予測システムの導入
この例では、Pythonスクリプトを使用して住宅価格の予測に役立つ予測モデルを作成してデプロイする方法を学習します。予測システムの展開に使用される重要なフレームワークには、Anacondaと「JupyterNotebook」が含まれます。
次の手順に従って、予測システムを展開します-
Step 1 −以下のコードを実装して、値をcsvファイルから関連する値に変換します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
%matplotlib inline
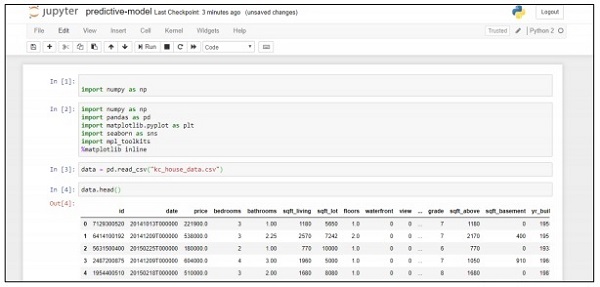
data = pd.read_csv("kc_house_data.csv")
data.head()上記のコードは次の出力を生成します-
Step 2 − describe関数を実行して、csvファイルの属性に含まれるデータ型を取得します。
data.describe()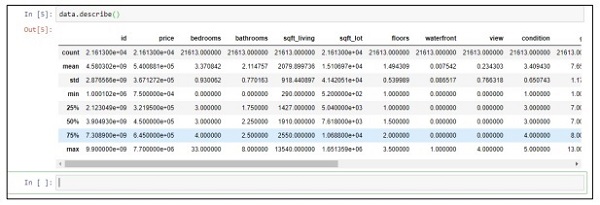
Step 3 −作成した予測モデルの展開に基づいて、関連する値を削除できます。
train1 = data.drop(['id', 'price'],axis=1)
train1.head()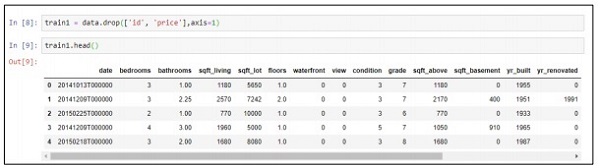
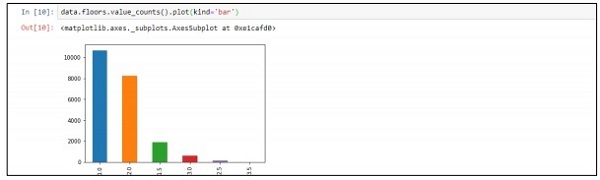
Step 4−レコードごとにデータを視覚化できます。このデータは、データサイエンスの分析とホワイトペーパーの出力に使用できます。
data.floors.value_counts().plot(kind='bar')