Pythonでのロジスティック回帰-クイックガイド
ロジスティック回帰は、オブジェクトを分類する統計的方法です。この章では、いくつかの例を使用してロジスティック回帰を紹介します。
分類
ロジスティック回帰を理解するには、分類の意味を知っておく必要があります。これをよりよく理解するために、次の例を考えてみましょう-
- 医師は腫瘍を悪性または良性に分類します。
- 銀行取引は詐欺的または本物である可能性があります。
何年もの間、人間はそのようなタスクを実行してきました-それらはエラーが発生しやすいですが。問題は、これらのタスクをより正確に実行するようにマシンをトレーニングできるかどうかです。
分類を行うマシンのそのような例の1つは、電子メールです。 Clientすべての受信メールを「スパム」または「非スパム」として分類するマシン上で、かなり高い精度でそれを行います。ロジスティック回帰の統計的手法は、電子メールクライアントに正常に適用されています。この場合、分類の問題を解決するためにマシンをトレーニングしました。
ロジスティック回帰は、この種の二項分類問題を解決するために使用される機械学習のほんの一部です。すでに開発され、他の種類の問題を解決するために実際に使用されている他のいくつかの機械学習手法があります。
上記のすべての例で、予測の結果には2つの値(YesまたはNo)しかありません。これらをクラスと呼びます。つまり、分類子はオブジェクトを2つのクラスに分類します。技術的には、結果またはターゲット変数は本質的に二分法であると言えます。
出力が3つ以上のクラスに分類される可能性がある他の分類問題があります。たとえば、果物がいっぱい入ったバスケットがある場合、さまざまな種類の果物を分けるように求められます。現在、バスケットにはオレンジ、リンゴ、マンゴーなどが含まれている可能性があります。したがって、果物を分離するときは、3つ以上のクラスに分けます。これは多変量分類の問題です。
ある銀行が、定期預金(一部の銀行では定期預金とも呼ばれます)を開く可能性のあるクライアントを特定するのに役立つ機械学習アプリケーションを開発するようにあなたにアプローチするとします。銀行は、潜在的な顧客に関する情報を収集するために、電話またはWebフォームを使用して定期的に調査を実施しています。調査は本質的に一般的なものであり、非常に多くの聴衆を対象に実施されており、その多くはこの銀行自体との取引に興味がない可能性があります。残りのうち、定期預金の開設に関心があるのはごくわずかです。他の人は銀行が提供する他の施設に興味があるかもしれません。したがって、調査は必ずしもTDを開く顧客を特定するために実施されるわけではありません。あなたの仕事は、銀行があなたと共有しようとしている膨大な調査データから、TDを開く可能性が高いすべての顧客を特定することです。
幸いなことに、そのような種類のデータの1つは、機械学習モデルの開発を目指す人々のために公開されています。このデータは、カリフォルニア大学アーバイン校の一部の学生が外部資金で作成したものです。データベースはの一部として利用可能ですUCI Machine Learning Repositoryまた、世界中の学生、教育者、研究者によって広く使用されています。データはこちらからダウンロードできます。
次の章では、同じデータを使用してアプリケーション開発を実行しましょう。
この章では、Pythonでロジスティック回帰を実行するプロジェクトの設定に関連するプロセスについて詳しく説明します。
Jupyterのインストール
機械学習で最も広く使用されているプラットフォームの1つであるJupyterを使用します。マシンにJupyterがインストールされていない場合は、ここからダウンロードしてください。インストールについては、彼らのサイトの指示に従ってプラットフォームをインストールできます。サイトが示唆するように、あなたは使用することを好むかもしれませんAnaconda Distributionこれは、Pythonと、科学計算およびデータサイエンスに一般的に使用される多くのPythonパッケージに付属しています。これにより、これらのパッケージを個別にインストールする必要がなくなります。
Jupyterのインストールが正常に完了したら、新しいプロジェクトを開始します。この段階の画面は、コードを受け入れる準備ができた次のようになります。
ここで、プロジェクトの名前をから変更します Untitled1 to “Logistic Regression” タイトル名をクリックして編集します。
まず、コードで必要となるいくつかのPythonパッケージをインポートします。
Pythonパッケージのインポート
この目的のために、コードエディタで次のコードを入力またはカットアンドペーストします-
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split君の Notebook この段階では次のようになります-
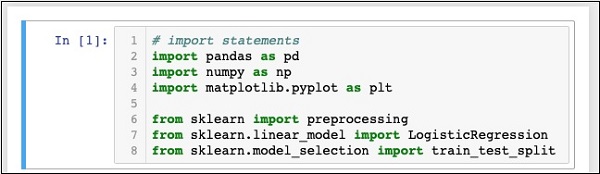
をクリックしてコードを実行します Runボタン。エラーが生成されない場合は、Jupyterが正常にインストールされており、残りの開発の準備ができています。
最初の3つのimportステートメントは、プロジェクトのpandas、numpy、およびmatplotlib.pyplotパッケージをインポートします。次の3つのステートメントは、指定されたモジュールをsklearnからインポートします。
次のタスクは、プロジェクトに必要なデータをダウンロードすることです。これについては、次の章で学習します。
この章では、Pythonでロジスティック回帰を実行するためのデータの取得に関連する手順について詳しく説明します。
データセットのダウンロード
前述のUCIデータセットをまだダウンロードしていない場合は、ここから今すぐダウンロードしてください。データフォルダをクリックします。次の画面が表示されます-

指定されたリンクをクリックして、bank.zipファイルをダウンロードします。zipファイルには次のファイルが含まれています-

モデル開発にはbank.csvファイルを使用します。bank-names.txtファイルには、後で必要になるデータベースの説明が含まれています。bank-full.csvには、より高度な開発に使用できるはるかに大きなデータセットが含まれています。
ここでは、bank.csvファイルをダウンロード可能なソースzipに含めています。このファイルには、コンマ区切りのフィールドが含まれています。また、ファイルにいくつかの変更を加えました。学習には、プロジェクトのソースzipに含まれているファイルを使用することをお勧めします。
データのロード
コピーしたcsvファイルからデータを読み込むには、次のステートメントを入力してコードを実行します。
In [2]: df = pd.read_csv('bank.csv', header=0)次のコードステートメントを実行して、ロードされたデータを調べることもできます-
IN [3]: df.head()コマンドを実行すると、次の出力が表示されます-
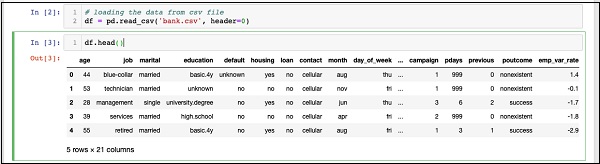
基本的に、ロードされたデータの最初の5行を印刷しました。存在する21列を調べます。モデル開発には、これらのいくつかの列のみを使用します。
次に、データをクリーンアップする必要があります。データには、NaN。このような行を削除するには、次のコマンドを使用します-
IN [4]: df = df.dropna()幸い、bank.csvにはNaNを含む行が含まれていないため、この手順はこの場合は実際には必要ありません。ただし、一般に、巨大なデータベースでそのような行を見つけることは困難です。したがって、上記のステートメントを実行してデータをクリーンアップする方が常に安全です。
Note −次のステートメントを使用すると、いつでもデータサイズを簡単に調べることができます。
IN [5]: print (df.shape)
(41188, 21)上記の2行目に示すように、行と列の数が出力に出力されます。
次に行うことは、構築しようとしているモデルに対する各列の適合性を調べることです。
組織が調査を実施するときはいつでも、顧客からできるだけ多くの情報を収集しようとします。この情報は、後で組織にとって何らかの形で役立つと考えています。現在の問題を解決するには、問題に直接関連する情報を収集する必要があります。
すべてのフィールドの表示
それでは、私たちに役立つデータフィールドを選択する方法を見てみましょう。コードエディタで次のステートメントを実行します。
In [6]: print(list(df.columns))次の出力が表示されます-
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan',
'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx',
'euribor3m', 'nr_employed', 'y']出力には、データベース内のすべての列の名前が表示されます。最後の列「y」は、この顧客が銀行に定期預金を持っているかどうかを示すブール値です。このフィールドの値は「y」または「n」のいずれかです。データの一部としてダウンロードされたbanks-name.txtファイルの各列の説明と目的を読むことができます。
不要なフィールドの排除
列名を調べると、一部のフィールドが目前の問題にとって重要ではないことがわかります。たとえば、month, day_of_week、キャンペーンなどは私たちには役に立たない。これらのフィールドをデータベースから削除します。列をドロップするには、以下に示すようにdropコマンドを使用します-
In [8]: #drop columns which are not needed.
df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]],
axis = 1, inplace = True)このコマンドは、列番号0、3、7、8などを削除することを示しています。インデックスが正しく選択されていることを確認するには、次のステートメントを使用します-
In [7]: df.columns[9]
Out[7]: 'day_of_week'これにより、指定されたインデックスの列名が出力されます。
不要な列を削除した後、headステートメントでデータを調べます。画面出力はここに示されています-
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1現在、データの分析と予測に重要と思われる分野しかありません。の重要性Data Scientistこの段階で思い浮かびます。データサイエンティストは、モデル構築に適切な列を選択する必要があります。
たとえば、 job一見、データベースに含めるようにすべての人を納得させることはできないかもしれませんが、それは非常に有用な分野になります。すべてのタイプの顧客がTDを開くわけではありません。低所得者はTDを開かないかもしれませんが、高所得者は通常、余剰金をTDに預けます。したがって、このシナリオでは、ジョブのタイプが非常に重要になります。同様に、分析に関連すると思われる列を慎重に選択してください。
次の章では、モデルを構築するためのデータを準備します。
分類器を作成するには、分類器構築モジュールから要求される形式でデータを準備する必要があります。を行うことでデータを準備しますOne Hot Encoding。
データのエンコード
データのエンコードとはどういう意味かについて簡単に説明します。まず、コードを実行しましょう。コードウィンドウで次のコマンドを実行します。
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])コメントが言うように、上記のステートメントはデータの1つのホットエンコーディングを作成します。それが何を生み出したのか見てみましょう。と呼ばれる作成されたデータを調べます“data” データベースにヘッドレコードを印刷する。
In [11]: data.head()次の出力が表示されます-
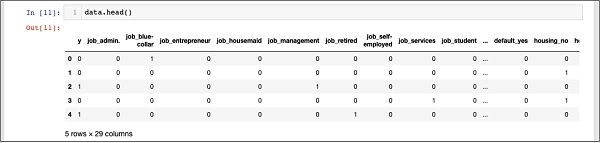
上記のデータを理解するために、を実行して列名をリストします。 data.columns 以下に示すコマンド-
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')ここで、1つのホットエンコーディングがどのように行われるかを説明します。 get_dummiesコマンド。新しく生成されたデータベースの最初の列は、このクライアントがTDにサブスクライブしているかどうかを示す「y」フィールドです。それでは、エンコードされている列を見てみましょう。最初にエンコードされた列は“job”。データベースでは、「job」列に「admin」、「blue-collar」、「entrepreneur」などの多くの可能な値が含まれていることがわかります。可能な値ごとに、データベースに新しい列が作成され、列名がプレフィックスとして追加されます。
したがって、「job_admin」、「job_blue-collar」などの列があります。元のデータベースのエンコードされたフィールドごとに、作成されたデータベースに追加された列のリストと、その列が元のデータベースで取る可能性のあるすべての値が表示されます。列のリストを注意深く調べて、データが新しいデータベースにどのようにマップされるかを理解します。
データマッピングを理解する
生成されたデータを理解するために、dataコマンドを使用してデータ全体を印刷してみましょう。コマンド実行後の部分出力を以下に示します。
In [13]: data
上の画面は最初の12行を示しています。さらに下にスクロールすると、すべての行に対してマッピングが行われていることがわかります。
クイックリファレンスとして、データベースのさらに下にある画面出力の一部をここに示します。
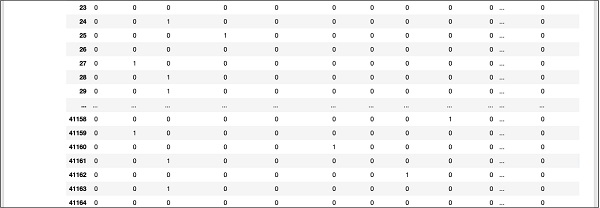
マップされたデータを理解するために、最初の行を調べてみましょう。

「y」フィールドの値で示されているように、この顧客はTDにサブスクライブしていないことを示しています。また、この顧客が「ブルーカラー」の顧客であることも示しています。水平方向に下にスクロールすると、彼には「住宅」があり、「ローン」を受け取っていないことがわかります。
この1つのホットエンコーディングの後、モデルの構築を開始する前に、さらにデータ処理が必要です。
「不明」を削除する
マップされたデータベースの列を調べると、「不明」で終わる列がいくつか存在することがわかります。たとえば、スクリーンショットに示されている次のコマンドを使用して、インデックス12の列を調べます。
In [14]: data.columns[12]
Out[14]: 'job_unknown'これは、指定された顧客のジョブが不明であることを示しています。明らかに、そのような列を分析とモデル構築に含めることには意味がありません。したがって、「不明」の値を持つすべての列を削除する必要があります。これは、次のコマンドで実行されます-
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)正しい列番号を指定していることを確認してください。疑わしい場合は、前述のように、columnsコマンドでインデックスを指定することにより、いつでも列名を調べることができます。
不要な列を削除した後、以下の出力に示すように、列の最終リストを調べることができます-
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')この時点で、データはモデル構築の準備ができています。
約4万1000の奇妙な記録があります。データ全体をモデル構築に使用する場合、テスト用のデータは残りません。したがって、一般的に、データセット全体を2つの部分、たとえば70/30パーセントに分割します。データの70%をモデル構築に使用し、残りを作成したモデルの予測の精度をテストするために使用します。要件に応じて、異なる分割比率を使用できます。
フィーチャ配列の作成
データを分割する前に、データを2つの配列XとYに分割します。X配列には分析するすべての特徴(データ列)が含まれ、Y配列はブール値の1次元配列であり、予測。これを理解するために、いくつかのコードを実行してみましょう。
まず、次のPythonステートメントを実行してX配列を作成します-
In [17]: X = data.iloc[:,1:]の内容を調べるには X 使用する headいくつかの初期レコードを印刷します。次の画面は、X配列の内容を示しています。
In [18]: X.head ()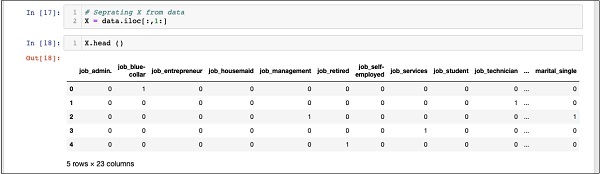
配列にはいくつかの行と23列があります。
次に、「」を含む出力配列を作成します。y」の値。
出力配列の作成
予測値列の配列を作成するには、次のPythonステートメントを使用します-
In [19]: Y = data.iloc[:,0]を呼び出してその内容を調べます head。以下の画面出力は結果を示しています-
In [20]: Y.head()
Out[20]: 0 0
1 0
2 1
3 0
4 1
Name: y, dtype: int64ここで、次のコマンドを使用してデータを分割します-
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)これにより、という4つの配列が作成されます X_train, Y_train, X_test, and Y_test。以前と同様に、headコマンドを使用してこれらの配列の内容を調べることができます。モデルのトレーニングにはX_train配列とY_train配列を使用し、テストと検証にはX_test配列とY_test配列を使用します。
これで、分類器を作成する準備が整いました。次の章でそれを調べます。
分類子を最初から作成する必要はありません。分類器の構築は複雑であり、統計、確率論、最適化手法などのいくつかの分野の知識が必要です。これらの分類子の完全にテストされた非常に効率的な実装を備えた、いくつかの構築済みライブラリが市場で入手可能です。からそのような構築済みモデルの1つを使用しますsklearn。
sklearn分類子
sklearnツールキットからロジスティック回帰分類子を作成するのは簡単で、ここに示すように単一のプログラムステートメントで実行されます-
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)分類器が作成されたら、トレーニングデータを分類器にフィードして、内部パラメーターを調整し、将来のデータの予測に備えることができるようにします。分類器を調整するには、次のステートメントを実行します-
In [23]: classifier.fit(X_train, Y_train)これで、分類器をテストする準備が整いました。次のコードは、上記の2つのステートメントの実行の出力です-
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2', random_state=0,
solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))これで、作成した分類子をテストする準備が整いました。これについては次の章で扱います。
上記で作成した分類子を本番環境で使用する前にテストする必要があります。テストの結果、モデルが目的の精度を満たしていないことが判明した場合は、上記のプロセスに戻り、別の機能セット(データフィールド)を選択して、モデルを再構築し、テストする必要があります。これは、分類子が目的の精度の要件を満たすまでの反復ステップになります。それでは、分類器をテストしましょう。
テストデータの予測
分類器をテストするには、前の段階で生成されたテストデータを使用します。私たちはpredict 作成されたオブジェクトのメソッドを渡し、 X 次のコマンドに示すようなテストデータの配列-
In [24]: predicted_y = classifier.predict(X_test)これにより、トレーニングデータセット全体に対して1次元配列が生成され、X配列の各行の予測が得られます。次のコマンドを使用して、この配列を調べることができます-
In [25]: predicted_y以下は、上記の2つのコマンドを実行したときの出力です。
Out[25]: array([0, 0, 0, ..., 0, 0, 0])出力は、最初と最後の3人の顧客が候補者ではないことを示しています。 Term Deposit。アレイ全体を調べて、潜在的な顧客を分類できます。これを行うには、次のPythonコードスニペットを使用します-
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")上記のコードを実行した結果を以下に示します-

出力には、TDにサブスクライブする可能性のあるすべての行のインデックスが表示されます。これで、この出力を銀行のマーケティングチームに渡して、選択した行の各顧客の連絡先の詳細を取得し、仕事を進めることができます。
このモデルを本番環境に導入する前に、予測の精度を検証する必要があります。
精度の検証
モデルの精度をテストするには、以下に示すように分類器でスコア法を使用します。
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))このコマンドを実行したときの画面出力を以下に示します。
Accuracy: 0.90これは、モデルの精度が90%であることを示しています。これは、ほとんどのアプリケーションで非常に優れていると考えられています。したがって、それ以上の調整は必要ありません。これで、お客様は次のキャンペーンを実行し、潜在的なお客様のリストを取得して、高い成功率でTDを開くためにそれらを追跡する準備が整いました。
上記の例からわかるように、機械学習にロジスティック回帰を適用することは難しい作業ではありません。ただし、独自の制限があります。ロジスティック回帰では、多数のカテゴリカル機能を処理できなくなります。これまでに説明した例では、機能の数を大幅に減らしました。
ただし、これらの機能が予測で重要である場合は、それらを含めることを余儀なくされますが、ロジスティック回帰では十分な精度が得られません。ロジスティック回帰も過剰適合に対して脆弱です。非線形問題には適用できません。ターゲットに相関しておらず、相互に相関している独立変数ではパフォーマンスが低下します。したがって、解決しようとしている問題に対するロジスティック回帰の適合性を慎重に評価する必要があります。
機械学習には、他の手法が考案された多くの分野があります。いくつか例を挙げると、k最近傍法(kNN)、線形回帰、サポートベクターマシン(SVM)、決定木、ナイーブベイズなどのアルゴリズムがあります。特定のモデルを完成させる前に、私たちが解決しようとしている問題に対するこれらのさまざまな手法の適用可能性を評価する必要があります。
ロジスティック回帰は、二項分類の統計的手法です。このチュートリアルでは、ロジスティック回帰を使用するようにマシンをトレーニングする方法を学習しました。機械学習モデルを作成する場合、最も重要な要件はデータの可用性です。適切で関連性のあるデータがなければ、単に機械に学習させることはできません。
データを取得したら、次の主要なタスクは、データをクレンジングして不要な行やフィールドを削除し、モデル開発に適切なフィールドを選択することです。これが完了したら、データを分類器がトレーニングに必要な形式にマッピングする必要があります。したがって、データの準備は、あらゆる機械学習アプリケーションの主要なタスクです。データの準備ができたら、特定のタイプの分類子を選択できます。
このチュートリアルでは、で提供されているロジスティック回帰分類器の使用方法を学習しました。 sklearn図書館。分類器をトレーニングするために、モデルのトレーニングにデータの約70%を使用します。残りのデータはテストに使用します。モデルの精度をテストします。これが許容範囲内にない場合は、新しい機能セットの選択に戻ります。
繰り返しになりますが、データを準備するプロセス全体に従い、モデルをトレーニングして、精度に満足するまでテストします。機械学習プロジェクトに取り組む前に、これまでに開発され、業界で成功裏に適用されているさまざまな技術を学び、それらに触れる必要があります。