Scikit Learn - API Estimator
Dalam bab ini, kita akan belajar tentang Estimator API(antarmuka pemrograman aplikasi). Mari kita mulai dengan memahami apa itu Estimator API.
Apa itu Estimator API
Ini adalah salah satu API utama yang diimplementasikan oleh Scikit-learn. Ini menyediakan antarmuka yang konsisten untuk berbagai aplikasi ML, itulah sebabnya semua algoritme pembelajaran mesin di Scikit-Learn diimplementasikan melalui Estimator API. Objek yang belajar dari data (menyesuaikan data) adalah penduga. Ini dapat digunakan dengan salah satu algoritme seperti klasifikasi, regresi, pengelompokan, atau bahkan dengan transformator, yang mengekstrak fitur berguna dari data mentah.
Untuk menyesuaikan data, semua objek estimator mengekspos metode fit yang mengambil dataset yang ditunjukkan sebagai berikut:
estimator.fit(data)Selanjutnya, semua parameter penduga dapat disetel, sebagai berikut, saat dibuat instance-nya oleh atribut yang sesuai.
estimator = Estimator (param1=1, param2=2)
estimator.param1Output di atas akan menjadi 1.
Setelah data dilengkapi dengan estimator, parameter diperkirakan dari data yang ada. Sekarang, semua parameter yang diestimasi akan menjadi atribut dari objek estimator yang diakhiri dengan garis bawah sebagai berikut -
estimator.estimated_param_Penggunaan Estimator API
Kegunaan utama estimator adalah sebagai berikut -
Estimasi dan decoding model
Objek Estimator digunakan untuk estimasi dan decoding suatu model. Selanjutnya, model diestimasi sebagai fungsi deterministik berikut ini -
Parameter yang disediakan dalam konstruksi objek.
Keadaan acak global (numpy.random) jika parameter random_state penduga diatur ke tidak ada.
Semua data yang diteruskan ke panggilan terakhir ke fit, fit_transform, or fit_predict.
Setiap data yang diteruskan dalam urutan panggilan ke partial_fit.
Memetakan representasi data non persegi panjang menjadi data persegi panjang
Ini memetakan representasi data non-persegi panjang menjadi data persegi panjang. Dengan kata sederhana, dibutuhkan input di mana setiap sampel tidak direpresentasikan sebagai objek seperti array dengan panjang tetap, dan menghasilkan objek fitur seperti array untuk setiap sampel.
Perbedaan antara sampel inti dan sampel luar
Ini memodelkan perbedaan antara sampel inti dan luar dengan menggunakan metode berikut -
fit
fit_predict jika transduktif
memprediksi jika induktif
Prinsip-Prinsip Panduan
Saat mendesain Scikit-Learn API, mengikuti prinsip-prinsip panduan selalu diingat -
Konsistensi
Prinsip ini menyatakan bahwa semua objek harus berbagi antarmuka umum yang diambil dari sekumpulan metode terbatas. Dokumentasi juga harus konsisten.
Hierarki objek terbatas
Prinsip panduan ini mengatakan -
Algoritma harus diwakili oleh kelas Python
Set data harus direpresentasikan dalam format standar seperti array NumPy, Pandas DataFrames, matriks jarang SciPy.
Nama parameter harus menggunakan string Python standar.
Komposisi
Seperti yang kita ketahui, algoritma ML dapat diekspresikan sebagai urutan dari banyak algoritma fundamental. Scikit-learn menggunakan algoritme dasar ini kapan pun diperlukan.
Default yang masuk akal
Menurut prinsip ini, pustaka Scikit-learn menentukan nilai default yang sesuai setiap kali model ML memerlukan parameter yang ditentukan pengguna.
Inspeksi
Sesuai prinsip panduan ini, setiap nilai parameter yang ditentukan diekspos sebagai atribut pubis.
Langkah-langkah dalam menggunakan Estimator API
Berikut adalah langkah-langkah dalam menggunakan Scikit-Learn estimator API -
Langkah 1: Pilih kelas model
Pada langkah pertama ini, kita perlu memilih kelas model. Itu bisa dilakukan dengan mengimpor kelas Estimator yang sesuai dari Scikit-learn.
Langkah 2: Pilih hyperparameter model
Pada langkah ini, kita perlu memilih hyperparameter model kelas. Ini dapat dilakukan dengan membuat instance kelas dengan nilai yang diinginkan.
Langkah 3: Mengatur data
Selanjutnya, kita perlu menyusun data tersebut menjadi matriks fitur (X) dan vektor target (y).
Langkah 4: Model Fitting
Sekarang, kami perlu menyesuaikan model dengan data Anda. Itu bisa dilakukan dengan memanggil metode fit () dari contoh model.
Langkah 5: Menerapkan model
Setelah menyesuaikan model, kita dapat menerapkannya ke data baru. Untuk pembelajaran yang diawasi, gunakanpredict()metode untuk memprediksi label untuk data yang tidak diketahui. Sedangkan untuk pembelajaran tanpa pengawasan, gunakanpredict() atau transform() untuk menyimpulkan properti data.
Contoh Pembelajaran yang Diawasi
Di sini, sebagai contoh dari proses ini kami mengambil kasus umum pemasangan garis ke data (x, y) yaitu simple linear regression.
Pertama, kita perlu memuat dataset, kita menggunakan dataset iris -
Contoh
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shapeKeluaran
(150, 4)Contoh
y_iris = iris['species']
y_iris.shapeKeluaran
(150,)Contoh
Sekarang, untuk contoh regresi ini, kita akan menggunakan contoh data berikut -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);Keluaran
Jadi, kami memiliki data di atas untuk contoh regresi linier kami.
Sekarang, dengan data ini, kita dapat menerapkan langkah-langkah yang disebutkan di atas.
Pilih kelas model
Di sini, untuk menghitung model regresi linier sederhana, kita perlu mengimpor kelas regresi linier sebagai berikut -
from sklearn.linear_model import LinearRegressionPilih hyperparameter model
Setelah kita memilih kelas model, kita perlu membuat beberapa pilihan penting yang sering direpresentasikan sebagai hyperparameter, atau parameter yang harus disetel sebelum model disesuaikan dengan data. Di sini, untuk contoh regresi linier ini, kami ingin menyesuaikan intersep dengan menggunakanfit_intercept hyperparameter sebagai berikut -
Example
model = LinearRegression(fit_intercept = True)
modelOutput
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)Mengatur data
Sekarang, seperti yang kita ketahui bahwa variabel target kita y dalam bentuk yang benar, yaitu panjang n_samplesarray 1-D. Tapi, kita perlu membentuk kembali matriks fiturX untuk menjadikannya matriks ukuran [n_samples, n_features]. Itu dapat dilakukan sebagai berikut -
Example
X = x[:, np.newaxis]
X.shapeOutput
(40, 1)Model pas
Setelah kita menyusun data, sekarang saatnya menyesuaikan model, yaitu menerapkan model kita ke data. Ini dapat dilakukan dengan bantuanfit() metode sebagai berikut -
Example
model.fit(X, y)Output
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)Di Scikit-learn, file fit() proses memiliki beberapa garis bawah.
Untuk contoh ini, parameter di bawah ini menunjukkan kemiringan kesesuaian linier sederhana dari data -
Example
model.coef_Output
array([1.99839352])Parameter di bawah ini mewakili intersep dari kesesuaian linier sederhana ke data -
Example
model.intercept_Output
-0.9895459457775022Menerapkan model ke data baru
Setelah melatih model, kita dapat menerapkannya ke data baru. Karena tugas utama supervised machine learning adalah mengevaluasi model berdasarkan data baru yang bukan merupakan bagian dari set pelatihan. Itu bisa dilakukan dengan bantuanpredict() metode sebagai berikut -
Example
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Output
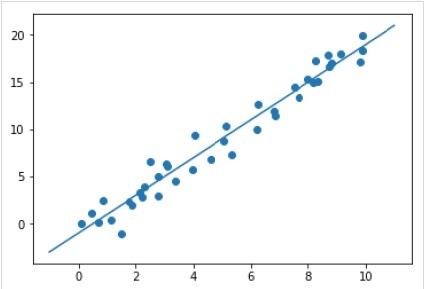
Contoh kerja / eksekusi lengkap
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Contoh Pembelajaran Tanpa Pengawasan
Di sini, sebagai contoh dari proses ini kami mengambil kasus umum pengurangan dimensi dataset Iris sehingga kami dapat memvisualisasikannya dengan lebih mudah. Untuk contoh ini, kita akan menggunakan analisis komponen utama (PCA), teknik reduksi dimensi linier cepat.
Seperti contoh yang diberikan di atas, kita dapat memuat dan memplot data acak dari dataset iris. Setelah itu kita bisa mengikuti langkah-langkah seperti di bawah ini -
Pilih kelas model
from sklearn.decomposition import PCAPilih hyperparameter model
Example
model = PCA(n_components=2)
modelOutput
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Model pas
Example
model.fit(X_iris)Output
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Ubah data menjadi dua dimensi
Example
X_2D = model.transform(X_iris)Sekarang, kita dapat memplot hasilnya sebagai berikut -
Output
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);Output
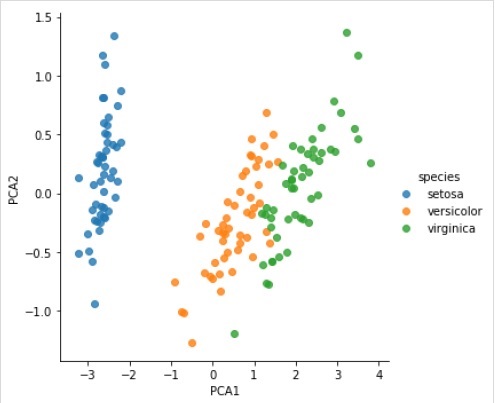
Contoh kerja / eksekusi lengkap
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);