डेटा संरचनाएं और एल्गोरिदम - त्वरित गाइड
डेटा संरचना कुशलता से उपयोग करने के लिए डेटा को व्यवस्थित करने का एक व्यवस्थित तरीका है। निम्नलिखित शर्तें एक डेटा संरचना की नींव की शर्तें हैं।
Interface- प्रत्येक डेटा संरचना में एक इंटरफ़ेस होता है। इंटरफ़ेस ऑपरेशन के सेट का प्रतिनिधित्व करता है जो एक डेटा संरचना का समर्थन करता है। एक इंटरफ़ेस केवल समर्थित संचालन की सूची प्रदान करता है, जिस प्रकार के पैरामीटर वे स्वीकार कर सकते हैं और इन कार्यों के प्रकार को वापस कर सकते हैं।
Implementation- कार्यान्वयन एक डेटा संरचना का आंतरिक प्रतिनिधित्व प्रदान करता है। कार्यान्वयन डेटा संरचना के संचालन में उपयोग किए जाने वाले एल्गोरिदम की परिभाषा भी प्रदान करता है।
एक डेटा संरचना के लक्षण
Correctness - डेटा संरचना कार्यान्वयन को इसके इंटरफ़ेस को सही ढंग से लागू करना चाहिए।
Time Complexity - डेटा संरचना के संचालन का समय या निष्पादन समय यथासंभव छोटा होना चाहिए।
Space Complexity - डेटा संरचना ऑपरेशन की मेमोरी का उपयोग यथासंभव कम होना चाहिए।
डेटा संरचना की आवश्यकता
जैसे-जैसे एप्लिकेशन जटिल और डेटा समृद्ध होते जा रहे हैं, तीन सामान्य समस्याएं हैं जो एप्लिकेशन अब-एक-दिन का सामना करती हैं।
Data Search- एक स्टोर की 1 मिलियन (10 6 ) वस्तुओं की एक सूची पर विचार करें । यदि एप्लिकेशन को किसी आइटम को खोजना है, तो उसे खोज को धीमा करने के लिए हर बार 1 मिलियन (10 6 ) आइटम खोजना होगा। जैसे-जैसे डेटा बढ़ता है, खोज धीमी हो जाएगी।
Processor speed - प्रोसेसर की गति हालांकि बहुत अधिक है, सीमित हो जाती है यदि डेटा अरब रिकॉर्ड तक बढ़ता है।
Multiple requests - जैसा कि हजारों उपयोगकर्ता वेब सर्वर पर एक साथ डेटा खोज सकते हैं, यहां तक कि डेटा की खोज करते समय फास्ट सर्वर भी विफल रहता है।
उपर्युक्त समस्याओं को हल करने के लिए, डेटा संरचनाएं बचाव के लिए आती हैं। डेटा को डेटा संरचना में इस तरह से व्यवस्थित किया जा सकता है कि सभी वस्तुओं को खोजने की आवश्यकता नहीं हो सकती है, और आवश्यक डेटा को लगभग तुरंत खोजा जा सकता है।
निष्पादन समय के मामले
ऐसे तीन मामले हैं जो आमतौर पर विभिन्न डेटा संरचना के निष्पादन समय की तुलना सापेक्ष रूप से करने के लिए किया जाता है।
Worst Case- यह वह परिदृश्य है जहां एक विशेष डेटा संरचना ऑपरेशन में अधिकतम समय लग सकता है। यदि किसी ऑपरेशन का सबसे खराब समय ƒ (n) है तो यह ऑपरेशन's (n) समय से अधिक नहीं लेगा जहां represents (n) n के कार्य का प्रतिनिधित्व करता है।
Average Case- यह एक डेटा संरचना के संचालन के औसत निष्पादन समय को दर्शाने वाला परिदृश्य है। यदि कोई कार्रवाई निष्पादन में an (n) समय लेती है, तो m संचालन में m n (n) समय लगेगा।
Best Case- यह एक डेटा संरचना के संचालन के कम से कम संभव निष्पादन समय को दर्शाने वाला परिदृश्य है। यदि कोई ऑपरेशन निष्पादन में an (n) समय लेता है, तो वास्तविक ऑपरेशन को यादृच्छिक संख्या के रूप में समय लग सकता है जो) (n) के रूप में अधिकतम होगा।
मूल शब्दावली
Data - डेटा वैल्यूज़ या मानों का समूह है।
Data Item - डेटा आइटम मूल्यों की एकल इकाई को संदर्भित करता है।
Group Items - डेटा आइटम जिन्हें उप आइटम में विभाजित किया जाता है उन्हें समूह आइटम कहा जाता है।
Elementary Items - जिन डेटा आइटम को विभाजित नहीं किया जा सकता है, उन्हें एलिमेंटरी आइटम कहा जाता है।
Attribute and Entity - एक इकाई वह है जिसमें कुछ विशेषताएँ या गुण होते हैं, जिन्हें मान निर्दिष्ट किया जा सकता है।
Entity Set - समान विशेषताओं की इकाइयां एक इकाई सेट बनाती हैं।
Field - फ़ील्ड एक इकाई की विशेषता का प्रतिनिधित्व करने वाली जानकारी की एक एकल प्राथमिक इकाई है।
Record - रिकॉर्ड किसी दिए गए इकाई के क्षेत्र मूल्यों का एक संग्रह है।
File - फ़ाइल किसी दिए गए निकाय सेट में संस्थाओं के रिकॉर्ड का एक संग्रह है।
यह विकल्प ऑनलाइन का प्रयास करें
C प्रोग्रामिंग लैंग्वेज सीखने के लिए आपको वास्तव में अपना वातावरण सेट करने की आवश्यकता नहीं है। कारण बहुत सरल है, हमने पहले से ही सी प्रोग्रामिंग वातावरण को ऑनलाइन स्थापित किया है, ताकि आप एक ही समय में सभी उपलब्ध उदाहरणों को ऑनलाइन संकलित और निष्पादित कर सकें जब आप अपना सिद्धांत काम कर रहे हों। इससे आप जो पढ़ रहे हैं उस पर विश्वास करते हैं और विभिन्न विकल्पों के साथ परिणाम की जांच कर सकते हैं। किसी भी उदाहरण को संशोधित करने और इसे ऑनलाइन निष्पादित करने के लिए स्वतंत्र महसूस करें।
निम्नलिखित उदाहरण का उपयोग करके देखें Try it नमूना कोड बॉक्स के ऊपरी दाएं कोने पर उपलब्ध विकल्प -
#include <stdio.h>
int main(){
/* My first program in C */
printf("Hello, World! \n");
return 0;
}इस ट्यूटोरियल में दिए गए अधिकांश उदाहरणों के लिए, आपको यह कोशिश विकल्प मिलेगा, इसलिए बस इसका उपयोग करें और अपनी शिक्षा का आनंद लें।
स्थानीय पर्यावरण सेटअप
यदि आप अभी भी C प्रोग्रामिंग लैंग्वेज के लिए अपना वातावरण सेट करने के लिए तैयार हैं, तो आपको अपने कंप्यूटर पर निम्न दो टूल उपलब्ध हैं, (a) टेक्स्ट एडिटर और (b) सी कंपाइलर।
पाठ संपादक
इसका उपयोग आपके प्रोग्राम को टाइप करने के लिए किया जाएगा। कुछ संपादकों के उदाहरणों में विंडोज नोटपैड, ओएस एडिट कमांड, ब्रीफ, एप्सिलॉन, ईएमएसीएस और विम या vi शामिल हैं।
टेक्स्ट एडिटर का नाम और संस्करण अलग-अलग ऑपरेटिंग सिस्टम पर भिन्न हो सकते हैं। उदाहरण के लिए, नोटपैड का उपयोग विंडोज पर किया जाएगा, और vim या vi का उपयोग विंडोज के साथ-साथ लिनक्स या यूनिक्स पर भी किया जा सकता है।
आपके द्वारा अपने संपादक के साथ बनाई गई फाइलों को सोर्स फाइल कहा जाता है और इसमें प्रोग्राम सोर्स कोड होता है। C प्रोग्राम्स के लिए स्रोत फ़ाइलों को आमतौर पर एक्सटेंशन के साथ नामित किया जाता है ".c"।
अपनी प्रोग्रामिंग शुरू करने से पहले, सुनिश्चित करें कि आपके पास एक पाठ संपादक है और आपके पास एक कंप्यूटर प्रोग्राम लिखने के लिए पर्याप्त अनुभव है, इसे एक फ़ाइल में सहेजें, इसे संकलित करें और अंत में इसे निष्पादित करें।
सी कंपाइलर
स्रोत फ़ाइल में लिखा गया स्रोत कोड आपके प्रोग्राम के लिए मानव पठनीय स्रोत है। इसे "संकलित" करने की आवश्यकता है, मशीन भाषा में बदलने के लिए ताकि आपका सीपीयू वास्तव में दिए गए निर्देशों के अनुसार कार्यक्रम को निष्पादित कर सके।
यह C प्रोग्रामिंग लैंग्वेज कंपाइलर आपके सोर्स कोड को अंतिम निष्पादन योग्य प्रोग्राम में संकलित करने के लिए उपयोग किया जाएगा। हम मानते हैं कि आपको प्रोग्रामिंग भाषा संकलक के बारे में बुनियादी ज्ञान है।
सबसे अधिक इस्तेमाल किया जाने वाला और मुफ्त उपलब्ध कंपाइलर GNU C / C ++ कंपाइलर है। अन्यथा, आपके पास एचपी या सोलारिस से कंपाइलर हो सकते हैं यदि आपके पास संबंधित ऑपरेटिंग सिस्टम (ओएस) है।
निम्न अनुभाग आपको विभिन्न ओएस पर GNU C / C ++ कंपाइलर स्थापित करने के बारे में बताता है। हम C / C ++ का एक साथ उल्लेख कर रहे हैं क्योंकि GNU GCC संकलक C और C ++ प्रोग्रामिंग दोनों भाषाओं के लिए काम करता है।
UNIX / Linux पर स्थापना
यदि आप उपयोग कर रहे हैं Linux or UNIX, फिर जांचें कि कमांड लाइन से निम्न कमांड दर्ज करके आपके सिस्टम पर GCC स्थापित है या नहीं -
$ gcc -vयदि आपके पास अपनी मशीन पर GNU कम्पाइलर स्थापित है, तो उसे एक संदेश प्रिंट करना चाहिए जैसे कि निम्नलिखित -
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix = /usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)यदि जीसीसी स्थापित नहीं है, तो आपको इसे उपलब्ध निर्देशों का उपयोग करके स्वयं स्थापित करना होगा https://gcc.gnu.org/install/
यह ट्यूटोरियल लिनक्स पर आधारित लिखा गया है और सभी दिए गए उदाहरणों को लिनक्स सिस्टम के सेंट ओएस फ्लेवर पर संकलित किया गया है।
मैक ओएस पर स्थापना
यदि आप मैक ओएस एक्स का उपयोग करते हैं, तो जीसीसी प्राप्त करने का सबसे आसान तरीका ऐप्पल की वेबसाइट से एक्सकोड विकास पर्यावरण को डाउनलोड करना और सरल इंस्टॉलेशन निर्देशों का पालन करना है। एक बार आपके पास Xcode सेटअप होने के बाद, आप C / C ++ के लिए GNU कंपाइलर का उपयोग कर पाएंगे।
Xcode वर्तमान में developer.apple.com/technologies/tools/ पर उपलब्ध है
विंडोज पर स्थापना
विंडोज पर जीसीसी स्थापित करने के लिए, आपको मिनगॉव को स्थापित करने की आवश्यकता है। MinGW को स्थापित करने के लिए, MinGW होमपेज, www.mingw.org पर जाएं , और MinGW डाउनलोड पृष्ठ के लिंक का अनुसरण करें। MinGW इंस्टालेशन प्रोग्राम का नवीनतम संस्करण डाउनलोड करें, जिसे MinGW- <version> .exe नाम दिया जाना चाहिए।
न्यूनतम मिनट में स्थापित करते समय, आपको gcc-core, gcc-g ++, binutils और MinGW रनटाइम स्थापित करना होगा, लेकिन आप और अधिक स्थापित करना चाह सकते हैं।
अपने MinGW स्थापना के बिन उपनिर्देशिका को अपने में जोड़ें PATH पर्यावरण चर, ताकि आप इन उपकरणों को उनके सरल नामों द्वारा कमांड लाइन पर निर्दिष्ट कर सकें।
जब इंस्टॉलेशन पूरा हो जाता है, तो आप विंडोज कमांड लाइन से gcc, g ++, ar, ranlib, dlltool और कई अन्य GNU टूल्स चला पाएंगे।
एल्गोरिथम एक चरण-दर-चरण प्रक्रिया है, जो वांछित आउटपुट प्राप्त करने के लिए एक निश्चित क्रम में निष्पादित होने वाले निर्देशों के एक सेट को परिभाषित करता है। एल्गोरिदम को आमतौर पर अंतर्निहित भाषाओं से स्वतंत्र बनाया जाता है, अर्थात एक एल्गोरिथ्म को एक से अधिक प्रोग्रामिंग भाषा में लागू किया जा सकता है।
डेटा संरचना के दृष्टिकोण से, एल्गोरिदम की कुछ महत्वपूर्ण श्रेणियां निम्नलिखित हैं -
Search - डेटा संरचना में किसी आइटम को खोजने के लिए एल्गोरिदम।
Sort - एक निश्चित क्रम में आइटम सॉर्ट करने के लिए एल्गोरिदम।
Insert - डेटा संरचना में आइटम सम्मिलित करने के लिए एल्गोरिदम।
Update - डेटा संरचना में किसी मौजूदा आइटम को अपडेट करने के लिए एल्गोरिदम।
Delete - डेटा संरचना से किसी मौजूदा आइटम को हटाने के लिए एल्गोरिदम।
एक एल्गोरिथ्म के लक्षण
सभी प्रक्रियाओं को एक एल्गोरिथ्म नहीं कहा जा सकता है। एक एल्गोरिथ्म में निम्नलिखित विशेषताएं होनी चाहिए -
Unambiguous- एल्गोरिथ्म स्पष्ट और स्पष्ट होना चाहिए। इसके प्रत्येक चरण (या चरण), और उनके इनपुट / आउटपुट स्पष्ट होने चाहिए और केवल एक अर्थ के लिए होने चाहिए।
Input - एक एल्गोरिथ्म में 0 या अधिक अच्छी तरह से परिभाषित इनपुट होना चाहिए।
Output - एक एल्गोरिथ्म में 1 या अधिक अच्छी तरह से परिभाषित आउटपुट होना चाहिए, और वांछित आउटपुट से मेल खाना चाहिए।
Finiteness - चरणों की एक सीमित संख्या के बाद एल्गोरिदम को समाप्त करना चाहिए।
Feasibility - उपलब्ध संसाधनों के साथ व्यवहार्य होना चाहिए।
Independent - एक एल्गोरिथ्म में चरण-दर-चरण निर्देश होना चाहिए, जो किसी भी प्रोग्रामिंग कोड से स्वतंत्र होना चाहिए।
एलगोरिदम कैसे लिखें?
एल्गोरिदम लिखने के लिए कोई अच्छी तरह से परिभाषित मानक नहीं हैं। बल्कि, यह समस्या और संसाधन निर्भर है। एल्गोरिदम कभी भी किसी विशेष प्रोग्रामिंग कोड का समर्थन करने के लिए नहीं लिखा जाता है।
जैसा कि हम जानते हैं कि सभी प्रोग्रामिंग भाषाओं में लूप (जैसे, के लिए, जबकि), प्रवाह-नियंत्रण (यदि-आदि), जैसे बुनियादी कोड निर्माण हैं, तो इन आम निर्माण का उपयोग एल्गोरिदम लिखने के लिए किया जा सकता है।
हम चरण-दर-चरण तरीके से एल्गोरिदम लिखते हैं, लेकिन यह हमेशा ऐसा नहीं होता है। एल्गोरिदम लेखन एक प्रक्रिया है और समस्या डोमेन के अच्छी तरह से परिभाषित होने के बाद निष्पादित की जाती है। यही है, हमें समस्या डोमेन पता होना चाहिए, जिसके लिए हम एक समाधान डिज़ाइन कर रहे हैं।
उदाहरण
आइए एक उदाहरण का उपयोग करके एल्गोरिथ्म-लेखन सीखने की कोशिश करें।
Problem - दो नंबर जोड़ने और परिणाम प्रदर्शित करने के लिए एक एल्गोरिथ्म डिज़ाइन करें।
Step 1 − START
Step 2 − declare three integers a, b & c
Step 3 − define values of a & b
Step 4 − add values of a & b
Step 5 − store output of step 4 to c
Step 6 − print c
Step 7 − STOPएल्गोरिदम प्रोग्रामर को बताते हैं कि प्रोग्राम को कैसे कोड किया जाए। वैकल्पिक रूप से, एल्गोरिथ्म के रूप में लिखा जा सकता है -
Step 1 − START ADD
Step 2 − get values of a & b
Step 3 − c ← a + b
Step 4 − display c
Step 5 − STOPएल्गोरिदम के डिजाइन और विश्लेषण में, आमतौर पर एक एल्गोरिथ्म का वर्णन करने के लिए दूसरी विधि का उपयोग किया जाता है। यह विश्लेषक के लिए सभी अवांछित परिभाषाओं की अनदेखी करने वाले एल्गोरिथम का विश्लेषण करना आसान बनाता है। वह देख सकता है कि किस ऑपरेशन का उपयोग किया जा रहा है और प्रक्रिया कैसे चल रही है।
लिख रहे हैं step numbers, वैकल्पिक है।
हम किसी दिए गए समस्या का समाधान पाने के लिए एक एल्गोरिथ्म डिज़ाइन करते हैं। एक समस्या को एक से अधिक तरीकों से हल किया जा सकता है।
इसलिए, किसी समस्या के लिए कई समाधान एल्गोरिदम निकाले जा सकते हैं। अगला कदम उन प्रस्तावित समाधान एल्गोरिदम का विश्लेषण करना और सर्वोत्तम उपयुक्त समाधान को लागू करना है।
एल्गोरिथम विश्लेषण
एक एल्गोरिथ्म की क्षमता का विश्लेषण दो अलग-अलग चरणों में किया जा सकता है, कार्यान्वयन से पहले और कार्यान्वयन के बाद। वे निम्नलिखित हैं -
A Priori Analysis- यह एक एल्गोरिथ्म का सैद्धांतिक विश्लेषण है। एक एल्गोरिथ्म की दक्षता यह मानकर मापा जाता है कि अन्य सभी कारक, उदाहरण के लिए, प्रोसेसर की गति स्थिर है, और कार्यान्वयन पर कोई प्रभाव नहीं है।
A Posterior Analysis- यह एक एल्गोरिथ्म का एक अनुभवजन्य विश्लेषण है। चयनित एल्गोरिथ्म को प्रोग्रामिंग भाषा का उपयोग करके कार्यान्वित किया जाता है। इसके बाद लक्ष्य कंप्यूटर मशीन पर क्रियान्वित किया जाता है। इस विश्लेषण में, रनिंग टाइम और स्पेस की आवश्यकता जैसे वास्तविक आंकड़े एकत्र किए जाते हैं।
हम एक प्राथमिक एल्गोरिथ्म विश्लेषण के बारे में सीखेंगे । एल्गोरिदम विश्लेषण शामिल विभिन्न कार्यों के निष्पादन या चलने के समय से संबंधित है। किसी ऑपरेशन के चल रहे समय को प्रति ऑपरेशन निष्पादित कंप्यूटर निर्देशों की संख्या के रूप में परिभाषित किया जा सकता है।
एल्गोरिथ्म जटिलता
मान लीजिए X एक एल्गोरिथ्म है और n इनपुट डेटा का आकार, एल्गोरिदम एक्स द्वारा उपयोग किए जाने वाले समय और स्थान दो मुख्य कारक हैं, जो एक्स की दक्षता तय करते हैं।
Time Factor - समय को छँटाई एल्गोरिथ्म में तुलना जैसे प्रमुख संचालन की संख्या की गणना करके मापा जाता है।
Space Factor - एल्गोरिथ्म द्वारा आवश्यक अधिकतम मेमोरी स्पेस की गणना करके अंतरिक्ष को मापा जाता है।
एक एल्गोरिथ्म की जटिलता f(n) एल्गोरिथ्म के संदर्भ में आवश्यक रनिंग टाइम और / या स्टोरेज स्पेस देता है n इनपुट डेटा के आकार के रूप में।
अंतरिक्ष जटिलता
एक एल्गोरिथ्म की अंतरिक्ष जटिलता एल्गोरिदम द्वारा अपने जीवन चक्र में आवश्यक मेमोरी स्पेस की मात्रा का प्रतिनिधित्व करती है। एक एल्गोरिथ्म के लिए आवश्यक स्थान निम्नलिखित दो घटकों के योग के बराबर है -
एक निश्चित भाग जो कुछ डेटा और चर को संग्रहीत करने के लिए आवश्यक स्थान है, जो समस्या के आकार से स्वतंत्र है। उदाहरण के लिए, सरल चर और स्थिरांक का उपयोग किया जाता है, कार्यक्रम का आकार, आदि।
एक चर हिस्सा चर के लिए आवश्यक स्थान है, जिसका आकार समस्या के आकार पर निर्भर करता है। उदाहरण के लिए, डायनामिक मेमोरी एलोकेशन, रिकर्सन स्टैक स्पेस आदि।
किसी भी एल्गोरिथ्म P का स्पेस जटिलता S (P) S (P) = C + SP (I) है, जहां C निश्चित भाग है और S (I) एल्गोरिथ्म का चर भाग है, जो कि उदाहरण विशेषता I पर निर्भर करता है। एक सरल उदाहरण है जो अवधारणा को समझाने की कोशिश करता है -
Algorithm: SUM(A, B)
Step 1 - START
Step 2 - C ← A + B + 10
Step 3 - Stopयहाँ हमारे पास तीन चर A, B, और C और एक स्थिर है। इसलिए S (P) = 1 + 3. अब, स्पेस दिए गए वैरिएबल और स्थिर प्रकार के डेटा प्रकारों पर निर्भर करता है और इसे उसी के अनुसार गुणा किया जाएगा।
समय जटिलता
एक एल्गोरिथ्म की समय जटिलता एल्गोरिदम को पूरा करने के लिए चलाने के लिए आवश्यक समय की मात्रा का प्रतिनिधित्व करती है। समय की आवश्यकताओं को एक संख्यात्मक कार्य T (n) के रूप में परिभाषित किया जा सकता है, जहां T (n) को चरणों की संख्या के रूप में मापा जा सकता है, बशर्ते प्रत्येक चरण में निरंतर समय की खपत हो।
उदाहरण के लिए, दो n-बिट पूर्णांकों के अलावा लेता है nकदम। नतीजतन, कुल कम्प्यूटेशनल समय T (n) = c where n है, जहां c दो बिट्स के जोड़ के लिए लिया गया समय है। यहां, हम मानते हैं कि इनपुट आकार बढ़ने के साथ टी (एन) रैखिक रूप से बढ़ता है।
एक एल्गोरिथ्म का असममित विश्लेषण गणितीय रनिंग को परिभाषित करने / इसके रन-टाइम प्रदर्शन को तैयार करने के लिए संदर्भित करता है। एसिम्प्टोटिक विश्लेषण का उपयोग करते हुए, हम एक एल्गोरिथ्म का सबसे अच्छा मामला, औसत मामला और सबसे खराब स्थिति का अच्छी तरह से निष्कर्ष निकाल सकते हैं।
असममित विश्लेषण इनपुट बाध्य है अर्थात, यदि एल्गोरिथ्म के लिए कोई इनपुट नहीं है, तो यह एक निरंतर समय में काम करने के लिए संपन्न होता है। "इनपुट" के अलावा अन्य सभी कारकों को स्थिर माना जाता है।
असममित विश्लेषण का तात्पर्य संगणना की गणितीय इकाइयों में किसी भी संचालन के चलने के समय की गणना करना है। उदाहरण के लिए, एक ऑपरेशन के रनिंग समय की गणना f (n) के रूप में की जाती है और दूसरे ऑपरेशन के लिए इसे g (n 2 ) के रूप में गणना की जाती है । इसका मतलब यह है कि पहले संचालन समय में वृद्धि के साथ रैखिक वृद्धि होगीn और दूसरे ऑपरेशन के चलने का समय तेजी से बढ़ेगा जब nबढ़ती है। इसी तरह, दोनों ऑपरेशंस का रनिंग टाइम लगभग एक जैसा होगाn काफी छोटा है।
आमतौर पर एक एल्गोरिथ्म के लिए आवश्यक समय तीन प्रकारों के अंतर्गत आता है -
Best Case - कार्यक्रम के निष्पादन के लिए न्यूनतम समय की आवश्यकता।
Average Case - कार्यक्रम के निष्पादन के लिए औसत समय आवश्यक है।
Worst Case - कार्यक्रम के निष्पादन के लिए अधिकतम समय की आवश्यकता।
असममित संकेतन
एल्गोरिथ्म के चल रहे समय की जटिलता की गणना करने के लिए आमतौर पर उपयोग किए जाने वाले स्पर्शोन्मुख नोटेशन निम्नलिखित हैं।
- Ο संकेतन
- Ω संकेतन
- θ संकेतन
बिग ओह संकेतन, Ο
नोटिफिकेशन express (n) एक एल्गोरिथ्म के चलने के समय की ऊपरी सीमा को व्यक्त करने का औपचारिक तरीका है। यह सबसे खराब स्थिति समय जटिलता को मापता है या एक एल्गोरिथ्म को पूरा करने में संभवतः सबसे लंबा समय लगता है।
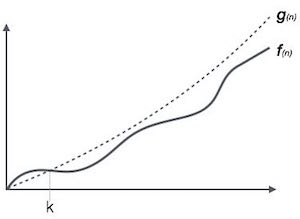
उदाहरण के लिए, एक फ़ंक्शन के लिए f(n)
Ο(f(n)) = { g(n) : there exists c > 0 and n0 such that f(n) ≤ c.g(n) for all n > n0. }ओमेगा संकेतन, Ω
नोटिफिकेशन express (n) एक एल्गोरिथ्म के रनिंग टाइम के निचले बाउंड को व्यक्त करने का औपचारिक तरीका है। यह सबसे अच्छा मामला समय जटिलता मापता है या सबसे अच्छा समय एक एल्गोरिथ्म संभवतः पूरा करने के लिए ले जा सकता है।
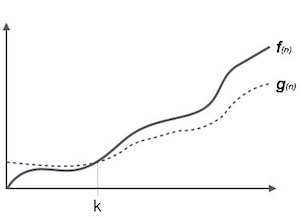
उदाहरण के लिए, एक फ़ंक्शन के लिए f(n)
Ω(f(n)) ≥ { g(n) : there exists c > 0 and n0 such that g(n) ≤ c.f(n) for all n > n0. }थीटा संकेतन, θ
नोटेशन express (n) एक एल्गोरिथ्म के चलने के समय की निचली सीमा और ऊपरी सीमा दोनों को व्यक्त करने का औपचारिक तरीका है। इसे निम्नानुसार दर्शाया गया है -
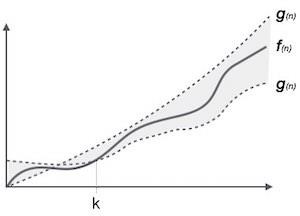
θ(f(n)) = { g(n) if and only if g(n) = Ο(f(n)) and g(n) = Ω(f(n)) for all n > n0. }आम विषमता संबंधी सूचनाएं
निम्नलिखित कुछ सामान्य स्पर्शोन्मुख सूचनाओं की एक सूची है -
| स्थिर | - | Ο (1) |
| लघुगणक | - | N (लॉग एन) |
| रैखिक | - | Ο (एन) |
| n लॉग एन | - | N (एन लॉग एन) |
| द्विघात | - | 2 (एन 2 ) |
| घन | - | 3 (एन 3 ) |
| बहुपद | - | एन n (1) |
| घातीय | - | 2 n (एन) |
एक एल्गोरिथ्म को किसी समस्या के लिए इष्टतम समाधान प्राप्त करने के लिए डिज़ाइन किया गया है। लालची एल्गोरिथ्म दृष्टिकोण में, दिए गए समाधान डोमेन से निर्णय किए जाते हैं। लालची होने के नाते, निकटतम समाधान जो एक इष्टतम समाधान प्रदान करता है, चुना जाता है।
लालची एल्गोरिदम एक स्थानीयकृत इष्टतम समाधान खोजने की कोशिश करते हैं, जो अंततः वैश्विक रूप से अनुकूलित समाधान हो सकता है। हालांकि, आमतौर पर लालची एल्गोरिदम वैश्विक रूप से अनुकूलित समाधान प्रदान नहीं करते हैं।
गिनती के सिक्के
यह समस्या कम से कम संभव सिक्कों को चुनकर वांछित मूल्य की गणना करना है और लालची दृष्टिकोण एल्गोरिदम को सबसे बड़ा संभव सिक्का लेने के लिए मजबूर करता है। यदि हमें, 1, 2, 5 और 10 के सिक्के प्रदान किए जाते हैं और हमें then 18 की गिनती करने के लिए कहा जाता है तो लालची प्रक्रिया होगी -
1 - एक Select 10 का सिक्का चुनें, शेष गिनती 8 है
2 - फिर एक coin 5 का सिक्का चुनें, शेष गिनती 3 है
3 - फिर एक coin 2 का सिक्का चुनें, शेष गिनती 1 है
4 - और अंत में, एक ₹ 1 के सिक्कों का चयन समस्या को हल करता है
हालांकि, यह ठीक काम कर रहा है, इस गिनती के लिए हमें केवल 4 सिक्के लेने होंगे। लेकिन अगर हम समस्या को थोड़ा बदलते हैं तो एक ही दृष्टिकोण एक ही इष्टतम परिणाम का उत्पादन करने में सक्षम नहीं हो सकता है।
मुद्रा प्रणाली के लिए, जहां हमारे पास 1, 7, 10 मूल्य के सिक्के हैं, मूल्य 18 के लिए सिक्के गिनना बिल्कुल इष्टतम होगा, लेकिन 15 की तरह गिनती के लिए, यह आवश्यक से अधिक सिक्कों का उपयोग कर सकता है। उदाहरण के लिए, लालची दृष्टिकोण 10 + 1 + 1 + 1 + 1 + 1, कुल 6 सिक्कों का उपयोग करेगा। जबकि केवल 3 सिक्कों (7 + 7 + 1) का उपयोग करके एक ही समस्या को हल किया जा सकता है
इसलिए, हम यह निष्कर्ष निकाल सकते हैं कि लालची दृष्टिकोण तत्काल अनुकूलित समाधान चुनता है और विफल हो सकता है जहां वैश्विक अनुकूलन एक प्रमुख चिंता का विषय है।
उदाहरण
अधिकांश नेटवर्किंग एल्गोरिदम लालची दृष्टिकोण का उपयोग करते हैं। यहाँ उनमें से कुछ की एक सूची है -
- ट्रैवलिंग सेल्समैन की समस्या
- प्राइम की मिनिमल स्पैनिंग ट्री एलगोरिदम
- क्रुश्कल की मिनिमल स्पैनिंग ट्री एलगोरिदम
- दिज्क्स्ट्रा का मिनिमल स्पैनिंग ट्री एलगोरिदम
- ग्राफ - नक्शा रंग
- ग्राफ - वर्टेक्स कवर
- क्लेश समस्या
- नौकरी निर्धारण समस्या
ऐसी कई समस्याएं हैं जो एक इष्टतम समाधान खोजने के लिए लालची दृष्टिकोण का उपयोग करती हैं।
विभाजित और विजेता दृष्टिकोण में, हाथ में समस्या, छोटी उप-समस्याओं में विभाजित होती है और फिर प्रत्येक समस्या को स्वतंत्र रूप से हल किया जाता है। जब हम उप-प्रकारों को छोटी-छोटी उप-समस्याओं में विभाजित करते रहते हैं, तो हम अंततः एक ऐसे चरण में पहुँच सकते हैं जहाँ कोई अधिक विभाजन संभव नहीं है। वे "परमाणु" सबसे छोटी संभव उप-समस्या (भिन्न) हल कर रहे हैं। सभी उप-समस्याओं का समाधान मूल समस्या का समाधान प्राप्त करने के लिए अंत में विलय कर दिया जाता है।
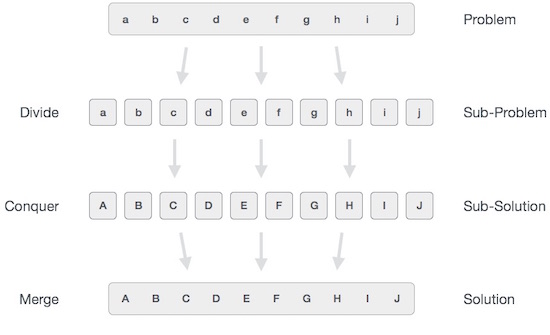
मोटे तौर पर, हम समझ सकते हैं divide-and-conquer तीन-चरणीय प्रक्रिया में दृष्टिकोण।
फूट डालो / तोड़
इस कदम में समस्या को छोटी उप-समस्याओं में तोड़ना शामिल है। उप-समस्याओं को मूल समस्या के एक भाग का प्रतिनिधित्व करना चाहिए। यह कदम आम तौर पर समस्या को विभाजित करने के लिए एक पुनरावर्ती दृष्टिकोण लेता है जब तक कि कोई उप-समस्या आगे विभाज्य न हो। इस स्तर पर, उप-समस्याएं प्रकृति में परमाणु बन जाती हैं लेकिन फिर भी वास्तविक समस्या के कुछ हिस्से का प्रतिनिधित्व करती हैं।
जीत / समाधान
इस चरण को हल करने के लिए बहुत छोटी उप-समस्याएं प्राप्त होती हैं। आमतौर पर, इस स्तर पर, समस्याओं को अपने दम पर 'हल' माना जाता है।
मर्ज / कम्बाइन
जब छोटी उप-समस्याएं हल हो जाती हैं, तो यह चरण उन्हें पुन: संयोजित करता है जब तक कि वे मूल समस्या का हल नहीं बनाते हैं। यह एल्गोरिदमिक दृष्टिकोण पुनरावर्ती रूप से काम करता है और जीतता है और मर्ज किए गए कदम इतने करीब काम करते हैं कि वे एक के रूप में दिखाई देते हैं।
उदाहरण
निम्नलिखित कंप्यूटर एल्गोरिदम पर आधारित हैं divide-and-conquer प्रोग्रामिंग दृष्टिकोण -
- मर्ज़ सॉर्ट
- जल्दी से सुलझाएं
- द्विआधारी खोज
- स्ट्रैसन की मैट्रिक्स गुणन
- निकटतम जोड़ी (अंक)
कंप्यूटर की किसी भी समस्या को हल करने के लिए विभिन्न तरीके उपलब्ध हैं, लेकिन उल्लिखित विभाजन और विजय दृष्टिकोण का एक अच्छा उदाहरण है।
डायनेमिक प्रोग्रामिंग अप्रोच छोटी और फिर भी छोटी उप-समस्याओं में समस्या को तोड़ने में विभाजित करने और जीतने के समान है। लेकिन इसके विपरीत, विभाजित और जीतना, इन उप-समस्याओं को स्वतंत्र रूप से हल नहीं किया जाता है। बल्कि, इन छोटी उप-समस्याओं के परिणामों को याद किया जाता है और उप-समस्याओं के समान या अतिव्यापी के लिए उपयोग किया जाता है।
डायनामिक प्रोग्रामिंग का उपयोग किया जाता है जहां हमें समस्याएं होती हैं, जिन्हें समान उप-समस्याओं में विभाजित किया जा सकता है, ताकि उनके परिणामों का फिर से उपयोग किया जा सके। अधिकतर, इन एल्गोरिदम का उपयोग अनुकूलन के लिए किया जाता है। इन-हैंड सब-प्रॉब्लम को हल करने से पहले डायनेमिक अल्गोरिदम पहले से हल की गई उप-समस्याओं के परिणामों की जांच करने की कोशिश करेगा। सबसे अच्छा समाधान प्राप्त करने के लिए उप-समस्याओं के समाधान को संयुक्त किया जाता है।
तो हम कह सकते हैं कि -
समस्या को छोटे अतिव्यापी उप-समस्या में विभाजित करने में सक्षम होना चाहिए।
छोटी उप-समस्याओं के इष्टतम समाधान का उपयोग करके एक इष्टतम समाधान प्राप्त किया जा सकता है।
डायनामिक एल्गोरिदम मेमोइज़ेशन का उपयोग करते हैं।
तुलना
लालची एल्गोरिदम के विपरीत, जहां स्थानीय अनुकूलन को संबोधित किया जाता है, गतिशील एल्गोरिदम समस्या के समग्र अनुकूलन के लिए प्रेरित होते हैं।
एल्गोरिदम को विभाजित करने और जीतने के विपरीत, जहां समाधानों को एक समग्र समाधान प्राप्त करने के लिए संयुक्त किया जाता है, गतिशील एल्गोरिदम एक छोटी उप-समस्या के आउटपुट का उपयोग करते हैं और फिर एक बड़ी उप-समस्या को अनुकूलित करने का प्रयास करते हैं। डायनामिक एल्गोरिदम पहले से हल की गई उप-समस्याओं के आउटपुट को याद रखने के लिए मेमोइज़ेशन का उपयोग करते हैं।
उदाहरण
निम्नलिखित कंप्यूटर समस्याओं को गतिशील प्रोग्रामिंग दृष्टिकोण का उपयोग करके हल किया जा सकता है -
- फाइबोनैचि संख्या श्रृंखला
- नैकपैक समस्या
- हनोई का टावर
- फ्लॉयड-वारशॉल द्वारा सभी जोड़ी सबसे छोटा रास्ता
- दिज्क्स्त्र द्वारा सबसे छोटा रास्ता
- प्रोजेक्ट शेड्यूलिंग
डायनेमिक प्रोग्रामिंग का उपयोग टॉप-डाउन और बॉटम-अप दोनों तरीके से किया जा सकता है। और हां, ज्यादातर समय, पिछले समाधान आउटपुट का जिक्र सीपीयू चक्रों के संदर्भ में पुनर्संयोजन की तुलना में सस्ता है।
यह अध्याय डेटा संरचना से संबंधित मूल शब्दों की व्याख्या करता है।
डेटा परिभाषा
डेटा परिभाषा एक विशेष डेटा को निम्नलिखित विशेषताओं के साथ परिभाषित करती है।
Atomic - परिभाषा को एक अवधारणा को परिभाषित करना चाहिए।
Traceable - परिभाषा को कुछ डेटा तत्व में मैप करने में सक्षम होना चाहिए।
Accurate - परिभाषा असंदिग्ध होनी चाहिए।
Clear and Concise - परिभाषा समझ में आनी चाहिए।
डेटा ऑब्जेक्ट
डेटा ऑब्जेक्ट एक ऑब्जेक्ट का प्रतिनिधित्व करता है जिसमें डेटा होता है।
डाटा प्रकार
डेटा प्रकार विभिन्न प्रकार के डेटा जैसे कि पूर्णांक, स्ट्रिंग, आदि को वर्गीकृत करने का एक तरीका है जो उन मानों को निर्धारित करता है जिनका उपयोग इसी प्रकार के डेटा के साथ किया जा सकता है, उसी प्रकार के डेटा पर किए जाने वाले ऑपरेशन के प्रकार। दो डेटा प्रकार हैं -
- अंतर्निहित डेटा प्रकार
- व्युत्पन्न डेटा प्रकार
अंतर्निहित डेटा प्रकार
वे डेटा प्रकार जिनके लिए किसी भाषा में अंतर्निहित समर्थन है, अंतर्निहित डेटा प्रकारों के रूप में जाना जाता है। उदाहरण के लिए, अधिकांश भाषाएँ निम्नलिखित अंतर्निहित डेटा प्रकार प्रदान करती हैं।
- Integers
- बूलियन (सच्चा, झूठा)
- फ्लोटिंग (दशमलव संख्या)
- चरित्र और स्ट्रिंग्स
व्युत्पन्न डेटा प्रकार
वे डेटा प्रकार जो स्वतंत्र रूप से कार्यान्वित हो रहे हैं क्योंकि वे एक या दूसरे तरीके से कार्यान्वित किए जा सकते हैं जिन्हें व्युत्पन्न डेटा प्रकार के रूप में जाना जाता है। ये डेटा प्रकार आम तौर पर प्राथमिक या बिल्ट-इन डेटा प्रकारों के संयोजन और उन पर संबंधित संचालन द्वारा बनाए जाते हैं। उदाहरण के लिए -
- List
- Array
- Stack
- Queue
मूलभूत क्रियाएं
डेटा संरचनाओं में डेटा को कुछ कार्यों द्वारा संसाधित किया जाता है। विशेष रूप से चुनी गई डेटा संरचना काफी हद तक ऑपरेशन की आवृत्ति पर निर्भर करती है जिसे डेटा संरचना पर निष्पादित करने की आवश्यकता होती है।
- Traversing
- Searching
- Insertion
- Deletion
- Sorting
- Merging
एरे एक कंटेनर है जो वस्तुओं की एक निश्चित संख्या को पकड़ सकता है और ये आइटम एक ही प्रकार के होने चाहिए। अधिकांश डेटा संरचनाएं अपने एल्गोरिदम को लागू करने के लिए सरणियों का उपयोग करती हैं। ऐरे की अवधारणा को समझने के लिए महत्वपूर्ण शर्तें निम्नलिखित हैं।
Element - एक सरणी में संग्रहीत प्रत्येक आइटम को एक तत्व कहा जाता है।
Index - एरे में किसी तत्व के प्रत्येक स्थान पर एक संख्यात्मक सूचकांक होता है, जिसका उपयोग तत्व की पहचान करने के लिए किया जाता है।
ऐरे प्रतिनिधित्व
विभिन्न भाषाओं में विभिन्न तरीकों से ऐरे को घोषित किया जा सकता है। चित्रण के लिए, आइए C सरणी घोषणा लें।

विभिन्न भाषाओं में विभिन्न तरीकों से ऐरे को घोषित किया जा सकता है। चित्रण के लिए, आइए C सरणी घोषणा लें।
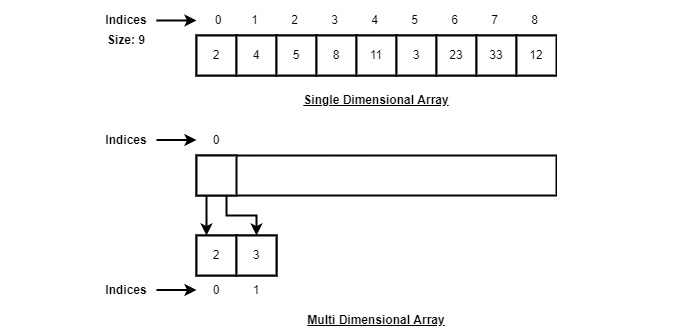
उपरोक्त उदाहरण के अनुसार, निम्नलिखित महत्वपूर्ण बिंदुओं पर विचार किया जाना है।
इंडेक्स 0 से शुरू होता है।
ऐरे की लंबाई 10 है जिसका मतलब है कि यह 10 तत्वों को संग्रहीत कर सकता है।
प्रत्येक तत्व को इसके सूचकांक के माध्यम से पहुँचा जा सकता है। उदाहरण के लिए, हम इंडेक्स 6 में 9 के रूप में एक तत्व ला सकते हैं।
मूलभूत क्रियाएं
एक सरणी द्वारा समर्थित मूल संचालन निम्नलिखित हैं।
Traverse - सभी ऐरे एलिमेंट को एक-एक करके प्रिंट करें।
Insertion - दिए गए इंडेक्स में एक तत्व जोड़ता है।
Deletion - दिए गए इंडेक्स में एक तत्व को हटाता है।
Search - दिए गए इंडेक्स का उपयोग करके या मान द्वारा एक तत्व खोजता है।
Update - दिए गए इंडेक्स में एक तत्व को अपडेट करता है।
C में, जब किसी सरणी को आकार के साथ आरंभीकृत किया जाता है, तो यह निम्नलिखित क्रम में अपने तत्वों को डिफॉल्ट मान प्रदान करता है।
| डाटा प्रकार | डिफ़ॉल्ट मान |
|---|---|
| bool | असत्य |
| चार | 0 |
| पूर्णांक | 0 |
| नाव | 0.0 |
| दोहरा | 0.0f |
| शून्य | |
| wchar_t | 0 |
ट्रैवर्स ऑपरेशन
यह ऑपरेशन एक एरे के तत्वों के माध्यम से पार करना है।
उदाहरण
निम्नलिखित प्रोग्राम ट्रैवर्स और एरे के तत्वों को प्रिंट करता है:
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}जब हम उपरोक्त कार्यक्रम को संकलित और निष्पादित करते हैं, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
उत्पादन
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8निवेशन ऑपरेशन
इन्सर्ट ऑपरेशन एक या एक से अधिक डेटा एलिमेंट्स को अरै में सम्मिलित करना है। आवश्यकता के आधार पर, सरणी के आरंभ, अंत या किसी दिए गए सूचकांक में एक नया तत्व जोड़ा जा सकता है।
यहां, हम सम्मिलन ऑपरेशन का एक व्यावहारिक कार्यान्वयन देखते हैं, जहां हम सरणी के अंत में डेटा जोड़ते हैं -
उदाहरण
निम्नलिखित एल्गोरिथ्म का कार्यान्वयन निम्नलिखित है -
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
n = n + 1;
while( j >= k) {
LA[j+1] = LA[j];
j = j - 1;
}
LA[k] = item;
printf("The array elements after insertion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}जब हम उपरोक्त कार्यक्रम को संकलित और निष्पादित करते हैं, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
उत्पादन
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after insertion :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 10
LA[4] = 7
LA[5] = 8सरणी सम्मिलन ऑपरेशन की अन्य विविधताओं के लिए यहां क्लिक करें
विलोपन ऑपरेशन
विलोपन से तात्पर्य किसी मौजूदा तत्व को सरणी से हटाने और सरणी के सभी तत्वों को फिर से व्यवस्थित करने से है।
कलन विधि
विचार करें LA के साथ एक रैखिक सरणी है N तत्वों और K एक सकारात्मक पूर्णांक है ऐसा K<=N। एलए के K वें स्थान पर उपलब्ध तत्व को हटाने के लिए एल्गोरिथ्म निम्नलिखित है ।
1. Start
2. Set J = K
3. Repeat steps 4 and 5 while J < N
4. Set LA[J] = LA[J + 1]
5. Set J = J+1
6. Set N = N-1
7. Stopउदाहरण
निम्नलिखित एल्गोरिथ्म का कार्यान्वयन निम्नलिखित है -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
j = k;
while( j < n) {
LA[j-1] = LA[j];
j = j + 1;
}
n = n -1;
printf("The array elements after deletion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}जब हम उपरोक्त कार्यक्रम को संकलित और निष्पादित करते हैं, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
उत्पादन
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after deletion :
LA[0] = 1
LA[1] = 3
LA[2] = 7
LA[3] = 8सर्च ऑपरेशन
आप इसके मूल्य या इसके सूचकांक के आधार पर एक सरणी तत्व की खोज कर सकते हैं।
कलन विधि
विचार करें LA के साथ एक रैखिक सरणी है N तत्वों और K एक सकारात्मक पूर्णांक है ऐसा K<=N। अनुक्रमिक खोज का उपयोग करके ITEM के मान के साथ एक तत्व को खोजने के लिए एल्गोरिथ्म निम्नलिखित है।
1. Start
2. Set J = 0
3. Repeat steps 4 and 5 while J < N
4. IF LA[J] is equal ITEM THEN GOTO STEP 6
5. Set J = J +1
6. PRINT J, ITEM
7. Stopउदाहरण
निम्नलिखित एल्गोरिथ्म का कार्यान्वयन निम्नलिखित है -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int item = 5, n = 5;
int i = 0, j = 0;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
while( j < n){
if( LA[j] == item ) {
break;
}
j = j + 1;
}
printf("Found element %d at position %d\n", item, j+1);
}जब हम उपरोक्त कार्यक्रम को संकलित और निष्पादित करते हैं, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
उत्पादन
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
Found element 5 at position 3अद्यतन अद्यतन करें
अद्यतन ऑपरेशन किसी दिए गए इंडेक्स में सरणी से मौजूदा तत्व को अपडेट करने के लिए संदर्भित करता है।
कलन विधि
विचार करें LA के साथ एक रैखिक सरणी है N तत्वों और K एक सकारात्मक पूर्णांक है ऐसा K<=N। एलए के K वें स्थान पर उपलब्ध तत्व को अपडेट करने के लिए एल्गोरिथ्म निम्नलिखित है ।
1. Start
2. Set LA[K-1] = ITEM
3. Stopउदाहरण
निम्नलिखित एल्गोरिथ्म का कार्यान्वयन निम्नलिखित है -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5, item = 10;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
LA[k-1] = item;
printf("The array elements after updation :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}जब हम उपरोक्त कार्यक्रम को संकलित और निष्पादित करते हैं, तो यह निम्नलिखित परिणाम उत्पन्न करता है -
उत्पादन
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after updation :
LA[0] = 1
LA[1] = 3
LA[2] = 10
LA[3] = 7
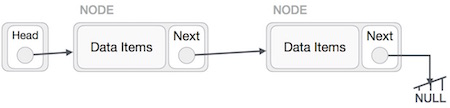
LA[4] = 8एक लिंक की गई सूची डेटा संरचनाओं का एक अनुक्रम है, जो लिंक के माध्यम से एक साथ जुड़े हुए हैं।
लिंक्ड लिस्ट उन लिंक्स का एक क्रम है जिसमें आइटम होते हैं। प्रत्येक लिंक में दूसरे लिंक का कनेक्शन होता है। लिंक की गई सूची सरणी के बाद दूसरी सबसे अधिक उपयोग की जाने वाली डेटा संरचना है। लिंक्ड लिस्ट की अवधारणा को समझने के लिए महत्वपूर्ण शर्तें निम्नलिखित हैं।
Link - लिंक की गई सूची के प्रत्येक लिंक में एक तत्व नामक एक डेटा संग्रहीत किया जा सकता है।
Next - लिंक्ड लिस्ट के प्रत्येक लिंक में नेक्सट नामक अगली लिंक का लिंक होता है।
LinkedList - एक लिंक की गई सूची में पहले नाम की पहली कड़ी का कनेक्शन होता है।
लिंक्ड सूची प्रतिनिधित्व
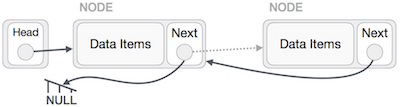
लिंक की गई सूची को नोड्स की एक श्रृंखला के रूप में देखा जा सकता है, जहां प्रत्येक नोड अगले नोड को इंगित करता है।

उपरोक्त उदाहरण के अनुसार, निम्नलिखित महत्वपूर्ण बिंदुओं पर विचार किया जाना है।
लिंक्ड लिस्ट में एक लिंक एलिमेंट होता है जिसे पहले कहा जाता है।
प्रत्येक लिंक एक डेटा फ़ील्ड (ओं) को ले जाता है और एक लिंक फ़ील्ड जिसे अगला कहा जाता है।
प्रत्येक लिंक अपने अगले लिंक का उपयोग करके अपने अगले लिंक के साथ जुड़ा हुआ है।
अंतिम लिंक सूची के अंत को चिह्नित करने के लिए अशक्त के रूप में एक लिंक करता है।
लिंक्ड सूची के प्रकार
निम्नलिखित विभिन्न प्रकार की लिंक की गई सूची हैं।
Simple Linked List - आइटम नेविगेशन केवल आगे है।
Doubly Linked List - आइटम को आगे और पीछे नेविगेट किया जा सकता है।
Circular Linked List - अंतिम आइटम में पहले तत्व का लिंक होता है और अगले तत्व में पिछले तत्व का लिंक होता है।
मूलभूत क्रियाएं
एक सूची द्वारा समर्थित मूल संचालन निम्नलिखित हैं।
Insertion - सूची की शुरुआत में एक तत्व जोड़ता है।
Deletion - सूची की शुरुआत में एक तत्व को हटाता है।
Display - पूरी सूची प्रदर्शित करता है।
Search - दिए गए कुंजी का उपयोग करके एक तत्व खोजता है।
Delete - दिए गए कुंजी का उपयोग करके एक तत्व को हटाता है।
निवेशन ऑपरेशन
लिंक की गई सूची में एक नया नोड जोड़ना एक से अधिक कदम गतिविधि है। हम इसे यहाँ आरेखों के साथ सीखेंगे। सबसे पहले, एक ही संरचना का उपयोग करके एक नोड बनाएं और उस स्थान को ढूंढें जहां इसे डाला जाना है।

कल्पना कीजिए कि हम एक नोड सम्मिलित कर रहे हैं B (न्यूनोड), के बीच A (वामनोड) और C(RightNode)। फिर B.next to C - को इंगित करें।
NewNode.next −> RightNode;यह इस तरह दिखना चाहिए -

अब, बाईं ओर अगला नोड नए नोड को इंगित करना चाहिए।
LeftNode.next −> NewNode;
यह दोनों के बीच में नया नोड रखेगा। नई सूची इस तरह दिखनी चाहिए -

यदि सूची की शुरुआत में नोड डाला जा रहा है तो इसी तरह के कदम उठाए जाने चाहिए। इसे अंत में सम्मिलित करते समय, सूची के दूसरे अंतिम नोड को नए नोड को इंगित करना चाहिए और नया नोड NULL को इंगित करेगा।
विलोपन ऑपरेशन
हटाव भी एक से अधिक कदम प्रक्रिया है। हम सचित्र प्रतिनिधित्व के साथ सीखेंगे। सबसे पहले, खोज एल्गोरिदम का उपयोग करके हटाए जाने वाले लक्ष्य नोड का पता लगाएं।

लक्ष्य नोड के बाएं (पिछले) नोड को अब लक्ष्य नोड के अगले नोड को इंगित करना चाहिए -
LeftNode.next −> TargetNode.next;
यह उस लिंक को हटा देगा जो लक्ष्य नोड को इंगित कर रहा था। अब, निम्न कोड का उपयोग करके, हम लक्ष्य नोड को इंगित कर रहे हैं को हटा देंगे।
TargetNode.next −> NULL;
हमें हटाए गए नोड का उपयोग करने की आवश्यकता है। हम इसे स्मृति में रख सकते हैं अन्यथा हम केवल मेमोरी को हटा सकते हैं और लक्ष्य नोड को पूरी तरह से मिटा सकते हैं।

रिवर्स ऑपरेशन
यह ऑपरेशन एक संपूर्ण है। हमें अंतिम नोड को हेड नोड द्वारा इंगित करने और संपूर्ण लिंक की गई सूची को उलटने की आवश्यकता है।
सबसे पहले, हम सूची के अंत तक चलते हैं। यह NULL को इंगित होना चाहिए। अब, हम इसे इसके पिछले नोड की ओर इंगित करेंगे -
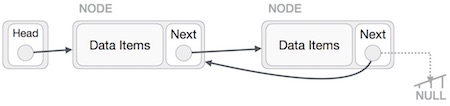
हमें यह सुनिश्चित करना होगा कि अंतिम नोड अंतिम नोड नहीं है। तो हमारे पास कुछ अस्थायी नोड होंगे, जो सिर के पिछले नोड की ओर इशारा करते हुए दिखते हैं। अब, हम सभी बाईं ओर के नोड्स को उनके पिछले नोड्स को एक-एक करके इंगित करेंगे।
सिर के नोड द्वारा इंगित किए गए नोड (पहले नोड) को छोड़कर, सभी नोड्स को अपने पूर्ववर्ती को इंगित करना चाहिए, जिससे उन्हें अपना नया उत्तराधिकारी बनाया जा सके। पहला नोड NULL को इंगित करेगा।

हम अस्थायी नोड का उपयोग करके हेड नोड बिंदु को नए पहले नोड में बनाएंगे।
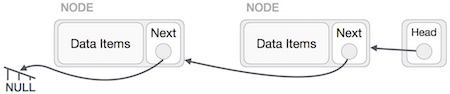
लिंक की गई सूची अब उलट है। सी प्रोग्रामिंग भाषा में लिंक्ड सूची कार्यान्वयन को देखने के लिए, कृपया यहां क्लिक करें ।
डाउनली लिंक्ड लिस्ट लिंक्ड लिस्ट की एक भिन्नता है जिसमें एकल लिंक्ड लिस्ट की तुलना में दोनों तरह से नेविगेशन संभव है, आगे और पीछे आसानी से। दोहरी रूप से जुड़ी सूची की अवधारणा को समझने के लिए महत्वपूर्ण शर्तें निम्नलिखित हैं।
Link - लिंक की गई सूची के प्रत्येक लिंक में एक तत्व नामक एक डेटा संग्रहीत किया जा सकता है।
Next - लिंक्ड लिस्ट के प्रत्येक लिंक में नेक्सट नामक अगली लिंक का लिंक होता है।
Prev - लिंक्ड लिस्ट के प्रत्येक लिंक में पिछले लिंक का लिंक होता है, जिसे Prev कहा जाता है।
LinkedList - एक लिंक्ड लिस्ट में पहले लिंक के कनेक्शन का लिंक होता है जिसे फर्स्ट कहा जाता है और लास्ट के आखिरी लिंक को।
डबली लिंक्ड लिस्ट रिप्रेजेंटेशन

उपरोक्त उदाहरण के अनुसार, निम्नलिखित महत्वपूर्ण बिंदुओं पर विचार किया जाना है।
Doubly Linked List में पहले और अंतिम नाम का एक लिंक तत्व होता है।
प्रत्येक लिंक एक डेटा फ़ील्ड (ओं) और दो लिंक फ़ील्ड्स को ले जाता है जिसे अगले और मौजूदा कहा जाता है।
प्रत्येक लिंक अपने अगले लिंक का उपयोग करके अपने अगले लिंक के साथ जुड़ा हुआ है।
प्रत्येक लिंक अपने पिछले लिंक का उपयोग करके अपने पिछले लिंक से जुड़ा हुआ है।
अंतिम लिंक सूची के अंत को चिह्नित करने के लिए एक लिंक को अशक्त करता है।
मूलभूत क्रियाएं
एक सूची द्वारा समर्थित मूल संचालन निम्नलिखित हैं।
Insertion - सूची की शुरुआत में एक तत्व जोड़ता है।
Deletion - सूची की शुरुआत में एक तत्व को हटाता है।
Insert Last - सूची के अंत में एक तत्व जोड़ता है।
Delete Last - सूची के अंत से एक तत्व हटाता है।
Insert After - सूची के एक आइटम के बाद एक तत्व जोड़ता है।
Delete - कुंजी का उपयोग करके सूची से एक तत्व हटाता है।
Display forward - आगे की सूची में पूरी सूची प्रदर्शित करता है।
Display backward - पूरी सूची को पिछड़े तरीके से प्रदर्शित करता है।
निवेशन ऑपरेशन
निम्नलिखित कोड दोहरे लिंक की गई सूची की शुरुआत में सम्मिलन ऑपरेशन को प्रदर्शित करता है।
उदाहरण
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//update first prev link
head->prev = link;
}
//point it to old first link
link->next = head;
//point first to new first link
head = link;
}विलोपन ऑपरेशन
निम्नलिखित कोड दोहरी लिंक की गई सूची की शुरुआत में डिलीट ऑपरेशन को दर्शाता है।
उदाहरण
//delete first item
struct node* deleteFirst() {
//save reference to first link
struct node *tempLink = head;
//if only one link
if(head->next == NULL) {
last = NULL;
} else {
head->next->prev = NULL;
}
head = head->next;
//return the deleted link
return tempLink;
}एक ऑपरेशन के अंत में प्रविष्टि
निम्नलिखित कोड दोहरे लिंक की गई सूची के अंतिम स्थान पर सम्मिलन ऑपरेशन को प्रदर्शित करता है।
उदाहरण
//insert link at the last location
void insertLast(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//make link a new last link
last->next = link;
//mark old last node as prev of new link
link->prev = last;
}
//point last to new last node
last = link;
}सी प्रोग्रामिंग भाषा में कार्यान्वयन देखने के लिए, कृपया यहां क्लिक करें ।
वृत्ताकार लिंक्ड सूची लिंक्ड सूची की एक भिन्नता है जिसमें पहला तत्व अंतिम तत्व को इंगित करता है और अंतिम तत्व पहले तत्व को इंगित करता है। सिंगली लिंक्ड लिस्ट और डब्ली लिंक्ड लिस्ट दोनों को एक सर्कुलर लिंक्ड लिस्ट में बनाया जा सकता है।
परिपत्र के रूप में एकल लिंक की गई सूची
एकल लिंक की गई सूची में, अंतिम नोड का अगला पॉइंटर पहले नोड को इंगित करता है।

डबली लिंक्ड लिस्ट सर्कुलर के रूप में
दोगुनी लिंक की गई सूची में, अंतिम नोड का अगला पॉइंटर पहले नोड की ओर इशारा करता है और पहले नोड का पिछला पॉइंटर दोनों दिशाओं में गोलाकार बनाकर अंतिम नोड को इंगित करता है।

उपरोक्त उदाहरण के अनुसार, निम्नलिखित महत्वपूर्ण बिंदुओं पर विचार किया जाना है।
अंतिम लिंक के अगले अंक सूची के पहले लिंक के दोनों मामलों के साथ-साथ एकल लिंक वाली सूची में भी शामिल हैं।
डबल लिंक की गई सूची के मामले में सूची के अंतिम में पहले लिंक के पिछले बिंदु।
मूलभूत क्रियाएं
एक परिपत्र सूची द्वारा समर्थित महत्वपूर्ण संचालन निम्नलिखित हैं।
insert - सूची के प्रारंभ में एक तत्व सम्मिलित करता है।
delete - सूची की शुरुआत से एक तत्व हटाता है।
display - सूची प्रदर्शित करता है।
निवेशन ऑपरेशन
निम्नलिखित कोड एकल लिंक की गई सूची के आधार पर एक परिपत्र लिंक्ड सूची में सम्मिलन ऑपरेशन को दर्शाता है।
उदाहरण
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data= data;
if (isEmpty()) {
head = link;
head->next = head;
} else {
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}विलोपन ऑपरेशन
निम्नलिखित कोड एकल लिंक की गई सूची के आधार पर एक परिपत्र लिंक्ड सूची में विलोपन ऑपरेशन को दर्शाता है।
//delete first item
struct node * deleteFirst() {
//save reference to first link
struct node *tempLink = head;
if(head->next == head) {
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}प्रदर्शन सूची ऑपरेशन
निम्नलिखित कोड एक परिपत्र लिंक्ड सूची में प्रदर्शन सूची संचालन को दर्शाता है।
//display the list
void printList() {
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL) {
while(ptr->next != ptr) {
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}सी प्रोग्रामिंग भाषा में इसके कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
स्टैक एक सार डेटा प्रकार (ADT) है, जो आमतौर पर अधिकांश प्रोग्रामिंग भाषाओं में उपयोग किया जाता है। इसे स्टैक नाम दिया गया है क्योंकि यह एक वास्तविक दुनिया स्टैक की तरह व्यवहार करता है, उदाहरण के लिए - कार्ड का एक डेक या प्लेटों का ढेर, आदि।

एक वास्तविक दुनिया स्टैक केवल एक छोर पर संचालन की अनुमति देता है। उदाहरण के लिए, हम केवल स्टैक के ऊपर से कार्ड या प्लेट को रख सकते हैं या हटा सकते हैं। इसी तरह, स्टैक एडीटी केवल एक छोर पर सभी डेटा संचालन की अनुमति देता है। किसी भी समय, हम केवल एक स्टैक के शीर्ष तत्व तक पहुंच सकते हैं।
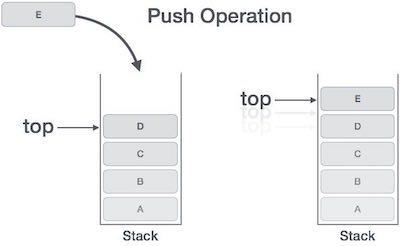
यह सुविधा इसे LIFO डेटा संरचना बनाती है। LIFO का उद्देश्य लास्ट-इन-प्रथम-आउट है। यहां, जो तत्व अंतिम (सम्मिलित या जोड़ा गया) है, उसे पहले एक्सेस किया जाता है। स्टैक शब्दावली में, सम्मिलन ऑपरेशन कहा जाता हैPUSH ऑपरेशन और रिमूवल ऑपरेशन कहलाता है POP ऑपरेशन।
ढेर का प्रतिनिधित्व
निम्नलिखित चित्र में एक स्टैक और उसके संचालन को दर्शाया गया है -

स्टैक को एरे, स्ट्रक्चर, पॉइंटर और लिंक्ड लिस्ट के माध्यम से लागू किया जा सकता है। स्टैक या तो एक निश्चित आकार का हो सकता है या इसमें गतिशील आकार बदलने की भावना हो सकती है। यहां, हम सरणियों का उपयोग करके स्टैक को लागू करने जा रहे हैं, जो इसे एक निश्चित आकार स्टैक कार्यान्वयन बनाता है।
मूलभूत क्रियाएं
स्टैक संचालन में स्टैक को इनिशियलाइज़ करना, इसका उपयोग करना और फिर इसे डी-इनिशियलाइज़ करना शामिल हो सकता है। इन बुनियादी सामानों के अलावा, एक स्टैक का उपयोग निम्नलिखित दो प्राथमिक कार्यों के लिए किया जाता है -
push() - स्टैक पर एक तत्व को पुश करना (स्टोर करना)।
pop() - स्टैक से एक तत्व को निकालना (एक्सेस करना)।
जब डेटा को स्टैक पर PUSHed किया जाता है।
स्टैक का कुशलतापूर्वक उपयोग करने के लिए, हमें स्टैक की स्थिति की भी जांच करने की आवश्यकता है। एक ही उद्देश्य के लिए, निम्नलिखित कार्यक्षमता को ढेर में जोड़ा जाता है -
peek() - स्टैक का शीर्ष डेटा तत्व प्राप्त करें, इसे हटाए बिना।
isFull() - जांच करें कि क्या स्टैक भरा हुआ है।
isEmpty() - जांचें कि क्या स्टैक खाली है।
हर समय, हम स्टैक पर अंतिम PUSHed डेटा के लिए एक संकेतक बनाए रखते हैं। जैसा कि यह सूचक हमेशा स्टैक के शीर्ष का प्रतिनिधित्व करता है, इसलिए नाम दिया गया हैtop। top पॉइंटर वास्तव में इसे हटाने के बिना स्टैक का शीर्ष मूल्य प्रदान करता है।
स्टैक फ़ंक्शंस का समर्थन करने के लिए पहले हमें प्रक्रियाओं के बारे में सीखना चाहिए -
झांकना ()
झाँकी का एल्गोरिथ्म () फ़ंक्शन -
begin procedure peek
return stack[top]
end procedureसी प्रोग्रामिंग भाषा में झांकना () फ़ंक्शन का कार्यान्वयन -
Example
int peek() {
return stack[top];
}पूर्ण है()
आइफुल का एल्गोरिथ्म () फ़ंक्शन -
begin procedure isfull
if top equals to MAXSIZE
return true
else
return false
endif
end procedureC प्रोग्रामिंग भाषा में isfull () फ़ंक्शन का कार्यान्वयन -
Example
bool isfull() {
if(top == MAXSIZE)
return true;
else
return false;
}खाली है()
समरूपता का समरूपता () फ़ंक्शन -
begin procedure isempty
if top less than 1
return true
else
return false
endif
end procedureC प्रोग्रामिंग भाषा में isempty () फ़ंक्शन का कार्यान्वयन थोड़ा अलग है। हम शीर्ष -1 पर इनिशियलाइज़ करते हैं, क्योंकि एरे में इंडेक्स 0. से शुरू होता है, इसलिए हम जाँचते हैं कि स्टैक शून्य है या नहीं, यह निर्धारित करने के लिए कि टॉप शून्य से नीचे है या नहीं। यहाँ कोड है -
Example
bool isempty() {
if(top == -1)
return true;
else
return false;
}पुश ऑपरेशन
स्टैक पर एक नया डेटा तत्व डालने की प्रक्रिया को पुश ऑपरेशन के रूप में जाना जाता है। पुश ऑपरेशन में चरणों की एक श्रृंखला शामिल है -
Step 1 - अगर स्टैक भरा हुआ है तो चेक करता है।
Step 2 - यदि स्टैक भरा हुआ है, तो एक त्रुटि और निकास पैदा करता है।
Step 3 - यदि स्टैक पूर्ण नहीं है, तो वेतन वृद्धि top अगले खाली स्थान को इंगित करने के लिए।
Step 4 - डेटा तत्व को स्टैक स्थान पर जोड़ता है, जहां शीर्ष इंगित कर रहा है।
Step 5 - सफलता लौटाता है।
यदि स्टैक को लागू करने के लिए लिंक की गई सूची का उपयोग किया जाता है, तो चरण 3 में, हमें गतिशील रूप से स्थान आवंटित करने की आवश्यकता है।
PUSH ऑपरेशन के लिए एल्गोरिदम
पुश ऑपरेशन के लिए एक सरल एल्गोरिथ्म निम्नानुसार व्युत्पन्न किया जा सकता है -
begin procedure push: stack, data
if stack is full
return null
endif
top ← top + 1
stack[top] ← data
end procedureसी में इस एल्गोरिथ्म का कार्यान्वयन बहुत आसान है। निम्नलिखित कोड देखें -
Example
void push(int data) {
if(!isFull()) {
top = top + 1;
stack[top] = data;
} else {
printf("Could not insert data, Stack is full.\n");
}
}पॉप ऑपरेशन
स्टैक से हटाते समय सामग्री तक पहुंचना, पॉप ऑपरेशन के रूप में जाना जाता है। पॉप () ऑपरेशन के एक सरणी कार्यान्वयन में, डेटा तत्व को वास्तव में नहीं हटाया जाता है, इसके बजायtopअगले मान को इंगित करने के लिए स्टैक में एक निम्न स्थिति में कमी की गई है। लेकिन लिंक्ड-लिस्ट कार्यान्वयन में, पॉप () वास्तव में डेटा तत्व को हटा देता है और मेमोरी स्पेस को हटा देता है।
पॉप ऑपरेशन में निम्नलिखित चरण शामिल हो सकते हैं -
Step 1 - जाँच करता है कि स्टैक खाली है या नहीं।
Step 2 - यदि स्टैक खाली है, तो एक त्रुटि और निकास पैदा करता है।
Step 3 - यदि स्टैक खाली नहीं है, तो डेटा तत्व को एक्सेस करता है top इशारा कर रहा है।
Step 4 - शीर्ष का मान 1 घटाता है।
Step 5 - सफलता लौटाता है।

पॉप ऑपरेशन के लिए एल्गोरिदम
पॉप ऑपरेशन के लिए एक सरल एल्गोरिथ्म निम्नानुसार व्युत्पन्न किया जा सकता है -
begin procedure pop: stack
if stack is empty
return null
endif
data ← stack[top]
top ← top - 1
return data
end procedureसी में इस एल्गोरिथ्म का कार्यान्वयन निम्नानुसार है -
Example
int pop(int data) {
if(!isempty()) {
data = stack[top];
top = top - 1;
return data;
} else {
printf("Could not retrieve data, Stack is empty.\n");
}
}सी प्रोग्रामिंग भाषा में एक पूर्ण स्टैक प्रोग्राम के लिए, कृपया यहां क्लिक करें ।
अंकगणितीय अभिव्यक्ति लिखने का तरीका a notation। एक अभिव्यक्ति के सार या आउटपुट को बदले बिना, अंकगणितीय अभिव्यक्ति को तीन अलग-अलग लेकिन समकक्ष संकेतन में लिखा जा सकता है। ये सूचनाएं हैं -
- Infix संकेतन
- उपसर्ग (पोलिश) संकेतन
- पोस्टफिक्स (रिवर्स-पोलिश) नोटेशन
इन सूचनाओं को नाम दिया गया है कि वे अभिव्यक्ति में ऑपरेटर का उपयोग कैसे करते हैं। हम यहाँ इस अध्याय में वही सीखेंगे।
Infix संकेतन
में हम अभिव्यक्ति लिखते हैं infix संकेतन, उदाहरण के लिए a - b + c, जहां ऑपरेटरों का उपयोग किया जाता है in-बेटे का संचालन। हमारे लिए इंफ़िक्स अंकन में पढ़ना, लिखना और बोलना मनुष्यों के लिए आसान है, लेकिन कंप्यूटिंग उपकरणों के साथ भी यह ठीक नहीं है। इन्फिक्स संकेतन की प्रक्रिया के लिए एक एल्गोरिथ्म समय और स्थान की खपत के मामले में मुश्किल और महंगा हो सकता है।
उपसर्ग सूचना
इस अंकन में, ऑपरेटर होता है prefixएड टू ऑपरेंड, यानी ऑपरेटर ऑपरेटर के आगे लिखा जाता है। उदाहरण के लिए,+ab। यह इसके infix नोटेशन के बराबर हैa + b। उपसर्ग संकेतन के रूप में भी जाना जाता हैPolish Notation।
उपसर्ग सूचना
इस अंकन शैली के रूप में जाना जाता है Reversed Polish Notation। इस नोटेशन शैली में, ऑपरेटर हैpostfixऑपरेंड्स को एड यानी ऑपरेटर को ऑपरेंड्स के बाद लिखा जाता है। उदाहरण के लिए,ab+। यह इसके infix नोटेशन के बराबर हैa + b।
निम्नलिखित तालिका संक्षेप में तीनों अधिसूचनाओं में अंतर दिखाने की कोशिश करती है -
| अनु क्रमांक। | Infix संकेतन | उपसर्ग सूचना | उपसर्ग सूचना |
|---|---|---|---|
| 1 | ए + बी | + अब | ab + |
| 2 | (a + b) ∗ c | C + एबीसी | ab + c ∗ |
| 3 | एक + (बी + सी) | C ए + बी.सी. | abc + ∗ |
| 4 | ए / बी + सी / डी | + / एबी / सीडी | ab / cd / + |
| 5 | (a + b) ∗ (c + d) | C + अब + सीडी | ab + cd + ∗ |
| 6 | ((ए + बी)) सी) - डी | - - + एबीसी | अब + सी + डी - |
पार्सिंग एक्सप्रेशंस
जैसा कि हमने चर्चा की है, यह एक बहुत ही कुशल तरीका नहीं है कि एल्गोरिथ्म या प्रोग्राम को डिजाइन करने के लिए इन्फिक्स नोटेशन को पार्स करें। इसके बजाय, इन infix अंकन को पहले उपसर्ग या उपसर्ग संकेतन में परिवर्तित किया जाता है और फिर गणना की जाती है।
किसी भी अंकगणितीय अभिव्यक्ति को पार्स करने के लिए, हमें ऑपरेटर की पूर्ववर्तीता और सहानुभूति का भी ध्यान रखना होगा।
प्रधानता
जब एक ऑपरेंड दो अलग-अलग ऑपरेटरों के बीच होता है, तो कौन सा ऑपरेटर पहले ऑपरेटर को ले जाएगा, इसका फैसला दूसरों पर ऑपरेटर की पूर्वता से होता है। उदाहरण के लिए -

जैसा कि गुणन ऑपरेशन में इसके अलावा पूर्वता है, b * c का मूल्यांकन पहले किया जाएगा। ऑपरेटर पूर्वता की एक तालिका बाद में प्रदान की जाती है।
संबद्धता
संघात्मकता उस नियम का वर्णन करती है जहां एक ही पूर्वता वाले ऑपरेटर एक अभिव्यक्ति में दिखाई देते हैं। उदाहरण के लिए, अभिव्यक्ति में a + b - c, दोनों + और - की एक ही पूर्वता है, फिर अभिव्यक्ति के किस भाग का मूल्यांकन पहले किया जाएगा, यह उन ऑपरेटरों की सहानुभूति द्वारा निर्धारित किया जाता है। यहां, दोनों + और - बाएं सहयोगी हैं, इसलिए अभिव्यक्ति का मूल्यांकन किया जाएगा(a + b) − c।
वरीयता और सहानुभूति एक अभिव्यक्ति के मूल्यांकन के क्रम को निर्धारित करती है। निम्नलिखित एक ऑपरेटर पूर्वता और संघात सारणी है (उच्चतम से निम्नतम) -
| अनु क्रमांक। | ऑपरेटर | प्रधानता | संबद्धता |
|---|---|---|---|
| 1 | घातांक ^ | उच्चतम | सही सहयोगी |
| 2 | गुणन (∗) और प्रभाग (/) | दूसरा सबसे ऊँचा | वाम सहयोगी |
| 3 | जोड़ (+) और घटाव (-) | सबसे कम | वाम सहयोगी |
उपरोक्त तालिका ऑपरेटरों के डिफ़ॉल्ट व्यवहार को दिखाती है। अभिव्यक्ति मूल्यांकन में किसी भी समय, कोष्ठक का उपयोग करके आदेश को बदला जा सकता है। उदाहरण के लिए -
में a + b*cअभिव्यक्ति भाग b*cपहले मूल्यांकन किया जाएगा, इसके अलावा गुणा के रूप में इसके अतिरिक्त। हम यहाँ के लिए कोष्ठक का उपयोग करते हैंa + b पहले मूल्यांकन किया जाना है, जैसे (a + b)*c।
उपसर्ग का मूल्यांकन एल्गोरिथम
अब हम पोस्टऑफिस संकेतन का मूल्यांकन करने के लिए एल्गोरिथ्म को देखेंगे -
Step 1 − scan the expression from left to right
Step 2 − if it is an operand push it to stack
Step 3 − if it is an operator pull operand from stack and perform operation
Step 4 − store the output of step 3, back to stack
Step 5 − scan the expression until all operands are consumed
Step 6 − pop the stack and perform operationसी प्रोग्रामिंग भाषा में कार्यान्वयन देखने के लिए, कृपया यहां क्लिक करें ।
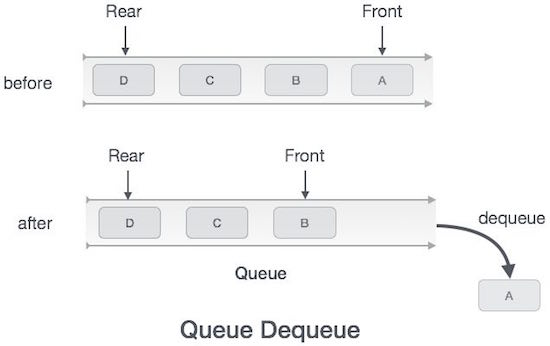
कतार एक सार डेटा संरचना है, जो कुछ हद तक स्टैक्स के समान है। स्टैक के विपरीत, इसके दोनों सिरों पर एक कतार खुली होती है। एक सिरा हमेशा डेटा (enqueue) डालने के लिए और दूसरा डेटा (dequeue) को हटाने के लिए उपयोग किया जाता है। कतार फर्स्ट-इन-फर्स्ट-आउट कार्यप्रणाली का अनुसरण करती है, अर्थात, पहले संग्रहीत डेटा आइटम को पहले एक्सेस किया जाएगा।

कतार की वास्तविक दुनिया का उदाहरण सिंगल-लेन वन-वे रोड हो सकता है, जहां वाहन पहले प्रवेश करता है, पहले बाहर निकलता है। अधिक वास्तविक दुनिया के उदाहरणों को टिकट खिड़कियों और बस-स्टॉप पर कतारों के रूप में देखा जा सकता है।
कतार प्रतिनिधित्व
जैसा कि अब हम समझते हैं कि कतार में, हम अलग-अलग कारणों से दोनों छोरों तक पहुंचते हैं। नीचे दिए गए निम्नलिखित चित्र डेटा संरचना के रूप में कतार प्रतिनिधित्व को समझाने की कोशिश करते हैं -

स्टैक्स की तरह, Arrays, लिंक्ड-लिस्ट, पॉइंटर्स और स्ट्रक्चर्स का उपयोग करके एक कतार भी लागू की जा सकती है। सादगी के लिए, हम एक-आयामी सरणी का उपयोग करके कतारों को लागू करेंगे।
मूलभूत क्रियाएं
कतार के संचालन में कतार को प्रारंभिक या परिभाषित करना, उसका उपयोग करना, और फिर इसे स्मृति से पूरी तरह से मिटाना शामिल हो सकता है। यहां हम कतारों से जुड़े बुनियादी कार्यों को समझने की कोशिश करेंगे -
enqueue() - कतार में एक आइटम जोड़ें (स्टोर करें)।
dequeue() - कतार से किसी आइटम को निकालें (एक्सेस करें)।
उपर्युक्त कतार संचालन को कुशल बनाने के लिए कुछ और कार्यों की आवश्यकता होती है। ये हैं -
peek() - कतार के सामने तत्व को बिना हटाए रखा जाता है।
isfull() - कतार भर गई तो चेक।
isempty() - कतार खाली होने पर चेक करता है।
कतार में, हम हमेशा इंगित किए गए डेटा (या एक्सेस) को धोखा देते हैं front पॉइंटर और जबकि (या भंडारण) डेटा कतार में हम मदद लेते हैं rear सूचक।
आइए पहले एक कतार के सहायक कार्यों के बारे में जानें -
झांकना ()
यह फ़ंक्शन डेटा को देखने में मदद करता है frontकतार का। झाँकी का एल्गोरिथ्म () फ़ंक्शन निम्नानुसार है -
Algorithm
begin procedure peek
return queue[front]
end procedureसी प्रोग्रामिंग भाषा में झांकना () फ़ंक्शन का कार्यान्वयन -
Example
int peek() {
return queue[front];
}पूर्ण है()
जैसा कि हम कतार को लागू करने के लिए एकल आयाम सरणी का उपयोग कर रहे हैं, हम सिर्फ यह निर्धारित करने के लिए अधिकतम सूचक की जांच करते हैं कि कतार पूर्ण है या नहीं। मामले में हम कतार को एक गोलाकार लिंक-सूची में बनाए रखते हैं, एल्गोरिथ्म अलग होगा। आइफुल का एल्गोरिथ्म () फ़ंक्शन -
Algorithm
begin procedure isfull
if rear equals to MAXSIZE
return true
else
return false
endif
end procedureC प्रोग्रामिंग भाषा में isfull () फ़ंक्शन का कार्यान्वयन -
Example
bool isfull() {
if(rear == MAXSIZE - 1)
return true;
else
return false;
}खाली है()
समरूपता का समरूपता () फ़ंक्शन -
Algorithm
begin procedure isempty
if front is less than MIN OR front is greater than rear
return true
else
return false
endif
end procedureयदि का मान front यह MIN या 0 से कम है, यह बताता है कि कतार अभी आरंभिक नहीं है, इसलिए खाली है।
यहाँ C प्रोग्रामिंग कोड है -
Example
bool isempty() {
if(front < 0 || front > rear)
return true;
else
return false;
}एनक्यू ऑपरेशन
कतारें दो डेटा पॉइंट बनाए रखती हैं, front तथा rear। इसलिए, स्टैक की तुलना में इसके संचालन को तुलनात्मक रूप से लागू करना मुश्किल है।
निम्नलिखित चरणों को एक कतार में डेटा (सम्मिलित) करने के लिए लिया जाना चाहिए -
Step 1 - जाँच करें कि कतार भरी हुई है या नहीं।
Step 2 - यदि कतार भरी है, तो अतिप्रवाह त्रुटि और बाहर निकलें।
Step 3 - कतार पूरी न होने पर वेतन वृद्धि rear पॉइंटर अगली खाली जगह को इंगित करने के लिए।
Step 4 - कतार के स्थान पर डेटा तत्व जोड़ें, जहां रियर इंगित कर रहा है।
Step 5 - सफलता लौटाओ।

कभी-कभी, हम यह देखने के लिए भी जाँच करते हैं कि कोई विषम परिस्थितियों को संभालने के लिए कोई कतार आरम्भिक है या नहीं।
एन्क्यू ऑपरेशन के लिए एल्गोरिदम
procedure enqueue(data)
if queue is full
return overflow
endif
rear ← rear + 1
queue[rear] ← data
return true
end procedureC प्रोग्रामिंग भाषा में enqueue () का कार्यान्वयन -
Example
int enqueue(int data)
if(isfull())
return 0;
rear = rear + 1;
queue[rear] = data;
return 1;
end procedureDequeue ऑपरेशन
कतार से डेटा एक्सेस करना दो कार्यों की एक प्रक्रिया है - डेटा को एक्सेस करना जहाँ frontपहुँच के बाद डेटा को इंगित और निकाल रहा है। प्रदर्शन करने के लिए निम्नलिखित कदम उठाए जाते हैंdequeue ऑपरेशन -
Step 1 - जाँच करें कि कतार खाली है या नहीं।
Step 2 - यदि कतार खाली है, तो अंडरफ़्लो त्रुटि और बाहर निकलें।
Step 3 - यदि कतार खाली नहीं है, तो डेटा तक पहुंचें जहां front इशारा कर रहा है।
Step 4 - वृद्धि front पॉइंटर अगले उपलब्ध डेटा तत्व को इंगित करने के लिए।
Step 5 - वापसी सफलता।
Dequeue ऑपरेशन के लिए एल्गोरिथ्म
procedure dequeue
if queue is empty
return underflow
end if
data = queue[front]
front ← front + 1
return true
end procedureसी प्रोग्रामिंग भाषा में छल का कार्यान्वयन () -
Example
int dequeue() {
if(isempty())
return 0;
int data = queue[front];
front = front + 1;
return data;
}सी प्रोग्रामिंग भाषा में एक पूर्ण कतार कार्यक्रम के लिए, कृपया यहां क्लिक करें ।
रैखिक खोज एक बहुत ही सरल खोज एल्गोरिथ्म है। इस प्रकार की खोज में एक-एक करके सभी वस्तुओं पर क्रमबद्ध खोज की जाती है। प्रत्येक आइटम की जाँच की जाती है और यदि कोई मेल मिलता है तो उस विशेष आइटम को वापस कर दिया जाता है, अन्यथा डेटा संग्रह के अंत तक खोज जारी रहती है।

कलन विधि
Linear Search ( Array A, Value x)
Step 1: Set i to 1
Step 2: if i > n then go to step 7
Step 3: if A[i] = x then go to step 6
Step 4: Set i to i + 1
Step 5: Go to Step 2
Step 6: Print Element x Found at index i and go to step 8
Step 7: Print element not found
Step 8: Exitस्यूडोकोड
procedure linear_search (list, value)
for each item in the list
if match item == value
return the item's location
end if
end for
end procedureसी प्रोग्रामिंग भाषा में रैखिक खोज कार्यान्वयन के बारे में जानने के लिए, कृपया यहाँ क्लिक करें ।
बाइनरी खोज ity (लॉग एन) की रन-टाइम जटिलता के साथ एक तेज़ खोज एल्गोरिथ्म है। यह खोज एल्गोरिथ्म विभाजन और जीत के सिद्धांत पर काम करता है। इस एल्गोरिथम को ठीक से काम करने के लिए, डेटा संग्रह क्रमबद्ध रूप में होना चाहिए।
बाइनरी खोज संग्रह के मध्य अधिकांश आइटम की तुलना करके किसी विशेष आइटम की तलाश करती है। यदि एक मैच होता है, तो आइटम का सूचकांक वापस आ जाता है। यदि मध्य आइटम मद से अधिक है, तो आइटम को मध्य आइटम के बाईं ओर उप-सरणी में खोजा जाता है। अन्यथा, आइटम को मध्य आइटम के दाईं ओर उप-सरणी में खोजा जाता है। यह प्रक्रिया उप-सरणी पर भी जारी रहती है, जब तक कि सबर्रे का आकार शून्य तक कम नहीं हो जाता।
बाइनरी सर्च कैसे काम करता है?
काम करने के लिए एक द्विआधारी खोज के लिए, लक्ष्य सरणी को क्रमबद्ध करना अनिवार्य है। हम चित्रात्मक उदाहरण के साथ द्विआधारी खोज की प्रक्रिया सीखेंगे। निम्नलिखित हमारे सॉर्ट किए गए सरणी है और हमें मान लेते हैं कि हमें बाइनरी खोज का उपयोग करके मूल्य 31 के स्थान की खोज करने की आवश्यकता है।

सबसे पहले, हम इस सूत्र का उपयोग करके सरणी का आधा हिस्सा निर्धारित करेंगे -
mid = low + (high - low) / 2यहाँ यह है, 0 + (9 - 0) / 2 = 4 (4.5 का पूर्णांक मान)। तो, 4 सरणी के मध्य है।

अब हम स्थान 4 पर संग्रहीत मूल्य की तुलना करते हैं, जिसका मूल्य खोजा जा रहा है, अर्थात 31। हम पाते हैं कि स्थान 4 पर मूल्य 27 है, जो एक मैच नहीं है। चूंकि मान 27 से अधिक है और हमारे पास एक क्रमबद्ध सरणी है, इसलिए हम यह भी जानते हैं कि लक्ष्य मान सरणी के ऊपरी हिस्से में होना चाहिए।

हम अपने निम्न को मध्य + 1 में बदलते हैं और नए मध्य मान को फिर से पाते हैं।
low = mid + 1
mid = low + (high - low) / 2हमारा नया मध्य अब now है। हम अपने लक्ष्य मान 31 के साथ स्थान 7 पर संग्रहीत मूल्य की तुलना करते हैं।

स्थान 7 पर संग्रहीत मूल्य एक मैच नहीं है, बल्कि यह उस चीज़ से अधिक है जो हम खोज रहे हैं। तो, मान इस स्थान से निचले हिस्से में होना चाहिए।

इसलिए, हम फिर से मध्य की गणना करते हैं। इस समय यह 5 है।

हम अपने लक्ष्य मान के साथ स्थान 5 पर संग्रहीत मूल्य की तुलना करते हैं। हम पाते हैं कि यह एक मैच है।

हम निष्कर्ष निकालते हैं कि लक्ष्य 5 को स्थान 5 पर संग्रहीत किया गया है।
बाइनरी खोज खोज योग्य वस्तुओं को आधा कर देती है और इस तरह तुलना की संख्या को बहुत कम संख्या में कर देती है।
स्यूडोकोड
द्विआधारी खोज एल्गोरिदम के छद्मकोड को इस तरह देखना चाहिए -
Procedure binary_search
A ← sorted array
n ← size of array
x ← value to be searched
Set lowerBound = 1
Set upperBound = n
while x not found
if upperBound < lowerBound
EXIT: x does not exists.
set midPoint = lowerBound + ( upperBound - lowerBound ) / 2
if A[midPoint] < x
set lowerBound = midPoint + 1
if A[midPoint] > x
set upperBound = midPoint - 1
if A[midPoint] = x
EXIT: x found at location midPoint
end while
end procedureसी प्रोग्रामिंग भाषा में सरणी का उपयोग करके द्विआधारी खोज कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
इंटरपोलेशन खोज बाइनरी खोज का एक बेहतर संस्करण है। यह खोज एल्गोरिथ्म आवश्यक मूल्य की जांच स्थिति पर काम करता है। इस एल्गोरिथम को ठीक से काम करने के लिए, डेटा संग्रह एक क्रमबद्ध रूप में होना चाहिए और समान रूप से वितरित किया जाना चाहिए।
बाइनरी खोज का रैखिक खोज पर समय की जटिलता का एक बड़ा लाभ है। रैखिक खोज में search (n) की सबसे खराब स्थिति है जबकि बाइनरी खोज में has (लॉग एन) है।
ऐसे मामले हैं जहां लक्ष्य डेटा का स्थान पहले से जाना जा सकता है। उदाहरण के लिए, टेलीफोन डायरेक्टरी के मामले में, यदि हम मॉर्फियस का टेलीफोन नंबर खोजना चाहते हैं। यहां, रैखिक खोज और यहां तक कि द्विआधारी खोज धीमी प्रतीत होगी क्योंकि हम सीधे मेमोरी स्पेस में कूद सकते हैं जहां 'एम' से शुरू होने वाले नाम संग्रहीत होते हैं।
बाइनरी सर्च में पोजिशनिंग
बाइनरी खोज में, यदि वांछित डेटा नहीं मिला है, तो बाकी सूची को दो भागों में विभाजित किया गया है, निचले और उच्च। उनमें से किसी एक में खोज की जाती है।




जब डेटा को सॉर्ट किया जाता है, तब भी द्विआधारी खोज वांछित डेटा की स्थिति की जांच करने के लिए लाभ नहीं उठाती है।
इंटरपोलेशन खोज में स्थिति जांच
जांच स्थिति की गणना करके इंटरपोलेशन खोज एक विशेष वस्तु को खोजती है। प्रारंभ में, जांच की स्थिति संग्रह के मध्य अधिकांश आइटम की स्थिति है।


यदि एक मैच होता है, तो आइटम का सूचकांक वापस आ जाता है। सूची को दो भागों में विभाजित करने के लिए, हम निम्नलिखित विधि का उपयोग करते हैं -
mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
where −
A = list
Lo = Lowest index of the list
Hi = Highest index of the list
A[n] = Value stored at index n in the listयदि मध्य आइटम मद से अधिक है, तो जांच की स्थिति फिर से मध्य मद के दाईं ओर उप-सरणी में गणना की जाती है। अन्यथा, आइटम को मध्य आइटम के बाईं ओर सबर्रे में खोजा जाता है। यह प्रक्रिया उप-सरणी पर भी जारी रहती है, जब तक कि सब्रे का आकार शून्य तक कम नहीं हो जाता।
प्रक्षेप खोज एल्गोरिथ्म की रनटाइम जटिलता है Ο(log (log n)) इसकी तुलना में Ο(log n) अनुकूल परिस्थितियों में BST का।
कलन विधि
चूंकि यह मौजूदा BST एल्गोरिथ्म का एक कामचलाऊ व्यवस्था है, हम स्थिति जांच का उपयोग करके 'लक्ष्य' डेटा वैल्यू इंडेक्स की खोज करने के चरणों का उल्लेख कर रहे हैं -
Step 1 − Start searching data from middle of the list.
Step 2 − If it is a match, return the index of the item, and exit.
Step 3 − If it is not a match, probe position.
Step 4 − Divide the list using probing formula and find the new midle.
Step 5 − If data is greater than middle, search in higher sub-list.
Step 6 − If data is smaller than middle, search in lower sub-list.
Step 7 − Repeat until match.स्यूडोकोड
A → Array list
N → Size of A
X → Target Value
Procedure Interpolation_Search()
Set Lo → 0
Set Mid → -1
Set Hi → N-1
While X does not match
if Lo equals to Hi OR A[Lo] equals to A[Hi]
EXIT: Failure, Target not found
end if
Set Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
if A[Mid] = X
EXIT: Success, Target found at Mid
else
if A[Mid] < X
Set Lo to Mid+1
else if A[Mid] > X
Set Hi to Mid-1
end if
end if
End While
End Procedureसी प्रोग्रामिंग भाषा में प्रक्षेप खोज के कार्यान्वयन के बारे में जानने के लिए, यहां क्लिक करें ।
हैश टेबल एक डेटा संरचना है जो डेटा को एक सहयोगी तरीके से संग्रहीत करता है। हैश तालिका में, डेटा को एक सरणी प्रारूप में संग्रहीत किया जाता है, जहां प्रत्येक डेटा मूल्य का अपना विशिष्ट सूचकांक मूल्य होता है। यदि हम वांछित डेटा के सूचकांक को जानते हैं, तो डेटा की पहुंच बहुत तेज़ हो जाती है।
इस प्रकार, यह एक डेटा संरचना बन जाता है जिसमें डेटा के आकार के बावजूद सम्मिलन और खोज संचालन बहुत तेज होते हैं। हैश टेबल एक स्टोरेज माध्यम के रूप में एक सरणी का उपयोग करता है और एक इंडेक्स उत्पन्न करने के लिए हैश तकनीक का उपयोग करता है जहां एक तत्व डाला जाना है या जहां से स्थित होना है।
हैशिंग
हैशिंग एक सरणी के अनुक्रमित की श्रेणी में प्रमुख मूल्यों की एक श्रृंखला को परिवर्तित करने की एक तकनीक है। हम प्रमुख मूल्यों की एक सीमा प्राप्त करने के लिए मोडुलो ऑपरेटर का उपयोग करने जा रहे हैं। आकार 20 की हैश तालिका के एक उदाहरण पर विचार करें, और निम्नलिखित वस्तुओं को संग्रहीत किया जाना है। आइटम एक (कुंजी, मूल्य) प्रारूप में हैं।

- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| अनु क्रमांक। | चाभी | हैश | अर्रे सूचकांक |
|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 |
| 4 | 4 | 4% 20 = 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 |
| 8 | 13 | १३% २० = १३ | 13 |
| 9 | 37 | 37% 20 = 17 | 17 |
रैखिक जांच
जैसा कि हम देख सकते हैं, ऐसा हो सकता है कि हैशिंग तकनीक का उपयोग सरणी के पहले से ही उपयोग किए गए सूचकांक बनाने के लिए किया जाता है। ऐसे मामले में, हम अगली सेल में अगली खाली जगह खोज सकते हैं, जब तक हम एक खाली सेल नहीं खोज लेते। इस तकनीक को रैखिक जांच कहा जाता है।
| अनु क्रमांक। | चाभी | हैश | अर्रे सूचकांक | रैखिक जांच के बाद, ऐरे इंडेक्स |
|---|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 | 3 |
| 4 | 4 | 4% 20 = 4 | 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 | 17 |
| 8 | 13 | १३% २० = १३ | 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 | 18 |
मूलभूत क्रियाएं
एक हैश तालिका के मूल प्राथमिक संचालन निम्नलिखित हैं।
Search - हैश टेबल में एक तत्व खोजता है।
Insert - हैश तालिका में एक तत्व सम्मिलित करता है।
delete - हैश टेबल से किसी तत्व को हटाता है।
डेटा आइटम
कुछ डेटा और कुंजी वाले डेटा आइटम को परिभाषित करें, जिसके आधार पर खोज को हैश तालिका में संचालित किया जाना है।
struct DataItem {
int data;
int key;
};हैश विधि
डेटा आइटम की कुंजी के हैश कोड की गणना करने के लिए एक हैशिंग विधि को परिभाषित करें।
int hashCode(int key){
return key % SIZE;
}सर्च ऑपरेशन
जब भी किसी तत्व की खोज की जानी हो, तो पास किए गए कुंजी के हैश कोड की गणना करें और उस हैश कोड का उपयोग करके तत्व को इंडेक्स के रूप में देखें। तत्व को हैश कोड में नहीं पाए जाने पर तत्व को आगे लाने के लिए रैखिक जांच का उपयोग करें।
उदाहरण
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}ऑपरेशन डालें
जब भी कोई तत्व सम्मिलित करना हो, तो पास किए गए कुंजी के हैश कोड की गणना करें और उस हैश कोड का उपयोग करके इंडेक्स को एक इंडेक्स के रूप में देखें। यदि खाली हैश कोड में एक तत्व पाया जाता है, तो खाली स्थान के लिए रैखिक जांच का उपयोग करें।
उदाहरण
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}ऑपरेशन हटाएँ
जब भी किसी तत्व को हटाना हो, तो पास किए गए कुंजी के हैश कोड की गणना करें और सरणी में इंडेक्स के रूप में उस हैश कोड का उपयोग करके सूचकांक का पता लगाएं। यदि तत्व हैश कोड में नहीं पाया जाता है, तो तत्व को आगे लाने के लिए रैखिक जांच का उपयोग करें। जब पाया जाता है, हैश टेबल के प्रदर्शन को बनाए रखने के लिए एक डमी आइटम को स्टोर करें।
उदाहरण
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}सी प्रोग्रामिंग भाषा में हैश कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
सॉर्टिंग एक विशेष प्रारूप में डेटा की व्यवस्था करने को संदर्भित करता है। सॉर्टिंग एल्गोरिथ्म एक विशेष क्रम में डेटा को व्यवस्थित करने का तरीका निर्दिष्ट करता है। अधिकांश सामान्य आदेश संख्यात्मक या शाब्दिक क्रम में होते हैं।
छंटनी का महत्व इस तथ्य में निहित है कि डेटा खोज को बहुत उच्च स्तर पर अनुकूलित किया जा सकता है, यदि डेटा को सॉर्ट किए गए तरीके से संग्रहीत किया जाता है। अधिक पठनीय प्रारूपों में डेटा का प्रतिनिधित्व करने के लिए सॉर्टिंग का भी उपयोग किया जाता है। वास्तविक जीवन के परिदृश्यों में छँटाई के कुछ उदाहरण निम्नलिखित हैं -
Telephone Directory - टेलीफोन निर्देशिका अपने नाम से छांटे गए लोगों के टेलीफोन नंबर संग्रहीत करती है, ताकि नामों को आसानी से खोजा जा सके।
Dictionary - शब्दकोश शब्दों को वर्णमाला क्रम में संग्रहीत करता है ताकि किसी भी शब्द की खोज आसान हो जाए।
इन-प्लेस सॉर्टिंग और नॉट-इन-प्लेस सॉर्टिंग
छँटाई एल्गोरिदम कुछ डेटा तत्वों की तुलना और अस्थायी भंडारण के लिए कुछ अतिरिक्त स्थान की आवश्यकता हो सकती है। इन एल्गोरिदम को किसी भी अतिरिक्त स्थान की आवश्यकता नहीं होती है और छँटाई को जगह में या उदाहरण के लिए, सरणी के भीतर ही होने के लिए कहा जाता है। यह कहा जाता हैin-place sorting। बबल सॉर्ट इन-प्लेस सॉर्टिंग का एक उदाहरण है।
हालाँकि, कुछ सॉर्टिंग एल्गोरिदम में, प्रोग्राम को स्पेस की आवश्यकता होती है जो सॉर्ट किए जा रहे तत्वों से अधिक या बराबर होता है। छँटाई जो समान या अधिक स्थान का उपयोग करता है उसे कहा जाता हैnot-in-place sorting। मर्ज-सॉर्ट जगह-जगह छँटाई का एक उदाहरण है।
स्थिर और स्थिर नहीं छँटाई
यदि एक छँटाई एल्गोरिथ्म, सामग्री को छाँटने के बाद, समान सामग्री के अनुक्रम को नहीं बदलता है जिसमें वे दिखाई देते हैं, इसे कहा जाता है stable sorting।

यदि एक छँटाई एल्गोरिथ्म, सामग्री को क्रमबद्ध करने के बाद, उसी सामग्री के अनुक्रम को बदलता है जिसमें वे दिखाई देते हैं, इसे कहा जाता है unstable sorting।

एक एल्गोरिथ्म की स्थिरता मायने रखती है जब हम मूल तत्वों के अनुक्रम को बनाए रखना चाहते हैं, जैसे कि उदाहरण के लिए एक टपल में।
अनुकूली और गैर-अनुकूली छँटाई एल्गोरिथ्म
एक छँटाई एल्गोरिथ्म को अनुकूली कहा जाता है, अगर यह सूची में पहले से ही 'क्रमबद्ध' तत्वों का लाभ उठाता है जिसे क्रमबद्ध किया जाना है। यदि स्रोत सूची में कुछ तत्व पहले से ही छंटे हुए हैं, तो यह छांटते समय, अनुकूली एल्गोरिदम इसे ध्यान में रखेंगे और उन्हें फिर से क्रम में नहीं लाने का प्रयास करेंगे।
एक गैर-अनुकूली एल्गोरिथ्म वह है जो पहले से ही हल किए गए तत्वों को ध्यान में नहीं रखता है। वे हर एक तत्व को उनकी छँटाई की पुष्टि के लिए फिर से आदेश देने के लिए मजबूर करने की कोशिश करते हैं।
महत्वपूर्ण शर्तें
कुछ शर्तों को आमतौर पर छँटाई तकनीकों पर चर्चा करते समय गढ़ा जाता है, यहाँ उनका संक्षिप्त परिचय दिया गया है -
बढ़ता हुआ क्रम
मूल्यों का एक क्रम में कहा जाता है increasing order, यदि क्रमिक तत्व पिछले एक से अधिक है। उदाहरण के लिए, 1, 3, 4, 6, 8, 9 बढ़ते क्रम में हैं, क्योंकि प्रत्येक अगला तत्व पिछले तत्व से अधिक है।
घटता क्रम
मूल्यों का एक क्रम में कहा जाता है decreasing order, यदि क्रमिक तत्व वर्तमान से कम है। उदाहरण के लिए, 9, 8, 6, 4, 3, 1 घटते क्रम में हैं, क्योंकि प्रत्येक अगला तत्व पिछले तत्व से कम है।
गैर-बढ़ते आदेश
मूल्यों का एक क्रम में कहा जाता है non-increasing order, यदि क्रमिक तत्व अनुक्रम में अपने पिछले तत्व से कम या बराबर है। यह क्रम तब होता है जब अनुक्रम में डुप्लिकेट मान होते हैं। उदाहरण के लिए, 9, 8, 6, 3, 3, 1 गैर-बढ़ते क्रम में हैं, क्योंकि हर अगला तत्व (3 के मामले में) से कम या बराबर है, लेकिन किसी भी पिछले तत्व से अधिक नहीं है।
गैर-घटता क्रम
मूल्यों का एक क्रम में कहा जाता है non-decreasing order, यदि क्रमिक तत्व अनुक्रम में अपने पिछले तत्व से अधिक या बराबर है। यह क्रम तब होता है जब अनुक्रम में डुप्लिकेट मान होते हैं। उदाहरण के लिए, 1, 3, 3, 6, 8, 9 गैर-घटते क्रम में हैं, क्योंकि प्रत्येक अगला तत्व (3 के मामले में) से अधिक या बराबर है, लेकिन पिछले एक से कम नहीं है।
बबल सॉर्ट एक साधारण सॉर्टिंग एल्गोरिथ्म है। यह छँटाई एल्गोरिथ्म तुलना-आधारित एल्गोरिथ्म है जिसमें आसन्न तत्वों की प्रत्येक जोड़ी की तुलना की जाती है और यदि वे क्रम में नहीं हैं, तो तत्वों की अदला-बदली की जाती है। यह एल्गोरिथ्म बड़े डेटा सेट के लिए उपयुक्त नहीं है क्योंकि इसकी औसत और सबसे खराब स्थिति जटिलता n (n 2 ) की हैn मदों की संख्या है।
बुलबुला कैसे काम करता है?
हम अपने उदाहरण के लिए एक अनसुलझा सरणी लेते हैं। बबल सॉर्ट में it (n 2 ) समय लगता है इसलिए हम इसे छोटा और सटीक रख रहे हैं।

बबल सॉर्ट पहले दो तत्वों के साथ शुरू होता है, उनकी तुलना करके यह जांचने के लिए कि कौन अधिक है।

इस स्थिति में, मान 33 14 से अधिक है, इसलिए यह पहले से ही सॉर्ट किए गए स्थानों में है। अगला, हम 33 की तुलना 27 से करते हैं।

हम पाते हैं कि 27 33 से छोटा है और इन दो मूल्यों की अदला-बदली होनी चाहिए।

नए सरणी को इस तरह दिखना चाहिए -

अगला हम 33 और 35 की तुलना करते हैं। हम पाते हैं कि दोनों पहले से ही सॉर्ट किए गए पदों पर हैं।

फिर हम अगले दो मूल्यों, 35 और 10 पर जाते हैं।

हम जानते हैं कि 10 छोटा 35 है। इसलिए उन्हें छांटा नहीं गया है।

हम इन मूल्यों की अदला-बदली करते हैं। हम पाते हैं कि हम सरणी के अंत तक पहुँच चुके हैं। एक पुनरावृत्ति के बाद, सरणी इस तरह दिखना चाहिए -

सटीक होने के लिए, हम अब दिखा रहे हैं कि प्रत्येक पुनरावृत्ति के बाद सरणी कैसे दिखनी चाहिए। दूसरी पुनरावृत्ति के बाद, यह इस तरह दिखना चाहिए -

ध्यान दें कि प्रत्येक पुनरावृत्ति के बाद, अंत में कम से कम एक मान चलता है।

और जब कोई स्वैप की आवश्यकता नहीं होती है, तो बुलबुला प्रकार सीखता है कि एक सरणी पूरी तरह से सॉर्ट की गई है।

अब हमें बबल सॉर्ट के कुछ व्यावहारिक पहलुओं पर गौर करना चाहिए।
कलन विधि
हमारा मानना है list की एक सरणी है nतत्वों। हम आगे मान लेते हैंswap फ़ंक्शन दिए गए सरणी तत्वों के मूल्यों को स्वैप करता है।
begin BubbleSort(list)
for all elements of list
if list[i] > list[i+1]
swap(list[i], list[i+1])
end if
end for
return list
end BubbleSortस्यूडोकोड
हम एल्गोरिथ्म में निरीक्षण करते हैं कि बबल सॉर्ट एरे तत्व के प्रत्येक जोड़े की तुलना करता है जब तक कि संपूर्ण एरे पूरी तरह से आरोही क्रम में सॉर्ट न हो जाए। इसके कारण कुछ जटिलताएँ हो सकती हैं, जैसे कि यदि सभी तत्वों के पहले से आरोही होने पर सरणी को और अधिक स्वैपिंग की आवश्यकता न हो।
समस्या को कम करने के लिए, हम एक ध्वज चर का उपयोग करते हैं swappedजो हमें यह देखने में मदद करेगा कि कोई स्वैप हुआ है या नहीं। यदि कोई स्वैप नहीं हुआ है, अर्थात सरणी को सॉर्ट करने के लिए अधिक प्रसंस्करण की आवश्यकता नहीं है, तो यह लूप से बाहर आ जाएगा।
बबलोर्ट एल्गोरिथ्म के छद्मकोड को इस प्रकार लिखा जा सकता है -
procedure bubbleSort( list : array of items )
loop = list.count;
for i = 0 to loop-1 do:
swapped = false
for j = 0 to loop-1 do:
/* compare the adjacent elements */
if list[j] > list[j+1] then
/* swap them */
swap( list[j], list[j+1] )
swapped = true
end if
end for
/*if no number was swapped that means
array is sorted now, break the loop.*/
if(not swapped) then
break
end if
end for
end procedure return listकार्यान्वयन
एक और मुद्दा जिसे हमने अपने मूल एल्गोरिथ्म और इसके सुधारित छद्मकोश में नहीं संबोधित किया है, वह यह है कि प्रत्येक पुनरावृत्ति के बाद उच्चतम मान सरणी के अंत में बस जाते हैं। इसलिए, अगले पुनरावृत्ति में पहले से ही हल किए गए तत्व शामिल नहीं हैं। इस प्रयोजन के लिए, हमारे कार्यान्वयन में, हम पहले से ही हल किए गए मूल्यों से बचने के लिए आंतरिक लूप को प्रतिबंधित करते हैं।
सी प्रोग्रामिंग भाषा में बबल सॉर्ट कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
यह एक इन-प्लेस तुलना-आधारित सॉर्टिंग एल्गोरिथम है। यहां, एक उप-सूची बनाए रखी जाती है जो हमेशा हल होती है। उदाहरण के लिए, एक सरणी के निचले हिस्से को क्रमबद्ध किया जाना है। एक तत्व जो इस क्रमबद्ध उप-सूची में 'सम्मिलित' किया जाना है, उसे अपनी उपयुक्त जगह ढूंढनी होगी और फिर उसे वहां डालना होगा। इसलिए यह नाम,insertion sort।
सरणी को क्रमिक रूप से खोजा जाता है और अनसुलझी वस्तुओं को ले जाया जाता है और क्रमबद्ध उप-सूची (उसी सरणी में) में डाला जाता है। यह एल्गोरिथ्म बड़े डेटा सेट के लिए उपयुक्त नहीं है क्योंकि इसकी औसत और सबसे खराब स्थिति जटिलता n (n 2 ) की है, जहांn मदों की संख्या है।
प्रविष्टि कैसे काम करती है?
हम अपने उदाहरण के लिए एक अनसुलझा सरणी लेते हैं।

सम्मिलन क्रम पहले दो तत्वों की तुलना करता है।

यह पाता है कि 14 और 33 दोनों पहले से ही आरोही क्रम में हैं। अभी के लिए, 14 क्रमबद्ध उप-सूची में है।

सम्मिलन क्रम आगे बढ़ता है और 33 की तुलना 27 के साथ करता है।

और पाता है कि 33 सही स्थिति में नहीं है।

यह 27 के साथ 33 स्वैप करता है। यह सॉर्ट किए गए उप-सूची के सभी तत्वों के साथ भी जांच करता है। यहां हम देखते हैं कि सॉर्ट की गई उप-सूची में केवल एक तत्व 14 है, और 27 14. से अधिक है। इसलिए, सॉर्ट की गई उप-सूची को स्वैप करने के बाद सॉर्ट किया जाता है।

अब तक हमारे पास क्रमबद्ध उप-सूची में 14 और 27 हैं। अगला, यह 10 के साथ 33 की तुलना करता है।

ये मान क्रमबद्ध क्रम में नहीं हैं।

इसलिए हम उन्हें स्वैप करते हैं।

हालाँकि, अदला-बदली 27 और 10 को अनसोल्ड कर देती है।

इसलिए, हम उन्हें स्वैप भी करते हैं।

फिर से हम 14 और 10 को एक अनसुलझी क्रम में पाते हैं।

हम उन्हें फिर से स्वैप करते हैं। तीसरी पुनरावृत्ति के अंत तक, हमारे पास 4 आइटमों की क्रमबद्ध उप-सूची है।

यह प्रक्रिया तब तक चलती है जब तक कि सभी अनसुलझे मान एक क्रमबद्ध उप-सूची में शामिल नहीं हो जाते। अब हम प्रविष्टि प्रकार के कुछ प्रोग्रामिंग पहलुओं को देखेंगे।
कलन विधि
अब हमारे पास एक बड़ा चित्र है कि यह छँटाई तकनीक कैसे काम करती है, इसलिए हम सरल चरणों को प्राप्त कर सकते हैं जिनके द्वारा हम सम्मिलन क्रम को प्राप्त कर सकते हैं।
Step 1 − If it is the first element, it is already sorted. return 1;
Step 2 − Pick next element
Step 3 − Compare with all elements in the sorted sub-list
Step 4 − Shift all the elements in the sorted sub-list that is greater than the
value to be sorted
Step 5 − Insert the value
Step 6 − Repeat until list is sortedस्यूडोकोड
procedure insertionSort( A : array of items )
int holePosition
int valueToInsert
for i = 1 to length(A) inclusive do:
/* select value to be inserted */
valueToInsert = A[i]
holePosition = i
/*locate hole position for the element to be inserted */
while holePosition > 0 and A[holePosition-1] > valueToInsert do:
A[holePosition] = A[holePosition-1]
holePosition = holePosition -1
end while
/* insert the number at hole position */
A[holePosition] = valueToInsert
end for
end procedureसी प्रोग्रामिंग भाषा में प्रविष्टि सॉर्ट कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
चयन सॉर्ट एक सरल सॉर्टिंग एल्गोरिथ्म है। यह सॉर्टिंग एल्गोरिथ्म एक इन-प्लेस तुलना-आधारित एल्गोरिथ्म है जिसमें सूची को दो भागों में विभाजित किया गया है, बाएं छोर पर सॉर्ट किए गए भाग और दाएं छोर पर अनसोल्ड भाग। प्रारंभ में, सॉर्ट किया गया भाग खाली है और अनसरा हुआ भाग पूरी सूची है।
सबसे छोटे तत्व को अनसोल्ड एरे से चुना जाता है और सबसे लेफ्ट एलिमेंट से स्वैप किया जाता है, और यह एलिमेंट सॉर्ट किए गए एरे का एक हिस्सा बन जाता है। यह प्रक्रिया एक तत्व द्वारा दाईं ओर बनी हुई बिना झुकी सरणी सीमा को आगे बढ़ाती है।
यह एल्गोरिथ्म बड़े डेटा सेट के लिए उपयुक्त नहीं है क्योंकि इसकी औसत और सबसे खराब स्थिति जटिलताएं n (n 2 ) की हैं, जहांn मदों की संख्या है।
चयन कैसे कार्य करता है?
एक उदाहरण के रूप में निम्नलिखित चित्रित सरणी पर विचार करें।
क्रमबद्ध सूची में पहले स्थान के लिए, पूरी सूची क्रमिक रूप से स्कैन की जाती है। पहली स्थिति जहां 14 वर्तमान में संग्रहीत है, हम पूरी सूची खोजते हैं और पाते हैं कि 10 सबसे कम मूल्य है।

इसलिए हम 14 को 10. के साथ प्रतिस्थापित करते हैं। एक पुनरावृत्ति 10 के बाद, जो सूची में न्यूनतम मान होता है, क्रमबद्ध सूची की पहली स्थिति में दिखाई देता है।

दूसरी स्थिति के लिए, जहां 33 का निवास है, हम बाकी की सूची को रेखीय तरीके से स्कैन करना शुरू करते हैं।

हम पाते हैं कि 14 सूची में दूसरा सबसे कम मूल्य है और इसे दूसरे स्थान पर दिखाई देना चाहिए। हम इन मूल्यों की अदला-बदली करते हैं।

दो पुनरावृत्तियों के बाद, क्रमबद्ध तरीके से शुरुआत में दो कम से कम मान दिए जाते हैं।

सरणी में बाकी वस्तुओं पर भी यही प्रक्रिया लागू होती है।
निम्नलिखित पूरी छँटाई प्रक्रिया का एक चित्रमय चित्रण है -

अब, हम चयन प्रकार के कुछ प्रोग्रामिंग पहलुओं को सीखते हैं।
कलन विधि
Step 1 − Set MIN to location 0
Step 2 − Search the minimum element in the list
Step 3 − Swap with value at location MIN
Step 4 − Increment MIN to point to next element
Step 5 − Repeat until list is sortedस्यूडोकोड
procedure selection sort
list : array of items
n : size of list
for i = 1 to n - 1
/* set current element as minimum*/
min = i
/* check the element to be minimum */
for j = i+1 to n
if list[j] < list[min] then
min = j;
end if
end for
/* swap the minimum element with the current element*/
if indexMin != i then
swap list[min] and list[i]
end if
end for
end procedureसी प्रोग्रामिंग भाषा में चयन प्रकार कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
मर्ज सॉर्ट डिवाइड और विजय तकनीक पर आधारित एक सॉर्टिंग तकनीक है। सबसे खराब समय जटिलता Ο (n लॉग एन) होने के साथ, यह सबसे सम्मानित एल्गोरिदम में से एक है।
मर्ज सॉर्ट पहले सरणी को बराबर हिस्सों में विभाजित करता है और फिर उन्हें क्रमबद्ध तरीके से जोड़ता है।
कैसे काम करता है मर्ज?
मर्ज सॉर्ट को समझने के लिए, हम निम्नलिखित के रूप में एक अनसुलझा सरणी लेते हैं -
हम जानते हैं कि मर्ज सॉर्ट पहले पूरे सरणी को समान रूप से हिस्सों में विभाजित करता है जब तक कि परमाणु मूल्य प्राप्त नहीं होते हैं। हम यहां देखते हैं कि 8 मदों की एक सरणी को आकार 4 के दो सरणियों में विभाजित किया गया है।

यह मूल में वस्तुओं की उपस्थिति के अनुक्रम को नहीं बदलता है। अब हम इन दो सरणियों को हिस्सों में विभाजित करते हैं।

हम आगे इन सरणियों को विभाजित करते हैं और हम परमाणु मूल्य प्राप्त करते हैं जिसे और अधिक विभाजित नहीं किया जा सकता है।

अब, हम उन्हें ठीक उसी तरह से जोड़ते हैं जैसे वे टूट गए थे। कृपया इन सूचियों को दिए गए रंग कोड पर ध्यान दें।
हम पहले प्रत्येक सूची के लिए तत्व की तुलना करते हैं और फिर उन्हें अन्य सूची में क्रमबद्ध तरीके से जोड़ते हैं। हम देखते हैं कि 14 और 33 क्रमबद्ध पदों पर हैं। हम 27 और 10 की तुलना करते हैं और 2 मानों की लक्ष्य सूची में हम पहले 10 डालते हैं, 27 के बाद। हम 19 और 35 के क्रम को बदलते हैं जबकि 42 और 44 क्रमिक रूप से रखे जाते हैं।

संयोजन चरण के अगले पुनरावृत्ति में, हम दो डेटा मानों की सूचियों की तुलना करते हैं, और उन्हें क्रमबद्ध क्रम में रखने वाले पाए गए डेटा मानों की सूची में विलय कर देते हैं।

अंतिम विलय के बाद, सूची इस तरह दिखनी चाहिए -

अब हमें मर्ज सॉर्टिंग के कुछ प्रोग्रामिंग पहलुओं को सीखना चाहिए।
कलन विधि
मर्ज सॉर्ट सूची को बराबर हिस्सों में विभाजित करता रहता है जब तक कि इसे और अधिक विभाजित नहीं किया जा सकता। परिभाषा के अनुसार, यदि यह सूची में केवल एक तत्व है, तो इसे सॉर्ट किया जाता है। फिर, मर्ज सॉर्ट नई सूची को भी सॉर्ट करते हुए छोटी सॉर्ट की गई सूचियों को जोड़ती है।
Step 1 − if it is only one element in the list it is already sorted, return.
Step 2 − divide the list recursively into two halves until it can no more be divided.
Step 3 − merge the smaller lists into new list in sorted order.स्यूडोकोड
अब हम मर्ज सॉर्ट फ़ंक्शन के लिए छद्म कोड देखेंगे। जैसा कि हमारे एल्गोरिदम दो मुख्य कार्य बताते हैं - विभाजन और विलय।
मर्ज सॉर्ट पुनरावृत्ति के साथ काम करता है और हम उसी तरह हमारे कार्यान्वयन को देखेंगे।
procedure mergesort( var a as array )
if ( n == 1 ) return a
var l1 as array = a[0] ... a[n/2]
var l2 as array = a[n/2+1] ... a[n]
l1 = mergesort( l1 )
l2 = mergesort( l2 )
return merge( l1, l2 )
end procedure
procedure merge( var a as array, var b as array )
var c as array
while ( a and b have elements )
if ( a[0] > b[0] )
add b[0] to the end of c
remove b[0] from b
else
add a[0] to the end of c
remove a[0] from a
end if
end while
while ( a has elements )
add a[0] to the end of c
remove a[0] from a
end while
while ( b has elements )
add b[0] to the end of c
remove b[0] from b
end while
return c
end procedureसी प्रोग्रामिंग भाषा में मर्ज सॉर्ट कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
शैल सॉर्ट एक अत्यधिक कुशल छँटाई एल्गोरिथ्म है और सम्मिलन सॉर्ट एल्गोरिथ्म पर आधारित है। यह एल्गोरिथ्म सम्मिलन के क्रम में बड़े बदलावों से बचता है, यदि छोटा मान दाईं ओर है और इसे बाईं ओर ले जाया जाना है।
यह एल्गोरिथ्म व्यापक रूप से फैले तत्वों पर सम्मिलन प्रकार का उपयोग करता है, पहले उन्हें सॉर्ट करने के लिए और फिर कम व्यापक रूप से फैलाने वाले तत्वों को क्रमबद्ध करता है। इस रिक्ति को कहा जाता हैinterval। इस अंतराल की गणना नथ के फार्मूले के आधार पर की जाती है -
नुथ का सूत्र
h = h * 3 + 1
where −
h is interval with initial value 1मध्यम-आकार के डेटा सेट के लिए यह एल्गोरिथ्म काफी कुशल है क्योंकि इसकी औसत और सबसे खराब स्थिति जटिलता quite (n) की है, जहां n मदों की संख्या है।
शेल कैसे काम करता है?
आइए हम निम्नलिखित उदाहरण पर विचार करें कि शेल प्रकार कैसे काम करता है। हम उसी सरणी को लेते हैं जिसका उपयोग हमने अपने पिछले उदाहरणों में किया है। हमारे उदाहरण और समझने में आसानी के लिए, हम 4 का अंतराल लेते हैं। 4 पदों के अंतराल पर स्थित सभी मूल्यों की एक आभासी उप-सूची बनाएं। यहाँ ये मान {35, 14}, {33, 19}, {42, 27} और {10, 44} हैं

हम प्रत्येक उप-सूची के मूल्यों की तुलना करते हैं और मूल सरणी में उन्हें (यदि आवश्यक हो) स्वैप करते हैं। इस चरण के बाद, नई सरणी इस तरह दिखनी चाहिए -

फिर, हम 2 का अंतराल लेते हैं और यह अंतर दो उप-सूचियाँ उत्पन्न करता है - {14, 27, 35, 42}, {19, 10, 33, 44}

यदि आवश्यक हो, तो हम मूल सरणी में मानों की तुलना और अदला-बदली करते हैं। इस चरण के बाद, सरणी इस तरह दिखनी चाहिए -

अंत में, हम बाकी सरणी को मान के अंतराल का उपयोग करके सॉर्ट करते हैं। शेल प्रकार सरणी को सॉर्ट करने के लिए सम्मिलन प्रकार का उपयोग करता है।
निम्नलिखित चरण-दर-चरण चित्रण है -

हम देखते हैं कि बाकी सरणी को छांटने के लिए केवल चार स्वैप की आवश्यकता है।
कलन विधि
शेल प्रकार के लिए एल्गोरिथ्म निम्नलिखित है।
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedस्यूडोकोड
निम्नलिखित शेल छँटाई के लिए छद्मकोश है।
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureसी प्रोग्रामिंग भाषा में शेल सॉर्ट कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
शैल सॉर्ट एक अत्यधिक कुशल छँटाई एल्गोरिथ्म है और सम्मिलन सॉर्ट एल्गोरिथ्म पर आधारित है। यह एल्गोरिथ्म सम्मिलन के क्रम में बड़े बदलावों से बचता है, यदि छोटा मान दाईं ओर है और इसे बाईं ओर ले जाया जाना है।
यह एल्गोरिथ्म व्यापक रूप से फैले तत्वों पर सम्मिलन प्रकार का उपयोग करता है, पहले उन्हें सॉर्ट करने के लिए और फिर कम व्यापक रूप से फैलाने वाले तत्वों को क्रमबद्ध करता है। इस रिक्ति को कहा जाता हैinterval। इस अंतराल की गणना नथ के फार्मूले के आधार पर की जाती है -
नुथ का सूत्र
h = h * 3 + 1
where −
h is interval with initial value 1यह एल्गोरिथ्म मध्यम आकार के डेटा सेट के लिए काफी कुशल है क्योंकि इस एल्गोरिथम की औसत और सबसे खराब स्थिति जटिलता अंतर अनुक्रम पर निर्भर करती है जिसे सबसे अच्छा ज्ञात best (n) है, जहां n आइटमों की संख्या है। और सबसे खराब स्थिति अंतरिक्ष जटिलता O (n) है।
शेल कैसे काम करता है?
आइए हम निम्नलिखित उदाहरण पर विचार करें कि शेल प्रकार कैसे काम करता है। हम उसी सरणी को लेते हैं जिसका उपयोग हमने अपने पिछले उदाहरणों में किया है। हमारे उदाहरण और समझने में आसानी के लिए, हम 4 का अंतराल लेते हैं। 4 पदों के अंतराल पर स्थित सभी मूल्यों की एक आभासी उप-सूची बनाएं। यहाँ ये मान {35, 14}, {33, 19}, {42, 27} और {10, 44} हैं
हम प्रत्येक उप-सूची के मूल्यों की तुलना करते हैं और मूल सरणी में उन्हें (यदि आवश्यक हो) स्वैप करते हैं। इस चरण के बाद, नई सरणी इस तरह दिखनी चाहिए -
फिर, हम 1 का अंतराल लेते हैं और यह अंतर दो उप-सूचियाँ उत्पन्न करता है - {14, 27, 35, 42}, {19, 10, 33, 44}
यदि आवश्यक हो, तो हम मूल सरणी में मानों की तुलना और अदला-बदली करते हैं। इस चरण के बाद, सरणी इस तरह दिखनी चाहिए -
अंत में, हम बाकी सरणी को मान के अंतराल का उपयोग करके सॉर्ट करते हैं। शेल प्रकार सरणी को सॉर्ट करने के लिए सम्मिलन प्रकार का उपयोग करता है।
निम्नलिखित चरण-दर-चरण चित्रण है -
हम देखते हैं कि बाकी सरणी को छांटने के लिए केवल चार स्वैप की आवश्यकता है।
कलन विधि
शेल प्रकार के लिए एल्गोरिथ्म निम्नलिखित है।
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedस्यूडोकोड
निम्नलिखित शेल छँटाई के लिए छद्मकोश है।
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureसी प्रोग्रामिंग भाषा में शेल सॉर्ट कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
त्वरित सॉर्ट एक अत्यधिक कुशल छँटाई एल्गोरिथ्म है और डेटा की सरणी को छोटे सरणियों में विभाजित करने पर आधारित है। एक बड़े सरणी को दो सरणियों में विभाजित किया जाता है, जिनमें से एक निर्दिष्ट मान से छोटा मान रखता है, जिसे धुरी कहते हैं, जिसके आधार पर विभाजन किया जाता है और दूसरा सरणी धुरी मूल्य से अधिक मान रखता है।
Quicksort एक सरणी को विभाजित करता है और फिर दो परिणामी उप-प्रकारों को सॉर्ट करने के लिए खुद को पुनरावर्ती रूप से दो बार कॉल करता है। यह एल्गोरिथम बड़े आकार के डेटा सेट के लिए काफी कुशल है क्योंकि इसकी औसत और सबसे खराब स्थिति क्रमशः ओ (nLogn) और image.png (n 2 ) है।
क्विक सॉर्ट में विभाजन
एनिमेटेड प्रतिनिधित्व के बाद एक सरणी में धुरी मूल्य को खोजने का तरीका बताता है।

पिवट मान सूची को दो भागों में विभाजित करता है। और पुनरावर्ती रूप से, हम प्रत्येक उप-सूचियों के लिए धुरी पाते हैं जब तक कि सभी सूचियों में केवल एक तत्व न हो।
त्वरित सॉर्ट धुरी एल्गोरिदम
त्वरित क्रम में विभाजन की हमारी समझ के आधार पर, अब हम इसके लिए एक एल्गोरिथ्म लिखने की कोशिश करेंगे, जो इस प्रकार है।
Step 1 − Choose the highest index value has pivot
Step 2 − Take two variables to point left and right of the list excluding pivot
Step 3 − left points to the low index
Step 4 − right points to the high
Step 5 − while value at left is less than pivot move right
Step 6 − while value at right is greater than pivot move left
Step 7 − if both step 5 and step 6 does not match swap left and right
Step 8 − if left ≥ right, the point where they met is new pivotक्विक सॉर्ट पिवट स्यूडोकोड
उपरोक्त एल्गोरिथ्म के लिए छद्मकोश को निम्नानुसार लिया जा सकता है -
function partitionFunc(left, right, pivot)
leftPointer = left
rightPointer = right - 1
while True do
while A[++leftPointer] < pivot do
//do-nothing
end while
while rightPointer > 0 && A[--rightPointer] > pivot do
//do-nothing
end while
if leftPointer >= rightPointer
break
else
swap leftPointer,rightPointer
end if
end while
swap leftPointer,right
return leftPointer
end functionत्वरित क्रमबद्ध एल्गोरिथ्म
धुरी एल्गोरिदम का पुनरावर्ती उपयोग करते हुए, हम छोटे संभव विभाजन के साथ समाप्त होते हैं। प्रत्येक विभाजन को फिर त्वरित क्रम के लिए संसाधित किया जाता है। हम क्विकर के लिए पुनरावर्ती एल्गोरिदम को निम्नानुसार परिभाषित करते हैं -
Step 1 − Make the right-most index value pivot
Step 2 − partition the array using pivot value
Step 3 − quicksort left partition recursively
Step 4 − quicksort right partition recursivelyक्विक सॉर्ट छद्मकोड
इसे और अधिक प्राप्त करने के लिए, त्वरित सॉर्ट एल्गोरिथ्म के लिए छद्मकोड देखें -
procedure quickSort(left, right)
if right-left <= 0
return
else
pivot = A[right]
partition = partitionFunc(left, right, pivot)
quickSort(left,partition-1)
quickSort(partition+1,right)
end if
end procedureसी प्रोग्रामिंग भाषा में त्वरित सॉर्ट कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
एक ग्राफ वस्तुओं के एक सेट का एक चित्रमय प्रतिनिधित्व है जहां कुछ जोड़े वस्तुओं के लिंक से जुड़े होते हैं। परस्पर जुड़ी वस्तुओं को ऐसे बिंदुओं द्वारा दर्शाया जाता है जिन्हें कहा जाता हैvertices, और कड़ियों को जोड़ने वाले लिंक को कहा जाता है edges।
औपचारिक रूप से, एक ग्राफ सेट की एक जोड़ी है (V, E), कहाँ पे V कोने का सेट है और Eकिनारों का एक सेट है, जोडों के जोड़े को जोड़ता है। निम्नलिखित ग्राफ पर एक नज़र डालें -
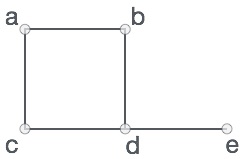
उपरोक्त ग्राफ में,
वी = {ए, बी, सी, डी, ई}
E = {अब, एसी, बीडी, सीडी, डे}
ग्राफ डेटा संरचना
गणितीय रेखांकन को डेटा संरचना में दर्शाया जा सकता है। हम वर्टिकल की एक सरणी और किनारों के दो-आयामी सरणी का उपयोग करके एक ग्राफ का प्रतिनिधित्व कर सकते हैं। इससे पहले कि हम आगे बढ़ें, चलो कुछ महत्वपूर्ण शब्दों से खुद को परिचित करते हैं -
Vertex- ग्राफ के प्रत्येक नोड को एक शीर्ष के रूप में दर्शाया गया है। निम्नलिखित उदाहरण में, लेबल सर्कल वर्टिकल का प्रतिनिधित्व करता है। इस प्रकार, A से G लंबवत हैं। हम निम्न छवि में दिखाए गए अनुसार एक सरणी का उपयोग करके उनका प्रतिनिधित्व कर सकते हैं। यहां ए को इंडेक्स 0. बी द्वारा पहचाना जा सकता है और इंडेक्स 1 का उपयोग करके पहचाना जा सकता है।
Edge- एज दो कोने के बीच एक पथ या दो कोने के बीच की रेखा का प्रतिनिधित्व करता है। निम्नलिखित उदाहरण में, ए से बी, बी से सी, और इसी तरह की रेखाएं किनारों का प्रतिनिधित्व करती हैं। हम एक सरणी का प्रतिनिधित्व करने के लिए दो आयामी सरणी का उपयोग कर सकते हैं जैसा कि निम्नलिखित छवि में दिखाया गया है। यहाँ AB को 0 पर पंक्ति 1, स्तंभ 1, BC के रूप में 1 पंक्ति 1, स्तंभ 2 और इतने पर, अन्य संयोजनों को 0 के रूप में प्रस्तुत किया जा सकता है।
Adjacency- दो नोड या कोने सटे हुए हैं यदि वे एक किनारे के माध्यम से एक दूसरे से जुड़े हुए हैं। निम्नलिखित उदाहरण में, बी ए के निकट है, सी बी के निकट है, और इसी तरह।
Path- पथ दो कोने के बीच किनारों के अनुक्रम का प्रतिनिधित्व करता है। निम्नलिखित उदाहरण में, ABCD A से D तक के मार्ग का प्रतिनिधित्व करता है।
मूलभूत क्रियाएं
ग्राफ के प्राथमिक प्राथमिक ऑपरेशन निम्नलिखित हैं -
Add Vertex - ग्राफ के लिए एक शीर्ष जोड़ता है।
Add Edge - ग्राफ के दो कोने के बीच एक बढ़त जोड़ता है।
Display Vertex - ग्राफ के एक शीर्ष को प्रदर्शित करता है।
ग्राफ़ के बारे में अधिक जानने के लिए, कृपया ग्राफ़ थ्योरी ट्यूटोरियल पढ़ें । हम आने वाले अध्यायों में एक ग्राफ को ट्रेस करने के बारे में सीखेंगे।
डेप्थ फर्स्ट सर्च (डीएफएस) एल्गोरिथ्म एक ग्राफ को गहराई से गति करता है और एक खोज शुरू करने के लिए अगला शीर्ष प्राप्त करने के लिए याद रखने के लिए एक स्टैक का उपयोग करता है, जब किसी भी पुनरावृत्ति में एक मृत अंत होता है।

जैसा कि ऊपर दिए गए उदाहरण में बताया गया है, DFS एल्गोरिथ्म S से A से D तक G से E से B पहले, फिर F से और अंत में C. से पता चलता है। यह निम्नलिखित नियमों को नियोजित करता है।
Rule 1- समीपवर्ती अप्रकाशित शिखर पर जाएँ। इसे चिह्नित के रूप में चिह्नित करें। इसे प्रदर्शित करें। इसे ढेर में दबा दें।
Rule 2- यदि कोई निकटवर्ती शीर्ष नहीं पाया जाता है, तो स्टैक से एक शीर्ष को पॉप करें। (यह स्टैक से सभी कोने को पॉप अप करेगा, जिसमें आसन्न कोने नहीं हैं।)
Rule 3 - स्टैक खाली होने तक नियम 1 और नियम 2 को दोहराएं।
| कदम | traversal | विवरण |
|---|---|---|
| 1 |

|
स्टैक को प्रारंभ करें। |
| 2 |

|
निशान Sके रूप में दौरा किया और यह ढेर पर डाल दिया। किसी भी गैर-समीपवर्ती नोड का अन्वेषण करेंS। हमारे पास तीन नोड हैं और हम उनमें से किसी को भी चुन सकते हैं। इस उदाहरण के लिए, हम नोड को एक वर्णमाला क्रम में लेंगे। |
| 3 |

|
निशान Aके रूप में दौरा किया और यह ढेर पर डाल दिया। ए। दोनों से किसी भी गैर-समीपवर्ती नोड का अन्वेषण करेंS तथा D से सटे हुए हैं A लेकिन हम केवल गैर-अधिकृत नोड्स के लिए चिंतित हैं। |
| 4 |

|
यात्रा Dऔर उस पर जाएँ और स्टैक पर रखें। हमारे पास हैB तथा C नोड्स, जो आसन्न हैं Dऔर दोनों की परिकल्पना नहीं की गई है। हालाँकि, हम फिर से एक वर्णमाला क्रम में चयन करेंगे। |
| 5 |

|
हम चुनेंगे Bके रूप में यह दौरा किया और ढेर पर डाल दिया। यहाँBकिसी भी गैर-समीपवर्ती नोड के पास नहीं है। तो, हम पॉपB ढेर से। |
| 6 |

|
हम पिछले नोड पर लौटने के लिए स्टैक शीर्ष की जांच करते हैं और जांचते हैं कि क्या यह किसी भी गैर-नोड नोड्स में है। यहाँ, हम पाते हैंD ढेर के शीर्ष पर होना। |
| 7 |

|
केवल अप्रयुक्त आसन्न नोड से है D है Cअभी। इसलिए हम यात्रा करते हैंCके रूप में चिह्नित पर जाएँ और इसे स्टैक पर रखें। |
जैसा Cहमारे पास किसी भी तरह के गैर-समीपवर्ती नोड नहीं है, इसलिए हम स्टैक को तब तक पॉपअप करते रहते हैं जब तक कि हमें एक नोड न मिल जाए जो कि आसन्न नोड है। इस स्थिति में, कोई भी नहीं है और हम तब तक पॉपिंग करते रहते हैं जब तक कि स्टैक खाली न हो जाए।
सी प्रोग्रामिंग भाषा में इस एल्गोरिथ्म के कार्यान्वयन के बारे में जानने के लिए, यहां क्लिक करें ।
चौड़ाई पहली खोज (बीएफएस) एल्गोरिथ्म एक चौड़ाई को एक गति में बदल देता है और एक खोज शुरू करने के लिए अगला शीर्ष प्राप्त करने के लिए याद रखने के लिए एक कतार का उपयोग करता है, जब किसी भी पुनरावृत्ति में एक मृत अंत होता है।

जैसा कि ऊपर दिए गए उदाहरण में बताया गया है, BFS एल्गोरिथ्म A से B तक E से F तक पहले C और G से अंत में D. तक जाता है। यह निम्नलिखित नियमों को नियोजित करता है।
Rule 1- समीपवर्ती अप्रकाशित शिखर पर जाएँ। इसे चिह्नित के रूप में चिह्नित करें। इसे प्रदर्शित करें। इसे एक कतार में डालें।
Rule 2 - यदि कोई निकटवर्ती शीर्ष नहीं पाया जाता है, तो कतार से पहला शीर्ष हटा दें।
Rule 3 - जब तक कतार खाली न हो जाए तब तक नियम 1 और नियम 2 को दोहराएं।
| कदम | traversal | विवरण |
|---|---|---|
| 1 |

|
कतार को प्रारंभ करें। |
| 2 |
|
हम दौरा शुरू करते हैं S (नोड शुरू), और इसे दौरा के रूप में चिह्नित करें। |
| 3 |

|
हम तब से एक असंगत आसन्न नोड देखते हैं S। इस उदाहरण में, हमारे पास तीन नोड हैं लेकिन वर्णानुक्रम में हम चुनते हैंAके रूप में चिह्नित और इसे enqueue चिह्नित करें। |
| 4 |

|
अगला, से अप्राप्त आसन्न नोड S है B। हम इसे यात्रा के रूप में चिह्नित करते हैं और इसे संलग्न करते हैं। |
| 5 |

|
अगला, से अप्राप्त आसन्न नोड S है C। हम इसे यात्रा के रूप में चिह्नित करते हैं और इसे संलग्न करते हैं। |
| 6 |

|
अभी, Sबिना किसी आसन्न नोड के साथ छोड़ दिया जाता है। तो, हम धोखा देते हैं और पाते हैंA। |
| 7 |

|
से A हमारे पास है Dअसमान आसन्न नोड के रूप में। हम इसे यात्रा के रूप में चिह्नित करते हैं और इसे संलग्न करते हैं। |
इस स्तर पर, हमें बिना किसी चिन्हित (अप्रभावित) नोड्स के साथ छोड़ दिया जाता है। लेकिन एल्गोरिथ्म के अनुसार हम सभी गैर-प्रमाणित नोड्स प्राप्त करने के लिए छलावा करते रहते हैं। जब कतार खाली हो जाती है, तो कार्यक्रम समाप्त हो जाता है।
सी प्रोग्रामिंग भाषा में इस एल्गोरिथ्म के कार्यान्वयन को यहां देखा जा सकता है ।
ट्री किनारों द्वारा जुड़े नोड्स का प्रतिनिधित्व करता है। हम बाइनरी ट्री या बाइनरी सर्च ट्री पर विशेष रूप से चर्चा करेंगे।
बाइनरी ट्री एक विशेष डाटास्ट्रक्चर है जिसका उपयोग डेटा स्टोरेज उद्देश्यों के लिए किया जाता है। एक बाइनरी ट्री में एक विशेष शर्त है कि प्रत्येक नोड में अधिकतम दो बच्चे हो सकते हैं। एक बाइनरी ट्री में एक ऑर्डर किए गए सरणी और लिंक की गई सूची दोनों के फायदे हैं, जैसे कि खोज एक त्वरित क्रमबद्ध सरणी में है और प्रविष्टि सूची में प्रविष्टि या विलोपन ऑपरेशन उतनी ही तेजी से होते हैं।

महत्वपूर्ण शर्तें
पेड़ के संबंध में निम्नलिखित महत्वपूर्ण शर्तें हैं।
Path - पथ एक पेड़ के किनारों के साथ नोड्स के अनुक्रम को संदर्भित करता है।
Root- पेड़ के शीर्ष पर स्थित नोड को रूट कहा जाता है। प्रति पेड़ केवल एक जड़ और रूट नोड से किसी भी नोड के लिए एक रास्ता है।
Parent - रूट नोड को छोड़कर किसी भी नोड में एक किनारे ऊपर की ओर अभिभावक कहलाता है।
Child - इसके किनारे से नीचे दिए गए नोड से नीचे के नोड को उसका बच्चा नोड कहा जाता है।
Leaf - जिस नोड में कोई बच्चा नोड नहीं होता है, उसे लीफ नोड कहा जाता है।
Subtree - उपशीर्षक एक नोड के वंशज का प्रतिनिधित्व करता है।
Visiting - जब नोड पर नियंत्रण होता है, तो विजिटिंग एक नोड के मूल्य की जांच करने के लिए संदर्भित करता है।
Traversing - ट्रैवर्सिंग का मतलब एक विशिष्ट क्रम में नोड्स से गुजरना है।
Levels- एक नोड का स्तर एक नोड की पीढ़ी का प्रतिनिधित्व करता है। यदि रूट नोड 0 के स्तर पर है, तो इसका अगला बच्चा नोड स्तर 1 पर है, इसका पोता 2 स्तर पर है, और इसी तरह।
keys - कुंजी एक नोड के मूल्य को दर्शाता है जिसके आधार पर एक नोड के लिए एक खोज ऑपरेशन किया जाना है।
बाइनरी सर्च ट्री रिप्रेजेंटेशन
बाइनरी सर्च ट्री एक विशेष व्यवहार प्रदर्शित करता है। नोड के बाएं बच्चे का अपने माता-पिता के मूल्य से कम मूल्य होना चाहिए और नोड के दाहिने बच्चे का मूल्य उसके मूल मूल्य से अधिक होना चाहिए।

हम नोड ऑब्जेक्ट का उपयोग करके पेड़ को लागू करने जा रहे हैं और उन्हें संदर्भों के माध्यम से जोड़ रहे हैं।
पेड़ का नोड
ट्री नोड लिखने के लिए कोड नीचे दिए गए के समान होगा। इसमें एक डेटा हिस्सा है और इसके बाएं और दाएं बच्चे के नोड्स हैं।
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};एक पेड़ में, सभी नोड्स सामान्य निर्माण साझा करते हैं।
BST बेसिक ऑपरेशंस
एक बाइनरी खोज ट्री डेटा संरचना पर किए जा सकने वाले मूल संचालन निम्नलिखित हैं -
Insert - एक पेड़ में एक तत्व सम्मिलित करता है / एक पेड़ बनाता है।
Search - एक पेड़ में एक तत्व खोजता है।
Preorder Traversal - एक पेड़ को प्री-ऑर्डर तरीके से लगाया जाता है।
Inorder Traversal - एक पेड़ को इन-ऑर्डर तरीके से ट्रेस करता है।
Postorder Traversal - एक पेड़ को पोस्ट-ऑर्डर तरीके से लगाया जाता है।
हम इस अध्याय में एक पेड़ की संरचना और एक पेड़ में एक डेटा आइटम की खोज करना (सम्मिलित करना) सीखेंगे। हम आने वाले अध्याय में पेड़ की ट्रेसिंग विधियों के बारे में जानेंगे।
ऑपरेशन डालें
बहुत पहले सम्मिलन पेड़ बनाता है। बाद में, जब भी कोई तत्व सम्मिलित करना हो, तो पहले उसके उचित स्थान का पता लगाएं। रूट नोड से खोज शुरू करें, फिर यदि डेटा कुंजी मूल्य से कम है, तो बाएं सबट्री में खाली स्थान खोजें और डेटा डालें। अन्यथा, सही सबट्री में खाली स्थान खोजें और डेटा डालें।
कलन विधि
If root is NULL
then create root node
return
If root exists then
compare the data with node.data
while until insertion position is located
If data is greater than node.data
goto right subtree
else
goto left subtree
endwhile
insert data
end Ifकार्यान्वयन
इंसर्ट फंक्शन का क्रियान्वयन इस तरह होना चाहिए -
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty, create root node
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
}
//go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}सर्च ऑपरेशन
जब भी किसी तत्व को खोजना हो, तो रूट नोड से खोजना शुरू करें, फिर यदि डेटा मुख्य मान से कम है, तो तत्व को बाएं सबट्री में खोजें। अन्यथा, सही उपशीर्षक में तत्व की खोज करें। प्रत्येक नोड के लिए समान एल्गोरिथ्म का पालन करें।
कलन विधि
If root.data is equal to search.data
return root
else
while data not found
If data is greater than node.data
goto right subtree
else
goto left subtree
If data found
return node
endwhile
return data not found
end ifइस एल्गोरिथ्म के कार्यान्वयन को इस तरह दिखना चाहिए।
struct node* search(int data) {
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data) {
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data) {
current = current->leftChild;
}
//else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL) {
return NULL;
}
return current;
}
}बाइनरी सर्च ट्री डेटा संरचना के कार्यान्वयन के बारे में जानने के लिए, कृपया यहां क्लिक करें ।
ट्रावर्सल एक पेड़ के सभी नोड्स का दौरा करने की एक प्रक्रिया है और उनके मूल्यों को भी मुद्रित कर सकता है। क्योंकि, सभी नोड्स किनारों (लिंक) से जुड़े होते हैं, हम हमेशा रूट (हेड) नोड से शुरू करते हैं। यही है, हम एक पेड़ में एक नोड को बेतरतीब ढंग से एक्सेस नहीं कर सकते हैं। एक पेड़ को पार करने के लिए तीन तरीके हैं -
- इन-ऑर्डर ट्रैवर्सल
- ट्रैवर्सल को प्री-ऑर्डर करें
- पोस्ट-ऑर्डर ट्रैवर्सल
आम तौर पर, हम पेड़ में दी गई वस्तु या कुंजी को खोजने या उसमें मौजूद सभी मूल्यों को प्रिंट करने के लिए किसी पेड़ को खोजते हैं।
इन-ऑर्डर ट्रैवर्सल
इस त्रैमासिक विधि में, बाएं उपप्रकार का दौरा पहले किया जाता है, फिर मूल और बाद में दाएं उप-पेड़। हमें हमेशा याद रखना चाहिए कि प्रत्येक नोड एक उपप्रकार का प्रतिनिधित्व कर सकता है।
यदि एक बाइनरी ट्री को ट्रेस किया जाता है in-orderआउटपुट एक आरोही क्रम में प्रमुख मानों को हल करेगा।

हम से शुरू करते हैं A, और इन-ऑर्डर ट्रैवर्सल का अनुसरण करते हुए, हम इसके बाएं सबट्री पर जाते हैं B। Bभी आदेश में फंस गया है। प्रक्रिया तब तक चलती है जब तक कि सभी नोड्स का दौरा नहीं किया जाता है। इस पेड़ के इनवर्टर ट्रैवर्सल का उत्पादन होगा -
D → B → E → A → F → C → G
कलन विधि
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.ट्रैवर्सल को प्री-ऑर्डर करें
इस ट्रैवर्सल विधि में, रूट नोड का दौरा पहले किया जाता है, फिर बाएं सबट्री और अंत में राइट सबट्री।

हम से शुरू करते हैं A, और प्री-ऑर्डर ट्रैवर्सल के बाद, हम पहले यात्रा करते हैं A स्वयं और उसके बाद अपने बाएँ उपप्रकार में जाएँ B। Bपूर्व-आदेश का भी पता लगाया गया है। प्रक्रिया तब तक चलती है जब तक कि सभी नोड्स का दौरा नहीं किया जाता है। इस पेड़ के प्री-ऑर्डर ट्रैवर्सल का उत्पादन होगा -
A → B → D → E → C → F → G
कलन विधि
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.पोस्ट-ऑर्डर ट्रैवर्सल
इस ट्रैवर्सल विधि में, रूट नोड को अंतिम बार देखा जाता है, इसलिए नाम। पहले हम बाईं सबट्री को पार करते हैं, फिर राइट सबट्री को और अंत में रूट नोड को।

हम से शुरू करते हैं A, और पोस्ट-ऑर्डर ट्रैवर्सल के बाद, हम पहले बाएं सबट्री पर जाते हैं B। Bआदेश के बाद ट्रैवर्स किया गया है। प्रक्रिया तब तक चलती है जब तक कि सभी नोड्स का दौरा नहीं किया जाता है। इस पेड़ के बाद के आदेश के उत्पादन का उत्पादन होगा -
D → E → B → F → G → C → A
कलन विधि
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.ट्री ट्रैवर्सिंग के सी कार्यान्वयन की जांच करने के लिए, कृपया यहां क्लिक करें ।
एक बाइनरी सर्च ट्री (BST) एक पेड़ है जिसमें सभी नोड्स नीचे दिए गए गुणों का पालन करते हैं -
बाएं उप-पेड़ की कुंजी का मूल्य उसके माता-पिता (रूट) नोड की कुंजी के मूल्य से कम है।
सही उप-पेड़ की कुंजी का मूल्य उसके मूल (रूट) नोड की कुंजी के मूल्य से अधिक या उसके बराबर है।
इस प्रकार, BST अपने सभी उप-वृक्षों को दो खंडों में विभाजित करता है; बाएं उप-पेड़ और सही उप-पेड़ और इसे इस प्रकार परिभाषित किया जा सकता है -
left_subtree (keys) < node (key) ≤ right_subtree (keys)प्रतिनिधित्व
BST एक तरह से व्यवस्थित नोड्स का संग्रह है जहां वे BST संपत्तियों को बनाए रखते हैं। प्रत्येक नोड में एक कुंजी और एक संबद्ध मूल्य होता है। खोज करते समय, वांछित कुंजी की तुलना BST में की गई है और यदि पाया जाता है, तो संबंधित मान पुनर्प्राप्त किया जाता है।
निम्नलिखित BST का एक चित्रमय प्रतिनिधित्व है -
हम देखते हैं कि रूट नोड कुंजी (27) में बाईं उप-ट्री पर सभी कम-मूल्यवान कुंजियाँ हैं और दाएं उप-ट्री पर उच्च मूल्यवान कुंजियाँ हैं।
मूलभूत क्रियाएं
एक पेड़ के बुनियादी संचालन निम्नलिखित हैं -
Search - एक पेड़ में एक तत्व खोजता है।
Insert - एक पेड़ में एक तत्व सम्मिलित करता है।
Pre-order Traversal - एक पेड़ को प्री-ऑर्डर तरीके से लगाया जाता है।
In-order Traversal - एक पेड़ को इन-ऑर्डर तरीके से ट्रेस करता है।
Post-order Traversal - एक पेड़ को पोस्ट-ऑर्डर तरीके से लगाया जाता है।
नोड
कुछ डेटा वाले नोड को परिभाषित करें, इसके बाएं और दाएं बच्चे के नोड्स के संदर्भ।
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};सर्च ऑपरेशन
जब भी कोई तत्व खोजना हो, तो रूट नोड से खोजना शुरू करें। फिर यदि डेटा कुंजी मूल्य से कम है, तो बाएं सबट्री में तत्व की खोज करें। अन्यथा, सही उपशीर्षक में तत्व की खोज करें। प्रत्येक नोड के लिए समान एल्गोरिथ्म का पालन करें।
कलन विधि
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL) {
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
} //else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
}
return current;
}ऑपरेशन डालें
जब भी कोई तत्व सम्मिलित करना हो, तो पहले उसके उचित स्थान का पता लगाएं। रूट नोड से खोज शुरू करें, फिर यदि डेटा कुंजी मूल्य से कम है, तो बाएं सबट्री में खाली स्थान खोजें और डेटा डालें। अन्यथा, सही सबट्री में खाली स्थान खोजें और डेटा डालें।
कलन विधि
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
} //go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}क्या होगा यदि बाइनरी सर्च ट्री में इनपुट एक क्रमबद्ध (आरोही या अवरोही) तरीके से आता है? यह इस तरह दिखेगा -

यह देखा गया है कि BST का सबसे खराब प्रदर्शन रैखिक खोज एल्गोरिदम के सबसे करीब है, जो कि that (n) है। वास्तविक समय के डेटा में, हम डेटा पैटर्न और उनकी आवृत्तियों का अनुमान नहीं लगा सकते हैं। इसलिए, मौजूदा बीएसटी को संतुलित करने की आवश्यकता है।
उनके आविष्कारक के नाम पर रखा गया Adelson, Velski और Landis, AVL treesऊंचाई संतुलन बाइनरी सर्च ट्री हैं। एवीएल पेड़ बाएं और दाएं उप-पेड़ों की ऊंचाई की जांच करता है और आश्वासन देता है कि अंतर 1 से अधिक नहीं है। इस अंतर को अंतर कहा जाता हैBalance Factor।
यहाँ हम देखते हैं कि पहला पेड़ संतुलित है और अगले दो पेड़ संतुलित नहीं हैं -
दूसरे पेड़ में, बाईं उपश्रेणी C ऊँचाई 2 है और दायें सबट्री की ऊँचाई 0 है, इसलिए अंतर 2 है। तीसरे पेड़ में, दायीं ओर का उपरी हिस्सा Aऊंचाई 2 है और बाईं ओर गायब है, इसलिए यह 0 है, और अंतर 2 फिर से है। एवीएल ट्री केवल 1 होने के लिए अंतर (संतुलन कारक) की अनुमति देता है।
BalanceFactor = height(left-sutree) − height(right-sutree)यदि बाएं और दाएं उप-पेड़ों की ऊंचाई में अंतर 1 से अधिक है, तो पेड़ को कुछ रोटेशन तकनीकों का उपयोग करके संतुलित किया जाता है।
एवीएल रोटेशन
अपने आप को संतुलित करने के लिए, एक एवीएल वृक्ष निम्नलिखित चार प्रकार के चक्कर लगा सकता है -
- बाएं घूमना
- सही रोटेशन
- बाएँ-दाएँ घूमना
- दाएं-बाएं घूमना
पहले दो घुमाव एकल रोटेशन हैं और अगले दो रोटेशन डबल रोटेशन हैं। असंतुलित वृक्ष होने के लिए, हमें कम से कम ऊंचाई वाले वृक्ष की आवश्यकता होती है। 2. इस साधारण वृक्ष के साथ, आइए एक-एक करके उन्हें समझें।
वाम रोटेशन
यदि एक पेड़ असंतुलित हो जाता है, जब एक नोड को सही उपप्रकार के दाहिने हिस्से में डाला जाता है, तो हम एक एकल बायां भाग बनाते हैं -

हमारे उदाहरण में, नोड Aके रूप में असंतुलित हो गया है एक नोड ए के सही उपशीर्षक के सही उपशीर्षक में डाला जाता है। हम बाएं रोटेशन को बनाकर प्रदर्शन करते हैंA B के बाएं उपरी भाग में।
राइट रोटेशन
एवीएल वृक्ष असंतुलित हो सकता है, यदि बाईं ओर के उपप्रकार में एक नोड डाला जाता है। पेड़ को फिर एक सही घुमाव की जरूरत होती है।

जैसा कि दर्शाया गया है, असंतुलित नोड दाएं घूमने से अपने बाएं बच्चे का दायां बच्चा बन जाता है।
बाएँ-दाएँ घूमना
डबल रोटेशन पहले से ही समझाया गया संस्करणों का थोड़ा जटिल संस्करण है। उन्हें बेहतर समझने के लिए, हमें रोटेशन के दौरान किए गए प्रत्येक क्रिया पर ध्यान देना चाहिए। आइए पहले देखते हैं कि बाएं-दाएं रोटेशन कैसे करें। एक बाएं-दाएं रोटेशन बाएं रोटेशन का एक संयोजन है, जिसके बाद दाएं रोटेशन होता है।
| राज्य | कार्य |
|---|---|

|
एक नोड को बाएं सबट्री के दाहिने उपप्रकार में डाला गया है। यह बनाता हैCएक असंतुलित नोड। ये परिदृश्य एवीएल पेड़ को बाएं-दाएं घुमाव का कारण बनाते हैं। |

|
हम पहले बाईं ओर की बारीक बारीक बारी बारी से करते हैं C। यह बनाता हैAके बाएँ उपप्रकार B। |

|
नोड C अभी भी असंतुलित है, हालांकि अब, यह बाएं-उपप्रतिष्ठि के उप-वर्ग के कारण है। |

|
अब हम पेड़ को बनाते हुए, उसे राइट-रोटेट करेंगे B इस उपप्रकार का नया रूट नोड C अब अपने स्वयं के बाएं उपप्रकार के दाहिने उपप्रकार बन जाता है। |

|
पेड़ अब संतुलित है। |
दाएं-बाएं घूमना
दूसरे प्रकार का दोहरा रोटेशन राइट-लेफ्ट रोटेशन है। यह दाएं रोटेशन का एक संयोजन है जिसके बाद बाएं रोटेशन होता है।
| राज्य | कार्य |
|---|---|

|
एक नोड को दाएं उपप्रकार के बाएं उपप्रकार में डाला गया है। यह बनाता हैA, संतुलन कारक 2 के साथ एक असंतुलित नोड। |

|
सबसे पहले, हम साथ में सही रोटेशन करते हैं C नोड, बना रही है C अपने स्वयं के बाएं सबट्री के दाईं ओर सबट्री B। अभी,B का सही उपप्रकार बन जाता है A। |

|
नोड A अभी भी असंतुलित है क्योंकि इसके सही उपप्रकार के सही उपप्रकार के कारण और बाएं घुमाव की आवश्यकता होती है। |

|
एक बाएं घुमाव बनाकर प्रदर्शन किया जाता है B उप-रूट का नया रूट नोड। A इसके दायें सबट्री के बाएं सबट्री बन जाता है B। |
|
|
पेड़ अब संतुलित है। |
एक फैले हुए पेड़ ग्राफ जी का एक उपसमुच्चय है, जिसमें सभी कोनों को न्यूनतम संभव किनारों के साथ कवर किया गया है। इसलिए, एक फैले हुए पेड़ में चक्र नहीं होते हैं और इसे काट नहीं किया जा सकता है।
इस परिभाषा के द्वारा, हम एक निष्कर्ष निकाल सकते हैं कि हर जुड़े और अप्रत्यक्ष ग्राफ़ G में कम से कम एक फैले हुए वृक्ष हैं। डिस्कनेक्ट किए गए ग्राफ़ में कोई फैले हुए पेड़ नहीं है, क्योंकि इसे अपने सभी कोने तक नहीं फैलाया जा सकता है।

हमें एक पूरे ग्राफ से तीन फैले हुए पेड़ मिले। एक पूर्ण अप्रत्यक्ष ग्राफ अधिकतम हो सकता हैnn-2 फैले पेड़ों की संख्या, जहां nनोड्स की संख्या है। उपरोक्त संबोधित उदाहरण में,n is 3, इसलिये 33−2 = 3 फैले हुए पेड़ संभव हैं।
स्पानिंग ट्री के सामान्य गुण
अब हम समझते हैं कि एक ग्राफ में एक से अधिक फैले पेड़ हो सकते हैं। ग्राफ जी से जुड़े फैले पेड़ के कुछ गुण निम्नलिखित हैं -
एक जुड़ा हुआ ग्राफ जी में एक से अधिक फैले हुए पेड़ हो सकते हैं।
ग्राफ जी के सभी संभव फैले पेड़ों में किनारों और कोने की संख्या समान है।
फैले हुए वृक्ष का कोई चक्र (लूप) नहीं होता है।
फैले पेड़ से एक किनारे को हटाने से ग्राफ काट दिया जाएगा, यानी फैले हुए पेड़ है minimally connected।
फैले हुए पेड़ में एक किनारे जोड़ने से एक सर्किट या लूप बनेगा, यानी फैले हुए पेड़ maximally acyclic।
स्पानिंग ट्री के गणितीय गुण
स्पानिंग ट्री है n-1 किनारों, जहां n नोड्स (कोने) की संख्या है।
पूर्ण ग्राफ़ से, अधिकतम हटाकर e - n + 1 किनारों, हम एक फैले हुए पेड़ का निर्माण कर सकते हैं।
एक पूरा ग्राफ अधिकतम हो सकता है nn-2 फैले पेड़ों की संख्या।
इस प्रकार, हम निष्कर्ष निकाल सकते हैं कि फैले हुए पेड़ जुड़े हुए ग्राफ जी के सबसेट हैं और डिस्कनेक्ट किए गए ग्राफ़ में फैले हुए पेड़ नहीं हैं।
स्पानिंग ट्री का अनुप्रयोग
स्पैनिंग ट्री मूल रूप से एक ग्राफ में सभी नोड्स को जोड़ने के लिए एक न्यूनतम पथ खोजने के लिए उपयोग किया जाता है। फैले पेड़ों के सामान्य अनुप्रयोग हैं -
Civil Network Planning
Computer Network Routing Protocol
Cluster Analysis
इसे एक छोटे से उदाहरण के माध्यम से समझते हैं। विचार करें, शहर नेटवर्क को एक विशाल ग्राफ़ के रूप में और अब टेलीफोन लाइनों को इस तरह से तैनात करने की योजना है कि न्यूनतम लाइनों में हम सभी शहर नोड्स से जुड़ सकें। यह वह जगह है जहाँ फैले पेड़ चित्र में आते हैं।
न्यूनतम स्पानिंग ट्री (MST)
भारित ग्राफ़ में, एक न्यूनतम फैले हुए पेड़ एक फैले हुए पेड़ होते हैं, जिसमें एक ही ग्राफ के अन्य फैले हुए पेड़ों की तुलना में न्यूनतम वजन होता है। वास्तविक दुनिया की स्थितियों में, इस वजन को दूरी, भीड़, यातायात भार या किनारों पर निरूपित किसी भी मनमाने मूल्य के रूप में मापा जा सकता है।
न्यूनतम स्पैनिंग-ट्री एल्गोरिदम
हम यहां दो सबसे महत्वपूर्ण फैले हुए पेड़ एल्गोरिदम के बारे में जानेंगे -
क्रुस्कल का एल्गोरिदम
प्राइम का एल्गोरिथम
दोनों लालची एल्गोरिदम हैं।
हीप संतुलित बाइनरी ट्री डेटा संरचना का एक विशेष मामला है जहां रूट-नोड कुंजी की अपने बच्चों के साथ तुलना की जाती है और तदनुसार व्यवस्था की जाती है। अगरα बच्चे का नोड है β तब -
कुंजी (α) (कुंजी (≥)
चूंकि माता-पिता का मूल्य बच्चे की तुलना में अधिक है, इसलिए यह संपत्ति उत्पन्न करता है Max Heap। इस मापदंड के आधार पर, ढेर दो प्रकार के हो सकते हैं -
For Input → 35 33 42 10 14 19 27 44 26 31Min-Heap - जहाँ रूट नोड का मान उसके किसी भी बच्चे से कम या उसके बराबर है।
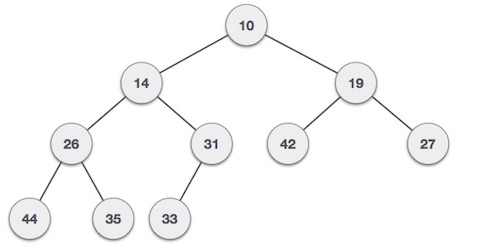
Max-Heap - जहां रूट नोड का मान उसके किसी भी बच्चे से अधिक या उसके बराबर है।

दोनों पेड़ों का निर्माण एक ही इनपुट और आगमन के क्रम का उपयोग करके किया जाता है।
मैक्स हीप कंस्ट्रक्शन एलगोरिदम
हम एक ही उदाहरण का उपयोग करके प्रदर्शित करेंगे कि मैक्स हीप कैसे बनाया जाता है। मिन हीप बनाने की प्रक्रिया समान है लेकिन हम अधिकतम मूल्यों के बजाय न्यूनतम मूल्यों के लिए जाते हैं।
हम एक बार में एक तत्व डालकर अधिकतम ढेर के लिए एक एल्गोरिथ्म प्राप्त करने जा रहे हैं। किसी भी समय, ढेर को अपनी संपत्ति बनाए रखना चाहिए। सम्मिलन करते समय, हम यह भी मानते हैं कि हम पहले से ही ढेर किए गए पेड़ में एक नोड डाल रहे हैं।
Step 1 − Create a new node at the end of heap.
Step 2 − Assign new value to the node.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.Note - मिन हीप निर्माण एल्गोरिथ्म में, हम उम्मीद करते हैं कि मूल नोड का मान बाल नोड की तुलना में कम होगा।
आइए एक एनिमेटेड चित्रण द्वारा मैक्स हीप निर्माण को समझें। हम उसी इनपुट नमूने पर विचार करते हैं जिसका उपयोग हमने पहले किया था।

मैक्स हीप डिलेक्शन एल्गोरिथम
अधिकतम ढेर से हटाने के लिए एक एल्गोरिथ्म प्राप्त करते हैं। अधिकतम (या न्यूनतम) हीप में हमेशा अधिकतम (या न्यूनतम) मान को निकालने के लिए जड़ में होता है।
Step 1 − Remove root node.
Step 2 − Move the last element of last level to root.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.
कुछ कंप्यूटर प्रोग्रामिंग भाषाएं खुद को कॉल करने के लिए एक मॉड्यूल या फ़ंक्शन की अनुमति देती हैं। इस तकनीक को रिकर्सन के रूप में जाना जाता है। पुनरावर्तन में, एक कार्यα या तो सीधे कॉल करता है या फ़ंक्शन को कॉल करता है β बदले में मूल फ़ंक्शन को कॉल करता है α। कार्यक्रमα को पुनरावर्ती कार्य कहा जाता है।
Example - एक समारोह खुद को बुला रहा है।
int function(int value) {
if(value < 1)
return;
function(value - 1);
printf("%d ",value);
}Example - एक फ़ंक्शन जो दूसरे फ़ंक्शन को कॉल करता है जो बदले में इसे फिर से कॉल करता है।
int function1(int value1) {
if(value1 < 1)
return;
function2(value1 - 1);
printf("%d ",value1);
}
int function2(int value2) {
function1(value2);
}गुण
एक पुनरावर्ती फ़ंक्शन लूप की तरह अनंत जा सकता है। पुनरावर्ती फ़ंक्शन के अनंत भाग से बचने के लिए, दो गुण हैं जो एक पुनरावर्ती फ़ंक्शन के पास होना चाहिए -
Base criteria - कम से कम एक आधार मानदंड या शर्त होनी चाहिए, जैसे कि, जब यह शर्त पूरी हो जाती है तो फ़ंक्शन खुद को पुनरावर्ती कॉल करना बंद कर देता है।
Progressive approach - पुनरावर्ती कॉल इस तरह से प्रगति करना चाहिए कि हर बार एक पुनरावर्ती कॉल किया जाता है यह आधार मानदंड के करीब आता है।
कार्यान्वयन
कई प्रोग्रामिंग भाषाओं के माध्यम से पुनरावृत्ति को लागू करते हैं stacks। आम तौर पर, जब भी कोई फ़ंक्शन (caller) दूसरे फ़ंक्शन को कॉल करता है (callee) या खुद को केली के रूप में, कॉलर फ़ंक्शन कैली के लिए निष्पादन नियंत्रण स्थानांतरित करता है। इस हस्तांतरण प्रक्रिया में कॉल करने वाले से कैली तक कुछ डेटा शामिल किया जा सकता है।
इसका तात्पर्य है, कॉलर फ़ंक्शन को अस्थायी रूप से इसके निष्पादन को निलंबित करना और बाद में फिर से शुरू करना है जब निष्पादन नियंत्रण कैली फ़ंक्शन से लौटता है। यहां, कॉलर फ़ंक्शन को निष्पादन के बिंदु से बिल्कुल शुरू करने की आवश्यकता है जहां यह खुद को पकड़ में रखता है। इसे उसी सटीक डेटा मान की भी आवश्यकता है जिस पर यह काम कर रहा था। इस प्रयोजन के लिए, कॉलर फ़ंक्शन के लिए एक सक्रियण रिकॉर्ड (या स्टैक फ़्रेम) बनाया जाता है।

यह सक्रियण रिकॉर्ड स्थानीय चर, औपचारिक मापदंडों, वापसी पते और कॉलर फ़ंक्शन को दी गई सभी जानकारी के बारे में जानकारी रखता है।
पुनरावर्तन का विश्लेषण
एक तर्क हो सकता है कि पुनरावृत्ति का उपयोग क्यों करना है, क्योंकि एक ही कार्य पुनरावृत्ति के साथ किया जा सकता है। पहला कारण है, पुनरावृत्ति एक प्रोग्राम को अधिक पठनीय बनाता है और नवीनतम बढ़ाया सीपीयू सिस्टम के कारण पुनरावृत्ति पुनरावृत्तियों की तुलना में अधिक कुशल है।
समय जटिलता
पुनरावृत्तियों के मामले में, हम समय की जटिलता को गिनने के लिए पुनरावृत्तियों की संख्या लेते हैं। इसी तरह, पुनरावृत्ति के मामले में, सब कुछ स्थिर है, हम यह पता लगाने की कोशिश करते हैं कि एक पुनरावर्ती कॉल कितनी बार किया जा रहा है। एक फ़ंक्शन के लिए की गई कॉल Ο (1) है, इसलिए एक पुनरावर्ती कॉल किए जाने की संख्या (n) बार बार पुनरावर्ती फ़ंक्शन rec (n) बनाती है।
अंतरिक्ष जटिलता
अंतरिक्ष की जटिलता को गिना जाता है कि मॉड्यूल को निष्पादित करने के लिए कितनी अतिरिक्त जगह की आवश्यकता होती है। पुनरावृत्तियों के मामले में, कंपाइलर को शायद ही किसी अतिरिक्त स्थान की आवश्यकता होती है। संकलक पुनरावृत्तियों में प्रयुक्त चर के मूल्यों को अद्यतन करता रहता है। लेकिन पुनरावृत्ति के मामले में, सिस्टम को हर बार एक पुनरावर्ती कॉल किए जाने पर सक्रियण रिकॉर्ड को संग्रहीत करने की आवश्यकता होती है। इसलिए, यह माना जाता है कि पुनरावर्ती फ़ंक्शन की अंतरिक्ष जटिलता पुनरावृत्ति वाले फ़ंक्शन की तुलना में अधिक हो सकती है।
हनोई की मीनार, एक गणितीय पहेली है जिसमें तीन टावरों (खूंटे) होते हैं और एक से अधिक छल्लों को दर्शाया गया है -

ये छल्ले अलग-अलग आकार के होते हैं और ऊपर चढ़ते क्रम में स्टैक्ड होते हैं, यानी छोटा बड़ा के ऊपर बैठता है। पहेली की अन्य विविधताएँ हैं जहाँ डिस्क की संख्या में वृद्धि होती है, लेकिन टॉवर की गिनती समान रहती है।
नियमों
मिशन व्यवस्था के अनुक्रम का उल्लंघन किए बिना सभी डिस्क को किसी अन्य टॉवर में स्थानांतरित करना है। हनोई के टॉवर के लिए कुछ नियमों का पालन किया जाना है -
- किसी भी समय केवल एक डिस्क को टावरों के बीच ले जाया जा सकता है।
- केवल "शीर्ष" डिस्क को हटाया जा सकता है।
- कोई भी बड़ी डिस्क छोटी डिस्क पर नहीं बैठ सकती है।
निम्नलिखित तीन डिस्क के साथ हनोई पहेली के टॉवर को हल करने का एक एनिमेटेड प्रतिनिधित्व है।

एन डिस्क के साथ हनोई पहेली का टॉवर न्यूनतम में हल किया जा सकता है 2n−1कदम। इस प्रस्तुति से पता चलता है कि 3 डिस्क के साथ एक पहेली ली गई है23 - 1 = 7 कदम।
कलन विधि
हनोई के टॉवर के लिए एक एल्गोरिथ्म लिखने के लिए, पहले हमें यह सीखने की जरूरत है कि डिस्क की कम मात्रा के साथ इस समस्या को कैसे हल किया जाए, → → 1 या 2. हम नाम के साथ तीन टावरों को चिह्नित करते हैं, source, destination तथा aux(केवल डिस्क को स्थानांतरित करने में मदद करने के लिए)। यदि हमारे पास केवल एक डिस्क है, तो इसे आसानी से स्रोत से गंतव्य खूंटी में स्थानांतरित किया जा सकता है।
अगर हमारे पास 2 डिस्क हैं -
- सबसे पहले, हम छोटी (शीर्ष) डिस्क को ऑक्स पेग में स्थानांतरित करते हैं।
- उसके बाद, हम बड़े (नीचे) डिस्क को गंतव्य खूंटी पर ले जाते हैं।
- और अंत में, हम छोटी डिस्क को ऐक्स से गंतव्य खूंटी में स्थानांतरित करते हैं।

तो अब, हम दो से अधिक डिस्क के साथ हनोई के टॉवर के लिए एक एल्गोरिथ्म डिजाइन करने की स्थिति में हैं। हम डिस्क के ढेर को दो भागों में विभाजित करते हैं। सबसे बड़ी डिस्क (n th डिस्क) एक भाग में है और अन्य सभी (n-1) डिस्क दूसरे भाग में हैं।
हमारा अंतिम उद्देश्य डिस्क को स्थानांतरित करना है nस्रोत से गंतव्य तक और फिर उस पर अन्य सभी (n1) डिस्क डालें। हम डिस्क के सभी सेट के लिए पुनरावर्ती तरीके से समान लागू करने की कल्पना कर सकते हैं।
अनुसरण करने के चरण हैं -
Step 1 − Move n-1 disks from source to aux
Step 2 − Move nth disk from source to dest
Step 3 − Move n-1 disks from aux to destहनोई के टॉवर के लिए एक पुनरावर्ती एल्गोरिदम निम्नानुसार संचालित किया जा सकता है -
START
Procedure Hanoi(disk, source, dest, aux)
IF disk == 1, THEN
move disk from source to dest
ELSE
Hanoi(disk - 1, source, aux, dest) // Step 1
move disk from source to dest // Step 2
Hanoi(disk - 1, aux, dest, source) // Step 3
END IF
END Procedure
STOPसी प्रोग्रामिंग में कार्यान्वयन की जांच करने के लिए, यहां क्लिक करें ।
फाइबोनैचि श्रृंखला दो पिछली संख्याओं को जोड़कर बाद की संख्या उत्पन्न करती है। फाइबोनैचि श्रृंखला दो संख्याओं से शुरू होती है -F0 & F1। एफ 0 और एफ 1 के प्रारंभिक मूल्यों को क्रमशः 0, 1 या 1, 1 लिया जा सकता है।
फाइबोनैचि श्रृंखला निम्नलिखित स्थितियों को संतुष्ट करती है -
Fn = Fn-1 + Fn-2इसलिए, एक फिबोनाची श्रृंखला इस तरह दिख सकती है -
एफ 8 = 0 1 1 2 3 3 5 8 13
या, यह -
एफ 8 = 1 1 2 3 5 8 13 21
चित्रण उद्देश्य के लिए, एफ 8 के फाइबोनैचि को निम्न के रूप में प्रदर्शित किया जाता है -

फाइबोनैचि Iterative एल्गोरिथम
पहले हम फिबोनाची श्रृंखला के लिए पुनरावृत्त एल्गोरिथ्म का मसौदा तैयार करने की कोशिश करते हैं।
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
end procedureसी प्रोग्रामिंग भाषा में उपरोक्त एल्गोरिदम के कार्यान्वयन के बारे में जानने के लिए, यहां क्लिक करें ।
फाइबोनैचि पुनरावर्ती एल्गोरिथम
आइए जानें कि एक पुनरावर्ती एल्गोरिथ्म फाइबोनैचि श्रृंखला कैसे बनाएं। पुनरावर्तन का आधार मानदंड।
START
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
ENDसी प्रोग्रामिंग भाषा में उपरोक्त एल्गोरिदम के कार्यान्वयन को देखने के लिए, यहां क्लिक करें ।