R-クイックガイド
Rは、統計分析、グラフィックス表現、およびレポート作成のためのプログラミング言語およびソフトウェア環境です。Rは、ニュージーランドのオークランド大学のRossIhakaとRobertGentlemanによって作成され、現在R開発コアチームによって開発されています。
Rのコアは、関数を使用したモジュラープログラミングだけでなく、分岐とループを可能にするインタープリター型コンピューター言語です。Rを使用すると、C、C ++ 、. Net、Python、またはFORTRAN言語で記述されたプロシージャと統合して効率を高めることができます。
RはGNUGeneral Public Licenseの下で無料で入手でき、Linux、Windows、Macなどのさまざまなオペレーティングシステム用にコンパイル済みのバイナリバージョンが提供されています。
RはGNUスタイルのコピーレフトの下で配布されているフリーソフトウェアであり、GNUプロジェクトの公式部分は GNU S。
Rの進化
Rは最初にによって書かれました Ross Ihaka そして Robert Gentlemanニュージーランドのオークランドにあるオークランド大学の統計学部で。Rは1993年に初登場しました。
個人の大規模なグループが、コードとバグレポートを送信することでRに貢献しています。
1997年半ば以降、Rソースコードアーカイブを変更できるコアグループ(「Rコアチーム」)が存在します。
Rの特徴
前述のように、Rは、統計分析、グラフィックス表現、およびレポート作成のためのプログラミング言語およびソフトウェア環境です。R −の重要な機能は次のとおりです。
Rは、条件付き、ループ、ユーザー定義の再帰関数、および入出力機能を含む、十分に開発された、シンプルで効果的なプログラミング言語です。
Rには、効果的なデータ処理および保存機能があります。
Rは、配列、リスト、ベクトル、および行列を計算するための一連の演算子を提供します。
Rは、データ分析のためのツールの大規模で一貫性のある統合されたコレクションを提供します。
Rは、データ分析のためのグラフィカル機能を提供し、コンピューターで直接表示するか、新聞で印刷します。
結論として、Rは世界で最も広く使用されている統計プログラミング言語です。これはデータサイエンティストの第1の選択肢であり、活気に満ちた才能のある貢献者のコミュニティによってサポートされています。Rは大学で教えられ、ミッションクリティカルなビジネスアプリケーションに展開されます。このチュートリアルでは、Rプログラミングと適切な例を簡単な手順で説明します。
ローカル環境のセットアップ
それでもRの環境をセットアップする場合は、以下の手順に従ってください。
Windowsのインストール
RのWindowsインストーラバージョンをR -3.2.2for Windows(32/64ビット)からダウンロードして、ローカルディレクトリに保存できます。
「R-version-win.exe」という名前のWindowsインストーラー(.exe)であるため。ダブルクリックして、デフォルト設定を受け入れてインストーラーを実行できます。Windowsが32ビットバージョンの場合、32ビットバージョンがインストールされます。ただし、Windowsが64ビットの場合は、32ビットバージョンと64ビットバージョンの両方がインストールされます。
インストール後、Windows ProgramFilesの下のディレクトリ構造「R \ R3.2.2 \ bin \ i386 \ Rgui.exe」でプログラムを実行するためのアイコンを見つけることができます。このアイコンをクリックすると、Rプログラミングを行うためのRコンソールであるR-GUIが表示されます。
Linuxのインストール
Rは、RBinariesの場所にあるLinuxの多くのバージョンのバイナリとして利用できます。
Linuxをインストールする手順は、フレーバーによって異なります。これらの手順は、前述のリンクのLinuxバージョンの各タイプで説明されています。ただし、お急ぎの場合はご利用いただけますyum 次のようにRをインストールするコマンド-
$ yum install R上記のコマンドは、標準パッケージとともにRプログラミングのコア機能をインストールしますが、追加のパッケージが必要な場合は、次のようにRプロンプトを起動できます。
$ R
R version 3.2.0 (2015-04-16) -- "Full of Ingredients"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-redhat-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>これで、Rプロンプトでinstallコマンドを使用して、必要なパッケージをインストールできます。たとえば、次のコマンドはインストールされますplotrix 3Dチャートに必要なパッケージ。
> install.packages("plotrix")慣例として、「Hello、World!」を作成して、Rプログラミングの学習を開始します。プログラム。必要に応じて、Rコマンドプロンプトでプログラムするか、Rスクリプトファイルを使用してプログラムを作成できます。両方を一つずつチェックしていきましょう。
Rコマンドプロンプト
R環境をセットアップしたら、コマンドプロンプトで次のコマンドを入力するだけでRコマンドプロンプトを簡単に開始できます-
$ RこれによりRインタープリターが起動し、次のようにプログラムの入力を開始できるプロンプトが表示されます。
> myString <- "Hello, World!"
> print ( myString)
[1] "Hello, World!"ここで、最初のステートメントは文字列変数myStringを定義し、ここで文字列「Hello、World!」を割り当てます。次に、次のステートメントprint()を使用して、変数myStringに格納されている値を出力します。
Rスクリプトファイル
通常は、スクリプトファイルにプログラムを記述してプログラミングを行い、コマンドプロンプトでRインタープリターを使用してこれらのスクリプトを実行します。 Rscript。それでは、次のコードをtest.Rというテキストファイルに次のように記述してみましょう。
# My first program in R Programming
myString <- "Hello, World!"
print ( myString)上記のコードをファイルtest.Rに保存し、以下のようにLinuxコマンドプロンプトで実行します。Windowsまたは他のシステムを使用している場合でも、構文は同じままです。
$ Rscript test.R上記のプログラムを実行すると、次の結果が得られます。
[1] "Hello, World!"コメント
コメントは、Rプログラムのテキストを支援するようなものであり、実際のプログラムの実行中にインタプリタによって無視されます。単一のコメントは、ステートメントの先頭に#を使用して次のように記述されます-
# My first program in R ProgrammingRは複数行コメントをサポートしていませんが、次のようなトリックを実行できます-
if(FALSE) {
"This is a demo for multi-line comments and it should be put inside either a
single OR double quote"
}
myString <- "Hello, World!"
print ( myString)[1] "Hello, World!"上記のコメントはRインタープリターによって実行されますが、実際のプログラムに干渉することはありません。このようなコメントは、一重引用符または二重引用符で囲む必要があります。
一般に、任意のプログラミング言語でプログラミングを行う場合、さまざまな情報を格納するためにさまざまな変数を使用する必要があります。変数は、値を格納するために予約されたメモリ位置に他なりません。これは、変数を作成するときに、メモリにいくらかのスペースを予約することを意味します。
文字、ワイド文字、整数、浮動小数点、倍精度浮動小数点、ブールなどのさまざまなデータ型の情報を格納したい場合があります。変数のデータ型に基づいて、オペレーティングシステムはメモリを割り当て、格納できるものを決定します。予約済みメモリ。
CやRのjavaなどの他のプログラミング言語とは対照的に、変数は一部のデータ型として宣言されていません。変数にはR-Objectが割り当てられ、R-objectのデータ型が変数のデータ型になります。Rオブジェクトには多くの種類があります。よく使われるのは−
- Vectors
- Lists
- Matrices
- Arrays
- Factors
- データフレーム
これらのオブジェクトの中で最も単純なものは vector objectこれらの原子ベクトルには6つのデータ型があり、6つのクラスのベクトルとも呼ばれます。他のRオブジェクトは、原子ベクトルに基づいて構築されています。
| データ・タイプ | 例 | 確認 |
|---|---|---|
| 論理的 | 真/偽 |
次の結果が得られます- |
| 数値 | 12.3、5、999 |
次の結果が得られます- |
| 整数 | 2L、34L、0L |
次の結果が得られます- |
| 繁雑 | 3 + 2i |
次の結果が得られます- |
| キャラクター | 'a'、 '"good"、 "TRUE"、'23 .4' |
次の結果が得られます- |
| 生 | 「こんにちは」は4865 6c 6c6fとして保存されます |
次の結果が得られます- |
Rプログラミングでは、非常に基本的なデータ型は、と呼ばれるRオブジェクトです。 vectors上記のように異なるクラスの要素を保持します。Rでは、クラスの数は上記の6つのタイプだけに限定されないことに注意してください。たとえば、多くのアトミックベクトルを使用して、クラスが配列になる配列を作成できます。
ベクトル
複数の要素を持つベクトルを作成する場合は、次を使用する必要があります c() 要素をベクトルに結合することを意味する関数。
# Create a vector.
apple <- c('red','green',"yellow")
print(apple)
# Get the class of the vector.
print(class(apple))上記のコードを実行すると、次の結果が生成されます-
[1] "red" "green" "yellow"
[1] "character"リスト
リストはRオブジェクトであり、ベクトル、関数、さらには別のリストなど、さまざまな種類の要素をリスト内に含めることができます。
# Create a list.
list1 <- list(c(2,5,3),21.3,sin)
# Print the list.
print(list1)上記のコードを実行すると、次の結果が生成されます-
[[1]]
[1] 2 5 3
[[2]]
[1] 21.3
[[3]]
function (x) .Primitive("sin")行列
行列は、2次元の長方形のデータセットです。行列関数へのベクトル入力を使用して作成できます。
# Create a matrix.
M = matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
print(M)上記のコードを実行すると、次の結果が生成されます-
[,1] [,2] [,3]
[1,] "a" "a" "b"
[2,] "c" "b" "a"配列
行列は2次元に制限されていますが、配列は任意の数の次元にすることができます。配列関数は、必要な数の次元を作成するdim属性を取ります。以下の例では、それぞれ3x3の行列である2つの要素を持つ配列を作成します。
# Create an array.
a <- array(c('green','yellow'),dim = c(3,3,2))
print(a)上記のコードを実行すると、次の結果が生成されます-
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"要因
ファクターは、ベクトルを使用して作成されたrオブジェクトです。ベクトルは、ベクトル内の要素の個別の値とともにラベルとして格納されます。ラベルは、入力ベクトルの数値、文字、ブール値などに関係なく、常に文字です。それらは統計モデリングに役立ちます。
ファクターは、 factor()関数。ザ・nlevels 関数はレベルの数を示します。
# Create a vector.
apple_colors <- c('green','green','yellow','red','red','red','green')
# Create a factor object.
factor_apple <- factor(apple_colors)
# Print the factor.
print(factor_apple)
print(nlevels(factor_apple))上記のコードを実行すると、次の結果が生成されます-
[1] green green yellow red red red green
Levels: green red yellow
[1] 3データフレーム
データフレームは表形式のデータオブジェクトです。データフレームの行列とは異なり、各列にはさまざまなモードのデータを含めることができます。最初の列は数値、2番目の列は文字、3番目の列は論理にすることができます。これは、同じ長さのベクトルのリストです。
データフレームは、 data.frame() 関数。
# Create the data frame.
BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
print(BMI)上記のコードを実行すると、次の結果が生成されます-
gender height weight Age
1 Male 152.0 81 42
2 Male 171.5 93 38
3 Female 165.0 78 26変数は、プログラムが操作できる名前付きストレージを提供します。Rの変数は、アトミックベクトル、アトミックベクトルのグループ、または多くのRオブジェクトの組み合わせを格納できます。有効な変数名は、文字、数字、およびドットまたは下線文字で構成されます。変数名は文字またはドットで始まり、その後に数字が続きません。
| 変数名 | 有効 | 理由 |
|---|---|---|
| var_name2。 | 有効 | 文字、数字、ドット、アンダースコアがあります |
| var_name% | 無効 | 文字 '%'があります。ドット(。)とアンダースコアのみが許可されます。 |
| 2var_name | 無効 | 数字で始まります |
.var_name、 var.name |
有効 | ドット(。)で始めることができますが、ドット(。)の後に数字を続けることはできません。 |
| .2var_name | 無効 | 開始ドットの後に数字が続き、無効になります。 |
| _var_name | 無効 | 無効な_で始まります |
変数の割り当て
変数には、leftward、rightward、equal演算子を使用して値を割り当てることができます。変数の値は、を使用して印刷できます。print() または cat()関数。ザ・cat() この機能は、複数のアイテムを組み合わせて連続印刷出力にします。
# Assignment using equal operator.
var.1 = c(0,1,2,3)
# Assignment using leftward operator.
var.2 <- c("learn","R")
# Assignment using rightward operator.
c(TRUE,1) -> var.3
print(var.1)
cat ("var.1 is ", var.1 ,"\n")
cat ("var.2 is ", var.2 ,"\n")
cat ("var.3 is ", var.3 ,"\n")上記のコードを実行すると、次の結果が生成されます-
[1] 0 1 2 3
var.1 is 0 1 2 3
var.2 is learn R
var.3 is 1 1Note−ベクトルc(TRUE、1)には、論理クラスと数値クラスが混在しています。したがって、論理クラスは数値クラスに強制変換され、TRUEを1にします。
変数のデータ型
Rでは、変数自体はどのデータ型でも宣言されておらず、割り当てられたRオブジェクトのデータ型を取得します。したがって、Rは動的型付け言語と呼ばれます。つまり、プログラムで使用するときに、同じ変数の変数のデータ型を何度も変更できます。
var_x <- "Hello"
cat("The class of var_x is ",class(var_x),"\n")
var_x <- 34.5
cat(" Now the class of var_x is ",class(var_x),"\n")
var_x <- 27L
cat(" Next the class of var_x becomes ",class(var_x),"\n")上記のコードを実行すると、次の結果が生成されます-
The class of var_x is character
Now the class of var_x is numeric
Next the class of var_x becomes integer変数の検索
ワークスペースで現在使用可能なすべての変数を知るために、 ls()関数。また、ls()関数は、パターンを使用して変数名を照合できます。
print(ls())上記のコードを実行すると、次の結果が生成されます-
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"Note −これは、環境で宣言されている変数に応じたサンプル出力です。
ls()関数は、パターンを使用して変数名を照合できます。
# List the variables starting with the pattern "var".
print(ls(pattern = "var"))上記のコードを実行すると、次の結果が生成されます-
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"で始まる変数 dot(.) 非表示の場合は、ls()関数の「all.names = TRUE」引数を使用して一覧表示できます。
print(ls(all.name = TRUE))上記のコードを実行すると、次の結果が生成されます-
[1] ".cars" ".Random.seed" ".var_name" ".varname" ".varname2"
[6] "my var" "my_new_var" "my_var" "var.1" "var.2"
[11]"var.3" "var.name" "var_name2." "var_x"変数の削除
変数は、を使用して削除できます rm()関数。以下では、変数var.3を削除します。印刷時に、変数エラーの値がスローされます。
rm(var.3)
print(var.3)上記のコードを実行すると、次の結果が生成されます-
[1] "var.3"
Error in print(var.3) : object 'var.3' not foundすべての変数は、を使用して削除できます rm() そして ls() 一緒に機能します。
rm(list = ls())
print(ls())上記のコードを実行すると、次の結果が生成されます-
character(0)演算子は、特定の数学的または論理的操作を実行するようにコンパイラーに指示する記号です。R言語には組み込みの演算子が豊富にあり、次のタイプの演算子を提供します。
演算子の種類
Rプログラミングには次のタイプの演算子があります-
- 算術演算子
- 関係演算子
- 論理演算子
- 代入演算子
- その他の演算子
算術演算子
次の表は、R言語でサポートされている算術演算子を示しています。演算子は、ベクトルの各要素に作用します。
| オペレーター | 説明 | 例 |
|---|---|---|
| + | 2つのベクトルを追加します |
次の結果が得られます- |
| − | 最初のベクトルから2番目のベクトルを減算します |
次の結果が得られます- |
| * | 両方のベクトルを乗算します |
次の結果が得られます- |
| / | 最初のベクトルを2番目のベクトルで除算します |
上記のコードを実行すると、次の結果が生成されます- |
| %% | 最初のベクトルの残りを2番目のベクトルで与える |
次の結果が得られます- |
| %/% | 最初のベクトルを2番目のベクトル(商)で除算した結果 |
次の結果が得られます- |
| ^ | 2番目のベクトルの指数に上げられた最初のベクトル |
次の結果が得られます- |
関係演算子
次の表は、R言語でサポートされている関係演算子を示しています。最初のベクトルの各要素は、2番目のベクトルの対応する要素と比較されます。比較の結果はブール値です。
| オペレーター | 説明 | 例 |
|---|---|---|
| >> | 最初のベクトルの各要素が2番目のベクトルの対応する要素より大きいかどうかを確認します。 |
次の結果が得られます- |
| < | 最初のベクトルの各要素が2番目のベクトルの対応する要素よりも小さいかどうかを確認します。 |
次の結果が得られます- |
| == | 最初のベクトルの各要素が2番目のベクトルの対応する要素と等しいかどうかを確認します。 |
次の結果が得られます- |
| <= | 最初のベクトルの各要素が2番目のベクトルの対応する要素以下であるかどうかを確認します。 |
次の結果が得られます- |
| > = | 最初のベクトルの各要素が2番目のベクトルの対応する要素以上であるかどうかを確認します。 |
次の結果が得られます- |
| != | 最初のベクトルの各要素が2番目のベクトルの対応する要素と等しくないかどうかを確認します。 |
次の結果が得られます- |
論理演算子
次の表は、R言語でサポートされている論理演算子を示しています。これは、論理型、数値型、または複合型のベクトルにのみ適用できます。1より大きい数値はすべて、論理値TRUEと見なされます。
最初のベクトルの各要素は、2番目のベクトルの対応する要素と比較されます。比較の結果はブール値です。
| オペレーター | 説明 | 例 |
|---|---|---|
| & | これは、要素ごとの論理AND演算子と呼ばれます。これは、最初のベクトルの各要素を2番目のベクトルの対応する要素と組み合わせ、両方の要素がTRUEの場合にTRUEを出力します。 |
次の結果が得られます- |
| | | これは、要素ごとの論理OR演算子と呼ばれます。これは、最初のベクトルの各要素を2番目のベクトルの対応する要素と組み合わせ、要素の1つがTRUEの場合に出力TRUEを返します。 |
次の結果が得られます- |
| ! | これは論理NOT演算子と呼ばれます。ベクトルの各要素を取り、反対の論理値を与えます。 |
次の結果が得られます- |
論理演算子&&および|| ベクトルの最初の要素のみを考慮し、単一要素のベクトルを出力として提供します。
| オペレーター | 説明 | 例 |
|---|---|---|
| && | 論理AND演算子と呼ばれます。両方のベクトルの最初の要素を取り、両方がTRUEの場合にのみTRUEを与えます。 |
次の結果が得られます- |
| || | 論理OR演算子と呼ばれます。両方のベクトルの最初の要素を取り、それらの1つがTRUEの場合はTRUEを与えます。 |
次の結果が得られます- |
代入演算子
これらの演算子は、ベクトルに値を割り当てるために使用されます。
| オペレーター | 説明 | 例 |
|---|---|---|
| <− または = または << − |
左の割り当てと呼ばれる |
次の結果が得られます- |
| -> または ->> |
正しい割り当てと呼ばれる |
次の結果が得られます- |
その他の演算子
これらの演算子は、一般的な数学的または論理的な計算ではなく、特定の目的のために使用されます。
| オペレーター | 説明 | 例 |
|---|---|---|
| : | コロン演算子。ベクトルの一連の数値を順番に作成します。 |
次の結果が得られます- |
| %に% | この演算子は、要素がベクトルに属しているかどうかを識別するために使用されます。 |
次の結果が得られます- |
| %*% | この演算子は、行列にその転置を乗算するために使用されます。 |
次の結果が得られます- |
意思決定構造では、プログラマーは、プログラムによって評価またはテストされる1つ以上の条件と、条件が次のように決定された場合に実行される1つまたは複数のステートメントを指定する必要があります。 true、およびオプションで、条件が次のように決定された場合に実行される他のステートメント false。
以下は、ほとんどのプログラミング言語に見られる典型的な意思決定構造の一般的な形式です。
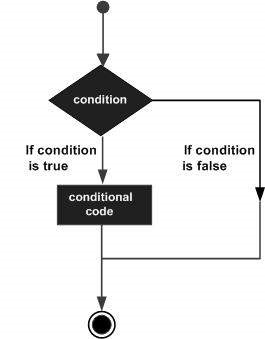
Rは、次のタイプの意思決定ステートメントを提供します。詳細を確認するには、次のリンクをクリックしてください。
| シニア番号 | ステートメントと説明 |
|---|---|
| 1 | ifステートメント アン if ステートメントは、ブール式とそれに続く1つ以上のステートメントで構成されます。 |
| 2 | if ... elseステートメント アン if ステートメントの後にオプションを続けることができます else ブール式がfalseの場合に実行されるステートメント。 |
| 3 | switchステートメント A switch ステートメントを使用すると、値のリストに対して変数が等しいかどうかをテストできます。 |
コードのブロックを数回実行する必要がある場合があります。一般に、ステートメントは順番に実行されます。関数の最初のステートメントが最初に実行され、次に2番目のステートメントが実行されます。
プログラミング言語は、より複雑な実行パスを可能にするさまざまな制御構造を提供します。
ループステートメントを使用すると、ステートメントまたはステートメントのグループを複数回実行できます。以下は、ほとんどのプログラミング言語でのループステートメントの一般的な形式です。
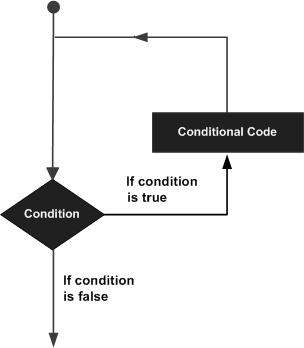
Rプログラミング言語は、ループ要件を処理するために次の種類のループを提供します。詳細を確認するには、次のリンクをクリックしてください。
| シニア番号 | ループの種類と説明 |
|---|---|
| 1 | ループを繰り返す 一連のステートメントを複数回実行し、ループ変数を管理するコードを省略します。 |
| 2 | whileループ 指定された条件が真である間、ステートメントまたはステートメントのグループを繰り返します。ループ本体を実行する前に条件をテストします。 |
| 3 | forループ whileステートメントと同様ですが、ループ本体の最後で条件をテストする点が異なります。 |
ループ制御ステートメント
ループ制御ステートメントは、実行を通常のシーケンスから変更します。実行がスコープを離れると、そのスコープで作成されたすべての自動オブジェクトが破棄されます。
Rは、次の制御ステートメントをサポートします。詳細を確認するには、次のリンクをクリックしてください。
| シニア番号 | 制御ステートメントと説明 |
|---|---|
| 1 | breakステートメント を終了します loop ステートメントを実行し、ループの直後のステートメントに実行を転送します。 |
| 2 | 次のステートメント ザ・ next ステートメントは、Rスイッチの動作をシミュレートします。 |
関数は、特定のタスクを実行するために一緒に編成されたステートメントのセットです。Rには多数の関数が組み込まれており、ユーザーは独自の関数を作成できます。
Rでは、関数はオブジェクトであるため、Rインタープリターは、関数がアクションを実行するために必要な引数とともに、関数に制御を渡すことができます。
次に、関数はそのタスクを実行し、他のオブジェクトに格納される可能性のある結果だけでなく、インタプリタに制御を返します。
関数定義
R関数はキーワードを使用して作成されます function。R関数定義の基本的な構文は次のとおりです。
function_name <- function(arg_1, arg_2, ...) {
Function body
}機能コンポーネント
関数のさまざまな部分は次のとおりです。
Function Name−これは関数の実際の名前です。この名前のオブジェクトとしてR環境に保存されます。
Arguments−引数はプレースホルダーです。関数が呼び出されると、引数に値を渡します。引数はオプションです。つまり、関数に引数を含めることはできません。また、引数にはデフォルト値を設定できます。
Function Body −関数本体には、関数の機能を定義するステートメントのコレクションが含まれています。
Return Value −関数の戻り値は、評価される関数本体の最後の式です。
Rにはたくさんあります in-built最初に定義せずにプログラムで直接呼び出すことができる関数。と呼ばれる独自の関数を作成して使用することもできますuser defined 関数。
内蔵機能
組み込み関数の簡単な例は次のとおりです。 seq()、 mean()、 max()、 sum(x) そして paste(...)など。ユーザーが作成したプログラムによって直接呼び出されます。最も広く使用されているR関数を参照できます。
# Create a sequence of numbers from 32 to 44.
print(seq(32,44))
# Find mean of numbers from 25 to 82.
print(mean(25:82))
# Find sum of numbers frm 41 to 68.
print(sum(41:68))上記のコードを実行すると、次の結果が生成されます-
[1] 32 33 34 35 36 37 38 39 40 41 42 43 44
[1] 53.5
[1] 1526ユーザー定義関数
Rでユーザー定義関数を作成できます。これらはユーザーが望むものに固有であり、一度作成すると、組み込み関数のように使用できます。以下は、関数がどのように作成および使用されるかの例です。
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}関数の呼び出し
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}
# Call the function new.function supplying 6 as an argument.
new.function(6)上記のコードを実行すると、次の結果が生成されます-
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25
[1] 36引数なしで関数を呼び出す
# Create a function without an argument.
new.function <- function() {
for(i in 1:5) {
print(i^2)
}
}
# Call the function without supplying an argument.
new.function()上記のコードを実行すると、次の結果が生成されます-
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25引数値を使用した関数の呼び出し(位置および名前による)
関数呼び出しへの引数は、関数で定義されているのと同じ順序で指定することも、異なる順序で指定して引数の名前に割り当てることもできます。
# Create a function with arguments.
new.function <- function(a,b,c) {
result <- a * b + c
print(result)
}
# Call the function by position of arguments.
new.function(5,3,11)
# Call the function by names of the arguments.
new.function(a = 11, b = 5, c = 3)上記のコードを実行すると、次の結果が生成されます-
[1] 26
[1] 58デフォルトの引数を使用して関数を呼び出す
関数定義で引数の値を定義し、引数を指定せずに関数を呼び出して、デフォルトの結果を取得できます。ただし、引数の新しい値を指定してこのような関数を呼び出し、デフォルト以外の結果を取得することもできます。
# Create a function with arguments.
new.function <- function(a = 3, b = 6) {
result <- a * b
print(result)
}
# Call the function without giving any argument.
new.function()
# Call the function with giving new values of the argument.
new.function(9,5)上記のコードを実行すると、次の結果が生成されます-
[1] 18
[1] 45機能の遅延評価
関数への引数は遅延評価されます。つまり、関数本体で必要な場合にのみ評価されます。
# Create a function with arguments.
new.function <- function(a, b) {
print(a^2)
print(a)
print(b)
}
# Evaluate the function without supplying one of the arguments.
new.function(6)上記のコードを実行すると、次の結果が生成されます-
[1] 36
[1] 6
Error in print(b) : argument "b" is missing, with no defaultRで一重引用符または二重引用符のペア内に書き込まれた値は、文字列として扱われます。内部的にRは、一重引用符で作成した場合でも、すべての文字列を二重引用符で囲んで格納します。
文字列構築に適用されるルール
文字列の最初と最後の引用符は、両方とも二重引用符または両方とも一重引用符である必要があります。それらを混合することはできません。
二重引用符は、一重引用符で開始および終了する文字列に挿入できます。
一重引用符は、二重引用符で開始および終了する文字列に挿入できます。
二重引用符で始まり二重引用符で終わる文字列に二重引用符を挿入することはできません。
一重引用符で始まり一重引用符で終わる文字列に一重引用符を挿入することはできません。
有効な文字列の例
次の例は、Rで文字列を作成する際のルールを明確にしています。
a <- 'Start and end with single quote'
print(a)
b <- "Start and end with double quotes"
print(b)
c <- "single quote ' in between double quotes"
print(c)
d <- 'Double quotes " in between single quote'
print(d)上記のコードを実行すると、次の出力が得られます-
[1] "Start and end with single quote"
[1] "Start and end with double quotes"
[1] "single quote ' in between double quote"
[1] "Double quote \" in between single quote"無効な文字列の例
e <- 'Mixed quotes"
print(e)
f <- 'Single quote ' inside single quote'
print(f)
g <- "Double quotes " inside double quotes"
print(g)スクリプトを実行すると、以下の結果が得られません。
Error: unexpected symbol in:
"print(e)
f <- 'Single"
Execution halted文字列操作
文字列の連結-paste()関数
Rの多くの文字列は、 paste()関数。組み合わせるには、いくつでも引数を取ることができます。
構文
貼り付け関数の基本的な構文は次のとおりです。
paste(..., sep = " ", collapse = NULL)以下は、使用されるパラメーターの説明です-
... 組み合わせる引数をいくつでも表します。
sep引数間の区切り文字を表します。オプションです。
collapse2つの文字列の間のスペースを削除するために使用されます。ただし、1つの文字列の2つの単語内のスペースではありません。
例
a <- "Hello"
b <- 'How'
c <- "are you? "
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(a,b,c, sep = "", collapse = ""))上記のコードを実行すると、次の結果が生成されます-
[1] "Hello How are you? "
[1] "Hello-How-are you? "
[1] "HelloHoware you? "数値と文字列のフォーマット-format()関数
数値と文字列は、を使用して特定のスタイルにフォーマットできます。 format() 関数。
構文
format関数の基本的な構文は次のとおりです。
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))以下は、使用されるパラメーターの説明です-
x ベクトル入力です。
digits 表示される合計桁数です。
nsmall は、小数点の右側の最小桁数です。
scientific 科学的記数法を表示するには、TRUEに設定します。
width 最初に空白を埋めて表示する最小幅を示します。
justify 文字列を左、右、または中央に表示します。
例
# Total number of digits displayed. Last digit rounded off.
result <- format(23.123456789, digits = 9)
print(result)
# Display numbers in scientific notation.
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# The minimum number of digits to the right of the decimal point.
result <- format(23.47, nsmall = 5)
print(result)
# Format treats everything as a string.
result <- format(6)
print(result)
# Numbers are padded with blank in the beginning for width.
result <- format(13.7, width = 6)
print(result)
# Left justify strings.
result <- format("Hello", width = 8, justify = "l")
print(result)
# Justfy string with center.
result <- format("Hello", width = 8, justify = "c")
print(result)上記のコードを実行すると、次の結果が生成されます-
[1] "23.1234568"
[1] "6.000000e+00" "1.314521e+01"
[1] "23.47000"
[1] "6"
[1] " 13.7"
[1] "Hello "
[1] " Hello "文字列内の文字数を数える-nchar()関数
この関数は、文字列内のスペースを含む文字数をカウントします。
構文
nchar()関数の基本的な構文は次のとおりです。
nchar(x)以下は、使用されるパラメーターの説明です-
x ベクトル入力です。
例
result <- nchar("Count the number of characters")
print(result)上記のコードを実行すると、次の結果が生成されます-
[1] 30大文字と小文字の変更-toupper()およびtolower()関数
これらの関数は、文字列の文字の大文字と小文字を変更します。
構文
toupper()およびtolower()関数の基本的な構文は次のとおりです。
toupper(x)
tolower(x)以下は、使用されるパラメーターの説明です-
x ベクトル入力です。
例
# Changing to Upper case.
result <- toupper("Changing To Upper")
print(result)
# Changing to lower case.
result <- tolower("Changing To Lower")
print(result)上記のコードを実行すると、次の結果が生成されます-
[1] "CHANGING TO UPPER"
[1] "changing to lower"文字列の一部を抽出する-substring()関数
この関数は、文字列の一部を抽出します。
構文
substring()関数の基本的な構文は次のとおりです。
substring(x,first,last)以下は、使用されるパラメーターの説明です-
x 文字ベクトル入力です。
first 抽出される最初の文字の位置です。
last 抽出される最後の文字の位置です。
例
# Extract characters from 5th to 7th position.
result <- substring("Extract", 5, 7)
print(result)上記のコードを実行すると、次の結果が生成されます-
[1] "act"ベクトルは最も基本的なRデータオブジェクトであり、6種類の原子ベクトルがあります。それらは、論理、整数、二重、複合、文字、および生です。
ベクトルの作成
単一要素ベクトル
Rに値を1つだけ書き込んだ場合でも、その値は長さ1のベクトルになり、上記のベクトルタイプのいずれかに属します。
# Atomic vector of type character.
print("abc");
# Atomic vector of type double.
print(12.5)
# Atomic vector of type integer.
print(63L)
# Atomic vector of type logical.
print(TRUE)
# Atomic vector of type complex.
print(2+3i)
# Atomic vector of type raw.
print(charToRaw('hello'))上記のコードを実行すると、次の結果が生成されます-
[1] "abc"
[1] 12.5
[1] 63
[1] TRUE
[1] 2+3i
[1] 68 65 6c 6c 6f複数の要素のベクトル
Using colon operator with numeric data
# Creating a sequence from 5 to 13.
v <- 5:13
print(v)
# Creating a sequence from 6.6 to 12.6.
v <- 6.6:12.6
print(v)
# If the final element specified does not belong to the sequence then it is discarded.
v <- 3.8:11.4
print(v)上記のコードを実行すると、次の結果が生成されます-
[1] 5 6 7 8 9 10 11 12 13
[1] 6.6 7.6 8.6 9.6 10.6 11.6 12.6
[1] 3.8 4.8 5.8 6.8 7.8 8.8 9.8 10.8Using sequence (Seq.) operator
# Create vector with elements from 5 to 9 incrementing by 0.4.
print(seq(5, 9, by = 0.4))上記のコードを実行すると、次の結果が生成されます-
[1] 5.0 5.4 5.8 6.2 6.6 7.0 7.4 7.8 8.2 8.6 9.0Using the c() function
要素の1つが文字である場合、文字以外の値は文字タイプに強制変換されます。
# The logical and numeric values are converted to characters.
s <- c('apple','red',5,TRUE)
print(s)上記のコードを実行すると、次の結果が生成されます-
[1] "apple" "red" "5" "TRUE"ベクトル要素へのアクセス
ベクトルの要素には、インデックスを使用してアクセスします。ザ・[ ] bracketsインデックス作成に使用されます。インデックス付けは位置1から始まります。インデックスに負の値を指定すると、その要素が結果から削除されます。TRUE、 FALSE または 0 そして 1 インデックス作成にも使用できます。
# Accessing vector elements using position.
t <- c("Sun","Mon","Tue","Wed","Thurs","Fri","Sat")
u <- t[c(2,3,6)]
print(u)
# Accessing vector elements using logical indexing.
v <- t[c(TRUE,FALSE,FALSE,FALSE,FALSE,TRUE,FALSE)]
print(v)
# Accessing vector elements using negative indexing.
x <- t[c(-2,-5)]
print(x)
# Accessing vector elements using 0/1 indexing.
y <- t[c(0,0,0,0,0,0,1)]
print(y)上記のコードを実行すると、次の結果が生成されます-
[1] "Mon" "Tue" "Fri"
[1] "Sun" "Fri"
[1] "Sun" "Tue" "Wed" "Fri" "Sat"
[1] "Sun"ベクトル操作
ベクトル演算
同じ長さの2つのベクトルを加算、減算、乗算、または除算して、結果をベクトル出力として得ることができます。
# Create two vectors.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11,0,8,1,2)
# Vector addition.
add.result <- v1+v2
print(add.result)
# Vector subtraction.
sub.result <- v1-v2
print(sub.result)
# Vector multiplication.
multi.result <- v1*v2
print(multi.result)
# Vector division.
divi.result <- v1/v2
print(divi.result)上記のコードを実行すると、次の結果が生成されます-
[1] 7 19 4 13 1 13
[1] -1 -3 4 -3 -1 9
[1] 12 88 0 40 0 22
[1] 0.7500000 0.7272727 Inf 0.6250000 0.0000000 5.5000000ベクトル要素のリサイクル
長さが等しくない2つのベクトルに算術演算を適用すると、短い方のベクトルの要素が再利用されて演算が完了します。
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11)
# V2 becomes c(4,11,4,11,4,11)
add.result <- v1+v2
print(add.result)
sub.result <- v1-v2
print(sub.result)上記のコードを実行すると、次の結果が生成されます-
[1] 7 19 8 16 4 22
[1] -1 -3 0 -6 -4 0ベクトル要素の並べ替え
ベクトル内の要素は、 sort() 関数。
v <- c(3,8,4,5,0,11, -9, 304)
# Sort the elements of the vector.
sort.result <- sort(v)
print(sort.result)
# Sort the elements in the reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)
# Sorting character vectors.
v <- c("Red","Blue","yellow","violet")
sort.result <- sort(v)
print(sort.result)
# Sorting character vectors in reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)上記のコードを実行すると、次の結果が生成されます-
[1] -9 0 3 4 5 8 11 304
[1] 304 11 8 5 4 3 0 -9
[1] "Blue" "Red" "violet" "yellow"
[1] "yellow" "violet" "Red" "Blue"リストは、-数値、文字列、ベクトル、およびその中に別のリストなど、さまざまなタイプの要素を含むRオブジェクトです。リストには、その要素として行列または関数を含めることもできます。リストはを使用して作成されますlist() 関数。
リストの作成
以下は、文字列、数値、ベクトル、および論理値を含むリストを作成する例です。
# Create a list containing strings, numbers, vectors and a logical
# values.
list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1)
print(list_data)上記のコードを実行すると、次の結果が生成されます-
[[1]]
[1] "Red"
[[2]]
[1] "Green"
[[3]]
[1] 21 32 11
[[4]]
[1] TRUE
[[5]]
[1] 51.23
[[6]]
[1] 119.1ネーミングリスト要素
リスト要素には名前を付けることができ、これらの名前を使用してアクセスできます。
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Show the list.
print(list_data)上記のコードを実行すると、次の結果が生成されます-
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Matrix
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
$A_Inner_list $A_Inner_list[[1]]
[1] "green"
$A_Inner_list[[2]]
[1] 12.3リスト要素へのアクセス
リストの要素には、リスト内の要素のインデックスからアクセスできます。名前付きリストの場合は、名前を使用してアクセスすることもできます。
上記の例のリストを引き続き使用します-
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Access the first element of the list.
print(list_data[1])
# Access the thrid element. As it is also a list, all its elements will be printed.
print(list_data[3])
# Access the list element using the name of the element.
print(list_data$A_Matrix)上記のコードを実行すると、次の結果が生成されます-
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Inner_list
$A_Inner_list[[1]] [1] "green" $A_Inner_list[[2]]
[1] 12.3
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8リスト要素の操作
以下に示すように、リスト要素を追加、削除、更新できます。リストの最後でのみ要素を追加および削除できます。ただし、任意の要素を更新できます。
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Add element at the end of the list.
list_data[4] <- "New element"
print(list_data[4])
# Remove the last element.
list_data[4] <- NULL
# Print the 4th Element.
print(list_data[4])
# Update the 3rd Element.
list_data[3] <- "updated element"
print(list_data[3])上記のコードを実行すると、次の結果が生成されます-
[[1]]
[1] "New element"
$<NA> NULL $`A Inner list`
[1] "updated element"リストのマージ
すべてのリストを1つのlist()関数内に配置することで、多くのリストを1つのリストにマージできます。
# Create two lists.
list1 <- list(1,2,3)
list2 <- list("Sun","Mon","Tue")
# Merge the two lists.
merged.list <- c(list1,list2)
# Print the merged list.
print(merged.list)上記のコードを実行すると、次の結果が生成されます-
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "Sun"
[[5]]
[1] "Mon"
[[6]]
[1] "Tue"リストをベクトルに変換する
リストをベクトルに変換して、ベクトルの要素をさらに操作するために使用できるようにすることができます。ベクトルに対するすべての算術演算は、リストがベクトルに変換された後に適用できます。この変換を行うには、unlist()関数。リストを入力として受け取り、ベクトルを生成します。
# Create lists.
list1 <- list(1:5)
print(list1)
list2 <-list(10:14)
print(list2)
# Convert the lists to vectors.
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# Now add the vectors
result <- v1+v2
print(result)上記のコードを実行すると、次の結果が生成されます-
[[1]]
[1] 1 2 3 4 5
[[1]]
[1] 10 11 12 13 14
[1] 1 2 3 4 5
[1] 10 11 12 13 14
[1] 11 13 15 17 19行列は、要素が2次元の長方形のレイアウトに配置されたRオブジェクトです。それらには同じ原子タイプの要素が含まれています。文字のみまたは論理値のみを含む行列を作成できますが、それらはあまり役に立ちません。数学計算で使用する数値要素を含む行列を使用します。
マトリックスは、 matrix() 関数。
構文
Rで行列を作成するための基本的な構文は次のとおりです。
matrix(data, nrow, ncol, byrow, dimnames)以下は、使用されるパラメーターの説明です-
data は、行列のデータ要素となる入力ベクトルです。
nrow 作成される行の数です。
ncol 作成する列の数です。
byrow論理的な手がかりです。TRUEの場合、入力ベクトル要素は行ごとに配置されます。
dimname 行と列に割り当てられた名前です。
例
数値のベクトルを入力として取る行列を作成します。
# Elements are arranged sequentially by row.
M <- matrix(c(3:14), nrow = 4, byrow = TRUE)
print(M)
# Elements are arranged sequentially by column.
N <- matrix(c(3:14), nrow = 4, byrow = FALSE)
print(N)
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)上記のコードを実行すると、次の結果が生成されます-
[,1] [,2] [,3]
[1,] 3 4 5
[2,] 6 7 8
[3,] 9 10 11
[4,] 12 13 14
[,1] [,2] [,3]
[1,] 3 7 11
[2,] 4 8 12
[3,] 5 9 13
[4,] 6 10 14
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14マトリックスの要素へのアクセス
行列の要素には、要素の列と行のインデックスを使用してアクセスできます。上記の行列Pを考慮して、以下の特定の要素を見つけます。
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
# Create the matrix.
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
# Access the element at 3rd column and 1st row.
print(P[1,3])
# Access the element at 2nd column and 4th row.
print(P[4,2])
# Access only the 2nd row.
print(P[2,])
# Access only the 3rd column.
print(P[,3])上記のコードを実行すると、次の結果が生成されます-
[1] 5
[1] 13
col1 col2 col3
6 7 8
row1 row2 row3 row4
5 8 11 14マトリックス計算
R演算子を使用して、行列に対してさまざまな数学演算が実行されます。操作の結果も行列になります。
次元(行と列の数)は、操作に関係する行列で同じである必要があります。
行列の加算と減算
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Add the matrices.
result <- matrix1 + matrix2
cat("Result of addition","\n")
print(result)
# Subtract the matrices
result <- matrix1 - matrix2
cat("Result of subtraction","\n")
print(result)上記のコードを実行すると、次の結果が生成されます-
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of addition
[,1] [,2] [,3]
[1,] 8 -1 5
[2,] 11 13 10
Result of subtraction
[,1] [,2] [,3]
[1,] -2 -1 -1
[2,] 7 -5 2行列の乗算と除算
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Multiply the matrices.
result <- matrix1 * matrix2
cat("Result of multiplication","\n")
print(result)
# Divide the matrices
result <- matrix1 / matrix2
cat("Result of division","\n")
print(result)上記のコードを実行すると、次の結果が生成されます-
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of multiplication
[,1] [,2] [,3]
[1,] 15 0 6
[2,] 18 36 24
Result of division
[,1] [,2] [,3]
[1,] 0.6 -Inf 0.6666667
[2,] 4.5 0.4444444 1.5000000配列は、3次元以上のデータを格納できるRデータオブジェクトです。例-次元(2、3、4)の配列を作成すると、それぞれ2行3列の4つの長方形行列が作成されます。配列はデータ型のみを格納できます。
配列は、を使用して作成されます array()関数。入力としてベクトルを受け取り、の値を使用しますdim 配列を作成するためのパラメーター。
例
次の例では、それぞれ3行3列の2つの3x3行列の配列を作成します。
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2))
print(result)上記のコードを実行すると、次の結果が生成されます-
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15列と行の命名
を使用して、配列内の行、列、および行列に名前を付けることができます。 dimnames パラメータ。
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,
matrix.names))
print(result)上記のコードを実行すると、次の結果が生成されます-
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15配列要素へのアクセス
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,
column.names, matrix.names))
# Print the third row of the second matrix of the array.
print(result[3,,2])
# Print the element in the 1st row and 3rd column of the 1st matrix.
print(result[1,3,1])
# Print the 2nd Matrix.
print(result[,,2])上記のコードを実行すると、次の結果が生成されます-
COL1 COL2 COL3
3 12 15
[1] 13
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15配列要素の操作
配列は多次元の行列で構成されているため、配列の要素に対する操作は、行列の要素にアクセスすることによって実行されます。
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
array1 <- array(c(vector1,vector2),dim = c(3,3,2))
# Create two vectors of different lengths.
vector3 <- c(9,1,0)
vector4 <- c(6,0,11,3,14,1,2,6,9)
array2 <- array(c(vector1,vector2),dim = c(3,3,2))
# create matrices from these arrays.
matrix1 <- array1[,,2]
matrix2 <- array2[,,2]
# Add the matrices.
result <- matrix1+matrix2
print(result)上記のコードを実行すると、次の結果が生成されます-
[,1] [,2] [,3]
[1,] 10 20 26
[2,] 18 22 28
[3,] 6 24 30配列要素全体の計算
を使用して、配列内の要素全体で計算を行うことができます。 apply() 関数。
構文
apply(x, margin, fun)以下は、使用されるパラメーターの説明です-
x は配列です。
margin 使用されるデータセットの名前です。
fun 配列の要素全体に適用される関数です。
例
以下のapply()関数を使用して、すべての行列にわたる配列の行の要素の合計を計算します。
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
new.array <- array(c(vector1,vector2),dim = c(3,3,2))
print(new.array)
# Use apply to calculate the sum of the rows across all the matrices.
result <- apply(new.array, c(1), sum)
print(result)上記のコードを実行すると、次の結果が生成されます-
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
[1] 56 68 60ファクターは、データを分類してレベルとして保存するために使用されるデータオブジェクトです。文字列と整数の両方を格納できます。これらは、一意の値の数が限られている列で役立ちます。「男性」、「女性」、True、Falseなどのように、統計モデリングのデータ分析に役立ちます。
ファクターは、 factor () ベクトルを入力として使用する関数。
例
# Create a vector as input.
data <- c("East","West","East","North","North","East","West","West","West","East","North")
print(data)
print(is.factor(data))
# Apply the factor function.
factor_data <- factor(data)
print(factor_data)
print(is.factor(factor_data))上記のコードを実行すると、次の結果が生成されます-
[1] "East" "West" "East" "North" "North" "East" "West" "West" "West" "East" "North"
[1] FALSE
[1] East West East North North East West West West East North
Levels: East North West
[1] TRUEデータフレームの要因
テキストデータの列を含むデータフレームを作成すると、Rはテキスト列をカテゴリデータとして扱い、その上に要素を作成します。
# Create the vectors for data frame.
height <- c(132,151,162,139,166,147,122)
weight <- c(48,49,66,53,67,52,40)
gender <- c("male","male","female","female","male","female","male")
# Create the data frame.
input_data <- data.frame(height,weight,gender)
print(input_data)
# Test if the gender column is a factor.
print(is.factor(input_data$gender)) # Print the gender column so see the levels. print(input_data$gender)上記のコードを実行すると、次の結果が生成されます-
height weight gender
1 132 48 male
2 151 49 male
3 162 66 female
4 139 53 female
5 166 67 male
6 147 52 female
7 122 40 male
[1] TRUE
[1] male male female female male female male
Levels: female maleレベルの順序を変更する
因子のレベルの順序は、レベルの新しい順序で因子関数を再度適用することによって変更できます。
data <- c("East","West","East","North","North","East","West",
"West","West","East","North")
# Create the factors
factor_data <- factor(data)
print(factor_data)
# Apply the factor function with required order of the level.
new_order_data <- factor(factor_data,levels = c("East","West","North"))
print(new_order_data)上記のコードを実行すると、次の結果が生成されます-
[1] East West East North North East West West West East North
Levels: East North West
[1] East West East North North East West West West East North
Levels: East West North因子レベルの生成
を使用して因子レベルを生成できます gl()関数。入力として2つの整数を取り、レベルの数と各レベルの回数を示します。
構文
gl(n, k, labels)以下は、使用されるパラメーターの説明です-
n レベル数を与える整数です。
k は、複製の数を示す整数です。
labels 結果の因子レベルのラベルのベクトルです。
例
v <- gl(3, 4, labels = c("Tampa", "Seattle","Boston"))
print(v)上記のコードを実行すると、次の結果が生成されます-
Tampa Tampa Tampa Tampa Seattle Seattle Seattle Seattle Boston
[10] Boston Boston Boston
Levels: Tampa Seattle Bostonデータフレームは、テーブルまたは2次元配列のような構造であり、各列には1つの変数の値が含まれ、各行には各列の値のセットが1つ含まれます。
データフレームの特徴は次のとおりです。
- 列名は空でない必要があります。
- 行名は一意である必要があります。
- データフレームに格納されるデータは、数値、係数、または文字タイプにすることができます。
- 各列には、同じ数のデータ項目が含まれている必要があります。
データフレームを作成する
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the data frame.
print(emp.data)上記のコードを実行すると、次の結果が生成されます-
emp_id emp_name salary start_date
1 1 Rick 623.30 2012-01-01
2 2 Dan 515.20 2013-09-23
3 3 Michelle 611.00 2014-11-15
4 4 Ryan 729.00 2014-05-11
5 5 Gary 843.25 2015-03-27データフレームの構造を取得する
データフレームの構造は、を使用して確認できます。 str() 関数。
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Get the structure of the data frame.
str(emp.data)上記のコードを実行すると、次の結果が生成されます-
'data.frame': 5 obs. of 4 variables:
$ emp_id : int 1 2 3 4 5 $ emp_name : chr "Rick" "Dan" "Michelle" "Ryan" ...
$ salary : num 623 515 611 729 843 $ start_date: Date, format: "2012-01-01" "2013-09-23" "2014-11-15" "2014-05-11" ...データフレーム内のデータの要約
データの統計的要約と性質は、以下を適用することによって取得できます。 summary() 関数。
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the summary.
print(summary(emp.data))上記のコードを実行すると、次の結果が生成されます-
emp_id emp_name salary start_date
Min. :1 Length:5 Min. :515.2 Min. :2012-01-01
1st Qu.:2 Class :character 1st Qu.:611.0 1st Qu.:2013-09-23
Median :3 Mode :character Median :623.3 Median :2014-05-11
Mean :3 Mean :664.4 Mean :2014-01-14
3rd Qu.:4 3rd Qu.:729.0 3rd Qu.:2014-11-15
Max. :5 Max. :843.2 Max. :2015-03-27データフレームからデータを抽出する
列名を使用して、データフレームから特定の列を抽出します。
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01","2013-09-23","2014-11-15","2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract Specific columns.
result <- data.frame(emp.data$emp_name,emp.data$salary)
print(result)上記のコードを実行すると、次の結果が生成されます-
emp.data.emp_name emp.data.salary
1 Rick 623.30
2 Dan 515.20
3 Michelle 611.00
4 Ryan 729.00
5 Gary 843.25最初の2行を抽出し、次にすべての列を抽出します
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract first two rows.
result <- emp.data[1:2,]
print(result)上記のコードを実行すると、次の結果が生成されます-
emp_id emp_name salary start_date
1 1 Rick 623.3 2012-01-01
2 2 Dan 515.2 2013-09-232番目と4番目の列で3番目と5番目の行を抽出します
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract 3rd and 5th row with 2nd and 4th column.
result <- emp.data[c(3,5),c(2,4)]
print(result)上記のコードを実行すると、次の結果が生成されます-
emp_name start_date
3 Michelle 2014-11-15
5 Gary 2015-03-27データフレームを展開
データフレームは、列と行を追加することで拡張できます。
列を追加
新しい列名を使用して列ベクトルを追加するだけです。
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Add the "dept" coulmn.
emp.data$dept <- c("IT","Operations","IT","HR","Finance")
v <- emp.data
print(v)上記のコードを実行すると、次の結果が生成されます-
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance行を追加する
既存のデータフレームに永続的に行を追加するには、既存のデータフレームと同じ構造で新しい行を取り込み、を使用する必要があります。 rbind() 関数。
以下の例では、新しい行を含むデータフレームを作成し、それを既存のデータフレームとマージして、最終的なデータフレームを作成します。
# Create the first data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
dept = c("IT","Operations","IT","HR","Finance"),
stringsAsFactors = FALSE
)
# Create the second data frame
emp.newdata <- data.frame(
emp_id = c (6:8),
emp_name = c("Rasmi","Pranab","Tusar"),
salary = c(578.0,722.5,632.8),
start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")),
dept = c("IT","Operations","Fianance"),
stringsAsFactors = FALSE
)
# Bind the two data frames.
emp.finaldata <- rbind(emp.data,emp.newdata)
print(emp.finaldata)上記のコードを実行すると、次の結果が生成されます-
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance
6 6 Rasmi 578.00 2013-05-21 IT
7 7 Pranab 722.50 2013-07-30 Operations
8 8 Tusar 632.80 2014-06-17 FiananceRパッケージは、R関数、コンパイルされたコード、およびサンプルデータのコレクションです。それらはと呼ばれるディレクトリの下に保存されます"library"R環境で。デフォルトでは、Rはインストール中に一連のパッケージをインストールします。後で特定の目的で必要になったときに、さらにパッケージが追加されます。Rコンソールを起動すると、デフォルトでデフォルトのパッケージのみが使用可能になります。すでにインストールされている他のパッケージは、それらを使用するRプログラムで使用するために、明示的にロードする必要があります。
R言語で利用可能なすべてのパッケージは、Rパッケージにリストされています。
以下は、Rパッケージをチェック、検証、および使用するために使用されるコマンドのリストです。
利用可能なRパッケージを確認する
Rパッケージを含むライブラリの場所を取得する
.libPaths()上記のコードを実行すると、次のような結果になります。PCのローカル設定によって異なる場合があります。
[2] "C:/Program Files/R/R-3.2.2/library"インストールされているすべてのパッケージのリストを取得します
library()上記のコードを実行すると、次のような結果になります。PCのローカル設定によって異なる場合があります。
Packages in library ‘C:/Program Files/R/R-3.2.2/library’:
base The R Base Package
boot Bootstrap Functions (Originally by Angelo Canty
for S)
class Functions for Classification
cluster "Finding Groups in Data": Cluster Analysis
Extended Rousseeuw et al.
codetools Code Analysis Tools for R
compiler The R Compiler Package
datasets The R Datasets Package
foreign Read Data Stored by 'Minitab', 'S', 'SAS',
'SPSS', 'Stata', 'Systat', 'Weka', 'dBase', ...
graphics The R Graphics Package
grDevices The R Graphics Devices and Support for Colours
and Fonts
grid The Grid Graphics Package
KernSmooth Functions for Kernel Smoothing Supporting Wand
& Jones (1995)
lattice Trellis Graphics for R
MASS Support Functions and Datasets for Venables and
Ripley's MASS
Matrix Sparse and Dense Matrix Classes and Methods
methods Formal Methods and Classes
mgcv Mixed GAM Computation Vehicle with GCV/AIC/REML
Smoothness Estimation
nlme Linear and Nonlinear Mixed Effects Models
nnet Feed-Forward Neural Networks and Multinomial
Log-Linear Models
parallel Support for Parallel computation in R
rpart Recursive Partitioning and Regression Trees
spatial Functions for Kriging and Point Pattern
Analysis
splines Regression Spline Functions and Classes
stats The R Stats Package
stats4 Statistical Functions using S4 Classes
survival Survival Analysis
tcltk Tcl/Tk Interface
tools Tools for Package Development
utils The R Utils PackageR環境に現在ロードされているすべてのパッケージを取得します
search()上記のコードを実行すると、次のような結果になります。PCのローカル設定によって異なる場合があります。
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"新しいパッケージをインストールする
新しいRパッケージを追加する方法は2つあります。1つはCRANディレクトリから直接インストールする方法で、もう1つはパッケージをローカルシステムにダウンロードして手動でインストールする方法です。
CRANから直接インストール
次のコマンドは、CRAN Webページから直接パッケージを取得し、R環境にパッケージをインストールします。最も近いミラーを選択するように求められる場合があります。お住まいの地域に適したものを選択してください。
install.packages("Package Name")
# Install the package named "XML".
install.packages("XML")パッケージを手動でインストールする
リンクRパッケージに移動して、必要なパッケージをダウンロードします。パッケージをとして保存します.zip ローカルシステムの適切な場所にファイルします。
これで、次のコマンドを実行して、このパッケージをR環境にインストールできます。
install.packages(file_name_with_path, repos = NULL, type = "source")
# Install the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")パッケージをライブラリにロード
パッケージをコードで使用する前に、現在のR環境にロードする必要があります。また、以前にインストールされているが、現在の環境では使用できないパッケージをロードする必要があります。
次のコマンドを使用してパッケージをロードします-
library("package Name", lib.loc = "path to library")
# Load the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")Rでのデータの再形成とは、データを行と列に編成する方法を変更することです。ほとんどの場合、Rでのデータ処理は、入力データをデータフレームとして取得することによって行われます。データフレームの行と列からデータを抽出するのは簡単ですが、受信した形式とは異なる形式のデータフレームが必要になる場合があります。Rには、データフレーム内で行を分割、マージ、および列に、またはその逆に変更するための多くの関数があります。
データフレーム内の列と行の結合
複数のベクトルを結合して、を使用してデータフレームを作成できます。 cbind()関数。また、を使用して2つのデータフレームをマージできますrbind() 関数。
# Create vector objects.
city <- c("Tampa","Seattle","Hartford","Denver")
state <- c("FL","WA","CT","CO")
zipcode <- c(33602,98104,06161,80294)
# Combine above three vectors into one data frame.
addresses <- cbind(city,state,zipcode)
# Print a header.
cat("# # # # The First data frame\n")
# Print the data frame.
print(addresses)
# Create another data frame with similar columns
new.address <- data.frame(
city = c("Lowry","Charlotte"),
state = c("CO","FL"),
zipcode = c("80230","33949"),
stringsAsFactors = FALSE
)
# Print a header.
cat("# # # The Second data frame\n")
# Print the data frame.
print(new.address)
# Combine rows form both the data frames.
all.addresses <- rbind(addresses,new.address)
# Print a header.
cat("# # # The combined data frame\n")
# Print the result.
print(all.addresses)上記のコードを実行すると、次の結果が生成されます-
# # # # The First data frame
city state zipcode
[1,] "Tampa" "FL" "33602"
[2,] "Seattle" "WA" "98104"
[3,] "Hartford" "CT" "6161"
[4,] "Denver" "CO" "80294"
# # # The Second data frame
city state zipcode
1 Lowry CO 80230
2 Charlotte FL 33949
# # # The combined data frame
city state zipcode
1 Tampa FL 33602
2 Seattle WA 98104
3 Hartford CT 6161
4 Denver CO 80294
5 Lowry CO 80230
6 Charlotte FL 33949データフレームのマージ
を使用して2つのデータフレームをマージできます merge()関数。データフレームには、マージが行われるのと同じ列名が必要です。
以下の例では、ライブラリ名「MASS」で利用可能なピマインディアン女性の糖尿病に関するデータセットを検討します。血圧( "bp")とボディマス指数( "bmi")の値に基づいて2つのデータセットをマージします。マージするためにこれらの2つの列を選択すると、両方のデータセットでこれらの2つの変数の値が一致するレコードが結合され、単一のデータフレームが形成されます。
library(MASS)
merged.Pima <- merge(x = Pima.te, y = Pima.tr,
by.x = c("bp", "bmi"),
by.y = c("bp", "bmi")
)
print(merged.Pima)
nrow(merged.Pima)上記のコードを実行すると、次の結果が生成されます-
bp bmi npreg.x glu.x skin.x ped.x age.x type.x npreg.y glu.y skin.y ped.y
1 60 33.8 1 117 23 0.466 27 No 2 125 20 0.088
2 64 29.7 2 75 24 0.370 33 No 2 100 23 0.368
3 64 31.2 5 189 33 0.583 29 Yes 3 158 13 0.295
4 64 33.2 4 117 27 0.230 24 No 1 96 27 0.289
5 66 38.1 3 115 39 0.150 28 No 1 114 36 0.289
6 68 38.5 2 100 25 0.324 26 No 7 129 49 0.439
7 70 27.4 1 116 28 0.204 21 No 0 124 20 0.254
8 70 33.1 4 91 32 0.446 22 No 9 123 44 0.374
9 70 35.4 9 124 33 0.282 34 No 6 134 23 0.542
10 72 25.6 1 157 21 0.123 24 No 4 99 17 0.294
11 72 37.7 5 95 33 0.370 27 No 6 103 32 0.324
12 74 25.9 9 134 33 0.460 81 No 8 126 38 0.162
13 74 25.9 1 95 21 0.673 36 No 8 126 38 0.162
14 78 27.6 5 88 30 0.258 37 No 6 125 31 0.565
15 78 27.6 10 122 31 0.512 45 No 6 125 31 0.565
16 78 39.4 2 112 50 0.175 24 No 4 112 40 0.236
17 88 34.5 1 117 24 0.403 40 Yes 4 127 11 0.598
age.y type.y
1 31 No
2 21 No
3 24 No
4 21 No
5 21 No
6 43 Yes
7 36 Yes
8 40 No
9 29 Yes
10 28 No
11 55 No
12 39 No
13 39 No
14 49 Yes
15 49 Yes
16 38 No
17 28 No
[1] 17溶解と鋳造
Rプログラミングの最も興味深い側面の1つは、データの形状を複数のステップで変更して、目的の形状を取得することです。これを行うために使用される関数は呼び出されますmelt() そして cast()。
「MASS」というライブラリに存在するshipsというデータセットを検討します。
library(MASS)
print(ships)上記のコードを実行すると、次の結果が生成されます-
type year period service incidents
1 A 60 60 127 0
2 A 60 75 63 0
3 A 65 60 1095 3
4 A 65 75 1095 4
5 A 70 60 1512 6
.............
.............
8 A 75 75 2244 11
9 B 60 60 44882 39
10 B 60 75 17176 29
11 B 65 60 28609 58
............
............
17 C 60 60 1179 1
18 C 60 75 552 1
19 C 65 60 781 0
............
............データを溶かす
次に、データを溶かして整理し、タイプと年以外のすべての列を複数の行に変換します。
molten.ships <- melt(ships, id = c("type","year"))
print(molten.ships)上記のコードを実行すると、次の結果が生成されます-
type year variable value
1 A 60 period 60
2 A 60 period 75
3 A 65 period 60
4 A 65 period 75
............
............
9 B 60 period 60
10 B 60 period 75
11 B 65 period 60
12 B 65 period 75
13 B 70 period 60
...........
...........
41 A 60 service 127
42 A 60 service 63
43 A 65 service 1095
...........
...........
70 D 70 service 1208
71 D 75 service 0
72 D 75 service 2051
73 E 60 service 45
74 E 60 service 0
75 E 65 service 789
...........
...........
101 C 70 incidents 6
102 C 70 incidents 2
103 C 75 incidents 0
104 C 75 incidents 1
105 D 60 incidents 0
106 D 60 incidents 0
...........
...........溶融データをキャストする
溶融したデータを新しい形式にキャストして、各年の各タイプの船の集計を作成できます。それはを使用して行われますcast() 関数。
recasted.ship <- cast(molten.ships, type+year~variable,sum)
print(recasted.ship)上記のコードを実行すると、次の結果が生成されます-
type year period service incidents
1 A 60 135 190 0
2 A 65 135 2190 7
3 A 70 135 4865 24
4 A 75 135 2244 11
5 B 60 135 62058 68
6 B 65 135 48979 111
7 B 70 135 20163 56
8 B 75 135 7117 18
9 C 60 135 1731 2
10 C 65 135 1457 1
11 C 70 135 2731 8
12 C 75 135 274 1
13 D 60 135 356 0
14 D 65 135 480 0
15 D 70 135 1557 13
16 D 75 135 2051 4
17 E 60 135 45 0
18 E 65 135 1226 14
19 E 70 135 3318 17
20 E 75 135 542 1Rでは、R環境の外部に保存されているファイルからデータを読み取ることができます。また、オペレーティングシステムによって保存およびアクセスされるファイルにデータを書き込むこともできます。Rは、csv、excel、xmlなどのさまざまなファイル形式の読み取りと書き込みを行うことができます。
この章では、csvファイルからデータを読み取り、csvファイルにデータを書き込む方法を学習します。Rがファイルを読み取れるように、ファイルは現在の作業ディレクトリに存在する必要があります。もちろん、独自のディレクトリを設定して、そこからファイルを読み取ることもできます。
作業ディレクトリの取得と設定
Rワークスペースが指しているディレクトリを確認するには、 getwd()関数。を使用して新しい作業ディレクトリを設定することもできますsetwd()関数。
# Get and print current working directory.
print(getwd())
# Set current working directory.
setwd("/web/com")
# Get and print current working directory.
print(getwd())上記のコードを実行すると、次の結果が生成されます-
[1] "/web/com/1441086124_2016"
[1] "/web/com"この結果は、OSと作業している現在のディレクトリによって異なります。
CSVファイルとして入力
csvファイルは、列の値がコンマで区切られたテキストファイルです。名前の付いたファイルに存在する次のデータについて考えてみましょう。input.csv。
このデータをコピーして貼り付けることにより、Windowsのメモ帳を使用してこのファイルを作成できます。ファイルを名前を付けて保存input.csv メモ帳の[すべてのファイルとして保存(*。*)]オプションを使用します。
id,name,salary,start_date,dept
1,Rick,623.3,2012-01-01,IT
2,Dan,515.2,2013-09-23,Operations
3,Michelle,611,2014-11-15,IT
4,Ryan,729,2014-05-11,HR
5,Gary,843.25,2015-03-27,Finance
6,Nina,578,2013-05-21,IT
7,Simon,632.8,2013-07-30,Operations
8,Guru,722.5,2014-06-17,FinanceCSVファイルの読み取り
以下はの簡単な例です read.csv() 現在の作業ディレクトリで利用可能なCSVファイルを読み取る機能-
data <- read.csv("input.csv")
print(data)上記のコードを実行すると、次の結果が生成されます-
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceCSVファイルの分析
デフォルトでは read.csv()関数は、出力をデータフレームとして提供します。これは次のように簡単に確認できます。また、列数と行数を確認することもできます。
data <- read.csv("input.csv")
print(is.data.frame(data))
print(ncol(data))
print(nrow(data))上記のコードを実行すると、次の結果が生成されます-
[1] TRUE
[1] 5
[1] 8データフレーム内のデータを読み取ると、次のセクションで説明するように、データフレームに適用可能なすべての機能を適用できます。
最大給与を取得する
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
print(sal)上記のコードを実行すると、次の結果が生成されます-
[1] 843.25最大給与の人の詳細を取得します
SQLのwhere句と同様に、特定のフィルター条件を満たす行をフェッチできます。
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
# Get the person detail having max salary.
retval <- subset(data, salary == max(salary))
print(retval)上記のコードを実行すると、次の結果が生成されます-
id name salary start_date dept
5 NA Gary 843.25 2015-03-27 FinanceIT部門で働くすべての人を獲得する
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset( data, dept == "IT")
print(retval)上記のコードを実行すると、次の結果が生成されます-
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 IT
6 6 Nina 578.0 2013-05-21 IT給与が600を超えるIT部門の人を取得します
# Create a data frame.
data <- read.csv("input.csv")
info <- subset(data, salary > 600 & dept == "IT")
print(info)上記のコードを実行すると、次の結果が生成されます-
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 IT2014年以降に参加した人を取得する
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
print(retval)上記のコードを実行すると、次の結果が生成されます-
id name salary start_date dept
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
8 8 Guru 722.50 2014-06-17 FinanceCSVファイルへの書き込み
Rは既存のデータフレームからcsvファイルを作成できます。ザ・write.csv()関数は、csvファイルを作成するために使用されます。このファイルは作業ディレクトリに作成されます。
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv")
newdata <- read.csv("output.csv")
print(newdata)上記のコードを実行すると、次の結果が生成されます-
X id name salary start_date dept
1 3 3 Michelle 611.00 2014-11-15 IT
2 4 4 Ryan 729.00 2014-05-11 HR
3 5 NA Gary 843.25 2015-03-27 Finance
4 8 8 Guru 722.50 2014-06-17 Financeここで、列Xはデータセットnewperからのものです。これは、ファイルの書き込み中に追加のパラメーターを使用して削除できます。
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv", row.names = FALSE)
newdata <- read.csv("output.csv")
print(newdata)上記のコードを実行すると、次の結果が生成されます-
id name salary start_date dept
1 3 Michelle 611.00 2014-11-15 IT
2 4 Ryan 729.00 2014-05-11 HR
3 NA Gary 843.25 2015-03-27 Finance
4 8 Guru 722.50 2014-06-17 FinanceMicrosoft Excelは、データを.xlsまたは.xlsx形式で保存する最も広く使用されているスプレッドシートプログラムです。Rは、いくつかのExcel固有のパッケージを使用して、これらのファイルから直接読み取ることができます。そのようなパッケージはほとんどありません-XLConnect、xlsx、gdataなど。xlsxパッケージを使用します。Rは、このパッケージを使用してExcelファイルに書き込むこともできます。
xlsxパッケージをインストールします
Rコンソールで次のコマンドを使用して、「xlsx」パッケージをインストールできます。このパッケージが依存しているいくつかの追加パッケージをインストールするように求められる場合があります。必要なパッケージ名を指定して同じコマンドを実行し、追加のパッケージをインストールします。
install.packages("xlsx")「xlsx」パッケージを確認してロードします
次のコマンドを使用して、「xlsx」パッケージを確認してロードします。
# Verify the package is installed.
any(grepl("xlsx",installed.packages()))
# Load the library into R workspace.
library("xlsx")スクリプトを実行すると、次の出力が得られます。
[1] TRUE
Loading required package: rJava
Loading required package: methods
Loading required package: xlsxjarsxlsxファイルとして入力
MicrosoftExcelを開きます。次のデータをコピーして、sheet1という名前のワークシートに貼り付けます。
id name salary start_date dept
1 Rick 623.3 1/1/2012 IT
2 Dan 515.2 9/23/2013 Operations
3 Michelle 611 11/15/2014 IT
4 Ryan 729 5/11/2014 HR
5 Gary 43.25 3/27/2015 Finance
6 Nina 578 5/21/2013 IT
7 Simon 632.8 7/30/2013 Operations
8 Guru 722.5 6/17/2014 Financeまた、次のデータをコピーして別のワークシートに貼り付け、このワークシートの名前を「city」に変更します。
name city
Rick Seattle
Dan Tampa
Michelle Chicago
Ryan Seattle
Gary Houston
Nina Boston
Simon Mumbai
Guru DallasExcelファイルを「input.xlsx」として保存します。Rワークスペースの現在の作業ディレクトリに保存する必要があります。
Excelファイルを読む
input.xlsxは、 read.xlsx()以下のように機能します。結果は、R環境にデータフレームとして保存されます。
# Read the first worksheet in the file input.xlsx.
data <- read.xlsx("input.xlsx", sheetIndex = 1)
print(data)上記のコードを実行すると、次の結果が生成されます-
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Financeバイナリファイルは、ビットとバイト(0と1)の形式でのみ格納された情報を含むファイルです。その中のバイトは、他の多くの印刷不可能な文字を含む文字や記号に変換されるため、人間が読める形式ではありません。テキストエディタを使用してバイナリファイルを読み取ろうとすると、Øやðなどの文字が表示されます。
バイナリファイルを使用するには、特定のプログラムで読み取る必要があります。たとえば、Microsoft Wordプログラムのバイナリファイルは、Wordプログラムによってのみ人間が読める形式に読み取ることができます。これは、人間が読めるテキストの他に、文字の書式設定やページ番号など、英数字と一緒に保存される情報がたくさんあることを示しています。そして最後に、バイナリファイルはバイトの連続シーケンスです。テキストファイルに表示される改行は、最初の行を次の行に結合する文字です。
他のプログラムで生成されたデータは、Rでバイナリファイルとして処理する必要がある場合があります。また、他のプログラムと共有できるバイナリファイルを作成するにはRが必要です。
Rには2つの機能があります WriteBin() そして readBin() バイナリファイルを作成して読み取る。
構文
writeBin(object, con)
readBin(con, what, n )以下は、使用されるパラメーターの説明です-
con バイナリファイルを読み書きするための接続オブジェクトです。
object 書き込まれるバイナリファイルです。
what 読み取られるバイトを表す文字、整数などのモードです。
n バイナリファイルから読み取るバイト数です。
例
Rの組み込みデータ「mtcars」を検討します。まず、そこからcsvファイルを作成し、バイナリファイルに変換して、OSファイルとして保存します。次に、Rに作成されたこのバイナリファイルを読み取ります。
バイナリファイルの書き込み
データフレーム「mtcars」をcsvファイルとして読み取り、バイナリファイルとしてOSに書き込みます。
# Read the "mtcars" data frame as a csv file and store only the columns
"cyl", "am" and "gear".
write.table(mtcars, file = "mtcars.csv",row.names = FALSE, na = "",
col.names = TRUE, sep = ",")
# Store 5 records from the csv file as a new data frame.
new.mtcars <- read.table("mtcars.csv",sep = ",",header = TRUE,nrows = 5)
# Create a connection object to write the binary file using mode "wb".
write.filename = file("/web/com/binmtcars.dat", "wb")
# Write the column names of the data frame to the connection object.
writeBin(colnames(new.mtcars), write.filename)
# Write the records in each of the column to the file.
writeBin(c(new.mtcars$cyl,new.mtcars$am,new.mtcars$gear), write.filename)
# Close the file for writing so that it can be read by other program.
close(write.filename)バイナリファイルの読み取り
上で作成されたバイナリファイルは、すべてのデータを連続バイトとして保存します。したがって、列名と列値の適切な値を選択して読みます。
# Create a connection object to read the file in binary mode using "rb".
read.filename <- file("/web/com/binmtcars.dat", "rb")
# First read the column names. n = 3 as we have 3 columns.
column.names <- readBin(read.filename, character(), n = 3)
# Next read the column values. n = 18 as we have 3 column names and 15 values.
read.filename <- file("/web/com/binmtcars.dat", "rb")
bindata <- readBin(read.filename, integer(), n = 18)
# Print the data.
print(bindata)
# Read the values from 4th byte to 8th byte which represents "cyl".
cyldata = bindata[4:8]
print(cyldata)
# Read the values form 9th byte to 13th byte which represents "am".
amdata = bindata[9:13]
print(amdata)
# Read the values form 9th byte to 13th byte which represents "gear".
geardata = bindata[14:18]
print(geardata)
# Combine all the read values to a dat frame.
finaldata = cbind(cyldata, amdata, geardata)
colnames(finaldata) = column.names
print(finaldata)上記のコードを実行すると、次の結果とチャートが生成されます-
[1] 7108963 1728081249 7496037 6 6 4
[7] 6 8 1 1 1 0
[13] 0 4 4 4 3 3
[1] 6 6 4 6 8
[1] 1 1 1 0 0
[1] 4 4 4 3 3
cyl am gear
[1,] 6 1 4
[2,] 6 1 4
[3,] 4 1 4
[4,] 6 0 3
[5,] 8 0 3ご覧のとおり、Rのバイナリファイルを読み取ることで元のデータを取得しました。
XMLは、標準のASCIIテキストを使用して、ワールドワイドウェブ、イントラネット、およびその他の場所でファイル形式とデータの両方を共有するファイル形式です。Extensible Markup Language(XML)の略です。HTMLと同様に、マークアップタグが含まれています。ただし、マークアップタグがページの構造を記述するHTMLとは異なり、xmlではマークアップタグはファイルに含まれるデータの意味を記述します。
「XML」パッケージを使用して、Rでxmlファイルを読み取ることができます。このパッケージは、次のコマンドを使用してインストールできます。
install.packages("XML")入力データ
以下のデータをメモ帳などのテキストエディタにコピーして、XMlファイルを作成します。でファイルを保存します.xml 拡張子とファイルタイプの選択 all files(*.*)。
<RECORDS>
<EMPLOYEE>
<ID>1</ID>
<NAME>Rick</NAME>
<SALARY>623.3</SALARY>
<STARTDATE>1/1/2012</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>2</ID>
<NAME>Dan</NAME>
<SALARY>515.2</SALARY>
<STARTDATE>9/23/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>3</ID>
<NAME>Michelle</NAME>
<SALARY>611</SALARY>
<STARTDATE>11/15/2014</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>4</ID>
<NAME>Ryan</NAME>
<SALARY>729</SALARY>
<STARTDATE>5/11/2014</STARTDATE>
<DEPT>HR</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>5</ID>
<NAME>Gary</NAME>
<SALARY>843.25</SALARY>
<STARTDATE>3/27/2015</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>6</ID>
<NAME>Nina</NAME>
<SALARY>578</SALARY>
<STARTDATE>5/21/2013</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>7</ID>
<NAME>Simon</NAME>
<SALARY>632.8</SALARY>
<STARTDATE>7/30/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>8</ID>
<NAME>Guru</NAME>
<SALARY>722.5</SALARY>
<STARTDATE>6/17/2014</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
</RECORDS>XMLファイルの読み取り
xmlファイルは関数を使用してRによって読み取られます xmlParse()。Rにリストとして保存されます。
# Load the package required to read XML files.
library("XML")
# Also load the other required package.
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Print the result.
print(result)上記のコードを実行すると、次の結果が生成されます-
1
Rick
623.3
1/1/2012
IT
2
Dan
515.2
9/23/2013
Operations
3
Michelle
611
11/15/2014
IT
4
Ryan
729
5/11/2014
HR
5
Gary
843.25
3/27/2015
Finance
6
Nina
578
5/21/2013
IT
7
Simon
632.8
7/30/2013
Operations
8
Guru
722.5
6/17/2014
FinanceXMLファイルに存在するノードの数を取得する
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Find number of nodes in the root.
rootsize <- xmlSize(rootnode)
# Print the result.
print(rootsize)上記のコードを実行すると、次の結果が生成されます-
output
[1] 8最初のノードの詳細
解析されたファイルの最初のレコードを見てみましょう。これにより、最上位ノードに存在するさまざまな要素がわかります。
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Print the result.
print(rootnode[1])上記のコードを実行すると、次の結果が生成されます-
$EMPLOYEE
1
Rick
623.3
1/1/2012
IT
attr(,"class")
[1] "XMLInternalNodeList" "XMLNodeList"ノードのさまざまな要素を取得する
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Get the first element of the first node.
print(rootnode[[1]][[1]])
# Get the fifth element of the first node.
print(rootnode[[1]][[5]])
# Get the second element of the third node.
print(rootnode[[3]][[2]])上記のコードを実行すると、次の結果が生成されます-
1
IT
MichelleXMLからデータフレームへ
大きなファイルのデータを効果的に処理するために、xmlファイルのデータをデータフレームとして読み取ります。次に、データ分析のためにデータフレームを処理します。
# Load the packages required to read XML files.
library("XML")
library("methods")
# Convert the input xml file to a data frame.
xmldataframe <- xmlToDataFrame("input.xml")
print(xmldataframe)上記のコードを実行すると、次の結果が生成されます-
ID NAME SALARY STARTDATE DEPT
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Financeデータがデータフレームとして利用できるようになったので、データフレーム関連の関数を使用してファイルを読み取って操作できます。
JSONファイルは、データを人間が読める形式のテキストとして保存します。JsonはJavaScriptObjectNotationの略です。Rは、rjsonパッケージを使用してJSONファイルを読み取ることができます。
rjsonパッケージをインストールします
Rコンソールで、次のコマンドを発行してrjsonパッケージをインストールできます。
install.packages("rjson")入力データ
以下のデータをメモ帳などのテキストエディタにコピーして、JSONファイルを作成します。でファイルを保存します.json 拡張子とファイルタイプの選択 all files(*.*)。
{
"ID":["1","2","3","4","5","6","7","8" ],
"Name":["Rick","Dan","Michelle","Ryan","Gary","Nina","Simon","Guru" ],
"Salary":["623.3","515.2","611","729","843.25","578","632.8","722.5" ],
"StartDate":[ "1/1/2012","9/23/2013","11/15/2014","5/11/2014","3/27/2015","5/21/2013",
"7/30/2013","6/17/2014"],
"Dept":[ "IT","Operations","IT","HR","Finance","IT","Operations","Finance"]
}JSONファイルを読む
JSONファイルは、次の関数を使用してRによって読み取られます。 JSON()。Rにリストとして保存されます。
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Print the result.
print(result)上記のコードを実行すると、次の結果が生成されます-
$ID
[1] "1" "2" "3" "4" "5" "6" "7" "8"
$Name [1] "Rick" "Dan" "Michelle" "Ryan" "Gary" "Nina" "Simon" "Guru" $Salary
[1] "623.3" "515.2" "611" "729" "843.25" "578" "632.8" "722.5"
$StartDate [1] "1/1/2012" "9/23/2013" "11/15/2014" "5/11/2014" "3/27/2015" "5/21/2013" "7/30/2013" "6/17/2014" $Dept
[1] "IT" "Operations" "IT" "HR" "Finance" "IT"
"Operations" "Finance"JSONをデータフレームに変換する
上記で抽出したデータをRデータフレームに変換して、 as.data.frame() 関数。
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Convert JSON file to a data frame.
json_data_frame <- as.data.frame(result)
print(json_data_frame)上記のコードを実行すると、次の結果が生成されます-
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 Finance多くのウェブサイトは、ユーザーが消費するためのデータを提供しています。たとえば、世界保健機関(WHO)は、CSV、txt、およびXMLファイルの形式で健康および医療情報に関するレポートを提供しています。Rプログラムを使用すると、そのようなWebサイトから特定のデータをプログラムで抽出できます。Webからデータをスクラップするために使用されるRのパッケージには、「RCurl」、XML、「stringr」があります。これらは、URLに接続し、ファイルに必要なリンクを識別して、ローカル環境にダウンロードするために使用されます。
Rパッケージをインストールする
URLとファイルへのリンクを処理するには、次のパッケージが必要です。R環境で使用できない場合は、次のコマンドを使用してインストールできます。
install.packages("RCurl")
install.packages("XML")
install.packages("stringr")
install.packages("plyr")入力データ
URLの気象データにアクセスし、2015年のRを使用してCSVファイルをダウンロードします。
例
関数を使用します getHTMLLinks()ファイルのURLを収集します。次に、関数を使用しますdownload.file()ファイルをローカルシステムに保存します。同じコードを複数のファイルに何度も適用するため、複数回呼び出される関数を作成します。ファイル名は、Rリストオブジェクトの形式でパラメーターとしてこの関数に渡されます。
# Read the URL.
url <- "http://www.geos.ed.ac.uk/~weather/jcmb_ws/"
# Gather the html links present in the webpage.
links <- getHTMLLinks(url)
# Identify only the links which point to the JCMB 2015 files.
filenames <- links[str_detect(links, "JCMB_2015")]
# Store the file names as a list.
filenames_list <- as.list(filenames)
# Create a function to download the files by passing the URL and filename list.
downloadcsv <- function (mainurl,filename) {
filedetails <- str_c(mainurl,filename)
download.file(filedetails,filename)
}
# Now apply the l_ply function and save the files into the current R working directory.
l_ply(filenames,downloadcsv,mainurl = "http://www.geos.ed.ac.uk/~weather/jcmb_ws/")ファイルのダウンロードを確認する
上記のコードを実行すると、現在のR作業ディレクトリで次のファイルを見つけることができます。
"JCMB_2015.csv" "JCMB_2015_Apr.csv" "JCMB_2015_Feb.csv" "JCMB_2015_Jan.csv"
"JCMB_2015_Mar.csv"データはリレーショナルデータベースシステムであり、正規化された形式で保存されます。したがって、統計計算を実行するには、非常に高度で複雑なSQLクエリが必要になります。しかし、Rは、MySql、Oracle、Sqlサーバーなどの多くのリレーショナルデータベースに簡単に接続し、それらからレコードをデータフレームとしてフェッチできます。データがR環境で利用可能になると、それは通常のRデータセットになり、すべての強力なパッケージと機能を使用して操作または分析できます。
このチュートリアルでは、Rに接続するための参照データベースとしてMySqlを使用します。
RMySQLパッケージ
Rには、MySqlデータベースとのネイティブ接続を提供する「RMySQL」という名前の組み込みパッケージがあります。次のコマンドを使用して、このパッケージをR環境にインストールできます。
install.packages("RMySQL")RをMySqlに接続する
パッケージがインストールされたら、データベースに接続するためにRに接続オブジェクトを作成します。ユーザー名、パスワード、データベース名、ホスト名を入力として受け取ります。
# Create a connection Object to MySQL database.
# We will connect to the sampel database named "sakila" that comes with MySql installation.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# List the tables available in this database.
dbListTables(mysqlconnection)上記のコードを実行すると、次の結果が生成されます-
[1] "actor" "actor_info"
[3] "address" "category"
[5] "city" "country"
[7] "customer" "customer_list"
[9] "film" "film_actor"
[11] "film_category" "film_list"
[13] "film_text" "inventory"
[15] "language" "nicer_but_slower_film_list"
[17] "payment" "rental"
[19] "sales_by_film_category" "sales_by_store"
[21] "staff" "staff_list"
[23] "store"テーブルのクエリ
関数を使用してMySqlのデータベーステーブルをクエリできます dbSendQuery()。クエリはMySqlで実行され、結果セットはRを使用して返されますfetch()関数。最後に、データフレームとしてRに格納されます。
# Query the "actor" tables to get all the rows.
result = dbSendQuery(mysqlconnection, "select * from actor")
# Store the result in a R data frame object. n = 5 is used to fetch first 5 rows.
data.frame = fetch(result, n = 5)
print(data.fame)上記のコードを実行すると、次の結果が生成されます-
actor_id first_name last_name last_update
1 1 PENELOPE GUINESS 2006-02-15 04:34:33
2 2 NICK WAHLBERG 2006-02-15 04:34:33
3 3 ED CHASE 2006-02-15 04:34:33
4 4 JENNIFER DAVIS 2006-02-15 04:34:33
5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33フィルタ句を使用したクエリ
有効なselectクエリを渡して、結果を取得できます。
result = dbSendQuery(mysqlconnection, "select * from actor where last_name = 'TORN'")
# Fetch all the records(with n = -1) and store it as a data frame.
data.frame = fetch(result, n = -1)
print(data)上記のコードを実行すると、次の結果が生成されます-
actor_id first_name last_name last_update
1 18 DAN TORN 2006-02-15 04:34:33
2 94 KENNETH TORN 2006-02-15 04:34:33
3 102 WALTER TORN 2006-02-15 04:34:33テーブルの行を更新する
更新クエリをdbSendQuery()関数に渡すことで、Mysqlテーブルの行を更新できます。
dbSendQuery(mysqlconnection, "update mtcars set disp = 168.5 where hp = 110")上記のコードを実行した後、MySql環境で更新されたテーブルを確認できます。
テーブルへのデータの挿入
dbSendQuery(mysqlconnection,
"insert into mtcars(row_names, mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb)
values('New Mazda RX4 Wag', 21, 6, 168.5, 110, 3.9, 2.875, 17.02, 0, 1, 4, 4)"
)上記のコードを実行した後、MySql環境のテーブルに挿入された行を確認できます。
MySqlでテーブルを作成する
関数を使用してMySqlにテーブルを作成できます dbWriteTable()。テーブルがすでに存在する場合は上書きし、データフレームを入力として受け取ります。
# Create the connection object to the database where we want to create the table.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# Use the R data frame "mtcars" to create the table in MySql.
# All the rows of mtcars are taken inot MySql.
dbWriteTable(mysqlconnection, "mtcars", mtcars[, ], overwrite = TRUE)上記のコードを実行すると、MySql環境で作成されたテーブルが表示されます。
MySqlでのテーブルの削除
テーブルからデータをクエリするために使用したのと同じ方法で、Drop tableステートメントをdbSendQuery()に渡してMySqlデータベースにテーブルをドロップできます。
dbSendQuery(mysqlconnection, 'drop table if exists mtcars')上記のコードを実行した後、テーブルがMySql環境にドロップされていることがわかります。
Rプログラミング言語には、チャートやグラフを作成するための多数のライブラリがあります。円グラフは、さまざまな色の円のスライスとしての値の表現です。スライスにはラベルが付けられ、各スライスに対応する番号もチャートに表示されます。
Rでは、円グラフは pie()ベクトル入力として正の数をとる関数。追加のパラメータは、ラベル、色、タイトルなどを制御するために使用されます。
構文
Rを使用して円グラフを作成するための基本的な構文は次のとおりです。
pie(x, labels, radius, main, col, clockwise)以下は、使用されるパラメーターの説明です-
x 円グラフで使用される数値を含むベクトルです。
labels スライスに説明を与えるために使用されます。
radius 円グラフの円の半径を示します(-1から+1の間の値)。
main チャートのタイトルを示します。
col カラーパレットを示します。
clockwise スライスが時計回りに描画されるか反時計回りに描画されるかを示す論理値です。
例
非常に単純な円グラフは、入力ベクトルとラベルのみを使用して作成されます。以下のスクリプトは、円グラフを作成して現在のR作業ディレクトリに保存します。
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city.png")
# Plot the chart.
pie(x,labels)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
円グラフのタイトルと色
関数にパラメーターを追加することで、チャートの機能を拡張できます。パラメータを使用しますmain チャートにタイトルを追加し、別のパラメータは colチャートを描くときに虹色のパレットを利用します。パレットの長さは、グラフの値の数と同じである必要があります。したがって、length(x)を使用します。
例
以下のスクリプトは、円グラフを作成して現在のR作業ディレクトリに保存します。
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city_title_colours.jpg")
# Plot the chart with title and rainbow color pallet.
pie(x, labels, main = "City pie chart", col = rainbow(length(x)))
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
スライスのパーセンテージとグラフの凡例
追加のグラフ変数を作成することで、スライスのパーセンテージとグラフの凡例を追加できます。
# Create data for the graph.
x <- c(21, 62, 10,53)
labels <- c("London","New York","Singapore","Mumbai")
piepercent<- round(100*x/sum(x), 1)
# Give the chart file a name.
png(file = "city_percentage_legends.jpg")
# Plot the chart.
pie(x, labels = piepercent, main = "City pie chart",col = rainbow(length(x)))
legend("topright", c("London","New York","Singapore","Mumbai"), cex = 0.8,
fill = rainbow(length(x)))
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
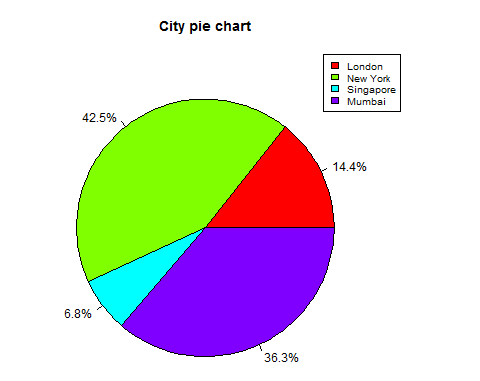
3D円グラフ
追加のパッケージを使用して、3次元の円グラフを描画できます。その包みplotrix と呼ばれる機能があります pie3D() これに使用されます。
# Get the library.
library(plotrix)
# Create data for the graph.
x <- c(21, 62, 10,53)
lbl <- c("London","New York","Singapore","Mumbai")
# Give the chart file a name.
png(file = "3d_pie_chart.jpg")
# Plot the chart.
pie3D(x,labels = lbl,explode = 0.1, main = "Pie Chart of Countries ")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
棒グラフは、変数の値に比例する棒の長さを持つ長方形の棒でデータを表します。Rは関数を使用しますbarplot()棒グラフを作成します。Rは、棒グラフに垂直バーと水平バーの両方を描画できます。棒グラフでは、各棒に異なる色を付けることができます。
構文
Rで棒グラフを作成するための基本的な構文は次のとおりです。
barplot(H,xlab,ylab,main, names.arg,col)以下は、使用されるパラメーターの説明です-
- H 棒グラフで使用される数値を含むベクトルまたは行列です。
- xlab x軸のラベルです。
- ylab y軸のラベルです。
- main 棒グラフのタイトルです。
- names.arg 各バーの下に表示される名前のベクトルです。
- col グラフのバーに色を付けるために使用されます。
例
入力ベクトルと各棒の名前だけを使用して、単純な棒グラフが作成されます。
以下のスクリプトは、棒グラフを作成して現在のR作業ディレクトリに保存します。
# Create the data for the chart
H <- c(7,12,28,3,41)
# Give the chart file a name
png(file = "barchart.png")
# Plot the bar chart
barplot(H)
# Save the file
dev.off()上記のコードを実行すると、次の結果が生成されます-
棒グラフのラベル、タイトル、色
棒グラフの機能は、パラメータを追加することで拡張できます。ザ・main パラメータは追加に使用されます title。ザ・colパラメータは、バーに色を追加するために使用されます。ザ・args.name は、各バーの意味を説明するための入力ベクトルと同じ数の値を持つベクトルです。
例
以下のスクリプトは、棒グラフを作成して現在のR作業ディレクトリに保存します。
# Create the data for the chart
H <- c(7,12,28,3,41)
M <- c("Mar","Apr","May","Jun","Jul")
# Give the chart file a name
png(file = "barchart_months_revenue.png")
# Plot the bar chart
barplot(H,names.arg=M,xlab="Month",ylab="Revenue",col="blue",
main="Revenue chart",border="red")
# Save the file
dev.off()上記のコードを実行すると、次の結果が生成されます-
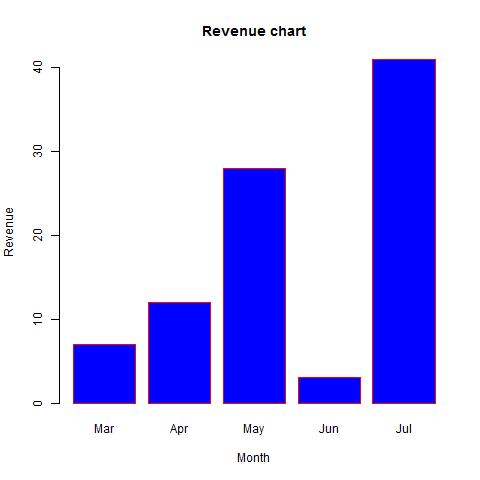
グループ棒グラフと積み上げ棒グラフ
行列を入力値として使用することにより、各棒に棒とスタックのグループを含む棒グラフを作成できます。
3つ以上の変数は、グループ棒グラフと積み上げ棒グラフを作成するために使用される行列として表されます。
# Create the input vectors.
colors = c("green","orange","brown")
months <- c("Mar","Apr","May","Jun","Jul")
regions <- c("East","West","North")
# Create the matrix of the values.
Values <- matrix(c(2,9,3,11,9,4,8,7,3,12,5,2,8,10,11), nrow = 3, ncol = 5, byrow = TRUE)
# Give the chart file a name
png(file = "barchart_stacked.png")
# Create the bar chart
barplot(Values, main = "total revenue", names.arg = months, xlab = "month", ylab = "revenue", col = colors)
# Add the legend to the chart
legend("topleft", regions, cex = 1.3, fill = colors)
# Save the file
dev.off()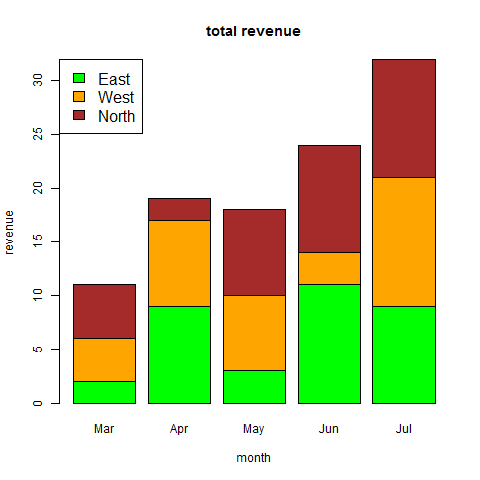
箱ひげ図は、データセット内のデータがどの程度分散しているかを示す尺度です。データセットを3つの四分位数に分割します。このグラフは、データセットの最小、最大、中央値、第1四分位数、および第3四分位数を表します。また、データセットごとに箱ひげ図を描くことで、データセット間のデータの分布を比較するのにも役立ちます。
箱ひげ図は、Rで boxplot() 関数。
構文
Rで箱ひげ図を作成するための基本的な構文は次のとおりです。
boxplot(x, data, notch, varwidth, names, main)以下は、使用されるパラメーターの説明です-
x ベクトルまたは式です。
data データフレームです。
notchは論理値です。ノッチを描画するには、TRUEに設定します。
varwidthは論理値です。サンプルサイズに比例したボックスの幅を描画するには、trueに設定します。
names 各箱ひげ図の下に印刷されるグループラベルです。
main グラフにタイトルを付けるために使用されます。
例
R環境で利用可能なデータセット「mtcars」を使用して、基本的な箱ひげ図を作成します。mtcarsの列「mpg」と「cyl」を見てみましょう。
input <- mtcars[,c('mpg','cyl')]
print(head(input))上記のコードを実行すると、次の結果が生成されます-
mpg cyl
Mazda RX4 21.0 6
Mazda RX4 Wag 21.0 6
Datsun 710 22.8 4
Hornet 4 Drive 21.4 6
Hornet Sportabout 18.7 8
Valiant 18.1 6箱ひげ図の作成
以下のスクリプトは、mpg(ガロンあたりのマイル数)とcyl(シリンダー数)の関係の箱ひげ図を作成します。
# Give the chart file a name.
png(file = "boxplot.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars, xlab = "Number of Cylinders",
ylab = "Miles Per Gallon", main = "Mileage Data")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
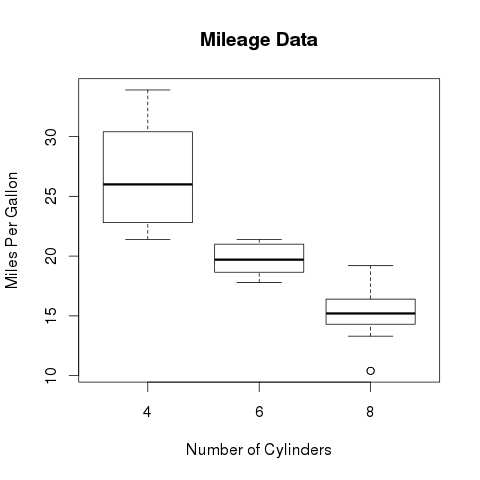
ノッチ付き箱ひげ図
異なるデータグループの中央値が互いにどのように一致するかを調べるために、ノッチ付きの箱ひげ図を描くことができます。
以下のスクリプトは、データグループごとにノッチのある箱ひげ図を作成します。
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars,
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon",
main = "Mileage Data",
notch = TRUE,
varwidth = TRUE,
col = c("green","yellow","purple"),
names = c("High","Medium","Low")
)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
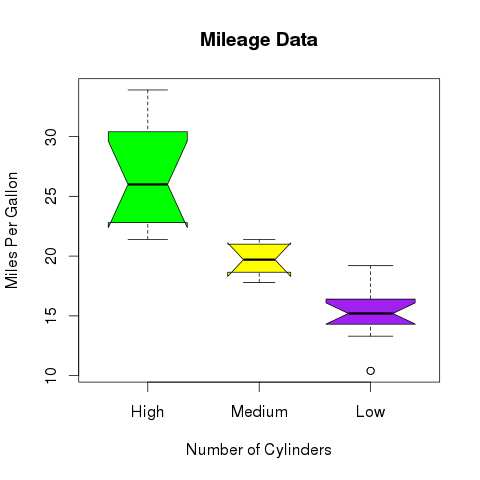
ヒストグラムは、範囲にバケット化された変数の値の頻度を表します。ヒストグラムはバーチャットに似ていますが、違いは値を連続範囲にグループ化することです。ヒストグラムの各バーは、その範囲に存在する値の数の高さを表します。
Rはを使用してヒストグラムを作成します hist()関数。この関数は、入力としてベクトルを受け取り、さらにいくつかのパラメーターを使用してヒストグラムをプロットします。
構文
Rを使用してヒストグラムを作成するための基本的な構文は次のとおりです。
hist(v,main,xlab,xlim,ylim,breaks,col,border)以下は、使用されるパラメーターの説明です-
v ヒストグラムで使用される数値を含むベクトルです。
main チャートのタイトルを示します。
col バーの色を設定するために使用されます。
border 各バーの境界線の色を設定するために使用されます。
xlab x軸の説明に使用されます。
xlim x軸の値の範囲を指定するために使用されます。
ylim y軸の値の範囲を指定するために使用されます。
breaks 各バーの幅を示すために使用されます。
例
単純なヒストグラムは、入力ベクトル、ラベル、列、および境界線パラメーターを使用して作成されます。
以下のスクリプトは、ヒストグラムを作成して現在のR作業ディレクトリに保存します。
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "yellow",border = "blue")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
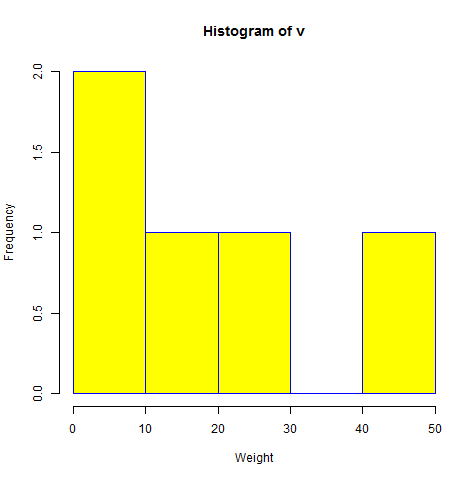
X値とY値の範囲
X軸とY軸で許可される値の範囲を指定するには、xlimパラメーターとylimパラメーターを使用できます。
各バーの幅は、ブレークを使用して決定できます。
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram_lim_breaks.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "green",border = "red", xlim = c(0,40), ylim = c(0,5),
breaks = 5)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
折れ線グラフは、一連の点の間に線分を描画することによって一連の点を接続するグラフです。これらのポイントは、それらの座標(通常はx座標)値の1つで順序付けられます。折れ線グラフは通常、データの傾向を特定するために使用されます。
ザ・ plot() Rの関数は、折れ線グラフを作成するために使用されます。
構文
Rで折れ線グラフを作成するための基本的な構文は次のとおりです。
plot(v,type,col,xlab,ylab)以下は、使用されるパラメーターの説明です-
v 数値を含むベクトルです。
type 値「p」は点のみを描画し、「l」は線のみを描画し、「o」は点と線の両方を描画します。
xlab x軸のラベルです。
ylab y軸のラベルです。
main チャートのタイトルです。
col ポイントとラインの両方に色を付けるために使用されます。
例
入力ベクトルとタイプパラメータを「O」として使用して、単純な折れ線グラフが作成されます。以下のスクリプトは、折れ線グラフを作成して現在のR作業ディレクトリに保存します。
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart.jpg")
# Plot the bar chart.
plot(v,type = "o")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
折れ線グラフのタイトル、色、ラベル
折れ線グラフの機能は、追加のパラメーターを使用して拡張できます。ポイントとラインに色を追加し、チャートにタイトルを付け、軸にラベルを追加します。
例
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart_label_colored.jpg")
# Plot the bar chart.
plot(v,type = "o", col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
折れ線グラフの複数の線
を使用して、同じチャートに複数の線を引くことができます。 lines()関数。
最初の線がプロットされた後、lines()関数は追加のベクトルを入力として使用して、チャートに2番目の線を描画できます。
# Create the data for the chart.
v <- c(7,12,28,3,41)
t <- c(14,7,6,19,3)
# Give the chart file a name.
png(file = "line_chart_2_lines.jpg")
# Plot the bar chart.
plot(v,type = "o",col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
lines(t, type = "o", col = "blue")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
散布図は、デカルト平面にプロットされた多くの点を示しています。各点は、2つの変数の値を表します。1つの変数が横軸で選択され、別の変数が縦軸で選択されます。
単純な散布図は、 plot() 関数。
構文
Rで散布図を作成するための基本的な構文は次のとおりです。
plot(x, y, main, xlab, ylab, xlim, ylim, axes)以下は、使用されるパラメーターの説明です-
x は、値が水平座標であるデータセットです。
y は、値が垂直座標であるデータセットです。
main グラフのタイルです。
xlab 横軸のラベルです。
ylab 縦軸のラベルです。
xlim プロットに使用されるxの値の限界です。
ylim プロットに使用されるyの値の限界です。
axes 両方の軸をプロットに描画する必要があるかどうかを示します。
例
データセットを使用します "mtcars"基本的な散布図を作成するためにR環境で利用できます。mtcarsの列「wt」と「mpg」を使用してみましょう。
input <- mtcars[,c('wt','mpg')]
print(head(input))上記のコードを実行すると、次の結果が生成されます-
wt mpg
Mazda RX4 2.620 21.0
Mazda RX4 Wag 2.875 21.0
Datsun 710 2.320 22.8
Hornet 4 Drive 3.215 21.4
Hornet Sportabout 3.440 18.7
Valiant 3.460 18.1散布図の作成
以下のスクリプトは、wt(重量)とmpg(マイル/ガロン)の関係の散布図グラフを作成します。
# Get the input values.
input <- mtcars[,c('wt','mpg')]
# Give the chart file a name.
png(file = "scatterplot.png")
# Plot the chart for cars with weight between 2.5 to 5 and mileage between 15 and 30.
plot(x = input$wt,y = input$mpg,
xlab = "Weight",
ylab = "Milage",
xlim = c(2.5,5),
ylim = c(15,30),
main = "Weight vs Milage"
)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
散布図行列
3つ以上の変数があり、1つの変数と残りの変数の相関関係を見つけたい場合は、散布図行列を使用します。を使用しておりますpairs() 散布図の行列を作成する関数。
構文
Rで散布図行列を作成するための基本的な構文は次のとおりです。
pairs(formula, data)以下は、使用されるパラメーターの説明です-
formula ペアで使用される一連の変数を表します。
data 変数が取得されるデータセットを表します。
例
各変数は、残りの各変数とペアになっています。ペアごとに散布図がプロットされます。
# Give the chart file a name.
png(file = "scatterplot_matrices.png")
# Plot the matrices between 4 variables giving 12 plots.
# One variable with 3 others and total 4 variables.
pairs(~wt+mpg+disp+cyl,data = mtcars,
main = "Scatterplot Matrix")
# Save the file.
dev.off()上記のコードを実行すると、次の出力が得られます。
Rの統計分析は、多くの組み込み関数を使用して実行されます。これらの関数のほとんどは、R基本パッケージの一部です。これらの関数は、引数とともにRベクトルを入力として受け取り、結果を返します。
この章で説明している関数は、平均、中央値、最頻値です。
平均
これは、値の合計を取り、データ系列の値の数で割ることによって計算されます。
関数 mean() これをRで計算するために使用されます。
構文
Rの平均を計算するための基本的な構文は次のとおりです。
mean(x, trim = 0, na.rm = FALSE, ...)以下は、使用されるパラメーターの説明です-
x 入力ベクトルです。
trim ソートされたベクトルの両端からいくつかの観測値を削除するために使用されます。
na.rm 入力ベクトルから欠落値を削除するために使用されます。
例
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x)
print(result.mean)上記のコードを実行すると、次の結果が生成されます-
[1] 8.22トリムオプションの適用
トリムパラメーターを指定すると、ベクトルの値が並べ替えられ、必要な数の観測値が平均の計算から除外されます。
トリム= 0.3の場合、平均を見つけるために、両端から3つの値が計算から削除されます。
この場合、ソートされたベクトルは(-21、-5、2、3、4.2、7、8、12、18、54)であり、平均を計算するためにベクトルから削除された値は(-21、-5,2)です。左から、(12,18,54)右から。
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x,trim = 0.3)
print(result.mean)上記のコードを実行すると、次の結果が生成されます-
[1] 5.55NAオプションの適用
欠落している値がある場合、平均関数はNAを返します。
不足している値を計算から削除するには、na.rm = TRUEを使用します。これは、NA値を削除することを意味します。
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5,NA)
# Find mean.
result.mean <- mean(x)
print(result.mean)
# Find mean dropping NA values.
result.mean <- mean(x,na.rm = TRUE)
print(result.mean)上記のコードを実行すると、次の結果が生成されます-
[1] NA
[1] 8.22中央値
データ系列の真ん中の値は中央値と呼ばれます。ザ・median() 関数は、この値を計算するためにRで使用されます。
構文
Rの中央値を計算するための基本的な構文は次のとおりです。
median(x, na.rm = FALSE)以下は、使用されるパラメーターの説明です-
x 入力ベクトルです。
na.rm 入力ベクトルから欠落値を削除するために使用されます。
例
# Create the vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find the median.
median.result <- median(x)
print(median.result)上記のコードを実行すると、次の結果が生成されます-
[1] 5.6モード
モードは、データセット内で最も多く発生する値です。Unikeの平均と中央値、モードは数値データと文字データの両方を持つことができます。
Rには、モードを計算するための標準の組み込み関数がありません。そこで、Rのデータセットのモードを計算するユーザー関数を作成します。この関数は、入力としてベクトルを受け取り、出力としてモード値を提供します。
例
# Create the function.
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
# Create the vector with numbers.
v <- c(2,1,2,3,1,2,3,4,1,5,5,3,2,3)
# Calculate the mode using the user function.
result <- getmode(v)
print(result)
# Create the vector with characters.
charv <- c("o","it","the","it","it")
# Calculate the mode using the user function.
result <- getmode(charv)
print(result)上記のコードを実行すると、次の結果が生成されます-
[1] 2
[1] "it"回帰分析は、2つの変数間の関係モデルを確立するために非常に広く使用されている統計ツールです。これらの変数の1つは予測変数と呼ばれ、その値は実験を通じて収集されます。もう1つの変数は応答変数と呼ばれ、その値は予測変数から導出されます。
線形回帰では、これら2つの変数は方程式によって関連付けられます。ここで、これらの変数の両方の指数(累乗)は1です。数学的には、線形関係はグラフとしてプロットされたときに直線を表します。変数の指数が1に等しくない非線形関係は、曲線を作成します。
線形回帰の一般的な数式は次のとおりです。
y = ax + b以下は、使用されるパラメーターの説明です-
y は応答変数です。
x は予測変数です。
a そして b 係数と呼ばれる定数です。
回帰を確立する手順
回帰の簡単な例は、身長がわかっているときに人の体重を予測することです。これを行うには、人の身長と体重の関係が必要です。
関係を作成する手順は次のとおりです。
高さと対応する重量の観測値のサンプルを収集する実験を実行します。
を使用して関係モデルを作成します lm() Rで機能します。
作成したモデルから係数を見つけ、これらを使用して数式を作成します
関係モデルの要約を取得して、予測の平均誤差を把握します。とも呼ばれているresiduals。
新しい人の体重を予測するには、 predict() Rの関数。
入力データ
以下は、観測値を表すサンプルデータです-
# Values of height
151, 174, 138, 186, 128, 136, 179, 163, 152, 131
# Values of weight.
63, 81, 56, 91, 47, 57, 76, 72, 62, 48lm()関数
この関数は、予測変数と応答変数の間の関係モデルを作成します。
構文
の基本構文 lm() 線形回帰の関数は−です
lm(formula,data)以下は、使用されるパラメーターの説明です-
formula xとyの関係を表す記号です。
data 式が適用されるベクトルです。
関係モデルを作成し、係数を取得します
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(relation)上記のコードを実行すると、次の結果が生成されます-
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-38.4551 0.6746関係の概要を取得する
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(summary(relation))上記のコードを実行すると、次の結果が生成されます-
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-6.3002 -1.6629 0.0412 1.8944 3.9775
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -38.45509 8.04901 -4.778 0.00139 **
x 0.67461 0.05191 12.997 1.16e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.253 on 8 degrees of freedom
Multiple R-squared: 0.9548, Adjusted R-squared: 0.9491
F-statistic: 168.9 on 1 and 8 DF, p-value: 1.164e-06予測()関数
構文
線形回帰におけるpredict()の基本的な構文は次のとおりです。
predict(object, newdata)以下は、使用されるパラメーターの説明です-
object は、lm()関数を使用してすでに作成されている式です。
newdata 予測変数の新しい値を含むベクトルです。
新しい人の体重を予測する
# The predictor vector.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
# The resposne vector.
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
# Find weight of a person with height 170.
a <- data.frame(x = 170)
result <- predict(relation,a)
print(result)上記のコードを実行すると、次の結果が生成されます-
1
76.22869回帰をグラフィカルに視覚化する
# Create the predictor and response variable.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
relation <- lm(y~x)
# Give the chart file a name.
png(file = "linearregression.png")
# Plot the chart.
plot(y,x,col = "blue",main = "Height & Weight Regression",
abline(lm(x~y)),cex = 1.3,pch = 16,xlab = "Weight in Kg",ylab = "Height in cm")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
重回帰は、3つ以上の変数間の関係への線形回帰の拡張です。単純な線形関係では、1つの予測変数と1つの応答変数がありますが、重回帰では、複数の予測変数と1つの応答変数があります。
重回帰の一般的な数式は次のとおりです。
y = a + b1x1 + b2x2 +...bnxn以下は、使用されるパラメーターの説明です-
y は応答変数です。
a, b1, b2...bn は係数です。
x1, x2, ...xn 予測変数です。
を使用して回帰モデルを作成します lm()Rの関数。モデルは、入力データを使用して係数の値を決定します。次に、これらの係数を使用して、特定の予測変数のセットの応答変数の値を予測できます。
lm()関数
この関数は、予測変数と応答変数の間の関係モデルを作成します。
構文
の基本構文 lm() 重回帰の関数は−です
lm(y ~ x1+x2+x3...,data)以下は、使用されるパラメーターの説明です-
formula は、応答変数と予測変数の間の関係を表す記号です。
data 式が適用されるベクトルです。
例
入力データ
R環境で利用可能なデータセット「mtcars」について考えてみます。ガロンあたりの走行距離(mpg)、シリンダー変位( "disp")、馬力( "hp")、車の重量( "wt")、およびその他のパラメーターに関して、さまざまな車のモデルを比較します。
モデルの目標は、応答変数としての「mpg」と、予測変数としての「disp」、「hp」、および「wt」の間の関係を確立することです。この目的のために、mtcarsデータセットからこれらの変数のサブセットを作成します。
input <- mtcars[,c("mpg","disp","hp","wt")]
print(head(input))上記のコードを実行すると、次の結果が生成されます-
mpg disp hp wt
Mazda RX4 21.0 160 110 2.620
Mazda RX4 Wag 21.0 160 110 2.875
Datsun 710 22.8 108 93 2.320
Hornet 4 Drive 21.4 258 110 3.215
Hornet Sportabout 18.7 360 175 3.440
Valiant 18.1 225 105 3.460関係モデルを作成し、係数を取得します
input <- mtcars[,c("mpg","disp","hp","wt")]
# Create the relationship model.
model <- lm(mpg~disp+hp+wt, data = input)
# Show the model.
print(model)
# Get the Intercept and coefficients as vector elements.
cat("# # # # The Coefficient Values # # # ","\n")
a <- coef(model)[1]
print(a)
Xdisp <- coef(model)[2]
Xhp <- coef(model)[3]
Xwt <- coef(model)[4]
print(Xdisp)
print(Xhp)
print(Xwt)上記のコードを実行すると、次の結果が生成されます-
Call:
lm(formula = mpg ~ disp + hp + wt, data = input)
Coefficients:
(Intercept) disp hp wt
37.105505 -0.000937 -0.031157 -3.800891
# # # # The Coefficient Values # # #
(Intercept)
37.10551
disp
-0.0009370091
hp
-0.03115655
wt
-3.800891回帰モデルの方程式を作成する
上記の切片と係数の値に基づいて、数式を作成します。
Y = a+Xdisp.x1+Xhp.x2+Xwt.x3
or
Y = 37.15+(-0.000937)*x1+(-0.0311)*x2+(-3.8008)*x3新しい値を予測するための方程式を適用する
上で作成した回帰式を使用して、排気量、馬力、および重量の新しい値のセットが提供されたときの走行距離を予測できます。
disp = 221、hp = 102、wt = 2.91の車の場合、予測走行距離は−です。
Y = 37.15+(-0.000937)*221+(-0.0311)*102+(-3.8008)*2.91 = 22.7104ロジスティック回帰は、応答変数(従属変数)がTrue / Falseや0/1などのカテゴリ値を持つ回帰モデルです。実際には、バイナリ応答の確率を、予測変数に関連付ける数式に基づいて応答変数の値として測定します。
ロジスティック回帰の一般的な数式は次のとおりです。
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))以下は、使用されるパラメーターの説明です-
y は応答変数です。
x は予測変数です。
a そして b 数値定数である係数です。
回帰モデルの作成に使用される関数は、 glm() 関数。
構文
の基本構文 glm() ロジスティック回帰の関数は-
glm(formula,data,family)以下は、使用されるパラメーターの説明です-
formula 変数間の関係を表す記号です。
data これらの変数の値を与えるデータセットです。
familyモデルの詳細を指定するRオブジェクトです。その値はロジスティック回帰の二項式です。
例
組み込みのデータセット「mtcars」は、さまざまなエンジン仕様で車のさまざまなモデルを記述します。「mtcars」データセットでは、送信モード(自動または手動)は、バイナリ値(0または1)である列amによって記述されます。「am」列と他の3つの列(hp、wt、cyl)の間にロジスティック回帰モデルを作成できます。
# Select some columns form mtcars.
input <- mtcars[,c("am","cyl","hp","wt")]
print(head(input))上記のコードを実行すると、次の結果が生成されます-
am cyl hp wt
Mazda RX4 1 6 110 2.620
Mazda RX4 Wag 1 6 110 2.875
Datsun 710 1 4 93 2.320
Hornet 4 Drive 0 6 110 3.215
Hornet Sportabout 0 8 175 3.440
Valiant 0 6 105 3.460回帰モデルの作成
私たちは使用します glm() 回帰モデルを作成し、分析のためにその要約を取得する関数。
input <- mtcars[,c("am","cyl","hp","wt")]
am.data = glm(formula = am ~ cyl + hp + wt, data = input, family = binomial)
print(summary(am.data))上記のコードを実行すると、次の結果が生成されます-
Call:
glm(formula = am ~ cyl + hp + wt, family = binomial, data = input)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.17272 -0.14907 -0.01464 0.14116 1.27641
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 19.70288 8.11637 2.428 0.0152 *
cyl 0.48760 1.07162 0.455 0.6491
hp 0.03259 0.01886 1.728 0.0840 .
wt -9.14947 4.15332 -2.203 0.0276 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.2297 on 31 degrees of freedom
Residual deviance: 9.8415 on 28 degrees of freedom
AIC: 17.841
Number of Fisher Scoring iterations: 8結論
要約では、最後の列のp値は変数「cyl」と「hp」で0.05を超えているため、変数「am」の値に寄与することは重要ではないと見なします。この回帰モデルの「am」値に影響を与えるのは、重み(wt)のみです。
独立したソースからのデータのランダムな収集では、データの分布は正規分布であることが一般的に観察されます。つまり、横軸に変数の値を、縦軸に値の数をとってグラフをプロットすると、ベル型の曲線が得られます。曲線の中心は、データセットの平均を表します。グラフでは、値の50%が平均の左側にあり、残りの50%がグラフの右側にあります。これは、統計では正規分布と呼ばれます。
Rには、正規分布を生成するための4つの組み込み関数があります。それらについて以下に説明します。
dnorm(x, mean, sd)
pnorm(x, mean, sd)
qnorm(p, mean, sd)
rnorm(n, mean, sd)以下は、上記の関数で使用されるパラメーターの説明です。
x は数のベクトルです。
p 確率のベクトルです。
n は観測数(サンプルサイズ)です。
meanサンプルデータの平均値です。デフォルト値はゼロです。
sdは標準偏差です。デフォルト値は1です。
dnorm()
この関数は、特定の平均と標準偏差に対する各ポイントでの確率分布の高さを示します。
# Create a sequence of numbers between -10 and 10 incrementing by 0.1.
x <- seq(-10, 10, by = .1)
# Choose the mean as 2.5 and standard deviation as 0.5.
y <- dnorm(x, mean = 2.5, sd = 0.5)
# Give the chart file a name.
png(file = "dnorm.png")
plot(x,y)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
pnorm()
この関数は、正規分布の乱数が特定の数値の値よりも小さくなる確率を示します。「累積分布関数」とも呼ばれます。
# Create a sequence of numbers between -10 and 10 incrementing by 0.2.
x <- seq(-10,10,by = .2)
# Choose the mean as 2.5 and standard deviation as 2.
y <- pnorm(x, mean = 2.5, sd = 2)
# Give the chart file a name.
png(file = "pnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
qnorm()
この関数は確率値を取り、累積値が確率値と一致する数値を返します。
# Create a sequence of probability values incrementing by 0.02.
x <- seq(0, 1, by = 0.02)
# Choose the mean as 2 and standard deviation as 3.
y <- qnorm(x, mean = 2, sd = 1)
# Give the chart file a name.
png(file = "qnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
rnorm()
この関数は、分布が正規分布の乱数を生成するために使用されます。サンプルサイズを入力として受け取り、その数の乱数を生成します。生成された数値の分布を示すヒストグラムを描画します。
# Create a sample of 50 numbers which are normally distributed.
y <- rnorm(50)
# Give the chart file a name.
png(file = "rnorm.png")
# Plot the histogram for this sample.
hist(y, main = "Normal DIstribution")
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
二項分布モデルは、一連の実験で2つの可能な結果しかないイベントの成功の確率を見つけることを扱います。たとえば、コインを投げると常に頭または尾が出ます。二項分布では、コインを10回繰り返し投げるときに正確に3つの頭が見つかる確率が推定されます。
Rには、二項分布を生成するための4つの組み込み関数があります。それらについて以下に説明します。
dbinom(x, size, prob)
pbinom(x, size, prob)
qbinom(p, size, prob)
rbinom(n, size, prob)以下は、使用されるパラメーターの説明です-
x は数のベクトルです。
p 確率のベクトルです。
n 観測数です。
size 試行回数です。
prob 各試行の成功の確率です。
dbinom()
この関数は、各ポイントでの確率密度分布を示します。
# Create a sample of 50 numbers which are incremented by 1.
x <- seq(0,50,by = 1)
# Create the binomial distribution.
y <- dbinom(x,50,0.5)
# Give the chart file a name.
png(file = "dbinom.png")
# Plot the graph for this sample.
plot(x,y)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
pbinom()
この関数は、イベントの累積確率を示します。これは、確率を表す単一の値です。
# Probability of getting 26 or less heads from a 51 tosses of a coin.
x <- pbinom(26,51,0.5)
print(x)上記のコードを実行すると、次の結果が生成されます-
[1] 0.610116qbinom()
この関数は確率値を取り、累積値が確率値と一致する数値を返します。
# How many heads will have a probability of 0.25 will come out when a coin
# is tossed 51 times.
x <- qbinom(0.25,51,1/2)
print(x)上記のコードを実行すると、次の結果が生成されます-
[1] 23rbinom()
この関数は、特定のサンプルから特定の確率の必要な数のランダム値を生成します。
# Find 8 random values from a sample of 150 with probability of 0.4.
x <- rbinom(8,150,.4)
print(x)上記のコードを実行すると、次の結果が生成されます-
[1] 58 61 59 66 55 60 61 67ポアソン回帰には、応答変数が分数ではなくカウントの形式である回帰モデルが含まれます。たとえば、サッカーの試合シリーズの出生数や勝利数などです。また、応答変数の値はポアソン分布に従います。
ポアソン回帰の一般的な数式は次のとおりです。
log(y) = a + b1x1 + b2x2 + bnxn.....以下は、使用されるパラメーターの説明です-
y は応答変数です。
a そして b は数値係数です。
x は予測変数です。
ポアソン回帰モデルの作成に使用される関数は、 glm() 関数。
構文
の基本構文 glm() ポアソン回帰の関数は−です
glm(formula,data,family)以下は、上記の関数で使用されるパラメーターの説明です。
formula 変数間の関係を表す記号です。
data これらの変数の値を与えるデータセットです。
familyモデルの詳細を指定するRオブジェクトです。値はロジスティック回帰の「ポアソン」です。
例
ウールタイプ(AまたはB)と張力(低、中、高)が織機あたりのワープブレーク数に及ぼす影響を説明するデータセット「ワープブレーク」が組み込まれています。ブレーク数のカウントである応答変数として「ブレーク」を考えてみましょう。ウールの「タイプ」と「張力」が予測変数として使用されます。
Input Data
input <- warpbreaks
print(head(input))上記のコードを実行すると、次の結果が生成されます-
breaks wool tension
1 26 A L
2 30 A L
3 54 A L
4 25 A L
5 70 A L
6 52 A L回帰モデルの作成
output <-glm(formula = breaks ~ wool+tension, data = warpbreaks,
family = poisson)
print(summary(output))上記のコードを実行すると、次の結果が生成されます-
Call:
glm(formula = breaks ~ wool + tension, family = poisson, data = warpbreaks)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.6871 -1.6503 -0.4269 1.1902 4.2616
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69196 0.04541 81.302 < 2e-16 ***
woolB -0.20599 0.05157 -3.994 6.49e-05 ***
tensionM -0.32132 0.06027 -5.332 9.73e-08 ***
tensionH -0.51849 0.06396 -8.107 5.21e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 297.37 on 53 degrees of freedom
Residual deviance: 210.39 on 50 degrees of freedom
AIC: 493.06
Number of Fisher Scoring iterations: 4要約では、応答変数に対する予測変数の影響を検討するために、最後の列のp値が0.05未満であることを確認します。見られるように、張力タイプMおよびHを有するウールタイプBは、破損の数に影響を及ぼします。
回帰分析を使用して、応答変数に対する予測変数の変動の影響を説明するモデルを作成します。はい/いいえや男性/女性などの値を持つカテゴリ変数がある場合があります。単純な回帰分析では、カテゴリ変数の値ごとに複数の結果が得られます。このようなシナリオでは、予測変数と一緒に使用し、カテゴリ変数の各レベルの回帰直線を比較することで、カテゴリ変数の効果を調べることができます。このような分析は、Analysis of Covariance とも呼ばれます ANCOVA。
例
R組み込みデータセットmtcarsについて考えてみます。その中で、フィールド「am」がトランスミッションのタイプ(自動または手動)を表していることがわかります。これは、値が0と1のカテゴリ変数です。車のガロンあたりのマイル数(mpg)は、馬力( "hp")の値以外にも依存する可能性があります。
「mpg」と「hp」の間の回帰に対する「am」の値の影響を調べます。それはを使用して行われますaov() 関数の後に anova() 重回帰を比較する関数。
入力データ
データセットmtcarsから、フィールド「mpg」、「hp」、および「am」を含むデータフレームを作成します。ここでは、「mpg」を応答変数、「hp」を予測変数、「am」をカテゴリ変数とします。
input <- mtcars[,c("am","mpg","hp")]
print(head(input))上記のコードを実行すると、次の結果が生成されます-
am mpg hp
Mazda RX4 1 21.0 110
Mazda RX4 Wag 1 21.0 110
Datsun 710 1 22.8 93
Hornet 4 Drive 0 21.4 110
Hornet Sportabout 0 18.7 175
Valiant 0 18.1 105ANCOVA分析
「am」と「hp」の間の相互作用を考慮して、予測変数として「hp」を、応答変数として「mpg」を使用して回帰モデルを作成します。
カテゴリ変数と予測変数の間の交互作用を持つモデル
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp*am,data = input)
print(summary(result))上記のコードを実行すると、次の結果が生成されます-
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 77.391 1.50e-09 ***
am 1 202.2 202.2 23.072 4.75e-05 ***
hp:am 1 0.0 0.0 0.001 0.981
Residuals 28 245.4 8.8
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1この結果は、両方の場合のp値が0.05未満であるため、馬力とトランスミッションタイプの両方がガロンあたりのマイル数に大きな影響を与えることを示しています。ただし、p値が0.05を超えるため、これら2つの変数間の交互作用は重要ではありません。
カテゴリ変数と予測変数間の交互作用のないモデル
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp+am,data = input)
print(summary(result))上記のコードを実行すると、次の結果が生成されます-
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 80.15 7.63e-10 ***
am 1 202.2 202.2 23.89 3.46e-05 ***
Residuals 29 245.4 8.5
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1この結果は、両方の場合のp値が0.05未満であるため、馬力とトランスミッションタイプの両方がガロンあたりのマイル数に大きな影響を与えることを示しています。
2つのモデルの比較
これで、2つのモデルを比較して、変数の交互作用が本当に重要でないかどうかを結論付けることができます。これには、anova() 関数。
# Get the dataset.
input <- mtcars
# Create the regression models.
result1 <- aov(mpg~hp*am,data = input)
result2 <- aov(mpg~hp+am,data = input)
# Compare the two models.
print(anova(result1,result2))上記のコードを実行すると、次の結果が生成されます-
Model 1: mpg ~ hp * am
Model 2: mpg ~ hp + am
Res.Df RSS Df Sum of Sq F Pr(>F)
1 28 245.43
2 29 245.44 -1 -0.0052515 6e-04 0.9806p値が0.05より大きいため、馬力と伝達タイプの間の相互作用は重要ではないと結論付けます。したがって、ガロンあたりの走行距離は、自動変速機モードと手動変速機モードの両方で、同様に車の馬力に依存します。
時系列は、各データポイントがタイムスタンプに関連付けられている一連のデータポイントです。簡単な例は、特定の日のさまざまな時点での株式市場の株式の価格です。別の例は、1年のさまざまな月における地域の降雨量です。R言語は、時系列データを作成、操作、およびプロットするために多くの関数を使用します。時系列のデータは、と呼ばれるRオブジェクトに格納されます。time-series object。これは、ベクトルやデータフレームのようなRデータオブジェクトでもあります。
時系列オブジェクトは、 ts() 関数。
構文
の基本構文 ts() 時系列分析の関数は−
timeseries.object.name <- ts(data, start, end, frequency)以下は、使用されるパラメーターの説明です-
data 時系列で使用される値を含むベクトルまたは行列です。
start 時系列の最初の観測の開始時刻を指定します。
end 時系列の最後の観測の終了時刻を指定します。
frequency 単位時間あたりの観測数を指定します。
パラメータ「data」を除いて、他のすべてのパラメータはオプションです。
例
2012年1月以降の場所での年間降雨量の詳細を検討します。12か月間のR時系列オブジェクトを作成してプロットします。
# Get the data points in form of a R vector.
rainfall <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
# Convert it to a time series object.
rainfall.timeseries <- ts(rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall.png")
# Plot a graph of the time series.
plot(rainfall.timeseries)
# Save the file.
dev.off()上記のコードを実行すると、次の結果とチャートが生成されます-
Jan Feb Mar Apr May Jun Jul Aug Sep
2012 799.0 1174.8 865.1 1334.6 635.4 918.5 685.5 998.6 784.2
Oct Nov Dec
2012 985.0 882.8 1071.0時系列チャート-
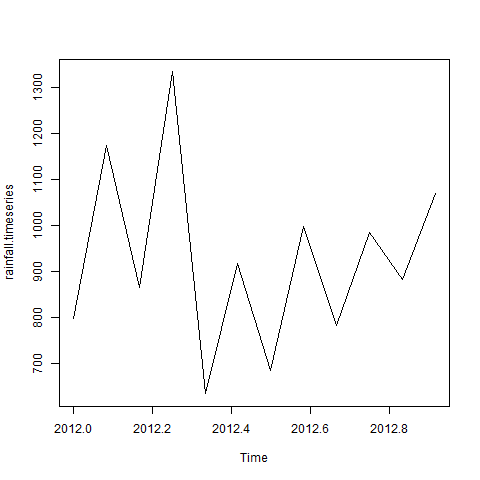
異なる時間間隔
の値 frequencyts()関数のパラメーターは、データポイントが測定される時間間隔を決定します。値12は、時系列が12か月であることを示します。その他の値とその意味は以下のとおりです。
frequency = 12 1年の毎月のデータポイントをペグします。
frequency = 4 1年の四半期ごとにデータポイントをペグします。
frequency = 6 1時間の10分ごとにデータポイントをペグします。
frequency = 24*6 1日の10分ごとにデータポイントをペグします。
複数の時系列
両方の系列を行列に結合することにより、1つのグラフに複数の時系列をプロットできます。
# Get the data points in form of a R vector.
rainfall1 <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
rainfall2 <-
c(655,1306.9,1323.4,1172.2,562.2,824,822.4,1265.5,799.6,1105.6,1106.7,1337.8)
# Convert them to a matrix.
combined.rainfall <- matrix(c(rainfall1,rainfall2),nrow = 12)
# Convert it to a time series object.
rainfall.timeseries <- ts(combined.rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall_combined.png")
# Plot a graph of the time series.
plot(rainfall.timeseries, main = "Multiple Time Series")
# Save the file.
dev.off()上記のコードを実行すると、次の結果とチャートが生成されます-
Series 1 Series 2
Jan 2012 799.0 655.0
Feb 2012 1174.8 1306.9
Mar 2012 865.1 1323.4
Apr 2012 1334.6 1172.2
May 2012 635.4 562.2
Jun 2012 918.5 824.0
Jul 2012 685.5 822.4
Aug 2012 998.6 1265.5
Sep 2012 784.2 799.6
Oct 2012 985.0 1105.6
Nov 2012 882.8 1106.7
Dec 2012 1071.0 1337.8複数の時系列チャート-
回帰分析のために実世界のデータをモデル化する場合、モデルの方程式が線形グラフを与える線形方程式である場合はめったにないことがわかります。ほとんどの場合、実世界のデータのモデルの方程式には、3の指数やsin関数などのより高度な数学関数が含まれます。このようなシナリオでは、モデルのプロットは線ではなく曲線を示します。線形回帰と非線形回帰の両方の目標は、モデルのパラメーターの値を調整して、データに最も近い線または曲線を見つけることです。これらの値を見つけると、応答変数を高い精度で推定できるようになります。
最小二乗回帰では、回帰曲線からのさまざまな点の垂直距離の二乗の合計が最小化される回帰モデルを確立します。通常、定義されたモデルから始めて、係数にいくつかの値を想定します。次に、nls() 信頼区間とともにより正確な値を取得するためのRの関数。
構文
Rで非線形最小二乗検定を作成するための基本的な構文は次のとおりです。
nls(formula, data, start)以下は、使用されるパラメーターの説明です-
formula は、変数とパラメーターを含む非線形モデル式です。
data 式の変数を評価するために使用されるデータフレームです。
start 開始推定値の名前付きリストまたは名前付き数値ベクトルです。
例
係数の初期値を仮定した非線形モデルを検討します。次に、これらの仮定値の信頼区間を確認して、これらの値がモデルにどの程度適合しているかを判断できるようにします。
それでは、この目的のために以下の方程式を考えてみましょう-
a = b1*x^2+b2初期係数を1と3と仮定し、これらの値をnls()関数に適合させます。
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))上記のコードを実行すると、次の結果が生成されます-
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484
b1の値は1に近く、b2の値は3ではなく2に近いと結論付けることができます。
デシジョンツリーは、選択肢とその結果をツリー形式で表すグラフです。グラフのノードはイベントまたは選択を表し、グラフのエッジは決定ルールまたは条件を表します。これは主に、Rを使用する機械学習およびデータマイニングアプリケーションで使用されます。
デシジョントレスの使用例は、電子メールをスパムまたは非スパムとして予測する、腫瘍が癌性であると予測する、またはこれらのそれぞれの要因に基づいてローンを信用リスクの良し悪しとして予測することです。一般に、モデルは、トレーニングデータとも呼ばれる観測データを使用して作成されます。次に、一連の検証データを使用して、モデルを検証および改善します。Rには、決定木を作成および視覚化するために使用されるパッケージがあります。予測変数の新しいセットについては、このモデルを使用して、データのカテゴリ(yes / No、スパム/非スパム)を決定します。
Rパッケージ "party" デシジョンツリーを作成するために使用されます。
Rパッケージをインストールする
パッケージをインストールするには、Rコンソールで以下のコマンドを使用します。依存パッケージがある場合は、それもインストールする必要があります。
install.packages("party")パッケージ「パーティー」には機能があります ctree() これは、決定木を作成および分析するために使用されます。
構文
Rで決定木を作成するための基本的な構文は次のとおりです。
ctree(formula, data)以下は、使用されるパラメーターの説明です-
formula は、予測変数と応答変数を説明する式です。
data 使用されるデータセットの名前です。
入力データ
名前の付いたRの組み込みデータセットを使用します readingSkillsデシジョンツリーを作成します。変数「age」、「shoesize」、「score」がわかっている場合、およびその人がネイティブスピーカーであるかどうかを知っている場合は、その人のreadingSkillsのスコアを表します。
これがサンプルデータです。
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))上記のコードを実行すると、次の結果とチャートが生成されます-
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................例
を使用します ctree() 決定木を作成し、そのグラフを表示する関数。
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Create the input data frame.
input.dat <- readingSkills[c(1:105),]
# Give the chart file a name.
png(file = "decision_tree.png")
# Create the tree.
output.tree <- ctree(
nativeSpeaker ~ age + shoeSize + score,
data = input.dat)
# Plot the tree.
plot(output.tree)
# Save the file.
dev.off()上記のコードを実行すると、次の結果が生成されます-
null device
1
Loading required package: methods
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Loading required package: strucchange
Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
Loading required package: sandwich
結論
上記の決定木から、readingSkillsスコアが38.3未満で、年齢が6歳を超える人はネイティブスピーカーではないと結論付けることができます。
ランダムフォレストアプローチでは、多数の決定木が作成されます。すべての観測値は、すべての決定木に入力されます。各観測の最も一般的な結果は、最終出力として使用されます。新しい観測値がすべてのツリーに入力され、各分類モデルに多数決が行われます。
ツリーの構築中に使用されなかったケースについては、エラー推定が行われます。それはと呼ばれますOOB (Out-of-bag) パーセンテージで示される誤差推定。
Rパッケージ "randomForest" ランダムフォレストを作成するために使用されます。
Rパッケージをインストールする
パッケージをインストールするには、Rコンソールで以下のコマンドを使用します。依存パッケージがある場合は、それもインストールする必要があります。
install.packages("randomForest)パッケージ「randomForest」には機能があります randomForest() これは、ランダムフォレストを作成および分析するために使用されます。
構文
Rでランダムフォレストを作成するための基本的な構文は次のとおりです。
randomForest(formula, data)以下は、使用されるパラメーターの説明です-
formula は、予測変数と応答変数を説明する式です。
data 使用されるデータセットの名前です。
入力データ
readingSkillsという名前のRの組み込みデータセットを使用して、決定木を作成します。変数「age」、「shoesize」、「score」がわかっている場合は、誰かのreadingSkillsのスコアと、その人がネイティブスピーカーであるかどうかを示します。
これがサンプルデータです。
# Load the party package. It will automatically load other
# required packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))上記のコードを実行すると、次の結果とチャートが生成されます-
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................例
を使用します randomForest() 決定木を作成し、そのグラフを表示する関数。
# Load the party package. It will automatically load other
# required packages.
library(party)
library(randomForest)
# Create the forest.
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
# View the forest results.
print(output.forest)
# Importance of each predictor.
print(importance(fit,type = 2))上記のコードを実行すると、次の結果が生成されます-
Call:
randomForest(formula = nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
OOB estimate of error rate: 1%
Confusion matrix:
no yes class.error
no 99 1 0.01
yes 1 99 0.01
MeanDecreaseGini
age 13.95406
shoeSize 18.91006
score 56.73051結論
上に示したランダムフォレストから、靴のサイズとスコアが、誰かがネイティブスピーカーであるかどうかを決定する重要な要素であると結論付けることができます。また、モデルの誤差は1%しかないため、99%の精度で予測できます。
生存分析は、特定のイベントが発生する時間を予測することを扱います。これは、故障時間分析または死亡までの時間の分析としても知られています。たとえば、癌を患っている人が生き残る日数を予測したり、機械システムが故障する時間を予測したりします。
名前の付いたRパッケージ survival生存分析を実行するために使用されます。このパッケージには機能が含まれていますSurv()これは、入力データをR式として受け取り、分析のために選択された変数の中に生存オブジェクトを作成します。次に、関数を使用しますsurvfit() 分析用のプロットを作成します。
パッケージのインストール
install.packages("survival")構文
Rで生存分析を作成するための基本的な構文は次のとおりです。
Surv(time,event)
survfit(formula)以下は、使用されるパラメーターの説明です-
time イベントが発生するまでのフォローアップ時間です。
event 予期されるイベントの発生状況を示します。
formula 予測変数間の関係です。
例
上記でインストールされたサバイバルパッケージに存在する「pbc」という名前のデータセットを検討します。肝臓の原発性胆汁性肝硬変(PBC)に冒された人々に関する生存データポイントについて説明します。データセットに存在する多くの列の中で、主にフィールド「時間」と「ステータス」に関係しています。時間は、患者の登録から、肝移植を受ける患者または患者の死亡との間のイベントの初期までの日数を表します。
# Load the library.
library("survival")
# Print first few rows.
print(head(pbc))上記のコードを実行すると、次の結果とチャートが生成されます-
id time status trt age sex ascites hepato spiders edema bili chol
1 1 400 2 1 58.76523 f 1 1 1 1.0 14.5 261
2 2 4500 0 1 56.44627 f 0 1 1 0.0 1.1 302
3 3 1012 2 1 70.07255 m 0 0 0 0.5 1.4 176
4 4 1925 2 1 54.74059 f 0 1 1 0.5 1.8 244
5 5 1504 1 2 38.10541 f 0 1 1 0.0 3.4 279
6 6 2503 2 2 66.25873 f 0 1 0 0.0 0.8 248
albumin copper alk.phos ast trig platelet protime stage
1 2.60 156 1718.0 137.95 172 190 12.2 4
2 4.14 54 7394.8 113.52 88 221 10.6 3
3 3.48 210 516.0 96.10 55 151 12.0 4
4 2.54 64 6121.8 60.63 92 183 10.3 4
5 3.53 143 671.0 113.15 72 136 10.9 3
6 3.98 50 944.0 93.00 63 NA 11.0 3上記のデータから、分析の時間とステータスを検討しています。
Surv()およびsurvfit()関数の適用
次に、適用に進みます。 Surv() 上記のデータセットに関数を適用し、傾向を示すプロットを作成します。
# Load the library.
library("survival")
# Create the survival object.
survfit(Surv(pbc$time,pbc$status == 2)~1) # Give the chart file a name. png(file = "survival.png") # Plot the graph. plot(survfit(Surv(pbc$time,pbc$status == 2)~1))
# Save the file.
dev.off()上記のコードを実行すると、次の結果とチャートが生成されます-
Call: survfit(formula = Surv(pbc$time, pbc$status == 2) ~ 1)
n events median 0.95LCL 0.95UCL
418 161 3395 3090 3853
上のグラフの傾向は、特定の日数の終わりに生存する確率を予測するのに役立ちます。
Chi-Square testは、2つのカテゴリ変数がそれらの間に有意な相関関係があるかどうかを判断するための統計的方法です。これらの変数は両方とも同じ母集団からのものである必要があり、-はい/いいえ、男性/女性、赤/緑などのカテゴリである必要があります。
たとえば、人々のアイスクリームの購入パターンを観察したデータセットを作成し、人の性別を好みのアイスクリームの味と相関させることができます。相関関係が見つかった場合は、訪問する人々の性別の数を知ることにより、適切なフレーバーの在庫を計画できます。
構文
カイ二乗検定の実行に使用される関数は次のとおりです。 chisq.test()。
Rでカイ2乗検定を作成するための基本的な構文は次のとおりです。
chisq.test(data)以下は、使用されるパラメーターの説明です-
data は、観測値の変数のカウント値を含むテーブル形式のデータです。
例
1993年のさまざまなモデルの自動車の販売を表す「MASS」ライブラリのCars93データを取得します。
library("MASS")
print(str(Cars93))上記のコードを実行すると、次の結果が生成されます-
'data.frame': 93 obs. of 27 variables:
$ Manufacturer : Factor w/ 32 levels "Acura","Audi",..: 1 1 2 2 3 4 4 4 4 5 ...
$ Model : Factor w/ 93 levels "100","190E","240",..: 49 56 9 1 6 24 54 74 73 35 ... $ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ...
$ Min.Price : num 12.9 29.2 25.9 30.8 23.7 14.2 19.9 22.6 26.3 33 ... $ Price : num 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ...
$ Max.Price : num 18.8 38.7 32.3 44.6 36.2 17.3 21.7 24.9 26.3 36.3 ... $ MPG.city : int 25 18 20 19 22 22 19 16 19 16 ...
$ MPG.highway : int 31 25 26 26 30 31 28 25 27 25 ... $ AirBags : Factor w/ 3 levels "Driver & Passenger",..: 3 1 2 1 2 2 2 2 2 2 ...
$ DriveTrain : Factor w/ 3 levels "4WD","Front",..: 2 2 2 2 3 2 2 3 2 2 ... $ Cylinders : Factor w/ 6 levels "3","4","5","6",..: 2 4 4 4 2 2 4 4 4 5 ...
$ EngineSize : num 1.8 3.2 2.8 2.8 3.5 2.2 3.8 5.7 3.8 4.9 ... $ Horsepower : int 140 200 172 172 208 110 170 180 170 200 ...
$ RPM : int 6300 5500 5500 5500 5700 5200 4800 4000 4800 4100 ... $ Rev.per.mile : int 2890 2335 2280 2535 2545 2565 1570 1320 1690 1510 ...
$ Man.trans.avail : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 1 1 1 1 ... $ Fuel.tank.capacity: num 13.2 18 16.9 21.1 21.1 16.4 18 23 18.8 18 ...
$ Passengers : int 5 5 5 6 4 6 6 6 5 6 ... $ Length : int 177 195 180 193 186 189 200 216 198 206 ...
$ Wheelbase : int 102 115 102 106 109 105 111 116 108 114 ... $ Width : int 68 71 67 70 69 69 74 78 73 73 ...
$ Turn.circle : int 37 38 37 37 39 41 42 45 41 43 ... $ Rear.seat.room : num 26.5 30 28 31 27 28 30.5 30.5 26.5 35 ...
$ Luggage.room : int 11 15 14 17 13 16 17 21 14 18 ... $ Weight : int 2705 3560 3375 3405 3640 2880 3470 4105 3495 3620 ...
$ Origin : Factor w/ 2 levels "USA","non-USA": 2 2 2 2 2 1 1 1 1 1 ... $ Make : Factor w/ 93 levels "Acura Integra",..: 1 2 4 3 5 6 7 9 8 10 ...上記の結果は、データセットにカテゴリ変数と見なすことができる多くの因子変数があることを示しています。このモデルでは、変数「AirBags」と「Type」を検討します。ここでは、販売された車のタイプとエアバッグのタイプとの間に有意な相関関係があるかどうかを調べることを目的としています。相関関係が観察されれば、どのタイプの車がどのタイプのエアバッグでより売れるかを見積もることができます。
# Load the library.
library("MASS")
# Create a data frame from the main data set.
car.data <- data.frame(Cars93$AirBags, Cars93$Type)
# Create a table with the needed variables.
car.data = table(Cars93$AirBags, Cars93$Type)
print(car.data)
# Perform the Chi-Square test.
print(chisq.test(car.data))上記のコードを実行すると、次の結果が生成されます-
Compact Large Midsize Small Sporty Van
Driver & Passenger 2 4 7 0 3 0
Driver only 9 7 11 5 8 3
None 5 0 4 16 3 6
Pearson's Chi-squared test
data: car.data
X-squared = 33.001, df = 10, p-value = 0.0002723
Warning message:
In chisq.test(car.data) : Chi-squared approximation may be incorrect結論
結果は、文字列の相関を示す0.05未満のp値を示しています。