컴파일러 설계-코드 최적화
최적화는 프로그램 변환 기술로, 리소스 (예 : CPU, 메모리)를 적게 사용하고 고속을 제공하여 코드를 개선합니다.
최적화에서 고수준의 일반 프로그래밍 구조는 매우 효율적인 저수준 프로그래밍 코드로 대체됩니다. 코드 최적화 프로세스는 아래 주어진 세 가지 규칙을 따라야합니다.
출력 코드는 어떤 식 으로든 프로그램의 의미를 변경해서는 안됩니다.
최적화는 프로그램의 속도를 높여야하며 가능하면 프로그램에서 더 적은 수의 리소스를 요구해야합니다.
최적화는 그 자체로 빠르며 전체 컴파일 프로세스를 지연시키지 않아야합니다.
최적화 된 코드를위한 노력은 다양한 수준의 프로세스 컴파일에서 이루어질 수 있습니다.
처음에는 사용자가 코드를 변경 / 재정렬하거나 더 나은 알고리즘을 사용하여 코드를 작성할 수 있습니다.
중간 코드를 생성 한 후 컴파일러는 주소 계산 및 루프 개선을 통해 중간 코드를 수정할 수 있습니다.
대상 기계 코드를 생성하는 동안 컴파일러는 메모리 계층 구조 및 CPU 레지스터를 사용할 수 있습니다.
최적화는 크게 기계 독립형과 기계 종속 형의 두 가지 유형으로 분류 할 수 있습니다.
기계 독립적 인 최적화
이 최적화에서 컴파일러는 중간 코드를 받아 CPU 레지스터 및 / 또는 절대 메모리 위치를 포함하지 않는 코드의 일부를 변환합니다. 예를 들면 :
do
{
item = 10;
value = value + item;
} while(value<100);이 코드는 식별자 항목의 반복적 인 할당을 포함합니다.
Item = 10;
do
{
value = value + item;
} while(value<100);CPU주기를 절약 할뿐만 아니라 모든 프로세서에서 사용할 수 있습니다.
기계 의존적 최적화
기계 의존적 최적화는 대상 코드가 생성 된 후 대상 기계 아키텍처에 따라 코드가 변환 될 때 수행됩니다. 여기에는 CPU 레지스터가 포함되며 상대 참조가 아닌 절대 메모리 참조가있을 수 있습니다. 기계 종속적 최적화 프로그램은 메모리 계층 구조를 최대한 활용하기 위해 노력합니다.
기본 블록
소스 코드에는 일반적으로 여러 명령이 있으며 항상 순서대로 실행되며 코드의 기본 블록으로 간주됩니다. 이러한 기본 블록에는 점프 문이 없습니다. 즉, 첫 번째 명령이 실행될 때 동일한 기본 블록의 모든 명령이 프로그램의 흐름 제어를 잃지 않고 순서대로 실행됩니다.
프로그램은 IF-THEN-ELSE, SWITCH-CASE 조건문 및 DO-WHILE, FOR 및 REPEAT-UNTIL 등과 같은 루프와 같은 기본 블록과 같은 다양한 구성을 가질 수 있습니다.
기본 블록 식별
다음 알고리즘을 사용하여 프로그램의 기본 블록을 찾을 수 있습니다.
기본 블록이 시작되는 모든 기본 블록의 헤더 문을 검색합니다.
- 프로그램의 첫 번째 진술.
- 모든 분기의 대상이되는 문 (조건부 / 무조건 부).
- 분기 문 뒤에 오는 문.
헤더 문과 그 뒤의 문은 기본 블록을 형성합니다.
기본 블록은 다른 기본 블록의 헤더 문을 포함하지 않습니다.
기본 블록은 코드 생성 및 최적화 관점에서 중요한 개념입니다.
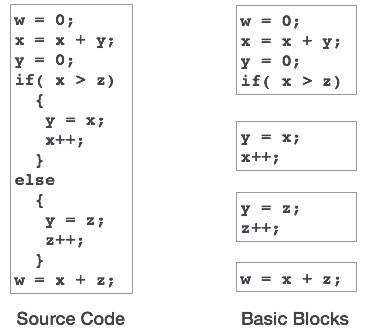
기본 블록은 단일 기본 블록에서 두 번 이상 사용되는 변수를 식별하는 데 중요한 역할을합니다. 변수가 두 번 이상 사용되는 경우 해당 변수에 할당 된 레지스터 메모리는 블록 실행이 완료되지 않는 한 비울 필요가 없습니다.
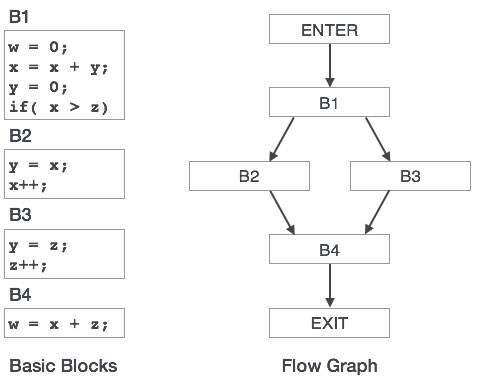
제어 흐름 그래프
프로그램의 기본 블록은 제어 흐름 그래프를 통해 나타낼 수 있습니다. 제어 흐름 그래프는 프로그램 제어가 블록간에 전달되는 방식을 나타냅니다. 프로그램에서 원하지 않는 루프를 찾는 데 도움을줌으로써 최적화에 도움이되는 유용한 도구입니다.
루프 최적화
대부분의 프로그램은 시스템에서 루프로 실행됩니다. CPU 사이클과 메모리를 절약하기 위해 루프를 최적화해야합니다. 루프는 다음 기술로 최적화 할 수 있습니다.
Invariant code: 루프에 상주하고 각 반복에서 동일한 값을 계산하는 코드 조각을 루프 불변 코드라고합니다. 이 코드는 각 반복이 아닌 한 번만 계산되도록 저장하여 루프 밖으로 이동할 수 있습니다.
Induction analysis : 변수는 루프 불변 값에 의해 루프 내에서 값이 변경되는 경우 유도 변수라고합니다.
Strength reduction: CPU주기, 시간 및 메모리를 더 많이 소비하는 표현식이 있습니다. 이러한 표현은 표현의 출력을 손상시키지 않으면 서 저렴한 표현으로 대체되어야합니다. 예를 들어 곱셈 (x * 2)은 CPU주기 측면에서 (x << 1)보다 비용이 많이 들고 동일한 결과를 산출합니다.
데드 코드 제거
데드 코드는 다음과 같은 하나 이상의 코드 문입니다.
- 실행되지 않았거나 도달 할 수없는 경우
- 또는 실행되면 출력이 사용되지 않습니다.
따라서 데드 코드는 프로그램 작동에 아무런 역할을하지 않으므로 간단히 제거 할 수 있습니다.
부분적으로 죽은 코드
계산 된 값이 특정 상황에서만 사용되는 일부 코드 문이 있습니다. 즉, 값이 사용되는 경우도 있고 그렇지 않은 경우도 있습니다. 이러한 코드를 부분적으로 데드 코드라고합니다.
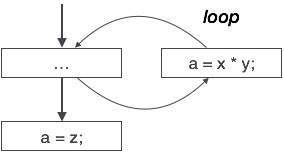
위의 제어 흐름 그래프는 변수 'a'가 'x * y'표현식의 출력을 할당하는 데 사용되는 프로그램 청크를 나타냅니다. 'a'에 할당 된 값이 루프 내부에서 사용되지 않는다고 가정 해 보겠습니다. 컨트롤이 루프를 떠나는 즉시 'a'에 변수 'z'가 할당되어 나중에 프로그램에서 사용됩니다. 여기서 'a'의 할당 코드는 어디에도 사용되지 않으므로 제거 할 수 있다는 결론을 내립니다.
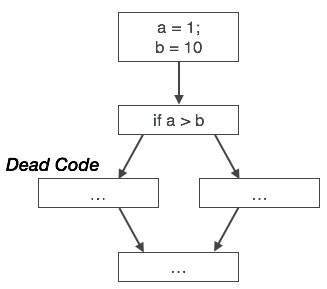
마찬가지로, 위의 그림은 조건문이 항상 거짓임을 나타내며, 실제 케이스로 작성된 코드가 실행되지 않으므로 제거 할 수 있음을 의미합니다.
부분 중복
중복 표현식은 피연산자 변경없이 병렬 경로에서 두 번 이상 계산되는 반면 부분 중복 표현식은 피연산자 변경없이 경로에서 두 번 이상 계산됩니다. 예를 들면
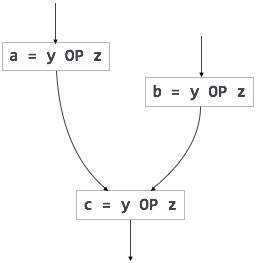
[중복 식] |
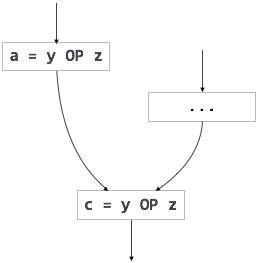
[부분 중복 표현] |
루프 불변 코드는 부분적으로 중복되며 코드 모션 기술을 사용하여 제거 할 수 있습니다.
부분적으로 중복 된 코드의 또 다른 예는 다음과 같습니다.
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;우리는 피연산자의 값 (y 과 z)는 변수 할당에서 변경되지 않습니다. a 변수에 c. 여기서 조건문이 참이면 y OP z가 두 번 계산되고 그렇지 않으면 한 번 계산됩니다. 아래와 같이 코드 동작을 사용하여 이러한 중복성을 제거 할 수 있습니다.
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;여기서 조건이 참인지 거짓인지 여부. y OP z는 한 번만 계산해야합니다.