Struktur Data & Algoritma - Panduan Cepat
Struktur Data adalah cara sistematis untuk mengatur data agar dapat digunakan secara efisien. Istilah berikut adalah istilah dasar dari struktur data.
Interface- Setiap struktur data memiliki antarmuka. Antarmuka merepresentasikan rangkaian operasi yang didukung oleh struktur data. Antarmuka hanya menyediakan daftar operasi yang didukung, jenis parameter yang dapat mereka terima, dan jenis pengembalian dari operasi ini.
Implementation- Implementasi memberikan representasi internal dari struktur data. Implementasi juga memberikan definisi dari algoritma yang digunakan dalam operasi struktur data.
Karakteristik Struktur Data
Correctness - Implementasi struktur data harus mengimplementasikan antarmuka dengan benar.
Time Complexity - Running time atau waktu pelaksanaan operasi struktur data harus sekecil mungkin.
Space Complexity - Penggunaan memori dari operasi struktur data harus sesedikit mungkin.
Kebutuhan Struktur Data
Karena aplikasi menjadi semakin kompleks dan data menjadi kaya, ada tiga masalah umum yang dihadapi aplikasi saat ini.
Data Search- Pertimbangkan inventaris 1 juta (10 6 ) item toko. Jika aplikasi untuk mencari item, itu harus mencari item dalam 1 juta (10 6 ) item setiap kali memperlambat pencarian. Seiring bertambahnya data, penelusuran akan menjadi lebih lambat.
Processor speed - Kecepatan prosesor meskipun sangat tinggi, turun terbatas jika datanya bertambah hingga miliaran catatan.
Multiple requests - Karena ribuan pengguna dapat mencari data secara bersamaan di server web, bahkan server yang cepat pun gagal saat mencari data.
Untuk mengatasi masalah yang disebutkan di atas, struktur data datang untuk menyelamatkan. Data dapat diatur dalam struktur data sedemikian rupa sehingga semua item mungkin tidak perlu dicari, dan data yang diperlukan dapat dicari hampir secara instan.
Kasus Waktu Eksekusi
Ada tiga kasus yang biasanya digunakan untuk membandingkan waktu eksekusi berbagai struktur data secara relatif.
Worst Case- Ini adalah skenario di mana operasi struktur data tertentu membutuhkan waktu maksimum yang diperlukan. Jika waktu kasus terburuk suatu operasi adalah ƒ (n) maka operasi ini tidak akan memakan waktu lebih dari ƒ (n) waktu di mana ƒ (n) mewakili fungsi n.
Average Case- Ini adalah skenario yang menggambarkan waktu eksekusi rata-rata dari suatu operasi struktur data. Jika sebuah operasi membutuhkan ƒ (n) waktu dalam eksekusi, maka operasi m akan membutuhkan waktu mƒ (n).
Best Case- Ini adalah skenario yang menggambarkan waktu eksekusi sesingkat mungkin dari suatu operasi struktur data. Jika sebuah operasi membutuhkan ƒ (n) waktu dalam eksekusi, maka operasi sebenarnya mungkin membutuhkan waktu sebagai bilangan acak yang akan menjadi maksimum sebagai ƒ (n).
Terminologi Dasar
Data - Data adalah nilai atau kumpulan nilai.
Data Item - Item data mengacu pada satu unit nilai.
Group Items - Item data yang dibagi menjadi sub item disebut sebagai Item Grup.
Elementary Items - Item data yang tidak dapat dibagi disebut sebagai Item Dasar.
Attribute and Entity - Entitas adalah yang berisi atribut atau properti tertentu, yang mungkin diberi nilai.
Entity Set - Entitas dengan atribut serupa membentuk kumpulan entitas.
Field - Bidang adalah satu unit dasar informasi yang mewakili atribut dari suatu entitas.
Record - Record adalah kumpulan nilai field dari suatu entitas.
File - File adalah kumpulan catatan entitas dalam kumpulan entitas tertentu.
Cobalah Opsi Online
Anda benar-benar tidak perlu menyiapkan lingkungan sendiri untuk mulai belajar bahasa pemrograman C. Alasannya sangat sederhana, kami telah menyiapkan lingkungan Pemrograman C secara online, sehingga Anda dapat mengumpulkan dan menjalankan semua contoh yang tersedia secara online pada saat yang sama saat Anda mengerjakan pekerjaan teori. Ini memberi Anda keyakinan pada apa yang Anda baca dan untuk memeriksa hasilnya dengan opsi yang berbeda. Jangan ragu untuk memodifikasi contoh apa pun dan menjalankannya secara online.
Coba contoh berikut menggunakan Try it opsi yang tersedia di sudut kanan atas kotak kode contoh -
#include <stdio.h>
int main(){
/* My first program in C */
printf("Hello, World! \n");
return 0;
}Untuk sebagian besar contoh yang diberikan dalam tutorial ini, Anda akan menemukan opsi Try it, jadi manfaatkan saja dan nikmati pembelajaran Anda.
Pengaturan Lingkungan Lokal
Jika Anda masih ingin mengatur lingkungan Anda untuk bahasa pemrograman C, Anda memerlukan dua alat berikut yang tersedia di komputer Anda, (a) Editor Teks dan (b) Kompilator C.
Editor Teks
Ini akan digunakan untuk mengetik program Anda. Contoh beberapa editor termasuk Windows Notepad, perintah OS Edit, Brief, Epsilon, EMACS, dan vim atau vi.
Nama dan versi editor teks dapat berbeda di setiap sistem operasi. Misalnya, Notepad akan digunakan di Windows, dan vim atau vi dapat digunakan di Windows serta Linux atau UNIX.
File yang Anda buat dengan editor Anda disebut file sumber dan berisi kode sumber program. File sumber untuk program C biasanya dinamai dengan ekstensi ".c".
Sebelum memulai pemrograman Anda, pastikan Anda memiliki satu editor teks dan Anda memiliki cukup pengalaman untuk menulis program komputer, menyimpannya dalam sebuah file, mengkompilasinya, dan akhirnya menjalankannya.
Penyusun C
Kode sumber yang ditulis dalam file sumber adalah sumber yang dapat dibaca manusia untuk program Anda. Ini perlu "dikompilasi", untuk diubah menjadi bahasa mesin sehingga CPU Anda benar-benar dapat menjalankan program sesuai instruksi yang diberikan.
Kompilator bahasa pemrograman C ini akan digunakan untuk mengkompilasi kode sumber Anda menjadi program akhir yang dapat dieksekusi. Kami menganggap Anda memiliki pengetahuan dasar tentang kompiler bahasa pemrograman.
Kompiler yang paling sering digunakan dan tersedia gratis adalah kompiler GNU C / C ++. Jika tidak, Anda dapat memiliki kompiler dari HP atau Solaris jika Anda memiliki Sistem Operasi (OS) masing-masing.
Bagian berikut memandu Anda tentang cara menginstal compiler GNU C / C ++ pada berbagai OS. Kami menyebut C / C ++ bersama karena kompiler GNU GCC berfungsi untuk bahasa pemrograman C dan C ++.
Instalasi di UNIX / Linux
Jika Anda menggunakan Linux or UNIX, lalu periksa apakah GCC diinstal pada sistem Anda dengan memasukkan perintah berikut dari baris perintah -
$ gcc -vJika Anda memiliki kompiler GNU yang diinstal pada mesin Anda, maka itu akan mencetak pesan seperti berikut -
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix = /usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)Jika GCC tidak diinstal, Anda harus menginstalnya sendiri menggunakan petunjuk terperinci yang tersedia di https://gcc.gnu.org/install/
Tutorial ini ditulis berdasarkan Linux dan semua contoh yang diberikan telah dikompilasi pada sistem Linux Cent OS.
Instalasi di Mac OS
Jika Anda menggunakan Mac OS X, cara termudah untuk mendapatkan GCC adalah dengan mengunduh lingkungan pengembangan Xcode dari situs web Apple dan ikuti petunjuk penginstalan sederhana. Setelah Anda menyiapkan Xcode, Anda akan dapat menggunakan kompiler GNU untuk C / C ++.
Xcode saat ini tersedia di developer.apple.com/technologies/tools/
Instalasi di Windows
Untuk menginstal GCC di Windows, Anda perlu menginstal MinGW. Untuk menginstal MinGW, buka beranda MinGW, www.mingw.org , dan ikuti tautan ke halaman unduh MinGW. Unduh versi terbaru program penginstalan MinGW, yang akan diberi nama MinGW- <version> .exe.
Saat menginstal MinWG, minimal Anda harus menginstal gcc-core, gcc-g ++, binutils, dan runtime MinGW, tetapi Anda mungkin ingin menginstal lebih banyak.
Tambahkan subdirektori bin dari instalasi MinGW Anda ke PATH variabel lingkungan, sehingga Anda dapat menentukan alat ini pada baris perintah dengan nama sederhananya.
Setelah instalasi selesai, Anda akan dapat menjalankan gcc, g ++, ar, ranlib, dlltool, dan beberapa alat GNU lainnya dari baris perintah Windows.
Algoritma adalah prosedur langkah demi langkah, yang mendefinisikan sekumpulan instruksi yang akan dieksekusi dalam urutan tertentu untuk mendapatkan keluaran yang diinginkan. Algoritma umumnya dibuat independen dari bahasa yang mendasarinya, yaitu suatu algoritma dapat diimplementasikan di lebih dari satu bahasa pemrograman.
Dari sudut pandang struktur data, berikut adalah beberapa kategori penting dari algoritma -
Search - Algoritma untuk mencari item dalam struktur data.
Sort - Algoritma untuk mengurutkan item dalam urutan tertentu.
Insert - Algoritma untuk memasukkan item ke dalam struktur data.
Update - Algoritma untuk memperbarui item yang ada dalam struktur data.
Delete - Algoritma untuk menghapus item yang ada dari struktur data.
Karakteristik Algoritma
Tidak semua prosedur bisa disebut algoritma. Algoritme harus memiliki karakteristik berikut -
Unambiguous- Algoritma harus jelas dan tidak ambigu. Setiap langkah (atau fase), dan masukan / keluarannya harus jelas dan hanya mengarah pada satu makna.
Input - Algoritme harus memiliki 0 atau lebih input yang terdefinisi dengan baik.
Output - Algoritme harus memiliki 1 atau lebih keluaran yang terdefinisi dengan baik, dan harus cocok dengan keluaran yang diinginkan.
Finiteness - Algoritme harus dihentikan setelah sejumlah langkah terbatas.
Feasibility - Harus layak dengan sumber daya yang tersedia.
Independent - Algoritme harus memiliki petunjuk langkah demi langkah, yang harus independen dari kode pemrograman apa pun.
Bagaimana Cara Menulis Algoritma?
Tidak ada standar yang didefinisikan dengan baik untuk penulisan algoritma. Sebaliknya, ini tergantung pada masalah dan sumber daya. Algoritma tidak pernah ditulis untuk mendukung kode pemrograman tertentu.
Seperti yang kita ketahui bahwa semua bahasa pemrograman berbagi konstruksi kode dasar seperti loop (do, for, while), flow-control (if-else), dll. Konstruksi umum ini dapat digunakan untuk menulis algoritme.
Kami menulis algoritme secara selangkah demi selangkah, tetapi tidak selalu demikian. Penulisan algoritme adalah sebuah proses dan dijalankan setelah domain masalah didefinisikan dengan baik. Artinya, kita harus mengetahui domain masalahnya, untuk itu kita sedang merancang solusinya.
Contoh
Mari kita coba belajar penulisan algoritma dengan menggunakan sebuah contoh.
Problem - Rancang algoritma untuk menambahkan dua angka dan menampilkan hasilnya.
Step 1 − START
Step 2 − declare three integers a, b & c
Step 3 − define values of a & b
Step 4 − add values of a & b
Step 5 − store output of step 4 to c
Step 6 − print c
Step 7 − STOPAlgoritme memberi tahu pemrogram cara membuat kode program. Atau, algoritme dapat ditulis sebagai -
Step 1 − START ADD
Step 2 − get values of a & b
Step 3 − c ← a + b
Step 4 − display c
Step 5 − STOPDalam perancangan dan analisis algoritma, biasanya metode kedua digunakan untuk mendeskripsikan suatu algoritma. Ini memudahkan analis untuk menganalisis algoritme dengan mengabaikan semua definisi yang tidak diinginkan. Dia dapat mengamati operasi apa yang digunakan dan bagaimana prosesnya mengalir.
Penulisan step numbers, bersifat opsional.
Kami merancang algoritme untuk mendapatkan solusi dari masalah tertentu. Sebuah masalah dapat diselesaikan dengan lebih dari satu cara.
Oleh karena itu, banyak algoritma solusi yang dapat diturunkan untuk masalah tertentu. Langkah selanjutnya adalah menganalisis algoritma solusi yang diusulkan tersebut dan menerapkan solusi terbaik yang sesuai.
Analisis Algoritma
Efisiensi suatu algoritma dapat dianalisis pada dua tahap yang berbeda, sebelum implementasi dan setelah implementasi. Mereka adalah sebagai berikut -
A Priori Analysis- Ini adalah analisis teoritis dari suatu algoritma. Efisiensi algoritme diukur dengan mengasumsikan bahwa semua faktor lain, misalnya, kecepatan prosesor, adalah konstan dan tidak berpengaruh pada implementasi.
A Posterior Analysis- Ini adalah analisis empiris dari suatu algoritma. Algoritma yang dipilih diimplementasikan dengan menggunakan bahasa pemrograman. Ini kemudian dijalankan pada mesin komputer target. Dalam analisis ini, statistik aktual seperti waktu dan ruang berjalan yang diperlukan, dikumpulkan.
Kita akan belajar tentang analisis algoritma apriori . Analisis algoritme berkaitan dengan eksekusi atau waktu berjalan berbagai operasi yang terlibat. Waktu berjalan suatu operasi dapat didefinisikan sebagai jumlah instruksi komputer yang dijalankan per operasi.
Kompleksitas Algoritma
Seharusnya X adalah sebuah algoritma dan n adalah ukuran data masukan, waktu dan ruang yang digunakan oleh algoritma X adalah dua faktor utama yang menentukan efisiensi X.
Time Factor - Waktu diukur dengan menghitung jumlah operasi kunci seperti perbandingan dalam algoritma pengurutan.
Space Factor - Ruang diukur dengan menghitung ruang memori maksimum yang dibutuhkan oleh algoritma.
Kompleksitas suatu algoritma f(n) memberikan waktu berjalan dan / atau ruang penyimpanan yang dibutuhkan oleh algoritme dalam istilah n sebagai ukuran data masukan.
Kompleksitas Ruang
Kompleksitas ruang suatu algoritme merepresentasikan jumlah ruang memori yang dibutuhkan algoritme dalam siklus hidupnya. Ruang yang dibutuhkan oleh algoritme sama dengan jumlah dari dua komponen berikut -
Bagian tetap yang merupakan ruang yang diperlukan untuk menyimpan data dan variabel tertentu, yang tidak bergantung pada ukuran masalah. Misalnya, variabel dan konstanta sederhana yang digunakan, ukuran program, dll.
Bagian variabel adalah ruang yang dibutuhkan oleh variabel, yang ukurannya bergantung pada ukuran masalah. Misalnya, alokasi memori dinamis, ruang tumpukan rekursi, dll.
Kompleksitas spasi S (P) dari setiap algoritma P adalah S (P) = C + SP (I), di mana C adalah bagian tetap dan S (I) adalah bagian variabel dari algoritma, yang bergantung pada karakteristik instance I. Berikut adalah contoh sederhana yang mencoba menjelaskan konsep -
Algorithm: SUM(A, B)
Step 1 - START
Step 2 - C ← A + B + 10
Step 3 - StopDi sini kita memiliki tiga variabel A, B, dan C dan satu konstanta. Oleh karena itu S (P) = 1 + 3. Sekarang, ruang bergantung pada tipe data dari variabel yang diberikan dan tipe konstanta dan akan dikalikan sesuai.
Kompleksitas Waktu
Kompleksitas waktu suatu algoritme merepresentasikan jumlah waktu yang dibutuhkan algoritme untuk berjalan hingga selesai. Persyaratan waktu dapat didefinisikan sebagai fungsi numerik T (n), di mana T (n) dapat diukur sebagai jumlah langkah, asalkan setiap langkah menggunakan waktu yang konstan.
Sebagai contoh, diperlukan penambahan dua bilangan bulat n-bit nLangkah. Akibatnya, total waktu komputasi adalah T (n) = c ∗ n, di mana c adalah waktu yang dibutuhkan untuk penambahan dua bit. Di sini, kami mengamati bahwa T (n) tumbuh secara linier dengan bertambahnya ukuran input.
Analisis asimtotik dari suatu algoritme mengacu pada penentuan batas / pembingkaian matematis dari kinerja run-time-nya. Dengan menggunakan analisis asimtotik, kita dapat menyimpulkan kasus terbaik, kasus rata-rata, dan skenario kasus terburuk dari suatu algoritme.
Analisis asimtotik terikat dengan input, yaitu jika tidak ada input ke algoritme, disimpulkan untuk bekerja dalam waktu yang konstan. Selain "masukan", semua faktor lainnya dianggap konstan.
Analisis asimtotik mengacu pada penghitungan waktu berjalan operasi apa pun dalam unit komputasi matematika. Misalnya, waktu berjalan dari satu operasi dihitung sebagai f (n) dan mungkin untuk operasi lain dihitung sebagai g (n 2 ). Ini berarti waktu berjalan operasi pertama akan meningkat secara linier dengan peningkatann dan waktu berjalan operasi kedua akan meningkat secara eksponensial saat nmeningkat. Demikian pula, waktu berjalan dari kedua operasi tersebut akan hampir sama jikan sangat kecil.
Biasanya, waktu yang dibutuhkan oleh algoritme termasuk dalam tiga jenis -
Best Case - Waktu minimum yang dibutuhkan untuk pelaksanaan program.
Average Case - Rata-rata waktu yang dibutuhkan untuk pelaksanaan program.
Worst Case - Waktu maksimum yang dibutuhkan untuk pelaksanaan program.
Notasi Asymptotic
Berikut ini adalah notasi asimtotik yang umum digunakan untuk menghitung kompleksitas waktu berjalan suatu algoritme.
- Ο Notasi
- Ω Notasi
- θ Notasi
Notasi Big Oh, Ο
Notasi Ο (n) adalah cara formal untuk mengekspresikan batas atas dari waktu berjalan suatu algoritma. Ini mengukur kompleksitas waktu kasus terburuk atau jumlah waktu terlama yang mungkin diperlukan algoritme untuk menyelesaikannya.
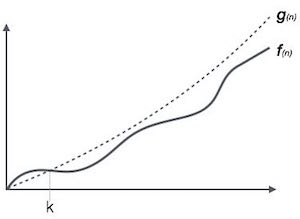
Misalnya, untuk suatu fungsi f(n)
Ο(f(n)) = { g(n) : there exists c > 0 and n0 such that f(n) ≤ c.g(n) for all n > n0. }Notasi Omega, Ω
Notasi Ω (n) adalah cara formal untuk menyatakan batas bawah waktu berjalan suatu algoritma. Ini mengukur kompleksitas waktu kasus terbaik atau jumlah waktu terbaik yang mungkin diperlukan algoritme untuk menyelesaikannya.
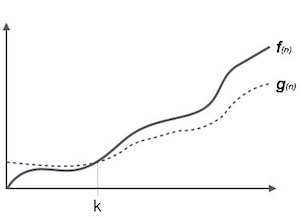
Misalnya, untuk suatu fungsi f(n)
Ω(f(n)) ≥ { g(n) : there exists c > 0 and n0 such that g(n) ≤ c.f(n) for all n > n0. }Notasi Theta, θ
Notasi θ (n) adalah cara formal untuk menyatakan batas bawah dan batas atas dari waktu berjalan suatu algoritme. Ini direpresentasikan sebagai berikut -
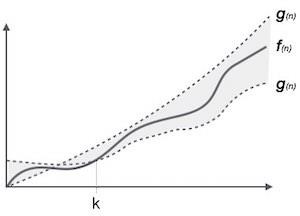
θ(f(n)) = { g(n) if and only if g(n) = Ο(f(n)) and g(n) = Ω(f(n)) for all n > n0. }Notasi Asymptotic Umum
Berikut ini adalah daftar beberapa notasi asimtotik yang umum -
| konstan | - | Ο (1) |
| logaritma | - | Ο (log n) |
| linier | - | Ο (n) |
| n log n | - | Ο (n log n) |
| kuadrat | - | Ο (n 2 ) |
| kubik | - | Ο (n 3 ) |
| polinomial | - | n Ο (1) |
| eksponensial | - | 2 Ο (n) |
Algoritme dirancang untuk mencapai solusi optimal untuk masalah tertentu. Dalam pendekatan algoritma serakah, keputusan dibuat dari domain solusi yang diberikan. Karena tamak, solusi terdekat yang tampaknya memberikan solusi optimal dipilih.
Algoritme serakah mencoba menemukan solusi optimal yang dilokalkan, yang pada akhirnya dapat menghasilkan solusi yang dioptimalkan secara global. Namun, umumnya algoritme serakah tidak memberikan solusi yang dioptimalkan secara global.
Menghitung Koin
Masalah ini adalah menghitung ke nilai yang diinginkan dengan memilih koin yang paling sedikit mungkin dan pendekatan serakah memaksa algoritme untuk memilih koin terbesar yang mungkin. Jika kita diberikan koin sebesar ₹ 1, 2, 5 dan 10 dan kita diminta untuk menghitung ₹ 18 maka prosedur serakah adalah -
1 - Pilih satu koin ₹ 10, sisa hitungannya adalah 8
2 - Kemudian pilih satu koin ₹ 5, sisa hitungannya adalah 3
3 - Lalu pilih satu koin ₹ 2, sisa hitungannya 1
4 - Dan akhirnya, pemilihan satu koin ₹ 1 menyelesaikan masalah
Meskipun, tampaknya berfungsi dengan baik, untuk hitungan ini kita hanya perlu memilih 4 koin. Tetapi jika kita sedikit mengubah masalah maka pendekatan yang sama mungkin tidak dapat memberikan hasil optimal yang sama.
Untuk sistem mata uang, di mana kita memiliki koin dengan nilai 1, 7, 10, menghitung koin untuk nilai 18 akan benar-benar optimal tetapi untuk hitungan seperti 15, mungkin menggunakan lebih banyak koin daripada yang diperlukan. Misalnya, pendekatan serakah akan menggunakan 10 + 1 + 1 + 1 + 1 + 1, total 6 koin. Sedangkan masalah yang sama dapat diselesaikan dengan hanya menggunakan 3 koin (7 + 7 + 1)
Oleh karena itu, kami dapat menyimpulkan bahwa pendekatan serakah memilih solusi yang segera dioptimalkan dan mungkin gagal jika pengoptimalan global menjadi perhatian utama.
Contoh
Sebagian besar algoritme jaringan menggunakan pendekatan serakah. Berikut adalah daftar beberapa di antaranya -
- Masalah Penjual Bepergian
- Algoritma Pohon Rentang Minimal Prim
- Algoritma Pohon Rentang Minimal Kruskal
- Algoritma Pohon Rentang Minimal Dijkstra
- Grafik - Mewarnai Peta
- Grafik - Penutup Vertex
- Masalah Knapsack
- Masalah Penjadwalan Pekerjaan
Ada banyak masalah serupa yang menggunakan pendekatan serakah untuk menemukan solusi optimal.
Dalam pendekatan divide and conquer, masalah yang ada, dibagi menjadi sub-sub masalah yang lebih kecil dan kemudian setiap masalah diselesaikan secara mandiri. Ketika kita terus membagi subproblem menjadi sub-sub masalah yang lebih kecil, pada akhirnya kita mungkin mencapai tahap di mana tidak ada lagi pembagian yang memungkinkan. Sub-masalah (pecahan) sekecil mungkin yang "atomik" terpecahkan. Solusi dari semua sub masalah akhirnya digabungkan untuk mendapatkan solusi dari masalah asli.
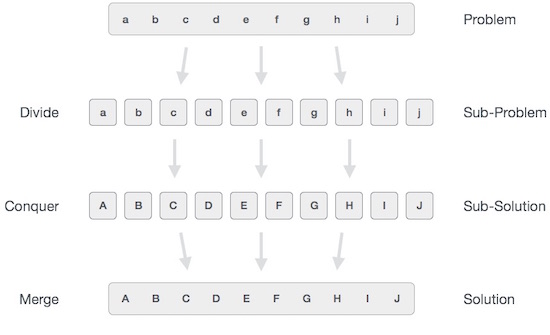
Secara luas, kita bisa mengerti divide-and-conquer pendekatan dalam proses tiga langkah.
Bagilah / Pecahkan
Langkah ini melibatkan pemecahan masalah menjadi sub-masalah yang lebih kecil. Sub-masalah harus mewakili bagian dari masalah asli. Langkah ini umumnya mengambil pendekatan rekursif untuk membagi masalah sampai tidak ada sub-masalah yang dapat dibagi lagi. Pada tahap ini, sub-masalah menjadi atom tetapi masih mewakili beberapa bagian dari masalah yang sebenarnya.
Taklukkan / Pecahkan
Langkah ini menerima banyak sub-masalah kecil yang harus diselesaikan. Umumnya, pada level ini, masalah dianggap 'terselesaikan' dengan sendirinya.
Gabungkan / Gabungkan
Ketika sub-masalah yang lebih kecil diselesaikan, tahap ini secara rekursif menggabungkan mereka sampai mereka merumuskan solusi dari masalah aslinya. Pendekatan algoritmik ini bekerja secara rekursif dan langkah menaklukkan & menggabungkan bekerja sangat dekat sehingga tampak sebagai satu kesatuan.
Contoh
Algoritme komputer berikut didasarkan pada divide-and-conquer pendekatan pemrograman -
- Gabungkan Sortir
- Sortir Cepat
- Pencarian Biner
- Perkalian Matriks Strassen
- Pasangan terdekat (poin)
Ada berbagai cara yang tersedia untuk menyelesaikan masalah komputer apa pun, tetapi yang disebutkan adalah contoh yang baik dari pendekatan divide and conquer.
Pendekatan pemrograman dinamis mirip dengan membagi dan menaklukkan dalam memecah masalah menjadi masalah yang lebih kecil namun lebih kecil. Tetapi tidak seperti, bagi dan taklukkan, sub-masalah ini tidak diselesaikan secara mandiri. Sebaliknya, hasil dari sub-masalah yang lebih kecil ini diingat dan digunakan untuk sub-masalah yang serupa atau tumpang tindih.
Pemrograman dinamis digunakan di mana kita memiliki masalah, yang dapat dibagi menjadi sub-sub masalah yang serupa, sehingga hasilnya dapat digunakan kembali. Sebagian besar, algoritma ini digunakan untuk pengoptimalan. Sebelum menyelesaikan sub-masalah yang ada, algoritma dinamis akan mencoba untuk memeriksa hasil dari sub-masalah yang diselesaikan sebelumnya. Solusi dari sub-masalah digabungkan untuk mencapai solusi terbaik.
Jadi kami dapat mengatakan bahwa -
Masalah harus dapat dibagi menjadi sub-masalah kecil yang tumpang tindih.
Solusi optimal dapat dicapai dengan menggunakan solusi optimal dari sub-masalah yang lebih kecil.
Algoritme dinamis menggunakan Memoisasi.
Perbandingan
Berbeda dengan algoritme serakah, di mana pengoptimalan lokal ditangani, algoritme dinamis dimotivasi untuk pengoptimalan masalah secara keseluruhan.
Berbeda dengan algoritma membagi dan menaklukkan, di mana solusi digabungkan untuk mencapai solusi keseluruhan, algoritma dinamis menggunakan keluaran dari sub-masalah yang lebih kecil dan kemudian mencoba untuk mengoptimalkan sub-masalah yang lebih besar. Algoritme dinamis menggunakan Memoisasi untuk mengingat keluaran dari sub-masalah yang sudah terpecahkan.
Contoh
Masalah komputer berikut ini dapat diselesaikan dengan menggunakan pendekatan pemrograman dinamis -
- Deret angka Fibonacci
- Masalah ransel
- Menara Hanoi
- Semua pasangan jalur terpendek oleh Floyd-Warshall
- Jalur terpendek oleh Dijkstra
- Penjadwalan proyek
Pemrograman dinamis dapat digunakan dengan cara top-down dan bottom-up. Dan tentu saja, seringkali, mengacu pada keluaran solusi sebelumnya lebih murah daripada menghitung ulang dalam hal siklus CPU.
Bab ini menjelaskan istilah-istilah dasar yang berkaitan dengan struktur data.
Definisi Data
Definisi Data mendefinisikan data tertentu dengan karakteristik sebagai berikut.
Atomic - Definisi harus mendefinisikan satu konsep.
Traceable - Definisi harus dapat dipetakan ke beberapa elemen data.
Accurate - Definisi harus jelas.
Clear and Concise - Definisi harus bisa dimengerti.
Objek Data
Objek Data merupakan objek yang memiliki data.
Tipe data
Tipe data adalah cara untuk mengklasifikasikan berbagai tipe data seperti integer, string, dll. Yang menentukan nilai-nilai yang dapat digunakan dengan tipe data yang sesuai, tipe operasi yang dapat dilakukan pada tipe data yang sesuai. Ada dua tipe data -
- Jenis Data Bawaan
- Tipe Data Turunan
Jenis Data Bawaan
Tipe data yang bahasa memiliki dukungan bawaan dikenal sebagai tipe Data Bawaan. Misalnya, sebagian besar bahasa menyediakan tipe data bawaan berikut.
- Integers
- Boolean (benar, salah)
- Mengambang (angka desimal)
- Karakter dan String
Tipe Data Turunan
Tipe data yang implementasi independen karena dapat diimplementasikan dengan satu atau cara lain dikenal sebagai tipe data turunan. Tipe data ini biasanya dibuat dengan kombinasi tipe data primer atau bawaan dan operasi terkait padanya. Misalnya -
- List
- Array
- Stack
- Queue
Operasi Dasar
Data dalam struktur data diproses oleh operasi tertentu. Struktur data tertentu yang dipilih sangat bergantung pada frekuensi operasi yang perlu dilakukan pada struktur data.
- Traversing
- Searching
- Insertion
- Deletion
- Sorting
- Merging
Array adalah wadah yang dapat menampung sejumlah item tetap dan item ini harus berjenis sama. Sebagian besar struktur data menggunakan array untuk mengimplementasikan algoritme mereka. Berikut adalah istilah-istilah penting untuk memahami konsep Array.
Element - Setiap item yang disimpan dalam array disebut elemen.
Index - Setiap lokasi elemen dalam array memiliki indeks numerik, yang digunakan untuk mengidentifikasi elemen.
Representasi Array
Array dapat dideklarasikan dengan berbagai cara dalam berbagai bahasa. Sebagai ilustrasi, mari kita ambil deklarasi array C.

Array dapat dideklarasikan dengan berbagai cara dalam berbagai bahasa. Sebagai ilustrasi, mari kita ambil deklarasi array C.
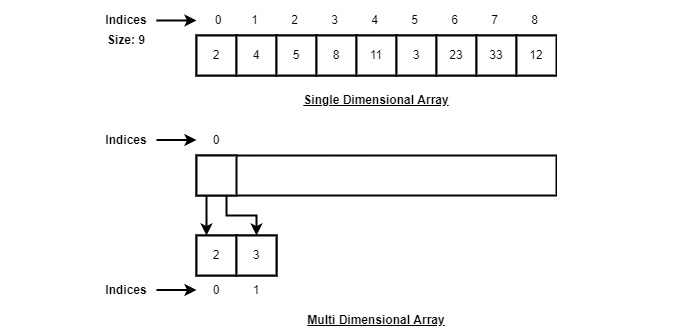
Sesuai ilustrasi di atas, berikut adalah poin-poin penting yang harus diperhatikan.
Indeks dimulai dengan 0.
Panjang larik adalah 10 yang artinya dapat menyimpan 10 elemen.
Setiap elemen dapat diakses melalui indeksnya. Misalnya, kita dapat mengambil elemen di indeks 6 sebagai 9.
Operasi Dasar
Berikut adalah operasi dasar yang didukung oleh array.
Traverse - cetak semua elemen array satu per satu.
Insertion - Menambahkan elemen pada indeks yang diberikan.
Deletion - Menghapus elemen pada indeks yang diberikan.
Search - Mencari elemen menggunakan indeks yang diberikan atau berdasarkan nilainya.
Update - Memperbarui elemen pada indeks yang diberikan.
Di C, ketika sebuah array diinisialisasi dengan ukuran, maka itu memberikan nilai default ke elemennya dalam urutan berikut.
| Tipe data | Nilai Default |
|---|---|
| bool | Salah |
| arang | 0 |
| int | 0 |
| mengapung | 0.0 |
| dua kali lipat | 0.0f |
| kosong | |
| wchar_t | 0 |
Operasi Traverse
Operasi ini untuk melintasi elemen-elemen array.
Contoh
Program berikut melintasi dan mencetak elemen dari sebuah array:
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Ketika kita mengkompilasi dan menjalankan program di atas, hasilnya adalah sebagai berikut:
Keluaran
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8Operasi Penyisipan
Operasi sisipkan adalah memasukkan satu atau lebih elemen data ke dalam larik. Berdasarkan persyaratan, elemen baru dapat ditambahkan di awal, akhir, atau indeks larik apa pun.
Di sini, kita melihat implementasi praktis dari operasi penyisipan, di mana kita menambahkan data di akhir larik -
Contoh
Berikut adalah implementasi dari algoritma di atas -
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
n = n + 1;
while( j >= k) {
LA[j+1] = LA[j];
j = j - 1;
}
LA[k] = item;
printf("The array elements after insertion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Ketika kita mengkompilasi dan menjalankan program di atas, hasilnya adalah sebagai berikut:
Keluaran
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after insertion :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 10
LA[4] = 7
LA[5] = 8Untuk variasi lain dari operasi penyisipan larik, klik di sini
Operasi Penghapusan
Penghapusan mengacu pada penghapusan elemen yang ada dari larik dan mengatur ulang semua elemen larik.
Algoritma
Mempertimbangkan LA adalah array linier dengan N elemen dan K adalah bilangan bulat positif sehingga K<=N. Berikut adalah algoritma untuk menghapus elemen yang tersedia di K th posisi LA.
1. Start
2. Set J = K
3. Repeat steps 4 and 5 while J < N
4. Set LA[J] = LA[J + 1]
5. Set J = J+1
6. Set N = N-1
7. StopContoh
Berikut adalah implementasi dari algoritma di atas -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
j = k;
while( j < n) {
LA[j-1] = LA[j];
j = j + 1;
}
n = n -1;
printf("The array elements after deletion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Ketika kita mengkompilasi dan menjalankan program di atas, hasilnya adalah sebagai berikut:
Keluaran
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after deletion :
LA[0] = 1
LA[1] = 3
LA[2] = 7
LA[3] = 8Operasi Pencarian
Anda dapat melakukan pencarian untuk elemen array berdasarkan nilainya atau indeksnya.
Algoritma
Mempertimbangkan LA adalah array linier dengan N elemen dan K adalah bilangan bulat positif sehingga K<=N. Berikut algoritma untuk mencari elemen dengan nilai ITEM menggunakan pencarian sekuensial.
1. Start
2. Set J = 0
3. Repeat steps 4 and 5 while J < N
4. IF LA[J] is equal ITEM THEN GOTO STEP 6
5. Set J = J +1
6. PRINT J, ITEM
7. StopContoh
Berikut adalah implementasi dari algoritma di atas -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int item = 5, n = 5;
int i = 0, j = 0;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
while( j < n){
if( LA[j] == item ) {
break;
}
j = j + 1;
}
printf("Found element %d at position %d\n", item, j+1);
}Ketika kita mengkompilasi dan menjalankan program di atas, hasilnya adalah sebagai berikut:
Keluaran
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
Found element 5 at position 3Perbarui Operasi
Operasi pembaruan mengacu pada memperbarui elemen yang ada dari larik pada indeks tertentu.
Algoritma
Mempertimbangkan LA adalah array linier dengan N elemen dan K adalah bilangan bulat positif sehingga K<=N. Berikut adalah algoritma untuk memperbarui elemen yang tersedia di K th posisi LA.
1. Start
2. Set LA[K-1] = ITEM
3. StopContoh
Berikut adalah implementasi dari algoritma di atas -
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5, item = 10;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
LA[k-1] = item;
printf("The array elements after updation :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}Ketika kita mengkompilasi dan menjalankan program di atas, hasilnya adalah sebagai berikut:
Keluaran
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after updation :
LA[0] = 1
LA[1] = 3
LA[2] = 10
LA[3] = 7
LA[4] = 8Daftar tertaut adalah urutan struktur data, yang dihubungkan bersama melalui tautan.
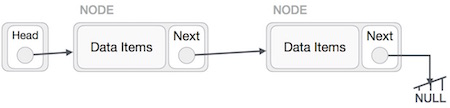
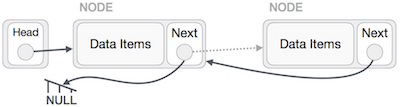
Linked List adalah urutan link yang berisi item. Setiap tautan berisi koneksi ke tautan lain. Daftar tertaut adalah struktur data yang paling banyak digunakan kedua setelah larik. Berikut adalah istilah-istilah penting untuk memahami konsep Linked List.
Link - Setiap tautan dari daftar tertaut dapat menyimpan data yang disebut elemen.
Next - Setiap tautan dari daftar tertaut berisi tautan ke tautan berikutnya yang disebut Berikutnya.
LinkedList - Sebuah Daftar Tertaut berisi tautan koneksi ke tautan pertama yang disebut Pertama.
Representasi Daftar Tertaut
Daftar tertaut dapat divisualisasikan sebagai rangkaian node, di mana setiap node mengarah ke node berikutnya.

Sesuai ilustrasi di atas, berikut adalah poin-poin penting yang harus diperhatikan.
Daftar Tertaut berisi elemen tautan yang disebut pertama.
Setiap tautan membawa bidang data dan bidang tautan disebut berikutnya.
Setiap tautan ditautkan dengan tautan berikutnya menggunakan tautan berikutnya.
Tautan terakhir membawa tautan sebagai null untuk menandai akhir dari daftar.
Jenis Daftar Tertaut
Berikut adalah berbagai jenis daftar tertaut.
Simple Linked List - Navigasi item hanya untuk maju.
Doubly Linked List - Item dapat dinavigasi maju dan mundur.
Circular Linked List - Item terakhir berisi tautan dari elemen pertama sebagai elemen berikutnya dan elemen pertama memiliki tautan ke elemen terakhir seperti sebelumnya.
Operasi Dasar
Berikut adalah operasi dasar yang didukung oleh daftar.
Insertion - Menambahkan elemen di awal daftar.
Deletion - Menghapus elemen di awal daftar.
Display - Menampilkan daftar lengkap.
Search - Mencari elemen menggunakan kunci yang diberikan.
Delete - Menghapus elemen menggunakan kunci yang diberikan.
Operasi Penyisipan
Menambahkan node baru dalam daftar tertaut adalah aktivitas lebih dari satu langkah. Kita akan mempelajari ini dengan diagram di sini. Pertama, buat node menggunakan struktur yang sama dan temukan lokasi tempat node tersebut harus disisipkan.

Bayangkan kita memasukkan sebuah node B (NewNode), di antara A (LeftNode) dan C(RightNode). Kemudian titik B. di sebelah C -
NewNode.next −> RightNode;Ini akan terlihat seperti ini -

Sekarang, simpul berikutnya di kiri harus mengarah ke simpul baru.
LeftNode.next −> NewNode;
Ini akan menempatkan simpul baru di tengah keduanya. Daftar baru akan terlihat seperti ini -

Langkah serupa harus diambil jika node disisipkan di awal daftar. Saat memasukkannya di akhir, simpul terakhir kedua dari daftar harus mengarah ke simpul baru dan simpul baru akan mengarah ke NULL.
Operasi Penghapusan
Penghapusan juga merupakan proses lebih dari satu langkah. Kita akan belajar dengan representasi gambar. Pertama, temukan node target yang akan dihapus, dengan menggunakan algoritma pencarian.

Node kiri (sebelumnya) dari node target sekarang harus mengarah ke node berikutnya dari node target -
LeftNode.next −> TargetNode.next;
Ini akan menghapus tautan yang mengarah ke node target. Sekarang, dengan menggunakan kode berikut, kami akan menghapus apa yang ditunjuk oleh node target.
TargetNode.next −> NULL;
Kita perlu menggunakan node yang dihapus. Kita dapat menyimpannya di memori jika tidak kita dapat membatalkan alokasi memori dan menghapus node target sepenuhnya.

Operasi Terbalik
Operasi ini menyeluruh. Kita perlu membuat simpul terakhir untuk diarahkan oleh simpul kepala dan membalikkan seluruh daftar tertaut.
Pertama, kami menelusuri akhir daftar. Ini harus mengarah ke NULL. Sekarang, kita akan membuatnya menunjuk ke simpul sebelumnya -
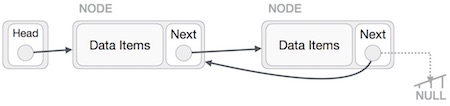
Kita harus memastikan bahwa simpul terakhir bukanlah simpul terakhir. Jadi kita akan memiliki beberapa node temp, yang terlihat seperti node kepala yang menunjuk ke node terakhir. Sekarang, kita akan membuat semua node sisi kiri mengarah ke node sebelumnya satu per satu.
Kecuali node (node pertama) yang ditunjukkan oleh node kepala, semua node harus mengarah ke pendahulunya, menjadikannya penerus baru. Node pertama akan mengarah ke NULL.

Kita akan membuat simpul kepala mengarah ke simpul pertama yang baru dengan menggunakan simpul temp.
Daftar terkait sekarang dibalik. Untuk melihat implementasi linked list dalam bahasa pemrograman C, silakan klik di sini .
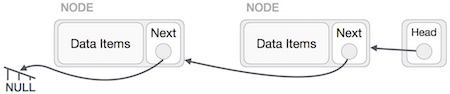
Doubly Linked List adalah variasi dari Linked List dimana navigasi dimungkinkan dengan kedua cara, baik maju maupun mundur dengan mudah dibandingkan dengan Single Linked List. Berikut adalah istilah-istilah penting untuk memahami konsep daftar tertaut ganda.
Link - Setiap tautan dari daftar tertaut dapat menyimpan data yang disebut elemen.
Next - Setiap tautan dari daftar tertaut berisi tautan ke tautan berikutnya yang disebut Berikutnya.
Prev - Setiap tautan dari daftar tertaut berisi tautan ke tautan sebelumnya yang disebut Sebelumnya.
LinkedList - Sebuah Daftar Tertaut berisi tautan koneksi ke tautan pertama yang disebut Pertama dan ke tautan terakhir yang disebut Terakhir.
Representasi Daftar Tertaut Ganda

Sesuai ilustrasi di atas, berikut adalah poin-poin penting yang harus diperhatikan.
Daftar Tertaut Ganda berisi elemen tautan yang disebut pertama dan terakhir.
Setiap tautan membawa bidang data dan dua bidang tautan yang disebut next dan prev.
Setiap tautan ditautkan dengan tautan berikutnya menggunakan tautan berikutnya.
Setiap tautan ditautkan dengan tautan sebelumnya menggunakan tautan sebelumnya.
Tautan terakhir membawa tautan sebagai null untuk menandai akhir dari daftar.
Operasi Dasar
Berikut adalah operasi dasar yang didukung oleh daftar.
Insertion - Menambahkan elemen di awal daftar.
Deletion - Menghapus elemen di awal daftar.
Insert Last - Menambahkan elemen di akhir daftar.
Delete Last - Menghapus elemen dari akhir daftar.
Insert After - Menambahkan elemen setelah item daftar.
Delete - Menghapus elemen dari daftar menggunakan kunci.
Display forward - Menampilkan daftar lengkap dengan cara maju.
Display backward - Menampilkan daftar lengkap secara terbalik.
Operasi Penyisipan
Kode berikut menunjukkan operasi penyisipan di awal daftar tertaut ganda.
Contoh
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//update first prev link
head->prev = link;
}
//point it to old first link
link->next = head;
//point first to new first link
head = link;
}Operasi Penghapusan
Kode berikut menunjukkan operasi penghapusan di awal daftar tertaut ganda.
Contoh
//delete first item
struct node* deleteFirst() {
//save reference to first link
struct node *tempLink = head;
//if only one link
if(head->next == NULL) {
last = NULL;
} else {
head->next->prev = NULL;
}
head = head->next;
//return the deleted link
return tempLink;
}Penyisipan di Akhir Operasi
Kode berikut menunjukkan operasi penyisipan di posisi terakhir dari daftar tertaut ganda.
Contoh
//insert link at the last location
void insertLast(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()) {
//make it the last link
last = link;
} else {
//make link a new last link
last->next = link;
//mark old last node as prev of new link
link->prev = last;
}
//point last to new last node
last = link;
}Untuk melihat implementasinya dalam bahasa pemograman C, silahkan klik disini .
Circular Linked List adalah variasi dari Linked list dimana elemen pertama mengarah ke elemen terakhir dan elemen terakhir mengarah ke elemen pertama. Daftar Tertaut Tunggal dan Daftar Tertaut Ganda dapat dibuat menjadi daftar tertaut melingkar.
Daftar Tertaut Tunggal sebagai Edaran
Dalam daftar tertaut tunggal, penunjuk berikutnya dari simpul terakhir menunjuk ke simpul pertama.

Daftar Tertaut Ganda sebagai Edaran
Dalam daftar tertaut ganda, penunjuk berikutnya dari simpul terakhir menunjuk ke simpul pertama dan penunjuk sebelumnya dari simpul pertama menunjuk ke simpul terakhir yang membuat lingkaran di kedua arah.

Sesuai ilustrasi di atas, berikut adalah poin-poin penting yang harus diperhatikan.
Tautan terakhir menunjuk ke tautan pertama dari daftar dalam kedua kasus daftar tertaut tunggal maupun ganda.
Tautan pertama sebelumnya menunjuk ke yang terakhir dari daftar jika ada daftar tertaut ganda.
Operasi Dasar
Berikut adalah operasi penting yang didukung oleh daftar melingkar.
insert - Menyisipkan elemen di awal daftar.
delete - Menghapus elemen dari awal daftar.
display - Menampilkan daftar.
Operasi Penyisipan
Kode berikut menunjukkan operasi penyisipan dalam daftar tertaut melingkar berdasarkan daftar tertaut tunggal.
Contoh
//insert link at the first location
void insertFirst(int key, int data) {
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data= data;
if (isEmpty()) {
head = link;
head->next = head;
} else {
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}Operasi Penghapusan
Kode berikut menunjukkan operasi penghapusan dalam daftar tertaut melingkar berdasarkan daftar tertaut tunggal.
//delete first item
struct node * deleteFirst() {
//save reference to first link
struct node *tempLink = head;
if(head->next == head) {
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}Operasi Daftar Tampilan
Kode berikut menunjukkan operasi daftar tampilan dalam daftar tertaut melingkar.
//display the list
void printList() {
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL) {
while(ptr->next != ptr) {
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}Untuk mengetahui implementasinya dalam bahasa pemograman C, silahkan klik disini .
Tumpukan adalah Tipe Data Abstrak (ADT), yang umum digunakan di sebagian besar bahasa pemrograman. Dinamai tumpukan karena berperilaku seperti tumpukan dunia nyata, misalnya - setumpuk kartu atau tumpukan piring, dll.

Tumpukan dunia nyata memungkinkan operasi di satu ujung saja. Misalnya, kita dapat menempatkan atau mengeluarkan kartu atau piring hanya dari atas tumpukan. Demikian pula, Stack ADT memungkinkan semua operasi data di satu ujung saja. Pada waktu tertentu, kami hanya dapat mengakses elemen teratas tumpukan.
Fitur ini membuatnya menjadi struktur data LIFO. LIFO adalah singkatan dari Last-in-first-out. Di sini elemen yang ditempatkan (disisipkan atau ditambahkan) terakhir, diakses terlebih dahulu. Dalam terminologi stack, operasi penyisipan disebutPUSH operasi operasi dan pemindahan disebut POP operasi.
Representasi Stack
Diagram berikut menggambarkan tumpukan dan operasinya -

Tumpukan dapat diimplementasikan melalui Array, Structure, Pointer, dan Linked List. Tumpukan dapat berupa ukuran tetap atau mungkin memiliki kesan perubahan ukuran dinamis. Di sini, kita akan mengimplementasikan stack menggunakan array, yang menjadikannya implementasi stack dengan ukuran tetap.
Operasi Dasar
Operasi tumpukan mungkin melibatkan menginisialisasi tumpukan, menggunakannya dan kemudian membatalkan inisialisasi. Terlepas dari hal-hal dasar ini, tumpukan digunakan untuk dua operasi utama berikut -
push() - Mendorong (menyimpan) elemen di stack.
pop() - Menghapus (mengakses) elemen dari stack.
Saat data DITOLAK ke stack.
Untuk menggunakan tumpukan secara efisien, kita perlu memeriksa status tumpukan juga. Untuk tujuan yang sama, fungsi berikut ditambahkan ke tumpukan -
peek() - dapatkan elemen data teratas dari tumpukan, tanpa menghapusnya.
isFull() - periksa apakah tumpukan sudah penuh.
isEmpty() - periksa apakah tumpukan kosong.
Setiap saat, kami mempertahankan penunjuk ke data PUSHed terakhir di tumpukan. Karena penunjuk ini selalu mewakili bagian atas tumpukan, maka dinamaitop. Itutop pointer memberikan nilai teratas dari tumpukan tanpa benar-benar menghapusnya.
Pertama kita harus belajar tentang prosedur untuk mendukung fungsi stack -
mengintip()
Algoritma peek () fungsi -
begin procedure peek
return stack[top]
end procedureImplementasi fungsi peek () dalam bahasa pemrograman C -
Example
int peek() {
return stack[top];
}penuh()
Algoritma dari fungsi isfull () -
begin procedure isfull
if top equals to MAXSIZE
return true
else
return false
endif
end procedureImplementasi fungsi isfull () dalam bahasa pemrograman C -
Example
bool isfull() {
if(top == MAXSIZE)
return true;
else
return false;
}kosong()
Algoritma fungsi isempty () -
begin procedure isempty
if top less than 1
return true
else
return false
endif
end procedureImplementasi fungsi isempty () dalam bahasa pemrograman C sedikit berbeda. Kami menginisialisasi top di -1, karena indeks dalam array dimulai dari 0. Jadi kami memeriksa apakah top di bawah nol atau -1 untuk menentukan apakah stack kosong. Ini kodenya -
Example
bool isempty() {
if(top == -1)
return true;
else
return false;
}Operasi Dorong
Proses menempatkan elemen data baru ke dalam tumpukan dikenal sebagai Operasi Dorong. Operasi dorong melibatkan serangkaian langkah -
Step 1 - Memeriksa apakah tumpukan sudah penuh.
Step 2 - Jika tumpukan penuh, menghasilkan kesalahan dan keluar.
Step 3 - Jika tumpukan tidak penuh, tambahkan top untuk menunjukkan ruang kosong berikutnya.
Step 4 - Menambahkan elemen data ke lokasi tumpukan, di mana bagian atas mengarah.
Step 5 - Mengembalikan kesuksesan.
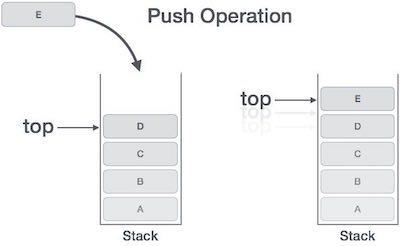
Jika daftar tertaut digunakan untuk mengimplementasikan tumpukan, maka pada langkah 3, kita perlu mengalokasikan ruang secara dinamis.
Algoritma untuk Operasi PUSH
Algoritma sederhana untuk operasi Push dapat diturunkan sebagai berikut -
begin procedure push: stack, data
if stack is full
return null
endif
top ← top + 1
stack[top] ← data
end procedureImplementasi algoritma ini di C, sangat mudah. Lihat kode berikut -
Example
void push(int data) {
if(!isFull()) {
top = top + 1;
stack[top] = data;
} else {
printf("Could not insert data, Stack is full.\n");
}
}Operasi Pop
Mengakses konten sambil menghapusnya dari tumpukan, dikenal sebagai Operasi Pop. Dalam implementasi array dari operasi pop (), elemen data sebenarnya tidak dihapustopditurunkan ke posisi yang lebih rendah dalam tumpukan untuk menunjuk ke nilai berikutnya. Tapi dalam implementasi linked-list, pop () sebenarnya menghapus elemen data dan membatalkan alokasi ruang memori.
Operasi Pop mungkin melibatkan langkah-langkah berikut -
Step 1 - Memeriksa apakah tumpukan kosong.
Step 2 - Jika tumpukan kosong, menghasilkan kesalahan dan keluar.
Step 3 - Jika tumpukan tidak kosong, mengakses elemen data di mana top menunjuk.
Step 4 - Mengurangi nilai teratas sebanyak 1.
Step 5 - Mengembalikan kesuksesan.

Algoritma untuk Operasi Pop
Algoritme sederhana untuk operasi Pop dapat diturunkan sebagai berikut -
begin procedure pop: stack
if stack is empty
return null
endif
data ← stack[top]
top ← top - 1
return data
end procedureImplementasi algoritma ini di C, adalah sebagai berikut -
Example
int pop(int data) {
if(!isempty()) {
data = stack[top];
top = top - 1;
return data;
} else {
printf("Could not retrieve data, Stack is empty.\n");
}
}Untuk program stack lengkap dalam bahasa pemrograman C, silakan klik di sini .
Cara penulisan ekspresi aritmatika dikenal dengan a notation. Ekspresi aritmatika dapat ditulis dalam tiga notasi yang berbeda tetapi ekuivalen, yaitu, tanpa mengubah esensi atau keluaran ekspresi. Notasi ini adalah -
- Notasi Infix
- Notasi Awalan (Polandia)
- Notasi Postfix (Reverse-Polish)
Notasi ini dinamai seperti bagaimana mereka menggunakan operator dalam ekspresi. Kita akan mempelajari hal yang sama di sini, di bab ini.
Notasi Infix
Kami menulis ekspresi dalam infix notasi, misalnya a - b + c, di mana operator digunakan in-di antara operan. Mudah bagi kita manusia untuk membaca, menulis, dan berbicara dalam notasi infix tetapi hal yang sama tidak berjalan dengan baik dengan perangkat komputasi. Algoritme untuk memproses notasi infiks bisa jadi sulit dan mahal dalam hal konsumsi waktu dan ruang.
Notasi Awalan
Dalam notasi ini, operator adalah prefixed ke operan, yaitu operator ditulis sebelum operan. Sebagai contoh,+ab. Ini setara dengan notasi infiksnyaa + b. Notasi awalan juga dikenal sebagaiPolish Notation.
Notasi Postfix
Gaya notasi ini dikenal sebagai Reversed Polish Notation. Dalam gaya notasi ini, operatornya adalahpostfixed ke operan yaitu, operator ditulis setelah operan. Sebagai contoh,ab+. Ini setara dengan notasi infiksnyaa + b.
Tabel berikut secara singkat mencoba menunjukkan perbedaan di ketiga notasi -
| Sr.No. | Notasi Infix | Notasi Awalan | Notasi Postfix |
|---|---|---|---|
| 1 | a + b | + ab | ab + |
| 2 | (a + b) ∗ c | ∗ + abc | ab + c ∗ |
| 3 | a ∗ (b + c) | ∗ a + bc | abc + ∗ |
| 4 | a / b + c / d | + / ab / cd | ab / cd / + |
| 5 | (a + b) ∗ (c + d) | ∗ + ab + cd | ab + cd + ∗ |
| 6 | ((a + b) ∗ c) - d | - ∗ + abcd | ab + c ∗ d - |
Ekspresi Parsing
Seperti yang telah kita diskusikan, ini bukanlah cara yang sangat efisien untuk mendesain algoritma atau program untuk mengurai notasi infiks. Sebaliknya, notasi infiks ini pertama-tama diubah menjadi notasi postfix atau prefiks dan kemudian dihitung.
Untuk mengurai ekspresi aritmatika apa pun, kita perlu menjaga prioritas operator dan asosiativitas juga.
Hak lebih tinggi
Ketika operan berada di antara dua operator yang berbeda, operator mana yang akan mengambil operan terlebih dahulu, ditentukan oleh prioritas operator di atas yang lain. Misalnya -

Karena operasi perkalian lebih diutamakan daripada penjumlahan, b * c akan dievaluasi terlebih dahulu. Tabel prioritas operator disediakan nanti.
Asosiatif
Asosiatif mendeskripsikan aturan di mana operator dengan prioritas yang sama muncul dalam ekspresi. Misalnya, dalam ekspresi a + b - c, + dan - memiliki prioritas yang sama, lalu bagian ekspresi mana yang akan dievaluasi terlebih dahulu, ditentukan oleh asosiativitas operator tersebut. Di sini, + dan - dibiarkan asosiatif, jadi ekspresi akan dievaluasi sebagai(a + b) − c.
Presedensi dan asosiatif menentukan urutan evaluasi ekspresi. Berikut adalah tabel prioritas dan asosiasi operator (dari tertinggi ke terendah) -
| Sr.No. | Operator | Hak lebih tinggi | Asosiatif |
|---|---|---|---|
| 1 | Eksponensial ^ | Paling tinggi | Asosiatif yang Benar |
| 2 | Perkalian (∗) & Pembagian (/) | Tertinggi Kedua | Asosiatif Kiri |
| 3 | Penjumlahan (+) & Pengurangan (-) | Terendah | Asosiatif Kiri |
Tabel di atas menunjukkan perilaku default operator. Kapan pun dalam evaluasi ekspresi, urutan dapat diubah dengan menggunakan tanda kurung. Misalnya -
Di a + b*c, bagian ekspresi b*cakan dievaluasi terlebih dahulu, dengan perkalian sebagai diutamakan daripada penjumlahan. Kami di sini menggunakan tanda kurung untuka + b untuk dievaluasi terlebih dahulu, seperti (a + b)*c.
Algoritma Evaluasi Postfix
Sekarang kita akan melihat algoritma tentang bagaimana mengevaluasi notasi postfix -
Step 1 − scan the expression from left to right
Step 2 − if it is an operand push it to stack
Step 3 − if it is an operator pull operand from stack and perform operation
Step 4 − store the output of step 3, back to stack
Step 5 − scan the expression until all operands are consumed
Step 6 − pop the stack and perform operationUntuk melihat implementasinya dalam bahasa pemograman C, silahkan klik disini .
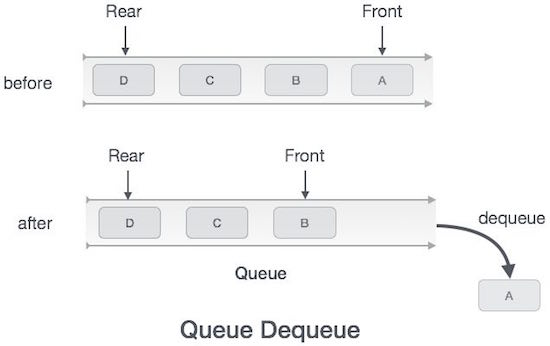
Antrian adalah struktur data abstrak, agak mirip dengan Tumpukan. Tidak seperti tumpukan, antrean terbuka di kedua ujungnya. Satu ujung selalu digunakan untuk memasukkan data (enqueue) dan yang lainnya digunakan untuk menghapus data (dequeue). Antrian mengikuti metodologi First-In-First-Out, yaitu item data yang disimpan terlebih dahulu akan diakses terlebih dahulu.

Contoh antrian dunia nyata dapat berupa jalan satu arah satu jalur, di mana kendaraan masuk lebih dulu, keluar lebih dulu. Contoh dunia nyata lainnya dapat dilihat sebagai antrian di loket tiket dan halte bus.
Representasi Antrian
Seperti yang sekarang kita pahami bahwa dalam antrian, kita mengakses kedua ujungnya karena alasan yang berbeda. Diagram berikut yang diberikan di bawah ini mencoba menjelaskan representasi antrian sebagai struktur data -

Seperti di stack, antrian juga dapat diimplementasikan menggunakan Array, Linked-list, Pointers dan Structures. Demi kesederhanaan, kita akan mengimplementasikan antrian menggunakan array satu dimensi.
Operasi Dasar
Operasi antrian mungkin melibatkan menginisialisasi atau menentukan antrian, memanfaatkannya, dan kemudian menghapusnya sepenuhnya dari memori. Di sini kita akan mencoba memahami operasi dasar yang terkait dengan antrian -
enqueue() - menambahkan (menyimpan) item ke antrian.
dequeue() - hapus (akses) item dari antrian.
Beberapa fungsi lagi diperlukan untuk membuat operasi antrian yang disebutkan di atas efisien. Ini adalah -
peek() - Mendapat elemen di depan antrian tanpa menghapusnya.
isfull() - Memeriksa apakah antrian penuh.
isempty() - Memeriksa apakah antrian kosong.
Dalam antrian, kami selalu dequeue (atau mengakses) data, yang ditunjukkan oleh front pointer dan saat memasukkan (atau menyimpan) data dalam antrian yang kami bantu rear penunjuk.
Pertama-tama, mari kita pelajari tentang fungsi pendukung antrean -
mengintip()
Fungsi ini membantu untuk melihat data di frontdari antrian. Algoritme fungsi peek () adalah sebagai berikut -
Algorithm
begin procedure peek
return queue[front]
end procedureImplementasi fungsi peek () dalam bahasa pemrograman C -
Example
int peek() {
return queue[front];
}penuh()
Karena kami menggunakan array dimensi tunggal untuk mengimplementasikan antrian, kami hanya memeriksa penunjuk belakang untuk mencapai MAXSIZE untuk menentukan bahwa antrian sudah penuh. Jika kita mempertahankan antrian dalam daftar tertaut melingkar, algoritme akan berbeda. Algoritma dari fungsi isfull () -
Algorithm
begin procedure isfull
if rear equals to MAXSIZE
return true
else
return false
endif
end procedureImplementasi fungsi isfull () dalam bahasa pemrograman C -
Example
bool isfull() {
if(rear == MAXSIZE - 1)
return true;
else
return false;
}kosong()
Algoritma fungsi isempty () -
Algorithm
begin procedure isempty
if front is less than MIN OR front is greater than rear
return true
else
return false
endif
end procedureJika nilai front kurang dari MIN atau 0, ini memberitahu bahwa antrian belum diinisialisasi, oleh karena itu kosong.
Berikut kode pemrograman C -
Example
bool isempty() {
if(front < 0 || front > rear)
return true;
else
return false;
}Operasi Enqueue
Antrian mempertahankan dua penunjuk data, front dan rear. Oleh karena itu, operasinya relatif sulit untuk diterapkan dibandingkan dengan stack.
Langkah-langkah berikut harus dilakukan untuk memasukkan (memasukkan) data ke dalam antrian -
Step 1 - Periksa apakah antriannya penuh.
Step 2 - Jika antrian penuh, menghasilkan error overflow dan keluar.
Step 3 - Jika antrian tidak penuh, tambahkan rear pointer untuk menunjukkan ruang kosong berikutnya.
Step 4 - Tambahkan elemen data ke lokasi antrian, di mana bagian belakang mengarah.
Step 5 - sukses kembali.

Terkadang, kami juga memeriksa untuk melihat apakah antrian diinisialisasi atau tidak, untuk menangani situasi yang tidak terduga.
Algoritma untuk operasi antrian
procedure enqueue(data)
if queue is full
return overflow
endif
rear ← rear + 1
queue[rear] ← data
return true
end procedureImplementasi enqueue () dalam bahasa pemrograman C -
Example
int enqueue(int data)
if(isfull())
return 0;
rear = rear + 1;
queue[rear] = data;
return 1;
end procedureOperasi Dequeue
Mengakses data dari antrian adalah proses dari dua tugas - mengakses data di mana frontmenunjuk dan menghapus data setelah akses. Langkah-langkah berikut diambil untuk melakukandequeue operasi -
Step 1 - Periksa apakah antrian kosong.
Step 2 - Jika antrian kosong, menghasilkan kesalahan aliran bawah dan keluar.
Step 3 - Jika antrian tidak kosong, akses data dimana front menunjuk.
Step 4 - Penambahan front pointer untuk menunjuk ke elemen data berikutnya yang tersedia.
Step 5 - Kembalikan sukses.
Algoritma untuk operasi dequeue
procedure dequeue
if queue is empty
return underflow
end if
data = queue[front]
front ← front + 1
return true
end procedureImplementasi dequeue () dalam bahasa pemrograman C -
Example
int dequeue() {
if(isempty())
return 0;
int data = queue[front];
front = front + 1;
return data;
}Untuk program Queue lengkap dalam bahasa pemograman C, silahkan klik disini .
Pencarian linier adalah algoritma pencarian yang sangat sederhana. Dalam jenis pencarian ini, pencarian berurutan dilakukan pada semua item satu per satu. Setiap item dicentang dan jika kecocokan ditemukan maka item tersebut dikembalikan, jika tidak pencarian berlanjut hingga akhir pengumpulan data.

Algoritma
Linear Search ( Array A, Value x)
Step 1: Set i to 1
Step 2: if i > n then go to step 7
Step 3: if A[i] = x then go to step 6
Step 4: Set i to i + 1
Step 5: Go to Step 2
Step 6: Print Element x Found at index i and go to step 8
Step 7: Print element not found
Step 8: ExitPseudocode
procedure linear_search (list, value)
for each item in the list
if match item == value
return the item's location
end if
end for
end procedureUntuk mengetahui tentang implementasi pencarian linier dalam bahasa pemrograman C, silakan klik di sini .
Pencarian biner adalah algoritma pencarian cepat dengan kompleksitas run-time Ο (log n). Algoritma pencarian ini bekerja berdasarkan prinsip divide and conquer. Agar algoritme ini berfungsi dengan baik, pengumpulan data harus dalam bentuk yang diurutkan.
Pencarian biner mencari item tertentu dengan membandingkan item paling tengah dari koleksi. Jika terjadi kecocokan, maka indeks item dikembalikan. Jika item tengah lebih besar dari item, maka item tersebut dicari di sub-larik di sebelah kiri item tengah. Jika tidak, item dicari di sub-larik di sebelah kanan item tengah. Proses ini berlanjut pada sub-larik juga sampai ukuran sub larik berkurang menjadi nol.
Bagaimana Pencarian Biner Bekerja?
Agar pencarian biner berfungsi, array target wajib diurutkan. Kita akan mempelajari proses pencarian biner dengan contoh gambar. Berikut ini adalah array yang diurutkan dan mari kita asumsikan bahwa kita perlu mencari lokasi nilai 31 menggunakan pencarian biner.

Pertama, kita akan menentukan setengah dari larik dengan menggunakan rumus ini -
mid = low + (high - low) / 2Ini dia, 0 + (9 - 0) / 2 = 4 (nilai integer 4,5). Jadi, 4 adalah tengah larik.

Sekarang kita bandingkan nilai yang disimpan di lokasi 4, dengan nilai yang sedang dicari, yaitu 31. Kita temukan bahwa nilai di lokasi 4 adalah 27, yang tidak sama. Karena nilainya lebih besar dari 27 dan kita memiliki array yang diurutkan, maka kita juga tahu bahwa nilai target harus berada di bagian atas array.

Kami mengubah rendah ke pertengahan + 1 dan menemukan nilai tengah baru lagi.
low = mid + 1
mid = low + (high - low) / 2Pertengahan baru kami adalah 7 sekarang. Kami membandingkan nilai yang disimpan di lokasi 7 dengan nilai target kami 31.

Nilai yang disimpan di lokasi 7 bukanlah kecocokan, melainkan lebih dari apa yang kita cari. Jadi, nilainya harus di bagian bawah dari lokasi ini.

Oleh karena itu, kami menghitung lagi tengahnya. Kali ini jam 5.

Kami membandingkan nilai yang disimpan di lokasi 5 dengan nilai target kami. Kami menemukan bahwa itu cocok.

Kami menyimpulkan bahwa nilai target 31 disimpan di lokasi 5.
Pencarian biner membagi dua item yang dapat dicari dan dengan demikian mengurangi jumlah perbandingan yang akan dibuat menjadi angka yang sangat sedikit.
Pseudocode
Pseudocode dari algoritma pencarian biner akan terlihat seperti ini -
Procedure binary_search
A ← sorted array
n ← size of array
x ← value to be searched
Set lowerBound = 1
Set upperBound = n
while x not found
if upperBound < lowerBound
EXIT: x does not exists.
set midPoint = lowerBound + ( upperBound - lowerBound ) / 2
if A[midPoint] < x
set lowerBound = midPoint + 1
if A[midPoint] > x
set upperBound = midPoint - 1
if A[midPoint] = x
EXIT: x found at location midPoint
end while
end procedureUntuk mengetahui tentang implementasi pencarian biner menggunakan array dalam bahasa pemrograman C, silahkan klik disini .
Pencarian interpolasi adalah varian yang ditingkatkan dari pencarian biner. Algoritma pencarian ini bekerja pada posisi probing dari nilai yang dibutuhkan. Agar algoritme ini berfungsi dengan baik, pengumpulan data harus dalam bentuk yang diurutkan dan didistribusikan secara merata.
Pencarian biner memiliki keuntungan besar dari kompleksitas waktu dibandingkan pencarian linier. Pencarian linier memiliki kompleksitas kasus terburuk Ο (n) sedangkan pencarian biner memiliki Ο (log n).
Ada kasus dimana lokasi data target dapat diketahui sebelumnya. Misalnya, dalam kasus direktori telepon, jika kita ingin mencari nomor telepon Morphius. Di sini, pencarian linier dan bahkan pencarian biner akan tampak lambat karena kita dapat langsung beralih ke ruang memori tempat penyimpanan nama yang dimulai dari 'M'.
Memposisikan dalam Pencarian Biner
Dalam pencarian biner, jika data yang diinginkan tidak ditemukan maka sisa daftar dibagi menjadi dua bagian, lebih rendah dan lebih tinggi. Pencarian dilakukan di salah satu dari mereka.




Bahkan ketika data diurutkan, pencarian biner tidak memanfaatkan untuk menyelidiki posisi data yang diinginkan.
Posisikan Probing dalam Pencarian Interpolasi
Pencarian interpolasi menemukan item tertentu dengan menghitung posisi probe. Awalnya, posisi probe adalah posisi paling tengah item koleksi.


Jika terjadi kecocokan, maka indeks item dikembalikan. Untuk membagi daftar menjadi dua bagian, kami menggunakan metode berikut -
mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
where −
A = list
Lo = Lowest index of the list
Hi = Highest index of the list
A[n] = Value stored at index n in the listJika item tengah lebih besar dari item, maka posisi probe dihitung lagi di sub-larik di sebelah kanan item tengah. Jika tidak, item akan dicari di subarray di sebelah kiri item tengah. Proses ini berlanjut pada sub-larik juga sampai ukuran sub larik berkurang menjadi nol.
Kompleksitas runtime dari algoritma pencarian interpolasi adalah Ο(log (log n)) jika dibandingkan dengan Ο(log n) dari BST dalam situasi yang menguntungkan.
Algoritma
Karena ini adalah improvisasi dari algoritma BST yang ada, kami menyebutkan langkah-langkah untuk mencari indeks nilai data 'target', menggunakan pemeriksaan posisi -
Step 1 − Start searching data from middle of the list.
Step 2 − If it is a match, return the index of the item, and exit.
Step 3 − If it is not a match, probe position.
Step 4 − Divide the list using probing formula and find the new midle.
Step 5 − If data is greater than middle, search in higher sub-list.
Step 6 − If data is smaller than middle, search in lower sub-list.
Step 7 − Repeat until match.Pseudocode
A → Array list
N → Size of A
X → Target Value
Procedure Interpolation_Search()
Set Lo → 0
Set Mid → -1
Set Hi → N-1
While X does not match
if Lo equals to Hi OR A[Lo] equals to A[Hi]
EXIT: Failure, Target not found
end if
Set Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo])
if A[Mid] = X
EXIT: Success, Target found at Mid
else
if A[Mid] < X
Set Lo to Mid+1
else if A[Mid] > X
Set Hi to Mid-1
end if
end if
End While
End ProcedureUntuk mengetahui tentang implementasi pencarian interpolasi dalam bahasa pemrograman C, klik disini .
Tabel Hash adalah struktur data yang menyimpan data secara asosiatif. Dalam tabel hash, data disimpan dalam format array, di mana setiap nilai data memiliki nilai indeks uniknya sendiri. Akses data menjadi sangat cepat jika kita mengetahui indeks dari data yang diinginkan.
Dengan demikian, ini menjadi struktur data di mana operasi penyisipan dan pencarian sangat cepat terlepas dari ukuran datanya. Tabel Hash menggunakan array sebagai media penyimpanan dan menggunakan teknik hash untuk menghasilkan indeks di mana elemen akan dimasukkan atau akan ditempatkan.
Hashing
Hashing adalah teknik untuk mengubah rentang nilai kunci menjadi rentang indeks larik. Kami akan menggunakan operator modulo untuk mendapatkan berbagai nilai kunci. Pertimbangkan contoh tabel hash ukuran 20, dan item berikut ini akan disimpan. Item dalam format (key, value).

- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | Kunci | Hash | Indeks Array |
|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 |
| 4 | 4 | 4% 20 = 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 |
Pemeriksaan Linier
Seperti yang bisa kita lihat, mungkin saja teknik hashing digunakan untuk membuat indeks array yang sudah digunakan. Dalam kasus seperti itu, kita dapat mencari lokasi kosong berikutnya dalam larik dengan melihat ke sel berikutnya hingga menemukan sel kosong. Teknik ini disebut probing linier.
| Sr.No. | Kunci | Hash | Indeks Array | Setelah Probing Linear, Indeks Array |
|---|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 | 3 |
| 4 | 4 | 4% 20 = 4 | 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 | 18 |
Operasi Dasar
Berikut adalah operasi utama dasar dari tabel hash.
Search - Mencari elemen dalam tabel hash.
Insert - menyisipkan elemen dalam tabel hash.
delete - Menghapus elemen dari tabel hash.
DataItem
Tentukan item data yang memiliki beberapa data dan kunci, berdasarkan mana pencarian akan dilakukan dalam tabel hash.
struct DataItem {
int data;
int key;
};Metode Hash
Tentukan metode hashing untuk menghitung kode hash dari kunci item data.
int hashCode(int key){
return key % SIZE;
}Operasi Pencarian
Kapan pun sebuah elemen akan dicari, hitung kode hash dari kunci yang dilewatkan dan temukan elemen tersebut menggunakan kode hash tersebut sebagai indeks dalam larik. Gunakan probing linier untuk mendapatkan elemen di depan jika elemen tidak ditemukan pada kode hash yang dihitung.
Contoh
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}Sisipkan Operasi
Kapan pun sebuah elemen akan disisipkan, hitung kode hash dari kunci yang dilewatkan dan temukan indeks menggunakan kode hash tersebut sebagai indeks dalam larik. Gunakan penyelidikan linier untuk lokasi kosong, jika elemen ditemukan pada kode hash yang dihitung.
Contoh
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}Hapus Operasi
Setiap kali sebuah elemen akan dihapus, hitung kode hash dari kunci yang dilewatkan dan temukan indeks menggunakan kode hash tersebut sebagai indeks dalam larik. Gunakan probing linier untuk mendapatkan elemen di depan jika elemen tidak ditemukan pada kode hash yang dihitung. Saat ditemukan, simpan item dummy di sana untuk menjaga performa tabel hash tetap utuh.
Contoh
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}Untuk mengetahui tentang implementasi hash dalam bahasa pemrograman C, silakan klik di sini .
Pengurutan mengacu pada pengaturan data dalam format tertentu. Algoritme pengurutan menentukan cara untuk mengatur data dalam urutan tertentu. Urutan paling umum dalam urutan numerik atau leksikografis.
Pentingnya pengurutan terletak pada kenyataan bahwa pencarian data dapat dioptimalkan hingga tingkat yang sangat tinggi, jika data disimpan dengan cara yang diurutkan. Pengurutan juga digunakan untuk merepresentasikan data dalam format yang lebih mudah dibaca. Berikut adalah beberapa contoh pengurutan dalam skenario kehidupan nyata -
Telephone Directory - Direktori telepon menyimpan nomor telepon orang yang diurutkan berdasarkan namanya, sehingga nama tersebut dapat dicari dengan mudah.
Dictionary - Kamus menyimpan kata-kata dalam urutan abjad sehingga pencarian kata apa pun menjadi mudah.
Penyortiran Di Tempat dan Penyortiran Tidak Di Tempat
Algoritme pengurutan mungkin memerlukan beberapa ruang ekstra untuk perbandingan dan penyimpanan sementara dari beberapa elemen data. Algoritme ini tidak memerlukan ruang ekstra dan penyortiran dikatakan terjadi di tempat, atau misalnya, di dalam larik itu sendiri. Ini disebutin-place sorting. Jenis gelembung adalah contoh pengurutan di tempat.
Namun, dalam beberapa algoritma pengurutan, program membutuhkan ruang yang lebih dari atau sama dengan elemen yang diurutkan. Penyortiran yang menggunakan ruang yang sama atau lebih disebutnot-in-place sorting. Merge-sort adalah contoh pengurutan tidak di tempat.
Penyortiran Stabil dan Tidak Stabil
Jika algoritme pengurutan, setelah menyortir konten, tidak mengubah urutan konten serupa di mana mereka muncul, hal itu disebut stable sorting.

Jika algoritme pengurutan, setelah menyortir konten, mengubah urutan konten serupa di mana mereka muncul, hal itu disebut unstable sorting.

Stabilitas suatu algoritma penting ketika kita ingin mempertahankan urutan elemen asli, seperti dalam tupel misalnya.
Algoritma Penyortiran Adaptif dan Non-Adaptif
Algoritme pengurutan dikatakan adaptif, jika memanfaatkan elemen yang sudah 'diurutkan' dalam daftar yang akan disortir. Artinya, saat menyortir jika daftar sumber memiliki beberapa elemen yang sudah diurutkan, algoritme adaptif akan mempertimbangkan hal ini dan akan mencoba untuk tidak mengurutkan ulang.
Algoritme non-adaptif adalah algoritme yang tidak memperhitungkan elemen yang sudah disortir. Mereka mencoba memaksa setiap elemen untuk diatur ulang untuk mengkonfirmasi urutannya.
Istilah Penting
Beberapa istilah umumnya diciptakan saat membahas teknik pengurutan, berikut adalah pengantar singkat untuk mereka -
Meningkatkan Ketertiban
Urutan nilai dikatakan masuk increasing order, jika elemen yang berurutan lebih besar dari yang sebelumnya. Misalnya, 1, 3, 4, 6, 8, 9 berada dalam urutan naik, karena setiap elemen berikutnya lebih besar dari elemen sebelumnya.
Penurunan Pesanan
Urutan nilai dikatakan masuk decreasing order, jika elemen yang berurutan lebih kecil dari yang sekarang. Misalnya, 9, 8, 6, 4, 3, 1 berada dalam urutan menurun, karena setiap elemen berikutnya lebih kecil dari elemen sebelumnya.
Pesanan Tidak Meningkat
Urutan nilai dikatakan masuk non-increasing order, jika elemen berurutan kurang dari atau sama dengan elemen sebelumnya dalam urutan tersebut. Urutan ini terjadi ketika urutan berisi nilai duplikat. Misalnya, 9, 8, 6, 3, 3, 1 berada dalam urutan tidak bertambah, karena setiap elemen berikutnya kurang dari atau sama dengan (dalam kasus 3) tetapi tidak lebih besar dari elemen sebelumnya.
Pesanan Tidak Menurun
Urutan nilai dikatakan masuk non-decreasing order, jika elemen berurutan lebih besar dari atau sama dengan elemen sebelumnya dalam urutan tersebut. Urutan ini terjadi ketika urutan berisi nilai duplikat. Misalnya, 1, 3, 3, 6, 8, 9 berada dalam urutan tidak menurun, karena setiap elemen berikutnya lebih besar dari atau sama dengan (dalam kasus 3) tetapi tidak kurang dari yang sebelumnya.
Bubble sort adalah algoritme pengurutan sederhana. Algoritme pengurutan ini adalah algoritme berbasis perbandingan di mana setiap pasangan elemen yang berdekatan dibandingkan dan elemen-elemen tersebut ditukar jika tidak berurutan. Algoritma ini tidak cocok untuk kumpulan data besar karena kompleksitas kasus rata-rata dan terburuknya adalah Ο (n 2 ) di manan adalah jumlah item.
Bagaimana Cara Kerja Bubble Sort?
Kami mengambil array yang tidak disortir untuk contoh kami. Pengurutan gelembung membutuhkan waktu Ο (n 2 ) jadi kami menjaganya agar tetap singkat dan tepat.

Jenis gelembung dimulai dengan dua elemen pertama, membandingkannya untuk memeriksa mana yang lebih besar.

Dalam hal ini, nilai 33 lebih besar dari 14, jadi sudah ada di lokasi yang diurutkan. Selanjutnya, kami membandingkan 33 dengan 27.

Kami menemukan bahwa 27 lebih kecil dari 33 dan kedua nilai ini harus ditukar.

Array baru akan terlihat seperti ini -

Selanjutnya kami membandingkan 33 dan 35. Kami menemukan bahwa keduanya berada pada posisi yang sudah diurutkan.

Kemudian kami pindah ke dua nilai berikutnya, 35 dan 10.

Kita tahu bahwa 10 lebih kecil 35. Oleh karena itu mereka tidak diurutkan.

Kami menukar nilai-nilai ini. Kami menemukan bahwa kami telah mencapai akhir larik. Setelah satu iterasi, array akan terlihat seperti ini -

Tepatnya, kami sekarang menunjukkan bagaimana sebuah array akan terlihat setelah setiap iterasi. Setelah iterasi kedua, akan terlihat seperti ini -

Perhatikan bahwa setelah setiap iterasi, setidaknya satu nilai bergerak di akhir.

Dan ketika tidak ada swap yang diperlukan, bubble sort mengetahui bahwa array sudah diurutkan sepenuhnya.

Sekarang kita harus melihat beberapa aspek praktis dari bubble sort.
Algoritma
Kami berasumsi list adalah larik nelemen. Kami selanjutnya berasumsi bahwaswap fungsi menukar nilai dari elemen array yang diberikan.
begin BubbleSort(list)
for all elements of list
if list[i] > list[i+1]
swap(list[i], list[i+1])
end if
end for
return list
end BubbleSortPseudocode
Kami mengamati dalam algoritme bahwa Bubble Sort membandingkan setiap pasangan elemen array kecuali jika seluruh array sepenuhnya diurutkan dalam urutan menaik. Ini dapat menyebabkan beberapa masalah kompleksitas seperti bagaimana jika array tidak perlu lagi bertukar karena semua elemen sudah naik.
Untuk mengatasi masalah ini, kami menggunakan satu variabel bendera swappedyang akan membantu kami melihat apakah ada pertukaran yang terjadi atau tidak. Jika tidak ada pertukaran yang terjadi, yaitu array tidak memerlukan pemrosesan lagi untuk disortir, itu akan keluar dari loop.
Pseudocode dari algoritma BubbleSort dapat ditulis sebagai berikut -
procedure bubbleSort( list : array of items )
loop = list.count;
for i = 0 to loop-1 do:
swapped = false
for j = 0 to loop-1 do:
/* compare the adjacent elements */
if list[j] > list[j+1] then
/* swap them */
swap( list[j], list[j+1] )
swapped = true
end if
end for
/*if no number was swapped that means
array is sorted now, break the loop.*/
if(not swapped) then
break
end if
end for
end procedure return listPenerapan
Satu lagi masalah yang tidak kami tangani dalam algoritme asli kami dan kodesemu improvisasinya, adalah bahwa, setelah setiap iterasi, nilai tertinggi berada di akhir larik. Karenanya, iterasi berikutnya tidak perlu menyertakan elemen yang sudah diurutkan. Untuk tujuan ini, dalam implementasi kami, kami membatasi loop dalam untuk menghindari nilai yang sudah diurutkan.
Untuk mengetahui tentang implementasi bubble sort dalam bahasa pemrograman C, silakan klik disini .
Ini adalah algoritme pengurutan berbasis perbandingan di tempat. Di sini, sub-daftar dipertahankan yang selalu diurutkan. Misalnya, bagian bawah larik dipertahankan untuk diurutkan. Sebuah elemen yang akan 'disisipkan' dalam sub-daftar yang diurutkan ini, harus menemukan tempat yang sesuai dan kemudian harus disisipkan di sana. Maka nama,insertion sort.
Array dicari secara berurutan dan item yang tidak diurutkan dipindahkan dan dimasukkan ke dalam sub-list yang diurutkan (dalam array yang sama). Algoritme ini tidak cocok untuk kumpulan data besar karena kompleksitas kasus rata-rata dan terburuknya adalah Ο (n 2 ), di manan adalah jumlah item.
Bagaimana Cara Kerja Insertion Sort?
Kami mengambil array yang tidak disortir untuk contoh kami.

Sortir penyisipan membandingkan dua elemen pertama.

Ia menemukan bahwa 14 dan 33 sudah dalam urutan menaik. Untuk saat ini, 14 ada di sub-daftar yang diurutkan.

Urutan penyisipan bergerak maju dan membandingkan 33 dengan 27.

Dan menemukan bahwa 33 tidak dalam posisi yang benar.

Ini menukar 33 dengan 27. Ia juga memeriksa dengan semua elemen sub-daftar yang diurutkan. Di sini kita melihat bahwa sub-daftar yang diurutkan hanya memiliki satu elemen 14, dan 27 lebih besar dari 14. Oleh karena itu, sub-daftar yang diurutkan tetap diurutkan setelah bertukar.

Sekarang kami memiliki 14 dan 27 di sub-daftar yang diurutkan. Selanjutnya, membandingkan 33 dengan 10.

Nilai-nilai ini tidak dalam urutan yang diurutkan.

Jadi kami menukar mereka.

Namun, pertukaran membuat 27 dan 10 tidak disortir.

Karenanya, kami menukar mereka juga.

Sekali lagi kami menemukan 14 dan 10 dalam urutan yang tidak diurutkan.

Kami menukar mereka lagi. Pada akhir iterasi ketiga, kami memiliki sub-daftar yang diurutkan dari 4 item.

Proses ini berlangsung hingga semua nilai yang tidak diurutkan tercakup dalam sub-daftar yang diurutkan. Sekarang kita akan melihat beberapa aspek pemrograman dari semacam penyisipan.
Algoritma
Sekarang kita memiliki gambaran yang lebih besar tentang bagaimana teknik pengurutan ini bekerja, sehingga kita dapat memperoleh langkah-langkah sederhana yang dengannya kita dapat mencapai pengurutan penyisipan.
Step 1 − If it is the first element, it is already sorted. return 1;
Step 2 − Pick next element
Step 3 − Compare with all elements in the sorted sub-list
Step 4 − Shift all the elements in the sorted sub-list that is greater than the
value to be sorted
Step 5 − Insert the value
Step 6 − Repeat until list is sortedPseudocode
procedure insertionSort( A : array of items )
int holePosition
int valueToInsert
for i = 1 to length(A) inclusive do:
/* select value to be inserted */
valueToInsert = A[i]
holePosition = i
/*locate hole position for the element to be inserted */
while holePosition > 0 and A[holePosition-1] > valueToInsert do:
A[holePosition] = A[holePosition-1]
holePosition = holePosition -1
end while
/* insert the number at hole position */
A[holePosition] = valueToInsert
end for
end procedureUntuk mengetahui tentang implementasi insertion sort dalam bahasa pemrograman C, silakan klik di sini .
Sortir pilihan adalah algoritme pengurutan sederhana. Algoritma pengurutan ini adalah algoritma berbasis perbandingan di tempat di mana daftarnya dibagi menjadi dua bagian, bagian yang diurutkan di ujung kiri dan bagian yang tidak diurutkan di ujung kanan. Awalnya, bagian yang diurutkan kosong dan bagian yang tidak diurutkan adalah seluruh daftar.
Elemen terkecil dipilih dari array yang tidak diurutkan dan ditukar dengan elemen paling kiri, dan elemen itu menjadi bagian dari array yang diurutkan. Proses ini terus memindahkan batas array yang tidak disortir dengan satu elemen ke kanan.
Algoritme ini tidak cocok untuk kumpulan data besar karena kompleksitas kasus rata-rata dan terburuknya adalah Ο (n 2 ), di manan adalah jumlah item.
Bagaimana Cara Kerja Sortir Seleksi?
Pertimbangkan larik yang digambarkan berikut sebagai contoh.
Untuk posisi pertama dalam daftar yang diurutkan, seluruh daftar dipindai secara berurutan. Posisi pertama di mana 14 disimpan saat ini, kami mencari seluruh daftar dan menemukan bahwa 10 adalah nilai terendah.

Jadi kami mengganti 14 dengan 10. Setelah satu iterasi 10, yang kebetulan merupakan nilai minimum dalam daftar, muncul di posisi pertama daftar yang diurutkan.

Untuk posisi kedua, di mana 33 berada, kami mulai memindai sisa daftar secara linier.

Kami menemukan bahwa 14 adalah nilai terendah kedua dalam daftar dan seharusnya muncul di tempat kedua. Kami menukar nilai-nilai ini.

Setelah dua iterasi, dua nilai terkecil ditempatkan di awal dengan cara yang diurutkan.

Proses yang sama diterapkan ke item lainnya dalam larik.
Berikut adalah penggambaran bergambar dari seluruh proses penyortiran -

Sekarang, mari kita pelajari beberapa aspek pemrograman dari selection sort.
Algoritma
Step 1 − Set MIN to location 0
Step 2 − Search the minimum element in the list
Step 3 − Swap with value at location MIN
Step 4 − Increment MIN to point to next element
Step 5 − Repeat until list is sortedPseudocode
procedure selection sort
list : array of items
n : size of list
for i = 1 to n - 1
/* set current element as minimum*/
min = i
/* check the element to be minimum */
for j = i+1 to n
if list[j] < list[min] then
min = j;
end if
end for
/* swap the minimum element with the current element*/
if indexMin != i then
swap list[min] and list[i]
end if
end for
end procedureUntuk mengetahui tentang implementasi sortir seleksi dalam bahasa pemrograman C, silakan klik di sini .
Merge sort adalah teknik pengurutan berdasarkan teknik divide and conquer. Dengan kompleksitas waktu kasus terburuk menjadi Ο (n log n), ini adalah salah satu algoritme yang paling dihormati.
Gabungkan sortir terlebih dahulu membagi larik menjadi dua bagian yang sama, lalu menggabungkannya dalam cara yang diurutkan.
Bagaimana Cara Kerja Merge Sort?
Untuk memahami merge sort, kita mengambil array yang tidak disortir sebagai berikut -
Kita tahu bahwa merge sort pertama-tama membagi seluruh array secara iteratif menjadi dua bagian yang sama kecuali jika nilai atomnya tercapai. Kita melihat di sini bahwa array 8 item dibagi menjadi dua array dengan ukuran 4.

Ini tidak mengubah urutan kemunculan item di aslinya. Sekarang kami membagi dua larik ini menjadi dua.

Kami selanjutnya membagi array ini dan kami mencapai nilai atom yang tidak dapat lagi dibagi.

Sekarang, kami menggabungkannya dengan cara yang persis sama seperti saat dipecah. Harap perhatikan kode warna yang diberikan untuk daftar ini.
Kami pertama-tama membandingkan elemen untuk setiap daftar dan kemudian menggabungkannya ke dalam daftar lain dengan cara yang diurutkan. Kami melihat bahwa 14 dan 33 berada di posisi yang diurutkan. Kami membandingkan 27 dan 10 dan dalam daftar target dari 2 nilai kami menempatkan 10 terlebih dahulu, diikuti oleh 27. Kami mengubah urutan 19 dan 35 sedangkan 42 dan 44 ditempatkan secara berurutan.

Pada iterasi berikutnya dari fase penggabungan, kami membandingkan daftar dua nilai data, dan menggabungkannya ke dalam daftar nilai data yang ditemukan dengan menempatkan semua dalam urutan yang diurutkan.

Setelah penggabungan terakhir, daftarnya akan terlihat seperti ini -

Sekarang kita harus mempelajari beberapa aspek pemrograman dari merge sorting.
Algoritma
Gabung sortir terus membagi daftar menjadi dua bagian yang sama hingga tidak dapat lagi dibagi. Menurut definisi, jika hanya satu elemen dalam daftar, itu diurutkan. Kemudian, gabungkan sortir menggabungkan daftar yang diurutkan yang lebih kecil sehingga daftar baru juga diurutkan.
Step 1 − if it is only one element in the list it is already sorted, return.
Step 2 − divide the list recursively into two halves until it can no more be divided.
Step 3 − merge the smaller lists into new list in sorted order.Pseudocode
Sekarang kita akan melihat pseudocodes untuk fungsi merge sort. Karena algoritme kami menunjukkan dua fungsi utama - bagi & gabungkan.
Merge sort berfungsi dengan rekursi dan kita akan melihat implementasi kita dengan cara yang sama.
procedure mergesort( var a as array )
if ( n == 1 ) return a
var l1 as array = a[0] ... a[n/2]
var l2 as array = a[n/2+1] ... a[n]
l1 = mergesort( l1 )
l2 = mergesort( l2 )
return merge( l1, l2 )
end procedure
procedure merge( var a as array, var b as array )
var c as array
while ( a and b have elements )
if ( a[0] > b[0] )
add b[0] to the end of c
remove b[0] from b
else
add a[0] to the end of c
remove a[0] from a
end if
end while
while ( a has elements )
add a[0] to the end of c
remove a[0] from a
end while
while ( b has elements )
add b[0] to the end of c
remove b[0] from b
end while
return c
end procedureUntuk mengetahui tentang implementasi merge sort dalam bahasa pemrograman C, silakan klik di sini .
Jenis shell adalah algoritma pengurutan yang sangat efisien dan didasarkan pada algoritma pengurutan penyisipan. Algoritme ini menghindari pergeseran besar seperti dalam kasus penyisipan sort, jika nilai yang lebih kecil berada di paling kanan dan harus dipindahkan ke paling kiri.
Algoritme ini menggunakan semacam penyisipan pada elemen yang tersebar luas, pertama untuk mengurutkannya lalu mengurutkan elemen yang berjarak kurang luas. Jarak ini disebut sebagaiinterval. Interval ini dihitung berdasarkan rumus Knuth sebagai -
Formula Knuth
h = h * 3 + 1
where −
h is interval with initial value 1Algoritma ini cukup efisien untuk kumpulan data berukuran sedang karena rata-rata dan kompleksitas kasus terburuknya adalah Ο (n), di mana n adalah jumlah item.
Bagaimana Shell Sort Bekerja?
Mari kita pertimbangkan contoh berikut untuk mendapatkan gambaran tentang cara kerja shell sort. Kami mengambil larik yang sama yang telah kami gunakan dalam contoh kami sebelumnya. Untuk contoh dan kemudahan pemahaman kami, kami mengambil interval 4. Buat sub-daftar virtual dari semua nilai yang terletak pada interval 4 posisi. Berikut nilai-nilai tersebut adalah {35, 14}, {33, 19}, {42, 27} dan {10, 44}

Kami membandingkan nilai di setiap sub-daftar dan menukarnya (jika perlu) dalam larik asli. Setelah langkah ini, array baru akan terlihat seperti ini -

Kemudian, kami mengambil interval 2 dan celah ini menghasilkan dua sub-daftar - {14, 27, 35, 42}, {19, 10, 33, 44}

Kami membandingkan dan menukar nilai, jika diperlukan, dalam larik asli. Setelah langkah ini, array akan terlihat seperti ini -

Terakhir, kita mengurutkan sisa array menggunakan interval nilai 1. Pengurutan shell menggunakan jenis penyisipan untuk mengurutkan array.
Berikut ini adalah penggambaran langkah demi langkah -

Kami melihat bahwa itu hanya membutuhkan empat swap untuk mengurutkan sisa array.
Algoritma
Berikut algoritma untuk shell sort.
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedPseudocode
Berikut adalah pseudocode untuk shell sort.
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureUntuk mengetahui tentang implementasi shell sort dalam bahasa pemrograman C, silakan klik di sini .
Jenis shell adalah algoritma pengurutan yang sangat efisien dan didasarkan pada algoritma pengurutan penyisipan. Algoritme ini menghindari pergeseran besar seperti dalam kasus penyisipan sort, jika nilai yang lebih kecil berada di paling kanan dan harus dipindahkan ke paling kiri.
Algoritme ini menggunakan semacam penyisipan pada elemen yang tersebar luas, pertama untuk mengurutkannya lalu mengurutkan elemen yang berjarak kurang luas. Jarak ini disebut sebagaiinterval. Interval ini dihitung berdasarkan rumus Knuth sebagai -
Formula Knuth
h = h * 3 + 1
where −
h is interval with initial value 1Algoritme ini cukup efisien untuk kumpulan data berukuran sedang karena rata-rata dan kompleksitas kasus terburuk dari algoritme ini bergantung pada urutan celah yang paling dikenal adalah Ο (n), di mana n adalah jumlah item. Dan kompleksitas ruang kasus terburuk adalah O (n).
Bagaimana Shell Sort Bekerja?
Mari kita pertimbangkan contoh berikut untuk mendapatkan gambaran tentang cara kerja shell sort. Kami mengambil larik yang sama yang telah kami gunakan dalam contoh kami sebelumnya. Untuk contoh dan kemudahan pemahaman kami, kami mengambil interval 4. Buat sub-daftar virtual dari semua nilai yang terletak pada interval 4 posisi. Berikut nilai-nilai tersebut adalah {35, 14}, {33, 19}, {42, 27} dan {10, 44}
Kami membandingkan nilai di setiap sub-daftar dan menukarnya (jika perlu) dalam larik asli. Setelah langkah ini, array baru akan terlihat seperti ini -
Kemudian, kami mengambil interval 1 dan celah ini menghasilkan dua sub-daftar - {14, 27, 35, 42}, {19, 10, 33, 44}
Kami membandingkan dan menukar nilai, jika diperlukan, dalam larik asli. Setelah langkah ini, array akan terlihat seperti ini -
Terakhir, kita mengurutkan sisa array menggunakan interval nilai 1. Pengurutan shell menggunakan jenis penyisipan untuk mengurutkan array.
Berikut ini adalah penggambaran langkah demi langkah -
Kami melihat bahwa itu hanya membutuhkan empat swap untuk mengurutkan sisa array.
Algoritma
Berikut algoritma untuk shell sort.
Step 1 − Initialize the value of h
Step 2 − Divide the list into smaller sub-list of equal interval h
Step 3 − Sort these sub-lists using insertion sort
Step 3 − Repeat until complete list is sortedPseudocode
Berikut adalah pseudocode untuk shell sort.
procedure shellSort()
A : array of items
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 + 1
end while
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner - interval]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedureUntuk mengetahui tentang implementasi shell sort dalam bahasa pemrograman C, silakan klik di sini .
Pengurutan cepat adalah algoritma pengurutan yang sangat efisien dan didasarkan pada partisi array data menjadi array yang lebih kecil. Sebuah array besar dipartisi menjadi dua array yang salah satunya menyimpan nilai yang lebih kecil dari nilai yang ditentukan, katakanlah pivot, berdasarkan partisi itu dibuat dan array lain menyimpan nilai lebih besar dari nilai pivot.
Quicksort mempartisi larik dan kemudian memanggil dirinya sendiri secara rekursif dua kali untuk mengurutkan dua sub larik yang dihasilkan. Algoritme ini cukup efisien untuk kumpulan data berukuran besar karena rata-rata dan kompleksitas kasus terburuknya masing-masing adalah O (nLogn) dan image.png (n 2 ).
Partisi di Quick Sort
Representasi animasi berikut menjelaskan cara menemukan nilai pivot dalam array.

Nilai pivot membagi daftar menjadi dua bagian. Dan secara rekursif, kami menemukan poros untuk setiap sub-daftar hingga semua daftar hanya berisi satu elemen.
Algoritma Pivot Sortir Cepat
Berdasarkan pemahaman kita tentang pemartisian dalam quick sort, sekarang kita akan mencoba menulis algoritme untuk itu, yaitu sebagai berikut.
Step 1 − Choose the highest index value has pivot
Step 2 − Take two variables to point left and right of the list excluding pivot
Step 3 − left points to the low index
Step 4 − right points to the high
Step 5 − while value at left is less than pivot move right
Step 6 − while value at right is greater than pivot move left
Step 7 − if both step 5 and step 6 does not match swap left and right
Step 8 − if left ≥ right, the point where they met is new pivotPseudocode Pivot Sortir Cepat
Pseudocode untuk algoritma di atas dapat diturunkan sebagai -
function partitionFunc(left, right, pivot)
leftPointer = left
rightPointer = right - 1
while True do
while A[++leftPointer] < pivot do
//do-nothing
end while
while rightPointer > 0 && A[--rightPointer] > pivot do
//do-nothing
end while
if leftPointer >= rightPointer
break
else
swap leftPointer,rightPointer
end if
end while
swap leftPointer,right
return leftPointer
end functionAlgoritma Pengurutan Cepat
Menggunakan algoritma pivot secara rekursif, kami berakhir dengan kemungkinan partisi yang lebih kecil. Setiap partisi kemudian diproses untuk penyortiran cepat. Kami mendefinisikan algoritma rekursif untuk quicksort sebagai berikut -
Step 1 − Make the right-most index value pivot
Step 2 − partition the array using pivot value
Step 3 − quicksort left partition recursively
Step 4 − quicksort right partition recursivelyPseudocode Sortir Cepat
Untuk memahami lebih lanjut, lihat pseudocode untuk algoritma pengurutan cepat -
procedure quickSort(left, right)
if right-left <= 0
return
else
pivot = A[right]
partition = partitionFunc(left, right, pivot)
quickSort(left,partition-1)
quickSort(partition+1,right)
end if
end procedureUntuk mengetahui tentang implementasi quick sort dalam bahasa pemrograman C, silakan klik di sini .
Grafik adalah representasi bergambar dari sekumpulan objek di mana beberapa pasang objek dihubungkan oleh tautan. Objek yang saling berhubungan diwakili oleh poin yang disebut sebagaivertices, dan tautan yang menghubungkan simpul disebut edges.
Secara formal, grafik adalah sepasang himpunan (V, E), dimana V adalah himpunan simpul dan Eadalah himpunan tepi, menghubungkan pasangan simpul. Perhatikan grafik berikut -
Pada grafik di atas,
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}
Grafik Struktur Data
Grafik matematika dapat direpresentasikan dalam struktur data. Kita dapat merepresentasikan grafik menggunakan larik simpul dan larik tepi dua dimensi. Sebelum melangkah lebih jauh, mari kita membiasakan diri dengan beberapa istilah penting -
Vertex- Setiap simpul pada grafik direpresentasikan sebagai simpul. Dalam contoh berikut, lingkaran berlabel mewakili simpul. Jadi, A ke G adalah simpul. Kami dapat mewakili mereka menggunakan array seperti yang ditunjukkan pada gambar berikut. Di sini A dapat diidentifikasi dengan indeks 0. B dapat diidentifikasi menggunakan indeks 1 dan seterusnya.
Edge- Edge mewakili jalur antara dua simpul atau garis antara dua simpul. Dalam contoh berikut, garis dari A ke B, B ke C, dan seterusnya mewakili tepian. Kita bisa menggunakan array dua dimensi untuk merepresentasikan array seperti yang ditunjukkan pada gambar berikut. Di sini AB dapat direpresentasikan sebagai 1 pada baris 0, kolom 1, BC sebagai 1 pada baris 1, kolom 2 dan seterusnya, dengan kombinasi lainnya sebagai 0.
Adjacency- Dua buah simpul atau simpul bersebelahan jika keduanya terhubung satu sama lain melalui sebuah sisi. Dalam contoh berikut, B berdekatan dengan A, C berdekatan dengan B, dan seterusnya.
Path- Path merepresentasikan urutan tepi antara dua simpul. Dalam contoh berikut, ABCD merepresentasikan jalur dari A ke D.
Operasi Dasar
Berikut ini adalah operasi utama dasar dari sebuah Grafik -
Add Vertex - Menambahkan titik sudut ke grafik.
Add Edge - Menambahkan tepi di antara dua simpul pada grafik.
Display Vertex - Menampilkan simpul dari grafik.
Untuk mengetahui lebih lanjut tentang Grafik, silakan baca Tutorial Teori Grafik . Kita akan belajar tentang melintasi grafik di bab-bab selanjutnya.
Algoritma Depth First Search (DFS) melintasi grafik dalam gerakan mendalam dan menggunakan tumpukan untuk mengingat untuk mendapatkan simpul berikutnya untuk memulai pencarian, ketika jalan buntu terjadi dalam iterasi apa pun.

Seperti pada contoh yang diberikan di atas, algoritma DFS melintasi dari S ke A ke D ke G ke E ke B terlebih dahulu, kemudian ke F dan terakhir ke C. Algoritma ini menggunakan aturan berikut.
Rule 1- Kunjungi puncak yang belum dikunjungi yang berdekatan. Tandai sebagai telah dikunjungi. Tampilkan itu. Dorong dalam tumpukan.
Rule 2- Jika tidak ada simpul yang berdekatan ditemukan, munculkan simpul dari tumpukan. (Ini akan memunculkan semua simpul dari tumpukan, yang tidak memiliki simpul yang berdekatan.)
Rule 3 - Ulangi Aturan 1 dan Aturan 2 hingga tumpukan kosong.
| Langkah | Traversal | Deskripsi |
|---|---|---|
| 1 |

|
Inisialisasi tumpukan. |
| 2 |

|
Menandai Ssaat dikunjungi dan menaruhnya di tumpukan. Jelajahi simpul berdekatan yang belum dikunjungi dariS. Kami memiliki tiga node dan kami dapat memilih salah satunya. Untuk contoh ini, kita akan mengambil node dalam urutan abjad. |
| 3 |

|
Menandai Asaat dikunjungi dan menaruhnya di tumpukan. Jelajahi setiap node berdekatan yang belum dikunjungi dari A. KeduanyaS dan D berbatasan dengan A tapi kami prihatin hanya untuk node yang belum dikunjungi. |
| 4 |

|
Mengunjungi Ddan tandai sebagai telah dikunjungi dan dimasukkan ke dalam tumpukan. Di sini, kami punyaB dan C node, yang berdekatan dengan Ddan keduanya belum dikunjungi. Namun, kita akan memilih lagi dalam urutan abjad. |
| 5 |

|
Kami memilih B, tandai sebagai telah dikunjungi dan taruh di tumpukan. SiniBtidak memiliki simpul yang berdekatan yang belum dikunjungi. Jadi, kami meletusB dari tumpukan. |
| 6 |

|
Kami memeriksa tumpukan atas untuk kembali ke node sebelumnya dan memeriksa apakah ada node yang belum dikunjungi. Di sini, kami temukanD untuk berada di atas tumpukan. |
| 7 |

|
Hanya simpul bersebelahan yang belum dikunjungi berasal dari D adalah Csekarang. Jadi kami mengunjungiC, tandai sebagai telah dikunjungi dan taruh di tumpukan. |
Sebagai Ctidak memiliki node yang berdekatan yang belum dikunjungi jadi kami terus memunculkan tumpukan sampai kami menemukan node yang memiliki node yang berdekatan yang belum dikunjungi. Dalam hal ini, tidak ada dan kami terus bermunculan hingga tumpukan kosong.
Untuk mengetahui tentang implementasi algoritma ini dalam bahasa pemrograman C, klik disini .
Algoritme Breadth First Search (BFS) melintasi grafik dalam gerakan luas dan menggunakan antrian untuk mengingat untuk mendapatkan simpul berikutnya untuk memulai pencarian, ketika jalan buntu terjadi dalam iterasi apa pun.

Seperti dalam contoh yang diberikan di atas, algoritma BFS melintasi dari A ke B ke E ke F terlebih dahulu kemudian ke C dan G terakhir ke D. Ini menggunakan aturan berikut.
Rule 1- Kunjungi puncak yang belum dikunjungi yang berdekatan. Tandai sebagai telah dikunjungi. Tampilkan itu. Sisipkan dalam antrian.
Rule 2 - Jika tidak ada simpul yang berdekatan ditemukan, hapus simpul pertama dari antrian.
Rule 3 - Ulangi Aturan 1 dan Aturan 2 hingga antrian kosong.
| Langkah | Traversal | Deskripsi |
|---|---|---|
| 1 |

|
Inisialisasi antrian. |
| 2 |
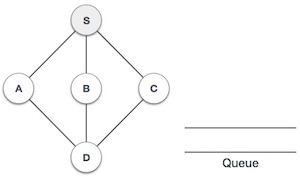
|
Kami mulai dari mengunjungi S (simpul awal), dan tandai sebagai telah dikunjungi. |
| 3 |

|
Kami kemudian melihat simpul berdekatan yang belum dikunjungi dari S. Dalam contoh ini, kami memiliki tiga node tetapi menurut abjad kami memilihA, tandai sebagai telah dikunjungi dan mengantrekannya. |
| 4 |

|
Selanjutnya, simpul berdekatan yang belum dikunjungi dari S adalah B. Kami menandainya sebagai telah dikunjungi dan mengantrekannya. |
| 5 |

|
Selanjutnya, simpul berdekatan yang belum dikunjungi dari S adalah C. Kami menandainya sebagai telah dikunjungi dan mengantrekannya. |
| 6 |

|
Sekarang, Sdibiarkan tanpa node berdekatan yang belum dikunjungi. Jadi, kami dequeue dan temukanA. |
| 7 |

|
Dari A kita punya Dsebagai node berdekatan yang belum dikunjungi. Kami menandainya sebagai telah dikunjungi dan mengantrekannya. |
Pada tahap ini, kita tidak memiliki node yang tidak ditandai (belum dikunjungi). Namun sesuai algoritme kami terus melakukan dequeue untuk mendapatkan semua node yang belum dikunjungi. Saat antrian dikosongkan, program selesai.
Implementasi algoritma ini pada bahasa pemrograman C dapat dilihat disini .
Pohon mewakili simpul yang dihubungkan oleh tepi. Kami akan membahas pohon biner atau pohon pencarian biner secara khusus.
Binary Tree adalah struktur data khusus yang digunakan untuk tujuan penyimpanan data. Pohon biner memiliki syarat khusus dimana setiap node dapat memiliki maksimal dua anak. Pohon biner memiliki keuntungan dari array terurut dan daftar tertaut karena pencarian secepat dalam array terurut dan operasi penyisipan atau penghapusan secepat dalam daftar tertaut.

Istilah Penting
Berikut ini adalah istilah-istilah penting yang berkaitan dengan pohon.
Path - Path mengacu pada urutan node di sepanjang tepi pohon.
Root- Titik di atas pohon disebut root. Hanya ada satu akar per pohon dan satu jalur dari simpul akar ke simpul manapun.
Parent - Setiap simpul kecuali simpul akar memiliki satu sisi ke atas ke simpul yang disebut induk.
Child - Simpul di bawah simpul tertentu yang dihubungkan dengan ujungnya ke bawah disebut simpul anak.
Leaf - Simpul yang tidak memiliki simpul anak disebut simpul daun.
Subtree - Subpohon mewakili keturunan dari sebuah node.
Visiting - Visiting mengacu pada pengecekan nilai sebuah node saat kontrol berada di node.
Traversing - Melintasi berarti melewati node dalam urutan tertentu.
Levels- Level dari sebuah node merupakan generasi dari sebuah node. Jika node root berada di level 0, maka node turunan berikutnya ada di level 1, cucunya di level 2, dan seterusnya.
keys - Key merepresentasikan nilai dari sebuah node yang menjadi dasar operasi pencarian yang akan dilakukan untuk sebuah node.
Representasi Pohon Pencarian Biner
Pohon Pencarian Biner menunjukkan perilaku khusus. Anak kiri node harus memiliki nilai yang kurang dari nilai induknya dan anak kanan node harus memiliki nilai yang lebih besar dari nilai induknya.

Kami akan mengimplementasikan pohon menggunakan objek node dan menghubungkannya melalui referensi.
Node Pohon
Kode untuk menulis simpul pohon akan serupa dengan yang diberikan di bawah ini. Ini memiliki bagian data dan referensi ke node anak kiri dan kanannya.
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};Dalam pohon, semua node memiliki konstruksi yang sama.
Operasi Dasar BST
Operasi dasar yang dapat dilakukan pada struktur data pohon pencarian biner, adalah sebagai berikut -
Insert - Menyisipkan elemen di pohon / membuat pohon.
Search - Mencari elemen di pohon.
Preorder Traversal - Melintasi pohon dengan cara pre-order.
Inorder Traversal - Melintasi pohon secara berurutan.
Postorder Traversal - Melintasi pohon dengan cara pasca-order.
Kita akan belajar membuat (menyisipkan ke) struktur pohon dan mencari item data di pohon dalam bab ini. Kita akan belajar tentang metode melintasi pohon di bab selanjutnya.
Sisipkan Operasi
Penyisipan pertama membuat pohon. Setelah itu, setiap kali elemen akan dimasukkan, pertama cari lokasi yang tepat. Mulailah mencari dari root node, kemudian jika datanya kurang dari nilai kunci, cari lokasi kosong di sub-pohon kiri dan masukkan datanya. Jika tidak, cari lokasi kosong di subtree kanan dan masukkan datanya.
Algoritma
If root is NULL
then create root node
return
If root exists then
compare the data with node.data
while until insertion position is located
If data is greater than node.data
goto right subtree
else
goto left subtree
endwhile
insert data
end IfPenerapan
Implementasi fungsi insert akan terlihat seperti ini -
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty, create root node
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
}
//go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}Operasi Pencarian
Kapanpun sebuah elemen akan dicari, mulailah mencari dari root node, kemudian jika datanya kurang dari nilai kunci, cari elemen tersebut di subtree kiri. Jika tidak, cari elemen di subtree kanan. Ikuti algoritma yang sama untuk setiap node.
Algoritma
If root.data is equal to search.data
return root
else
while data not found
If data is greater than node.data
goto right subtree
else
goto left subtree
If data found
return node
endwhile
return data not found
end ifImplementasi algoritma ini akan terlihat seperti ini.
struct node* search(int data) {
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data) {
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data) {
current = current->leftChild;
}
//else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL) {
return NULL;
}
return current;
}
}Untuk mengetahui tentang implementasi struktur data pohon pencarian biner, silakan klik di sini .
Traversal adalah proses untuk mengunjungi semua node dari pohon dan dapat mencetak nilainya juga. Sebab, semua node terhubung melalui edge (tautan) kami selalu memulai dari node root (kepala). Artinya, kita tidak dapat mengakses node di pohon secara acak. Ada tiga cara yang kami gunakan untuk melintasi pohon -
- In-order Traversal
- Praorder Traversal
- Traversal pasca pesanan
Umumnya, kita melintasi pohon untuk mencari atau menemukan item atau kunci tertentu di pohon atau untuk mencetak semua nilai yang dikandungnya.
In-order Traversal
Dalam metode traversal ini, sub-pohon kiri dikunjungi terlebih dahulu, kemudian akar dan kemudian sub-pohon kanan. Kita harus selalu ingat bahwa setiap node dapat mewakili subpohon itu sendiri.
Jika pohon biner dilintasi in-order, keluarannya akan menghasilkan nilai kunci yang diurutkan dalam urutan menaik.

Kami mulai dari A, dan mengikuti traversal berurutan, kita pindah ke subtree kirinya B. Bjuga dilintasi secara berurutan. Proses ini berlangsung hingga semua node dikunjungi. Output dari inorder traversal pohon ini adalah -
D → B → E → A → F → C → G
Algoritma
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.Praorder Traversal
Dalam metode traversal ini, simpul akar dikunjungi pertama, kemudian subpohon kiri dan terakhir subpohon kanan.

Kami mulai dari A, dan mengikuti traversal pre-order, kami mengunjungi pertama A sendiri dan kemudian pindah ke subtree kirinya B. Bjuga akan dilintasi praorder. Proses ini berlangsung hingga semua node dikunjungi. Output dari traversal pre-order pohon ini adalah -
A → B → D → E → C → F → G
Algoritma
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.Traversal pasca pesanan
Dalam metode traversal ini, simpul akar dikunjungi terakhir, karena itulah namanya. Pertama kita melintasi subtree kiri, lalu subtree kanan dan terakhir node root.

Kami mulai dari A, dan mengikuti Post-order traversal, pertama-tama kita mengunjungi subtree kiri B. Bjuga dilintasi pasca pemesanan. Proses ini berlangsung hingga semua node dikunjungi. Output traversal post-order dari pohon ini adalah -
D → E → B → F → G → C → A
Algoritma
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.Untuk memeriksa implementasi C dari penjelajahan pohon, silakan klik di sini .
Pohon Pencarian Biner (BST) adalah pohon di mana semua node mengikuti properti yang disebutkan di bawah ini -
Nilai kunci sub-pohon kiri kurang dari nilai kunci simpul induknya (root).
Nilai kunci sub-pohon kanan lebih besar dari atau sama dengan nilai kunci simpul induknya (root).
Jadi, BST membagi semua sub-pohonnya menjadi dua segmen; sub-pohon kiri dan sub-pohon kanan dan dapat didefinisikan sebagai -
left_subtree (keys) < node (key) ≤ right_subtree (keys)Perwakilan
BST adalah kumpulan node yang diatur sedemikian rupa sehingga mereka mempertahankan properti BST. Setiap node memiliki kunci dan nilai terkait. Saat mencari, kunci yang diinginkan dibandingkan dengan kunci di BST dan jika ditemukan, nilai terkait diambil.
Berikut adalah representasi bergambar BST -
Kami mengamati bahwa kunci simpul akar (27) memiliki semua kunci yang nilainya lebih rendah di sub-pohon kiri dan kunci yang bernilai lebih tinggi di sub-pohon kanan.
Operasi Dasar
Berikut adalah operasi dasar dari sebuah pohon -
Search - Mencari elemen di pohon.
Insert - Menyisipkan elemen di pohon.
Pre-order Traversal - Melintasi pohon dengan cara pre-order.
In-order Traversal - Melintasi pohon secara berurutan.
Post-order Traversal - Melintasi pohon dengan cara pasca-order.
Node
Tentukan node yang memiliki beberapa data, referensi ke node anak kiri dan kanannya.
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};Operasi Pencarian
Kapanpun sebuah elemen akan dicari, mulailah mencari dari root node. Kemudian jika datanya kurang dari nilai kunci, cari elemen di subtree kiri. Jika tidak, cari elemen di subtree kanan. Ikuti algoritma yang sama untuk setiap node.
Algoritma
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL) {
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
} //else go to right tree
else {
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
}
return current;
}Sisipkan Operasi
Kapanpun sebuah elemen akan dimasukkan, pertama cari lokasi yang tepat. Mulailah mencari dari root node, kemudian jika datanya kurang dari nilai kunci, cari lokasi kosong di sub-pohon kiri dan masukkan datanya. Jika tidak, cari lokasi kosong di subtree kanan dan masukkan datanya.
Algoritma
void insert(int data) {
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL) {
root = tempNode;
} else {
current = root;
parent = NULL;
while(1) {
parent = current;
//go to left of the tree
if(data < parent->data) {
current = current->leftChild;
//insert to the left
if(current == NULL) {
parent->leftChild = tempNode;
return;
}
} //go to right of the tree
else {
current = current->rightChild;
//insert to the right
if(current == NULL) {
parent->rightChild = tempNode;
return;
}
}
}
}
}Bagaimana jika masukan ke pohon pencarian biner datang dengan cara yang diurutkan (menaik atau menurun)? Kemudian akan terlihat seperti ini -

Teramati bahwa kinerja kasus terburuk BST paling dekat dengan algoritma pencarian linier, yaitu Ο (n). Pada data real-time, kita tidak dapat memprediksi pola data dan frekuensinya. Jadi, muncul kebutuhan untuk mengimbangi BST yang ada.
Dinamai menurut penemunya Adelson, Velski & Landis, AVL treesadalah pohon pencarian biner penyeimbang ketinggian. Pohon AVL memeriksa ketinggian sub-pohon kiri dan kanan dan memastikan bahwa perbedaannya tidak lebih dari 1. Perbedaan ini disebutBalance Factor.
Di sini kita melihat bahwa pohon pertama seimbang dan dua pohon berikutnya tidak seimbang -
Di pohon kedua, subtree kiri dari C memiliki tinggi 2 dan subtree kanan memiliki tinggi 0, sehingga selisihnya adalah 2. Pada pohon ketiga, subtree kanan Amemiliki tinggi 2 dan kiri hilang, jadi 0, dan perbedaannya adalah 2 lagi. Pohon AVL mengizinkan perbedaan (faktor keseimbangan) menjadi hanya 1.
BalanceFactor = height(left-sutree) − height(right-sutree)Jika selisih ketinggian sub-pohon kiri dan kanan lebih dari 1, pohon tersebut diimbangi dengan beberapa teknik rotasi.
Rotasi AVL
Untuk menyeimbangkan dirinya sendiri, pohon AVL dapat melakukan empat jenis rotasi berikut -
- Rotasi kiri
- Rotasi yang tepat
- Rotasi Kiri-Kanan
- Rotasi Kanan-Kiri
Dua rotasi pertama adalah rotasi tunggal dan dua rotasi berikutnya adalah rotasi ganda. Untuk memiliki pohon yang tidak seimbang, paling tidak kita membutuhkan pohon dengan tinggi 2. Dengan pohon sederhana ini mari kita pahami satu persatu.
Rotasi Kiri
Jika pohon menjadi tidak seimbang, ketika sebuah node dimasukkan ke dalam sub-pohon kanan dari sub-pohon kanan, maka kami melakukan satu rotasi kiri -

Dalam contoh kami, node Atelah menjadi tidak seimbang saat sebuah node disisipkan di subpohon kanan dari subpohon kanan A. Kami melakukan rotasi kiri dengan membuatA sub-pohon kiri dari B.
Rotasi Kanan
Pohon AVL mungkin menjadi tidak seimbang, jika sebuah node disisipkan di subpohon kiri dari subpohon kiri. Pohon itu kemudian membutuhkan rotasi yang tepat.

Seperti yang digambarkan, simpul yang tidak seimbang menjadi anak kanan dari anak kirinya dengan melakukan rotasi ke kanan.
Rotasi Kiri-Kanan
Rotasi ganda adalah versi yang sedikit rumit dari versi rotasi yang sudah dijelaskan. Untuk memahaminya dengan lebih baik, kita harus mencatat setiap tindakan yang dilakukan saat rotasi. Pertama mari kita periksa bagaimana melakukan rotasi Kiri-Kanan. Rotasi kiri-kanan adalah kombinasi dari rotasi kiri diikuti dengan rotasi kanan.
| Negara | Tindakan |
|---|---|

|
Sebuah node telah disisipkan ke sub pohon kanan dari sub pohon kiri. Ini membuatCnode yang tidak seimbang. Skenario ini menyebabkan pohon AVL melakukan rotasi kiri-kanan. |

|
Kami pertama kali melakukan rotasi kiri di subpohon kiri C. Ini membuatA, subtree kiri dari B. |

|
Node C masih tidak seimbang, namun sekarang, itu karena subtree kiri dari subtree kiri. |

|
Sekarang kita akan memutar pohon ke kanan, membuatnya B simpul akar baru dari subpohon ini. C sekarang menjadi subtree kanan dari subtree kirinya sendiri. |

|
Pohon itu sekarang seimbang. |
Rotasi Kanan-Kiri
Jenis rotasi ganda kedua adalah Rotasi Kanan-Kiri. Ini adalah kombinasi dari rotasi kanan diikuti dengan rotasi kiri.
| Negara | Tindakan |
|---|---|

|
Sebuah node telah disisipkan ke subpohon kiri dari subpohon kanan. Ini membuatA, simpul tidak seimbang dengan faktor keseimbangan 2. |

|
Pertama, kami melakukan rotasi yang benar C simpul, membuat C subtree kanan dari subtree kirinya sendiri B. Sekarang,B menjadi subtree kanan dari A. |

|
Node A masih tidak seimbang karena subtree kanan dari subtree kanan dan membutuhkan rotasi kiri. |

|
Rotasi kiri dilakukan dengan membuat B simpul akar baru dari subpohon. A menjadi subtree kiri dari subtree kanannya B. |
|
|
Pohon itu sekarang seimbang. |
Pohon merentang adalah himpunan bagian dari Grafik G, yang memiliki semua simpul yang ditutupi dengan jumlah tepi seminimal mungkin. Karenanya, pohon rentang tidak memiliki siklus dan tidak dapat diputuskan ..
Dengan definisi ini, kita dapat menarik kesimpulan bahwa setiap Grafik G yang terhubung dan tidak diarahkan memiliki setidaknya satu pohon rentang. Grafik yang terputus tidak memiliki pohon rentang, karena tidak dapat direntang ke semua simpulnya.

Kami menemukan tiga pohon rentang dari satu grafik lengkap. Grafik tidak terarah lengkap dapat memiliki maksimumnn-2 jumlah pohon merentang, di mana nadalah jumlah node. Dalam contoh yang dialamatkan di atas,n is 3, karenanya 33−2 = 3 rentang pohon dimungkinkan.
Properti Umum Spanning Tree
Kami sekarang memahami bahwa satu grafik dapat memiliki lebih dari satu pohon rentang. Berikut adalah beberapa properti dari pohon rentang yang terhubung ke grafik G -
Grafik terhubung G dapat memiliki lebih dari satu pohon rentang.
Semua pohon rentang yang mungkin dari grafik G, memiliki jumlah sisi dan simpul yang sama.
Pohon rentang tidak memiliki siklus apa pun (loop).
Menghapus satu sisi dari pohon rentang akan membuat grafik terputus, yaitu pohon rentang minimally connected.
Menambahkan satu sisi ke pohon rentang akan membuat sirkuit atau lingkaran, yaitu pohon rentang maximally acyclic.
Properti Matematika Pohon Rentang
Spanning tree memiliki n-1 tepi, dimana n adalah jumlah node (simpul).
Dari grafik lengkap, dengan menghapus maksimum e - n + 1 tepi, kita dapat membangun pohon rentang.
Grafik lengkap bisa maksimal nn-2 jumlah pohon merentang.
Dengan demikian, kita dapat menyimpulkan bahwa pohon merentang adalah himpunan bagian dari Grafik G yang terhubung dan grafik yang terputus tidak memiliki pohon rentang.
Penerapan Spanning Tree
Spanning tree pada dasarnya digunakan untuk mencari jalur minimum untuk menghubungkan semua node dalam sebuah grafik. Penerapan umum pohon merentang adalah -
Civil Network Planning
Computer Network Routing Protocol
Cluster Analysis
Mari kita pahami ini melalui contoh kecil. Pertimbangkan, jaringan kota sebagai grafik yang sangat besar dan sekarang berencana untuk menggunakan saluran telepon sedemikian rupa sehingga dalam saluran minimum kita dapat terhubung ke semua node kota. Di sinilah pohon bentang muncul.
Minimum Spanning Tree (MST)
Dalam grafik berbobot, pohon bentang minimum adalah pohon bentang yang memiliki bobot minimum daripada semua pohon bentang lain dari grafik yang sama. Dalam situasi dunia nyata, bobot ini dapat diukur sebagai jarak, kemacetan, beban lalu lintas, atau nilai arbitrer apa pun yang ditunjukkan ke tepinya.
Algoritma Pohon Rentang Minimum
Kita akan belajar tentang dua algoritma spanning tree paling penting di sini -
Algoritma Kruskal
Algoritma Prim
Keduanya adalah algoritma serakah.
Heap adalah kasus khusus dari struktur data pohon biner yang seimbang di mana kunci root-node dibandingkan dengan turunannya dan disusun sesuai. Jikaα memiliki simpul anak β kemudian -
kunci (α) ≥ kunci (β)
Karena nilai induk lebih besar dari nilai anak, properti ini akan dihasilkan Max Heap. Berdasarkan kriteria ini, heap dapat terdiri dari dua jenis -
For Input → 35 33 42 10 14 19 27 44 26 31Min-Heap - Jika nilai dari simpul akar kurang dari atau sama dengan salah satu dari anak-anaknya.
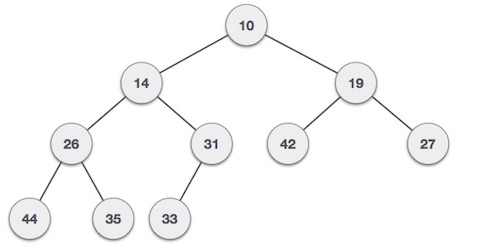
Max-Heap - Di mana nilai dari simpul akar lebih besar dari atau sama dengan salah satu dari anak-anaknya.

Kedua pohon dibangun menggunakan masukan dan urutan kedatangan yang sama.
Algoritma Konstruksi Heap Maks
Kita akan menggunakan contoh yang sama untuk mendemonstrasikan bagaimana Max Heap dibuat. Prosedur untuk membuat Min Heap serupa tetapi kami menggunakan nilai min alih-alih nilai maks.
Kita akan mendapatkan algoritma untuk tumpukan maksimal dengan memasukkan satu elemen pada satu waktu. Kapan pun, heap harus mempertahankan propertinya. Saat penyisipan, kami juga mengasumsikan bahwa kami menyisipkan node di pohon yang sudah menumpuk.
Step 1 − Create a new node at the end of heap.
Step 2 − Assign new value to the node.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.Note - Dalam algoritma konstruksi Min Heap, kami mengharapkan nilai node induk lebih kecil dari nilai node anak.
Mari kita pahami konstruksi Max Heap dengan ilustrasi animasi. Kami mempertimbangkan sampel input yang sama yang kami gunakan sebelumnya.

Algoritma Penghapusan Heap Maks
Mari kita turunkan algoritma untuk menghapus dari tumpukan maksimum. Penghapusan di Max (atau Min) Heap selalu terjadi di root untuk menghapus nilai Maksimum (atau minimum).
Step 1 − Remove root node.
Step 2 − Move the last element of last level to root.
Step 3 − Compare the value of this child node with its parent.
Step 4 − If value of parent is less than child, then swap them.
Step 5 − Repeat step 3 & 4 until Heap property holds.
Beberapa bahasa pemrograman komputer mengizinkan modul atau fungsi untuk memanggil dirinya sendiri. Teknik ini dikenal sebagai rekursi. Dalam rekursi, sebuah fungsiα baik memanggil dirinya sendiri secara langsung atau memanggil suatu fungsi β yang pada gilirannya memanggil fungsi asli α. Fungsinyaα disebut fungsi rekursif.
Example - fungsi yang memanggil dirinya sendiri.
int function(int value) {
if(value < 1)
return;
function(value - 1);
printf("%d ",value);
}Example - fungsi yang memanggil fungsi lain yang pada gilirannya memanggilnya lagi.
int function1(int value1) {
if(value1 < 1)
return;
function2(value1 - 1);
printf("%d ",value1);
}
int function2(int value2) {
function1(value2);
}Properti
Fungsi rekursif bisa menjadi tak terbatas seperti loop. Untuk menghindari berjalannya fungsi rekursif tanpa batas, ada dua properti yang harus dimiliki fungsi rekursif -
Base criteria - Harus ada setidaknya satu kriteria atau ketentuan dasar, sehingga, jika ketentuan ini terpenuhi, fungsi berhenti memanggil dirinya sendiri secara rekursif.
Progressive approach - Panggilan rekursif harus berkembang sedemikian rupa sehingga setiap kali panggilan rekursif dibuat, itu mendekati kriteria dasar.
Penerapan
Banyak bahasa pemrograman mengimplementasikan rekursi melalui stacks. Umumnya, setiap kali suatu fungsi (caller) memanggil fungsi lain (callee) atau dirinya sendiri sebagai callee, fungsi pemanggil mentransfer kontrol eksekusi ke callee. Proses transfer ini mungkin juga melibatkan beberapa data untuk diteruskan dari pemanggil ke callee.
Artinya, fungsi pemanggil harus menangguhkan eksekusinya untuk sementara dan melanjutkannya nanti saat kontrol eksekusi kembali dari fungsi callee. Di sini, fungsi pemanggil harus dimulai persis dari titik eksekusi yang menahannya. Itu juga membutuhkan nilai data yang sama persis dengan yang sedang dikerjakannya. Untuk tujuan ini, catatan aktivasi (atau bingkai tumpukan) dibuat untuk fungsi pemanggil.

Catatan aktivasi ini menyimpan informasi tentang variabel lokal, parameter formal, alamat pengirim dan semua informasi yang diteruskan ke fungsi pemanggil.
Analisis Rekursi
Orang mungkin berdebat mengapa menggunakan rekursi, karena tugas yang sama dapat dilakukan dengan iterasi. Alasan pertama adalah, rekursi membuat program lebih mudah dibaca dan karena sistem CPU terbaru yang disempurnakan, rekursi lebih efisien daripada iterasi.
Kompleksitas Waktu
Dalam kasus iterasi, kami mengambil jumlah iterasi untuk menghitung kompleksitas waktu. Demikian juga, dalam kasus rekursi, dengan asumsi semuanya konstan, kami mencoba mencari tahu berapa kali panggilan rekursif dilakukan. Panggilan yang dilakukan ke suatu fungsi adalah Ο (1), oleh karena itu (n) berapa kali panggilan rekursif dibuat membuat fungsi rekursif Ο (n).
Kompleksitas Ruang
Kompleksitas ruang dihitung sebagai jumlah ruang ekstra yang diperlukan untuk menjalankan modul. Dalam kasus iterasi, kompilator hampir tidak membutuhkan ruang ekstra. Kompilator terus memperbarui nilai variabel yang digunakan dalam iterasi. Namun dalam kasus rekursi, sistem perlu menyimpan catatan aktivasi setiap kali panggilan rekursif dilakukan. Oleh karena itu, dianggap bahwa kompleksitas ruang dari fungsi rekursif mungkin lebih tinggi daripada fungsi dengan iterasi.
Tower of Hanoi, adalah teka-teki matematika yang terdiri dari tiga menara (pasak) dan lebih dari satu cincin seperti yang digambarkan -

Cincin ini memiliki ukuran yang berbeda dan ditumpuk dalam urutan menaik, yaitu cincin yang lebih kecil diletakkan di atas cincin yang lebih besar. Ada variasi lain dari teka-teki di mana jumlah cakram bertambah, tetapi jumlah menara tetap sama.
Aturan
Misinya adalah memindahkan semua disk ke menara lain tanpa melanggar urutan pengaturan. Beberapa aturan yang harus diikuti untuk Tower of Hanoi adalah -
- Hanya satu disk yang dapat dipindahkan di antara menara pada waktu tertentu.
- Hanya disk "atas" yang dapat dihapus.
- Tidak ada disk besar yang dapat menempati disk kecil.
Berikut ini adalah representasi animasi dari memecahkan teka-teki Menara Hanoi dengan tiga disk.

Teka-teki Tower of Hanoi dengan n disk dapat diselesaikan minimal 2n−1Langkah. Presentasi ini menunjukkan bahwa puzzle dengan 3 disk telah diambil23 - 1 = 7 Langkah.
Algoritma
Untuk menulis algoritme Menara Hanoi, pertama-tama kita perlu mempelajari cara menyelesaikan masalah ini dengan jumlah disk yang lebih sedikit, misalnya → 1 atau 2. Kami menandai tiga menara dengan nama, source, destination dan aux(hanya untuk membantu memindahkan disk). Jika kita hanya memiliki satu disk, maka dengan mudah dapat dipindahkan dari sumber ke pasak tujuan.
Jika kami memiliki 2 disk -
- Pertama, kami memindahkan disk yang lebih kecil (atas) ke peg aux.
- Kemudian, kami memindahkan disk yang lebih besar (bawah) ke pasak tujuan.
- Dan terakhir, kami memindahkan disk yang lebih kecil dari aux ke pasak tujuan.

Jadi sekarang, kami berada dalam posisi untuk merancang algoritme untuk Tower of Hanoi dengan lebih dari dua disk. Kami membagi tumpukan disk menjadi dua bagian. Disk terbesar (disk ke n ) ada di satu bagian dan semua disk lainnya (n-1) ada di bagian kedua.
Tujuan utama kami adalah untuk memindahkan disk ndari sumber ke tujuan dan kemudian meletakkan semua disk (n1) lainnya ke dalamnya. Kita dapat membayangkan untuk menerapkan hal yang sama secara rekursif untuk semua kumpulan disk yang diberikan.
Langkah-langkah yang harus diikuti adalah -
Step 1 − Move n-1 disks from source to aux
Step 2 − Move nth disk from source to dest
Step 3 − Move n-1 disks from aux to destAlgoritme rekursif untuk Tower of Hanoi dapat dijalankan sebagai berikut -
START
Procedure Hanoi(disk, source, dest, aux)
IF disk == 1, THEN
move disk from source to dest
ELSE
Hanoi(disk - 1, source, aux, dest) // Step 1
move disk from source to dest // Step 2
Hanoi(disk - 1, aux, dest, source) // Step 3
END IF
END Procedure
STOPUntuk memeriksa implementasi dalam pemrograman C, klik di sini .
Deret Fibonacci menghasilkan angka berikutnya dengan menambahkan dua angka sebelumnya. Deret Fibonacci dimulai dari dua angka -F0 & F1. Nilai awal F 0 & F 1 dapat diambil masing-masing 0, 1 atau 1, 1.
Deret Fibonacci memenuhi kondisi berikut -
Fn = Fn-1 + Fn-2Karenanya, deret Fibonacci bisa terlihat seperti ini -
F 8 = 0 1 1 2 3 5 8 13
atau, ini -
F 8 = 1 1 2 3 5 8 13 21
Sebagai ilustrasi, Fibonacci dari F 8 ditampilkan sebagai -

Algoritma Fibonacci Iteratif
Pertama kami mencoba untuk menyusun algoritma iteratif untuk deret Fibonacci.
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
end procedureUntuk mengetahui tentang implementasi algoritma di atas dalam bahasa pemograman C, klik disini .
Algoritma Rekursif Fibonacci
Mari kita pelajari cara membuat algoritma rekursif deret Fibonacci. Kriteria dasar rekursi.
START
Procedure Fibonacci(n)
declare f0, f1, fib, loop
set f0 to 0
set f1 to 1
display f0, f1
for loop ← 1 to n
fib ← f0 + f1
f0 ← f1
f1 ← fib
display fib
end for
ENDUntuk melihat implementasi algoritma di atas dalam bahasa pemrograman c, klik disini .