Weka-エクスプローラーの起動
この章では、エクスプローラーがビッグデータを操作するために提供するさまざまな機能を調べてみましょう。
あなたがクリックすると Explorer のボタン Applications セレクター、それは次の画面を開きます-
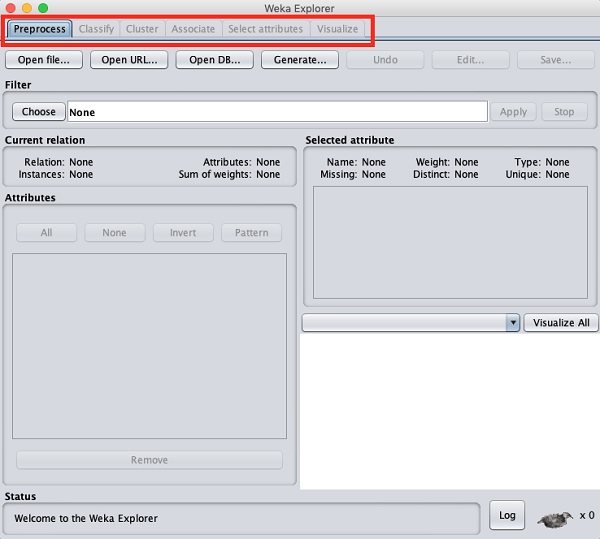
上部には、ここにリストされているいくつかのタブが表示されます-
- Preprocess
- Classify
- Cluster
- Associate
- 属性を選択
- Visualize
これらのタブの下には、事前に実装された機械学習アルゴリズムがいくつかあります。ここで、それぞれについて詳しく見ていきましょう。
前処理タブ
最初にエクスプローラーを開くと、 Preprocessタブが有効になります。機械学習の最初のステップは、データを前処理することです。したがって、Preprocess オプションで、データファイルを選択して処理し、さまざまな機械学習アルゴリズムの適用に適合させます。
[分類]タブ
ザ・ Classifyタブには、データを分類するためのいくつかの機械学習アルゴリズムが用意されています。いくつか挙げると、線形回帰、ロジスティック回帰、サポートベクターマシン、ディシジョンツリー、ランダムツリー、ランダムフォレスト、ナイーブベイズなどのアルゴリズムを適用できます。このリストは非常に網羅的であり、教師ありと教師なしの両方の機械学習アルゴリズムを提供します。
[クラスター]タブ
下 Cluster タブには、SimpleKMeans、FilteredClusterer、HierarchicalClustererなどのいくつかのクラスタリングアルゴリズムが用意されています。
[関連付け]タブ
下 Associate タブには、Apriori、FilteredAssociator、FPGrowthがあります。
[属性]タブを選択します
Select Attributes ClassifierSubsetEval、PrinicipalComponentsなどのいくつかのアルゴリズムに基づいて特徴選択を行うことができます。
タブを視覚化
最後に、 Visualize オプションを使用すると、分析のために処理済みデータを視覚化できます。
お気づきのとおり、WEKAは、機械学習アプリケーションをテストおよび構築するための、すぐに使用できるアルゴリズムをいくつか提供しています。WEKAを効果的に使用するには、これらのアルゴリズム、それらがどのように機能するか、どのような状況でどのアルゴリズムを選択するか、処理された出力で何を探すかなどについて十分な知識が必要です。つまり、アプリの構築にWEKAを効果的に使用するには、機械学習の強固な基盤が必要です。
次の章では、エクスプローラーの各タブについて詳しく説明します。