ディープニューラルネットワーク
ディープニューラルネットワーク(DNN)は、入力層と出力層の間に複数の隠れ層があるANNです。浅いANNと同様に、DNNは複雑な非線形関係をモデル化できます。
ニューラルネットワークの主な目的は、一連の入力を受け取り、それらに対して徐々に複雑な計算を実行し、分類などの現実世界の問題を解決するために出力を提供することです。ニューラルネットワークをフィードフォワードするように制限します。
ディープネットワークには、入力、出力、およびシーケンシャルデータのフローがあります。
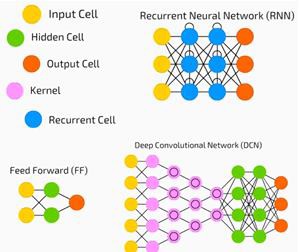
ニューラルネットワークは、教師あり学習と強化学習の問題で広く使用されています。これらのネットワークは、相互に接続された一連のレイヤーに基づいています。
深層学習では、ほとんどが非線形である隠れ層の数が多くなる可能性があります。約1000層と言います。
DLモデルは、通常のMLネットワークよりもはるかに優れた結果を生成します。
ネットワークを最適化し、損失関数を最小化するために、主に勾配降下法を使用します。
使用できます Imagenet、データセットを猫や犬などのカテゴリに分類するための数百万のデジタル画像のリポジトリ。DLネットは、静的画像以外の動的画像や、時系列およびテキスト分析にますます使用されています。
データセットのトレーニングは、ディープラーニングモデルの重要な部分を形成します。さらに、バックプロパゲーションはDLモデルのトレーニングにおける主要なアルゴリズムです。
DLは、複雑な入出力変換を使用した大規模なニューラルネットワークのトレーニングを扱います。
DLの1つの例は、ソーシャルネットワークで行うように、写真を写真内の人物の名前にマッピングすることです。フレーズを使用して写真を記述することは、DLのもう1つの最近のアプリケーションです。
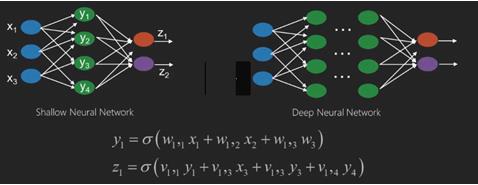
ニューラルネットワークは、x1、x2、x3などの入力を持つ関数であり、2つ(浅いネットワーク)またはレイヤー(深いネットワーク)とも呼ばれるいくつかの中間操作でz1、z2、z3などの出力に変換されます。
重みとバイアスはレイヤーごとに異なります。「w」と「v」は、ニューラルネットワークの層の重みまたはシナプスです。
深層学習の最良の使用例は、教師あり学習の問題です。ここでは、必要な出力のセットを備えた大量のデータ入力のセットがあります。
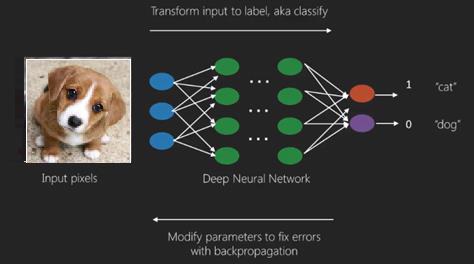
ここでは、バックプロパゲーションアルゴリズムを適用して、正しい出力予測を取得します。
ディープラーニングの最も基本的なデータセットは、手書き数字のデータセットであるMNISTです。
このデータセットから手書き数字の画像を分類するために、Kerasを使用して畳み込みニューラルネットワークを深くトレーニングできます。
ニューラルネット分類器の起動またはアクティブ化により、スコアが生成されます。たとえば、患者を病気と健康に分類するために、身長、体重、体温、血圧などのパラメータを考慮します。
高いスコアは患者が病気であることを意味し、低いスコアは彼が健康であることを意味します。
出力層と非表示層の各ノードには、独自の分類子があります。入力レイヤーは入力を受け取り、そのスコアを次の非表示レイヤーに渡してさらにアクティブ化します。これは、出力に到達するまで続きます。
この入力から出力への左から右への順方向の進行は、 forward propagation.
ニューラルネットワークのクレジット割り当てパス(CAP)は、入力から出力までの一連の変換です。CAPは、入力と出力の間の考えられる因果関係を詳しく説明します。
特定のフィードフォワードニューラルネットワークのCAP深度、またはCAP深度は、隠れ層の数に出力層が含まれるため1を加えたものです。信号がレイヤーを数回伝播する可能性があるリカレントニューラルネットワークの場合、CAPの深さは潜在的に無制限になる可能性があります。
深いネットと浅いネット
浅い学習と深い学習を分ける明確な深さのしきい値はありません。ただし、複数の非線形層を持つ深層学習の場合、CAPは2より大きくなければならないことにほとんど同意しています。
ニューラルネットの基本ノードは、生物学的ニューラルネットワークのニューロンを模倣した知覚です。次に、多層知覚またはMLPがあります。入力の各セットは、重みとバイアスのセットによって変更されます。各エッジには固有の重みがあり、各ノードには固有のバイアスがあります。
予測 accuracy ニューラルネットの weights and biases.
ニューラルネットワークの精度を向上させるプロセスは、 training. フォワードプロペラネットからの出力は、正しいことがわかっている値と比較されます。
ザ・ cost function or the loss function 生成された出力と実際の出力の差です。
トレーニングのポイントは、数百万のトレーニング例にわたってトレーニングのコストを可能な限り小さくすることです。これを行うために、ネットワークは、予測が正しい出力と一致するまで、重みとバイアスを微調整します。
よく訓練されると、ニューラルネットは毎回正確な予測を行う可能性があります。
パターンが複雑になり、コンピューターに認識させたい場合は、ニューラルネットワークを使用する必要があります。このような複雑なパターンのシナリオでは、ニューラルネットワークは他のすべての競合アルゴリズムよりも優れています。
これまで以上に高速にトレーニングできるGPUが登場しました。ディープニューラルネットワークはすでにAIの分野に革命をもたらしています
コンピューターは、繰り返し計算を実行し、詳細な指示に従うのは得意であることが証明されていますが、複雑なパターンを認識するのはそれほど得意ではありません。
単純なパターンの認識に問題がある場合は、サポートベクターマシン(svm)またはロジスティック回帰分類器でうまく機能しますが、パターンの複雑さが増すにつれて、ディープニューラルネットワークを使用する以外に方法はありません。
したがって、人間の顔のような複雑なパターンの場合、浅いニューラルネットワークは失敗し、より多くの層を持つ深いニューラルネットワークを選択する以外に選択肢はありません。ディープネットは、複雑なパターンをより単純なパターンに分解することで、その役割を果たします。たとえば、人間の顔。アディープネットは、エッジを使用して唇、鼻、目、耳などの部分を検出し、これらを再結合して人間の顔を形成します
正しい予測の精度が非常に正確になったため、最近のGoogleパターン認識チャレンジでは、深いネットが人間を打ち負かしました。
層状パーセプトロンのウェブのこのアイデアは、しばらく前から存在しています。この領域では、深い網が人間の脳を模倣しています。しかし、これの1つの欠点は、トレーニングに時間がかかることです。これはハードウェアの制約です。
ただし、最近の高性能GPUは、このようなディープネットを1週間以内にトレーニングすることができました。高速CPUは、同じことを行うのに数週間またはおそらく数か月かかる可能性があります。
ディープネットの選択
ディープネットの選び方は?分類器を構築するのか、データ内のパターンを見つけようとするのか、教師なし学習を使用するのかを決定する必要があります。ラベルのないデータのセットからパターンを抽出するには、制限付きボルツマンマシンまたはオートエンコーダーを使用します。
ディープネットを選択する際は、以下の点を考慮してください。
テキスト処理、感情分析、構文解析、および名前エンティティの認識には、リカレントネットまたは再帰型ニューラルテンソルネットワークまたはRNTNを使用します。
文字レベルで動作する言語モデルには、リカレントネットを使用します。
画像認識には、ディープビリーフネットワークDBNまたは畳み込みネットワークを使用します。
オブジェクト認識には、RNTNまたは畳み込みネットワークを使用します。
音声認識には、リカレントネットを使用します。
一般に、ディープビリーフネットワークと、正規化線形ユニットまたはRELUを備えた多層パーセプトロンの両方が分類に適しています。
時系列分析では、リカレントネットを使用することを常にお勧めします。
ニューラルネットは50年以上前から存在しています。しかし、今だけ彼らは目立つようになりました。その理由は、彼らが訓練するのが難しいからです。バックプロパゲーションと呼ばれる方法でトレーニングしようとすると、勾配の消失または爆発と呼ばれる問題が発生します。その場合、トレーニングに時間がかかり、精度が後回しになります。データセットをトレーニングするとき、ラベル付けされたトレーニングデータのセットからの予測出力と実際の出力の差であるコスト関数を常に計算しています。次に、重みとバイアスの値を最小値まで調整することにより、コスト関数を最小化します。が得られます。トレーニングプロセスでは、勾配を使用します。これは、重みまたはバイアス値の変化に対してコストが変化する速度です。
制限付きボルツマンネットワークまたはオートエンコーダ-RBN
2006年には、勾配消失問題への取り組みにおいて画期的な成果が達成されました。ジェフヒントンは、の開発につながる新しい戦略を考案しましたRestricted Boltzman Machine - RBM、浅い2層ネット。
最初のレイヤーは visible レイヤーと2番目のレイヤーは hidden層。可視層の各ノードは、非表示層のすべてのノードに接続されています。同じレイヤー内の2つのレイヤーが接続を共有できないため、ネットワークは制限付きと呼ばれます。
オートエンコーダは、入力データをベクトルとしてエンコードするネットワークです。それらは、生データの非表示または圧縮された表現を作成します。ベクトルは次元削減に役立ちます。ベクトルは、生データを少数の重要な次元に圧縮します。オートエンコーダーはデコーダーとペアになっており、非表示の表現に基づいて入力データを再構築できます。
RBMは、双方向トランスレータと数学的に同等です。フォワードパスは入力を受け取り、それらを入力をエンコードする一連の数値に変換します。一方、バックワードパスは、この数値のセットを取得し、それらを再構築された入力に変換し直します。よく訓練されたネットは、高い精度でバックプロップを実行します。
どちらのステップでも、重みとバイアスが重要な役割を果たします。これらは、RBMが入力間の相互関係をデコードし、パターンの検出に不可欠な入力を決定するのに役立ちます。順方向パスと逆方向パスを介して、RBMは、入力とその構築が可能な限り近くなるまで、異なる重みとバイアスで入力を再構築するようにトレーニングされます。RBMの興味深い側面は、データにラベルを付ける必要がないことです。これは、写真、ビデオ、音声、センサーデータなど、ラベルが付けられていない傾向のある実際のデータセットにとって非常に重要であることがわかります。RBMは、人間が手動でデータにラベルを付ける代わりに、データを自動的に並べ替えます。重みとバイアスを適切に調整することにより、RBMは重要な特徴を抽出し、入力を再構築することができます。RBMは、データの固有のパターンを認識するように設計された特徴抽出ニューラルネットのファミリーの一部です。これらは、独自の構造をエンコードする必要があるため、オートエンコーダとも呼ばれます。

ディープビリーフネットワーク-DBN
ディープビリーフネットワーク(DBN)は、RBMを組み合わせ、巧妙なトレーニング方法を導入することによって形成されます。勾配消失の問題を最終的に解決する新しいモデルがあります。ジェフヒントンは、バックプロパゲーションの代わりにRBMとディープビリーフネットを発明しました。
DBNは、構造がMLP(多層パーセプトロン)に似ていますが、トレーニングに関しては非常に異なります。DBNが浅い対応物よりも優れたパフォーマンスを発揮できるようにするのはトレーニングです
DBNは、RBMのスタックとして視覚化できます。ここで、1つのRBMの非表示層は、その上のRBMの可視層です。最初のRBMは、入力を可能な限り正確に再構築するようにトレーニングされています。
最初のRBMの隠れ層は、2番目のRBMの可視層と見なされ、2番目のRBMは、最初のRBMからの出力を使用してトレーニングされます。このプロセスは、ネットワーク内のすべてのレイヤーがトレーニングされるまで繰り返されます。
DBNでは、各RBMが入力全体を学習します。DBNは、カメラのレンズがゆっくりと画像の焦点を合わせるようにモデルがゆっくりと改善されるため、入力全体を連続して微調整することでグローバルに機能します。多層パーセプトロンMLPは単一のパーセプトロンよりも優れているため、RBMのスタックは単一のRBMよりも優れています。
この段階で、RBMはデータに固有のパターンを検出しましたが、名前やラベルはありません。DBNのトレーニングを終了するには、パターンにラベルを導入し、教師あり学習でネットを微調整する必要があります。
特徴とパターンを名前に関連付けることができるように、ラベル付けされたサンプルの非常に小さなセットが必要です。この小さなラベルの付いたデータセットは、トレーニングに使用されます。このラベル付きデータのセットは、元のデータセットと比較すると非常に小さい場合があります。
重みとバイアスがわずかに変更されるため、ネットのパターンの認識がわずかに変化し、多くの場合、全体の精度がわずかに向上します。
GPUを使用することで、浅いネットと比較して非常に正確な結果が得られるため、トレーニングを妥当な時間で完了することもできます。勾配消失問題の解決策もあります。
生成的敵対的ネットワーク-GAN
生成的敵対的ネットワークは、2つのネットで構成される深いニューラルネットであり、一方が他方にピットインしているため、「敵対的」という名前が付けられています。
GANは、2014年にモントリオール大学の研究者によって発表された論文で紹介されました。FacebookのAI専門家であるYann LeCunは、GANについて言及し、敵対的トレーニングを「MLでの過去10年間で最も興味深いアイデア」と呼びました。
ネットワークスキャンはデータの分布を模倣することを学ぶため、GANの可能性は非常に大きいです。GANは、画像、音楽、スピーチ、散文など、あらゆるドメインで私たちと非常によく似た並列世界を作成するように教えることができます。彼らはある意味ロボットアーティストであり、彼らのアウトプットは非常に印象的です。
GANでは、ジェネレーターと呼ばれる1つのニューラルネットワークが新しいデータインスタンスを生成し、もう1つのニューラルネットワークであるディスクリミネーターがそれらの真正性を評価します。
実世界から取得したMNISTデータセットにあるような手書きの数字を生成しようとしているとしましょう。弁別器の働きは、真のMNISTデータセットからのインスタンスが表示された場合、それらを本物として認識することです。
ここで、GANの次の手順を検討してください-
ジェネレータネットワークは、乱数の形式で入力を受け取り、画像を返します。
この生成された画像は、実際のデータセットから取得された画像のストリームとともに、ディスクリミネーターネットワークへの入力として提供されます。
弁別器は、実際の画像と偽の画像の両方を取り込んで、0から1までの数値を返します。1は真正性の予測を表し、0は偽の画像を表します。
したがって、二重フィードバックループがあります-
弁別器は、私たちが知っている画像のグラウンドトゥルースとのフィードバックループにあります。
ジェネレータは、ディスクリミネータとのフィードバックループにあります。
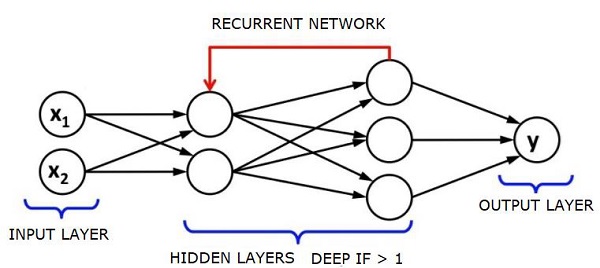
リカレントニューラルネットワーク-RNN
RNNデータが任意の方向に流れることができる希少なニューラルネットワーク。これらのネットワークは、言語モデリングや自然言語処理(NLP)などのアプリケーションに使用されます。
RNNの基礎となる基本的な概念は、シーケンシャル情報を利用することです。通常のニューラルネットワークでは、すべての入力と出力が互いに独立していると想定されています。文中の次の単語を予測したい場合は、その前にある単語を知る必要があります。
RNNは、シーケンスのすべての要素に対して同じタスクを繰り返し、出力が前の計算に基づいているため、リカレントと呼ばれます。したがって、RNNは、以前に計算されたものに関する情報をキャプチャする「メモリ」を備えていると言えます。理論的には、RNNは非常に長いシーケンスで情報を使用できますが、実際には、数ステップしか振り返ることができません。
長期短期記憶ネットワーク(LSTM)は、最も一般的に使用されるRNNです。
畳み込みニューラルネットワークとともに、RNNは、ラベルのない画像の説明を生成するためのモデルの一部として使用されてきました。これがどれほどうまく機能しているように見えるかは非常に驚くべきことです。
畳み込みディープニューラルネットワーク-CNN
ニューラルネットワークの層数を増やして深くすると、ネットワークの複雑さが増し、より複雑な関数をモデル化できるようになります。ただし、重みとバイアスの数は指数関数的に増加します。実際のところ、このような難しい問題を学習することは、通常のニューラルネットワークでは不可能になる可能性があります。これは、解決策である畳み込みニューラルネットワークにつながります。
CNNは、コンピュータービジョンで広く使用されています。自動音声認識の音響モデリングにも適用されています。
畳み込みニューラルネットワークの背後にある考え方は、画像を通過する「移動フィルター」の考え方です。この移動フィルター、または畳み込みは、ノードの特定の近傍に適用されます。たとえば、ピクセルの場合、適用されるフィルターはノード値の0.5xです。
著名な研究者であるヤン・ルカンは、畳み込みニューラルネットワークを開拓しました。顔認識ソフトウェアとしてのFacebookはこれらのネットを使用しています。CNNは、マシンビジョンプロジェクトのソリューションになりました。畳み込みネットワークには多くの層があります。Imagenetチャレンジでは、2015年に機械が物体認識で人間を打ち負かすことができました。
一言で言えば、畳み込みニューラルネットワーク(CNN)は多層ニューラルネットワークです。レイヤーは最大17以上の場合があり、入力データを画像と見なします。
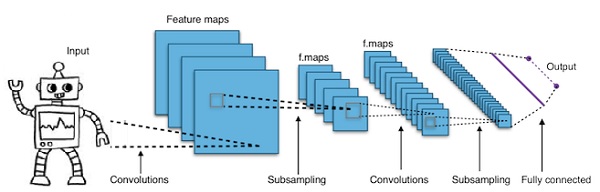
CNNは、調整が必要なパラメーターの数を大幅に削減します。そのため、CNNは生画像の高次元性を効率的に処理します。