アジャイルデータサイエンス-予測の役割
この章では、アジャイルデータサイエンスにおける予測の役割について学びます。インタラクティブレポートは、データのさまざまな側面を公開します。予測は、アジャイルスプリントの第4層を形成します。
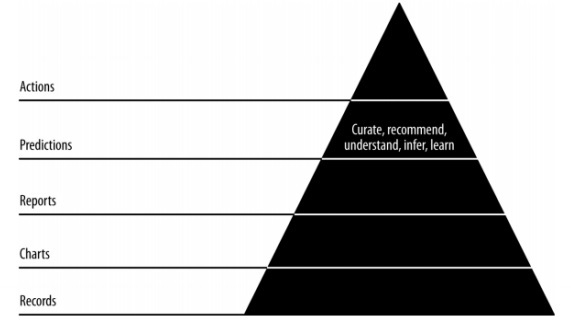
予測を行うときは、常に過去のデータを参照し、将来の反復の推論として使用します。この完全なプロセスでは、データを履歴データのバッチ処理から将来に関するリアルタイムデータに移行します。
予測の役割には、次のものが含まれます。
予測は予測に役立ちます。一部の予測は、統計的推論に基づいています。いくつかの予測は、専門家の意見に基づいています。
統計的推論は、あらゆる種類の予測に関係しています。
予測が正確な場合もあれば、不正確な場合もあります。
予測分析
予測分析には、予測モデリング、機械学習、データマイニングなど、現在および過去の事実を分析して将来および未知のイベントに関する予測を行うさまざまな統計手法が含まれます。
予測分析にはトレーニングデータが必要です。トレーニングされたデータには、独立した機能と依存する機能が含まれます。依存機能は、ユーザーが予測しようとしている値です。独立機能は、依存機能に基づいて予測したいことを説明する機能です。
機能の研究は機能エンジニアリングと呼ばれます。これは、予測を行うために重要です。データの視覚化と探索的データ分析は、機能エンジニアリングの一部です。これらはのコアを形成しますAgile data science。
予測をする
アジャイルデータサイエンスで予測を行うには2つの方法があります-
Regression
Classification
回帰または分類の構築は、ビジネス要件とその分析に完全に依存します。連続変数の予測は回帰モデルにつながり、カテゴリ変数の予測は分類モデルにつながります。
回帰
回帰は、特徴を含む例を考慮し、それによって数値出力を生成します。
分類
分類は入力を受け取り、カテゴリ分類を生成します。
Note −統計的予測への入力を定義し、マシンが学習できるようにするデータセットの例は、「トレーニングデータ」と呼ばれます。