समानांतर कंप्यूटर वास्तुकला - त्वरित गाइड
पिछले 50 वर्षों में, कंप्यूटर प्रणाली के प्रदर्शन और क्षमता में भारी विकास हुआ है। यह वेरी लार्ज स्केल इंटीग्रेशन (वीएलएसआई) तकनीक की मदद से संभव हुआ है। वीएलएसआई तकनीक बड़ी संख्या में घटकों को एक चिप और घड़ी की दरों को बढ़ाने की अनुमति देती है। इसलिए, समानांतर में, एक बार में अधिक संचालन किया जा सकता है।
समानांतर प्रसंस्करण डेटा स्थानीयता और डेटा संचार के साथ भी जुड़ा हुआ है। Parallel Computer Architecture प्रौद्योगिकी द्वारा दी गई सीमाओं और किसी भी समय की लागत के भीतर प्रदर्शन और प्रोग्राम क्षमता को अधिकतम करने के लिए सभी संसाधनों को व्यवस्थित करने की विधि है।
समानांतर वास्तुकला क्यों?
समानांतर कंप्यूटर वास्तुकला अधिक से अधिक संख्या में प्रोसेसर का उपयोग करके कंप्यूटर सिस्टम के विकास में एक नया आयाम जोड़ता है। सिद्धांत रूप में, बड़ी संख्या में प्रोसेसर का उपयोग करके प्राप्त किया गया प्रदर्शन किसी दिए गए बिंदु पर एकल प्रोसेसर के प्रदर्शन से अधिक होता है।
आवेदन रुझान
हार्डवेयर क्षमता की प्रगति के साथ, एक अच्छा प्रदर्शन करने वाले अनुप्रयोग की मांग भी बढ़ गई, जिसने बदले में कंप्यूटर वास्तुकला के विकास पर एक मांग रखी।
माइक्रोप्रोसेसर युग से पहले, उच्च प्रदर्शन वाली कंप्यूटर प्रणाली विदेशी सर्किट प्रौद्योगिकी और मशीन संगठन द्वारा प्राप्त की गई थी, जिसने उन्हें महंगा बना दिया था। अब, कई प्रोसेसर का उपयोग करके अत्यधिक प्रदर्शन करने वाली कंप्यूटर प्रणाली प्राप्त की जाती है, और सबसे महत्वपूर्ण और मांग वाले अनुप्रयोगों को समानांतर कार्यक्रमों के रूप में लिखा जाता है। इस प्रकार, उच्च प्रदर्शन के लिए समानांतर आर्किटेक्चर और समानांतर अनुप्रयोगों दोनों को विकसित करने की आवश्यकता है।
एक अनुप्रयोग के प्रदर्शन को बढ़ाने के लिए स्पीडअप को माना जाने वाला प्रमुख कारक है। Speedup p प्रोसेसर के रूप में परिभाषित किया गया है -
$$Speedup(p \ processors)\equiv\frac{Performance(p \ processors)}{Performance(1 \ processor)}$$एकल निश्चित समस्या के लिए,
$$performance \ of \ a \ computer \ system = \frac{1}{Time \ needed \ to \ complete \ the \ problem}$$ $$Speedup \ _{fixed \ problem} (p \ processors) =\frac{Time(1 \ processor)}{Time(p \ processor)}$$वैज्ञानिक और इंजीनियरिंग कम्प्यूटिंग
वैज्ञानिक वास्तुकला (जैसे भौतिकी, रसायन विज्ञान, जीव विज्ञान, खगोल विज्ञान, आदि) और इंजीनियरिंग अनुप्रयोगों (जैसे जलाशय मॉडलिंग, एयरफ्लो विश्लेषण, दहन दक्षता, आदि) में समानांतर वास्तुकला अपरिहार्य हो गई है। लगभग सभी अनुप्रयोगों में, कम्प्यूटेशनल आउटपुट के विज़ुअलाइज़ेशन की भारी मांग है जिसके परिणामस्वरूप कम्प्यूटेशनल गति को बढ़ाने के लिए समानांतर कंप्यूटिंग के विकास की मांग की जाती है।
वाणिज्यिक कम्प्यूटिंग
वाणिज्यिक कंप्यूटिंग (जैसे वीडियो, ग्राफिक्स, डेटाबेस, ओएलटीपी, आदि) में भी एक निर्धारित समय के भीतर बड़ी मात्रा में डेटा को संसाधित करने के लिए उच्च गति वाले कंप्यूटरों की आवश्यकता होती है। डेस्कटॉप मल्टीथ्रेडेड प्रोग्रामों का उपयोग करता है जो लगभग समानांतर कार्यक्रमों की तरह हैं। यह बदले में समानांतर वास्तुकला विकसित करने की मांग करता है।
प्रौद्योगिकी रुझान
प्रौद्योगिकी और वास्तुकला के विकास के साथ, उच्च प्रदर्शन वाले अनुप्रयोगों के विकास के लिए एक मजबूत मांग है। प्रयोग बताते हैं कि समानांतर कंप्यूटर एकल विकसित प्रोसेसर की तुलना में बहुत तेजी से काम कर सकते हैं। इसके अलावा, समानांतर कंप्यूटर को प्रौद्योगिकी और लागत की सीमा के भीतर विकसित किया जा सकता है।
यहां इस्तेमाल की जाने वाली प्राथमिक तकनीक वीएलएसआई तकनीक है। इसलिए, आजकल अधिक से अधिक ट्रांजिस्टर, गेट और सर्किट एक ही क्षेत्र में फिट किए जा सकते हैं। मूल वीएलएसआई सुविधा आकार में कमी के साथ, घड़ी की दर भी इसके अनुपात में सुधार करती है, जबकि ट्रांजिस्टर की संख्या वर्ग के रूप में बढ़ती है। एक साथ कई ट्रांजिस्टर का उपयोग (समानांतरवाद) घड़ी की दर को बढ़ाकर इससे बेहतर प्रदर्शन करने की उम्मीद की जा सकती है
प्रौद्योगिकी के रुझान बताते हैं कि बुनियादी सिंगल चिप बिल्डिंग ब्लॉक तेजी से बड़ी क्षमता देगा। इसलिए, एकल चिप पर कई प्रोसेसर रखने की संभावना बढ़ जाती है।
वास्तुकला के रुझान
प्रौद्योगिकी में विकास तय करता है कि क्या संभव है; वास्तुकला प्रौद्योगिकी की क्षमता को प्रदर्शन और क्षमता में परिवर्तित करता है।Parallelism तथा localityदो तरीके हैं जहाँ संसाधनों का अधिक मात्रा और अधिक ट्रांजिस्टर प्रदर्शन को बढ़ाते हैं। हालाँकि, ये दोनों विधियाँ समान संसाधनों के लिए प्रतिस्पर्धा करती हैं। जब कई ऑपरेशन समानांतर में निष्पादित होते हैं, तो प्रोग्राम को निष्पादित करने के लिए आवश्यक चक्रों की संख्या कम हो जाती है।
हालाँकि, प्रत्येक समवर्ती गतिविधियों का समर्थन करने के लिए संसाधनों की आवश्यकता होती है। स्थानीय भंडारण को आवंटित करने के लिए संसाधनों की भी आवश्यकता होती है। सबसे अच्छा प्रदर्शन एक मध्यवर्ती कार्रवाई योजना द्वारा प्राप्त किया जाता है जो संसाधनों का उपयोग समानता और स्थानीयता की डिग्री का उपयोग करने के लिए करता है।
आम तौर पर, कंप्यूटर वास्तुकला के इतिहास को चार पीढ़ियों में विभाजित किया गया है, जिसमें बुनियादी प्रौद्योगिकियां निम्नलिखित हैं -
- वैक्यूम ट्यूब
- Transistors
- एकीकृत सर्किट
- VLSI
1985 तक, बिट-लेवल समानता में वृद्धि की अवधि हावी थी। 4-बिट माइक्रोप्रोसेसरों के बाद 8-बिट, 16-बिट, और इसी तरह। पूर्ण 32-बिट ऑपरेशन करने के लिए आवश्यक चक्रों की संख्या को कम करने के लिए, डेटा पथ की चौड़ाई दोगुनी हो गई थी। बाद में, 64-बिट ऑपरेशन शुरू किए गए थे।
में वृद्धि instruction-level-parallelism80 के दशक के मध्य से 90 के दशक के मध्य तक हावी रही। RISC दृष्टिकोण से पता चला कि अनुदेश प्रसंस्करण के चरणों को पाइप करना सरल था ताकि औसतन एक अनुदेश लगभग हर चक्र में निष्पादित हो। संकलक प्रौद्योगिकी के विकास ने अनुदेश पाइपलाइनों को अधिक उत्पादक बना दिया है।
80 के दशक के मध्य में, माइक्रोप्रोसेसर आधारित कंप्यूटर शामिल थे
- एक पूर्णांक प्रसंस्करण इकाई
- एक फ्लोटिंग-पॉइंट यूनिट
- एक कैश कंट्रोलर
- कैश डेटा के लिए SRAMs
- टैग भंडारण
जैसे ही चिप की क्षमता बढ़ी, इन सभी घटकों को एक चिप में मिला दिया गया। इस प्रकार, एक एकल चिप में पूर्णांक अंकगणितीय, फ्लोटिंग पॉइंट संचालन, मेमोरी संचालन और शाखा संचालन के लिए अलग-अलग हार्डवेयर शामिल थे। व्यक्तिगत निर्देशों को पाइपलाइन करने के अलावा, यह एक समय में कई निर्देशों को प्राप्त करता है और जब भी संभव हो विभिन्न कार्यात्मक इकाइयों के समानांतर उन्हें भेजता है। इस प्रकार के निर्देश स्तर समानता को कहा जाता हैsuperscalar execution।
समानांतर मशीनों को कई विशिष्ट वास्तुकला के साथ विकसित किया गया है। इस खंड में, हम विभिन्न समानांतर कंप्यूटर वास्तुकला और उनके अभिसरण की प्रकृति पर चर्चा करेंगे।
संचार वास्तुकला
समानांतर वास्तुकला संचार वास्तुकला के साथ कंप्यूटर वास्तुकला की पारंपरिक अवधारणाओं को बढ़ाती है। कंप्यूटर वास्तुकला महत्वपूर्ण अमूर्तता (जैसे उपयोगकर्ता-सिस्टम सीमा और हार्डवेयर-सॉफ़्टवेयर सीमा) और संगठनात्मक संरचना को परिभाषित करता है, जबकि संचार वास्तुकला बुनियादी संचार और सिंक्रनाइज़ेशन संचालन को परिभाषित करता है। यह संगठनात्मक संरचना को भी संबोधित करता है।
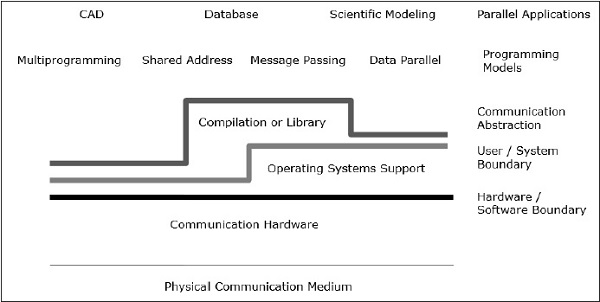
प्रोग्रामिंग मॉडल शीर्ष परत है। एप्लिकेशन प्रोग्रामिंग मॉडल में लिखे गए हैं। समानांतर प्रोग्रामिंग मॉडल में शामिल हैं -
- पता स्थान साझा किया गया
- संदेश देना
- डेटा समानांतर प्रोग्रामिंग
Shared addressप्रोग्रामिंग एक बुलेटिन बोर्ड का उपयोग करने जैसा है, जहां कोई व्यक्ति किसी विशेष स्थान पर जानकारी पोस्ट करके एक या कई व्यक्तियों के साथ संवाद कर सकता है, जिसे अन्य सभी व्यक्तियों द्वारा साझा किया जाता है। व्यक्तिगत गतिविधि को यह देखते हुए समन्वित किया जाता है कि कौन क्या कार्य कर रहा है।
Message passing एक टेलीफोन कॉल या पत्रों की तरह है जहां एक विशिष्ट रिसीवर एक विशिष्ट प्रेषक से जानकारी प्राप्त करता है।
Data parallelप्रोग्रामिंग सहयोग का एक संगठित रूप है। यहां, कई व्यक्ति समवर्ती रूप से सेट किए गए डेटा के अलग-अलग तत्वों पर कार्रवाई करते हैं और विश्व स्तर पर जानकारी साझा करते हैं।
शेयर्ड मेमोरी
साझा मेमोरी मल्टीप्रोसेसर समानांतर मशीनों के सबसे महत्वपूर्ण वर्गों में से एक हैं। यह मल्टीप्रोग्रामिंग वर्कलोड पर बेहतर थ्रूपुट देता है और समानांतर कार्यक्रमों का समर्थन करता है।
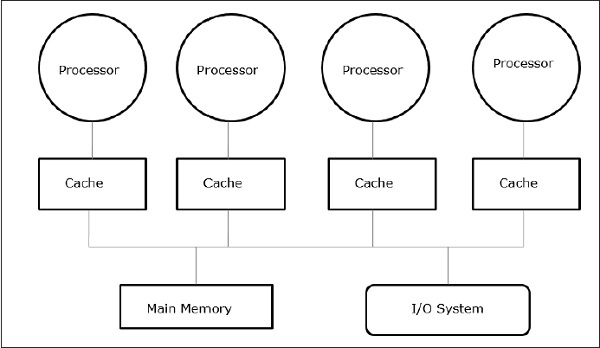
इस स्थिति में, सभी कंप्यूटर सिस्टम कुछ हार्डवेयर इंटरकनेक्शन द्वारा मेमोरी मॉड्यूल के संग्रह तक पहुंचने के लिए एक प्रोसेसर और I / O नियंत्रक के एक सेट की अनुमति देते हैं। मेमोरी मॉड्यूल को जोड़कर मेमोरी क्षमता बढ़ाई जाती है और I / O कंट्रोलर में डिवाइस जोड़कर या अतिरिक्त I / O कंट्रोलर जोड़कर I / O क्षमता बढ़ाई जाती है। तेजी से प्रोसेसर उपलब्ध होने या अधिक प्रोसेसर जोड़कर प्रतीक्षा करने से प्रसंस्करण क्षमता बढ़ाई जा सकती है।
सभी संसाधन एक केंद्रीय मेमोरी बस के आसपास आयोजित किए जाते हैं। बस पहुंच तंत्र के माध्यम से, कोई भी प्रोसेसर सिस्टम में किसी भी भौतिक पते तक पहुंच सकता है। जैसा कि सभी प्रोसेसर सभी मेमोरी स्थानों से समान होते हैं, सभी प्रोसेसर का एक्सेस समय या विलंबता मेमोरी लोकेशन पर समान होती है। यह कहा जाता हैsymmetric multiprocessor।
संदेश-पासिंग आर्किटेक्चर
संदेश पासिंग आर्किटेक्चर भी समानांतर मशीनों का एक महत्वपूर्ण वर्ग है। यह स्पष्ट आई / ओ संचालन के रूप में प्रोसेसर के बीच संचार प्रदान करता है। इस मामले में, संचार को मेमोरी सिस्टम के बजाय I / O स्तर पर संयोजित किया जाता है।
संदेश पासिंग आर्किटेक्चर में, ऑपरेटिंग सिस्टम या लाइब्रेरी कॉल का उपयोग करके निष्पादित उपयोगकर्ता संचार जो कई निचले स्तर की क्रियाएं करते हैं, जिसमें वास्तविक संचार ऑपरेशन शामिल है। नतीजतन, भौतिक हार्डवेयर स्तर पर प्रोग्रामिंग मॉडल और संचार संचालन के बीच एक दूरी है।
Send तथा receiveसंदेश पासिंग सिस्टम में सबसे आम उपयोगकर्ता स्तर का संचार संचालन है। भेजें एक स्थानीय डेटा बफ़र (जो प्रेषित किया जाना है) और एक दूरस्थ प्रोसेसर प्राप्त करता है। प्राप्त एक भेजने की प्रक्रिया और एक स्थानीय डेटा बफर निर्दिष्ट करता है जिसमें प्रेषित डेटा रखा जाएगा। भेजने के संचालन में, एidentifier या ए tag संदेश से जुड़ा हुआ है और प्राप्त करने का कार्य किसी विशिष्ट प्रोसेसर से किसी विशिष्ट टैग या किसी भी प्रोसेसर से किसी भी टैग की तरह मिलान नियम को निर्दिष्ट करता है।
एक भेजने और एक मिलान प्राप्त करने का संयोजन एक मेमोरी-टू-मेमोरी कॉपी को पूरा करता है। प्रत्येक छोर अपने स्थानीय डेटा पते और एक जोड़ी वार सिंक्रोनाइज़ेशन घटना को निर्दिष्ट करता है।
अभिसरण
हार्डवेयर और सॉफ्टवेयर के विकास ने साझा मेमोरी और संदेश पासिंग कैंपों के बीच स्पष्ट सीमा को फीका कर दिया है। संदेश पासिंग और एक साझा पता स्थान दो अलग प्रोग्रामिंग मॉडल का प्रतिनिधित्व करता है; प्रत्येक साझाकरण, सिंक्रनाइज़ेशन और संचार के लिए एक पारदर्शी प्रतिमान देता है। हालांकि, बुनियादी मशीन संरचनाएं एक आम संगठन की ओर परिवर्तित हो गई हैं।
डेटा समानांतर प्रसंस्करण
समानांतर मशीन का एक अन्य महत्वपूर्ण वर्ग विभिन्न रूप से कहा जाता है - प्रोसेसर सरणियाँ, डेटा समानांतर वास्तुकला और एकल-निर्देश-एकाधिक-डेटा मशीन। प्रोग्रामिंग मॉडल की मुख्य विशेषता यह है कि बड़े नियमित डेटा संरचना (जैसे सरणी या मैट्रिक्स) के प्रत्येक तत्व पर समानांतर में संचालन निष्पादित किया जा सकता है।
डेटा समानांतर प्रोग्रामिंग भाषाओं को आमतौर पर प्रक्रियाओं के एक समूह के स्थानीय पता स्थान, एक प्रति प्रोसेसर, एक स्पष्ट वैश्विक स्थान बनाते हुए लागू किया जाता है। जैसा कि सभी प्रोसेसर एक साथ संचार करते हैं और सभी ऑपरेशनों का एक वैश्विक दृष्टिकोण है, इसलिए या तो एक साझा पता स्थान या संदेश पासिंग का उपयोग किया जा सकता है।
मौलिक डिजाइन मुद्दे
प्रोग्रामिंग मॉडल का विकास न केवल कंप्यूटर की दक्षता को बढ़ा सकता है और न ही अकेले हार्डवेयर का विकास कर सकता है। हालांकि, कंप्यूटर आर्किटेक्चर में विकास कंप्यूटर के प्रदर्शन में अंतर ला सकता है। हम डिज़ाइन समस्या को समझ सकते हैं कि कैसे प्रोग्राम एक मशीन का उपयोग करते हैं और कौन सी बुनियादी तकनीक प्रदान की जाती हैं।
इस खंड में, हम संचार अमूर्त और प्रोग्रामिंग मॉडल की बुनियादी आवश्यकताओं के बारे में चर्चा करेंगे।
संचार अमूर्तता
संचार अमूर्त प्रोग्रामिंग मॉडल और सिस्टम कार्यान्वयन के बीच मुख्य इंटरफ़ेस है। यह निर्देश सेट की तरह है जो एक मंच प्रदान करता है ताकि एक ही कार्यक्रम कई कार्यान्वयन पर सही ढंग से चल सके। इस स्तर पर संचालन सरल होना चाहिए।
संचार अमूर्त हार्डवेयर और सॉफ्टवेयर के बीच एक अनुबंध की तरह है, जो एक दूसरे को काम को प्रभावित किए बिना लचीलेपन में सुधार करने की अनुमति देता है।
प्रोग्रामिंग मॉडल आवश्यकताएँ
समानांतर प्रोग्राम में डेटा पर एक या अधिक थ्रेड्स संचालित होते हैं। एक समानांतर प्रोग्रामिंग मॉडल परिभाषित करता है कि थ्रेड्स क्या डेटा कर सकते हैंname, कौन कौन से operations नामित डेटा पर प्रदर्शन किया जा सकता है, और संचालन के बाद किस आदेश का पालन किया जाता है।
यह पुष्टि करने के लिए कि कार्यक्रमों के बीच निर्भरताएं लागू हैं, एक समानांतर कार्यक्रम को अपने थ्रेड्स की गतिविधि का समन्वय करना चाहिए।
वास्तविक जीवन में उच्च प्रदर्शन, कम लागत और सटीक परिणामों की मांग को पूरा करने के लिए आधुनिक कंप्यूटर में समानांतर प्रसंस्करण को एक प्रभावी तकनीक के रूप में विकसित किया गया है। मल्टीप्रोग्रामिंग, मल्टीप्रोसेसिंग या मल्टीकंप्यूटिंग के अभ्यास के कारण आज के कंप्यूटर में समवर्ती घटनाएं आम हैं।
आधुनिक कंप्यूटर में शक्तिशाली और व्यापक सॉफ्टवेयर पैकेज हैं। कंप्यूटर के प्रदर्शन के विकास का विश्लेषण करने के लिए, पहले हमें हार्डवेयर और सॉफ्टवेयर के बुनियादी विकास को समझना होगा।
Computer Development Milestones - कंप्यूटर के विकास के दो प्रमुख चरण हैं - mechanical या electromechanicalभागों। आधुनिक कंप्यूटर इलेक्ट्रॉनिक उपकरणों की शुरूआत के बाद विकसित हुए। इलेक्ट्रॉनिक कंप्यूटरों में उच्च गतिशीलता इलेक्ट्रॉनों ने यांत्रिक कंप्यूटरों में परिचालन भागों को बदल दिया। सूचना प्रसारण के लिए, विद्युत संकेत जो प्रकाश की गति पर लगभग यांत्रिक गियर या लीवर की यात्रा करता है।
Elements of Modern computers - एक आधुनिक कंप्यूटर सिस्टम में कंप्यूटर हार्डवेयर, इंस्ट्रक्शंस सेट, एप्लिकेशन प्रोग्राम, सिस्टम सॉफ्टवेयर और यूजर इंटरफेस होते हैं।

कंप्यूटिंग समस्याओं को संख्यात्मक कंप्यूटिंग, तार्किक तर्क और लेनदेन प्रसंस्करण के रूप में वर्गीकृत किया गया है। कुछ जटिल समस्याओं को तीनों प्रसंस्करण मोड के संयोजन की आवश्यकता हो सकती है।
Evolution of Computer Architecture- पिछले चार दशकों में, कंप्यूटर वास्तुकला क्रांतिकारी परिवर्तनों से गुजरा है। हमने वॉन न्यूमैन वास्तुकला के साथ शुरुआत की और अब हमारे पास मल्टीकॉमपॉइंट और मल्टीप्रोसेसर हैं।
Performance of a computer system- कंप्यूटर सिस्टम का प्रदर्शन मशीन की क्षमता और प्रोग्राम व्यवहार दोनों पर निर्भर करता है। बेहतर हार्डवेयर प्रौद्योगिकी, उन्नत वास्तुशिल्प सुविधाओं और कुशल संसाधन प्रबंधन के साथ मशीन की क्षमता में सुधार किया जा सकता है। कार्यक्रम का व्यवहार अप्रत्याशित है क्योंकि यह अनुप्रयोग और रन-टाइम स्थितियों पर निर्भर है
मल्टीप्रोसेसर और मल्टीकॉमपॉइंट्स
इस भाग में, हम दो प्रकार के समानांतर कंप्यूटरों पर चर्चा करेंगे -
- Multiprocessors
- Multicomputers
साझा-मेमोरी मल्टीकॉमपॉइंट्स
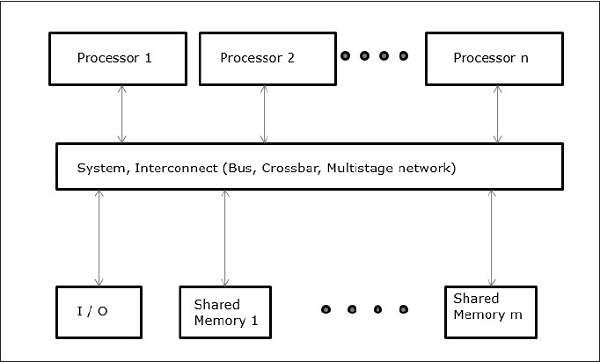
तीन सबसे आम साझा मेमोरी मल्टीप्रोसेसर मॉडल हैं -
यूनिफ़ॉर्म मेमोरी एक्सेस (UMA)
इस मॉडल में, सभी प्रोसेसर समान रूप से भौतिक मेमोरी साझा करते हैं। सभी प्रोसेसरों के पास सभी मेमोरी शब्दों के लिए समान पहुंच समय है। प्रत्येक प्रोसेसर में एक निजी कैश मेमोरी हो सकती है। परिधीय उपकरणों के लिए एक ही नियम का पालन किया जाता है।
जब सभी प्रोसेसर सभी परिधीय उपकरणों के लिए समान पहुंच रखते हैं, तो सिस्टम को ए कहा जाता है symmetric multiprocessor। जब केवल एक या कुछ प्रोसेसर परिधीय उपकरणों तक पहुंच सकते हैं, तो सिस्टम को ए कहा जाता हैasymmetric multiprocessor।
गैर-समान मेमोरी एक्सेस (NUMA)
NUMA मल्टीप्रोसेसर मॉडल में, मेमोरी शब्द के स्थान के साथ एक्सेस टाइम बदलता रहता है। यहां, साझा मेमोरी सभी प्रोसेसर के बीच भौतिक रूप से वितरित की जाती है, जिसे स्थानीय मेमोरी कहा जाता है। सभी स्थानीय यादों का संग्रह एक वैश्विक पता स्थान बनाता है जिसे सभी प्रोसेसर द्वारा पहुँचा जा सकता है।
कैश केवल मेमोरी आर्किटेक्चर (COMA)
COMA मॉडल NUMA मॉडल का एक विशेष मामला है। यहां, सभी वितरित मुख्य यादें कैश यादों में बदल जाती हैं।

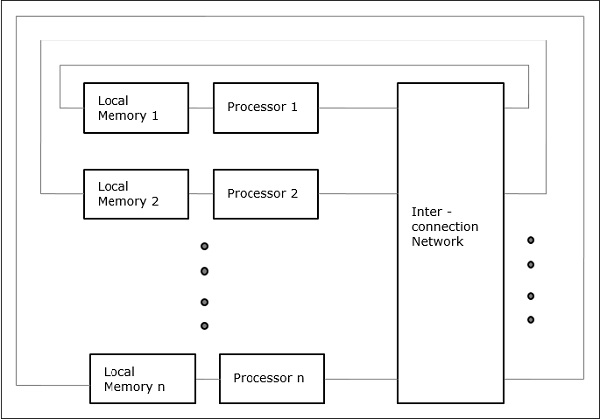
Distributed - Memory Multicomputers- एक वितरित मेमोरी मल्टीकोम्प्यूटर सिस्टम में कई कंप्यूटर होते हैं, जिन्हें नोड्स के रूप में जाना जाता है, संदेश गुजर नेटवर्क द्वारा इंटर-कनेक्ट किया जाता है। प्रत्येक नोड एक स्वायत्त कंप्यूटर के रूप में कार्य करता है जिसमें एक प्रोसेसर, एक स्थानीय मेमोरी और कभी-कभी I / O डिवाइस होते हैं। इस मामले में, सभी स्थानीय यादें निजी हैं और केवल स्थानीय प्रोसेसर तक ही पहुँच योग्य हैं। यही कारण है, पारंपरिक मशीनों कहा जाता हैno-remote-memory-access (NORMA) मशीनों।

मल्टीवेक्टर और SIMD कंप्यूटर
इस खंड में, हम वेक्टर प्रसंस्करण और डेटा समानता के लिए सुपर कंप्यूटर और समानांतर प्रोसेसर पर चर्चा करेंगे।
वेक्टर सुपर कंप्यूटर
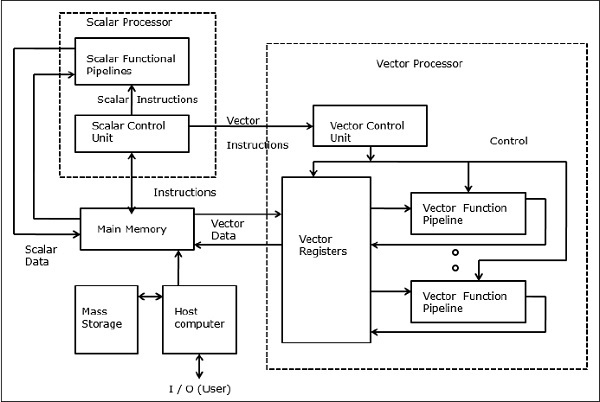
वेक्टर कंप्यूटर में, एक वेक्टर प्रोसेसर स्केलर प्रोसेसर से एक वैकल्पिक विशेषता के रूप में जुड़ा होता है। होस्ट कंप्यूटर पहले प्रोग्राम और डेटा को मुख्य मेमोरी में लोड करता है। फिर स्केलर कंट्रोल यूनिट सभी निर्देशों को डिकोड करता है। यदि डिकोड किए गए निर्देश स्केलर ऑपरेशन या प्रोग्राम ऑपरेशन हैं, तो स्केलर प्रोसेसर स्केलर कार्यात्मक पाइपलाइनों का उपयोग करके उन कार्यों को निष्पादित करता है।
दूसरी ओर, यदि डिकोड किए गए निर्देश वेक्टर ऑपरेशन हैं तो निर्देश वेक्टर कंट्रोल यूनिट को भेजे जाएंगे।
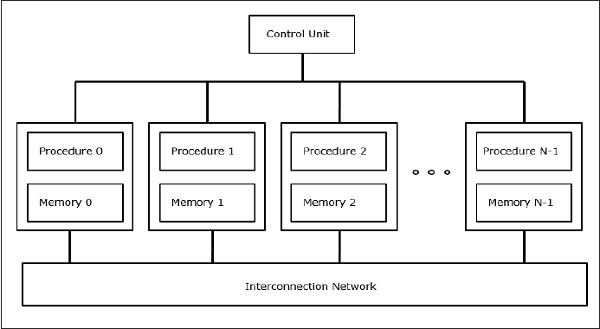
SIMD सुपर कंप्यूटर
SIMD कंप्यूटरों में, 'N' नंबर के प्रोसेसर एक कंट्रोल यूनिट से जुड़े होते हैं और सभी प्रोसेसर में उनकी अलग-अलग मेमोरी यूनिट होती हैं। सभी प्रोसेसर एक इंटरकनेक्शन नेटवर्क द्वारा जुड़े हुए हैं।
PRAM और VLSI मॉडल
आदर्श मॉडल भौतिक बाधाओं या कार्यान्वयन विवरणों पर विचार किए बिना समानांतर एल्गोरिदम विकसित करने के लिए एक उपयुक्त ढांचा देता है।
मॉडल समानांतर कंप्यूटरों पर सैद्धांतिक प्रदर्शन सीमा प्राप्त करने या चिप क्षेत्र पर वीएलएसआई जटिलता का मूल्यांकन करने और चिप के निर्माण से पहले परिचालन समय से पहले लागू किया जा सकता है।
समानांतर रैंडम-एक्सेस मशीनें
शेपर्डन और स्टर्गिस (1963) ने पारंपरिक यूनिप्रोसेर कंप्यूटर को रैंडम-एक्सेस-मशीन (रैम) के रूप में बनाया। फॉर्च्यून और वायली (1978) ने शून्य मेमोरी एक्सेस ओवरहेड और सिंक्रोनाइज़ेशन के साथ एक आदर्श समानांतर कंप्यूटर के मॉडलिंग के लिए एक समानांतर रैंडम-एक्सेस-मशीन (PRAM) मॉडल विकसित किया।

एन-प्रोसेसर PRAM की एक साझा मेमोरी यूनिट है। इस साझा मेमोरी को प्रोसेसर के बीच केंद्रीकृत या वितरित किया जा सकता है। ये प्रोसेसर एक सिंक्रनाइज़ रीड-मेमोरी, राइट-मेमोरी और कंप्यूट चक्र पर काम करते हैं। इसलिए, ये मॉडल निर्दिष्ट करते हैं कि समवर्ती पढ़ना और लिखना कैसे संभाला जाता है।
निम्नलिखित मेमोरी अपडेट के संचालन संभव हैं -
Exclusive read (ER) - इस विधि में, प्रत्येक चक्र में किसी भी मेमोरी स्थान से केवल एक प्रोसेसर को पढ़ने की अनुमति है।
Exclusive write (EW) - इस विधि में, एक समय में कम से कम एक प्रोसेसर को मेमोरी लोकेशन में लिखने की अनुमति दी जाती है।
Concurrent read (CR) - यह कई प्रोसेसरों को एक ही साइकल में एक ही मेमोरी लोकेशन से एक ही जानकारी को पढ़ने की अनुमति देता है।
Concurrent write (CW)- यह एक ही मेमोरी स्थान पर एक साथ लिखने के संचालन की अनुमति देता है। संघर्ष से बचने के लिए कुछ नीतियां निर्धारित की जाती हैं।
वीएलएसआई जटिलता मॉडल
समानांतर कंप्यूटर प्रोसेसर एरे, मेमोरी एरे और बड़े पैमाने पर स्विचिंग नेटवर्क को बनाने के लिए वीएलएसआई चिप्स का उपयोग करते हैं।
आजकल, वीएलएसआई प्रौद्योगिकियां 2-आयामी हैं। वीएलएसआई चिप का आकार उस चिप में उपलब्ध संग्रहण (मेमोरी) स्थान की मात्रा के अनुपात में होता है।
हम उस एल्गोरिथ्म के वीएलएसआई चिप कार्यान्वयन के चिप क्षेत्र (ए) द्वारा एक एल्गोरिथ्म के अंतरिक्ष जटिलता की गणना कर सकते हैं। यदि टी एल्गोरिथ्म को निष्पादित करने के लिए आवश्यक समय (विलंबता) है, तो एटी चिप (या आई / ओ) के माध्यम से संसाधित बिट्स की कुल संख्या पर एक ऊपरी बाध्य देता है। कुछ कंप्यूटिंग के लिए, एक कम बाउंड, f (s) मौजूद है, जैसे कि
एटी 2 > = ओ (एफ (एस))
जहाँ A = चिप क्षेत्र और T = समय
आर्किटेक्चरल डेवलपमेंट ट्रैक
समानांतर कंप्यूटरों का विकास जो मैंने निम्नलिखित पटरियों के साथ फैलाया है -
- एकाधिक प्रोसेसर ट्रैक्स
- मल्टीप्रोसेसर ट्रैक
- मल्टीकॉम्प्यूटर ट्रैक
- एकाधिक डेटा ट्रैक
- वेक्टर ट्रैक
- SIMD ट्रैक
- एकाधिक धागे ट्रैक
- बहुस्तरीय ट्रैक
- डाटाफ्लो ट्रैक
में multiple processor track, यह माना जाता है कि विभिन्न धागे विभिन्न प्रोसेसर पर समवर्ती रूप से निष्पादित होते हैं और साझा मेमोरी (मल्टीप्रोसेसर ट्रैक) या संदेश पासिंग (मल्टीकोम्प्यूटर ट्रैक) प्रणाली के माध्यम से संचार करते हैं।
में multiple data track, यह माना जाता है कि डेटा की भारी मात्रा पर एक ही कोड निष्पादित किया जाता है। यह डेटा तत्वों (वेक्टर ट्रैक) के अनुक्रम पर समान निर्देशों को निष्पादित करने या डेटा के समान सेट (SIMD ट्रैक) पर निर्देशों के उसी अनुक्रम के निष्पादन के द्वारा किया जाता है।
में multiple threads track, यह माना जाता है कि विभिन्न प्रोसेसर पर निष्पादित थ्रेड्स के बीच सिंक्रनाइज़ेशन देरी को छिपाने के लिए एक ही प्रोसेसर पर विभिन्न थ्रेड्स के interleaved निष्पादन। थ्रेड इंटरलायविंग मोटे (मल्टीट्र्रेड ट्रैक) या फाइन (डेटाफ्लो ट्रैक) हो सकते हैं।
80 के दशक में, एक विशेष उद्देश्य प्रोसेसर जिसे मल्टीकॉमपैक कहा जाता है बनाने के लिए लोकप्रिय था Transputer। एक ट्रांसप्यूटर में एक कोर प्रोसेसर, एक छोटा एसआरएएम मेमोरी, एक डीआरएएम मुख्य मेमोरी इंटरफेस और चार संचार चैनल होते हैं, जो सभी एक चिप पर होते हैं। एक समानांतर कंप्यूटर संचार करने के लिए, चैनलों को ट्रांसपॉइंट का एक नेटवर्क बनाने के लिए जोड़ा गया था। लेकिन इसमें कम्प्यूटेशनल शक्ति की कमी है और इसलिए यह समानांतर अनुप्रयोगों की बढ़ती मांग को पूरा नहीं कर सकता है। यह समस्या RISC प्रोसेसर के विकास से हल हुई और यह सस्ती भी थी।
आधुनिक समानांतर कंप्यूटर माइक्रोप्रोसेसरों का उपयोग करता है जो अनुदेश-स्तर समानता और डेटा स्तर समानता जैसे कई स्तरों पर समानता का उपयोग करता है।
उच्च प्रदर्शन प्रोसेसर
आज के समानांतर कंप्यूटर बाजार में RISC और RISCy प्रोसेसर हावी हैं।
पारंपरिक आरआईएससी के लक्षण हैं -
- कुछ संबोधित मोड है।
- निर्देशों के लिए एक निश्चित प्रारूप है, आमतौर पर 32 या 64 बिट्स।
- डेटा को रजिस्टर से मेमोरी में लोड करने और रजिस्टर से मेमोरी में डेटा स्टोर करने के लिए समर्पित लोड / स्टोर निर्देश है।
- रजिस्टरों पर अंकगणित संचालन हमेशा किया जाता है।
- पाइप लाइनिंग का उपयोग करता है।
इन दिनों अधिकांश माइक्रोप्रोसेसरों में सुपरस्केलर हैं, अर्थात एक समानांतर कंप्यूटर में कई निर्देश पाइपलाइनों का उपयोग किया जाता है। इसलिए, सुपरस्क्लेयर प्रोसेसर एक ही समय में एक से अधिक निर्देशों को निष्पादित कर सकते हैं। सुपरस्लेकर प्रोसेसर की प्रभावशीलता अनुप्रयोगों में उपलब्ध अनुदेश-स्तरीय समानता (ILP) की मात्रा पर निर्भर है। पाइपलाइनों को भरा रखने के लिए, हार्डवेयर स्तर पर निर्देशों को प्रोग्राम ऑर्डर की तुलना में एक अलग क्रम में निष्पादित किया जाता है।
कई आधुनिक माइक्रोप्रोसेसर सुपर पाइपेलिंग दृष्टिकोण का उपयोग करते हैं । में सुपर पाइपलाइनिंग ,, घड़ी आवृत्ति को बढ़ाने के काम एक पाइप लाइन के मंच के भीतर किया कम हो जाता है और पाइपलाइन चरणों की संख्या बढ़ जाती है।
बहुत बड़े इंस्ट्रक्शन वर्ड (वीएलआईडब्ल्यू) प्रोसेसर
ये क्षैतिज माइक्रोप्रोग्रामिंग और सुपरस्लेकर प्रसंस्करण से प्राप्त होते हैं। वीएलआईडब्ल्यू प्रोसेसर में निर्देश बहुत बड़े हैं। एक निर्देश के भीतर संचालन समानांतर में निष्पादित किया जाता है और निष्पादन के लिए उपयुक्त कार्यात्मक इकाइयों को अग्रेषित किया जाता है। इसलिए, वीएलआईडब्ल्यू निर्देश लाने के बाद, इसके संचालन को डिकोड किया जाता है। फिर संचालन को कार्यात्मक इकाइयों में भेजा जाता है जिसमें उन्हें समानांतर में निष्पादित किया जाता है।
वेक्टर प्रोसेसर
वेक्टर प्रोसेसर सामान्य-प्रयोजन माइक्रोप्रोसेसर के सह-प्रोसेसर हैं। वेक्टर प्रोसेसर आम तौर पर रजिस्टर-रजिस्टर या मेमोरी-मेमोरी होते हैं। एक वेक्टर निर्देश को लाया और डिकोड किया जाता है और फिर ऑपरेंड वैक्टर के प्रत्येक तत्व के लिए एक निश्चित ऑपरेशन किया जाता है, जबकि एक सामान्य प्रोसेसर में एक वेक्टर ऑपरेशन को कोड में एक लूप संरचना की आवश्यकता होती है। इसे और अधिक कुशल बनाने के लिए, वेक्टर प्रोसेसर एक साथ कई वेक्टर ऑपरेशन को चेन करते हैं, अर्थात, एक वेक्टर ऑपरेशन से परिणाम को ऑपरेंड के रूप में दूसरे में भेजा जाता है।
कैशिंग
कैश उच्च-प्रदर्शन माइक्रोप्रोसेसर के महत्वपूर्ण तत्व हैं। प्रत्येक 18 महीनों के बाद, माइक्रोप्रोसेसरों की गति दो बार हो जाती है, लेकिन मुख्य मेमोरी के लिए DRAM चिप्स इस गति का मुकाबला नहीं कर सकते हैं। तो, प्रोसेसर और मेमोरी के बीच स्पीड गैप को कम करने के लिए कैश पेश किए जाते हैं। एक कैश एक तेज़ और छोटी SRAM मेमोरी है। आधुनिक प्रोसेसर में कई और कैश लगाए जाते हैं जैसे ट्रांसलेशन लुक-साइड बफ़र्स (टीएलबी) कैश, इंस्ट्रक्शन और डेटा कैश इत्यादि।
डायरेक्ट मैप्ड कैश
प्रत्यक्ष मैप किए गए कैश में, कैश स्थान पर मुख्य मेमोरी में पते के एक-से-एक मैपिंग के लिए एक 'मोडुलो' फ़ंक्शन का उपयोग किया जाता है। जैसे ही कैश प्रविष्टि में कई मुख्य मेमोरी ब्लॉक मैप किए जा सकते हैं, प्रोसेसर को यह निर्धारित करने में सक्षम होना चाहिए कि कैश में डेटा ब्लॉक वास्तव में आवश्यक डेटा ब्लॉक है या नहीं। यह पहचान कैशे ब्लॉक के साथ टैग को संग्रहीत करके की जाती है।
पूरी तरह से सहयोगी कैश
पूरी तरह से साहचर्य मानचित्रण कैश में कहीं भी कैश ब्लॉक रखने की अनुमति देता है। कुछ प्रतिस्थापन नीति का उपयोग करके, कैश एक कैश प्रविष्टि निर्धारित करता है जिसमें यह कैश ब्लॉक को संग्रहीत करता है। पूरी तरह से सहयोगी कैश में लचीली मैपिंग है, जो कैश-एंट्री संघर्षों की संख्या को कम करता है। चूंकि पूरी तरह से साहचर्य कार्यान्वयन महंगा है, इसलिए इनका उपयोग बड़े पैमाने पर नहीं किया जाता है।
सेट-एसोसिएटिव कैश
एक सेट-एसोसिएटिव मैपिंग एक डायरेक्ट मैपिंग और एक पूरी तरह से एसोसिएटिव मैपिंग का एक संयोजन है। इस स्थिति में, कैश प्रविष्टियों को कैश सेट में विभाजित किया जाता है। जैसा कि डायरेक्ट मैपिंग में होता है, कैश में सेट करने के लिए मेमोरी ब्लॉक की एक निश्चित मैपिंग होती है। लेकिन कैश सेट के अंदर, एक मेमोरी ब्लॉक को पूरी तरह से साहचर्य तरीके से मैप किया जाता है।
कैश की रणनीतियाँ
मैपिंग तंत्र के अलावा, कैश को कई रणनीतियों की भी आवश्यकता होती है जो निर्दिष्ट करती हैं कि कुछ घटनाओं के मामले में क्या होना चाहिए। (सेट-) साहचर्य कैश के मामले में, कैश को यह निर्धारित करना होगा कि कैश ब्लॉक को कैश में प्रवेश करने के लिए किस नए ब्लॉक से बदलना है।
कुछ प्रसिद्ध प्रतिस्थापन रणनीति हैं -
- पहला-पहला आउट (FIFO)
- कम से कम हाल ही में प्रयुक्त (LRU)
हम इस अध्याय में मल्टीप्रोसेसर और मल्टीकॉमपर्स पर चर्चा करेंगे।
मल्टीप्रोसेसर सिस्टम इंटरकनेक्ट्स
समानांतर प्रसंस्करण को इनपुट / आउटपुट और परिधीय उपकरणों, मल्टीप्रोसेसर और साझा मेमोरी के बीच तेजी से संचार के लिए कुशल सिस्टम इंटरकनेक्ट का उपयोग करने की आवश्यकता है।
पदानुक्रमित बस सिस्टम
एक पदानुक्रमित बस प्रणाली में कंप्यूटर में विभिन्न प्रणालियों और उप-प्रणालियों / घटकों को जोड़ने वाली बसों का एक पदानुक्रम होता है। प्रत्येक बस कई सिग्नल, नियंत्रण और बिजली लाइनों से बनी होती है। विभिन्न बसों जैसे स्थानीय बसों, बैकप्लेन बसों और I / O बसों का उपयोग विभिन्न अंतर्संबंध कार्यों को करने के लिए किया जाता है।
स्थानीय बसें प्रिंटेड-सर्किट बोर्डों पर लागू होने वाली बसें हैं। एक बैकप्लेन बस एक मुद्रित सर्किट है जिस पर कार्यात्मक बोर्डों में प्लग करने के लिए कई कनेक्टर्स का उपयोग किया जाता है। बसें जो इनपुट / आउटपुट डिवाइस को कंप्यूटर सिस्टम से जोड़ती हैं, उन्हें I / O बस के रूप में जाना जाता है।
क्रॉसबार स्विच और मल्टीपोर्ट मेमोरी
स्विच्ड नेटवर्क इनपुट और आउटपुट के बीच डायनामिक इंटरकनेक्शन देते हैं। छोटे या मध्यम आकार के सिस्टम ज्यादातर क्रॉसबार नेटवर्क का उपयोग करते हैं। मल्टीस्टेज नेटवर्क को बड़े सिस्टम में विस्तारित किया जा सकता है, अगर बढ़ी हुई विलंबता समस्या को हल किया जा सकता है।
क्रॉसबार स्विच और मेमोरी संगठन दोनों ही एक एकल-चरण नेटवर्क है। हालांकि एक एकल चरण नेटवर्क बनाने के लिए सस्ता है, लेकिन कुछ कनेक्शन स्थापित करने के लिए कई पास की आवश्यकता हो सकती है। एक मल्टीस्टेज नेटवर्क में स्विच बॉक्स के एक से अधिक चरण होते हैं। ये नेटवर्क किसी भी इनपुट को किसी भी आउटपुट से जोड़ने में सक्षम होना चाहिए।
मल्टीस्टेज और कंबाइंडिंग नेटवर्क
मल्टीस्टेज नेटवर्क या मल्टीस्टेज इंटरकनेक्शन नेटवर्क उच्च गति वाले कंप्यूटर नेटवर्क का एक वर्ग है जो मुख्य रूप से नेटवर्क के एक छोर पर प्रसंस्करण तत्वों से बना होता है और दूसरे छोर पर मेमोरी तत्वों को स्विचिंग तत्वों द्वारा जोड़ा जाता है।
ये नेटवर्क बड़े मल्टीप्रोसेसर सिस्टम बनाने के लिए लगाए जाते हैं। इसमें ओमेगा नेटवर्क, बटरफ्लाई नेटवर्क और कई और अधिक शामिल हैं।
Multicomputers
Multicomputers को मेमोरी MIMD आर्किटेक्चर वितरित किया जाता है। निम्नलिखित आरेख एक बहुविकल्पी के वैचारिक मॉडल को दर्शाता है -
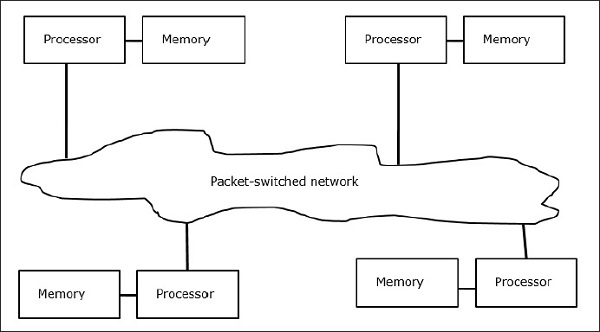
मल्टीकॉमपॉइंट संदेश-गुजरने वाली मशीनें हैं जो डेटा को आदान-प्रदान करने के लिए पैकेट स्विचिंग विधि लागू करती हैं। यहां, प्रत्येक प्रोसेसर में एक निजी मेमोरी होती है, लेकिन प्रोसेसर के रूप में कोई वैश्विक पता स्थान केवल अपनी स्थानीय मेमोरी तक नहीं पहुंच सकता है। इसलिए, संचार पारदर्शी नहीं है: यहां प्रोग्रामर को स्पष्ट रूप से संचार प्रिमिटिव को अपने कोड में रखना होगा।
वैश्विक रूप से सुलभ मेमोरी नहीं होने से मल्टीकॉमर्स की कमी है। इसे निम्नलिखित दो योजनाओं का उपयोग करके हल किया जा सकता है -
- वर्चुअल साझा मेमोरी (VSM)
- साझा वर्चुअल मेमोरी (SVM)
इन योजनाओं में, एप्लिकेशन प्रोग्रामर एक बड़ी साझा मेमोरी मानता है जो विश्व स्तर पर पता करने योग्य है। यदि आवश्यक हो, तो अनुप्रयोगों द्वारा किए गए मेमोरी संदर्भों को संदेश-गुजर प्रतिमान में अनुवादित किया जाता है।
वर्चुअल साझा मेमोरी (VSM)
वीएसएम एक हार्डवेयर कार्यान्वयन है। इसलिए, ऑपरेटिंग सिस्टम का वर्चुअल मेमोरी सिस्टम पारदर्शी रूप से वीएसएम के शीर्ष पर लागू किया जाता है। तो, ऑपरेटिंग सिस्टम को लगता है कि यह मशीन पर एक साझा मेमोरी के साथ चल रहा है।
साझा वर्चुअल मेमोरी (SVM)
एसवीएम प्रोसेसर के मेमोरी मैनेजमेंट यूनिट (एमएमयू) से हार्डवेयर समर्थन के साथ ऑपरेटिंग सिस्टम स्तर पर एक सॉफ्टवेयर कार्यान्वयन है। यहां, साझा करने की इकाई ऑपरेटिंग सिस्टम मेमोरी पेज है।
यदि कोई प्रोसेसर किसी विशेष मेमोरी लोकेशन को संबोधित करता है, तो MMU निर्धारित करता है कि मेमोरी एक्सेस से जुड़ा मेमोरी पेज लोकल मेमोरी में है या नहीं। यदि पृष्ठ मेमोरी में नहीं है, तो एक सामान्य कंप्यूटर सिस्टम में इसे ऑपरेटिंग सिस्टम द्वारा डिस्क से स्वैप किया जाता है। लेकिन, SVM में, ऑपरेटिंग सिस्टम पृष्ठ को दूरस्थ नोड से प्राप्त करता है जो उस विशेष पेज का मालिक है।
मल्टीकॉमपॉइंट की तीन जेनरेशन
इस खंड में, हम मल्टीकंप्यूटर की तीन पीढ़ियों पर चर्चा करेंगे।
अतीत में डिजाइन विकल्प
प्रोसेसर तकनीक का चयन करते समय, एक मल्टीकोम्प्यूटर डिज़ाइनर कम-लागत वाले मध्यम अनाज प्रोसेसर का निर्माण ब्लॉकों के रूप में करता है। समानांतर कंप्यूटरों के अधिकांश मानक ऑफ-द-शेल्फ शेल्फप्रोसेसर के साथ निर्मित होते हैं। वितरित मेमोरी को साझा मेमोरी का उपयोग करने के बजाय मल्टी-कंप्यूटर के लिए चुना गया था, जो स्केलेबिलिटी को सीमित करेगा। प्रत्येक प्रोसेसर की अपनी स्थानीय मेमोरी यूनिट होती है।
इंटरकनेक्शन स्कीम के लिए, मल्टीकॉमपॉइंट्स में एड्रेस स्विचिंग नेटवर्क के बजाय संदेश पासिंग, पॉइंट-टू-पॉइंट डायरेक्ट नेटवर्क होते हैं। नियंत्रण रणनीति के लिए, बहु-कंप्यूटर के डिजाइनर अतुल्यकालिक एमआईएमडी, एमपीएमडी और एसएमपीडी संचालन चुनते हैं। कैल्टेक कॉस्मिक क्यूब (सेज, 1983) पहली पीढ़ी के बहु-कंप्यूटरों में से पहला है।
वर्तमान और भविष्य का विकास
अगली पीढ़ी के कंप्यूटर मध्यम से बारीक अनाज वाले मल्टीकंप्यूटरों में विकसित हुए जो विश्व स्तर पर साझा की गई आभासी स्मृति का उपयोग करते हैं। वर्तमान में दूसरी पीढ़ी के मल्टी-कंप्यूटर अभी भी उपयोग में हैं। लेकिन i386, i860, आदि जैसे बेहतर प्रोसेसर का उपयोग करते हुए दूसरी पीढ़ी के कंप्यूटर बहुत विकसित हो गए हैं।
तीसरी पीढ़ी के कंप्यूटर अगली पीढ़ी के कंप्यूटर हैं जहां वीएलएसआई कार्यान्वित नोड्स का उपयोग किया जाएगा। प्रत्येक नोड में एक एकल चिप पर एकीकृत 14-MIPS प्रोसेसर, 20-Mbytes / s रूटिंग चैनल और 16 Kbytes RAM हो सकते हैं।
इंटेल पैरागॉन प्रणाली
पहले, सजातीय नोड्स का उपयोग हाइपरक्यूब मल्टीकंपेकर्स बनाने के लिए किया गया था, क्योंकि सभी फ़ंक्शन होस्ट को दिए गए थे। तो, इसने I / O बैंडविड्थ को सीमित कर दिया। इस प्रकार बड़े पैमाने पर समस्याओं को कुशलतापूर्वक या उच्च थ्रूपुट के साथ हल करने के लिए, इन कंप्यूटरों का उपयोग नहीं किया जा सकता है। इंटेल पैरागॉन सिस्टम को इस कठिनाई को दूर करने के लिए डिज़ाइन किया गया था। इसने मल्टीकॉम्प्यूटर को एक नेटवर्क वातावरण में मल्टीसियर एक्सेस के साथ एक एप्लिकेशन सर्वर में बदल दिया।
संदेश पासिंग मैकेनिज्म
मल्टीकोम्प्यूटर नेटवर्क में संदेश गुजरने वाले तंत्र को विशेष हार्डवेयर और सॉफ्टवेयर समर्थन की आवश्यकता होती है। इस खंड में, हम कुछ योजनाओं पर चर्चा करेंगे।
संदेश-रूटिंग योजनाएँ
स्टोर और फॉरवर्ड राउटिंग स्कीम के साथ मल्टीकाम्प्यूटर में, पैकेट सूचना प्रसारण की सबसे छोटी इकाई है। वर्महोल-राउड नेटवर्क में, पैकेट को आगे चलकर फ्लिट्स में विभाजित किया जाता है। पैकेट की लंबाई मार्ग योजना और नेटवर्क कार्यान्वयन द्वारा निर्धारित की जाती है, जबकि फ़्लिट लंबाई नेटवर्क आकार से प्रभावित होती है।
में Store and forward routing, पैकेट सूचना प्रसारण की मूल इकाई है। इस स्थिति में, प्रत्येक नोड एक पैकेट बफ़र का उपयोग करता है। एक पैकेट एक नोड से एक स्रोत नोड से मध्यवर्ती नोड के अनुक्रम के माध्यम से प्रेषित होता है। स्रोत और गंतव्य के बीच की दूरी के लिए विलंबता सीधे आनुपातिक है।
में wormhole routingस्रोत नोड से गंतव्य नोड तक ट्रांसमिशन राउटर के अनुक्रम के माध्यम से किया जाता है। एक ही पैकेट के सभी फ्लिट्स को पाइपलाइड फैशन में एक अविभाज्य अनुक्रम में प्रेषित किया जाता है। इस मामले में, केवल हेडर फ्लिट जानता है कि पैकेट कहाँ जा रहा है।
गतिरोध और आभासी चैनल
एक वर्चुअल चैनल दो नोड्स के बीच एक तार्किक लिंक है। यह स्रोत नोड और रिसीवर नोड में फ्लिट बफर और उनके बीच एक भौतिक चैनल द्वारा बनता है। जब किसी भौतिक चैनल को एक जोड़ी के लिए आवंटित किया जाता है, तो एक स्रोत बफर को आभासी चैनल बनाने के लिए एक रिसीवर बफर के साथ जोड़ा जाता है।
जब सभी चैनलों पर संदेशों का कब्जा होता है और चक्र में किसी भी चैनल को मुक्त नहीं किया जाता है, तो एक गतिरोध की स्थिति उत्पन्न होगी। इससे बचने के लिए गतिरोध से बचाव योजना का पालन करना होगा।
इस अध्याय में, हम मल्टीकाच विसंगति की समस्याओं से निपटने के लिए कैश सुसंगत प्रोटोकॉल पर चर्चा करेंगे।
कैश कोहेरेंस समस्या
मल्टीप्रोसेसर सिस्टम में, आसन्न स्तरों के बीच या मेमोरी पदानुक्रम के समान स्तर के भीतर डेटा असंगति हो सकती है। उदाहरण के लिए, कैश और मुख्य मेमोरी में एक ही ऑब्जेक्ट की असंगत प्रतियां हो सकती हैं।
जैसा कि कई प्रोसेसर समानांतर में काम करते हैं, और स्वतंत्र रूप से कई कैश एक ही मेमोरी ब्लॉक की विभिन्न प्रतियों के अधिकारी हो सकते हैं, यह बनाता है cache coherence problem। Cache coherence schemes डेटा के प्रत्येक कैश्ड ब्लॉक के लिए एक समान स्थिति बनाए रखकर इस समस्या से बचने में मदद करें।
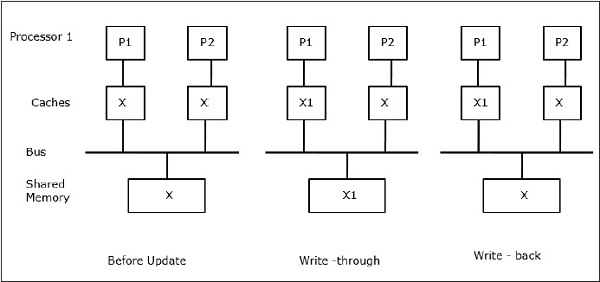
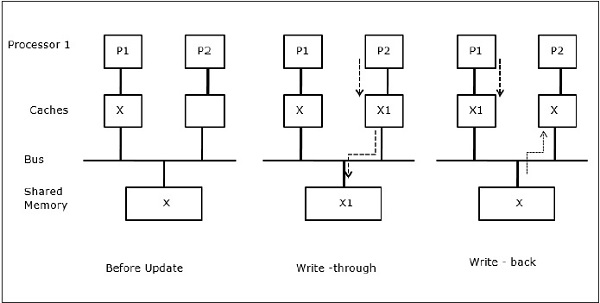
बता दें कि X साझा डेटा का एक तत्व है जिसे दो प्रोसेसर, P1 और P2 द्वारा संदर्भित किया गया है। शुरुआत में, एक्स की तीन प्रतियां सुसंगत हैं। यदि प्रोसेसर P1 कैश में एक नया डेटा X1 लिखता है, तो उपयोग करकेwrite-through policy, एक ही प्रति साझा स्मृति में तुरंत लिखी जाएगी। इस स्थिति में, कैश मेमोरी और मुख्य मेमोरी के बीच असंगति होती है। जब एकwrite-back policy उपयोग किया जाता है, कैश में संशोधित डेटा को प्रतिस्थापित या अमान्य किए जाने पर मुख्य मेमोरी अपडेट की जाएगी।
सामान्य तौर पर, असंगति समस्या के तीन स्रोत हैं -
- लेखन योग्य डेटा साझा करना
- प्रक्रिया माइग्रेशन
- मैं / हे गतिविधि
Snoopy बस प्रोटोकॉल
Snoopy प्रोटोकॉल कैश मेमोरी और साझा मेमोरी के बीच डेटा आधारितता को बस-आधारित मेमोरी सिस्टम के माध्यम से प्राप्त करते हैं। Write-invalidate तथा write-update नीतियों का उपयोग कैश स्थिरता बनाए रखने के लिए किया जाता है।
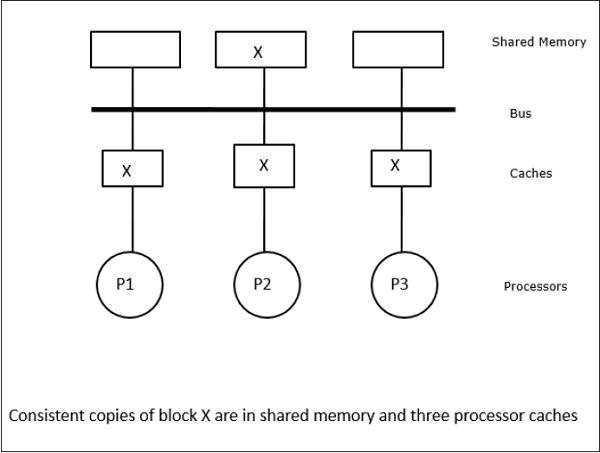
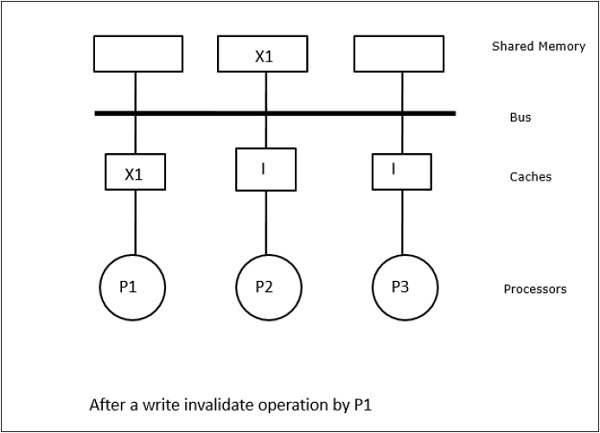
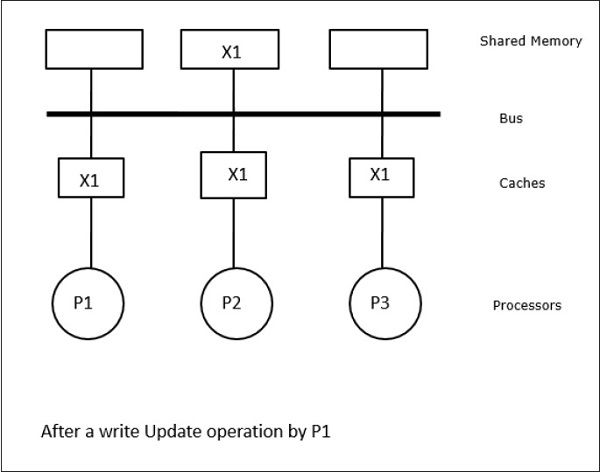
इस स्थिति में, हमारे पास तीन प्रोसेसर पी 1, पी 2, और पी 3 हैं, जिनके स्थानीय कैश मेमोरी और साझा मेमोरी (चित्रा-ए) में डेटा तत्व 'एक्स' की एक सुसंगत प्रति है। प्रोसेसर P1 अपनी कैश मेमोरी का उपयोग करके X1 लिखता हैwrite-invalidate protocol। इसलिए, अन्य सभी प्रतियां बस के माध्यम से अमान्य हैं। इसे 'I' (चित्र-ब) द्वारा निरूपित किया गया है। अमान्य ब्लॉक के रूप में भी जाना जाता हैdirty, यानी उनका उपयोग नहीं किया जाना चाहिए। write-update protocolबस के माध्यम से सभी कैश प्रतियां अद्यतन करता है। का उपयोग करकेwrite back cache, मेमोरी कॉपी भी अपडेट की गई है (चित्रा-सी)।
कैश इवेंट्स एंड एक्ट्स
मेमोरी-एक्सेस और अमान्य कमांड के निष्पादन पर निम्नलिखित घटनाएं और क्रियाएं होती हैं -
Read-miss- जब कोई प्रोसेसर ब्लॉक पढ़ना चाहता है और यह कैश में नहीं है, तो रीड-मिस होता है। यह एक पहल करता हैbus-readऑपरेशन। यदि कोई गंदी प्रति मौजूद नहीं है, तो मुख्य मेमोरी जिसमें एक सुसंगत प्रति है, अनुरोधित कैश मेमोरी में एक प्रति प्रदान करता है। यदि एक दूरस्थ कैश मेमोरी में एक गंदा प्रतिलिपि मौजूद है, तो वह कैश मुख्य मेमोरी को रोक देगा और अनुरोधित कैश मेमोरी में एक कॉपी भेज देगा। दोनों मामलों में, कैश कॉपी एक रीड मिस के बाद वैध स्थिति में प्रवेश करेगी।
Write-hit - अगर कॉपी गंदी है या reservedराज्य, लेखन स्थानीय रूप से किया जाता है और नया राज्य गंदा है। यदि नया राज्य मान्य है, तो लेखन-अमान्य आदेश को सभी कैश में प्रसारित किया जाता है, उनकी प्रतियों को अमान्य किया जाता है। जब साझा मेमोरी के माध्यम से लिखा जाता है, तो परिणामी स्थिति इस पहले लिखने के बाद आरक्षित होती है।
Write-miss- यदि कोई प्रोसेसर स्थानीय कैश मेमोरी में लिखने में विफल रहता है, तो कॉपी को मुख्य मेमोरी से या रिमोट कैश मेमोरी से एक गंदे ब्लॉक के साथ आना चाहिए। यह एक भेजने के द्वारा किया जाता हैread-invalidateकमांड, जो सभी कैश प्रतियों को अमान्य कर देगा। फिर गंदे राज्य के साथ स्थानीय प्रति अपडेट की जाती है।
Read-hit - राज्य के संक्रमण के कारण या अमान्यकरण के लिए स्नोपॉपी बस का उपयोग किए बिना हमेशा स्थानीय कैश मेमोरी में पढ़ें-हिट किया जाता है।
Block replacement- जब कोई कॉपी गन्दी होती है, तो उसे ब्लॉक रिप्लेसमेंट विधि द्वारा मुख्य मेमोरी में वापस लिखना होता है। हालाँकि, जब प्रतिलिपि या तो मान्य या आरक्षित या अमान्य स्थिति में होती है, तो कोई प्रतिस्थापन नहीं होगा।
निर्देशिका-आधारित प्रोटोकॉल
सैकड़ों प्रोसेसर के साथ एक बड़े मल्टीप्रोसेसर के निर्माण के लिए मल्टीस्टेज नेटवर्क का उपयोग करके, नेटवर्क क्षमताओं के अनुरूप स्नोपॉपी कैश प्रोटोकॉल को संशोधित करने की आवश्यकता है। एक मल्टीस्टेज नेटवर्क में प्रदर्शन करने के लिए प्रसारण बहुत महंगा है, संगतता कमांड केवल उन कैश को भेजा जाता है जो ब्लॉक की एक प्रति रखते हैं। यह नेटवर्क-कनेक्टेड मल्टीप्रोसेसर के लिए निर्देशिका-आधारित प्रोटोकॉल के विकास का कारण है।
निर्देशिका-आधारित प्रोटोकॉल प्रणाली में, साझा किए जाने वाले डेटा को एक सामान्य निर्देशिका में रखा जाता है जो कि कैश के बीच सामंजस्य बनाए रखता है। यहां, निर्देशिका एक फिल्टर के रूप में कार्य करती है जहां प्रोसेसर प्राथमिक मेमोरी से इसकी कैश मेमोरी में प्रवेश को लोड करने की अनुमति मांगते हैं। यदि एक प्रविष्टि को बदल दिया जाता है तो निर्देशिका उसे अपडेट कर देती है या उस प्रविष्टि के साथ अन्य कैश को अमान्य कर देती है।
हार्डवेयर सिंक्रोनाइज़ेशन मैकेनिज्म
सिंक्रोनाइज़ेशन संचार का एक विशेष रूप है जहाँ डेटा नियंत्रण के बजाय, एक ही या अलग-अलग प्रोसेसर में रहने वाली संचार प्रक्रियाओं के बीच सूचना का आदान-प्रदान होता है।
मल्टीप्रोसेसर सिस्टम निम्न-स्तरीय सिंक्रनाइज़ेशन ऑपरेशन को लागू करने के लिए हार्डवेयर तंत्र का उपयोग करते हैं। अधिकांश मल्टीप्रोसेसर के पास कुछ सिंक्रनाइज़ेशन प्राइमरी को लागू करने के लिए परमाणु संचालन जैसे मेमोरी रीड, राइट या रीड-मॉडिफाई-राइट ऑपरेशन को लागू करने के लिए हार्डवेयर मैकेनिज्म होता है। परमाणु मेमोरी ऑपरेशन के अलावा, कुछ इंटर-प्रोसेसर इंटरप्ट को सिंक्रोनाइज़ेशन उद्देश्यों के लिए भी उपयोग किया जाता है।
साझा मेमोरी मशीनों में कैश सुसंगतता
जब कैश प्रोसेसर में स्थानीय कैश मेमोरी होती है, तो कैश सुसंगतता को बनाए रखना एक समस्या है। इस प्रणाली में विभिन्न कैश के बीच डेटा असंगतता आसानी से होती है।
प्रमुख चिंता क्षेत्र हैं -
- लेखन योग्य डेटा साझा करना
- प्रक्रिया माइग्रेशन
- मैं / हे गतिविधि
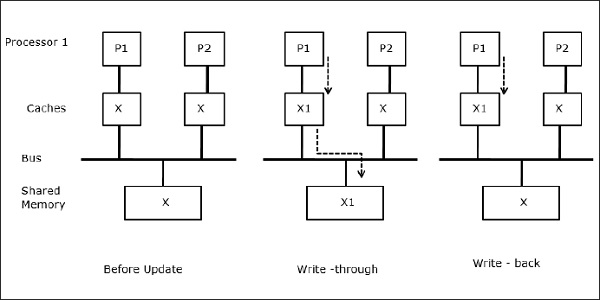
लेखन योग्य डेटा साझा करना
जब दो प्रोसेसर (P1 और P2) में उनके स्थानीय कैश में समान डेटा तत्व (X) होता है और एक प्रक्रिया (P1) डेटा तत्व (X) को लिखती है, क्योंकि कैश P1 के स्थानीय कैश के माध्यम से लिखते हैं, मुख्य मेमोरी है भी अद्यतन किया गया। अब जब पी 2 डेटा एलिमेंट (एक्स) को पढ़ने की कोशिश करता है, तो यह एक्स को नहीं ढूंढता है क्योंकि पी 2 के कैश में डेटा एलिमेंट पुराना हो गया है।
प्रक्रिया माइग्रेशन
पहले चरण में, पी 1 के कैश में डेटा एलिमेंट एक्स है, जबकि पी 2 में कुछ भी नहीं है। पी 2 पर एक प्रक्रिया पहले एक्स पर लिखती है और फिर पी 1 पर माइग्रेट करती है। अब, प्रक्रिया डेटा तत्व X पढ़ना शुरू कर देती है, लेकिन प्रोसेसर P1 के पास पुराना डेटा होने के कारण प्रक्रिया इसे पढ़ नहीं सकती है। तो, P1 पर एक प्रक्रिया डेटा तत्व X को लिखती है और फिर P2 में माइग्रेट करती है। माइग्रेशन के बाद, पी 2 पर एक प्रक्रिया डेटा तत्व एक्स को पढ़ना शुरू करती है लेकिन यह मुख्य मेमोरी में एक्स का एक पुराना संस्करण ढूंढती है।
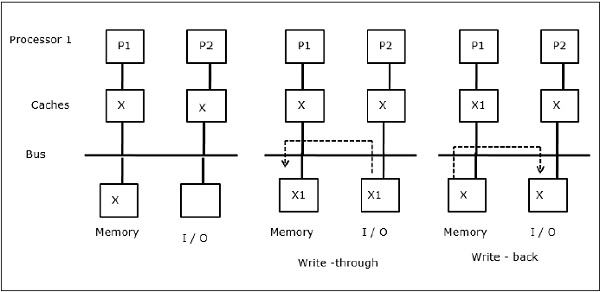
मैं / हे गतिविधि
जैसा कि चित्र में दर्शाया गया है, एक दो-प्रोसेसर मल्टीप्रोसेसर आर्किटेक्चर में बस में एक I / O उपकरण जोड़ा जाता है। शुरुआत में, दोनों कैश में डेटा तत्व X होता है। जब I / O डिवाइस एक नया तत्व X प्राप्त करता है, तो यह नए तत्व को मुख्य मेमोरी में सीधे स्टोर करता है। अब, जब या तो P1 या P2 (मान P1) एलिमेंट एक्स को पढ़ने की कोशिश करता है तो उसे एक पुरानी कॉपी मिलती है। इसलिए, P1, X को तत्व देता है। अब, यदि I / O डिवाइस X को प्रसारित करने की कोशिश करता है तो उसे एक पुरानी कॉपी मिलती है।
यूनिफ़ॉर्म मेमोरी एक्सेस (UMA)
यूनिफ़ॉर्म मेमोरी एक्सेस (UMA) आर्किटेक्चर का अर्थ है कि सिस्टम में सभी प्रोसेसर के लिए साझा मेमोरी समान है। यूएमए मशीनों की लोकप्रिय कक्षाएं, जो आमतौर पर (फ़ाइल) सर्वर के लिए उपयोग की जाती हैं, तथाकथित सिमेट्रिक मल्टीप्रोसेसर (एसएमपी) हैं। एक एसएमपी में, सभी सिस्टम संसाधन जैसे मेमोरी, डिस्क, अन्य I / O डिवाइस, आदि एक समान तरीके से प्रोसेसर द्वारा सुलभ हैं।
गैर-वर्दी मेमोरी एक्सेस (NUMA)
NUMA आर्किटेक्चर में, एक आंतरिक अप्रत्यक्ष / साझा नेटवर्क वाले कई एसएमपी क्लस्टर हैं, जो स्केलेबल संदेश-गुजर नेटवर्क में जुड़े हुए हैं। तो, NUMA आर्किटेक्चर तार्किक रूप से भौतिक रूप से वितरित मेमोरी आर्किटेक्चर साझा करता है।
NUMA मशीन में, एक प्रोसेसर का कैश-नियंत्रक यह निर्धारित करता है कि मेमोरी का संदर्भ एसएमपी की मेमोरी के लिए स्थानीय है या यह रिमोट है। दूरस्थ मेमोरी एक्सेस की संख्या को कम करने के लिए, NUMA आर्किटेक्चर आमतौर पर कैशिंग प्रोसेसर लागू करते हैं जो दूरस्थ डेटा को कैश कर सकते हैं। लेकिन जब कैश शामिल होते हैं, तो कैश सुसंगतता बनाए रखने की आवश्यकता होती है। इसलिए इन प्रणालियों को CC-NUMA (कैश सुसंगत NUMA) के रूप में भी जाना जाता है।
कैश केवल मेमोरी आर्किटेक्चर (COMA)
COMA मशीनें NUMA मशीनों के समान हैं, एकमात्र अंतर यह है कि COMA मशीनों की मुख्य यादें डायरेक्ट-मैप्ड या सेट-एसोसिएटिव कैश के रूप में कार्य करती हैं। डेटा ब्लॉक को उनके पते के अनुसार DRAM कैश में किसी स्थान पर हैशड किया गया है। दूरस्थ रूप से लाए गए डेटा को वास्तव में स्थानीय मुख्य मेमोरी में संग्रहीत किया जाता है। इसके अलावा, डेटा ब्लॉकों में एक निश्चित घर स्थान नहीं है, वे स्वतंत्र रूप से पूरे सिस्टम में स्थानांतरित कर सकते हैं।
COMA आर्किटेक्चर में ज्यादातर एक पदानुक्रमित संदेश-पासिंग नेटवर्क है। इस तरह के पेड़ में एक स्विच में उप-वृक्ष के रूप में डेटा तत्वों के साथ एक निर्देशिका होती है। चूंकि डेटा का कोई घरेलू स्थान नहीं है, इसलिए इसे स्पष्ट रूप से खोजा जाना चाहिए। इसका मतलब है कि आवश्यक डेटा के लिए अपनी निर्देशिकाओं को खोजने के लिए रिमोट एक्सेस के लिए ट्री में स्विच के साथ एक ट्रावर्सल की आवश्यकता होती है। इसलिए, यदि नेटवर्क में एक स्विच एक ही डेटा के लिए अपने सबट्री से कई अनुरोध प्राप्त करता है, तो यह उन्हें एकल अनुरोध में जोड़ता है जो स्विच के माता-पिता को भेजा जाता है। जब अनुरोधित डेटा वापस आ जाता है, तो स्विच इसकी उपप्रकार नीचे कई प्रतियाँ भेजता है।
COMA बनाम CC-NUMA
COMA और CC-NUMA के बीच अंतर हैं।
COMA CC-NUMA से अधिक लचीला हो जाता है क्योंकि COMA OS की आवश्यकता के बिना डेटा के माइग्रेशन और प्रतिकृति का पारदर्शी समर्थन करता है।
COMA मशीनें निर्माण के लिए महंगी और जटिल हैं क्योंकि उन्हें गैर-मानक मेमोरी प्रबंधन हार्डवेयर की आवश्यकता होती है और कार्यान्वयन के लिए सुसंगतता प्रोटोकॉल कठिन होता है।
COMA में रिमोट एक्सेस अक्सर CC-NUMA की तुलना में धीमी होती है क्योंकि ट्री नेटवर्क को डेटा खोजने के लिए ट्रैवर्स करने की आवश्यकता होती है।
हार्डवेयर लागत को कम करने के कई तरीके हैं। एक तरीका यह है कि संचार सहायता और नेटवर्क को कम मजबूती से प्रसंस्करण नोड में एकीकृत किया जाए और संचार विलंबता और अधिभोग को बढ़ाया जाए।
एक अन्य तरीका हार्डवेयर के बजाय सॉफ्टवेयर में स्वचालित प्रतिकृति और सुसंगतता प्रदान करना है। उत्तरार्द्ध विधि मुख्य मेमोरी में प्रतिकृति और सुसंगतता प्रदान करती है, और विभिन्न प्रकार की बारीकियों पर निष्पादित कर सकती है। यह नोड्स और इंटरकनेक्ट के लिए ऑफ-द-शेल्फ शेल्फ पार्ट्स के उपयोग की अनुमति देता है, हार्डवेयर लागत को कम करता है। यह प्रोग्रामर पर अच्छा प्रदर्शन हासिल करने का दबाव डालता है।
आराम स्मृति संगति मॉडल
एक साझा पता स्थान के लिए मेमोरी संगतता मॉडल उस क्रम में बाधाओं को परिभाषित करता है जिसमें समान या अलग-अलग स्थानों में स्मृति संचालन एक दूसरे के संबंध में निष्पादित होते हैं। वास्तव में, किसी भी सिस्टम परत जो एक साझा पता स्थान नामकरण मॉडल का समर्थन करता है, उसके पास एक मेमोरी स्थिरता मॉडल होना चाहिए जिसमें प्रोग्रामर का इंटरफ़ेस, उपयोगकर्ता-सिस्टम इंटरफ़ेस और हार्डवेयर-सॉफ़्टवेयर इंटरफ़ेस शामिल है। सॉफ़्टवेयर जो उस परत के साथ इंटरैक्ट करता है, उसे अपनी मेमोरी संगति मॉडल के बारे में पता होना चाहिए।
सिस्टम विनिर्देशों
किसी आर्किटेक्चर का सिस्टम स्पेसिफिकेशन, मेमोरी ऑपरेशंस के ऑर्डरिंग और रीऑर्डरिंग को निर्दिष्ट करता है और वास्तव में इससे कितना प्रदर्शन प्राप्त किया जा सकता है।
कार्यक्रम क्रम में छूट का उपयोग करते हुए कुछ विनिर्देशन मॉडल निम्नलिखित हैं -
Relaxing the Write-to-Read Program Order- मॉडल का यह वर्ग हार्डवेयर को लिखने के संचालन की विलंबता को दबाने की अनुमति देता है जो प्रथम-स्तरीय कैश मेमोरी में याद किया गया था। जब लिखने की याद राइट बफ़र में होती है और अन्य प्रोसेसर से दिखाई नहीं देती है, तो प्रोसेसर यह पढ़ सकता है कि इसकी कैश मेमोरी में कौन सी हिट है या एक भी रीड जो कि कैश मेमोरी में छूट जाती है।
Relaxing the Write-to-Read and Write-to-Write Program Orders- अल्विगिंग लिखता है पिछले बकाया को विभिन्न स्थानों पर लिखने के लिए मुख्य मेमोरी को अपडेट करने से पहले कई राइट्स को लिखने वाले बफर में विलय कर दिया जाता है। इस प्रकार एकाधिक लेखन अतिव्याप्त हो जाता है और क्रम से बाहर दिखाई देता है। प्रेरणा का उद्देश्य प्रोसेसर के टूटने के समय पर विलंबता लिखने के प्रभाव को कम करना है, और अन्य प्रोसेसर के लिए नए डेटा मानों को बनाकर प्रोसेसर के बीच संचार दक्षता को बढ़ाना है।
Relaxing All Program Orders- प्रक्रिया के भीतर डेटा और नियंत्रण निर्भरता को छोड़कर कोई भी प्रोग्राम ऑर्डर डिफ़ॉल्ट रूप से आश्वासन नहीं दिया जाता है। इस प्रकार, लाभ यह है कि एक ही समय में कई पढ़े गए अनुरोध बकाया हो सकते हैं, और प्रोग्राम ऑर्डर में बाद में लिखकर बाईपास किया जा सकता है, और खुद को ऑर्डर से पूरा कर सकते हैं, जिससे हम रीड लेटेंसी को छिपा सकते हैं। इस प्रकार के मॉडल गतिशील रूप से अनुसूचित प्रोसेसर के लिए विशेष रूप से उपयोगी होते हैं, जो कि पिछले रीड मिसेज को अन्य मेमोरी संदर्भों में जारी रख सकते हैं। वे कई री-ऑर्डरिंग की अनुमति देते हैं, यहां तक कि कंपाइल ऑप्टिमाइज़ेशन द्वारा किए गए एक्सेस को भी समाप्त कर देते हैं।
प्रोग्रामिंग इंटरफ़ेस
प्रोग्रामिंग इंटरफेस यह मान लेते हैं कि प्रोग्राम ऑर्डर को सिंक्रोनाइज़ेशन ऑपरेशंस के बीच में बनाए रखने की ज़रूरत नहीं है। यह सुनिश्चित किया जाता है कि सभी सिंक्रनाइज़ेशन ऑपरेशन स्पष्ट रूप से लेबल किए गए हैं या इस तरह से पहचाने जाते हैं। रनटाइम लाइब्रेरी या कंपाइलर इन सिंक्रोनाइज़ेशन ऑपरेशंस को सिस्टम स्पेसिफिकेशन के लिए उपयुक्त ऑर्डर-प्रोटेक्शन ऑपरेशंस में तब्दील करता है।
सिस्टम तब भी क्रमिक रूप से लगातार निष्पादन का आश्वासन देता है, भले ही यह किसी भी तरह से एक प्रक्रिया के भीतर किसी स्थान पर निर्भरता को बाधित किए बिना इच्छाओं के सिंक्रनाइज़ेशन संचालन के बीच संचालन को पुन: व्यवस्थित कर सकता है। यह संकलक को इच्छित इच्छाओं के लिए सिंक्रोनाइज़ेशन बिंदुओं के बीच संकलक के पर्याप्त लचीलेपन की अनुमति देता है, और प्रोसेसर को उसके मेमोरी मॉडल द्वारा अनुमत के रूप में कई पुन: व्यवस्थित करने के लिए अनुदान भी देता है। प्रोग्रामर के इंटरफ़ेस में, कमज़ोरी मॉडल कम से कम हार्डवेयर इंटरफ़ेस की तरह कमज़ोर होना चाहिए, लेकिन ऐसा नहीं होना चाहिए।
अनुवाद तंत्र
अधिकांश माइक्रोप्रोसेसरों में, सिंक्रनाइज़ेशन के रूप में लेबल किए गए प्रत्येक ऑपरेशन से पहले और / या बाद में एक उपयुक्त मेमोरी बैरियर इंस्ट्रक्शन डालने के लिए तंत्र मात्रा बनाए रखने के लिए लेबल का अनुवाद करना। यह अलग-अलग लोड / स्टोर के साथ निर्देशों को सहेजता है जो दर्शाता है कि अतिरिक्त निर्देशों को लागू करने और बचने के लिए क्या आदेश हैं। हालांकि, चूंकि ऑपरेशन आम तौर पर असंगत होते हैं, यह ऐसा तरीका नहीं है जो अधिकांश माइक्रोप्रोसेसरों ने अब तक लिया है।
आगामी क्षमता सीमाएँ
हमने उन प्रणालियों को डिसकस किया है जो प्रोसेसर कैश मेमोरी में केवल हार्डवेयर में स्वचालित प्रतिकृति और सुसंगतता प्रदान करते हैं। एक प्रोसेसर कैश, इसे स्थानीय मुख्य मेमोरी में पहले दोहराया जाने के बिना, संदर्भ पर दूरस्थ रूप से आवंटित डेटा को दोहराता है।
इन प्रणालियों के साथ एक समस्या यह है कि स्थानीय प्रतिकृति की गुंजाइश हार्डवेयर कैश तक सीमित है। यदि कैश मेमोरी से एक ब्लॉक को हटा दिया जाता है, तो इसे फिर से आवश्यकता होने पर रिमोट मेमोरी से लाया जाना चाहिए। इस खंड में चर्चा की गई प्रणालियों का मुख्य उद्देश्य प्रतिकृति क्षमता की समस्या को हल करना है, लेकिन अभी भी हार्डवेयर और दक्षता के लिए कैश ब्लॉकों की बारीक बारीकियों में सुसंगतता प्रदान करना है।
तृतीयक कैश
प्रतिकृति क्षमता की समस्या को हल करने के लिए, एक विधि एक बड़े लेकिन धीमी रिमोट एक्सेस कैश का उपयोग करना है। यह कार्यक्षमता के लिए आवश्यक है, जब मशीन के नोड्स स्वयं छोटे पैमाने के मल्टीप्रोसेसर होते हैं और केवल प्रदर्शन के लिए बड़े किए जा सकते हैं। यह स्थानीय प्रोसेसर कैश मेमोरी से प्रतिस्थापित किए गए प्रतिकृति दूरस्थ ब्लॉक भी रखेगा।
कैश-केवल मेमोरी आर्किटेक्चर (COMA)
COMA मशीनों में, पूरे मुख्य मेमोरी में प्रत्येक मेमोरी ब्लॉक में एक हार्डवेयर टैग जुड़ा होता है। कोई निश्चित नोड नहीं है जहाँ मेमोरी ब्लॉक के लिए हमेशा जगह आवंटित करने का आश्वासन दिया जाता है। डेटा गतिशील रूप से माइग्रेट करता है या उन नोड्स की मुख्य यादों में दोहराया जाता है जो उन्हें एक्सेस / आकर्षित करते हैं। जब एक रिमोट ब्लॉक एक्सेस किया जाता है, तो इसे आकर्षण मेमोरी में दोहराया जाता है और कैश में लाया जाता है, और हार्डवेयर द्वारा दोनों स्थानों पर संगत रखा जाता है। एक डेटा ब्लॉक किसी भी आकर्षण मेमोरी में निवास कर सकता है और एक से दूसरे में आसानी से स्थानांतरित हो सकता है।
हार्डवेयर की लागत कम करना
लागत को कम करने का मतलब मौजूदा हार्डवेयर पर चलने वाले सॉफ़्टवेयर के लिए विशेष हार्डवेयर की कुछ कार्यक्षमता को बढ़ाना है। सॉफ़्टवेयर के लिए हार्डवेयर मेमोरी में मुख्य मेमोरी में प्रतिकृति और सुसंगतता को प्रबंधित करना बहुत आसान है। कम लागत वाली विधियाँ मुख्य मेमोरी में प्रतिकृति और सुसंगतता प्रदान करती हैं। कुशलता से नियंत्रित होने के लिए, सहायता के अन्य कार्यात्मक घटकों में से प्रत्येक को हार्डवेयर विशेषज्ञता और एकीकरण से लाभान्वित किया जा सकता है।
अनुसंधान प्रयासों का उद्देश्य विभिन्न दृष्टिकोणों के साथ लागत को कम करना है, जैसे कि विशेष हार्डवेयर में अभिगम नियंत्रण द्वारा, लेकिन सॉफ्टवेयर और कमोडिटी हार्डवेयर को अन्य गतिविधियाँ प्रदान करना। एक अन्य दृष्टिकोण सॉफ्टवेयर में एक्सेस कंट्रोल करने का है, और बिना किसी विशेष हार्डवेयर समर्थन के कमोडिटी नोड्स और नेटवर्क पर एक सुसंगत साझा पता स्थान अमूर्त को आवंटित करने के लिए डिज़ाइन किया गया है।
समानांतर सॉफ्टवेयर के लिए निहितार्थ
रिलैक्स्ड मेमोरी कंसिस्टेंसी मॉडल की जरूरत है कि समानांतर प्रोग्राम वांछित परस्पर विरोधी एक्सेस को सिंक्रोनाइज़ेशन पॉइंट के रूप में लेबल करें। एक प्रोग्रामिंग भाषा कुछ चर को सिंक्रोनाइज़ेशन के रूप में लेबल करने के लिए समर्थन प्रदान करती है, जिसे तब कंपाइलर द्वारा उपयुक्त ऑर्डर-प्रोटेक्शन इंस्ट्रक्शन में अनुवादित किया जाएगा। संकलक को साझा मेमोरी में एक्सेस के पुन: संयोजक को प्रतिबंधित करने के लिए, कंपाइलर स्वयं द्वारा लेबल का उपयोग कर सकता है।
एक interconnection networkएक समानांतर मशीन में किसी भी स्रोत नोड से किसी भी वांछित गंतव्य नोड के लिए जानकारी स्थानांतरित करता है। इस कार्य को यथासंभव छोटी विलंबता के साथ पूरा किया जाना चाहिए। इसे बड़ी संख्या में ऐसे स्थानांतरणों को समवर्ती रूप से करने की अनुमति देनी चाहिए। इसके अलावा, यह मशीन के बाकी हिस्सों की लागत की तुलना में सस्ती होनी चाहिए।
नेटवर्क लिंक और स्विच से बना है, जो स्रोत नोड से गंतव्य नोड तक जानकारी भेजने में मदद करता है। एक नेटवर्क इसकी टोपोलॉजी, रूटिंग एल्गोरिदम, स्विचिंग रणनीति और प्रवाह नियंत्रण तंत्र द्वारा निर्दिष्ट किया गया है।
संगठनात्मक संरचना
इंटरकनेक्शन नेटवर्क तीन मूल घटकों से बना है -
Links- एक लिंक एक स्विच या नेटवर्क इंटरफ़ेस पोर्ट से जुड़े प्रत्येक छोर पर कनेक्टर के साथ एक या एक से अधिक ऑप्टिकल फाइबर या बिजली के तारों की एक केबल है। इसके माध्यम से, एक एनालॉग सिग्नल को एक छोर से प्रेषित किया जाता है, मूल डिजिटल सूचना स्ट्रीम प्राप्त करने के लिए दूसरे पर प्राप्त किया जाता है।
Switches- एक स्विच इनपुट और आउटपुट पोर्ट के सेट से बना होता है, एक आंतरिक "क्रॉस-बार" जो इनपुट को आउटपुट आउटपुट कनेक्शन को प्रभावित करने के लिए सभी आउटपुट, आंतरिक बफरिंग, और कंट्रोल लॉजिक से जोड़ता है। आम तौर पर, इनपुट पोर्ट की संख्या आउटपुट पोर्ट की संख्या के बराबर होती है।
Network Interfaces- नेटवर्क इंटरफ़ेस स्विच नोड्स की तुलना में काफी अलग तरीके से व्यवहार करता है और विशेष लिंक के माध्यम से जुड़ा हो सकता है। नेटवर्क इंटरफ़ेस पैकेट को प्रारूपित करता है और रूटिंग और नियंत्रण सूचना का निर्माण करता है। इसमें स्विच की तुलना में इनपुट और आउटपुट बफरिंग हो सकती है। यह एंड-टू-एंड एरर चेकिंग और फ्लो कंट्रोल कर सकता है। इसलिए, इसकी लागत इसकी प्रसंस्करण जटिलता, भंडारण क्षमता और बंदरगाहों की संख्या से प्रभावित होती है।
इंटरकनेक्शन नेटवर्क
इंटरकनेक्शन नेटवर्क स्विचिंग तत्वों से बना होता है। टोपोलॉजी व्यक्तिगत स्विच को अन्य तत्वों से कनेक्ट करने का पैटर्न है, जैसे प्रोसेसर, मेमोरी और अन्य स्विच। एक नेटवर्क समानांतर प्रणाली में प्रोसेसर के बीच डेटा के आदान-प्रदान की अनुमति देता है।
Direct connection networks- डायरेक्ट नेटवर्क्स में पड़ोसी नोड्स के बीच पॉइंट-टू-पॉइंट कनेक्शन होते हैं। ये नेटवर्क स्थिर हैं, जिसका अर्थ है कि पॉइंट-टू-पॉइंट कनेक्शन तय हो गए हैं। प्रत्यक्ष नेटवर्क के कुछ उदाहरण रिंग, मेष और क्यूब्स हैं।
Indirect connection networks- अप्रत्यक्ष नेटवर्क का कोई निश्चित पड़ोसी नहीं है। संचार टोपोलॉजी को एप्लिकेशन की मांगों के आधार पर गतिशील रूप से बदला जा सकता है। अप्रत्यक्ष नेटवर्क को तीन भागों में विभाजित किया जा सकता है: बस नेटवर्क, मल्टीस्टेज नेटवर्क और क्रॉसबार स्विच।
Bus networks- एक बस नेटवर्क कई बिट लाइनों से बना होता है जिस पर कई संसाधन जुड़े होते हैं। जब busses डेटा और पतों के लिए एक ही भौतिक रेखाओं का उपयोग करते हैं, तो डेटा और एड्रेस लाइन्स का समय मल्टीप्लेक्स हो जाता है। जब बस में कई बस-मास्टर्स जुड़े होते हैं, तो एक मध्यस्थ की आवश्यकता होती है।
Multistage networks- एक मल्टीस्टेज नेटवर्क में कई चरणों के स्विच होते हैं। यह 'एक्सब' स्विच से बना है जो एक विशेष इंटरस्टेज कनेक्शन पैटर्न (आईएससी) का उपयोग करके जुड़ा हुआ है। छोटे 2x2 स्विच तत्व कई मल्टीस्टेज नेटवर्क के लिए एक आम विकल्प हैं। चरणों की संख्या नेटवर्क की देरी को निर्धारित करती है। विभिन्न इंटरस्टेज कनेक्शन पैटर्न को चुनकर, विभिन्न प्रकार के मल्टीस्टेज नेटवर्क बनाए जा सकते हैं।
Crossbar switches- एक क्रॉसबार स्विच में सरल स्विच तत्वों का एक मैट्रिक्स होता है जो कनेक्शन बनाने या तोड़ने के लिए चालू और बंद हो सकता है। मैट्रिक्स में एक स्विच तत्व को चालू करना, एक प्रोसेसर और मेमोरी के बीच एक संबंध बनाया जा सकता है। क्रॉसबार स्विच गैर-अवरोधक हैं, यह सभी संचार क्रमपरिवर्तन को अवरुद्ध किए बिना किया जा सकता है।
नेटवर्क टोपोलॉजी में डिजाइन ट्रेड-ऑफ का मूल्यांकन
यदि मुख्य चिंता रूटिंग दूरी है, तो आयाम को अधिकतम करना होगा और एक हाइपरक्यूब बनाया जाना चाहिए। स्टोर-एंड-फॉरवर्ड रूटिंग में, यह मानते हुए कि स्विच की डिग्री और लिंक की संख्या एक महत्वपूर्ण लागत कारक नहीं थी, और लिंक या स्विच की संख्या मुख्य लागत हैं, आयाम को कम से कम करना होगा और एक जाल बनाया।
प्रत्येक नेटवर्क के लिए सबसे खराब ट्रैफ़िक पैटर्न में, उच्च आयामी नेटवर्क होना पसंद किया जाता है जहाँ सभी रास्ते कम होते हैं। पैटर्न में जहां प्रत्येक नोड केवल एक या दो पास के पड़ोसियों के साथ संवाद कर रहा है, यह कम आयामी नेटवर्क पसंद किया जाता है, क्योंकि केवल कुछ आयाम वास्तव में उपयोग किए जाते हैं।
मार्ग
किसी नेटवर्क का रूटिंग एल्गोरिदम निर्धारित करता है कि स्रोत से गंतव्य तक के संभावित रास्तों का उपयोग मार्गों के रूप में किया जाता है और प्रत्येक विशेष पैकेट के बाद मार्ग कैसे निर्धारित किया जाता है। डायमेंशन ऑर्डर रूटिंग कानूनी रास्तों के सेट को सीमित करता है ताकि प्रत्येक स्रोत से प्रत्येक गंतव्य तक बिल्कुल एक मार्ग हो। पहले उच्च क्रम के आयाम में सही दूरी की यात्रा करके, फिर अगले आयाम और इतने पर।
रूटिंग मैकेनिज्म
अंकगणित, स्रोत-आधारित पोर्ट का चयन, और टेबल लुक-अप तीन तंत्र हैं जो पैकेट हेडर में जानकारी से आउटपुट चैनल निर्धारित करने के लिए उच्च गति स्विच का उपयोग करते हैं। ये सभी तंत्र पारंपरिक LAN और WAN राउटर में लागू होने वाले सामान्य राउटिंग कंप्यूटर्स की तुलना में सरल हैं। समानांतर कंप्यूटर नेटवर्क में, स्विच को हर चक्र में अपने सभी इनपुट के लिए रूटिंग निर्णय लेने की आवश्यकता होती है, इसलिए तंत्र को सरल और तेज होना चाहिए।
नियतात्मक रूटिंग
एक राउटिंग एल्गोरिथ्म नियतात्मक है यदि संदेश द्वारा लिया गया मार्ग विशेष रूप से उसके स्रोत और गंतव्य द्वारा निर्धारित किया जाता है, और नेटवर्क में अन्य ट्रैफ़िक द्वारा नहीं। यदि कोई रूटिंग एल्गोरिथम केवल गंतव्य की ओर सबसे छोटे पथ का चयन करता है, तो यह न्यूनतम है, अन्यथा यह गैर-न्यूनतम है।
डेडलॉक फ्रीडम
गतिरोध विभिन्न स्थितियों में हो सकता है। जब दो नोड्स एक-दूसरे को डेटा भेजने का प्रयास करते हैं और प्रत्येक प्राप्त होने से पहले भेजने लगते हैं, तो 'हेड-ऑन' गतिरोध हो सकता है। गतिरोध का एक और मामला तब होता है, जब नेटवर्क के भीतर संसाधनों के लिए कई संदेश प्रतिस्पर्धा करते हैं।
एक नेटवर्क को साबित करने के लिए बुनियादी तकनीक गतिरोध मुक्त है, जो नेटवर्क के माध्यम से चल रहे संदेशों के परिणामस्वरूप चैनलों के बीच हो सकने वाली निर्भरता को साफ करने और यह दिखाने के लिए है कि समग्र चैनल निर्भरता ग्राफ में कोई चक्र नहीं हैं; इसलिए कोई यातायात पैटर्न नहीं है जो गतिरोध पैदा कर सकता है। ऐसा करने का सामान्य तरीका चैनल संसाधनों की संख्या है, ताकि सभी मार्ग एक विशेष रूप से बढ़ते या घटते क्रम का पालन करें, ताकि कोई निर्भरता चक्र उत्पन्न न हो।
स्विच डिजाइन
नेटवर्क का डिज़ाइन स्विच के डिज़ाइन पर निर्भर करता है और स्विच एक साथ कैसे वायर्ड होते हैं। स्विच की डिग्री, इसके आंतरिक मार्ग तंत्र, और इसकी आंतरिक बफरिंग यह तय करती है कि टोपोलॉजी का समर्थन किया जा सकता है और क्या अनुमार्गण एल्गोरिदम को लागू किया जा सकता है। कंप्यूटर सिस्टम के किसी भी अन्य हार्डवेयर घटक की तरह, एक नेटवर्क स्विच में डेटा पथ, नियंत्रण और भंडारण होता है।
बंदरगाहों
पिन की कुल संख्या वास्तव में चैनल चौड़ाई की इनपुट और आउटपुट पोर्ट की कुल संख्या है। जैसे ही चिप की परिधि क्षेत्र की तुलना में धीरे-धीरे बढ़ती है, स्विच पिन सीमित हो जाते हैं।
आंतरिक दातापाठ
डेटापाट इनपुट पोर्ट के प्रत्येक सेट और हर आउटपुट पोर्ट के बीच की कनेक्टिविटी है। इसे आमतौर पर आंतरिक क्रॉस-बार के रूप में जाना जाता है। एक गैर-अवरोधक क्रॉस-बार वह है जहां प्रत्येक इनपुट पोर्ट को एक साथ किसी भी क्रमचय में एक अलग आउटपुट से जोड़ा जा सकता है।
चैनल बफ़र्स
स्विच के भीतर बफर स्टोरेज के संगठन का स्विच प्रदर्शन पर महत्वपूर्ण प्रभाव पड़ता है। पारंपरिक राउटर और स्विच में एसआरएएम या डीआरएएम बफ़र्स बाहरी होते हैं जो स्विच कपड़े के लिए बाहरी होते हैं, जबकि वीएलएसआई स्विच में बफरिंग स्विच के लिए आंतरिक होती है और डेटापथ और नियंत्रण अनुभाग के समान सिलिकॉन बजट से बाहर आती है। जैसे ही चिप का आकार और घनत्व बढ़ता है, अधिक बफरिंग उपलब्ध होती है और नेटवर्क डिजाइनर के पास अधिक विकल्प होते हैं, लेकिन फिर भी बफर रियल-एस्टेट एक प्रमुख विकल्प पर आता है और इसका संगठन महत्वपूर्ण है।
प्रवाह नियंत्रण
जब एक ही समय में एक ही साझा नेटवर्क संसाधनों का उपयोग करने के प्रयास में कई डेटा प्रवाहित होते हैं, तो इन प्रवाह को नियंत्रित करने के लिए कुछ कार्रवाई की जानी चाहिए। यदि हम कोई डेटा नहीं खोना चाहते हैं, तो कुछ प्रवाह अवरुद्ध होना चाहिए, जबकि अन्य आगे बढ़ते हैं।
प्रवाह नियंत्रण की समस्या सभी नेटवर्क और कई स्तरों पर उत्पन्न होती है। लेकिन यह स्थानीय और व्यापक क्षेत्र नेटवर्क की तुलना में समानांतर कंप्यूटर नेटवर्क में गुणात्मक रूप से भिन्न है। समानांतर कंप्यूटरों में, नेटवर्क ट्रैफ़िक को एक बस में ट्रैफ़िक की तरह सटीक रूप से वितरित करने की आवश्यकता होती है और बहुत छोटे समय के पैमाने पर बहुत बड़ी संख्या में समानांतर प्रवाह होते हैं।
माइक्रोप्रोसेसरों की गति प्रति दशक दस से अधिक के कारक से बढ़ी है, लेकिन कमोडिटी यादों (डीआरएएम) की गति केवल दोगुनी हो गई है, अर्थात, एक्सेस समय आधा हो गया है। इसलिए, प्रोसेसर घड़ी चक्र के संदर्भ में मेमोरी एक्सेस की विलंबता 10 वर्षों में छह के कारक से बढ़ती है। मल्टीप्रोसेसर ने समस्या को और तेज कर दिया।
बस-आधारित प्रणालियों में, प्रोसेसर और मेमोरी के बीच एक उच्च-बैंडविड्थ बस की स्थापना से मेमोरी से डेटा प्राप्त करने की विलंबता बढ़ जाती है। जब मेमोरी को भौतिक रूप से वितरित किया जाता है, तो नेटवर्क की विलंबता और नेटवर्क इंटरफ़ेस को नोड पर स्थानीय मेमोरी तक पहुंचने के लिए जोड़ा जाता है।
आमतौर पर मशीन के आकार के साथ विलंबता बढ़ती है, क्योंकि अधिक नोड्स गणना के सापेक्ष अधिक संचार का संकेत देते हैं, सामान्य संचार के लिए नेटवर्क में अधिक कूद, और अधिक विवाद होने की संभावना है। हार्डवेयर डिज़ाइन का मुख्य लक्ष्य उच्च, मापनीय बैंडविड्थ को बनाए रखते हुए डेटा एक्सेस की विलंबता को कम करना है।
विलंबता सहिष्णुता का अवलोकन
मशीन में संसाधनों को देखकर और उन्हें कैसे उपयोग किया जाता है, यह समझने के लिए विलंबता सहिष्णुता को कैसे नियंत्रित किया जाता है। प्रोसेसर के दृष्टिकोण से, एक नोड से दूसरे नोड में संचार वास्तुकला को पाइप लाइन के रूप में देखा जा सकता है। पाइपलाइन के चरणों में स्रोत और गंतव्य पर नेटवर्क इंटरफेस, साथ ही साथ नेटवर्क लिंक और स्विच शामिल हैं। संचार सहायता में भी चरण होते हैं, स्थानीय मेमोरी / कैश सिस्टम, और मुख्य प्रोसेसर, इस बात पर निर्भर करता है कि वास्तुकला संचार का प्रबंधन कैसे करता है।
बेसलाइन संचार संरचना में उपयोग की समस्या या तो प्रोसेसर है या संचार वास्तुकला एक निश्चित समय में व्यस्त है, और संचार पाइपलाइन में केवल एक चरण व्यस्त है क्योंकि एकल शब्द प्रेषित किया जा रहा है जो स्रोत से गंतव्य तक अपना रास्ता बनाता है। विलंबता सहिष्णुता का उद्देश्य इन संसाधनों के उपयोग को यथासंभव अधिक करना है।
स्पष्ट संदेश पारित करने में विलंबता सहिष्णुता
संदेश भेजने में डेटा का वास्तविक हस्तांतरण आम तौर पर प्रेषक-आरंभ होता है, एक भेजने के संचालन का उपयोग करके। एक प्राप्त ऑपरेशन अपने आप में डेटा को संचारित करने के लिए प्रेरित नहीं करता है, बल्कि एक आने वाले बफर से डेटा को एप्लिकेशन एड्रेस स्पेस में कॉपी करता है। रिसीवर-आरंभ संचार उस प्रक्रिया को एक अनुरोध संदेश जारी करके किया जाता है जो डेटा का स्रोत है। इसके बाद प्रक्रिया दूसरे डेटा को वापस भेजती है।
एक सिंक्रोनस सेंड ऑपरेशन में संचार लेटेंसी के बराबर समय होता है, जो मैसेज में मौजूद सभी डेटा को डेस्टिनेशन, और प्रोसेसिंग प्राप्त करने का समय, और पावती के वापस आने के समय के बराबर होता है। एक तुल्यकालिक प्राप्त ऑपरेशन की विलंबता इसकी प्रसंस्करण ओवरहेड है; जिसमें डेटा को एप्लिकेशन में कॉपी करना, और अतिरिक्त विलंबता शामिल है यदि डेटा अभी तक नहीं आया है। हम इन अक्षांशों को छिपाना चाहते हैं, यदि संभव हो तो ओवरहेड्स सहित, दोनों सिरों पर।
साझा पता स्थान में विलंबता सहिष्णुता
बेसलाइन संचार एक साझा पता स्थान में रीड और राइट के माध्यम से होता है। सुविधा के लिए, इसे रीड-राइट संचार कहा जाता है। प्राप्तकर्ता द्वारा आरंभ किए गए संचार को पढ़ने के संचालन के साथ किया जाता है जिसके परिणामस्वरूप किसी अन्य प्रोसेसर की मेमोरी या कैश तक डेटा का उपयोग किया जाता है। यदि साझा डेटा की कोई कैशिंग नहीं है, तो प्रेषक द्वारा आरंभ किए गए संचार को उन डेटा के माध्यम से किया जा सकता है जो दूरस्थ यादों में आवंटित किए गए हैं।
कैश सुसंगतता के साथ, राइट्स का प्रभाव अधिक जटिल होता है: या तो लिखता है या प्रेषक या रिसीवर द्वारा शुरू किया गया संचार कैश कोहेरेंस प्रोटोकॉल पर निर्भर करता है। या तो रिसीवर द्वारा शुरू किया गया या प्रेषक द्वारा शुरू किया गया, एक हार्डवेयर समर्थित रीड में साझा साझा स्थान पर संचार स्वाभाविक रूप से ठीक है, जो सहिष्णुता विलंबता को बहुत महत्वपूर्ण बनाता है।
साझा पता स्थान में डेटा स्थानांतरण ब्लॉक करें
एक साझा पता स्थान में, हार्डवेयर या सॉफ़्टवेयर द्वारा डेटा का तालमेल और ब्लॉक स्थानांतरण की दीक्षा उपयोगकर्ता प्रोग्राम में या सिस्टम द्वारा पारदर्शी रूप से की जा सकती है। उपयोगकर्ता प्रोग्राम में भेजने के समान एक कमांड निष्पादित करके स्पष्ट ब्लॉक स्थानांतरण शुरू किए जाते हैं। प्रेषक कमांड को संचार सहायता द्वारा समझाया जाता है, जो स्रोत नोड से गंतव्य तक पाइपलाइज्ड तरीके से डेटा स्थानांतरित करता है। गंतव्य पर, संचार सहायता नेटवर्क इंटरफ़ेस से डेटा शब्दों को खींचती है और उन्हें निर्दिष्ट स्थानों में संग्रहीत करती है।
सेंड-रिसीव मैसेज पासिंग से दो मुख्य अंतर हैं, दोनों इस तथ्य से उत्पन्न होते हैं कि भेजने की प्रक्रिया सीधे प्रोग्राम डेटा संरचनाओं को निर्दिष्ट कर सकती है जहां डेटा को गंतव्य पर रखा जाना है, क्योंकि ये स्थान साझा पता स्थान में हैं ।
साझा पता स्थान में पिछले लंबे समय तक विलंबता घटनाओं को आगे बढ़ाना
यदि मेमोरी ऑपरेशन को गैर-अवरुद्ध किया जाता है, तो एक प्रोसेसर अन्य निर्देशों के लिए मेमोरी ऑपरेशन को आगे बढ़ा सकता है। लिखने के लिए, यह आमतौर पर लागू करने के लिए काफी सरल होता है यदि लेखन को एक बफर में डाल दिया जाता है, और प्रोसेसर तब तक चलता है जब बफर मेमोरी सिस्टम को लिखने को जारी करने और आवश्यकतानुसार इसके पूरा होने पर नज़र रखता है। अंतर यह है कि एक लेखन के विपरीत, एक रीड आम तौर पर एक निर्देश द्वारा बहुत जल्द ही पालन किया जाता है जिसे रीड द्वारा वापस किए गए मान की आवश्यकता होती है।
साझा पता स्थान में पूर्व संचार
पूर्व-संचार एक ऐसी तकनीक है जिसे पहले से ही व्यापक रूप से वाणिज्यिक माइक्रोप्रोसेसरों में अपनाया गया है, और भविष्य में इसके महत्व में वृद्धि होने की संभावना है। प्रीफ़ैच निर्देश डेटा आइटम के वास्तविक रीड को प्रतिस्थापित नहीं करता है, और प्रीफ़ैच इंस्ट्रक्शन स्वयं को गैर-अवरोधक होना चाहिए, अगर यह ओवरलैप के माध्यम से विलंबता को छिपाने के अपने लक्ष्य को प्राप्त करना है।
इस मामले में, जैसा कि साझा डेटा को कैश नहीं किया जाता है, प्रीफ़ेट किए गए डेटा को एक विशेष हार्डवेयर संरचना में लाया जाता है जिसे प्रीफ़ेच बफर कहा जाता है। जब शब्द वास्तव में अगले पुनरावृत्ति में एक रजिस्टर में पढ़ा जाता है, तो इसे मेमोरी से बजाय प्रीफ़च बफर के सिर से पढ़ा जाता है। यदि छिपने की विलंबता एकल लूप पुनरावृत्ति की गणना करने के लिए समय से बहुत बड़ी थी, तो हम कई पुनरावृत्तियों को आगे पीछे करेंगे और संभवतः एक समय में प्रीफ़च बफर में कई शब्द होंगे।
एक साझा पता स्थान में मल्टीथ्रेडिंग
विभिन्न प्रकार की विलंबता को छिपाने के संदर्भ में, हार्डवेयर समर्थित मल्टीथ्रेडिंग शायद बहुमुखी तकनीक है। अन्य दृष्टिकोणों पर इसके वैचारिक लाभ हैं -
इसके लिए किसी विशेष सॉफ्टवेयर विश्लेषण या समर्थन की आवश्यकता नहीं है।
जैसा कि यह गतिशील रूप से आह्वान किया गया है, यह अप्रत्याशित स्थितियों को संभाल सकता है, जैसे कि कैश टकराव आदि, साथ ही साथ पूर्वानुमान लगाने योग्य भी।
प्रीफ़ेटिंग की तरह, यह मेमोरी संगतता मॉडल को नहीं बदलता है क्योंकि यह एक थ्रेड के भीतर एक्सेस को फिर से नहीं करता है।
जबकि पिछली तकनीकों को मेमोरी एक्सेस लेटेंसी को छिपाने के लिए लक्षित किया जाता है, मल्टीथ्रेडिंग किसी भी लंबी-विलंबता घटना की विलंबता को आसानी से छिपा सकती है, जब तक कि रनटाइम पर घटना का पता लगाया जा सकता है। इसमें सिंक्रोनाइज़ेशन और इंस्ट्रक्शन लेटेंसी भी शामिल है।
यह प्रवृत्ति भविष्य में बदल सकती है, क्योंकि प्रोसेसर की गति की तुलना में विलंबता अधिक लंबी होती जा रही है। इसके अलावा अधिक परिष्कृत माइक्रोप्रोसेसरों के साथ जो पहले से ही उन तरीकों को प्रदान करते हैं जिन्हें मल्टीथ्रेडिंग के लिए बढ़ाया जा सकता है, और अनुदेश-स्तरीय समानता के साथ मल्टीथ्रेडिंग को संयोजित करने के लिए नई मल्टीथ्रेडिंग तकनीक विकसित की जा रही है, यह प्रवृत्ति निश्चित रूप से भविष्य में कुछ बदलाव से गुजर रही है।