मल्टीप्रोसेसर और मल्टीकॉमपॉइंट्स
हम इस अध्याय में मल्टीप्रोसेसर और मल्टीकॉमपर्स पर चर्चा करेंगे।
मल्टीप्रोसेसर सिस्टम इंटरकनेक्ट्स
समानांतर प्रसंस्करण को इनपुट / आउटपुट और परिधीय उपकरणों, मल्टीप्रोसेसर और साझा मेमोरी के बीच तेजी से संचार के लिए कुशल सिस्टम इंटरकनेक्ट का उपयोग करने की आवश्यकता है।
पदानुक्रमित बस सिस्टम
एक पदानुक्रमित बस प्रणाली में कंप्यूटर में विभिन्न प्रणालियों और उप-प्रणालियों / घटकों को जोड़ने वाली बसों का एक पदानुक्रम होता है। प्रत्येक बस कई सिग्नल, नियंत्रण और बिजली लाइनों से बनी होती है। विभिन्न बसों जैसे स्थानीय बसों, बैकप्लेन बसों और I / O बसों का उपयोग विभिन्न अंतर्संबंध कार्यों को करने के लिए किया जाता है।
स्थानीय बसें प्रिंटेड-सर्किट बोर्डों पर लागू की जाने वाली बसें हैं। एक बैकप्लेन बस एक मुद्रित सर्किट है जिस पर कार्यात्मक बोर्डों में प्लग करने के लिए कई कनेक्टर्स का उपयोग किया जाता है। बसें जो इनपुट / आउटपुट डिवाइस को कंप्यूटर सिस्टम से जोड़ती हैं, उन्हें I / O बस के रूप में जाना जाता है।
क्रॉसबार स्विच और मल्टीपोर्ट मेमोरी
स्विच्ड नेटवर्क इनपुट और आउटपुट के बीच डायनामिक इंटरकनेक्शन देते हैं। छोटे या मध्यम आकार के सिस्टम ज्यादातर क्रॉसबार नेटवर्क का उपयोग करते हैं। मल्टीस्टेज नेटवर्क को बड़ी प्रणालियों में विस्तारित किया जा सकता है, यदि बढ़ी हुई विलंबता समस्या को हल किया जा सकता है।
क्रॉसबार स्विच और मेमोरी संगठन दोनों ही एक एकल-चरण नेटवर्क है। हालांकि एक एकल चरण नेटवर्क बनाने के लिए सस्ता है, लेकिन कुछ कनेक्शन स्थापित करने के लिए कई पास की आवश्यकता हो सकती है। एक मल्टीस्टेज नेटवर्क में स्विच बॉक्स के एक से अधिक चरण होते हैं। ये नेटवर्क किसी भी इनपुट को किसी भी आउटपुट से जोड़ने में सक्षम होना चाहिए।
मल्टीस्टेज और संयोजन नेटवर्क
मल्टीस्टेज नेटवर्क या मल्टीस्टेज इंटरकनेक्शन नेटवर्क उच्च गति वाले कंप्यूटर नेटवर्क का एक वर्ग है जो मुख्य रूप से नेटवर्क के एक छोर पर प्रसंस्करण तत्वों से बना होता है और दूसरे छोर पर मेमोरी तत्वों को स्विचिंग तत्वों द्वारा जोड़ा जाता है।
ये नेटवर्क बड़े मल्टीप्रोसेसर सिस्टम बनाने के लिए लगाए जाते हैं। इसमें ओमेगा नेटवर्क, बटरफ्लाई नेटवर्क और कई और अधिक शामिल हैं।
Multicomputers
Multicomputers को मेमोरी MIMD आर्किटेक्चर वितरित किया जाता है। निम्नलिखित आरेख एक बहुविकल्पी के वैचारिक मॉडल को दर्शाता है -
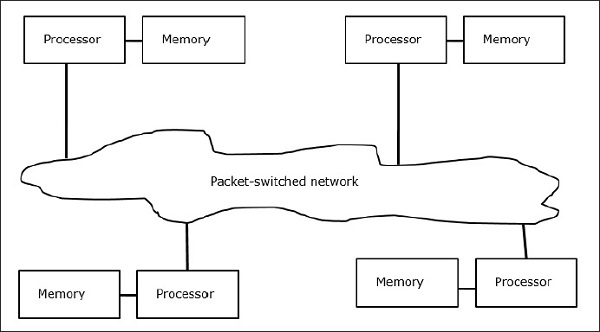
मल्टीकंप्यूटर संदेश-गुजरने वाली मशीनें हैं जो डेटा को विनिमय करने के लिए पैकेट स्विचिंग विधि को लागू करती हैं। यहां, प्रत्येक प्रोसेसर में एक निजी मेमोरी होती है, लेकिन प्रोसेसर के रूप में कोई वैश्विक पता स्थान केवल अपनी स्थानीय मेमोरी तक नहीं पहुंच सकता है। इसलिए, संचार पारदर्शी नहीं है: यहाँ प्रोग्रामर को स्पष्ट रूप से संचार प्रिमिटिव को अपने कोड में रखना होगा।
विश्व स्तर पर सुलभ मेमोरी न होना मल्टीकॉमर्स की कमी है। इसे निम्नलिखित दो योजनाओं का उपयोग करके हल किया जा सकता है -
- वर्चुअल साझा मेमोरी (VSM)
- साझा वर्चुअल मेमोरी (SVM)
इन योजनाओं में, एप्लिकेशन प्रोग्रामर एक बड़ी साझा मेमोरी को मानता है जो विश्व स्तर पर पता करने योग्य है। यदि आवश्यक हो, तो अनुप्रयोगों द्वारा किए गए मेमोरी संदर्भों को संदेश-गुजर प्रतिमान में अनुवादित किया जाता है।
वर्चुअल साझा मेमोरी (VSM)
वीएसएम एक हार्डवेयर कार्यान्वयन है। इसलिए, ऑपरेटिंग सिस्टम का वर्चुअल मेमोरी सिस्टम पारदर्शी रूप से वीएसएम के शीर्ष पर लागू किया जाता है। तो, ऑपरेटिंग सिस्टम को लगता है कि यह मशीन पर एक साझा मेमोरी के साथ चल रहा है।
साझा वर्चुअल मेमोरी (SVM)
एसवीएम प्रोसेसर के मेमोरी मैनेजमेंट यूनिट (एमएमयू) से हार्डवेयर समर्थन के साथ ऑपरेटिंग सिस्टम स्तर पर एक सॉफ्टवेयर कार्यान्वयन है। यहां, साझा करने की इकाई ऑपरेटिंग सिस्टम मेमोरी पेज है।
यदि कोई प्रोसेसर किसी विशेष मेमोरी लोकेशन को संबोधित करता है, तो MMU यह निर्धारित करता है कि मेमोरी एक्सेस से जुड़ा मेमोरी पेज लोकल मेमोरी में है या नहीं। यदि पृष्ठ मेमोरी में नहीं है, तो सामान्य कंप्यूटर सिस्टम में इसे ऑपरेटिंग सिस्टम द्वारा डिस्क से स्वैप किया जाता है। लेकिन, SVM में, ऑपरेटिंग सिस्टम पृष्ठ को दूरस्थ नोड से प्राप्त करता है जो उस विशेष पेज का मालिक है।
मल्टीकॉमपॉइंट्स की तीन जनरेशन
इस खंड में, हम मल्टीकंप्यूटर की तीन पीढ़ियों पर चर्चा करेंगे।
अतीत में डिजाइन विकल्प
प्रोसेसर तकनीक का चयन करते समय, एक मल्टीकोम्प्यूटर डिज़ाइनर कम-लागत वाले मध्यम अनाज प्रोसेसर का निर्माण ब्लॉकों के रूप में करता है। समांतर संगणक का निर्माण मानक ऑफ-द-शेल्फ माइक्रोप्रोसेसर के साथ किया जाता है। साझा मेमोरी का उपयोग करने के बजाय वितरित कंप्यूटर को मल्टी-कंप्यूटर के लिए चुना गया, जो स्केलेबिलिटी को सीमित करेगा। प्रत्येक प्रोसेसर की अपनी स्थानीय मेमोरी यूनिट होती है।
इंटरकनेक्शन स्कीम के लिए, मल्टीकॉमपॉइंट्स में संदेश स्विचिंग नेटवर्क के बजाय संदेश पासिंग, पॉइंट-टू-पॉइंट डायरेक्ट नेटवर्क होते हैं। नियंत्रण रणनीति के लिए, बहु-कंप्यूटर के डिजाइनर अतुल्यकालिक एमआईएमडी, एमपीएमडी और एसएमपीडी संचालन चुनते हैं। कैल्टेक कॉस्मिक क्यूब (सेज, 1983) पहली पीढ़ी के बहु-कंप्यूटरों में से पहला है।
वर्तमान और भविष्य का विकास
अगली पीढ़ी के कंप्यूटर एक विश्व स्तर पर साझा आभासी मेमोरी का उपयोग करते हुए मध्यम से ठीक अनाज मल्टीकोमप्वाइंट्स तक विकसित हुए। वर्तमान में दूसरी पीढ़ी के मल्टी-कंप्यूटर अभी भी उपयोग में हैं। लेकिन i386, i860, आदि जैसे बेहतर प्रोसेसर का उपयोग करते हुए दूसरी पीढ़ी के कंप्यूटर बहुत विकसित हो गए हैं।
तीसरी पीढ़ी के कंप्यूटर अगली पीढ़ी के कंप्यूटर हैं जहां वीएलएसआई कार्यान्वित नोड्स का उपयोग किया जाएगा। प्रत्येक नोड में एक 14-MIPS प्रोसेसर, 20-Mbytes / s रूटिंग चैनल और 16 Kbytes RAM एक एकल चिप पर एकीकृत हो सकते हैं।
इंटेल पैरागॉन प्रणाली
पहले, सजातीय नोड्स का उपयोग हाइपरक्यूब मल्टीकोमपेक बनाने के लिए किया गया था, क्योंकि सभी कार्य मेजबान को दिए गए थे। तो, इसने I / O बैंडविड्थ को सीमित कर दिया। इस प्रकार बड़े पैमाने पर समस्याओं को कुशलतापूर्वक या उच्च थ्रूपुट के साथ हल करने के लिए, इन कंप्यूटरों का उपयोग नहीं किया जा सकता है। इंटेल पैरागॉन सिस्टम को इस कठिनाई को दूर करने के लिए डिज़ाइन किया गया था। इसने मल्टीकॉम्प्यूटर को एक नेटवर्क वातावरण में मल्टीसियर एक्सेस के साथ एक एप्लिकेशन सर्वर में बदल दिया।
संदेश पासिंग मैकेनिज्म
मल्टीकोम्प्यूटर नेटवर्क में संदेश गुजरने वाले तंत्र को विशेष हार्डवेयर और सॉफ्टवेयर समर्थन की आवश्यकता होती है। इस खंड में, हम कुछ योजनाओं पर चर्चा करेंगे।
संदेश-रूटिंग योजनाएँ
स्टोर और फॉरवर्ड रूटिंग स्कीम के साथ मल्टीकाम्प्यूटर में, पैकेट सूचना प्रसारण की सबसे छोटी इकाई है। वर्महोल-राउडेड नेटवर्क में, पैकेट को फ़्लिट्स में विभाजित किया जाता है। पैकेट की लंबाई मार्ग योजना और नेटवर्क कार्यान्वयन द्वारा निर्धारित की जाती है, जबकि फ़्लिट लंबाई नेटवर्क आकार से प्रभावित होती है।
में Store and forward routing, पैकेट सूचना प्रसारण की मूल इकाई है। इस स्थिति में, प्रत्येक नोड एक पैकेट बफ़र का उपयोग करता है। मध्यवर्ती नोड के अनुक्रम के माध्यम से एक पैकेट को नोड से एक स्रोत नोड से एक गंतव्य नोड तक प्रेषित किया जाता है। स्रोत और गंतव्य के बीच की दूरी के लिए विलंबता सीधे आनुपातिक है।
में wormhole routingस्रोत नोड से गंतव्य नोड तक ट्रांसमिशन राउटर के अनुक्रम के माध्यम से किया जाता है। एक ही पैकेट के सभी फ्लिट्स को एक पाइपलाइन किए गए फैशन में एक अविभाज्य अनुक्रम में प्रेषित किया जाता है। इस मामले में, केवल हेडर फ़्लिट जानता है कि पैकेट कहाँ जा रहा है।
गतिरोध और आभासी चैनल
एक वर्चुअल चैनल दो नोड्स के बीच एक तार्किक लिंक है। यह स्रोत नोड और रिसीवर नोड में फ्लिट बफर और उनके बीच एक भौतिक चैनल द्वारा बनता है। जब एक जोड़ी के लिए एक भौतिक चैनल आवंटित किया जाता है, तो एक स्रोत बफर को आभासी चैनल बनाने के लिए एक रिसीवर बफर के साथ जोड़ा जाता है।
जब सभी चैनलों पर संदेशों का कब्जा है और चक्र में किसी भी चैनल को मुक्त नहीं किया गया है, तो एक गतिरोध की स्थिति उत्पन्न होगी। इससे बचने के लिए गतिरोध से बचाव योजना का पालन करना होगा।