R-非線形最小二乗
回帰分析のために実世界のデータをモデル化する場合、モデルの方程式が線形グラフを与える線形方程式である場合はめったにないことがわかります。ほとんどの場合、実世界のデータのモデルの方程式には、3の指数やsin関数などのより高度な数学関数が含まれます。このようなシナリオでは、モデルのプロットは線ではなく曲線を示します。線形回帰と非線形回帰の両方の目標は、モデルのパラメーターの値を調整して、データに最も近い線または曲線を見つけることです。これらの値を見つけると、応答変数を高い精度で推定できるようになります。
最小二乗回帰では、回帰曲線からのさまざまな点の垂直距離の二乗の合計が最小化される回帰モデルを確立します。通常、定義されたモデルから始めて、係数にいくつかの値を想定します。次に、nls() 信頼区間とともにより正確な値を取得するためのRの関数。
構文
Rで非線形最小二乗検定を作成するための基本的な構文は次のとおりです。
nls(formula, data, start)以下は、使用されるパラメーターの説明です-
formula は、変数とパラメーターを含む非線形モデル式です。
data 式の変数を評価するために使用されるデータフレームです。
start 開始推定値の名前付きリストまたは名前付き数値ベクトルです。
例
係数の初期値を仮定した非線形モデルを検討します。次に、これらの仮定値の信頼区間を確認して、これらの値がモデルにどの程度適合しているかを判断できるようにします。
それで、この目的のために以下の方程式を考えてみましょう-
a = b1*x^2+b2初期係数を1と3と仮定し、これらの値をnls()関数に適合させます。
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))上記のコードを実行すると、次の結果が生成されます-
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484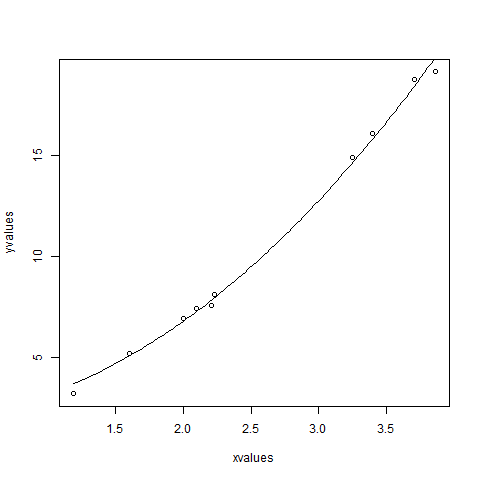
b1の値は1に近く、b2の値は3ではなく2に近いと結論付けることができます。