Pythonでのロジスティック回帰-データの準備
分類器を作成するには、分類器構築モジュールから要求される形式でデータを準備する必要があります。を行うことでデータを準備しますOne Hot Encoding。
データのエンコード
データのエンコードとはどういう意味かについて簡単に説明します。まず、コードを実行しましょう。コードウィンドウで次のコマンドを実行します。
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])コメントが言うように、上記のステートメントはデータの1つのホットエンコーディングを作成します。それが何を生み出したのか見てみましょう。と呼ばれる作成されたデータを調べます“data” データベースにヘッドレコードを印刷する。
In [11]: data.head()次の出力が表示されます-
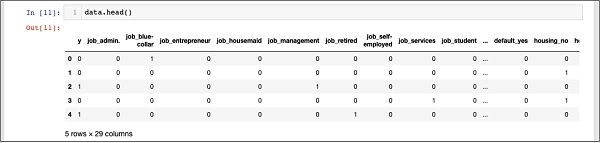
上記のデータを理解するために、を実行して列名をリストします。 data.columns 以下に示すコマンド-
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')ここで、1つのホットエンコーディングがどのように行われるかを説明します。 get_dummiesコマンド。新しく生成されたデータベースの最初の列は、このクライアントがTDにサブスクライブしているかどうかを示す「y」フィールドです。それでは、エンコードされている列を見てみましょう。最初にエンコードされた列は“job”。データベースでは、「job」列に「admin」、「blue-collar」、「entrepreneur」などの多くの可能な値が含まれていることがわかります。可能な値ごとに、データベースに新しい列が作成され、列名がプレフィックスとして追加されます。
したがって、「job_admin」、「job_blue-collar」などの列があります。元のデータベースのエンコードされたフィールドごとに、作成されたデータベースに追加された列のリストと、その列が元のデータベースで取る可能性のあるすべての値が表示されます。列のリストを注意深く調べて、データが新しいデータベースにどのようにマップされるかを理解します。
データマッピングを理解する
生成されたデータを理解するために、dataコマンドを使用してデータ全体を印刷してみましょう。コマンド実行後の部分出力を以下に示します。
In [13]: data
上の画面は最初の12行を示しています。さらに下にスクロールすると、すべての行に対してマッピングが行われていることがわかります。
クイックリファレンスとして、データベースのさらに下にある画面出力の一部をここに示します。
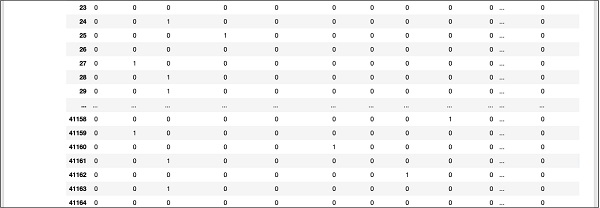
マップされたデータを理解するために、最初の行を調べてみましょう。

「y」フィールドの値で示されているように、この顧客はTDにサブスクライブしていないことを示しています。また、この顧客が「ブルーカラー」の顧客であることも示しています。水平方向に下にスクロールすると、彼には「住宅」があり、「ローン」を受け取っていないことがわかります。
この1つのホットエンコーディングの後、モデルの構築を開始する前に、さらにデータ処理が必要です。
「不明」を削除する
マップされたデータベースの列を調べると、「不明」で終わる列がいくつか存在することがわかります。たとえば、スクリーンショットに示されている次のコマンドを使用して、インデックス12の列を調べます。
In [14]: data.columns[12]
Out[14]: 'job_unknown'これは、指定された顧客のジョブが不明であることを示しています。明らかに、そのような列を分析とモデル構築に含めることには意味がありません。したがって、「不明」の値を持つすべての列を削除する必要があります。これは、次のコマンドで実行されます-
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)正しい列番号を指定していることを確認してください。疑わしい場合は、前述のように、columnsコマンドでインデックスを指定することにより、いつでも列名を調べることができます。
不要な列を削除した後、以下の出力に示すように、列の最終リストを調べることができます-
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')この時点で、データはモデル構築の準備ができています。