R - Guida rapida
R è un linguaggio di programmazione e un ambiente software per l'analisi statistica, la rappresentazione grafica e il reporting. R è stato creato da Ross Ihaka e Robert Gentleman presso l'Università di Auckland, in Nuova Zelanda, ed è attualmente sviluppato dall'R Development Core Team.
Il nucleo di R è un linguaggio per computer interpretato che consente la ramificazione e il loop, nonché la programmazione modulare utilizzando le funzioni. R consente l'integrazione con le procedure scritte nei linguaggi C, C ++, .Net, Python o FORTRAN per l'efficienza.
R è disponibile gratuitamente sotto la GNU General Public License e sono fornite versioni binarie precompilate per vari sistemi operativi come Linux, Windows e Mac.
R è un software gratuito distribuito sotto una copia in stile GNU a sinistra e una parte ufficiale del progetto GNU chiamata GNU S.
Evoluzione di R
R è stato inizialmente scritto da Ross Ihaka e Robert Gentlemanpresso il Dipartimento di Statistica dell'Università di Auckland ad Auckland, Nuova Zelanda. R ha fatto la sua prima apparizione nel 1993.
Un folto gruppo di persone ha contribuito a R inviando codice e segnalazioni di bug.
Dalla metà del 1997 esiste un gruppo principale ("R Core Team") che può modificare l'archivio del codice sorgente R.
Caratteristiche di R
Come affermato in precedenza, R è un linguaggio di programmazione e un ambiente software per l'analisi statistica, la rappresentazione grafica e il reporting. Le seguenti sono le caratteristiche importanti di R -
R è un linguaggio di programmazione ben sviluppato, semplice ed efficace che include condizionali, cicli, funzioni ricorsive definite dall'utente e funzionalità di input e output.
R dispone di un'efficace struttura di gestione e archiviazione dei dati,
R fornisce una suite di operatori per calcoli su array, liste, vettori e matrici.
R fornisce una raccolta ampia, coerente e integrata di strumenti per l'analisi dei dati.
R fornisce funzionalità grafiche per l'analisi e la visualizzazione dei dati direttamente sul computer o per la stampa sui giornali.
In conclusione, R è il linguaggio di programmazione statistica più utilizzato al mondo. È la scelta n. 1 dei data scientist ed è supportata da una vivace e talentuosa comunità di contributori. R viene insegnato nelle università e distribuito in applicazioni aziendali mission-critical. Questo tutorial ti insegnerà la programmazione R insieme ad esempi adatti in passaggi semplici e facili.
Configurazione dell'ambiente locale
Se sei ancora disposto a configurare il tuo ambiente per R, puoi seguire i passaggi indicati di seguito.
Installazione di Windows
È possibile scaricare la versione Windows installer di R da R-3.2.2 per Windows (32/64 bit) e salvarla in una directory locale.
Poiché è un programma di installazione di Windows (.exe) con un nome "R-version-win.exe". Puoi semplicemente fare doppio clic ed eseguire il programma di installazione accettando le impostazioni predefinite. Se la tua versione di Windows è a 32 bit, installa la versione a 32 bit. Ma se Windows è a 64 bit, installa entrambe le versioni a 32 bit e 64 bit.
Dopo l'installazione è possibile individuare l'icona per eseguire il programma in una struttura di directory "R \ R3.2.2 \ bin \ i386 \ Rgui.exe" sotto i Programmi di Windows. Facendo clic su questa icona viene visualizzata la R-GUI che è la console R per eseguire la programmazione R.
Installazione di Linux
R è disponibile come binario per molte versioni di Linux nella posizione R Binaries .
Le istruzioni per installare Linux variano da un gusto all'altro. Questi passaggi sono menzionati sotto ogni tipo di versione Linux nel collegamento citato. Tuttavia, se hai fretta, puoi usareyum comando per installare R come segue -
$ yum install RIl comando sopra installerà le funzionalità principali della programmazione R insieme ai pacchetti standard, tuttavia è necessario un pacchetto aggiuntivo, quindi è possibile avviare il prompt R come segue:
$ R
R version 3.2.0 (2015-04-16) -- "Full of Ingredients"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-redhat-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>Ora puoi utilizzare il comando di installazione al prompt R per installare il pacchetto richiesto. Ad esempio, verrà installato il seguente comandoplotrix pacchetto necessario per i grafici 3D.
> install.packages("plotrix")Come convenzione, inizieremo ad apprendere la programmazione R scrivendo un "Hello, World!" programma. A seconda delle esigenze, è possibile programmare al prompt dei comandi R oppure è possibile utilizzare un file di script R per scrivere il programma. Controlliamo entrambi uno per uno.
Prompt dei comandi R.
Dopo aver configurato l'ambiente R, è facile avviare il prompt dei comandi R semplicemente digitando il seguente comando al prompt dei comandi:
$ RQuesto avvierà l'interprete R e riceverai un prompt> dove puoi iniziare a digitare il tuo programma come segue:
> myString <- "Hello, World!"
> print ( myString)
[1] "Hello, World!"Qui la prima istruzione definisce una variabile stringa myString, dove assegniamo una stringa "Hello, World!" e quindi viene utilizzata l'istruzione successiva print () per stampare il valore memorizzato nella variabile myString.
File di script R.
Di solito, farai la tua programmazione scrivendo i tuoi programmi in file di script e poi eseguirai quegli script al prompt dei comandi con l'aiuto dell'interprete R chiamato Rscript. Quindi iniziamo con la scrittura del codice seguente in un file di testo chiamato test.R come sotto -
# My first program in R Programming
myString <- "Hello, World!"
print ( myString)Salvare il codice sopra in un file test.R ed eseguirlo al prompt dei comandi di Linux come indicato di seguito. Anche se utilizzi Windows o un altro sistema, la sintassi rimarrà la stessa.
$ Rscript test.RQuando eseguiamo il programma sopra, produce il seguente risultato.
[1] "Hello, World!"Commenti
I commenti sono come aiutare il testo nel programma R e vengono ignorati dall'interprete durante l'esecuzione del programma effettivo. Il singolo commento viene scritto usando # all'inizio dell'istruzione come segue:
# My first program in R ProgrammingR non supporta i commenti su più righe ma puoi eseguire un trucco che è qualcosa come segue:
if(FALSE) {
"This is a demo for multi-line comments and it should be put inside either a
single OR double quote"
}
myString <- "Hello, World!"
print ( myString)[1] "Hello, World!"Anche se i commenti sopra saranno eseguiti dall'interprete R, non interferiranno con il tuo programma attuale. Dovresti inserire tali commenti all'interno, virgolette singole o doppie.
In genere, durante la programmazione in qualsiasi linguaggio di programmazione, è necessario utilizzare varie variabili per memorizzare varie informazioni. Le variabili non sono altro che posizioni di memoria riservate per memorizzare i valori. Ciò significa che, quando crei una variabile, riservi dello spazio in memoria.
Potresti voler memorizzare informazioni di vari tipi di dati come carattere, carattere largo, intero, virgola mobile, doppio virgola mobile, booleano ecc. In base al tipo di dati di una variabile, il sistema operativo alloca memoria e decide cosa può essere memorizzato nel memoria riservata.
A differenza di altri linguaggi di programmazione come C e Java in R, le variabili non vengono dichiarate come un tipo di dati. Le variabili vengono assegnate con R-Objects e il tipo di dati dell'oggetto R diventa il tipo di dati della variabile. Esistono molti tipi di oggetti R. Quelli di uso frequente sono:
- Vectors
- Lists
- Matrices
- Arrays
- Factors
- Frame di dati
Il più semplice di questi oggetti è il file vector objecte ci sono sei tipi di dati di questi vettori atomici, chiamati anche sei classi di vettori. Gli altri R-Oggetti sono costruiti sui vettori atomici.
| Tipo di dati | Esempio | Verificare |
|---|---|---|
| Logico | VERO FALSO |
produce il seguente risultato: |
| Numerico | 12.3, 5, 999 |
produce il seguente risultato: |
| Numero intero | 2L, 34L, 0L |
produce il seguente risultato: |
| Complesso | 3 + 2i |
produce il seguente risultato: |
| Personaggio | 'a', '"buono", "TRUE", '23 .4' |
produce il seguente risultato: |
| Crudo | "Hello" è memorizzato come 48 65 6c 6c 6f |
produce il seguente risultato: |
Nella programmazione R, i tipi di dati di base sono gli oggetti R chiamati vectorsche contengono elementi di classi diverse come mostrato sopra. Si noti che in R il numero di classi non è limitato ai soli sei tipi di cui sopra. Ad esempio, possiamo usare molti vettori atomici e creare un array la cui classe diventerà array.
Vettori
Quando vuoi creare un vettore con più di un elemento, dovresti usare c() funzione che significa combinare gli elementi in un vettore.
# Create a vector.
apple <- c('red','green',"yellow")
print(apple)
# Get the class of the vector.
print(class(apple))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "red" "green" "yellow"
[1] "character"Liste
Una lista è un oggetto R che può contenere molti diversi tipi di elementi al suo interno come vettori, funzioni e anche un'altra lista al suo interno.
# Create a list.
list1 <- list(c(2,5,3),21.3,sin)
# Print the list.
print(list1)Quando eseguiamo il codice sopra, produce il seguente risultato:
[[1]]
[1] 2 5 3
[[2]]
[1] 21.3
[[3]]
function (x) .Primitive("sin")Matrici
Una matrice è un set di dati rettangolare bidimensionale. Può essere creato utilizzando un input vettoriale per la funzione matrice.
# Create a matrix.
M = matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
print(M)Quando eseguiamo il codice sopra, produce il seguente risultato:
[,1] [,2] [,3]
[1,] "a" "a" "b"
[2,] "c" "b" "a"Array
Mentre le matrici sono limitate a due dimensioni, le matrici possono avere un numero qualsiasi di dimensioni. La funzione array accetta un attributo dim che crea il numero richiesto di dimensione. Nell'esempio seguente creiamo un array con due elementi che sono matrici 3x3 ciascuno.
# Create an array.
a <- array(c('green','yellow'),dim = c(3,3,2))
print(a)Quando eseguiamo il codice sopra, produce il seguente risultato:
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"Fattori
I fattori sono gli oggetti r che vengono creati utilizzando un vettore. Memorizza il vettore insieme ai valori distinti degli elementi nel vettore come etichette. Le etichette sono sempre caratteri indipendentemente dal fatto che siano numeriche, caratteri o booleane ecc. Nel vettore di input. Sono utili nella modellazione statistica.
I fattori vengono creati utilizzando il factor()funzione. Ilnlevels funzioni fornisce il conteggio dei livelli.
# Create a vector.
apple_colors <- c('green','green','yellow','red','red','red','green')
# Create a factor object.
factor_apple <- factor(apple_colors)
# Print the factor.
print(factor_apple)
print(nlevels(factor_apple))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] green green yellow red red red green
Levels: green red yellow
[1] 3Frame di dati
I data frame sono oggetti dati tabulari. A differenza di una matrice nel frame di dati, ogni colonna può contenere diverse modalità di dati. La prima colonna può essere numerica mentre la seconda colonna può essere carattere e la terza colonna può essere logica. È un elenco di vettori di uguale lunghezza.
I data frame vengono creati utilizzando l'estensione data.frame() funzione.
# Create the data frame.
BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
print(BMI)Quando eseguiamo il codice sopra, produce il seguente risultato:
gender height weight Age
1 Male 152.0 81 42
2 Male 171.5 93 38
3 Female 165.0 78 26Una variabile ci fornisce una memoria con nome che i nostri programmi possono manipolare. Una variabile in R può memorizzare un vettore atomico, un gruppo di vettori atomici o una combinazione di molti Robject. Un nome di variabile valido è composto da lettere, numeri e caratteri punto o sottolineatura. Il nome della variabile inizia con una lettera o il punto non seguito da un numero.
| Nome variabile | Validità | Motivo |
|---|---|---|
| var_name2. | valido | Contiene lettere, numeri, punti e trattini bassi |
| var_name% | Non valido | Ha il carattere "%". Sono consentiti solo il punto (.) E il trattino basso. |
| 2var_name | non valido | Inizia con un numero |
.var_name, var.name |
valido | Può iniziare con un punto (.) Ma il punto (.) Non deve essere seguito da un numero. |
| .2var_name | non valido | Il punto iniziale è seguito da un numero che lo rende non valido. |
| _var_name | non valido | Inizia con _ che non è valido |
Assegnazione variabile
Alle variabili possono essere assegnati valori utilizzando l'operatore sinistro, destro e uguale a. I valori delle variabili possono essere stampati utilizzandoprint() o cat()funzione. Ilcat() combina più elementi in un output di stampa continuo.
# Assignment using equal operator.
var.1 = c(0,1,2,3)
# Assignment using leftward operator.
var.2 <- c("learn","R")
# Assignment using rightward operator.
c(TRUE,1) -> var.3
print(var.1)
cat ("var.1 is ", var.1 ,"\n")
cat ("var.2 is ", var.2 ,"\n")
cat ("var.3 is ", var.3 ,"\n")Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 0 1 2 3
var.1 is 0 1 2 3
var.2 is learn R
var.3 is 1 1Note- Il vettore c (TRUE, 1) ha una combinazione di classe logica e numerica. Quindi la classe logica viene forzata in classe numerica rendendo TRUE come 1.
Tipo di dati di una variabile
In R, una variabile stessa non è dichiarata di alcun tipo di dati, ma ottiene il tipo di dati dell'oggetto R assegnato ad essa. Quindi R è chiamato linguaggio tipizzato dinamicamente, il che significa che possiamo cambiare il tipo di dati di una variabile della stessa variabile ancora e ancora quando lo si utilizza in un programma.
var_x <- "Hello"
cat("The class of var_x is ",class(var_x),"\n")
var_x <- 34.5
cat(" Now the class of var_x is ",class(var_x),"\n")
var_x <- 27L
cat(" Next the class of var_x becomes ",class(var_x),"\n")Quando eseguiamo il codice sopra, produce il seguente risultato:
The class of var_x is character
Now the class of var_x is numeric
Next the class of var_x becomes integerTrovare variabili
Per conoscere tutte le variabili attualmente disponibili nell'area di lavoro utilizziamo il file ls()funzione. Anche la funzione ls () può utilizzare modelli per abbinare i nomi delle variabili.
print(ls())Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"Note - È un output di esempio a seconda delle variabili dichiarate nel proprio ambiente.
La funzione ls () può utilizzare modelli per abbinare i nomi delle variabili.
# List the variables starting with the pattern "var".
print(ls(pattern = "var"))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"Le variabili che iniziano con dot(.) sono nascosti, possono essere elencati utilizzando l'argomento "all.names = TRUE" nella funzione ls ().
print(ls(all.name = TRUE))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] ".cars" ".Random.seed" ".var_name" ".varname" ".varname2"
[6] "my var" "my_new_var" "my_var" "var.1" "var.2"
[11]"var.3" "var.name" "var_name2." "var_x"Eliminazione di variabili
Le variabili possono essere eliminate utilizzando il file rm()funzione. Di seguito cancelliamo la variabile var.3. Durante la stampa viene lanciato il valore della variabile error.
rm(var.3)
print(var.3)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "var.3"
Error in print(var.3) : object 'var.3' not foundTutte le variabili possono essere eliminate utilizzando il file rm() e ls() funzionano insieme.
rm(list = ls())
print(ls())Quando eseguiamo il codice sopra, produce il seguente risultato:
character(0)Un operatore è un simbolo che dice al compilatore di eseguire specifiche manipolazioni matematiche o logiche. Il linguaggio R è ricco di operatori incorporati e fornisce i seguenti tipi di operatori.
Tipi di operatori
Abbiamo i seguenti tipi di operatori nella programmazione R:
- Operatori aritmetici
- Operatori relazionali
- Operatori logici
- Operatori di assegnazione
- Operatori vari
Operatori aritmetici
La tabella seguente mostra gli operatori aritmetici supportati dal linguaggio R. Gli operatori agiscono su ogni elemento del vettore.
| Operatore | Descrizione | Esempio |
|---|---|---|
| + | Aggiunge due vettori |
produce il seguente risultato: |
| - | Sottrae il secondo vettore dal primo |
produce il seguente risultato: |
| * | Moltiplica entrambi i vettori |
produce il seguente risultato: |
| / | Dividi il primo vettore con il secondo |
Quando eseguiamo il codice sopra, produce il seguente risultato: |
| %% | Dare il resto del primo vettore con il secondo |
produce il seguente risultato: |
| % /% | Il risultato della divisione del primo vettore con il secondo (quoziente) |
produce il seguente risultato: |
| ^ | Il primo vettore elevato all'esponente del secondo vettore |
produce il seguente risultato: |
Operatori relazionali
La tabella seguente mostra gli operatori relazionali supportati dal linguaggio R. Ciascun elemento del primo vettore viene confrontato con l'elemento corrispondente del secondo vettore. Il risultato del confronto è un valore booleano.
| Operatore | Descrizione | Esempio |
|---|---|---|
| > | Controlla se ogni elemento del primo vettore è maggiore dell'elemento corrispondente del secondo vettore. |
produce il seguente risultato: |
| < | Controlla se ogni elemento del primo vettore è minore dell'elemento corrispondente del secondo vettore. |
produce il seguente risultato: |
| == | Controlla se ogni elemento del primo vettore è uguale all'elemento corrispondente del secondo vettore. |
produce il seguente risultato: |
| <= | Controlla se ogni elemento del primo vettore è minore o uguale all'elemento corrispondente del secondo vettore. |
produce il seguente risultato: |
| > = | Controlla se ogni elemento del primo vettore è maggiore o uguale all'elemento corrispondente del secondo vettore. |
produce il seguente risultato: |
| ! = | Controlla se ogni elemento del primo vettore è diverso dall'elemento corrispondente del secondo vettore. |
produce il seguente risultato: |
Operatori logici
La tabella seguente mostra gli operatori logici supportati dal linguaggio R. È applicabile solo a vettori di tipo logico, numerico o complesso. Tutti i numeri maggiori di 1 sono considerati come valore logico VERO.
Ciascun elemento del primo vettore viene confrontato con l'elemento corrispondente del secondo vettore. Il risultato del confronto è un valore booleano.
| Operatore | Descrizione | Esempio |
|---|---|---|
| & | Si chiama operatore AND logico per elementi. Combina ogni elemento del primo vettore con l'elemento corrispondente del secondo vettore e fornisce un output TRUE se entrambi gli elementi sono TRUE. |
produce il seguente risultato: |
| | | Si chiama operatore OR logico per elemento. Combina ogni elemento del primo vettore con l'elemento corrispondente del secondo vettore e fornisce un output VERO se uno degli elementi è VERO. |
produce il seguente risultato: |
| ! | Si chiama operatore NOT logico. Prende ogni elemento del vettore e fornisce il valore logico opposto. |
produce il seguente risultato: |
L'operatore logico && e || considera solo il primo elemento dei vettori e fornisce come output un vettore di singolo elemento.
| Operatore | Descrizione | Esempio |
|---|---|---|
| && | Chiamato operatore AND logico. Prende il primo elemento di entrambi i vettori e fornisce il TRUE solo se entrambi sono TRUE. |
produce il seguente risultato: |
| || | Chiamato operatore OR logico. Prende il primo elemento di entrambi i vettori e fornisce il VERO se uno di essi è VERO. |
produce il seguente risultato: |
Operatori di assegnazione
Questi operatori vengono utilizzati per assegnare valori ai vettori.
| Operatore | Descrizione | Esempio |
|---|---|---|
| <- o = o << - |
Chiamato Assegnazione di sinistra |
produce il seguente risultato: |
| -> o - >> |
Chiamato incarico corretto |
produce il seguente risultato: |
Operatori vari
Questi operatori sono utilizzati per scopi specifici e non per calcoli matematici o logici generali.
| Operatore | Descrizione | Esempio |
|---|---|---|
| : | Operatore del colon. Crea la serie di numeri in sequenza per un vettore. |
produce il seguente risultato: |
| %in% | Questo operatore viene utilizzato per identificare se un elemento appartiene a un vettore. |
produce il seguente risultato: |
| % *% | Questo operatore viene utilizzato per moltiplicare una matrice con la sua trasposizione. |
produce il seguente risultato: |
Le strutture decisionali richiedono che il programmatore specifichi una o più condizioni che devono essere valutate o testate dal programma, insieme a una o più istruzioni da eseguire se la condizione è determinata truee, facoltativamente, altre istruzioni da eseguire se si determina che la condizione è false.
Di seguito è riportata la forma generale di una tipica struttura decisionale presente nella maggior parte dei linguaggi di programmazione:
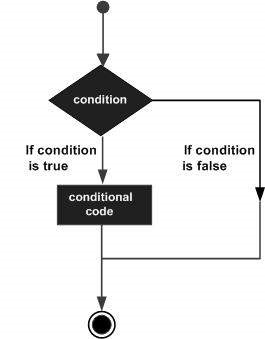
R fornisce i seguenti tipi di dichiarazioni sul processo decisionale. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| Sr.No. | Dichiarazione e descrizione |
|---|---|
| 1 | istruzione if Un if L'istruzione consiste in un'espressione booleana seguita da una o più istruzioni. |
| 2 | if ... else dichiarazione Un if L'istruzione può essere seguita da un opzionale else istruzione, che viene eseguita quando l'espressione booleana è falsa. |
| 3 | istruzione switch UN switch consente di verificare l'uguaglianza di una variabile rispetto a un elenco di valori. |
Potrebbe esserci una situazione in cui è necessario eseguire un blocco di codice più volte. In generale, le istruzioni vengono eseguite in sequenza. La prima istruzione in una funzione viene eseguita per prima, seguita dalla seconda e così via.
I linguaggi di programmazione forniscono varie strutture di controllo che consentono percorsi di esecuzione più complicati.
Un'istruzione loop ci consente di eseguire un'istruzione o un gruppo di istruzioni più volte e la seguente è la forma generale di un'istruzione loop nella maggior parte dei linguaggi di programmazione:
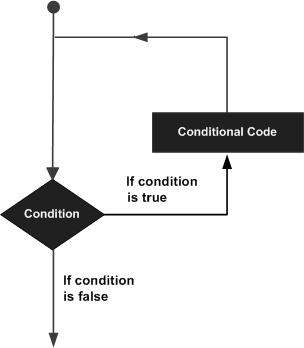
Il linguaggio di programmazione R fornisce i seguenti tipi di loop per gestire i requisiti di loop. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| Sr.No. | Tipo e descrizione del loop |
|---|---|
| 1 | ripetere il ciclo Esegue una sequenza di istruzioni più volte e abbrevia il codice che gestisce la variabile del ciclo. |
| 2 | while loop Ripete un'istruzione o un gruppo di istruzioni finché una determinata condizione è vera. Verifica la condizione prima di eseguire il corpo del ciclo. |
| 3 | per loop Come un'istruzione while, tranne per il fatto che verifica la condizione alla fine del corpo del ciclo. |
Dichiarazioni di controllo del loop
Le istruzioni di controllo del ciclo cambiano l'esecuzione dalla sua sequenza normale. Quando l'esecuzione esce da un ambito, tutti gli oggetti automatici creati in tale ambito vengono eliminati.
R supporta le seguenti istruzioni di controllo. Fare clic sui seguenti collegamenti per verificarne i dettagli.
| Sr.No. | Dichiarazione di controllo e descrizione |
|---|---|
| 1 | dichiarazione di interruzione Termina il loop istruzione e trasferisce l'esecuzione all'istruzione immediatamente successiva al ciclo. |
| 2 | Prossima dichiarazione Il next L'istruzione simula il comportamento dell'interruttore R. |
Una funzione è un insieme di istruzioni organizzate insieme per eseguire un'attività specifica. R ha un gran numero di funzioni integrate e l'utente può creare le proprie funzioni.
In R, una funzione è un oggetto quindi l'interprete R è in grado di passare il controllo alla funzione, insieme agli argomenti che potrebbero essere necessari affinché la funzione compia le azioni.
La funzione a sua volta svolge il suo compito e restituisce il controllo all'interprete così come qualsiasi risultato che può essere memorizzato in altri oggetti.
Definizione di funzione
Una funzione R viene creata utilizzando la parola chiave function. La sintassi di base della definizione di una funzione R è la seguente:
function_name <- function(arg_1, arg_2, ...) {
Function body
}Componenti della funzione
Le diverse parti di una funzione sono:
Function Name- Questo è il nome effettivo della funzione. È memorizzato nell'ambiente R come un oggetto con questo nome.
Arguments- Un argomento è un segnaposto. Quando viene invocata una funzione, si passa un valore all'argomento. Gli argomenti sono facoltativi; ovvero, una funzione non può contenere argomenti. Anche gli argomenti possono avere valori predefiniti.
Function Body - Il corpo della funzione contiene una raccolta di istruzioni che definisce cosa fa la funzione.
Return Value - Il valore di ritorno di una funzione è l'ultima espressione nel corpo della funzione da valutare.
R ne ha molti in-builtfunzioni che possono essere richiamate direttamente nel programma senza prima definirle. Possiamo anche creare e utilizzare le nostre funzioni denominateuser defined funzioni.
Funzione incorporata
Semplici esempi di funzioni integrate sono seq(), mean(), max(), sum(x) e paste(...)ecc. Vengono richiamati direttamente dai programmi scritti dall'utente. È possibile fare riferimento alle funzioni R più utilizzate.
# Create a sequence of numbers from 32 to 44.
print(seq(32,44))
# Find mean of numbers from 25 to 82.
print(mean(25:82))
# Find sum of numbers frm 41 to 68.
print(sum(41:68))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 32 33 34 35 36 37 38 39 40 41 42 43 44
[1] 53.5
[1] 1526Funzione definita dall'utente
Possiamo creare funzioni definite dall'utente in R. Sono specifiche per ciò che un utente desidera e una volta create possono essere utilizzate come le funzioni integrate. Di seguito è riportato un esempio di come viene creata e utilizzata una funzione.
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}Chiamare una funzione
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}
# Call the function new.function supplying 6 as an argument.
new.function(6)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25
[1] 36Chiamare una funzione senza un argomento
# Create a function without an argument.
new.function <- function() {
for(i in 1:5) {
print(i^2)
}
}
# Call the function without supplying an argument.
new.function()Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25Chiamare una funzione con valori di argomento (per posizione e nome)
Gli argomenti di una chiamata di funzione possono essere forniti nella stessa sequenza definita nella funzione oppure possono essere forniti in una sequenza diversa ma assegnati ai nomi degli argomenti.
# Create a function with arguments.
new.function <- function(a,b,c) {
result <- a * b + c
print(result)
}
# Call the function by position of arguments.
new.function(5,3,11)
# Call the function by names of the arguments.
new.function(a = 11, b = 5, c = 3)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 26
[1] 58Chiamata a una funzione con argomento predefinito
Possiamo definire il valore degli argomenti nella definizione della funzione e chiamare la funzione senza fornire alcun argomento per ottenere il risultato predefinito. Ma possiamo anche chiamare tali funzioni fornendo nuovi valori dell'argomento e ottenere un risultato non predefinito.
# Create a function with arguments.
new.function <- function(a = 3, b = 6) {
result <- a * b
print(result)
}
# Call the function without giving any argument.
new.function()
# Call the function with giving new values of the argument.
new.function(9,5)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 18
[1] 45Valutazione pigra della funzione
Gli argomenti delle funzioni vengono valutati pigramente, il che significa che vengono valutati solo quando necessario dal corpo della funzione.
# Create a function with arguments.
new.function <- function(a, b) {
print(a^2)
print(a)
print(b)
}
# Evaluate the function without supplying one of the arguments.
new.function(6)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 36
[1] 6
Error in print(b) : argument "b" is missing, with no defaultQualsiasi valore scritto all'interno di una coppia di virgolette singole o doppie in R viene considerato come una stringa. Internamente R memorizza ogni stringa tra virgolette doppie, anche quando le crei con virgolette singole.
Regole applicate nella costruzione di stringhe
Le virgolette all'inizio e alla fine di una stringa devono essere entrambe virgolette doppie o entrambe virgolette singole. Non possono essere mescolati.
Le virgolette doppie possono essere inserite in una stringa che inizia e finisce con virgolette singole.
Le virgolette singole possono essere inserite in una stringa che inizia e finisce con virgolette doppie.
Le virgolette doppie non possono essere inserite in una stringa che inizia e finisce con virgolette doppie.
Non è possibile inserire virgolette singole in una stringa che inizia e finisce con virgolette singole.
Esempi di stringhe valide
I seguenti esempi chiariscono le regole sulla creazione di una stringa in R.
a <- 'Start and end with single quote'
print(a)
b <- "Start and end with double quotes"
print(b)
c <- "single quote ' in between double quotes"
print(c)
d <- 'Double quotes " in between single quote'
print(d)Quando viene eseguito il codice sopra, otteniamo il seguente output:
[1] "Start and end with single quote"
[1] "Start and end with double quotes"
[1] "single quote ' in between double quote"
[1] "Double quote \" in between single quote"Esempi di stringhe non valide
e <- 'Mixed quotes"
print(e)
f <- 'Single quote ' inside single quote'
print(f)
g <- "Double quotes " inside double quotes"
print(g)Quando eseguiamo lo script non riesce a fornire i risultati seguenti.
Error: unexpected symbol in:
"print(e)
f <- 'Single"
Execution haltedManipolazione delle stringhe
Concatenazione di stringhe - funzione paste ()
Molte stringhe in R vengono combinate usando il paste()funzione. Può richiedere un numero qualsiasi di argomenti per essere combinati insieme.
Sintassi
La sintassi di base per la funzione Incolla è:
paste(..., sep = " ", collapse = NULL)Di seguito la descrizione dei parametri utilizzati:
... rappresenta un numero qualsiasi di argomenti da combinare.
seprappresenta qualsiasi separatore tra gli argomenti. È opzionale.
collapseviene utilizzato per eliminare lo spazio tra due stringhe. Ma non lo spazio all'interno di due parole di una stringa.
Esempio
a <- "Hello"
b <- 'How'
c <- "are you? "
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(a,b,c, sep = "", collapse = ""))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "Hello How are you? "
[1] "Hello-How-are you? "
[1] "HelloHoware you? "Formattazione di numeri e stringhe - funzione format ()
Numeri e stringhe possono essere formattati con uno stile specifico utilizzando format() funzione.
Sintassi
La sintassi di base per la funzione formato è:
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))Di seguito la descrizione dei parametri utilizzati:
x è l'input vettoriale.
digits è il numero totale di cifre visualizzate.
nsmall è il numero minimo di cifre a destra del separatore decimale.
scientific è impostato su TRUE per visualizzare la notazione scientifica.
width indica la larghezza minima da visualizzare riempiendo gli spazi all'inizio.
justify è la visualizzazione della stringa a sinistra, a destra o al centro.
Esempio
# Total number of digits displayed. Last digit rounded off.
result <- format(23.123456789, digits = 9)
print(result)
# Display numbers in scientific notation.
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# The minimum number of digits to the right of the decimal point.
result <- format(23.47, nsmall = 5)
print(result)
# Format treats everything as a string.
result <- format(6)
print(result)
# Numbers are padded with blank in the beginning for width.
result <- format(13.7, width = 6)
print(result)
# Left justify strings.
result <- format("Hello", width = 8, justify = "l")
print(result)
# Justfy string with center.
result <- format("Hello", width = 8, justify = "c")
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "23.1234568"
[1] "6.000000e+00" "1.314521e+01"
[1] "23.47000"
[1] "6"
[1] " 13.7"
[1] "Hello "
[1] " Hello "Conteggio del numero di caratteri in una funzione stringa - nchar ()
Questa funzione conta il numero di caratteri inclusi gli spazi in una stringa.
Sintassi
La sintassi di base per la funzione nchar () è:
nchar(x)Di seguito la descrizione dei parametri utilizzati:
x è l'input vettoriale.
Esempio
result <- nchar("Count the number of characters")
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 30Modifica delle maiuscole e minuscole - funzioni toupper () e tolower ()
Queste funzioni cambiano il caso dei caratteri di una stringa.
Sintassi
La sintassi di base per le funzioni toupper () e tolower () è:
toupper(x)
tolower(x)Di seguito la descrizione dei parametri utilizzati:
x è l'input vettoriale.
Esempio
# Changing to Upper case.
result <- toupper("Changing To Upper")
print(result)
# Changing to lower case.
result <- tolower("Changing To Lower")
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "CHANGING TO UPPER"
[1] "changing to lower"Estrazione di parti di una funzione stringa - sottostringa ()
Questa funzione estrae parti di una stringa.
Sintassi
La sintassi di base per la funzione substring () è:
substring(x,first,last)Di seguito la descrizione dei parametri utilizzati:
x è l'input del vettore di caratteri.
first è la posizione del primo carattere da estrarre.
last è la posizione dell'ultimo carattere da estrarre.
Esempio
# Extract characters from 5th to 7th position.
result <- substring("Extract", 5, 7)
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "act"I vettori sono gli oggetti dati R più basilari e ci sono sei tipi di vettori atomici. Sono logici, interi, doppi, complessi, di carattere e grezzi.
Creazione di vettore
Vettore di elemento singolo
Anche quando scrivi un solo valore in R, diventa un vettore di lunghezza 1 e appartiene a uno dei tipi di vettore sopra.
# Atomic vector of type character.
print("abc");
# Atomic vector of type double.
print(12.5)
# Atomic vector of type integer.
print(63L)
# Atomic vector of type logical.
print(TRUE)
# Atomic vector of type complex.
print(2+3i)
# Atomic vector of type raw.
print(charToRaw('hello'))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "abc"
[1] 12.5
[1] 63
[1] TRUE
[1] 2+3i
[1] 68 65 6c 6c 6fVettore di più elementi
Using colon operator with numeric data
# Creating a sequence from 5 to 13.
v <- 5:13
print(v)
# Creating a sequence from 6.6 to 12.6.
v <- 6.6:12.6
print(v)
# If the final element specified does not belong to the sequence then it is discarded.
v <- 3.8:11.4
print(v)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 5 6 7 8 9 10 11 12 13
[1] 6.6 7.6 8.6 9.6 10.6 11.6 12.6
[1] 3.8 4.8 5.8 6.8 7.8 8.8 9.8 10.8Using sequence (Seq.) operator
# Create vector with elements from 5 to 9 incrementing by 0.4.
print(seq(5, 9, by = 0.4))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 5.0 5.4 5.8 6.2 6.6 7.0 7.4 7.8 8.2 8.6 9.0Using the c() function
I valori non di carattere vengono forzati al tipo di carattere se uno degli elementi è un carattere.
# The logical and numeric values are converted to characters.
s <- c('apple','red',5,TRUE)
print(s)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "apple" "red" "5" "TRUE"Accesso agli elementi vettoriali
Gli elementi di un vettore sono accessibili tramite l'indicizzazione. Il[ ] bracketsvengono utilizzati per l'indicizzazione. L'indicizzazione inizia con la posizione 1. Dare un valore negativo nell'indice elimina quell'elemento dal risultato.TRUE, FALSE o 0 e 1 può essere utilizzato anche per l'indicizzazione.
# Accessing vector elements using position.
t <- c("Sun","Mon","Tue","Wed","Thurs","Fri","Sat")
u <- t[c(2,3,6)]
print(u)
# Accessing vector elements using logical indexing.
v <- t[c(TRUE,FALSE,FALSE,FALSE,FALSE,TRUE,FALSE)]
print(v)
# Accessing vector elements using negative indexing.
x <- t[c(-2,-5)]
print(x)
# Accessing vector elements using 0/1 indexing.
y <- t[c(0,0,0,0,0,0,1)]
print(y)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "Mon" "Tue" "Fri"
[1] "Sun" "Fri"
[1] "Sun" "Tue" "Wed" "Fri" "Sat"
[1] "Sun"Manipolazione vettoriale
Aritmetica vettoriale
È possibile aggiungere, sottrarre, moltiplicare o dividere due vettori della stessa lunghezza, ottenendo il risultato come output vettoriale.
# Create two vectors.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11,0,8,1,2)
# Vector addition.
add.result <- v1+v2
print(add.result)
# Vector subtraction.
sub.result <- v1-v2
print(sub.result)
# Vector multiplication.
multi.result <- v1*v2
print(multi.result)
# Vector division.
divi.result <- v1/v2
print(divi.result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 7 19 4 13 1 13
[1] -1 -3 4 -3 -1 9
[1] 12 88 0 40 0 22
[1] 0.7500000 0.7272727 Inf 0.6250000 0.0000000 5.5000000Riciclaggio di elementi vettoriali
Se applichiamo operazioni aritmetiche a due vettori di lunghezza diversa, gli elementi del vettore più corto vengono riciclati per completare le operazioni.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11)
# V2 becomes c(4,11,4,11,4,11)
add.result <- v1+v2
print(add.result)
sub.result <- v1-v2
print(sub.result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 7 19 8 16 4 22
[1] -1 -3 0 -6 -4 0Ordinamento degli elementi vettoriali
Gli elementi in un vettore possono essere ordinati utilizzando il sort() funzione.
v <- c(3,8,4,5,0,11, -9, 304)
# Sort the elements of the vector.
sort.result <- sort(v)
print(sort.result)
# Sort the elements in the reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)
# Sorting character vectors.
v <- c("Red","Blue","yellow","violet")
sort.result <- sort(v)
print(sort.result)
# Sorting character vectors in reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] -9 0 3 4 5 8 11 304
[1] 304 11 8 5 4 3 0 -9
[1] "Blue" "Red" "violet" "yellow"
[1] "yellow" "violet" "Red" "Blue"Le liste sono gli oggetti R che contengono elementi di diverso tipo come - numeri, stringhe, vettori e un altro elenco al suo interno. Un elenco può anche contenere una matrice o una funzione come suoi elementi. L'elenco viene creato utilizzandolist() funzione.
Creazione di un elenco
Di seguito è riportato un esempio per creare un elenco contenente stringhe, numeri, vettori e valori logici.
# Create a list containing strings, numbers, vectors and a logical
# values.
list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1)
print(list_data)Quando eseguiamo il codice sopra, produce il seguente risultato:
[[1]]
[1] "Red"
[[2]]
[1] "Green"
[[3]]
[1] 21 32 11
[[4]]
[1] TRUE
[[5]]
[1] 51.23
[[6]]
[1] 119.1Denominazione degli elementi dell'elenco
È possibile assegnare nomi agli elementi dell'elenco ed è possibile accedervi utilizzando questi nomi.
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Show the list.
print(list_data)Quando eseguiamo il codice sopra, produce il seguente risultato:
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Matrix
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
$A_Inner_list $A_Inner_list[[1]]
[1] "green"
$A_Inner_list[[2]]
[1] 12.3Accesso agli elementi dell'elenco
È possibile accedere agli elementi della lista tramite l'indice dell'elemento nella lista. In caso di elenchi denominati è possibile accedervi anche utilizzando i nomi.
Continuiamo a utilizzare l'elenco nell'esempio precedente:
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Access the first element of the list.
print(list_data[1])
# Access the thrid element. As it is also a list, all its elements will be printed.
print(list_data[3])
# Access the list element using the name of the element.
print(list_data$A_Matrix)Quando eseguiamo il codice sopra, produce il seguente risultato:
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Inner_list
$A_Inner_list[[1]] [1] "green" $A_Inner_list[[2]]
[1] 12.3
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8Manipolazione degli elementi dell'elenco
Possiamo aggiungere, eliminare e aggiornare gli elementi dell'elenco come mostrato di seguito. Possiamo aggiungere ed eliminare elementi solo alla fine di un elenco. Ma possiamo aggiornare qualsiasi elemento.
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Add element at the end of the list.
list_data[4] <- "New element"
print(list_data[4])
# Remove the last element.
list_data[4] <- NULL
# Print the 4th Element.
print(list_data[4])
# Update the 3rd Element.
list_data[3] <- "updated element"
print(list_data[3])Quando eseguiamo il codice sopra, produce il seguente risultato:
[[1]]
[1] "New element"
$<NA> NULL $`A Inner list`
[1] "updated element"Unione di elenchi
Puoi unire molti elenchi in un elenco inserendo tutti gli elenchi all'interno di una funzione list ().
# Create two lists.
list1 <- list(1,2,3)
list2 <- list("Sun","Mon","Tue")
# Merge the two lists.
merged.list <- c(list1,list2)
# Print the merged list.
print(merged.list)Quando eseguiamo il codice sopra, produce il seguente risultato:
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "Sun"
[[5]]
[1] "Mon"
[[6]]
[1] "Tue"Conversione da elenco a vettore
Un elenco può essere convertito in un vettore in modo che gli elementi del vettore possano essere utilizzati per ulteriori manipolazioni. Tutte le operazioni aritmetiche sui vettori possono essere applicate dopo che l'elenco è stato convertito in vettori. Per fare questa conversione, usiamo ilunlist()funzione. Prende l'elenco come input e produce un vettore.
# Create lists.
list1 <- list(1:5)
print(list1)
list2 <-list(10:14)
print(list2)
# Convert the lists to vectors.
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# Now add the vectors
result <- v1+v2
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[[1]]
[1] 1 2 3 4 5
[[1]]
[1] 10 11 12 13 14
[1] 1 2 3 4 5
[1] 10 11 12 13 14
[1] 11 13 15 17 19Le matrici sono gli oggetti R in cui gli elementi sono disposti in un layout rettangolare bidimensionale. Contengono elementi degli stessi tipi atomici. Sebbene possiamo creare una matrice contenente solo caratteri o solo valori logici, non sono di grande utilità. Utilizziamo matrici contenenti elementi numerici da utilizzare nei calcoli matematici.
Una matrice viene creata utilizzando il matrix() funzione.
Sintassi
La sintassi di base per creare una matrice in R è:
matrix(data, nrow, ncol, byrow, dimnames)Di seguito la descrizione dei parametri utilizzati:
data è il vettore di input che diventa l'elemento dati della matrice.
nrow è il numero di righe da creare.
ncol è il numero di colonne da creare.
byrowè un indizio logico. Se TRUE, gli elementi del vettore di input sono disposti per riga.
dimname sono i nomi assegnati alle righe e alle colonne.
Esempio
Crea una matrice prendendo come input un vettore di numeri.
# Elements are arranged sequentially by row.
M <- matrix(c(3:14), nrow = 4, byrow = TRUE)
print(M)
# Elements are arranged sequentially by column.
N <- matrix(c(3:14), nrow = 4, byrow = FALSE)
print(N)
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)Quando eseguiamo il codice sopra, produce il seguente risultato:
[,1] [,2] [,3]
[1,] 3 4 5
[2,] 6 7 8
[3,] 9 10 11
[4,] 12 13 14
[,1] [,2] [,3]
[1,] 3 7 11
[2,] 4 8 12
[3,] 5 9 13
[4,] 6 10 14
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14Accesso agli elementi di una matrice
È possibile accedere agli elementi di una matrice utilizzando l'indice di colonna e riga dell'elemento. Consideriamo la matrice P sopra per trovare gli elementi specifici di seguito.
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
# Create the matrix.
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
# Access the element at 3rd column and 1st row.
print(P[1,3])
# Access the element at 2nd column and 4th row.
print(P[4,2])
# Access only the 2nd row.
print(P[2,])
# Access only the 3rd column.
print(P[,3])Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 5
[1] 13
col1 col2 col3
6 7 8
row1 row2 row3 row4
5 8 11 14Calcoli di matrici
Varie operazioni matematiche vengono eseguite sulle matrici utilizzando gli operatori R. Anche il risultato dell'operazione è una matrice.
Le dimensioni (numero di righe e colonne) devono essere le stesse per le matrici coinvolte nell'operazione.
Addizione e sottrazione di matrici
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Add the matrices.
result <- matrix1 + matrix2
cat("Result of addition","\n")
print(result)
# Subtract the matrices
result <- matrix1 - matrix2
cat("Result of subtraction","\n")
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of addition
[,1] [,2] [,3]
[1,] 8 -1 5
[2,] 11 13 10
Result of subtraction
[,1] [,2] [,3]
[1,] -2 -1 -1
[2,] 7 -5 2Moltiplicazione e divisione di matrici
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Multiply the matrices.
result <- matrix1 * matrix2
cat("Result of multiplication","\n")
print(result)
# Divide the matrices
result <- matrix1 / matrix2
cat("Result of division","\n")
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of multiplication
[,1] [,2] [,3]
[1,] 15 0 6
[2,] 18 36 24
Result of division
[,1] [,2] [,3]
[1,] 0.6 -Inf 0.6666667
[2,] 4.5 0.4444444 1.5000000Gli array sono gli oggetti dati R che possono memorizzare dati in più di due dimensioni. Ad esempio: se creiamo un array di dimensioni (2, 3, 4), vengono create 4 matrici rettangolari ciascuna con 2 righe e 3 colonne. Gli array possono memorizzare solo il tipo di dati.
Un array viene creato utilizzando il array()funzione. Prende i vettori come input e utilizza i valori indim parametro per creare un array.
Esempio
L'esempio seguente crea una matrice di due matrici 3x3 ciascuna con 3 righe e 3 colonne.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2))
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15Denominazione di colonne e righe
Possiamo dare nomi alle righe, colonne e matrici nell'array usando il dimnames parametro.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,
matrix.names))
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15Accesso agli elementi dell'array
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,
column.names, matrix.names))
# Print the third row of the second matrix of the array.
print(result[3,,2])
# Print the element in the 1st row and 3rd column of the 1st matrix.
print(result[1,3,1])
# Print the 2nd Matrix.
print(result[,,2])Quando eseguiamo il codice sopra, produce il seguente risultato:
COL1 COL2 COL3
3 12 15
[1] 13
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15Manipolazione di elementi di array
Essendo l'array composto da matrici in più dimensioni, le operazioni sugli elementi di array si effettuano accedendo agli elementi delle matrici.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
array1 <- array(c(vector1,vector2),dim = c(3,3,2))
# Create two vectors of different lengths.
vector3 <- c(9,1,0)
vector4 <- c(6,0,11,3,14,1,2,6,9)
array2 <- array(c(vector1,vector2),dim = c(3,3,2))
# create matrices from these arrays.
matrix1 <- array1[,,2]
matrix2 <- array2[,,2]
# Add the matrices.
result <- matrix1+matrix2
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[,1] [,2] [,3]
[1,] 10 20 26
[2,] 18 22 28
[3,] 6 24 30Calcoli sugli elementi dell'array
Possiamo fare calcoli attraverso gli elementi in un array usando il apply() funzione.
Sintassi
apply(x, margin, fun)Di seguito la descrizione dei parametri utilizzati:
x è un array.
margin è il nome del set di dati utilizzato.
fun è la funzione da applicare agli elementi dell'array.
Esempio
Usiamo la funzione apply () di seguito per calcolare la somma degli elementi nelle righe di un array su tutte le matrici.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
new.array <- array(c(vector1,vector2),dim = c(3,3,2))
print(new.array)
# Use apply to calculate the sum of the rows across all the matrices.
result <- apply(new.array, c(1), sum)
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
[1] 56 68 60I fattori sono gli oggetti dati che vengono utilizzati per classificare i dati e archiviarli come livelli. Possono memorizzare sia stringhe che numeri interi. Sono utili nelle colonne che hanno un numero limitato di valori univoci. Come "Male," Female "e True, False ecc. Sono utili nell'analisi dei dati per la modellazione statistica.
I fattori vengono creati utilizzando il factor () prendendo un vettore come input.
Esempio
# Create a vector as input.
data <- c("East","West","East","North","North","East","West","West","West","East","North")
print(data)
print(is.factor(data))
# Apply the factor function.
factor_data <- factor(data)
print(factor_data)
print(is.factor(factor_data))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "East" "West" "East" "North" "North" "East" "West" "West" "West" "East" "North"
[1] FALSE
[1] East West East North North East West West West East North
Levels: East North West
[1] TRUEFattori nel frame di dati
Quando si crea un frame di dati con una colonna di dati di testo, R tratta la colonna di testo come dati categoriali e crea fattori su di essa.
# Create the vectors for data frame.
height <- c(132,151,162,139,166,147,122)
weight <- c(48,49,66,53,67,52,40)
gender <- c("male","male","female","female","male","female","male")
# Create the data frame.
input_data <- data.frame(height,weight,gender)
print(input_data)
# Test if the gender column is a factor.
print(is.factor(input_data$gender)) # Print the gender column so see the levels. print(input_data$gender)Quando eseguiamo il codice sopra, produce il seguente risultato:
height weight gender
1 132 48 male
2 151 49 male
3 162 66 female
4 139 53 female
5 166 67 male
6 147 52 female
7 122 40 male
[1] TRUE
[1] male male female female male female male
Levels: female maleModifica dell'ordine dei livelli
L'ordine dei livelli in un fattore può essere modificato applicando nuovamente la funzione fattore con un nuovo ordine dei livelli.
data <- c("East","West","East","North","North","East","West",
"West","West","East","North")
# Create the factors
factor_data <- factor(data)
print(factor_data)
# Apply the factor function with required order of the level.
new_order_data <- factor(factor_data,levels = c("East","West","North"))
print(new_order_data)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] East West East North North East West West West East North
Levels: East North West
[1] East West East North North East West West West East North
Levels: East West NorthGenerazione di livelli di fattore
Possiamo generare livelli di fattore utilizzando il gl()funzione. Richiede due numeri interi come input che indica quanti livelli e quante volte ogni livello.
Sintassi
gl(n, k, labels)Di seguito la descrizione dei parametri utilizzati:
n è un numero intero che fornisce il numero di livelli.
k è un numero intero che fornisce il numero di repliche.
labels è un vettore di etichette per i livelli di fattore risultanti.
Esempio
v <- gl(3, 4, labels = c("Tampa", "Seattle","Boston"))
print(v)Quando eseguiamo il codice sopra, produce il seguente risultato:
Tampa Tampa Tampa Tampa Seattle Seattle Seattle Seattle Boston
[10] Boston Boston Boston
Levels: Tampa Seattle BostonUn data frame è una tabella o una struttura a matrice bidimensionale in cui ogni colonna contiene i valori di una variabile e ogni riga contiene un insieme di valori da ogni colonna.
Di seguito sono riportate le caratteristiche di un data frame.
- I nomi delle colonne non devono essere vuoti.
- I nomi delle righe dovrebbero essere univoci.
- I dati memorizzati in un data frame possono essere di tipo numerico, di fattore o di carattere.
- Ogni colonna dovrebbe contenere lo stesso numero di elementi di dati.
Crea frame di dati
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the data frame.
print(emp.data)Quando eseguiamo il codice sopra, produce il seguente risultato:
emp_id emp_name salary start_date
1 1 Rick 623.30 2012-01-01
2 2 Dan 515.20 2013-09-23
3 3 Michelle 611.00 2014-11-15
4 4 Ryan 729.00 2014-05-11
5 5 Gary 843.25 2015-03-27Ottieni la struttura del data frame
La struttura del data frame può essere vista utilizzando str() funzione.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Get the structure of the data frame.
str(emp.data)Quando eseguiamo il codice sopra, produce il seguente risultato:
'data.frame': 5 obs. of 4 variables:
$ emp_id : int 1 2 3 4 5 $ emp_name : chr "Rick" "Dan" "Michelle" "Ryan" ...
$ salary : num 623 515 611 729 843 $ start_date: Date, format: "2012-01-01" "2013-09-23" "2014-11-15" "2014-05-11" ...Riepilogo dei dati nel frame di dati
Il riepilogo statistico e la natura dei dati possono essere ottenuti applicando summary() funzione.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the summary.
print(summary(emp.data))Quando eseguiamo il codice sopra, produce il seguente risultato:
emp_id emp_name salary start_date
Min. :1 Length:5 Min. :515.2 Min. :2012-01-01
1st Qu.:2 Class :character 1st Qu.:611.0 1st Qu.:2013-09-23
Median :3 Mode :character Median :623.3 Median :2014-05-11
Mean :3 Mean :664.4 Mean :2014-01-14
3rd Qu.:4 3rd Qu.:729.0 3rd Qu.:2014-11-15
Max. :5 Max. :843.2 Max. :2015-03-27Estrai dati dal frame di dati
Estrai una colonna specifica da un data frame utilizzando il nome della colonna.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01","2013-09-23","2014-11-15","2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract Specific columns.
result <- data.frame(emp.data$emp_name,emp.data$salary)
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
emp.data.emp_name emp.data.salary
1 Rick 623.30
2 Dan 515.20
3 Michelle 611.00
4 Ryan 729.00
5 Gary 843.25Estrai le prime due righe e poi tutte le colonne
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract first two rows.
result <- emp.data[1:2,]
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
emp_id emp_name salary start_date
1 1 Rick 623.3 2012-01-01
2 2 Dan 515.2 2013-09-23Estrarre 3 ° e 5 ° fila con 2 ° e 4 ° colonna
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract 3rd and 5th row with 2nd and 4th column.
result <- emp.data[c(3,5),c(2,4)]
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
emp_name start_date
3 Michelle 2014-11-15
5 Gary 2015-03-27Espandi Data Frame
Un data frame può essere espanso aggiungendo colonne e righe.
Aggiungi colonna
Basta aggiungere il vettore della colonna usando un nuovo nome di colonna.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Add the "dept" coulmn.
emp.data$dept <- c("IT","Operations","IT","HR","Finance")
v <- emp.data
print(v)Quando eseguiamo il codice sopra, produce il seguente risultato:
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 FinanceAggiungi riga
Per aggiungere più righe in modo permanente a un data frame esistente, dobbiamo portare le nuove righe nella stessa struttura del data frame esistente e utilizzare il rbind() funzione.
Nell'esempio seguente creiamo un data frame con nuove righe e lo uniamo al data frame esistente per creare il data frame finale.
# Create the first data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
dept = c("IT","Operations","IT","HR","Finance"),
stringsAsFactors = FALSE
)
# Create the second data frame
emp.newdata <- data.frame(
emp_id = c (6:8),
emp_name = c("Rasmi","Pranab","Tusar"),
salary = c(578.0,722.5,632.8),
start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")),
dept = c("IT","Operations","Fianance"),
stringsAsFactors = FALSE
)
# Bind the two data frames.
emp.finaldata <- rbind(emp.data,emp.newdata)
print(emp.finaldata)Quando eseguiamo il codice sopra, produce il seguente risultato:
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance
6 6 Rasmi 578.00 2013-05-21 IT
7 7 Pranab 722.50 2013-07-30 Operations
8 8 Tusar 632.80 2014-06-17 FiananceI pacchetti R sono una raccolta di funzioni R, codice conforme e dati di esempio. Sono memorizzati in una directory chiamata"library"nell'ambiente R. Per impostazione predefinita, R installa una serie di pacchetti durante l'installazione. Più pacchetti vengono aggiunti in seguito, quando sono necessari per uno scopo specifico. Quando si avvia la console R, per impostazione predefinita sono disponibili solo i pacchetti predefiniti. Altri pacchetti già installati devono essere caricati esplicitamente per essere utilizzati dal programma R che li utilizzerà.
Tutti i pacchetti disponibili in linguaggio R sono elencati in Pacchetti R.
Di seguito è riportato un elenco di comandi da utilizzare per controllare, verificare e utilizzare i pacchetti R.
Controllare i pacchetti R disponibili
Ottieni percorsi di libreria contenenti pacchetti R.
.libPaths()Quando eseguiamo il codice precedente, produce il seguente risultato. Può variare a seconda delle impostazioni locali del tuo PC.
[2] "C:/Program Files/R/R-3.2.2/library"Ottieni l'elenco di tutti i pacchetti installati
library()Quando eseguiamo il codice precedente, produce il seguente risultato. Può variare a seconda delle impostazioni locali del tuo PC.
Packages in library ‘C:/Program Files/R/R-3.2.2/library’:
base The R Base Package
boot Bootstrap Functions (Originally by Angelo Canty
for S)
class Functions for Classification
cluster "Finding Groups in Data": Cluster Analysis
Extended Rousseeuw et al.
codetools Code Analysis Tools for R
compiler The R Compiler Package
datasets The R Datasets Package
foreign Read Data Stored by 'Minitab', 'S', 'SAS',
'SPSS', 'Stata', 'Systat', 'Weka', 'dBase', ...
graphics The R Graphics Package
grDevices The R Graphics Devices and Support for Colours
and Fonts
grid The Grid Graphics Package
KernSmooth Functions for Kernel Smoothing Supporting Wand
& Jones (1995)
lattice Trellis Graphics for R
MASS Support Functions and Datasets for Venables and
Ripley's MASS
Matrix Sparse and Dense Matrix Classes and Methods
methods Formal Methods and Classes
mgcv Mixed GAM Computation Vehicle with GCV/AIC/REML
Smoothness Estimation
nlme Linear and Nonlinear Mixed Effects Models
nnet Feed-Forward Neural Networks and Multinomial
Log-Linear Models
parallel Support for Parallel computation in R
rpart Recursive Partitioning and Regression Trees
spatial Functions for Kriging and Point Pattern
Analysis
splines Regression Spline Functions and Classes
stats The R Stats Package
stats4 Statistical Functions using S4 Classes
survival Survival Analysis
tcltk Tcl/Tk Interface
tools Tools for Package Development
utils The R Utils PackageOttieni tutti i pacchetti attualmente caricati nell'ambiente R.
search()Quando eseguiamo il codice precedente, produce il seguente risultato. Può variare a seconda delle impostazioni locali del tuo PC.
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"Installa un nuovo pacchetto
Esistono due modi per aggiungere nuovi pacchetti R. Uno sta installando direttamente dalla directory CRAN e un altro sta scaricando il pacchetto sul tuo sistema locale e installandolo manualmente.
Installa direttamente da CRAN
Il comando seguente ottiene i pacchetti direttamente dalla pagina Web di CRAN e installa il pacchetto nell'ambiente R. Potrebbe essere richiesto di scegliere il mirror più vicino. Scegli quello appropriato alla tua posizione.
install.packages("Package Name")
# Install the package named "XML".
install.packages("XML")Installa il pacchetto manualmente
Vai al collegamento Pacchetti R per scaricare il pacchetto necessario. Salva il pacchetto come file.zip file in una posizione adatta nel sistema locale.
Ora puoi eseguire il seguente comando per installare questo pacchetto nell'ambiente R.
install.packages(file_name_with_path, repos = NULL, type = "source")
# Install the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")Carica il pacchetto nella libreria
Prima che un pacchetto possa essere utilizzato nel codice, deve essere caricato nell'ambiente R corrente. È inoltre necessario caricare un pacchetto già installato in precedenza ma non disponibile nell'ambiente corrente.
Un pacchetto viene caricato utilizzando il seguente comando:
library("package Name", lib.loc = "path to library")
# Load the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")Il rimodellamento dei dati in R riguarda la modifica del modo in cui i dati sono organizzati in righe e colonne. La maggior parte delle volte l'elaborazione dei dati in R viene eseguita prendendo i dati di input come frame di dati. È facile estrarre i dati dalle righe e dalle colonne di un frame di dati, ma ci sono situazioni in cui abbiamo bisogno del frame di dati in un formato diverso dal formato in cui lo abbiamo ricevuto. R ha molte funzioni per dividere, unire e modificare le righe in colonne e viceversa in un frame di dati.
Unione di colonne e righe in un frame di dati
Possiamo unire più vettori per creare un data frame usando il cbind()funzione. Inoltre possiamo unire due frame di dati usandorbind() funzione.
# Create vector objects.
city <- c("Tampa","Seattle","Hartford","Denver")
state <- c("FL","WA","CT","CO")
zipcode <- c(33602,98104,06161,80294)
# Combine above three vectors into one data frame.
addresses <- cbind(city,state,zipcode)
# Print a header.
cat("# # # # The First data frame\n")
# Print the data frame.
print(addresses)
# Create another data frame with similar columns
new.address <- data.frame(
city = c("Lowry","Charlotte"),
state = c("CO","FL"),
zipcode = c("80230","33949"),
stringsAsFactors = FALSE
)
# Print a header.
cat("# # # The Second data frame\n")
# Print the data frame.
print(new.address)
# Combine rows form both the data frames.
all.addresses <- rbind(addresses,new.address)
# Print a header.
cat("# # # The combined data frame\n")
# Print the result.
print(all.addresses)Quando eseguiamo il codice sopra, produce il seguente risultato:
# # # # The First data frame
city state zipcode
[1,] "Tampa" "FL" "33602"
[2,] "Seattle" "WA" "98104"
[3,] "Hartford" "CT" "6161"
[4,] "Denver" "CO" "80294"
# # # The Second data frame
city state zipcode
1 Lowry CO 80230
2 Charlotte FL 33949
# # # The combined data frame
city state zipcode
1 Tampa FL 33602
2 Seattle WA 98104
3 Hartford CT 6161
4 Denver CO 80294
5 Lowry CO 80230
6 Charlotte FL 33949Unione di frame di dati
Possiamo unire due frame di dati usando il merge()funzione. I frame di dati devono avere gli stessi nomi di colonna su cui avviene l'unione.
Nell'esempio seguente, consideriamo i set di dati sul diabete nelle donne indiane Pima disponibili nei nomi di libreria "MASS". uniamo i due set di dati in base ai valori di pressione sanguigna ("bp") e indice di massa corporea ("bmi"). Scegliendo queste due colonne per l'unione, i record in cui i valori di queste due variabili corrispondono in entrambi i set di dati vengono combinati insieme per formare un unico frame di dati.
library(MASS)
merged.Pima <- merge(x = Pima.te, y = Pima.tr,
by.x = c("bp", "bmi"),
by.y = c("bp", "bmi")
)
print(merged.Pima)
nrow(merged.Pima)Quando eseguiamo il codice sopra, produce il seguente risultato:
bp bmi npreg.x glu.x skin.x ped.x age.x type.x npreg.y glu.y skin.y ped.y
1 60 33.8 1 117 23 0.466 27 No 2 125 20 0.088
2 64 29.7 2 75 24 0.370 33 No 2 100 23 0.368
3 64 31.2 5 189 33 0.583 29 Yes 3 158 13 0.295
4 64 33.2 4 117 27 0.230 24 No 1 96 27 0.289
5 66 38.1 3 115 39 0.150 28 No 1 114 36 0.289
6 68 38.5 2 100 25 0.324 26 No 7 129 49 0.439
7 70 27.4 1 116 28 0.204 21 No 0 124 20 0.254
8 70 33.1 4 91 32 0.446 22 No 9 123 44 0.374
9 70 35.4 9 124 33 0.282 34 No 6 134 23 0.542
10 72 25.6 1 157 21 0.123 24 No 4 99 17 0.294
11 72 37.7 5 95 33 0.370 27 No 6 103 32 0.324
12 74 25.9 9 134 33 0.460 81 No 8 126 38 0.162
13 74 25.9 1 95 21 0.673 36 No 8 126 38 0.162
14 78 27.6 5 88 30 0.258 37 No 6 125 31 0.565
15 78 27.6 10 122 31 0.512 45 No 6 125 31 0.565
16 78 39.4 2 112 50 0.175 24 No 4 112 40 0.236
17 88 34.5 1 117 24 0.403 40 Yes 4 127 11 0.598
age.y type.y
1 31 No
2 21 No
3 24 No
4 21 No
5 21 No
6 43 Yes
7 36 Yes
8 40 No
9 29 Yes
10 28 No
11 55 No
12 39 No
13 39 No
14 49 Yes
15 49 Yes
16 38 No
17 28 No
[1] 17Fusione e colata
Uno degli aspetti più interessanti della programmazione R riguarda la modifica della forma dei dati in più passaggi per ottenere la forma desiderata. Vengono chiamate le funzioni utilizzate per farlomelt() e cast().
Consideriamo il dataset denominato navi presente nella libreria denominato "MASS".
library(MASS)
print(ships)Quando eseguiamo il codice sopra, produce il seguente risultato:
type year period service incidents
1 A 60 60 127 0
2 A 60 75 63 0
3 A 65 60 1095 3
4 A 65 75 1095 4
5 A 70 60 1512 6
.............
.............
8 A 75 75 2244 11
9 B 60 60 44882 39
10 B 60 75 17176 29
11 B 65 60 28609 58
............
............
17 C 60 60 1179 1
18 C 60 75 552 1
19 C 65 60 781 0
............
............Sciogli i dati
Ora fondiamo i dati per organizzarli, convertendo tutte le colonne diverse da tipo e anno in più righe.
molten.ships <- melt(ships, id = c("type","year"))
print(molten.ships)Quando eseguiamo il codice sopra, produce il seguente risultato:
type year variable value
1 A 60 period 60
2 A 60 period 75
3 A 65 period 60
4 A 65 period 75
............
............
9 B 60 period 60
10 B 60 period 75
11 B 65 period 60
12 B 65 period 75
13 B 70 period 60
...........
...........
41 A 60 service 127
42 A 60 service 63
43 A 65 service 1095
...........
...........
70 D 70 service 1208
71 D 75 service 0
72 D 75 service 2051
73 E 60 service 45
74 E 60 service 0
75 E 65 service 789
...........
...........
101 C 70 incidents 6
102 C 70 incidents 2
103 C 75 incidents 0
104 C 75 incidents 1
105 D 60 incidents 0
106 D 60 incidents 0
...........
...........Cast the Molten Data
Possiamo trasformare i dati fusi in una nuova forma in cui viene creato l'aggregato di ogni tipo di nave per ogni anno. È fatto usando ilcast() funzione.
recasted.ship <- cast(molten.ships, type+year~variable,sum)
print(recasted.ship)Quando eseguiamo il codice sopra, produce il seguente risultato:
type year period service incidents
1 A 60 135 190 0
2 A 65 135 2190 7
3 A 70 135 4865 24
4 A 75 135 2244 11
5 B 60 135 62058 68
6 B 65 135 48979 111
7 B 70 135 20163 56
8 B 75 135 7117 18
9 C 60 135 1731 2
10 C 65 135 1457 1
11 C 70 135 2731 8
12 C 75 135 274 1
13 D 60 135 356 0
14 D 65 135 480 0
15 D 70 135 1557 13
16 D 75 135 2051 4
17 E 60 135 45 0
18 E 65 135 1226 14
19 E 70 135 3318 17
20 E 75 135 542 1In R, possiamo leggere i dati dai file archiviati al di fuori dell'ambiente R. Possiamo anche scrivere dati in file che verranno archiviati e accessibili dal sistema operativo. R può leggere e scrivere in vari formati di file come csv, excel, xml ecc.
In questo capitolo impareremo a leggere i dati da un file csv e poi scrivere i dati in un file csv. Il file dovrebbe essere presente nella directory di lavoro corrente in modo che R possa leggerlo. Ovviamente possiamo anche impostare la nostra directory e leggere i file da lì.
Recupero e impostazione della directory di lavoro
È possibile controllare a quale directory punta lo spazio di lavoro R utilizzando getwd()funzione. Puoi anche impostare una nuova directory di lavoro usandosetwd()funzione.
# Get and print current working directory.
print(getwd())
# Set current working directory.
setwd("/web/com")
# Get and print current working directory.
print(getwd())Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "/web/com/1441086124_2016"
[1] "/web/com"Questo risultato dipende dal tuo sistema operativo e dalla directory corrente in cui stai lavorando.
Input come file CSV
Il file csv è un file di testo in cui i valori nelle colonne sono separati da una virgola. Consideriamo i seguenti dati presenti nel file denominatoinput.csv.
È possibile creare questo file utilizzando il blocco note di Windows copiando e incollando questi dati. Salva il file comeinput.csv utilizzando l'opzione Salva come tutti i file (*. *) nel blocco note.
id,name,salary,start_date,dept
1,Rick,623.3,2012-01-01,IT
2,Dan,515.2,2013-09-23,Operations
3,Michelle,611,2014-11-15,IT
4,Ryan,729,2014-05-11,HR
5,Gary,843.25,2015-03-27,Finance
6,Nina,578,2013-05-21,IT
7,Simon,632.8,2013-07-30,Operations
8,Guru,722.5,2014-06-17,FinanceLeggere un file CSV
Di seguito è riportato un semplice esempio di read.csv() funzione per leggere un file CSV disponibile nella directory di lavoro corrente -
data <- read.csv("input.csv")
print(data)Quando eseguiamo il codice sopra, produce il seguente risultato:
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceAnalisi del file CSV
Per impostazione predefinita, il file read.csv()la funzione fornisce l'output come frame di dati. Questo può essere facilmente verificato come segue. Inoltre possiamo controllare il numero di colonne e righe.
data <- read.csv("input.csv")
print(is.data.frame(data))
print(ncol(data))
print(nrow(data))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] TRUE
[1] 5
[1] 8Una volta letti i dati in un data frame, possiamo applicare tutte le funzioni applicabili ai data frame come spiegato nella sezione successiva.
Ottieni lo stipendio massimo
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
print(sal)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 843.25Ottieni i dettagli della persona con lo stipendio massimo
Possiamo recuperare le righe che soddisfano criteri di filtro specifici simili a una clausola WHERE di SQL.
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
# Get the person detail having max salary.
retval <- subset(data, salary == max(salary))
print(retval)Quando eseguiamo il codice sopra, produce il seguente risultato:
id name salary start_date dept
5 NA Gary 843.25 2015-03-27 FinanceOttieni tutte le persone che lavorano nel reparto IT
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset( data, dept == "IT")
print(retval)Quando eseguiamo il codice sopra, produce il seguente risultato:
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 IT
6 6 Nina 578.0 2013-05-21 ITOttieni le persone nel reparto IT il cui stipendio è superiore a 600
# Create a data frame.
data <- read.csv("input.csv")
info <- subset(data, salary > 600 & dept == "IT")
print(info)Quando eseguiamo il codice sopra, produce il seguente risultato:
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 ITOttieni le persone che si sono iscritte a partire dal 2014
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
print(retval)Quando eseguiamo il codice sopra, produce il seguente risultato:
id name salary start_date dept
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
8 8 Guru 722.50 2014-06-17 FinanceScrittura in un file CSV
R può creare file CSV dal data frame esistente. Ilwrite.csv()viene utilizzata per creare il file csv. Questo file viene creato nella directory di lavoro.
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv")
newdata <- read.csv("output.csv")
print(newdata)Quando eseguiamo il codice sopra, produce il seguente risultato:
X id name salary start_date dept
1 3 3 Michelle 611.00 2014-11-15 IT
2 4 4 Ryan 729.00 2014-05-11 HR
3 5 NA Gary 843.25 2015-03-27 Finance
4 8 8 Guru 722.50 2014-06-17 FinanceQui la colonna X proviene dal data set newper. Questo può essere eliminato utilizzando parametri aggiuntivi durante la scrittura del file.
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv", row.names = FALSE)
newdata <- read.csv("output.csv")
print(newdata)Quando eseguiamo il codice sopra, produce il seguente risultato:
id name salary start_date dept
1 3 Michelle 611.00 2014-11-15 IT
2 4 Ryan 729.00 2014-05-11 HR
3 NA Gary 843.25 2015-03-27 Finance
4 8 Guru 722.50 2014-06-17 FinanceMicrosoft Excel è il programma di fogli di calcolo più utilizzato che memorizza i dati nel formato .xls o .xlsx. R può leggere direttamente da questi file utilizzando alcuni pacchetti specifici di Excel. Alcuni di questi pacchetti sono: XLConnect, xlsx, gdata ecc. Useremo il pacchetto xlsx. R può anche scrivere in un file excel usando questo pacchetto.
Installa il pacchetto xlsx
È possibile utilizzare il seguente comando nella console R per installare il pacchetto "xlsx". Potrebbe richiedere l'installazione di alcuni pacchetti aggiuntivi da cui dipende questo pacchetto. Segui lo stesso comando con il nome del pacchetto richiesto per installare i pacchetti aggiuntivi.
install.packages("xlsx")Verifica e carica il pacchetto "xlsx"
Utilizzare il seguente comando per verificare e caricare il pacchetto "xlsx".
# Verify the package is installed.
any(grepl("xlsx",installed.packages()))
# Load the library into R workspace.
library("xlsx")Quando lo script viene eseguito, otteniamo il seguente output.
[1] TRUE
Loading required package: rJava
Loading required package: methods
Loading required package: xlsxjarsImmettere come file xlsx
Apri Microsoft Excel. Copia e incolla i seguenti dati nel foglio di lavoro denominato foglio1.
id name salary start_date dept
1 Rick 623.3 1/1/2012 IT
2 Dan 515.2 9/23/2013 Operations
3 Michelle 611 11/15/2014 IT
4 Ryan 729 5/11/2014 HR
5 Gary 43.25 3/27/2015 Finance
6 Nina 578 5/21/2013 IT
7 Simon 632.8 7/30/2013 Operations
8 Guru 722.5 6/17/2014 FinanceCopia e incolla anche i seguenti dati in un altro foglio di lavoro e rinomina questo foglio di lavoro in "città".
name city
Rick Seattle
Dan Tampa
Michelle Chicago
Ryan Seattle
Gary Houston
Nina Boston
Simon Mumbai
Guru DallasSalva il file Excel come "input.xlsx". Dovresti salvarlo nella directory di lavoro corrente dello spazio di lavoro R.
Leggere il file Excel
Il file input.xlsx viene letto utilizzando il file read.xlsx()funzionare come mostrato di seguito. Il risultato viene memorizzato come frame di dati nell'ambiente R.
# Read the first worksheet in the file input.xlsx.
data <- read.xlsx("input.xlsx", sheetIndex = 1)
print(data)Quando eseguiamo il codice sopra, produce il seguente risultato:
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceUn file binario è un file che contiene informazioni memorizzate solo sotto forma di bit e byte (0 e 1). Non sono leggibili dall'uomo poiché i byte in esso contenuti si traducono in caratteri e simboli che contengono molti altri caratteri non stampabili. Il tentativo di leggere un file binario utilizzando un qualsiasi editor di testo mostrerà caratteri come Ø e ð.
Il file binario deve essere letto da programmi specifici per essere utilizzabile. Ad esempio, il file binario di un programma Microsoft Word può essere letto in un formato leggibile solo dal programma Word. Il che indica che, oltre al testo leggibile dall'uomo, ci sono molte più informazioni come la formattazione dei caratteri e dei numeri di pagina, ecc., Che sono anche memorizzati insieme ai caratteri alfanumerici. E infine un file binario è una sequenza continua di byte. L'interruzione di riga che vediamo in un file di testo è un carattere che unisce la prima riga alla successiva.
A volte, i dati generati da altri programmi devono essere elaborati da R come file binario. Anche R è necessario per creare file binari che possono essere condivisi con altri programmi.
R ha due funzioni WriteBin() e readBin() per creare e leggere file binari.
Sintassi
writeBin(object, con)
readBin(con, what, n )Di seguito la descrizione dei parametri utilizzati:
con è l'oggetto di connessione per leggere o scrivere il file binario.
object è il file binario che deve essere scritto.
what è la modalità come carattere, numero intero ecc. che rappresenta i byte da leggere.
n è il numero di byte da leggere dal file binario.
Esempio
Consideriamo i dati R incorporati "mtcars". Per prima cosa creiamo un file csv da esso e lo convertiamo in un file binario e lo memorizziamo come file del sistema operativo. Successivamente leggiamo questo file binario creato in R.
Scrittura del file binario
Leggiamo il data frame "mtcars" come file csv e poi lo scriviamo come file binario nel sistema operativo.
# Read the "mtcars" data frame as a csv file and store only the columns
"cyl", "am" and "gear".
write.table(mtcars, file = "mtcars.csv",row.names = FALSE, na = "",
col.names = TRUE, sep = ",")
# Store 5 records from the csv file as a new data frame.
new.mtcars <- read.table("mtcars.csv",sep = ",",header = TRUE,nrows = 5)
# Create a connection object to write the binary file using mode "wb".
write.filename = file("/web/com/binmtcars.dat", "wb")
# Write the column names of the data frame to the connection object.
writeBin(colnames(new.mtcars), write.filename)
# Write the records in each of the column to the file.
writeBin(c(new.mtcars$cyl,new.mtcars$am,new.mtcars$gear), write.filename)
# Close the file for writing so that it can be read by other program.
close(write.filename)Leggere il file binario
Il file binario creato sopra memorizza tutti i dati come byte continui. Quindi lo leggeremo scegliendo i valori appropriati dei nomi delle colonne e dei valori delle colonne.
# Create a connection object to read the file in binary mode using "rb".
read.filename <- file("/web/com/binmtcars.dat", "rb")
# First read the column names. n = 3 as we have 3 columns.
column.names <- readBin(read.filename, character(), n = 3)
# Next read the column values. n = 18 as we have 3 column names and 15 values.
read.filename <- file("/web/com/binmtcars.dat", "rb")
bindata <- readBin(read.filename, integer(), n = 18)
# Print the data.
print(bindata)
# Read the values from 4th byte to 8th byte which represents "cyl".
cyldata = bindata[4:8]
print(cyldata)
# Read the values form 9th byte to 13th byte which represents "am".
amdata = bindata[9:13]
print(amdata)
# Read the values form 9th byte to 13th byte which represents "gear".
geardata = bindata[14:18]
print(geardata)
# Combine all the read values to a dat frame.
finaldata = cbind(cyldata, amdata, geardata)
colnames(finaldata) = column.names
print(finaldata)Quando eseguiamo il codice sopra, produce il seguente risultato e grafico:
[1] 7108963 1728081249 7496037 6 6 4
[7] 6 8 1 1 1 0
[13] 0 4 4 4 3 3
[1] 6 6 4 6 8
[1] 1 1 1 0 0
[1] 4 4 4 3 3
cyl am gear
[1,] 6 1 4
[2,] 6 1 4
[3,] 4 1 4
[4,] 6 0 3
[5,] 8 0 3Come possiamo vedere, abbiamo recuperato i dati originali leggendo il file binario in R.
XML è un formato di file che condivide sia il formato di file che i dati sul World Wide Web, intranet e altrove utilizzando testo ASCII standard. È l'acronimo di Extensible Markup Language (XML). Simile all'HTML, contiene tag di markup. Ma a differenza dell'HTML dove il tag di markup descrive la struttura della pagina, in xml i tag di markup descrivono il significato dei dati contenuti nel file.
Puoi leggere un file xml in R usando il pacchetto "XML". Questo pacchetto può essere installato utilizzando il seguente comando.
install.packages("XML")Dati in ingresso
Crea un file XMl copiando i dati seguenti in un editor di testo come il blocco note. Salva il file con estensione.xml estensione e scegliendo il tipo di file come all files(*.*).
<RECORDS>
<EMPLOYEE>
<ID>1</ID>
<NAME>Rick</NAME>
<SALARY>623.3</SALARY>
<STARTDATE>1/1/2012</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>2</ID>
<NAME>Dan</NAME>
<SALARY>515.2</SALARY>
<STARTDATE>9/23/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>3</ID>
<NAME>Michelle</NAME>
<SALARY>611</SALARY>
<STARTDATE>11/15/2014</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>4</ID>
<NAME>Ryan</NAME>
<SALARY>729</SALARY>
<STARTDATE>5/11/2014</STARTDATE>
<DEPT>HR</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>5</ID>
<NAME>Gary</NAME>
<SALARY>843.25</SALARY>
<STARTDATE>3/27/2015</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>6</ID>
<NAME>Nina</NAME>
<SALARY>578</SALARY>
<STARTDATE>5/21/2013</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>7</ID>
<NAME>Simon</NAME>
<SALARY>632.8</SALARY>
<STARTDATE>7/30/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>8</ID>
<NAME>Guru</NAME>
<SALARY>722.5</SALARY>
<STARTDATE>6/17/2014</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
</RECORDS>Lettura del file XML
Il file xml viene letto da R utilizzando la funzione xmlParse(). È memorizzato come elenco in R.
# Load the package required to read XML files.
library("XML")
# Also load the other required package.
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Print the result.
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
1
Rick
623.3
1/1/2012
IT
2
Dan
515.2
9/23/2013
Operations
3
Michelle
611
11/15/2014
IT
4
Ryan
729
5/11/2014
HR
5
Gary
843.25
3/27/2015
Finance
6
Nina
578
5/21/2013
IT
7
Simon
632.8
7/30/2013
Operations
8
Guru
722.5
6/17/2014
FinanceOttieni il numero di nodi presenti nel file XML
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Find number of nodes in the root.
rootsize <- xmlSize(rootnode)
# Print the result.
print(rootsize)Quando eseguiamo il codice sopra, produce il seguente risultato:
output
[1] 8Dettagli del primo nodo
Diamo un'occhiata al primo record del file analizzato. Ci darà un'idea dei vari elementi presenti nel nodo di primo livello.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Print the result.
print(rootnode[1])Quando eseguiamo il codice sopra, produce il seguente risultato:
$EMPLOYEE
1
Rick
623.3
1/1/2012
IT
attr(,"class")
[1] "XMLInternalNodeList" "XMLNodeList"Ottieni diversi elementi di un nodo
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Get the first element of the first node.
print(rootnode[[1]][[1]])
# Get the fifth element of the first node.
print(rootnode[[1]][[5]])
# Get the second element of the third node.
print(rootnode[[3]][[2]])Quando eseguiamo il codice sopra, produce il seguente risultato:
1
IT
MichelleDa XML a frame di dati
Per gestire i dati in modo efficace in file di grandi dimensioni, leggiamo i dati nel file xml come frame di dati. Quindi elaborare il frame di dati per l'analisi dei dati.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Convert the input xml file to a data frame.
xmldataframe <- xmlToDataFrame("input.xml")
print(xmldataframe)Quando eseguiamo il codice sopra, produce il seguente risultato:
ID NAME SALARY STARTDATE DEPT
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinancePoiché i dati sono ora disponibili come dataframe, possiamo utilizzare la funzione relativa al data frame per leggere e manipolare il file.
Il file JSON memorizza i dati come testo in formato leggibile dall'uomo. Json sta per JavaScript Object Notation. R può leggere file JSON utilizzando il pacchetto rjson.
Installa il pacchetto rjson
Nella console R, puoi emettere il seguente comando per installare il pacchetto rjson.
install.packages("rjson")Dati in ingresso
Crea un file JSON copiando i dati seguenti in un editor di testo come il blocco note. Salva il file con estensione.json estensione e scegliendo il tipo di file come all files(*.*).
{
"ID":["1","2","3","4","5","6","7","8" ],
"Name":["Rick","Dan","Michelle","Ryan","Gary","Nina","Simon","Guru" ],
"Salary":["623.3","515.2","611","729","843.25","578","632.8","722.5" ],
"StartDate":[ "1/1/2012","9/23/2013","11/15/2014","5/11/2014","3/27/2015","5/21/2013",
"7/30/2013","6/17/2014"],
"Dept":[ "IT","Operations","IT","HR","Finance","IT","Operations","Finance"]
}Leggi il file JSON
Il file JSON viene letto da R utilizzando la funzione da JSON(). È memorizzato come elenco in R.
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Print the result.
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
$ID
[1] "1" "2" "3" "4" "5" "6" "7" "8"
$Name [1] "Rick" "Dan" "Michelle" "Ryan" "Gary" "Nina" "Simon" "Guru" $Salary
[1] "623.3" "515.2" "611" "729" "843.25" "578" "632.8" "722.5"
$StartDate [1] "1/1/2012" "9/23/2013" "11/15/2014" "5/11/2014" "3/27/2015" "5/21/2013" "7/30/2013" "6/17/2014" $Dept
[1] "IT" "Operations" "IT" "HR" "Finance" "IT"
"Operations" "Finance"Converti JSON in un frame di dati
Possiamo convertire i dati estratti sopra in un data frame R per ulteriori analisi utilizzando il as.data.frame() funzione.
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Convert JSON file to a data frame.
json_data_frame <- as.data.frame(result)
print(json_data_frame)Quando eseguiamo il codice sopra, produce il seguente risultato:
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceMolti siti Web forniscono dati per il consumo da parte dei propri utenti. Ad esempio, l'Organizzazione mondiale della sanità (OMS) fornisce rapporti su informazioni sanitarie e mediche sotto forma di file CSV, txt e XML. Utilizzando i programmi R, possiamo estrarre in modo programmatico dati specifici da tali siti Web. Alcuni pacchetti in R che vengono utilizzati per scartare i dati dal web sono - "RCurl", XML "e" stringr ". Sono usati per connettersi agli URL, identificare i collegamenti richiesti per i file e scaricarli nell'ambiente locale.
Installa pacchetti R.
I seguenti pacchetti sono necessari per l'elaborazione degli URL e dei collegamenti ai file. Se non sono disponibili nel tuo ambiente R, puoi installarli utilizzando i seguenti comandi.
install.packages("RCurl")
install.packages("XML")
install.packages("stringr")
install.packages("plyr")Dati in ingresso
Visiteremo i dati meteorologici dell'URL e scaricheremo i file CSV utilizzando R per l'anno 2015.
Esempio
Useremo la funzione getHTMLLinks()per raccogliere gli URL dei file. Quindi useremo la funzionedownload.file()per salvare i file nel sistema locale. Poiché applicheremo lo stesso codice ripetutamente per più file, creeremo una funzione da chiamare più volte. I nomi dei file vengono passati come parametri sotto forma di un oggetto elenco R a questa funzione.
# Read the URL.
url <- "http://www.geos.ed.ac.uk/~weather/jcmb_ws/"
# Gather the html links present in the webpage.
links <- getHTMLLinks(url)
# Identify only the links which point to the JCMB 2015 files.
filenames <- links[str_detect(links, "JCMB_2015")]
# Store the file names as a list.
filenames_list <- as.list(filenames)
# Create a function to download the files by passing the URL and filename list.
downloadcsv <- function (mainurl,filename) {
filedetails <- str_c(mainurl,filename)
download.file(filedetails,filename)
}
# Now apply the l_ply function and save the files into the current R working directory.
l_ply(filenames,downloadcsv,mainurl = "http://www.geos.ed.ac.uk/~weather/jcmb_ws/")Verifica il download del file
Dopo aver eseguito il codice precedente, è possibile individuare i seguenti file nella directory di lavoro corrente R.
"JCMB_2015.csv" "JCMB_2015_Apr.csv" "JCMB_2015_Feb.csv" "JCMB_2015_Jan.csv"
"JCMB_2015_Mar.csv"I dati sono sistemi di database relazionali sono memorizzati in un formato normalizzato. Quindi, per eseguire calcoli statistici avremo bisogno di query Sql molto avanzate e complesse. Ma R può connettersi facilmente a molti database relazionali come MySql, Oracle, server SQL ecc. E recuperare i record da essi come frame di dati. Una volta che i dati sono disponibili nell'ambiente R, diventano un normale set di dati R e possono essere manipolati o analizzati utilizzando tutti i potenti pacchetti e funzioni.
In questo tutorial utilizzeremo MySql come database di riferimento per la connessione a R.
Pacchetto RMySQL
R ha un pacchetto integrato denominato "RMySQL" che fornisce la connettività nativa tra il database MySql. È possibile installare questo pacchetto nell'ambiente R utilizzando il seguente comando.
install.packages("RMySQL")Collegamento di R a MySql
Una volta installato il pacchetto, creiamo un oggetto di connessione in R per connetterci al database. Prende il nome utente, la password, il nome del database e il nome host come input.
# Create a connection Object to MySQL database.
# We will connect to the sampel database named "sakila" that comes with MySql installation.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# List the tables available in this database.
dbListTables(mysqlconnection)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] "actor" "actor_info"
[3] "address" "category"
[5] "city" "country"
[7] "customer" "customer_list"
[9] "film" "film_actor"
[11] "film_category" "film_list"
[13] "film_text" "inventory"
[15] "language" "nicer_but_slower_film_list"
[17] "payment" "rental"
[19] "sales_by_film_category" "sales_by_store"
[21] "staff" "staff_list"
[23] "store"Interrogare le tabelle
Possiamo interrogare le tabelle del database in MySql usando la funzione dbSendQuery(). La query viene eseguita in MySql e il set di risultati viene restituito utilizzando Rfetch()funzione. Infine viene memorizzato come frame di dati in R.
# Query the "actor" tables to get all the rows.
result = dbSendQuery(mysqlconnection, "select * from actor")
# Store the result in a R data frame object. n = 5 is used to fetch first 5 rows.
data.frame = fetch(result, n = 5)
print(data.fame)Quando eseguiamo il codice sopra, produce il seguente risultato:
actor_id first_name last_name last_update
1 1 PENELOPE GUINESS 2006-02-15 04:34:33
2 2 NICK WAHLBERG 2006-02-15 04:34:33
3 3 ED CHASE 2006-02-15 04:34:33
4 4 JENNIFER DAVIS 2006-02-15 04:34:33
5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33Query con clausola di filtro
Possiamo passare qualsiasi query di selezione valida per ottenere il risultato.
result = dbSendQuery(mysqlconnection, "select * from actor where last_name = 'TORN'")
# Fetch all the records(with n = -1) and store it as a data frame.
data.frame = fetch(result, n = -1)
print(data)Quando eseguiamo il codice sopra, produce il seguente risultato:
actor_id first_name last_name last_update
1 18 DAN TORN 2006-02-15 04:34:33
2 94 KENNETH TORN 2006-02-15 04:34:33
3 102 WALTER TORN 2006-02-15 04:34:33Aggiornamento delle righe nelle tabelle
Possiamo aggiornare le righe in una tabella Mysql passando la query di aggiornamento alla funzione dbSendQuery ().
dbSendQuery(mysqlconnection, "update mtcars set disp = 168.5 where hp = 110")Dopo aver eseguito il codice sopra possiamo vedere la tabella aggiornata nell'ambiente MySql.
Inserimento di dati nelle tabelle
dbSendQuery(mysqlconnection,
"insert into mtcars(row_names, mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb)
values('New Mazda RX4 Wag', 21, 6, 168.5, 110, 3.9, 2.875, 17.02, 0, 1, 4, 4)"
)Dopo aver eseguito il codice sopra possiamo vedere la riga inserita nella tabella nell'ambiente MySql.
Creazione di tabelle in MySql
Possiamo creare tabelle in MySql usando la funzione dbWriteTable(). Sovrascrive la tabella se esiste già e prende un frame di dati come input.
# Create the connection object to the database where we want to create the table.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# Use the R data frame "mtcars" to create the table in MySql.
# All the rows of mtcars are taken inot MySql.
dbWriteTable(mysqlconnection, "mtcars", mtcars[, ], overwrite = TRUE)Dopo aver eseguito il codice sopra possiamo vedere la tabella creata nell'ambiente MySql.
Eliminazione di tabelle in MySql
Possiamo rilasciare le tabelle nel database MySql passando l'istruzione drop table in dbSendQuery () nello stesso modo in cui l'abbiamo usata per interrogare i dati dalle tabelle.
dbSendQuery(mysqlconnection, 'drop table if exists mtcars')Dopo aver eseguito il codice sopra, possiamo vedere che la tabella viene rilasciata nell'ambiente MySql.
Il linguaggio di programmazione R ha numerose librerie per creare grafici e tabelle. Un grafico a torta è una rappresentazione di valori come fette di un cerchio con colori diversi. Le sezioni vengono etichettate e nel grafico vengono rappresentati anche i numeri corrispondenti a ciascuna sezione.
In R il grafico a torta viene creato utilizzando il pie()funzione che accetta numeri positivi come input vettoriale. I parametri aggiuntivi vengono utilizzati per controllare etichette, colore, titolo ecc.
Sintassi
La sintassi di base per creare un grafico a torta usando la R è:
pie(x, labels, radius, main, col, clockwise)Di seguito la descrizione dei parametri utilizzati:
x è un vettore contenente i valori numerici utilizzati nel grafico a torta.
labels è usato per dare una descrizione alle fette.
radius indica il raggio del cerchio del grafico a torta (valore compreso tra −1 e +1).
main indica il titolo del grafico.
col indica la tavolozza dei colori.
clockwise è un valore logico che indica se le fette sono disegnate in senso orario o antiorario.
Esempio
Viene creato un grafico a torta molto semplice utilizzando solo il vettore di input e le etichette. Lo script seguente creerà e salverà il grafico a torta nella directory di lavoro corrente R.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city.png")
# Plot the chart.
pie(x,labels)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Titolo e colori del grafico a torta
Possiamo espandere le caratteristiche del grafico aggiungendo più parametri alla funzione. Useremo parametromain per aggiungere un titolo al grafico e un altro parametro è colche utilizzerà la tavolozza dei colori dell'arcobaleno durante il disegno del grafico. La lunghezza del pallet dovrebbe essere uguale al numero di valori che abbiamo per il grafico. Quindi usiamo length (x).
Esempio
Lo script seguente creerà e salverà il grafico a torta nella directory di lavoro corrente R.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city_title_colours.jpg")
# Plot the chart with title and rainbow color pallet.
pie(x, labels, main = "City pie chart", col = rainbow(length(x)))
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Percentuali di sezione e legenda del grafico
Possiamo aggiungere la percentuale della fetta e una legenda del grafico creando variabili del grafico aggiuntive.
# Create data for the graph.
x <- c(21, 62, 10,53)
labels <- c("London","New York","Singapore","Mumbai")
piepercent<- round(100*x/sum(x), 1)
# Give the chart file a name.
png(file = "city_percentage_legends.jpg")
# Plot the chart.
pie(x, labels = piepercent, main = "City pie chart",col = rainbow(length(x)))
legend("topright", c("London","New York","Singapore","Mumbai"), cex = 0.8,
fill = rainbow(length(x)))
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
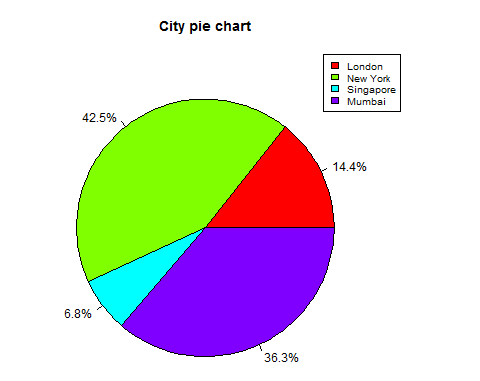
Grafico a torta 3D
Un grafico a torta con 3 dimensioni può essere disegnato utilizzando pacchetti aggiuntivi. Il pacchettoplotrix ha una funzione chiamata pie3D() che viene utilizzato per questo.
# Get the library.
library(plotrix)
# Create data for the graph.
x <- c(21, 62, 10,53)
lbl <- c("London","New York","Singapore","Mumbai")
# Give the chart file a name.
png(file = "3d_pie_chart.jpg")
# Plot the chart.
pie3D(x,labels = lbl,explode = 0.1, main = "Pie Chart of Countries ")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Un grafico a barre rappresenta i dati in barre rettangolari con lunghezza della barra proporzionale al valore della variabile. R utilizza la funzionebarplot()per creare grafici a barre. R può disegnare barre sia verticali che orizzontali nel grafico a barre. Nel grafico a barre a ciascuna delle barre possono essere assegnati colori diversi.
Sintassi
La sintassi di base per creare un grafico a barre in R è:
barplot(H,xlab,ylab,main, names.arg,col)Di seguito la descrizione dei parametri utilizzati:
- H è un vettore o una matrice contenente valori numerici utilizzati nel grafico a barre.
- xlab è l'etichetta per l'asse x.
- ylab è l'etichetta per l'asse y.
- main è il titolo del grafico a barre.
- names.arg è un vettore di nomi che appaiono sotto ogni barra.
- col viene utilizzato per dare colori alle barre nel grafico.
Esempio
Viene creato un semplice grafico a barre utilizzando solo il vettore di input e il nome di ciascuna barra.
Lo script seguente creerà e salverà il grafico a barre nella directory di lavoro R corrente.
# Create the data for the chart
H <- c(7,12,28,3,41)
# Give the chart file a name
png(file = "barchart.png")
# Plot the bar chart
barplot(H)
# Save the file
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Etichette, titolo e colori del grafico a barre
Le caratteristiche del grafico a barre possono essere ampliate aggiungendo più parametri. Ilmain parametro viene utilizzato per aggiungere title. Ilcolparametro viene utilizzato per aggiungere colori alle barre. Ilargs.name è un vettore avente lo stesso numero di valori del vettore di input per descrivere il significato di ciascuna barra.
Esempio
Lo script seguente creerà e salverà il grafico a barre nella directory di lavoro R corrente.
# Create the data for the chart
H <- c(7,12,28,3,41)
M <- c("Mar","Apr","May","Jun","Jul")
# Give the chart file a name
png(file = "barchart_months_revenue.png")
# Plot the bar chart
barplot(H,names.arg=M,xlab="Month",ylab="Revenue",col="blue",
main="Revenue chart",border="red")
# Save the file
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Grafico a barre di gruppo e grafico a barre in pila
Possiamo creare un grafico a barre con gruppi di barre e pile in ogni barra utilizzando una matrice come valori di input.
Più di due variabili sono rappresentate come una matrice che viene utilizzata per creare il grafico a barre di gruppo e il grafico a barre in pila.
# Create the input vectors.
colors = c("green","orange","brown")
months <- c("Mar","Apr","May","Jun","Jul")
regions <- c("East","West","North")
# Create the matrix of the values.
Values <- matrix(c(2,9,3,11,9,4,8,7,3,12,5,2,8,10,11), nrow = 3, ncol = 5, byrow = TRUE)
# Give the chart file a name
png(file = "barchart_stacked.png")
# Create the bar chart
barplot(Values, main = "total revenue", names.arg = months, xlab = "month", ylab = "revenue", col = colors)
# Add the legend to the chart
legend("topleft", regions, cex = 1.3, fill = colors)
# Save the file
dev.off()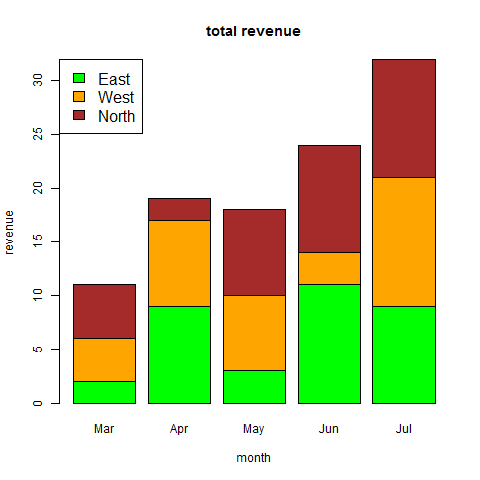
I boxplot sono una misura di quanto ben distribuiti sono i dati in un set di dati. Divide il set di dati in tre quartili. Questo grafico rappresenta il minimo, il massimo, la mediana, il primo quartile e il terzo quartile nel set di dati. È anche utile per confrontare la distribuzione dei dati tra i set di dati disegnando boxplot per ciascuno di essi.
I grafici a scatole vengono creati in R utilizzando il boxplot() funzione.
Sintassi
La sintassi di base per creare un boxplot in R è:
boxplot(x, data, notch, varwidth, names, main)Di seguito la descrizione dei parametri utilizzati:
x è un vettore o una formula.
data è il data frame.
notchè un valore logico. Imposta come TRUE per disegnare una tacca.
varwidthè un valore logico. Imposta come true per disegnare la larghezza della casella proporzionata alla dimensione del campione.
names sono le etichette di gruppo che verranno stampate sotto ogni boxplot.
main è usato per dare un titolo al grafico.
Esempio
Usiamo il set di dati "mtcars" disponibile nell'ambiente R per creare un boxplot di base. Diamo un'occhiata alle colonne "mpg" e "cil" in mtcars.
input <- mtcars[,c('mpg','cyl')]
print(head(input))Quando eseguiamo il codice sopra, produce il seguente risultato:
mpg cyl
Mazda RX4 21.0 6
Mazda RX4 Wag 21.0 6
Datsun 710 22.8 4
Hornet 4 Drive 21.4 6
Hornet Sportabout 18.7 8
Valiant 18.1 6Creazione del boxplot
Lo script seguente creerà un grafico a scatole per la relazione tra mpg (miglia per gallone) e cil (numero di cilindri).
# Give the chart file a name.
png(file = "boxplot.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars, xlab = "Number of Cylinders",
ylab = "Miles Per Gallon", main = "Mileage Data")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
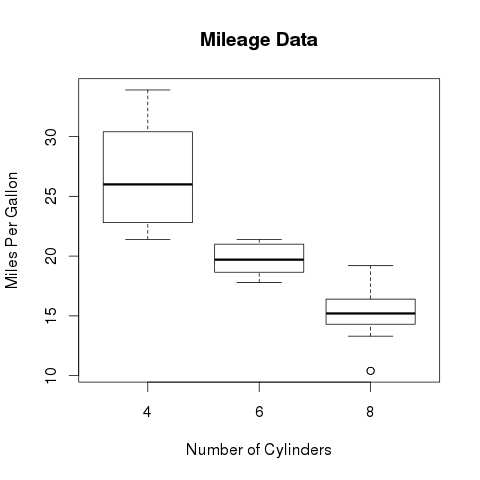
Boxplot con Notch
Possiamo disegnare un boxplot con notch per scoprire come le mediane di diversi gruppi di dati corrispondono tra loro.
Lo script seguente creerà un grafico a scatole con tacca per ciascuno dei gruppi di dati.
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars,
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon",
main = "Mileage Data",
notch = TRUE,
varwidth = TRUE,
col = c("green","yellow","purple"),
names = c("High","Medium","Low")
)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
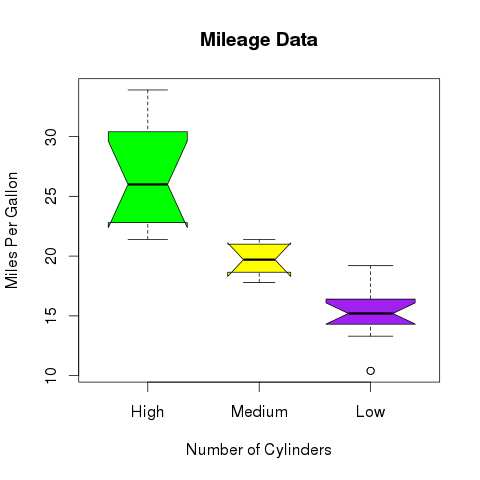
Un istogramma rappresenta le frequenze dei valori di una variabile suddivisa in intervalli. L'istogramma è simile alla chat bar, ma la differenza è che raggruppa i valori in intervalli continui. Ogni barra nell'istogramma rappresenta l'altezza del numero di valori presenti in quell'intervallo.
R crea l'istogramma usando hist()funzione. Questa funzione accetta un vettore come input e utilizza alcuni parametri in più per tracciare gli istogrammi.
Sintassi
La sintassi di base per creare un istogramma utilizzando R è:
hist(v,main,xlab,xlim,ylim,breaks,col,border)Di seguito la descrizione dei parametri utilizzati:
v è un vettore contenente valori numerici utilizzati nell'istogramma.
main indica il titolo del grafico.
col viene utilizzato per impostare il colore delle barre.
border viene utilizzato per impostare il colore del bordo di ciascuna barra.
xlab viene utilizzato per fornire una descrizione dell'asse x.
xlim viene utilizzato per specificare l'intervallo di valori sull'asse x.
ylim viene utilizzato per specificare l'intervallo di valori sull'asse y.
breaks è usato per menzionare la larghezza di ogni barra.
Esempio
Viene creato un semplice istogramma utilizzando i parametri di input vector, label, col e border.
Lo script fornito di seguito creerà e salverà l'istogramma nella directory di lavoro R corrente.
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "yellow",border = "blue")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
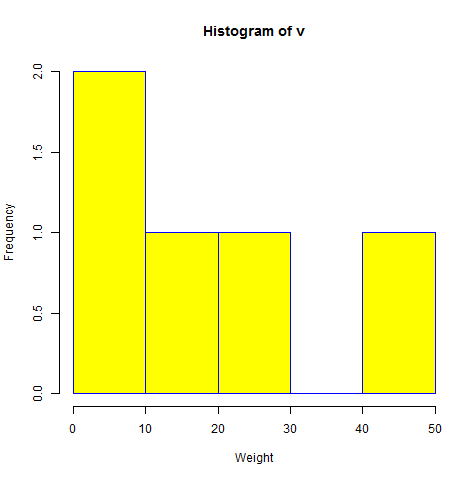
Intervallo di valori X e Y.
Per specificare l'intervallo di valori consentito nell'asse X e nell'asse Y, possiamo utilizzare i parametri xlim e ylim.
La larghezza di ciascuna barra può essere decisa utilizzando le interruzioni.
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram_lim_breaks.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "green",border = "red", xlim = c(0,40), ylim = c(0,5),
breaks = 5)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Un grafico a linee è un grafico che collega una serie di punti tracciando segmenti di linea tra di loro. Questi punti sono ordinati secondo uno dei loro valori di coordinate (di solito la coordinata x). I grafici a linee vengono solitamente utilizzati per identificare le tendenze nei dati.
Il plot() la funzione in R viene utilizzata per creare il grafico a linee.
Sintassi
La sintassi di base per creare un grafico a linee in R è:
plot(v,type,col,xlab,ylab)Di seguito la descrizione dei parametri utilizzati:
v è un vettore contenente i valori numerici.
type prende il valore "p" per disegnare solo i punti, "l" per disegnare solo le linee e "o" per disegnare sia i punti che le linee.
xlab è l'etichetta per l'asse x.
ylab è l'etichetta per l'asse y.
main è il titolo del grafico.
col è usato per dare colori sia ai punti che alle linee.
Esempio
Viene creato un semplice grafico a linee utilizzando il vettore di input e il parametro type come "O". Lo script seguente creerà e salverà un grafico a linee nella directory di lavoro R corrente.
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart.jpg")
# Plot the bar chart.
plot(v,type = "o")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Titolo, colore ed etichette del grafico a linee
Le funzionalità del grafico a linee possono essere espanse utilizzando parametri aggiuntivi. Aggiungiamo colore ai punti e alle linee, assegniamo un titolo al grafico e aggiungiamo etichette agli assi.
Esempio
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart_label_colored.jpg")
# Plot the bar chart.
plot(v,type = "o", col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Più linee in un grafico a linee
È possibile tracciare più di una linea sullo stesso grafico utilizzando il lines()funzione.
Dopo che la prima linea è stata tracciata, la funzione lines () può usare un vettore aggiuntivo come input per disegnare la seconda linea nel grafico,
# Create the data for the chart.
v <- c(7,12,28,3,41)
t <- c(14,7,6,19,3)
# Give the chart file a name.
png(file = "line_chart_2_lines.jpg")
# Plot the bar chart.
plot(v,type = "o",col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
lines(t, type = "o", col = "blue")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
I grafici a dispersione mostrano molti punti tracciati nel piano cartesiano. Ogni punto rappresenta i valori di due variabili. Una variabile viene scelta sull'asse orizzontale e un'altra sull'asse verticale.
Il semplice grafico a dispersione viene creato utilizzando il plot() funzione.
Sintassi
La sintassi di base per creare un grafico a dispersione in R è:
plot(x, y, main, xlab, ylab, xlim, ylim, axes)Di seguito la descrizione dei parametri utilizzati:
x è il set di dati i cui valori sono le coordinate orizzontali.
y è il set di dati i cui valori sono le coordinate verticali.
main è la tessera del grafico.
xlab è l'etichetta sull'asse orizzontale.
ylab è l'etichetta sull'asse verticale.
xlim sono i limiti dei valori di x utilizzati per la stampa.
ylim sono i limiti dei valori di y utilizzati per la stampa.
axes indica se entrambi gli assi devono essere disegnati sul grafico.
Esempio
Usiamo il set di dati "mtcars"disponibile nell'ambiente R per creare un grafico a dispersione di base. Usiamo le colonne "wt" e "mpg" in mtcars.
input <- mtcars[,c('wt','mpg')]
print(head(input))Quando eseguiamo il codice sopra, produce il seguente risultato:
wt mpg
Mazda RX4 2.620 21.0
Mazda RX4 Wag 2.875 21.0
Datsun 710 2.320 22.8
Hornet 4 Drive 3.215 21.4
Hornet Sportabout 3.440 18.7
Valiant 3.460 18.1Creazione del grafico a dispersione
Lo script seguente creerà un grafico a dispersione per la relazione tra wt (peso) e mpg (miglia per gallone).
# Get the input values.
input <- mtcars[,c('wt','mpg')]
# Give the chart file a name.
png(file = "scatterplot.png")
# Plot the chart for cars with weight between 2.5 to 5 and mileage between 15 and 30.
plot(x = input$wt,y = input$mpg,
xlab = "Weight",
ylab = "Milage",
xlim = c(2.5,5),
ylim = c(15,30),
main = "Weight vs Milage"
)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Matrici del grafico a dispersione
Quando abbiamo più di due variabili e vogliamo trovare la correlazione tra una variabile rispetto alle rimanenti, utilizziamo la matrice del grafico a dispersione. Noi usiamopairs() funzione per creare matrici di grafici a dispersione.
Sintassi
La sintassi di base per creare matrici di grafici a dispersione in R è:
pairs(formula, data)Di seguito la descrizione dei parametri utilizzati:
formula rappresenta la serie di variabili usate a coppie.
data rappresenta il set di dati da cui verranno prese le variabili.
Esempio
Ogni variabile è abbinata a ciascuna delle rimanenti variabili. Viene tracciato un grafico a dispersione per ciascuna coppia.
# Give the chart file a name.
png(file = "scatterplot_matrices.png")
# Plot the matrices between 4 variables giving 12 plots.
# One variable with 3 others and total 4 variables.
pairs(~wt+mpg+disp+cyl,data = mtcars,
main = "Scatterplot Matrix")
# Save the file.
dev.off()Quando il codice precedente viene eseguito, otteniamo il seguente output.
L'analisi statistica in R viene eseguita utilizzando molte funzioni integrate. La maggior parte di queste funzioni fa parte del pacchetto base R. Queste funzioni accettano il vettore R come input insieme agli argomenti e danno il risultato.
Le funzioni che stiamo discutendo in questo capitolo sono media, mediana e modo.
Significare
Viene calcolato prendendo la somma dei valori e dividendo per il numero di valori in una serie di dati.
La funzione mean() viene utilizzato per calcolare questo in R.
Sintassi
La sintassi di base per il calcolo della media in R è:
mean(x, trim = 0, na.rm = FALSE, ...)Di seguito la descrizione dei parametri utilizzati:
x è il vettore di input.
trim viene utilizzato per eliminare alcune osservazioni da entrambe le estremità del vettore ordinato.
na.rm viene utilizzato per rimuovere i valori mancanti dal vettore di input.
Esempio
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x)
print(result.mean)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 8.22Applicazione dell'opzione Trim
Quando viene fornito il parametro trim, i valori nel vettore vengono ordinati e quindi i numeri richiesti di osservazioni vengono eliminati dal calcolo della media.
Quando trim = 0,3, 3 valori da ciascuna estremità verranno eliminati dai calcoli per trovare la media.
In questo caso il vettore ordinato è (−21, −5, 2, 3, 4.2, 7, 8, 12, 18, 54) ei valori rimossi dal vettore per il calcolo della media sono (−21, −5,2) da sinistra e (12,18,54) da destra.
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x,trim = 0.3)
print(result.mean)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 5.55Applicazione dell'opzione NA
Se sono presenti valori mancanti, la funzione media restituisce NA.
Per eliminare i valori mancanti dal calcolo, utilizzare na.rm = TRUE. il che significa rimuovere i valori NA.
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5,NA)
# Find mean.
result.mean <- mean(x)
print(result.mean)
# Find mean dropping NA values.
result.mean <- mean(x,na.rm = TRUE)
print(result.mean)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] NA
[1] 8.22Mediano
Il valore più medio in una serie di dati è chiamato mediana. Ilmedian() viene utilizzata in R per calcolare questo valore.
Sintassi
La sintassi di base per il calcolo della mediana in R è:
median(x, na.rm = FALSE)Di seguito la descrizione dei parametri utilizzati:
x è il vettore di input.
na.rm viene utilizzato per rimuovere i valori mancanti dal vettore di input.
Esempio
# Create the vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find the median.
median.result <- median(x)
print(median.result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 5.6Modalità
La modalità è il valore con il maggior numero di occorrenze in un insieme di dati. Media e mediana Unike, la modalità può avere sia dati numerici che caratteri.
R non ha una funzione incorporata standard per calcolare la modalità. Quindi creiamo una funzione utente per calcolare la modalità di un set di dati in R. Questa funzione prende il vettore come input e fornisce il valore della modalità come output.
Esempio
# Create the function.
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
# Create the vector with numbers.
v <- c(2,1,2,3,1,2,3,4,1,5,5,3,2,3)
# Calculate the mode using the user function.
result <- getmode(v)
print(result)
# Create the vector with characters.
charv <- c("o","it","the","it","it")
# Calculate the mode using the user function.
result <- getmode(charv)
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 2
[1] "it"L'analisi di regressione è uno strumento statistico molto diffuso per stabilire un modello di relazione tra due variabili. Una di queste variabili è chiamata variabile predittore il cui valore viene raccolto tramite esperimenti. L'altra variabile è chiamata variabile di risposta il cui valore è derivato dalla variabile predittore.
Nella regressione lineare queste due variabili sono correlate tramite un'equazione, dove l'esponente (potenza) di entrambe queste variabili è 1. Matematicamente una relazione lineare rappresenta una linea retta quando tracciata come grafico. Una relazione non lineare in cui l'esponente di qualsiasi variabile non è uguale a 1 crea una curva.
L'equazione matematica generale per una regressione lineare è:
y = ax + bDi seguito la descrizione dei parametri utilizzati:
y è la variabile di risposta.
x è la variabile predittore.
a e b sono costanti chiamate coefficienti.
Passaggi per stabilire una regressione
Un semplice esempio di regressione è prevedere il peso di una persona quando la sua altezza è nota. Per fare questo dobbiamo avere il rapporto tra altezza e peso di una persona.
I passaggi per creare la relazione sono:
Eseguire l'esperimento di raccolta di un campione dei valori osservati di altezza e peso corrispondente.
Crea un modello di relazione utilizzando il lm() funzioni in R.
Trova i coefficienti dal modello creato e crea l'equazione matematica usando questi
Ottieni un riepilogo del modello di relazione per conoscere l'errore medio nella previsione. Chiamato ancheresiduals.
Per prevedere il peso di nuove persone, utilizzare il predict() funzione in R.
Dati in ingresso
Di seguito sono riportati i dati campione che rappresentano le osservazioni:
# Values of height
151, 174, 138, 186, 128, 136, 179, 163, 152, 131
# Values of weight.
63, 81, 56, 91, 47, 57, 76, 72, 62, 48Funzione lm ()
Questa funzione crea il modello di relazione tra il predittore e la variabile di risposta.
Sintassi
La sintassi di base per lm() funzione nella regressione lineare è -
lm(formula,data)Di seguito la descrizione dei parametri utilizzati:
formula è un simbolo che presenta la relazione tra x e y.
data è il vettore su cui verrà applicata la formula.
Crea un modello di relazione e ottieni i coefficienti
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(relation)Quando eseguiamo il codice sopra, produce il seguente risultato:
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-38.4551 0.6746Ottieni il riepilogo della relazione
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(summary(relation))Quando eseguiamo il codice sopra, produce il seguente risultato:
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-6.3002 -1.6629 0.0412 1.8944 3.9775
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -38.45509 8.04901 -4.778 0.00139 **
x 0.67461 0.05191 12.997 1.16e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.253 on 8 degrees of freedom
Multiple R-squared: 0.9548, Adjusted R-squared: 0.9491
F-statistic: 168.9 on 1 and 8 DF, p-value: 1.164e-06Funzione predicire ()
Sintassi
La sintassi di base per predire () nella regressione lineare è:
predict(object, newdata)Di seguito la descrizione dei parametri utilizzati:
object è la formula che è già stata creata utilizzando la funzione lm ().
newdata è il vettore contenente il nuovo valore per la variabile predittore.
Prevedi il peso delle nuove persone
# The predictor vector.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
# The resposne vector.
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
# Find weight of a person with height 170.
a <- data.frame(x = 170)
result <- predict(relation,a)
print(result)Quando eseguiamo il codice sopra, produce il seguente risultato:
1
76.22869Visualizza graficamente la regressione
# Create the predictor and response variable.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
relation <- lm(y~x)
# Give the chart file a name.
png(file = "linearregression.png")
# Plot the chart.
plot(y,x,col = "blue",main = "Height & Weight Regression",
abline(lm(x~y)),cex = 1.3,pch = 16,xlab = "Weight in Kg",ylab = "Height in cm")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
La regressione multipla è un'estensione della regressione lineare in relazione tra più di due variabili. Nella relazione lineare semplice abbiamo un predittore e una variabile di risposta, ma nella regressione multipla abbiamo più di una variabile predittore e una variabile di risposta.
L'equazione matematica generale per la regressione multipla è:
y = a + b1x1 + b2x2 +...bnxnDi seguito la descrizione dei parametri utilizzati:
y è la variabile di risposta.
a, b1, b2...bn sono i coefficienti.
x1, x2, ...xn sono le variabili predittive.
Creiamo il modello di regressione utilizzando il lm()funzione in R. Il modello determina il valore dei coefficienti utilizzando i dati di input. Successivamente possiamo prevedere il valore della variabile di risposta per un dato insieme di variabili predittore utilizzando questi coefficienti.
Funzione lm ()
Questa funzione crea il modello di relazione tra il predittore e la variabile di risposta.
Sintassi
La sintassi di base per lm() la funzione nella regressione multipla è -
lm(y ~ x1+x2+x3...,data)Di seguito la descrizione dei parametri utilizzati:
formula è un simbolo che presenta la relazione tra la variabile di risposta e le variabili predittive.
data è il vettore su cui verrà applicata la formula.
Esempio
Dati in ingresso
Considera il set di dati "mtcars" disponibile nell'ambiente R. Fornisce un confronto tra i diversi modelli di auto in termini di chilometraggio per gallone (mpg), cilindrata ("disp"), potenza del motore ("hp"), peso dell'auto ("wt") e altri parametri.
L'obiettivo del modello è stabilire la relazione tra "mpg" come variabile di risposta con "disp", "hp" e "wt" come variabili predittive. A questo scopo creiamo un sottoinsieme di queste variabili dal set di dati mtcars.
input <- mtcars[,c("mpg","disp","hp","wt")]
print(head(input))Quando eseguiamo il codice sopra, produce il seguente risultato:
mpg disp hp wt
Mazda RX4 21.0 160 110 2.620
Mazda RX4 Wag 21.0 160 110 2.875
Datsun 710 22.8 108 93 2.320
Hornet 4 Drive 21.4 258 110 3.215
Hornet Sportabout 18.7 360 175 3.440
Valiant 18.1 225 105 3.460Crea un modello di relazione e ottieni i coefficienti
input <- mtcars[,c("mpg","disp","hp","wt")]
# Create the relationship model.
model <- lm(mpg~disp+hp+wt, data = input)
# Show the model.
print(model)
# Get the Intercept and coefficients as vector elements.
cat("# # # # The Coefficient Values # # # ","\n")
a <- coef(model)[1]
print(a)
Xdisp <- coef(model)[2]
Xhp <- coef(model)[3]
Xwt <- coef(model)[4]
print(Xdisp)
print(Xhp)
print(Xwt)Quando eseguiamo il codice sopra, produce il seguente risultato:
Call:
lm(formula = mpg ~ disp + hp + wt, data = input)
Coefficients:
(Intercept) disp hp wt
37.105505 -0.000937 -0.031157 -3.800891
# # # # The Coefficient Values # # #
(Intercept)
37.10551
disp
-0.0009370091
hp
-0.03115655
wt
-3.800891Crea equazione per modello di regressione
Sulla base dei valori di intercetta e coefficiente di cui sopra, creiamo l'equazione matematica.
Y = a+Xdisp.x1+Xhp.x2+Xwt.x3
or
Y = 37.15+(-0.000937)*x1+(-0.0311)*x2+(-3.8008)*x3Applica equazione per la previsione di nuovi valori
Possiamo utilizzare l'equazione di regressione creata sopra per prevedere il chilometraggio quando viene fornito un nuovo set di valori per spostamento, potenza e peso.
Per un'auto con disp = 221, hp = 102 e wt = 2,91 il chilometraggio previsto è -
Y = 37.15+(-0.000937)*221+(-0.0311)*102+(-3.8008)*2.91 = 22.7104La regressione logistica è un modello di regressione in cui la variabile di risposta (variabile dipendente) ha valori categoriali come Vero / Falso o 0/1. In realtà misura la probabilità di una risposta binaria come il valore della variabile di risposta in base all'equazione matematica che la mette in relazione con le variabili predittive.
L'equazione matematica generale per la regressione logistica è:
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))Di seguito la descrizione dei parametri utilizzati:
y è la variabile di risposta.
x è la variabile predittore.
a e b sono i coefficienti che sono costanti numeriche.
La funzione utilizzata per creare il modello di regressione è glm() funzione.
Sintassi
La sintassi di base per glm() la funzione nella regressione logistica è:
glm(formula,data,family)Di seguito la descrizione dei parametri utilizzati:
formula è il simbolo che presenta la relazione tra le variabili.
data è il set di dati che fornisce i valori di queste variabili.
familyè un oggetto R per specificare i dettagli del modello. Il suo valore è binomiale per la regressione logistica.
Esempio
Il set di dati integrato "mtcars" descrive diversi modelli di un'auto con le loro varie specifiche del motore. Nel dataset "mtcars" la modalità di trasmissione (automatica o manuale) è descritta dalla colonna am che è un valore binario (0 o 1). Possiamo creare un modello di regressione logistica tra le colonne "am" e altre 3 colonne: hp, wt e cil.
# Select some columns form mtcars.
input <- mtcars[,c("am","cyl","hp","wt")]
print(head(input))Quando eseguiamo il codice sopra, produce il seguente risultato:
am cyl hp wt
Mazda RX4 1 6 110 2.620
Mazda RX4 Wag 1 6 110 2.875
Datsun 710 1 4 93 2.320
Hornet 4 Drive 0 6 110 3.215
Hornet Sportabout 0 8 175 3.440
Valiant 0 6 105 3.460Crea modello di regressione
Noi usiamo il glm() funzione per creare il modello di regressione e ottenere il suo riepilogo per l'analisi.
input <- mtcars[,c("am","cyl","hp","wt")]
am.data = glm(formula = am ~ cyl + hp + wt, data = input, family = binomial)
print(summary(am.data))Quando eseguiamo il codice sopra, produce il seguente risultato:
Call:
glm(formula = am ~ cyl + hp + wt, family = binomial, data = input)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.17272 -0.14907 -0.01464 0.14116 1.27641
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 19.70288 8.11637 2.428 0.0152 *
cyl 0.48760 1.07162 0.455 0.6491
hp 0.03259 0.01886 1.728 0.0840 .
wt -9.14947 4.15332 -2.203 0.0276 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.2297 on 31 degrees of freedom
Residual deviance: 9.8415 on 28 degrees of freedom
AIC: 17.841
Number of Fisher Scoring iterations: 8Conclusione
Nel riepilogo, poiché il valore p nell'ultima colonna è maggiore di 0,05 per le variabili "cil" e "hp", le consideriamo non significative nel contribuire al valore della variabile "am". Solo il peso (wt) influisce sul valore "am" in questo modello di regressione.
In una raccolta casuale di dati da fonti indipendenti, si osserva generalmente che la distribuzione dei dati è normale. Ciò significa che, tracciando un grafico con il valore della variabile sull'asse orizzontale e il conteggio dei valori sull'asse verticale, otteniamo una curva a campana. Il centro della curva rappresenta la media del set di dati. Nel grafico, il cinquanta percento dei valori si trova a sinistra della media e l'altro cinquanta percento si trova a destra del grafico. Questa viene definita distribuzione normale nelle statistiche.
R ha quattro funzioni integrate per generare la distribuzione normale. Sono descritti di seguito.
dnorm(x, mean, sd)
pnorm(x, mean, sd)
qnorm(p, mean, sd)
rnorm(n, mean, sd)Di seguito è riportata la descrizione dei parametri utilizzati nelle funzioni di cui sopra:
x è un vettore di numeri.
p è un vettore di probabilità.
n è il numero di osservazioni (dimensione del campione).
meanè il valore medio dei dati del campione. Il suo valore predefinito è zero.
sdè la deviazione standard. Il valore predefinito è 1.
dnorm ()
Questa funzione fornisce l'altezza della distribuzione di probabilità in ogni punto per una data media e deviazione standard.
# Create a sequence of numbers between -10 and 10 incrementing by 0.1.
x <- seq(-10, 10, by = .1)
# Choose the mean as 2.5 and standard deviation as 0.5.
y <- dnorm(x, mean = 2.5, sd = 0.5)
# Give the chart file a name.
png(file = "dnorm.png")
plot(x,y)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
pnorm ()
Questa funzione fornisce la probabilità che un numero casuale distribuito normalmente sia inferiore al valore di un dato numero. È anche chiamata "Funzione di distribuzione cumulativa".
# Create a sequence of numbers between -10 and 10 incrementing by 0.2.
x <- seq(-10,10,by = .2)
# Choose the mean as 2.5 and standard deviation as 2.
y <- pnorm(x, mean = 2.5, sd = 2)
# Give the chart file a name.
png(file = "pnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
qnorm ()
Questa funzione prende il valore di probabilità e fornisce un numero il cui valore cumulativo corrisponde al valore di probabilità.
# Create a sequence of probability values incrementing by 0.02.
x <- seq(0, 1, by = 0.02)
# Choose the mean as 2 and standard deviation as 3.
y <- qnorm(x, mean = 2, sd = 1)
# Give the chart file a name.
png(file = "qnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
rnorm ()
Questa funzione viene utilizzata per generare numeri casuali la cui distribuzione è normale. Prende la dimensione del campione come input e genera tanti numeri casuali. Disegniamo un istogramma per mostrare la distribuzione dei numeri generati.
# Create a sample of 50 numbers which are normally distributed.
y <- rnorm(50)
# Give the chart file a name.
png(file = "rnorm.png")
# Plot the histogram for this sample.
hist(y, main = "Normal DIstribution")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
Il modello di distribuzione binomiale si occupa di trovare la probabilità di successo di un evento che ha solo due possibili esiti in una serie di esperimenti. Ad esempio, il lancio di una moneta dà sempre una testa o una coda. La probabilità di trovare esattamente 3 teste nel lanciare una moneta ripetutamente per 10 volte è stimata durante la distribuzione binomiale.
R ha quattro funzioni integrate per generare la distribuzione binomiale. Sono descritti di seguito.
dbinom(x, size, prob)
pbinom(x, size, prob)
qbinom(p, size, prob)
rbinom(n, size, prob)Di seguito la descrizione dei parametri utilizzati:
x è un vettore di numeri.
p è un vettore di probabilità.
n è il numero di osservazioni.
size è il numero di prove.
prob è la probabilità di successo di ogni prova.
dbinom ()
Questa funzione fornisce la distribuzione della densità di probabilità in ogni punto.
# Create a sample of 50 numbers which are incremented by 1.
x <- seq(0,50,by = 1)
# Create the binomial distribution.
y <- dbinom(x,50,0.5)
# Give the chart file a name.
png(file = "dbinom.png")
# Plot the graph for this sample.
plot(x,y)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
pbinom ()
Questa funzione fornisce la probabilità cumulativa di un evento. È un singolo valore che rappresenta la probabilità.
# Probability of getting 26 or less heads from a 51 tosses of a coin.
x <- pbinom(26,51,0.5)
print(x)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 0.610116qbinom ()
Questa funzione prende il valore di probabilità e fornisce un numero il cui valore cumulativo corrisponde al valore di probabilità.
# How many heads will have a probability of 0.25 will come out when a coin
# is tossed 51 times.
x <- qbinom(0.25,51,1/2)
print(x)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 23rbinom ()
Questa funzione genera il numero richiesto di valori casuali di una data probabilità da un dato campione.
# Find 8 random values from a sample of 150 with probability of 0.4.
x <- rbinom(8,150,.4)
print(x)Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 58 61 59 66 55 60 61 67La regressione di Poisson coinvolge modelli di regressione in cui la variabile di risposta è sotto forma di conteggi e non di numeri frazionari. Ad esempio, il conteggio del numero di nascite o il numero di vittorie in una serie di partite di calcio. Anche i valori delle variabili di risposta seguono una distribuzione di Poisson.
L'equazione matematica generale per la regressione di Poisson è:
log(y) = a + b1x1 + b2x2 + bnxn.....Di seguito la descrizione dei parametri utilizzati:
y è la variabile di risposta.
a e b sono i coefficienti numerici.
x è la variabile predittore.
La funzione utilizzata per creare il modello di regressione di Poisson è la glm() funzione.
Sintassi
La sintassi di base per glm() funzione nella regressione di Poisson è -
glm(formula,data,family)Di seguito è riportata la descrizione dei parametri utilizzati nelle funzioni di cui sopra:
formula è il simbolo che presenta la relazione tra le variabili.
data è il set di dati che fornisce i valori di queste variabili.
familyè un oggetto R per specificare i dettagli del modello. Il suo valore è "Poisson" per la regressione logistica.
Esempio
Abbiamo il set di dati integrato "warpbreak" che descrive l'effetto del tipo di lana (A o B) e della tensione (bassa, media o alta) sul numero di rotture di ordito per telaio. Consideriamo le "pause" come la variabile di risposta che è un conteggio del numero di interruzioni. Il "tipo" e la "tensione" della lana vengono presi come variabili predittive.
Input Data
input <- warpbreaks
print(head(input))Quando eseguiamo il codice sopra, produce il seguente risultato:
breaks wool tension
1 26 A L
2 30 A L
3 54 A L
4 25 A L
5 70 A L
6 52 A LCrea modello di regressione
output <-glm(formula = breaks ~ wool+tension, data = warpbreaks,
family = poisson)
print(summary(output))Quando eseguiamo il codice sopra, produce il seguente risultato:
Call:
glm(formula = breaks ~ wool + tension, family = poisson, data = warpbreaks)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.6871 -1.6503 -0.4269 1.1902 4.2616
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69196 0.04541 81.302 < 2e-16 ***
woolB -0.20599 0.05157 -3.994 6.49e-05 ***
tensionM -0.32132 0.06027 -5.332 9.73e-08 ***
tensionH -0.51849 0.06396 -8.107 5.21e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 297.37 on 53 degrees of freedom
Residual deviance: 210.39 on 50 degrees of freedom
AIC: 493.06
Number of Fisher Scoring iterations: 4Nel riepilogo cerchiamo che il valore p nell'ultima colonna sia inferiore a 0,05 per considerare un impatto della variabile predittore sulla variabile di risposta. Come visto il tipo di lana B con tensione di tipo M e H ha un impatto sul conteggio delle rotture.
Usiamo l'analisi di regressione per creare modelli che descrivono l'effetto della variazione nelle variabili predittori sulla variabile di risposta. A volte, se abbiamo una variabile categoriale con valori come Sì / No o Maschio / Femmina ecc. La semplice analisi di regressione fornisce più risultati per ogni valore della variabile categoriale. In tale scenario, possiamo studiare l'effetto della variabile categoriale utilizzandola insieme alla variabile predittore e confrontando le linee di regressione per ogni livello della variabile categoriale. Tale analisi è definita comeAnalysis of Covariance chiamato anche come ANCOVA.
Esempio
Considera il set di dati R incorporato mtcars. In esso osserviamo che il campo "sono" rappresenta il tipo di trasmissione (automatica o manuale). È una variabile categoriale con valori 0 e 1. Da essa può dipendere anche il valore di miglia per gallone (mpg) di un'auto oltre al valore della potenza del motore ("hp").
Studiamo l'effetto del valore di "am" sulla regressione tra "mpg" e "hp". È fatto usando ilaov() funzione seguita dal anova() funzione per confrontare le regressioni multiple.
Dati in ingresso
Crea un data frame contenente i campi "mpg", "hp" e "am" dal data set mtcars. Qui prendiamo "mpg" come variabile di risposta, "hp" come variabile predittore e "am" come variabile categoriale.
input <- mtcars[,c("am","mpg","hp")]
print(head(input))Quando eseguiamo il codice sopra, produce il seguente risultato:
am mpg hp
Mazda RX4 1 21.0 110
Mazda RX4 Wag 1 21.0 110
Datsun 710 1 22.8 93
Hornet 4 Drive 0 21.4 110
Hornet Sportabout 0 18.7 175
Valiant 0 18.1 105ANCOVA Analisi
Creiamo un modello di regressione prendendo "hp" come variabile predittore e "mpg" come variabile di risposta tenendo conto dell'interazione tra "am" e "hp".
Modello con interazione tra variabile categoriale e variabile predittiva
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp*am,data = input)
print(summary(result))Quando eseguiamo il codice sopra, produce il seguente risultato:
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 77.391 1.50e-09 ***
am 1 202.2 202.2 23.072 4.75e-05 ***
hp:am 1 0.0 0.0 0.001 0.981
Residuals 28 245.4 8.8
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Questo risultato mostra che sia la potenza che il tipo di trasmissione hanno un effetto significativo sulle miglia per gallone poiché il valore p in entrambi i casi è inferiore a 0,05. Ma l'interazione tra queste due variabili non è significativa poiché il valore p è superiore a 0,05.
Modello senza interazione tra variabile categoriale e variabile predittiva
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp+am,data = input)
print(summary(result))Quando eseguiamo il codice sopra, produce il seguente risultato:
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 80.15 7.63e-10 ***
am 1 202.2 202.2 23.89 3.46e-05 ***
Residuals 29 245.4 8.5
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Questo risultato mostra che sia la potenza che il tipo di trasmissione hanno un effetto significativo sulle miglia per gallone poiché il valore p in entrambi i casi è inferiore a 0,05.
Confronto di due modelli
Ora possiamo confrontare i due modelli per concludere se l'interazione delle variabili è veramente non significativa. Per questo usiamo ilanova() funzione.
# Get the dataset.
input <- mtcars
# Create the regression models.
result1 <- aov(mpg~hp*am,data = input)
result2 <- aov(mpg~hp+am,data = input)
# Compare the two models.
print(anova(result1,result2))Quando eseguiamo il codice sopra, produce il seguente risultato:
Model 1: mpg ~ hp * am
Model 2: mpg ~ hp + am
Res.Df RSS Df Sum of Sq F Pr(>F)
1 28 245.43
2 29 245.44 -1 -0.0052515 6e-04 0.9806Poiché il valore p è maggiore di 0,05, concludiamo che l'interazione tra la potenza del motore e il tipo di trasmissione non è significativa. Quindi il chilometraggio per gallone dipenderà in modo simile dalla potenza del motore dell'auto sia in modalità di trasmissione automatica che manuale.
Le serie temporali sono una serie di punti dati in cui ogni punto dati è associato a un timestamp. Un semplice esempio è il prezzo di un'azione nel mercato azionario in diversi momenti in un dato giorno. Un altro esempio è la quantità di pioggia in una regione in diversi mesi dell'anno. Il linguaggio R utilizza molte funzioni per creare, manipolare e tracciare i dati delle serie temporali. I dati per la serie temporale vengono archiviati in un oggetto R chiamatotime-series object. È anche un oggetto dati R come un vettore o un data frame.
L'oggetto della serie temporale viene creato utilizzando l'estensione ts() funzione.
Sintassi
La sintassi di base per ts() la funzione nell'analisi delle serie temporali è:
timeseries.object.name <- ts(data, start, end, frequency)Di seguito la descrizione dei parametri utilizzati:
data è un vettore o una matrice contenente i valori utilizzati nelle serie temporali.
start specifica l'ora di inizio per la prima osservazione nelle serie temporali.
end specifica l'ora di fine dell'ultima osservazione nelle serie temporali.
frequency specifica il numero di osservazioni per unità di tempo.
Ad eccezione del parametro "dati", tutti gli altri parametri sono opzionali.
Esempio
Considera i dettagli delle precipitazioni annuali in un luogo a partire da gennaio 2012. Creiamo un oggetto serie temporale R per un periodo di 12 mesi e lo tracciamo.
# Get the data points in form of a R vector.
rainfall <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
# Convert it to a time series object.
rainfall.timeseries <- ts(rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall.png")
# Plot a graph of the time series.
plot(rainfall.timeseries)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato e grafico:
Jan Feb Mar Apr May Jun Jul Aug Sep
2012 799.0 1174.8 865.1 1334.6 635.4 918.5 685.5 998.6 784.2
Oct Nov Dec
2012 985.0 882.8 1071.0Il grafico delle serie temporali -
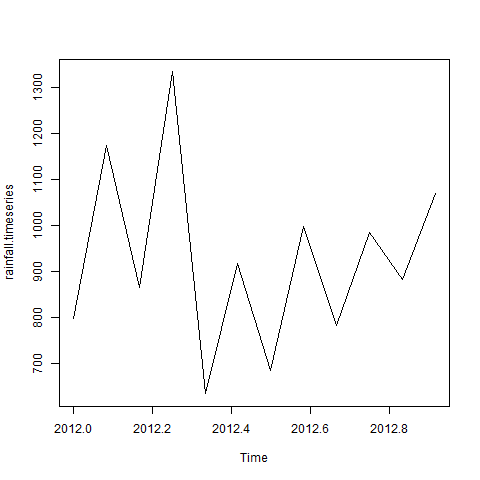
Intervalli di tempo diversi
Il valore di frequencyparametro nella funzione ts () decide gli intervalli di tempo in cui vengono misurati i punti dati. Un valore di 12 indica che la serie temporale è per 12 mesi. Altri valori e il loro significato sono i seguenti:
frequency = 12 fissa i punti dati per ogni mese dell'anno.
frequency = 4 fissa i punti dati per ogni trimestre dell'anno.
frequency = 6 fissa i punti dati per ogni 10 minuti di un'ora.
frequency = 24*6 fissa i punti dati per ogni 10 minuti di un giorno.
Serie temporali multiple
Possiamo tracciare più serie temporali in un grafico combinando entrambe le serie in una matrice.
# Get the data points in form of a R vector.
rainfall1 <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
rainfall2 <-
c(655,1306.9,1323.4,1172.2,562.2,824,822.4,1265.5,799.6,1105.6,1106.7,1337.8)
# Convert them to a matrix.
combined.rainfall <- matrix(c(rainfall1,rainfall2),nrow = 12)
# Convert it to a time series object.
rainfall.timeseries <- ts(combined.rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall_combined.png")
# Plot a graph of the time series.
plot(rainfall.timeseries, main = "Multiple Time Series")
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato e grafico:
Series 1 Series 2
Jan 2012 799.0 655.0
Feb 2012 1174.8 1306.9
Mar 2012 865.1 1323.4
Apr 2012 1334.6 1172.2
May 2012 635.4 562.2
Jun 2012 918.5 824.0
Jul 2012 685.5 822.4
Aug 2012 998.6 1265.5
Sep 2012 784.2 799.6
Oct 2012 985.0 1105.6
Nov 2012 882.8 1106.7
Dec 2012 1071.0 1337.8Il grafico delle serie temporali multiple -
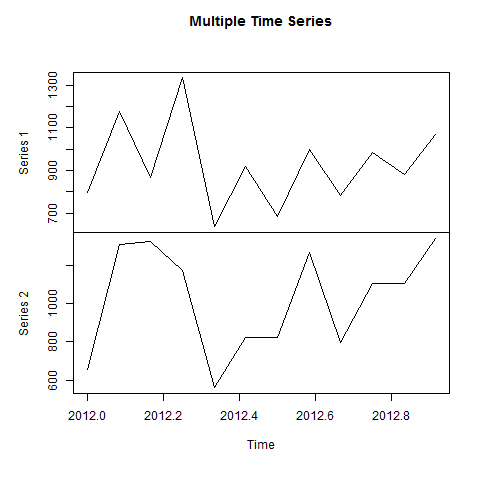
Quando si modellano i dati del mondo reale per l'analisi di regressione, si osserva che è raro che l'equazione del modello sia un'equazione lineare che fornisce un grafico lineare. Il più delle volte, l'equazione del modello dei dati del mondo reale coinvolge funzioni matematiche di grado più elevato come un esponente di 3 o una funzione sin. In un tale scenario, il grafico del modello fornisce una curva piuttosto che una linea. L'obiettivo della regressione lineare e non lineare è regolare i valori dei parametri del modello per trovare la linea o la curva che si avvicina di più ai dati. Trovando questi valori saremo in grado di stimare la variabile di risposta con buona precisione.
Nella regressione dei minimi quadrati, stabiliamo un modello di regressione in cui la somma dei quadrati delle distanze verticali di diversi punti dalla curva di regressione è ridotta al minimo. In genere iniziamo con un modello definito e assumiamo alcuni valori per i coefficienti. Quindi applichiamo ilnls() funzione di R per ottenere i valori più accurati insieme agli intervalli di confidenza.
Sintassi
La sintassi di base per creare un test dei minimi quadrati non lineare in R è:
nls(formula, data, start)Di seguito la descrizione dei parametri utilizzati:
formula è una formula del modello non lineare che include variabili e parametri.
data è un data frame utilizzato per valutare le variabili nella formula.
start è una lista con nome o un vettore numerico con nome di stime iniziali.
Esempio
Considereremo un modello non lineare con l'assunzione dei valori iniziali dei suoi coefficienti. Successivamente vedremo quali sono gli intervalli di confidenza di questi valori presunti in modo da poter giudicare quanto bene questi valori siano inseriti nel modello.
Quindi consideriamo l'equazione seguente per questo scopo:
a = b1*x^2+b2Supponiamo che i coefficienti iniziali siano 1 e 3 e adattiamo questi valori alla funzione nls ().
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))Quando eseguiamo il codice sopra, produce il seguente risultato:
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484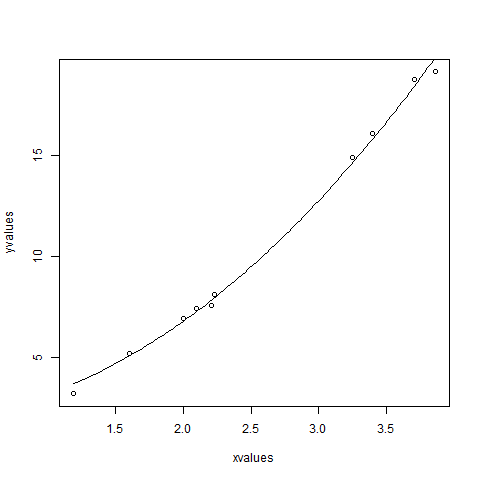
Possiamo concludere che il valore di b1 è più vicino a 1 mentre il valore di b2 è più vicino a 2 e non a 3.
L'albero decisionale è un grafico per rappresentare le scelte ei loro risultati sotto forma di albero. I nodi nel grafico rappresentano un evento o una scelta e i bordi del grafico rappresentano le regole o le condizioni di decisione. Viene utilizzato principalmente nelle applicazioni di Machine Learning e Data Mining che utilizzano R.
Esempi di utilizzo del tress decisionale sono: prevedere un'e-mail come spam o non spam, prevedere un tumore canceroso o prevedere un prestito come un rischio di credito buono o cattivo in base ai fattori di ciascuno di questi. In genere, viene creato un modello con i dati osservati chiamati anche dati di addestramento. Quindi una serie di dati di convalida viene utilizzata per verificare e migliorare il modello. R ha pacchetti che vengono utilizzati per creare e visualizzare alberi decisionali. Per il nuovo set di variabili predittive, utilizziamo questo modello per arrivare a una decisione sulla categoria (sì / no, spam / non spam) dei dati.
Il pacchetto R. "party" viene utilizzato per creare alberi decisionali.
Installa il pacchetto R.
Utilizzare il comando seguente nella console R per installare il pacchetto. È inoltre necessario installare i pacchetti dipendenti, se presenti.
install.packages("party")Il pacchetto "party" ha la funzione ctree() che viene utilizzato per creare e analizzare l'albero decisionale.
Sintassi
La sintassi di base per creare un albero decisionale in R è:
ctree(formula, data)Di seguito la descrizione dei parametri utilizzati:
formula è una formula che descrive il predittore e le variabili di risposta.
data è il nome del set di dati utilizzato.
Dati in ingresso
Useremo il set di dati R in-built denominato readingSkillsper creare un albero decisionale. Descrive il punteggio delle capacità di lettura di qualcuno se conosciamo le variabili "età", "taglia", "punteggio" e se la persona è madrelingua o meno.
Ecco i dati di esempio.
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))Quando eseguiamo il codice sopra, produce il seguente risultato e grafico:
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................Esempio
Useremo il file ctree() funzione per creare l'albero decisionale e vederne il grafico.
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Create the input data frame.
input.dat <- readingSkills[c(1:105),]
# Give the chart file a name.
png(file = "decision_tree.png")
# Create the tree.
output.tree <- ctree(
nativeSpeaker ~ age + shoeSize + score,
data = input.dat)
# Plot the tree.
plot(output.tree)
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato:
null device
1
Loading required package: methods
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Loading required package: strucchange
Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
Loading required package: sandwich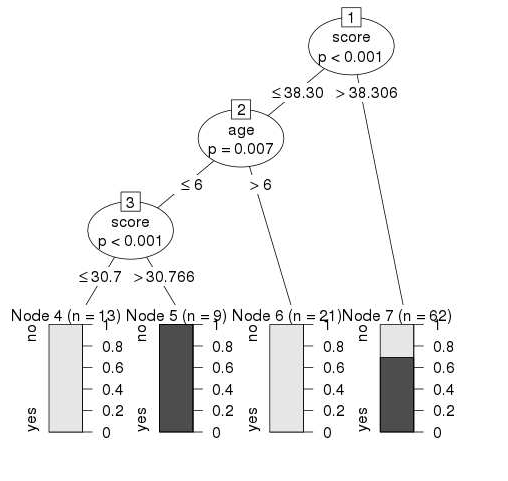
Conclusione
Dall'albero decisionale mostrato sopra possiamo concludere che chiunque abbia un punteggio di readingSkills inferiore a 38,3 e l'età superiore a 6 non è un madrelingua.
Nell'approccio forestale casuale, viene creato un gran numero di alberi decisionali. Ogni osservazione viene inserita in ogni albero decisionale. Il risultato più comune per ciascuna osservazione viene utilizzato come output finale. Una nuova osservazione viene inserita in tutti gli alberi e con un voto a maggioranza per ogni modello di classificazione.
Viene effettuata una stima degli errori per i casi che non sono stati utilizzati durante la costruzione dell'albero. Questo è chiamato un fileOOB (Out-of-bag) stima dell'errore che è indicata come percentuale.
Il pacchetto R. "randomForest" viene utilizzato per creare foreste casuali.
Installa il pacchetto R.
Utilizzare il comando seguente nella console R per installare il pacchetto. È inoltre necessario installare i pacchetti dipendenti, se presenti.
install.packages("randomForest)Il pacchetto "randomForest" ha la funzione randomForest() che viene utilizzato per creare e analizzare foreste casuali.
Sintassi
La sintassi di base per creare una foresta casuale in R è:
randomForest(formula, data)Di seguito la descrizione dei parametri utilizzati:
formula è una formula che descrive il predittore e le variabili di risposta.
data è il nome del set di dati utilizzato.
Dati in ingresso
Useremo il set di dati R in-built denominato readingSkills per creare un albero decisionale. Descrive il punteggio delle capacità di lettura di qualcuno se conosciamo le variabili "età", "taglia", "punteggio" e se la persona è madrelingua.
Ecco i dati di esempio.
# Load the party package. It will automatically load other
# required packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))Quando eseguiamo il codice sopra, produce il seguente risultato e grafico:
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................Esempio
Useremo il file randomForest() funzione per creare l'albero decisionale e vedere il suo grafico.
# Load the party package. It will automatically load other
# required packages.
library(party)
library(randomForest)
# Create the forest.
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
# View the forest results.
print(output.forest)
# Importance of each predictor.
print(importance(fit,type = 2))Quando eseguiamo il codice sopra, produce il seguente risultato:
Call:
randomForest(formula = nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
OOB estimate of error rate: 1%
Confusion matrix:
no yes class.error
no 99 1 0.01
yes 1 99 0.01
MeanDecreaseGini
age 13.95406
shoeSize 18.91006
score 56.73051Conclusione
Dalla foresta casuale mostrata sopra possiamo concludere che le dimensioni delle scarpe e il punteggio sono i fattori importanti per decidere se qualcuno è un madrelingua o meno. Inoltre il modello ha solo l'1% di errore, il che significa che possiamo prevedere con una precisione del 99%.
L'analisi di sopravvivenza si occupa di prevedere il momento in cui si verificherà un evento specifico. È anche noto come analisi del tempo di guasto o analisi del tempo fino alla morte. Ad esempio, prevedere il numero di giorni in cui una persona malata di cancro sopravviverà o prevedere il tempo in cui un sistema meccanico fallirà.
Il pacchetto R denominato survivalviene utilizzato per eseguire analisi di sopravvivenza. Questo pacchetto contiene la funzioneSurv()che prende i dati di input come una formula R e crea un oggetto di sopravvivenza tra le variabili scelte per l'analisi. Quindi usiamo la funzionesurvfit() per creare un grafico per l'analisi.
Installa pacchetto
install.packages("survival")Sintassi
La sintassi di base per creare analisi di sopravvivenza in R è:
Surv(time,event)
survfit(formula)Di seguito la descrizione dei parametri utilizzati:
time è il tempo di follow-up fino al verificarsi dell'evento.
event indica lo stato di accadimento dell'evento atteso.
formula è la relazione tra le variabili predittive.
Esempio
Considereremo il set di dati denominato "pbc" presente nei pacchetti di sopravvivenza installati sopra. Descrive i punti di dati di sopravvivenza sulle persone affette da cirrosi biliare primaria (PBC) del fegato. Tra le tante colonne presenti nel set di dati ci occupiamo principalmente dei campi "ora" e "stato". Il tempo rappresenta il numero di giorni tra la registrazione del paziente e la prima dell'evento tra il paziente che riceve un trapianto di fegato o la morte del paziente.
# Load the library.
library("survival")
# Print first few rows.
print(head(pbc))Quando eseguiamo il codice sopra, produce il seguente risultato e grafico:
id time status trt age sex ascites hepato spiders edema bili chol
1 1 400 2 1 58.76523 f 1 1 1 1.0 14.5 261
2 2 4500 0 1 56.44627 f 0 1 1 0.0 1.1 302
3 3 1012 2 1 70.07255 m 0 0 0 0.5 1.4 176
4 4 1925 2 1 54.74059 f 0 1 1 0.5 1.8 244
5 5 1504 1 2 38.10541 f 0 1 1 0.0 3.4 279
6 6 2503 2 2 66.25873 f 0 1 0 0.0 0.8 248
albumin copper alk.phos ast trig platelet protime stage
1 2.60 156 1718.0 137.95 172 190 12.2 4
2 4.14 54 7394.8 113.52 88 221 10.6 3
3 3.48 210 516.0 96.10 55 151 12.0 4
4 2.54 64 6121.8 60.63 92 183 10.3 4
5 3.53 143 671.0 113.15 72 136 10.9 3
6 3.98 50 944.0 93.00 63 NA 11.0 3Dai dati di cui sopra stiamo considerando il tempo e lo stato per la nostra analisi.
Applicazione delle funzioni Surv () e survfit ()
Ora procediamo ad applicare il Surv() funzione al set di dati sopra e creare un grafico che mostrerà la tendenza.
# Load the library.
library("survival")
# Create the survival object.
survfit(Surv(pbc$time,pbc$status == 2)~1) # Give the chart file a name. png(file = "survival.png") # Plot the graph. plot(survfit(Surv(pbc$time,pbc$status == 2)~1))
# Save the file.
dev.off()Quando eseguiamo il codice sopra, produce il seguente risultato e grafico:
Call: survfit(formula = Surv(pbc$time, pbc$status == 2) ~ 1)
n events median 0.95LCL 0.95UCL
418 161 3395 3090 3853
L'andamento nel grafico sopra ci aiuta a prevedere la probabilità di sopravvivenza alla fine di un certo numero di giorni.
Chi-Square testè un metodo statistico per determinare se due variabili categoriali hanno una correlazione significativa tra di loro. Entrambe queste variabili dovrebbero provenire dalla stessa popolazione e dovrebbero essere categoriche come - Sì / No, Maschio / Femmina, Rosso / Verde ecc.
Ad esempio, possiamo costruire un set di dati con osservazioni sul modello di acquisto del gelato delle persone e provare a correlare il sesso di una persona con il sapore del gelato che preferiscono. Se viene trovata una correlazione, possiamo pianificare uno stock appropriato di sapori conoscendo il numero di sesso delle persone che visitano.
Sintassi
La funzione utilizzata per eseguire il test chi-quadrato è chisq.test().
La sintassi di base per creare un test chi-quadrato in R è:
chisq.test(data)Di seguito la descrizione dei parametri utilizzati:
data è il dato sotto forma di tabella contenente il valore di conteggio delle variabili nell'osservazione.
Esempio
Porteremo i dati Cars93 nella libreria "MASS" che rappresenta le vendite di diversi modelli di auto nell'anno 1993.
library("MASS")
print(str(Cars93))Quando eseguiamo il codice sopra, produce il seguente risultato:
'data.frame': 93 obs. of 27 variables:
$ Manufacturer : Factor w/ 32 levels "Acura","Audi",..: 1 1 2 2 3 4 4 4 4 5 ...
$ Model : Factor w/ 93 levels "100","190E","240",..: 49 56 9 1 6 24 54 74 73 35 ... $ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ...
$ Min.Price : num 12.9 29.2 25.9 30.8 23.7 14.2 19.9 22.6 26.3 33 ... $ Price : num 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ...
$ Max.Price : num 18.8 38.7 32.3 44.6 36.2 17.3 21.7 24.9 26.3 36.3 ... $ MPG.city : int 25 18 20 19 22 22 19 16 19 16 ...
$ MPG.highway : int 31 25 26 26 30 31 28 25 27 25 ... $ AirBags : Factor w/ 3 levels "Driver & Passenger",..: 3 1 2 1 2 2 2 2 2 2 ...
$ DriveTrain : Factor w/ 3 levels "4WD","Front",..: 2 2 2 2 3 2 2 3 2 2 ... $ Cylinders : Factor w/ 6 levels "3","4","5","6",..: 2 4 4 4 2 2 4 4 4 5 ...
$ EngineSize : num 1.8 3.2 2.8 2.8 3.5 2.2 3.8 5.7 3.8 4.9 ... $ Horsepower : int 140 200 172 172 208 110 170 180 170 200 ...
$ RPM : int 6300 5500 5500 5500 5700 5200 4800 4000 4800 4100 ... $ Rev.per.mile : int 2890 2335 2280 2535 2545 2565 1570 1320 1690 1510 ...
$ Man.trans.avail : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 1 1 1 1 ... $ Fuel.tank.capacity: num 13.2 18 16.9 21.1 21.1 16.4 18 23 18.8 18 ...
$ Passengers : int 5 5 5 6 4 6 6 6 5 6 ... $ Length : int 177 195 180 193 186 189 200 216 198 206 ...
$ Wheelbase : int 102 115 102 106 109 105 111 116 108 114 ... $ Width : int 68 71 67 70 69 69 74 78 73 73 ...
$ Turn.circle : int 37 38 37 37 39 41 42 45 41 43 ... $ Rear.seat.room : num 26.5 30 28 31 27 28 30.5 30.5 26.5 35 ...
$ Luggage.room : int 11 15 14 17 13 16 17 21 14 18 ... $ Weight : int 2705 3560 3375 3405 3640 2880 3470 4105 3495 3620 ...
$ Origin : Factor w/ 2 levels "USA","non-USA": 2 2 2 2 2 1 1 1 1 1 ... $ Make : Factor w/ 93 levels "Acura Integra",..: 1 2 4 3 5 6 7 9 8 10 ...Il risultato sopra mostra che il set di dati ha molte variabili Fattore che possono essere considerate come variabili categoriali. Per il nostro modello considereremo le variabili "AirBags" e "Type". Qui ci proponiamo di scoprire qualsiasi correlazione significativa tra i tipi di auto vendute e il tipo di Airbag che ha. Se si osserva una correlazione, possiamo stimare quali tipi di auto possono vendere meglio con quali tipi di airbag.
# Load the library.
library("MASS")
# Create a data frame from the main data set.
car.data <- data.frame(Cars93$AirBags, Cars93$Type)
# Create a table with the needed variables.
car.data = table(Cars93$AirBags, Cars93$Type)
print(car.data)
# Perform the Chi-Square test.
print(chisq.test(car.data))Quando eseguiamo il codice sopra, produce il seguente risultato:
Compact Large Midsize Small Sporty Van
Driver & Passenger 2 4 7 0 3 0
Driver only 9 7 11 5 8 3
None 5 0 4 16 3 6
Pearson's Chi-squared test
data: car.data
X-squared = 33.001, df = 10, p-value = 0.0002723
Warning message:
In chisq.test(car.data) : Chi-squared approximation may be incorrectConclusione
Il risultato mostra il valore p inferiore a 0,05 che indica una correlazione tra stringhe.