KNIME-独自のモデルの構築
この章では、観察されたいくつかの特徴に基づいて植物を分類するための独自の機械学習モデルを構築します。よく知られているものを使用しますiris からのデータセット UCI Machine Learning Repositoryこの目的のために。データセットには、3つの異なるクラスの植物が含まれています。モデルをトレーニングして、未知の植物をこれら3つのクラスのいずれかに分類します。
機械学習モデルを作成するために、KNIMEで新しいワークフローを作成することから始めます。
ワークフローの作成
新しいワークフローを作成するには、KNIMEワークベンチで次のメニューオプションを選択します。
File → New次の画面が表示されます-

を選択 New KNIME Workflow オプションをクリックし、 Nextボタン。次の画面で、ワークフローの名前と保存先フォルダーの入力を求められます。必要に応じてこの情報を入力し、をクリックしますFinish 新しいワークスペースを作成します。
指定された名前の新しいワークスペースがに追加されます Workspace ここに見られるように見る-
次に、このワークスペースにさまざまなノードを追加して、モデルを作成します。ノードを追加する前に、ダウンロードして準備する必要がありますiris 私たちが使用するデータセット。
データセットの準備
UCI Machine LearningRepositoryサイトからアイリスデータセットをダウンロードします。アイリスデータセットをダウンロードします。ダウンロードしたiris.dataファイルはCSV形式です。列名を追加するために、いくつかの変更を加えます。
ダウンロードしたファイルをお気に入りのテキストエディタで開き、最初に次の行を追加します。
sepal length, petal length, sepal width, petal width, class私たちのとき File Reader ノードはこのファイルを読み取り、上記のフィールドを列名として自動的に取得します。
ここで、さまざまなノードの追加を開始します。
ファイルリーダーの追加
に移動します Node Repository ビューで、検索ボックスに「ファイル」と入力して、 File Readerノード。これは下のスクリーンショットに見られます-

を選択してダブルクリックします File Readerノードをワークスペースに追加します。または、ドラッグアンドドロップ機能を使用してノードをワークスペースに追加することもできます。ノードを追加したら、ノードを構成する必要があります。ノードを右クリックして、Configureメニューオプション。これは前のレッスンで行いました。
データファイルを読み込んだ後の設定画面は次のようになります。

データセットを読み込むには、をクリックします Browseボタンをクリックして、iris.dataファイルの場所を選択します。ノードは、構成ボックスの下部に表示されるファイルの内容をロードします。データファイルが適切に配置されて読み込まれたことを確認したら、をクリックします。OK ボタンをクリックして、構成ダイアログを閉じます。
ここで、このノードに注釈を追加します。ノードを右クリックして、New Workflow Annotationメニューオプション。次のスクリーンショットに示すように、注釈ボックスが画面に表示されます。
ボックス内をクリックして、次の注釈を追加します-
Reads iris.dataボックスの外側をクリックして、編集モードを終了します。必要に応じて、ボックスのサイズを変更し、ノードの周囲に配置します。最後に、をダブルクリックしますNode 1 この文字列を次のように変更するためのノードの下のテキスト-
Loads dataこの時点で、画面は次のようになります-
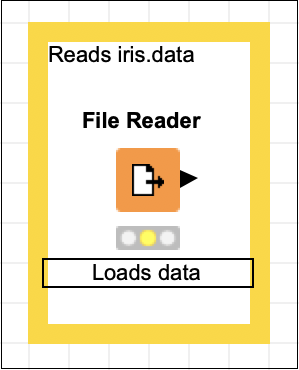
ロードしたデータセットをトレーニングとテストに分割するための新しいノードを追加します。
パーティショニングノードの追加
の中に Node Repository 検索ウィンドウで、数文字を入力して Partitioning 以下のスクリーンショットに見られるように、ノード-
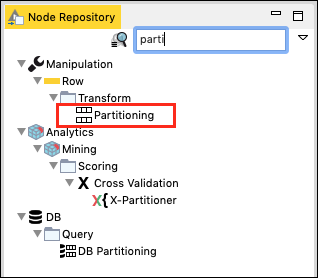
ノードをワークスペースに追加します。その構成を次のように設定します-
Relative (%) : 95
Draw Randomly次のスクリーンショットは、構成パラメーターを示しています。

次に、2つのノードを接続します。これを行うには、の出力をクリックしますFile Reader ノード、マウスボタンをクリックしたままにすると、ラバーバンドラインが表示され、の入力にドラッグします。 Partitioningノードで、マウスボタンを放します。これで、2つのノード間に接続が確立されました。
注釈を追加し、説明を変更し、必要に応じてノードと注釈ビューを配置します。この段階では、画面は次のようになります。

次に、を追加します k-Means ノード。
k-Meansノードの追加
を選択 k-Meansリポジトリからノードを作成し、ワークスペースに追加します。k-Meansアルゴリズムに関する知識を更新したい場合は、ワークベンチの説明ビューでその説明を検索してください。これは下のスクリーンショットに示されています-

ちなみに、どのアルゴリズムを使用するかを最終的に決定する前に、説明ウィンドウでさまざまなアルゴリズムの説明を調べることができます。
ノードの構成ダイアログを開きます。ここに示すように、すべてのフィールドにデフォルトを使用します-

クリック OK デフォルトを受け入れてダイアログを閉じます。
注釈と説明を次のように設定します-
注釈:クラスターを分類する
説明:クラスタリングを実行します
の上部出力を接続します Partitioning の入力へのノード k-Meansノード。アイテムの位置を変更すると、画面は次のようになります。

次に、を追加します Cluster Assigner ノード。
ClusterAssignerの追加
ザ・ Cluster Assigner新しいデータを既存のプロトタイプのセットに割り当てます。プロトタイプモデルと入力データを含むデータテーブルの2つの入力を取ります。以下のスクリーンショットに示されている説明ウィンドウでノードの説明を検索します-

したがって、このノードでは、2つの接続を行う必要があります-
のPMMLクラスターモデル出力 Partitioning ノード→プロトタイプ入力 Cluster Assigner
の2番目のパーティション出力 Partitioning ノード→の入力データ Cluster Assigner
これらの2つの接続は、以下のスクリーンショットに示されています-

ザ・ Cluster Assigner特別な設定は必要ありません。デフォルトを受け入れるだけです。
次に、このノードに注釈と説明を追加します。ノードを再配置します。画面は次のようになります-

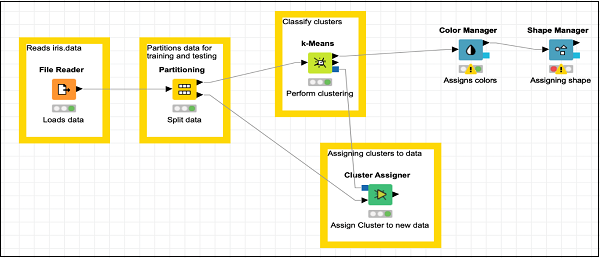
この時点で、クラスタリングは完了です。出力をグラフィカルに視覚化する必要があります。このために、散布図を追加します。散布図では、3つのクラスの色と形状を異なる方法で設定します。したがって、出力をフィルタリングしますk-Means 最初にノードを介して Color Manager ノードを介して Shape Manager ノード。
カラーマネージャーの追加
を見つけます Color Managerリポジトリ内のノード。ワークスペースに追加します。構成はデフォルトのままにします。構成ダイアログを開いて、を押す必要があることに注意してくださいOKデフォルトを受け入れる。ノードの説明テキストを設定します。
の出力から接続します k-Means の入力に Color Manager。この段階での画面は次のようになります-

ShapeManagerの追加
を見つけます Shape Managerリポジトリに入れて、ワークスペースに追加します。構成はデフォルトのままにします。前の例と同様に、構成ダイアログを開いて、OKデフォルトを設定します。の出力から接続を確立しますColor Manager の入力に Shape Manager。ノードの説明を設定します。
画面は次のようになります-
ここで、モデルの最後のノードを追加します。これが散布図です。
散布図の追加
見つける Scatter Plotリポジトリ内のノードを作成し、ワークスペースに追加します。の出力を接続しますShape Manager の入力に Scatter Plot。構成はデフォルトのままにします。説明を設定します。
最後に、最近追加された3つのノードにグループ注釈を追加します
注釈:視覚化
必要に応じてノードを再配置します。この段階では、画面は次のようになります。
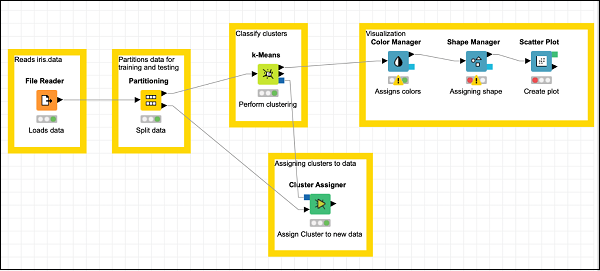
これでモデル構築のタスクは完了です。