計算グラフ
バックプロパゲーションは、計算グラフを使用して、Tensorflow、Torch、Theanoなどのディープラーニングフレームワークに実装されます。さらに重要なことに、計算グラフでのバックプロパゲーションを理解するには、いくつかの異なるアルゴリズムと、時間の経過に伴うバックプロパゲーションや共有の重みを持つバックプロパゲーションなどのバリエーションを組み合わせます。すべてが計算グラフに変換された後も、それらは同じアルゴリズムであり、計算グラフでのバックプロパゲーションだけです。
計算グラフとは
計算グラフは、ノードが数学演算に対応する有向グラフとして定義されます。計算グラフは、数式を表現および評価する方法です。
たとえば、ここに簡単な数式があります-
$$ p = x + y $$
上記の式の計算グラフは次のように描くことができます。
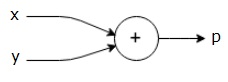
上記の計算グラフには、2つの入力変数xとyと1つの出力qを持つ加算ノード(「+」記号の付いたノード)があります。
もう少し複雑な例を見てみましょう。次の式があります。
$$ g = \ left(x + y \ right)\ ast z $$
上記の式は、次の計算グラフで表されます。
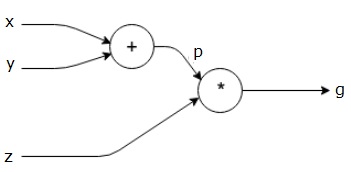
計算グラフとバックプロパゲーション
計算グラフとバックプロパゲーションはどちらも、ニューラルネットワークをトレーニングするための深層学習における重要なコアコンセプトです。
フォワードパス
フォワードパスは、計算グラフで表される数式の値を評価するための手順です。フォワードパスを実行するということは、変数からの値を、出力がある左(入力)から右に順方向に渡すことを意味します。
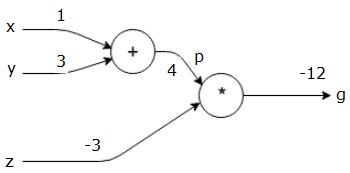
すべての入力に何らかの値を与えることによる例を考えてみましょう。次の値がすべての入力に与えられていると仮定します。
$$ x = 1、y = 3、z = −3 $$
これらの値を入力に与えることにより、フォワードパスを実行し、各ノードの出力に対して次の値を取得できます。
まず、x = 1およびy = 3の値を使用して、p = 4を取得します。

次に、p = 4およびz = -3を使用して、g = -12を取得します。左から右へ、前方へ。
バックワードパスの目的
バックワードパスでは、最終出力に対する各入力の勾配を計算することを目的としています。これらの勾配は、勾配降下法を使用してニューラルネットワークをトレーニングするために不可欠です。
たとえば、次の勾配が必要です。
必要なグラデーション
$$ \ frac {\ partial x} {\ partial f}、\ frac {\ partial y} {\ partial f}、\ frac {\ partial z} {\ partial f} $$
バックワードパス(バックプロパゲーション)
最終出力(それ自体!)に対する最終出力の導関数を見つけることによって、後方パスを開始します。したがって、IDが派生し、値は1になります。
$$ \ frac {\ partial g} {\ partial g} = 1 $$
計算グラフは次のようになります-
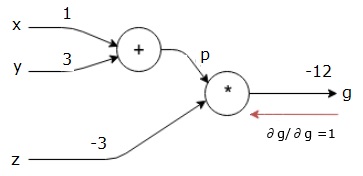
次に、「*」操作を逆方向に通過させます。pとzでの勾配を計算します。g = p * zなので、次のことがわかります。
$$ \ frac {\ partial g} {\ partial z} = p $$
$$ \ frac {\ partial g} {\ partial p} = z $$
フォワードパスからzとpの値はすでにわかっています。したがって、次のようになります。
$$ \ frac {\ partial g} {\ partial z} = p = 4 $$
そして
$$ \ frac {\ partial g} {\ partial p} = z = -3 $$
xとy−での勾配を計算したい
$$ \ frac {\ partial g} {\ partial x}、\ frac {\ partial g} {\ partial y} $$
ただし、これを効率的に実行したいと考えています(このグラフでは、xとgは2ホップしか離れていませんが、互いに実際に離れていると想像してください)。これらの値を効率的に計算するために、微分の連鎖律を使用します。連鎖律から、次のようになります。
$$ \ frac {\ partial g} {\ partial x} = \ frac {\ partial g} {\ partial p} \ ast \ frac {\ partial p} {\ partial x} $$
$$ \ frac {\ partial g} {\ partial y} = \ frac {\ partial g} {\ partial p} \ ast \ frac {\ partial p} {\ partial y} $$
しかし、pはxとyに直接依存するため、dg / dp = -3、dp / dxおよびdp / dyは簡単であることはすでにわかっています。私たちは-
$$ p = x + y \ Rightarrow \ frac {\ partial x} {\ partial p} = 1、\ frac {\ partial y} {\ partial p} = 1 $$
したがって、次のようになります。
$$ \ frac {\ partial g} {\ partial f} = \ frac {\ partial g} {\ partial p} \ ast \ frac {\ partial p} {\ partial x} = \ left(-3 \ right) .1 = -3 $$
さらに、入力y −
$$ \ frac {\ partial g} {\ partial y} = \ frac {\ partial g} {\ partial p} \ ast \ frac {\ partial p} {\ partial y} = \ left(-3 \ right) .1 = -3 $$
これを逆方向に行う主な理由は、xで勾配を計算する必要がある場合、すでに計算された値とdq / dx(同じノードの入力に関するノード出力の導関数)のみを使用したためです。ローカル情報を使用してグローバル値を計算しました。
ニューラルネットワークをトレーニングするための手順
次の手順に従って、ニューラルネットワークをトレーニングします-
データセット内のデータポイントxについて、xを入力としてフォワードパスを実行し、コストcを出力として計算します。
cからバックワードパスを実行し、グラフ内のすべてのノードの勾配を計算します。これには、ニューラルネットワークの重みを表すノードが含まれます。
次に、W = W-学習率*勾配を実行して重みを更新します。
停止基準が満たされるまで、このプロセスを繰り返します。