réseau feedforward. Par conséquent, le réseau affiche des tableaux vides pour les modules et les connexions.
Ajout de modules et de connexions
Nous allons d'abord créer des couches d'entrée, cachées et de sortie et ajouter la même chose aux modules comme indiqué ci-dessous -
ffy.py
from pybrain.structure import FeedForwardNetwork
from pybrain.structure import LinearLayer, SigmoidLayer
network = FeedForwardNetwork()
#creating layer for input => 2 , hidden=> 3 and output=>1
inputLayer = LinearLayer(2)
hiddenLayer = SigmoidLayer(3)
outputLayer = LinearLayer(1)
#adding the layer to feedforward network
network.addInputModule(inputLayer)
network.addModule(hiddenLayer)
network.addOutputModule(outputLayer)
print(network)Production
C:\pybrain\pybrain\src>python ffn.py
FeedForwardNetwork-3
Modules:
[]
Connections:
[]Nous obtenons toujours les modules et les connexions vides. Nous devons fournir une connexion aux modules créés comme indiqué ci-dessous -
Voici le code où nous avons créé une connexion entre les couches d'entrée, cachées et de sortie et ajoutons la connexion au réseau.
ffy.py
from pybrain.structure import FeedForwardNetwork
from pybrain.structure import LinearLayer, SigmoidLayer
from pybrain.structure import FullConnection
network = FeedForwardNetwork()
#creating layer for input => 2 , hidden=> 3 and output=>1
inputLayer = LinearLayer(2)
hiddenLayer = SigmoidLayer(3)
outputLayer = LinearLayer(1)
#adding the layer to feedforward network
network.addInputModule(inputLayer)
network.addModule(hiddenLayer)
network.addOutputModule(outputLayer)
#Create connection between input ,hidden and output
input_to_hidden = FullConnection(inputLayer, hiddenLayer)
hidden_to_output = FullConnection(hiddenLayer, outputLayer)
#add connection to the network
network.addConnection(input_to_hidden)
network.addConnection(hidden_to_output)
print(network)Production
C:\pybrain\pybrain\src>python ffn.py
FeedForwardNetwork-3
Modules:
[]
Connections:
[]Nous ne sommes toujours pas en mesure d'obtenir les modules et les connexions. Ajoutons maintenant l'étape finale, c'est-à-dire que nous devons ajouter la méthode sortModules () comme indiqué ci-dessous -
ffy.py
from pybrain.structure import FeedForwardNetwork
from pybrain.structure import LinearLayer, SigmoidLayer
from pybrain.structure import FullConnection
network = FeedForwardNetwork()
#creating layer for input => 2 , hidden=> 3 and output=>1
inputLayer = LinearLayer(2)
hiddenLayer = SigmoidLayer(3)
outputLayer = LinearLayer(1)
#adding the layer to feedforward network
network.addInputModule(inputLayer)
network.addModule(hiddenLayer)
network.addOutputModule(outputLayer)
#Create connection between input ,hidden and output
input_to_hidden = FullConnection(inputLayer, hiddenLayer)
hidden_to_output = FullConnection(hiddenLayer, outputLayer)
#add connection to the network
network.addConnection(input_to_hidden)
network.addConnection(hidden_to_output)
network.sortModules()
print(network)Production
C:\pybrain\pybrain\src>python ffn.py
FeedForwardNetwork-6
Modules:
[<LinearLayer 'LinearLayer-3'gt;, <SigmoidLayer 'SigmoidLayer-7'>,
<LinearLayer 'LinearLayer-8'>]
Connections:
[<FullConnection 'FullConnection-4': 'SigmoidLayer-7' -> 'LinearLayer-8'>,
<FullConnection 'FullConnection-5': 'LinearLayer-3' -> 'SigmoidLayer-7'>]Nous sommes maintenant en mesure de voir les modules et les détails des connexions pour feedforwardnetwork.
Les réseaux récurrents sont identiques au réseau à réaction avec la seule différence que vous devez vous souvenir des données à chaque étape. L'historique de chaque étape doit être sauvegardé.
Nous apprendrons à -
- Créer un réseau récurrent
- Ajout de modules et connexion
Créer un réseau récurrent
Pour créer un réseau récurrent, nous utiliserons la classe RecurrentNetwork comme indiqué ci-dessous -
rn.py
from pybrain.structure import RecurrentNetwork
recurrentn = RecurrentNetwork()
print(recurrentn)python rn.py
C:\pybrain\pybrain\src>python rn.py
RecurrentNetwork-0
Modules:
[]
Connections:
[]
Recurrent Connections:
[]Nous pouvons voir une nouvelle connexion appelée Connexions récurrentes pour le réseau récurrent. À l'heure actuelle, aucune donnée n'est disponible.
Créons maintenant les couches et ajoutons aux modules et créons des connexions.
Ajout de modules et connexion
Nous allons créer des couches, c.-à-d. Entrée, caché et sortie. Les couches seront ajoutées au module d'entrée et de sortie. Ensuite, nous allons créer la connexion pour l'entrée à caché, caché à la sortie et une connexion récurrente entre caché à caché.
Voici le code du réseau récurrent avec modules et connexions.
rn.py
from pybrain.structure import RecurrentNetwork
from pybrain.structure import LinearLayer, SigmoidLayer
from pybrain.structure import FullConnection
recurrentn = RecurrentNetwork()
#creating layer for input => 2 , hidden=> 3 and output=>1
inputLayer = LinearLayer(2, 'rn_in')
hiddenLayer = SigmoidLayer(3, 'rn_hidden')
outputLayer = LinearLayer(1, 'rn_output')
#adding the layer to feedforward network
recurrentn.addInputModule(inputLayer)
recurrentn.addModule(hiddenLayer)
recurrentn.addOutputModule(outputLayer)
#Create connection between input ,hidden and output
input_to_hidden = FullConnection(inputLayer, hiddenLayer)
hidden_to_output = FullConnection(hiddenLayer, outputLayer)
hidden_to_hidden = FullConnection(hiddenLayer, hiddenLayer)
#add connection to the network
recurrentn.addConnection(input_to_hidden)
recurrentn.addConnection(hidden_to_output)
recurrentn.addRecurrentConnection(hidden_to_hidden)
recurrentn.sortModules()
print(recurrentn)python rn.py
C:\pybrain\pybrain\src>python rn.py
RecurrentNetwork-6
Modules:
[<LinearLayer 'rn_in'>, <SigmoidLayer 'rn_hidden'>,
<LinearLayer 'rn_output'>]
Connections:
[<FullConnection 'FullConnection-4': 'rn_hidden' -> 'rn_output'>,
<FullConnection 'FullConnection-5': 'rn_in' -> 'rn_hidden'>]
Recurrent Connections:
[<FullConnection 'FullConnection-3': 'rn_hidden' -> 'rn_hidden'>]Dans la sortie ci-dessus, nous pouvons voir les modules, les connexions et les connexions récurrentes.
Activons maintenant le réseau en utilisant la méthode d'activation comme indiqué ci-dessous -
rn.py
Ajoutez ci-dessous le code à celui créé précédemment -
#activate network using activate() method
act1 = recurrentn.activate((2, 2))
print(act1)
act2 = recurrentn.activate((2, 2))
print(act2)python rn.py
C:\pybrain\pybrain\src>python rn.py
[-1.24317586]
[-0.54117783]Nous avons vu comment former un réseau à l'aide de formateurs en pybrain. Dans ce chapitre, nous utiliserons les algorithmes d'optimisation disponibles avec Pybrain pour former un réseau.
Dans l'exemple, nous utiliserons l'algorithme d'optimisation GA qui doit être importé comme indiqué ci-dessous -
from pybrain.optimization.populationbased.ga import GAExemple
Voici un exemple de travail d'un réseau de formation utilisant un algorithme d'optimisation GA -
from pybrain.datasets.classification import ClassificationDataSet
from pybrain.optimization.populationbased.ga import GA
from pybrain.tools.shortcuts import buildNetwork
# create XOR dataset
ds = ClassificationDataSet(2)
ds.addSample([0., 0.], [0.])
ds.addSample([0., 1.], [1.])
ds.addSample([1., 0.], [1.])
ds.addSample([1., 1.], [0.])
ds.setField('class', [ [0.],[1.],[1.],[0.]])
net = buildNetwork(2, 3, 1)
ga = GA(ds.evaluateModuleMSE, net, minimize=True)
for i in range(100):
net = ga.learn(0)[0]
print(net.activate([0,0]))
print(net.activate([1,0]))
print(net.activate([0,1]))
print(net.activate([1,1]))Production
La méthode d'activation sur le réseau pour les entrées correspond presque à la sortie comme indiqué ci-dessous -
C:\pybrain\pybrain\src>python example15.py
[0.03055398]
[0.92094839]
[1.12246157]
[0.02071285]Les couches sont essentiellement un ensemble de fonctions utilisées sur les couches cachées d'un réseau.
Nous allons passer en revue les détails suivants sur les couches dans ce chapitre -
- Comprendre la couche
- Créer un calque à l'aide de Pybrain
Comprendre les couches
Nous avons vu des exemples plus tôt où nous avons utilisé des couches comme suit -
- TanhLayer
- SoftmaxLayer
Exemple utilisant TanhLayer
Voici un exemple où nous avons utilisé TanhLayer pour construire un réseau -
testnetwork.py
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
norgate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))
# Add input and target values to dataset
# Values for NOR truth table
nortrain.addSample((0, 0), (1,))
nortrain.addSample((0, 1), (0,))
nortrain.addSample((1, 0), (0,))
nortrain.addSample((1, 1), (0,))
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=nortrain, verbose = True)Production
La sortie pour le code ci-dessus est la suivante -
python testnetwork.py
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218,
0.005227359234093431, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)Exemple utilisant SoftMaxLayer
Voici un exemple où nous avons utilisé SoftmaxLayer pour construire un réseau -
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure.modules import SoftmaxLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=SoftmaxLayer)
# Create a dataset that matches network input and output sizes:
norgate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))
# Add input and target values to dataset
# Values for NOR truth table
nortrain.addSample((0, 0), (1,))
nortrain.addSample((0, 1), (0,))
nortrain.addSample((1, 0), (0,))
nortrain.addSample((1, 1), (0,))
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=nortrain, verbose = True)Production
La sortie est la suivante -
C:\pybrain\pybrain\src>python example16.py
Testing on data:
('out: ', '[0.918 ]')
('correct:', '[1 ]')
error: 0.00333524
('out: ', '[0.082 ]')
('correct:', '[0 ]')
error: 0.00333484
('out: ', '[0.078 ]')
('correct:', '[0 ]')
error: 0.00303433
('out: ', '[-0.082]')
('correct:', '[0 ]')
error: 0.00340005
('All errors:', [0.0033352368788838365, 0.003334842961037291,
0.003034328685718761, 0.0034000458892589056])
('Average error:', 0.0032761136037246985)
('Max error:', 0.0034000458892589056, 'Median error:', 0.0033352368788838365)Créer un calque dans Pybrain
Dans Pybrain, vous pouvez créer votre propre calque comme suit -
Pour créer un calque, vous devez utiliser NeuronLayer class comme classe de base pour créer tous les types de calques.
Exemple
from pybrain.structure.modules.neuronlayer import NeuronLayer
class LinearLayer(NeuronLayer):
def _forwardImplementation(self, inbuf, outbuf):
outbuf[:] = inbuf
def _backwardImplementation(self, outerr, inerr, outbuf, inbuf):
inerr[:] = outerPour créer une couche, nous devons implémenter deux méthodes: _forwardImplementation () et _backwardImplementation () .
The _forwardImplementation() takes in 2 arguments inbufet outbuf, qui sont des tableaux Scipy. Sa taille dépend des dimensions d'entrée et de sortie des couches.
Le _backwardImplementation () est utilisée pour calculer la dérivée de la sortie par rapport à l'entrée donnée.
Donc, pour implémenter un calque dans Pybrain, c'est le squelette de la classe layer -
from pybrain.structure.modules.neuronlayer import NeuronLayer
class NewLayer(NeuronLayer):
def _forwardImplementation(self, inbuf, outbuf):
pass
def _backwardImplementation(self, outerr, inerr, outbuf, inbuf):
passSi vous souhaitez implémenter une fonction polynomiale quadratique en tant que couche, nous pouvons le faire comme suit -
Considérons que nous avons une fonction polynomiale comme -
f(x) = 3x2La dérivée de la fonction polynomiale ci-dessus sera la suivante -
f(x) = 6 xLa classe de couche finale pour la fonction polynomiale ci-dessus sera la suivante -
testlayer.py
from pybrain.structure.modules.neuronlayer import NeuronLayer
class PolynomialLayer(NeuronLayer):
def _forwardImplementation(self, inbuf, outbuf):
outbuf[:] = 3*inbuf**2
def _backwardImplementation(self, outerr, inerr, outbuf, inbuf):
inerr[:] = 6*inbuf*outerrMaintenant, utilisons le calque créé comme indiqué ci-dessous -
testlayer1.py
from testlayer import PolynomialLayer
from pybrain.tools.shortcuts import buildNetwork
from pybrain.tests.helpers import gradientCheck
n = buildNetwork(2, 3, 1, hiddenclass=PolynomialLayer)
n.randomize()
gradientCheck(n)GradientCheck () testera si le calque fonctionne correctement ou non. Nous devons passer le réseau où le calque est utilisé à gradientCheck (n). Il donnera la sortie en tant que «Gradient parfait» si le calque fonctionne correctement.
Production
C:\pybrain\pybrain\src>python testlayer1.py
Perfect gradientUne connexion fonctionne comme une couche; une seule différence est qu'il déplace les données d'un nœud à l'autre dans un réseau.
Dans ce chapitre, nous allons en apprendre davantage sur -
- Comprendre les connexions
- Créer des connexions
Comprendre les connexions
Voici un exemple fonctionnel de connexions utilisées lors de la création d'un réseau.
Exemple
ffy.py
from pybrain.structure import FeedForwardNetwork
from pybrain.structure import LinearLayer, SigmoidLayer
from pybrain.structure import FullConnection
network = FeedForwardNetwork()
#creating layer for input => 2 , hidden=> 3 and output=>1
inputLayer = LinearLayer(2)
hiddenLayer = SigmoidLayer(3)
outputLayer = LinearLayer(1)
#adding the layer to feedforward network
network.addInputModule(inputLayer)
network.addModule(hiddenLayer)
network.addOutputModule(outputLayer)
#Create connection between input ,hidden and output
input_to_hidden = FullConnection(inputLayer, hiddenLayer)
hidden_to_output = FullConnection(hiddenLayer, outputLayer)
#add connection to the network
network.addConnection(input_to_hidden)
network.addConnection(hidden_to_output)
network.sortModules()
print(network)Production
C:\pybrain\pybrain\src>python ffn.py
FeedForwardNetwork-6
Modules:
[<LinearLayer 'LinearLayer-3'>, <SigmoidLayer 'SigmoidLayer-7'>,
<LinearLayer 'LinearLayer-8'>]
Connections:
[<FullConnection 'FullConnection-4': 'SigmoidLayer-7' -> 'LinearLayer-8'>,
<FullConnection 'FullConnection-5': 'LinearLayer-3' -> 'SigmoidLayer-7'>]Créer des connexions
Dans Pybrain, nous pouvons créer des connexions en utilisant le module de connexion comme indiqué ci-dessous -
Exemple
connect.py
from pybrain.structure.connections.connection import Connection
class YourConnection(Connection):
def __init__(self, *args, **kwargs):
Connection.__init__(self, *args, **kwargs)
def _forwardImplementation(self, inbuf, outbuf):
outbuf += inbuf
def _backwardImplementation(self, outerr, inerr, inbuf):
inerr += outerPour créer une connexion, il existe 2 méthodes - _forwardImplementation () et _backwardImplementation () .
Le _forwardImplementation () est appelée avec le tampon de sortie du module d' entrée qui est inbuf , et la mémoire tampon d'entrée du module de sortie appelé outbuf . L' inbuf est ajouté au module sortant outbuf .
Le _backwardImplementation () est appelée avec outerr , inerr et inbuf . L'erreur de module sortant est ajoutée à l'erreur de module entrant dans _backwardImplementation () .
Utilisons maintenant le YourConnection dans un réseau.
testconnection.py
from pybrain.structure import FeedForwardNetwork
from pybrain.structure import LinearLayer, SigmoidLayer
from connect import YourConnection
network = FeedForwardNetwork()
#creating layer for input => 2 , hidden=> 3 and output=>1
inputLayer = LinearLayer(2)
hiddenLayer = SigmoidLayer(3)
outputLayer = LinearLayer(1)
#adding the layer to feedforward network
network.addInputModule(inputLayer)
network.addModule(hiddenLayer)
network.addOutputModule(outputLayer)
#Create connection between input ,hidden and output
input_to_hidden = YourConnection(inputLayer, hiddenLayer)
hidden_to_output = YourConnection(hiddenLayer, outputLayer)
#add connection to the network
network.addConnection(input_to_hidden)
network.addConnection(hidden_to_output)
network.sortModules()
print(network)Production
C:\pybrain\pybrain\src>python testconnection.py
FeedForwardNetwork-6
Modules:
[<LinearLayer 'LinearLayer-3'>, <SigmoidLayer 'SigmoidLayer-7'>,
<LinearLayer 'LinearLayer-8'>]
Connections:
[<YourConnection 'YourConnection-4': 'LinearLayer-3' -> 'SigmoidLayer-7'>,
<YourConnection 'YourConnection-5': 'SigmoidLayer-7' -> 'LinearLayer-8'>]L'apprentissage par renforcement (RL) est une partie importante de l'apprentissage automatique. L'apprentissage par renforcement permet à l'agent d'apprendre son comportement en fonction des intrants de l'environnement.
Les composants qui interagissent les uns avec les autres pendant le renforcement sont les suivants -
- Environment
- Agent
- Task
- Experiment
La disposition de l'apprentissage par renforcement est donnée ci-dessous -
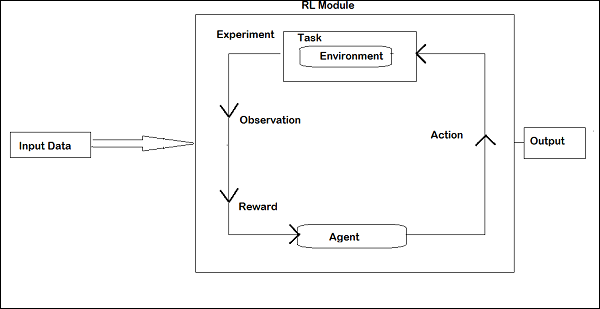
Dans RL, l'agent parle avec l'environnement par itération. A chaque itération, l'agent reçoit une observation qui a la récompense. Il choisit ensuite l'action et l'envoie à l'environnement. L'environnement à chaque itération passe à un nouvel état et la récompense reçue à chaque fois est enregistrée.
Le but de l'agent RL est de collecter autant de récompenses que possible. Entre les itérations, la performance de l'agent est comparée à celle de l'agent qui agit correctement et la différence de performance donne lieu à une récompense ou à un échec. RL est essentiellement utilisé dans les tâches de résolution de problèmes telles que le contrôle du robot, l'ascenseur, les télécommunications, les jeux, etc.
Voyons comment travailler avec RL dans Pybrain.
Nous allons travailler sur le labyrinthe environmentqui sera représenté en utilisant un tableau numpy à 2 dimensions où 1 est un mur et 0 est un champ libre. La responsabilité de l'agent est de se déplacer sur le terrain libre et de trouver le point de but.
Voici un flux de travail étape par étape avec l'environnement de labyrinthe.
Étape 1
Importez les packages dont nous avons besoin avec le code ci-dessous -
from scipy import *
import sys, time
import matplotlib.pyplot as pylab # for visualization we are using mathplotlib
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import TaskÉtape 2
Créez l'environnement de labyrinthe en utilisant le code ci-dessous -
# create the maze with walls as 1 and 0 is a free field
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7)) # create the environment, the first parameter is the
maze array and second one is the goal field tupleÉtape 3
L'étape suivante consiste à créer l'agent.
L'agent joue un rôle important dans RL. Il interagira avec l'environnement du labyrinthe en utilisant les méthodes getAction () et integrObservation ().
L'agent a un contrôleur (qui mappera les états aux actions) et un apprenant.
Le contrôleur dans PyBrain est comme un module, pour lequel l'entrée est des états et les convertit en actions.
controller = ActionValueTable(81, 4)
controller.initialize(1.)le ActionValueTablenécessite 2 entrées, c'est-à-dire le nombre d'états et d'actions. L'environnement de labyrinthe standard comporte 4 actions: nord, sud, est, ouest.
Nous allons maintenant créer un apprenant. Nous allons utiliser l'algorithme d'apprentissage SARSA () pour l'apprenant à utiliser avec l'agent.
learner = SARSA()
agent = LearningAgent(controller, learner)Étape 4
Cette étape ajoute l'agent à l'environnement.
Pour connecter l'agent à l'environnement, nous avons besoin d'un composant spécial appelé tâche. Le rôle d'untask est de rechercher le but dans l'environnement et comment l'agent obtient des récompenses pour ses actions.
L'environnement a sa propre tâche. L'environnement Maze que nous avons utilisé a la tâche MDPMazeTask. MDP signifie“markov decision process”ce qui signifie que l'agent connaît sa position dans le labyrinthe. L'environnement sera un paramètre de la tâche.
task = MDPMazeTask(env)Étape 5
La prochaine étape après l'ajout de l'agent à l'environnement consiste à créer une expérience.
Maintenant, nous devons créer l'expérience, afin que nous puissions avoir la tâche et l'agent coordonnés les uns avec les autres.
experiment = Experiment(task, agent)Nous allons maintenant exécuter l'expérience 1000 fois comme indiqué ci-dessous -
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()L'environnement s'exécutera 100 fois entre l'agent et la tâche lorsque le code suivant sera exécuté -
experiment.doInteractions(100)Après chaque itération, il redonne un nouvel état à la tâche qui décide quelles informations et récompenses doivent être transmises à l'agent. Nous allons tracer une nouvelle table après avoir appris et réinitialisé l'agent dans la boucle for.
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(table.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")Voici le code complet -
Exemple
maze.py
from scipy import *
import sys, time
import matplotlib.pyplot as pylab
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Task
# create maze array
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7))
# create task
task = MDPMazeTask(env)
#controller in PyBrain is like a module, for which the input is states and
convert them into actions.
controller = ActionValueTable(81, 4)
controller.initialize(1.)
# create agent with controller and learner - using SARSA()
learner = SARSA()
# create agent
agent = LearningAgent(controller, learner)
# create experiment
experiment = Experiment(task, agent)
# prepare plotting
pylab.gray()
pylab.ion()
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(controller.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")Production
python maze.py
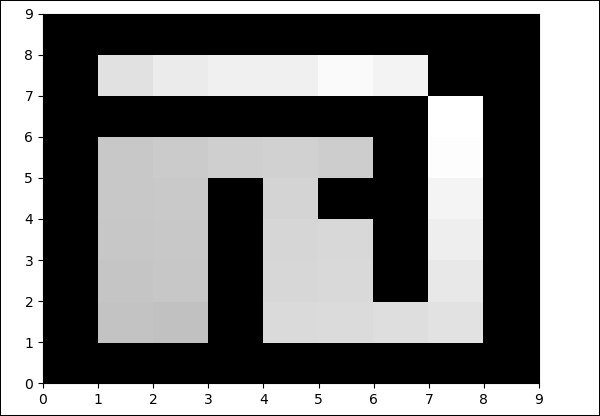
La couleur du champ libre sera modifiée à chaque itération.
Nous savons maintenant comment construire un réseau et le former. Dans ce chapitre, nous allons comprendre comment créer et enregistrer le réseau, et utiliser le réseau chaque fois que nécessaire.
Enregistrer et récupérer le réseau
Nous allons utiliser NetworkWriter et NetworkReader de Pybrain tool, c'est-à-dire pybrain.tools.customxml.
Voici un exemple de travail de la même chose -
from pybrain.tools.shortcuts import buildNetwork
from pybrain.tools.customxml import NetworkWriter
from pybrain.tools.customxml import NetworkReader
net = buildNetwork(2,1,1)
NetworkWriter.writeToFile(net, 'network.xml')
net = NetworkReader.readFrom('network.xml')Le réseau est enregistré dans network.xml.
NetworkWriter.writeToFile(net, 'network.xml')Pour lire le xml si nécessaire, nous pouvons utiliser le code comme suit -
net = NetworkReader.readFrom('network.xml')Voici le fichier network.xml créé -
<?xml version="1.0" ?>
<PyBrain>
<Network class="pybrain.structure.networks.feedforward.FeedForwardNetwork" name="FeedForwardNetwork-8">
<name val="'FeedForwardNetwork-8'"/>
<Modules>
<LinearLayer class="pybrain.structure.modules.linearlayer.LinearLayer" inmodule="True" name="in">
<name val="'in'"/>
<dim val="2"/>
</LinearLayer>
<LinearLayer class="pybrain.structure.modules.linearlayer.LinearLayer" name="out" outmodule="True">
<name val="'out'"/>
<dim val="1"/>
</LinearLayer>
<BiasUnit class="pybrain.structure.modules.biasunit.BiasUnit" name="bias">
<name val="'bias'"/>
</BiasUnit>
<SigmoidLayer class="pybrain.structure.modules.sigmoidlayer.SigmoidLayer" name="hidden0">
<name val="'hidden0'"/>
<dim val="1"/>
</SigmoidLayer>
</Modules>
<Connections>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-6">
<inmod val="bias"/>
<outmod val="out"/>
<Parameters>[1.2441093186965146]</Parameters>
</FullConnection>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-7">
<inmod val="bias"/>
<outmod val="hidden0"/>
<Parameters>[-1.5743530012126412]</Parameters>
</FullConnection>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-4">
<inmod val="in"/>
<outmod val="hidden0"/>
<Parameters>[-0.9429546042034236, -0.09858196752687162]</Parameters>
</FullConnection>
<FullConnection class="pybrain.structure.connections.full.FullConnection" name="FullConnection-5">
<inmod val="hidden0"/>
<outmod val="out"/>
<Parameters>[-0.29205472354634304]</Parameters>
</FullConnection>
</Connections>
</Network>
</PyBrain>API
Vous trouverez ci-dessous une liste des API que nous avons utilisées tout au long de ce didacticiel.
Pour les réseaux
activate(input)- Il prend le paramètre, c'est-à-dire la valeur à tester. Il renverra le résultat en fonction de l'entrée donnée.
activateOnDataset(dataset) - Il itérera sur l'ensemble de données donné et retournera la sortie.
addConnection(c) - Ajoute la connexion au réseau.
addInputModule(m) - Ajoute le module donné au réseau et le marque comme module d'entrée.
addModule(m) - Ajoute le module donné au réseau.
addOutputModule(m) - Ajoute le module au réseau et le marque comme module de sortie.
reset() - Réinitialise les modules et le réseau.
sortModules()- Il prépare le réseau à l'activation en triant en interne. Il doit être appelé avant l'activation.
Pour les ensembles de données supervisés
addSample(inp, target) - Ajoute un nouvel échantillon d'entrée et de cible.
splitWithProportion(proportion=0.5) - Divise l'ensemble de données en deux parties, la première partie contenant les données de la partie proportion et l'ensemble suivant contenant le reste.
Pour les formateurs
trainUntilConvergence(dataset=None, maxEpochs=None, verbose=None, continueEpochs=10, validationProportion=0.25)- Il est utilisé pour entraîner le module sur l'ensemble de données jusqu'à ce qu'il converge. Si le jeu de données n'est pas donné, il essaiera de s'entraîner sur le jeu de données formé utilisé au début.
Dans ce chapitre, tous les exemples possibles exécutés à l'aide de PyBrain sont répertoriés.
Exemple 1
Travailler avec NOR Truth Table et tester son exactitude.
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
norgate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
norgate.addSample((0, 0), (1,))
norgate.addSample((0, 1), (0,))
norgate.addSample((1, 0), (0,))
norgate.addSample((1, 1), (0,))
# Add input and target values to dataset
# Values for NOR truth table
nortrain.addSample((0, 0), (1,))
nortrain.addSample((0, 1), (0,))
nortrain.addSample((1, 0), (0,))
nortrain.addSample((1, 1), (0,))
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, norgate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=nortrain, verbose = True)Production
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218,
0.005227359234093431, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)Exemple 2
Pour les ensembles de données, nous allons utiliser les ensembles de données des ensembles de données sklearn comme indiqué ci-dessous: Reportez-vous aux ensembles de données load_digits de sklearn: scikit-learn.org
Il comporte 10 classes, c'est-à-dire des chiffres à prédire de 0 à 9.
Le total des données d'entrée dans X est de 64.
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10) )
# we are having inputs are 64 dim array and since the digits are from 0-9
the classes considered is 10.
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # adding sample to datasets
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
#Splitting the datasets 25% as testdata and 75% as trained data
# Using splitWithProportion() method on dataset converts the dataset to
#superviseddataset, so we will convert the dataset back to classificationdataset
#as shown in above step.
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(
training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer
)
#creating a network wherein the input and output are used from the training data.
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
#Training the Network
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
#Visualizing the error and validation data
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))Production
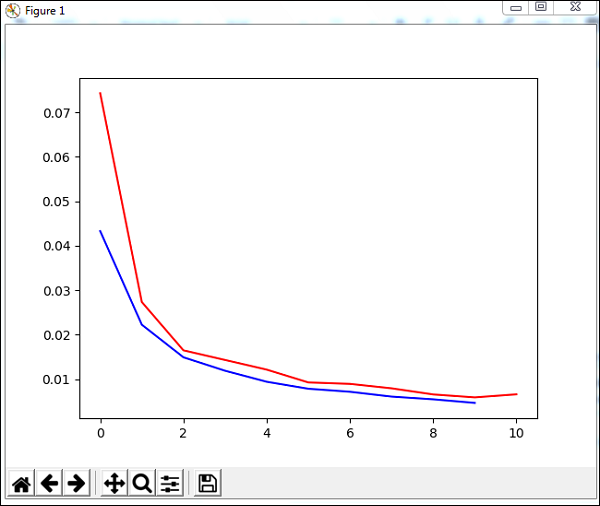
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735