Scikit Learn - Mendukung Mesin Vektor
Bab ini membahas metode pembelajaran mesin yang disebut sebagai Support Vector Machines (SVM).
pengantar
Mesin vektor dukungan (SVM) adalah metode pembelajaran mesin yang diawasi dan kuat namun fleksibel yang digunakan untuk klasifikasi, regresi, dan, deteksi pencilan. SVM sangat efisien dalam ruang dimensi tinggi dan umumnya digunakan dalam masalah klasifikasi. SVM populer dan hemat memori karena menggunakan subset poin pelatihan dalam fungsi keputusan.
Tujuan utama SVM adalah untuk membagi dataset menjadi beberapa kelas untuk menemukan a maximum marginal hyperplane (MMH) yang dapat dilakukan dengan dua langkah berikut -
Support Vector Machines pertama-tama akan membuat hyperplanes secara iteratif yang memisahkan kelas dengan cara terbaik.
Setelah itu akan memilih hyperplane yang memisahkan kelas dengan benar.
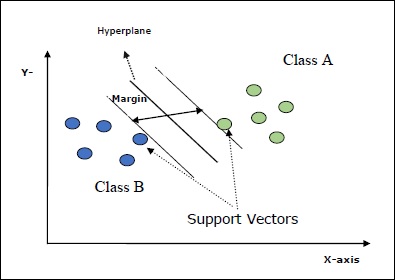
Beberapa konsep penting dalam SVM adalah sebagai berikut -
Support Vectors- Mereka dapat didefinisikan sebagai titik data yang paling dekat dengan bidang-hiper. Vektor pendukung membantu dalam menentukan garis pemisah.
Hyperplane - Pesawat keputusan atau ruang yang membagi sekumpulan objek yang memiliki kelas berbeda.
Margin - Kesenjangan antara dua garis pada titik data lemari dari kelas yang berbeda disebut margin.
Diagram berikut akan memberi Anda wawasan tentang konsep SVM ini -
SVM di Scikit-learn mendukung vektor sampel renggang dan padat sebagai input.
Klasifikasi SVM
Scikit-learn menyediakan tiga kelas yaitu SVC, NuSVC dan LinearSVC yang dapat melakukan klasifikasi kelas multikelas.
SVC
Ini adalah klasifikasi vektor C-support yang implementasinya didasarkan pada libsvm. Modul yang digunakan oleh scikit-learn adalahsklearn.svm.SVC. Kelas ini menangani dukungan multikelas menurut skema satu-vs-satu.
Parameter
Tabel berikut berisi parameter yang digunakan oleh sklearn.svm.SVC kelas -
| Sr Tidak | Parameter & Deskripsi |
|---|---|
| 1 | C - float, opsional, default = 1.0 Ini adalah parameter hukuman dari istilah kesalahan. |
| 2 | kernel - string, opsional, default = 'rbf' Parameter ini menentukan jenis kernel yang akan digunakan dalam algoritme. kita bisa memilih salah satu di antara,‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’. Nilai default kernel adalah‘rbf’. |
| 3 | degree - int, opsional, default = 3 Ini mewakili derajat fungsi kernel 'poli' dan akan diabaikan oleh semua kernel lainnya. |
| 4 | gamma - {'scale', 'auto'} atau float, Ini adalah koefisien kernel untuk kernel 'rbf', 'poly' dan 'sigmoid'. |
| 5 | optinal default - = 'skala' Jika anda memilih default yaitu gamma = 'scale' maka nilai gamma yang akan digunakan SVC adalah 1 / (_ ∗. ()). Di sisi lain, jika gamma = 'auto', itu menggunakan 1 / _. |
| 6 | coef0 - float, opsional, Default = 0.0 Istilah independen dalam fungsi kernel yang hanya signifikan dalam 'poli' dan 'sigmoid'. |
| 7 | tol - float, opsional, default = 1.e-3 Parameter ini mewakili kriteria penghentian untuk iterasi. |
| 8 | shrinking - Boolean, opsional, default = True Parameter ini menyatakan apakah kita ingin menggunakan heuristik menyusut atau tidak. |
| 9 | verbose - Boolean, default: false Ini mengaktifkan atau menonaktifkan output verbose. Nilai defaultnya salah. |
| 10 | probability - boolean, opsional, default = true Parameter ini mengaktifkan atau menonaktifkan perkiraan probabilitas. Nilai defaultnya salah, tetapi harus diaktifkan sebelum kita menyebutnya fit. |
| 11 | max_iter - int, opsional, default = -1 Seperti namanya, ini mewakili jumlah maksimum iterasi dalam pemecah. Nilai -1 artinya tidak ada batasan jumlah iterasi. |
| 12 | cache_size - float, opsional Parameter ini akan menentukan ukuran cache kernel. Nilainya akan dalam MB (MegaBytes). |
| 13 | random_state - int, instance RandomState atau Tidak Ada, opsional, default = tidak ada Parameter ini mewakili seed dari bilangan acak semu yang dihasilkan yang digunakan saat mengacak data. Berikut adalah pilihannya -
|
| 14 | class_weight - {dict, 'balanced'}, opsional Parameter ini akan mengatur parameter C kelas j ke _ℎ [] ∗ untuk SVC. Jika kita menggunakan opsi default, itu berarti semua kelas seharusnya memiliki bobot satu. Di sisi lain, jika Anda memilihclass_weight:balanced, ini akan menggunakan nilai y untuk menyesuaikan bobot secara otomatis. |
| 15 | decision_function_shape - ovo ',' ovr ', default =' ovr ' Parameter ini akan menentukan apakah algoritma akan kembali ‘ovr’ (one-vs-rest) fungsi keputusan bentuk sebagai semua pengklasifikasi lainnya, atau aslinya ovo(satu-vs-satu) fungsi keputusan libsvm. |
| 16 | break_ties - boolean, opsional, default = false True - Prediksi akan memutuskan hubungan sesuai dengan nilai kepercayaan dari fungsi_keputusan False - Prediksi akan mengembalikan kelas pertama di antara kelas yang terikat. |
Atribut
Tabel berikut berisi atribut-atribut yang digunakan oleh sklearn.svm.SVC kelas -
| Sr Tidak | Atribut & Deskripsi |
|---|---|
| 1 | support_ - seperti larik, bentuk = [n_SV] Ini mengembalikan indeks vektor dukungan. |
| 2 | support_vectors_ - seperti larik, bentuk = [n_SV, n_features] Ini mengembalikan vektor dukungan. |
| 3 | n_support_ - seperti larik, dtype = int32, bentuk = [n_class] Ini mewakili jumlah vektor dukungan untuk setiap kelas. |
| 4 | dual_coef_ - larik, bentuk = [n_class-1, n_SV] Ini adalah koefisien vektor pendukung dalam fungsi keputusan. |
| 5 | coef_ - larik, bentuk = [n_class * (n_class-1) / 2, n_features] Atribut ini, hanya tersedia dalam kasus kernel linier, memberikan bobot yang ditetapkan ke fitur. |
| 6 | intercept_ - larik, bentuk = [n_class * (n_class-1) / 2] Ini mewakili istilah independen (konstanta) dalam fungsi keputusan. |
| 7 | fit_status_ - int Outputnya akan menjadi 0 jika dipasang dengan benar. Outputnya akan menjadi 1 jika tidak dipasang dengan benar. |
| 8 | classes_ - array bentuk = [n_class] Ini memberi label kelas. |
Implementation Example
Seperti pengklasifikasi lainnya, SVC juga harus dilengkapi dengan dua larik berikut -
Sebuah array Xmemegang sampel pelatihan. Ini adalah ukuran [n_samples, n_features].
Sebuah array Ymemegang nilai target yaitu label kelas untuk sampel pelatihan. Ini adalah ukuran [n_samples].
Mengikuti penggunaan skrip Python sklearn.svm.SVC kelas -
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)Output
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, probability = False, random_state = None, shrinking = False,
tol = 0.001, verbose = False)Example
Sekarang, setelah dipasang, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
SVCClf.coef_Output
array([[0.5, 0.5]])Example
Demikian pula, kita bisa mendapatkan nilai atribut lain sebagai berikut -
SVCClf.predict([[-0.5,-0.8]])Output
array([1])Example
SVCClf.n_support_Output
array([1, 1])Example
SVCClf.support_vectors_Output
array(
[
[-1., -1.],
[ 1., 1.]
]
)Example
SVCClf.support_Output
array([0, 2])Example
SVCClf.intercept_Output
array([-0.])Example
SVCClf.fit_status_Output
0NuSVC
NuSVC adalah Klasifikasi Vektor Dukungan Nu. Ini adalah kelas lain yang disediakan oleh scikit-learn yang dapat melakukan klasifikasi kelas jamak. Ini seperti SVC tetapi NuSVC menerima set parameter yang sedikit berbeda. Parameter yang berbeda dari SVC adalah sebagai berikut -
nu - float, opsional, default = 0,5
Ini mewakili batas atas pada pecahan kesalahan pelatihan dan batas bawah dari pecahan vektor dukungan. Nilainya harus dalam interval (o, 1].
Parameter dan atribut lainnya sama dengan SVC.
Contoh Implementasi
Kita dapat menerapkan contoh yang sama menggunakan sklearn.svm.NuSVC kelas juga.
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import NuSVC
NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
NuSVCClf.fit(X, y)Keluaran
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, nu = 0.5, probability = False, random_state = None,
shrinking = False, tol = 0.001, verbose = False)Kita bisa mendapatkan keluaran dari atribut lainnya seperti yang dilakukan dalam kasus SVC.
LinearSVC
Ini adalah Klasifikasi Vektor Dukungan Linear. Ini mirip dengan SVC yang memiliki kernel = 'linear'. Perbedaan di antara mereka adalah ituLinearSVC diimplementasikan dalam bentuk liblinear sementara SVC diimplementasikan di libsvm. Itulah alasannyaLinearSVCmemiliki lebih banyak fleksibilitas dalam pemilihan fungsi penalti dan kerugian. Ini juga menskalakan lebih baik untuk sejumlah besar sampel.
Jika kita berbicara tentang parameter dan atributnya maka itu tidak mendukung ‘kernel’ karena diasumsikan linier dan juga kekurangan beberapa atribut seperti support_, support_vectors_, n_support_, fit_status_ dan, dual_coef_.
Namun, itu mendukung penalty dan loss parameter sebagai berikut -
penalty − string, L1 or L2(default = ‘L2’)
Parameter ini digunakan untuk menentukan norma (L1 atau L2) yang digunakan dalam hukuman (regularisasi).
loss − string, hinge, squared_hinge (default = squared_hinge)
Ini mewakili fungsi kerugian di mana 'engsel' adalah kerugian SVM standar dan 'squared_hinge' adalah kuadrat kerugian engsel.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.LinearSVC kelas -
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 4, random_state = 0)
LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5)
LSVCClf.fit(X, y)Keluaran
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000,
multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)Contoh
Sekarang, setelah dipasang, model dapat memprediksi nilai baru sebagai berikut -
LSVCClf.predict([[0,0,0,0]])Keluaran
[1]Contoh
Untuk contoh di atas, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
LSVCClf.coef_Keluaran
[[0. 0. 0.91214955 0.22630686]]Contoh
Demikian pula, kita bisa mendapatkan nilai intersep dengan bantuan skrip python berikut -
LSVCClf.intercept_Keluaran
[0.26860518]Regresi dengan SVM
Seperti dibahas sebelumnya, SVM digunakan untuk masalah klasifikasi dan regresi. Metode Support Vector Classification (SVC) Scikit-learn dapat diperluas untuk memecahkan masalah regresi juga. Metode yang diperluas itu disebut Support Vector Regression (SVR).
Kesamaan dasar antara SVM dan SVR
Model yang dibuat oleh SVC hanya bergantung pada subset data pelatihan. Mengapa? Karena fungsi biaya untuk membangun model tidak peduli dengan poin data pelatihan yang berada di luar margin.
Sedangkan model yang dihasilkan oleh SVR (Support Vector Regression) juga hanya bergantung pada subset dari data training. Mengapa? Karena fungsi biaya untuk membangun model mengabaikan poin data pelatihan yang dekat dengan prediksi model.
Scikit-learn menyediakan tiga kelas yaitu SVR, NuSVR and LinearSVR sebagai tiga implementasi SVR yang berbeda.
SVR
Ini adalah regresi vektor dukungan Epsilon yang implementasinya didasarkan pada libsvm. Kebalikan dariSVC Ada dua parameter gratis dalam model yaitu ‘C’ dan ‘epsilon’.
epsilon - float, opsional, default = 0,1
Ini mewakili epsilon dalam model epsilon-SVR, dan menentukan tabung-epsilon di mana tidak ada penalti yang dikaitkan dalam fungsi kerugian pelatihan dengan titik-titik yang diprediksi dalam jarak epsilon dari nilai sebenarnya.
Parameter dan atribut lainnya serupa seperti yang kita gunakan di SVC.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.SVR kelas -
from sklearn import svm
X = [[1, 1], [2, 2]]
y = [1, 2]
SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’)
SVRReg.fit(X, y)Keluaran
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto',
kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)Contoh
Sekarang, setelah dipasang, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
SVRReg.coef_Keluaran
array([[0.4, 0.4]])Contoh
Demikian pula, kita bisa mendapatkan nilai atribut lain sebagai berikut -
SVRReg.predict([[1,1]])Keluaran
array([1.1])Demikian pula, kita bisa mendapatkan nilai atribut lain juga.
NuSVR
NuSVR adalah Nu Support Vector Regression. Ini seperti NuSVC, tetapi NuSVR menggunakan parameternuuntuk mengontrol jumlah vektor dukungan. Dan terlebih lagi, tidak seperti NuSVC dimananu mengganti parameter C, ini dia menggantikan epsilon.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.SVR kelas -
from sklearn.svm import NuSVR
import numpy as np
n_samples, n_features = 20, 15
np.random.seed(0)
y = np.random.randn(n_samples)
X = np.random.randn(n_samples, n_features)
NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M
NuSVRReg.fit(X, y)Keluaran
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto',
kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001,
verbose = False)Contoh
Sekarang, setelah dipasang, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
NuSVRReg.coef_Keluaran
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)Demikian pula, kita bisa mendapatkan nilai atribut lainnya juga.
LinearSVR
Ini adalah Regresi Vektor Dukungan Linear. Ini mirip dengan SVR yang memiliki kernel = 'linear'. Perbedaan di antara mereka adalah ituLinearSVR diterapkan dalam hal liblinear, sementara SVC diterapkan di libsvm. Itulah alasannyaLinearSVRmemiliki lebih banyak fleksibilitas dalam pemilihan fungsi penalti dan kerugian. Ini juga menskalakan lebih baik untuk sejumlah besar sampel.
Jika kita berbicara tentang parameter dan atributnya maka itu tidak mendukung ‘kernel’ karena diasumsikan linier dan juga kekurangan beberapa atribut seperti support_, support_vectors_, n_support_, fit_status_ dan, dual_coef_.
Namun, ini mendukung parameter 'kerugian' sebagai berikut -
loss - string, opsional, default = 'epsilon_insensitive'
Ini mewakili fungsi kerugian di mana kerugian epsilon_insensitive adalah kerugian L1 dan kerugian epsilon-insensitive kuadrat adalah kerugian L2.
Contoh Implementasi
Mengikuti penggunaan skrip Python sklearn.svm.LinearSVR kelas -
from sklearn.svm import LinearSVR
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 4, random_state = 0)
LSVRReg = LinearSVR(dual = False, random_state = 0,
loss = 'squared_epsilon_insensitive',tol = 1e-5)
LSVRReg.fit(X, y)Keluaran
LinearSVR(
C=1.0, dual=False, epsilon=0.0, fit_intercept=True,
intercept_scaling=1.0, loss='squared_epsilon_insensitive',
max_iter=1000, random_state=0, tol=1e-05, verbose=0
)Contoh
Sekarang, setelah dipasang, model dapat memprediksi nilai baru sebagai berikut -
LSRReg.predict([[0,0,0,0]])Keluaran
array([-0.01041416])Contoh
Untuk contoh di atas, kita bisa mendapatkan vektor bobot dengan bantuan skrip python berikut -
LSRReg.coef_Keluaran
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])Contoh
Demikian pula, kita bisa mendapatkan nilai intersep dengan bantuan skrip python berikut -
LSRReg.intercept_Keluaran
array([-0.01041416])