Scikit Learn - Representasi Data
Seperti yang kita ketahui bahwa pembelajaran mesin akan membuat model dari data. Untuk keperluan ini, komputer harus memahami data terlebih dahulu. Selanjutnya kita akan membahas berbagai cara untuk merepresentasikan data agar dapat dipahami oleh komputer -
Data sebagai tabel
Cara terbaik untuk merepresentasikan data di Scikit-learn adalah dalam bentuk tabel. Tabel mewakili data grid 2-D di mana baris mewakili elemen individu dari dataset dan kolom mewakili jumlah yang terkait dengan elemen individu tersebut.
Contoh
Dengan contoh yang diberikan di bawah ini, kita dapat mengunduh iris dataset dalam bentuk Pandas DataFrame dengan bantuan python seaborn Perpustakaan.
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()Keluaran
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaDari keluaran di atas, kita dapat melihat bahwa setiap baris data mewakili satu bunga yang diamati dan jumlah baris mewakili jumlah total bunga dalam dataset. Umumnya, kami merujuk baris matriks sebagai sampel.
Di sisi lain, setiap kolom data mewakili informasi kuantitatif yang menggambarkan setiap sampel. Umumnya, kami merujuk kolom matriks sebagai fitur.
Data sebagai Matriks Fitur
Matriks fitur dapat didefinisikan sebagai tata letak tabel di mana informasi dapat dianggap sebagai matriks 2-D. Itu disimpan dalam variabel bernamaXdan diasumsikan dua dimensi dengan bentuk [n_samples, n_features]. Sebagian besar, ini dimuat dalam array NumPy atau Pandas DataFrame. Seperti yang diceritakan sebelumnya, sampel selalu mewakili objek individu yang dideskripsikan oleh dataset dan fiturnya mewakili pengamatan berbeda yang mendeskripsikan setiap sampel secara kuantitatif.
Data sebagai larik Target
Bersama dengan matriks Fitur, dilambangkan dengan X, kami juga memiliki larik target. Ini juga disebut label. Ini dilambangkan dengan y. Label atau larik target biasanya satu dimensi yang memiliki panjang n_sampel. Ini umumnya terkandung dalam NumPyarray atau Panda Series. Array target dapat memiliki nilai, nilai numerik kontinu, dan nilai diskrit.
Apa perbedaan larik target dengan kolom fitur?
Kita dapat membedakan keduanya dengan satu poin bahwa larik target biasanya adalah kuantitas yang ingin kita prediksi dari data yaitu dalam istilah statistik itu adalah variabel dependen.
Contoh
Pada contoh di bawah ini, dari dataset iris kami memprediksi spesies bunga berdasarkan pengukuran lainnya. Dalam hal ini, kolom Spesies akan dianggap sebagai fitur.
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);Keluaran
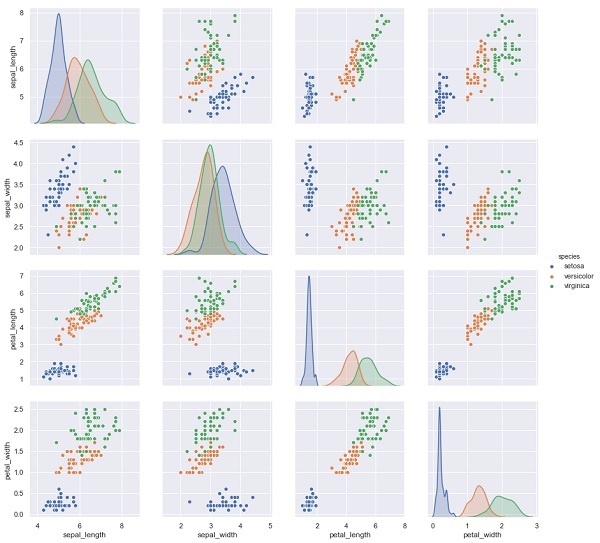
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shapeKeluaran
(150,4)
(150,)