アジャイルデータサイエンス-データエンリッチメント
データエンリッチメントとは、生データを強化、改良、改善するために使用される一連のプロセスを指します。これは、有用なデータ変換(生データから有用な情報)を指します。データ強化のプロセスは、データを現代のビジネスまたは企業にとって価値のあるデータ資産にすることに重点を置いています。
最も一般的なデータ強化プロセスには、特定の決定アルゴリズムを使用した、データベース内のスペルミスや誤植の修正が含まれます。データエンリッチメントツールは、単純なデータテーブルに有用な情報を追加します。
単語のスペル修正については、次のコードを検討してください-
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probabilities of words"
return WORDS[word] / N
def correction(word):
"Spelling correction of word"
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
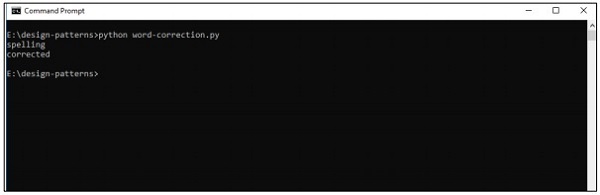
print(correction('speling'))
print(correction('korrectud'))このプログラムでは、修正された単語を含む「big.txt」と照合します。単語はテキストファイルに含まれている単語と一致し、それに応じて適切な結果を出力します。
出力
上記のコードは次の出力を生成します-