Pythonを使用したAI–クイックガイド
コンピュータまたはマシンの発明以来、さまざまなタスクを実行するそれらの能力は指数関数的に成長しました。人間は、多様な作業領域、速度の向上、時間に対するサイズの縮小という観点から、コンピューターシステムの能力を開発してきました。
人工知能という名前のコンピュータサイエンスの分野は、人間と同じくらいインテリジェントなコンピュータまたはマシンの作成を追求しています。
人工知能(AI)の基本概念
人工知能の父であるジョン・マッカーシーによれば、それは「インテリジェントマシン、特にインテリジェントコンピュータプログラムを作成するための科学と工学」です。
人工知能は、コンピューター、コンピューター制御ロボット、またはソフトウェアを、インテリジェントな人間が考えるのと同じようにインテリジェントに考えさせる方法です。AIは、人間の脳がどのように考え、人間が問題を解決しようとしながらどのように学び、決定し、働くかを研究し、この研究の結果をインテリジェントなソフトウェアとシステムの開発の基礎として使用することによって実現されます。
コンピュータシステムの力、人間の好奇心を利用している間、彼は「機械は人間のように考え、行動できるのだろうか」と疑問に思います。
このように、AIの開発は、人間が高く評価しているマシンで同様のインテリジェンスを作成することを目的として始まりました。
AI学習の必要性
私たちが知っているように、AIは人間と同じくらいインテリジェントなマシンの作成を追求しています。私たちがAIを研究する理由はたくさんあります。理由は以下の通りです−
AIはデータを通じて学ぶことができます
私たちの日常生活では、膨大な量のデータを扱っており、人間の脳はそれほど多くのデータを追跡することができません。そのため、自動化する必要があります。自動化を行うには、AIがデータから学習でき、繰り返しのタスクを正確かつ飽きることなく実行できるため、AIを研究する必要があります。
AIはそれ自体を教えることができます
データ自体は絶えず変化し、そのようなデータから得られる知識は絶えず更新されなければならないので、システムはそれ自体を教える必要があります。AI対応のシステムはそれ自体を教えることができるため、AIを使用してこの目的を達成できます。
AIはリアルタイムで応答できます
ニューラルネットワークの助けを借りた人工知能は、データをより深く分析することができます。この機能により、AIは状況に基づいてリアルタイムで状況を考え、対応することができます。
AIが精度を実現
ディープニューラルネットワークの助けを借りて、AIは驚異的な精度を達成できます。AIは、医学の分野で患者のMRIから癌などの病気を診断するのに役立ちます。
AIは、データを整理して最大限に活用できます
データは、自己学習アルゴリズムを使用しているシステムの知的財産です。常に最良の結果が得られるようにデータにインデックスを付けて整理するには、AIが必要です。
インテリジェンスを理解する
AIを使用すると、スマートシステムを構築できます。私たちの脳がそれ自体のような別の知性システムを構築できるように、私たちは知性の概念を理解する必要があります。
インテリジェンスとは何ですか?
関係や類推を計算、推論、認識し、経験から学び、記憶から情報を保存および取得し、問題を解決し、複雑なアイデアを理解し、自然言語を流暢に使用し、分類し、一般化し、新しい状況に適応するシステムの能力。
インテリジェンスの種類
アメリカの発達心理学者であるハワードガードナーが説明したように、インテリジェンスにはさまざまな要素があります。
| シニア番号 | インテリジェンスと説明 | 例 |
|---|---|---|
| 1 | Linguistic intelligence 音韻論(スピーチ音)、構文(文法)、および意味論(意味)のメカニズムを話し、認識し、使用する能力。 |
ナレーター、オレーター |
| 2 | Musical intelligence 音の意味、音程、リズムの理解を創造し、コミュニケーションし、理解する能力。 |
ミュージシャン、歌手、作曲家 |
| 3 | Logical-mathematical intelligence アクションやオブジェクトがない場合に関係を使用して理解する能力。また、複雑で抽象的なアイデアを理解する能力でもあります。 |
数学者、科学者 |
| 4 | Spatial intelligence 視覚的または空間的情報を認識し、それを変更し、オブジェクトを参照せずに視覚的画像を再作成し、3D画像を構築し、それらを移動および回転する機能。 |
地図リーダー、宇宙飛行士、物理学者 |
| 5 | Bodily-Kinesthetic intelligence 身体の全体または一部を使用して、問題やファッション製品を解決し、細かい運動技能と粗い運動技能を制御し、オブジェクトを操作する能力。 |
プレーヤー、ダンサー |
| 6 | Intra-personal intelligence 自分の感情、意図、動機を区別する能力。 |
ゴータムブッダ |
| 7 | Interpersonal intelligence 他の人の感情、信念、意図を認識し、区別する能力。 |
マスコミュニケーター、インタビュアー |
マシンまたはシステムは、少なくとも1つまたはすべてのインテリジェンスが搭載されている場合、人工知能であると言えます。
インテリジェンスは何で構成されていますか?
インテリジェンスは無形です。−で構成されています
- Reasoning
- Learning
- 問題解決
- Perception
- 言語インテリジェンス

すべてのコンポーネントを簡単に見ていきましょう-
推論
これは、判断、意思決定、および予測の基礎を提供できるようにする一連のプロセスです。大きく2つのタイプがあります-
| 帰納的推理 | 演繹的推論 |
|---|---|
| それは、幅広い一般的な声明を出すために特定の観察を行います。 | それは一般的な声明から始まり、特定の論理的な結論に到達する可能性を検討します。 |
| 声明ですべての前提が真であるとしても、帰納的推論は結論が偽であることを可能にします。 | 一般にあるクラスの事柄に当てはまる場合、そのクラスのすべてのメンバーにも当てはまります。 |
| Example −「ニタは教師です。ニタは勤勉です。したがって、すべての教師は勤勉です。」 | Example −「60歳以上の女性はすべて祖母です。シャリーニは65歳です。したがって、シャリーニは祖母です。」 |
学習− l
学習能力は、人間、特定の動物種、およびAI対応システムによって所有されています。学習は次のように分類されます-
聴覚学習
聞くことと聞くことによって学ぶことです。たとえば、録音された音声講義を聞いている学生。
エピソード学習
人が目撃または経験した一連の出来事を思い出すことによって学ぶこと。これは直線的で整然としています。
運動学習
筋肉の正確な動きで学習しています。たとえば、オブジェクトの選択、書き込みなど。
観察学習
他人を見て真似して学ぶこと。たとえば、子供は親を模倣して学習しようとします。
知覚学習
以前に見た刺激を認識することを学んでいます。たとえば、オブジェクトと状況を識別して分類します。
リレーショナル学習
それは、絶対的な特性ではなく、関係的な特性に基づいてさまざまな刺激を区別することを学ぶことを含みます。たとえば、前回塩辛くなったジャガイモを調理するときに、大さじ1杯の塩を加えて調理したときに「少し少ない」塩を加える。
Spatial Learning −画像、色、地図などの視覚刺激を通じて学習します。たとえば、人は実際に道路をたどる前にロードマップを作成することができます。
Stimulus-Response Learning−特定の刺激が存在するときに特定の行動を実行することを学習しています。たとえば、犬はドアベルを聞いて耳を上げます。
問題解決
それは、既知または未知のハードルによってブロックされている何らかの道をたどることによって、現在の状況から望ましい解決策を認識し、到達しようとするプロセスです。
問題解決には、 decision making、これは、目的の目標を達成するために、複数の選択肢から最適な選択肢を選択するプロセスです。
知覚
これは、感覚情報を取得、解釈、選択、および整理するプロセスです。
知覚は推定します sensing。人間では、知覚は感覚器官によって助けられます。AIの領域では、知覚メカニズムにより、センサーによって取得されたデータが意味のある方法でまとめられます。
言語インテリジェンス
それは、口頭および書記言語を使用し、理解し、話し、そして書く能力です。対人コミュニケーションにおいて重要です。
AIに関係するもの
人工知能は広大な研究分野です。この研究分野は、現実世界の問題の解決策を見つけるのに役立ちます。
AI内のさまざまな研究分野を見てみましょう-
機械学習
AIの最も人気のある分野の1つです。このフィールドの基本的な概念は、人間が自分の経験から学ぶことができるように、データから機械学習を行うことです。これには、未知のデータに対して予測を行うための基礎となる学習モデルが含まれています。
論理
これは、数理論理学を使用してコンピュータプログラムを実行するもう1つの重要な研究分野です。パターンマッチング、セマンティック分析などを実行するためのルールとファクトが含まれています。
検索中
この研究分野は、基本的にチェス、チックタックトーなどのゲームで使用されます。検索アルゴリズムは、検索空間全体を検索した後、最適なソリューションを提供します。
人工ニューラルネットワーク
これは効率的なコンピューティングシステムのネットワークであり、その中心的なテーマは生物学的神経ネットワークのアナロジーから借用されています。ANNは、ロボット工学、音声認識、音声処理などで使用できます。
遺伝的アルゴリズム
遺伝的アルゴリズムは、複数のプログラムの助けを借りて問題を解決するのに役立ちます。結果は、最も適切なものを選択することに基づいています。
知識表現
それは、機械が理解できる方法で事実を表現できる助けを借りて研究分野です。より効率的に知識が表現されます。より多くのシステムがインテリジェントになります。
AIの応用
このセクションでは、AIでサポートされているさまざまなフィールドを確認します-
ゲーム
AIは、チェス、ポーカー、三目並べなどの戦略ゲームで重要な役割を果たします。このゲームでは、機械がヒューリスティックな知識に基づいて多数の可能な位置を考えることができます。
自然言語処理
人間が話す自然言語を理解するコンピュータと対話することが可能です。
エキスパートシステム
マシン、ソフトウェア、および特別な情報を統合して、推論とアドバイスを与えるアプリケーションがいくつかあります。ユーザーに説明やアドバイスを提供します。
ビジョンシステム
これらのシステムは、コンピューター上の視覚入力を理解、解釈、および理解します。例えば、
スパイ飛行機が写真を撮り、それを使って空間情報や地域の地図を把握します。
医師は臨床エキスパートシステムを使用して患者を診断します。
警察は、法医学の芸術家によって作成された保存された肖像画で犯罪者の顔を認識することができるコンピュータソフトウェアを使用しています。
音声認識
一部のインテリジェントシステムは、人間が話している間、文とその意味の観点から言語を聞いて理解することができます。さまざまなアクセント、俗語、背景のノイズ、寒さによる人間のノイズの変化などを処理できます。
手書き認識
手書き認識ソフトウェアは、紙にペンで、または画面にスタイラスで書かれたテキストを読み取ります。文字の形を認識し、編集可能なテキストに変換できます。
インテリジェントロボット
ロボットは人間が与えたタスクを実行することができます。それらには、光、熱、温度、動き、音、バンプ、圧力などの実世界からの物理データを検出するセンサーがあります。彼らは、インテリジェンスを発揮するために、効率的なプロセッサ、複数のセンサー、および巨大なメモリを備えています。さらに、彼らは自分の過ちから学ぶことができ、新しい環境に適応することができます。
認知モデリング:人間の思考手順のシミュレーション
認知モデリングは、基本的にコンピュータサイエンスの研究分野であり、人間の思考プロセスの研究とシミュレーションを扱います。AIの主なタスクは、機械を人間のように考えさせることです。人間の思考プロセスの最も重要な特徴は問題解決です。そのため、多かれ少なかれ認知モデリングは、人間が問題を解決する方法を理解しようとします。その後、このモデルは、機械学習、ロボット工学、自然言語処理などのさまざまなAIアプリケーションに使用できます。以下は、人間の脳のさまざまな思考レベルの図です。

エージェントと環境
このセクションでは、エージェントと環境、およびこれらが人工知能にどのように役立つかに焦点を当てます。
エージェント
エージェントとは、センサーを介してその環境を認識し、エフェクターを介してその環境に作用することができるものです。
A human agent センサーと平行に目、耳、鼻、舌、皮膚などの感覚器官と、エフェクター用の手、脚、口などの他の器官があります。
A robotic agent センサー用のカメラと赤外線距離計、およびエフェクター用のさまざまなモーターとアクチュエーターに取って代わります。
A software agent プログラムおよびアクションとしてビット文字列をエンコードしました。
環境
一部のプログラムは完全に動作します artificial environment キーボード入力、データベース、コンピューターファイルシステム、および画面上の文字出力に限定されます。
対照的に、一部のソフトウェアエージェント(ソフトウェアロボットまたはソフトボット)は、リッチで無制限のソフトボットドメインに存在します。シミュレータにはvery detailed, complex environment。ソフトウェアエージェントは、多数のアクションからリアルタイムで選択する必要があります。ソフトボットは、顧客のオンライン設定をスキャンするように設計されており、顧客の作品に興味深いアイテムを表示します。real だけでなく、 artificial 環境。
この章では、Pythonの使用を開始する方法を学習します。また、Pythonが人工知能にどのように役立つかについても理解します。
なぜPythonfor AI
人工知能は、将来のトレンド技術であると考えられています。すでに多くのアプリケーションが作成されています。このため、多くの企業や研究者がそれに興味を持っています。しかし、ここで発生する主な問題は、これらのAIアプリケーションをどのプログラミング言語で開発できるかということです。Lisp、Prolog、C ++、Java、Pythonなど、AIのアプリケーションの開発に使用できるさまざまなプログラミング言語があります。その中でも、Pythonプログラミング言語は非常に人気があり、その理由は次のとおりです。
シンプルな構文と少ないコーディング
Pythonは、AIアプリケーションの開発に使用できる他のプログラミング言語の中でも、コーディングが非常に少なく、構文が単純です。この機能により、テストが簡単になり、プログラミングに集中できます。
AIプロジェクト用の組み込みライブラリ
Python for AIを使用する主な利点は、組み込みのライブラリが付属していることです。Pythonには、ほぼすべての種類のAIプロジェクト用のライブラリがあります。例えば、NumPy, SciPy, matplotlib, nltk, SimpleAI Pythonのいくつかの重要な組み込みライブラリです。
Open source−Pythonはオープンソースのプログラミング言語です。これにより、コミュニティで広く人気があります。
Can be used for broad range of programming− Pythonは、小さなシェルスクリプトからエンタープライズWebアプリケーションまで、幅広いプログラミングタスクに使用できます。これが、PythonがAIプロジェクトに適しているもう1つの理由です。
Pythonの機能
Pythonは、高水準のインタープリター型のインタラクティブなオブジェクト指向スクリプト言語です。Pythonは非常に読みやすいように設計されています。他の言語が句読点を使用するのに対し、英語のキーワードを頻繁に使用し、他の言語よりも構文構造が少なくなっています。Pythonの機能は次のとおりです。
Easy-to-learn− Pythonには、キーワードがほとんどなく、構造が単純で、構文が明確に定義されています。これにより、生徒は言語をすばやく習得できます。
Easy-to-read − Pythonコードはより明確に定義され、目に見えます。
Easy-to-maintain −Pythonのソースコードは保守がかなり簡単です。
A broad standard library − Pythonのライブラリの大部分は、UNIX、Windows、およびMacintoshで非常に移植性が高く、クロスプラットフォーム互換です。
Interactive Mode − Pythonは、コードスニペットのインタラクティブなテストとデバッグを可能にするインタラクティブモードをサポートしています。
Portable − Pythonは、さまざまなハードウェアプラットフォームで実行でき、すべてのプラットフォームで同じインターフェイスを備えています。
Extendable−Pythonインタープリターに低レベルのモジュールを追加できます。これらのモジュールを使用すると、プログラマーはツールを追加またはカスタマイズして、より効率的にすることができます。
Databases − Pythonは、すべての主要な商用データベースへのインターフェイスを提供します。
GUI Programming − Pythonは、作成して、Windows MFC、Macintosh、UnixのX Windowシステムなど、多くのシステムコール、ライブラリ、Windowsシステムに移植できるGUIアプリケーションをサポートしています。
Scalable − Pythonは、シェルスクリプトよりも優れた構造と大規模プログラムのサポートを提供します。
Pythonの重要な機能
ここで、Pythonの次の重要な機能について考えてみましょう。
関数型および構造化プログラミング手法とOOPをサポートします。
スクリプト言語として使用することも、大規模なアプリケーションを構築するためにバイトコードにコンパイルすることもできます。
非常に高レベルの動的データ型を提供し、動的型チェックをサポートします。
自動ガベージコレクションをサポートします。
C、C ++、COM、ActiveX、CORBA、およびJavaと簡単に統合できます。
Pythonのインストール
Pythonディストリビューションは、多数のプラットフォームで利用できます。プラットフォームに適用可能なバイナリコードのみをダウンロードして、Pythonをインストールする必要があります。
プラットフォームのバイナリコードが利用できない場合は、ソースコードを手動でコンパイルするためにCコンパイラが必要です。ソースコードをコンパイルすると、インストールに必要な機能の選択に関してより柔軟になります。
さまざまなプラットフォームへのPythonのインストールの概要は次のとおりです-
UnixおよびLinuxのインストール
次の手順に従って、Unix / LinuxマシンにPythonをインストールします。
Webブラウザーを開き、 https://www.python.org/downloads
リンクをたどって、Unix / Linuxで利用可能なzip形式のソースコードをダウンロードします。
ファイルをダウンロードして抽出します。
一部のオプションをカスタマイズする場合は、モジュール/セットアップファイルを編集します。
./configureスクリプトを実行します
make
インストールする
これにより、Pythonが標準の場所/ usr / local / binにインストールされ、そのライブラリが/ usr / local / lib / pythonXXにインストールされます。XXはPythonのバージョンです。
Windowsのインストール
次の手順に従って、WindowsマシンにPythonをインストールします。
Webブラウザーを開き、 https://www.python.org/downloads
Windowsインストーラーのpython- XYZ.msiファイルのリンクをたどります。XYZはインストールする必要のあるバージョンです。
このインストーラーpython-XYZ.msiを使用するには、WindowsシステムがMicrosoftインストーラー2.0をサポートしている必要があります。インストーラーファイルをローカルマシンに保存してから実行し、マシンがMSIをサポートしているかどうかを確認します。
ダウンロードしたファイルを実行します。これにより、Pythonインストールウィザードが表示されます。これは非常に使いやすいです。デフォルト設定を受け入れて、インストールが完了するまで待ちます。
Macintoshのインストール
Mac OS Xを使用している場合は、Homebrewを使用してPython3をインストールすることをお勧めします。これはMacOS Xの優れたパッケージインストーラーであり、非常に使いやすいです。Homebrewをお持ちでない場合は、次のコマンドを使用してインストールできます-
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"以下のコマンドでパッケージマネージャーを更新できます-
$ brew update次のコマンドを実行して、Python3をシステムにインストールします-
$ brew install python3PATHの設定
プログラムやその他の実行可能ファイルは多くのディレクトリに存在する可能性があるため、オペレーティングシステムは、OSが実行可能ファイルを検索するディレクトリを一覧表示する検索パスを提供します。
パスは、オペレーティングシステムによって維持される名前付き文字列である環境変数に格納されます。この変数には、コマンドシェルやその他のプログラムで利用できる情報が含まれています。
パス変数は、UnixではPATHまたはWindowsではPathと呼ばれます(Unixでは大文字と小文字が区別されますが、Windowsでは区別されません)。
Mac OSでは、インストーラーがパスの詳細を処理します。特定のディレクトリからPythonインタプリタを呼び出すには、Pythonディレクトリをパスに追加する必要があります。
Unix / Linuxでのパスの設定
Unixの特定のセッションのパスにPythonディレクトリを追加するには-
cshシェルで
タイプ setenv PATH "$PATH:/usr/local/bin/python" を押して Enter。
bashシェル内(Linux)
タイプ export ATH = "$PATH:/usr/local/bin/python" を押して Enter。
shまたはkshシェル内
タイプ PATH = "$PATH:/usr/local/bin/python" を押して Enter。
Note − / usr / local / bin / pythonはPythonディレクトリのパスです。
Windowsでパスを設定する
Windowsの特定のセッションのパスにPythonディレクトリを追加するには-
At the command prompt −タイプ path %path%;C:\Python を押して Enter。
Note − c:\ Pythonは、Pythonディレクトリのパスです。
Pythonの実行
Pythonを実行するさまざまな方法を見てみましょう。方法は以下のとおりです-
インタラクティブ通訳
Pythonは、Unix、DOS、またはコマンドラインインタープリターやシェルウィンドウを提供するその他のシステムから起動できます。
入る python コマンドラインで。
インタラクティブインタプリタですぐにコーディングを開始します。
$python # Unix/Linuxまたは
python% # Unix/Linuxまたは
C:> python # Windows/DOS使用可能なすべてのコマンドラインオプションのリストは次のとおりです-
| S.No. | オプションと説明 |
|---|---|
| 1 | -d デバッグ出力を提供します。 |
| 2 | -o 最適化されたバイトコードを生成します(結果として.pyoファイルになります)。 |
| 3 | -S 起動時にPythonパスを探すためにインポートサイトを実行しないでください。 |
| 4 | -v 詳細な出力(インポートステートメントの詳細なトレース)。 |
| 5 | -x クラスベースの組み込み例外を無効にします(文字列を使用するだけです)。バージョン1.6以降は廃止されました。 |
| 6 | -c cmd cmd文字列として送信されたPythonスクリプトを実行します。 |
| 7 | File 指定されたファイルからPythonスクリプトを実行します。 |
コマンドラインからのスクリプト
Pythonスクリプトは、次のように、アプリケーションでインタープリターを呼び出すことにより、コマンドラインで実行できます。
$python script.py # Unix/Linuxまたは、
python% script.py # Unix/Linuxまたは、
C:> python script.py # Windows/DOSNote −ファイル許可モードで実行が許可されていることを確認してください。
統合開発環境
システムにPythonをサポートするGUIアプリケーションがある場合は、グラフィカルユーザーインターフェイス(GUI)環境からPythonを実行することもできます。
Unix − IDLEは、Python用の最初のUnixIDEです。
Windows − PythonWinは、Python用の最初のWindowsインターフェイスであり、GUIを備えたIDEです。
Macintosh −MacintoshバージョンのPythonとIDLEIDEは、メインのWebサイトから入手でき、MacBinaryファイルまたはBinHexファイルとしてダウンロードできます。
環境を適切に設定できない場合は、システム管理者の助けを借りることができます。Python環境が適切に設定され、完全に正常に機能していることを確認してください。
Anacondaと呼ばれる別のPythonプラットフォームを使用することもできます。これには、数百の人気のあるデータサイエンスパッケージと、Windows、Linux、およびMacOS用のcondaパッケージと仮想環境マネージャーが含まれています。リンクからオペレーティングシステムごとにダウンロードできますhttps://www.anaconda.com/download/。
このチュートリアルでは、MSWindowsでPython3.6.3バージョンを使用しています。
学習とは、学習や経験を通じて知識やスキルを習得することを意味します。これに基づいて、機械学習(ML)を次のように定義できます。
これは、コンピューターサイエンスの分野、より具体的には人工知能のアプリケーションとして定義できます。これにより、コンピューターシステムは、明示的にプログラムすることなく、データを学習し、経験から改善することができます。
基本的に、機械学習の主な焦点は、人間の介入なしにコンピューターが自動的に学習できるようにすることです。ここで、そのような学習をどのように開始して実行できるのかという疑問が生じます。それはデータの観察から始めることができます。データは、いくつかの例、指示、またはいくつかの直接的な経験でもあります。次に、この入力に基づいて、マシンはデータ内のいくつかのパターンを探すことにより、より適切な決定を下します。
機械学習(ML)の種類
機械学習アルゴリズムは、明示的にプログラムされていなくても、コンピューターシステムが学習するのに役立ちます。これらのアルゴリズムは、教師ありまたは教師なしに分類されます。いくつかのアルゴリズムを見てみましょう-
教師あり機械学習アルゴリズム
これは、最も一般的に使用される機械学習アルゴリズムです。トレーニングデータセットからのアルゴリズム学習のプロセスは、学習プロセスを監督する教師と見なすことができるため、教師ありと呼ばれます。この種のMLアルゴリズムでは、考えられる結果はすでにわかっており、トレーニングデータにも正解のラベルが付けられています。それは次のように理解することができます-
入力変数があるとします x および出力変数 y そして、アルゴリズムを適用して、入力から出力へのマッピング関数を学習します。
Y = f(x)ここでの主な目標は、マッピング関数を適切に近似して、新しい入力データ(x)がある場合に、そのデータの出力変数(Y)を予測できるようにすることです。
主に教師あり学習の問題は、次の2種類の問題に分けることができます。
Classification −問題は、「黒」、「教育」、「非教育」などの分類された出力がある場合、分類問題と呼ばれます。
Regression −「距離」、「キログラム」などの実際の値が出力される場合、問題は回帰問題と呼ばれます。
決定木、ランダムフォレスト、knn、ロジスティック回帰は、教師あり機械学習アルゴリズムの例です。
教師なし機械学習アルゴリズム
名前が示すように、これらの種類の機械学習アルゴリズムには、あらゆる種類のガイダンスを提供するスーパーバイザーがありません。そのため、教師なし機械学習アルゴリズムは、真の人工知能と呼ばれるものと密接に連携しています。それは次のように理解することができます-
入力変数xがあるとすると、教師あり学習アルゴリズムのように対応する出力変数はありません。
簡単に言えば、教師なし学習では正解はなく、指導のための教師もいないと言えます。アルゴリズムは、データの興味深いパターンを発見するのに役立ちます。
教師なし学習の問題は、次の2種類の問題に分けることができます-
Clustering−クラスタリングの問題では、データに固有のグループ化を発見する必要があります。たとえば、購入行動によって顧客をグループ化します。
Association−このような種類の問題では、データの大部分を説明するルールを発見する必要があるため、問題は関連付け問題と呼ばれます。たとえば、両方を購入する顧客を見つけるx そして y。
クラスタリングのK-means、関連付けのAprioriアルゴリズムは、教師なし機械学習アルゴリズムの例です。
強化機械学習アルゴリズム
これらの種類の機械学習アルゴリズムは、ほとんど使用されていません。これらのアルゴリズムは、特定の決定を行うようにシステムをトレーニングします。基本的に、マシンは試行錯誤の方法を使用して継続的にトレーニングを行う環境にさらされています。これらのアルゴリズムは、過去の経験から学習し、正確な決定を行うために可能な限り最良の知識を取得しようとします。マルコフ決定過程は、強化機械学習アルゴリズムの一例です。
最も一般的な機械学習アルゴリズム
このセクションでは、最も一般的な機械学習アルゴリズムについて学習します。アルゴリズムは以下のとおりです-
線形回帰
これは、統計と機械学習で最もよく知られているアルゴリズムの1つです。
基本概念-主に線形回帰は、入力変数(x)と単一の出力変数(y)の間の線形関係を想定する線形モデルです。言い換えれば、yは入力変数xの線形結合から計算できると言えます。変数間の関係は、最適な線を当てはめることによって確立できます。
線形回帰の種類
線形回帰には次の2つのタイプがあります-
Simple linear regression −線形回帰アルゴリズムは、独立変数が1つしかない場合、単純線形回帰と呼ばれます。
Multiple linear regression −線形回帰アルゴリズムは、複数の独立変数がある場合、多重線形回帰と呼ばれます。
線形回帰は、主に連続変数に基づいて実数値を推定するために使用されます。たとえば、実際の値に基づく1日の店舗の総売上高は、線形回帰によって推定できます。
ロジスティック回帰
これは分類アルゴリズムであり、別名 logit 回帰。
主にロジスティック回帰は、特定の独立変数のセットに基づいて、0または1、真または偽、はいまたはいいえなどの離散値を推定するために使用される分類アルゴリズムです。基本的に、それは確率を予測するので、その出力は0と1の間にあります。
デシジョンツリー
決定木は、主に分類問題に使用される教師あり学習アルゴリズムです。
基本的には、独立変数に基づく再帰的パーティションとして表現される分類子です。デシジョンツリーには、ルートツリーを形成するノードがあります。ルートツリーは、「ルート」と呼ばれるノードを持つ有向ツリーです。ルートには入力エッジがなく、他のすべてのノードには1つの入力エッジがあります。これらのノードは、リーフまたは決定ノードと呼ばれます。たとえば、次の決定木を検討して、人が健康であるかどうかを確認します。

サポートベクターマシン(SVM)
分類と回帰の両方の問題に使用されます。しかし、主に分類問題に使用されます。SVMの主な概念は、各データ項目をn次元空間の点としてプロットし、各特徴の値を特定の座標の値にすることです。ここで、nは私たちが持つであろう機能です。以下は、SVMの概念を理解するための簡単なグラフィック表現です。

上の図では、2つの特徴があるため、最初にこれら2つの変数を2次元空間にプロットする必要があります。各点には、サポートベクターと呼ばれる2つの座標があります。この行は、データを2つの異なる分類されたグループに分割します。この行が分類子になります。
ナイーブベイズ
分類手法でもあります。この分類手法の背後にあるロジックは、分類器を構築するためにベイズの定理を使用することです。予測子は独立していることが前提です。簡単に言うと、クラス内の特定の機能の存在は、他の機能の存在とは無関係であると想定しています。以下はベイズの定理の方程式です-
$$ P \ left(\ frac {A} {B} \ right)= \ frac {P \ left(\ frac {B} {A} \ right)P \ left(A \ right)} {P \ left( B \ right)} $$
ナイーブベイズモデルは構築が簡単で、大規模なデータセットに特に役立ちます。
K最近傍法(KNN)
これは、問題の分類と回帰の両方に使用されます。分類問題を解決するために広く使用されています。このアルゴリズムの主な概念は、使用可能なすべてのケースを格納し、k近傍の多数決によって新しいケースを分類するために使用されることです。次に、距離関数によって測定された、K最近傍の中で最も一般的なクラスにケースが割り当てられます。距離関数は、ユークリッド、ミンコフスキー、ハミング距離にすることができます。KNNを使用するには、次のことを考慮してください。
計算上、KNNは分類問題に使用される他のアルゴリズムよりも高価です。
必要な変数の正規化は、そうでなければより高い範囲の変数がバイアスをかける可能性があります。
KNNでは、ノイズ除去などの前処理段階に取り組む必要があります。
K-Meansクラスタリング
名前が示すように、クラスタリングの問題を解決するために使用されます。これは基本的に教師なし学習の一種です。K-Meansクラスタリングアルゴリズムの主なロジックは、いくつかのクラスターを介してデータセットを分類することです。次の手順に従って、K-means-でクラスターを形成します。
K-meansは、重心と呼ばれる各クラスターのk個の点を選択します。
これで、各データポイントは、最も近い重心を持つクラスター、つまりkクラスターを形成します。
これで、既存のクラスターメンバーに基づいて各クラスターの重心が検出されます。
収束が発生するまで、これらの手順を繰り返す必要があります。
ランダムフォレスト
これは、教師あり分類アルゴリズムです。ランダムフォレストアルゴリズムの利点は、分類と回帰の両方の種類の問題に使用できることです。基本的に、それは決定木のコレクション(つまり、フォレスト)であるか、決定木のアンサンブルと言えます。ランダムフォレストの基本的な概念は、各ツリーが分類を与え、フォレストがそれらから最良の分類を選択することです。以下は、ランダムフォレストアルゴリズムの利点です-
ランダムフォレスト分類子は、分類タスクと回帰タスクの両方に使用できます。
不足している値を処理できます。
森にたくさんの木があったとしても、モデルに適合しすぎることはありません。
教師ありおよび教師なしの機械学習アルゴリズムについては、すでに学習しました。これらのアルゴリズムでは、トレーニングプロセスを開始するためにフォーマットされたデータが必要です。MLアルゴリズムへの入力として提供できるように、特定の方法でデータを準備またはフォーマットする必要があります。
この章では、機械学習アルゴリズムのデータ準備に焦点を当てます。
データの前処理
私たちの日常生活では、たくさんのデータを扱っていますが、このデータは生の形です。機械学習アルゴリズムの入力としてデータを提供するには、データを意味のあるデータに変換する必要があります。そこで、データの前処理が思い浮かびます。言い換えれば、機械学習アルゴリズムにデータを提供する前に、データを前処理する必要があると言えます。
データ前処理ステップ
次の手順に従って、Pythonでデータを前処理します-
Step 1 − Importing the useful packages − Pythonを使用している場合、これはデータを特定の形式に変換するための最初のステップ、つまり前処理になります。それは次のように行うことができます-
import numpy as np
import sklearn.preprocessingここでは、次の2つのパッケージを使用しました-
NumPy −基本的に、NumPyは、小さな多次元配列の速度をあまり犠牲にすることなく、任意のレコードの大きな多次元配列を効率的に操作するように設計された汎用配列処理パッケージです。
Sklearn.preprocessing −このパッケージは、生の特徴ベクトルを機械学習アルゴリズムにより適した表現に変更するための多くの一般的なユーティリティ関数とトランスフォーマークラスを提供します。
Step 2 − Defining sample data −パッケージをインポートした後、サンプルデータを定義して、そのデータに前処理技術を適用できるようにする必要があります。ここで、次のサンプルデータを定義します-
input_data = np.array([2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8])Step3 − Applying preprocessing technique −このステップでは、前処理技術のいずれかを適用する必要があります。
次のセクションでは、データの前処理手法について説明します。
データ前処理の手法
データ前処理の手法を以下に説明します-
二値化
これは、数値をブール値に変換する必要がある場合に使用される前処理手法です。次のように、しきい値として0.5を使用することにより、組み込みメソッドを使用して入力データを2値化できます。
data_binarized = preprocessing.Binarizer(threshold = 0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)上記のコードを実行すると、次の出力が得られます。0.5(しきい値)を超えるすべての値は1に変換され、0.5未満のすべての値は0に変換されます。
Binarized data
[[ 1. 0. 1.]
[ 0. 1. 1.]
[ 0. 0. 1.]
[ 1. 1. 0.]]平均除去
これは、機械学習で使用されるもう1つの非常に一般的な前処理手法です。基本的に、すべての特徴がゼロを中心とするように、特徴ベクトルから平均を削除するために使用されます。特徴ベクトルの特徴からバイアスを取り除くこともできます。サンプルデータに平均除去前処理手法を適用するために、以下に示すPythonコードを記述できます。コードは、入力データの平均と標準偏差を表示します-
print("Mean = ", input_data.mean(axis = 0))
print("Std deviation = ", input_data.std(axis = 0))上記のコード行を実行すると、次の出力が得られます-
Mean = [ 1.75 -1.275 2.2]
Std deviation = [ 2.71431391 4.20022321 4.69414529]ここで、以下のコードは入力データの平均と標準偏差を削除します-
data_scaled = preprocessing.scale(input_data)
print("Mean =", data_scaled.mean(axis=0))
print("Std deviation =", data_scaled.std(axis = 0))上記のコード行を実行すると、次の出力が得られます-
Mean = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00]
Std deviation = [ 1. 1. 1.]スケーリング
これは、特徴ベクトルをスケーリングするために使用される別のデータ前処理手法です。すべての特徴の値は多くのランダムな値の間で変化する可能性があるため、特徴ベクトルのスケーリングが必要です。言い換えれば、フィーチャを総合的に大きくしたり小さくしたりしたくないので、スケーリングが重要であると言えます。次のPythonコードを使用して、入力データ、つまり特徴ベクトルのスケーリングを行うことができます。
# Min max scaling
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)上記のコード行を実行すると、次の出力が得られます-
Min max scaled data
[ [ 0.48648649 0.58252427 0.99122807]
[ 0. 1. 0.81578947]
[ 0.27027027 0. 1. ]
[ 1. 0. 99029126 0. ]]正規化
これは、特徴ベクトルを変更するために使用される別のデータ前処理手法です。このような変更は、共通のスケールで特徴ベクトルを測定するために必要です。以下は、機械学習で使用できる2種類の正規化です。
L1 Normalization
とも呼ばれます Least Absolute Deviations。この種の正規化は、絶対値の合計が各行で常に最大1になるように値を変更します。次のPythonコードを使用して、入力データに実装できます。
# Normalize data
data_normalized_l1 = preprocessing.normalize(input_data, norm = 'l1')
print("\nL1 normalized data:\n", data_normalized_l1)上記のコード行は、次の出力を生成します&miuns;
L1 normalized data:
[[ 0.22105263 -0.2 0.57894737]
[ -0.2027027 0.32432432 0.47297297]
[ 0.03571429 -0.56428571 0.4 ]
[ 0.42142857 0.16428571 -0.41428571]]L2 Normalization
とも呼ばれます least squares。この種の正規化は、二乗の合計が各行で常に最大1になるように値を変更します。次のPythonコードを使用して、入力データに実装できます。
# Normalize data
data_normalized_l2 = preprocessing.normalize(input_data, norm = 'l2')
print("\nL2 normalized data:\n", data_normalized_l2)上記のコード行は、次の出力を生成します-
L2 normalized data:
[[ 0.33946114 -0.30713151 0.88906489]
[ -0.33325106 0.53320169 0.7775858 ]
[ 0.05156558 -0.81473612 0.57753446]
[ 0.68706914 0.26784051 -0.6754239 ]]データのラベル付け
機械学習アルゴリズムには、特定の形式のデータが必要であることはすでにわかっています。もう1つの重要な要件は、機械学習アルゴリズムの入力としてデータを送信する前に、データに適切なラベルを付ける必要があることです。たとえば、分類について言えば、データには多くのラベルがあります。これらのラベルは、単語や数字などの形式になっています。機械学習に関連する機能sklearnデータには番号ラベルが必要です。したがって、データが他の形式である場合は、数値に変換する必要があります。単語ラベルを数値形式に変換するこのプロセスは、ラベルエンコーディングと呼ばれます。
ラベルのエンコード手順
Pythonでデータラベルをエンコードするには、次の手順に従います-
Step1 − Importing the useful packages
Pythonを使用している場合、これはデータを特定の形式に変換するための最初のステップ、つまり前処理になります。それは次のように行うことができます-
import numpy as np
from sklearn import preprocessingStep 2 − Defining sample labels
パッケージをインポートした後、ラベルエンコーダーを作成してトレーニングできるように、いくつかのサンプルラベルを定義する必要があります。次のサンプルラベルを定義します-
# Sample input labels
input_labels = ['red','black','red','green','black','yellow','white']Step 3 − Creating & training of label encoder object
このステップでは、ラベルエンコーダーを作成してトレーニングする必要があります。次のPythonコードは、これを行うのに役立ちます-
# Creating the label encoder
encoder = preprocessing.LabelEncoder()
encoder.fit(input_labels)上記のPythonコードを実行した後の出力は次のとおりです-
LabelEncoder()Step4 − Checking the performance by encoding random ordered list
このステップは、ランダムな順序のリストをエンコードすることにより、パフォーマンスをチェックするために使用できます。次のPythonコードは、同じことを行うように記述できます-
# encoding a set of labels
test_labels = ['green','red','black']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)ラベルは次のように印刷されます-
Labels = ['green', 'red', 'black']これで、エンコードされた値のリスト、つまり単語ラベルを次のように数値に変換して取得できます。
print("Encoded values =", list(encoded_values))エンコードされた値は次のように出力されます-
Encoded values = [1, 2, 0]Step 5 − Checking the performance by decoding a random set of numbers −
このステップは、ランダムな数値のセットをデコードすることにより、パフォーマンスをチェックするために使用できます。次のPythonコードは、同じことを行うように記述できます-
# decoding a set of values
encoded_values = [3,0,4,1]
decoded_list = encoder.inverse_transform(encoded_values)
print("\nEncoded values =", encoded_values)これで、エンコードされた値は次のように出力されます-
Encoded values = [3, 0, 4, 1]
print("\nDecoded labels =", list(decoded_list))これで、デコードされた値は次のように出力されます-
Decoded labels = ['white', 'black', 'yellow', 'green']ラベル付きv / sラベルなしデータ
ラベルのないデータは、主に、世界から簡単に入手できる自然または人間が作成したオブジェクトのサンプルで構成されています。それらには、オーディオ、ビデオ、写真、ニュース記事などが含まれます。
一方、ラベル付きデータは、ラベルなしデータのセットを取得し、そのラベルなしデータの各部分に、意味のあるタグ、ラベル、またはクラスを追加します。たとえば、写真がある場合は、写真の内容に基づいてラベルを付けることができます。つまり、男の子、女の子、動物などの写真です。データにラベルを付けるには、ラベルのない特定のデータに関する人間の専門知識または判断が必要です。
ラベルのないデータが豊富で簡単に取得できるシナリオはたくさんありますが、ラベルの付いたデータには多くの場合、人間/専門家が注釈を付ける必要があります。半教師あり学習は、ラベル付きデータとラベルなしデータを組み合わせて、より良いモデルを構築しようとします。
この章では、教師あり学習-分類の実装に焦点を当てます。
分類手法またはモデルは、観測値から何らかの結論を得ようとします。分類問題では、「黒」、「白」、「教育」、「非教育」などの分類された出力があります。分類モデルを構築する際、データポイントと対応するラベルを含むトレーニングデータセットが必要です。たとえば、画像が車の画像であるかどうかを確認したい場合です。これを確認するために、「車」と「車なし」に関連する2つのクラスを持つトレーニングデータセットを作成します。次に、トレーニングサンプルを使用してモデルをトレーニングする必要があります。分類モデルは、主に顔認識、スパム識別などで使用されます。
Pythonで分類子を作成する手順
Pythonで分類子を構築するには、Python3と機械学習のツールであるScikit-learnを使用します。次の手順に従って、Pythonで分類子を作成します-
ステップ1-Scikit-learnをインポートする
これは、Pythonで分類子を構築するための非常に最初のステップになります。このステップでは、Pythonで最高の機械学習モジュールの1つであるScikit-learnと呼ばれるPythonパッケージをインストールします。次のコマンドは、パッケージのインポートに役立ちます-
Import Sklearnステップ2-Scikit-learnのデータセットをインポートする
このステップでは、機械学習モデルのデータセットの操作を開始できます。ここでは、the 乳がんウィスコンシン診断データベース。データセットには、乳がん腫瘍に関するさまざまな情報と、malignant または benign。データセットには、569個の腫瘍に関する569個のインスタンスまたはデータがあり、腫瘍の半径、テクスチャ、滑らかさ、面積など、30個の属性または特徴に関する情報が含まれています。次のコマンドを使用して、Scikit-learnの乳がんデータセットをインポートできます-
from sklearn.datasets import load_breast_cancerここで、次のコマンドはデータセットをロードします。
data = load_breast_cancer()以下は重要な辞書キーのリストです-
- 分類ラベル名(target_names)
- 実際のラベル(ターゲット)
- 属性/機能名(feature_names)
- 属性(データ)
これで、次のコマンドを使用して、重要な情報セットごとに新しい変数を作成し、データを割り当てることができます。つまり、次のコマンドでデータを整理できます。
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']ここで、わかりやすくするために、次のコマンドを使用して、クラスラベル、最初のデータインスタンスのラベル、機能名、および機能の値を出力できます。
print(label_names)上記のコマンドは、それぞれ悪性および良性のクラス名を出力します。以下の出力として表示されます-
['malignant' 'benign']ここで、以下のコマンドは、それらがバイナリ値0および1にマップされていることを示します。ここで、0は悪性癌を表し、1は良性癌を表します。次の出力が表示されます-
print(labels[0])
0以下に示す2つのコマンドは、機能名と機能値を生成します。
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]上記の出力から、最初のデータインスタンスは、半径が1.7990000e +01の悪性腫瘍であることがわかります。
ステップ3-データをセットに整理する
このステップでは、データをトレーニングセットとテストセットの2つの部分に分割します。見えないデータでモデルをテストする必要があるため、データをこれらのセットに分割することは非常に重要です。データをセットに分割するために、sklearnにはtrain_test_split()関数。次のコマンドを使用して、これらのセットのデータを分割できます-
from sklearn.model_selection import train_test_split上記のコマンドは、 train_test_splitsklearnの関数と以下のコマンドは、データをトレーニングデータとテストデータに分割します。以下の例では、データの40%をテストに使用し、残りのデータをモデルのトレーニングに使用します。
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)ステップ4-モデルの構築
このステップでは、モデルを作成します。モデルの構築には、ナイーブベイズアルゴリズムを使用します。次のコマンドを使用してモデルを構築できます-
from sklearn.naive_bayes import GaussianNB上記のコマンドはGaussianNBモジュールをインポートします。次のコマンドは、モデルを初期化するのに役立ちます。
gnb = GaussianNB()gnb.fit()を使用してモデルをデータに適合させることにより、モデルをトレーニングします。
model = gnb.fit(train, train_labels)ステップ5-モデルとその精度を評価する
このステップでは、テストデータを予測してモデルを評価します。次に、その精度も調べます。予測を行うには、predict()関数を使用します。次のコマンドは、これを行うのに役立ちます-
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]上記の一連の0と1は、悪性と良性の腫瘍クラスの予測値です。
さて、2つの配列を比較することによって test_labels そして preds、モデルの精度を確認できます。を使用しますaccuracy_score()精度を決定する関数。これについては、次のコマンドを検討してください-
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965結果は、単純ベイズ分類器が95.17%正確であることを示しています。
このようにして、上記の手順を使用して、Pythonで分類子を構築できます。
Pythonで分類子を構築する
このセクションでは、Pythonで分類子を作成する方法を学習します。
単純ベイズ分類器
ナイーブベイズは、ベイズの定理を使用して分類器を構築するために使用される分類手法です。予測子は独立していることが前提です。簡単に言うと、クラス内の特定の機能の存在は、他の機能の存在とは無関係であると想定しています。単純ベイズ分類器を構築するには、scikitlearnと呼ばれるPythonライブラリを使用する必要があります。名前の付いたナイーブベイズモデルには3つのタイプがありますGaussian, Multinomial and Bernoulli scikitlearnパッケージの下。
ナイーブベイズ機械学習分類器モデルを構築するには、次の&minusが必要です。
データセット
Breast Cancer Wisconsin DiagnosticDatabaseという名前のデータセットを使用します。データセットには、乳がん腫瘍に関するさまざまな情報と、malignant または benign。データセットには、569個の腫瘍に関する569個のインスタンスまたはデータがあり、腫瘍の半径、テクスチャ、滑らかさ、面積など、30個の属性または特徴に関する情報が含まれています。このデータセットはsklearnパッケージからインポートできます。
ナイーブベイズモデル
ナイーブベイズ分類器を構築するには、ナイーブベイズモデルが必要です。前に述べたように、名前が付けられたナイーブベイズモデルには3つのタイプがありますGaussian, Multinomial そして Bernoulliscikitlearnパッケージの下。ここで、次の例では、ガウスナイーブベイズモデルを使用します。
上記を使用して、腫瘍情報を使用して腫瘍が悪性か良性かを予測するナイーブベイズ機械学習モデルを構築します。
まず、sklearnモジュールをインストールする必要があります。次のコマンドを使用して実行できます-
Import Sklearn次に、Breast Cancer Wisconsin DiagnosticDatabaseという名前のデータセットをインポートする必要があります。
from sklearn.datasets import load_breast_cancerここで、次のコマンドはデータセットをロードします。
data = load_breast_cancer()データは次のように整理できます-
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']ここで、わかりやすくするために、次のコマンドを使用して、クラスラベル、最初のデータインスタンスのラベル、機能名、および機能の値を出力できます。
print(label_names)上記のコマンドは、それぞれ悪性および良性のクラス名を出力します。以下の出力として表示されます-
['malignant' 'benign']ここで、以下のコマンドは、それらがバイナリ値0および1にマップされていることを示します。ここで、0は悪性癌を表し、1は良性癌を表します。以下の出力として表示されます-
print(labels[0])
0次の2つのコマンドは、機能名と機能値を生成します。
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]上記の出力から、最初のデータインスタンスは、主半径が1.7990000e +01である悪性腫瘍であることがわかります。
見えないデータでモデルをテストするには、データをトレーニングデータとテストデータに分割する必要があります。それは次のコードの助けを借りて行うことができます-
from sklearn.model_selection import train_test_split上記のコマンドは、 train_test_splitsklearnの関数と以下のコマンドは、データをトレーニングデータとテストデータに分割します。以下の例では、データの40%をテストに使用しており、リマイニングデータはモデルのトレーニングに使用されます。
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)現在、次のコマンドを使用してモデルを構築しています-
from sklearn.naive_bayes import GaussianNB上記のコマンドは、 GaussianNBモジュール。次に、以下のコマンドを使用して、モデルを初期化する必要があります。
gnb = GaussianNB()を使用してモデルをデータに適合させてトレーニングします gnb.fit()。
model = gnb.fit(train, train_labels)ここで、テストデータを予測してモデルを評価すると、次のように実行できます。
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]上記の一連の0と1は、腫瘍クラス、つまり悪性と良性の予測値です。
さて、2つの配列を比較することによって test_labels そして preds、モデルの精度を確認できます。を使用しますaccuracy_score()精度を決定する関数。次のコマンドを検討してください-
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965結果は、単純ベイズ分類器が95.17%正確であることを示しています。
これは、ナイーブベイズガウスモデルに基づく機械学習分類器でした。
サポートベクターマシン(SVM)
基本的に、サポートベクターマシン(SVM)は、回帰と分類の両方に使用できる教師あり機械学習アルゴリズムです。SVMの主な概念は、各データ項目をn次元空間の点としてプロットし、各特徴の値を特定の座標の値にすることです。ここで、nは私たちが持つであろう機能です。以下は、SVMの概念を理解するための簡単なグラフィック表現です。
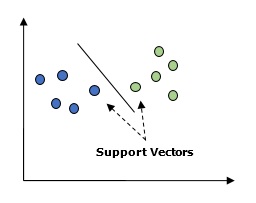
上の図には、2つの機能があります。したがって、最初に、これら2つの変数を2次元空間にプロットする必要があります。各点には、サポートベクターと呼ばれる2つの座標があります。この行は、データを2つの異なる分類されたグループに分割します。この行が分類子になります。
ここでは、scikit-learnとirisデータセットを使用してSVM分類器を構築します。Scikitlearnライブラリにはsklearn.svmモジュールであり、分類用のsklearn.svm.svcを提供します。4つの特徴に基づいてアヤメ植物のクラスを予測するためのSVM分類器を以下に示します。
データセット
それぞれ50インスタンスの3つのクラスを含むアイリスデータセットを使用します。各クラスはアイリス植物のタイプを参照します。各インスタンスには、がく片の長さ、がく片の幅、花びらの長さ、花びらの幅の4つの機能があります。4つの特徴に基づいてアヤメ植物のクラスを予測するSVM分類器を以下に示します。
カーネル
これはSVMで使用される手法です。基本的に、これらは低次元の入力空間を取り、それを高次元の空間に変換する関数です。分離不可能な問題を分離可能な問題に変換します。カーネル関数は、線形、多項式、rbf、およびシグモイドのいずれかです。この例では、線形カーネルを使用します。
次のパッケージをインポートしましょう-
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as pltここで、入力データをロードします-
iris = datasets.load_iris()最初の2つの機能を採用しています-
X = iris.data[:, :2]
y = iris.target元のデータを使用してサポートベクターマシンの境界をプロットします。プロットするメッシュを作成しています。
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]正則化パラメーターの値を指定する必要があります。
C = 1.0SVM分類器オブジェクトを作成する必要があります。
Svc_classifier = svm_classifier.SVC(kernel='linear',
C=C, decision_function_shape = 'ovr').fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
ロジスティック回帰
基本的に、ロジスティック回帰モデルは、教師あり分類アルゴリズムファミリーのメンバーの1つです。ロジスティック回帰は、ロジスティック関数を使用して確率を推定することにより、従属変数と独立変数の間の関係を測定します。
ここで、従属変数と独立変数について話す場合、従属変数は予測するターゲットクラス変数であり、反対側では、独立変数はターゲットクラスを予測するために使用する機能です。
ロジスティック回帰では、確率を推定することは、イベントの発生の可能性を予測することを意味します。たとえば、店のオーナーは、店に入った顧客が(たとえば)プレイステーションを購入するかどうかを予測したいと考えています。店主がプレイステーションを購入するかどうかなど、発生の可能性を予測するために観察する、顧客の多くの特徴(性別、年齢など)があります。ロジスティック関数は、さまざまなパラメーターを使用して関数を作成するために使用されるシグモイド曲線です。
前提条件
ロジスティック回帰を使用して分類器を構築する前に、システムにTkinterパッケージをインストールする必要があります。からインストールできますhttps://docs.python.org/2/library/tkinter.html。
ここで、以下のコードを使用して、ロジスティック回帰を使用して分類器を作成できます。
まず、いくつかのパッケージをインポートします-
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as pltここで、次のように実行できるサンプルデータを定義する必要があります。
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4],
[3.2, 0.9], [2.9, 1.9],[2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])次に、ロジスティック回帰分類器を作成する必要があります。これは次のように実行できます。
Classifier_LR = linear_model.LogisticRegression(solver = 'liblinear', C = 75)最後になりましたが、この分類器をトレーニングする必要があります-
Classifier_LR.fit(X, y)では、出力をどのように視覚化できるでしょうか。Logistic_visualize()-という名前の関数を作成することで実行できます。
Def Logistic_visualize(Classifier_LR, X, y):
min_x, max_x = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
min_y, max_y = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0上記の行では、メッシュグリッドで使用される最小値と最大値XとYを定義しました。さらに、メッシュグリッドをプロットするためのステップサイズを定義します。
mesh_step_size = 0.02X値とY値のメッシュグリッドを次のように定義しましょう-
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size),
np.arange(min_y, max_y, mesh_step_size))次のコードの助けを借りて、メッシュグリッド上で分類器を実行できます-
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = 'black',
linewidth=1, cmap = plt.cm.Paired)次のコード行は、プロットの境界を指定します
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(X[:, 0].min() - 1), int(X[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(X[:, 1].min() - 1), int(X[:, 1].max() + 1), 1.0)))
plt.show()これで、コードを実行した後、次の出力が得られます。ロジスティック回帰分類子-

デシジョンツリー分類子
決定木は基本的に二分木フローチャートであり、各ノードはいくつかの特徴変数に従って観測値のグループを分割します。
ここでは、男性または女性を予測するための決定木分類器を構築しています。19個のサンプルを持つ非常に小さなデータセットを取得します。これらのサンプルは、「高さ」と「髪の長さ」の2つの機能で構成されます。
前提条件
次の分類器を構築するには、インストールする必要があります pydotplus そして graphviz。基本的に、graphvizはドットファイルを使用してグラフィックを描画するためのツールであり、pydotplusGraphvizのDot言語のモジュールです。パッケージマネージャーまたはpipを使用してインストールできます。
これで、次のPythonコードを使用して決定木分類器を構築できます-
まず、次のようにいくつかの重要なライブラリをインポートしましょう-
import pydotplus
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn import cross_validation
import collectionsここで、次のようにデータセットを提供する必要があります-
X = [[165,19],[175,32],[136,35],[174,65],[141,28],[176,15],[131,32],
[166,6],[128,32],[179,10],[136,34],[186,2],[126,25],[176,28],[112,38],
[169,9],[171,36],[116,25],[196,25]]
Y = ['Man','Woman','Woman','Man','Woman','Man','Woman','Man','Woman',
'Man','Woman','Man','Woman','Woman','Woman','Man','Woman','Woman','Man']
data_feature_names = ['height','length of hair']
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split
(X, Y, test_size=0.40, random_state=5)データセットを提供した後、次のように実行できるモデルを適合させる必要があります-
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,Y)予測は、次のPythonコードを使用して行うことができます-
prediction = clf.predict([[133,37]])
print(prediction)次のPythonコードを使用して、決定木を視覚化できます。
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names,
out_file = None,filled = True,rounded = True)
graph = pydotplus.graph_from_dot_data(dot_data)
colors = ('orange', 'yellow')
edges = collections.defaultdict(list)
for edge in graph.get_edge_list():
edges[edge.get_source()].append(int(edge.get_destination()))
for edge in edges: edges[edge].sort()
for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0]
dest.set_fillcolor(colors[i])
graph.write_png('Decisiontree16.png')上記のコードの予測は次のようになります。 [‘Woman’] 次の決定木を作成します-

予測の特徴の値を変更してテストすることができます。
ランダムフォレスト分類子
アンサンブルメソッドは、機械学習モデルをより強力な機械学習モデルに結合するメソッドであることを私たちは知っています。決定木のコレクションであるランダムフォレストはその1つです。予測力を保持しながら、結果を平均化することで過剰適合を減らすことができるため、単一の決定木よりも優れています。ここでは、scikitlearn癌データセットにランダムフォレストモデルを実装します。
必要なパッケージをインポートする-
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as npここで、次のように実行できるデータセットを提供する必要があります&minus
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)データセットを提供した後、次のように実行できるモデルを適合させる必要があります-
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)ここで、サブセットのテストだけでなくトレーニングの精度も取得します。推定量の数を増やすと、サブセットのテストの精度も向上します。
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train)))
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test)))出力
Accuracy on the training subset:(:.3f) 1.0
Accuracy on the training subset:(:.3f) 0.965034965034965さて、決定木のように、ランダムフォレストには feature_importance決定木よりも特徴の重みのより良いビューを提供するモジュール。次のようにプロットして視覚化できます-
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()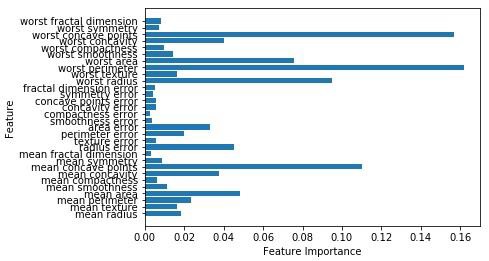
分類器のパフォーマンス
機械学習アルゴリズムを実装した後、モデルがどれほど効果的であるかを調べる必要があります。有効性を測定するための基準は、データセットとメトリックに基づく場合があります。さまざまな機械学習アルゴリズムを評価するために、さまざまなパフォーマンス指標を使用できます。たとえば、分類子を使用して異なるオブジェクトの画像を区別する場合、平均精度、AUCなどの分類パフォーマンスメトリックを使用できます。ある意味で、機械学習モデルを評価するために選択するメトリックは次のとおりです。指標の選択は、機械学習アルゴリズムのパフォーマンスの測定方法と比較方法に影響を与えるため、非常に重要です。以下はいくつかの指標です-
混同行列
基本的に、出力が2つ以上のタイプのクラスである可能性がある分類問題に使用されます。これは、分類器のパフォーマンスを測定する最も簡単な方法です。混同行列は、基本的に「実際」と「予測」の2つの次元を持つテーブルです。どちらのディメンションにも、「真のポジティブ(TP)」、「真のネガティブ(TN)」、「偽のポジティブ(FP)」、「偽のネガティブ(FN)」があります。
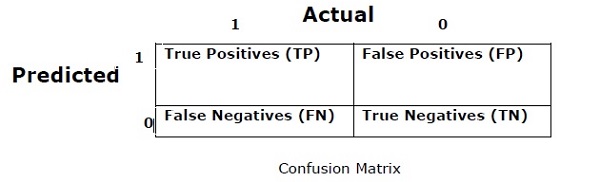
上記の混同行列では、1は正のクラスを表し、0は負のクラスを表します。
以下は、混同行列に関連する用語です-
True Positives − TPは、データポイントの実際のクラスが1で、予測値も1の場合です。
True Negatives − TNは、データポイントの実際のクラスが0で、予測値も0の場合です。
False Positives − FPは、データポイントの実際のクラスが0で、予測値も1の場合です。
False Negatives − FNは、データポイントの実際のクラスが1で、予測値も0の場合です。
正確さ
混同行列自体はパフォーマンス指標ではありませんが、ほとんどすべてのパフォーマンスマトリックスは混同行列に基づいています。それらの1つは精度です。分類問題では、これは、行われたすべての種類の予測に対してモデルによって行われた正しい予測の数として定義できます。精度の計算式は次のとおりです。
$$精度= \ frac {TP + TN} {TP + FP + FN + TN} $$
精度
これは主にドキュメントの取得に使用されます。これは、返されたドキュメントの何個が正しいかとして定義できます。以下は、精度を計算するための式です-
$$精度= \ frac {TP} {TP + FP} $$
再現率または感度
これは、モデルが返すポジティブの数として定義できます。以下は、モデルの想起/感度を計算するための式です-
$$リコール= \ frac {TP} {TP + FN} $$
特異性
これは、モデルが返すネガの数として定義できます。リコールとは正反対です。以下は、モデルの特異性を計算するための式です。
$$特異性= \ frac {TN} {TN + FP} $$
クラスの不均衡の問題
クラスの不均衡は、1つのクラスに属する観測値の数が他のクラスに属する観測値よりも大幅に少ないシナリオです。たとえば、この問題は、希少疾患、銀行での不正取引などを特定する必要があるシナリオで顕著です。
不均衡なクラスの例
不均衡なクラスの概念を理解するために、不正検出データセットの例を考えてみましょう-
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%解決
Balancing the classes’不均衡なクラスの解決策として機能します。クラスのバランスをとる主な目的は、少数派クラスの頻度を増やすか、多数派クラスの頻度を減らすことです。以下は、不均衡クラスの問題を解決するためのアプローチです。
リサンプリング
リサンプリングは、サンプルデータセット(トレーニングセットとテストセットの両方)を再構築するために使用される一連の方法です。モデルの精度を向上させるために、リサンプリングが行われます。以下は、いくつかのリサンプリング手法です-
Random Under-Sampling−この手法は、多数派クラスの例をランダムに排除することにより、クラス分布のバランスを取ることを目的としています。これは、多数派と少数派のクラスインスタンスのバランスがとれるまで行われます。
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%この場合、不正でないインスタンスから置き換えずに10%のサンプルを取得し、それらを不正なインスタンスと組み合わせます-
サンプリング中のランダム後の不正でない観測= 4950の10%= 495
それらを不正な観測と組み合わせた後の合計観測= 50 + 495 = 545
したがって、現在、サンプリング不足後の新しいデータセットのイベント率= 9%
この手法の主な利点は、実行時間を短縮し、ストレージを改善できることです。しかし一方で、トレーニングデータサンプルの数を減らしながら、有用な情報を破棄することができます。
Random Over-Sampling −この手法は、少数派クラスのインスタンスを複製して数を増やすことにより、クラス分布のバランスを取ることを目的としています。
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%50個の不正な観測値を30回複製する場合、少数派クラスの観測値を複製した後の不正な観測値は1500になります。また、オーバーサンプリング後の新しいデータの合計観測値は4950 + 1500 = 6450になります。したがって、新しいデータセットのイベント率1500/6450 = 23%になります。
この方法の主な利点は、有用な情報が失われないことです。ただし、その一方で、少数派クラスのイベントを複製するため、過剰適合の可能性が高くなります。
アンサンブルテクニック
この方法論は基本的に、既存の分類アルゴリズムを変更して、不均衡なデータセットに適したものにするために使用されます。このアプローチでは、元のデータからいくつかの2段階分類器を構築し、それらの予測を集計します。ランダムフォレスト分類器は、アンサンブルベースの分類器の例です。

回帰は、最も重要な統計および機械学習ツールの1つです。機械学習の旅は回帰から始まると言っても過言ではありません。これは、データに基づいて決定を下すことができる、言い換えれば、入力変数と出力変数の関係を学習することによってデータに基づいて予測を行うことができるパラメトリック手法として定義できます。ここで、入力変数に依存する出力変数は、連続値の実数です。回帰では、入力変数と出力変数の関係が重要であり、入力変数の変化に伴って出力変数の値がどのように変化するかを理解するのに役立ちます。回帰は、価格、経済、変動などの予測に頻繁に使用されます。
Pythonでリグレッサを構築する
このセクションでは、単一変数と多変数のリグレッサーを作成する方法を学習します。
線形リグレッサ/単一変数リグレッサ
いくつかの必要なパッケージを重要にしましょう-
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as pltここで、入力データを提供する必要があり、linear.txtという名前のファイルにデータを保存しました。
input = 'D:/ProgramData/linear.txt'を使用してこのデータをロードする必要があります np.loadtxt 関数。
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]次のステップは、モデルをトレーニングすることです。トレーニングとテストのサンプルを提供しましょう。
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]次に、線形リグレッサオブジェクトを作成する必要があります。
reg_linear = linear_model.LinearRegression()トレーニングサンプルを使用してオブジェクトをトレーニングします。
reg_linear.fit(X_train, y_train)テストデータを使用して予測を行う必要があります。
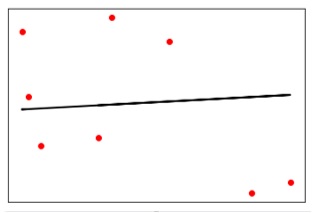
y_test_pred = reg_linear.predict(X_test)次に、データをプロットして視覚化します。
plt.scatter(X_test, y_test, color = 'red')
plt.plot(X_test, y_test_pred, color = 'black', linewidth = 2)
plt.xticks(())
plt.yticks(())
plt.show()出力
これで、線形回帰のパフォーマンスを次のように計算できます。
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred),
2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))出力
線形リグレッサのパフォーマンス-
Mean absolute error = 1.78
Mean squared error = 3.89
Median absolute error = 2.01
Explain variance score = -0.09
R2 score = -0.09上記のコードでは、この小さなデータを使用しています。大きなデータセットが必要な場合は、sklearn.datasetを使用して大きなデータセットをインポートできます。
2,4.82.9,4.72.5,53.2,5.56,57.6,43.2,0.92.9,1.92.4,
3.50.5,3.41,40.9,5.91.2,2.583.2,5.65.1,1.54.5,
1.22.3,6.32.1,2.8多変数リグレッサ
まず、いくつかの必要なパッケージをインポートしましょう-
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeaturesここで、入力データを提供する必要があり、linear.txtという名前のファイルにデータを保存しました。
input = 'D:/ProgramData/Mul_linear.txt'を使用してこのデータをロードします np.loadtxt 関数。
input_data = np.loadtxt(input, delimiter=',')
X, y = input_data[:, :-1], input_data[:, -1]次のステップは、モデルをトレーニングすることです。トレーニングとテストのサンプルを提供します。
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]次に、線形リグレッサオブジェクトを作成する必要があります。
reg_linear_mul = linear_model.LinearRegression()トレーニングサンプルを使用してオブジェクトをトレーニングします。
reg_linear_mul.fit(X_train, y_train)さて、最後に、テストデータを使用して予測を行う必要があります。
y_test_pred = reg_linear_mul.predict(X_test)
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))出力
線形リグレッサのパフォーマンス-
Mean absolute error = 0.6
Mean squared error = 0.65
Median absolute error = 0.41
Explain variance score = 0.34
R2 score = 0.33ここで、次数10の多項式を作成し、リグレッサーをトレーニングします。サンプルデータポイントを提供します。
polynomial = PolynomialFeatures(degree = 10)
X_train_transformed = polynomial.fit_transform(X_train)
datapoint = [[2.23, 1.35, 1.12]]
poly_datapoint = polynomial.fit_transform(datapoint)
poly_linear_model = linear_model.LinearRegression()
poly_linear_model.fit(X_train_transformed, y_train)
print("\nLinear regression:\n", reg_linear_mul.predict(datapoint))
print("\nPolynomial regression:\n", poly_linear_model.predict(poly_datapoint))出力
線形回帰-
[2.40170462]多項式回帰-
[1.8697225]上記のコードでは、この小さなデータを使用しています。大きなデータセットが必要な場合は、sklearn.datasetを使用して大きなデータセットをインポートできます。
2,4.8,1.2,3.22.9,4.7,1.5,3.62.5,5,2.8,23.2,5.5,3.5,2.16,5,
2,3.27.6,4,1.2,3.23.2,0.9,2.3,1.42.9,1.9,2.3,1.22.4,3.5,
2.8,3.60.5,3.4,1.8,2.91,4,3,2.50.9,5.9,5.6,0.81.2,2.58,
3.45,1.233.2,5.6,2,3.25.1,1.5,1.2,1.34.5,1.2,4.1,2.32.3,
6.3,2.5,3.22.1,2.8,1.2,3.6この章では、論理プログラミングとそれが人工知能でどのように役立つかに焦点を当てます。
論理は正しい推論の原理の研究であるか、簡単に言えば、何が何の後に来るのかを研究することであることはすでに知っています。たとえば、2つのステートメントが真の場合、そこから3番目のステートメントを推測できます。
概念
論理プログラミングは、論理とプログラミングの2つの単語を組み合わせたものです。論理プログラミングは、問題がプログラムステートメントによって事実とルールとして表現されるプログラミングパラダイムですが、形式論理のシステム内にあります。オブジェクト指向、機能、宣言型、手続き型などの他のプログラミングパラダイムと同様に、プログラミングにアプローチするための特別な方法でもあります。
論理プログラミングの問題を解決する方法
論理プログラミングは、問題を解決するために事実とルールを使用します。それが、それらが論理プログラミングの構成要素と呼ばれる理由です。論理プログラミングのすべてのプログラムに目標を指定する必要があります。論理プログラミングで問題をどのように解決できるかを理解するには、ビルディングブロック-事実とルール-について知る必要があります。
事実
実際、すべての論理プログラムは、与えられた目標を達成できるように、連携するための事実を必要とします。事実は基本的にプログラムとデータについての真実の声明です。たとえば、デリーはインドの首都です。
ルール
実際、ルールは、問題の領域について結論を出すことを可能にする制約です。基本的に、さまざまな事実を表現するための論理節として記述されたルール。たとえば、ゲームを作成する場合は、すべてのルールを定義する必要があります。
ルールは、論理プログラミングの問題を解決するために非常に重要です。ルールは基本的に事実を表現できる論理的な結論です。以下はルールの構文です-
A:- B1、B2、...、B N。
ここで、Aは頭、B1、B2、... Bnは体です。
例-ancestor(X、Y):-father(X、Y)。
ancestor(X、Z):-father(X、Y)、ancestor(Y、Z)。
これは、すべてのXとYについて、XがYの父であり、YがZの祖先である場合、XはZの祖先であると読むことができます。すべてのXとYについて、XはZの祖先であり、XがYとYの父はZの祖先です。
便利なパッケージのインストール
Pythonで論理プログラミングを開始するには、次の2つのパッケージをインストールする必要があります-
かんれん
これは、ビジネスロジックのコードを作成する方法を簡素化する方法を提供します。ルールと事実の観点から論理を表現することができます。次のコマンドは、kanrenのインストールに役立ちます-
pip install kanrenSymPy
SymPyは、記号数学用のPythonライブラリです。わかりやすく、簡単に拡張できるように、コードを可能な限り単純に保ちながら、フル機能の数式処理システム(CAS)になることを目指しています。次のコマンドは、SymPyのインストールに役立ちます-
pip install sympy論理プログラミングの例
以下は、論理プログラミングによって解決できるいくつかの例です。
マッチング数式
実際、論理プログラミングを非常に効果的に使用することで、未知の値を見つけることができます。次のPythonコードは、数式を照合するのに役立ちます-
最初に次のパッケージをインポートすることを検討してください-
from kanren import run, var, fact
from kanren.assoccomm import eq_assoccomm as eq
from kanren.assoccomm import commutative, associative使用する数学演算を定義する必要があります-
add = 'add'
mul = 'mul'足し算と掛け算はどちらもコミュニケーションのプロセスです。したがって、それを指定する必要があり、これは次のように実行できます。
fact(commutative, mul)
fact(commutative, add)
fact(associative, mul)
fact(associative, add)変数の定義は必須です。これは次のように行うことができます-
a, b = var('a'), var('b')式を元のパターンと一致させる必要があります。基本的に(5 + a)* b −である次の元のパターンがあります
Original_pattern = (mul, (add, 5, a), b)元のパターンと一致する次の2つの式があります-
exp1 = (mul, 2, (add, 3, 1))
exp2 = (add,5,(mul,8,1))次のコマンドで出力を印刷できます-
print(run(0, (a,b), eq(original_pattern, exp1)))
print(run(0, (a,b), eq(original_pattern, exp2)))このコードを実行すると、次の出力が得られます-
((3,2))
()最初の出力は、の値を表します a そして b。最初の式は元のパターンと一致し、の値を返しましたa そして b しかし、2番目の式は元のパターンと一致しなかったため、何も返されませんでした。
素数の確認
論理プログラミングの助けを借りて、数のリストから素数を見つけることができ、素数を生成することもできます。以下に示すPythonコードは、数字のリストから素数を見つけ、最初の10個の素数も生成します。
まず、次のパッケージのインポートを検討しましょう-
from kanren import isvar, run, membero
from kanren.core import success, fail, goaleval, condeseq, eq, var
from sympy.ntheory.generate import prime, isprime
import itertools as it次に、指定された数に基づいて素数をデータとしてチェックするprime_checkという関数を定義します。
def prime_check(x):
if isvar(x):
return condeseq([(eq,x,p)] for p in map(prime, it.count(1)))
else:
return success if isprime(x) else failここで、使用する変数を宣言する必要があります-
x = var()
print((set(run(0,x,(membero,x,(12,14,15,19,20,21,22,23,29,30,41,44,52,62,65,85)),
(prime_check,x)))))
print((run(10,x,prime_check(x))))上記のコードの出力は次のようになります-
{19, 23, 29, 41}
(2, 3, 5, 7, 11, 13, 17, 19, 23, 29)パズルを解く
論理プログラミングは、8パズル、ゼブラパズル、数独、Nクイーンなど、多くの問題を解決するために使用できます。ここでは、次のようなゼブラパズルのバリエーションの例を取り上げます。
There are five houses.
The English man lives in the red house.
The Swede has a dog.
The Dane drinks tea.
The green house is immediately to the left of the white house.
They drink coffee in the green house.
The man who smokes Pall Mall has birds.
In the yellow house they smoke Dunhill.
In the middle house they drink milk.
The Norwegian lives in the first house.
The man who smokes Blend lives in the house next to the house with cats.
In a house next to the house where they have a horse, they smoke Dunhill.
The man who smokes Blue Master drinks beer.
The German smokes Prince.
The Norwegian lives next to the blue house.
They drink water in a house next to the house where they smoke Blend.私たちは質問のためにそれを解決しています who owns zebra Pythonの助けを借りて。
必要なパッケージをインポートしましょう-
from kanren import *
from kanren.core import lall
import timeここで、2つの関数を定義する必要があります- left() そして next() 誰の家が残っているか、誰の家の隣にあるかを確認する-
def left(q, p, list):
return membero((q,p), zip(list, list[1:]))
def next(q, p, list):
return conde([left(q, p, list)], [left(p, q, list)])ここで、可変ハウスを次のように宣言します-
houses = var()次のように、lallパッケージを使用してルールを定義する必要があります。
5軒の家があります-
rules_zebraproblem = lall(
(eq, (var(), var(), var(), var(), var()), houses),
(membero,('Englishman', var(), var(), var(), 'red'), houses),
(membero,('Swede', var(), var(), 'dog', var()), houses),
(membero,('Dane', var(), 'tea', var(), var()), houses),
(left,(var(), var(), var(), var(), 'green'),
(var(), var(), var(), var(), 'white'), houses),
(membero,(var(), var(), 'coffee', var(), 'green'), houses),
(membero,(var(), 'Pall Mall', var(), 'birds', var()), houses),
(membero,(var(), 'Dunhill', var(), var(), 'yellow'), houses),
(eq,(var(), var(), (var(), var(), 'milk', var(), var()), var(), var()), houses),
(eq,(('Norwegian', var(), var(), var(), var()), var(), var(), var(), var()), houses),
(next,(var(), 'Blend', var(), var(), var()),
(var(), var(), var(), 'cats', var()), houses),
(next,(var(), 'Dunhill', var(), var(), var()),
(var(), var(), var(), 'horse', var()), houses),
(membero,(var(), 'Blue Master', 'beer', var(), var()), houses),
(membero,('German', 'Prince', var(), var(), var()), houses),
(next,('Norwegian', var(), var(), var(), var()),
(var(), var(), var(), var(), 'blue'), houses),
(next,(var(), 'Blend', var(), var(), var()),
(var(), var(), 'water', var(), var()), houses),
(membero,(var(), var(), var(), 'zebra', var()), houses)
)ここで、前述の制約を使用してソルバーを実行します-
solutions = run(0, houses, rules_zebraproblem)次のコードの助けを借りて、ソルバーからの出力を抽出できます-
output_zebra = [house for house in solutions[0] if 'zebra' in house][0][0]次のコードは、ソリューションの印刷に役立ちます-
print ('\n'+ output_zebra + 'owns zebra.')上記のコードの出力は次のようになります-
German owns zebra.教師なし機械学習アルゴリズムには、あらゆる種類のガイダンスを提供するスーパーバイザーがいません。そのため、彼らは真の人工知能と呼ばれるものと密接に連携しています。
教師なし学習では、正解はなく、指導のための教師もいません。アルゴリズムは、学習のためにデータの興味深いパターンを発見する必要があります。
クラスタリングとは何ですか?
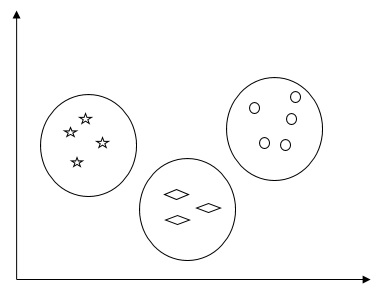
基本的には、教師なし学習法の一種であり、多くの分野で使用される統計データ分析の一般的な手法です。クラスタリングは主に、同じクラスター内の観測値が1つの意味で類似しており、他のクラスター内の観測値とは異なるように、観測値のセットをクラスターと呼ばれるサブセットに分割するタスクです。簡単に言えば、クラスタリングの主な目的は、類似性と非類似性に基づいてデータをグループ化することであると言えます。
たとえば、次の図は、さまざまなクラスター内の同様の種類のデータを示しています。
データをクラスタリングするためのアルゴリズム
以下は、データをクラスタリングするためのいくつかの一般的なアルゴリズムです-
K-Meansアルゴリズム
K-meansクラスタリングアルゴリズムは、データをクラスタリングするためのよく知られたアルゴリズムの1つです。クラスターの数はすでにわかっていると想定する必要があります。これはフラットクラスタリングとも呼ばれます。これは、反復クラスタリングアルゴリズムです。このアルゴリズムでは、以下の手順に従う必要があります-
Step 1 −必要なK個のサブグループの数を指定する必要があります。
Step 2−クラスターの数を修正し、各データポイントをクラスターにランダムに割り当てます。つまり、クラスターの数に基づいてデータを分類する必要があります。
このステップでは、クラスター重心を計算する必要があります。
これは反復アルゴリズムであるため、グローバル最適値が見つかるまで、つまり重心が最適な位置に到達するまで、反復ごとにK重心の位置を更新する必要があります。
次のコードは、PythonでK-meansクラスタリングアルゴリズムを実装するのに役立ちます。Scikit-learnモジュールを使用します。
必要なパッケージをインポートしましょう-
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans次のコード行は、次のコードを使用して、4つのblobを含む2次元データセットを生成するのに役立ちます。 make_blob から sklearn.dataset パッケージ。
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)次のコードを使用してデータセットを視覚化できます-
plt.scatter(X[:, 0], X[:, 1], s = 50);
plt.show()
ここでは、クラスターの数(n_clusters)の必要なパラメーターを使用して、kmeansをKMeansアルゴリズムとして初期化しています。
kmeans = KMeans(n_clusters = 4)入力データを使用してK-meansモデルをトレーニングする必要があります。
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis')
centers = kmeans.cluster_centers_以下に示すコードは、データに基づいたマシンの結果と、検出されるクラスターの数に応じたフィッティングをプロットして視覚化するのに役立ちます。
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5);
plt.show()
平均シフトアルゴリズム
これは、教師なし学習で使用されるもう1つの一般的で強力なクラスタリングアルゴリズムです。仮定を行わないため、ノンパラメトリックアルゴリズムです。階層的クラスタリングまたは平均シフトクラスター分析とも呼ばれます。以下は、このアルゴリズムの基本的な手順です。
まず、独自のクラスターに割り当てられたデータポイントから始める必要があります。
ここで、図心を計算し、新しい図心の位置を更新します。
このプロセスを繰り返すことにより、クラスターのピークに近づきます。つまり、密度の高い領域に向かって移動します。
このアルゴリズムは、重心が動かなくなった段階で停止します。
次のコードの助けを借りて、Pythonで平均シフトクラスタリングアルゴリズムを実装しています。Scikit-learnモジュールを使用します。
必要なパッケージをインポートしましょう-
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")次のコードは、次のコードを使用して、4つのblobを含む2次元データセットを生成するのに役立ちます。 make_blob から sklearn.dataset パッケージ。
from sklearn.datasets.samples_generator import make_blobs次のコードでデータセットを視覚化できます
centers = [[2,2],[4,5],[3,10]]
X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1)
plt.scatter(X[:,0],X[:,1])
plt.show()
次に、入力データを使用して平均シフトクラスターモデルをトレーニングする必要があります。
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_次のコードは、入力データに従ってクラスターの中心とクラスターの予想数を出力します-
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2以下に示すコードは、データに基づいたマシンの結果と、検出されるクラスターの数に応じた装備をプロットして視覚化するのに役立ちます。
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10)
plt.show()
クラスタリングパフォーマンスの測定
実世界のデータは、多くの特徴的なクラスターに自然に編成されていません。このため、推論を視覚化して描画することは容易ではありません。そのため、クラスタリングのパフォーマンスと品質を測定する必要があります。それはシルエット分析の助けを借りて行うことができます。
シルエット分析
この方法は、クラスター間の距離を測定することにより、クラスタリングの品質をチェックするために使用できます。基本的に、シルエットスコアを与えることにより、クラスターの数などのパラメーターを評価する方法を提供します。このスコアは、1つのクラスター内の各ポイントが隣接するクラスター内のポイントにどれだけ近いかを測定するメトリックです。
シルエットスコアの分析
スコアの範囲は[-1、1]です。以下は、このスコアの分析です-
Score of +1 − +1に近いスコアは、サンプルが隣接するクラスターから遠く離れていることを示します。
Score of 0 −スコア0は、サンプルが2つの隣接するクラスター間の決定境界上にあるか非常に近いことを示します。
Score of -1 −負のスコアは、サンプルが間違ったクラスターに割り当てられていることを示します。
シルエットスコアの計算
このセクションでは、シルエットスコアの計算方法を学習します。
シルエットスコアは、次の式を使用して計算できます。
$$ silhouetteスコア= \ frac {\ left(pq \ right)} {max \ left(p、q \ right)} $$
ここで、は、データポイントが含まれていない最も近いクラスター内のポイントまでの平均距離です。また、は、独自のクラスター内のすべてのポイントまでのクラスター内の平均距離です。
クラスターの最適な数を見つけるには、をインポートしてクラスタリングアルゴリズムを再度実行する必要があります。 metrics からのモジュール sklearnパッケージ。次の例では、K-meansクラスタリングアルゴリズムを実行して、最適なクラスター数を見つけます。
図のように必要なパッケージをインポートします-
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans次のコードを使用して、次のコードを使用して、4つのblobを含む2次元データセットを生成します。 make_blob から sklearn.dataset パッケージ。
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0)図のように変数を初期化します-
scores = []
values = np.arange(2, 10)すべての値を介してK-meansモデルを反復する必要があり、入力データを使用してモデルをトレーニングする必要もあります。
for num_clusters in values:
kmeans = KMeans(init = 'k-means++', n_clusters = num_clusters, n_init = 10)
kmeans.fit(X)ここで、ユークリッド距離メトリックを使用して、現在のクラスタリングモデルのシルエットスコアを推定します。
score = metrics.silhouette_score(X, kmeans.labels_,
metric = 'euclidean', sample_size = len(X))次のコード行は、クラスターの数とシルエットスコアを表示するのに役立ちます。
print("\nNumber of clusters =", num_clusters)
print("Silhouette score =", score)
scores.append(score)次の出力が表示されます-
Number of clusters = 9
Silhouette score = 0.340391138371
num_clusters = np.argmax(scores) + values[0]
print('\nOptimal number of clusters =', num_clusters)ここで、最適なクラスター数の出力は次のようになります。
Optimal number of clusters = 2最近傍を見つける
映画のレコメンダーシステムなどのレコメンダーシステムを構築する場合は、最近傍を見つけるという概念を理解する必要があります。これは、レコメンダーシステムが最近傍の概念を利用しているためです。
ザ・ concept of finding nearest neighbors指定されたデータセットから入力ポイントに最も近いポイントを見つけるプロセスとして定義できます。このKNN)K最近傍)アルゴリズムの主な用途は、入力データポイントがさまざまなクラスに近接しているデータポイントを分類する分類システムを構築することです。
以下に示すPythonコードは、特定のデータセットのK最近傍を見つけるのに役立ちます-
以下に示すように、必要なパッケージをインポートします。ここでは、NearestNeighbors からのモジュール sklearn パッケージ
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import NearestNeighbors入力データを定義しましょう-
A = np.array([[3.1, 2.3], [2.3, 4.2], [3.9, 3.5], [3.7, 6.4], [4.8, 1.9],
[8.3, 3.1], [5.2, 7.5], [4.8, 4.7], [3.5, 5.1], [4.4, 2.9],])ここで、最近傍を定義する必要があります-
k = 3また、最近傍を見つけるためのテストデータを提供する必要があります-
test_data = [3.3, 2.9]次のコードは、私たちが定義した入力データを視覚化してプロットできます-
plt.figure()
plt.title('Input data')
plt.scatter(A[:,0], A[:,1], marker = 'o', s = 100, color = 'black')
次に、K最近傍法を作成する必要があります。オブジェクトもトレーニングする必要があります
knn_model = NearestNeighbors(n_neighbors = k, algorithm = 'auto').fit(X)
distances, indices = knn_model.kneighbors([test_data])これで、K最近傍を次のように出力できます。
print("\nK Nearest Neighbors:")
for rank, index in enumerate(indices[0][:k], start = 1):
print(str(rank) + " is", A[index])テストデータポイントとともに最近傍を視覚化できます
plt.figure()
plt.title('Nearest neighbors')
plt.scatter(A[:, 0], X[:, 1], marker = 'o', s = 100, color = 'k')
plt.scatter(A[indices][0][:][:, 0], A[indices][0][:][:, 1],
marker = 'o', s = 250, color = 'k', facecolors = 'none')
plt.scatter(test_data[0], test_data[1],
marker = 'x', s = 100, color = 'k')
plt.show()
出力
K Nearest Neighbors
1 is [ 3.1 2.3]
2 is [ 3.9 3.5]
3 is [ 4.4 2.9]K最近傍分類器
K最近傍(KNN)分類器は、最近傍アルゴリズムを使用して特定のデータポイントを分類する分類モデルです。前のセクションでKNNアルゴリズムを実装しました。次に、そのアルゴリズムを使用してKNN分類器を構築します。
KNN分類器の概念
K最近傍分類の基本的な概念は、事前定義された数、つまり、分類する必要のある新しいサンプルに距離が最も近いトレーニングサンプルの「k」-を見つけることです。新しいサンプルは、ネイバー自体からラベルを取得します。KNN分類器には、決定する必要のある近傍の数に対してユーザー定義の固定定数があります。距離については、標準のユークリッド距離が最も一般的な選択です。KNN分類器は、学習のルールを作成するのではなく、学習したサンプルを直接処理します。KNNアルゴリズムは、すべての機械学習アルゴリズムの中で最も単純なものの1つです。これは、文字認識や画像分析など、多数の分類および回帰の問題で非常に成功しています。
Example
数字を認識するためのKNN分類器を構築しています。このために、MNISTデータセットを使用します。このコードをJupyterNotebookに記述します。
以下に示すように、必要なパッケージをインポートします。
ここでは、 KNeighborsClassifier からのモジュール sklearn.neighbors パッケージ-
from sklearn.datasets import *
import pandas as pd
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as np次のコードは、テストする必要のある画像を確認するために数字の画像を表示します-
def Image_display(i):
plt.imshow(digit['images'][i],cmap = 'Greys_r')
plt.show()次に、MNISTデータセットをロードする必要があります。実際には合計1797枚の画像がありますが、最初の1600枚の画像をトレーニングサンプルとして使用しており、残りの197枚はテスト目的で保持されます。
digit = load_digits()
digit_d = pd.DataFrame(digit['data'][0:1600])ここで、画像を表示すると、次のように出力が表示されます。
Image_display(0)Image_display(0)
0の画像は次のように表示されます-

Image_display(9)
9の画像は次のように表示されます-

Digit.keys()
次に、トレーニングとテストのデータセットを作成し、テストデータセットをKNN分類器に提供する必要があります。
train_x = digit['data'][:1600]
train_y = digit['target'][:1600]
KNN = KNeighborsClassifier(20)
KNN.fit(train_x,train_y)次の出力は、K最近傍分類器コンストラクターを作成します-
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2,
weights = 'uniform')トレーニングサンプルである1600を超える任意の数を指定して、テストサンプルを作成する必要があります。
test = np.array(digit['data'][1725])
test1 = test.reshape(1,-1)
Image_display(1725)Image_display(6)
6の画像は次のように表示されます-

ここで、テストデータを次のように予測します-
KNN.predict(test1)上記のコードは次の出力を生成します-
array([6])ここで、次のことを考慮してください。
digit['target_names']上記のコードは次の出力を生成します-
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])自然言語処理(NLP)は、英語などの自然言語を使用してインテリジェントシステムと通信するAI方式を指します。
自然言語の処理は、ロボットのようなインテリジェントシステムを指示どおりに実行したい場合、対話ベースの臨床エキスパートシステムからの決定を聞きたい場合などに必要です。
NLPの分野では、人間が使用する自然言語を使用してコンピューターに有用なタスクを実行させることが含まれます。NLPシステムの入力と出力は次のようになります。
- Speech
- 書かれたテキスト
NLPのコンポーネント
このセクションでは、NLPのさまざまなコンポーネントについて学習します。NLPには2つのコンポーネントがあります。コンポーネントについて以下に説明します-
自然言語理解(NLU)
以下のタスクが含まれます-
自然言語で与えられた入力を有用な表現にマッピングします。
言語のさまざまな側面を分析します。
自然言語生成(NLG)
これは、内部表現から自然言語の形で意味のあるフレーズや文を生成するプロセスです。それは以下を含みます-
Text planning −これには、ナレッジベースからの関連コンテンツの取得が含まれます。
Sentence planning −これには、必要な単語の選択、意味のあるフレーズの形成、文のトーンの設定が含まれます。
Text Realization −これは文の計画を文の構造にマッピングしています。
NLUの難しさ
NLUは形式と構造が非常に豊富です。ただし、あいまいです。あいまいさにはさまざまなレベルがあります-
語彙のあいまいさ
それは単語レベルのような非常に原始的なレベルにあります。たとえば、「ボード」という単語を名詞または動詞として扱いますか?
構文レベルのあいまいさ
文はさまざまな方法で解析できます。たとえば、「彼は赤い帽子でカブトムシを持ち上げました。」−キャップを使ってカブトムシを持ち上げましたか、それとも赤いキャップの付いたカブトムシを持ち上げましたか?
参照のあいまいさ
代名詞を使用して何かを参照します。たとえば、リマはガウリに行きました。彼女は「私は疲れています」と言いました。−正確に誰が疲れていますか?
NLPの用語
ここで、NLP用語のいくつかの重要な用語を見てみましょう。
Phonology −音を体系的に整理する研究です。
Morphology −それは原始的な意味のある単位からの単語の構成の研究です。
Morpheme −それは言語における意味の原始的な単位です。
Syntax−文を作るために単語を並べることを指します。また、文やフレーズにおける単語の構造的役割を決定することも含まれます。
Semantics −単語の意味と、単語を意味のあるフレーズや文に組み合わせる方法に関係しています。
Pragmatics −さまざまな状況での文の使用と理解、および文の解釈がどのように影響を受けるかを扱います。
Discourse −直前の文が次の文の解釈にどのように影響するかを扱います。
World Knowledge −世界に関する一般的な知識が含まれています。
NLPの手順
このセクションでは、NLPのさまざまな手順を示します。
字句解析
単語の構造を特定して分析する必要があります。言語の辞書とは、言語内の単語やフレーズの集まりを意味します。字句解析は、txtのチャンク全体を段落、文、および単語に分割します。
構文解析(構文解析)
文中の単語を文法的に分析し、単語間の関係を示すように配置します。「学校は男の子に行く」などの文は、英語の構文アナライザーによって拒否されます。
セマンティック分析
テキストから正確な意味または辞書の意味を引き出します。テキストの意味がチェックされます。これは、タスクドメイン内の構文構造とオブジェクトをマッピングすることによって行われます。セマンティックアナライザーは、「ホットアイスクリーム」などの文を無視します。
談話統合
文の意味は、その直前の文の意味によって異なります。また、直後の文の意味も持ちます。
語用論的分析
この間、言われたことはそれが実際に何を意味したかについて再解釈されます。それには、現実世界の知識を必要とする言語の側面を導き出すことが含まれます。
この章では、Natural LanguageToolkitパッケージの使用を開始する方法を学習します。
前提条件
自然言語処理を使用してアプリケーションを構築する場合は、コンテキストの変更が最も困難になります。コンテキストファクターは、マシンが特定の文を理解する方法に影響を与えます。したがって、人間がコンテキストを理解する方法も機械が理解できるように、機械学習アプローチを使用して自然言語アプリケーションを開発する必要があります。
このようなアプリケーションを構築するには、NLTK(Natural Language Toolkit Package)と呼ばれるPythonパッケージを使用します。
NLTKのインポート
NLTKを使用する前にインストールする必要があります。次のコマンドを使用してインストールできます-
pip install nltkNLTKのcondaパッケージを作成するには、次のコマンドを使用します-
conda install -c anaconda nltkNLTKパッケージをインストールした後、pythonコマンドプロンプトからインポートする必要があります。Pythonコマンドプロンプトで次のコマンドを書くことでインポートできます-
>>> import nltkNLTKのデータのダウンロード
NLTKをインポートした後、必要なデータをダウンロードする必要があります。これは、Pythonコマンドプロンプトで次のコマンドを使用して実行できます-
>>> nltk.download()その他の必要なパッケージのインストール
NLTKを使用して自然言語処理アプリケーションを構築するには、必要なパッケージをインストールする必要があります。パッケージは以下の通りです−
gensim
これは、多くのアプリケーションに役立つ堅牢なセマンティックモデリングライブラリです。次のコマンドを実行してインストールできます-
pip install gensimパターン
それは作るために使用されます gensimパッケージは正しく機能します。次のコマンドを実行してインストールできます
pip install patternトークン化、ステミング、およびレマタイゼーションの概念
このセクションでは、トークン化、ステミング、およびレンマ化とは何かを理解します。
トークン化
これは、指定されたテキスト、つまり文字シーケンスをトークンと呼ばれる小さな単位に分割するプロセスとして定義できます。トークンは、単語、数字、句読点などです。単語のセグメンテーションとも呼ばれます。以下はトークン化の簡単な例です-
Input −マンゴー、バナナ、パイナップル、リンゴはすべて果物です。
Output −

与えられたテキストを壊すプロセスは、単語の境界を見つける助けを借りて行うことができます。単語の終わりと新しい単語の始まりは、単語の境界と呼ばれます。書記体系と単語の誤植構造が境界に影響を与えます。
Python NLTKモジュールには、トークン化に関連するさまざまなパッケージがあり、要件に応じてテキストをトークンに分割するために使用できます。いくつかのパッケージは次のとおりです-
sent_tokenizeパッケージ
名前が示すように、このパッケージは入力テキストを文に分割します。次のPythonコードを使用してこのパッケージをインポートできます-
from nltk.tokenize import sent_tokenizeword_tokenizeパッケージ
このパッケージは、入力テキストを単語に分割します。次のPythonコードを使用してこのパッケージをインポートできます-
from nltk.tokenize import word_tokenizeWordPunctTokenizerパッケージ
このパッケージは、入力テキストを単語と句読点に分割します。次のPythonコードを使用してこのパッケージをインポートできます-
from nltk.tokenize import WordPuncttokenizerステミング
単語を扱うとき、文法上の理由から多くのバリエーションに出くわします。ここでのバリエーションの概念は、次のような同じ単語のさまざまな形式を処理する必要があることを意味します。democracy, democratic, そして democratization。これらの異なる単語が同じ基本形を持っていることを機械が理解することは非常に必要です。このように、テキストを分析しているときに単語の基本形を抽出すると便利です。
ステミングによってこれを達成することができます。このように、ステミングとは、単語の末尾を切り取って単語の基本形を抽出するヒューリスティックなプロセスであると言えます。
Python NLTKモジュールには、ステミングに関連するさまざまなパッケージがあります。これらのパッケージは、単語の基本形式を取得するために使用できます。これらのパッケージはアルゴリズムを使用します。いくつかのパッケージは次のとおりです-
PorterStemmerパッケージ
このPythonパッケージは、Porterのアルゴリズムを使用して基本フォームを抽出します。次のPythonコードを使用してこのパッケージをインポートできます-
from nltk.stem.porter import PorterStemmerたとえば、私たちが単語を与える場合 ‘writing’ このステマーへの入力として、それらは単語を取得します ‘write’ ステミング後。
LancasterStemmerパッケージ
このPythonパッケージは、ランカスターのアルゴリズムを使用して基本フォームを抽出します。次のPythonコードを使用してこのパッケージをインポートできます-
from nltk.stem.lancaster import LancasterStemmerたとえば、私たちが単語を与える場合 ‘writing’ このステマーへの入力として、それらは単語を取得します ‘write’ ステミング後。
SnowballStemmerパッケージ
このPythonパッケージは、snowballのアルゴリズムを使用して基本フォームを抽出します。次のPythonコードを使用してこのパッケージをインポートできます-
from nltk.stem.snowball import SnowballStemmerたとえば、私たちが単語を与える場合 ‘writing’ このステマーへの入力として、それらは単語を取得します ‘write’ ステミング後。
これらのアルゴリズムはすべて、異なるレベルの厳密性を持っています。これらの3つのステマーを比較すると、ポーターステマーが最も厳しくなく、ランカスターが最も厳しくなります。スノーボールステマーは、スピードと厳格さの点で使用するのに適しています。
Lemmatization
また、語彙化によって単語の基本形を抽出することもできます。基本的に、このタスクは単語の語彙と形態素解析を使用して実行され、通常は語尾変化のみを削除することを目的としています。このような単語の基本形は補題と呼ばれます。
ステミングとレンマ化の主な違いは、語彙の使用と単語の形態素解析です。もう1つの違いは、ステミングは最も一般的に派生的に関連する単語を崩壊させるのに対し、レンマ化は一般に異なる語形変化のレンマのみを崩壊させることです。たとえば、sawという単語を入力単語として指定すると、ステミングは「s」という単語を返す可能性がありますが、lemmatizationは、トークンの使用が動詞であるか名詞であるかに応じて、seeまたはsawのいずれかの単語を返そうとします。
Python NLTKモジュールには、単語の基本形式を取得するために使用できる、レンマ化プロセスに関連する次のパッケージがあります。
WordNetLemmatizerパッケージ
このPythonパッケージは、名詞として使用されているか動詞として使用されているかに応じて、単語の基本形を抽出します。次のPythonコードを使用してこのパッケージをインポートできます-
from nltk.stem import WordNetLemmatizerチャンキング:データをチャンクに分割する
これは、自然言語処理における重要なプロセスの1つです。チャンクの主な仕事は、品詞や名詞句などの短いフレーズを識別することです。トークン化のプロセス、トークンの作成についてはすでに学習しました。チャンキングは基本的にそれらのトークンのラベル付けです。言い換えれば、チャンクは文の構造を示します。
次のセクションでは、さまざまなタイプのチャンキングについて学習します。
チャンクの種類
チャンクには2つのタイプがあります。タイプは次のとおりです-
チャンクアップ
このチャンク化のプロセスでは、オブジェクトや物などがより一般的になり、言語がより抽象的になります。合意の可能性が高くなります。このプロセスでは、ズームアウトします。たとえば、「車は何のためにあるのか」という質問をまとめるとしたらどうでしょうか。「輸送」という答えが返ってくるかもしれません。
チャンクダウン
このチャンク化のプロセスでは、オブジェクトや物などがより具体的になり、言語がより浸透します。より深い構造は、チャンクダウンで調べられます。このプロセスでは、ズームインします。たとえば、「車について具体的に教えてください」という質問をチャンクダウンするとしますか?車に関する小さな情報を取得します。
Example
この例では、PythonのNLTKモジュールを使用して、文中の名詞句のチャンクを見つけるチャンクのカテゴリである名詞句チャンクを実行します。
Follow these steps in python for implementing noun phrase chunking −
Step 1−このステップでは、チャンクの文法を定義する必要があります。それは私たちが従う必要のあるルールで構成されます。
Step 2−このステップでは、チャンクパーサーを作成する必要があります。文法を解析して出力します。
Step 3 −この最後のステップでは、出力はツリー形式で生成されます。
次のように必要なNLTKパッケージをインポートしましょう-
import nltk次に、文を定義する必要があります。ここで、DTは行列式、VBPは動詞、JJは形容詞、INは前置詞、NNは名詞を意味します。
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]ここで、文法を与える必要があります。ここでは、正規表現の形で文法を示します。
grammar = "NP:{<DT>?<JJ>*<NN>}"文法を解析するパーサーを定義する必要があります。
parser_chunking = nltk.RegexpParser(grammar)パーサーは次のように文を解析します-
parser_chunking.parse(sentence)次に、出力を取得する必要があります。出力は、と呼ばれる単純な変数で生成されますoutput_chunk。
Output_chunk = parser_chunking.parse(sentence)次のコードを実行すると、出力をツリーの形で描画できます。
output.draw()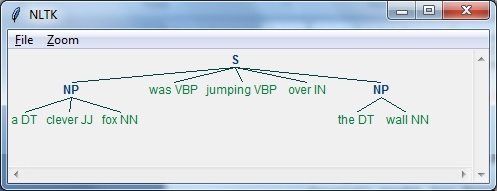
Bag of Word(BoW)モデル
自然言語処理のモデルであるBagof Word(BoW)は、基本的にテキストから特徴を抽出するために使用され、機械学習アルゴリズムなどのモデリングでテキストを使用できるようにします。
ここで、なぜテキストから特徴を抽出する必要があるのかという疑問が生じます。これは、機械学習アルゴリズムが生データを処理できず、そこから意味のある情報を抽出できるように数値データが必要なためです。テキストデータの数値データへの変換は、特徴抽出または特徴エンコーディングと呼ばれます。
使い方
これは、テキストから特徴を抽出するための非常に単純なアプローチです。テキストドキュメントがあり、それを数値データに変換するか、そこから特徴を抽出したいとします。次に、このモデルはまず、ドキュメント内のすべての単語から語彙を抽出します。次に、ドキュメント用語マトリックスを使用して、モデルを構築します。このように、BoWはドキュメントを単語の袋としてのみ表します。ドキュメント内の単語の順序または構造に関する情報はすべて破棄されます。
ドキュメント用語マトリックスの概念
BoWアルゴリズムは、ドキュメント用語マトリックスを使用してモデルを構築します。名前が示すように、ドキュメント用語マトリックスは、ドキュメント内で発生するさまざまな単語数のマトリックスです。このマトリックスの助けを借りて、テキストドキュメントはさまざまな単語の加重された組み合わせとして表すことができます。しきい値を設定し、より意味のある単語を選択することで、特徴ベクトルとして使用できるドキュメント内のすべての単語のヒストグラムを作成できます。以下は、ドキュメント用語マトリックスの概念を理解するための例です。
Example
次の2つの文があるとします-
Sentence 1 − Bag ofWordsモデルを使用しています。
Sentence 2 −特徴を抽出するためにBag ofWordsモデルが使用されます。
さて、これらの2つの文を考慮すると、次の13の異なる単語があります。
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
ここで、各文の単語数を使用して、各文のヒストグラムを作成する必要があります-
Sentence 1 − [1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 − [0,0,0,1,1,1,1,1,1,1,1,1,1]
このようにして、抽出された特徴ベクトルが得られます。13個の異なる単語があるため、各特徴ベクトルは13次元です。
統計の概念
統計の概念は、TermFrequency-Inverse Document Frequency(tf-idf)と呼ばれます。ドキュメント内のすべての単語が重要です。統計は、すべての単語の重要性を理解するのに役立ちます。
期間頻度(tf)
これは、各単語がドキュメントに表示される頻度の尺度です。これは、各単語の数を特定のドキュメント内の単語の総数で割ることによって取得できます。
逆ドキュメント頻度(idf)
これは、特定のドキュメントセット内でこのドキュメントに対して単語がどれだけ一意であるかを示す尺度です。idfを計算し、特徴的な特徴ベクトルを定式化するには、のような一般的に出現する単語の重みを減らし、まれな単語の重みを付ける必要があります。
NLTKでBagofWordsモデルを構築する
このセクションでは、CountVectorizerを使用してこれらの文からベクトルを作成することにより、文字列のコレクションを定義します。
必要なパッケージをインポートしましょう-
from sklearn.feature_extraction.text import CountVectorizer次に、文のセットを定義します。
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)上記のプログラムは、以下に示すような出力を生成します。上記の2つの文に13の異なる単語があることを示しています-
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}これらは、機械学習に使用できる特徴ベクトル(テキストから数値形式)です。
問題を解決する
このセクションでは、いくつかの関連する問題を解決します。
カテゴリ予測
一連のドキュメントでは、単語だけでなく単語のカテゴリも重要です。特定の単語がテキストのどのカテゴリに分類されるか。たとえば、特定の文が電子メール、ニュース、スポーツ、コンピューターなどのカテゴリに属するかどうかを予測する必要があります。次の例では、tf-idfを使用して特徴ベクトルを作成し、ドキュメントのカテゴリを検索します。sklearnの20のニュースグループデータセットからのデータを使用します。
必要なパッケージをインポートする必要があります-
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerカテゴリマップを定義します。宗教、自動車、スポーツ、電子機器、宇宙という5つの異なるカテゴリを使用しています。
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}トレーニングセットを作成する-
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)カウントベクトライザーを構築し、用語カウントを抽出します-
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)tf-idfトランスフォーマーは次のように作成されます-
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)ここで、テストデータを定義します-
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]上記のデータは、多項単純ベイズ分類器のトレーニングに役立ちます-
classifier = MultinomialNB().fit(train_tfidf, training_data.target)カウントベクトライザーを使用して入力データを変換します-
input_tc = vectorizer_count.transform(input_data)ここで、tfidfトランスフォーマーを使用してベクトル化されたデータを変換します-
input_tfidf = tfidf.transform(input_tc)出力カテゴリを予測します-
predictions = classifier.predict(input_tfidf)出力は次のように生成されます-
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])カテゴリ予測子は、次の出力を生成します-
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: Electronicsジェンダーファインダー
この問題ステートメントでは、分類子は、名前を提供することによって性別(男性または女性)を見つけるようにトレーニングされます。ヒューリスティックを使用して特徴ベクトルを構築し、分類器をトレーニングする必要があります。scikit-learnパッケージのラベル付きデータを使用します。以下は、性別ファインダーを構築するためのPythonコードです-
必要なパッケージをインポートしましょう-
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import names次に、入力単語から最後のN文字を抽出する必要があります。これらの文字は機能として機能します-
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':NLTKで利用可能なラベル付きの名前(男性と女性)を使用してトレーニングデータを作成します-
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)これで、テストデータは次のように作成されます-
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']次のコードを使用して、トレーニングとテストに使用されるサンプルの数を定義します
train_sample = int(0.8 * len(data))ここで、精度を比較できるように、さまざまな長さを反復処理する必要があります。
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)分類器の精度は次のように計算できます-
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')これで、出力を予測できます-
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))上記のプログラムは次の出力を生成します-
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female上記の出力では、終了文字の最大数の精度は2であり、終了文字の数が増えるにつれて精度が低下していることがわかります。
トピックモデリング:テキストデータのパターンの識別
一般に、ドキュメントはトピックにグループ化されていることを私たちは知っています。特定のトピックに対応するテキストのパターンを特定する必要がある場合があります。これを行う手法は、トピックモデリングと呼ばれます。言い換えれば、トピックモデリングは、特定のドキュメントセット内の抽象的なテーマまたは隠された構造を明らかにする手法であると言えます。
次のシナリオでトピックモデリング手法を使用できます-
テキスト分類
トピックモデリングを使用すると、各単語を個別に機能として使用するのではなく、類似した単語をグループ化するため、分類を改善できます。
レコメンダーシステム
トピックモデリングの助けを借りて、類似性の尺度を使用してレコメンダーシステムを構築できます。
トピックモデリングのアルゴリズム
トピックモデリングは、アルゴリズムを使用して実装できます。アルゴリズムは次のとおりです-
潜在的ディリクレ配分(LDA)
このアルゴリズムは、トピックモデリングで最も一般的です。トピックモデリングを実装するために確率的グラフィカルモデルを使用します。LDA slgorithmを使用するには、Pythonでgensimパッケージをインポートする必要があります。
潜在意味解析(LDA)または潜在意味索引付け(LSI)
このアルゴリズムは線形代数に基づいています。基本的には、ドキュメント用語マトリックスでSVD(特異値分解)の概念を使用します。
非負行列因子分解(NMF)
また、線形代数に基づいています。
トピックモデリングのための上記のすべてのアルゴリズムには、 number of topics パラメータとして、 Document-Word Matrix 入力としておよび WTM (Word Topic Matrix) & TDM (Topic Document Matrix) 出力として。
与えられた入力シーケンスの次を予測することは、機械学習におけるもう1つの重要な概念です。この章では、時系列データの分析について詳しく説明します。
前書き
時系列データとは、一連の特定の時間間隔にあるデータを意味します。機械学習でシーケンス予測を構築する場合は、シーケンシャルデータと時間を処理する必要があります。系列データは、順次データの要約です。データの順序付けは、シーケンシャルデータの重要な機能です。
配列分析または時系列分析の基本概念
シーケンス分析または時系列分析は、以前に観察されたものに基づいて、特定の入力シーケンスの次のシーケンスを予測することです。予測は、記号、数字、翌日の天気、スピーチの次の用語など、次に来る可能性のあるものであれば何でもかまいません。シーケンス分析は、株式市場分析、天気予報、製品の推奨などのアプリケーションで非常に便利です。
Example
シーケンス予測を理解するために、次の例を検討してください。ここにA,B,C,D 与えられた値であり、値を予測する必要があります E シーケンス予測モデルを使用します。

便利なパッケージのインストール
Pythonを使用した時系列データ分析では、次のパッケージをインストールする必要があります-
パンダ
Pandasは、Python用の高性能で使いやすいデータ構造とデータ分析ツールを提供するオープンソースのBSDライセンスライブラリです。次のコマンドを使用してパンダをインストールできます-
pip install pandasAnacondaを使用していて、を使用してインストールする場合 conda パッケージマネージャーの場合、次のコマンドを使用できます-
conda install -c anaconda pandashmmlearn
これは、Pythonで隠れマルコフモデル(HMM)を学習するための単純なアルゴリズムとモデルで構成されるオープンソースのBSDライセンスライブラリです。次のコマンドを使用してインストールできます-
pip install hmmlearnAnacondaを使用していて、を使用してインストールする場合 conda パッケージマネージャーの場合、次のコマンドを使用できます-
conda install -c omnia hmmlearnPyStruct
これは、構造化された学習および予測ライブラリです。PyStructに実装されている学習アルゴリズムには、条件付き確率場(CRF)、最大マージンマルコフ確率場(M3N)、構造サポートベクターマシンなどの名前があります。次のコマンドを使用してインストールできます-
pip install pystructCVXOPT
Pythonプログラミング言語に基づく凸最適化に使用されます。また、無料のソフトウェアパッケージです。次のコマンドを使用してインストールできます-
pip install cvxoptAnacondaを使用していて、を使用してインストールする場合 conda パッケージマネージャーの場合、次のコマンドを使用できます-
conda install -c anaconda cvdoxtパンダ:時系列データからの統計の処理、スライス、抽出
Pandasは、時系列データを操作する必要がある場合に非常に便利なツールです。パンダの助けを借りて、あなたは以下を実行することができます-
を使用して日付の範囲を作成します pd.date_range パッケージ
を使用してパンダに日付のインデックスを付ける pd.Series パッケージ
を使用してリサンプリングを実行します ts.resample パッケージ
頻度を変更する
例
次の例は、Pandasを使用して時系列データを処理およびスライスする方法を示しています。ここでは、monthly.ao.index.b50.current.asciiからダウンロードでき、使用するためにテキスト形式に変換できる月次北極振動データを使用していることに注意してください。
時系列データの処理
時系列データを処理するには、次の手順を実行する必要があります-
最初のステップでは、次のパッケージをインポートします-
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd次に、以下のコードに示すように、入力ファイルからデータを読み取る関数を定義します。
def read_data(input_file):
input_data = np.loadtxt(input_file, delimiter = None)次に、このデータを時系列に変換します。このために、時系列の日付の範囲を作成します。この例では、データの頻度として1か月を保持しています。私たちのファイルには、1950年1月から始まるデータが含まれています。
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')このステップでは、以下に示すように、Pandasシリーズを使用して時系列データを作成します。
output = pd.Series(input_data[:, index], index = dates)
return output
if __name__=='__main__':ここに示すように、入力ファイルのパスを入力します-
input_file = "/Users/admin/AO.txt"次に、次に示すように、列を時系列形式に変換します。
timeseries = read_data(input_file)最後に、示されているコマンドを使用して、データをプロットして視覚化します。
plt.figure()
timeseries.plot()
plt.show()次の画像に示すようにプロットを観察します-


時系列データのスライス
スライスには、時系列データの一部のみを取得することが含まれます。例の一部として、1980年から1990年までのデータのみをスライスしています。このタスクを実行する次のコードを確認してください。
timeseries['1980':'1990'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00>
plt.show()時系列データをスライスするためのコードを実行すると、次の画像に示すような次のグラフを確認できます。

時系列データからの統計の抽出
重要な結論を導き出す必要がある場合は、特定のデータからいくつかの統計を抽出する必要があります。平均、分散、相関、最大値、および最小値は、そのような統計の一部です。特定の時系列データからそのような統計を抽出する場合は、次のコードを使用できます-
平均
あなたは使用することができます mean() ここに示すように、平均を見つけるための関数-
timeseries.mean()次に、説明した例で観察される出力は次のとおりです。
-0.11143128165238671最大
あなたは使用することができます max() ここに示すように、最大値を見つけるための関数-
timeseries.max()次に、説明した例で観察される出力は次のとおりです。
3.4952999999999999最小
次に示すように、最小値を見つけるためにmin()関数を使用できます。
timeseries.min()次に、説明した例で観察される出力は次のとおりです。
-4.2656999999999998すべてを一度に取得
一度にすべての統計を計算したい場合は、 describe() ここに示すように機能します-
timeseries.describe()次に、説明した例で観察される出力は次のとおりです。
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64リサンプリング
データを別の時間周波数にリサンプリングできます。リサンプリングを実行するための2つのパラメータは次のとおりです。
- 期間
- Method
mean()によるリサンプリング
次のコードを使用して、デフォルトのメソッドであるmean()メソッドでデータをリサンプリングできます。
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()次に、mean()−を使用したリサンプリングの出力として次のグラフを確認できます。

median()によるリサンプリング
次のコードを使用して、を使用してデータをリサンプリングできます。 median()方法−
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()次に、median()−を使用したリサンプリングの出力として次のグラフを確認できます。

移動平均
次のコードを使用して、ローリング(移動)平均を計算できます-
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()次に、ローリング(移動)平均の出力として次のグラフを観察できます。
隠れマルコフモデル(HMM)によるシーケンシャルデータの分析
HMMは、時系列の株式市場分析、健康診断、音声認識など、継続性と拡張性を備えたデータに広く使用されている統計モデルです。このセクションでは、隠れマルコフモデル(HMM)を使用したシーケンシャルデータの分析について詳しく説明します。
隠れマルコフモデル(HMM)
HMMは、将来の統計の確率が前の状態ではなく現在のプロセス状態にのみ依存するという仮定に基づいて、マルコフ連鎖の概念に基づいて構築された確率モデルです。たとえば、コインを投げるとき、5回目の投げの結果が頭になるとは言えません。これは、コインにメモリがなく、次の結果が前の結果に依存しないためです。
数学的には、HMMは次の変数で構成されます-
州(S)
これは、HMMに存在する隠れ状態または潜在状態のセットです。Sで表されます。
出力記号(O)
これは、HMMに存在する可能性のある出力シンボルのセットです。Oで表されます。
状態遷移確率行列(A)
これは、ある状態から他の各状態に遷移する確率です。Aで表されます。
観測放出確率行列(B)
これは、特定の状態でシンボルを放出/観測する確率です。Bで表されます。
事前確率行列(Π)
これは、システムのさまざまな状態から特定の状態で開始する確率です。Πで表されます。
したがって、HMMは次のように定義できます。 = (S,O,A,B,)、
どこ、
- S = {s1,s2,…,sN} N個の可能な状態のセットです。
- O = {o1,o2,…,oM} M個の可能な観測記号のセットです。
- Aは NN 状態遷移確率行列(TPM)、
- Bは NM 観測または放出確率行列(EPM)、
- πはN次元の初期状態確率分布ベクトルです。
例:株式市場データの分析
この例では、株式市場のデータを段階的に分析して、HMMがシーケンシャルデータまたは時系列データでどのように機能するかを理解します。この例はPythonで実装していることに注意してください。
以下に示すように、必要なパッケージをインポートします-
import datetime
import warnings次に、からの株式市場データを使用します。 matpotlib.finance ここに示すように、パッケージ-
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMM開始日と終了日から、つまりここに示すように2つの特定の日付の間でデータをロードします-
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)このステップでは、終値を毎日抽出します。これには、次のコマンドを使用します-
closing_quotes = np.array([quote[2] for quote in quotes])ここで、毎日取引される株式の量を抽出します。これには、次のコマンドを使用します-
volumes = np.array([quote[5] for quote in quotes])[1:]ここでは、以下に示すコードを使用して、終値のパーセンテージの差を取ります-
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])このステップでは、ガウスHMMを作成してトレーニングします。これには、次のコードを使用します-
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)次に、示されているコマンドを使用して、HMMモデルを使用してデータを生成します。
num_samples = 300
samples, _ = hmm.sample(num_samples)最後に、このステップでは、グラフの形式で出力として取引された株式の差の割合と量をプロットして視覚化します。
次のコードを使用して、差異のパーセンテージをプロットおよび視覚化します-
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')次のコードを使用して、取引された株式の量をプロットして視覚化します-
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()この章では、PythonでAIを使用した音声認識について学習します。
スピーチは、成人の人間のコミュニケーションの最も基本的な手段です。音声処理の基本的な目標は、人間と機械の間の相互作用を提供することです。
音声処理システムには主に3つのタスクがあります-
First、私たちが話す単語、フレーズ、文を機械がキャッチできるようにする音声認識
Second、機械が私たちの話すことを理解できるようにする自然言語処理、および
Third、機械が話すことを可能にする音声合成。
この章では、 speech recognition、人間が話す言葉を理解するプロセス。音声信号はマイクを使用してキャプチャされ、システムによって理解される必要があることを忘れないでください。
音声認識機能の構築
音声認識または自動音声認識(ASR)は、ロボット工学などのAIプロジェクトの注目の的です。ASRがなければ、認知ロボットが人間と相互作用することを想像することはできません。ただし、音声認識機能を構築するのは簡単ではありません。
音声認識システムの開発の難しさ
高品質の音声認識システムを開発することは、本当に難しい問題です。音声認識技術の難しさは、以下で説明するように、さまざまな側面に沿って広く特徴付けることができます。
Size of the vocabulary−語彙のサイズは、ASRの開発のしやすさに影響します。理解を深めるために、次のサイズの語彙を検討してください。
小さなサイズの語彙は、たとえば、音声メニューシステムのように、2〜100語で構成されます。
中規模の語彙は、たとえばデータベース検索タスクのように、数百から数千の単語で構成されます。
大きなサイズの語彙は、一般的な口述タスクのように、数十万の単語で構成されています。
Channel characteristics−チャネル品質も重要な側面です。たとえば、人間のスピーチには全周波数範囲の高帯域幅が含まれますが、電話のスピーチには限られた周波数範囲の低帯域幅が含まれます。後者の方が難しいことに注意してください。
Speaking mode− ASRの開発のしやすさは、発話モード、つまり、発話が孤立語モード、接続語モード、または連続発話モードのいずれであるかによっても異なります。連続したスピーチは認識しにくいことに注意してください。
Speaking style−読み上げのスピーチは、フォーマルなスタイルでも、カジュアルなスタイルで自発的かつ会話的なものでもかまいません。後者は認識が困難です。
Speaker dependency−音声は、話者に依存する、話者に適応する、または話者に依存しない場合があります。独立したスピーカーは構築が最も困難です。
Type of noise− ASRを開発する際に考慮すべきもう1つの要素は、ノイズです。信号対雑音比は、バックグラウンドノイズが少ない場合と多い場合の音響環境に応じて、さまざまな範囲になります。
信号対雑音比が30dBより大きい場合、それは高範囲と見なされます
信号対雑音比が30dBから10dbの間にある場合、それは中程度のSNRと見なされます
信号対雑音比が10dB未満の場合、低範囲と見なされます
Microphone characteristics−マイクの品質は、良好、平均、または平均以下の場合があります。また、口とマイクの間の距離は変化する可能性があります。これらの要素は、認識システムでも考慮する必要があります。
語彙のサイズが大きいほど、認識を実行するのが難しくなることに注意してください。
たとえば、静止した、人間以外のノイズ、バックグラウンドスピーチ、他のスピーカーによるクロストークなどのバックグラウンドノイズのタイプも、問題の難しさに寄与します。
これらの困難にもかかわらず、研究者は、音声信号、話者の理解、アクセントの特定など、音声のさまざまな側面に多くの作業を行いました。
音声認識機能を構築するには、以下の手順に従う必要があります-
オーディオ信号の視覚化-ファイルからの読み取りと作業
これは、音声信号がどのように構成されているかを理解できるため、音声認識システムを構築するための最初のステップです。オーディオ信号を操作するために従うことができるいくつかの一般的な手順は次のとおりです-
録音
ファイルからオーディオ信号を読み取る必要がある場合は、最初にマイクを使用して録音します。
サンプリング
マイクで録音する場合、信号はデジタル化された形式で保存されます。しかし、それに取り組むために、マシンは離散的な数値形式でそれらを必要とします。したがって、特定の周波数でサンプリングを実行し、信号を離散数値形式に変換する必要があります。サンプリングに高周波数を選択することは、人間が信号を聞くとき、それを連続的なオーディオ信号として感じることを意味します。
例
次の例は、ファイルに保存されているPythonを使用して、オーディオ信号を分析するための段階的なアプローチを示しています。このオーディオ信号の周波数は44,100HZです。
ここに示すように、必要なパッケージをインポートします-
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile次に、保存されているオーディオファイルを読み取ります。サンプリング周波数とオーディオ信号の2つの値を返します。ここに示すように、オーディオファイルが保存されているパスを指定します-
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")示されているコマンドを使用して、オーディオ信号のサンプリング周波数、信号のデータタイプ、およびその持続時間などのパラメータを表示します。
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')このステップでは、以下に示すように信号を正規化します。
audio_signal = audio_signal / np.power(2, 15)このステップでは、この信号から最初の100個の値を抽出して視覚化します。この目的のために次のコマンドを使用します-
audio_signal = audio_signal [:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling)次に、以下のコマンドを使用して信号を視覚化します。
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()ここの画像に示すように、上記のオーディオ信号に対して抽出された出力グラフとデータを見ることができます。

Signal shape: (132300,)
Signal Datatype: int16
Signal duration: 3.0 secondsオーディオ信号の特性評価:周波数領域への変換
オーディオ信号の特性評価には、時間領域信号を周波数領域に変換し、その周波数成分を理解することが含まれます。これは、信号に関する多くの情報を提供するため、重要なステップです。フーリエ変換などの数学ツールを使用して、この変換を実行できます。
例
次の例は、ファイルに保存されているPythonを使用して、信号を特徴付ける方法を段階的に示しています。ここでは、フーリエ変換数学ツールを使用して周波数領域に変換していることに注意してください。
ここに示すように、必要なパッケージをインポートします-
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile次に、保存されているオーディオファイルを読み取ります。サンプリング周波数とオーディオ信号の2つの値を返します。ここのコマンドに示すように、オーディオファイルが保存されているパスを指定します-
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav")このステップでは、以下のコマンドを使用して、オーディオ信号のサンプリング周波数、信号のデータタイプ、およびその持続時間などのパラメーターを表示します。
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')このステップでは、次のコマンドに示すように、信号を正規化する必要があります。
audio_signal = audio_signal / np.power(2, 15)このステップでは、信号の長さと半分の長さを抽出します。この目的のために次のコマンドを使用します-
length_signal = len(audio_signal)
half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int)次に、周波数領域に変換するための数学ツールを適用する必要があります。ここでは、フーリエ変換を使用しています。
signal_frequency = np.fft.fft(audio_signal)ここで、周波数領域信号の正規化を行い、それを2乗します-
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal
signal_frequency **= 2次に、周波数変換された信号の長さと半分の長さを抽出します-
len_fts = len(signal_frequency)フーリエ変換された信号は、奇数の場合だけでなく偶数の場合にも調整する必要があることに注意してください。
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts-1] *= 2ここで、パワーをデシベル(dB)で抽出します-
signal_power = 10 * np.log10(signal_frequency)X軸の周波数をkHzで調整します-
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0ここで、信号の特性を次のように視覚化します。
plt.figure()
plt.plot(x_axis, signal_power, color='black')
plt.xlabel('Frequency (kHz)')
plt.ylabel('Signal power (dB)')
plt.show()下の画像に示すように、上記のコードの出力グラフを確認できます。

モノトーンオーディオ信号の生成
これまで見てきた2つのステップは、シグナルについて学ぶために重要です。ここで、この手順は、いくつかの事前定義されたパラメーターを使用してオーディオ信号を生成する場合に役立ちます。この手順では、オーディオ信号が出力ファイルに保存されることに注意してください。
例
次の例では、Pythonを使用して単調な信号を生成します。これは、ファイルに保存されます。このためには、次の手順を実行する必要があります-
図のように必要なパッケージをインポートします-
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import write出力ファイルを保存するファイルを指定します
output_file = 'audio_signal_generated.wav'次に、図のように、選択したパラメーターを指定します。
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piこのステップでは、次のようにオーディオ信号を生成できます。
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)ここで、オーディオファイルを出力ファイルに保存します-
write(output_file, frequency_sampling, signal_scaled)図のように、グラフの最初の100個の値を抽出します-
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)ここで、生成されたオーディオ信号を次のように視覚化します。
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()ここに示す図に示すように、プロットを観察できます。
音声からの特徴抽出
これは、音声信号を周波数領域に変換した後、それを使用可能な形式の特徴ベクトルに変換する必要があるため、音声認識機能を構築する上で最も重要なステップです。この目的のために、MFCC、PLP、PLP-RASTAなどのさまざまな特徴抽出手法を使用できます。
例
次の例では、Pythonを使用し、MFCC手法を使用して、信号から特徴を段階的に抽出します。
ここに示すように、必要なパッケージをインポートします-
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbank次に、保存されているオーディオファイルを読み取ります。サンプリング周波数とオーディオ信号の2つの値を返します。保存されているオーディオファイルのパスを指定します。
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")ここでは、分析のために最初の15000サンプルを取得していることに注意してください。
audio_signal = audio_signal[:15000]MFCC手法を使用し、次のコマンドを実行してMFCC機能を抽出します-
features_mfcc = mfcc(audio_signal, frequency_sampling)次に、次に示すように、MFCCパラメーターを出力します。
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])次に、以下のコマンドを使用してMFCC機能をプロットおよび視覚化します。
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')このステップでは、次のようにフィルターバンク機能を操作します-
フィルタバンクの特徴を抽出する-
filterbank_features = logfbank(audio_signal, frequency_sampling)次に、フィルターバンクパラメーターを出力します。
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])次に、フィルターバンクの特徴をプロットして視覚化します。
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()上記の手順の結果として、次の出力を確認できます。MFCCの場合は図1、フィルターバンクの場合は図2

話し言葉の認識
音声認識とは、人間が話しているときに機械がそれを理解することを意味します。ここでは、PythonでGoogle SpeechAPIを使用してそれを実現しています。このために次のパッケージをインストールする必要があります-
Pyaudio −を使用してインストールできます pip install Pyaudio コマンド。
SpeechRecognition −このパッケージは以下を使用してインストールできます pip install SpeechRecognition.
Google-Speech-API −コマンドを使用してインストールできます pip install google-api-python-client。
例
次の例を観察して、話し言葉の認識について理解してください。
図のように必要なパッケージをインポートします-
import speech_recognition as sr以下に示すようにオブジェクトを作成します-
recording = sr.Recognizer()さて、 Microphone() モジュールは音声を入力として受け取ります-
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)これで、google APIが音声を認識し、出力を提供します。
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)次の出力を見ることができます-
Please Say Something:
You said:たとえば、あなたが言った場合 tutorialspoint.com、システムはそれを次のように正しく認識します-
tutorialspoint.comヒューリスティック検索は、人工知能において重要な役割を果たします。この章では、それについて詳しく学びます。
AIにおけるヒューリスティック検索の概念
ヒューリスティックは、考えられる解決策につながる経験則です。人工知能のほとんどの問題は指数関数的な性質のものであり、多くの可能な解決策があります。どのソリューションが正しいか正確にはわからないため、すべてのソリューションをチェックすると非常にコストがかかります。
したがって、ヒューリスティックを使用すると、ソリューションの検索が絞り込まれ、間違ったオプションが排除されます。ヒューリスティックを使用して検索空間での検索をリードする方法は、ヒューリスティック検索と呼ばれます。ヒューリスティック手法は、使用すると検索を強化できるため、非常に便利です。
インフォームド検索とインフォームド検索の違い
制御戦略または検索手法には、情報なしと情報ありの2種類があります。それらはここで与えられるように詳細に説明されます-
情報に基づいていない検索
ブラインドサーチまたはブラインドコントロール戦略とも呼ばれます。問題の定義に関する情報のみがあり、状態に関する他の追加情報がないため、この名前が付けられています。この種の検索手法では、状態空間全体を検索して解決策を取得します。幅優先探索(BFS)と深さ優先探索(DFS)は、情報に基づいていない検索の例です。
インフォームドサーチ
これは、ヒューリスティック検索またはヒューリスティック制御戦略とも呼ばれます。州に関する追加情報があるため、この名前が付けられています。この追加情報は、探索および拡張する子ノード間の優先度を計算するのに役立ちます。各ノードに関連付けられたヒューリスティック関数があります。最良優先探索(BFS)、A *、平均および分析は、情報に基づく検索の例です。
制約充足問題(CSP)
制約とは、制限または制限を意味します。AIでは、制約充足問題は、いくつかの制約の下で解決しなければならない問題です。そのような問題を解決する間、制約に違反しないことに焦点を合わせる必要があります。最後に、最終的な解決策に到達したとき、CSPは制限に従わなければなりません。
制約の満足によって解決される現実世界の問題
前のセクションでは、制約充足問題の作成について説明しました。さて、これを現実世界の問題にも適用しましょう。制約を満たすことによって解決される現実世界の問題のいくつかの例は次のとおりです。
代数関係を解く
制約充足問題の助けを借りて、代数関係を解くことができます。この例では、単純な代数関係を解こうとしますa*2 = b。の値を返しますa そして b 定義する範囲内。
このPythonプログラムを完了すると、制約を満たす問題を解決するための基本を理解できるようになります。
プログラムを作成する前に、python-constraintというPythonパッケージをインストールする必要があることに注意してください。次のコマンドを使用してインストールできます-
pip install python-constraint次の手順は、制約の満足度を使用して代数関係を解くためのPythonプログラムを示しています。
をインポートします constraint 次のコマンドを使用したパッケージ-
from constraint import *次に、という名前のモジュールのオブジェクトを作成します problem() 以下に示すように-
problem = Problem()次に、変数を定義します。ここでは、2つの変数aとbがあり、それらの範囲として10を定義していることに注意してください。これは、最初の10個の数値内で解を得たことを意味します。
problem.addVariable('a', range(10))
problem.addVariable('b', range(10))次に、この問題に適用する特定の制約を定義します。ここで制約を使用していることに注意してくださいa*2 = b。
problem.addConstraint(lambda a, b: a * 2 == b)次に、のオブジェクトを作成します getSolution() 次のコマンドを使用するモジュール-
solutions = problem.getSolutions()最後に、次のコマンドを使用して出力を出力します-
print (solutions)上記のプログラムの出力は次のように観察できます-
[{'a': 4, 'b': 8}, {'a': 3, 'b': 6}, {'a': 2, 'b': 4}, {'a': 1, 'b': 2}, {'a': 0, 'b': 0}]魔方陣
魔方陣は、正方形グリッド内の個別の数値(通常は整数)の配置であり、各行と各列の数値、および対角線の数値はすべて、「マジック定数」と呼ばれる同じ数値になります。 。
以下は、魔方陣を生成するための単純なPythonコードの段階的な実行です。
名前の付いた関数を定義します magic_square、以下に示すように-
def magic_square(matrix_ms):
iSize = len(matrix_ms[0])
sum_list = []次のコードは、正方形の垂直方向のコードを示しています-
for col in range(iSize):
sum_list.append(sum(row[col] for row in matrix_ms))次のコードは、正方形の水平方向のコードを示しています-
sum_list.extend([sum (lines) for lines in matrix_ms])次のコードは、正方形の水平方向のコードを示しています-
dlResult = 0
for i in range(0,iSize):
dlResult +=matrix_ms[i][i]
sum_list.append(dlResult)
drResult = 0
for i in range(iSize-1,-1,-1):
drResult +=matrix_ms[i][i]
sum_list.append(drResult)
if len(set(sum_list))>1:
return False
return Trueここで、行列の値を指定し、出力を確認します-
print(magic_square([[1,2,3], [4,5,6], [7,8,9]]))出力が次のようになることがわかります False 合計が同じ数までではないため。
print(magic_square([[3,9,2], [3,5,7], [9,1,6]]))出力が次のようになることがわかります True 合計が同じ数であるため、つまり 15 ここに。
ゲームは戦略を持ってプレイされます。すべてのプレーヤーまたはチームは、ゲームを開始する前に戦略を立て、ゲームの現在の状況に応じて新しい戦略を変更または構築する必要があります。
検索アルゴリズム
上記と同じ戦略でコンピュータゲームも検討する必要があります。検索アルゴリズムは、コンピュータゲームの戦略を理解するものであることに注意してください。
使い方
検索アルゴリズムの目標は、最終目的地に到達して勝つことができるように、最適な一連の動きを見つけることです。これらのアルゴリズムは、ゲームごとに異なる勝利条件のセットを使用して、最良の動きを見つけます。
コンピュータゲームをツリーとして視覚化します。ツリーにはノードがあることがわかっています。ルートから始めて、最終的な勝者ノードに到達できますが、最適な動きがあります。それが検索アルゴリズムの仕事です。このようなツリーのすべてのノードは、将来の状態を表します。検索アルゴリズムは、このツリーを検索して、ゲームの各ステップまたはノードで決定を下します。
組み合わせ検索
検索アルゴリズムを使用することの主な欠点は、本質的に網羅的であるということです。そのため、検索スペース全体を探索して、リソースの浪費につながるソリューションを見つけます。これらのアルゴリズムが最終的な解決策を見つけるために検索空間全体を検索する必要がある場合は、より面倒になります。
このような問題を解消するために、ヒューリスティックを使用して検索スペースを探索し、誤った動きの可能性を排除することでサイズを縮小する組み合わせ検索を使用できます。したがって、そのようなアルゴリズムはリソースを節約できます。ここでは、ヒューリスティックを使用してスペースを検索し、リソースを節約するアルゴリズムのいくつかについて説明します。
ミニマックスアルゴリズム
これは、ヒューリスティックを使用して検索戦略を高速化する、組み合わせ検索で使用される戦略です。ミニマックス戦略の概念は、各プレーヤーが対戦相手の次の動きを予測し、その機能を最小化しようとする2人のプレーヤーのゲームの例で理解できます。また、勝つために、プレイヤーは常に現在の状況に基づいて自分の機能を最大化しようとします。
ヒューリスティックは、ミニマックスのような種類の戦略で重要な役割を果たします。ツリーのすべてのノードには、ヒューリスティック関数が関連付けられています。そのヒューリスティックに基づいて、最も利益をもたらすノードに向かって移動するかどうかを決定します。
アルファベータ法
Minimaxアルゴリズムの主な問題は、ツリーの無関係な部分を探索できることであり、リソースの浪費につながります。したがって、ツリーのどの部分が関連していて、どの部分が無関係であるかを決定し、無関係な部分を未踏のままにしておく戦略が必要です。アルファベータ法はそのような戦略の1つです。
アルファベータプルーニングアルゴリズムの主な目標は、解決策がないツリーの部分を検索しないようにすることです。アルファベータ法の主な概念は、次の名前の2つの境界を使用することです。Alpha、最大下限、および Beta、最小上限。これらの2つのパラメーターは、可能な解決策のセットを制限する値です。現在のノードの値をアルファおよびベータパラメータの値と比較して、ソリューションのあるツリーの部分に移動し、残りを破棄できるようにします。
Negamaxアルゴリズム
このアルゴリズムはMinimaxアルゴリズムと同じですが、より洗練された実装になっています。Minimaxアルゴリズムを使用する主な欠点は、2つの異なるヒューリスティック関数を定義する必要があることです。これらのヒューリスティック間の関係は、ゲームの状態が1人のプレーヤーにとって良いほど、他のプレーヤーにとっては悪いということです。Negamaxアルゴリズムでは、2つのヒューリスティック関数の同じ作業が1つのヒューリスティック関数の助けを借りて行われます。
ゲームをプレイするためのボットの構築
AIで2人のプレーヤーのゲームをプレイするボットを構築するには、 easyAI図書館。これは、2人用ゲームを構築するためのすべての機能を提供する人工知能フレームワークです。次のコマンドを使用してダウンロードできます-
pip install easyAIラストコインスタンディングをプレイするボット
このゲームでは、コインの山があります。各プレイヤーは、その山からいくつかのコインを取得する必要があります。ゲームの目的は、山の最後のコインを取るのを避けることです。クラスを使用しますLastCoinStanding から継承 TwoPlayersGame のクラス easyAI図書館。次のコードは、このゲームのPythonコードを示しています-
図のように必要なパッケージをインポートします-
from easyAI import TwoPlayersGame, id_solve, Human_Player, AI_Player
from easyAI.AI import TT今、からクラスを継承します TwoPlayerGame ゲームのすべての操作を処理するクラス-
class LastCoin_game(TwoPlayersGame):
def __init__(self, players):ここで、プレーヤーとゲームを開始するプレーヤーを定義します。
self.players = players
self.nplayer = 1ここで、ゲーム内のコインの数を定義します。ここでは、ゲームに15枚のコインを使用しています。
self.num_coins = 15プレイヤーが移動で取ることができるコインの最大数を定義します。
self.max_coins = 4次のコードに示すように、定義する特定の事項がいくつかあります。可能な動きを定義します。
def possible_moves(self):
return [str(a) for a in range(1, self.max_coins + 1)]コインの除去を定義します
def make_move(self, move):
self.num_coins -= int(move)最後のコインを誰が取ったかを定義します。
def win_game(self):
return self.num_coins <= 0ゲームを停止するタイミング、つまり誰かが勝つタイミングを定義します。
def is_over(self):
return self.win()スコアの計算方法を定義します。
def score(self):
return 100 if self.win_game() else 0パイルに残っているコインの数を定義します。
def show(self):
print(self.num_coins, 'coins left in the pile')
if __name__ == "__main__":
tt = TT()
LastCoin_game.ttentry = lambda self: self.num_coins次のコードブロックでゲームを解く-
r, d, m = id_solve(LastCoin_game,
range(2, 20), win_score=100, tt=tt)
print(r, d, m)誰がゲームを開始するかを決める
game = LastCoin_game([AI_Player(tt), Human_Player()])
game.play()次の出力とこのゲームの簡単なプレイを見つけることができます-
d:2, a:0, m:1
d:3, a:0, m:1
d:4, a:0, m:1
d:5, a:0, m:1
d:6, a:100, m:4
1 6 4
15 coins left in the pile
Move #1: player 1 plays 4 :
11 coins left in the pile
Player 2 what do you play ? 2
Move #2: player 2 plays 2 :
9 coins left in the pile
Move #3: player 1 plays 3 :
6 coins left in the pile
Player 2 what do you play ? 1
Move #4: player 2 plays 1 :
5 coins left in the pile
Move #5: player 1 plays 4 :
1 coins left in the pile
Player 2 what do you play ? 1
Move #6: player 2 plays 1 :
0 coins left in the pile三目並べをプレイするボット
Tic-Tac-Toeは非常によく知られており、最も人気のあるゲームの1つです。を使用してこのゲームを作成しましょうeasyAIPythonのライブラリ。次のコードは、このゲームのPythonコードです-
図のようにパッケージをインポートします-
from easyAI import TwoPlayersGame, AI_Player, Negamax
from easyAI.Player import Human_Playerからクラスを継承します TwoPlayerGame ゲームのすべての操作を処理するクラス-
class TicTacToe_game(TwoPlayersGame):
def __init__(self, players):ここで、プレーヤーとゲームを開始するプレーヤーを定義します-
self.players = players
self.nplayer = 1ボードのタイプを定義する-
self.board = [0] * 9今、次のように定義するいくつかの特定のものがあります-
可能な動きを定義する
def possible_moves(self):
return [x + 1 for x, y in enumerate(self.board) if y == 0]プレイヤーの動きを定義する-
def make_move(self, move):
self.board[int(move) - 1] = self.nplayerAIを強化するには、プレーヤーがいつ移動するかを定義します-
def umake_move(self, move):
self.board[int(move) - 1] = 0対戦相手が3列に並んでいるという負け条件を定義します
def condition_for_lose(self):
possible_combinations = [[1,2,3], [4,5,6], [7,8,9],
[1,4,7], [2,5,8], [3,6,9], [1,5,9], [3,5,7]]
return any([all([(self.board[z-1] == self.nopponent)
for z in combination]) for combination in possible_combinations])ゲームの終了のチェックを定義します
def is_over(self):
return (self.possible_moves() == []) or self.condition_for_lose()ゲーム内のプレーヤーの現在の位置を表示します
def show(self):
print('\n'+'\n'.join([' '.join([['.', 'O', 'X'][self.board[3*j + i]]
for i in range(3)]) for j in range(3)]))スコアを計算します。
def scoring(self):
return -100 if self.condition_for_lose() else 0アルゴリズムを定義してゲームを開始するためのメインメソッドを定義します-
if __name__ == "__main__":
algo = Negamax(7)
TicTacToe_game([Human_Player(), AI_Player(algo)]).play()次の出力とこのゲームの簡単なプレイを見ることができます-
. . .
. . .
. . .
Player 1 what do you play ? 1
Move #1: player 1 plays 1 :
O . .
. . .
. . .
Move #2: player 2 plays 5 :
O . .
. X .
121
. . .
Player 1 what do you play ? 3
Move #3: player 1 plays 3 :
O . O
. X .
. . .
Move #4: player 2 plays 2 :
O X O
. X .
. . .
Player 1 what do you play ? 4
Move #5: player 1 plays 4 :
O X O
O X .
. . .
Move #6: player 2 plays 8 :
O X O
O X .
. X .ニューラルネットワークは、脳のコンピューターモデルを作成する試みである並列コンピューティングデバイスです。背後にある主な目的は、従来のシステムよりも高速にさまざまな計算タスクを実行するシステムを開発することです。これらのタスクには、パターン認識と分類、近似、最適化、およびデータクラスタリングが含まれます。
人工ニューラルネットワーク(ANN)とは
人工ニューラルネットワーク(ANN)は、生物学的ニューラルネットワークのアナロジーから中心的なテーマを借りた効率的なコンピューティングシステムです。ANNは、人工ニューラルシステム、並列分散処理システム、コネクショニストシステムとも呼ばれます。ANNは、ユニット間の通信を可能にするために、何らかのパターンで相互接続されたユニットの大規模なコレクションを取得します。これらのユニットは、nodes または neuronsは、並列に動作する単純なプロセッサです。
すべてのニューロンは、を介して他のニューロンと接続されています connection link。各接続リンクは、入力信号に関する情報を持つウェイトに関連付けられています。これは、ニューロンが特定の問題を解決するための最も有用な情報です。weight通常、通信されている信号を励起または抑制します。各ニューロンは、と呼ばれる内部状態を持っていますactivation signal。入力信号とアクティベーションルールを組み合わせた後に生成される出力信号は、他のユニットに送信される場合があります。
ニューラルネットワークを詳細に研究したい場合は、リンク-人工ニューラルネットワークをたどることができます。
便利なパッケージのインストール
Pythonでニューラルネットワークを作成するために、次のようなニューラルネットワーク用の強力なパッケージを使用できます。 NeuroLab。これは、Python用の柔軟なネットワーク構成と学習アルゴリズムを備えた基本的なニューラルネットワークアルゴリズムのライブラリです。このパッケージは、コマンドプロンプトで次のコマンドを使用してインストールできます-
pip install NeuroLabAnaconda環境を使用している場合は、次のコマンドを使用してNeuroLabをインストールします-
conda install -c labfabulous neurolabニューラルネットワークの構築
このセクションでは、NeuroLabパッケージを使用してPythonでいくつかのニューラルネットワークを構築しましょう。
パーセプトロンベースの分類子
パーセプトロンはANNの構成要素です。-あなたはパーセプトロンについての詳細をお知りになりたい場合は、リンクをたどることができartificial_neural_networkを
以下は、単純なニューラルネットワークパーセプトロンベースの分類器を構築するためのPythonコードの段階的な実行です。
図のように必要なパッケージをインポートします-
import matplotlib.pyplot as plt
import neurolab as nl入力値を入力します。これは教師あり学習の例であるため、ターゲット値も指定する必要があることに注意してください。
input = [[0, 0], [0, 1], [1, 0], [1, 1]]
target = [[0], [0], [0], [1]]2つの入力と1つのニューロンでネットワークを作成します-
net = nl.net.newp([[0, 1],[0, 1]], 1)次に、ネットワークをトレーニングします。ここでは、トレーニングにデルタルールを使用しています。
error_progress = net.train(input, target, epochs=100, show=10, lr=0.1)ここで、出力を視覚化し、グラフをプロットします-
plt.figure()
plt.plot(error_progress)
plt.xlabel('Number of epochs')
plt.ylabel('Training error')
plt.grid()
plt.show()エラーメトリックを使用したトレーニングの進行状況を示す次のグラフを確認できます-

単層ニューラルネットワーク
この例では、入力データに作用して出力を生成する独立したニューロンで構成される単層ニューラルネットワークを作成しています。名前の付いたテキストファイルを使用していることに注意してくださいneural_simple.txt 入力として。
図のように便利なパッケージをインポートします-
import numpy as np
import matplotlib.pyplot as plt
import neurolab as nl次のようにデータセットをロードします-
input_data = np.loadtxt(“/Users/admin/neural_simple.txt')以下は、これから使用するデータです。このデータでは、最初の2列がフィーチャで、最後の2列がラベルであることに注意してください。
array([[2. , 4. , 0. , 0. ],
[1.5, 3.9, 0. , 0. ],
[2.2, 4.1, 0. , 0. ],
[1.9, 4.7, 0. , 0. ],
[5.4, 2.2, 0. , 1. ],
[4.3, 7.1, 0. , 1. ],
[5.8, 4.9, 0. , 1. ],
[6.5, 3.2, 0. , 1. ],
[3. , 2. , 1. , 0. ],
[2.5, 0.5, 1. , 0. ],
[3.5, 2.1, 1. , 0. ],
[2.9, 0.3, 1. , 0. ],
[6.5, 8.3, 1. , 1. ],
[3.2, 6.2, 1. , 1. ],
[4.9, 7.8, 1. , 1. ],
[2.1, 4.8, 1. , 1. ]])ここで、これらの4つの列を2つのデータ列と2つのラベルに分割します-
data = input_data[:, 0:2]
labels = input_data[:, 2:]次のコマンドを使用して入力データをプロットします-
plt.figure()
plt.scatter(data[:,0], data[:,1])
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Input data')ここで、次に示すように、各ディメンションの最小値と最大値を定義します。
dim1_min, dim1_max = data[:,0].min(), data[:,0].max()
dim2_min, dim2_max = data[:,1].min(), data[:,1].max()次に、出力層のニューロン数を次のように定義します。
nn_output_layer = labels.shape[1]ここで、単層ニューラルネットワークを定義します-
dim1 = [dim1_min, dim1_max]
dim2 = [dim2_min, dim2_max]
neural_net = nl.net.newp([dim1, dim2], nn_output_layer)示されているように、エポック数と学習率を使用してニューラルネットワークをトレーニングします-
error = neural_net.train(data, labels, epochs = 200, show = 20, lr = 0.01)次に、次のコマンドを使用してトレーニングの進行状況を視覚化してプロットします-
plt.figure()
plt.plot(error)
plt.xlabel('Number of epochs')
plt.ylabel('Training error')
plt.title('Training error progress')
plt.grid()
plt.show()ここで、上記の分類器のテストデータポイントを使用します-
print('\nTest Results:')
data_test = [[1.5, 3.2], [3.6, 1.7], [3.6, 5.7],[1.6, 3.9]] for item in data_test:
print(item, '-->', neural_net.sim([item])[0])ここに示すようにテスト結果を見つけることができます-
[1.5, 3.2] --> [1. 0.]
[3.6, 1.7] --> [1. 0.]
[3.6, 5.7] --> [1. 1.]
[1.6, 3.9] --> [1. 0.]これまでに説明したコードの出力として、次のグラフを見ることができます-


多層ニューラルネットワーク
この例では、トレーニングデータの基礎となるパターンを抽出するために、複数のレイヤーで構成されるマルチレイヤーニューラルネットワークを作成しています。この多層ニューラルネットワークは、リグレッサーのように機能します。次の式に基づいていくつかのデータポイントを生成します:y = 2x 2 + 8。
図のように必要なパッケージをインポートします-
import numpy as np
import matplotlib.pyplot as plt
import neurolab as nl上記の式に基づいてデータポイントを生成します-
min_val = -30
max_val = 30
num_points = 160
x = np.linspace(min_val, max_val, num_points)
y = 2 * np.square(x) + 8
y /= np.linalg.norm(y)ここで、このデータセットを次のように再形成します-
data = x.reshape(num_points, 1)
labels = y.reshape(num_points, 1)次のコマンドを使用して、入力データセットを視覚化してプロットします-
plt.figure()
plt.scatter(data, labels)
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Data-points')次に、2つの隠れ層を持つニューラルネットワークを構築します。 neurolab と ten 最初の隠れ層のニューロン、 six 2番目の隠しレイヤーで one 出力層で。
neural_net = nl.net.newff([[min_val, max_val]], [10, 6, 1])ここで、勾配トレーニングアルゴリズムを使用します-
neural_net.trainf = nl.train.train_gd次に、上記で生成されたデータを学習することを目標にネットワークをトレーニングします。
error = neural_net.train(data, labels, epochs = 1000, show = 100, goal = 0.01)ここで、トレーニングデータポイントでニューラルネットワークを実行します-
output = neural_net.sim(data)
y_pred = output.reshape(num_points)次に、プロットと視覚化のタスク-
plt.figure()
plt.plot(error)
plt.xlabel('Number of epochs')
plt.ylabel('Error')
plt.title('Training error progress')次に、実際の出力と予測された出力をプロットします。
x_dense = np.linspace(min_val, max_val, num_points * 2)
y_dense_pred = neural_net.sim(x_dense.reshape(x_dense.size,1)).reshape(x_dense.size)
plt.figure()
plt.plot(x_dense, y_dense_pred, '-', x, y, '.', x, y_pred, 'p')
plt.title('Actual vs predicted')
plt.show()上記のコマンドの結果として、以下に示すようなグラフを観察できます。



この章では、Pythonを使用したAIでの強化学習の概念について詳しく学習します。
強化学習の基礎
この種の学習は、批評家の情報に基づいてネットワークを強化または強化するために使用されます。つまり、強化学習の下でトレーニングされているネットワークは、環境からフィードバックを受け取ります。ただし、フィードバックは評価的であり、教師あり学習の場合のように有益ではありません。このフィードバックに基づいて、ネットワークは重みの調整を実行し、将来、より良い批評家情報を取得します。
この学習プロセスは教師あり学習に似ていますが、情報が非常に少ない可能性があります。次の図は、強化学習のブロック図を示しています。

ビルディングブロック:環境とエージェント
環境とエージェントは、AIにおける強化学習の主要な構成要素です。このセクションでは、それらについて詳しく説明します-
エージェント
エージェントとは、センサーを介してその環境を認識し、エフェクターを介してその環境に作用することができるものです。
A human agent センサーと平行に目、耳、鼻、舌、皮膚などの感覚器官と、エフェクター用の手、脚、口などの他の器官があります。
A robotic agent センサー用のカメラと赤外線距離計、およびエフェクター用のさまざまなモーターとアクチュエーターに取って代わります。
A software agent プログラムおよびアクションとしてビット文字列をエンコードしました。
エージェントの用語
次の用語は、AIの強化学習でより頻繁に使用されます-
Performance Measure of Agent −エージェントがどれだけ成功するかを決定する基準です。
Behavior of Agent −これは、エージェントが特定の一連の知覚の後に実行するアクションです。
Percept −特定のインスタンスでのエージェントの知覚入力です。
Percept Sequence −エージェントがこれまでに認識してきたすべての歴史です。
Agent Function −これは、プリセプトシーケンスからアクションへのマップです。
環境
一部のプログラムは完全に動作します artificial environment キーボード入力、データベース、コンピューターファイルシステム、および画面上の文字出力に限定されます。
対照的に、ソフトウェアロボットやソフトボットなどの一部のソフトウェアエージェントは、豊富で無制限のソフトボットドメインに存在します。シミュレータにはvery detailed、および complex environment。ソフトウェアエージェントは、多数のアクションからリアルタイムで選択する必要があります。
たとえば、顧客のオンライン設定をスキャンして顧客に興味深いアイテムを表示するように設計されたソフトボットは、 real だけでなく、 artificial 環境。
環境の特性
以下で説明するように、環境には複数の特性があります。
Discrete/Continuous−環境の明確に定義された明確な状態の数が限られている場合、環境は離散的です。それ以外の場合、環境は連続的です。たとえば、チェスは離散的な環境であり、運転は継続的な環境です。
Observable/Partially Observable−知覚から各時点での環境の完全な状態を判断することが可能である場合、それは観察可能です。それ以外の場合は、部分的にしか観察できません。
Static/Dynamic−エージェントの動作中に環境が変化しない場合、環境は静的です。それ以外の場合は動的です。
Single agent/Multiple agents −環境には、エージェントと同じまたは異なる種類の他のエージェントが含まれている場合があります。
Accessible/Inaccessible−エージェントの感覚装置が環境の完全な状態にアクセスできる場合、そのエージェントは環境にアクセスできます。それ以外の場合はアクセスできません。
Deterministic/Non-deterministic−環境の次の状態が、現在の状態とエージェントのアクションによって完全に決定される場合、環境は決定論的です。それ以外の場合は、非決定論的です。
Episodic/Non-episodic−エピソード環境では、各エピソードは、エージェントが認識して行動することで構成されます。そのアクションの質は、エピソード自体に依存します。後続のエピソードは、前のエピソードのアクションに依存しません。エージェントが先を考える必要がないため、一時的な環境ははるかに単純です。
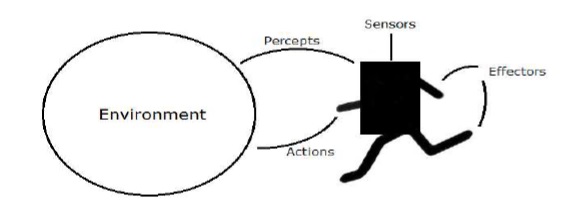
Pythonで環境を構築する
強化学習エージェントの構築には、 OpenAI Gym 次のコマンドを使用してインストールできるパッケージ-
pip install gymOpenAIジムにはさまざまな目的に使用できるさまざまな環境があります。それらのいくつかはCartpole-v0, Hopper-v1、および MsPacman-v0。それらは異なるエンジンを必要とします。の詳細なドキュメントOpenAI Gym で見つけることができます https://gym.openai.com/docs/#environments。
次のコードは、cartpole-v0環境のPythonコードの例を示しています-
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())
同様の方法で他の環境を構築できます。
Pythonを使用した学習エージェントの構築
強化学習エージェントの構築には、 OpenAI Gym 示されているパッケージ-
import gym
env = gym.make('CartPole-v0')
for _ in range(20):
observation = env.reset()
for i in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(i+1))
break
カートポールがバランスをとることができることを確認してください。
この章では、AIの遺伝的アルゴリズムについて詳しく説明します。
遺伝的アルゴリズムとは何ですか?
遺伝的アルゴリズム(GA)は、自然淘汰と遺伝学の概念に基づく検索ベースのアルゴリズムです。GAは、進化的計算として知られるはるかに大きな計算ブランチのサブセットです。
GAは、ミシガン大学のJohn Hollandと彼の学生および同僚、特にDavid E.Goldbergによって開発されました。それ以来、さまざまな最適化問題で試行され、高い成功を収めています。
GAには、特定の問題に対する可能な解決策のプールがあります。次に、これらのソリューションは(自然遺伝学のように)組換えと突然変異を受け、新しい子供を生み出し、このプロセスがさまざまな世代で繰り返されます。各個体(または候補解)には(その目的関数値に基づいて)適応度値が割り当てられ、より適切な個体には、交尾して降伏する可能性が高くなります。fitter個人。これはダーウィンの理論と一致していますSurvival of the Fittest。
したがって、それは維持します evolving それが停止基準に達するまで、世代を超えてより良い個人または解決策。
遺伝的アルゴリズムは本質的に十分にランダム化されていますが、履歴情報も活用するため、ランダムローカル検索(ランダムソリューションを試し、これまでの最良のものを追跡する)よりもはるかに優れたパフォーマンスを発揮します。
最適化問題にGAを使用する方法は?
最適化とは、設計、状況、リソース、およびシステムを可能な限り効果的にするためのアクションです。次のブロック図は、最適化プロセスを示しています-

最適化プロセスのためのGAメカニズムの段階
以下は、問題の最適化に使用される場合のGAメカニズムの一連のステップです。
ステップ1-初期母集団をランダムに生成します。
ステップ2-最適な適合値を持つ初期解を選択します。
ステップ3-ミューテーション演算子とクロスオーバー演算子を使用して、選択したソリューションを再結合します。
ステップ4-子孫を母集団に挿入します。
ステップ5-ここで、停止条件が満たされた場合、最適な適合値を持つソリューションを返します。それ以外の場合は、手順2に進みます。
必要なパッケージのインストール
Pythonで遺伝的アルゴリズムを使用して問題を解決するために、GA用の強力なパッケージを使用します。 DEAP。これは、アイデアのラピッドプロトタイピングとテストのための新しい進化的計算フレームワークのライブラリです。このパッケージは、コマンドプロンプトで次のコマンドを使用してインストールできます-
pip install deap使用している場合 anaconda 環境の場合、次のコマンドを使用してdeapをインストールできます-
conda install -c conda-forge deap遺伝的アルゴリズムを使用したソリューションの実装
このセクションでは、遺伝的アルゴリズムを使用したソリューションの実装について説明します。
ビットパターンの生成
次の例は、に基づいて15個のビット文字列を含むビット文字列を生成する方法を示しています。 One Max 問題。
図のように必要なパッケージをインポートします-
import random
from deap import base, creator, tools評価関数を定義します。これは、遺伝的アルゴリズムを作成するための最初のステップです。
def eval_func(individual):
target_sum = 15
return len(individual) - abs(sum(individual) - target_sum),次に、適切なパラメータを使用してツールボックスを作成します-
def create_toolbox(num_bits):
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)ツールボックスを初期化します
toolbox = base.Toolbox()
toolbox.register("attr_bool", random.randint, 0, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual,
toolbox.attr_bool, num_bits)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)評価演算子を登録する-
toolbox.register("evaluate", eval_func)ここで、クロスオーバー演算子を登録します-
toolbox.register("mate", tools.cxTwoPoint)突然変異演算子を登録する-
toolbox.register("mutate", tools.mutFlipBit, indpb = 0.05)繁殖のための演算子を定義する-
toolbox.register("select", tools.selTournament, tournsize = 3)
return toolbox
if __name__ == "__main__":
num_bits = 45
toolbox = create_toolbox(num_bits)
random.seed(7)
population = toolbox.population(n = 500)
probab_crossing, probab_mutating = 0.5, 0.2
num_generations = 10
print('\nEvolution process starts')母集団全体を評価する-
fitnesses = list(map(toolbox.evaluate, population))
for ind, fit in zip(population, fitnesses):
ind.fitness.values = fit
print('\nEvaluated', len(population), 'individuals')世代を超えて作成および反復-
for g in range(num_generations):
print("\n- Generation", g)次世代の個人を選ぶ-
offspring = toolbox.select(population, len(population))次に、選択した個人のクローンを作成します-
offspring = list(map(toolbox.clone, offspring))子孫にクロスオーバーと突然変異を適用する-
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < probab_crossing:
toolbox.mate(child1, child2)子供の適応度の値を削除します
del child1.fitness.values
del child2.fitness.valuesここで、突然変異を適用します-
for mutant in offspring:
if random.random() < probab_mutating:
toolbox.mutate(mutant)
del mutant.fitness.values無効なフィットネスを持つ個人を評価する-
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
print('Evaluated', len(invalid_ind), 'individuals')さて、人口を次世代の個人に置き換えましょう-
population[:] = offspring現在の世代の統計を出力します-
fits = [ind.fitness.values[0] for ind in population]
length = len(population)
mean = sum(fits) / length
sum2 = sum(x*x for x in fits)
std = abs(sum2 / length - mean**2)**0.5
print('Min =', min(fits), ', Max =', max(fits))
print('Average =', round(mean, 2), ', Standard deviation =',
round(std, 2))
print("\n- Evolution ends")最終出力を印刷する-
best_ind = tools.selBest(population, 1)[0]
print('\nBest individual:\n', best_ind)
print('\nNumber of ones:', sum(best_ind))
Following would be the output:
Evolution process starts
Evaluated 500 individuals
- Generation 0
Evaluated 295 individuals
Min = 32.0 , Max = 45.0
Average = 40.29 , Standard deviation = 2.61
- Generation 1
Evaluated 292 individuals
Min = 34.0 , Max = 45.0
Average = 42.35 , Standard deviation = 1.91
- Generation 2
Evaluated 277 individuals
Min = 37.0 , Max = 45.0
Average = 43.39 , Standard deviation = 1.46
… … … …
- Generation 9
Evaluated 299 individuals
Min = 40.0 , Max = 45.0
Average = 44.12 , Standard deviation = 1.11
- Evolution ends
Best individual:
[0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1,
1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0,
1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1]
Number of ones: 15シンボル回帰問題
これは、遺伝的プログラミングで最もよく知られている問題の1つです。すべてのシンボリック回帰問題は、任意のデータ分布を使用し、最も正確なデータをシンボリック式に適合させようとします。通常、RMSE(二乗平均平方根誤差)のような測定値は、個人の適応度を測定するために使用されます。これは古典的なリグレッサーの問題であり、ここでは方程式を使用しています5x3-6x2+8x=1。上記の例のようにすべての手順を実行する必要がありますが、評価を開始できるように、プリミティブセットは個人の構成要素であるため、主要な部分はプリミティブセットを作成することです。ここでは、プリミティブの古典的なセットを使用します。
次のPythonコードはこれを詳細に説明しています-
import operator
import math
import random
import numpy as np
from deap import algorithms, base, creator, tools, gp
def division_operator(numerator, denominator):
if denominator == 0:
return 1
return numerator / denominator
def eval_func(individual, points):
func = toolbox.compile(expr=individual)
return math.fsum(mse) / len(points),
def create_toolbox():
pset = gp.PrimitiveSet("MAIN", 1)
pset.addPrimitive(operator.add, 2)
pset.addPrimitive(operator.sub, 2)
pset.addPrimitive(operator.mul, 2)
pset.addPrimitive(division_operator, 2)
pset.addPrimitive(operator.neg, 1)
pset.addPrimitive(math.cos, 1)
pset.addPrimitive(math.sin, 1)
pset.addEphemeralConstant("rand101", lambda: random.randint(-1,1))
pset.renameArguments(ARG0 = 'x')
creator.create("FitnessMin", base.Fitness, weights = (-1.0,))
creator.create("Individual",gp.PrimitiveTree,fitness=creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register("expr", gp.genHalfAndHalf, pset=pset, min_=1, max_=2)
toolbox.expr)
toolbox.register("population",tools.initRepeat,list, toolbox.individual)
toolbox.register("compile", gp.compile, pset = pset)
toolbox.register("evaluate", eval_func, points = [x/10. for x in range(-10,10)])
toolbox.register("select", tools.selTournament, tournsize = 3)
toolbox.register("mate", gp.cxOnePoint)
toolbox.register("expr_mut", gp.genFull, min_=0, max_=2)
toolbox.register("mutate", gp.mutUniform, expr = toolbox.expr_mut, pset = pset)
toolbox.decorate("mate", gp.staticLimit(key = operator.attrgetter("height"), max_value = 17))
toolbox.decorate("mutate", gp.staticLimit(key = operator.attrgetter("height"), max_value = 17))
return toolbox
if __name__ == "__main__":
random.seed(7)
toolbox = create_toolbox()
population = toolbox.population(n = 450)
hall_of_fame = tools.HallOfFame(1)
stats_fit = tools.Statistics(lambda x: x.fitness.values)
stats_size = tools.Statistics(len)
mstats = tools.MultiStatistics(fitness=stats_fit, size = stats_size)
mstats.register("avg", np.mean)
mstats.register("std", np.std)
mstats.register("min", np.min)
mstats.register("max", np.max)
probab_crossover = 0.4
probab_mutate = 0.2
number_gen = 10
population, log = algorithms.eaSimple(population, toolbox,
probab_crossover, probab_mutate, number_gen,
stats = mstats, halloffame = hall_of_fame, verbose = True)すべての基本的な手順は、ビットパターンの生成時に使用されるものと同じであることに注意してください。このプログラムは、10世代後の出力を最小、最大、標準(標準偏差)として提供します。
コンピュータビジョンは、コンピュータソフトウェアとハードウェアを使用して人間の視覚をモデル化および複製することに関係しています。この章では、これについて詳しく学習します。
コンピュータビジョン
コンピュータビジョンは、シーンに存在する構造のプロパティの観点から、2D画像から3Dシーンを再構築、中断、および理解する方法を研究する分野です。
コンピュータビジョン階層
コンピュータビジョンは、次の3つの基本的なカテゴリに分類されます。
Low-level vision −特徴抽出用のプロセスイメージが含まれています。
Intermediate-level vision −オブジェクト認識と3Dシーン解釈が含まれます
High-level vision −活動、意図、行動などのシーンの概念的な説明が含まれています。
コンピュータビジョン対画像処理
画像処理は、画像から画像への変換を研究します。画像処理の入力と出力は両方とも画像です。
コンピュータビジョンは、画像から物理的なオブジェクトの明示的で意味のある記述を構築することです。コンピュータビジョンの出力は、3Dシーンの構造の説明または解釈です。
アプリケーション
コンピュータビジョンは、次の分野でアプリケーションを見つけます-
Robotics
ローカリゼーション-ロボットの位置を自動的に決定します
Navigation
障害物の回避
組立(ペグインホール、溶接、塗装)
操作(例:PUMAロボットマニピュレーター)
ヒューマンロボットインタラクション(HRI):人々と対話してサービスを提供するインテリジェントロボティクス
Medicine
分類と検出(例:病変または細胞の分類と腫瘍の検出)
2D / 3Dセグメンテーション
3D人間の臓器の再構成(MRIまたは超音波)
視覚誘導ロボット手術
Security
- バイオメトリクス(虹彩、指紋、顔認識)
- 監視-特定の疑わしい活動または行動を検出する
Transportation
- 自動運転車
- 安全性、例えば、ドライバーの警戒監視
Industrial Automation Application
- 産業検査(欠陥検出)
- Assembly
- バーコードとパッケージラベルの読み取り
- オブジェクトの並べ替え
- 文書の理解(例:OCR)
便利なパッケージのインストール
Pythonを使用したコンピュータービジョンの場合、次のような人気のあるライブラリを使用できます。 OpenCV(オープンソースコンピュータビジョン)。これは、主にリアルタイムのコンピュータビジョンを目的としたプログラミング機能のライブラリです。これはC ++で記述されており、その主要なインターフェイスはC ++です。このパッケージは、次のコマンドを使用してインストールできます-
pip install opencv_python-X.X-cp36-cp36m-winX.whlここで、Xは、マシンにインストールされているPythonのバージョンと、使用しているwin32または64ビットを表します。
を使用している場合 anaconda 環境の場合は、次のコマンドを使用してOpenCVをインストールします-
conda install -c conda-forge opencv画像の読み取り、書き込み、表示
ほとんどのCVアプリケーションは、入力として画像を取得し、出力として画像を生成する必要があります。このセクションでは、OpenCVが提供する機能を使用して画像ファイルを読み書きする方法を学習します。
画像ファイルの読み取り、表示、書き込みのためのOpenCV関数
OpenCVは、この目的のために次の機能を提供します-
imread() function−画像を読み取る機能です。OpenCV imread()は、PNG、JPEG、JPG、TIFFなどのさまざまな画像形式をサポートしています。
imshow() function−ウィンドウに画像を表示する機能です。ウィンドウは自動的に画像サイズに合わせます。OpenCV imshow()は、PNG、JPEG、JPG、TIFFなどのさまざまな画像形式をサポートしています。
imwrite() function−画像を書き込むための機能です。OpenCV imwrite()は、PNG、JPEG、JPG、TIFFなどのさまざまな画像形式をサポートしています。
例
この例は、ある形式で画像を読み取り、ウィンドウに表示し、同じ画像を別の形式で書き込むためのPythonコードを示しています。以下に示す手順を検討してください-
図のようにOpenCVパッケージをインポートします-
import cv2ここで、特定の画像を読み取るには、imread()関数を使用します-
image = cv2.imread('image_flower.jpg')画像を表示するには、 imshow()関数。画像を見ることができるウィンドウの名前は次のようになりますimage_flower。
cv2.imshow('image_flower',image)
cv2.destroyAllwindows()
これで、imwrite()関数を使用して、同じ画像を他の形式、たとえば.pngに書き込むことができます。
cv2.imwrite('image_flower.png',image)Trueの出力は、画像が同じフォルダーにも.pngファイルとして正常に書き込まれたことを意味します。
True注-関数destroyallWindows()は、作成したすべてのウィンドウを単に破棄します。
色空間変換
OpenCVでは、画像は従来のRGBカラーを使用して保存されるのではなく、逆の順序、つまりBGRの順序で保存されます。したがって、画像の読み取り中のデフォルトのカラーコードはBGRです。ザ・cvtColor() 画像をあるカラーコードから別のカラーコードに変換するための色変換機能。
例
この例を検討して、画像をBGRからグレースケールに変換します。
をインポートします OpenCV 示されているパッケージ-
import cv2ここで、特定の画像を読み取るには、imread()関数を使用します-
image = cv2.imread('image_flower.jpg')さて、この画像を使用して見ると imshow() 関数を実行すると、この画像がBGRにあることがわかります。
cv2.imshow('BGR_Penguins',image)
今、使用します cvtColor() この画像をグレースケールに変換する関数。
image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray_penguins',image)
エッジ検出
人間は、ラフスケッチを見た後、多くのオブジェクトタイプとそのポーズを簡単に認識できます。そのため、エッジは人間の生活やコンピュータビジョンのアプリケーションで重要な役割を果たします。OpenCVは、と呼ばれる非常にシンプルで便利な関数を提供しますCanny()エッジを検出するため。
例
次の例は、エッジの明確な識別を示しています。
図のようにOpenCVパッケージをインポートします-
import cv2
import numpy as npここで、特定の画像を読み取るには、 imread() 関数。
image = cv2.imread('Penguins.jpg')今、使用します Canny () すでに読み取った画像のエッジを検出する機能。
cv2.imwrite(‘edges_Penguins.jpg’,cv2.Canny(image,200,300))ここで、エッジのある画像を表示するには、imshow()関数を使用します。
cv2.imshow(‘edges’, cv2.imread(‘‘edges_Penguins.jpg’))このPythonプログラムは、という名前の画像を作成します edges_penguins.jpg エッジ検出付き。

顔検出
顔検出は、コンピュータービジョンの魅力的なアプリケーションの1つであり、より現実的で未来的なものになります。OpenCVには、顔検出を実行するための機能が組み込まれています。を使用しますHaar 顔検出用のカスケード分類器。
Haarカスケードデータ
Haarカスケード分類器を使用するにはデータが必要です。このデータは、OpenCVパッケージに含まれています。OpenCvをインストールすると、フォルダ名が表示されますhaarcascades。さまざまなアプリケーション用の.xmlファイルがあります。次に、それらすべてをさまざまな用途にコピーして、現在のプロジェクトの下の新しいフォルダーに貼り付けます。
Example
以下は、HaarCascadeを使用して次の画像に示すAmitabhBachanの顔を検出するPythonコードです。

をインポートします OpenCV 示されているパッケージ-
import cv2
import numpy as np今、使用します HaarCascadeClassifier 顔を検出するため-
face_detection=
cv2.CascadeClassifier('D:/ProgramData/cascadeclassifier/
haarcascade_frontalface_default.xml')ここで、特定の画像を読み取るには、 imread() 関数-
img = cv2.imread('AB.jpg')グレー画像を受け入れるので、グレースケールに変換します-
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)今、を使用して face_detection.detectMultiScale、実際の顔検出を実行します
faces = face_detection.detectMultiScale(gray, 1.3, 5)次に、顔全体の周りに長方形を描きます-
for (x,y,w,h) in faces:
img = cv2.rectangle(img,(x,y),(x+w, y+h),(255,0,0),3)
cv2.imwrite('Face_AB.jpg',img)このPythonプログラムは、という名前の画像を作成します Face_AB.jpg 示されているように顔検出付き

目の検出
目の検出は、コンピュータビジョンのもう1つの魅力的なアプリケーションであり、より現実的で未来的なものになります。OpenCVには、目の検出を実行するための機能が組み込まれています。を使用しますHaar cascade 目の検出のための分類器。
例
次の例は、Haar Cascadeを使用して次の画像に示されているAmitabhBachanの顔を検出するPythonコードを示しています。

図のようにOpenCVパッケージをインポートします-
import cv2
import numpy as np今、使用します HaarCascadeClassifier 顔を検出するため-
eye_cascade = cv2.CascadeClassifier('D:/ProgramData/cascadeclassifier/haarcascade_eye.xml')ここで、特定の画像を読み取るには、 imread() 関数
img = cv2.imread('AB_Eye.jpg')グレー画像を受け入れるので、グレースケールに変換します-
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)今の助けを借りて eye_cascade.detectMultiScale、実際の顔検出を実行します
eyes = eye_cascade.detectMultiScale(gray, 1.03, 5)次に、顔全体の周りに長方形を描きます-
for (ex,ey,ew,eh) in eyes:
img = cv2.rectangle(img,(ex,ey),(ex+ew, ey+eh),(0,255,0),2)
cv2.imwrite('Eye_AB.jpg',img)このPythonプログラムは、という名前の画像を作成します Eye_AB.jpg 示されているように目の検出で-

人工ニューラルネットワーク(ANN)は効率的なコンピューティングシステムであり、その中心的なテーマは生物学的ニューラルネットワークのアナロジーから借用されています。ニューラルネットワークは、機械学習のモデルの1つのタイプです。1980年代半ばから1990年代初頭にかけて、ニューラルネットワークで非常に重要なアーキテクチャの進歩が見られました。この章では、AIのアプローチであるディープラーニングについて詳しく学習します。
ディープラーニングは、この分野での真剣な競争相手としての10年にわたる爆発的な計算の成長から生まれました。したがって、深層学習は特定の種類の機械学習であり、そのアルゴリズムは人間の脳の構造と機能に触発されています。
機械学習v / sディープラーニング
ディープラーニングは、最近最も強力な機械学習手法です。彼らは問題を解決する方法を学びながら問題を表現するための最良の方法を学ぶので、それはとても強力です。ディープラーニングと機械学習の比較を以下に示します-
データの依存関係
最初の違いは、データの規模が大きくなったときのDLとMLのパフォーマンスに基づいています。データが大きい場合、深層学習アルゴリズムは非常にうまく機能します。
マシンの依存関係
ディープラーニングアルゴリズムが完全に機能するには、ハイエンドマシンが必要です。一方、機械学習アルゴリズムはローエンドのマシンでも機能します。
特徴抽出
深層学習アルゴリズムは、高レベルの特徴を抽出し、同じものから学習しようとすることができます。一方、機械学習によって抽出された特徴のほとんどを特定するには、専門家が必要です。
実行時間
実行時間は、アルゴリズムで使用される多数のパラメーターによって異なります。深層学習には、機械学習アルゴリズムよりも多くのパラメーターがあります。したがって、DLアルゴリズムの実行時間、特にトレーニング時間は、MLアルゴリズムよりもはるかに長くなります。ただし、DLアルゴリズムのテスト時間はMLアルゴリズムよりも短くなります。
問題解決へのアプローチ
深層学習は問題をエンドツーエンドで解決しますが、機械学習は問題を解決する従来の方法、つまり問題を部分に分解する方法を使用します。
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワークは、学習可能な重みとバイアスを持つニューロンで構成されているため、通常のニューラルネットワークと同じです。通常のニューラルネットワークは入力データの構造を無視し、すべてのデータはネットワークに入力する前に1次元配列に変換されます。このプロセスは通常のデータに適していますが、データに画像が含まれている場合、プロセスが煩雑になる可能性があります。
CNNはこの問題を簡単に解決します。画像を処理するときに画像の2D構造が考慮されるため、画像に固有のプロパティを抽出できます。このように、CNNの主な目標は、入力層の生の画像データから出力層の正しいクラスに移動することです。通常のNNとCNNの唯一の違いは、入力データの処理とレイヤーのタイプにあります。
CNNのアーキテクチャの概要
アーキテクチャ的には、通常のニューラルネットワークは入力を受け取り、一連の隠れ層を介してそれを変換します。すべての層はニューロンの助けを借りて他の層に接続されています。通常のニューラルネットワークの主な欠点は、完全な画像にうまくスケーリングできないことです。
CNNのアーキテクチャには、幅、高さ、深さと呼ばれる3次元に配置されたニューロンがあります。現在の層の各ニューロンは、前の層からの出力の小さなパッチに接続されています。オーバーレイに似ています×入力画像をフィルタリングします。それは使用していますMすべての詳細を確実に取得するためのフィルター。これらM フィルタは、エッジ、コーナーなどの特徴を抽出する特徴抽出器です。
CNNの構築に使用されるレイヤー
次のレイヤーを使用してCNNを構築します-
Input Layer −生の画像データをそのまま取得します。
Convolutional Layer−この層は、ほとんどの計算を行うCNNのコアビルディングブロックです。この層は、ニューロンと入力内のさまざまなパッチの間の畳み込みを計算します。
Rectified Linear Unit Layer−前のレイヤーの出力に活性化関数を適用します。ネットワークに非線形性を追加するため、あらゆるタイプの関数に適切に一般化できます。
Pooling Layer−プーリングは、ネットワークの進行中に重要な部分のみを保持するのに役立ちます。プーリングレイヤーは、入力のすべての深度スライスで独立して動作し、空間的にサイズを変更します。MAX関数を使用します。
Fully Connected layer/Output layer −このレイヤーは、最後のレイヤーの出力スコアを計算します。結果の出力は次のサイズになります×× 、ここで、Lはトレーニングデータセットクラスの数です。
便利なPythonパッケージのインストール
使用できます Kerasは、Pythonで記述された高レベルのニューラルネットワークAPIであり、TensorFlow、CNTK、またはTheno上で実行できます。Python2.7-3.6と互換性があります。あなたはそれについてもっと学ぶことができますhttps://keras.io/。
次のコマンドを使用してkerasをインストールします-
pip install kerasオン conda 環境では、次のコマンドを使用できます-
conda install –c conda-forge kerasANNを使用した線形リグレッサの構築
このセクションでは、人工ニューラルネットワークを使用して線形リグレッサを構築する方法を学習します。使用できますKerasRegressorこれを達成するために。この例では、ボストンのプロパティに13の数値を含むボストンの住宅価格データセットを使用しています。同じもののPythonコードをここに示します-
図のように、必要なすべてのパッケージをインポートします-
import numpy
import pandas
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold次に、ローカルディレクトリに保存されているデータセットをロードします。
dataframe = pandas.read_csv("/Usrrs/admin/data.csv", delim_whitespace = True, header = None)
dataset = dataframe.valuesここで、データを入力変数と出力変数、つまりXとY −に分割します。
X = dataset[:,0:13]
Y = dataset[:,13]ベースラインニューラルネットワークを使用するため、モデルを定義します-
def baseline_model():ここで、次のようにモデルを作成します-
model_regressor = Sequential()
model_regressor.add(Dense(13, input_dim = 13, kernel_initializer = 'normal',
activation = 'relu'))
model_regressor.add(Dense(1, kernel_initializer = 'normal'))次に、モデルをコンパイルします-
model_regressor.compile(loss='mean_squared_error', optimizer='adam')
return model_regressorここで、再現性のためにランダムシードを次のように修正します-
seed = 7
numpy.random.seed(seed)で使用するKerasラッパーオブジェクト scikit-learn 回帰推定量が呼ばれるように KerasRegressor。このセクションでは、標準化されたデータセットを使用してこのモデルを評価します。
estimator = KerasRegressor(build_fn = baseline_model, nb_epoch = 100, batch_size = 5, verbose = 0)
kfold = KFold(n_splits = 10, random_state = seed)
baseline_result = cross_val_score(estimator, X, Y, cv = kfold)
print("Baseline: %.2f (%.2f) MSE" % (Baseline_result.mean(),Baseline_result.std()))上記のコードの出力は、見えないデータの問題に対するモデルのパフォーマンスの推定値になります。これは、交差検定評価の10倍すべてにわたる平均および標準偏差を含む平均二乗誤差になります。
画像分類器:ディープラーニングのアプリケーション
畳み込みニューラルネットワーク(CNN)は、画像分類の問題、つまり入力画像がどのクラスに属するかを解決します。Kerasディープラーニングライブラリを使用できます。次のリンクから猫と犬の画像のトレーニングとテストのデータセットを使用していることに注意してくださいhttps://www.kaggle.com/c/dogs-vs-cats/data。
図のように重要なkerasライブラリとパッケージをインポートします-
シーケンシャルと呼ばれる次のパッケージは、ニューラルネットワークをシーケンシャルネットワークとして初期化します。
from keras.models import Sequential次のパッケージは Conv2D CNNの最初のステップである畳み込み演算を実行するために使用されます。
from keras.layers import Conv2D次のパッケージは MaxPoling2D CNNの2番目のステップであるプーリング操作を実行するために使用されます。
from keras.layers import MaxPooling2D次のパッケージは Flatten 結果として得られるすべての2D配列を単一の長い連続線形ベクトルに変換するプロセスです。
from keras.layers import Flatten次のパッケージは Dense CNNの4番目のステップであるニューラルネットワークの完全な接続を実行するために使用されます。
from keras.layers import Dense次に、シーケンシャルクラスのオブジェクトを作成します。
S_classifier = Sequential()次のステップは、畳み込み部分のコーディングです。
S_classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))ここに relu 整流器機能です。
ここで、CNNの次のステップは、畳み込み部分の後の結果のフィーチャマップに対するプーリング操作です。
S-classifier.add(MaxPooling2D(pool_size = (2, 2)))ここで、お世辞を使用して、プールされたすべての画像を連続ベクトルに変換します-
S_classifier.add(Flatten())次に、完全に接続されたレイヤーを作成します。
S_classifier.add(Dense(units = 128, activation = 'relu'))ここで、128は隠しユニットの数です。非表示のユニットの数を2の累乗として定義するのが一般的な方法です。
ここで、出力レイヤーを次のように初期化します-
S_classifier.add(Dense(units = 1, activation = 'sigmoid'))さて、CNNをコンパイルして、構築しました-
S_classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])ここで、オプティマイザーパラメーターは確率的勾配降下アルゴリズムを選択し、損失パラメーターは損失関数を選択し、メトリックパラメーターはパフォーマンスメトリックを選択します。
次に、画像の拡張を実行してから、画像をニューラルネットワークに適合させます-
train_datagen = ImageDataGenerator(rescale = 1./255,shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
training_set =
train_datagen.flow_from_directory(”/Users/admin/training_set”,target_size =
(64, 64),batch_size = 32,class_mode = 'binary')
test_set =
test_datagen.flow_from_directory('test_set',target_size =
(64, 64),batch_size = 32,class_mode = 'binary')ここで、作成したモデルにデータを適合させます-
classifier.fit_generator(training_set,steps_per_epoch = 8000,epochs =
25,validation_data = test_set,validation_steps = 2000)ここで、steps_per_epochにはトレーニング画像の数があります。
モデルがトレーニングされたので、次のように予測に使用できます。
from keras.preprocessing import image
test_image = image.load_img('dataset/single_prediction/cat_or_dog_1.jpg',
target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
if result[0][0] == 1:
prediction = 'dog'
else:
prediction = 'cat'