कैश कोहेरेंस और सिंक्रोनाइज़ेशन
इस अध्याय में, हम मल्टीकाच विसंगति की समस्याओं से निपटने के लिए कैश सुसंगत प्रोटोकॉल पर चर्चा करेंगे।
कैश कोहेरेंस समस्या
मल्टीप्रोसेसर सिस्टम में, आसन्न स्तरों के बीच या मेमोरी पदानुक्रम के समान स्तर के भीतर डेटा असंगति हो सकती है। उदाहरण के लिए, कैश और मुख्य मेमोरी में एक ही ऑब्जेक्ट की असंगत प्रतियां हो सकती हैं।
जैसा कि कई प्रोसेसर समानांतर में काम करते हैं, और स्वतंत्र रूप से कई कैश में एक ही मेमोरी ब्लॉक की विभिन्न प्रतियां हो सकती हैं, यह बनाता है cache coherence problem। Cache coherence schemes डेटा के प्रत्येक कैश्ड ब्लॉक के लिए एक समान स्थिति बनाए रखकर इस समस्या से बचने में मदद करें।
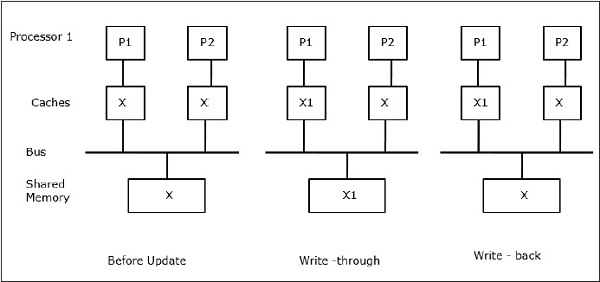
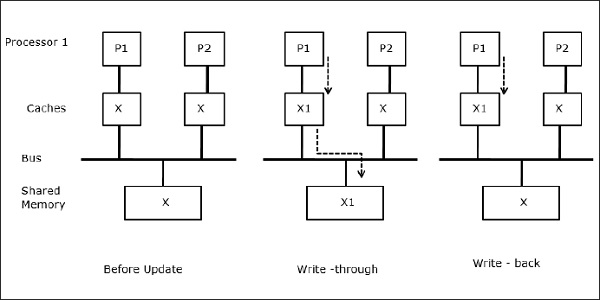
आइए X साझा डेटा का एक तत्व है जिसे दो प्रोसेसर, P1 और P2 द्वारा संदर्भित किया गया है। शुरुआत में, एक्स की तीन प्रतियां सुसंगत हैं। यदि प्रोसेसर P1 कैश में एक नया डेटा X1 लिखता है, तो उपयोग करकेwrite-through policyएक ही प्रति साझा स्मृति में तुरंत लिखी जाएगी। इस स्थिति में, कैश मेमोरी और मुख्य मेमोरी के बीच असंगति होती है। जब एकwrite-back policy उपयोग किया जाता है, कैश में संशोधित डेटा को प्रतिस्थापित या अमान्य किए जाने पर मुख्य मेमोरी अपडेट की जाएगी।
सामान्य तौर पर, असंगति समस्या के तीन स्रोत हैं -
- लेखन योग्य डेटा साझा करना
- प्रक्रिया माइग्रेशन
- मैं / हे गतिविधि
Snoopy बस प्रोटोकॉल
Snoopy प्रोटोकॉल कैश मेमोरी और साझा मेमोरी के बीच डेटा आधारितता को बस-आधारित मेमोरी सिस्टम के माध्यम से प्राप्त करते हैं। Write-invalidate तथा write-update नीतियों का उपयोग कैश स्थिरता बनाए रखने के लिए किया जाता है।
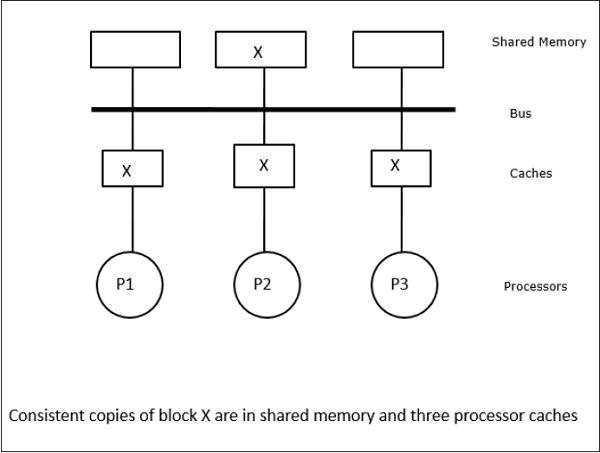
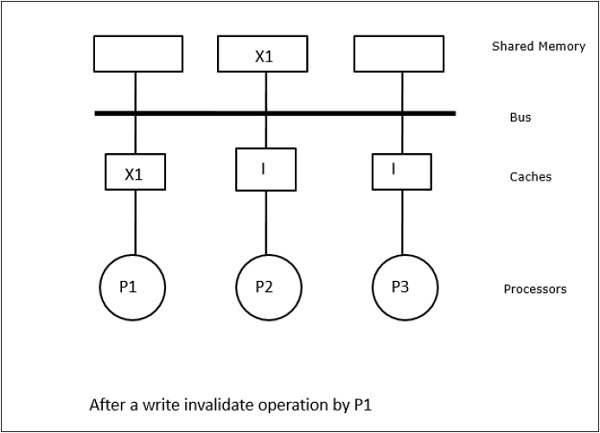
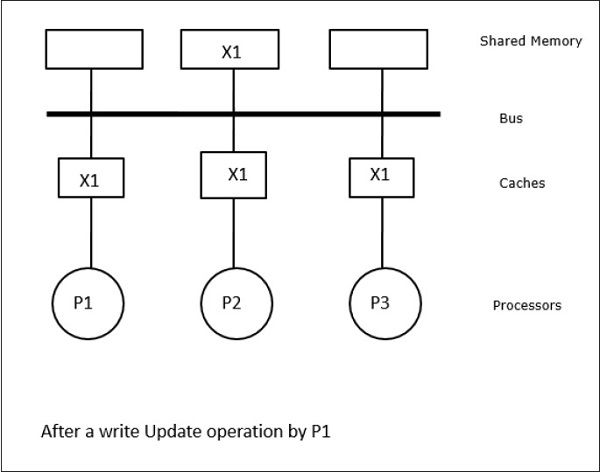
इस स्थिति में, हमारे पास तीन प्रोसेसर P1, P2, और P3 हैं, जिनकी स्थानीय कैश मेमोरी और साझा मेमोरी (चित्र-ए) में डेटा तत्व 'X' की एक सुसंगत प्रति है। प्रोसेसर P1 अपनी कैश मेमोरी का उपयोग करके X1 लिखता हैwrite-invalidate protocol। इसलिए, अन्य सभी प्रतियां बस के माध्यम से अमान्य हैं। इसे 'I' (चित्र-ब) द्वारा निरूपित किया गया है। अमान्य ब्लॉक के रूप में भी जाना जाता हैdirty, यानी उनका उपयोग नहीं किया जाना चाहिए। write-update protocolबस के माध्यम से सभी कैश प्रतियां अद्यतन करता है। का उपयोग करकेwrite back cache, मेमोरी कॉपी भी अपडेट की गई है (चित्र-सी)।
कैश इवेंट्स एंड एक्ट्स
मेमोरी-एक्सेस और अमान्य कमांड के निष्पादन पर निम्नलिखित घटनाएं और क्रियाएं होती हैं -
Read-miss- जब एक प्रोसेसर एक ब्लॉक पढ़ना चाहता है और यह कैश में नहीं है, तो एक रीड-मिस होता है। यह एक पहल करता हैbus-readऑपरेशन। यदि कोई गंदी प्रतिलिपि मौजूद नहीं है, तो मुख्य मेमोरी जिसमें एक सुसंगत प्रति है, अनुरोधित कैश मेमोरी में एक प्रति प्रदान करता है। यदि कोई दूरस्थ कैश मेमोरी में एक गंदा प्रतिलिपि मौजूद है, तो वह कैश मुख्य मेमोरी को रोक देगा और अनुरोधित कैश मेमोरी में एक कॉपी भेज देगा। दोनों मामलों में, कैश कॉपी एक रीड मिस के बाद वैध स्थिति में प्रवेश करेगी।
Write-hit - अगर कॉपी गंदी है या reservedराज्य, लेखन स्थानीय रूप से किया जाता है और नया राज्य गंदा है। यदि नया राज्य मान्य है, तो लेखन-अमान्य आदेश को सभी कैश में प्रसारित किया जाता है, उनकी प्रतियों को अमान्य किया जाता है। जब साझा मेमोरी के माध्यम से लिखा जाता है, तो परिणामी स्थिति इस पहले लिखने के बाद आरक्षित होती है।
Write-miss- यदि कोई प्रोसेसर स्थानीय कैश मेमोरी में लिखने में विफल रहता है, तो कॉपी को मुख्य मेमोरी से या रिमोट कैश मेमोरी से एक गंदे ब्लॉक के साथ आना चाहिए। यह एक भेजने के द्वारा किया जाता हैread-invalidateकमांड, जो सभी कैश प्रतियों को अमान्य कर देगा। फिर गंदे राज्य के साथ स्थानीय प्रति अपडेट की जाती है।
Read-hit - राज्य के संक्रमण के कारण या अमान्यकरण के लिए स्नोपॉपी बस का उपयोग किए बिना हमेशा स्थानीय कैश मेमोरी में पढ़ें-हिट किया जाता है।
Block replacement- जब कोई कॉपी गन्दी होती है, तो उसे ब्लॉक मेमोरी मेथड द्वारा मुख्य मेमोरी में वापस लिखना होता है। हालाँकि, जब प्रतिलिपि या तो मान्य या आरक्षित या अमान्य स्थिति में होती है, तो कोई प्रतिस्थापन नहीं होगा।
निर्देशिका-आधारित प्रोटोकॉल
सैकड़ों प्रोसेसर के साथ एक बड़े मल्टीप्रोसेसर के निर्माण के लिए मल्टीस्टेज नेटवर्क का उपयोग करके, नेटवर्क क्षमताओं के अनुरूप स्नोपॉपी कैश प्रोटोकॉल को संशोधित करने की आवश्यकता है। एक मल्टीस्टेज नेटवर्क में प्रदर्शन करने के लिए प्रसारण बहुत महंगा है, संगतता कमांड केवल उन कैश को भेजा जाता है जो ब्लॉक की एक प्रति रखते हैं। यह नेटवर्क से जुड़े मल्टीप्रोसेसर के लिए निर्देशिका-आधारित प्रोटोकॉल के विकास का कारण है।
निर्देशिका-आधारित प्रोटोकॉल प्रणाली में, साझा किए जाने वाले डेटा को एक सामान्य निर्देशिका में रखा जाता है जो कि कैश के बीच सामंजस्य बनाए रखता है। यहां, निर्देशिका एक फिल्टर के रूप में कार्य करती है जहां प्रोसेसर प्राथमिक मेमोरी से इसकी कैश मेमोरी में एक प्रविष्टि लोड करने की अनुमति मांगते हैं। यदि एक प्रविष्टि को बदल दिया जाता है तो निर्देशिका उसे अपडेट कर देती है या उस प्रविष्टि के साथ अन्य कैश को अमान्य कर देती है।
हार्डवेयर सिंक्रोनाइज़ेशन मैकेनिज्म
सिंक्रोनाइज़ेशन संचार का एक विशेष रूप है, जहाँ डेटा नियंत्रण के बजाय, एक ही या अलग-अलग प्रोसेसर में रहने वाली संचार प्रक्रियाओं के बीच सूचना का आदान-प्रदान होता है।
मल्टीप्रोसेसर सिस्टम निम्न-स्तरीय सिंक्रनाइज़ेशन ऑपरेशन को लागू करने के लिए हार्डवेयर तंत्र का उपयोग करते हैं। अधिकांश मल्टीप्रोसेसर के पास कुछ सिंक्रनाइज़ेशन प्राइमरी को लागू करने के लिए परमाणु संचालन जैसे मेमोरी रीड, राइट या रीड-संशोधित-राइट ऑपरेशन को लागू करने के लिए हार्डवेयर मैकेनिज्म होता है। परमाणु मेमोरी ऑपरेशन के अलावा, कुछ इंटर-प्रोसेसर इंटरप्ट को सिंक्रोनाइज़ेशन उद्देश्यों के लिए भी उपयोग किया जाता है।
साझा मेमोरी मशीनों में कैश सुसंगतता
जब कैश प्रोसेसर में स्थानीय कैश मेमोरी होती है, तो कैश सुसंगतता को बनाए रखना एक समस्या है। इस प्रणाली में विभिन्न कैश के बीच डेटा असंगतता आसानी से होती है।
प्रमुख चिंता क्षेत्र हैं -
- लेखन योग्य डेटा साझा करना
- प्रक्रिया माइग्रेशन
- मैं / हे गतिविधि
लेखन योग्य डेटा साझा करना
जब दो प्रोसेसर (P1 और P2) के पास अपने स्थानीय कैश में समान डेटा तत्व (X) होता है और एक प्रक्रिया (P1) डेटा तत्व (X) को लिखती है, क्योंकि कैश P1 के स्थानीय कैश के माध्यम से लिखते हैं, मुख्य मेमोरी है भी अद्यतन किया गया। अब जब पी 2 डेटा एलिमेंट (एक्स) को पढ़ने की कोशिश करता है, तो यह एक्स को नहीं ढूंढता है क्योंकि पी 2 के कैश में डेटा एलिमेंट पुराना हो गया है।
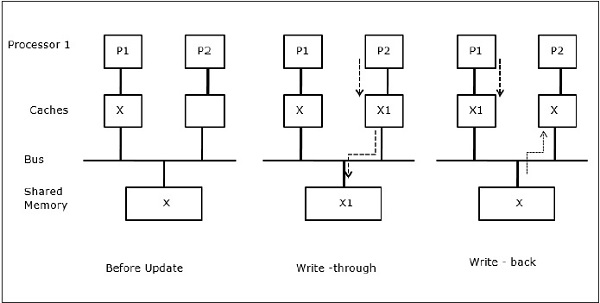
प्रक्रिया माइग्रेशन
पहले चरण में, कैश ऑफ़ पी 1 में डेटा एलिमेंट एक्स है, जबकि पी 2 में कुछ भी नहीं है। पी 2 पर एक प्रक्रिया पहले एक्स पर लिखती है और फिर पी 1 पर माइग्रेट करती है। अब, प्रक्रिया डेटा तत्व X पढ़ना शुरू कर देती है, लेकिन प्रोसेसर P1 के पास पुराना डेटा होने के कारण प्रक्रिया इसे पढ़ नहीं सकती है। तो, P1 पर एक प्रक्रिया डेटा तत्व X को लिखती है और फिर P2 में माइग्रेट करती है। माइग्रेशन के बाद, पी 2 पर एक प्रक्रिया डेटा तत्व एक्स को पढ़ना शुरू करती है लेकिन यह मुख्य मेमोरी में एक्स का एक पुराना संस्करण ढूंढती है।
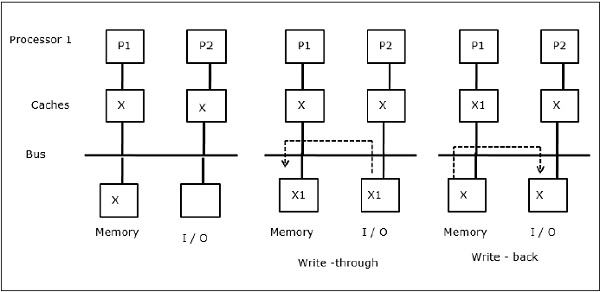
मैं / हे गतिविधि
जैसा कि चित्र में दर्शाया गया है, एक दो-प्रोसेसर मल्टीप्रोसेसर आर्किटेक्चर में बस में एक I / O डिवाइस जोड़ा जाता है। शुरुआत में, दोनों कैश में डेटा तत्व X होता है। जब I / O डिवाइस एक नया तत्व X प्राप्त करता है, तो यह नए तत्व को सीधे मुख्य मेमोरी में संग्रहीत करता है। अब, जब या तो P1 या P2 (मान P1) एलिमेंट एक्स को पढ़ने की कोशिश करता है तो उसे एक पुरानी कॉपी मिलती है। तो, P1 X को तत्व देता है। अब, अगर I / O डिवाइस X को प्रसारित करने की कोशिश करता है तो उसे एक पुरानी कॉपी मिल जाती है।
यूनिफ़ॉर्म मेमोरी एक्सेस (UMA)
यूनिफ़ॉर्म मेमोरी एक्सेस (UMA) आर्किटेक्चर का मतलब है कि सिस्टम में सभी प्रोसेसर के लिए साझा मेमोरी समान है। यूएमए मशीनों की लोकप्रिय कक्षाएं, जो आमतौर पर (फ़ाइल-) सर्वर के लिए उपयोग की जाती हैं, तथाकथित सिमेट्रिक मल्टीप्रोसेसर (एसएमपी) हैं। एक एसएमपी में, सभी सिस्टम संसाधन जैसे मेमोरी, डिस्क, अन्य I / O डिवाइस, आदि एक समान तरीके से प्रोसेसर द्वारा सुलभ हैं।
गैर-यूनिफ़ॉर्म मेमोरी एक्सेस (NUMA)
NUMA आर्किटेक्चर में, एक आंतरिक अप्रत्यक्ष / साझा नेटवर्क वाले कई एसएमपी क्लस्टर हैं, जो स्केलेबल संदेश-गुजर नेटवर्क में जुड़े हुए हैं। तो, NUMA आर्किटेक्चर तार्किक रूप से भौतिक रूप से वितरित मेमोरी आर्किटेक्चर साझा करता है।
NUMA मशीन में, एक प्रोसेसर का कैश-नियंत्रक यह निर्धारित करता है कि मेमोरी का संदर्भ एसएमपी की मेमोरी के लिए स्थानीय है या यह रिमोट है। दूरस्थ मेमोरी एक्सेस की संख्या को कम करने के लिए, NUMA आर्किटेक्चर आमतौर पर कैशिंग प्रोसेसर लागू करते हैं जो दूरस्थ डेटा को कैश कर सकते हैं। लेकिन जब कैश शामिल होते हैं, तो कैश सुसंगतता बनाए रखने की आवश्यकता होती है। इसलिए इन प्रणालियों को CC-NUMA (कैश सुसंगत NUMA) के रूप में भी जाना जाता है।
कैश केवल मेमोरी आर्किटेक्चर (COMA)
COMA मशीनें NUMA मशीनों के समान हैं, एकमात्र अंतर यह है कि COMA मशीनों की मुख्य यादें डायरेक्ट-मैप्ड या सेट-एसोसिएटिव कैश के रूप में कार्य करती हैं। डेटा ब्लॉकों को उनके पते के अनुसार DRAM कैश में किसी स्थान पर हैशड किया गया है। दूरस्थ रूप से लाए गए डेटा को वास्तव में स्थानीय मुख्य मेमोरी में संग्रहीत किया जाता है। इसके अलावा, डेटा ब्लॉक में एक निश्चित घर स्थान नहीं है, वे स्वतंत्र रूप से पूरे सिस्टम में स्थानांतरित कर सकते हैं।
COMA आर्किटेक्चर में ज्यादातर एक पदानुक्रमित संदेश-पासिंग नेटवर्क है। इस तरह के पेड़ में एक स्विच में उप-वृक्ष के रूप में डेटा तत्वों के साथ एक निर्देशिका होती है। चूंकि डेटा का कोई घरेलू स्थान नहीं है, इसलिए इसे स्पष्ट रूप से खोजा जाना चाहिए। इसका अर्थ है कि आवश्यक डेटा के लिए अपनी निर्देशिका को खोजने के लिए रिमोट एक्सेस के लिए ट्री में स्विच के साथ एक ट्रावर्सल की आवश्यकता होती है। इसलिए, यदि नेटवर्क में एक स्विच को उसी डेटा के लिए उसके सबट्री से कई अनुरोध प्राप्त होते हैं, तो यह उन्हें एकल अनुरोध में जोड़ता है जो स्विच के माता-पिता को भेजा जाता है। जब अनुरोधित डेटा वापस आ जाता है, तो स्विच इसकी उप-प्रकार की कई प्रतियाँ भेजता है।
COMA बनाम CC-NUMA
COMA और CC-NUMA के बीच अंतर हैं।
COMA CC-NUMA से अधिक लचीला हो जाता है क्योंकि COMA पारदर्शिता और OS की आवश्यकता के बिना डेटा के प्रतिकृति का समर्थन करता है।
COMA मशीनें निर्माण के लिए महंगी और जटिल हैं क्योंकि उन्हें गैर-मानक मेमोरी मैनेजमेंट हार्डवेयर की आवश्यकता होती है और कार्यान्वयन के लिए सुसंगतता प्रोटोकॉल कठिन होता है।
COMA में रिमोट एक्सेस अक्सर CC-NUMA की तुलना में धीमी होती है क्योंकि डेटा को खोजने के लिए ट्री नेटवर्क की आवश्यकता होती है।