PyBrain - Réseau de test
Dans ce chapitre, nous allons voir un exemple où nous allons former les données et tester les erreurs sur les données entraînées.
Nous allons utiliser des formateurs -
BackpropTrainer
BackpropTrainer est un formateur qui entraîne les paramètres d'un module selon un ensemble de données supervisé ou ClassificationDataSet (potentiellement séquentiel) en rétropropropageant les erreurs (dans le temps).
TrainJusqu'àConvergence
Il est utilisé pour entraîner le module sur l'ensemble de données jusqu'à ce qu'il converge.
Lorsque nous créons un réseau de neurones, il sera formé en fonction des données d'apprentissage qui lui sont données.Maintenant, si le réseau est formé correctement ou non, cela dépendra de la prédiction des données de test testées sur ce réseau.
Voyons un exemple de travail étape par étape où va construire un réseau neuronal et prédire les erreurs d'entraînement, les erreurs de test et les erreurs de validation.
Tester notre réseau
Voici les étapes que nous suivrons pour tester notre réseau -
- Importation de PyBrain et d'autres packages requis
- Créer un ensemble de données de classification
- Fractionnement des ensembles de données 25% en tant que données de test et 75% en tant que données entraînées
- Conversion des données de test et des données formées en tant que ClassificationDataSet
- Créer un réseau neuronal
- Former le réseau
- Visualisation des données d'erreur et de validation
- Pourcentage d'erreur des données de test
Step 1
Importation de PyBrain et d'autres packages requis.
Les packages dont nous avons besoin sont importés comme indiqué ci-dessous -
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravelStep 2
L'étape suivante consiste à créer ClassificationDataSet.
Pour les ensembles de données, nous allons utiliser les ensembles de données des ensembles de données sklearn comme indiqué ci-dessous -
Reportez-vous aux ensembles de données load_digits de sklearn dans le lien ci-dessous -
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
# we are having inputs are 64 dim array and since the digits are from 0-9 the
classes considered is 10.
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # adding sample to datasetsStep 3
Fractionnement des ensembles de données 25% en tant que données de test et 75% en tant que données entraînées -
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)Donc, ici, nous avons utilisé une méthode sur l'ensemble de données appelée splitWithProportion () avec la valeur 0,25, elle divisera l'ensemble de données en 25% en tant que données de test et 75% en tant que données d'entraînement.
Step 4
Conversion des données de test et des données formées en tant que ClassificationDataSet.
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()L'utilisation de la méthode splitWithProportion () sur l'ensemble de données convertit l'ensemble de données en ensemble de données supervisé, nous allons donc reconvertir l'ensemble de données en ensemble de données de classification comme indiqué à l'étape ci-dessus.
Step 5
La prochaine étape consiste à créer un réseau neuronal.
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)Nous créons un réseau dans lequel l'entrée et la sortie sont utilisées à partir des données d'entraînement.
Step 6
Former le réseau
Maintenant, la partie importante consiste à entraîner le réseau sur l'ensemble de données comme indiqué ci-dessous -
trainer = BackpropTrainer(net, dataset=training_data,
momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01)Nous utilisons la méthode BackpropTrainer () et le jeu de données sur le réseau créé.
Step 7
L'étape suivante consiste à visualiser l'erreur et à valider les données.
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()Nous utiliserons une méthode appelée trainUntilConvergence sur les données d'entraînement qui convergeront pour des époques de 10. Elle renverra une erreur d'entraînement et une erreur de validation que nous avons tracées comme indiqué ci-dessous. La ligne bleue montre les erreurs d'entraînement et la ligne rouge montre l'erreur de validation.
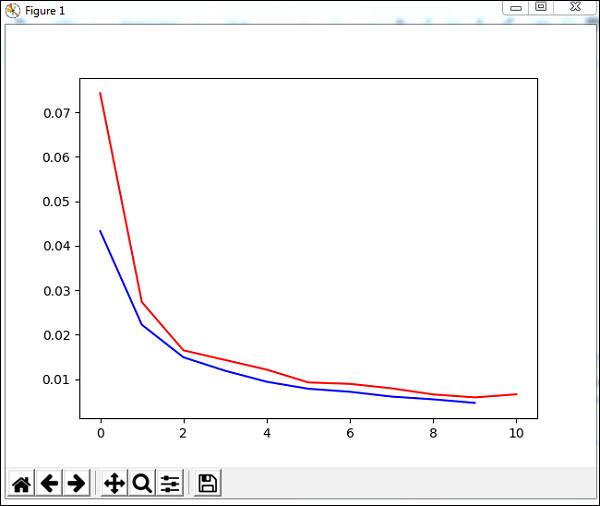
L'erreur totale reçue lors de l'exécution du code ci-dessus est indiquée ci-dessous -
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')L'erreur commence à 0,04 et diminue plus tard pour chaque époque, ce qui signifie que le réseau est formé et s'améliore à chaque époque.
Step 8
Pourcentage d'erreur des données de test
Nous pouvons vérifier le pourcentage d'erreur en utilisant la méthode percentError comme indiqué ci-dessous -
print('Percent Error on
testData:',percentError(trainer.testOnClassData(dataset=test_data),
test_data['class']))Percent Error on testData - 3.34075723830735
Nous obtenons le pourcentage d'erreur, soit 3,34%, ce qui signifie que le réseau neuronal est précis à 97%.
Ci-dessous le code complet -
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,
learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))