回帰モデルの構築
ロジスティック回帰は、カテゴリ従属変数の確率を予測するために使用される機械学習アルゴリズムを指します。ロジスティック回帰では、従属変数はバイナリ変数であり、1(trueとfalseのブール値)としてコード化されたデータで構成されます。
この章では、連続変数を使用したPythonでの回帰モデルの開発に焦点を当てます。線形回帰モデルの例では、CSVファイルからのデータ探索に焦点を当てます。
分類の目標は、クライアントが定期預金を購読するかどうか(1/0)を予測することです。
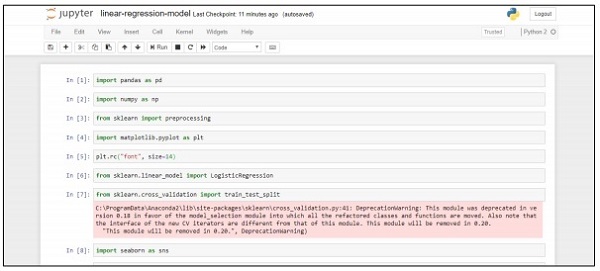
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
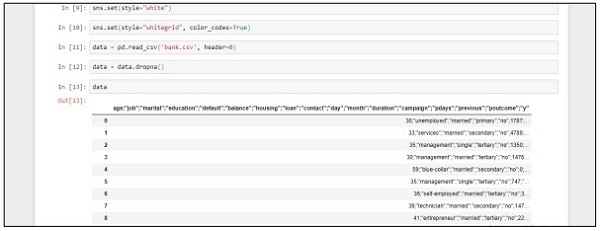
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))次の手順に従って、「JupyterNotebook」を使用してAnacondaNavigatorに上記のコードを実装します-
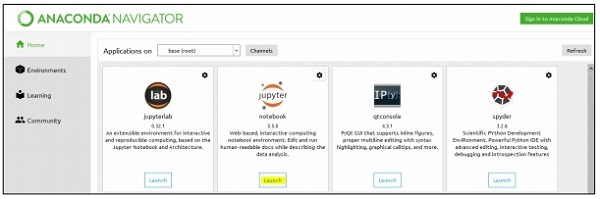
Step 1 − AnacondaNavigatorを使用してJupyterNotebookを起動します。
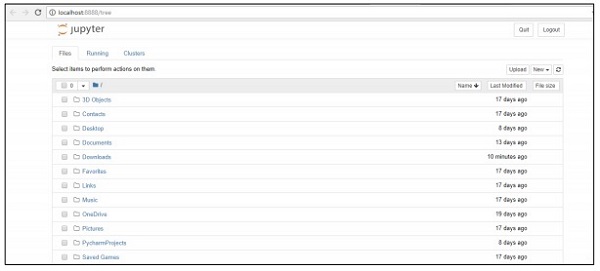
Step 2 − csvファイルをアップロードして、体系的な方法で回帰モデルの出力を取得します。
Step 3 −新しいファイルを作成し、上記のコード行を実行して、目的の出力を取得します。