Scikit Learn - Panduan Cepat
Dalam bab ini, kita akan memahami apa itu Scikit-Learn atau Sklearn, asal-usul Scikit-Learn dan beberapa topik terkait lainnya seperti komunitas dan kontributor yang bertanggung jawab untuk pengembangan dan pemeliharaan Scikit-Learn, prasyaratnya, instalasi dan fitur-fiturnya.
Apa itu Scikit-Learn (Sklearn)
Scikit-learn (Sklearn) adalah library paling berguna dan tangguh untuk pembelajaran mesin dengan Python. Ini menyediakan pilihan alat yang efisien untuk pembelajaran mesin dan pemodelan statistik termasuk klasifikasi, regresi, pengelompokan, dan pengurangan dimensi melalui antarmuka konsistensi dengan Python. Library ini, yang sebagian besar ditulis dengan Python, dibangun di atasnyaNumPy, SciPy dan Matplotlib.
Asal-usul Scikit-Learn
Awalnya disebut scikits.learn dan pada awalnya dikembangkan oleh David Cournapeau sebagai proyek kode musim panas Google pada tahun 2007. Kemudian, pada tahun 2010, Fabian Pedregosa, Gael Varoquaux, Alexandre Gramfort, dan Vincent Michel, dari FIRCA (Institut Penelitian Perancis dalam Ilmu Komputer dan Otomasi), mengambil proyek ini di tingkat lain dan membuat rilis publik pertama (v0.1 beta) pada 1 Februari 2010.
Mari kita lihat riwayat versinya -
Mei 2019: scikit-learn 0.21.0
Maret 2019: scikit-learn 0.20.3
Desember 2018: scikit-learn 0.20.2
November 2018: scikit-learn 0.20.1
September 2018: scikit-learn 0.20.0
Juli 2018: scikit-learn 0.19.2
Juli 2017: scikit-learn 0.19.0
September 2016. scikit-learn 0.18.0
November 2015. scikit-learn 0.17.0
Maret 2015. scikit-learn 0.16.0
Juli 2014. scikit-learn 0.15.0
Agustus 2013. scikit-learn 0.14
Komunitas & kontributor
Scikit-learn adalah upaya komunitas dan siapa pun dapat berkontribusi padanya. Proyek ini dihosting padahttps://github.com/scikit-learn/scikit-learn. Orang-orang yang mengikuti saat ini merupakan kontributor inti untuk pengembangan dan pemeliharaan Sklearn -
Joris Van den Bossche (Ilmuwan Data)
Thomas J Fan (Pengembang Perangkat Lunak)
Alexandre Gramfort (Peneliti Pembelajaran Mesin)
Olivier Grisel (Pakar Pembelajaran Mesin)
Nicolas Hug (Ilmuwan Riset Asosiasi)
Andreas Mueller (Ilmuwan Pembelajaran Mesin)
Hanmin Qin (Insinyur Perangkat Lunak)
Adrin Jalali (Pengembang Sumber Terbuka)
Nelle Varoquaux (Peneliti Ilmu Data)
Roman Yurchak (Ilmuwan Data)
Berbagai organisasi seperti Booking.com, JP Morgan, Evernote, Inria, AWeber, Spotify, dan banyak lagi menggunakan Sklearn.
Prasyarat
Sebelum kami mulai menggunakan scikit-learn rilis terbaru, kami memerlukan yang berikut -
Python (> = 3.5)
NumPy (> = 1.11.0)
Scipy (> = 0.17.0) li
Joblib (> = 0,11)
Matplotlib (> = 1.5.1) diperlukan untuk kapabilitas plotting Sklearn.
Pandas (> = 0.18.0) diperlukan untuk beberapa contoh scikit-learn yang menggunakan struktur dan analisis data.
Instalasi
Jika Anda sudah menginstal NumPy dan Scipy, berikut adalah dua cara termudah untuk menginstal scikit-learn -
Menggunakan pip
Perintah berikut dapat digunakan untuk menginstal scikit-learn melalui pip -
pip install -U scikit-learnMenggunakan conda
Perintah berikut dapat digunakan untuk menginstal scikit-learn melalui conda -
conda install scikit-learnDi sisi lain, jika NumPy dan Scipy belum diinstal pada workstation Python Anda, Anda dapat menginstalnya dengan menggunakan pip atau conda.
Pilihan lain untuk menggunakan scikit-learn adalah menggunakan distribusi Python seperti Canopy dan Anaconda karena keduanya mengirimkan versi terbaru scikit-learn.
fitur
Daripada berfokus pada memuat, memanipulasi, dan meringkas data, perpustakaan Scikit-learn difokuskan pada pemodelan data. Beberapa grup model terpopuler yang disediakan oleh Sklearn adalah sebagai berikut -
Supervised Learning algorithms - Hampir semua algoritme pembelajaran terawasi yang populer, seperti Regresi Linier, Mesin Vektor Dukungan (SVM), Pohon Keputusan, dll., Adalah bagian dari scikit-learn.
Unsupervised Learning algorithms - Di sisi lain, ia juga memiliki semua algoritme pembelajaran tanpa pengawasan yang populer mulai dari pengelompokan, analisis faktor, PCA (Analisis Komponen Utama) hingga jaringan neural tanpa pengawasan.
Clustering - Model ini digunakan untuk mengelompokkan data yang tidak berlabel.
Cross Validation - Digunakan untuk memeriksa keakuratan model yang diawasi pada data yang tidak terlihat.
Dimensionality Reduction - Digunakan untuk mengurangi jumlah atribut dalam data yang selanjutnya dapat digunakan untuk peringkasan, visualisasi, dan pemilihan fitur.
Ensemble methods - Seperti namanya, ini digunakan untuk menggabungkan prediksi beberapa model yang diawasi.
Feature extraction - Digunakan untuk mengekstrak fitur dari data untuk menentukan atribut dalam data gambar dan teks.
Feature selection - Digunakan untuk mengidentifikasi atribut yang berguna untuk membuat model yang diawasi.
Open Source - Ini adalah perpustakaan sumber terbuka dan juga dapat digunakan secara komersial di bawah lisensi BSD.
Bab ini membahas proses pemodelan yang terlibat dalam Sklearn. Mari kita pahami hal yang sama secara detail dan mulai dengan pemuatan dataset.
Pemuatan Set Data
Kumpulan data disebut dataset. Itu memiliki dua komponen berikut -
Features- Variabel data disebut fiturnya. Mereka juga dikenal sebagai prediktor, input, atau atribut.
Feature matrix - Ini adalah kumpulan fitur, jika ada lebih dari satu.
Feature Names - Ini adalah daftar semua nama fitur.
Response- Ini adalah variabel keluaran yang pada dasarnya bergantung pada variabel fitur. Mereka juga dikenal sebagai target, label, atau keluaran.
Response Vector- Digunakan untuk merepresentasikan kolom respon. Umumnya, kami hanya memiliki satu kolom tanggapan.
Target Names - Ini mewakili nilai yang mungkin diambil oleh vektor respons.
Scikit-learn memiliki beberapa contoh kumpulan data iris dan digits untuk klasifikasi dan Boston house prices untuk regresi.
Contoh
Berikut adalah contoh untuk dimuat iris kumpulan data -
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print("Feature names:", feature_names)
print("Target names:", target_names)
print("\nFirst 10 rows of X:\n", X[:10])Keluaran
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Target names: ['setosa' 'versicolor' 'virginica']
First 10 rows of X:
[
[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
]Memisahkan dataset
Untuk memeriksa keakuratan model kami, kami dapat membagi dataset menjadi dua bagian-a training set dan a testing set. Gunakan set pelatihan untuk melatih model dan set pengujian untuk menguji model. Setelah itu, kami dapat mengevaluasi seberapa baik model kami.
Contoh
Contoh berikut akan membagi data menjadi rasio 70:30, yaitu 70% data akan digunakan sebagai data latih dan 30% akan digunakan sebagai data uji. Dataset tersebut merupakan dataset iris seperti contoh di atas.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 1
)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)Keluaran
(105, 4)
(45, 4)
(105,)
(45,)Seperti yang terlihat pada contoh di atas, ini menggunakan train_test_split()fungsi scikit-learn untuk membagi dataset. Fungsi ini memiliki argumen berikut -
X, y - Di sini, X adalah feature matrix dan y adalah response vector, yang perlu dipecah.
test_size- Ini mewakili rasio data uji terhadap total data yang diberikan. Seperti pada contoh di atas, kita sedang melakukan settingtest_data = 0.3 untuk 150 baris X. Ini akan menghasilkan data uji 150 * 0,3 = 45 baris.
random_size- Digunakan untuk menjamin bahwa pembagian akan selalu sama. Ini berguna dalam situasi di mana Anda ingin hasil yang dapat direproduksi.
Latih Modelnya
Selanjutnya, kita bisa menggunakan dataset kita untuk melatih beberapa model prediksi. Seperti yang telah dibahas, scikit-learn memiliki jangkauan yang luasMachine Learning (ML) algorithms yang memiliki antarmuka yang konsisten untuk pemasangan, prediksi akurasi, penarikan kembali, dll.
Contoh
Dalam contoh di bawah ini, kita akan menggunakan pengklasifikasi KNN (K tetangga terdekat). Jangan membahas detail algoritma KNN, karena akan ada bab terpisah untuk itu. Contoh ini digunakan untuk membuat Anda memahami bagian implementasi saja.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.4, random_state=1
)
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors = 3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Finding accuracy by comparing actual response values(y_test)with predicted response value(y_pred)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)Keluaran
Accuracy: 0.9833333333333333
Predictions: ['versicolor', 'virginica']Ketekunan Model
Setelah Anda melatih model, sebaiknya model tersebut dipertahankan untuk penggunaan di masa mendatang sehingga kami tidak perlu melatihnya lagi dan lagi. Itu bisa dilakukan dengan bantuandump dan load fitur dari joblib paket.
Pertimbangkan contoh di bawah ini di mana kita akan menyimpan model terlatih di atas (classifier_knn) untuk digunakan di masa mendatang -
from sklearn.externals import joblib
joblib.dump(classifier_knn, 'iris_classifier_knn.joblib')Kode di atas akan menyimpan model ke dalam file bernama iris_classifier_knn.joblib. Sekarang, objek dapat dimuat ulang dari file dengan bantuan kode berikut -
joblib.load('iris_classifier_knn.joblib')Memproses Data
Karena kita berurusan dengan banyak data dan data itu dalam bentuk mentah, sebelum memasukkan data itu ke algoritma pembelajaran mesin, kita perlu mengubahnya menjadi data yang bermakna. Proses ini disebut preprocessing data. Scikit-learn memiliki nama paketpreprocessinguntuk tujuan ini. Itupreprocessing paket memiliki teknik berikut -
Binarisasi
Teknik preprocessing ini digunakan ketika kita perlu mengubah nilai numerik kita menjadi nilai Boolean.
Contoh
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
data_binarized = preprocessing.Binarizer(threshold=0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)Dalam contoh di atas, kami menggunakan threshold value = 0,5 dan itulah sebabnya, semua nilai di atas 0,5 akan diubah menjadi 1, dan semua nilai di bawah 0,5 akan diubah menjadi 0.
Keluaran
Binarized data:
[
[ 1. 0. 1.]
[ 0. 1. 1.]
[ 0. 0. 1.]
[ 1. 1. 0.]
]Penghapusan Berarti
Teknik ini digunakan untuk menghilangkan mean dari vektor ciri sehingga setiap ciri berpusat pada nol.
Contoh
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
#displaying the mean and the standard deviation of the input data
print("Mean =", input_data.mean(axis=0))
print("Stddeviation = ", input_data.std(axis=0))
#Removing the mean and the standard deviation of the input data
data_scaled = preprocessing.scale(input_data)
print("Mean_removed =", data_scaled.mean(axis=0))
print("Stddeviation_removed =", data_scaled.std(axis=0))Keluaran
Mean = [ 1.75 -1.275 2.2 ]
Stddeviation = [ 2.71431391 4.20022321 4.69414529]
Mean_removed = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00]
Stddeviation_removed = [ 1. 1. 1.]Penskalaan
Kami menggunakan teknik preprocessing ini untuk menskalakan vektor fitur. Penskalaan vektor fitur itu penting, karena fitur tidak boleh besar atau kecil secara sintetis.
Contoh
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)Keluaran
Min max scaled data:
[
[ 0.48648649 0.58252427 0.99122807]
[ 0. 1. 0.81578947]
[ 0.27027027 0. 1. ]
[ 1. 0.99029126 0. ]
]Normalisasi
Kami menggunakan teknik preprocessing ini untuk memodifikasi vektor fitur. Normalisasi vektor fitur diperlukan agar vektor fitur dapat diukur pada skala yang sama. Ada dua jenis normalisasi sebagai berikut -
Normalisasi L1
Ini juga disebut Penyimpangan Mutlak Terkecil. Ini mengubah nilai sedemikian rupa sehingga jumlah nilai absolut tetap selalu hingga 1 di setiap baris. Contoh berikut menunjukkan implementasi normalisasi L1 pada data masukan.
Contoh
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l1 = preprocessing.normalize(input_data, norm='l1')
print("\nL1 normalized data:\n", data_normalized_l1)Keluaran
L1 normalized data:
[
[ 0.22105263 -0.2 0.57894737]
[-0.2027027 0.32432432 0.47297297]
[ 0.03571429 -0.56428571 0.4 ]
[ 0.42142857 0.16428571 -0.41428571]
]Normalisasi L2
Juga disebut Kotak Terkecil. Ini mengubah nilai sedemikian rupa sehingga jumlah kuadrat tetap selalu hingga 1 di setiap baris. Contoh berikut menunjukkan implementasi normalisasi L2 pada data masukan.
Contoh
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l2 = preprocessing.normalize(input_data, norm='l2')
print("\nL1 normalized data:\n", data_normalized_l2)Keluaran
L2 normalized data:
[
[ 0.33946114 -0.30713151 0.88906489]
[-0.33325106 0.53320169 0.7775858 ]
[ 0.05156558 -0.81473612 0.57753446]
[ 0.68706914 0.26784051 -0.6754239 ]
]Seperti yang kita ketahui bahwa pembelajaran mesin akan membuat model dari data. Untuk keperluan ini, komputer harus memahami data terlebih dahulu. Selanjutnya kita akan membahas berbagai cara untuk merepresentasikan data agar dapat dipahami oleh komputer -
Data sebagai tabel
Cara terbaik untuk merepresentasikan data di Scikit-learn adalah dalam bentuk tabel. Tabel mewakili data grid 2-D di mana baris mewakili elemen individu dari dataset dan kolom mewakili jumlah yang terkait dengan elemen individu tersebut.
Contoh
Dengan contoh yang diberikan di bawah ini, kita dapat mengunduh iris dataset dalam bentuk Pandas DataFrame dengan bantuan python seaborn Perpustakaan.
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()Keluaran
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaDari keluaran di atas, kita dapat melihat bahwa setiap baris data mewakili satu bunga yang diamati dan jumlah baris mewakili jumlah total bunga dalam dataset. Umumnya, kami menyebut baris matriks sebagai sampel.
Di sisi lain, setiap kolom data mewakili informasi kuantitatif yang menggambarkan setiap sampel. Umumnya, kami merujuk kolom matriks sebagai fitur.
Data sebagai Matriks Fitur
Matriks fitur dapat didefinisikan sebagai tata letak tabel di mana informasi dapat dianggap sebagai matriks 2-D. Itu disimpan dalam variabel bernamaXdan diasumsikan dua dimensi dengan bentuk [n_samples, n_features]. Sebagian besar, ini dimuat dalam array NumPy atau Pandas DataFrame. Seperti yang diceritakan sebelumnya, sampel selalu mewakili objek individu yang dideskripsikan oleh dataset dan fiturnya mewakili pengamatan berbeda yang mendeskripsikan setiap sampel secara kuantitatif.
Data sebagai larik Target
Bersama dengan matriks Fitur, dilambangkan dengan X, kami juga memiliki larik target. Ini juga disebut label. Ini dilambangkan dengan y. Label atau larik target biasanya satu dimensi dengan panjang n_samples. Ini umumnya terkandung dalam NumPyarray atau Panda Series. Array target dapat memiliki nilai, nilai numerik kontinu, dan nilai diskrit.
Apa perbedaan larik target dengan kolom fitur?
Kita dapat membedakan keduanya dengan satu poin bahwa larik target biasanya adalah kuantitas yang ingin kita prediksi dari data yaitu dalam istilah statistik itu adalah variabel dependen.
Contoh
Pada contoh di bawah ini, dari dataset iris kami memprediksi spesies bunga berdasarkan pengukuran lainnya. Dalam hal ini, kolom Spesies akan dianggap sebagai fitur.
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);Keluaran
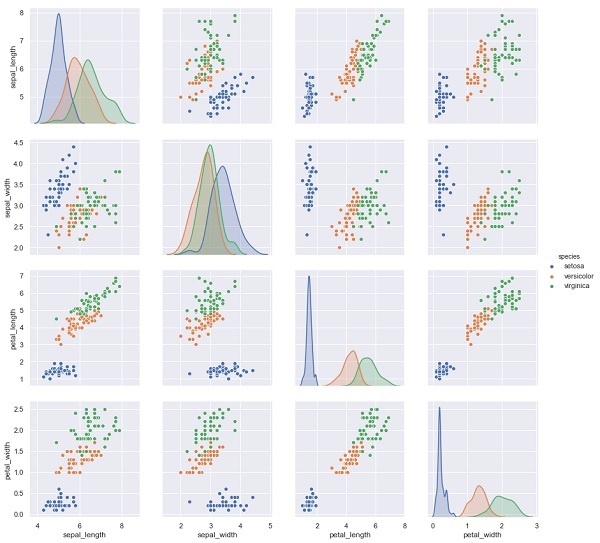
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shapeKeluaran
(150,4)
(150,)Dalam bab ini, kita akan belajar tentang Estimator API(antarmuka pemrograman aplikasi). Mari kita mulai dengan memahami apa itu Estimator API.
Apa itu Estimator API
Ini adalah salah satu API utama yang diimplementasikan oleh Scikit-learn. Ini menyediakan antarmuka yang konsisten untuk berbagai aplikasi ML, itulah sebabnya semua algoritme pembelajaran mesin di Scikit-Learn diimplementasikan melalui Estimator API. Objek yang belajar dari data (menyesuaikan data) adalah penduga. Ini dapat digunakan dengan salah satu algoritme seperti klasifikasi, regresi, pengelompokan, atau bahkan dengan transformator, yang mengekstrak fitur berguna dari data mentah.
Untuk menyesuaikan data, semua objek estimator mengekspos metode fit yang mengambil dataset yang ditunjukkan sebagai berikut:
estimator.fit(data)Selanjutnya, semua parameter penduga dapat disetel, sebagai berikut, saat dibuat instance-nya oleh atribut yang sesuai.
estimator = Estimator (param1=1, param2=2)
estimator.param1Output di atas akan menjadi 1.
Setelah data dilengkapi dengan estimator, parameter diperkirakan dari data yang ada. Sekarang, semua parameter yang diestimasi akan menjadi atribut dari objek estimator yang diakhiri dengan garis bawah sebagai berikut -
estimator.estimated_param_Penggunaan Estimator API
Kegunaan utama estimator adalah sebagai berikut -
Estimasi dan decoding model
Objek Estimator digunakan untuk estimasi dan decoding suatu model. Selanjutnya, model diestimasi sebagai fungsi deterministik berikut ini -
Parameter yang disediakan dalam konstruksi objek.
Keadaan acak global (numpy.random) jika parameter random_state penduga diatur ke tidak ada.
Semua data yang diteruskan ke panggilan terakhir ke fit, fit_transform, or fit_predict.
Setiap data yang diteruskan dalam urutan panggilan ke partial_fit.
Memetakan representasi data non-persegi panjang menjadi data persegi panjang
Ini memetakan representasi data non-persegi panjang menjadi data persegi panjang. Dengan kata sederhana, dibutuhkan input di mana setiap sampel tidak direpresentasikan sebagai objek seperti array dengan panjang tetap, dan menghasilkan objek fitur seperti array untuk setiap sampel.
Perbedaan antara sampel inti dan sampel luar
Ini memodelkan perbedaan antara sampel inti dan luar dengan menggunakan metode berikut -
fit
fit_predict jika transduktif
memprediksi jika induktif
Prinsip-Prinsip Panduan
Saat mendesain Scikit-Learn API, mengikuti prinsip panduan tetap diingat -
Konsistensi
Prinsip ini menyatakan bahwa semua objek harus berbagi antarmuka umum yang diambil dari sekumpulan metode terbatas. Dokumentasi juga harus konsisten.
Hierarki objek terbatas
Prinsip panduan ini mengatakan -
Algoritma harus diwakili oleh kelas Python
Set data harus direpresentasikan dalam format standar seperti array NumPy, Pandas DataFrames, matriks sparse SciPy.
Nama parameter harus menggunakan string Python standar.
Komposisi
Seperti yang kita ketahui, algoritma ML dapat diekspresikan sebagai urutan dari banyak algoritma fundamental. Scikit-learn menggunakan algoritme fundamental ini kapan pun diperlukan.
Default yang masuk akal
Menurut prinsip ini, pustaka Scikit-learn menentukan nilai default yang sesuai setiap kali model ML memerlukan parameter yang ditentukan pengguna.
Inspeksi
Sesuai prinsip panduan ini, setiap nilai parameter yang ditentukan diekspos sebagai atribut pubis.
Langkah-langkah dalam menggunakan Estimator API
Berikut adalah langkah-langkah dalam menggunakan Scikit-Learn estimator API -
Langkah 1: Pilih kelas model
Pada langkah pertama ini, kita perlu memilih kelas model. Itu bisa dilakukan dengan mengimpor kelas Estimator yang sesuai dari Scikit-learn.
Langkah 2: Pilih hyperparameter model
Pada langkah ini, kita perlu memilih hyperparameter model kelas. Ini dapat dilakukan dengan membuat instance kelas dengan nilai yang diinginkan.
Langkah 3: Mengatur data
Selanjutnya, kita perlu menyusun data menjadi matriks fitur (X) dan vektor target (y).
Langkah 4: Model Fitting
Sekarang, kami perlu menyesuaikan model dengan data Anda. Itu bisa dilakukan dengan memanggil metode fit () dari contoh model.
Langkah 5: Menerapkan model
Setelah menyesuaikan model, kita dapat menerapkannya ke data baru. Untuk pembelajaran yang diawasi, gunakanpredict()metode untuk memprediksi label untuk data yang tidak diketahui. Sedangkan untuk pembelajaran tanpa pengawasan, gunakanpredict() atau transform() untuk menyimpulkan properti data.
Contoh Pembelajaran yang Diawasi
Di sini, sebagai contoh dari proses ini kami mengambil kasus umum pemasangan garis ke data (x, y) yaitu simple linear regression.
Pertama, kita perlu memuat dataset, kita menggunakan dataset iris -
Contoh
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shapeKeluaran
(150, 4)Contoh
y_iris = iris['species']
y_iris.shapeKeluaran
(150,)Contoh
Sekarang, untuk contoh regresi ini, kita akan menggunakan contoh data berikut -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);Keluaran
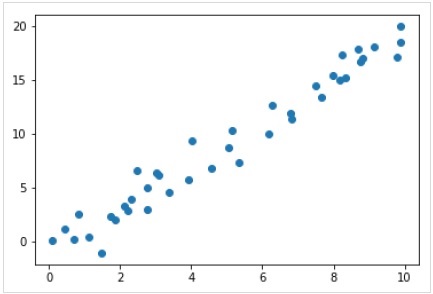
Jadi, kami memiliki data di atas untuk contoh regresi linier kami.
Sekarang, dengan data ini, kita dapat menerapkan langkah-langkah yang disebutkan di atas.
Pilih kelas model
Di sini, untuk menghitung model regresi linier sederhana, kita perlu mengimpor kelas regresi linier sebagai berikut -
from sklearn.linear_model import LinearRegressionPilih hyperparameter model
Setelah kita memilih kelas model, kita perlu membuat beberapa pilihan penting yang sering direpresentasikan sebagai hyperparameter, atau parameter yang harus disetel sebelum model disesuaikan dengan data. Di sini, untuk contoh regresi linier ini, kami ingin menyesuaikan intersep dengan menggunakanfit_intercept hyperparameter sebagai berikut -
Example
model = LinearRegression(fit_intercept = True)
modelOutput
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)Mengatur data
Sekarang, seperti yang kita ketahui bahwa variabel target kita y dalam bentuk yang benar, yaitu panjang n_samplesarray 1-D. Tapi, kita perlu membentuk kembali matriks fiturX untuk menjadikannya matriks ukuran [n_samples, n_features]. Itu dapat dilakukan sebagai berikut -
Example
X = x[:, np.newaxis]
X.shapeOutput
(40, 1)Model pas
Setelah kita menyusun data, sekarang saatnya menyesuaikan model, yaitu menerapkan model kita ke data. Ini dapat dilakukan dengan bantuanfit() metode sebagai berikut -
Example
model.fit(X, y)Output
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)Di Scikit-learn, file fit() proses memiliki beberapa garis bawah.
Untuk contoh ini, parameter di bawah ini menunjukkan kemiringan kesesuaian linier sederhana dari data -
Example
model.coef_Output
array([1.99839352])Parameter di bawah ini mewakili intersep dari kesesuaian linier sederhana ke data -
Example
model.intercept_Output
-0.9895459457775022Menerapkan model ke data baru
Setelah melatih model, kita dapat menerapkannya ke data baru. Karena tugas utama supervised machine learning adalah mengevaluasi model berdasarkan data baru yang bukan merupakan bagian dari set pelatihan. Itu bisa dilakukan dengan bantuanpredict() metode sebagai berikut -
Example
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Output
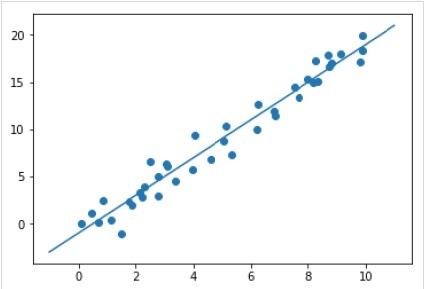
Contoh kerja / eksekusi lengkap
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Contoh Pembelajaran Tanpa Pengawasan
Di sini, sebagai contoh dari proses ini kami mengambil kasus umum pengurangan dimensi dataset Iris sehingga kami dapat memvisualisasikannya dengan lebih mudah. Untuk contoh ini, kita akan menggunakan analisis komponen utama (PCA), teknik reduksi dimensi linier cepat.
Seperti contoh yang diberikan di atas, kita dapat memuat dan memplot data acak dari dataset iris. Setelah itu kita bisa mengikuti langkah-langkah seperti di bawah ini -
Pilih kelas model
from sklearn.decomposition import PCAPilih hyperparameter model
Example
model = PCA(n_components=2)
modelOutput
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Model pas
Example
model.fit(X_iris)Output
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Ubah data menjadi dua dimensi
Example
X_2D = model.transform(X_iris)Sekarang, kita dapat memplot hasilnya sebagai berikut -
Output
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);Output
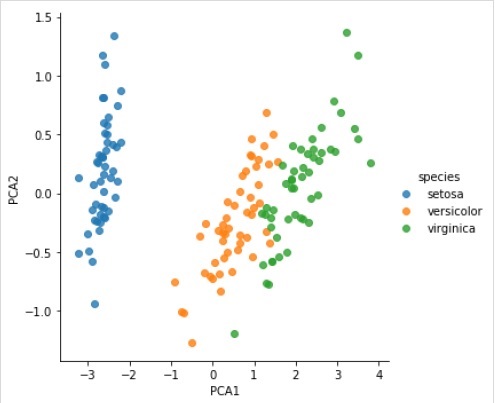
Contoh kerja / eksekusi lengkap
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);Objek Scikit-learn berbagi API dasar seragam yang terdiri dari tiga antarmuka pelengkap berikut -
Estimator interface - Ini untuk membangun dan memasang model.
Predictor interface - Ini untuk membuat prediksi.
Transformer interface - Ini untuk mengubah data.
API mengadopsi konvensi sederhana dan pilihan desain telah dipandu untuk menghindari penyebaran kode kerangka kerja.
Tujuan Konvensi
Tujuan konvensi adalah untuk memastikan bahwa API berpegang pada prinsip luas berikut -
Consistency - Semua objek apakah itu dasar, atau gabungan harus berbagi antarmuka yang konsisten yang selanjutnya terdiri dari serangkaian metode terbatas.
Inspection - Parameter konstruktor dan nilai parameter yang ditentukan oleh algoritma pembelajaran harus disimpan dan diekspos sebagai atribut publik.
Non-proliferation of classes - Kumpulan data harus direpresentasikan sebagai array NumPy atau matriks jarang Scipy sedangkan nama dan nilai hyper-parameter harus direpresentasikan sebagai string Python standar untuk menghindari penyebaran kode kerangka kerja.
Composition - Algoritme apakah dapat diekspresikan sebagai urutan atau kombinasi transformasi ke data atau secara alami dilihat sebagai meta-algoritme yang diparameterisasi pada algoritme lain, harus diimplementasikan dan disusun dari blok bangunan yang ada.
Sensible defaults- Dalam scikit-learn setiap kali sebuah operasi memerlukan parameter yang ditentukan pengguna, nilai default yang sesuai akan ditentukan. Nilai default ini harus menyebabkan operasi dilakukan dengan cara yang masuk akal, misalnya, memberikan solusi garis dasar untuk tugas yang sedang ditangani.
Berbagai Konvensi
Konvensi yang tersedia di Sklearn dijelaskan di bawah ini -
Ketik casting
Ini menyatakan bahwa masukan harus dilemparkan ke float64. Dalam contoh berikut, di manasklearn.random_projection modul yang digunakan untuk mengurangi dimensi data, akan menjelaskannya -
Example
import numpy as np
from sklearn import random_projection
rannge = np.random.RandomState(0)
X = range.rand(10,2000)
X = np.array(X, dtype = 'float32')
X.dtype
Transformer_data = random_projection.GaussianRandomProjection()
X_new = transformer.fit_transform(X)
X_new.dtypeOutput
dtype('float32')
dtype('float64')Dalam contoh di atas, kita dapat melihat bahwa X adalah float32 yang dilemparkan ke float64 oleh fit_transform(X).
Parameter Refitting & Updating
Hyper-parameter dari suatu estimator dapat diperbarui dan dipasang kembali setelah dibuat melalui set_params()metode. Mari kita lihat contoh berikut untuk memahaminya -
Example
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y = True)
clf = SVC()
clf.set_params(kernel = 'linear').fit(X, y)
clf.predict(X[:5])Output
array([0, 0, 0, 0, 0])Setelah estimator dibuat, kode di atas akan mengubah kernel default rbf untuk linier melalui SVC.set_params().
Sekarang, kode berikut akan mengubah kernel menjadi rbf untuk mereparasi estimator dan membuat prediksi kedua.
Example
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y)
clf.predict(X[:5])Output
array([0, 0, 0, 0, 0])Kode lengkap
Berikut ini adalah program yang dapat dieksekusi lengkap -
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y = True)
clf = SVC()
clf.set_params(kernel = 'linear').fit(X, y)
clf.predict(X[:5])
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y)
clf.predict(X[:5])Pemasangan multiclass & Multilabel
Dalam kasus pemasangan multikelas, tugas pembelajaran dan prediksi bergantung pada format data target yang sesuai. Modul yang digunakan adalahsklearn.multiclass. Periksa contoh di bawah ini, di mana pengklasifikasi multikelas cocok pada larik 1d.
Example
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]]
y = [0, 0, 1, 1, 2]
classif = OneVsRestClassifier(estimator = SVC(gamma = 'scale',random_state = 0))
classif.fit(X, y).predict(X)Output
array([0, 0, 1, 1, 2])Dalam contoh di atas, pengklasifikasi dipasang pada array satu dimensi dari label multikelas dan predict()metode sehingga memberikan prediksi multikelas yang sesuai. Tetapi di sisi lain, dimungkinkan juga untuk menyesuaikan dengan larik dua dimensi indikator label biner sebagai berikut -
Example
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]]
y = LabelBinarizer().fit_transform(y)
classif.fit(X, y).predict(X)Output
array(
[
[0, 0, 0],
[0, 0, 0],
[0, 1, 0],
[0, 1, 0],
[0, 0, 0]
]
)Demikian pula, dalam kasus pemasangan multilabel, sebuah instance dapat diberi beberapa label sebagai berikut -
Example
from sklearn.preprocessing import MultiLabelBinarizer
y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]]
y = MultiLabelBinarizer().fit_transform(y)
classif.fit(X, y).predict(X)Output
array(
[
[1, 0, 1, 0, 0],
[1, 0, 1, 0, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 0, 0]
]
)Dalam contoh di atas, sklearn.MultiLabelBinarizerdigunakan untuk membuat binarisasi array dua dimensi multilabel agar sesuai. Itulah mengapa fungsi predict () memberikan array 2d sebagai output dengan beberapa label untuk setiap instance.
Bab ini akan membantu Anda mempelajari tentang pemodelan linier di Scikit-Learn. Mari kita mulai dengan memahami apa itu regresi linier di Sklearn.
Tabel berikut mencantumkan berbagai model linier yang disediakan oleh Scikit-Learn -
| Sr Tidak | Model & Deskripsi |
|---|---|
| 1 | Regresi linier Ini adalah salah satu model statistik terbaik yang mempelajari hubungan antara variabel dependen (Y) dengan kumpulan variabel independen (X) tertentu. |
| 2 | Regresi logistik Regresi logistik, terlepas dari namanya, adalah algoritma klasifikasi daripada algoritma regresi. Berdasarkan kumpulan variabel independen tertentu, ini digunakan untuk memperkirakan nilai diskrit (0 atau 1, ya / tidak, benar / salah). |
| 3 | Regresi Ridge Regresi ridge atau regularisasi Tikhonov adalah teknik regularisasi yang melakukan regularisasi L2. Ini memodifikasi fungsi kerugian dengan menambahkan penalti (kuantitas penyusutan) yang setara dengan kuadrat dari besarnya koefisien. |
| 4 | Regresi Bayesian Ridge Regresi Bayesian memungkinkan mekanisme alami untuk bertahan dari data yang tidak mencukupi atau data yang terdistribusi dengan buruk dengan merumuskan regresi linier menggunakan distributor probabilitas daripada perkiraan titik. |
| 5 | LASO LASSO adalah teknik regularisasi yang melakukan regularisasi L1. Ini mengubah fungsi kerugian dengan menambahkan penalti (kuantitas penyusutan) yang setara dengan penjumlahan nilai absolut koefisien. |
| 6 | LASSO multi-tugas Ini memungkinkan untuk menyesuaikan beberapa masalah regresi yang secara bersama-sama memaksa fitur yang dipilih menjadi sama untuk semua masalah regresi, juga disebut tugas. Sklearn menyediakan model linier bernama MultiTaskLasso, dilatih dengan campuran L1, L2-norm untuk regularisasi, yang memperkirakan koefisien renggang untuk beberapa masalah regresi secara bersama-sama. |
| 7 | Elastis-Net Elastic-Net adalah metode regresi yang secara linier menggabungkan kedua penalti yaitu L1 dan L2 dari metode regresi Lasso dan Ridge. Ini berguna jika ada beberapa fitur yang berkorelasi. |
| 8 | Elastis-Net multi-tugas Ini adalah model Elastic-Net yang memungkinkan untuk menyesuaikan beberapa masalah regresi yang secara bersama-sama menerapkan fitur yang dipilih menjadi sama untuk semua masalah regresi, juga disebut tugas |
Bab ini berfokus pada fitur polinomial dan alat pemipaan di Sklearn.
Pengantar Fitur Polinomial
Model linier yang dilatih pada fungsi data non-linier umumnya mempertahankan performa cepat metode linier. Ini juga memungkinkan mereka menyesuaikan data yang jauh lebih luas. Itulah alasan dalam pembelajaran mesin model linier seperti itu, yang dilatih tentang fungsi nonlinier, digunakan.
Salah satu contohnya adalah regresi linier sederhana dapat diperpanjang dengan membangun fitur polinomial dari koefisien.
Secara matematis, misalkan kita memiliki model regresi linier standar maka untuk data 2-D akan terlihat seperti ini -
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}$$Sekarang, kita dapat menggabungkan fitur dalam polinomial orde dua dan model kita akan terlihat seperti berikut -
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}+W_{3}X_{1}X_{2}+W_{4}X_1^2+W_{5}X_2^2$$Di atas masih model linier. Di sini, kita melihat bahwa regresi polinomial yang dihasilkan berada dalam kelas model linier yang sama dan dapat diselesaikan dengan cara yang sama.
Untuk melakukannya, scikit-learn menyediakan modul bernama PolynomialFeatures. Modul ini mengubah matriks data masukan menjadi matriks data baru dengan derajat tertentu.
Parameter
Tabel berikut berisi parameter yang digunakan oleh PolynomialFeatures modul
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | degree - bilangan bulat, default = 2 Ini mewakili derajat fitur polinomial. |
| 2 | interaction_only - Boolean, default = false Secara default, ini salah tetapi jika disetel sebagai true, fitur-fitur yang merupakan produk dari sebagian besar fitur input yang berbeda, diproduksi. Fitur semacam itu disebut fitur interaksi. |
| 3 | include_bias - Boolean, default = true Ini mencakup kolom bias yaitu fitur di mana semua pangkat polinomial adalah nol. |
| 4 | order - str di {'C', 'F'}, default = 'C' Parameter ini mewakili urutan larik keluaran dalam kasus padat. Urutan 'F' berarti lebih cepat untuk menghitung tetapi di sisi lain, itu dapat memperlambat penduga berikutnya. |
Atribut
Tabel berikut berisi atribut-atribut yang digunakan oleh PolynomialFeatures modul
| Sr Tidak | Atribut & Deskripsi |
|---|---|
| 1 | powers_ - larik, bentuk (n_output_features, n_input_features) Ini menunjukkan pangkat_ [i, j] adalah eksponen dari input ke-j dalam output ke-i. |
| 2 | n_input_features _ - int Seperti namanya, ini memberikan jumlah total fitur input. |
| 3 | n_output_features _ - int Seperti namanya, ini memberikan jumlah total fitur keluaran polinomial. |
Contoh Implementasi
Mengikuti penggunaan skrip Python PolynomialFeatures transformator untuk mengubah susunan 8 menjadi bentuk (4,2) -
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
Y = np.arange(8).reshape(4, 2)
poly = PolynomialFeatures(degree=2)
poly.fit_transform(Y)Keluaran
array(
[
[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.],
[ 1., 6., 7., 36., 42., 49.]
]
)Penyederhanaan menggunakan alat Pipeline
Jenis preprocessing di atas yaitu mengubah matriks data masukan menjadi matriks data baru dengan derajat tertentu, dapat disederhanakan dengan Pipeline alat, yang pada dasarnya digunakan untuk menghubungkan beberapa penduga menjadi satu.
Contoh
Skrip python di bawah ini menggunakan alat Pipeline Scikit-learn untuk merampingkan pemrosesan awal (akan sesuai dengan data polinomial order-3).
#First, import the necessary packages.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
#Next, create an object of Pipeline tool
Stream_model = Pipeline([('poly', PolynomialFeatures(degree=3)), ('linear', LinearRegression(fit_intercept=False))])
#Provide the size of array and order of polynomial data to fit the model.
x = np.arange(5)
y = 3 - 2 * x + x ** 2 - x ** 3
Stream_model = model.fit(x[:, np.newaxis], y)
#Calculate the input polynomial coefficients.
Stream_model.named_steps['linear'].coef_Keluaran
array([ 3., -2., 1., -1.])Keluaran di atas menunjukkan bahwa model linier yang dilatih pada fitur polinomial mampu memulihkan koefisien polinomial masukan yang tepat.
Di sini, kita akan belajar tentang algoritma pengoptimalan di Sklearn, disebut sebagai Stochastic Gradient Descent (SGD).
Stochastic Gradient Descent (SGD) adalah algoritma optimasi sederhana namun efisien yang digunakan untuk mencari nilai parameter / koefisien fungsi yang meminimalkan suatu fungsi biaya. Dengan kata lain, ini digunakan untuk pembelajaran diskriminatif pengklasifikasi linier di bawah fungsi kerugian konveks seperti SVM dan regresi logistik. Ini telah berhasil diterapkan ke kumpulan data skala besar karena pembaruan pada koefisien dilakukan untuk setiap instance pelatihan, bukan di akhir instance.
Pengklasifikasi SGD
Pengklasifikasi Stochastic Gradient Descent (SGD) pada dasarnya mengimplementasikan rutinitas pembelajaran SGD biasa yang mendukung berbagai fungsi kerugian dan penalti untuk klasifikasi. Scikit-learn menyediakanSGDClassifier modul untuk menerapkan klasifikasi SGD.
Parameter
Tabel berikut berisi parameter yang digunakan oleh SGDClassifier modul -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | loss - str, default = 'engsel' Ini mewakili fungsi kerugian yang akan digunakan saat menerapkan. Nilai defaultnya adalah 'engsel' yang akan memberi kita SVM linier. Opsi lain yang dapat digunakan adalah -
|
| 2 | penalty - str, 'none', 'l2', 'l1', 'elasticnet' Ini adalah istilah regularisasi yang digunakan dalam model. Secara default, ini adalah L2. Kita bisa menggunakan L1 atau 'elasticnet; juga, tetapi keduanya mungkin membawa ketersebaran ke model, sehingga tidak dapat dicapai dengan L2. |
| 3 | alpha - float, default = 0,0001 Alpha, konstanta yang mengalikan suku regularisasi, adalah parameter penyetelan yang menentukan seberapa besar kita ingin menghukum model. Nilai defaultnya adalah 0,0001. |
| 4 | l1_ratio - float, default = 0.15 Ini disebut parameter pencampuran ElasticNet. Kisarannya adalah 0 <= l1_ratio <= 1. Jika l1_ratio = 1, hukumannya adalah penalti L1. Jika l1_ratio = 0, hukumannya adalah penalti L2. |
| 5 | fit_intercept - Boolean, Default = Benar Parameter ini menetapkan bahwa konstanta (bias atau intersep) harus ditambahkan ke fungsi keputusan. Tidak ada intersep yang akan digunakan dalam penghitungan dan data akan dianggap sudah berada di tengah, jika disetel ke false. |
| 6 | tol - float atau tidak ada, opsional, default = 1.e-3 Parameter ini mewakili kriteria penghentian untuk iterasi. Nilai defaultnya adalah False tetapi jika disetel ke None, iterasinya akan berhenti jikaloss > best_loss - tol for n_iter_no_changezaman yang berurutan. |
| 7 | shuffle - Boolean, opsional, default = True Parameter ini menyatakan apakah kita ingin data pelatihan kita diacak setelah setiap periode atau tidak. |
| 8 | verbose - bilangan bulat, default = 0 Ini mewakili tingkat verbositas. Nilai defaultnya adalah 0. |
| 9 | epsilon - float, default = 0,1 Parameter ini menentukan lebar dari daerah tidak sensitif. Jika loss = 'epsilon-insensitive', perbedaan apa pun, antara prediksi saat ini dan label yang benar, kurang dari ambang batas akan diabaikan. |
| 10 | max_iter - int, opsional, default = 1000 Seperti yang disarankan namanya, ini mewakili jumlah maksimum lintasan selama periode, yaitu data pelatihan. |
| 11 | warm_start - bool, opsional, default = false Dengan parameter ini disetel ke True, kita dapat menggunakan kembali solusi dari panggilan sebelumnya agar sesuai sebagai inisialisasi. Jika kita memilih default yaitu false, itu akan menghapus solusi sebelumnya. |
| 12 | random_state - int, instance RandomState atau Tidak Ada, opsional, default = tidak ada Parameter ini mewakili seed dari bilangan acak semu yang dihasilkan yang digunakan saat mengacak data. Berikut adalah pilihannya.
|
| 13 | n_jobs - int atau tidak ada, opsional, Default = Tidak Ada Ini mewakili jumlah CPU yang akan digunakan dalam komputasi OVA (One Versus All), untuk masalah multi-kelas. Nilai defaultnya adalah none yang artinya 1. |
| 14 | learning_rate - string, opsional, default = 'optimal'
|
| 15 | eta0 - ganda, default = 0,0 Ini mewakili kecepatan pembelajaran awal untuk opsi kecepatan pembelajaran yang disebutkan di atas, yaitu 'konstan', 'invscalling', atau 'adaptif'. |
| 16 | power_t - idouble, default = 0,5 Ini adalah eksponen untuk kecepatan pembelajaran 'incscalling'. |
| 17 | early_stopping - bool, default = False Parameter ini mewakili penggunaan penghentian awal untuk menghentikan pelatihan jika skor validasi tidak meningkat. Nilai defaultnya salah, tetapi jika disetel ke true, secara otomatis akan menyisihkan sebagian kecil dari data pelatihan sebagai validasi dan menghentikan pelatihan saat skor validasi tidak meningkat. |
| 18 | validation_fraction - float, default = 0,1 Ini hanya digunakan jika early_stopping benar. Ini mewakili proporsi data pelatihan untuk disisihkan sebagai set validasi untuk penghentian awal data pelatihan. |
| 19 | n_iter_no_change - int, default = 5 Ini mewakili jumlah iterasi tanpa peningkatan jika algoritma harus dijalankan sebelum penghentian awal. |
| 20 | classs_weight - dict, {class_label: weight} atau “balanced”, atau None, opsional Parameter ini mewakili bobot yang terkait dengan kelas. Jika tidak disediakan, kelas seharusnya memiliki bobot 1. |
| 20 | warm_start - bool, opsional, default = false Dengan parameter ini disetel ke True, kita dapat menggunakan kembali solusi dari panggilan sebelumnya agar sesuai sebagai inisialisasi. Jika kita memilih default yaitu false, itu akan menghapus solusi sebelumnya. |
| 21 | average - iBoolean atau int, opsional, default = false Ini mewakili jumlah CPU yang akan digunakan dalam komputasi OVA (One Versus All), untuk masalah multi-kelas. Nilai defaultnya adalah none yang artinya 1. |
Atribut
Tabel berikut berisi atribut yang digunakan oleh SGDClassifier modul -
| Sr Tidak | Atribut & Deskripsi |
|---|---|
| 1 | coef_ - larik, bentuk (1, n_features) jika n_classes == 2, lain (n_classes, n_features) Atribut ini memberikan bobot yang ditetapkan ke fitur. |
| 2 | intercept_ - larik, bentuk (1,) jika n_class == 2, lain (n_classes,) Ini mewakili istilah independen dalam fungsi keputusan. |
| 3 | n_iter_ - int Ini memberikan jumlah iterasi untuk mencapai kriteria penghentian. |
Implementation Example
Seperti pengklasifikasi lainnya, Stochastic Gradient Descent (SGD) harus dilengkapi dengan dua larik berikut -
Larik X yang menyimpan sampel pelatihan. Ini adalah ukuran [n_samples, n_features].
Larik Y yang memegang nilai target yaitu label kelas untuk sampel pelatihan. Ini adalah ukuran [n_samples].
Example
Mengikuti skrip Python menggunakan model linier SGDClassifier -
import numpy as np
from sklearn import linear_model
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
Y = np.array([1, 1, 2, 2])
SGDClf = linear_model.SGDClassifier(max_iter = 1000, tol=1e-3,penalty = "elasticnet")
SGDClf.fit(X, Y)Output
SGDClassifier(
alpha = 0.0001, average = False, class_weight = None,
early_stopping = False, epsilon = 0.1, eta0 = 0.0, fit_intercept = True,
l1_ratio = 0.15, learning_rate = 'optimal', loss = 'hinge', max_iter = 1000,
n_iter = None, n_iter_no_change = 5, n_jobs = None, penalty = 'elasticnet',
power_t = 0.5, random_state = None, shuffle = True, tol = 0.001,
validation_fraction = 0.1, verbose = 0, warm_start = False
)Example
Sekarang, setelah dipasang, model dapat memprediksi nilai baru sebagai berikut -
SGDClf.predict([[2.,2.]])Output
array([2])Example
Untuk contoh di atas, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
SGDClf.coef_Output
array([[19.54811198, 9.77200712]])Example
Demikian pula, kita bisa mendapatkan nilai intersep dengan bantuan skrip python berikut -
SGDClf.intercept_Output
array([10.])Example
Kita bisa mendapatkan jarak yang ditandatangani ke hyperplane dengan menggunakan SGDClassifier.decision_function seperti yang digunakan dalam skrip python berikut -
SGDClf.decision_function([[2., 2.]])Output
array([68.6402382])Regresor SGD
Stochastic Gradient Descent (SGD) regressor pada dasarnya menerapkan rutin pembelajaran SGD biasa yang mendukung berbagai fungsi kerugian dan penalti agar sesuai dengan model regresi linier. Scikit-learn menyediakanSGDRegressor modul untuk mengimplementasikan regresi SGD.
Parameter
Parameter yang digunakan oleh SGDRegressorhampir sama dengan yang digunakan di modul SGDClassifier. Perbedaannya terletak pada parameter 'loss'. UntukSGDRegressor parameter kerugian modul nilai positif adalah sebagai berikut -
squared_loss - Ini mengacu pada fit kotak terkecil biasa.
huber: SGDRegressor- perbaiki pencilan dengan beralih dari kerugian kuadrat ke linier melewati jarak epsilon. Pekerjaan 'huber' adalah memodifikasi 'squared_loss' sehingga algoritme kurang fokus pada koreksi pencilan.
epsilon_insensitive - Sebenarnya, ini mengabaikan kesalahan kurang dari epsilon.
squared_epsilon_insensitive- Ini sama dengan epsilon_insensitive. Satu-satunya perbedaan adalah bahwa itu menjadi kerugian kuadrat melewati toleransi epsilon.
Perbedaan lainnya adalah bahwa parameter bernama 'power_t' memiliki nilai default 0,25 daripada 0,5 seperti pada SGDClassifier. Selain itu, ia tidak memiliki parameter 'class_weight' dan 'n_jobs'.
Atribut
Atribut SGDRegressor juga sama dengan atribut modul SGDClassifier. Melainkan memiliki tiga atribut tambahan sebagai berikut -
average_coef_ - larik, bentuk (n_features,)
Seperti namanya, ini memberikan bobot rata-rata yang ditetapkan ke fitur.
average_intercept_ - larik, bentuk (1,)
Seperti namanya, ini memberikan istilah intersep rata-rata.
t_ - int
Ini memberikan jumlah pembaruan beban yang dilakukan selama fase pelatihan.
Note - atribut average_coef_ dan average_intercept_ akan berfungsi setelah mengaktifkan parameter 'average' ke True.
Implementation Example
Mengikuti penggunaan skrip Python SGDRegressor model linier -
import numpy as np
from sklearn import linear_model
n_samples, n_features = 10, 5
rng = np.random.RandomState(0)
y = rng.randn(n_samples)
X = rng.randn(n_samples, n_features)
SGDReg =linear_model.SGDRegressor(
max_iter = 1000,penalty = "elasticnet",loss = 'huber',tol = 1e-3, average = True
)
SGDReg.fit(X, y)Output
SGDRegressor(
alpha = 0.0001, average = True, early_stopping = False, epsilon = 0.1,
eta0 = 0.01, fit_intercept = True, l1_ratio = 0.15,
learning_rate = 'invscaling', loss = 'huber', max_iter = 1000,
n_iter = None, n_iter_no_change = 5, penalty = 'elasticnet', power_t = 0.25,
random_state = None, shuffle = True, tol = 0.001, validation_fraction = 0.1,
verbose = 0, warm_start = False
)Example
Sekarang, setelah dipasang, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
SGDReg.coef_Output
array([-0.00423314, 0.00362922, -0.00380136, 0.00585455, 0.00396787])Example
Demikian pula, kita bisa mendapatkan nilai intersep dengan bantuan skrip python berikut -
SGReg.intercept_Output
SGReg.intercept_Example
Kami bisa mendapatkan jumlah pembaruan bobot selama fase pelatihan dengan bantuan skrip python berikut -
SGDReg.t_Output
61.0Pro dan Kontra SGD
Mengikuti kelebihan SGD -
Stochastic Gradient Descent (SGD) sangat efisien.
Ini sangat mudah diterapkan karena ada banyak peluang untuk penyetelan kode.
Mengikuti kontra SGD -
Stochastic Gradient Descent (SGD) membutuhkan beberapa hyperparameter seperti parameter regularisasi.
Ini sensitif terhadap penskalaan fitur.
Bab ini membahas metode pembelajaran mesin yang disebut sebagai Support Vector Machines (SVM).
pengantar
Mesin vektor dukungan (SVM) adalah metode pembelajaran mesin yang diawasi dan kuat namun fleksibel yang digunakan untuk klasifikasi, regresi, dan, deteksi pencilan. SVM sangat efisien dalam ruang dimensi tinggi dan umumnya digunakan dalam masalah klasifikasi. SVM populer dan hemat memori karena menggunakan subset poin pelatihan dalam fungsi keputusan.
Tujuan utama SVM adalah membagi dataset menjadi beberapa kelas untuk menemukan a maximum marginal hyperplane (MMH) yang dapat dilakukan dengan dua langkah berikut -
Support Vector Machines pertama-tama akan membuat hyperplanes secara iteratif yang memisahkan kelas dengan cara terbaik.
Setelah itu akan dipilih hyperplane yang memisahkan kelas dengan benar.
Beberapa konsep penting dalam SVM adalah sebagai berikut -
Support Vectors- Mereka dapat didefinisikan sebagai titik data yang paling dekat dengan bidang-hiper. Vektor pendukung membantu dalam menentukan garis pemisah.
Hyperplane - Pesawat keputusan atau ruang yang membagi sekumpulan objek yang memiliki kelas berbeda.
Margin - Kesenjangan antara dua garis pada titik data lemari dari kelas yang berbeda disebut margin.
Diagram berikut akan memberi Anda wawasan tentang konsep SVM ini -
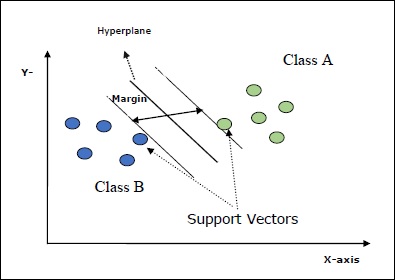
SVM di Scikit-learn mendukung vektor sampel renggang dan padat sebagai input.
Klasifikasi SVM
Scikit-learn menyediakan tiga kelas yaitu SVC, NuSVC dan LinearSVC yang dapat melakukan klasifikasi kelas multikelas.
SVC
Ini adalah klasifikasi vektor C-support yang implementasinya didasarkan pada libsvm. Modul yang digunakan oleh scikit-learn adalahsklearn.svm.SVC. Kelas ini menangani dukungan multikelas menurut skema satu-vs-satu.
Parameter
Tabel berikut berisi parameter yang digunakan oleh sklearn.svm.SVC kelas -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | C - float, opsional, default = 1.0 Ini adalah parameter hukuman dari istilah kesalahan. |
| 2 | kernel - string, opsional, default = 'rbf' Parameter ini menentukan jenis kernel yang akan digunakan dalam algoritme. kita bisa memilih salah satu di antara,‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’. Nilai default kernel adalah‘rbf’. |
| 3 | degree - int, opsional, default = 3 Ini mewakili derajat fungsi kernel 'poli' dan akan diabaikan oleh semua kernel lainnya. |
| 4 | gamma - {'scale', 'auto'} atau float, Ini adalah koefisien kernel untuk kernel 'rbf', 'poly' dan 'sigmoid'. |
| 5 | optinal default - = 'skala' Jika anda memilih default yaitu gamma = 'scale' maka nilai gamma yang akan digunakan SVC adalah 1 / (_ ∗. ()). Di sisi lain, jika gamma = 'auto', ini menggunakan 1 / _. |
| 6 | coef0 - float, opsional, Default = 0.0 Istilah independen dalam fungsi kernel yang hanya signifikan dalam 'poli' dan 'sigmoid'. |
| 7 | tol - float, opsional, default = 1.e-3 Parameter ini mewakili kriteria penghentian untuk iterasi. |
| 8 | shrinking - Boolean, opsional, default = True Parameter ini menyatakan apakah kita ingin menggunakan heuristik menyusut atau tidak. |
| 9 | verbose - Boolean, default: false Ini mengaktifkan atau menonaktifkan output verbose. Nilai defaultnya salah. |
| 10 | probability - boolean, opsional, default = true Parameter ini mengaktifkan atau menonaktifkan perkiraan probabilitas. Nilai defaultnya salah, tetapi harus diaktifkan sebelum kita menyebutnya fit. |
| 11 | max_iter - int, opsional, default = -1 Seperti namanya, ini mewakili jumlah maksimum iterasi dalam pemecah. Nilai -1 artinya tidak ada batasan jumlah iterasi. |
| 12 | cache_size - float, opsional Parameter ini akan menentukan ukuran cache kernel. Nilainya akan dalam MB (MegaBytes). |
| 13 | random_state - int, instance RandomState atau Tidak Ada, opsional, default = tidak ada Parameter ini mewakili seed dari bilangan acak semu yang dihasilkan yang digunakan saat mengacak data. Berikut adalah pilihannya -
|
| 14 | class_weight - {dict, 'balanced'}, opsional Parameter ini akan mengatur parameter C kelas j ke _ℎ [] ∗ untuk SVC. Jika kita menggunakan opsi default, itu berarti semua kelas seharusnya memiliki bobot satu. Di sisi lain, jika Anda memilihclass_weight:balanced, ini akan menggunakan nilai y untuk menyesuaikan bobot secara otomatis. |
| 15 | decision_function_shape - ovo ',' ovr ', default =' ovr ' Parameter ini akan menentukan apakah algoritma akan kembali ‘ovr’ (one-vs-rest) fungsi keputusan bentuk sebagai semua pengklasifikasi lainnya, atau aslinya ovo(satu-vs-satu) fungsi keputusan libsvm. |
| 16 | break_ties - boolean, opsional, default = false True - Prediksi akan memutuskan hubungan sesuai dengan nilai kepercayaan dari fungsi_keputusan False - Prediksi akan mengembalikan kelas pertama di antara kelas yang terikat. |
Atribut
Tabel berikut berisi atribut-atribut yang digunakan oleh sklearn.svm.SVC kelas -
| Sr Tidak | Atribut & Deskripsi |
|---|---|
| 1 | support_ - seperti larik, bentuk = [n_SV] Ini mengembalikan indeks vektor dukungan. |
| 2 | support_vectors_ - seperti larik, bentuk = [n_SV, n_features] Ini mengembalikan vektor dukungan. |
| 3 | n_support_ - seperti larik, dtype = int32, bentuk = [n_class] Ini mewakili jumlah vektor dukungan untuk setiap kelas. |
| 4 | dual_coef_ - larik, bentuk = [n_class-1, n_SV] Ini adalah koefisien dari vektor pendukung dalam fungsi keputusan. |
| 5 | coef_ - larik, bentuk = [n_class * (n_class-1) / 2, n_features] Atribut ini, hanya tersedia dalam kasus kernel linier, memberikan bobot yang ditetapkan ke fitur. |
| 6 | intercept_ - larik, bentuk = [n_class * (n_class-1) / 2] Ini mewakili istilah independen (konstanta) dalam fungsi keputusan. |
| 7 | fit_status_ - int Outputnya akan menjadi 0 jika dipasang dengan benar. Outputnya akan menjadi 1 jika tidak dipasang dengan benar. |
| 8 | classes_ - array bentuk = [n_class] Ini memberi label kelas. |
Implementation Example
Seperti pengklasifikasi lainnya, SVC juga harus dilengkapi dengan dua larik berikut -
Sebuah array Xmemegang sampel pelatihan. Ini adalah ukuran [n_samples, n_features].
Sebuah array Ymemegang nilai target yaitu label kelas untuk sampel pelatihan. Ini adalah ukuran [n_samples].
Mengikuti penggunaan skrip Python sklearn.svm.SVC kelas -
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)Output
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, probability = False, random_state = None, shrinking = False,
tol = 0.001, verbose = False)Example
Sekarang, setelah dipasang, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
SVCClf.coef_Output
array([[0.5, 0.5]])Example
Demikian pula, kita bisa mendapatkan nilai atribut lain sebagai berikut -
SVCClf.predict([[-0.5,-0.8]])Output
array([1])Example
SVCClf.n_support_Output
array([1, 1])Example
SVCClf.support_vectors_Output
array(
[
[-1., -1.],
[ 1., 1.]
]
)Example
SVCClf.support_Output
array([0, 2])Example
SVCClf.intercept_Output
array([-0.])Example
SVCClf.fit_status_Output
0NuSVC
NuSVC adalah Klasifikasi Vektor Dukungan Nu. Ini adalah kelas lain yang disediakan oleh scikit-learn yang dapat melakukan klasifikasi kelas jamak. Ini seperti SVC tetapi NuSVC menerima set parameter yang sedikit berbeda. Parameter yang berbeda dari SVC adalah sebagai berikut -
nu - float, opsional, default = 0,5
Ini mewakili batas atas pada pecahan kesalahan pelatihan dan batas bawah dari pecahan vektor dukungan. Nilainya harus dalam interval (o, 1].
Parameter dan atribut lainnya sama dengan SVC.
Contoh Implementasi
Kita dapat menerapkan contoh yang sama menggunakan sklearn.svm.NuSVC kelas juga.
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import NuSVC
NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
NuSVCClf.fit(X, y)Keluaran
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, nu = 0.5, probability = False, random_state = None,
shrinking = False, tol = 0.001, verbose = False)Kita bisa mendapatkan keluaran dari atribut lainnya seperti yang dilakukan dalam kasus SVC.
LinearSVC
Ini adalah Klasifikasi Vektor Dukungan Linear. Ini mirip dengan SVC yang memiliki kernel = 'linear'. Perbedaan di antara mereka adalah ituLinearSVC diimplementasikan dalam bentuk liblinear sementara SVC diimplementasikan di libsvm. Itulah alasannyaLinearSVCmemiliki lebih banyak fleksibilitas dalam pemilihan fungsi penalti dan kerugian. Ini juga menskalakan lebih baik untuk sejumlah besar sampel.
Jika kita berbicara tentang parameter dan atributnya maka itu tidak mendukung ‘kernel’ karena diasumsikan linier dan juga kekurangan beberapa atribut seperti support_, support_vectors_, n_support_, fit_status_ dan, dual_coef_.
Namun, itu mendukung penalty dan loss parameter sebagai berikut -
penalty − string, L1 or L2(default = ‘L2’)
Parameter ini digunakan untuk menentukan norma (L1 atau L2) yang digunakan dalam hukuman (regularisasi).
loss − string, hinge, squared_hinge (default = squared_hinge)
Ini mewakili fungsi kerugian di mana 'engsel' adalah kerugian SVM standar dan 'squared_hinge' adalah kuadrat kerugian engsel.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.LinearSVC kelas -
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 4, random_state = 0)
LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5)
LSVCClf.fit(X, y)Keluaran
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000,
multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)Contoh
Sekarang, setelah dipasang, model dapat memprediksi nilai baru sebagai berikut -
LSVCClf.predict([[0,0,0,0]])Keluaran
[1]Contoh
Untuk contoh di atas, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
LSVCClf.coef_Keluaran
[[0. 0. 0.91214955 0.22630686]]Contoh
Demikian pula, kita bisa mendapatkan nilai intersep dengan bantuan skrip python berikut -
LSVCClf.intercept_Keluaran
[0.26860518]Regresi dengan SVM
Seperti dibahas sebelumnya, SVM digunakan untuk masalah klasifikasi dan regresi. Metode Support Vector Classification (SVC) Scikit-learn dapat diperluas untuk memecahkan masalah regresi juga. Metode yang diperluas itu disebut Support Vector Regression (SVR).
Kesamaan dasar antara SVM dan SVR
Model yang dibuat oleh SVC hanya bergantung pada subset data pelatihan. Mengapa? Karena fungsi biaya untuk membangun model tidak peduli dengan titik data pelatihan yang berada di luar margin.
Sedangkan model yang dihasilkan oleh SVR (Support Vector Regression) juga hanya bergantung pada subset dari data training. Mengapa? Karena fungsi biaya untuk membangun model mengabaikan poin data pelatihan apa pun yang dekat dengan prediksi model.
Scikit-learn menyediakan tiga kelas yaitu SVR, NuSVR and LinearSVR sebagai tiga implementasi SVR yang berbeda.
SVR
Ini adalah regresi vektor dukungan Epsilon yang implementasinya didasarkan pada libsvm. Kebalikan dariSVC Ada dua parameter gratis dalam model yaitu ‘C’ dan ‘epsilon’.
epsilon - float, opsional, default = 0,1
Ini mewakili epsilon dalam model epsilon-SVR, dan menentukan tabung-epsilon di mana tidak ada penalti yang terkait dalam fungsi kerugian pelatihan dengan titik-titik yang diprediksi dalam jarak epsilon dari nilai sebenarnya.
Parameter dan atribut lainnya serupa seperti yang kita gunakan di SVC.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.SVR kelas -
from sklearn import svm
X = [[1, 1], [2, 2]]
y = [1, 2]
SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’)
SVRReg.fit(X, y)Keluaran
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto',
kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)Contoh
Sekarang, setelah dipasang, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
SVRReg.coef_Keluaran
array([[0.4, 0.4]])Contoh
Demikian pula, kita bisa mendapatkan nilai atribut lain sebagai berikut -
SVRReg.predict([[1,1]])Keluaran
array([1.1])Demikian pula, kita juga bisa mendapatkan nilai atribut lainnya.
NuSVR
NuSVR adalah Nu Support Vector Regression. Ini seperti NuSVC, tetapi NuSVR menggunakan parameternuuntuk mengontrol jumlah vektor dukungan. Dan terlebih lagi, tidak seperti NuSVC dimananu mengganti parameter C, ini dia menggantikan epsilon.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.SVR kelas -
from sklearn.svm import NuSVR
import numpy as np
n_samples, n_features = 20, 15
np.random.seed(0)
y = np.random.randn(n_samples)
X = np.random.randn(n_samples, n_features)
NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M
NuSVRReg.fit(X, y)Keluaran
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto',
kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001,
verbose = False)Contoh
Sekarang, setelah dipasang, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
NuSVRReg.coef_Keluaran
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)Demikian pula, kita juga bisa mendapatkan nilai atribut lainnya.
LinearSVR
Ini adalah Regresi Vektor Dukungan Linear. Ini mirip dengan SVR yang memiliki kernel = 'linear'. Perbedaan di antara mereka adalah ituLinearSVR diterapkan dalam hal liblinear, sementara SVC diterapkan di libsvm. Itulah alasannyaLinearSVRmemiliki lebih banyak fleksibilitas dalam pemilihan fungsi penalti dan kerugian. Ini juga menskalakan lebih baik untuk sejumlah besar sampel.
Jika kita berbicara tentang parameter dan atributnya maka itu tidak mendukung ‘kernel’ karena diasumsikan linier dan juga kekurangan beberapa atribut seperti support_, support_vectors_, n_support_, fit_status_ dan, dual_coef_.
Namun, ini mendukung parameter 'kerugian' sebagai berikut -
loss - string, opsional, default = 'epsilon_insensitive'
Ini mewakili fungsi kerugian di mana kerugian epsilon_insensitive adalah kerugian L1 dan kerugian epsilon-tidak sensitif kuadrat adalah kerugian L2.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.LinearSVR kelas -
from sklearn.svm import LinearSVR
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 4, random_state = 0)
LSVRReg = LinearSVR(dual = False, random_state = 0,
loss = 'squared_epsilon_insensitive',tol = 1e-5)
LSVRReg.fit(X, y)Keluaran
LinearSVR(
C=1.0, dual=False, epsilon=0.0, fit_intercept=True,
intercept_scaling=1.0, loss='squared_epsilon_insensitive',
max_iter=1000, random_state=0, tol=1e-05, verbose=0
)Contoh
Sekarang, setelah dipasang, model dapat memprediksi nilai baru sebagai berikut -
LSRReg.predict([[0,0,0,0]])Keluaran
array([-0.01041416])Contoh
Untuk contoh di atas, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
LSRReg.coef_Keluaran
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])Contoh
Demikian pula, kita bisa mendapatkan nilai intersep dengan bantuan skrip python berikut -
LSRReg.intercept_Keluaran
array([-0.01041416])Di sini, kita akan mempelajari tentang apa itu deteksi anomali di Sklearn dan bagaimana penggunaannya dalam identifikasi titik data.
Deteksi anomali adalah teknik yang digunakan untuk mengidentifikasi titik data dalam dataset yang tidak cocok dengan data lainnya. Ini memiliki banyak aplikasi dalam bisnis seperti deteksi penipuan, deteksi intrusi, pemantauan kesehatan sistem, pengawasan, dan pemeliharaan prediktif. Anomali, yang juga disebut pencilan, dapat dibagi menjadi tiga kategori berikut -
Point anomalies - Ini terjadi ketika contoh data individu dianggap sebagai anomali terhadap sisa data.
Contextual anomalies- Jenis anomali semacam itu adalah spesifik konteks. Ini terjadi jika contoh data anomali dalam konteks tertentu.
Collective anomalies - Ini terjadi ketika kumpulan contoh data terkait adalah seluruh kumpulan data anomali daripada nilai individual.
Metode
Dua metode yaitu outlier detection dan novelty detectiondapat digunakan untuk deteksi anomali. Penting untuk melihat perbedaan di antara mereka.
Deteksi pencilan
Data pelatihan berisi pencilan yang jauh dari data lainnya. Pencilan seperti itu didefinisikan sebagai observasi. Itulah alasannya, penduga pendeteksi pencilan selalu berusaha menyesuaikan dengan wilayah yang memiliki data pelatihan paling terkonsentrasi sambil mengabaikan pengamatan yang menyimpang. Ini juga dikenal sebagai deteksi anomali tanpa pengawasan.
Deteksi baru
Ini berkaitan dengan pendeteksian pola yang tidak teramati dalam pengamatan baru yang tidak termasuk dalam data pelatihan. Di sini, data pelatihan tidak tercemar oleh pencilan. Ia juga dikenal sebagai deteksi anomali semi-supervised.
Ada sekumpulan alat ML, yang disediakan oleh scikit-learn, yang bisa digunakan untuk deteksi pencilan serta deteksi kebaruan. Alat-alat ini pertama kali mengimplementasikan pembelajaran objek dari data secara tidak terbimbing dengan menggunakan metode fit () sebagai berikut:
estimator.fit(X_train)Sekarang, pengamatan baru akan diurutkan sebagai inliers (labeled 1) atau outliers (labeled -1) dengan menggunakan metode predict () sebagai berikut -
estimator.fit(X_test)Estimator pertama-tama akan menghitung fungsi penilaian mentah dan kemudian metode prediksi akan menggunakan nilai ambang pada fungsi penilaian mentah tersebut. Kita dapat mengakses fungsi penilaian mentah ini dengan bantuanscore_sample metode dan dapat mengontrol ambang dengan contamination parameter.
Kami juga bisa mendefinisikan decision_function metode yang mendefinisikan outlier sebagai nilai negatif dan inliers sebagai nilai non-negatif.
estimator.decision_function(X_test)Algoritme Sklearn untuk Deteksi Pencilan
Mari kita mulai dengan memahami apa itu amplop elips.
Pas dengan amplop elips
Algoritma ini mengasumsikan bahwa data reguler berasal dari distribusi yang diketahui seperti distribusi Gaussian. Untuk deteksi outlier, Scikit-learn menyediakan sebuah objek bernamacovariance.EllipticEnvelop.
Objek ini cocok dengan perkiraan kovarian yang kuat untuk data, dan dengan demikian, cocok dengan elips ke titik data pusat. Ini mengabaikan titik-titik di luar mode pusat.
Parameter
Tabel berikut berisi parameter yang digunakan oleh sklearn. covariance.EllipticEnvelop metode -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | store_precision - Boolean, opsional, default = True Kami dapat menentukannya jika perkiraan presisi disimpan. |
| 2 | assume_centered - Boolean, opsional, default = False Jika kita menetapkannya False, itu akan menghitung lokasi dan kovarian yang kuat secara langsung dengan bantuan algoritma FastMCD. Di sisi lain, jika disetel ke True, itu akan menghitung dukungan lokasi yang kuat dan covarian. |
| 3 | support_fraction - float in (0., 1.), opsional, default = Tidak ada Parameter ini memberitahu metode berapa banyak proporsi poin yang akan disertakan dalam mendukung perkiraan MCD mentah. |
| 4 | contamination - float in (0., 1.), opsional, default = 0.1 Ini memberikan proporsi pencilan dalam kumpulan data. |
| 5 | random_state - int, instance RandomState atau Tidak Ada, opsional, default = tidak ada Parameter ini mewakili seed dari bilangan acak semu yang dihasilkan yang digunakan saat mengacak data. Berikut adalah pilihannya -
|
Atribut
Tabel berikut berisi atribut yang digunakan oleh sklearn. covariance.EllipticEnvelop metode -
| Sr Tidak | Atribut & Deskripsi |
|---|---|
| 1 | support_ - seperti larik, bentuk (n_sampel,) Ini mewakili topeng pengamatan yang digunakan untuk menghitung perkiraan lokasi dan bentuk yang kuat. |
| 2 | location_ - seperti larik, bentuk (n_features) Ini mengembalikan perkiraan lokasi kuat. |
| 3 | covariance_ - seperti larik, bentuk (n_features, n_features) Ini mengembalikan matriks kovarians yang diperkirakan kuat. |
| 4 | precision_ - seperti larik, bentuk (n_features, n_features) Ini mengembalikan matriks invers semu yang diperkirakan. |
| 5 | offset_ - mengapung Ini digunakan untuk menentukan fungsi keputusan dari skor mentah. decision_function = score_samples -offset_ |
Implementation Example
import numpy as np^M
from sklearn.covariance import EllipticEnvelope^M
true_cov = np.array([[.5, .6],[.6, .4]])
X = np.random.RandomState(0).multivariate_normal(mean = [0, 0], cov=true_cov,size=500)
cov = EllipticEnvelope(random_state = 0).fit(X)^M
# Now we can use predict method. It will return 1 for an inlier and -1 for an outlier.
cov.predict([[0, 0],[2, 2]])Output
array([ 1, -1])Hutan Isolasi
Dalam kasus set data berdimensi tinggi, satu cara efisien untuk deteksi pencilan adalah dengan menggunakan forest acak. Scikit-learn menyediakanensemble.IsolationForestmetode yang mengisolasi pengamatan dengan memilih fitur secara acak. Setelah itu, secara acak memilih nilai antara nilai maksimum dan minimum dari fitur yang dipilih.
Di sini, jumlah pemisahan yang diperlukan untuk mengisolasi sampel setara dengan panjang jalur dari simpul akar ke simpul akhir.
Parameter
Tabel berikut berisi parameter yang digunakan oleh sklearn. ensemble.IsolationForest metode -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | n_estimators - int, opsional, default = 100 Ini mewakili jumlah penduga dasar dalam ansambel. |
| 2 | max_samples - int atau float, opsional, default = "auto" Ini mewakili jumlah sampel yang akan diambil dari X untuk melatih setiap penduga dasar. Jika kita memilih int sebagai nilainya, itu akan menarik sampel max_samples. Jika kita memilih float sebagai nilainya, itu akan menarik sampel max_samples ∗ .shape [0]. Dan, jika kita memilih auto sebagai nilainya, itu akan menarik max_samples = min (256, n_samples). |
| 3 | support_fraction - float in (0., 1.), opsional, default = Tidak ada Parameter ini memberitahu metode berapa banyak proporsi poin yang akan disertakan dalam mendukung perkiraan MCD mentah. |
| 4 | contamination - auto atau float, opsional, default = auto Ini memberikan proporsi pencilan dalam kumpulan data. Jika kita set default yaitu auto, maka akan menentukan threshold seperti pada kertas aslinya. Jika diatur ke float, kisaran kontaminasi akan berada dalam kisaran [0,0.5]. |
| 5 | random_state - int, instance RandomState atau Tidak Ada, opsional, default = tidak ada Parameter ini mewakili seed dari bilangan acak semu yang dihasilkan yang digunakan saat mengacak data. Berikut adalah pilihannya -
|
| 6 | max_features - int atau float, opsional (default = 1.0) Ini mewakili jumlah fitur yang akan diambil dari X untuk melatih setiap penduga dasar. Jika kita memilih int sebagai nilainya, itu akan menarik fitur max_features. Jika kita memilih float sebagai nilainya, itu akan menarik sampel max_features * X.shape []. |
| 7 | bootstrap - Boolean, opsional (default = False) Opsi defaultnya adalah False yang berarti pengambilan sampel akan dilakukan tanpa penggantian. Dan di sisi lain, jika disetel ke True, berarti setiap pohon cocok di subset acak dari data pelatihan yang diambil sampelnya dengan penggantian. |
| 8 | n_jobs - int atau None, opsional (default = None) Ini mewakili jumlah pekerjaan yang akan dijalankan secara paralel fit() dan predict() metode keduanya. |
| 9 | verbose - int, opsional (default = 0) Parameter ini mengontrol verbositas proses pembangunan pohon. |
| 10 | warm_start - Bool, opsional (default = False) Jika warm_start = true, kita dapat menggunakan kembali solusi panggilan sebelumnya agar sesuai dan dapat menambahkan lebih banyak estimator ke ensembel. Tapi jika disetel ke false, kita perlu menyesuaikan dengan hutan baru. |
Atribut
Tabel berikut berisi atribut yang digunakan oleh sklearn. ensemble.IsolationForest metode -
| Sr Tidak | Atribut & Deskripsi |
|---|---|
| 1 | estimators_ - daftar DecisionTreeClassifier Menyediakan koleksi dari semua sub-estimator yang dipasang. |
| 2 | max_samples_ - integer Ini memberikan jumlah sebenarnya dari sampel yang digunakan. |
| 3 | offset_ - mengapung Ini digunakan untuk menentukan fungsi keputusan dari skor mentah. decision_function = score_samples -offset_ |
Implementation Example
Skrip Python di bawah ini akan digunakan sklearn. ensemble.IsolationForest metode untuk menyesuaikan 10 pohon pada data yang diberikan
from sklearn.ensemble import IsolationForest
import numpy as np
X = np.array([[-1, -2], [-3, -3], [-3, -4], [0, 0], [-50, 60]])
OUTDClf = IsolationForest(n_estimators = 10)
OUTDclf.fit(X)Output
IsolationForest(
behaviour = 'old', bootstrap = False, contamination='legacy',
max_features = 1.0, max_samples = 'auto', n_estimators = 10, n_jobs=None,
random_state = None, verbose = 0
)Faktor Pencilan Lokal
Algoritma Local Outlier Factor (LOF) adalah algoritma lain yang efisien untuk melakukan deteksi outlier pada data berdimensi tinggi. Scikit-learn menyediakanneighbors.LocalOutlierFactormetode yang menghitung skor, disebut faktor pencilan lokal, yang mencerminkan derajat anomitas pengamatan. Logika utama dari algoritma ini adalah untuk mendeteksi sampel yang memiliki kepadatan yang jauh lebih rendah daripada tetangganya. Itulah mengapa ini mengukur deviasi kepadatan lokal dari titik data yang diberikan dengan tetangganya.
Parameter
Tabel berikut berisi parameter yang digunakan oleh sklearn. neighbors.LocalOutlierFactor metode
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | n_neighbors - int, opsional, default = 20 Ini mewakili jumlah tetangga yang digunakan secara default untuk kueri kneighbours. Semua sampel akan digunakan jika. |
| 2 | algorithm - opsional Algoritme mana yang akan digunakan untuk menghitung tetangga terdekat.
|
| 3 | leaf_size - int, opsional, default = 30 Nilai parameter ini dapat mempengaruhi kecepatan konstruksi dan permintaan. Ini juga mempengaruhi memori yang dibutuhkan untuk menyimpan pohon. Parameter ini diteruskan ke algoritma BallTree atau KdTree. |
| 4 | contamination - auto atau float, opsional, default = auto Ini memberikan proporsi pencilan dalam kumpulan data. Jika kita set default yaitu auto, maka akan menentukan threshold seperti pada kertas aslinya. Jika diatur ke float, kisaran kontaminasi akan berada dalam kisaran [0,0.5]. |
| 5 | metric - string atau callable, default Ini mewakili metrik yang digunakan untuk penghitungan jarak. |
| 6 | P - int, opsional (default = 2) Ini adalah parameter untuk metrik Minkowski. P = 1 ekivalen dengan menggunakan jarak_ manhattan yaitu L1, sedangkan P = 2 ekivalen dengan menggunakan jarak_ euclidean yaitu L2. |
| 7 | novelty - Boolean, (default = False) Secara default, algoritme LOF digunakan untuk deteksi outlier tetapi dapat digunakan untuk deteksi kebaruan jika kita menetapkan novelty = true. |
| 8 | n_jobs - int atau None, opsional (default = None) Ini mewakili jumlah pekerjaan yang akan dijalankan secara paralel untuk metode fit () dan predict () keduanya. |
Atribut
Tabel berikut berisi atribut yang digunakan oleh sklearn.neighbors.LocalOutlierFactor metode -
| Sr Tidak | Atribut & Deskripsi |
|---|---|
| 1 | negative_outlier_factor_ - larik numpy, bentuk (n_sampel,) Memberikan LOF yang berlawanan dari sampel pelatihan. |
| 2 | n_neighbors_ - integer Ini memberikan jumlah sebenarnya dari tetangga yang digunakan untuk kueri tetangga. |
| 3 | offset_ - mengapung Ini digunakan untuk menentukan label biner dari skor mentah. |
Implementation Example
Skrip Python yang diberikan di bawah ini akan digunakan sklearn.neighbors.LocalOutlierFactor metode untuk membangun kelas NeighboursClassifier dari array apa pun yang sesuai dengan kumpulan data kami
from sklearn.neighbors import NearestNeighbors
samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]]
LOFneigh = NearestNeighbors(n_neighbors = 1, algorithm = "ball_tree",p=1)
LOFneigh.fit(samples)Output
NearestNeighbors(
algorithm = 'ball_tree', leaf_size = 30, metric='minkowski',
metric_params = None, n_jobs = None, n_neighbors = 1, p = 1, radius = 1.0
)Example
Sekarang, kita dapat meminta dari pengklasifikasi yang dibangun ini adalah titik lemari ke [0.5, 1., 1.5] dengan menggunakan skrip python berikut -
print(neigh.kneighbors([[.5, 1., 1.5]])Output
(array([[1.7]]), array([[1]], dtype = int64))SVM Satu Kelas
SVM Satu-Kelas, yang diperkenalkan oleh Schölkopf et al., Adalah Deteksi Outlier tanpa pengawasan. Ini juga sangat efisien dalam data dimensi tinggi dan memperkirakan dukungan dari distribusi dimensi tinggi. Ini diterapkan diSupport Vector Machines modul di Sklearn.svm.OneClassSVMobyek. Untuk mendefinisikan sebuah frontier, dibutuhkan kernel (yang paling banyak digunakan adalah RBF) dan parameter skalar.
Untuk pemahaman yang lebih baik, mari menyesuaikan data kita dengan svm.OneClassSVM objek -
Contoh
from sklearn.svm import OneClassSVM
X = [[0], [0.89], [0.90], [0.91], [1]]
OSVMclf = OneClassSVM(gamma = 'scale').fit(X)Sekarang, kita bisa mendapatkan score_samples untuk input data sebagai berikut -
OSVMclf.score_samples(X)Keluaran
array([1.12218594, 1.58645126, 1.58673086, 1.58645127, 1.55713767])Bab ini akan membantu Anda memahami metode tetangga terdekat di Sklearn.
Metode pembelajaran berbasis tetangga ada dua jenis yaitu supervised dan unsupervised. Pembelajaran berbasis tetangga yang diawasi dapat digunakan untuk masalah klasifikasi serta prediksi regresi, tetapi ini terutama digunakan untuk masalah prediksi klasifikasi dalam industri.
Metode pembelajaran berbasis Neighbours tidak memiliki fase pelatihan khusus dan menggunakan semua data untuk pelatihan saat klasifikasi. Itu juga tidak mengasumsikan apa pun tentang data yang mendasarinya. Itulah alasan mereka malas dan non-parametrik.
Prinsip utama di balik metode tetangga terdekat adalah -
Untuk menemukan jumlah lemari sampel pelatihan yang telah ditentukan dalam jarak ke titik data baru
Prediksi label dari jumlah sampel pelatihan ini.
Di sini, jumlah sampel dapat berupa konstanta yang ditentukan pengguna seperti dalam pembelajaran tetangga terdekat K atau bervariasi berdasarkan kepadatan titik lokal seperti dalam pembelajaran tetangga berbasis radius.
Modul sklearn.neighbour
Scikit-learn miliki sklearn.neighborsmodul yang menyediakan fungsionalitas untuk metode pembelajaran berbasis tetangga yang tidak diawasi dan diawasi. Sebagai masukan, kelas dalam modul ini dapat menangani array NumPy atauscipy.sparse matriks.
Jenis algoritma
Berbagai jenis algoritma yang dapat digunakan dalam implementasi metode berbasis tetangga adalah sebagai berikut -
Paksaan
Perhitungan brute-force jarak antara semua pasangan titik dalam dataset memberikan implementasi pencarian tetangga yang paling naif. Secara matematis, untuk sampel N dalam dimensi D, pendekatan brute force berskala sebagai0[DN2]
Untuk sampel data kecil, algoritme ini bisa sangat berguna, tetapi menjadi tidak layak jika dan ketika jumlah sampel bertambah. Pencarian brute force neighbour dapat diaktifkan dengan menuliskan kata kuncialgorithm=’brute’.
KD Tree
Salah satu struktur data berbasis pohon yang telah ditemukan untuk mengatasi inefisiensi komputasi dari pendekatan brute-force, adalah struktur data pohon KD. Pada dasarnya pohon KD merupakan struktur pohon biner yang disebut dengan pohon berdimensi K. Ini secara rekursif mempartisi ruang parameter di sepanjang sumbu data dengan membaginya menjadi wilayah ortografi bersarang tempat titik data diisi.
Keuntungan
Berikut adalah beberapa keuntungan dari algoritma pohon KD -
Construction is fast - Karena partisi dilakukan hanya di sepanjang sumbu data, konstruksi pohon KD sangat cepat.
Less distance computations- Algoritma ini membutuhkan komputasi jarak yang sangat sedikit untuk menentukan tetangga terdekat dari sebuah titik kueri. Itu hanya butuh[ ()] perhitungan jarak.
Kekurangan
Fast for only low-dimensional neighbor searches- Ini sangat cepat untuk pencarian tetangga berdimensi rendah (D <20) tetapi ketika dan ketika D tumbuh itu menjadi tidak efisien. Karena partisi hanya dilakukan di sepanjang sumbu data,
Pencarian KD tree Neighbor dapat diaktifkan dengan menulis kata kunci algorithm=’kd_tree’.
Pohon Bola
Seperti kita ketahui bahwa KD Tree tidak efisien pada dimensi yang lebih tinggi, maka untuk mengatasi inefisiensi KD Tree ini dikembangkan struktur data Ball tree. Secara matematis, secara rekursif membagi data, menjadi node yang ditentukan oleh centroid C dan jari-jari r, sedemikian rupa sehingga setiap titik dalam node terletak di dalam hyper-sphere yang ditentukan oleh centroid.C dan radius r. Ini menggunakan ketidaksamaan segitiga, yang diberikan di bawah ini, yang mengurangi jumlah poin kandidat untuk pencarian tetangga
$$\arrowvert X+Y\arrowvert\leq \arrowvert X\arrowvert+\arrowvert Y\arrowvert$$Keuntungan
Berikut adalah beberapa keuntungan dari algoritma Ball Tree -
Efficient on highly structured data - Karena pohon bola mempartisi data dalam serangkaian hyper-spheres bersarang, hal ini efisien pada data yang sangat terstruktur.
Out-performs KD-tree - Pohon bola mengungguli pohon KD dalam dimensi tinggi karena memiliki geometri bola dari simpul pohon bola.
Kekurangan
Costly - Mempartisi data dalam serangkaian hyper-spheres bersarang membuat konstruksinya sangat mahal.
Pencarian tetangga pohon bola dapat diaktifkan dengan menuliskan kata kunci algorithm=’ball_tree’.
Memilih Algoritma Tetangga Terdekat
Pilihan algoritme yang optimal untuk kumpulan data tertentu bergantung pada faktor-faktor berikut -
Jumlah sampel (N) dan Dimensi (D)
Ini adalah faktor terpenting untuk dipertimbangkan saat memilih algoritma Tetangga Terdekat. Itu karena alasan yang diberikan di bawah ini -
Waktu kueri algoritma Brute Force tumbuh sebagai O [DN].
Waktu query dari algoritma pohon Bola tumbuh sebagai O [D log (N)].
Waktu kueri algoritma pohon KD berubah dengan D dengan cara yang aneh yang sangat sulit untuk dikarakterisasi. Ketika D <20, biayanya adalah O [D log (N)] dan algoritma ini sangat efisien. Di sisi lain, ini tidak efisien jika D> 20 karena biaya meningkat hampir O [DN].
Struktur data
Faktor lain yang mempengaruhi kinerja algoritma ini adalah dimensi intrinsik dari data atau ketersebaran data. Itu karena waktu kueri dari pohon Bola dan algoritma pohon KD dapat sangat dipengaruhi olehnya. Sedangkan waktu query algoritma Brute Force tidak berubah oleh struktur data. Umumnya, algoritma pohon Bola dan pohon KD menghasilkan waktu kueri yang lebih cepat ketika ditanamkan pada data yang lebih jarang dengan dimensi intrinsik yang lebih kecil.
Jumlah Tetangga (k)
Jumlah tetangga (k) yang diminta untuk sebuah titik kueri memengaruhi waktu kueri dari pohon Ball dan algoritme pohon KD. Waktu kueri mereka menjadi lebih lambat karena jumlah tetangga (k) meningkat. Sedangkan waktu query Brute Force akan tetap tidak terpengaruh oleh nilai k.
Jumlah titik kueri
Karena membutuhkan tahap konstruksi, baik algoritma KD tree maupun Ball tree akan efektif jika ada banyak titik query. Di sisi lain, jika ada jumlah titik kueri yang lebih kecil, algoritma Brute Force bekerja lebih baik daripada algoritma pohon KD dan pohon Bola.
k-NN (k-Nearest Neighbor), salah satu algoritme pembelajaran mesin yang paling sederhana, bersifat non-parametrik dan lazy. Non-parametrik berarti bahwa tidak ada asumsi untuk distribusi data yang mendasarinya, yaitu struktur model ditentukan dari dataset. Pembelajaran malas atau berbasis instans berarti bahwa untuk tujuan pembuatan model, tidak memerlukan poin data pelatihan dan seluruh data pelatihan digunakan dalam tahap pengujian.
Algoritma k-NN terdiri dari dua langkah berikut -
Langkah 1
Dalam langkah ini, ia menghitung dan menyimpan k tetangga terdekat untuk setiap sampel dalam set pelatihan.
Langkah 2
Dalam langkah ini, untuk sampel tak berlabel, ia mengambil k tetangga terdekat dari kumpulan data. Kemudian di antara k-tetangga terdekat ini, itu memprediksi kelas melalui pemungutan suara (kelas dengan suara terbanyak menang).
Modul, sklearn.neighbors yang mengimplementasikan algoritme k-terdekat tetangga, menyediakan fungsionalitas untuk unsupervised sebaik supervised metode pembelajaran berbasis tetangga.
Tetangga terdekat yang tidak diawasi menerapkan algoritme yang berbeda (BallTree, KDTree atau Brute Force) untuk menemukan tetangga terdekat untuk setiap sampel. Versi tanpa pengawasan ini pada dasarnya hanyalah langkah 1, yang telah dibahas di atas, dan fondasi dari banyak algoritme (KNN dan K-means menjadi yang terkenal) yang memerlukan pencarian tetangga. Dengan kata sederhana, itu adalah pelajar tanpa pengawasan untuk mengimplementasikan pencarian tetangga.
Di sisi lain, pembelajaran berbasis tetangga yang diawasi digunakan untuk klasifikasi serta regresi.
Pembelajaran KNN Tanpa Pengawasan
Seperti yang telah dibahas, ada banyak algoritma seperti KNN dan K-Means yang membutuhkan pencarian tetangga terdekat. Itulah mengapa Scikit-learn memutuskan untuk mengimplementasikan bagian pencarian tetangga sebagai "pelajar" -nya sendiri. Alasan di balik membuat penelusuran tetangga sebagai pembelajar terpisah adalah bahwa menghitung semua jarak berpasangan untuk menemukan tetangga terdekat jelas tidak terlalu efisien. Mari kita lihat modul yang digunakan oleh Sklearn untuk mengimplementasikan pembelajaran tetangga terdekat tanpa pengawasan beserta contohnya.
Modul Scikit-learn
sklearn.neighbors.NearestNeighborsadalah modul yang digunakan untuk mengimplementasikan pembelajaran tetangga terdekat tanpa pengawasan. Ia menggunakan algoritma tetangga terdekat tertentu bernama BallTree, KDTree atau Brute Force. Dengan kata lain, ini bertindak sebagai antarmuka yang seragam untuk ketiga algoritme ini.
Parameter
Tabel berikut berisi parameter yang digunakan oleh NearestNeighbors modul -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | n_neighbors - int, opsional Jumlah tetangga yang didapat. Nilai defaultnya adalah 5. |
| 2 | radius - float, opsional Itu membatasi jarak tetangga untuk kembali. Nilai defaultnya adalah 1.0. |
| 3 | algorithm - {'auto', 'ball_tree', 'kd_tree', 'brute'}, opsional Parameter ini akan mengambil algoritma (BallTree, KDTree atau Brute-force) yang ingin Anda gunakan untuk menghitung tetangga terdekat. Jika Anda memberikan 'auto', itu akan mencoba untuk memutuskan algoritma yang paling sesuai berdasarkan nilai yang diteruskan ke metode fit. |
| 4 | leaf_size - int, opsional Ini dapat mempengaruhi kecepatan konstruksi & kueri serta memori yang dibutuhkan untuk menyimpan pohon. Ini diteruskan ke BallTree atau KDTree. Meskipun nilai optimal bergantung pada sifat masalah, nilai defaultnya adalah 30. |
| 5 | metric - string atau callable Ini adalah metrik yang digunakan untuk penghitungan jarak antar titik. Kita bisa melewatkannya sebagai string atau fungsi yang dapat dipanggil. Dalam kasus fungsi yang dapat dipanggil, metrik dipanggil pada setiap pasangan baris dan nilai yang dihasilkan dicatat. Ini kurang efisien daripada meneruskan nama metrik sebagai string. Kita dapat memilih dari metrik dari scikit-learn atau scipy.spatial.distance. nilai yang valid adalah sebagai berikut - Scikit-learn - ['cosine', 'manhattan', 'Euclidean', 'l1', 'l2', 'cityblock'] Scipy.spatial.distance - ['braycurtis', 'canberra', 'chebyshev', 'dadu', 'hamming', 'jaccard', 'korelasi', 'kulsinski', 'mahalanobis', 'minkowski', 'rogerstanimoto', 'russellrao', ' sokalmicheme ',' sokalsneath ',' seuclidean ',' sqeuclidean ',' yule ']. Metrik default adalah 'Minkowski'. |
| 6 | P - integer, opsional Ini adalah parameter untuk metrik Minkowski. Nilai defaultnya adalah 2 yang setara dengan menggunakan jarak_ Euclidean (l2). |
| 7 | metric_params - dikt, opsional Ini adalah argumen kata kunci tambahan untuk fungsi metrik. Nilai defaultnya adalah Tidak Ada. |
| 8 | N_jobs - int atau None, opsional Ini mengatur ulang jumlah pekerjaan paralel untuk dijalankan untuk pencarian tetangga. Nilai defaultnya adalah Tidak Ada. |
Implementation Example
Contoh di bawah ini akan menemukan tetangga terdekat antara dua kumpulan data dengan menggunakan sklearn.neighbors.NearestNeighbors modul.
Pertama, kita perlu mengimpor modul dan paket yang diperlukan -
from sklearn.neighbors import NearestNeighbors
import numpy as npSekarang, setelah mengimpor paket, tentukan set data di antara kita ingin mencari tetangga terdekat -
Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]])Selanjutnya, terapkan algoritma pembelajaran tanpa pengawasan, sebagai berikut -
nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm = 'ball_tree')Selanjutnya, sesuaikan model dengan kumpulan data masukan.
nrst_neigh.fit(Input_data)Sekarang, temukan K-tetangga dari kumpulan data. Ini akan mengembalikan indeks dan jarak tetangga dari setiap titik.
distances, indices = nbrs.kneighbors(Input_data)
indicesOutput
array(
[
[0, 1, 3],
[1, 2, 0],
[2, 1, 0],
[3, 4, 0],
[4, 5, 3],
[5, 6, 4],
[6, 5, 4]
], dtype = int64
)
distancesOutput
array(
[
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712],
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712]
]
)Output di atas menunjukkan bahwa tetangga terdekat dari setiap titik adalah titik itu sendiri yaitu di nol. Itu karena set kueri cocok dengan set pelatihan.
Example
Kami juga dapat menunjukkan hubungan antara titik-titik tetangga dengan menghasilkan grafik renggang sebagai berikut -
nrst_neigh.kneighbors_graph(Input_data).toarray()Output
array(
[
[1., 1., 0., 1., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 0., 0., 1., 1., 0., 0.],
[0., 0., 0., 1., 1., 1., 0.],
[0., 0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 1., 1., 1.]
]
)Begitu kita cocok dengan yang tidak diawasi NearestNeighbors model, data akan disimpan dalam struktur data berdasarkan nilai yang ditetapkan untuk argumen ‘algorithm’. Setelah itu kita bisa menggunakan pembelajar tanpa pengawasan inikneighbors dalam model yang membutuhkan pencarian tetangga.
Complete working/executable program
from sklearn.neighbors import NearestNeighbors
import numpy as np
Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]])
nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm='ball_tree')
nrst_neigh.fit(Input_data)
distances, indices = nbrs.kneighbors(Input_data)
indices
distances
nrst_neigh.kneighbors_graph(Input_data).toarray()Pembelajaran KNN Terbimbing
Pembelajaran berbasis tetangga yang diawasi digunakan untuk mengikuti -
- Klasifikasi, untuk data dengan label terpisah
- Regresi, untuk data dengan label kontinu.
Pengklasifikasi Tetangga Terdekat
Kami dapat memahami klasifikasi berbasis Neighbours dengan bantuan dua karakteristik berikut -
- Ini dihitung dari suara mayoritas sederhana dari tetangga terdekat dari setiap poin.
- Ini hanya menyimpan contoh data pelatihan, itulah mengapa ini adalah jenis pembelajaran non-generalisasi.
Modul Scikit-learn
Berikut adalah dua jenis pengklasifikasi tetangga terdekat yang digunakan oleh scikit-learn -
| S.No. | Pengklasifikasi & Deskripsi |
|---|---|
| 1. | KNeighboursClassifier K dalam nama pengklasifikasi ini mewakili k tetangga terdekat, di mana k adalah nilai integer yang ditentukan oleh pengguna. Karenanya sesuai dengan namanya, classifier ini mengimplementasikan pembelajaran berbasis k tetangga terdekat. Pilihan nilai k bergantung pada data. |
| 2. | RadiusNeighboursClassifier Radius dalam nama pengklasifikasi ini mewakili tetangga terdekat dalam radius tertentu r, di mana r adalah nilai floating-point yang ditentukan oleh pengguna. Karenanya seperti namanya, pengklasifikasi ini mengimplementasikan pembelajaran berdasarkan jumlah tetangga dalam radius tetap r dari setiap titik pelatihan. |
Regresor Tetangga Terdekat
Ini digunakan dalam kasus di mana label data bersifat kontinu. Label data yang ditetapkan dihitung berdasarkan rata-rata label tetangga terdekatnya.
Berikut adalah dua jenis regresi tetangga terdekat yang digunakan oleh scikit-learn -
KNeighboursRegressor
K dalam nama regressor ini mewakili k tetangga terdekat, di mana k adalah integer valueditentukan oleh pengguna. Oleh karena itu, seperti namanya, regressor ini menerapkan pembelajaran berdasarkan k tetangga terdekat. Pilihan nilai k bergantung pada data. Mari kita pahami lebih lanjut dengan bantuan contoh implementasi.
Berikut adalah dua jenis regresi tetangga terdekat yang digunakan oleh scikit-learn -
Contoh Implementasi
Dalam contoh ini, kami akan mengimplementasikan KNN pada kumpulan data bernama kumpulan data Bunga Iris dengan menggunakan scikit-learn KNeighborsRegressor.
Pertama, impor dataset iris sebagai berikut -
from sklearn.datasets import load_iris
iris = load_iris()Sekarang, kita perlu membagi data menjadi data pelatihan dan pengujian. Kami akan menggunakan Sklearntrain_test_split berfungsi untuk membagi data menjadi rasio 70 (data latih) dan 20 (data uji) -
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)Selanjutnya, kita akan melakukan penskalaan data dengan bantuan modul preprocessing Sklearn sebagai berikut -
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Selanjutnya, impor file KNeighborsRegressor kelas dari Sklearn dan memberikan nilai tetangga sebagai berikut.
Contoh
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors = 8)
knnr.fit(X_train, y_train)Keluaran
KNeighborsRegressor(
algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = None, n_neighbors = 8, p = 2,
weights = 'uniform'
)Contoh
Sekarang, kita dapat menemukan MSE (Mean Squared Error) sebagai berikut -
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))Keluaran
The MSE is: 4.4333349609375Contoh
Sekarang, gunakan untuk memprediksi nilai sebagai berikut -
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors = 3)
knnr.fit(X, y)
print(knnr.predict([[2.5]]))Keluaran
[0.66666667]Selesaikan program kerja / eksekusi
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=8)
knnr.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=3)
knnr.fit(X, y)
print(knnr.predict([[2.5]]))RadiusNeighboursRegressor
Radius dalam nama regressor ini mewakili tetangga terdekat dalam radius tertentu r, di mana r adalah nilai floating-point yang ditentukan oleh pengguna. Karenanya seperti namanya, regressor ini mengimplementasikan pembelajaran berdasarkan jumlah tetangga dalam radius tetap r dari setiap titik pelatihan. Mari kita pahami lebih lanjut dengan bantuan jika contoh implementasi -
Contoh Implementasi
Dalam contoh ini, kami akan mengimplementasikan KNN pada kumpulan data bernama kumpulan data Bunga Iris dengan menggunakan scikit-learn RadiusNeighborsRegressor -
Pertama, impor dataset iris sebagai berikut -
from sklearn.datasets import load_iris
iris = load_iris()Sekarang, kita perlu membagi data menjadi data pelatihan dan pengujian. Kami akan menggunakan fungsi Sklearn train_test_split untuk membagi data menjadi rasio 70 (data pelatihan) dan 20 (data pengujian) -
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)Selanjutnya, kita akan melakukan penskalaan data dengan bantuan modul preprocessing Sklearn sebagai berikut -
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Selanjutnya, impor file RadiusneighborsRegressor class dari Sklearn dan berikan nilai radius sebagai berikut -
import numpy as np
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius=1)
knnr_r.fit(X_train, y_train)Contoh
Sekarang, kita dapat menemukan MSE (Mean Squared Error) sebagai berikut -
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))Keluaran
The MSE is: The MSE is: 5.666666666666667Contoh
Sekarang, gunakan untuk memprediksi nilai sebagai berikut -
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius=1)
knnr_r.fit(X, y)
print(knnr_r.predict([[2.5]]))Keluaran
[1.]Selesaikan program kerja / eksekusi
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X, y)
print(knnr_r.predict([[2.5]]))Metode Naïve Bayes adalah sekumpulan algoritma pembelajaran yang diawasi berdasarkan penerapan teorema Bayes dengan asumsi kuat bahwa semua prediktor tidak bergantung satu sama lain yaitu keberadaan fitur di kelas tidak bergantung pada keberadaan fitur lain di kelas yang sama. kelas. Asumsi yang naif inilah yang menyebabkan metode ini disebut metode Naïve Bayes.
Teorema Bayes menyatakan hubungan berikut untuk menemukan probabilitas posterior kelas yaitu probabilitas label dan beberapa fitur yang diamati, $P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$.
$$P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)=\left(\frac{P\lgroup Y\rgroup P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)}{P\left(\begin{array}{c} features\end{array}\right)}\right)$$Sini, $P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$ adalah probabilitas posterior kelas.
$P\left(\begin{array}{c} Y\end{array}\right)$ adalah probabilitas kelas sebelumnya.
$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$ adalah kemungkinan yang merupakan probabilitas kelas prediktor yang diberikan.
$P\left(\begin{array}{c} features\end{array}\right)$ adalah probabilitas prediktor sebelumnya.
Scikit-learn menyediakan model pengklasifikasi naïve Bayes yang berbeda yaitu Gaussian, Multinomial, Complement dan Bernoulli. Semuanya berbeda terutama oleh asumsi yang mereka buat tentang distribusi$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$ yaitu probabilitas kelas prediktor yang diberikan.
| Sr Tidak | Model & Deskripsi |
|---|---|
| 1 | Gaussian Naïve Bayes Pengklasifikasi Gaussian Naïve Bayes mengasumsikan bahwa data dari setiap label diambil dari distribusi Gaussian sederhana. |
| 2 | Multinomial Naïve Bayes Ini mengasumsikan bahwa fitur diambil dari distribusi Multinomial sederhana. |
| 3 | Bernoulli Naïve Bayes Asumsi dalam model ini adalah bahwa fitur-fitur biner (0s dan 1s) di alam. Aplikasi klasifikasi Bernoulli Naïve Bayes adalah klasifikasi teks dengan model 'bag of words' |
| 4 | Lengkapi Naïve Bayes Ini dirancang untuk memperbaiki asumsi berat yang dibuat oleh pengklasifikasi Multinomial Bayes. Pengklasifikasi NB jenis ini cocok untuk kumpulan data yang tidak seimbang |
Membangun Klasifikasi Naïve Bayes
Kita juga bisa menerapkan pengklasifikasi Naïve Bayes pada dataset Scikit-learn. Pada contoh di bawah ini, kami menerapkan GaussianNB dan menyesuaikan dataset breast_cancer dari Scikit-leran.
Contoh
Import Sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
data = load_breast_cancer()
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
print(label_names)
print(labels[0])
print(feature_names[0])
print(features[0])
train, test, train_labels, test_labels = train_test_split(
features,labels,test_size = 0.40, random_state = 42
)
from sklearn.naive_bayes import GaussianNB
GNBclf = GaussianNB()
model = GNBclf.fit(train, train_labels)
preds = GNBclf.predict(test)
print(preds)Keluaran
[
1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1
1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1
1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0
1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0
1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1
0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1
1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0
1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1
1 1 1 1 0 1 0 0 1 1 0 1
]Output diatas terdiri dari rangkaian 0s dan 1s yang pada dasarnya merupakan nilai prediksi dari kelas tumor yaitu malignant dan benign.
Pada bab ini, kita akan mempelajari tentang metode pembelajaran di Sklearn yang diistilahkan sebagai pohon keputusan.
Decisions tress (DTs) adalah metode pembelajaran yang diawasi non-parametrik yang paling kuat. Mereka dapat digunakan untuk tugas klasifikasi dan regresi. Tujuan utama DT adalah untuk membuat model yang memprediksi nilai variabel target dengan mempelajari aturan keputusan sederhana yang diambil dari fitur data. Pohon keputusan memiliki dua entitas utama; satu node root, di mana data terpecah, dan yang lainnya adalah node atau daun keputusan, di mana kita mendapatkan hasil akhir.
Algoritma Pohon Keputusan
Algoritma Decision Tree yang berbeda dijelaskan di bawah ini -
ID3
Ini dikembangkan oleh Ross Quinlan pada tahun 1986. Ini juga disebut Iterative Dichotomiser 3. Tujuan utama dari algoritma ini adalah untuk menemukan fitur kategorikal tersebut, untuk setiap node, yang akan menghasilkan perolehan informasi terbesar untuk target kategorikal.
Ini memungkinkan pohon untuk tumbuh hingga ukuran maksimumnya dan kemudian untuk meningkatkan kemampuan pohon pada data yang tidak terlihat, menerapkan langkah pemangkasan. Output dari algoritma ini adalah pohon multiway.
C4.5
Ini adalah penerus ID3 dan secara dinamis mendefinisikan atribut diskrit yang mempartisi nilai atribut kontinu menjadi satu set interval diskrit. Itulah alasannya menghapus batasan fitur kategorikal. Ini mengubah pohon terlatih ID3 menjadi set aturan 'IF-THEN'.
Untuk menentukan urutan penerapan aturan ini, keakuratan setiap aturan akan dievaluasi terlebih dahulu.
C5.0
Ia bekerja mirip dengan C4.5 tetapi menggunakan lebih sedikit memori dan membuat aturan yang lebih kecil. Ini lebih akurat dari C4.5.
GEROBAK
Ini disebut algoritma Klasifikasi dan Regresi Pohon. Ini pada dasarnya menghasilkan pemisahan biner dengan menggunakan fitur dan ambang batas yang menghasilkan perolehan informasi terbesar di setiap node (disebut indeks Gini).
Homogenitas bergantung pada indeks Gini, semakin tinggi nilai indeks Gini maka homogenitas akan semakin tinggi. Ini seperti algoritma C4.5, tetapi, perbedaannya adalah ia tidak menghitung kumpulan aturan dan tidak mendukung variabel target numerik (regresi) juga.
Klasifikasi dengan pohon keputusan
Dalam hal ini, variabel keputusan bersifat kategorikal.
Sklearn Module - Perpustakaan Scikit-learn menyediakan nama modul DecisionTreeClassifier untuk melakukan klasifikasi multikelas pada dataset.
Parameter
Tabel berikut berisi parameter yang digunakan oleh sklearn.tree.DecisionTreeClassifier modul -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | criterion - string, opsional default = "gini" Ini mewakili fungsi untuk mengukur kualitas split. Kriteria yang didukung adalah “gini” dan “entropy”. Standarnya adalah gini yang untuk ketidakmurnian Gini sedangkan entropi adalah untuk perolehan informasi. |
| 2 | splitter - string, opsional default = "terbaik" Ini memberi tahu model, strategi mana dari "terbaik" atau "acak" untuk memilih pemisahan di setiap node. |
| 3 | max_depth - int atau None, opsional default = None Parameter ini menentukan kedalaman maksimum pohon. Nilai defaultnya adalah None yang berarti node akan berkembang sampai semua daun murni atau sampai semua daun mengandung kurang dari sampel min_smaples_split. |
| 4 | min_samples_split - int, float, opsional default = 2 Parameter ini memberikan jumlah minimum sampel yang diperlukan untuk memisahkan node internal. |
| 5 | min_samples_leaf - int, float, opsional default = 1 Parameter ini memberikan jumlah minimum sampel yang diperlukan untuk berada di simpul daun. |
| 6 | min_weight_fraction_leaf - float, default opsional = 0. Dengan parameter ini, model akan mendapatkan fraksi bobot minimum dari jumlah bobot yang dibutuhkan untuk berada di simpul daun. |
| 7 | max_features - int, float, string atau None, opsional default = None Ini memberi model jumlah fitur yang harus dipertimbangkan saat mencari split terbaik. |
| 8 | random_state - int, instance RandomState atau Tidak Ada, opsional, default = tidak ada Parameter ini mewakili seed dari bilangan acak semu yang dihasilkan yang digunakan saat mengacak data. Berikut adalah pilihannya -
|
| 9 | max_leaf_nodes - int atau None, opsional default = None Parameter ini akan memungkinkan menumbuhkan pohon dengan max_leaf_nodes dengan cara terbaik-pertama. Standarnya tidak ada yang berarti akan ada jumlah node daun yang tidak terbatas. |
| 10 | min_impurity_decrease - float, default opsional = 0. Nilai ini berfungsi sebagai kriteria bagi node untuk dipisahkan karena model akan memisahkan node jika pemisahan ini menyebabkan penurunan pengotor lebih besar dari atau sama dengan min_impurity_decrease value. |
| 11 | min_impurity_split - float, default = 1e-7 Ini mewakili ambang batas untuk penghentian awal pertumbuhan pohon. |
| 12 | class_weight - dict, daftar dicts, “balanced” atau None, default = None Ini mewakili bobot yang terkait dengan kelas. Bentuknya adalah {class_label: weight}. Jika kita menggunakan opsi default, itu berarti semua kelas seharusnya memiliki bobot satu. Di sisi lain, jika Anda memilihclass_weight: balanced, ini akan menggunakan nilai y untuk menyesuaikan bobot secara otomatis. |
| 13 | presort - bool, opsional default = False Ini memberi tahu model apakah akan melakukan presort data untuk mempercepat penemuan split terbaik yang sesuai. Standarnya salah tetapi disetel ke true, ini dapat memperlambat proses pelatihan. |
Atribut
Tabel berikut berisi atribut yang digunakan oleh sklearn.tree.DecisionTreeClassifier modul -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | feature_importances_ - susunan bentuk = [n_features] Atribut ini akan mengembalikan kepentingan fitur. |
| 2 | classes_: - larik berbentuk = [n_class] atau daftar larik semacam itu Ini mewakili label kelas yaitu masalah keluaran tunggal, atau daftar array label kelas yaitu masalah keluaran banyak. |
| 3 | max_features_ - int Ini mewakili nilai deduksi dari parameter max_features. |
| 4 | n_classes_ - int atau daftar Ini mewakili jumlah kelas yaitu masalah output tunggal, atau daftar jumlah kelas untuk setiap output yaitu masalah multi-output. |
| 5 | n_features_ - int Ini memberi nomor features ketika metode fit () dilakukan. |
| 6 | n_outputs_ - int Ini memberi nomor outputs ketika metode fit () dilakukan. |
Metode
Tabel berikut berisi metode yang digunakan oleh sklearn.tree.DecisionTreeClassifier modul -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | apply(diri, X [, check_input]) Metode ini akan mengembalikan indeks daun. |
| 2 | decision_path(diri, X [, check_input]) Seperti namanya, metode ini akan mengembalikan jalur keputusan di pohon |
| 3 | fit(diri, X, y [, sample_weight,…]) Metode fit () akan membangun pengklasifikasi pohon keputusan dari set pelatihan yang diberikan (X, y). |
| 4 | get_depth(diri) Seperti namanya, metode ini akan mengembalikan kedalaman pohon keputusan |
| 5 | get_n_leaves(diri) Seperti namanya, metode ini akan mengembalikan jumlah daun pohon keputusan. |
| 6 | get_params(diri [, dalam]) Kita dapat menggunakan metode ini untuk mendapatkan parameter penduga. |
| 7 | predict(diri, X [, check_input]) Ini akan memprediksi nilai kelas untuk X. |
| 8 | predict_log_proba(diri, X) Ini akan memprediksi probabilitas log kelas dari sampel input yang kami berikan, X. |
| 9 | predict_proba(diri, X [, check_input]) Ini akan memprediksi probabilitas kelas dari sampel input yang disediakan oleh kami, X. |
| 10 | score(diri, X, y [, sample_weight]) Sesuai dengan namanya, metode score () akan mengembalikan akurasi rata-rata pada data dan label pengujian yang diberikan .. |
| 11 | set_params(diri, \ * \ * params) Kita dapat mengatur parameter penduga dengan metode ini. |
Contoh Implementasi
Skrip Python di bawah ini akan digunakan sklearn.tree.DecisionTreeClassifier modul untuk membuat pengklasifikasi untuk memprediksi pria atau wanita dari kumpulan data kami yang memiliki 25 sampel dan dua fitur yaitu 'tinggi' dan 'panjang rambut' -
from sklearn import tree
from sklearn.model_selection import train_test_split
X=[[165,19],[175,32],[136,35],[174,65],[141,28],[176,15]
,[131,32],[166,6],[128,32],[179,10],[136,34],[186,2],[12
6,25],[176,28],[112,38],[169,9],[171,36],[116,25],[196,2
5], [196,38], [126,40], [197,20], [150,25], [140,32],[136,35]]
Y=['Man','Woman','Woman','Man','Woman','Man','Woman','Ma
n','Woman','Man','Woman','Man','Woman','Woman','Woman','
Man','Woman','Woman','Man', 'Woman', 'Woman', 'Man', 'Man', 'Woman', 'Woman']
data_feature_names = ['height','length of hair']
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 1)
DTclf = tree.DecisionTreeClassifier()
DTclf = clf.fit(X,Y)
prediction = DTclf.predict([[135,29]])
print(prediction)Keluaran
['Woman']Kami juga dapat memprediksi probabilitas setiap kelas dengan menggunakan metode python predict_proba () berikut ini -
Contoh
prediction = DTclf.predict_proba([[135,29]])
print(prediction)Keluaran
[[0. 1.]]Regresi dengan pohon keputusan
Dalam hal ini variabel keputusan bersifat kontinu.
Sklearn Module - Perpustakaan Scikit-learn menyediakan nama modul DecisionTreeRegressor untuk menerapkan pohon keputusan pada masalah regresi.
Parameter
Parameter yang digunakan oleh DecisionTreeRegressor hampir sama dengan yang digunakan di DecisionTreeClassifiermodul. Perbedaannya terletak pada parameter 'kriteria'. UntukDecisionTreeRegressor modul ‘criterion: string, opsional default = parameter "mse" 'memiliki nilai berikut -
mse- Ini singkatan dari mean squared error. Ini sama dengan pengurangan varian sebagai kriteria pemilihan fitur. Ini meminimalkan kerugian L2 menggunakan rata-rata setiap node terminal.
freidman_mse - Ini juga menggunakan kesalahan kuadrat rata-rata tetapi dengan skor peningkatan Friedman.
mae- Ini adalah singkatan dari mean absolute error. Ini meminimalkan kerugian L1 menggunakan median dari setiap node terminal.
Perbedaan lainnya adalah tidak ada ‘class_weight’ parameter.
Atribut
Atribut dari DecisionTreeRegressor juga sama seperti sebelumnya DecisionTreeClassifiermodul. Perbedaannya adalah tidak ada‘classes_’ dan ‘n_classes_'atribut.
Metode
Metode DecisionTreeRegressor juga sama seperti sebelumnya DecisionTreeClassifiermodul. Perbedaannya adalah tidak ada‘predict_log_proba()’ dan ‘predict_proba()’'atribut.
Contoh Implementasi
Metode fit () dalam model regresi pohon keputusan akan mengambil nilai floating point y. mari kita lihat contoh implementasi sederhana dengan menggunakanSklearn.tree.DecisionTreeRegressor -
from sklearn import tree
X = [[1, 1], [5, 5]]
y = [0.1, 1.5]
DTreg = tree.DecisionTreeRegressor()
DTreg = clf.fit(X, y)Setelah dipasang, kita dapat menggunakan model regresi ini untuk membuat prediksi sebagai berikut -
DTreg.predict([[4, 5]])Keluaran
array([1.5])Bab ini akan membantu Anda memahami pohon keputusan acak di Sklearn.
Algoritma Pohon Keputusan Acak
Seperti yang kita ketahui bahwa DT biasanya dilatih dengan memisahkan data secara rekursif, tetapi rentan terhadap kecocokan berlebih, data tersebut telah diubah menjadi hutan acak dengan melatih banyak pohon pada berbagai sub-sampel data. Itusklearn.ensemble modul mengikuti dua algoritma berdasarkan pohon keputusan acak -
Algoritma Random Forest
Untuk setiap fitur yang dipertimbangkan, ini menghitung kombinasi fitur / pemisahan yang optimal secara lokal. Di Random forest, setiap pohon keputusan dalam ensemble dibangun dari sampel yang diambil dengan penggantian dari set pelatihan dan kemudian mendapatkan prediksi dari masing-masing dan akhirnya memilih solusi terbaik dengan cara voting. Ini dapat digunakan untuk tugas klasifikasi dan juga regresi.
Klasifikasi dengan Random Forest
Untuk membuat pengklasifikasi forest acak, modul Scikit-learn menyediakan sklearn.ensemble.RandomForestClassifier. Saat membuat pengklasifikasi hutan acak, parameter utama yang digunakan modul ini adalah‘max_features’ dan ‘n_estimators’.
Sini, ‘max_features’adalah ukuran subset fitur acak yang perlu dipertimbangkan saat memisahkan node. Jika kita memilih nilai parameter ini ke none maka itu akan mempertimbangkan semua fitur daripada subset acak. Di samping itu,n_estimatorsadalah jumlah pohon di hutan. Semakin tinggi jumlah pohon, semakin baik hasilnya. Tapi akan butuh waktu lebih lama untuk menghitungnya juga.
Contoh implementasi
Dalam contoh berikut, kami sedang membangun pengklasifikasi hutan acak dengan menggunakan sklearn.ensemble.RandomForestClassifier dan juga memeriksa keakuratannya juga dengan menggunakan cross_val_score modul.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
X, y = make_blobs(n_samples = 10000, n_features = 10, centers = 100,random_state = 0) RFclf = RandomForestClassifier(n_estimators = 10,max_depth = None,min_samples_split = 2, random_state = 0)
scores = cross_val_score(RFclf, X, y, cv = 5)
scores.mean()Keluaran
0.9997Contoh
Kita juga bisa menggunakan dataset sklearn untuk membangun pengklasifikasi Random Forest. Seperti pada contoh berikut kami menggunakan dataset iris. Kami juga akan menemukan skor akurasi dan matriks kebingungannya.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
path = "https://archive.ics.uci.edu/ml/machine-learning-database
s/iris/iris.data"
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
dataset = pd.read_csv(path, names = headernames)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
RFclf = RandomForestClassifier(n_estimators = 50)
RFclf.fit(X_train, y_train)
y_pred = RFclf.predict(X_test)
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)Keluaran
Confusion Matrix:
[[14 0 0]
[ 0 18 1]
[ 0 0 12]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 1.00 0.95 0.97 19
Iris-virginica 0.92 1.00 0.96 12
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Accuracy: 0.9777777777777777Regresi dengan Random Forest
Untuk membuat regresi forest acak, modul Scikit-learn menyediakan sklearn.ensemble.RandomForestRegressor. Saat membangun regressor hutan acak, ia akan menggunakan parameter yang sama seperti yang digunakan olehsklearn.ensemble.RandomForestClassifier.
Contoh implementasi
Dalam contoh berikut, kami sedang membangun regressor hutan acak dengan menggunakan sklearn.ensemble.RandomForestregressor dan juga memprediksi nilai baru dengan menggunakan metode predict ().
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
RFregr = RandomForestRegressor(max_depth = 10,random_state = 0,n_estimators = 100)
RFregr.fit(X, y)Keluaran
RandomForestRegressor(
bootstrap = True, criterion = 'mse', max_depth = 10,
max_features = 'auto', max_leaf_nodes = None,
min_impurity_decrease = 0.0, min_impurity_split = None,
min_samples_leaf = 1, min_samples_split = 2,
min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None,
oob_score = False, random_state = 0, verbose = 0, warm_start = False
)Setelah dipasang kita dapat memprediksi dari model regresi sebagai berikut -
print(RFregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Keluaran
[98.47729198]Metode Pohon Ekstra
Untuk setiap fitur yang dipertimbangkan, ini memilih nilai acak untuk pemisahan. Manfaat menggunakan metode pohon tambahan adalah memungkinkan untuk mengurangi varian model sedikit lebih banyak. Kerugian menggunakan metode ini adalah sedikit meningkatkan bias.
Klasifikasi dengan Metode Pohon Ekstra
Untuk membuat pengklasifikasi menggunakan metode Extra-tree, modul Scikit-learn menyediakan sklearn.ensemble.ExtraTreesClassifier. Ini menggunakan parameter yang sama seperti yang digunakan olehsklearn.ensemble.RandomForestClassifier. Satu-satunya perbedaan adalah cara, yang dibahas di atas, mereka membangun pohon.
Contoh implementasi
Dalam contoh berikut, kami sedang membangun pengklasifikasi hutan acak dengan menggunakan sklearn.ensemble.ExtraTreeClassifier dan juga memeriksa keakuratannya dengan menggunakan cross_val_score modul.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import ExtraTreesClassifier
X, y = make_blobs(n_samples = 10000, n_features = 10, centers=100,random_state = 0)
ETclf = ExtraTreesClassifier(n_estimators = 10,max_depth = None,min_samples_split = 10, random_state = 0)
scores = cross_val_score(ETclf, X, y, cv = 5)
scores.mean()Keluaran
1.0Contoh
Kita juga bisa menggunakan dataset sklearn untuk membangun pengklasifikasi menggunakan metode Extra-Tree. Seperti pada contoh berikut kami menggunakan dataset Pima-Indian.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import ExtraTreesClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 7
kfold = KFold(n_splits=10, random_state=seed)
num_trees = 150
max_features = 5
ETclf = ExtraTreesClassifier(n_estimators=num_trees, max_features=max_features)
results = cross_val_score(ETclf, X, Y, cv=kfold)
print(results.mean())Keluaran
0.7551435406698566Regresi dengan Metode Pohon Ekstra
Untuk membuat file Extra-Tree regresi, yang disediakan oleh modul Scikit-learn sklearn.ensemble.ExtraTreesRegressor. Saat membangun regressor hutan acak, ia akan menggunakan parameter yang sama seperti yang digunakan olehsklearn.ensemble.ExtraTreesClassifier.
Contoh implementasi
Dalam contoh berikut, kami menerapkan sklearn.ensemble.ExtraTreesregressordan pada data yang sama seperti yang kami gunakan saat membuat regressor hutan acak. Mari kita lihat perbedaannya di Output
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
ETregr = ExtraTreesRegressor(max_depth = 10,random_state = 0,n_estimators = 100)
ETregr.fit(X, y)Keluaran
ExtraTreesRegressor(bootstrap = False, criterion = 'mse', max_depth = 10,
max_features = 'auto', max_leaf_nodes = None,
min_impurity_decrease = 0.0, min_impurity_split = None,
min_samples_leaf = 1, min_samples_split = 2,
min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None,
oob_score = False, random_state = 0, verbose = 0, warm_start = False)Contoh
Setelah dipasang kita dapat memprediksi dari model regresi sebagai berikut -
print(ETregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Keluaran
[85.50955817]Dalam bab ini, kita akan belajar tentang metode peningkatan di Sklearn, yang memungkinkan pembuatan model ansambel.
Metode peningkatan membangun model ansambel dengan cara bertahap. Prinsip utamanya adalah membangun model secara bertahap dengan melatih setiap penduga model dasar secara berurutan. Untuk membangun ansambel yang kuat, metode ini pada dasarnya menggabungkan beberapa minggu pelajar yang dilatih secara berurutan melalui beberapa iterasi data pelatihan. Modul sklearn.ensemble mengikuti dua metode peningkatan berikut.
AdaBoost
Ini adalah salah satu metode ensembel penguat yang paling sukses yang kunci utamanya adalah cara mereka memberikan bobot pada instance dalam kumpulan data. Itulah mengapa algoritme perlu kurang memperhatikan instance saat membuat model selanjutnya.
Klasifikasi dengan AdaBoost
Untuk membuat pengklasifikasi AdaBoost, modul Scikit-learn menyediakan sklearn.ensemble.AdaBoostClassifier. Saat membangun pengklasifikasi ini, parameter utama yang digunakan modul ini adalahbase_estimator. Di sini, base_estimator adalah nilai daribase estimatordari mana ansambel yang ditingkatkan dibuat. Jika kita memilih nilai parameter ini menjadi none, maka penduga dasarnya adalahDecisionTreeClassifier(max_depth=1).
Contoh implementasi
Dalam contoh berikut, kami membangun pengklasifikasi AdaBoost dengan menggunakan sklearn.ensemble.AdaBoostClassifier dan juga memprediksi dan memeriksa skornya.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples = 1000, n_features = 10,n_informative = 2, n_redundant = 0,random_state = 0, shuffle = False)
ADBclf = AdaBoostClassifier(n_estimators = 100, random_state = 0)
ADBclf.fit(X, y)Keluaran
AdaBoostClassifier(algorithm = 'SAMME.R', base_estimator = None,
learning_rate = 1.0, n_estimators = 100, random_state = 0)Contoh
Setelah dipasang, kita dapat memprediksi nilai baru sebagai berikut -
print(ADBclf.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Keluaran
[1]Contoh
Sekarang kita dapat memeriksa skornya sebagai berikut -
ADBclf.score(X, y)Keluaran
0.995Contoh
Kita juga bisa menggunakan dataset sklearn untuk membangun pengklasifikasi menggunakan metode Extra-Tree. Misalnya, dalam contoh yang diberikan di bawah ini, kami menggunakan dataset Pima-Indian.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names = headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 5
kfold = KFold(n_splits = 10, random_state = seed)
num_trees = 100
max_features = 5
ADBclf = AdaBoostClassifier(n_estimators = num_trees, max_features = max_features)
results = cross_val_score(ADBclf, X, Y, cv = kfold)
print(results.mean())Keluaran
0.7851435406698566Regresi dengan AdaBoost
Untuk membuat regressor dengan metode Ada Boost, perpustakaan Scikit-learn menyediakan sklearn.ensemble.AdaBoostRegressor. Saat membangun regressor, ia akan menggunakan parameter yang sama seperti yang digunakan olehsklearn.ensemble.AdaBoostClassifier.
Contoh implementasi
Dalam contoh berikut, kami sedang membangun regressor AdaBoost dengan menggunakan sklearn.ensemble.AdaBoostregressor dan juga memprediksi nilai baru dengan menggunakan metode predict ().
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
ADBregr = RandomForestRegressor(random_state = 0,n_estimators = 100)
ADBregr.fit(X, y)Keluaran
AdaBoostRegressor(base_estimator = None, learning_rate = 1.0, loss = 'linear',
n_estimators = 100, random_state = 0)Contoh
Setelah dipasang kita dapat memprediksi dari model regresi sebagai berikut -
print(ADBregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Keluaran
[85.50955817]Peningkatan Pohon Gradien
Itu juga disebut Gradient Boosted Regression Trees(GRBT). Ini pada dasarnya adalah generalisasi peningkatan fungsi kerugian yang dapat dibedakan secara arbitrer. Ini menghasilkan model prediksi berupa ansambel model prediksi mingguan. Ini dapat digunakan untuk masalah regresi dan klasifikasi. Keuntungan utama mereka terletak pada kenyataan bahwa mereka secara alami menangani tipe data campuran.
Klasifikasi dengan Gradient Tree Boost
Untuk membuat pengklasifikasi Gradient Tree Boost, modul Scikit-learn menyediakan sklearn.ensemble.GradientBoostingClassifier. Saat membuat classifier ini, parameter utama yang digunakan modul ini adalah 'loss'. Di sini, 'kerugian' adalah nilai fungsi kerugian yang akan dioptimalkan. Jika kita memilih kerugian = penyimpangan, ini mengacu pada penyimpangan untuk klasifikasi dengan keluaran probabilistik.
Di sisi lain, jika kita memilih nilai parameter ini ke eksponensial, maka algoritma AdaBoost akan pulih. Parameternyan_estimatorsakan mengontrol jumlah pelajar minggu. Sebuah hyper-parameter bernamalearning_rate (dalam kisaran (0,0, 1,0]) akan mengontrol overfitting melalui penyusutan.
Contoh implementasi
Dalam contoh berikut, kami sedang membangun pengklasifikasi Gradient Boosting dengan menggunakan sklearn.ensemble.GradientBoostingClassifier. Kami menyesuaikan pengklasifikasi ini dengan pelajar 50 minggu.
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state = 0)
X_train, X_test = X[:5000], X[5000:]
y_train, y_test = y[:5000], y[5000:]
GDBclf = GradientBoostingClassifier(n_estimators = 50, learning_rate = 1.0,max_depth = 1, random_state = 0).fit(X_train, y_train)
GDBclf.score(X_test, y_test)Keluaran
0.8724285714285714Contoh
Kita juga bisa menggunakan dataset sklearn untuk membangun pengklasifikasi menggunakan Gradient Boosting Classifier. Seperti pada contoh berikut kami menggunakan dataset Pima-Indian.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names = headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 5
kfold = KFold(n_splits = 10, random_state = seed)
num_trees = 100
max_features = 5
ADBclf = GradientBoostingClassifier(n_estimators = num_trees, max_features = max_features)
results = cross_val_score(ADBclf, X, Y, cv = kfold)
print(results.mean())Keluaran
0.7946582356674234Regresi dengan Gradient Tree Boost
Untuk membuat regressor dengan metode Gradient Tree Boost, perpustakaan Scikit-learn menyediakannya sklearn.ensemble.GradientBoostingRegressor. Itu dapat menentukan fungsi kerugian untuk regresi melalui kehilangan nama parameter. Nilai default untuk kerugian adalah 'ls'.
Contoh implementasi
Dalam contoh berikut, kami sedang membangun regressor Peningkat Gradien dengan menggunakan sklearn.ensemble.GradientBoostingregressor dan juga menemukan kesalahan kuadrat rata-rata dengan menggunakan metode mean_squared_error ().
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples = 2000, random_state = 0, noise = 1.0)
X_train, X_test = X[:1000], X[1000:]
y_train, y_test = y[:1000], y[1000:]
GDBreg = GradientBoostingRegressor(n_estimators = 80, learning_rate=0.1,
max_depth = 1, random_state = 0, loss = 'ls').fit(X_train, y_train)Setelah dipasang, kita dapat menemukan kesalahan kuadrat rata-rata sebagai berikut -
mean_squared_error(y_test, GDBreg.predict(X_test))Keluaran
5.391246106657164Di sini, kita akan mempelajari tentang metode clustering di Sklearn yang akan membantu dalam mengidentifikasi kesamaan dalam sampel data.
Metode clustering, salah satu metode ML tanpa pengawasan yang paling berguna, digunakan untuk menemukan kesamaan & pola hubungan di antara sampel data. Setelah itu, mereka mengelompokkan sampel tersebut ke dalam kelompok-kelompok yang memiliki kesamaan berdasarkan fiturnya. Clustering menentukan pengelompokan intrinsik di antara data tak berlabel saat ini, itulah mengapa ini penting.
Perpustakaan Scikit-learn memiliki sklearn.clusteruntuk melakukan pengelompokan data yang tidak berlabel. Di bawah modul ini scikit-leran memiliki metode pengelompokan berikut -
KMeans
Algoritma ini menghitung sentroid dan melakukan iterasi hingga menemukan sentroid yang optimal. Ini membutuhkan jumlah cluster untuk ditentukan, itulah mengapa diasumsikan bahwa mereka sudah diketahui. Logika utama dari algoritma ini adalah untuk mengelompokkan data yang memisahkan sampel dalam jumlah n kelompok varians yang sama dengan meminimalkan kriteria yang dikenal sebagai inersia. Jumlah cluster yang diidentifikasi oleh algoritma diwakili oleh 'K.
Scikit-learn miliki sklearn.cluster.KMeansmodul untuk melakukan pengelompokan K-Means. Saat menghitung pusat cluster dan nilai inersia, parameternya dinamaisample_weight memungkinkan sklearn.cluster.KMeans modul untuk memberikan bobot lebih pada beberapa sampel.
Propagasi Afinitas
Algoritma ini didasarkan pada konsep 'message passing' antara pasangan sampel yang berbeda hingga konvergensi. Ini tidak memerlukan jumlah cluster ditentukan sebelum menjalankan algoritme. Algoritme memiliki kompleksitas waktu dari urutan (2), yang merupakan kerugian terbesar darinya.
Scikit-learn miliki sklearn.cluster.AffinityPropagation modul untuk melakukan clustering Affinity Propagation.
Berarti Shift
Algoritma ini terutama menemukan blobsdalam kepadatan sampel yang halus. Ini menetapkan titik data ke cluster secara iteratif dengan menggeser poin menuju kepadatan titik data tertinggi. Alih-alih mengandalkan parameter bernamabandwidth mendikte ukuran wilayah yang akan ditelusuri, secara otomatis mengatur jumlah cluster.
Scikit-learn miliki sklearn.cluster.MeanShift modul untuk melakukan pengelompokan Mean Shift.
Pengelompokan Spektral
Sebelum melakukan clustering, algoritma ini pada dasarnya menggunakan eigenvalues yaitu spektrum matriks kemiripan data untuk melakukan reduksi dimensionalitas dalam dimensi yang lebih sedikit. Penggunaan algoritme ini tidak disarankan jika ada banyak cluster.
Scikit-learn miliki sklearn.cluster.SpectralClustering modul untuk melakukan pengelompokan spektral.
Pengelompokan Hierarki
Algoritme ini membangun cluster bertingkat dengan menggabungkan atau memisahkan cluster secara berurutan. Hierarki cluster ini direpresentasikan sebagai dendrogram yaitu pohon. Itu terbagi dalam dua kategori berikut -
Agglomerative hierarchical algorithms- Dalam algoritma hierarki semacam ini, setiap titik data diperlakukan seperti satu cluster. Kemudian secara berturut-turut menggumpalkan pasangan cluster. Ini menggunakan pendekatan bottom-up.
Divisive hierarchical algorithms- Dalam algoritma hierarki ini, semua titik data diperlakukan sebagai satu cluster besar. Dalam proses clustering ini melibatkan pembagian, dengan menggunakan pendekatan top-down, satu cluster besar menjadi berbagai cluster kecil.
Scikit-learn miliki sklearn.cluster.AgglomerativeClustering modul untuk melakukan pengelompokan hierarki aglomeratif.
DBSCAN
Itu singkatan “Density-based spatial clustering of applications with noise”. Algoritme ini didasarkan pada gagasan intuitif "cluster" & "noise" bahwa cluster adalah wilayah padat dengan kepadatan lebih rendah dalam ruang data, dipisahkan oleh wilayah kepadatan titik data yang lebih rendah.
Scikit-learn miliki sklearn.cluster.DBSCANmodul untuk melakukan pengelompokan DBSCAN. Ada dua parameter penting yaitu min_samples dan eps yang digunakan algoritma ini untuk mendefinisikan dense.
Nilai parameter yang lebih tinggi min_samples atau nilai yang lebih rendah dari parameter eps akan memberikan indikasi tentang kepadatan titik data yang lebih tinggi yang diperlukan untuk membentuk sebuah cluster.
OPTIK
Itu singkatan “Ordering points to identify the clustering structure”. Algoritma ini juga menemukan cluster berbasis kepadatan dalam data spasial. Logika kerja dasarnya seperti DBSCAN.
Ini mengatasi kelemahan utama algoritma DBSCAN - masalah mendeteksi cluster yang berarti dalam data dengan kepadatan yang berbeda-beda - dengan memesan titik database sedemikian rupa sehingga titik terdekat spasial menjadi tetangga dalam pengurutan.
Scikit-learn miliki sklearn.cluster.OPTICS modul untuk melakukan pengelompokan OPTICS.
BIRCH
Itu singkatan dari Balanced iterative reduction dan clustering using hierarchies. Ini digunakan untuk melakukan pengelompokan hierarki pada kumpulan data besar. Itu membangun pohon bernamaCFT yaitu Characteristics Feature Tree, untuk data yang diberikan.
Keuntungan dari CFT adalah bahwa node data yang disebut node CF (Karakteristik Fitur) menyimpan informasi yang diperlukan untuk pengelompokan yang selanjutnya mencegah kebutuhan untuk menyimpan seluruh data input dalam memori.
Scikit-learn miliki sklearn.cluster.Birch modul untuk melakukan pengelompokan BIRCH.
Membandingkan Algoritma Pengelompokan
Tabel berikut akan memberikan perbandingan (berdasarkan parameter, skalabilitas, dan metrik) dari algoritme pengelompokan di scikit-learn.
| Sr Tidak | Nama Algoritme | Parameter | Skalabilitas | Metrik yang Digunakan |
|---|---|---|---|---|
| 1 | K-Means | Jumlah cluster | N_sample yang sangat besar | Jarak antar titik. |
| 2 | Propagasi Afinitas | Pembasahan | Ini tidak dapat diskalakan dengan n_samples | Jarak Grafik |
| 3 | Mean-Shift | Bandwidth | Ini tidak dapat diskalakan dengan n_samples. | Jarak antar titik. |
| 4 | Pengelompokan Spektral | Jumlah cluster | Skalabilitas tingkat menengah dengan n_samples. Skalabilitas tingkat kecil dengan n_clusters. | Jarak Grafik |
| 5 | Pengelompokan Hierarki | Ambang jarak atau Jumlah cluster | N_samples Besar n_clusters | Jarak antar titik. |
| 6 | DBSCAN | Ukuran lingkungan | N_sample yang sangat besar dan n_clusters sedang. | Jarak titik terdekat |
| 7 | OPTIK | Keanggotaan cluster minimum | N_sample yang sangat besar dan n_clusters yang besar. | Jarak antar titik. |
| 8 | BIRCH | Ambang batas, Faktor percabangan | N_samples Besar n_clusters | Jarak Euclidean antar titik. |
K-Means Clustering pada set data Scikit-learn Digit
Dalam contoh ini, kami akan menerapkan pengelompokan K-means pada kumpulan data digit. Algoritma ini akan mengidentifikasi digit yang mirip tanpa menggunakan informasi label asli. Implementasi dilakukan pada notebook Jupyter.
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shapeKeluaran
1797, 64)Keluaran ini menunjukkan bahwa dataset digit memiliki 1797 sampel dengan 64 fitur.
Contoh
Sekarang, lakukan pengelompokan K-Means sebagai berikut -
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shapeKeluaran
(10, 64)Keluaran ini menunjukkan bahwa clustering K-means menghasilkan 10 cluster dengan 64 fitur.
Contoh
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks = [], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)Keluaran
Output di bawah ini memiliki gambar yang menunjukkan pusat cluster yang dipelajari oleh K-Means Clustering.

Selanjutnya, skrip Python di bawah ini akan mencocokkan label cluster yang dipelajari (oleh K-Means) dengan label sebenarnya yang ditemukan di dalamnya -
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]Kami juga dapat memeriksa keakuratan dengan bantuan perintah yang disebutkan di bawah ini.
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)Keluaran
0.7935447968836951Contoh Implementasi Lengkap
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)Ada berbagai fungsi dengan bantuan yang kami dapat mengevaluasi kinerja algoritma pengelompokan.
Berikut adalah beberapa fungsi penting dan paling sering digunakan yang diberikan oleh Scikit-learn untuk mengevaluasi kinerja pengelompokan -
Indeks Rand yang Disesuaikan
Rand Index adalah fungsi yang menghitung ukuran kesamaan antara dua clustering. Untuk komputasi indeks rand ini mempertimbangkan semua pasangan sampel dan pasangan penghitungan yang ditugaskan di cluster yang sama atau berbeda dalam pengelompokan yang diprediksi dan benar. Setelah itu, skor Indeks Rand mentah 'disesuaikan untuk peluang' menjadi skor Indeks Rand yang Disesuaikan dengan menggunakan rumus berikut -
$$Adjusted\:RI=\left(RI-Expected_{-}RI\right)/\left(max\left(RI\right)-Expected_{-}RI\right)$$Ini memiliki dua parameter yaitu labels_true, yang merupakan label kelas kebenaran dasar, dan labels_pred, yang merupakan label cluster untuk dievaluasi.
Contoh
from sklearn.metrics.cluster import adjusted_rand_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
adjusted_rand_score(labels_true, labels_pred)Keluaran
0.4444444444444445Pelabelan sempurna akan diberi skor 1 dan pelabelan buruk atau pelabelan independen diberi skor 0 atau negatif.
Skor Berbasis Informasi Bersama
Saling Informasi adalah fungsi yang menghitung persetujuan dari dua penugasan. Ini mengabaikan permutasi. Ada versi berikut yang tersedia -
Informasi Mutual yang Dinormalisasi (NMI)
Scikit belajar punya sklearn.metrics.normalized_mutual_info_score modul.
Contoh
from sklearn.metrics.cluster import normalized_mutual_info_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
normalized_mutual_info_score (labels_true, labels_pred)Keluaran
0.7611702597222881Informasi Bersama yang Disesuaikan (AMI)
Scikit belajar punya sklearn.metrics.adjusted_mutual_info_score modul.
Contoh
from sklearn.metrics.cluster import adjusted_mutual_info_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
adjusted_mutual_info_score (labels_true, labels_pred)Keluaran
0.4444444444444448Skor Fowlkes-Mallows
Fungsi Fowlkes-Mallows mengukur kesamaan dua pengelompokan dari satu set titik. Ini dapat didefinisikan sebagai rata-rata geometris dari presisi dan perolehan berpasangan.
Secara matematis,
$$FMS=\frac{TP}{\sqrt{\left(TP+FP\right)\left(TP+FN\right)}}$$Sini, TP = True Positive - jumlah pasangan titik yang termasuk dalam kluster yang sama di label benar serta label prediksi keduanya.
FP = False Positive - jumlah pasangan titik yang termasuk dalam kelompok yang sama di label yang benar tetapi tidak dalam label yang diprediksi.
FN = False Negative - jumlah pasangan titik yang termasuk dalam kelompok yang sama di label yang diprediksi tetapi tidak dalam label sebenarnya.
Scikit belajar memiliki modul sklearn.metrics.fowlkes_mallows_score -
Contoh
from sklearn.metrics.cluster import fowlkes_mallows_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
fowlkes_mallows__score (labels_true, labels_pred)Keluaran
0.6546536707079771Koefisien Siluet
Fungsi Silhouette akan menghitung Koefisien Siluet rata-rata dari semua sampel menggunakan rata-rata jarak intra-kluster dan rata-rata jarak kluster terdekat untuk setiap sampel.
Secara matematis,
$$S=\left(b-a\right)/max\left(a,b\right)$$Di sini, a adalah jarak intra-cluster.
dan, b adalah jarak cluster terdekat.
The Scikit belajar memiliki sklearn.metrics.silhouette_score modul -
Contoh
from sklearn import metrics.silhouette_score
from sklearn.metrics import pairwise_distances
from sklearn import datasets
import numpy as np
from sklearn.cluster import KMeans
dataset = datasets.load_iris()
X = dataset.data
y = dataset.target
kmeans_model = KMeans(n_clusters = 3, random_state = 1).fit(X)
labels = kmeans_model.labels_
silhouette_score(X, labels, metric = 'euclidean')Keluaran
0.5528190123564091Matriks Kontingensi
Matriks ini akan melaporkan kardinalitas persimpangan untuk setiap pasangan tepercaya (benar, diprediksi). Matriks konfusi untuk masalah klasifikasi adalah matriks kontingensi persegi.
The Scikit belajar memiliki sklearn.metrics.contingency_matrix modul.
Contoh
from sklearn.metrics.cluster import contingency_matrix
x = ["a", "a", "a", "b", "b", "b"]
y = [1, 1, 2, 0, 1, 2]
contingency_matrix(x, y)Keluaran
array([
[0, 2, 1],
[1, 1, 1]
])Baris pertama keluaran di atas menunjukkan bahwa di antara tiga sampel yang cluster truenya adalah "a", tidak ada yang berada di 0, dua di antaranya ada di 1 dan 1 ada di 2. Sebaliknya, baris kedua menunjukkan bahwa di antara tiga sampel yang cluster sebenarnya adalah "b", 1 di 0, 1 di 1 dan 1 di 2.
Pengurangan dimensi, metode pembelajaran mesin tanpa pengawasan digunakan untuk mengurangi jumlah variabel fitur untuk setiap sampel data yang memilih kumpulan fitur utama. Principal Component Analysis (PCA) adalah salah satu algoritma populer untuk reduksi dimensi.
PCA persis
Principal Component Analysis (PCA) digunakan untuk reduksi dimensi linier Singular Value Decomposition(SVD) data untuk memproyeksikannya ke ruang dimensi yang lebih rendah. Saat dekomposisi menggunakan PCA, data masukan dipusatkan tetapi tidak diskalakan untuk setiap fitur sebelum menerapkan SVD.
Library Scikit-learn ML menyediakan sklearn.decomposition.PCAmodul yang diimplementasikan sebagai objek transformator yang mempelajari n komponen dalam metode fit () nya. Ini juga dapat digunakan pada data baru untuk memproyeksikannya pada komponen ini.
Contoh
Contoh di bawah ini akan menggunakan modul sklearn.decomposition.PCA untuk menemukan 5 komponen utama terbaik dari dataset Pima Indians Diabetes.
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', ‘class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 5)
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)Keluaran
Explained Variance: [0.88854663 0.06159078 0.02579012 0.01308614 0.00744094]
[
[-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03]
[-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01]
[-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]
[-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01]
[ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01]
]PCA inkremental
Incremental Principal Component Analysis (IPCA) digunakan untuk mengatasi batasan terbesar Principal Component Analysis (PCA) yaitu PCA hanya mendukung pemrosesan batch, artinya semua data input yang akan diproses harus sesuai dengan memori.
Library Scikit-learn ML menyediakan sklearn.decomposition.IPCA modul yang memungkinkan untuk mengimplementasikan Out-of-Core PCA baik dengan menggunakan partial_fit metode pada potongan data yang diambil secara berurutan atau dengan mengaktifkan penggunaan np.memmap, file yang dipetakan memori, tanpa memuat seluruh file ke dalam memori.
Sama seperti PCA, saat dekomposisi menggunakan IPCA, data input dipusatkan tetapi tidak diskalakan untuk setiap fitur sebelum menerapkan SVD.
Contoh
Contoh di bawah ini akan digunakan sklearn.decomposition.IPCA modul pada dataset digit Sklearn.
from sklearn.datasets import load_digits
from sklearn.decomposition import IncrementalPCA
X, _ = load_digits(return_X_y = True)
transformer = IncrementalPCA(n_components = 10, batch_size = 100)
transformer.partial_fit(X[:100, :])
X_transformed = transformer.fit_transform(X)
X_transformed.shapeKeluaran
(1797, 10)Di sini, kami dapat memuat sebagian pada kumpulan data yang lebih kecil (seperti yang kami lakukan pada 100 per kumpulan) atau Anda dapat membiarkan file fit() berfungsi untuk membagi data menjadi beberapa batch.
Kernel PCA
Kernel Principal Component Analysis, merupakan perpanjangan dari PCA, mencapai pengurangan dimensi non-linier menggunakan kernel. Ini mendukung keduanyatransform and inverse_transform.
Library Scikit-learn ML menyediakan sklearn.decomposition.KernelPCA modul.
Contoh
Contoh di bawah ini akan digunakan sklearn.decomposition.KernelPCAmodul pada dataset digit Sklearn. Kami menggunakan kernel sigmoid.
from sklearn.datasets import load_digits
from sklearn.decomposition import KernelPCA
X, _ = load_digits(return_X_y = True)
transformer = KernelPCA(n_components = 10, kernel = 'sigmoid')
X_transformed = transformer.fit_transform(X)
X_transformed.shapeKeluaran
(1797, 10)PCA menggunakan SVD acak
Principal Component Analysis (PCA) menggunakan SVD acak digunakan untuk memproyeksikan data ke ruang berdimensi lebih rendah yang menjaga sebagian besar varians dengan menghilangkan vektor tunggal komponen yang terkait dengan nilai singular yang lebih rendah. Di sinisklearn.decomposition.PCA modul dengan parameter opsional svd_solver=’randomized’ akan sangat berguna.
Contoh
Contoh di bawah ini akan digunakan sklearn.decomposition.PCA modul dengan parameter opsional svd_solver = 'randomized' untuk menemukan 7 komponen utama terbaik dari dataset Pima Indians Diabetes.
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 7,svd_solver = 'randomized')
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)Keluaran
Explained Variance: [8.88546635e-01 6.15907837e-02 2.57901189e-02 1.30861374e-027.44093864e-03 3.02614919e-03 5.12444875e-04]
[
[-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03]
[-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01]
[-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]
[-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01]
[ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01]
[-5.04730888e-03 5.07391813e-02 7.56365525e-02 2.21363068e-01-6.13326472e-03 -9.70776708e-01 -2.02903702e-03 -1.51133239e-02]
[ 9.86672995e-01 8.83426114e-04 -1.22975947e-03 -3.76444746e-041.42307394e-03 -2.73046214e-03 -6.34402965e-03 -1.62555343e-01]
]