KNIME-クイックガイド
機械学習モデルの開発は、その不可解な性質のため、常に非常に困難であると考えられています。一般に、機械学習アプリケーションを開発するには、コマンド駆動型開発の専門知識を持つ優れた開発者である必要があります。KNIMEの導入により、一般人の範囲内で機械学習モデルが開発されました。
KNIMEは、開発全体にグラフィカルインターフェイス(ユーザーフレンドリーなGUI)を提供します。KNIMEでは、リポジトリで提供されるさまざまな定義済みノード間のワークフローを定義するだけです。KNIMEは、データの読み取り、さまざまなMLアルゴリズムの適用、さまざまな形式でのデータの視覚化などのさまざまなタスクのために、ノードと呼ばれるいくつかの事前定義されたコンポーネントを提供します。したがって、KNIMEを使用する場合、プログラミングの知識は必要ありません。これはエキサイティングではありませんか?
このチュートリアルの次の章では、十分にテストされたいくつかのMLアルゴリズムを使用してデータ分析を習得する方法を説明します。
KNIME Analytics Platformは、Windows、Linux、およびMacOSで使用できます。この章では、Macにプラットフォームをインストールする手順を見ていきましょう。WindowsまたはLinuxを使用している場合は、KNIMEダウンロードページに記載されているインストール手順に従ってください。3つのプラットフォームすべてのバイナリインストールは、KNIMEのページで入手できます。
Macのインストール
KNIME公式サイトからバイナリインストールをダウンロードします。ダウンロードしたものをダブルクリックdmgインストールを開始するファイル。インストールが完了したら、ここに示すように、KNIMEアイコンをアプリケーションフォルダにドラッグするだけです-


KNIMEアイコンをダブルクリックして、KNIMEAnalyticsプラットフォームを起動します。最初に、作業を保存するためのワークスペースフォルダを設定するように求められます。画面は次のようになります-
選択したフォルダをデフォルトとして設定できますが、次にKNIMEを起動したときは設定されません。

このダイアログをもう一度表示します。
しばらくすると、KNIMEプラットフォームがデスクトップで起動します。これは、分析作業を行うワークベンチです。ここで、ワークベンチのさまざまな部分を見てみましょう。
KNIMEを起動すると、次の画面が表示されます-

スクリーンショットでマークされているように、ワークベンチはいくつかのビューで構成されています。私たちがすぐに使用できるビューは、スクリーンショットにマークされ、以下にリストされています-
Workspace
Outline
ノードリポジトリ
KNIME Explorer
Console
Description
この章を進めるにあたり、これらのビューをそれぞれ詳細に学習しましょう。
ワークスペースビュー
私たちにとって最も重要な見方は Workspace見る。ここで、機械学習モデルを作成します。以下のスクリーンショットでは、ワークスペースビューが強調表示されています-

スクリーンショットは、開いているワークスペースを示しています。すぐに、既存のワークスペースを開く方法を学びます。
各ワークスペースには、1つ以上のノードが含まれます。これらのノードの重要性については、チュートリアルの後半で学習します。ノードは矢印を使用して接続されます。通常、プログラムフローは左から右に定義されますが、これは必須ではありません。ワークスペース内の任意の場所に各ノードを自由に移動できます。2つの間の接続線は、ノード間の接続を維持するために適切に移動します。ノード間の接続はいつでも追加/削除できます。ノードごとに、オプションで簡単な説明を追加できます。
外形図
ワークスペースビューでは、ワークフロー全体を一度に表示できない場合があります。そのため、外形図を提供しています。

アウトラインビューには、ワークスペース全体のミニチュアビューが表示されます。このビュー内にはズームウィンドウがあり、スライドしてワークフローのさまざまな部分を確認できます。Workspace 見る。
ノードリポジトリ
これは、ワークベンチの次の重要なビューです。ノードリポジトリには、分析に使用できるさまざまなノードが一覧表示されます。リポジトリ全体は、ノードの機能に基づいて適切に分類されています。次のようなカテゴリがあります-
IO
Views
Analytics

各カテゴリの下にいくつかのオプションがあります。各カテゴリビューを展開するだけで、そこにあるものを確認できます。下IO カテゴリには、ARFF、CSV、PMML、XLSなどのさまざまなファイル形式でデータを読み取るノードがあります。

入力ソースデータ形式に応じて、データセットを読み取るための適切なノードを選択します。
この時点で、おそらくノードの目的を理解しているはずです。ノードは、ワークフローに視覚的に含めることができる特定の種類の機能を定義します。
Analyticsノードは、ベイズ、クラスタリング、ディシジョンツリー、アンサンブル学習などのさまざまな機械学習アルゴリズムを定義します。

これらのさまざまなMLアルゴリズムの実装は、これらのノードで提供されます。分析にアルゴリズムを適用するには、リポジトリから目的のノードを選択して、ワークスペースに追加するだけです。データリーダーノードの出力をこのMLノードの入力に接続すると、ワークフローが作成されます。
リポジトリで利用可能なさまざまなノードを調べることをお勧めします。
KNIME Explorer
ワークベンチの次の重要なビューは Explorer 下のスクリーンショットに示すように表示-

最初の2つのカテゴリーは、KNIMEサーバーで定義されたワークスペースをリストします。3番目のオプションLOCALは、ローカルマシンで作成したすべてのワークスペースを保存するために使用されます。これらのタブを展開して、事前定義されたさまざまなワークスペースを確認してください。特に、[例]タブを展開します。
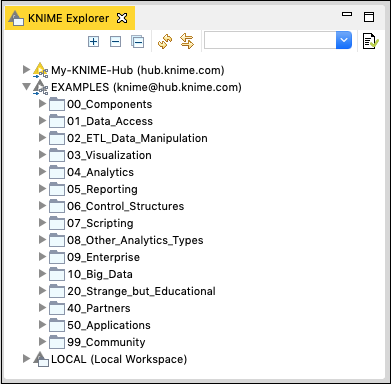
KNIMEは、プラットフォームを使い始めるためのいくつかの例を提供します。次の章では、これらの例の1つを使用して、プラットフォームについて理解します。
コンソールビュー
名前が示すように、 Console viewは、ワークフローの実行中にさまざまなコンソールメッセージのビューを提供します。

ザ・ Console ビューは、ワークフローの診断と分析結果の調査に役立ちます。
説明ビュー
私たちに直接関連する最後の重要な見解は Description見る。このビューは、ワークスペースで選択されたアイテムの説明を提供します。以下のスクリーンショットに典型的なビューを示します-

上のビューは、 File Readerノード。を選択するとFile Readerワークスペースのノードの場合、このビューにその説明が表示されます。他のノードをクリックすると、選択したノードの説明が表示されます。したがって、このビューは、ワークスペース内のさまざまなノードやノードリポジトリの目的が正確にわからない場合に、学習の初期段階で非常に役立ちます。
ツールバー
上記のビューに加えて、ワークベンチにはツールバーなどの他のビューがあります。ツールバーには、クイックアクションを容易にするさまざまなアイコンが含まれています。アイコンは、コンテキストに応じて有効/無効になります。各アイコンにマウスを合わせると、各アイコンが実行するアクションを確認できます。次の画面は、によって実行されたアクションを示していますConfigure アイコン。

ビューの有効化/無効化
これまでに見たさまざまなビューを簡単にオン/オフできます。ビューの閉じるアイコンをクリックすると、close景色。ビューを元に戻すには、に移動しますViewメニューオプションを選択し、目的のビューを選択します。選択したビューがワークベンチに追加されます。

さて、あなたはワークベンチに精通しているので、ワークフローを実行し、それによって実行される分析を研究する方法を紹介します。
KNIMEは、学習を容易にするためのいくつかの優れたワークフローを提供しています。この章では、インストールで提供されるワークフローの1つを取り上げて、分析プラットフォームのさまざまな機能と能力について説明します。に基づく単純な分類器を使用しますDecision Tree 私たちの研究のために。
デシジョンツリー分類子の読み込み
KNIME Explorerで、次のワークフローを見つけます-
LOCAL / Example Workflows / Basic Examples / Building a Simple Classifierこれは、クイックリファレンスとして以下のスクリーンショットにも示されています-

選択したアイテムをダブルクリックして、ワークフローを開きます。ワークスペースビューを確認します。複数のノードを含むワークフローが表示されます。このワークフローの目的は、UCI Machine LearningRepositoryから取得した成人データセットの民主的な属性から収入グループを予測することです。このMLモデルのタスクは、特定の地域の人々を5万人以上または5万人未満の収入があるものとして分類することです。
ザ・ Workspace ビューとその概要を下のスクリーンショットに示します-

からピックアップされたいくつかのノードの存在に注意してください Nodesリポジトリと矢印でワークフローに接続されています。この接続は、あるノードの出力が次のノードの入力に供給されることを示しています。ワークフロー内の各ノードの機能を学習する前に、まずワークフロー全体を実行しましょう。
ワークフローの実行
ワークフローの実行を検討する前に、各ノードのステータスレポートを理解することが重要です。ワークフロー内のノードを調べます。各ノードの下部には、3つの円を含むステータスインジケータがあります。デシジョンツリー学習ノードは、以下のスクリーンショットに示されています-

ステータスインジケータは赤で、このノードがこれまで実行されていないことを示します。実行中、黄色の中央の円が点灯します。正常に実行されると、最後の円が緑色に変わります。エラーが発生した場合にステータス情報を提供するためのインジケーターが他にもあります。処理中にエラーが発生したときにそれらを学習します。
現在、すべてのノードのインジケーターが赤で表示されており、これまでにノードが実行されていないことを示しています。すべてのノードを実行するには、次のメニュー項目をクリックします-
Node → Execute All
しばらくすると、各ノードのステータスインジケータが緑色に変わり、エラーがないことを示します。
次の章では、ワークフロー内のさまざまなノードの機能について説明します。
ワークフローのノードをチェックアウトすると、次のノードが含まれていることがわかります。
ファイルリーダー、
カラーマネージャー
Partitioning
デシジョンツリー学習者
デシジョンツリー予測子
Score
インタラクティブテーブル
散布図
Statistics
これらは簡単に見られます Outline ここに示すように表示-

各ノードは、ワークフローで特定の機能を提供します。次に、必要な機能を満たすようにこれらのノードを構成する方法について説明します。ワークフローを探索する現在のコンテキストで、私たちに関連するノードについてのみ説明することに注意してください。
ファイルリーダー
ファイルリーダーノードは、以下のスクリーンショットに示されています-

ウィンドウの上部には、ワークフローの作成者によって提供された説明があります。これは、このノードがアダルトデータセットを読み取ることを示しています。ファイルの名前はadult.csvノードシンボルの下の説明からわかるように。ザ・File Reader 2つの出力があります-1つはに行きます Color Manager ノードともう1つはに行きます Statistics ノード。
右クリックすると File Manager、ポップアップメニューは次のように表示されます-

ザ・ Configureメニューオプションを使用すると、ノードを構成できます。ザ・Executeメニューはノードを実行します。ノードがすでに実行されていて、緑色の状態にある場合、このメニューは無効になっていることに注意してください。また、の存在に注意してくださいEdit Note Descriptionメニューオプション。これにより、ノードの説明を書き込むことができます。
次に、 Configure メニューオプション、ここのスクリーンショットに見られるように、adult.csvファイルからのデータを含む画面を表示します-

このノードを実行すると、データがメモリにロードされます。データ読み込みプログラムコード全体がユーザーに表示されません。これで、このようなノードの有用性を理解できます。コーディングは必要ありません。
次のノードは Color Manager。
カラーマネージャー
を選択 Color Managerノードを右クリックして構成に入ります。色設定ダイアログが表示されます。を選択income ドロップダウンリストの列。
画面は次のようになります-

2つの制約があることに注意してください。収入が50K未満の場合、データポイントは緑色になり、それ以上の場合は赤色になります。この章の後半で散布図を見ると、データポイントのマッピングがわかります。
パーティショニング
機械学習では、通常、利用可能なデータ全体を2つの部分に分割します。大きい部分はモデルのトレーニングに使用され、小さい部分はテストに使用されます。データの分割に使用されるさまざまな戦略があります。
目的のパーティションを定義するには、を右クリックします。 Partitioning ノードを選択し、 Configureオプション。次の画面が表示されます-

この場合、システムモデラーは Relative(%)モードで、データは80:20の比率で分割されます。分割を実行している間、データポイントはランダムに取得されます。これにより、テストデータに偏りが生じないことが保証されます。線形サンプリングの場合、テストに使用される残りの20%のデータは、収集中に完全に偏っている可能性があるため、トレーニングデータを正しく表していない可能性があります。
データ収集中にランダム性が保証されていることが確実な場合は、線形サンプリングを選択できます。データをモデルのトレーニングの準備ができたら、次のノードにフィードします。Decision Tree Learner。
デシジョンツリー学習者
ザ・ Decision Tree Learner名前が示すように、ノードはトレーニングデータを使用してモデルを構築します。以下のスクリーンショットに示されている、このノードの構成設定を確認してください。

あなたが見るように Class です income。したがって、ツリーは収入列に基づいて構築され、それがこのモデルで達成しようとしていることです。収入が5万人以上または5万人未満の人を分離したいと考えています。
このノードが正常に実行されると、モデルをテストする準備が整います。
デシジョンツリー予測子
デシジョンツリー予測ノードは、開発されたモデルをテストデータセットに適用し、モデル予測を追加します。

予測子の出力は、2つの異なるノードに送られます- Scorer そして Scatter Plot。次に、予測の出力を調べます。
得点者
このノードは、 confusion matrix。表示するには、ノードを右クリックします。次のポップアップメニューが表示されます-

クリック View: Confusion Matrix ここのスクリーンショットに示すように、メニューオプションとマトリックスが別のウィンドウにポップアップ表示されます-
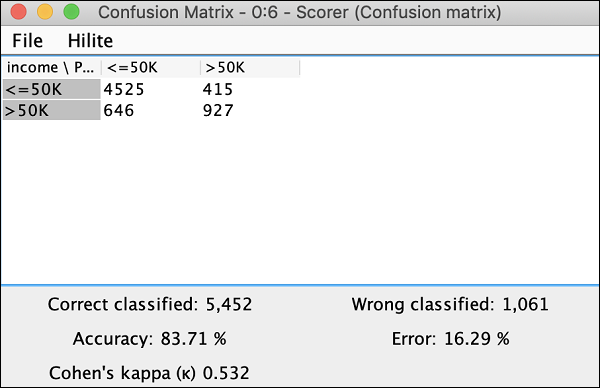
これは、開発したモデルの精度が83.71%であることを示しています。これに満足できない場合は、モデル構築で他のパラメーターを試してみることができます。特に、データを再確認してクレンジングすることができます。
散布図
データ分布の散布図を表示するには、を右クリックします。 Scatter Plot ノードを選択し、メニューオプションを選択します Interactive View: Scatter Plot。次のプロットが表示されます-

プロットは、赤と青の2つの異なる色の点で、50Kのしきい値に基づいて、さまざまな収入グループの人々の分布を示しています。これらは私たちに設定された色でしたColor Managerノード。分布は、x軸にプロットされた年齢を基準にしています。ノードの構成を変更することにより、x軸に別の機能を選択できます。
構成ダイアログがここに表示されます。ここで、 marital-status x軸の機能として。
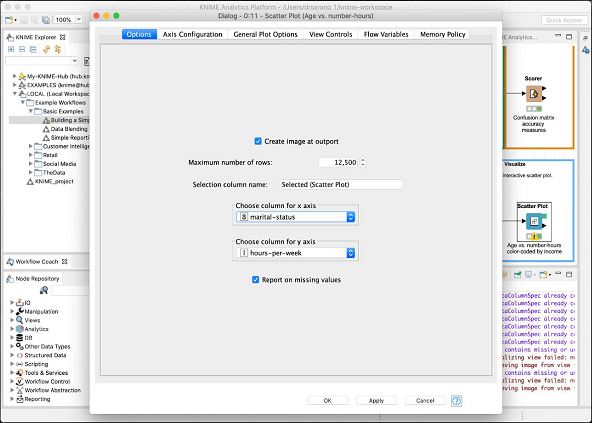
これで、KNIMEが提供する事前定義モデルに関する説明は完了です。自習のために、モデル内の他の2つのノード(統計とインタラクティブテーブル)を使用することをお勧めします。
次に、チュートリアルの最も重要な部分である独自のモデルの作成に移りましょう。
この章では、観察されたいくつかの特徴に基づいて植物を分類するための独自の機械学習モデルを構築します。よく知られているものを使用しますiris からのデータセット UCI Machine Learning Repositoryこの目的のために。データセットには、3つの異なるクラスの植物が含まれています。モデルをトレーニングして、未知の植物をこれら3つのクラスのいずれかに分類します。
機械学習モデルを作成するために、KNIMEで新しいワークフローを作成することから始めます。
ワークフローの作成
新しいワークフローを作成するには、KNIMEワークベンチで次のメニューオプションを選択します。
File → New次の画面が表示されます-

を選択 New KNIME Workflow オプションをクリックし、 Nextボタン。次の画面で、ワークフローの名前と保存先フォルダーの入力を求められます。必要に応じてこの情報を入力し、をクリックしますFinish 新しいワークスペースを作成します。
指定された名前の新しいワークスペースがに追加されます Workspace ここに見られるように見る-
次に、このワークスペースにさまざまなノードを追加して、モデルを作成します。ノードを追加する前に、ダウンロードして準備する必要がありますiris 私たちが使用するデータセット。
データセットの準備
UCI Machine LearningRepositoryサイトからアイリスデータセットをダウンロードします。アイリスデータセットをダウンロードします。ダウンロードしたiris.dataファイルはCSV形式です。列名を追加するために、いくつかの変更を加えます。
ダウンロードしたファイルをお気に入りのテキストエディタで開き、最初に次の行を追加します。
sepal length, petal length, sepal width, petal width, class私たちのとき File Reader ノードはこのファイルを読み取り、上記のフィールドを列名として自動的に取得します。
ここで、さまざまなノードの追加を開始します。
ファイルリーダーの追加
に移動します Node Repository ビューで、検索ボックスに「ファイル」と入力して、 File Readerノード。これは下のスクリーンショットに見られます-

を選択してダブルクリックします File Readerノードをワークスペースに追加します。または、ドラッグアンドドロップ機能を使用してノードをワークスペースに追加することもできます。ノードを追加したら、ノードを構成する必要があります。ノードを右クリックして、Configureメニューオプション。これは前のレッスンで行いました。
データファイルを読み込んだ後の設定画面は次のようになります。

データセットを読み込むには、をクリックします Browseボタンをクリックして、iris.dataファイルの場所を選択します。ノードは、構成ボックスの下部に表示されているファイルの内容をロードします。データファイルが適切に配置されて読み込まれたことを確認したら、をクリックします。OK ボタンをクリックして、構成ダイアログを閉じます。
ここで、このノードに注釈を追加します。ノードを右クリックして、New Workflow Annotationメニューオプション。次のスクリーンショットに示すように、注釈ボックスが画面に表示されます。
ボックス内をクリックして、次の注釈を追加します-
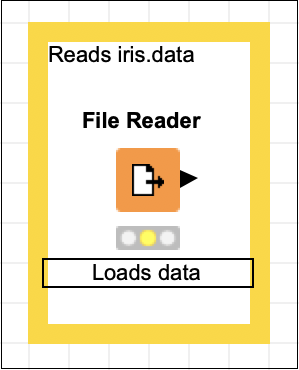
Reads iris.dataボックスの外側をクリックして、編集モードを終了します。必要に応じて、ボックスのサイズを変更し、ノードの周囲に配置します。最後に、をダブルクリックしますNode 1 この文字列を次のように変更するためのノードの下のテキスト-
Loads dataこの時点で、画面は次のようになります-
ロードしたデータセットをトレーニングとテストに分割するための新しいノードを追加します。
パーティショニングノードの追加
の中に Node Repository 検索ウィンドウで、数文字を入力して Partitioning 以下のスクリーンショットに見られるように、ノード-
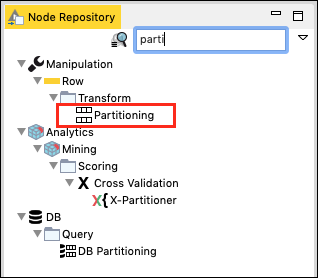
ノードをワークスペースに追加します。その構成を次のように設定します-
Relative (%) : 95
Draw Randomly次のスクリーンショットは、構成パラメーターを示しています。

次に、2つのノードを接続します。これを行うには、の出力をクリックしますFile Reader ノード、マウスボタンをクリックしたままにすると、ラバーバンドラインが表示され、の入力にドラッグします。 Partitioningノードで、マウスボタンを放します。これで、2つのノード間に接続が確立されました。
注釈を追加し、説明を変更し、必要に応じてノードと注釈ビューを配置します。この段階では、画面は次のようになります。

次に、を追加します k-Means ノード。
k-Meansノードの追加
を選択 k-Meansリポジトリからノードを作成し、ワークスペースに追加します。k-Meansアルゴリズムに関する知識を更新したい場合は、ワークベンチの説明ビューでその説明を検索してください。これは下のスクリーンショットに示されています-

ちなみに、どのアルゴリズムを使用するかを最終的に決定する前に、説明ウィンドウでさまざまなアルゴリズムの説明を調べることができます。
ノードの構成ダイアログを開きます。ここに示すように、すべてのフィールドにデフォルトを使用します-

クリック OK デフォルトを受け入れてダイアログを閉じます。
注釈と説明を次のように設定します-
注釈:クラスターを分類する
説明:クラスタリングを実行します
の上部出力を接続します Partitioning の入力へのノード k-Meansノード。アイテムの位置を変更すると、画面は次のようになります。

次に、を追加します Cluster Assigner ノード。
ClusterAssignerの追加
ザ・ Cluster Assigner新しいデータを既存のプロトタイプのセットに割り当てます。プロトタイプモデルと入力データを含むデータテーブルの2つの入力を取ります。以下のスクリーンショットに示されている説明ウィンドウでノードの説明を検索します-

したがって、このノードでは、2つの接続を行う必要があります-
のPMMLクラスターモデル出力 Partitioning ノード→プロトタイプ入力 Cluster Assigner
の2番目のパーティション出力 Partitioning ノード→の入力データ Cluster Assigner
これらの2つの接続は、以下のスクリーンショットに示されています-

ザ・ Cluster Assigner特別な設定は必要ありません。デフォルトを受け入れるだけです。
次に、このノードに注釈と説明を追加します。ノードを再配置します。画面は次のようになります-

この時点で、クラスタリングは完了です。出力をグラフィカルに視覚化する必要があります。このために、散布図を追加します。散布図では、3つのクラスの色と形状を異なる方法で設定します。したがって、出力をフィルタリングしますk-Means 最初にノードを介して Color Manager ノードを介して Shape Manager ノード。
カラーマネージャーの追加
を見つけます Color Managerリポジトリ内のノード。ワークスペースに追加します。構成はデフォルトのままにします。構成ダイアログを開いて、を押す必要があることに注意してくださいOKデフォルトを受け入れる。ノードの説明テキストを設定します。
の出力から接続します k-Means の入力に Color Manager。この段階での画面は次のようになります-

ShapeManagerの追加
を見つけます Shape Managerリポジトリに入れて、ワークスペースに追加します。構成はデフォルトのままにします。前の例と同様に、構成ダイアログを開いて、OKデフォルトを設定します。の出力から接続を確立しますColor Manager の入力に Shape Manager。ノードの説明を設定します。
画面は次のようになります-
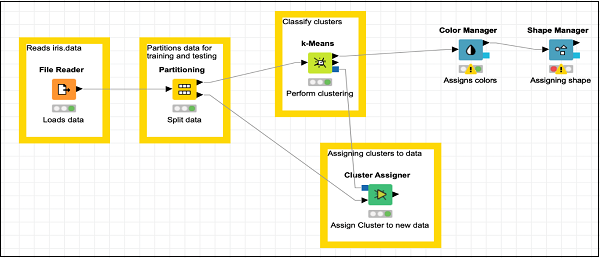
ここで、モデルの最後のノードを追加します。これが散布図です。
散布図の追加
見つける Scatter Plotリポジトリ内のノードを作成し、ワークスペースに追加します。の出力を接続しますShape Manager の入力に Scatter Plot。構成はデフォルトのままにします。説明を設定します。
最後に、最近追加された3つのノードにグループ注釈を追加します
注釈:視覚化
必要に応じてノードを再配置します。この段階では、画面は次のようになります。
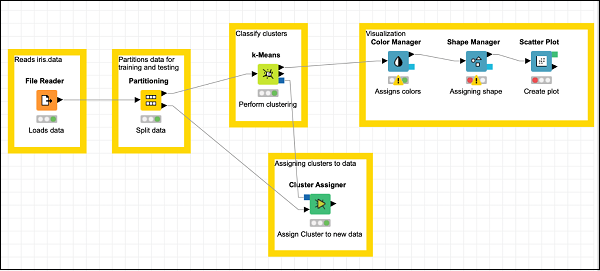
これでモデル構築のタスクは完了です。
モデルをテストするには、次のメニューオプションを実行します。 Node → Execute All
すべてが正常に行われると、各ノードの下部にあるステータス信号が緑色に変わります。そうでない場合は、検索する必要がありますConsole エラーを表示して修正し、ワークフローを再実行します。
これで、モデルの予測出力を視覚化する準備が整いました。これを行うには、右クリックしますScatter Plot ノードを選択し、次のメニューオプションを選択します。 Interactive View: Scatter Plot
これは下のスクリーンショットに示されています-

ここに示すように、画面に散布図が表示されます-

x軸とy軸を変更することで、さまざまな視覚化を実行できます。これを行うには、散布図の右上隅にある設定メニューをクリックします。以下のスクリーンショットに示すように、ポップアップメニューが表示されます-

この画面でプロットのさまざまなパラメータを設定して、いくつかの側面からデータを視覚化できます。
これで、モデル構築のタスクは完了です。
KNIMEは、機械学習モデルを構築するためのグラフィカルツールを提供します。このチュートリアルでは、KNIMEをマシンにダウンロードしてインストールする方法を学びました。
概要
KNIMEワークベンチで提供されるさまざまなビューを学習しました。KNIMEは、学習のためにいくつかの事前定義されたワークフローを提供します。そのようなワークフローの1つを使用して、KNIMEの機能を学習しました。KNIMEは、さまざまな形式でデータを読み取り、いくつかのMLアルゴリズムを使用してデータを分析し、最終的にさまざまな方法でデータを視覚化するための、事前にプログラムされたノードをいくつか提供します。チュートリアルの終わりに向けて、最初から独自のモデルを作成しました。よく知られているアイリスデータセットを使用して、k-Meansアルゴリズムを使用して植物を分類しました。
これで、これらの手法を独自の分析に使用する準備が整いました。
今後の作業
開発者であり、プログラミングアプリケーションでKNIMEコンポーネントを使用したい場合は、KNIMEがJava、R、Pythonなどのさまざまなプログラミング言語とネイティブに統合されていることを知っていただければ幸いです。