Pythonでのロジスティック回帰-データの取得
この章では、Pythonでロジスティック回帰を実行するためのデータの取得に関連する手順について詳しく説明します。
データセットのダウンロード
前述のUCIデータセットをまだダウンロードしていない場合は、ここから今すぐダウンロードしてください。データフォルダをクリックします。次の画面が表示されます-

指定されたリンクをクリックして、bank.zipファイルをダウンロードします。zipファイルには次のファイルが含まれています-

モデル開発にはbank.csvファイルを使用します。bank-names.txtファイルには、後で必要になるデータベースの説明が含まれています。bank-full.csvには、より高度な開発に使用できるはるかに大きなデータセットが含まれています。
ここでは、bank.csvファイルをダウンロード可能なソースzipに含めています。このファイルには、コンマ区切りのフィールドが含まれています。また、ファイルにいくつかの変更を加えました。学習には、プロジェクトのソースzipに含まれているファイルを使用することをお勧めします。
データのロード
コピーしたcsvファイルからデータを読み込むには、次のステートメントを入力してコードを実行します。
In [2]: df = pd.read_csv('bank.csv', header=0)次のコードステートメントを実行して、ロードされたデータを調べることもできます-
IN [3]: df.head()コマンドを実行すると、次の出力が表示されます-
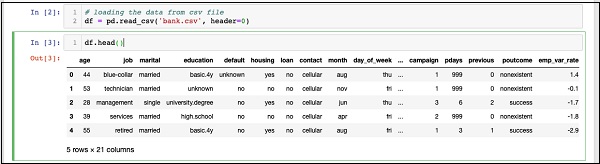
基本的に、ロードされたデータの最初の5行を印刷しました。存在する21列を調べます。モデル開発には、これらのいくつかの列のみを使用します。
次に、データをクリーンアップする必要があります。データには、NaN。このような行を削除するには、次のコマンドを使用します-
IN [4]: df = df.dropna()幸い、bank.csvにはNaNを含む行が含まれていないため、この手順はこの場合は実際には必要ありません。ただし、一般に、巨大なデータベースでそのような行を見つけることは困難です。したがって、上記のステートメントを実行してデータをクリーンアップする方が常に安全です。
Note −次のステートメントを使用すると、いつでもデータサイズを簡単に調べることができます。
IN [5]: print (df.shape)
(41188, 21)上記の2行目に示すように、行と列の数が出力に出力されます。
次に行うことは、構築しようとしているモデルに対する各列の適合性を調べることです。