SAPBODS-クイックガイド
データウェアハウスは、1つまたは複数の異種データソースからのデータを格納するための中央リポジトリとして知られています。データウェアハウスは、情報のレポートと分析に使用され、履歴データと現在のデータの両方を保存します。DWシステムのデータは分析レポートに使用され、後でビジネスアナリスト、セールスマネージャー、またはナレッジワーカーが意思決定に使用します。
DWシステムのデータは、Sales、Marketing、HR、SCMなどの運用トランザクションシステムからロードされます。情報処理のためにDWシステムにロードされる前に、運用データストアまたはその他の変換を通過する場合があります。
データウェアハウス-主な機能
DWシステムの主な機能は次のとおりです。
これは、1つ以上の異種データソースからのデータが保存される中央データリポジトリです。
DWシステムは、現在のデータと過去のデータの両方を保存します。通常、DWシステムは5〜10年の履歴データを保存します。
DWシステムは、常に運用トランザクションシステムから分離されています。
DWシステムのデータは、四半期ごとの比較から年次の比較まで、さまざまなタイプの分析レポートに使用されます。
DWシステムの必要性
マーケティング、販売、ERP、HRM、MMなどの複数のアプリケーションからデータが取得されている住宅ローン会社があるとします。このデータは抽出され、変換され、データウェアハウスに読み込まれます。
たとえば、製品の四半期/年間売上高を比較する必要がある場合、オペレーショナルトランザクションデータベースを使用することはできません。これにより、トランザクションシステムがハングします。したがって、この目的のためにデータウェアハウスが使用されます。
DWとODBの違い
データウェアハウスとオペレーショナルデータベース(トランザクションデータベース)の違いは次のとおりです。
トランザクションシステムは、既知のワークロードと、ユーザーレコードの更新、レコードの検索などのトランザクション用に設計されています。ただし、データウェアハウストランザクションはより複雑で、一般的な形式のデータを提供します。
トランザクションシステムには組織の現在のデータが含まれ、データウェアハウスには通常履歴データが含まれます。
トランザクションシステムは、複数のトランザクションの並列処理をサポートしています。データベースの一貫性を維持するには、同時実行制御と回復のメカニズムが必要です。
オペレーショナルデータベースクエリでは、操作の読み取りと変更(削除と更新)が可能ですが、OLAPクエリでは、保存されたデータへの読み取り専用アクセスのみが必要です(Selectステートメント)。
DWアーキテクチャ
データウェアハウジングには、データクリーニング、データ統合、およびデータ統合が含まれます。

データウェアハウスには3層アーキテクチャがあります- Data Source Layer, Integration Layer, そして Presentation Layer。上記の図は、データウェアハウスシステムの一般的なアーキテクチャを示しています。
データウェアハウスシステムには4つのタイプがあります。
- データ市場
- オンライン分析処理(OLAP)
- オンライントランザクション処理(OLTP)
- 予測分析(PA)
データ市場
データマートは、データウェアハウスシステムの最も単純な形式として知られており、通常、販売、財務、マーケティングなどの組織内の単一の機能領域で構成されます。
組織内のデータマートであり、単一の部門によって作成および管理されます。単一の部門に属しているため、部門は通常、少数または1つのタイプのソース/アプリケーションからのみデータを取得します。このソースは、内部運用システム、データウェアハウス、または外部システムである可能性があります。
オンライン分析処理
OLAPシステムでは、トランザクションシステムと比較してトランザクションの数が少なくなります。実行されるクエリは本質的に複雑であり、データの集計が含まれます。
アグリゲーションとは何ですか?
年次(1行)、四半期(4行)、月次(12行)などの集計データを使用してテーブルを保存します。年ごとの比較を行う必要がある場合は、1行のみが処理されます。ただし、集計されていないテーブルでは、すべての行が比較されます。
SELECT SUM(salary)
FROM employee
WHERE title = 'Programmer';OLAPシステムでの効果的な対策
応答時間は、最も効果的で重要な指標の1つとして知られています。 OLAPシステム。集約された格納データは、スタースキーマなどの多次元スキーマで維持されます(データが階層グループ(ディメンションと呼ばれることもあります)およびファクトと集約ファクトに配置される場合、スキーマと呼ばれます)。
OLAPシステムの遅延は、遅延が1日に近いと予想されるデータマートと比較して数時間です。
オンライントランザクション処理
OLTPシステムでは、INSERT、UPDATE、DELETEなどの短いオンライントランザクションが多数あります。
OLTPシステムでは、効果的な手段は短いトランザクションの処理時間であり、非常に短いです。マルチアクセス環境でのデータの整合性を制御します。OLTPシステムの場合、1秒あたりのトランザクション数はeffectiveness。OLTPデータウェアハウスシステムには、現在の詳細データが含まれており、エンティティモデル(3NF)のスキーマで維持されます。
例
小売店の日常のトランザクションシステム。顧客レコードは毎日挿入、更新、削除されます。非常に高速なクエリ処理を提供します。OLTPデータベースには、詳細な最新データが含まれています。OLTPデータベースを格納するために使用されるスキーマは、エンティティモデルです。
OLTPとOLAPの違い
次の図は、 OLTP そして OLAP システム。

Indexes − OLTPシステムにはインデックスがほとんどありませんが、OLAPシステムにはパフォーマンスを最適化するためのインデックスが多数あります。
Joins− OLTPシステムでは、多数の結合とデータが正規化されます。ただし、OLAPシステムでは、結合が少なく、非正規化されます。
Aggregation − OLTPシステムでは、データは集約されませんが、OLAPデータベースではより多くの集約が使用されます。
予測分析
予測分析は、さまざまな数学関数を使用して将来の結果を予測することにより、DWシステムに格納されているデータの隠れたパターンを見つけることとして知られています。
予測分析システムは、その使用法の点でOLAPシステムとは異なります。これは、将来の結果に焦点を当てるために使用されます。OALPシステムは、分析レポートのための現在および過去のデータ処理に焦点を合わせています。
DWシステムの機能を満たすさまざまなデータウェアハウス/データベースシステムが市場に出回っています。データウェアハウスシステムの最も一般的なベンダーは次のとおりです。
- Microsoft SQL Server
- Oracle Exadata
- IBM Netezza
- Teradata
- Sybase IQ
- SAP Business Warehouse(SAP BW)
SAP Business Warehouse
SAP Business WarehouseSAPNetWeaverリリースプラットフォームの一部です。NetWeaver 7.4より前は、SAP NetWeaver BusinessWarehouseと呼ばれていました。
SAP BWでのデータウェアハウジングとは、データ統合、変換、データクレンジング、保存、およびデータステージングを意味します。DWプロセスには、BWシステムでのデータモデリング、ステージング、および管理が含まれます。BWシステムでDWタスクを管理するために使用される主なツールは、管理ワークベンチです。
主な機能
SAP BWは、分析サービスと事業計画、分析レポート、クエリ処理と情報、エンタープライズデータウェアハウジングを含むビジネスインテリジェンスなどの機能を提供します。
意思決定に役立つデータベースとデータベース管理ツールの組み合わせを提供します。
BWシステムのその他の主要な機能には、非SAP R / 3アプリケーションへの接続をサポートするビジネスアプリケーションプログラミングインターフェイス(BAPI)、自動データ抽出とロード、統合OLAPプロセッサ、メタデータリポジトリ、管理ツール、多言語サポート、およびWeb対応インターフェース。
SAP BWは、1998年にドイツの企業であるSAPによって最初に導入されました。SAP BWシステムは、モデル駆動型アプローチに基づいており、エンタープライズデータウェアハウスをSAP R3データに対して簡単、シンプル、かつ効率的にしています。
過去16年間から、SAP BWは、多くの企業がエンタープライズデータウェアハウジングのニーズを管理するための重要なシステムの1つとして進化してきました。
ビジネスエクスプローラー (BEx) 社内での柔軟なレポート、戦略的分析、および運用レポートのオプションを提供します。
BIシステムでレポート、クエリ実行、分析機能を実行するために使用されます。また、現在および過去のデータを、WebおよびExcel形式でさまざまな詳細まで処理できます。
使用する BEx 情報ブロードキャスト、BIコンテンツは、ドキュメントとして電子メールで、またはライブデータとしてリンクの形式で共有できます。また、SAPEP機能を使用して公開することもできます。
ビジネスオブジェクツ&製品
最も一般的なビジネスインテリジェンスツールとして知られるSAPBusiness Objectsは、さまざまなプラットフォームでのデータの操作、ユーザーアクセス、分析、フォーマット、および情報の公開に使用されます。これはフロントエンドベースのツールセットであり、ビジネスユーザーと意思決定者がビジネスインテリジェンスの現在および過去のデータを表示、並べ替え、分析できるようにします。
以下のツールで構成されています-
Webインテリジェンス
Webインテリジェンス(WebI)は、ドリル、階層、グラフ、計算されたメジャーなどのデータ分析のさまざまな機能をサポートする最も一般的なBusiness Objects詳細レポートツールと呼ばれます。これにより、エンドユーザーはクエリパネルでアドホッククエリを作成できます。オンラインとオフラインの両方でデータ分析を実行します。
SAP Business Objects Xcelsius /ダッシュボード
ダッシュボードは、データの視覚化とダッシュボード機能をエンドユーザーに提供し、このツールを使用してインタラクティブなダッシュボードを作成できます。
また、さまざまな種類のチャートやグラフを追加したり、データを視覚化するための動的なダッシュボードを作成したりすることもできます。これらは主に、組織の財務会議で使用されます。
Crystal Reports
Crystal Reportsは、ピクセル単位の完全なレポートに使用されます。これにより、ユーザーはレポートを作成および設計し、後で印刷目的で使用できます。
冒険者
Explorerを使用すると、ユーザーはBIリポジトリ内のコンテンツを検索でき、最適な一致がグラフの形式で表示されます。検索を実行するためにクエリを書き留める必要はありません。
詳細なレポート、データの視覚化、ダッシュボードの目的で導入されたその他のさまざまなコンポーネントとツールは、Design Studio、Microsoft Office用の分析エディション、BIリポジトリ、およびBusiness ObjectsMobileプラットフォームです。
ETLは、Extract、Transform、Loadの略です。ETLツールは、さまざまなRDBMSソースシステムからデータを抽出し、計算の適用、連結などのようにデータを変換してから、データウェアハウスシステムにデータをロードします。データは、ディメンションテーブルとファクトテーブルの形式でDWシステムにロードされます。
抽出
ETLのロード中は、ステージング領域が必要です。ステージング領域が必要な理由はさまざまです。
ソースシステムは、データを抽出するために特定の期間のみ使用できます。この期間は、合計データロード時間よりも短くなります。したがって、ステージング領域を使用すると、ソースシステムからデータを抽出し、タイムスロットが終了する前にデータをステージング領域に保持できます。
複数のデータソースからデータをまとめて取得する場合、または2つ以上のシステムを結合する場合は、ステージング領域が必要です。たとえば、物理的に異なる2つのデータベースの2つのテーブルを結合するSQLクエリを実行することはできません。
さまざまなシステムのデータ抽出のタイムスロットは、タイムゾーンと運用時間によって異なります。
ソースシステムから抽出されたデータは、複数のデータウェアハウスシステム、オペレーションデータストアなどで使用できます。
ETLを使用すると、複雑な変換を実行でき、データを格納するために追加の領域が必要になります。

変換
データ変換では、抽出されたデータに一連の関数を適用して、データをターゲットシステムにロードします。変換を必要としないデータは、直接移動またはパススルーデータと呼ばれます。
ソースシステムから抽出されたデータにさまざまな変換を適用できます。たとえば、カスタマイズされた計算を実行できます。売上高の合計が必要で、これがデータベースにない場合は、SUM 変換中に式を作成し、データをロードします。
たとえば、テーブルの姓と名が異なる列にある場合は、ロードする前に連結を使用できます。
負荷
ロードフェーズでは、データがエンドターゲットシステムにロードされ、フラットファイルまたはデータウェアハウスシステムにすることができます。
SAP BO Data Servicesは、データ統合、データ品質、データプロファイリング、およびデータ処理に使用されるETLツールです。これにより、信頼できるデータからデータウェアハウスシステムを統合して変換し、分析レポートを作成できます。
BO Data Servicesは、UI開発インターフェイス、メタデータリポジトリ、ソースおよびターゲットシステムへのデータ接続、およびジョブのスケジューリング用の管理コンソールで構成されています。
データ統合とデータ管理
SAP BO Data Servicesは、データ統合および管理ツールであり、Data Integrator JobServerとDataIntegratorDesignerで構成されています。
主な機能
Data Integrator言語を使用してさまざまなデータ変換を適用し、複雑なデータ変換を適用して、カスタマイズされた関数を構築できます。
Data Integrator Designerは、リアルタイムおよびバッチジョブと新しいプロジェクトをリポジトリに保存するために使用されます。
DI Designerは、すべての基本機能を備えた中央リポジトリを提供することにより、チームベースのETL開発のオプションも提供します。
Data Integratorジョブサーバーは、DIDesignerを使用して作成されたジョブを処理する責任があります。
Web管理者
Data Integrator Web管理者は、システム管理者とデータベース管理者がデータサービスのリポジトリを維持するために使用します。Data Servicesには、メタデータリポジトリ、チームベースの開発用の中央リポジトリ、ジョブサーバーおよびWebサービスが含まれます。
DIWeb管理者の主な機能
- バッチジョブのスケジュール、監視、実行に使用されます。
- これは、リアルタイムサーバーの構成と開始および停止に使用されます。
- これは、Job Server、Access Server、およびリポジトリの使用法を構成するために使用されます。
- アダプターの構成に使用されます。
- これは、BO DataServicesのすべてのツールを構成および制御するために使用されます。
データ管理機能は、データ品質に重点を置いています。これには、データのクレンジング、拡張、およびデータの統合が含まれ、DWシステムで正しいデータを取得します。
この章では、SAPBODSアーキテクチャについて学習します。この図は、ステージング領域を備えたBODSシステムのアーキテクチャを示しています。
ソースレイヤー
ソースレイヤーには、SAPアプリケーションや非SAP RDBMSシステムなどのさまざまなデータソースが含まれ、データ統合はステージング領域で行われます。
SAP Business Objects Data Servicesには、Data Service Designer、Data Services Management Console、Repository Manager、Data Services Server Manager、Work Benchなどのさまざまなコンポーネントが含まれています。ターゲットシステムは、SAP HANA、SAP BW、または非SAPなどのDWシステムです。データウェアハウスシステム。

次のスクリーンショットは、SAPBODSのさまざまなコンポーネントを示しています。

BODSアーキテクチャを次のレイヤーに分割することもできます-
- Webアプリケーションレイヤー
- データベースサーバーレイヤー
- データサービスサービスレイヤー
次の図は、BODSアーキテクチャを示しています。

製品の進化– ATL、DI、DQ
Acta TechnologyInc。はSAPBusiness Objects Data Servicesを開発し、後にBusiness ObjectsCompanyがそれを買収しました。Acta Technology Inc.は米国を拠点とする企業であり、ファーストデータ統合プラットフォームの開発を担当しました。Acta Inc.によって開発された2つのETLソフトウェア製品は、Data Integration (DI) ツールと Data Management または Data Quality ((DQ)ツール。
フランスの企業であるBusinessObjectsは、2002年にActa Technology Inc.を買収し、その後、両方の製品の名前が Business Objects Data Integration (BODI) ツールと Business Objects Data Quality (BODQ) ツール。
SAPは2007年にBusinessObjectsを買収し、両方の製品の名前がSAPBODIおよびSAPBODQに変更されました。2008年、SAPは両方の製品をSAP Business Objects Data Services(BODS)という名前の単一のソフトウェア製品に統合しました。
SAP BODSは、データ統合およびデータ管理ソリューションを提供し、以前のバージョンのBODSには、テキストデータ処理ソリューションが含まれていました。
BODS –オブジェクト
BO Data ServicesDesignerで使用されるすべてのエンティティは呼び出されます Objects。プロジェクト、ジョブ、メタデータ、システム関数などのすべてのオブジェクトは、ローカルオブジェクトライブラリに保存されます。すべてのオブジェクトは本質的に階層的です。
オブジェクトには主に次のものが含まれます-
Properties−オブジェクトを説明するために使用され、その操作には影響しません。例-オブジェクトの名前、オブジェクトが作成された日付など。
Options −オブジェクトの操作を制御します。
オブジェクトの種類
システムには、再利用可能なオブジェクトとシングルユースオブジェクトの2種類のオブジェクトがあります。オブジェクトのタイプによって、そのオブジェクトの使用方法と取得方法が決まります。
再利用可能なオブジェクト
リポジトリに保存されているオブジェクトのほとんどは再利用できます。再利用可能なオブジェクトが定義され、ローカルリポジトリに保存されている場合、定義への呼び出しを作成することでオブジェクトを再利用できます。再利用可能な各オブジェクトには1つの定義しかなく、そのオブジェクトへのすべての呼び出しはその定義を参照します。これで、オブジェクトの定義が1つの場所で変更された場合、そのオブジェクトが表示されるすべての場所でオブジェクトの定義が変更されます。
オブジェクトライブラリは、オブジェクト定義を含むために使用され、オブジェクトがライブラリからドラッグアンドドロップされると、既存のオブジェクトへの新しい参照が作成されます。
シングルユースオブジェクト
ジョブまたはデータフローに対して特別に定義されているすべてのオブジェクトは、シングルユースオブジェクトと呼ばれます。たとえば、任意のデータロードで使用される特定の変換。
BODS –オブジェクト階層
すべてのオブジェクトは本質的に階層的です。次の図は、SAPBODSシステムのオブジェクト階層を示しています。

BODS-ツールと機能
以下に示すアーキテクチャに基づいて、SAP Business Objects DataServicesで定義された多くのツールがあります。各ツールには、システムランドスケープごとに独自の機能があります。

上部には、ユーザーと権利のセキュリティ管理のために情報プラットフォームサービスがインストールされています。BODSは中央管理コンソールに依存します(CMC)ユーザーアクセスとセキュリティ機能用。これは4.xバージョンに適用されます。以前のバージョンでは、管理コンソールで実行されていました。
Data Services Designerは、データマッピング、変換、およびロジックで構成されるオブジェクトを作成するために使用される開発者ツールです。これはGUIベースであり、データサービスの設計者として機能します。
リポジトリ
リポジトリは、BO DataServicesで使用されるオブジェクトのメタデータを格納するために使用されます。各リポジトリは中央管理コンソールに登録する必要があり、単一または複数のジョブサーバーにリンクされています。これらのサーバーは、ユーザーが作成したジョブの実行を担当します。
リポジトリの種類
リポジトリには3つのタイプがあります。
Local Repository −プロジェクト、ジョブ、データフロー、ワークフローなど、Data ServicesDesignerで作成されたすべてのオブジェクトのメタデータを格納するために使用されます。
Central Repository−オブジェクトのバージョン管理を制御するために使用され、多目的開発に使用されます。中央リポジトリには、アプリケーションオブジェクトのすべてのバージョンが格納されます。したがって、以前のバージョンに移動できます。
Profiler Repository−これは、SAP BODSDesignerで実行されるプロファイラータスクに関連するすべてのメタデータを管理するために使用されます。CMSリポジトリには、BIプラットフォーム上のCMCで実行されるすべてのタスクのメタデータが格納されます。Information Steward Repositoryには、InformationStewardで作成されたプロファイリングタスクとオブジェクトのすべてのメタデータが格納されます。
ジョブサーバー
ジョブサーバーは、ユーザーが作成したリアルタイムジョブとバッチジョブを実行するために使用されます。それぞれのリポジトリからジョブ情報を取得し、データエンジンを起動してジョブを実行します。ジョブサーバーは、リアルタイムまたはスケジュールされたジョブを実行でき、メモリキャッシュでマルチスレッドを使用し、並列処理を使用してパフォーマンスを最適化します。
アクセスサーバー
DataServicesのAccessServerは、リアルタイムメッセージブローカーシステムと呼ばれ、メッセージリクエストを受け取り、リアルタイムサービスに移行して、特定の時間枠でメッセージを表示します。
データサービス管理コンソール
データサービス管理コンソールは、ジョブのスケジュール設定、DSシステムでの品質レポートの生成、データ検証、ドキュメント化などの管理アクティビティを実行するために使用されます。
BODS –命名基準
リポジトリ内のオブジェクトを簡単に識別できるため、すべてのシステムのすべてのオブジェクトに標準の命名規則を使用することをお勧めします。
この表は、すべてのジョブおよびその他のオブジェクトに使用する必要がある推奨される命名規則のリストを示しています。
| プレフィックス | サフィックス | オブジェクト |
|---|---|---|
| DF_ | 該当なし | データフロー |
| EDF_ | _入力 | 埋め込まれたデータフロー |
| EDF_ | _出力 | 埋め込まれたデータフロー |
| RTJob_ | 該当なし | リアルタイムの仕事 |
| WF_ | 該当なし | ワークフロー |
| ジョブ_ | 該当なし | ジョブ |
| 該当なし | _DS | データストア |
| DC_ | 該当なし | データ構成 |
| SC_ | 該当なし | システム構成 |
| 該当なし | _Memory_DS | メモリデータストア |
| PROC_ | 該当なし | ストアドプロシージャ |
BO Data Serviceの基本には、プロジェクト、ジョブ、ワークフロー、データフロー、リポジトリなどのワークフローの設計における主要なオブジェクトが含まれています。
BODS –リポジトリとタイプ
リポジトリは、BO DataServicesで使用されるオブジェクトのメタデータを格納するために使用されます。各リポジトリは、中央管理コンソール(CMC)に登録する必要があり、作成したジョブの実行を担当する単一または複数のジョブサーバーにリンクされています。
リポジトリの種類
リポジトリには3つのタイプがあります。
Local Repository −プロジェクト、ジョブ、データフロー、ワークフローなど、Data ServicesDesignerで作成されたすべてのオブジェクトのメタデータを格納するために使用されます。
Central Repository−オブジェクトのバージョン管理を制御するために使用され、多目的開発に使用されます。中央リポジトリには、アプリケーションオブジェクトのすべてのバージョンが格納されます。したがって、以前のバージョンに移動できます。
Profiler Repository−これは、SAP BODSDesignerで実行されるプロファイラータスクに関連するすべてのメタデータを管理するために使用されます。CMSリポジトリには、BIプラットフォーム上のCMCで実行されるすべてのタスクのメタデータが格納されます。Information Steward Repositoryには、InformationStewardで作成されたプロファイリングタスクとオブジェクトのすべてのメタデータが格納されます。
BODSリポジトリを作成するには、データベースをインストールする必要があります。SQL Server、Oracleデータベース、My SQL、SAP HANA、Sybaseなどを使用できます。
リポジトリの作成
BODSのインストール中にデータベースに次のユーザーを作成し、リポジトリを作成する必要があります。これらのユーザーは、CMSサーバー、監査サーバーなどのさまざまなサーバーにログインする必要があります。
Bodsserver1によって識別されるユーザーBODSを作成する
- BODSへの接続を許可します。
- BODSにCreateSessionを付与します。
- DBAをBODSに付与します。
- Create AnyTableをBODSに付与します。
- Create AnyViewをBODSに付与します。
- Drop AnyTableをBODSに付与します。
- ドロップをBODSに付与します。
- InsertAnyテーブルをBODSに付与します。
- BODSに任意のテーブルの更新を許可します。
- BODSにDeleteAnyテーブルを付与します。
- ユーザーに無制限のユーザーボードQUOTAを変更します。
CMSserver1によって識別されるユーザーCMSの作成
- CMSへの接続を許可します。
- CMSにCreateSessionを付与します。
- DBAをCMSに付与します。
- Create AnyTableをCMSに付与します。
- Create AnyViewをCMSに付与します。
- ドロップをCMSに付与します。
- ドロップをCMSに付与します。
- InsertAnyテーブルをCMSに付与します。
- CMSに任意のテーブルの更新を許可します。
- CMSにDeleteAnyテーブルを付与します。
- ユーザーに無制限のユーザーCMSQUOTAを変更します。
CMSAUDITserver1によって識別されるユーザーCMSAUDITを作成します
- CMSAUDITへの接続を許可します。
- CMSAUDITにCreateSessionを付与します。
- DBAをCMSAUDITに付与します。
- Create AnyTableをCMSAUDITに付与します。
- CMSAUDITにCreateAnyViewを付与します。
- CMSAUDITに任意のテーブルのドロップを許可します。
- CMSAUDITに任意のビューをドロップすることを許可します。
- InsertAnyテーブルをCMSAUDITに付与します。
- CMSAUDITに任意のテーブルの更新を許可します。
- CMSAUDITにDeleteAnyテーブルを付与します。
- ユーザーに無制限のユーザーCMSAUDITQUOTAを変更します。
インストール後に新しいリポジトリを作成するには
Step 1 −データベースを作成する Local_Repoそして、Data Services RepositoryManagerに移動します。データベースをローカルリポジトリとして構成します。

新しいウィンドウが開きます。
Step 2 −次のフィールドに詳細を入力します−
リポジトリタイプ、データベースタイプ、データベースサーバー名、ポート、ユーザー名、およびパスワード。

Step 3 −をクリックします Createボタン。次のメッセージが表示されます-

Step 4 −ここで、中央管理コンソールCMCにログインします。 SAP BI Platform ユーザー名とパスワード付き。
Step 5 − CMCホームページで、をクリックします Data Services。

Step 6 −から Data Services メニュー、クリック Configure a new Data Services リポジトリ。

Step 7 −新しいウィンドウに表示される詳細を入力します。
- リポジトリ名:Local_Repo
- データベースタイプ:SAP HANA
- データベースサーバー名:最高
- データベース名:LOCAL_REPO
- ユーザー名:
- Password:*****

Step 8 −ボタンをクリックします Test Connection 成功した場合は、 Save。保存すると、CMCの[リポジトリ]タブに表示されます。
Step 9 −のローカルリポジトリにアクセス権とセキュリティを適用する CMC → User and Groups。
Step 10 −アクセスが許可されたら、Data ServicesDesigner→リポジトリの選択→ユーザー名とパスワードの入力に移動してログインします。

リポジトリの更新
リポジトリを更新するには、所定の手順に従います。
Step 1 −インストール後にリポジトリを更新するには、データベースを作成します Local_Repo そして、Data Services RepositoryManagerに移動します。
Step 2 −データベースをローカルリポジトリとして構成します。

新しいウィンドウが開きます。
Step 3 −以下のフィールドに詳細を入力します。
リポジトリタイプ、データベースタイプ、データベースサーバー名、ポート、ユーザー名、およびパスワード。

以下のスクリーンショットに示すような出力が表示されます。

データサービス管理コンソール(DSMC)は、ジョブのスケジュール設定、DSシステムでの品質レポートの生成、データ検証、文書化などの管理アクティビティを実行するために使用されます。
次の方法でDataServices ManagementConsoleにアクセスできます-
次の場所に移動すると、DataServices管理コンソールにアクセスできます。 Start → All Programs → Data Services → Data Service Management Console。
経由でデータサービス管理コンソールにアクセスすることもできます Designer すでにログインしている場合。
経由でデータサービス管理コンソールにアクセスするには Designer Home Page 以下の手順に従ってください。

ツールを介してデータサービス管理コンソールにアクセスするには、指定された手順に従います-
Step 1 −に移動 Tools → Data Services Management Console 次の画像に示すように。

Step 2 −ログインしたら Data Services Management Console、以下のスクリーンショットに示すように、ホーム画面が開きます。上部には、ログインに使用したユーザー名が表示されます。
ホームページには、次のオプションが表示されます-
- Administrator
- 自動ドキュメント
- データ検証
- 影響と系統分析
- 運用ダッシュボード
- データ品質レポート

この章では、Data Services ManagementConsoleの各モジュールの主な機能について説明します。
管理者モジュール
管理者オプションを使用して管理します-
- ユーザーと役割
- アクセスサーバーとリポジトリへの接続を追加するには
- Webサービス用に公開されたジョブデータにアクセスするには
- バッチジョブのスケジューリングと監視用
- アクセスサーバーのステータスとリアルタイムサービスを確認します。
クリックすると Administratorタブでは、左側のペインに多くのリンクが表示されます。それらは、-ステータス、バッチ、Webサービス、SAP接続、サーバーグループ、プロファイラーリポジトリ管理、およびジョブ実行履歴です。

ノード
管理者モジュールの下にあるさまざまなノードについては、以下で説明します。
状態
ステータスノードは、バッチジョブとリアルタイムジョブのステータス、アクセスサーバーのステータス、アダプタとプロファイラのリポジトリ、およびその他のシステムステータスを確認するために使用されます。
[ステータス]→[リポジトリの選択]をクリックします
右側のペインに、次のオプションのタブが表示されます-
Batch Job Status−バッチジョブのステータスを確認するために使用されます。トレース、モニター、エラー、パフォーマンスモニター、開始時間、終了時間、期間などのジョブ情報を確認できます。

Batch Job Configuration −バッチジョブ構成は、個々のジョブのスケジュールを確認するために使用されます。または、実行、スケジュールの追加、実行コマンドのエクスポートなどのアクションを追加できます。
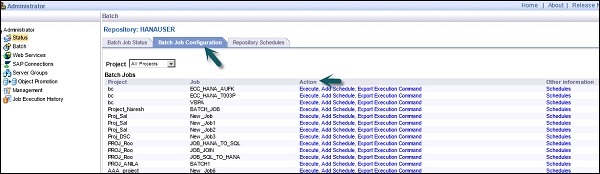
Repositories Schedules −リポジトリ内のすべてのジョブのスケジュールを表示および構成するために使用されます。
バッチノード
[バッチジョブ]ノードの下に、上記と同じオプションが表示されます。
| シニア番号 | オプションと説明 |
|---|---|
| 1 | Batch Job Status 最後の実行のステータスと各ジョブに関する詳細情報を表示します。 |
| 2 | Batch Job Configuration 個々のジョブの実行およびスケジューリングオプションを構成します。 |
| 3 | Repository Schedules リポジトリ内のすべてのジョブのスケジュールを表示および構成します。 |
Webサービスノード
Webサービスは、リアルタイムジョブとバッチジョブをWebサービス操作として公開し、これらの操作のステータスを確認するために使用されます。これは、Webサービスとして公開されたジョブのセキュリティを維持し、表示するためにも使用されますWSDL ファイル。

SAP接続
SAP接続は、ステータスの確認または構成に使用されます RFC server interface データサービス管理コンソールで。
RFCサーバーインターフェイスのステータスを確認するには、[RFCサーバーインターフェイスのステータス]タブに移動します。新しいRFCサーバーインターフェイスを追加するには、[構成]タブで[Add。
新しいウィンドウが開いたら、RFCサーバー構成の詳細を入力します。 Apply。

サーバーグループ
これは、同じリポジトリに関連付けられているすべてのジョブサーバーを1つのサーバーグループにグループ化するために使用されます。このタブは、データサービスでジョブを実行する際の負荷分散に使用されます。
ジョブが実行されると、対応するジョブサーバーがチェックされ、ダウンしている場合は、ジョブが同じグループ内の他のジョブサーバーに移動されます。これは主に、負荷分散のための本番環境で使用されます。

プロファイルリポジトリ
プロファイルリポジトリを管理者に接続すると、プロファイルリポジトリノードを拡張できます。プロファイルタスクのステータスページに移動できます。
管理ノード
[管理者]タブの機能を使用するには、管理ノードを使用してデータサービスへの接続を追加する必要があります。管理ノードは、管理アプリケーションのさまざまな構成オプションで構成されています。

ジョブ実行履歴
これは、ジョブまたはデータフローの実行履歴を確認するために使用されます。このオプションを使用すると、1つのバッチジョブまたは自分で作成したすべてのバッチジョブの実行履歴を確認できます。
ジョブを選択すると、リポジトリ名、ジョブ名、開始時刻、終了時刻、実行時刻、ステータスなどの情報が表形式で表示されます。

Data Service Designerは、データマッピング、変換、およびロジックで構成されるオブジェクトを作成するために使用される開発者ツールです。これはGUIベースであり、データサービスの設計者として機能します。
プロジェクト、ジョブ、ワークフロー、データフロー、マッピング、変換など、Data ServicesDesignerを使用してさまざまなオブジェクトを作成できます。
Data Services Designerを起動するには、以下の手順に従います。
Step 1 −「スタート」→「すべてのプログラム」→「SAPDataServices4.2」→「DataServicesDesigner」をポイントします。

Step 2 −リポジトリを選択し、パスワードを入力してログインします。

リポジトリを選択してDataServices Designerにログインすると、次の画像に示すようなホーム画面が表示されます。

左側のペインには、新しいプロジェクト、ジョブ、データフロー、ワークフローなどを作成できるプロジェクト領域があります。プロジェクト領域には、DataServicesで作成されたすべてのオブジェクトで構成されるローカルオブジェクトライブラリがあります。
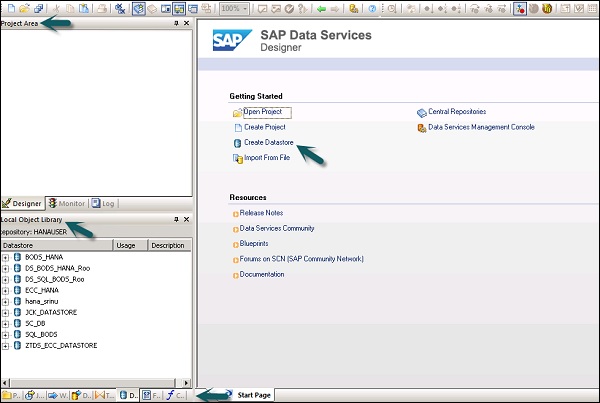
下のペインで、プロジェクト、ジョブ、データフロー、ワークフローなどの特定のオプションに移動して、既存のオブジェクトを開くことができます。下のペインからオブジェクトのいずれかを選択すると、すでに類似しているすべてのオブジェクトが表示されます。ローカルオブジェクトライブラリの下のリポジトリに作成されます。
右側にはホーム画面があり、これを使用して-
- プロジェクトの作成
- プロジェクトを開く
- データストアを作成する
- リポジトリを作成する
- フラットファイルからインポート
- データサービス管理コンソール
ETLフローを開発するには、最初にソースシステムとターゲットシステムのデータストアを作成する必要があります。与えられた手順に従って、ETLフローを開発します-
Step 1 −クリック Create Data Stores。

新しいウィンドウが開きます。
Step 2 −を入力します Datastore 名前、 Datastore以下に示すタイプとデータベースタイプ。以下のスクリーンショットに示すように、ソースシステムとして別のデータベースを選択できます。

Step 3−データソースとしてECCシステムを使用するには、データストアタイプとしてSAPアプリケーションを選択します。ユーザー名とパスワードを入力し、Advance タブで、システム番号とクライアント番号を入力します。

Step 4− [OK]をクリックすると、データストアがローカルオブジェクトライブラリリストに追加されます。データストアを展開すると、テーブルは表示されません。

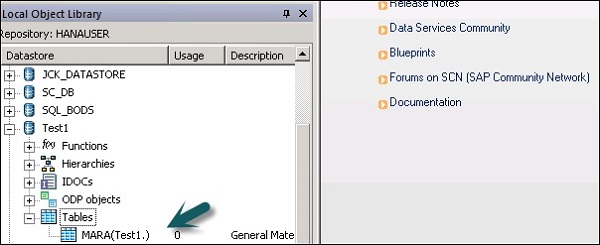
Step 5 − ECCシステムからテーブルを抽出してターゲットシステムにロードするには、「テーブル」→「名前でインポート」を右クリックします。

Step 6 −テーブル名を入力し、をクリックします Import。ここでは、ECCシステムのデフォルトテーブルであるTable–Maraが使用されています。
Step 7 −同様の方法で、 Datastoreターゲットシステム用。この例では、HANAがターゲットシステムとして使用されています。

[OK]をクリックすると、これ Datastore ローカルオブジェクトライブラリに追加され、その中にテーブルはありません。
ETLフローを作成する
ETLフローを作成するには、新しいプロジェクトを作成します。
Step 1 −オプションをクリックします。 Create Project。プロジェクト名を入力して、Create。プロジェクトエリアに追加されます。

Step 2 −プロジェクト名を右クリックして、新しいバッチジョブ/リアルタイムジョブを作成します。

Step 3−ジョブの名前を入力し、Enterキーを押します。これにワークフローとデータフローを追加する必要があります。ワークフローを選択し、作業領域をクリックしてジョブに追加します。ワークフローの名前を入力し、それをダブルクリックしてプロジェクト領域に追加します。
Step 4−同様の方法で、データフローを選択し、プロジェクト領域に移動します。データフローの名前を入力し、ダブルクリックして新しいプロジェクトの下に追加します。

Step 5−データストアの下のソーステーブルを作業領域にドラッグします。これで、同様のデータ型のターゲットテーブルを作業領域にドラッグするか、新しいテンプレートテーブルを作成できます。
新しいテンプレートテーブルを作成するには、ソーステーブルを右クリックし、[新規追加]→[テンプレートテーブル]を選択します。

Step 6−テーブル名を入力し、リストからターゲットデータストアとしてデータストアを選択します。所有者名は、テーブルを作成する必要があるスキーマ名を表します。

テーブルは、このテーブル名で作業領域に追加されます。
Step 7−ソーステーブルからターゲットテーブルに線をドラッグします。クリックSave All 上部のオプション。

これで、Data Service管理コンソールを使用してジョブをスケジュールするか、ジョブ名を右クリックして実行することで手動で実行できます。
データストアは、アプリケーションとデータベース間の接続をセットアップするために使用されます。データストアを直接作成することも、アダプターを使用して作成することもできます。データストアを使用すると、アプリケーション/ソフトウェアは、アプリケーションまたはデータベースからメタデータを読み書きしたり、そのデータベースまたはアプリケーションに書き込んだりできます。
Business Objects Data Servicesでは、Datastore-を使用して次のシステムに接続できます。
- メインフレームシステムとデータベース
- ユーザー作成のアダプターを備えたアプリケーションとソフトウェア
- SAPアプリケーション、SAP BW、Oracle Apps、Siebelなど。
SAP Business Objects Data Servicesは、を使用してメインフレームインターフェイスに接続するオプションを提供します Attunityコネクタ。使用するAttunity、データストアを以下に示すソースのリストに接続します-
- DB2 UDB for OS / 390
- DB2 UDB for OS / 400
- IMS/DB
- VSAM
- Adabas
- OS / 390およびOS / 400上のフラットファイル

Attunityコネクタを使用すると、ソフトウェアを使用してメインフレームデータに接続できます。このソフトウェアは、ODBCインターフェイスを使用して、メインフレームサーバーとローカルクライアントジョブサーバーに手動でインストールする必要があります。
ホストの場所、ポート、Attunityワークスペースなどの詳細を入力します。
データベースのデータストアを作成する
データベースのデータストアを作成するには、以下の手順に従います。
Step 1−以下の画像に示すように、データストア名、データストアタイプ、およびデータベースタイプを入力します。リストに示されているソースシステムとして、別のデータベースを選択できます。

Step 2−データソースとしてECCシステムを使用するには、データストアタイプとしてSAPアプリケーションを選択します。ユーザー名とパスワードを入力します。クリックAdvance タブをクリックし、システム番号とクライアント番号を入力します。

Step 3− [OK]をクリックすると、データストアがローカルオブジェクトライブラリリストに追加されます。データストアを展開すると、表示するテーブルがありません。
この章では、データストアを編集または変更する方法を学習します。データストアを変更または編集するには、以下の手順に従ってください。
Step 1−データストアを編集するには、データストア名を右クリックして[編集]をクリックします。データストアエディタが開きます。

現在のデータストア構成の接続情報を編集できます。
Step 2 −をクリックします Advance ボタンをクリックすると、クライアント番号、システムID、その他のプロパティを編集できます。
Step 3 −をクリックします Edit 構成を追加、編集、および削除するオプション。

Step 4 − [OK]をクリックすると、変更が適用されます。
データベースタイプとしてメモリを使用してデータストアを作成できます。メモリデータストアは、データをメモリに保存して迅速なアクセスを容易にし、元のデータソースに移動する必要がないため、リアルタイムジョブのデータフローのパフォーマンスを向上させるために使用されます。
メモリデータストアは、メモリテーブルスキーマをリポジトリに格納するために使用されます。これらのメモリテーブルは、リレーショナルデータベースのテーブルから、またはXMLメッセージやIDocなどの階層データファイルを使用してデータを取得します。メモリテーブルは、ジョブが実行されるまで存続し、メモリテーブル内のデータを異なるリアルタイムジョブ間で共有することはできません。
メモリデータストアの作成
メモリデータストアを作成するには、以下の手順に従います。
Step 1 − [データストアの作成]をクリックして、データストアの名前を入力します “Memory_DS_TEST”。メモリテーブルは通常のRDBMSテーブルで表示され、命名規則で識別できます。
Step 2 − [データストアタイプ]で[データベース]を選択し、[データベースタイプ]で[ Memory。[OK]をクリックします。

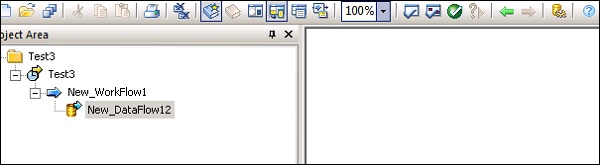
Step 3 −次に、以下のスクリーンショットに示すように、[プロジェクト]→[新規]→[プロジェクト]に移動します。

Step 4−右クリックして新しいジョブを作成します。以下に示すように、ワークフローとデータフローを追加します。
Step 5−テンプレートテーブルを選択し、作業領域にドラッグアンドドロップします。[テーブルの作成]ウィンドウが開きます。

Step 6−テーブルの名前を入力し、[データストア]で[メモリデータストア]を選択します。システムで生成された行IDが必要な場合は、create row idチェックボックス。[OK]をクリックします。
Step 7 −このメモリテーブルをデータフローに接続し、をクリックします Save All 頂点で。

ソースおよびターゲットとしてのメモリテーブル
メモリテーブルをターゲットとして使用するには-
Step 1−ローカルオブジェクトライブラリに移動し、[データストア]タブをクリックします。メモリデータストアを展開→テーブルを展開します。
Step 2−ソーステーブルまたはターゲットテーブルとして使用するメモリテーブルを選択し、ワークフローにドラッグします。このメモリテーブルをデータフローのソースまたはターゲットとして接続します。
Step 3 −をクリックします save ボタンをクリックしてジョブを保存します。
あるデータベースから別のデータベースへの一方向の通信パスのみを提供するさまざまなデータベースベンダーがあります。これらのパスは、データベースリンクと呼ばれます。SQL Serverでは、リンクサーバーにより、あるデータベースから別のデータベースへの一方向の通信パスが許可されます。
例
名前の付いたローカルデータベースサーバーについて考えてみます。 “Product” と呼ばれるリモートデータベースサーバー上の情報にアクセスするためのデータベースリンクを格納します Customer。これで、リモートデータベースサーバーCustomerに接続しているユーザーは、同じリンクを使用してデータベースサーバーProductのデータにアクセスできなくなります。に接続しているユーザー“Customer” 製品データベースサーバーのデータにアクセスするには、サーバーのデータディクショナリに個別のリンクが必要です。
2つのデータベース間のこの通信パスは、データベースリンクと呼ばれます。これらのリンクされたデータベース関係の間に作成されるデータストアは、リンクされたデータストアと呼ばれます。
あるデータストアを別のデータストアに接続し、データストアのオプションとして外部データベースリンクをインポートする可能性があります。

Adapter Datastoreを使用すると、アプリケーションのメタデータをリポジトリにインポートできます。アプリケーションのメタデータにアクセスして、異なるアプリケーションやソフトウェア間でバッチデータとリアルタイムデータを移動できます。
カスタマイズされたアダプタの開発に使用できるアダプタソフトウェア開発キット-SAPが提供するSDKがあります。これらのアダプタは、アダプタデータストアによってデータサービスデザイナに表示されます。
アダプターを使用してデータを抽出またはロードするには、この目的のために少なくとも1つのデータストアを定義する必要があります。
アダプタデータストア-定義
アダプティブデータストアを定義するには、指定された手順に従います-
Step 1 −クリック Create Datastore→データストアの名前を入力します。[データストアタイプ]を[アダプター]として選択します。を選択Job Server リストとアダプタインスタンス名から、をクリックします OK。

アプリケーションのメタデータを参照するには
データストア名を右クリックして、 Open。ソースメタデータを表示する新しいウィンドウが開きます。+記号をクリックしてオブジェクトを確認し、インポートするオブジェクトを右クリックします。
ファイル形式は、フラットファイルの構造を表す一連のプロパティとして定義されます。メタデータ構造を定義します。ファイル形式は、データがデータベースではなくファイルに保存されている場合に、ソースデータベースとターゲットデータベースに接続するために使用されます。
ファイル形式は以下の機能に使用されます-
- ファイル形式テンプレートを作成して、ファイルの構造を定義します。
- データフローに特定のソースおよびターゲットファイル形式を作成します。
以下のタイプのファイルは、ファイル形式を使用してソースファイルまたはターゲットファイルとして使用できます-
- Delimited
- SAPトランスポート
- 非構造化テキスト
- 非構造化バイナリ
- 固定幅
ファイル形式エディタ
ファイル形式エディターは、ファイル形式テンプレートとソースおよびターゲットファイル形式のプロパティを設定するために使用されます。
以下のモードはファイルフォーマットエディタで利用できます-
New mode −新しいファイル形式のテンプレートを作成できます。
Edit mode −既存のファイル形式テンプレートを編集できます。
Source mode −特定のソースファイルのファイル形式を編集できます。
Target mode −特定のターゲットファイルのファイル形式を編集できます。
ファイル形式エディタには3つの作業領域があります-
Properties Values −ファイル形式のプロパティの値を編集するために使用されます。
Column Attributes −ファイル内の列またはフィールドを編集および定義するために使用されます。
Data Preview −設定がサンプルデータにどのように影響するかを表示するために使用されます。
ファイル形式の作成
ファイル形式を作成するには、以下の手順に従います。
Step 1 −ローカルオブジェクトライブラリ→フラットファイルに移動します。

Step 2 −「フラットファイル」オプションを右クリック→「新規」。

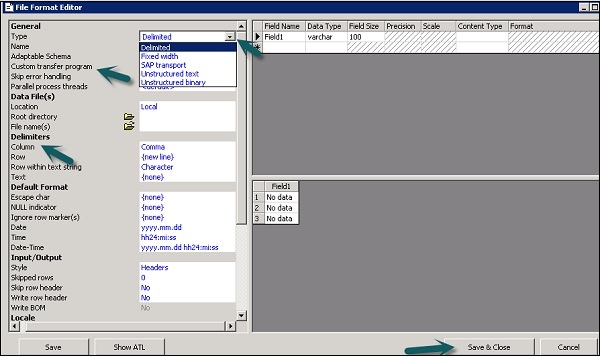
ファイル形式エディタの新しいウィンドウが開きます。
Step 3−ファイル形式の種類を選択します。ファイル形式テンプレートを説明する名前を入力します。区切りファイルと固定幅ファイルの場合、カスタム転送プログラムを使用して読み取りと読み込みを行うことができます。このテンプレートが表すファイルを説明する他のプロパティを入力します。
いくつかの特定のファイル形式の列属性ワークエリアで列の構造を指定することもできます。すべてのプロパティを定義したら、をクリックしますSave ボタン。
ファイル形式の編集
ファイル形式を編集するには、以下の手順に従ってください。
Step 1 −ローカルオブジェクトライブラリで、 Format タブ。
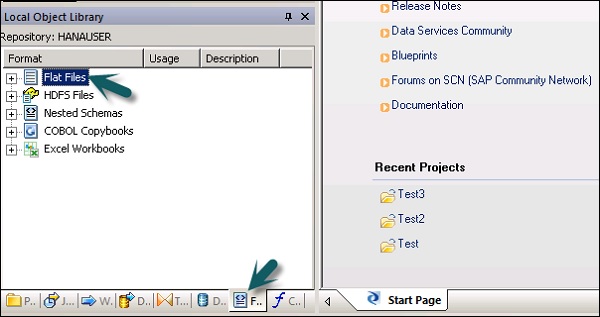
Step 2−編集するファイル形式を選択します。右クリックEdit オプション。

ファイル形式エディタで変更を加え、[ Save ボタン。
形式だけを作成するのに時間がかかるCOBOLコピーブックファイル形式を作成できます。フォーマットをデータフローに追加したら、後でソースを構成できます。
ファイル形式の作成とデータファイルへの接続を同時に行うことができます。以下の手順に従ってください。
Step 1 − [ローカルオブジェクトライブラリ]→[ファイル形式]→[COBOLコピーブック]に移動します。

Step 2 −右クリック New オプション。

Step 3−フォーマット名を入力します。[フォーマット]タブに移動し、インポートするCOBOLコピーブックを選択します。ファイルの拡張子は.cpy。
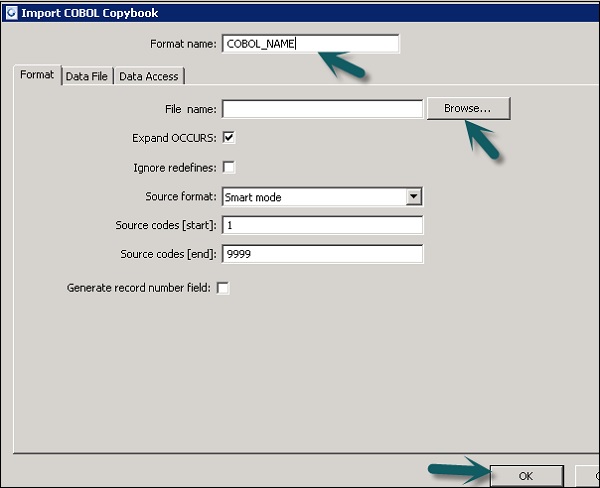
Step 4 −クリック OK。このファイル形式は、ローカルオブジェクトライブラリに追加されます。[COBOLコピーブックスキーマ名]ダイアログボックスが開きます。必要に応じて、スキーマの名前を変更し、[OK。
データベースデータストアを使用すると、データベース内のテーブルや関数からデータを抽出できます。メタデータのデータインポートを実行する場合、Tool 列名、データ型、説明などを編集できます。
次のオブジェクトを編集できます-
- テーブル名
- 列名
- テーブルの説明
- 列の説明
- 列のデータ型
- 列のコンテンツタイプ
- テーブル属性
- 主キー
- オーナー名
メタデータのインポート
メタデータをインポートするには、以下の手順に従います-
Step 1 −ローカルオブジェクトライブラリに移動→使用するデータストアに移動します。

Step 2 −データストア→開くを右クリックします。
ワークスペースには、インポート可能なすべてのアイテムが表示されます。メタデータをインポートするアイテムを選択します。

オブジェクトライブラリで、データストアに移動して、インポートされたオブジェクトのリストを表示します。
Data Servicesのファイル形式を使用して、MicrosoftExcelブックをデータソースとして使用できます。Excelワークブックは、WindowsファイルシステムまたはUnixファイルシステムで使用できる必要があります。
| シニア番号 | アクセスと説明 |
|---|---|
| 1 | In the object library, click the Formats tab. Excelブックの正式な形式では、Excelブックで定義されている構造(.xls拡張子で示されます)が記述されています。Excelデータ範囲のフォーマットテンプレートをオブジェクトライブラリに保存します。テンプレートを使用して、データフロー内の特定のソースの形式を定義します。SAP Data Servicesは、Excelワークブックをソースとしてのみ(ターゲットとしてではなく)アクセスします。 |
右クリック New オプションを選択し、 Excel Workbook 以下のスクリーンショットに示すように。

XMLファイルDTD、XSDからのデータ抽出
XMLまたはDTDスキーマファイル形式をインポートすることもできます。
Step 1 − [ローカルオブジェクトライブラリ]→[フォーマット]タブ→[ネストされたスキーマ]に移動します。
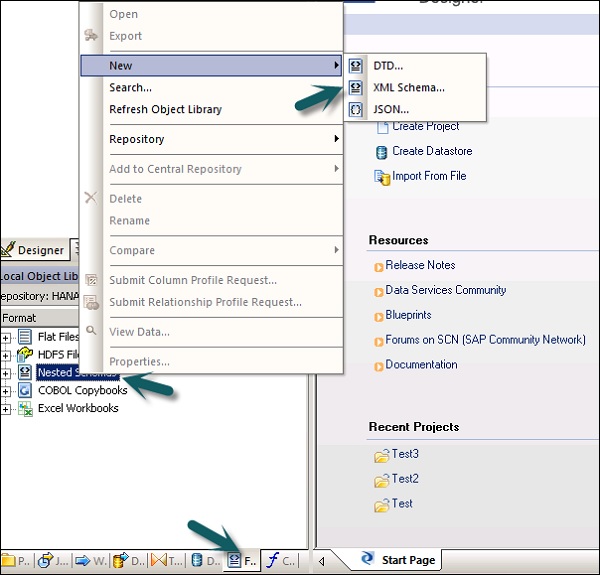
Step 2 −ポイント New(DTDファイルまたはXMLスキーマまたはJSONファイル形式を選択できます)。ファイル形式の名前を入力し、インポートするファイルを選択します。[OK]をクリックします。
COBOLコピーブックからのデータ抽出
COBOLコピーブックにファイル形式をインポートすることもできます。ローカルオブジェクトライブラリ→フォーマット→COBOLコピーブックに移動します。

データフローは、ソースからターゲットシステムへのデータの抽出、変換、およびロードに使用されます。すべての変換、ロード、およびフォーマットはデータフローで行われます。
プロジェクトでデータフローを定義すると、これをワークフローまたはETLジョブに追加できます。データフローは、パラメータを使用してオブジェクト/情報を送受信できます。データフローは形式で名前が付けられますDF_Name。

データフローの例
ソースシステムの2つのテーブルからのデータを使用してDWシステムのファクトテーブルをロードするとします。
データフローには次のオブジェクトが含まれています-
- 2つのソーステーブル
- 2つのテーブル間で結合し、クエリ変換で定義します
- ターゲットテーブル

データフローに追加できるオブジェクトには3つのタイプがあります。彼らは-
- Source
- Target
- Transforms
Step 1 −ローカルオブジェクトライブラリに移動し、両方のテーブルを作業スペースにドラッグします。

Step 2 −クエリ変換を追加するには、右側のツールバーからドラッグします。
Step 3 −両方のテーブルを結合し、[クエリ]ボックス→[新規追加]→[新しいテンプレートテーブル]を右クリックして、テンプレートターゲットテーブルを作成します。

Step 4 −ターゲットテーブルの名前、データストア名、およびテーブルが作成される所有者(スキーマ名)を入力します。
Step 5 −ターゲットテーブルを前にドラッグし、クエリトランスフォームに結合します。
パラメータの受け渡し
データフローに出入りするさまざまなパラメータを渡すこともできます。データフローにパラメータを渡す間、データフロー内のオブジェクトはそれらのパラメータを参照します。パラメータを使用して、さまざまな操作をデータフローに渡すことができます。
例-最終更新に関するパラメータをテーブルに入力したとします。前回の更新以降に変更された行のみを抽出できます。
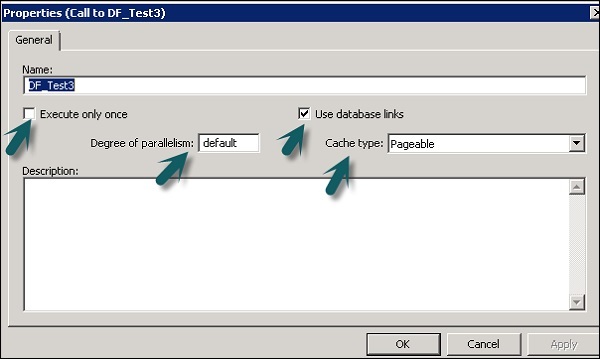
1回実行、キャッシュタイプ、データベースリンク、並列処理などのデータフローのプロパティを変更できます。
Step 1 −データフローのプロパティを変更するには、データフロー→プロパティを右クリックします。
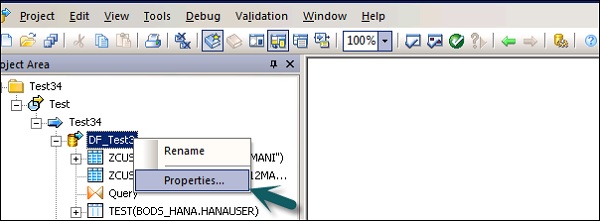
データフローにはさまざまなプロパティを設定できます。プロパティを以下に示します。
| シニア番号 | プロパティと説明 |
|---|---|
| 1 | Execute only once データフローを1回だけ実行するように指定すると、データフローが正常に完了した後、バッチジョブがそのデータフローを再実行することはありません。ただし、データフローが、再実行する回復ユニットであるワークフローに含まれている場合を除きます。リカバリユニット以外の場所で正常に完了していません。親ワークフローがリカバリユニットである場合は、データフローを1回だけ実行としてマークしないことをお勧めします。 |
| 2 | Use database links データベースリンクは、あるデータベースサーバーと別のデータベースサーバー間の通信パスです。データベースリンクを使用すると、ローカルユーザーはリモートデータベース上のデータにアクセスできます。リモートデータベースは、同じまたは異なるデータベースタイプのローカルコンピューターまたはリモートコンピューターにあります。 |
| 3 | Degree of parallelism Degree Of Parallelism(DOP)は、データフロー内の各変換が複製されて、データの並列サブセットを処理する回数を定義するデータフローのプロパティです。 |
| 4 | Cache type データをキャッシュして、結合、グループ化、並べ替え、フィルタリング、ルックアップ、テーブル比較などの操作のパフォーマンスを向上させることができます。データフローの[プロパティ]ウィンドウの[キャッシュの種類]オプションには、次のいずれかの値を選択できます。
|
Step 2 − 1回だけ実行、並列度、キャッシュタイプなどのプロパティを変更します。
ソースオブジェクトとターゲットオブジェクト
データフローは、次のオブジェクトを使用してデータを直接抽出またはロードできます-
Source objects −ソースオブジェクトは、データの抽出元またはデータの読み取り元を定義します。
Target objects −ターゲットオブジェクトは、データをロードまたは書き込むターゲットを定義します。
次のタイプのソースオブジェクトを使用でき、ソースオブジェクトにはさまざまなアクセス方法が使用されます。
| テーブル | リレーショナルデータベースで使用される列と行でフォーマットされたファイル | 直接またはアダプターを介して |
| テンプレートテーブル | 別のデータフローで作成および保存されたテンプレートテーブル(開発で使用) | 直接 |
| ファイル | 区切りまたは固定幅のフラットファイル | 直接 |
| 資料 | アプリケーション固有の形式のファイル(SQLまたはXMLパーサーでは読み取れません) | アダプターを介して |
| XMLファイル | XMLタグでフォーマットされたファイル | 直接 |
| XMLメッセージ | リアルタイムジョブのソースとして使用されます | 直接 |
次のターゲットオブジェクトを使用でき、さまざまなアクセス方法を適用できます。
| テーブル | リレーショナルデータベースで使用される列と行でフォーマットされたファイル | 直接またはアダプターを介して |
| テンプレートテーブル | 前の変換の出力に基づいた形式のテーブル(開発で使用) | 直接 |
| ファイル | 区切りまたは固定幅のフラットファイル | 直接 |
| 資料 | アプリケーション固有の形式のファイル(SQLまたはXMLパーサーでは読み取れません) | アダプターを介して |
| XMLファイル | XMLタグでフォーマットされたファイル | 直接 |
| XMLテンプレートファイル | 形式が前述の変換出力に基づくXMLファイル(開発で、主にデータフローのデバッグに使用されます) | 直接 |
ワークフローは、実行するプロセスを決定するために使用されます。ワークフローの主な目的は、データフローの実行の準備と、データフローの実行が完了した後のシステムの状態の設定です。
ETLプロジェクトのバッチジョブはワークフローに似ていますが、ジョブにパラメーターがない点が異なります。
さまざまなオブジェクトをワークフローに追加できます。彼らは-
- ワークフロー
- データフロー
- Scripts
- Loops
- Conditions
- ブロックを試すかキャッチする
ワークフローで他のワークフローを呼び出すことも、ワークフロー自体を呼び出すこともできます。
Note −ワークフローでは、ステップは左から右の順序で実行されます。
ワークフローの例
更新するファクトテーブルがあり、変換を使用してデータフローを作成したとします。ここで、ソースシステムからデータを移動する場合は、ファクトテーブルの最終変更を確認して、最終更新後に追加された行のみを抽出する必要があります。
これを実現するには、最終更新日を決定する1つのスクリプトを作成し、これを入力パラメーターとしてデータフローに渡す必要があります。
また、特定のファクトテーブルへのデータ接続がアクティブであるかどうかを確認する必要があります。アクティブでない場合は、catchブロックを設定する必要があります。これにより、この問題について通知するために管理者に電子メールが自動的に送信されます。
ワークフローは、次の方法を使用して作成できます-
- オブジェクトライブラリ
- ツールパレット
オブジェクトライブラリを使用したワークフローの作成
オブジェクトライブラリを使用してワークフローを作成するには、以下の手順に従います。
Step 1 − [オブジェクトライブラリ]→[ワークフロー]タブに移動します。

Step 2 −右クリック New オプション。

Step 3 −ワークフローの名前を入力します。
ツールパレットを使用したワークフローの作成
ツールパレットを使用してワークフローを作成するには、右側のアイコンをクリックして、ワークフローをワークスペースにドラッグします。
ワークフローのプロパティに移動して、ワークフローを1回だけ実行するように設定することもできます。
条件付き
ワークフローに条件文を追加することもできます。これにより、ワークフローにIf / Else / Thenロジックを実装できます。
| シニア番号 | 条件付き&説明 |
|---|---|
| 1 | If TRUEまたはFALSEと評価されるブール式。関数、変数、および標準演算子を使用して、式を作成できます。 |
| 2 | Then 次の場合に実行するワークフロー要素 If 式はTRUEと評価されます。 |
| 3 | Else (オプション)次の場合に実行するワークフロー要素 If 式はFALSEと評価されます。 |
条件付きを定義するには
Step 1 −ワークフローに移動→右側のツールパレットの条件付きアイコンをクリックします。
Step 2 −条件付きの名前をダブルクリックして開きます If-Then–Else 条件付きエディター。
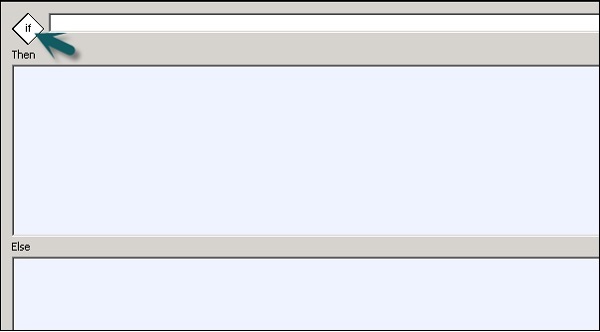
Step 3−条件を制御するブール式を入力します。[OK]をクリックします。
Step 4 −実行するデータフローをドラッグします Then and Else IF条件の式によるウィンドウ。

条件を完了すると、条件をデバッグおよび検証できます。
変換は、データセットを入力として操作し、1つまたは複数の出力を作成するために使用されます。DataServicesで使用できるさまざまな変換があります。変換のタイプは、購入したバージョンと製品によって異なります。
次のタイプの変換が利用可能です-
データ統合
データ統合変換は、データ抽出、変換、およびDWシステムへのロードに使用されます。データの整合性を確保し、開発者の生産性を向上させます。
- Data_Generator
- Data_Transfer
- Effective_Date
- Hierarchy_flattening
- Table_Comparisionなど。
データ品質
データ品質変換は、データ品質を向上させるために使用されます。ソースシステムから、解析、修正、標準化、強化されたデータセットを適用できます。
- Associate
- データクレンジング
- DSF2ウォークシーケンサーなど
プラットホーム
プラットフォームは、データセットの移動に使用されます。これを使用して、2つ以上のデータソースから行を生成、マッピング、およびマージできます。
- Case
- Merge
- クエリなど
テキストデータ処理
テキストデータ処理を使用すると、大量のテキストデータを処理できます。
この章では、追加する方法を説明します Transform データフローに。
Step 1 − [オブジェクトライブラリ]→[変換]タブに移動します。
Step 2−データフローに追加する変換を選択します。構成を選択するオプションがある変換を追加すると、プロンプトが開きます。
Step 3 −ソースをトランスフォームに接続するためのデータフロー接続を描画します。
Step 4 −トランスフォーメーション名をダブルクリックして、トランスフォーメーションエディタを開きます。
定義が完了したら、をクリックします OK エディターを閉じます。
これはDataServicesで使用される最も一般的な変換であり、次の機能を実行できます-
- ソースからのデータフィルタリング
- 複数のソースからのデータの結合
- データに対して関数と変換を実行する
- 入力スキーマから出力スキーマへの列マッピング
- 主キーの割り当て
- 結果として出力スキーマに新しい列、スキーマ、および関数を追加します
クエリ変換は最も一般的に使用される変換であるため、ツールパレットにこのクエリのショートカットが用意されています。
クエリ変換を追加するには、以下の手順に従います-
Step 1−クエリ変換ツールパレットをクリックします。データフローワークスペースの任意の場所をクリックします。これを入力と出力に接続します。

クエリ変換アイコンをダブルクリックすると、クエリ操作の実行に使用されるクエリエディタが開きます。
次の領域がクエリ変換に存在します-
- 入力スキーマ
- 出力スキーマ
- Parameters
入力スキーマと出力スキーマには、列、ネストされたスキーマ、および関数が含まれています。SchemaInとSchemaOutは、現在選択されているスキーマを変換で表示します。
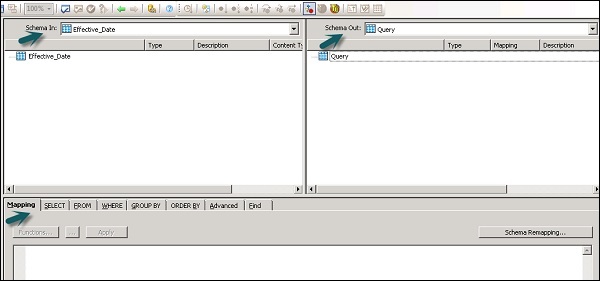
出力スキーマを変更するには、リストからスキーマを選択し、右クリックして[現在にする]を選択します。

データ品質の変革
データ品質トランスフォーメーションは、ネストされたテーブルを含むアップストリームトランスフォームに直接接続することはできません。これらの変換を接続するには、ネストされたテーブルからの変換とデータ品質変換の間にクエリ変換またはXMLパイプライン変換を追加する必要があります。
データ品質変換の使用方法は?
Step 1 − [オブジェクトライブラリ]→[変換]タブに移動します
Step 2 − Data Qualityトランスフォームを展開し、データフローに追加するトランスフォームまたはトランスフォーム構成を追加します。
Step 3−データフロー接続を描画します。トランスフォームの名前をダブルクリックすると、トランスフォームエディタが開きます。入力スキーマで、マップする入力フィールドを選択します。
Note − Associate Transformを使用するには、ユーザー定義フィールドを入力タブに追加できます。
テキストデータ処理変換
テキストデータ処理変換を使用すると、大量のテキストから特定の情報を抽出できます。組織に固有の、顧客、製品、財務上の事実などの事実やエンティティを検索できます。
この変換は、エンティティ間の関係もチェックし、抽出を可能にします。テキストデータ処理を使用して抽出されたデータは、ビジネスインテリジェンス、レポート、クエリ、および分析で使用できます。
エンティティ抽出変換
データサービスでは、テキストデータ処理は、非構造化データからエンティティとファクトを抽出するエンティティ抽出の助けを借りて行われます。
これには、大量のテキストデータの分析と処理、エンティティの検索、適切なタイプへの割り当て、および標準形式でのメタデータの表示が含まれます。
エンティティ抽出トランスフォームは、任意のテキスト、HTML、XML、または特定のバイナリ形式(PDFなど)のコンテンツから情報を抽出し、構造化された出力を生成できます。ワークフローに基づいて、いくつかの方法で出力を使用できます。別のトランスフォームへの入力として使用したり、データベーステーブルやフラットファイルなどの複数の出力ソースに書き込んだりできます。出力はUTF-16エンコーディングで生成されます。
Entity Extract Transform can be used in the following scenarios −
大量のテキストから特定の情報を見つける。
非構造化テキストから既存の情報を使用して構造化情報を検索し、新しい接続を確立します。
製品品質の報告と分析。
TDPとデータクレンジングの違い
テキストデータ処理は、非構造化テキストデータから関連情報を見つけるために使用されます。ただし、データクレンジングは、構造化データの標準化とクレンジングに使用されます。
| パラメーター | テキストデータ処理 | データクレンジング |
|---|---|---|
| 入力方式 | 非構造化データ | 構造化データ |
| 入力サイズ | 5KB以上 | 5KB未満 |
| 入力スコープ | 多くのバリエーションを持つ幅広いドメイン | 限られたバリエーション |
| 潜在的な使用法 | 非構造化データからの潜在的な意味のある情報 | リポジトリに保存するためのデータの品質 |
| 出力 | エンティティ、タイプなどの形式で注釈を作成します。入力は変更されません | 標準化されたフィールドを作成し、入力を変更します |
Data Servicesの管理には、リアルタイムジョブとバッチジョブの作成、ジョブのスケジューリング、埋め込みデータフロー、変数とパラメーター、回復メカニズム、データプロファイリング、パフォーマンスチューニングなどが含まれます。
リアルタイムジョブ
データサービスデザイナでリアルタイムメッセージを処理するためのリアルタイムジョブを作成できます。バッチジョブと同様に、リアルタイムジョブはデータを抽出し、変換してロードします。
各リアルタイムジョブは、単一のメッセージからデータを抽出できます。テーブルやファイルなどの他のソースからデータを抽出することもできます。
リアルタイムジョブは、バッチジョブとは異なり、トリガーを使用して実行されません。これらは、管理者によってリアルタイムサービスとして実行されます。リアルタイムサービスは、アクセスサーバーからのメッセージを待ちます。アクセスサーバーはこのメッセージを受信し、メッセージタイプを処理するように構成されたリアルタイムサービスに渡します。リアルタイムサービスはメッセージを実行して結果を返し、実行を停止する命令を受け取るまでメッセージの処理を続けます。
リアルタイムvsバッチジョブ
ブランチや制御ロジックなどの変換は、リアルタイムジョブでより頻繁に使用されますが、デザイナーのバッチジョブでは使用されません。
リアルタイムジョブは、バッチジョブとは異なり、スケジュールまたは内部トリガーに応答して実行されません。
リアルタイムジョブの作成
リアルタイムジョブは、データフロー、ワークフロー、ループ、条件、スクリプトなどの同じオブジェクトを使用して作成できます。
次のデータモデルを使用して、リアルタイムのジョブを作成できます-
- 単一のデータフローモデル
- 複数のデータフローモデル
単一のデータフローモデル
リアルタイム処理ループ内の単一のデータフローでリアルタイムジョブを作成でき、単一のメッセージソースと単一のメッセージターゲットが含まれます。
Creating Real Time job using single data model −
単一のデータモデルを使用してリアルタイムジョブを作成するには、所定の手順に従います。
Step 1 − Data ServicesDesigner→ProjectNew→Project→EnterProjectNameに移動します

Step 2 −プロジェクトエリアの空白を右クリック→新しいリアルタイムジョブ。

ワークスペースには、リアルタイムジョブの2つのコンポーネントが表示されます-
- RT_Process_begins
- Step_ends
リアルタイムジョブの開始と終了を示します。

Step 3 −単一のデータフローでリアルタイムジョブを作成するには、右側のペインのツールパレットからデータフローを選択し、それをワークスペースにドラッグします。
ループ内をクリックすると、リアルタイム処理ループで1つのメッセージソースと1つのメッセージターゲットを使用できます。開始マークと終了マークをデータフローに接続します。

Step 4 −必要に応じて、データフローに構成オブジェクトを追加し、ジョブを保存します。
複数のデータフローモデル
これにより、リアルタイム処理ループで複数のデータフローを使用してリアルタイムジョブを作成できます。また、次のメッセージに移動する前に、各データモデルのデータが完全に処理されていることを確認する必要があります。
リアルタイムジョブのテスト
サンプルメッセージをファイルからソースメッセージとして渡すことにより、リアルタイムジョブをテストできます。DataServicesが期待されるターゲットメッセージを生成するかどうかを確認できます。
ジョブで期待どおりの結果が得られるように、ビューデータモードでジョブを実行できます。このモードを使用すると、出力データをキャプチャして、リアルタイムジョブが正常に機能していることを確認できます。
埋め込まれたデータフロー
埋め込まれたデータフローはデータフローと呼ばれ、デザイン内の別のデータフローから呼び出されます。埋め込まれたデータフローには、複数のソースとターゲットを含めることができますが、メインデータフローにデータを渡す入力または出力は1つだけです。
以下のタイプの埋め込みデータフローを使用できます-
One Input −埋め込みデータフローはデータフローの最後に追加されます。
One Output −埋め込みデータフローは、データフローの先頭に追加されます。
No input or output −既存のデータフローを複製します。
埋め込みデータフローは、次の目的で使用できます-
データフローの表示を簡素化するため。
フローロジックを保存して、他のデータフローで再利用する場合。
データフローのセクションを埋め込みデータフローとして作成し、それらを個別に実行するデバッグ用。
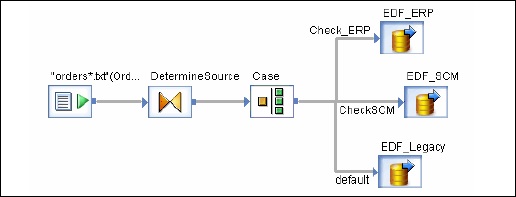
既存のデータフローでオブジェクトを選択できます。埋め込みデータフローを作成する方法は2つあります。
オプション1
オブジェクトを右クリックし、選択して埋め込みデータフローにします。

オプション2
完全な検証データフローをオブジェクトライブラリからワークスペースのオープンデータフローにドラッグします。次に、作成されたデータフローを開きます。入出力ポートとして使用するオブジェクトを選択し、をクリックしますmake port そのオブジェクトのために。

Data Servicesは、そのオブジェクトを埋め込みデータフローの接続ポイントとして追加します。
変数とパラメーター
ローカル変数とグローバル変数をデータフローとワークフローで使用できます。これにより、ジョブの設計がより柔軟になります。
主な機能は次のとおりです。
変数のデータ型は、数値、整数、10進数、日付、または文字のようなテキスト文字列にすることができます。
変数は、データフローとワークフローで関数として使用できます。 Where 句。
データサービスのローカル変数は、それらが作成されたオブジェクトに制限されています。
グローバル変数は、それらが作成されたジョブに制限されています。グローバル変数を使用すると、実行時にデフォルトのグローバル変数の値を変更できます。
ワークフローとデータフローで使用される式は、 parameters。
ワークフローとデータフローのすべての変数とパラメーターは、変数とパラメーターウィンドウに表示されます。
変数とパラメーターを表示するには、以下の手順に従います-
[ツール]→[変数]に移動します。

新しいウィンドウ Variables and parameters表示されています。定義と呼び出しの2つのタブがあります。
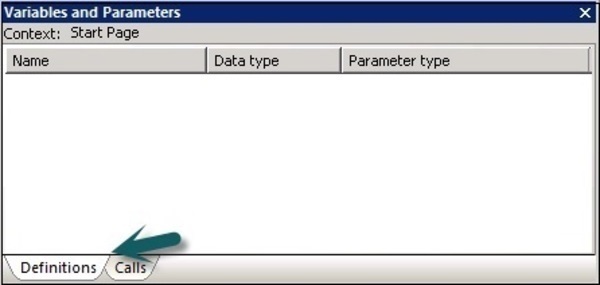
ザ・ Definitionsタブを使用すると、変数とパラメータを作成および表示できます。ローカル変数とパラメータは、ワークフローおよびデータフローレベルで使用できます。グローバル変数は、ジョブレベルで使用できます。
ジョブ |
ローカル変数 グローバル変数 |
ジョブ内のスクリプトまたは条件付き ジョブ内の任意のオブジェクト |
ワークフロー |
ローカル変数 パラメーター |
このワークフロー、またはパラメータを使用して他のワークフローまたはデータフローに渡されます。 ローカル変数を渡す親オブジェクト。ワークフローは、変数またはパラメーターを親オブジェクトに返す場合もあります。 |
データフロー |
パラメーター |
WHERE句、列マッピング、またはデータフロー内の関数。データフロー。データフローは出力値を返すことができません。 |
[呼び出し]タブで、親オブジェクトの定義内のすべてのオブジェクトに定義されているパラメーターの名前を確認できます。
ローカル変数の定義
ローカル変数を定義するには、リアルタイムジョブを開きます。
Step 1− [ツール]→[変数]に移動します。新しいVariables and Parameters ウィンドウが開きます。
Step 2 −「変数」→「右クリック」→「挿入」に移動します

新しいパラメータが作成されます $NewVariable0。
Step 3−新しい変数の名前を入力します。リストからデータ型を選択します。

定義したら、ウィンドウを閉じます。同様の方法で、データフローとワークフローのパラメータを定義できます。

ジョブが正常に実行されない場合は、エラーを修正してジョブを再実行する必要があります。ジョブが失敗した場合、一部のテーブルがロード、変更、または部分的にロードされている可能性があります。すべてのデータを取得し、重複または欠落しているデータを削除するには、ジョブを再実行する必要があります。
回復に使用できる2つの手法は次のとおりです。
Automatic Recovery −これにより、失敗したジョブをリカバリモードで実行できます。
Manually Recovery −これにより、前回の部分的な再実行を考慮せずにジョブを再実行できます。
To run a job with Recovery option enabled in Designer
Step 1 −ジョブ名を右クリック→実行。

Step 2 −すべての変更を保存し、実行→はい。
Step 3− [実行]タブ→[リカバリを有効にする]チェックボックスに移動します。このボックスがチェックされていない場合、失敗した場合、データサービスはジョブを回復しません。

To run a job in Recovery mode from Designer
Step 1−右クリックして、上記のようにジョブを実行します。変更内容を保存。
Step 2−実行オプションに移動します。オプションを確認する必要がありますRecover from last failed execution ボックスがチェックされています。
Note−ジョブがまだ実行されていない場合、このオプションは有効になりません。これは、失敗したジョブの自動回復として知られています。

Data Services Designerは、ソースデータの品質と構造を保証および改善するためのデータプロファイリングの機能を提供します。
データプロファイラーを使用すると、次のことができます。
ソースデータ、検証、修正措置、およびソースデータの品質の異常を見つけます。
ジョブ、ワークフロー、およびデータフローをより適切に実行するために、ソースデータの構造と関係を定義します。
ソースシステムとターゲットシステムのコンテンツを見つけて、ジョブが期待される結果を返すことを確認します。
データプロファイラーは、プロファイラーサーバーの実行に関する次の情報を提供します-
カラム分析
Basic Profiling −最小、最大、平均などの情報が含まれます。
Detailed Profiling −個別のカウント、個別のパーセント、中央値などの情報が含まれます。
関係分析
関係を定義する2つの列間のデータ異常。
データプロファイリング機能は、次のデータソースからのデータで使用できます-
- SQLサーバー
- Oracle
- DB2
- Attunityコネクタ
- Sybase IQ
- Teradata
プロファイラーサーバーへの接続
プロファイルサーバーに接続するには-
Step 1 − [ツール]→[プロファイラーサーバーログイン]に移動します

Step 2 −システム、ユーザー名、パスワード、認証などの詳細を入力します。
Step 3 −をクリックします Log on ボタン。
接続すると、プロファイラーリポジトリのリストが表示されます。選択するRepository をクリックします Connect。
ETLジョブのパフォーマンスは、Data Servicesソフトウェアを使用しているシステム、移動の数などによって異なります。
ETLタスクのパフォーマンスに寄与する他のさまざまな要因があります。彼らは-
Source Data Base −ソースデータベースは、を実行するように設定する必要があります Selectすぐにステートメント。これは、データベースI / Oのサイズを増やし、共有バッファーのサイズを増やしてより多くのデータをキャッシュし、小さなテーブルの並列処理を許可しないなどの方法で実行できます。
Source Operating System−ソースオペレーティングシステムは、ディスクからデータをすばやく読み取るように構成する必要があります。先読みプロトコルを64KBに設定します。
Target Database −ターゲットデータベースは、実行するように構成する必要があります INSERT そして UPDATE早く。これは次の方法で実行できます-
- アーカイブログの無効化。
- すべてのテーブルのREDOログを無効にします。
- 共有バッファのサイズを最大化します。
Target Operating System−データをディスクにすばやく書き込むには、ターゲットオペレーティングシステムを構成する必要があります。非同期I / Oをオンにして、入出力操作を可能な限り高速にすることができます。
Network −ネットワーク帯域幅は、ソースからターゲットシステムにデータを転送するのに十分でなければなりません。
BODS Repository Database − BODSジョブのパフォーマンスを向上させるために、以下を実行できます。
Monitor Sample Rate − ETLジョブで大量のデータセットを処理している場合は、サンプルレートをより高い値に監視して、ログファイルへのI / O呼び出しの数を減らし、パフォーマンスを向上させます。
パフォーマンスの低下を引き起こす可能性があるため、ウイルススキャンがジョブサーバーで構成されている場合は、データサービスログをウイルススキャンから除外することもできます。
Job Server OS − Data Servicesでは、ジョブ内の1つのデータフローが1つのデータフローを開始します ‘al_engine’4つのスレッドを開始するプロセス。最大のパフォーマンスを得るには、1つを実行する設計を検討してください‘al_engine’一度にCPUごとのプロセス。Job Server OSは、すべてのスレッドが使用可能なすべてのCPUに分散されるように調整する必要があります。
SAP BO Data Servicesは、各ユーザーが独自のローカルリポジトリ内のアプリケーションで作業できるマルチユーザー開発をサポートしています。各チームは中央リポジトリを使用して、アプリケーションのメインコピーとアプリケーション内のオブジェクトのすべてのバージョンを保存します。
主な機能は次のとおりです。
SAP Data Servicesでは、アプリケーションのチームコピーを保存するための中央リポジトリを作成できます。これには、ローカルリポジトリでも利用できるすべての情報が含まれています。ただし、オブジェクト情報の保存場所を提供するだけです。変更を加えるには、ローカルリポジトリで作業する必要があります。
中央リポジトリからローカルリポジトリにオブジェクトをコピーできます。ただし、変更を加える必要がある場合は、中央リポジトリでそのオブジェクトをチェックアウトする必要があります。このため、他のユーザーは中央リポジトリでそのオブジェクトをチェックアウトできず、したがって同じオブジェクトに変更を加えることができません。
オブジェクトに変更を加えたら、オブジェクトをチェックインする必要があります。これにより、DataServicesは新しい変更されたオブジェクトを中央リポジトリに保存できます。
Data Servicesを使用すると、ローカルリポジトリを持つ複数のユーザーが同時に中央リポジトリに接続できますが、特定のオブジェクトをチェックアウトして変更できるのは1人のユーザーだけです。
中央リポジトリは、各オブジェクトの履歴も保持します。必要に応じて変更が行われない場合は、オブジェクトの以前のバージョンに戻すことができます。
複数のユーザー
SAP BO Data Servicesを使用すると、複数のユーザーが同じアプリケーションで同時に作業できます。マルチユーザー環境では、次の用語を考慮する必要があります-
| シニア番号 | マルチユーザーと説明 |
|---|---|
| 1 | Highest level object 最上位のオブジェクトは、オブジェクト階層内のどのオブジェクトにも依存しないオブジェクトです。たとえば、ジョブ1がワークフロー1とデータフロー1で構成されている場合、ジョブ1は最上位のオブジェクトです。 |
| 2 | Object dependents オブジェクト依存は、階層の最上位オブジェクトの下に関連付けられているオブジェクトです。たとえば、ジョブ1がデータフロー1を含むワークフロー1で構成されている場合、ワークフロー1とデータフロー1の両方がジョブ1に依存します。さらに、データフロー1はワークフロー1に依存します。 |
| 3 | Object version オブジェクトバージョンは、オブジェクトのインスタンスです。中央リポジトリにオブジェクトを追加またはチェックインするたびに、ソフトウェアはオブジェクトの新しいバージョンを作成します。オブジェクトの最新バージョンは、作成された最後または最新のバージョンです。 |
マルチユーザー環境でローカルリポジトリを更新するには、中央リポジトリから各オブジェクトの最新のコピーを取得できます。オブジェクトを編集するには、チェックアウトとチェックインのオプションを使用できます。
中央リポジトリを安全にするために適用できるさまざまなセキュリティパラメータがあります。
さまざまなセキュリティパラメータは次のとおりです。
Authentication −これにより、本物のユーザーのみが中央リポジトリにログインできます。
Authorization −これにより、ユーザーはオブジェクトごとに異なるレベルの権限を割り当てることができます。
Auditing−これは、オブジェクトに加えられたすべての変更の履歴を維持するために使用されます。以前のすべてのバージョンを確認して、古いバージョンに戻すことができます。
安全でない中央リポジトリの作成
マルチユーザー開発環境では、中央リポジトリ方式で作業することを常にお勧めします。
安全でない中央リポジトリを作成するには、指定された手順に従います-
Step 1 −中央リポジトリとして機能するデータベース管理システムを使用して、データベースを作成します。
Step 2 −リポジトリマネージャに移動します。

Step 3−リポジトリタイプを中央として選択します。ユーザー名やパスワードなどのデータベースの詳細を入力し、をクリックしますCreate。

Step 4 −中央リポジトリへの接続を定義するには、 Tools → Central Repository。

Step 5 −中央リポジトリ接続でリポジトリを選択し、 Add アイコン。

Step 6 −中央リポジトリのパスワードを入力し、 Activate ボタン。
安全な中央リポジトリの作成
安全な中央リポジトリを作成するには、リポジトリマネージャに移動します。リポジトリタイプを中央として選択します。クリックEnable Security チェックボックス。

マルチユーザー環境での開発を成功させるには、チェックインやチェックアウトなどのプロセスを実装することをお勧めします。
マルチユーザー環境で次のプロセスを使用できます-
- Filtering
- オブジェクトのチェックアウト
- チェックアウトを元に戻す
- オブジェクトのチェックイン
- オブジェクトのラベル付け
フィルタリングは、オブジェクトを中央リポジトリに追加、チェックイン、チェックアウト、およびラベル付けするときに適用できます。
マルチユーザージョブの移行
SAP Data Servicesでは、ジョブの移行は、アプリケーションレベル、リポジトリレベル、アップグレードレベルなどのさまざまなレベルで適用できます。
1つの中央リポジトリのコンテンツを他の中央リポジトリに直接コピーすることはできません。ローカルリポジトリを利用する必要があります。
最初のステップは、中央リポジトリからローカルリポジトリにすべてのオブジェクトの最新バージョンを取得することです。コンテンツをコピーする中央リポジトリを有効化します。ローカルリポジトリから中央リポジトリにコピーするすべてのオブジェクトを追加します。
中央リポジトリの移行
SAP Data Servicesのバージョンを更新する場合は、リポジトリのバージョンも更新する必要があります。
中央リポジトリを移行してバージョンをアップグレードする場合は、次の点を考慮する必要があります。
すべてのテーブルとオブジェクトの中央リポジトリのバックアップを取ります。
データサービスでオブジェクトのバージョンを維持するには、バージョンごとに中央リポジトリを維持します。新しいバージョンのDataServicesソフトウェアを使用して新しい中央履歴を作成し、すべてのオブジェクトをこのリポジトリにコピーします。
新しいバージョンのDataServicesをインストールする場合は、常に推奨されます。中央リポジトリを新しいバージョンのオブジェクトにアップグレードする必要があります。
中央リポジトリとローカルリポジトリの異なるバージョンが同時に機能しない可能性があるため、ローカルリポジトリを同じバージョンにアップグレードします。
中央リポジトリを移行する前に、すべてのオブジェクトをチェックインしてください。中央リポジトリとローカルリポジトリを同時にアップグレードしないため、すべてのオブジェクトをチェックインする必要があります。中央リポジトリを新しいバージョンにアップグレードすると、古いバージョンのDataServicesがあるローカルリポジトリからオブジェクトをチェックインできなくなります。