Pythonディープラーニング-クイックガイド
ディープラーニングまたは階層学習またはディープラーニングは、それ自体が人工知能のより広い分野のサブセットである機械学習手法のファミリーの一部です。
深層学習は、特徴抽出と変換に非線形処理ユニットの複数のレイヤーを使用する機械学習アルゴリズムのクラスです。連続する各レイヤーは、前のレイヤーからの出力を入力として使用します。
ディープニューラルネットワーク、ディープビリーフネットワーク、リカレントニューラルネットワークは、コンピュータービジョン、音声認識、自然言語処理、音声認識、ソーシャルネットワークフィルタリング、機械翻訳、バイオインフォマティクスなどの分野に適用されており、場合によっては同等の結果が得られています。人間の専門家よりも優れています。
深層学習アルゴリズムとネットワーク-
データの複数レベルの特徴または表現の教師なし学習に基づいています。上位レベルの機能は、下位レベルの機能から派生して階層表現を形成します。
トレーニングには、ある種の勾配降下法を使用します。
この章では、Pythonディープラーニング用に設定された環境について学習します。深層学習アルゴリズムを作成するには、次のソフトウェアをインストールする必要があります。
- Python 2.7+
- NumpyのScipy
- Matplotlib
- Theano
- Keras
- TensorFlow
Python、NumPy、SciPy、およびMatplotlibをAnacondaディストリビューションからインストールすることを強くお勧めします。これらすべてのパッケージが付属しています。
さまざまな種類のソフトウェアが正しくインストールされていることを確認する必要があります。
コマンドラインプログラムに移動して、次のコマンドを入力します-
$ python
Python 3.6.3 |Anaconda custom (32-bit)| (default, Oct 13 2017, 14:21:34)
[GCC 7.2.0] on linux次に、必要なライブラリをインポートして、それらのバージョンを印刷できます-
import numpy
print numpy.__version__出力
1.14.2Theano、TensorFlow、Kerasのインストール
パッケージ(Theano、TensorFlow、Keras)のインストールを開始する前に、次のことを確認する必要があります。 pipがインストールされています。Anacondaのパッケージ管理システムはpipと呼ばれます。
pipのインストールを確認するには、コマンドラインに次のように入力します-
$ pippipのインストールが確認されたら、次のコマンドを実行してTensorFlowとKerasをインストールできます-
$pip install theano $pip install tensorflow
$pip install keras次のコード行を実行して、Theanoのインストールを確認します-
$python –c “import theano: print (theano.__version__)”出力
1.0.1次のコード行を実行して、Tensorflowのインストールを確認します-
$python –c “import tensorflow: print tensorflow.__version__”出力
1.7.0次のコード行を実行して、Kerasのインストールを確認します-
$python –c “import keras: print keras.__version__”
Using TensorFlow backend出力
2.1.5人工知能(AI)は、コンピューターが人間の認知行動または知能を模倣できるようにするコード、アルゴリズム、または手法です。機械学習(ML)は、統計的手法を使用して機械が経験に基づいて学習および改善できるようにするAIのサブセットです。ディープラーニングは機械学習のサブセットであり、多層ニューラルネットワークの計算を可能にします。機械学習は浅い学習と見なされ、深層学習は抽象化された階層的な学習と見なされます。
機械学習は幅広い概念を扱います。コンセプトは以下のとおりです-
- supervised
- unsupervised
- 強化学習
- 線形回帰
- コスト関数
- overfitting
- under-fitting
- ハイパーパラメータなど。
教師あり学習では、ラベル付けされたデータから値を予測することを学びます。ここで役立つML手法の1つは分類です。ここで、ターゲット値は離散値です。たとえば、猫と犬。役立つ可能性のある機械学習のもう1つの手法は、回帰です。回帰はターゲット値で機能します。目標値は連続値です。たとえば、株式市場のデータは回帰を使用して分析できます。
教師なし学習では、ラベル付けも構造化もされていない入力データから推論を行います。100万件の医療記録があり、それを理解し、基礎となる構造、外れ値を見つけたり、異常を検出したりする必要がある場合は、クラスタリング手法を使用してデータを幅広いクラスターに分割します。
データセットは、トレーニングセット、テストセット、検証セットなどに分けられます。
2012年の突破口は、ディープラーニングの概念を際立たせました。アルゴリズムは、2つのGPUとビッグデータなどの最新テクノロジーを使用して、100万枚の画像を1000のカテゴリに分類しました。
ディープラーニングと従来の機械学習の関連付け
従来の機械学習モデルで遭遇する主要な課題の1つは、特徴抽出と呼ばれるプロセスです。プログラマーは具体的であり、コンピューターに注意すべき機能を伝える必要があります。これらの機能は、意思決定に役立ちます。
生データをアルゴリズムに入力することはめったに機能しないため、特徴抽出は従来の機械学習ワークフローの重要な部分です。
これはプログラマーに大きな責任を負わせ、アルゴリズムの効率はプログラマーがいかに独創的であるかに大きく依存します。オブジェクト認識や手書き認識などの複雑な問題の場合、これは大きな問題です。
表現の複数のレイヤーを学習する機能を備えたディープラーニングは、自動特徴抽出に役立つ数少ない方法の1つです。下位層は自動特徴抽出を実行していると見なすことができ、プログラマーからのガイダンスはほとんどまたはまったく必要ありません。
人工ニューラルネットワーク、または単にニューラルネットワークは新しいアイデアではありません。それは約80年前からあります。
ディープニューラルネットワークが新しい技術の使用、膨大なデータセットの可用性、強力なコンピューターで普及したのは2011年のことでした。
ニューラルネットワークは、樹状突起、核、軸索、および終末軸索を持つニューロンを模倣します。
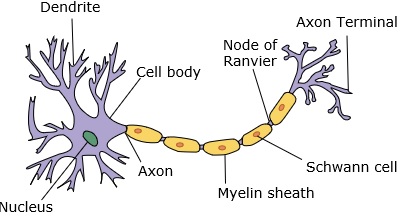
ネットワークの場合、2つのニューロンが必要です。これらのニューロンは、ある樹状突起と別の樹状突起の間のシナプスを介して情報を転送します。
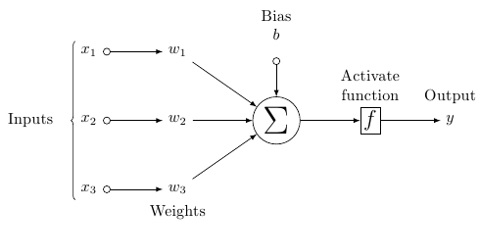
人工ニューロンの可能性のあるモデルは次のようになります-
ニューラルネットワークは次のようになります-
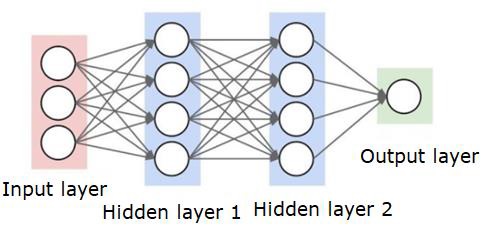
円はニューロンまたはノードであり、データ上のそれらの機能とそれらを接続する線/エッジは、渡される重み/情報です。
各列はレイヤーです。データの最初のレイヤーは入力レイヤーです。次に、入力レイヤーと出力レイヤーの間のすべてのレイヤーが非表示レイヤーになります。
1つまたはいくつかの隠れ層がある場合は、浅いニューラルネットワークがあります。隠れ層がたくさんある場合は、ディープニューラルネットワークがあります。
このモデルでは、入力データがあり、それを重み付けして、しきい値関数または活性化関数と呼ばれるニューロンの関数に渡します。
基本的には、特定の値と比較した後のすべての値の合計です。信号を発する場合、結果は(1)アウト、または何も発火されない場合、(0)になります。次に、それが重み付けされて次のニューロンに渡され、同じ種類の関数が実行されます。
活性化関数としてシグモイド(S字型)関数を持つことができます。
重みに関しては、開始はランダムであり、ノード/ニューロンへの入力ごとに一意です。
最も基本的なタイプのニューラルネットワークである典型的な「フィードフォワード」では、作成したネットワークを介して情報を直接通過させ、出力をサンプルデータを使用して期待したものと比較します。
ここから、出力を目的の出力に一致させるために重みを調整する必要があります。
ニューラルネットワークを介して直接データを送信する行為は、 feed forward neural network.
データは、入力からレイヤー、順番に、そして出力に送られます。
後方に戻って、損失/コストを最小限に抑えるために重みを調整し始めると、これは back propagation.
これは optimization problem. ニューラルネットワークでは、実際には、数十万、または数百万、またはそれ以上の変数を処理する必要があります。
最初の解決策は、最適化手法として確率的勾配降下法を使用することでした。現在、AdaGrad、AdamOptimizerなどのオプションがあります。いずれにせよ、これは大規模な計算操作です。そのため、ニューラルネットワークは半世紀以上にわたってほとんど棚に置かれていました。これらの操作の実行を検討するためのパワーとアーキテクチャ、およびそれに合わせて適切なサイズのデータセットがマシンに搭載されたのはごく最近のことです。
単純な分類タスクの場合、ニューラルネットワークのパフォーマンスはK最近傍法などの他の単純なアルゴリズムに比較的近いです。ニューラルネットワークの真の有用性は、はるかに大きなデータとはるかに複雑な質問があり、どちらも他の機械学習モデルよりも優れている場合に実現されます。
ディープニューラルネットワーク(DNN)は、入力層と出力層の間に複数の隠れ層があるANNです。浅いANNと同様に、DNNは複雑な非線形関係をモデル化できます。
ニューラルネットワークの主な目的は、一連の入力を受け取り、それらに対して徐々に複雑な計算を実行し、分類などの現実世界の問題を解決するために出力を提供することです。ニューラルネットワークをフィードフォワードするように制限します。
ディープネットワークには、入力、出力、およびシーケンシャルデータのフローがあります。
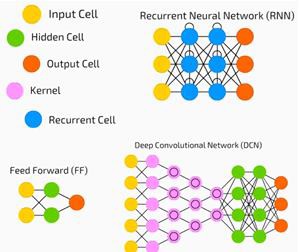
ニューラルネットワークは、教師あり学習と強化学習の問題で広く使用されています。これらのネットワークは、相互に接続された一連のレイヤーに基づいています。
深層学習では、ほとんどが非線形である隠れ層の数が多くなる可能性があります。約1000層と言います。
DLモデルは、通常のMLネットワークよりもはるかに優れた結果を生成します。
ネットワークを最適化し、損失関数を最小化するために、主に勾配降下法を使用します。
使用できます Imagenet、データセットを猫や犬などのカテゴリに分類するための数百万のデジタル画像のリポジトリ。DLネットは、静的画像以外の動的画像や、時系列およびテキスト分析にますます使用されています。
データセットのトレーニングは、ディープラーニングモデルの重要な部分を形成します。さらに、バックプロパゲーションはDLモデルのトレーニングにおける主要なアルゴリズムです。
DLは、複雑な入出力変換を使用した大規模なニューラルネットワークのトレーニングを扱います。
DLの1つの例は、ソーシャルネットワークで行うように、写真を写真内の人物の名前にマッピングすることです。フレーズを使用して写真を記述することは、DLのもう1つの最近のアプリケーションです。
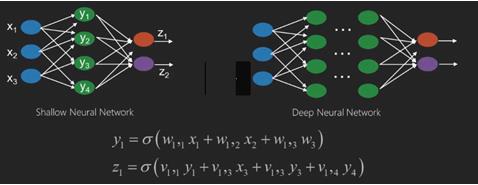
ニューラルネットワークは、x1、x2、x3などの入力を持つ関数であり、2つ(浅いネットワーク)またはレイヤー(ディープネットワーク)とも呼ばれるいくつかの中間操作でz1、z2、z3などの出力に変換されます。
重みとバイアスはレイヤーごとに異なります。「w」と「v」は、ニューラルネットワークの層の重みまたはシナプスです。
深層学習の最良の使用例は、教師あり学習の問題です。ここでは、必要な出力のセットを備えた大量のデータ入力のセットがあります。
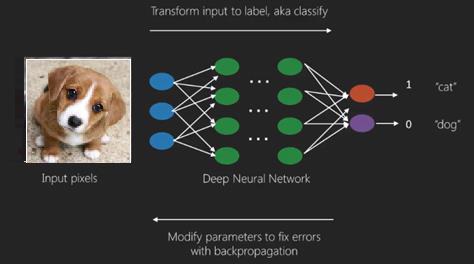
ここでは、バックプロパゲーションアルゴリズムを適用して、正しい出力予測を取得します。
ディープラーニングの最も基本的なデータセットは、手書き数字のデータセットであるMNISTです。
このデータセットから手書き数字の画像を分類するために、Kerasを使用して畳み込みニューラルネットワークを深くトレーニングできます。
ニューラルネット分類器の起動またはアクティブ化により、スコアが生成されます。たとえば、患者を病気と健康に分類するために、身長、体重、体温、血圧などのパラメータを考慮します。
高いスコアは患者が病気であることを意味し、低いスコアは彼が健康であることを意味します。
出力層と非表示層の各ノードには、独自の分類子があります。入力レイヤーは入力を受け取り、そのスコアを次の非表示レイヤーに渡してさらにアクティブ化します。これは、出力に到達するまで続きます。
この入力から出力への左から右への順方向の進行は、 forward propagation.
ニューラルネットワークのクレジット割り当てパス(CAP)は、入力から出力までの一連の変換です。CAPは、入力と出力の間の考えられる因果関係を詳しく説明します。
特定のフィードフォワードニューラルネットワークのCAP深度、またはCAP深度は、隠れ層の数に出力層が含まれるため1を加えたものです。信号がレイヤーを数回伝播する可能性があるリカレントニューラルネットワークの場合、CAPの深さは潜在的に無制限になる可能性があります。
深いネットと浅いネット
浅い学習と深い学習を分ける明確な深さのしきい値はありません。ただし、複数の非線形層を持つ深層学習の場合、CAPは2より大きくなければならないことにほとんど同意しています。
ニューラルネットの基本ノードは、生物学的ニューラルネットワークのニューロンを模倣した知覚です。次に、多層知覚またはMLPがあります。入力の各セットは、重みとバイアスのセットによって変更されます。各エッジには固有の重みがあり、各ノードには固有のバイアスがあります。
予測 accuracy ニューラルネットの weights and biases.
ニューラルネットワークの精度を向上させるプロセスは、 training. フォワードプロペラネットからの出力は、正しいことがわかっている値と比較されます。
ザ・ cost function or the loss function 生成された出力と実際の出力の差です。
トレーニングのポイントは、数百万のトレーニング例にわたってトレーニングのコストを可能な限り小さくすることです。これを行うために、ネットワークは、予測が正しい出力と一致するまで、重みとバイアスを微調整します。
よく訓練されると、ニューラルネットは毎回正確な予測を行う可能性があります。
パターンが複雑になり、コンピューターに認識させたい場合は、ニューラルネットワークを使用する必要があります。このような複雑なパターンのシナリオでは、ニューラルネットワークは他のすべての競合アルゴリズムよりも優れています。
これまで以上に高速にトレーニングできるGPUが登場しました。ディープニューラルネットワークはすでにAIの分野に革命をもたらしています
コンピューターは、繰り返し計算を実行し、詳細な指示に従うのは得意であることが証明されていますが、複雑なパターンを認識するのはそれほど得意ではありません。
単純なパターンの認識に問題がある場合は、サポートベクターマシン(svm)またはロジスティック回帰分類器でうまく機能しますが、パターンの複雑さが増すにつれて、ディープニューラルネットワークを使用する以外に方法はありません。
したがって、人間の顔のような複雑なパターンの場合、浅いニューラルネットワークは失敗し、より多くの層を持つ深いニューラルネットワークを選択する以外に選択肢はありません。ディープネットは、複雑なパターンをより単純なパターンに分解することで、その役割を果たします。たとえば、人間の顔。アディープネットは、エッジを使用して唇、鼻、目、耳などの部分を検出し、これらを再結合して人間の顔を形成します
正しい予測の精度が非常に正確になったため、最近のGoogleパターン認識チャレンジでは、深いネットが人間を打ち負かしました。
層状パーセプトロンのウェブのこのアイデアは、しばらく前から存在しています。この領域では、深い網が人間の脳を模倣しています。しかし、これの1つの欠点は、トレーニングに時間がかかることです。これはハードウェアの制約です。
ただし、最近の高性能GPUは、このようなディープネットを1週間以内にトレーニングすることができました。高速CPUは、同じことを行うのに数週間またはおそらく数か月かかる可能性があります。
ディープネットの選択
ディープネットの選び方は?分類器を構築するのか、データ内のパターンを見つけようとするのか、教師なし学習を使用するのかを決定する必要があります。ラベルのないデータのセットからパターンを抽出するには、制限付きボルツマンマシンまたはオートエンコーダーを使用します。
ディープネットを選択する際は、以下の点を考慮してください。
テキスト処理、感情分析、構文解析、および名前エンティティの認識には、リカレントネットまたは再帰型ニューラルテンソルネットワークまたはRNTNを使用します。
文字レベルで動作する言語モデルには、リカレントネットを使用します。
画像認識には、ディープビリーフネットワークDBNまたは畳み込みネットワークを使用します。
オブジェクト認識には、RNTNまたは畳み込みネットワークを使用します。
音声認識には、リカレントネットを使用します。
一般に、ディープビリーフネットワークと正規化線形ユニットまたはRELUを備えた多層パーセプトロンはどちらも分類に適しています。
時系列分析では、リカレントネットを使用することを常にお勧めします。
ニューラルネットは50年以上前から存在しています。しかし、今だけ彼らは目立つようになりました。その理由は、彼らが訓練するのが難しいからです。バックプロパゲーションと呼ばれる方法でトレーニングしようとすると、勾配の消失または爆発と呼ばれる問題が発生します。その場合、トレーニングに時間がかかり、精度が後回しになります。データセットをトレーニングするとき、ラベル付けされたトレーニングデータのセットからの予測出力と実際の出力の差であるコスト関数を常に計算しています。コスト関数は、重みとバイアス値を最小値まで調整することによって最小化されます。が得られます。トレーニングプロセスでは、勾配を使用します。これは、重みまたはバイアス値の変化に対してコストが変化する速度です。
制限付きボルツマンネットワークまたはオートエンコーダ-RBN
2006年には、勾配消失問題への取り組みにおいて画期的な成果が達成されました。ジェフヒントンは、の開発につながる新しい戦略を考案しましたRestricted Boltzman Machine - RBM、浅い2層ネット。
最初のレイヤーは visible レイヤーと2番目のレイヤーは hidden層。可視層の各ノードは、非表示層のすべてのノードに接続されています。同じレイヤー内の2つのレイヤーが接続を共有できないため、ネットワークは制限付きと呼ばれます。
オートエンコーダは、入力データをベクトルとしてエンコードするネットワークです。それらは、生データの非表示または圧縮された表現を作成します。ベクトルは次元削減に役立ちます。ベクトルは、生データを少数の重要な次元に圧縮します。オートエンコーダーはデコーダーとペアになっており、非表示の表現に基づいて入力データを再構築できます。
RBMは、双方向トランスレータと数学的に同等です。フォワードパスは入力を受け取り、それらを入力をエンコードする一連の数値に変換します。一方、バックワードパスは、この数値のセットを取得し、それらを再構築された入力に変換し直します。よく訓練されたネットは、高い精度でバックプロップを実行します。
どちらのステップでも、重みとバイアスが重要な役割を果たします。これらは、RBMが入力間の相互関係をデコードし、パターンの検出に不可欠な入力を決定するのに役立ちます。順方向パスと逆方向パスを介して、RBMは、入力とその構築が可能な限り近くなるまで、異なる重みとバイアスで入力を再構築するようにトレーニングされます。RBMの興味深い側面は、データにラベルを付ける必要がないことです。これは、写真、ビデオ、音声、センサーデータなど、ラベルが付けられていない傾向のある実際のデータセットにとって非常に重要であることがわかります。RBMは、人間が手動でデータにラベルを付ける代わりに、データを自動的に並べ替えます。重みとバイアスを適切に調整することにより、RBMは重要な特徴を抽出し、入力を再構築することができます。RBMは、データの固有のパターンを認識するように設計された特徴抽出ニューラルネットのファミリーの一部です。これらは、独自の構造をエンコードする必要があるため、オートエンコーダとも呼ばれます。

ディープビリーフネットワーク-DBN
ディープビリーフネットワーク(DBN)は、RBMを組み合わせ、巧妙なトレーニング方法を導入することによって形成されます。勾配消失の問題を最終的に解決する新しいモデルがあります。ジェフリーヒントンは、バックプロパゲーションの代わりにRBMとディープビリーフネットを発明しました。
DBNは、構造がMLP(多層パーセプトロン)に似ていますが、トレーニングに関しては非常に異なります。DBNが浅い対応物よりも優れたパフォーマンスを発揮できるようにするのはトレーニングです
DBNは、RBMのスタックとして視覚化できます。ここで、1つのRBMの非表示層は、その上のRBMの可視層です。最初のRBMは、入力を可能な限り正確に再構築するようにトレーニングされています。
最初のRBMの隠れ層は、2番目のRBMの可視層と見なされ、2番目のRBMは、最初のRBMからの出力を使用してトレーニングされます。このプロセスは、ネットワーク内のすべてのレイヤーがトレーニングされるまで繰り返されます。
DBNでは、各RBMが入力全体を学習します。DBNは、カメラのレンズがゆっくりと画像の焦点を合わせるようにモデルがゆっくりと改善されるため、入力全体を連続して微調整することでグローバルに機能します。多層パーセプトロンMLPは単一のパーセプトロンよりも優れているため、RBMのスタックは単一のRBMよりも優れています。
この段階で、RBMはデータに固有のパターンを検出しましたが、名前やラベルはありません。DBNのトレーニングを終了するには、パターンにラベルを導入し、教師あり学習でネットを微調整する必要があります。
特徴とパターンを名前に関連付けることができるように、ラベル付けされたサンプルの非常に小さなセットが必要です。この小さなラベルの付いたデータセットは、トレーニングに使用されます。このラベル付きデータのセットは、元のデータセットと比較すると非常に小さい場合があります。
重みとバイアスがわずかに変更されるため、ネットのパターンの認識がわずかに変化し、多くの場合、全体の精度がわずかに向上します。
GPUを使用することで、浅いネットと比較して非常に正確な結果が得られるため、トレーニングを妥当な時間で完了することもできます。勾配消失問題の解決策もあります。
生成的敵対的ネットワーク-GAN
生成的敵対的ネットワークは、2つのネットで構成される深いニューラルネットであり、一方が他方にピットインしているため、「敵対的」という名前が付けられています。
GANは、2014年にモントリオール大学の研究者によって発表された論文で紹介されました。FacebookのAI専門家であるYann LeCunは、GANについて言及し、敵対的トレーニングを「MLでの過去10年間で最も興味深いアイデア」と呼びました。
ネットワークスキャンはデータの分布を模倣することを学ぶため、GANの可能性は非常に大きいです。GANは、画像、音楽、スピーチ、散文など、あらゆるドメインで私たちと非常によく似た並列世界を作成するように教えることができます。彼らはある意味ロボットアーティストであり、彼らのアウトプットは非常に印象的です。
GANでは、ジェネレーターと呼ばれる1つのニューラルネットワークが新しいデータインスタンスを生成し、もう1つのニューラルネットワークであるディスクリミネーターがそれらの真正性を評価します。
実世界から取得したMNISTデータセットにあるような手書きの数字を生成しようとしているとしましょう。真のMNISTデータセットからのインスタンスが表示された場合、ディスクリミネーターの役割は、それらを本物として認識することです。
ここで、GANの次の手順を検討してください-
ジェネレータネットワークは、乱数の形式で入力を受け取り、画像を返します。
この生成された画像は、実際のデータセットから取得された画像のストリームとともに、ディスクリミネーターネットワークへの入力として提供されます。
弁別器は、実際の画像と偽の画像の両方を取り込んで、0から1までの数値の確率を返します。1は真正性の予測を表し、0は偽の画像を表します。
したがって、二重フィードバックループがあります-
弁別器は、私たちが知っている画像のグラウンドトゥルースとのフィードバックループにあります。
ジェネレータは、ディスクリミネータとのフィードバックループにあります。
リカレントニューラルネットワーク-RNN
RNNデータが任意の方向に流れることができる希少なニューラルネットワーク。これらのネットワークは、言語モデリングや自然言語処理(NLP)などのアプリケーションに使用されます。
RNNの基礎となる基本的な概念は、シーケンシャル情報を利用することです。通常のニューラルネットワークでは、すべての入力と出力が互いに独立していると想定されています。文中の次の単語を予測したい場合は、その前にある単語を知る必要があります。
RNNは、シーケンスのすべての要素に対して同じタスクを繰り返し、出力が前の計算に基づいているため、リカレントと呼ばれます。したがって、RNNは、以前に計算されたものに関する情報をキャプチャする「メモリ」を備えていると言えます。理論的には、RNNは非常に長いシーケンスで情報を使用できますが、実際には、数ステップしか振り返ることができません。
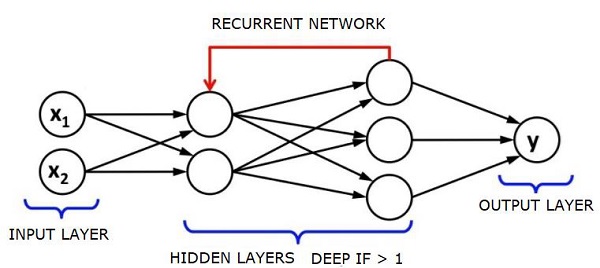
長期短期記憶ネットワーク(LSTM)は、最も一般的に使用されるRNNです。
畳み込みニューラルネットワークとともに、RNNは、ラベルのない画像の説明を生成するためのモデルの一部として使用されてきました。これがどれほどうまく機能しているように見えるかは非常に驚くべきことです。
畳み込みディープニューラルネットワーク-CNN
ニューラルネットワークの層数を増やして深くすると、ネットワークの複雑さが増し、より複雑な関数をモデル化できるようになります。ただし、重みとバイアスの数は指数関数的に増加します。実際のところ、このような難しい問題を学習することは、通常のニューラルネットワークでは不可能になる可能性があります。これは、解決策である畳み込みニューラルネットワークにつながります。
CNNは、コンピュータービジョンで広く使用されています。自動音声認識の音響モデリングにも適用されています。
畳み込みニューラルネットワークの背後にある考え方は、画像を通過する「移動フィルター」の考え方です。この移動フィルター、つまり畳み込みは、ノードの特定の近傍に適用されます。たとえば、ピクセルの場合、適用されるフィルターはノード値の0.5倍です。
著名な研究者であるヤン・ルカンは、畳み込みニューラルネットワークを開拓しました。顔認識ソフトウェアとしてのFacebookはこれらのネットを使用しています。CNNは、マシンビジョンプロジェクトのソリューションになりました。畳み込みネットワークには多くの層があります。Imagenetチャレンジでは、2015年に機械が物体認識で人間を打ち負かすことができました。
一言で言えば、畳み込みニューラルネットワーク(CNN)は多層ニューラルネットワークです。レイヤーは最大17以上の場合があり、入力データを画像と見なします。
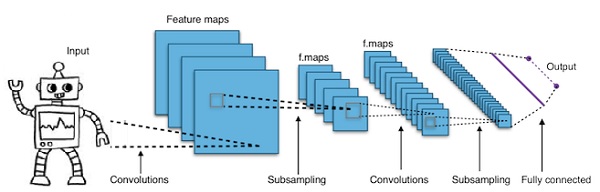
CNNは、調整が必要なパラメーターの数を大幅に削減します。そのため、CNNは生画像の高次元性を効率的に処理します。
この章では、Pythonディープラーニングの基礎について説明します。
ディープラーニングモデル/アルゴリズム
ここで、さまざまな深層学習モデル/アルゴリズムについて学習しましょう。
ディープラーニングで人気のあるモデルのいくつかは次のとおりです-
- 畳み込みニューラルネットワーク
- リカレントニューラルネットワーク
- ディープビリーフネットワーク
- 生成的敵対的ネットワーク
- オートエンコーダなど
入力と出力は、ベクトルまたはテンソルとして表されます。たとえば、ニューラルネットワークには、画像内の個々のピクセルRGB値がベクトルとして表される入力が含まれる場合があります。
入力層と出力層の間にあるニューロンの層は、隠れ層と呼ばれます。これは、ニューラルネットが問題を解決しようとするときにほとんどの作業が行われる場所です。隠れ層を詳しく見ると、ネットワークがデータから抽出することを学習した機能について多くのことが明らかになります。
ニューラルネットワークのさまざまなアーキテクチャは、次の層の他のニューロンに接続するニューロンを選択することによって形成されます。
出力を計算するための擬似コード
以下は、の出力を計算するための擬似コードです。 Forward-propagating Neural Network −
- #node []:=トポロジカルソートされたノードの配列
- #aからbへのエッジは、aがbの左側にあることを意味します
- #ニューラルネットワークにR入力とS出力がある場合、
- #次に、最初のRノードが入力ノードで、最後のSノードが出力ノードです。
- #incoming [x]:=ノードxに接続されたノード
- #weight [x]:= xへの入力エッジの重み
各ニューロンxについて、左から右へ-
- x <= Rの場合:何もしない#その入力ノード
- 入力[x] = [入力[x]のiの出力[i]]
- weighted_sum = dot_product(weights [x]、inputs [x])
- output [x] = Activation_function(weighted_sum)
次に、ニューラルネットワークをトレーニングする方法を学習します。また、Pythonディープラーニングでバックプロパゲーションアルゴリズムとバックワードパスについても学習します。
目的の出力を得るには、ニューラルネットワークの重みの最適値を見つける必要があります。ニューラルネットワークをトレーニングするには、反復勾配降下法を使用します。最初に、重みのランダムな初期化から始めます。ランダムな初期化の後、順伝播プロセスを使用してデータのサブセットを予測し、対応するコスト関数Cを計算し、各重みwをdC / dwに比例する量で更新します。つまり、コスト関数の導関数を重量。比例定数は学習率として知られています。
勾配は、バックプロパゲーションアルゴリズムを使用して効率的に計算できます。後方伝搬または後方プロップの重要な観察は、微分の連鎖律のために、ニューラルネットワークの各ニューロンでの勾配はニューロンでの勾配を使用して計算できることです。したがって、勾配を逆方向に計算します。つまり、最初に出力レイヤーの勾配を計算し、次に最上位の非表示レイヤー、次に前の非表示レイヤーというように、入力レイヤーで終了します。
バックプロパゲーションアルゴリズムは、主に計算グラフのアイデアを使用して実装されます。この場合、各ニューロンは計算グラフ内の多くのノードに展開され、加算、乗算などの単純な数学演算を実行します。計算グラフには、エッジに重みがありません。すべての重みがノードに割り当てられるため、重みは独自のノードになります。次に、逆伝播アルゴリズムが計算グラフで実行されます。計算が完了すると、重みノードの勾配のみが更新に必要になります。残りのグラデーションは破棄できます。
最急降下法の最適化手法
発生したエラーに応じて重みを調整する、一般的に使用される最適化関数の1つは、「最急降下法」と呼ばれます。
勾配は勾配の別名であり、xyグラフの勾配は、2つの変数が互いにどのように関連しているかを表します。つまり、実行中の上昇、時間の変化に対する距離の変化などです。この場合、勾配は次のようになります。ネットワークのエラーと単一の重みの比率。つまり、重みが変化するとエラーはどのように変化しますか。
より正確に言えば、どの重みが最小のエラーを生成するかを見つけたいと思います。入力データに含まれる信号を正しく表す重みを見つけて、それらを正しい分類に変換する必要があります。
ニューラルネットワークが学習すると、信号を意味に正しくマッピングできるように、多くの重みをゆっくりと調整します。ネットワークエラーとこれらの各重みの比率は、重みのわずかな変化がエラーのわずかな変化を引き起こす程度を計算する導関数dE / dwです。
それぞれの重みは、多くの変換を伴う深いネットワークの1つの要素にすぎません。重みの信号はアクティベーションを通過し、いくつかのレイヤーで合計されるため、微積分の連鎖律を使用して、ネットワークのアクティベーションと出力を処理します。これにより、問題の重みと、全体的なエラーとの関係がわかります。
エラーと重みの2つの変数が与えられると、3番目の変数によって媒介されます。 activation、重量が通過する。まず、アクティベーションの変更がエラーの変更にどのように影響するか、およびウェイトの変更がアクティベーションの変更にどのように影響するかを計算することで、重みの変更がエラーの変更にどのように影響するかを計算できます。
ディープラーニングの基本的な考え方は、それ以上のものではありません。エラーを減らすことができなくなるまで、モデルが生成するエラーに応じてモデルの重みを調整します。
深いネットは、勾配値が小さい場合はゆっくりとトレーニングし、値が大きい場合は速くトレーニングします。トレーニングの不正確さは、不正確な出力につながります。ネットを出力から入力にトレーニングするプロセスは、バックプロパゲーションまたはバックプロパゲーションと呼ばれます。順伝播は入力から始まり、順方向に機能することがわかっています。バックプロップは、右から左への勾配を計算する逆/反対を行います。
勾配を計算するたびに、その時点までの以前のすべての勾配を使用します。
出力層のノードから始めましょう。エッジはそのノードのグラデーションを使用します。隠されたレイヤーに戻ると、より複雑になります。0と1の間の2つの数値の積は、より小さな数値を与えます。勾配値は小さくなり続け、その結果、バックプロップはトレーニングに多くの時間がかかり、精度が低下します。
ディープラーニングアルゴリズムの課題
過剰適合や計算時間など、浅いニューラルネットワークと深いニューラルネットワークの両方に特定の課題があります。DNNは、トレーニングデータ内のまれな依存関係をモデル化できるようにする抽象化レイヤーを追加するため、過剰適合の影響を受けます。
Regularization過剰適合と戦うために、トレーニング中にドロップアウト、早期停止、データ拡張、転送学習などの方法が適用されます。ドロップアウト正則化は、トレーニング中に非表示レイヤーからユニットをランダムに省略します。これは、まれな依存関係を回避するのに役立ちます。DNNは、サイズ、つまり、レイヤーの数とレイヤーごとのユニットの数、学習率、初期の重みなど、いくつかのトレーニングパラメーターを考慮に入れます。時間と計算リソースに高いコストがかかるため、最適なパラメータを見つけることは必ずしも実用的ではありません。バッチ処理などのいくつかのハックは、計算を高速化できます。GPUの大きな処理能力は、必要な行列とベクトルの計算がGPUで適切に実行されるため、トレーニングプロセスに大きく役立ちました。
脱落
ドロップアウトは、ニューラルネットワークで一般的な正則化手法です。ディープニューラルネットワークは、特に過剰適合しがちです。
ドロップアウトとは何か、そしてそれがどのように機能するかを見てみましょう。
ディープラーニングのパイオニアの1人であるGeoffreyHintonの言葉によれば、「ディープニューラルネットがあり、それが過剰適合していない場合は、おそらくより大きなものを使用し、ドロップアウトを使用する必要があります」。
ドロップアウトは、勾配降下の各反復中に、ランダムに選択されたノードのセットをドロップする手法です。これは、いくつかのノードが存在しないかのようにランダムに無視することを意味します。
各ニューロンは確率qで保持され、確率1-qでランダムにドロップされます。値qは、ニューラルネットワークの各層で異なる場合があります。非表示レイヤーの値は0.5、入力レイヤーの値は0で、さまざまなタスクで適切に機能します。
評価および予測中、ドロップアウトは使用されません。次の層への入力が同じ期待値を持つように、各ニューロンの出力にqが乗算されます。
ドロップアウトの背後にある考え方は次のとおりです。ドロップアウトの正則化がないニューラルネットワークでは、ニューロンは相互に相互依存関係を発達させ、過剰適合につながります。
実装のトリック
ドロップアウトは、ランダムに選択されたニューロンの出力を0に保つことにより、TensorFlowやPytorchなどのライブラリに実装されます。つまり、ニューロンは存在しますが、その出力は0として上書きされます。
早期打ち切り
勾配降下法と呼ばれる反復アルゴリズムを使用してニューラルネットワークをトレーニングします。
早期打ち切りの背後にある考え方は直感的です。エラーが増加し始めると、トレーニングを停止します。ここで、エラーとは、ハイパーパラメーターの調整に使用されるトレーニングデータの一部である検証データで測定されたエラーを意味します。この場合、ハイパーパラメータが停止基準です。
データ拡張
私たちが持っているデータの量を増やす、または既存のデータを使用してそれにいくつかの変換を適用することによってデータを増やすプロセス。使用される正確な変換は、達成しようとしているタスクによって異なります。さらに、ニューラルネットを支援する変換は、そのアーキテクチャに依存します。
たとえば、オブジェクト分類などの多くのコンピュータビジョンタスクでは、効果的なデータ拡張手法は、元のデータのトリミングまたは変換されたバージョンである新しいデータポイントを追加することです。
コンピューターが画像を入力として受け入れると、ピクセル値の配列を受け取ります。画像全体が15ピクセル左にシフトしているとしましょう。さまざまな方向にさまざまなシフトを適用し、元のデータセットの何倍ものサイズの拡張データセットを作成します。
転移学習
事前にトレーニングされたモデルを取得し、独自のデータセットを使用してモデルを「微調整」するプロセスは、転移学習と呼ばれます。これを行うにはいくつかの方法があります。いくつかの方法を以下に説明します-
事前にトレーニングされたモデルを大規模なデータセットでトレーニングします。次に、ネットワークの最後のレイヤーを削除し、ランダムな重みを持つ新しいレイヤーに置き換えます。
次に、他のすべてのレイヤーの重みをフリーズし、ネットワークを通常どおりトレーニングします。ここで、レイヤーをフリーズしても、勾配降下法または最適化中に重みが変更されることはありません。
この背後にある概念は、事前にトレーニングされたモデルが特徴抽出器として機能し、最後のレイヤーのみが現在のタスクでトレーニングされるというものです。
バックプロパゲーションは、計算グラフを使用して、Tensorflow、Torch、Theanoなどのディープラーニングフレームワークに実装されます。さらに重要なことに、計算グラフでのバックプロパゲーションを理解するには、いくつかの異なるアルゴリズムと、時間の経過に伴うバックプロパゲーションや共有の重みを持つバックプロパゲーションなどのバリエーションを組み合わせます。すべてが計算グラフに変換された後も、それらは同じアルゴリズムであり、計算グラフでのバックプロパゲーションだけです。
計算グラフとは
計算グラフは、ノードが数学演算に対応する有向グラフとして定義されます。計算グラフは、数式を表現および評価する方法です。
たとえば、ここに簡単な数式があります-
$$p = x+y$$
上記の式の計算グラフは次のように描くことができます。
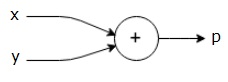
上記の計算グラフには、2つの入力変数xとyと1つの出力qを持つ加算ノード(「+」記号の付いたノード)があります。
もう少し複雑な例を見てみましょう。次の式があります。
$$g = \left (x+y \right ) \ast z $$
上記の式は、次の計算グラフで表されます。
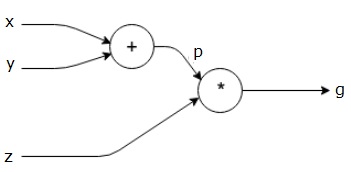
計算グラフとバックプロパゲーション
計算グラフとバックプロパゲーションはどちらも、ニューラルネットワークをトレーニングするための深層学習における重要なコアコンセプトです。
フォワードパス
フォワードパスは、計算グラフで表される数式の値を評価するための手順です。フォワードパスを実行するということは、変数からの値を、出力がある左(入力)から右に順方向に渡すことを意味します。
すべての入力に何らかの値を与えることによる例を考えてみましょう。次の値がすべての入力に与えられていると仮定します。
$$x=1, y=3, z=−3$$
これらの値を入力に与えることにより、フォワードパスを実行し、各ノードの出力に対して次の値を取得できます。
まず、x = 1およびy = 3の値を使用して、p = 4を取得します。

次に、p = 4およびz = -3を使用して、g = -12を取得します。左から右へ、前方へ。
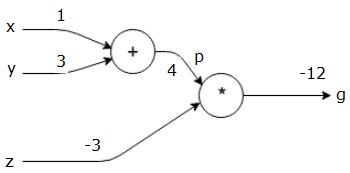
バックワードパスの目的
バックワードパスでは、最終出力に対する各入力の勾配を計算することを目的としています。これらの勾配は、勾配降下法を使用してニューラルネットワークをトレーニングするために不可欠です。
たとえば、次の勾配が必要です。
必要なグラデーション
$$\frac{\partial x}{\partial f}, \frac{\partial y}{\partial f}, \frac{\partial z}{\partial f}$$
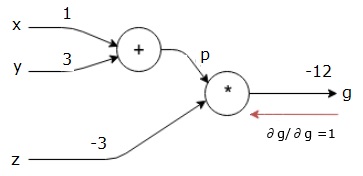
バックワードパス(バックプロパゲーション)
最終出力(それ自体!)に対する最終出力の導関数を見つけることによって、後方パスを開始します。したがって、IDが派生し、値は1になります。
$$\frac{\partial g}{\partial g} = 1$$
計算グラフは次のようになります-
次に、「*」操作を逆方向に通過させます。pとzでの勾配を計算します。g = p * zなので、次のことがわかります。
$$\frac{\partial g}{\partial z} = p$$
$$\frac{\partial g}{\partial p} = z$$
フォワードパスからzとpの値はすでにわかっています。したがって、次のようになります。
$$\frac{\partial g}{\partial z} = p = 4$$
そして
$$\frac{\partial g}{\partial p} = z = -3$$
xとy−での勾配を計算したい
$$\frac{\partial g}{\partial x}, \frac{\partial g}{\partial y}$$
ただし、これを効率的に実行したいと考えています(このグラフでは、xとgは2ホップしか離れていませんが、互いに実際に離れていると想像してください)。これらの値を効率的に計算するために、微分の連鎖律を使用します。連鎖律から、次のようになります。
$$\frac{\partial g}{\partial x}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial x}$$
$$\frac{\partial g}{\partial y}=\frac{\partial g}{\partial p}\ast \frac{\partial p}{\partial y}$$
しかし、pはxとyに直接依存するため、dg / dp = -3、dp / dxおよびdp / dyは簡単であることはすでにわかっています。私たちは-
$$p=x+y\Rightarrow \frac{\partial x}{\partial p} = 1, \frac{\partial y}{\partial p} = 1$$
したがって、次のようになります。
$$\frac{\partial g} {\partial f} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial x} = \left ( -3 \right ).1 = -3$$
さらに、入力y −
$$\frac{\partial g} {\partial y} = \frac{\partial g} {\partial p}\ast \frac{\partial p} {\partial y} = \left ( -3 \right ).1 = -3$$
これを逆方向に行う主な理由は、xで勾配を計算する必要がある場合、すでに計算された値とdq / dx(同じノードの入力に対するノード出力の導関数)のみを使用したためです。ローカル情報を使用してグローバル値を計算しました。
ニューラルネットワークをトレーニングするための手順
次の手順に従って、ニューラルネットワークをトレーニングします-
データセット内のデータポイントxについて、xを入力としてフォワードパスを実行し、コストcを出力として計算します。
cからバックワードパスを実行し、グラフ内のすべてのノードの勾配を計算します。これには、ニューラルネットワークの重みを表すノードが含まれます。
次に、W = W-学習率*勾配を実行して重みを更新します。
停止基準が満たされるまで、このプロセスを繰り返します。
ディープラーニングは、コンピュータービジョン、言語翻訳、画像キャプション、音声文字変換、分子生物学、音声認識、自然言語処理、自動運転車、脳腫瘍検出、リアルタイム音声翻訳、音楽など、いくつかのアプリケーションで優れた結果を生み出しています。作曲、自動ゲームプレイなど。
ディープラーニングは、より高度な実装による機械学習の次の大きな飛躍です。現在、生の非構造化データを扱う際にゲームチェンジャーになるという強い期待をもたらす業界標準になる方向に向かっています。
ディープラーニングは現在、さまざまな現実の問題に対応する最良のソリューションプロバイダーの1つです。開発者は、以前に与えられたルールを使用する代わりに、例から学習して複雑なタスクを解決するAIプログラムを構築しています。多くのデータサイエンティストがディープラーニングを使用しているため、より深いニューラルネットワークがこれまで以上に正確な結果をもたらしています。
アイデアは、各ネットワークのトレーニング層の数を増やすことによってディープニューラルネットワークを開発することです。マシンは、可能な限り正確になるまで、データについてさらに学習します。開発者は、深層学習技術を使用して複雑な機械学習タスクを実装し、AIネットワークをトレーニングして高レベルの知覚認識を実現できます。
ディープラーニングは、コンピュータービジョンで人気があります。ここで達成されるタスクの1つは、与えられた入力画像が猫、犬などとして、または画像を最もよく表すクラスまたはラベルとして分類される画像分類です。私たち人間は、人生の非常に早い段階でこのタスクを実行する方法を学び、パターンをすばやく認識し、事前の知識から一般化し、さまざまな画像環境に適応するこれらのスキルを持っています。
この章では、ディープラーニングをさまざまなライブラリとフレームワークに関連付けます。
ディープラーニングとTheano
ディープニューラルネットワークのコーディングを開始したい場合は、Theano、TensorFlow、Keras、PyTorchなどのさまざまなフレームワークがどのように機能するかを理解しておくとよいでしょう。
TheanoはPythonライブラリであり、マシン上ですばやくトレーニングするディープネットを構築するための一連の関数を提供します。
Theanoは、カナダのモントリオール大学で、ディープネットのパイオニアであるYoshuaBengioのリーダーシップの下で開発されました。
Theanoを使用すると、数値の長方形配列であるベクトルと行列を使用して数式を定義および評価できます。
技術的に言えば、ニューラルネットと入力データの両方を行列として表すことができ、すべての標準的なネット演算を行列演算として再定義できます。コンピューターは行列演算を非常に迅速に実行できるため、これは重要です。
複数の行列値を並列に処理できます。この基礎となる構造でニューラルネットを構築すると、GPUを備えた単一のマシンを使用して、妥当な時間枠で巨大なネットをトレーニングできます。
ただし、Theanoを使用する場合は、ゼロからディープネットを構築する必要があります。ライブラリは、特定のタイプのディープネットを作成するための完全な機能を提供していません。
代わりに、モデル、レイヤー、アクティベーション、トレーニング方法、および過剰適合を防ぐための特別な方法など、ディープネットのあらゆる側面をコーディングする必要があります。
ただし、幸いなことに、Theanoを使用すると、ベクトル化された関数の上に実装を構築して、高度に最適化されたソリューションを提供できます。
Theanoの機能を拡張するライブラリは他にもたくさんあります。TensorFlowとKerasは、Theanoをバックエンドとして使用できます。
TensorFlowによるディープラーニング
GoogleのTensorFlowはPythonライブラリです。このライブラリは、商用グレードの深層学習アプリケーションを構築するのに最適です。
TensorFlowは、Google BrainProjectの一部である別のライブラリDistBeliefV2から生まれました。このライブラリは、機械学習の移植性を拡張して、研究モデルを商用グレードのアプリケーションに適用できるようにすることを目的としています。
Theanoライブラリと同様に、TensorFlowは計算グラフに基づいており、ノードは永続的なデータまたは数学演算を表し、エッジはノード間のデータの流れを表します。これは多次元配列またはテンソルです。したがって、TensorFlowという名前
1つの操作または一連の操作からの出力は、次の入力として供給されます。
TensorFlowはニューラルネットワーク用に設計されていますが、計算をデータフローグラフとしてモデル化できる他のネットでもうまく機能します。
TensorFlowは、共通部分式除去、自動微分、共有変数、シンボリック変数など、Theanoのいくつかの機能も使用します。
畳み込みネット、オートエンコーダー、RNTN、RNN、RBM、DBM / MLPなど、さまざまなタイプのディープネットをTensorFlowを使用して構築できます。
ただし、TensorFlowではハイパーパラメータ設定はサポートされていません。この機能には、Kerasを使用できます。
ディープラーニングとKeras
Kerasは、深層学習モデルを開発および評価するための強力で使いやすいPythonライブラリです。
ミニマリストデザインで、レイヤーごとにネットを構築できます。それを訓練し、それを実行します。
効率的な数値計算ライブラリTheanoとTensorFlowをラップし、数行の短いコードでニューラルネットワークモデルを定義およびトレーニングできるようにします。
これは高レベルのニューラルネットワークAPIであり、ディープラーニングと人工知能を幅広く活用するのに役立ちます。TensorFlow、Theanoなどを含む多くの低レベルライブラリ上で実行されます。Kerasコードは移植可能です。コードを変更せずに、バックエンドとしてTheanoまたはTensorFlowを使用して、Kerasにニューラルネットワークを実装できます。
このディープラーニングの実装では、特定の銀行の顧客の減少または解約データを予測することを目的としています。これは、顧客がこの銀行サービスを離れる可能性が高いことです。使用されるデータセットは比較的小さく、14列の10000行が含まれています。Anacondaディストリビューションと、Theano、TensorFlow、Kerasなどのフレームワークを使用しています。Kerasは、バックエンドとして機能するTensorflowとTheanoの上に構築されています。
# Artificial Neural Network
# Installing Theano
pip install --upgrade theano
# Installing Tensorflow
pip install –upgrade tensorflow
# Installing Keras
pip install --upgrade kerasステップ1:データの前処理
In[]:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the database
dataset = pd.read_csv('Churn_Modelling.csv')ステップ2
データセットの特徴とターゲット変数(列14)のマトリックスを作成し、「終了」というラベルを付けます。
データの初期の外観は次のとおりです-
In[]:
X = dataset.iloc[:, 3:13].values
Y = dataset.iloc[:, 13].values
X出力
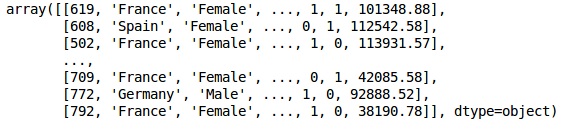
ステップ3
Y出力
array([1, 0, 1, ..., 1, 1, 0], dtype = int64)ステップ4
文字列変数をエンコードすることで、分析を簡単にします。ScikitLearn関数「LabelEncoder」を使用して、0〜n_classes-1の値で列内のさまざまなラベルを自動的にエンコードしています。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X_1 = LabelEncoder()
X[:,1] = labelencoder_X_1.fit_transform(X[:,1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
X出力

上記の出力では、国名は0、1、および2に置き換えられています。男性と女性は0と1に置き換えられます。
ステップ5
Labelling Encoded Data
同じものを使用します ScikitLearn ライブラリとと呼ばれる別の関数 OneHotEncoder ダミー変数を作成する列番号を渡すだけです。
onehotencoder = OneHotEncoder(categorical features = [1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
X現在、最初の2列は国を表し、4列目は性別を表します。
出力
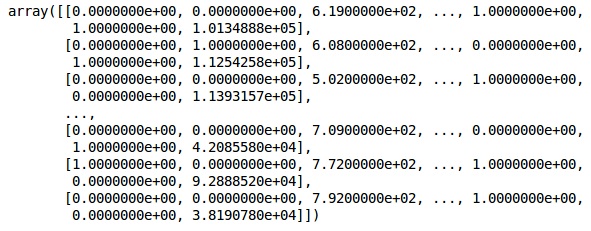
私たちは常にデータをトレーニングとテストの部分に分けています。トレーニングデータでモデルをトレーニングしてから、モデルの効率を評価するのに役立つテストデータでモデルの精度をチェックします。
ステップ6
ScikitLearnを使用しています train_test_splitデータをトレーニングセットとテストセットに分割する関数。トレインとテストの分割比を80:20に保ちます。
#Splitting the dataset into the Training set and the Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)変数の中には数千の値を持つものもあれば、数十または1の値を持つものもあります。より代表的なものになるようにデータをスケーリングします。
ステップ7
このコードでは、を使用してトレーニングデータをフィッティングおよび変換しています。 StandardScaler関数。同じ近似方法を使用してテストデータを変換/スケーリングするように、スケーリングを標準化します。
# Feature Scalingfromsklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)出力
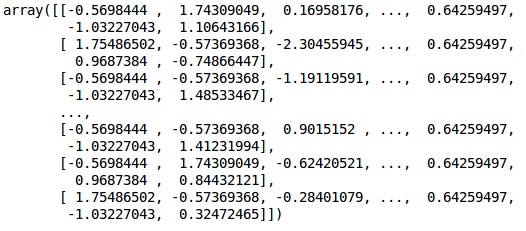
これで、データが適切にスケーリングされます。最後に、データの前処理が完了しました。それでは、モデルから始めましょう。
ステップ8
ここで必要なモジュールをインポートします。ニューラルネットワークを初期化するためのSequentialモジュールと、隠れ層を追加するための密なモジュールが必要です。
# Importing the Keras libraries and packages
import keras
from keras.models import Sequential
from keras.layers import Denseステップ9
顧客離れを分類することを目的としているため、モデルに分類子という名前を付けます。次に、初期化にSequentialモジュールを使用します。
#Initializing Neural Network
classifier = Sequential()ステップ10
密関数を使用して、非表示のレイヤーを1つずつ追加します。以下のコードでは、多くの引数が表示されます。
最初のパラメータは output_dim。これは、このレイヤーに追加するノードの数です。init確率的勾配降下法の初期化です。ニューラルネットワークでは、各ノードに重みを割り当てます。初期化時には、重みはゼロに近いはずであり、均一関数を使用して重みをランダムに初期化します。ザ・input_dimモデルは入力変数の数を認識していないため、パラメーターは最初のレイヤーにのみ必要です。ここで、入力変数の総数は11です。2番目のレイヤーでは、モデルは最初の非表示レイヤーからの入力変数の数を自動的に認識します。
次のコード行を実行して、入力レイヤーと最初の非表示レイヤーを追加します-
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu', input_dim = 11))次のコード行を実行して、2番目の隠れ層を追加します-
classifier.add(Dense(units = 6, kernel_initializer = 'uniform',
activation = 'relu'))次のコード行を実行して、出力レイヤーを追加します-
classifier.add(Dense(units = 1, kernel_initializer = 'uniform',
activation = 'sigmoid'))ステップ11
Compiling the ANN
これまで、分類器に複数のレイヤーを追加してきました。次に、を使用してコンパイルします。compile方法。最終的なコンパイル制御で追加された引数はニューラルネットワークを完成させるので、このステップでは注意する必要があります。
これが議論の簡単な説明です。
最初の引数は Optimizer。これは、最適な重みのセットを見つけるために使用されるアルゴリズムです。このアルゴリズムは、Stochastic Gradient Descent (SGD)。ここでは、「アダムオプティマイザー」と呼ばれるいくつかのタイプの1つを使用しています。SGDは損失に依存するため、2番目のパラメーターは損失です。従属変数がバイナリの場合、次の対数損失関数を使用します。‘binary_crossentropy’、および従属変数の出力に3つ以上のカテゴリがある場合は、 ‘categorical_crossentropy’。に基づいてニューラルネットワークのパフォーマンスを向上させたいaccuracy、追加します metrics 精度として。
# Compiling Neural Network
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])ステップ12
このステップでは、いくつかのコードを実行する必要があります。
ANNをトレーニングセットに適合させる
次に、トレーニングデータに基づいてモデルをトレーニングします。私たちは使用しますfitモデルに合わせる方法。また、モデルの効率を向上させるために重みを最適化します。このために、重みを更新する必要があります。Batch size は、重みを更新した後の観測数です。 Epochは反復の総数です。バッチサイズとエポックの値は、試行錯誤の方法で選択されます。
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)予測を行い、モデルを評価する
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)単一の新しい観測値を予測する
# Predicting a single new observation
"""Our goal is to predict if the customer with the following data will leave the bank:
Geography: Spain
Credit Score: 500
Gender: Female
Age: 40
Tenure: 3
Balance: 50000
Number of Products: 2
Has Credit Card: Yes
Is Active Member: Yesステップ13
Predicting the test set result
予測結果は、顧客が会社を辞める確率を示します。その確率をバイナリ0と1に変換します。
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)new_prediction = classifier.predict(sc.transform
(np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]])))
new_prediction = (new_prediction > 0.5)ステップ14
これは、モデルのパフォーマンスを評価する最後のステップです。すでに元の結果が得られているため、混同行列を作成してモデルの精度を確認できます。
Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print (cm)出力
loss: 0.3384 acc: 0.8605
[ [1541 54]
[230 175] ]混同行列から、モデルの精度は次のように計算できます。
Accuracy = 1541+175/2000=0.858We achieved 85.8% accuracy、 どっちがいい。
順伝播アルゴリズム
このセクションでは、単純なニューラルネットワークの順伝播(予測)を行うためのコードの記述方法を学習します。
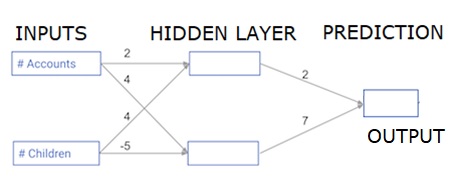
各データポイントは顧客です。最初の入力はアカウントの数であり、2番目の入力は子の数です。このモデルは、ユーザーが翌年に行うトランザクションの数を予測します。
入力データは入力データとしてプリロードされ、重みは重みと呼ばれる辞書にあります。隠れ層の最初のノードの重みの配列は重み['node_0']であり、隠れ層の2番目のノードの重みの配列はそれぞれ重み['node_1']です。
出力ノードに供給される重みは、重みで使用できます。
正規化線形活性化関数
「活性化関数」とは、各ノードで機能する関数です。ノードの入力を何らかの出力に変換します。
正規化線形活性化関数(ReLUと呼ばれる)は、非常に高性能なネットワークで広く使用されています。この関数は、単一の数値を入力として受け取り、入力が負の場合は0を返し、入力が正の場合は出力として入力を返します。
ここにいくつかの例があります-
- relu(4)= 4
- relu(-2)= 0
relu()関数の定義を入力します-
- max()関数を使用して、relu()の出力の値を計算します。
- relu()関数をnode_0_inputに適用して、node_0_outputを計算します。
- relu()関数をnode_1_inputに適用して、node_1_outputを計算します。
import numpy as np
input_data = np.array([-1, 2])
weights = {
'node_0': np.array([3, 3]),
'node_1': np.array([1, 5]),
'output': np.array([2, -1])
}
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = np.tanh(node_0_input)
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = np.tanh(node_1_input)
hidden_layer_output = np.array(node_0_output, node_1_output)
output =(hidden_layer_output * weights['output']).sum()
print(output)
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(input,0)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
odel_output = (hidden_layer_outputs * weights['output']).sum()
print(model_output)# Print model output出力
0.9950547536867305
-3ネットワークを多くの観測/データの行に適用する
このセクションでは、predict_with_network()という関数を定義する方法を学習します。この関数は、input_dataとして取得された上記のネットワークから取得された、複数のデータ観測の予測を生成します。上記のネットワークで指定された重みが使用されています。relu()関数の定義も使用されています。
2つの引数(input_data_rowとweights)を受け入れ、ネットワークからの予測を出力として返すpredict_with_network()という関数を定義しましょう。
各ノードの入力値と出力値を計算し、node_0_input、node_0_output、node_1_input、およびnode_1_outputとして保存します。
ノードの入力値を計算するには、関連する配列を乗算し、それらの合計を計算します。
ノードの出力値を計算するには、relu()関数をノードの入力値に適用します。'forループ'を使用してinput_dataを反復処理します-
また、predict_with_network()を使用して、input_data(input_data_row)の各行の予測を生成します。また、各予測を結果に追加します。
# Define predict_with_network()
def predict_with_network(input_data_row, weights):
# Calculate node 0 value
node_0_input = (input_data_row * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value
node_1_input = (input_data_row * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output
input_to_final_layer = (hidden_layer_outputs*weights['output']).sum()
model_output = relu(input_to_final_layer)
# Return model output
return(model_output)
# Create empty list to store prediction results
results = []
for input_data_row in input_data:
# Append prediction to results
results.append(predict_with_network(input_data_row, weights))
print(results)# Print results出力
[0, 12]ここでは、relu(26)= 26およびrelu(-13)= 0などのrelu関数を使用しました。
深い多層ニューラルネットワーク
ここでは、2つの隠れ層を持つニューラルネットワークの順伝播を行うコードを記述しています。各隠れ層には2つのノードがあります。入力データは次のようにプリロードされていますinput_data。最初の隠れ層のノードは、node_0_0およびnode_0_1と呼ばれます。
それらの重みは、それぞれweights ['node_0_0']およびweights ['node_0_1']としてプリロードされています。
2番目の隠れ層のノードは呼び出されます node_1_0 and node_1_1。それらの重みは次のように事前にロードされていますweights['node_1_0'] そして weights['node_1_1'] それぞれ。
次に、次のようにプリロードされた重みを使用して、非表示ノードからモデル出力を作成します。 weights['output']。
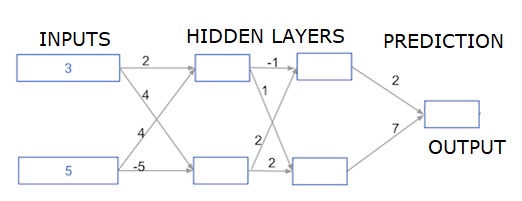
node_0_0_inputは、その重みweights ['node_0_0']と指定されたinput_dataを使用して計算します。次に、relu()関数を適用してnode_0_0_outputを取得します。
node_0_1_inputに対して上記と同じことを行い、node_0_1_outputを取得します。
node_1_0_inputは、その重みweights ['node_1_0']と最初の隠れ層からの出力(hidden_0_outputs)を使用して計算します。次に、relu()関数を適用してnode_1_0_outputを取得します。
node_1_1_inputに対して上記と同じことを行い、node_1_1_outputを取得します。
weights ['output']と2番目の隠れ層hidden_1_outputs配列からの出力を使用してmodel_outputを計算します。この出力にはrelu()関数を適用しません。
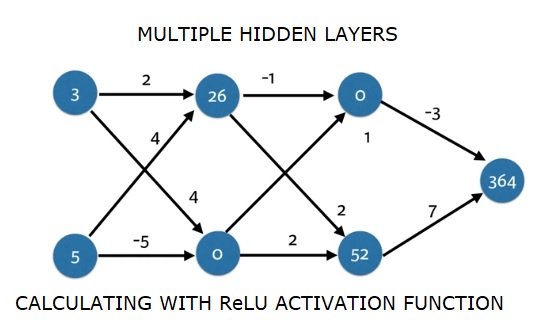
import numpy as np
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([4, -5]),
'node_1_0': np.array([-1, 1]),
'node_1_1': np.array([2, 2]),
'output': np.array([2, 7])
}
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data*weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs*weights['output']).sum()
# Return model_output
return(model_output)
output = predict_with_network(input_data)
print(output)出力
364