Weka-クラスタリング
クラスタリングアルゴリズムは、データセット全体で類似したインスタンスのグループを検索します。WEKAは、EM、FilteredClusterer、HierarchicalClusterer、SimpleKMeansなどのいくつかのクラスタリングアルゴリズムをサポートしています。WEKAの機能を十分に活用するには、これらのアルゴリズムを完全に理解する必要があります。
分類の場合と同様に、WEKAでは検出されたクラスターをグラフィカルに視覚化できます。クラスタリングを示すために、提供されているアイリスデータベースを使用します。データセットには、それぞれ50インスタンスの3つのクラスが含まれています。各クラスは、アイリス植物の種類を指します。
データのロード
WEKAエクスプローラーで、 Preprocessタブ。クリックしてくださいOpen file ...オプションを選択し、 iris.arffファイル選択ダイアログのファイル。データをロードすると、画面は次のようになります。
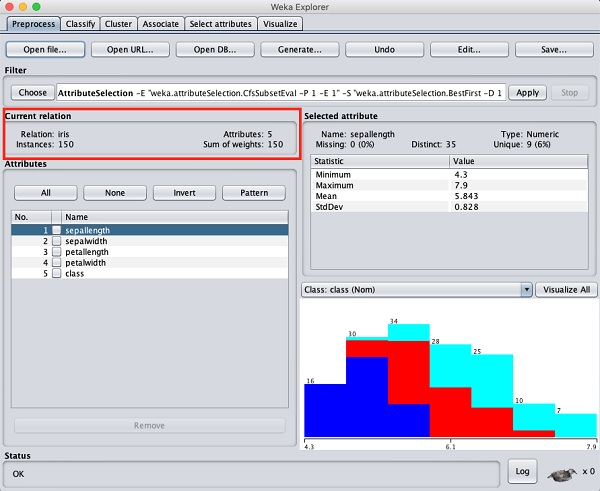
150個のインスタンスと5個の属性があることがわかります。属性の名前は次のようにリストされていますsepallength、 sepalwidth、 petallength、 petalwidth そして class。最初の4つの属性は数値型ですが、クラスは3つの異なる値を持つ名義型です。各属性を調べて、データベースの機能を理解します。このデータの前処理は行わず、すぐにモデル構築に進みます。
クラスタリング
クリックしてください Clusterロードされたデータにクラスタリングアルゴリズムを適用するためのTAB。クリックしてくださいChooseボタン。次の画面が表示されます-

ここで、 EMクラスタリングアルゴリズムとして。の中にCluster mode サブウィンドウで、 Classes to clusters evaluation 以下のスクリーンショットに示すオプション-

クリックしてください Startデータを処理するためのボタン。しばらくすると、結果が画面に表示されます。
次に、結果を調べてみましょう。
出力の調査
データ処理の出力を下の画面に示します-
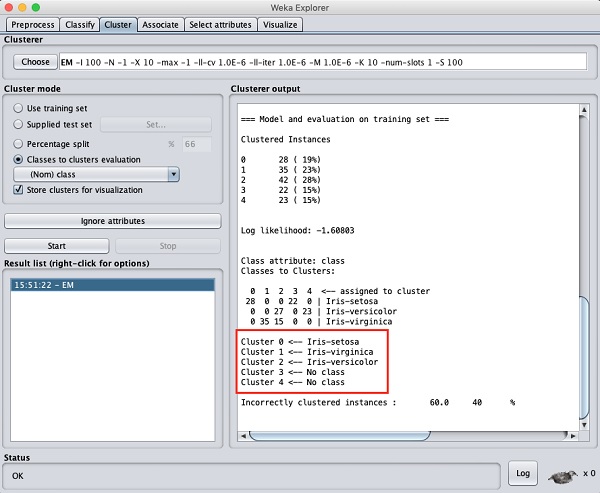
出力画面から、次のことがわかります。
データベースで5つのクラスター化されたインスタンスが検出されました。
ザ・ Cluster 0 setosaを表し、 Cluster 1 virginicaを表し、 Cluster 2 最後の2つのクラスターにはクラスが関連付けられていませんが、versicolorを表します。
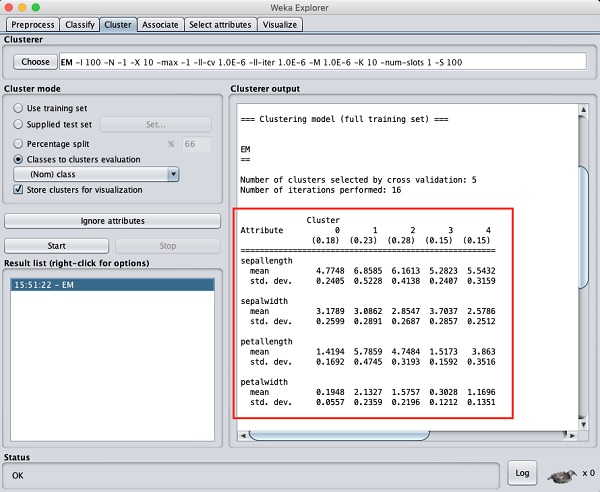
出力ウィンドウを上にスクロールすると、検出されたさまざまなクラスターの各属性の平均と標準偏差を示す統計も表示されます。これは、以下のスクリーンショットに示されています-
次に、クラスターの視覚的表現を見ていきます。
クラスターの視覚化
クラスターを視覚化するには、 EM 結果は Result list。次のオプションが表示されます-
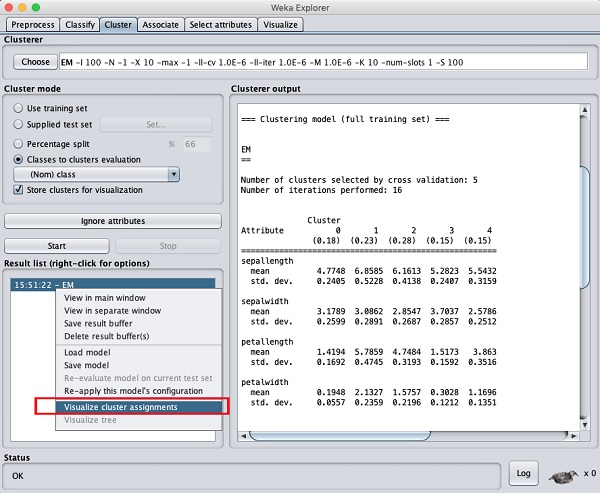
選択する Visualize cluster assignments。次の出力が表示されます-
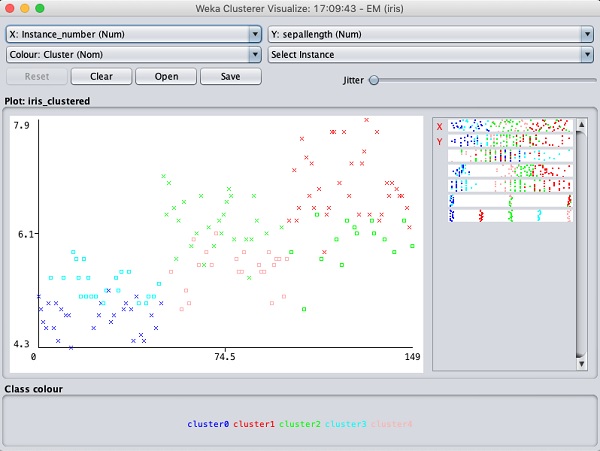
分類の場合と同様に、正しく識別されたインスタンスと誤って識別されたインスタンスの違いに気付くでしょう。X軸とY軸を変更して結果を分析することで、いろいろと試すことができます。分類の場合のようにジッターを使用して、正しく識別されたインスタンスの集中度を見つけることができます。視覚化プロットの操作は、分類の場合に学習した操作と似ています。
階層型クラスタリングの適用
WEKAの力を実証するために、別のクラスタリングアルゴリズムのアプリケーションを調べてみましょう。WEKAエクスプローラーで、HierarchicalClusterer 以下に示すスクリーンショットに示すように、MLアルゴリズムとして-
を選択してください Cluster mode 選択する Classes to cluster evaluation、をクリックし、 Startボタン。次の出力が表示されます-
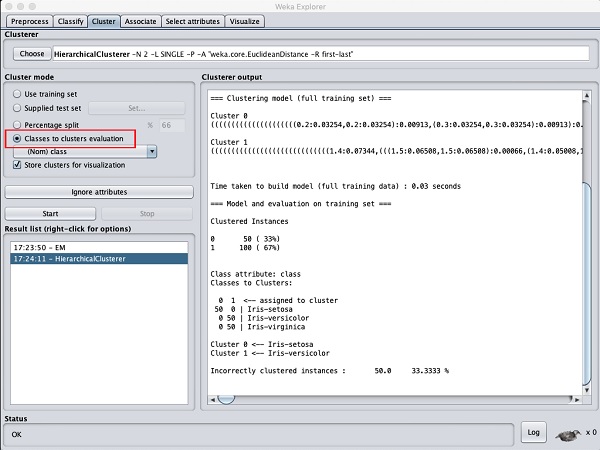
に注意してください Result list、リストされている2つの結果があります。最初の結果はEMの結果であり、2番目の結果は現在の階層です。同様に、同じデータセットに複数のMLアルゴリズムを適用して、それらの結果をすばやく比較できます。
このアルゴリズムによって生成されたツリーを調べると、次の出力が表示されます。
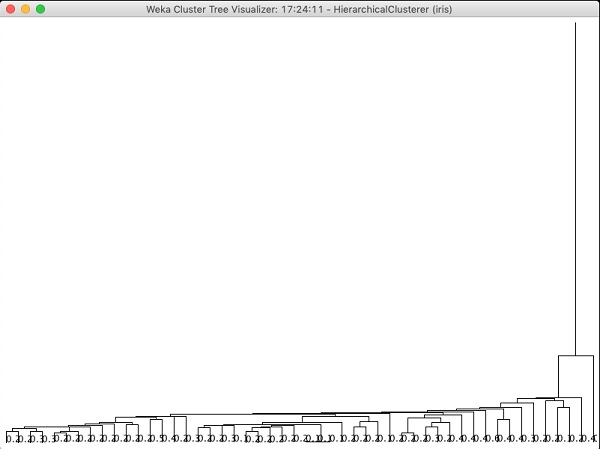
次の章では、 Associate MLアルゴリズムのタイプ。