Weka-データの読み込み
この章では、データの前処理に使用する最初のタブから始めます。これは、モデルを構築するためにデータに適用するすべてのアルゴリズムに共通であり、WEKAでの後続のすべての操作に共通のステップです。
機械学習アルゴリズムで許容可能な精度を得るには、最初にデータをクレンジングする必要があります。これは、フィールドから収集された生データにnull値、無関係な列などが含まれている可能性があるためです。
この章では、生データを前処理し、さらに使用するためのクリーンで意味のあるデータセットを作成する方法を学習します。
まず、データファイルをWEKAエクスプローラーにロードする方法を学びます。データは次のソースからロードできます-
- ローカルファイルシステム
- Web
- Database
この章では、データをロードする3つのオプションすべてについて詳しく説明します。
ローカルファイルシステムからのデータのロード
前のレッスンで学習した[機械学習]タブのすぐ下に、次の3つのボタンがあります-
- ファイルを開く..。
- URLを開く..。
- DBを開く..。
クリックしてください Open file...ボタン。次の画面に示すように、ディレクトリナビゲータウィンドウが開きます。
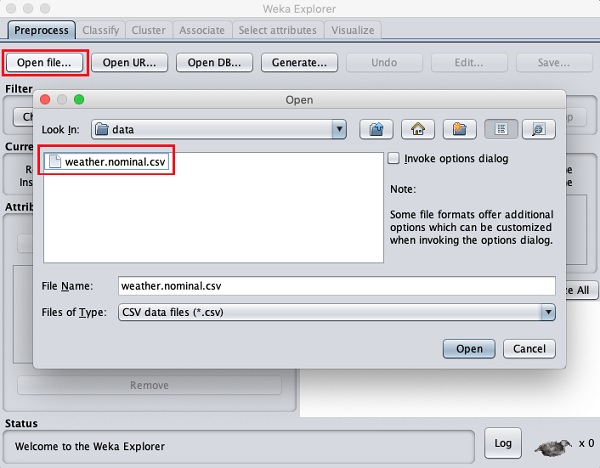
次に、データファイルが保存されているフォルダーに移動します。WEKAのインストールには、実験用のサンプルデータベースが多数用意されています。これらはで利用可能ですdata WEKAインストールのフォルダー。
学習目的で、このフォルダーから任意のデータファイルを選択します。ファイルの内容はWEKA環境にロードされます。このロードされたデータを検査して処理する方法をすぐに学びます。その前に、Webからデータファイルをロードする方法を見てみましょう。
Webからのデータのロード
あなたがクリックしたら Open URL ... ボタンをクリックすると、次のようなウィンドウが表示されます-
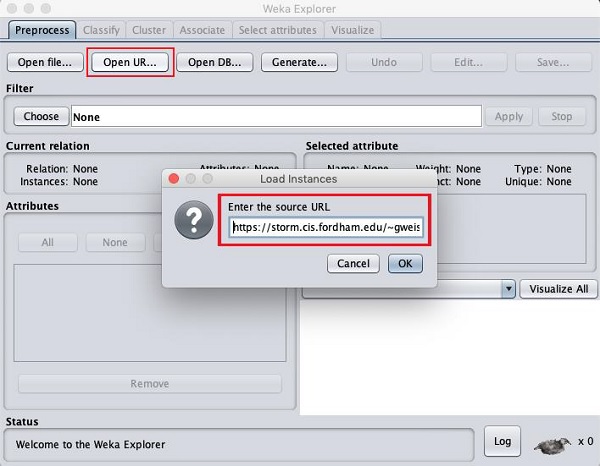
パブリックURLからファイルを開きますポップアップボックスに次のURLを入力します-
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
データが保存されている他のURLを指定できます。ザ・Explorer リモートサイトからその環境にデータをロードします。
DBからのデータのロード
あなたがクリックしたら Open DB ...ボタンをクリックすると、次のようなウィンドウが表示されます-
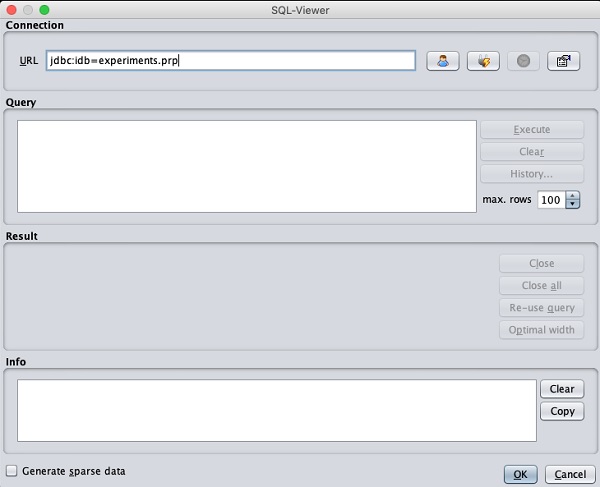
データベースへの接続文字列を設定し、データ選択用のクエリを設定し、クエリを処理して、選択したレコードをWEKAにロードします。