DCN - szybki przewodnik
System połączonych ze sobą komputerów i skomputeryzowanych urządzeń peryferyjnych, takich jak drukarki, nazywany jest siecią komputerową. To połączenie między komputerami ułatwia wymianę informacji między nimi. Komputery mogą łączyć się ze sobą za pomocą mediów przewodowych lub bezprzewodowych.
Klasyfikacja sieci komputerowych
Sieci komputerowe są klasyfikowane na podstawie różnych czynników, takich jak:
- Rozpiętość geograficzna
- Inter-connectivity
- Administration
- Architecture
Rozpiętość geograficzna
Pod względem geograficznym sieć można zobaczyć w jednej z następujących kategorii:
- Może być rozłożony na wszystkie urządzenia obsługujące Bluetooth. Nie więcej niż kilka metrów.
- Może obejmować cały budynek, w tym urządzenia pośrednie łączące wszystkie piętra.
- Może obejmować całe miasto.
- Może obejmować wiele miast lub prowincji.
- Może to być jedna sieć obejmująca cały świat.
Inter-Connectivity
Komponenty sieci można łączyć ze sobą na różne sposoby. Przez powiązanie rozumiemy logicznie, fizycznie lub w obie strony.
- Każde urządzenie można podłączyć do każdego innego urządzenia w sieci, tworząc sieć typu mesh.
- Wszystkie urządzenia mogą być podłączone do jednego medium, ale geograficznie odłączone, tworząc strukturę przypominającą magistralę.
- Każde urządzenie jest podłączone tylko do swojego lewego i prawego peera, tworząc liniową strukturę.
- Wszystkie urządzenia połączone razem w jedno urządzenie, tworząc strukturę przypominającą gwiazdę.
- Wszystkie urządzenia łączyły się w dowolny sposób przy użyciu wszystkich poprzednich sposobów łączenia, co daje w rezultacie strukturę hybrydową.
Administracja
Z punktu widzenia administratora, sieć może być siecią prywatną, która należy do jednego systemu autonomicznego i nie można uzyskać do niej dostępu poza domeną fizyczną lub logiczną. Sieć może być publiczna, do której mają dostęp wszyscy.
Architektura sieci
- Jako serwer może działać jeden lub więcej systemów. Innym klientem jest żądanie od serwera obsługi żądań, serwer przyjmuje i przetwarza żądania w imieniu klientów.
- Dwa systemy można połączyć punkt-punkt lub odwrotnie. Oboje mieszkają na tym samym poziomie i nazywają się rówieśnikami.
- Może istnieć sieć hybrydowa obejmująca architekturę sieci obu powyższych typów.
Sieci komputerowe można podzielić na różne typy, takie jak klient-serwer, peer-to-peer lub hybrydowe, w zależności od ich architektury.
Aplikacje sieciowe
Systemy komputerowe i urządzenia peryferyjne są połączone w sieć, co zapewnia wiele korzyści:
- Udostępnianie zasobów, takich jak drukarki i urządzenia pamięci masowej
- Wymiana informacji za pomocą e-maili i FTP
- Udostępnianie informacji za pośrednictwem sieci WWW lub Internetu
- Interakcja z innymi użytkownikami za pomocą dynamicznych stron internetowych
- Telefony IP
- Wideokonferencje
- Równoległe obliczenia
- Wiadomości błyskawiczne
Zasadniczo sieci rozróżnia się na podstawie ich zasięgu geograficznego. Sieć może być tak mała, jak odległość między telefonem komórkowym a słuchawką Bluetooth, a także tak duża, jak sam internet, obejmująca cały świat geograficzny,
Sieć osobista
Sieć osobista (PAN) to najmniejsza sieć, która jest bardzo osobista dla użytkownika. Może to obejmować urządzenia obsługujące technologię Bluetooth lub urządzenia obsługujące podczerwień. PAN ma zasięg łączności do 10 metrów. PAN może obejmować bezprzewodową klawiaturę i mysz komputerową, słuchawki z obsługą Bluetooth, drukarki bezprzewodowe i piloty telewizyjne.
Na przykład Piconet jest osobistą siecią komputerową z włączoną funkcją Bluetooth, która może zawierać do 8 urządzeń połączonych ze sobą na zasadzie master-slave.
Sieć lokalna
Sieć komputerowa rozpięta wewnątrz budynku i obsługiwana w ramach jednego systemu administracyjnego jest ogólnie określana jako sieć lokalna (LAN). Zwykle LAN obejmuje biura organizacji, szkoły, uczelnie lub uniwersytety. Liczba systemów połączonych w sieci LAN może wahać się od co najmniej dwóch do nawet 16 milionów.
Sieć LAN zapewnia przydatny sposób udostępniania zasobów między użytkownikami końcowymi. Zasoby, takie jak drukarki, serwery plików, skanery i internet, można łatwo współdzielić między komputerami.
Sieci LAN składają się z niedrogich urządzeń sieciowych i routingu. Może zawierać lokalne serwery obsługujące przechowywanie plików i inne lokalnie udostępniane aplikacje. Działa głównie na prywatnych adresach IP i nie wymaga intensywnego routingu. Sieć LAN działa pod własną domeną lokalną i jest kontrolowana centralnie.
LAN wykorzystuje technologię Ethernet lub Token Ring. Ethernet jest najczęściej stosowaną technologią LAN i wykorzystuje topologię gwiazdy, podczas gdy Token Ring jest rzadko spotykany.
Sieć LAN może być przewodowa, bezprzewodowa lub w obu formach jednocześnie.
Miejska Sieć Komputerowa
Metropolitan Area Network (MAN) zazwyczaj rozszerza się na całe miasto, na przykład sieć telewizji kablowej. Może to być Ethernet, Token Ring, ATM lub FDDI (Fiber Distributed Data Interface).
Metro Ethernet to usługa świadczona przez dostawców usług internetowych. Ta usługa umożliwia swoim użytkownikom rozszerzenie ich sieci lokalnych. Na przykład MAN może pomóc organizacji w połączeniu wszystkich biur w mieście.
Podstawą firmy MAN są wysokowydajne i szybkie światłowody. MAN działa pomiędzy siecią lokalną a siecią rozległą. MAN zapewnia uplink dla sieci LAN do sieci WAN lub Internetu.
Sieć rozległa
Jak sama nazwa wskazuje, sieć rozległa (WAN) obejmuje rozległy obszar, który może obejmować prowincje, a nawet cały kraj. Ogólnie rzecz biorąc, sieci telekomunikacyjne to sieci rozległe. Sieci te zapewniają łączność z sieciami MAN i LAN. Ponieważ sieci WAN są wyposażone w bardzo szybkie sieci szkieletowe, używają bardzo drogiego sprzętu sieciowego.
WAN może wykorzystywać zaawansowane technologie, takie jak Asynchronous Transfer Mode (ATM), Frame Relay i Synchronous Optical Network (SONET). WAN może być zarządzany przez wielu administratorów.
Intersieć
Sieć sieci nazywana jest intersiecią lub po prostu Internetem. Jest to największa istniejąca sieć na tej planecie. Internet w ogromnym stopniu łączy wszystkie sieci WAN i może mieć połączenie z sieciami LAN i sieciami domowymi. Internet używa zestawu protokołów TCP / IP i używa protokołu IP jako protokołu adresowania. Obecnie Internet jest szeroko wdrażany przy użyciu protokołu IPv4. Z powodu braku przestrzeni adresowych następuje stopniowa migracja z IPv4 do IPv6.
Internet umożliwia swoim użytkownikom dzielenie się i dostęp do ogromnych ilości informacji na całym świecie. Wykorzystuje WWW, FTP, usługi poczty elektronicznej, strumieniowanie audio i wideo itp. W ogromnym stopniu Internet działa w modelu klient-serwer.
Internet wykorzystuje bardzo szybki szkielet światłowodowy. Aby połączyć różne kontynenty, pod powierzchnią morza układane są włókna, które nazywamy podmorskim kablem komunikacyjnym.
Internet jest szeroko rozpowszechniony w usługach World Wide Web przy użyciu połączonych stron HTML i jest dostępny przez oprogramowanie klienckie znane jako przeglądarki internetowe. Gdy użytkownik zażąda strony przy użyciu przeglądarki internetowej znajdującej się na jakimś serwerze internetowym w dowolnym miejscu na świecie, serwer sieciowy odpowiada odpowiednią stroną HTML. Opóźnienie komunikacji jest bardzo małe.
Internet służy wielu propozycjom i jest zaangażowany w wiele aspektów życia. Niektórzy z nich są:
- Witryny internetowe
- Wiadomości błyskawiczne
- Blogging
- Media społecznościowe
- Marketing
- Networking
- Udostępnianie zasobów
- Streaming audio i wideo
Omówmy w skrócie różne technologie LAN:
Ethernet
Ethernet jest szeroko rozpowszechnioną technologią LAN. Technologia ta została wynaleziona przez Boba Metcalfe'a i DR Boggsa w roku 1970. Została znormalizowana w IEEE 802.3 w 1980 roku.
Ethernet udostępnia media. Sieć wykorzystująca współdzielone media ma duże prawdopodobieństwo kolizji danych. Ethernet wykorzystuje technologię Carrier Sense Multi Access / Collision Detection (CSMA / CD) do wykrywania kolizji. W przypadku wystąpienia kolizji w sieci Ethernet wszystkie jej hosty wycofują się, czekają przez jakiś losowy czas, a następnie ponownie przesyłają dane.
Złącze Ethernet to karta sieciowa wyposażona w 48-bitowy adres MAC. Pomaga to innym urządzeniom Ethernet w identyfikacji i komunikacji z urządzeniami zdalnymi w sieci Ethernet.
Tradycyjny Ethernet wykorzystuje specyfikacje 10BASE-T. 10 oznacza prędkość 10 Mb / s, BASE oznacza pasmo podstawowe, a T oznacza gruby Ethernet. 10BASE-T Ethernet zapewnia prędkość transmisji do 10 Mb / s i wykorzystuje kabel koncentryczny lub skrętkę Cat-5 ze złączem RJ-45. Ethernet jest zgodny z topologią gwiazdy z długością segmentu do 100 metrów. Wszystkie urządzenia są podłączone do koncentratora / przełącznika w gwiazdę.
Fast-Ethernet
Aby sprostać zapotrzebowaniu na szybko pojawiające się technologie programowe i sprzętowe, Ethernet rozszerza się jako Fast-Ethernet. Może działać na UTP, światłowodzie, a także bezprzewodowo. Może zapewnić prędkość do 100 MBPS. Ten standard nosi nazwę 100BASE-T w IEEE 803.2 przy użyciu skrętki komputerowej Cat-5. Wykorzystuje technikę CSMA / CD do przewodowego udostępniania mediów między hostami Ethernet i technikę CSMA / CA (CA oznacza unikanie kolizji) dla bezprzewodowej sieci Ethernet LAN.
Fast Ethernet na światłowodzie jest zdefiniowany w standardzie 100BASE-FX, który zapewnia prędkość do 100 MBPS na światłowodzie. Ethernet przez światłowód można rozszerzyć do 100 metrów w trybie półdupleksu i może osiągnąć maksymalnie 2000 metrów w trybie pełnego dupleksu na światłowodach wielomodowych.
Giga-Ethernet
Po wprowadzeniu w 1995 r. Fast-Ethernet mógł cieszyć się statusem wysokiej szybkości tylko przez 3 lata, aż do wprowadzenia Giga-Ethernet. Giga-Ethernet zapewnia prędkość do 1000 Mb / s. IEEE802.3ab standaryzuje Giga-Ethernet przez UTP przy użyciu kabli Cat-5, Cat-5e i Cat-6. IEEE802.3ah definiuje Giga-Ethernet over Fibre.
Wirtualna sieć LAN
LAN wykorzystuje Ethernet, który z kolei działa na współdzielonych mediach. Media współdzielone w sieci Ethernet tworzą jedną domenę rozgłoszeniową i jedną domenę kolizyjną. Wprowadzenie przełączników do sieci Ethernet usunęło problem z pojedynczą domeną kolizyjną, a każde urządzenie podłączone do przełącznika działa w oddzielnej domenie kolizyjnej. Ale nawet przełączniki nie mogą podzielić sieci na oddzielne domeny rozgłoszeniowe.
Wirtualna sieć LAN to rozwiązanie umożliwiające podzielenie pojedynczej domeny rozgłoszeniowej na wiele domen rozgłoszeniowych. Host w jednej sieci VLAN nie może komunikować się z hostem w innej. Domyślnie wszystkie hosty są umieszczane w tej samej sieci VLAN.
Na tym diagramie różne sieci VLAN są przedstawione za pomocą różnych kodów kolorów. Hosty w jednej sieci VLAN, nawet jeśli są podłączone do tego samego przełącznika, nie mogą widzieć ani rozmawiać z innymi hostami w różnych sieciach VLAN. VLAN to technologia warstwy 2, która ściśle współpracuje z siecią Ethernet. Do trasowania pakietów między dwiema różnymi sieciami VLAN wymagane jest urządzenie warstwy 3, takie jak router.
Topologia sieci to układ, za pomocą którego systemy komputerowe lub urządzenia sieciowe są ze sobą połączone. Topologie mogą definiować zarówno fizyczny, jak i logiczny aspekt sieci. Zarówno topologie logiczne, jak i fizyczne mogą być takie same lub różne w tej samej sieci.
Punkt-punkt
Sieci typu punkt-punkt zawierają dokładnie dwa hosty, takie jak komputer, przełączniki lub routery, serwery połączone z powrotem za pomocą jednego kawałka kabla. Często odbierający koniec jednego hosta jest połączony z wysyłającym końcem drugiego i odwrotnie.

Jeśli hosty są połączone logicznie punkt-punkt, może mieć wiele urządzeń pośredniczących. Ale hosty końcowe nie są świadome istnienia podstawowej sieci i widzą się nawzajem tak, jakby były bezpośrednio połączone.
Topologia magistrali
W przypadku topologii magistrali wszystkie urządzenia współdzielą jedną linię komunikacyjną lub kabel. Topologia magistrali może mieć problem, gdy wiele hostów wysyła dane w tym samym czasie. Dlatego topologia magistrali wykorzystuje technologię CSMA / CD lub rozpoznaje jeden host jako główny magistrali w celu rozwiązania problemu. Jest to jedna z prostych form tworzenia sieci, w której awaria urządzenia nie wpływa na inne urządzenia. Jednak awaria wspólnej linii komunikacyjnej może spowodować, że wszystkie inne urządzenia przestaną działać.
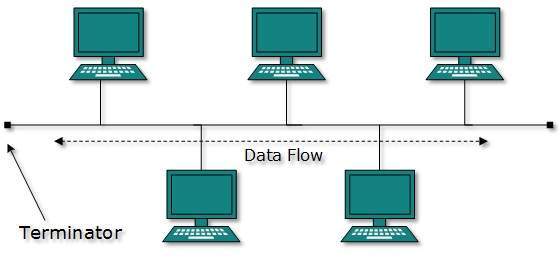
Oba końce wspólnego kanału mają terminator linii. Dane są przesyłane tylko w jednym kierunku i gdy tylko osiągną skrajny koniec, terminator usuwa dane z linii.
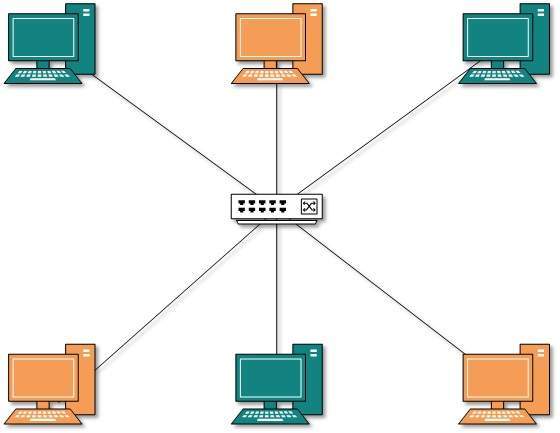
Topologia gwiazdy
Wszystkie hosty w topologii Star są podłączone do centralnego urządzenia, zwanego koncentratorem, za pomocą połączenia punkt-punkt. Oznacza to, że istnieje połączenie punkt-punkt między hostami a koncentratorem. Urządzeniem koncentratora może być dowolne z następujących:
- Urządzenie warstwy 1, takie jak koncentrator lub repeater
- Urządzenie warstwy 2, takie jak przełącznik lub most
- Urządzenie warstwy 3, takie jak router lub brama
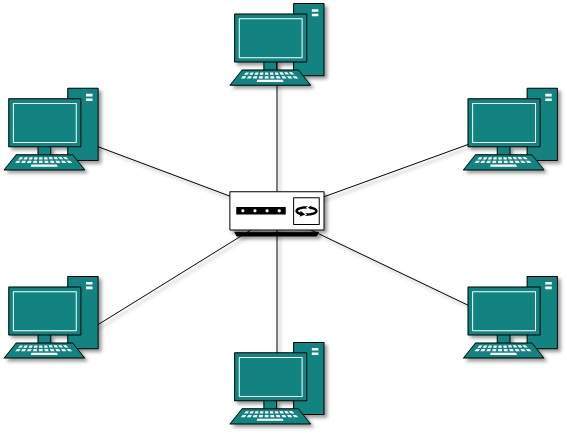
Podobnie jak w topologii magistrali, koncentrator działa jako pojedynczy punkt awarii. Jeśli koncentrator ulegnie awarii, połączenie wszystkich hostów z innymi hostami nie powiedzie się. Każda komunikacja między hostami odbywa się tylko za pośrednictwem koncentratora. Topologia gwiazdy nie jest droga, ponieważ do podłączenia jeszcze jednego hosta potrzebny jest tylko jeden kabel, a konfiguracja jest prosta.
Topologia pierścienia
W topologii pierścieniowej każdy komputer główny łączy się dokładnie z dwoma innymi komputerami, tworząc okrągłą strukturę sieci. Kiedy jeden host próbuje komunikować się lub wysyłać wiadomość do hosta, który nie sąsiaduje z nim, dane przechodzą przez wszystkie hosty pośrednie. Aby podłączyć jeszcze jeden host w istniejącej strukturze, administrator może potrzebować tylko jednego dodatkowego kabla.
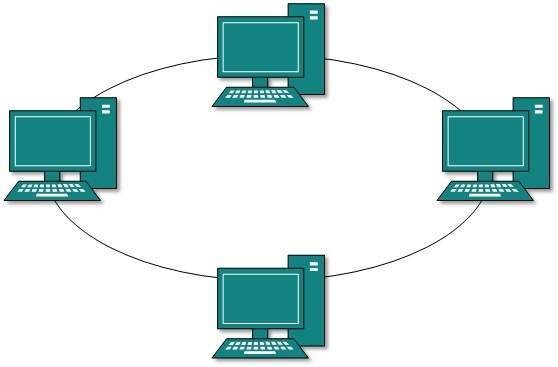
Awaria któregokolwiek hosta skutkuje awarią całego ringu, dlatego każde połączenie w ringu jest punktem awarii. Istnieją metody, które wykorzystują jeszcze jeden pierścień zapasowy.
Topologia siatki
W tego typu topologii host jest połączony z jednym lub wieloma hostami. W tej topologii hosty są połączone punkt-punkt z każdym innym hostem lub mogą mieć również hosty, które są w połączeniu punkt-punkt tylko z kilkoma hostami.
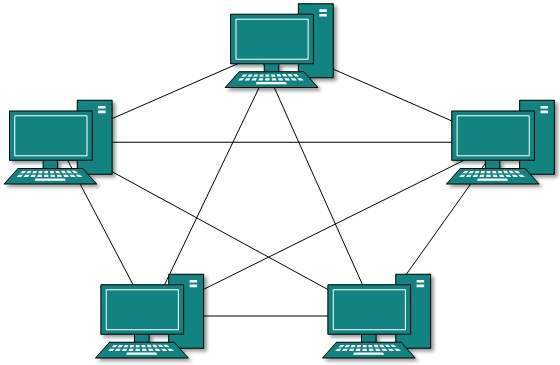
Hosty w topologii Mesh działają również jako przekaźniki dla innych hostów, które nie mają bezpośrednich łączy typu punkt-punkt. Technologia siatki dzieli się na dwa rodzaje:
- Full Mesh: Wszystkie hosty mają połączenie typu punkt-punkt z każdym innym hostem w sieci. Zatem dla każdego nowego hosta wymagane jest n (n-1) / 2 połączeń. Zapewnia najbardziej niezawodną strukturę sieci spośród wszystkich topologii sieci.
- Partially Mesh: Nie wszystkie hosty mają połączenie punkt-punkt z każdym innym hostem. Hosty łączą się ze sobą w dowolny sposób. Taka topologia istnieje, gdy musimy zapewnić niezawodność niektórym hostom ze wszystkich.
Topologia drzewa
Znana również jako topologia hierarchiczna, jest to obecnie najpowszechniejsza forma topologii sieci, która naśladuje rozszerzoną topologię gwiazdy i dziedziczy właściwości topologii magistrali.
Ta topologia dzieli sieć na wiele poziomów / warstw sieci. Głównie w sieciach LAN sieć jest podzielona na trzy typy urządzeń sieciowych. Najniższa warstwa to warstwa dostępu, do której podłączone są komputery. Warstwa środkowa jest znana jako warstwa dystrybucyjna, która działa jako pośrednik między warstwą górną a warstwą dolną. Najwyższa warstwa jest nazywana warstwą rdzeniową i jest centralnym punktem sieci, tj. Korzeniem drzewa, z którego rozwidlają się wszystkie węzły.
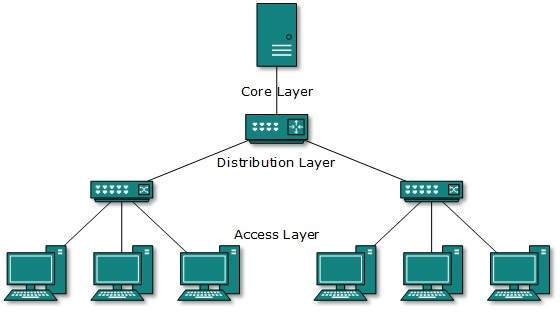
Wszystkie sąsiednie hosty mają między sobą połączenie punkt-punkt. Podobnie jak w topologii magistrali, jeśli root przestanie działać, cierpi nawet cała sieć, chociaż nie jest to pojedynczy punkt awarii. Każde połączenie służy jako punkt awarii, którego awaria dzieli sieć na nieosiągalny segment.
Wianuszek ze stokrotek
Ta topologia łączy wszystkie hosty w sposób liniowy. Podobnie jak w przypadku topologii pierścienia, wszystkie hosty są połączone tylko z dwoma hostami, z wyjątkiem hostów końcowych. Oznacza to, że jeśli hosty końcowe w łańcuchu są połączone, oznacza to topologię pierścienia.

Każde łącze w topologii łańcuchowej reprezentuje pojedynczy punkt awarii. Każda awaria łącza dzieli sieć na dwa segmenty, a każdy pośredni host działa jako przekaźnik dla swoich bezpośrednich hostów.
Topologia hybrydowa
Struktura sieci, której projekt zawiera więcej niż jedną topologię, nazywana jest topologią hybrydową. Topologia hybrydowa dziedziczy zalety i wady wszystkich wbudowanych topologii.
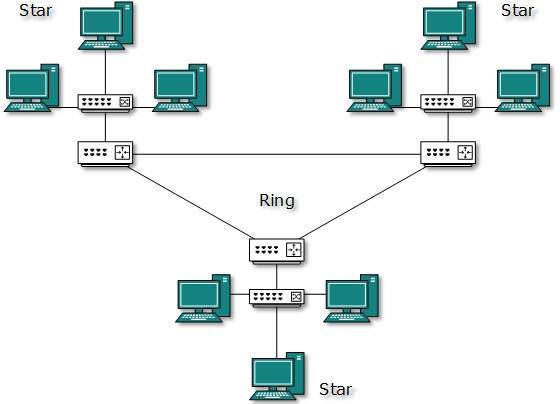
Powyższy rysunek przedstawia dowolnie hybrydową topologię. Topologie łączące mogą zawierać atrybuty topologii Gwiazdy, Pierścienia, Magistrali i Łańcucha. Większość sieci WAN jest połączonych za pomocą topologii Dual-Ring, a sieci z nimi połączone to w większości sieci o topologii gwiazdy. Internet jest najlepszym przykładem największej topologii hybrydowej
Inżynieria sieci to skomplikowane zadanie, które obejmuje oprogramowanie, oprogramowanie układowe, inżynierię na poziomie chipów, sprzęt i impulsy elektryczne. Aby ułatwić inżynierię sieci, cała koncepcja sieci została podzielona na wiele warstw. Każda warstwa jest zaangażowana w określone zadanie i jest niezależna od wszystkich innych warstw. Ale jako całość prawie wszystkie zadania sieciowe zależą od wszystkich tych warstw. Warstwy dzielą się danymi między sobą i zależą od siebie tylko w zakresie pobierania danych wejściowych i wysyłania danych wyjściowych.
Zadania warstwowe
W warstwowej architekturze modelu sieci jeden cały proces sieciowy jest podzielony na małe zadania. Każde małe zadanie jest następnie przypisywane do określonej warstwy, która działa wyłącznie w celu wykonania zadania. Każda warstwa wykonuje tylko określoną pracę.
W systemie komunikacji warstwowej jedna warstwa hosta zajmuje się zadaniami wykonywanymi przez lub do wykonania przez warstwę równorzędną na tym samym poziomie na hoście zdalnym. Zadanie jest inicjowane przez warstwę na najniższym lub najwyższym poziomie. Jeśli zadanie jest inicjowane przez najwyższą warstwę, jest przekazywane do warstwy poniżej w celu dalszego przetwarzania. Dolna warstwa robi to samo, przetwarza zadanie i przechodzi do niższej warstwy. Jeśli zadanie zostało zainicjowane przez niższą warstwę, wówczas wybierana jest ścieżka odwrotna.

Każda warstwa łączy w sobie wszystkie procedury, protokoły i metody, których potrzebuje do wykonania swojego zadania. Wszystkie warstwy identyfikują swoje odpowiedniki za pomocą nagłówka i końca hermetyzacji.
Model OSI
Open System Interconnect to otwarty standard dla wszystkich systemów komunikacyjnych. Model OSI został opracowany przez Międzynarodową Organizację Normalizacyjną (ISO). Ten model ma siedem warstw:
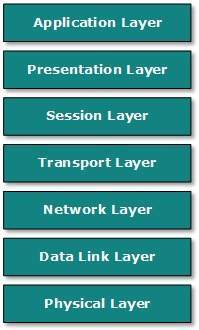
Application Layer: Ta warstwa jest odpowiedzialna za zapewnienie interfejsu dla użytkownika aplikacji. Ta warstwa obejmuje protokoły, które bezpośrednio współdziałają z użytkownikiem.
Presentation Layer: Ta warstwa określa, w jaki sposób dane w rodzimym formacie zdalnego hosta powinny być prezentowane w rodzimym formacie hosta.
Session Layer: Ta warstwa utrzymuje sesje między zdalnymi hostami. Na przykład po zakończeniu uwierzytelniania użytkownika / hasła zdalny host utrzymuje tę sesję przez jakiś czas i nie prosi o ponowne uwierzytelnienie w tym okresie.
Transport Layer: Ta warstwa jest odpowiedzialna za kompleksowe dostarczanie między hostami.
Network Layer: Ta warstwa jest odpowiedzialna za przypisywanie adresów i unikalne adresowanie hostów w sieci.
Data Link Layer: Ta warstwa jest odpowiedzialna za odczytywanie i zapisywanie danych zi do linii. W tej warstwie wykrywane są błędy łączy.
Physical Layer: Ta warstwa definiuje sprzęt, okablowanie, moc wyjściową, częstotliwość impulsów itp.
Model internetowy
Internet używa zestawu protokołów TCP / IP, znanego również jako pakiet internetowy. To definiuje model internetowy, który zawiera architekturę czterowarstwową. Model OSI to ogólny model komunikacji, ale Internet jest tym, czego używa Internet do całej komunikacji. Internet jest niezależny od podstawowej architektury sieci, podobnie jak jego Model. Ten model ma następujące warstwy:

Application Layer: Ta warstwa definiuje protokół, który umożliwia interakcję użytkownika z siecią, na przykład FTP, HTTP itp.
Transport Layer: Ta warstwa określa sposób przepływu danych między hostami. Głównym protokołem w tej warstwie jest protokół kontroli transmisji (TCP). Ta warstwa zapewnia, że dane dostarczane między hostami są w porządku i jest odpowiedzialna za dostarczanie od końca do końca.
Internet Layer: Protokół internetowy (IP) działa w tej warstwie. Ta warstwa ułatwia adresowanie i rozpoznawanie hostów. Ta warstwa definiuje routing.
Link Layer: Ta warstwa zapewnia mechanizm wysyłania i odbierania rzeczywistych danych W przeciwieństwie do swojego odpowiednika w modelu OSI, ta warstwa jest niezależna od podstawowej architektury sieci i sprzętu.
W początkowych dniach Internetu jego wykorzystanie było ograniczone do wojska i uniwersytetów w celach badawczo-rozwojowych. Później, gdy wszystkie sieci połączyły się i utworzyły Internet, dane używane do podróżowania przez sieć transportu publicznego Zwykłe osoby mogą wysyłać dane, które mogą być bardzo wrażliwe, takie jak dane logowania do banku, nazwa użytkownika i hasła, dokumenty osobiste, dane dotyczące zakupów online lub poufne dokumenty.
Wszystkie zagrożenia bezpieczeństwa są celowe, tj. Występują tylko wtedy, gdy są celowo wywołane. Zagrożenia bezpieczeństwa można podzielić na następujące kategorie:
Interruption
Przerwa jest zagrożeniem bezpieczeństwa, w przypadku którego atakowana jest dostępność zasobów. Na przykład użytkownik nie może uzyskać dostępu do swojego serwera WWW lub serwer WWW został przejęty.
Privacy-Breach
W przypadku tego zagrożenia prywatność użytkownika jest zagrożona. Ktoś, kto nie jest osobą upoważnioną, uzyskuje dostęp lub przechwytuje dane wysłane lub odebrane przez oryginalnego uwierzytelnionego użytkownika.
Integrity
Ten rodzaj zagrożenia obejmuje wszelkie zmiany lub modyfikacje oryginalnego kontekstu komunikacji. Atakujący przechwytuje i odbiera dane przesłane przez nadawcę, a następnie atakujący modyfikuje lub generuje fałszywe dane i wysyła do odbiorcy. Odbiorca otrzymuje dane przy założeniu, że są one wysyłane przez pierwotnego Nadawcę.
Authenticity
Zagrożenie to występuje, gdy osoba atakująca lub osoba naruszająca bezpieczeństwo podszywa się pod prawdziwą osobę i uzyskuje dostęp do zasobów lub komunikuje się z innymi prawdziwymi użytkownikami.
Żadna technika w obecnym świecie nie zapewnia 100% bezpieczeństwa. Można jednak podjąć kroki w celu zabezpieczenia danych podczas ich przesyłania w niezabezpieczonej sieci lub Internecie. Najpopularniejszą techniką jest kryptografia.
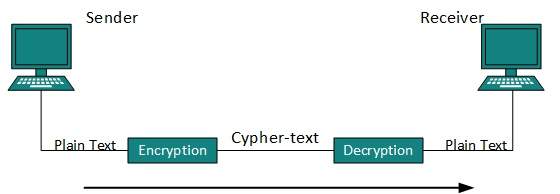
Kryptografia to technika szyfrowania danych w postaci zwykłego tekstu, która utrudnia zrozumienie i interpretację. Obecnie dostępnych jest kilka algorytmów kryptograficznych opisanych poniżej:
Sekretny klucz
Klucz publiczny
Przegląd wiadomości
Szyfrowanie tajnego klucza
Zarówno nadawca, jak i odbiorca mają jeden tajny klucz. Ten tajny klucz służy do szyfrowania danych po stronie nadawcy. Po zaszyfrowaniu dane są wysyłane do odbiorcy w domenie publicznej. Ponieważ odbiorca zna i ma tajny klucz, zaszyfrowane pakiety danych można łatwo odszyfrować.
Przykładem szyfrowania tajnym kluczem jest Data Encryption Standard (DES). W przypadku szyfrowania Secret Key wymagane jest posiadanie oddzielnego klucza dla każdego hosta w sieci, co utrudnia zarządzanie.
Szyfrowanie klucza publicznego
W tym systemie szyfrowania każdy użytkownik ma swój własny tajny klucz i nie znajduje się on we wspólnej domenie. Tajny klucz nigdy nie jest ujawniany w domenie publicznej. Oprócz tajnego klucza każdy użytkownik ma swój własny, ale publiczny klucz. Klucz publiczny jest zawsze upubliczniany i jest używany przez Nadawców do szyfrowania danych. Gdy użytkownik otrzyma zaszyfrowane dane, może je łatwo odszyfrować za pomocą własnego tajnego klucza.
Przykładem szyfrowania za pomocą klucza publicznego jest Rivest-Shamir-Adleman (RSA).
Przegląd wiadomości
W tej metodzie rzeczywiste dane nie są wysyłane, zamiast tego obliczana i wysyłana jest wartość skrótu. Drugi użytkownik końcowy oblicza własną wartość skrótu i porównuje z właśnie otrzymaną. Jeśli obie wartości skrótu są dopasowane, w przeciwnym razie jest akceptowana jako odrzucona.
Przykładem Message Digest jest mieszanie MD5. Jest najczęściej używany do uwierzytelniania, w którym hasło użytkownika jest porównywane z hasłem zapisanym na serwerze.
Warstwa fizyczna w modelu OSI odgrywa rolę w interakcji z rzeczywistym sprzętem i mechanizmem sygnalizacyjnym. Warstwa fizyczna jest jedyną warstwą modelu sieci OSI, która faktycznie zajmuje się fizyczną łącznością dwóch różnych stacji. Ta warstwa definiuje sprzęt, okablowanie, okablowanie, częstotliwości, impulsy używane do reprezentowania sygnałów binarnych itp.
Warstwa fizyczna udostępnia swoje usługi warstwie łącza danych. Warstwa łącza danych przekazuje ramki do warstwy fizycznej. Warstwa fizyczna przekształca je w impulsy elektryczne, które reprezentują dane binarne, które są następnie przesyłane przez media przewodowe lub bezprzewodowe.
Sygnały
Gdy dane są przesyłane na nośniku fizycznym, należy je najpierw przekształcić w sygnały elektromagnetyczne. Same dane mogą być analogowe, takie jak ludzki głos, lub cyfrowe, takie jak plik na dysku. Zarówno dane analogowe, jak i cyfrowe mogą być reprezentowane w postaci sygnałów cyfrowych lub analogowych.
Digital Signals
Sygnały cyfrowe mają charakter dyskretny i reprezentują sekwencję impulsów napięcia. Sygnały cyfrowe są używane w obwodach systemu komputerowego.
Analog Signals
Sygnały analogowe mają charakter ciągły i reprezentowane są przez ciągłe fale elektromagnetyczne.
Uszkodzenie transmisji
Kiedy sygnały przechodzą przez medium, mają tendencję do pogarszania się. Może to mieć wiele powodów:
Attenuation
Aby odbiornik mógł dokładnie zinterpretować dane, sygnał musi być dostatecznie silny, gdy przechodzi przez medium, ma tendencję do słabnięcia, a pokonując odległość traci siłę.
Dispersion
Gdy sygnał przechodzi przez media, ma tendencję do rozprzestrzeniania się i nakładania. Ilość dyspersji zależy od używanej częstotliwości.
Delay distortion
Sygnały są przesyłane przez media z predefiniowaną prędkością i częstotliwością. Jeśli prędkość sygnału i częstotliwość nie pasują do siebie, istnieje możliwość, że sygnał dotrze do celu w dowolny sposób. W mediach cyfrowych bardzo ważne jest, aby niektóre bity docierały wcześniej niż te wysłane wcześniej.
Noise
O przypadkowym zakłóceniu lub fluktuacji sygnału analogowego lub cyfrowego mówi się, że jest to szum sygnału, który może zniekształcać przenoszone informacje. Hałas można scharakteryzować w jednej z następujących klas:
Thermal Noise
Ciepło porusza elektroniczne przewodniki medium, co może powodować zakłócenia w mediach. Do pewnego poziomu hałas termiczny jest nieunikniony.
Intermodulation
Gdy wiele częstotliwości współdzieli medium, ich zakłócenia mogą powodować szum w medium. Hałas intermodulacyjny występuje, gdy dwie różne częstotliwości współdzielą medium, a jedna z nich ma nadmierną siłę lub sam komponent nie działa prawidłowo, to wynikowa częstotliwość może nie być dostarczona zgodnie z oczekiwaniami.
Crosstalk
Ten rodzaj szumu ma miejsce, gdy do nośnika dociera obcy sygnał. Dzieje się tak, ponieważ sygnał w jednym medium wpływa na sygnał drugiego medium.
Impulse
Ten hałas jest spowodowany nieregularnymi zakłóceniami, takimi jak wyładowania atmosferyczne, prąd, zwarcie lub wadliwe komponenty. Tego rodzaju szumy wpływają głównie na dane cyfrowe.
Środki przekazu
Media, przez które przesyłane są informacje między dwoma systemami komputerowymi, zwane mediami transmisyjnymi. Media transmisyjne występują w dwóch formach.
Guided Media
Wszystkie przewody / kable komunikacyjne są mediami prowadzonymi, takimi jak UTP, kable koncentryczne i światłowody. W tym medium nadawca i odbiorca są bezpośrednio połączeni, a informacje są przez niego przesyłane (kierowane).
Unguided Media
Mówi się, że przestrzeń bezprzewodowa lub otwarta przestrzeń jest nośnikiem niekierowanym, ponieważ nie ma łączności między nadawcą a odbiorcą. Informacje są rozrzucane w powietrzu i każdy, w tym faktyczny odbiorca, może je zbierać.
Pojemność kanału
Mówi się, że szybkość przesyłania informacji jest pojemnością kanału. Liczymy to jako szybkość transmisji danych w świecie cyfrowym. Zależy to od wielu czynników, takich jak:
Bandwidth: Fizyczne ograniczenie podstawowych mediów.
Error-rate: Nieprawidłowy odbiór informacji z powodu hałasu.
Encoding: Liczba poziomów używanych do sygnalizacji.
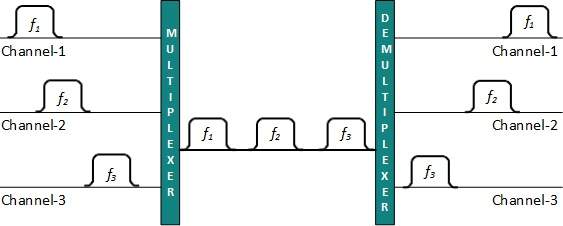
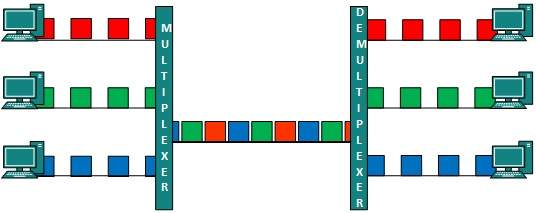
Multipleksowanie
Multipleksowanie to technika mieszania i wysyłania wielu strumieni danych na jednym nośniku. Technika ta wymaga sprzętu systemowego zwanego multiplekserem (MUX) do multipleksowania strumieni i wysyłania ich na nośniku oraz demultipleksera (DMUX), który pobiera informacje z nośnika i rozprowadza je do różnych miejsc docelowych.
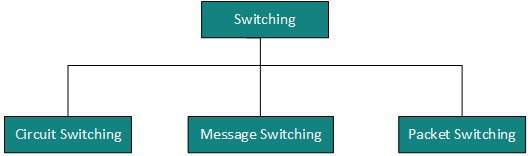
Przełączanie
Przełączanie to mechanizm, za pomocą którego dane / informacje przesyłane są ze źródła do celu, które nie są bezpośrednio połączone. Sieci mają urządzenia łączące, które otrzymują dane z bezpośrednio połączonych źródeł, przechowują dane, analizują je, a następnie przekazuje do następnego urządzenia łączącego najbliżej miejsca docelowego.
Przełączanie można podzielić na:
Dane lub informacje można przechowywać na dwa sposoby, analogowy i cyfrowy. Aby komputer mógł wykorzystać dane, musi mieć dyskretną postać cyfrową. Podobnie jak dane, sygnały mogą mieć również postać analogową i cyfrową. Aby przesyłać dane cyfrowo, należy je najpierw przekonwertować na postać cyfrową.
Konwersja cyfrowo-cyfrowa
W tej sekcji wyjaśniono, jak konwertować dane cyfrowe na sygnały cyfrowe. Można to zrobić na dwa sposoby: kodowanie liniowe i kodowanie blokowe. Dla całej komunikacji konieczne jest kodowanie liniowe, natomiast kodowanie blokowe jest opcjonalne.
Kodowanie linii
Proces konwersji danych cyfrowych na sygnał cyfrowy nazywa się kodowaniem liniowym. Dane cyfrowe znajdują się w formacie binarnym i są wewnętrznie reprezentowane (przechowywane) jako serie jedynek i zer.
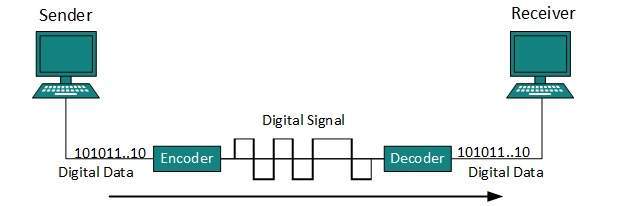
Sygnał cyfrowy jest oznaczony dyskretnym sygnałem, który reprezentuje dane cyfrowe Dostępne są trzy typy schematów kodowania linii:
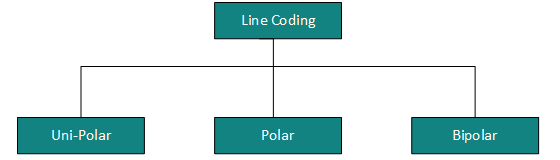
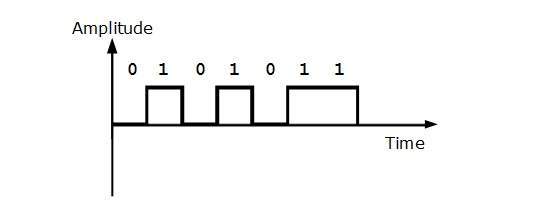
Kodowanie jednobiegunowe
Schematy kodowania unipolarnego wykorzystują pojedynczy poziom napięcia do reprezentowania danych. W tym przypadku, aby reprezentować binarne 1, przesyłane jest wysokie napięcie, a aby reprezentować 0, nie jest przesyłane żadne napięcie. Nazywa się go również jednobiegunowym-bez powrotu do zera, ponieważ nie ma warunku spoczynku, tj. Reprezentuje 1 lub 0.
Kodowanie biegunowe
Schemat kodowania Polar wykorzystuje wiele poziomów napięcia do reprezentowania wartości binarnych. Kodowania polarne są dostępne w czterech typach:
Polar Non-Return to Zero (Polar NRZ)
Wykorzystuje dwa różne poziomy napięcia do reprezentowania wartości binarnych. Generalnie, dodatnie napięcie reprezentuje 1, a ujemna wartość 0. Jest to również NRZ, ponieważ nie ma stanu spoczynku.
Schemat NRZ ma dwa warianty: NRZ-L i NRZ-I.
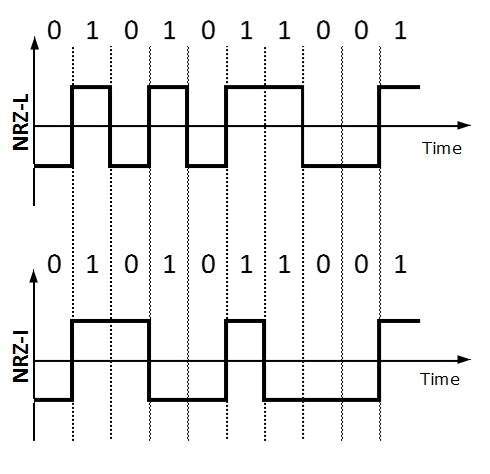
NRZ-L zmienia poziom napięcia, gdy napotkany jest inny bit, podczas gdy NRZ-I zmienia napięcie, gdy napotka się 1.
Powrót do zera (RZ)
Problem z NRZ polega na tym, że odbiornik nie może zakończyć, kiedy bit się skończył i kiedy następny bit jest uruchamiany, w przypadku, gdy zegar nadawcy i odbiorcy nie są zsynchronizowane.
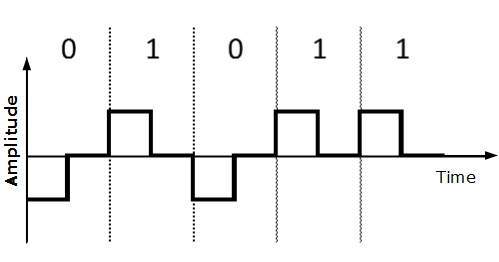
RZ wykorzystuje trzy poziomy napięcia: dodatnie napięcie reprezentuje 1, ujemne napięcie reprezentuje 0 i zerowe napięcie dla żadnego. Sygnały zmieniają się podczas bitów, a nie między bitami.
Manchester
Ten schemat kodowania jest połączeniem RZ i NRZ-L. Czas bitowy jest podzielony na dwie połowy. Przechodzi w środku bitu i zmienia fazę, gdy napotkany zostanie inny bit.
Różnicowy Manchester
Ten schemat kodowania jest połączeniem RZ i NRZ-I. Przechodzi również w środku bitu, ale zmienia fazę dopiero po napotkaniu 1.
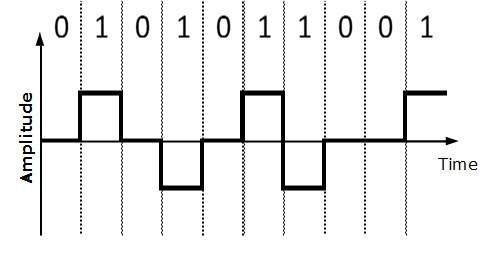
Kodowanie bipolarne
Kodowanie bipolarne wykorzystuje trzy poziomy napięcia: dodatni, ujemny i zerowy. Napięcie zerowe reprezentuje binarne 0, a bit 1 jest reprezentowany przez zmianę napięcia dodatniego i ujemnego.
Kodowanie blokowe
Aby zapewnić dokładność odbieranych ramek danych, używane są nadmiarowe bity. Na przykład w parzystości parzystości jeden bit parzystości jest dodawany, aby wyrównać liczbę jedynek w ramce. W ten sposób zwiększa się pierwotna liczba bitów. Nazywa się to kodowaniem blokowym.
Kodowanie blokowe jest reprezentowane przez notację ukośną, mB / nB Znaczy, blok m-bitowy jest zastępowany blokiem n-bitowym, gdzie n> m. Kodowanie blokowe obejmuje trzy kroki:
- Division,
- Substitution
- Combination.
Po zakończeniu kodowania blokowego jest kodowany liniowo do transmisji.
Konwersja analogowo-cyfrowa
Mikrofony tworzą analogowy głos, a kamera tworzy analogowe wideo, które są traktowane jako dane analogowe. Aby przesłać te dane analogowe za pomocą sygnałów cyfrowych, potrzebujemy konwersji analogowej na cyfrową.
Dane analogowe to ciągły strumień danych w postaci fali, podczas gdy dane cyfrowe są dyskretne. Aby przekonwertować sygnał analogowy na dane cyfrowe, używamy modulacji impulsowej (PCM).
PCM to jedna z najczęściej stosowanych metod konwersji danych analogowych na postać cyfrową. Obejmuje trzy kroki:
- Sampling
- Quantization
- Encoding.
Próbowanie
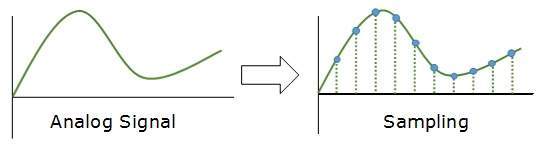
Sygnał analogowy jest próbkowany co interwał T. Najważniejszym czynnikiem w próbkowaniu jest szybkość próbkowania sygnału analogowego. Zgodnie z twierdzeniem Nyquista, częstotliwość próbkowania musi być co najmniej dwukrotnie większa od najwyższej częstotliwości sygnału.
Kwantyzacja
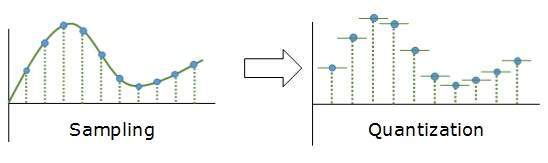
Próbkowanie daje dyskretną postać ciągłego sygnału analogowego. Każdy dyskretny wzorzec pokazuje w tym przypadku amplitudę sygnału analogowego. Kwantyzacja jest wykonywana pomiędzy maksymalną wartością amplitudy a minimalną wartością amplitudy. Kwantyzacja jest przybliżeniem chwilowej wartości analogowej.
Kodowanie
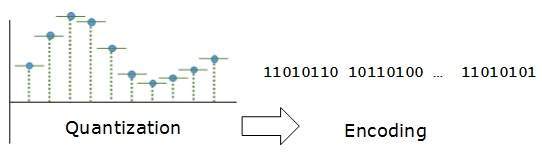
Podczas kodowania każda przybliżona wartość jest następnie konwertowana na format binarny.
Tryby transmisji
Tryb transmisji decyduje o sposobie przesyłania danych między dwoma komputerami. Dane binarne w postaci jedynek i zer mogą być przesyłane w dwóch różnych trybach: równoległym i szeregowym.
Transmisja równoległa
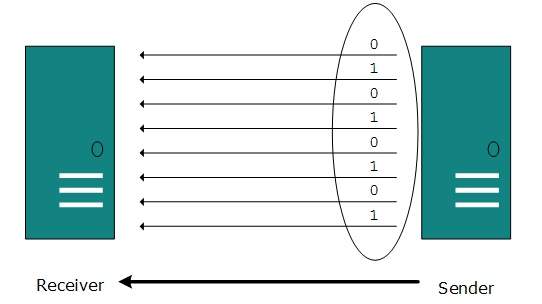
Bity binarne są zorganizowane w grupy o stałej długości. Zarówno nadawca, jak i odbiorca są połączeni równolegle z taką samą liczbą linii danych. Oba komputery rozróżniają linie danych wysokiego i niskiego rzędu. Nadawca wysyła wszystkie bity na raz we wszystkich liniach. Ponieważ linie danych są równe liczbie bitów w grupie lub ramce danych, cała grupa bitów (ramka danych) jest wysyłana za jednym razem. Zaletą transmisji równoległej jest duża prędkość, a wadą koszt przewodów, ponieważ jest równy liczbie bitów przesyłanych równolegle.
Transmisja szeregowa
W transmisji szeregowej bity są przesyłane jeden po drugim w kolejce. Transmisja szeregowa wymaga tylko jednego kanału komunikacyjnego.
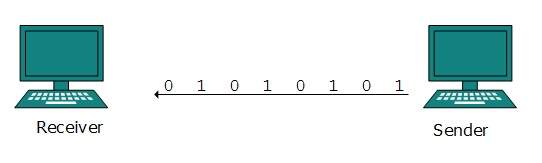
Transmisja szeregowa może być asynchroniczna lub synchroniczna.
Asynchroniczna transmisja szeregowa
Nazywa się tak, ponieważ nie ma znaczenia wyczucie czasu. Bity danych mają określony wzorzec i pomagają odbiorcy rozpoznać początkowy i końcowy bit danych. Na przykład 0 jest poprzedzone przedrostkiem na każdym bajcie danych, a jedna lub więcej jedynek jest dodawana na końcu.
Dwie ciągłe ramki danych (bajty) mogą mieć przerwę między nimi.
Synchroniczna transmisja szeregowa
Czas w transmisji synchronicznej ma znaczenie, ponieważ nie stosuje się mechanizmu rozpoznawania bitów danych początkowych i końcowych, nie ma wzoru ani metody przedrostka / sufiksu. Bity danych są wysyłane w trybie seryjnym bez zachowania odstępu między bajtami (8-bitów). Pojedyncza seria bitów danych może zawierać pewną liczbę bajtów. Dlatego czas staje się bardzo ważny.
Odbiornik rozpoznaje i rozdziela bity na bajty. Zaletą transmisji synchronicznej jest duża prędkość i nie ma narzutu dodatkowych bitów nagłówka i stopki, jak w przypadku transmisji asynchronicznej.
Aby przesłać dane cyfrowe na nośniku analogowym, należy je przekonwertować na sygnał analogowy. W zależności od formatowania danych mogą wystąpić dwa przypadki.
Bandpass:Filtry służą do filtrowania i przepuszczania interesujących nas częstotliwości. Pasmo przenoszenia to pasmo częstotliwości, które może przejść przez filtr.
Low-pass: Dolnoprzepustowy to filtr przepuszczający sygnały o niskiej częstotliwości.
Kiedy dane cyfrowe są konwertowane na pasmowoprzepustowy sygnał analogowy, nazywa się to konwersją cyfrowo-analogową. Kiedy dolnoprzepustowy sygnał analogowy jest konwertowany na pasmowy sygnał analogowy, nazywa się to konwersją analogowo-analogową.
Konwersja cyfrowo-analogowa
Gdy dane z jednego komputera są przesyłane do innego za pośrednictwem jakiegoś nośnika analogowego, są najpierw przekształcane na sygnały analogowe. Sygnały analogowe są modyfikowane w celu odzwierciedlenia danych cyfrowych.
Sygnał analogowy charakteryzuje się amplitudą, częstotliwością i fazą. Istnieją trzy rodzaje konwersji cyfrowo-analogowej:
Amplitude Shift Keying
W tej technice konwersji amplituda analogowego sygnału nośnego jest modyfikowana w celu odzwierciedlenia danych binarnych.
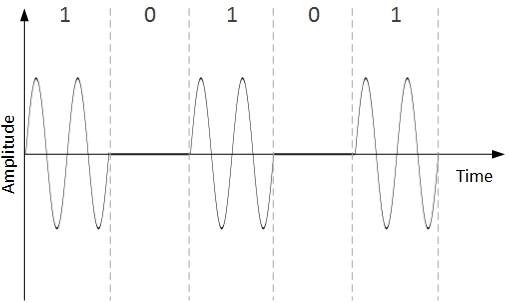
Gdy dane binarne reprezentują cyfrę 1, amplituda jest utrzymywana; w przeciwnym razie jest ustawiony na 0. Zarówno częstotliwość, jak i faza pozostają takie same, jak w oryginalnym sygnale nośnym.
Frequency Shift Keying
W tej technice konwersji częstotliwość analogowego sygnału nośnego jest modyfikowana w celu odzwierciedlenia danych binarnych.
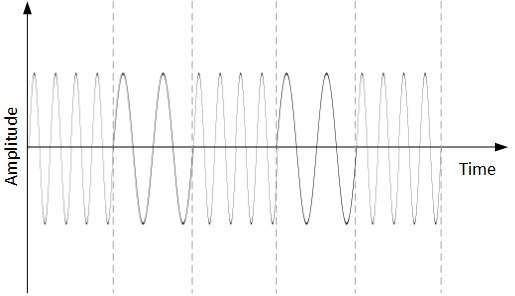
Ta technika wykorzystuje dwie częstotliwości, f1 i f2. Jeden z nich, na przykład f1, jest wybrany do reprezentowania cyfry binarnej 1, a drugi jest używany do reprezentowania cyfry binarnej 0. Zarówno amplituda, jak i faza fali nośnej pozostają nienaruszone.
Phase Shift Keying
W tym schemacie konwersji faza pierwotnego sygnału nośnej jest zmieniana, aby odzwierciedlić dane binarne.
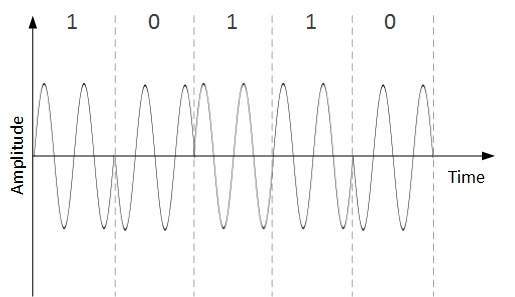
Napotkanie nowego symbolu binarnego powoduje zmianę fazy sygnału. Amplituda i częstotliwość oryginalnego sygnału nośnego pozostają nienaruszone.
Quadrature Phase Shift Keying
QPSK zmienia fazę, aby odzwierciedlić dwie cyfry binarne jednocześnie. Odbywa się to w dwóch różnych fazach. Główny strumień danych binarnych jest podzielony równo na dwa podstrumienie. Dane szeregowe są konwertowane równolegle w obu podstrumieniach, a następnie każdy strumień jest konwertowany na sygnał cyfrowy przy użyciu techniki NRZ. Później oba sygnały cyfrowe są łączone razem.
Konwersja analogowo-analogowa
Sygnały analogowe są modyfikowane, aby reprezentowały dane analogowe. Ta konwersja jest również znana jako modulacja analogowa. Modulacja analogowa jest wymagana, gdy używane jest pasmo przenoszenia. Konwersję analogowo-analogową można przeprowadzić na trzy sposoby:

Amplitude Modulation
W tej modulacji amplituda sygnału nośnego jest modyfikowana w celu odzwierciedlenia danych analogowych.
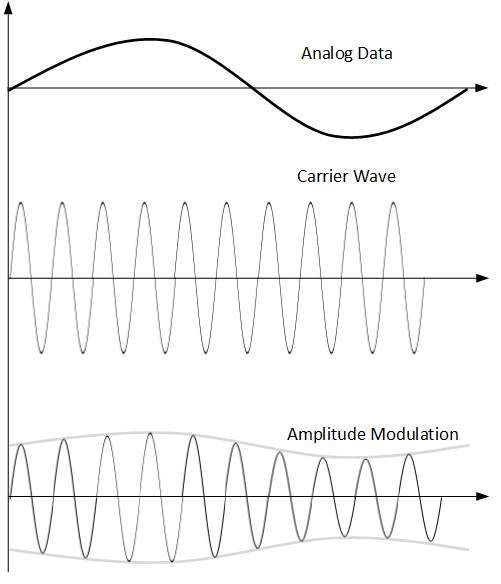
Modulacja amplitudy jest realizowana za pomocą mnożnika. Amplituda sygnału modulującego (dane analogowe) jest mnożona przez amplitudę częstotliwości nośnej, która następnie odzwierciedla dane analogowe.
Częstotliwość i faza sygnału nośnego pozostają niezmienione.
Frequency Modulation
W tej technice modulacji częstotliwość sygnału nośnego jest modyfikowana w celu odzwierciedlenia zmiany poziomów napięcia sygnału modulującego (dane analogowe).
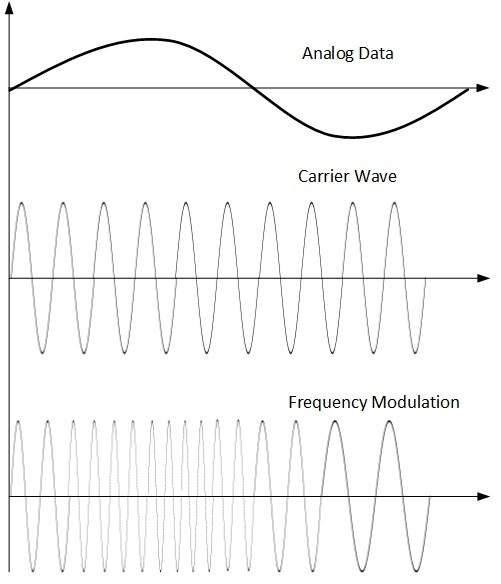
Amplituda i faza sygnału nośnego nie ulegają zmianie.
Phase Modulation
W technice modulacji faza sygnału nośnego jest modulowana w celu odzwierciedlenia zmiany napięcia (amplitudy) analogowego sygnału danych.
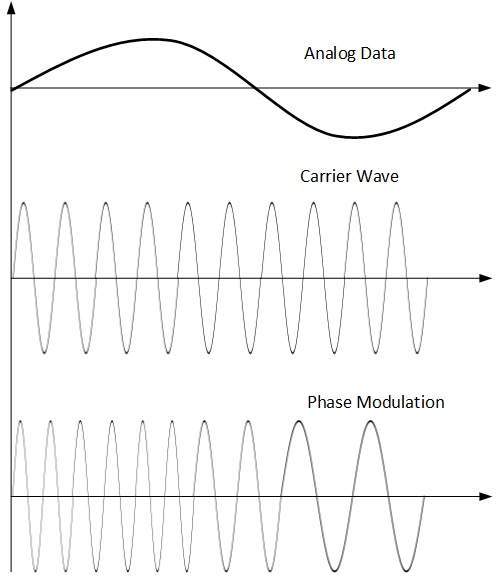
Modulacja fazy jest praktycznie podobna do modulacji częstotliwości, ale w modulacji fazy częstotliwość sygnału nośnego nie jest zwiększana. Częstotliwość nośnej sygnału jest zmieniana (gęstsza i rzadka) w celu odzwierciedlenia zmiany napięcia w amplitudzie sygnału modulującego.
Media transmisyjne to nic innego jak fizyczne media, za pośrednictwem których komunikacja odbywa się w sieciach komputerowych.
Media magnetyczne
Jednym z najwygodniejszych sposobów przesyłania danych z jednego komputera do drugiego, jeszcze przed narodzinami sieci, było zapisywanie ich na jakimś nośniku i fizyczny transfer z jednej stacji do drugiej. Chociaż może się to wydawać staromodne w dzisiejszym świecie szybkiego Internetu, ale gdy rozmiar danych jest ogromny, w grę wchodzą nośniki magnetyczne.
Na przykład bank musi obsługiwać i przesyłać ogromne dane swojego klienta, który przechowuje ich kopię zapasową w jakimś odległym geograficznie miejscu ze względów bezpieczeństwa i w celu ochrony przed niepewnymi katastrofami. Jeśli bank musi przechowywać swoje ogromne kopie zapasowe danych, to ich transfer przez Internet nie jest możliwy. Łącza WAN mogą nie obsługiwać tak dużej szybkości. Nawet jeśli tak jest; koszt zbyt wysoki, żeby sobie na to pozwolić.
W takich przypadkach kopia zapasowa danych jest przechowywana na taśmach magnetycznych lub dyskach magnetycznych, a następnie fizycznie przenoszona w odległe miejsca.
Skrętka
Skrętka dwużyłowa składa się z dwóch miedzianych drutów w izolacji z tworzywa sztucznego, skręconych razem w celu utworzenia jednego medium. Z tych dwóch przewodów tylko jeden przenosi rzeczywisty sygnał, a drugi służy do odniesienia masy. Skręcenia między przewodami są pomocne w redukcji szumów (zakłóceń elektromagnetycznych) i przesłuchów.

Istnieją dwa rodzaje skrętki dwużyłowej:
Ekranowany kabel typu skrętka (STP)
Nieekranowany kabel typu skrętka (UTP)
Kable STP są dostarczane ze skrętką dwużyłową pokrytą metalową folią. Dzięki temu jest bardziej obojętny na hałas i przesłuchy.
UTP ma siedem kategorii, z których każda nadaje się do określonego zastosowania. W sieciach komputerowych najczęściej stosuje się kable Cat-5, Cat-5e i Cat-6. Kable UTP są połączone złączami RJ45.
Kabel koncentryczny
Kabel koncentryczny ma dwa przewody miedziane. Drut rdzeniowy leży pośrodku i jest wykonany z litego przewodnika.Rdzeń jest zamknięty w osłonie izolacyjnej.Drugi drut jest owinięty wokół osłony, który z kolei jest osłonięty osłoną izolacyjną. .

Ze względu na swoją strukturę, kabel koncentryczny może przenosić sygnały o wysokiej częstotliwości niż skrętka. Konstrukcja owinięta zapewnia dobrą ochronę przed szumami i przesłuchami. Kable koncentryczne zapewniają wysoką przepustowość do 450 Mb / s.
Istnieją trzy kategorie kabli koncentrycznych, a mianowicie RG-59 (telewizja kablowa), RG-58 (cienki Ethernet) i RG-11 (gruby Ethernet). RG to skrót od Radio Government.
Kable podłącza się za pomocą złącza BNC i BNC-T. Terminator BNC służy do zakończenia przewodu na dalszych końcach.
Linie energetyczne
Komunikacja Power Line (PLC) to technologia warstwy 1 (warstwa fizyczna), która wykorzystuje kable zasilające do przesyłania sygnałów danych W PLC modulowane dane są przesyłane kablami. Odbiornik na drugim końcu demoduluje i interpretuje dane.
Ponieważ linie energetyczne są szeroko stosowane, PLC może sterować i monitorować wszystkie zasilane urządzenia. PLC działa w trybie półdupleksu.
Istnieją dwa typy sterowników PLC:
Wąskopasmowy sterownik PLC
Szerokopasmowy sterownik PLC
Wąskopasmowe sterowniki PLC zapewniają niższe prędkości transmisji do 100 kb / s, ponieważ pracują na niższych częstotliwościach (3-5000 kHz) i mogą być rozłożone na kilka kilometrów.
Szerokopasmowy sterownik PLC zapewnia wyższe szybkości transmisji danych do 100 s Mb / si działa na wyższych częstotliwościach (1,8 - 250 MHz). Nie można ich tak rozbudowywać, jak wąskopasmowy PLC.
Światłowody
Światłowód działa na właściwości światła. Kiedy promień światła pada pod kątem krytycznym, załamuje się pod kątem 90 stopni. Ta właściwość została wykorzystana w światłowodach. Rdzeń światłowodu wykonany jest z wysokiej jakości szkła lub tworzywa sztucznego. Z jednego jej końca emitowane jest światło, przez które przechodzi, a na drugim końcu detektor światła wykrywa strumień światła i przetwarza go na dane elektryczne.
Światłowód zapewnia najwyższą prędkość. Występuje w dwóch trybach, jeden to światłowód jednomodowy, a drugi to światłowód wielomodowy. Światłowód jednomodowy może przenosić pojedynczy promień światła, podczas gdy światłowód wielomodowy może przenosić wiele wiązek światła.

Światłowód ma również funkcje jednokierunkowe i dwukierunkowe. Aby podłączyć i uzyskać dostęp do światłowodów, stosuje się specjalne złącza. Może to być kanał abonenta (SC), prosta końcówka (ST) lub MT-RJ.
Transmisja bezprzewodowa jest formą niekierowanych mediów. Komunikacja bezprzewodowa nie obejmuje fizycznego łącza ustanowionego między dwoma lub więcej urządzeniami, które komunikują się bezprzewodowo. Sygnały bezprzewodowe rozprzestrzeniają się w powietrzu i są odbierane i interpretowane przez odpowiednie anteny.
Kiedy antena jest podłączona do obwodu elektrycznego komputera lub urządzenia bezprzewodowego, przekształca dane cyfrowe w sygnały bezprzewodowe i rozprzestrzenia się w całym zakresie częstotliwości. Receptor na drugim końcu odbiera te sygnały i przetwarza je z powrotem na dane cyfrowe.
Niewielka część widma elektromagnetycznego może zostać wykorzystana do transmisji bezprzewodowej.

Transmisja radiowa
Częstotliwość radiowa jest łatwiejsza do wygenerowania, a ze względu na dużą długość fali może przenikać zarówno przez ściany, jak i konstrukcje.Fale radiowe mogą mieć długość od 1 mm do 100 000 km i mieć częstotliwość w zakresie od 3 Hz (bardzo niska częstotliwość) do 300 GHz (skrajnie wysoka Częstotliwość). Częstotliwości radiowe są podzielone na sześć pasm.
Fale radiowe o niższych częstotliwościach mogą przenikać przez ściany, podczas gdy wyższe częstotliwości radiowe mogą przemieszczać się po linii prostej i odbijać się z powrotem. Moc fal o niskiej częstotliwości gwałtownie spada, gdy pokonują duże odległości. Fale radiowe o wysokiej częstotliwości mają większą moc.
Niższe częstotliwości, takie jak pasma VLF, LF, MF mogą przemieszczać się na ziemi do 1000 kilometrów nad powierzchnią ziemi.
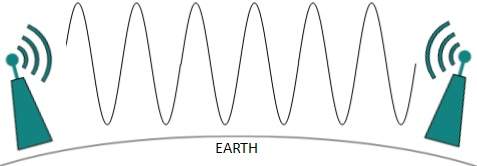
Fale radiowe o wysokich częstotliwościach są podatne na pochłanianie przez deszcz i inne przeszkody. Używają jonosfery ziemskiej atmosfery. Fale radiowe o wysokiej częstotliwości, takie jak pasma HF i VHF, rozprzestrzeniają się w górę. Kiedy docierają do Jonosfery, są załamywane z powrotem na ziemię.
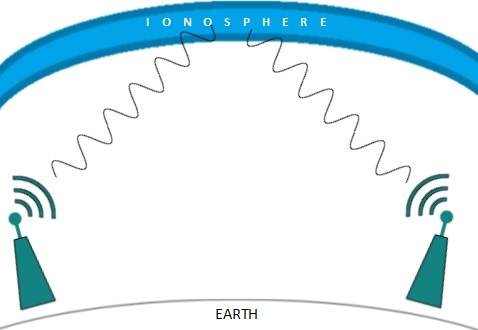
Transmisja mikrofalowa
Fale elektromagnetyczne powyżej 100 MHz mają tendencję do przemieszczania się w linii prostej, a sygnały nad nimi mogą być wysyłane poprzez wysyłanie tych fal w kierunku jednej określonej stacji. Ponieważ mikrofale przemieszczają się po liniach prostych, zarówno nadawca, jak i odbiornik muszą być wyrównane, aby znajdowały się dokładnie na linii wzroku.
Mikrofale mogą mieć długość fali od 1 mm do 1 metra i częstotliwość od 300 MHz do 300 GHz.
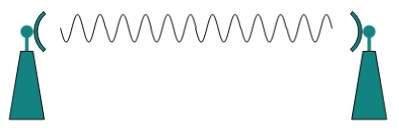
Anteny mikrofalowe skupiają fale, tworząc z nich wiązkę. Jak pokazano na powyższym rysunku, wiele anten można ustawić tak, aby sięgały dalej. Mikrofale mają wyższe częstotliwości i nie przenikają przez ściany jak przeszkody.
Transmisja mikrofalowa zależy w dużym stopniu od warunków pogodowych i częstotliwości, z której korzysta.
Transmisja w podczerwieni
Fala podczerwona leży pomiędzy widmem światła widzialnego a mikrofalami. Ma długość fali od 700 nm do 1 mm i zakres częstotliwości od 300 GHz do 430 THz.
Fala podczerwieni jest używana do celów komunikacji bardzo krótkiego zasięgu, takich jak telewizja i jest zdalne. Podczerwień porusza się po linii prostej, stąd z natury jest kierunkowa. Ze względu na zakres wysokich częstotliwości podczerwień nie może przenikać przez przeszkody przypominające ściany.
Transmisja światła
Najwyższym widmem elektromagnetycznym, które można wykorzystać do transmisji danych, jest sygnalizacja świetlna lub optyczna. Osiąga się to za pomocą LASERA.
Ze względu na wykorzystanie częstotliwości, światło ma tendencję do przemieszczania się ściśle w linii prostej, dlatego nadajnik i odbiornik muszą znajdować się na linii wzroku. Ponieważ transmisja laserowa jest jednokierunkowa, na obu końcach komunikacji należy zainstalować laser i fotodetektor. Wiązka laserowa ma zwykle szerokość 1 mm, dlatego precyzyjne ustawienie dwóch dalekich receptorów, z których każdy wskazuje na źródło lasera.
Laser działa jako Tx (nadajnik), a fotodetektory jako Rx (odbiornik).
Lasery nie mogą przenikać przez przeszkody, takie jak ściany, deszcz i gęsta mgła. Dodatkowo wiązka laserowa jest zniekształcana przez wiatr, temperaturę atmosfery lub wahania temperatury na ścieżce.
Laser jest bezpieczny do transmisji danych, ponieważ bardzo trudno jest dotknąć lasera o szerokości 1 mm bez przerywania kanału komunikacyjnego.
Multipleksowanie to technika, dzięki której różne analogowe i cyfrowe strumienie transmisji mogą być jednocześnie przetwarzane przez wspólne łącze. Multipleksowanie dzieli nośnik o dużej pojemności na nośnik logiczny o małej pojemności, który jest następnie współdzielony przez różne strumienie.
Komunikacja jest możliwa drogą radiową (częstotliwość radiowa), przy użyciu nośnika fizycznego (kabel) i światła (światłowód). Wszystkie nośniki są zdolne do multipleksowania.
Gdy wielu nadawców próbuje wysłać przesyłkę na jednym nośniku, urządzenie zwane multiplekserem dzieli kanał fizyczny i przydziela po jednym do każdego. Na drugim końcu komunikacji de-multiplekser odbiera dane z jednego nośnika, identyfikuje je i wysyła do różnych odbiorników.
Multipleksowanie z podziałem częstotliwości
Gdy nośnikiem jest częstotliwość, używany jest FDM. FDM to technologia analogowa. FDM dzieli widmo lub szerokość pasma nośnej na kanały logiczne i przydziela jednego użytkownika do każdego kanału. Każdy użytkownik może niezależnie korzystać z częstotliwości kanału i ma do niej wyłączny dostęp. Wszystkie kanały są podzielone w taki sposób, aby nie nakładały się na siebie. Kanały są oddzielone pasmami ochronnymi. Pasmo ochronne to częstotliwość, która nie jest używana przez żaden kanał.
Multipleksowanie z podziałem czasu
TDM jest stosowany głównie do sygnałów cyfrowych, ale może być również stosowany do sygnałów analogowych. W TDM kanał współdzielony jest dzielony między jego użytkowników za pomocą szczeliny czasowej. Każdy użytkownik może przesyłać dane tylko w wyznaczonym przedziale czasowym. Sygnały cyfrowe są podzielone na ramki odpowiadające szczelinie czasowej, czyli ramce o optymalnym rozmiarze, która może być transmitowana w danej szczelinie czasowej.
TDM działa w trybie zsynchronizowanym. Oba końce, tj. Multiplekser i de-multiplekser, są synchronizowane w czasie i oba jednocześnie przełączają się na następny kanał.
Kiedy kanał A transmituje swoją ramkę na jednym końcu, demultiplekser dostarcza media do kanału A na drugim końcu. Gdy tylko wygasa szczelina czasowa kanału A, ta strona przełącza się na kanał B. Z drugiej strony, demultiplekser działa w sposób zsynchronizowany i dostarcza media do kanału B. Sygnały z różnych kanałów przemieszczają się po ścieżce w sposób przeplatany.
Multipleksowanie z podziałem długości fali
Światło ma różną długość fali (kolory). W trybie światłowodowym wiele optycznych sygnałów nośnych jest multipleksowanych do światłowodu przy użyciu różnych długości fal. Jest to technika multipleksowania analogowego i jest realizowana koncepcyjnie w taki sam sposób jak FDM, ale wykorzystuje światło jako sygnały.

Ponadto na każdej długości fali można zastosować multipleksowanie z podziałem czasu, aby pomieścić więcej sygnałów danych.
Multipleksowanie z podziałem kodowym
Wiele sygnałów danych może być przesyłanych na jednej częstotliwości przy użyciu multipleksowania z podziałem kodowym. FDM dzieli częstotliwość na mniejsze kanały, ale CDM pozwala użytkownikom na pełne pasmo i przesyłanie sygnałów przez cały czas przy użyciu unikalnego kodu. CDM wykorzystuje ortogonalne kody do rozprzestrzeniania sygnałów.
Każda stacja ma przypisany unikalny kod, zwany chipem. Sygnały podróżują z tymi kodami niezależnie, w całym paśmie. Odbiornik zna z wyprzedzeniem sygnał kodu chipa, który ma odebrać.
Przełączanie to proces przekazywania pakietów przychodzących z jednego portu do portu prowadzącego do celu. Kiedy dane docierają do portu, nazywa się to wejściem, a gdy dane opuszczają port lub wychodzą, nazywa się to wyjściem. System komunikacyjny może zawierać wiele przełączników i węzłów. Ogólnie rzecz biorąc, zmianę można podzielić na dwie główne kategorie:
Connectionless: Dane są przekazywane w imieniu tabel przekazujących. Nie jest wymagane wcześniejsze uzgadnianie, a potwierdzenia są opcjonalne.
Connection Oriented: Przed przełączeniem danych, które mają być przesłane do miejsca docelowego, konieczne jest wstępne ustanowienie obwodu wzdłuż ścieżki między obydwoma punktami końcowymi. Dane są następnie przekazywane w tym obwodzie. Po zakończeniu przesyłania obwody można zachować do wykorzystania w przyszłości lub można je natychmiast wyłączyć.
Przełączanie obwodów
Kiedy dwa węzły komunikują się ze sobą za pośrednictwem dedykowanej ścieżki komunikacyjnej, nazywa się to przełączaniem obwodów. Istnieje potrzeba wcześniej określonej trasy, z której będą przesyłane dane, i żadne inne dane nie są dozwolone. należy ustanowić obwód, aby mógł nastąpić transfer danych.
Obwody mogą być stałe lub tymczasowe. Aplikacje korzystające z przełączania obwodów mogą wymagać przejścia przez trzy fazy:
Ustanów obwód
Przenieś dane
Odłącz obwód

Przełączanie obwodów zostało zaprojektowane do zastosowań głosowych. Telefon jest najlepszym przykładem komutacji obwodów. Zanim użytkownik będzie mógł wykonać połączenie, w sieci ustanawiana jest wirtualna ścieżka między dzwoniącym a odbierającym.
Przełączanie wiadomości
Ta technika znajdowała się gdzieś pośrodku przełączania obwodów i przełączania pakietów. W przełączaniu wiadomości cała wiadomość jest traktowana jako jednostka danych i jest przełączana / przesyłana w całości.
Przełącznik pracujący nad przełączaniem wiadomości najpierw odbiera całą wiadomość i buforuje ją, dopóki nie będą dostępne zasoby do przesłania jej do następnego przeskoku. Jeśli w następnym przeskoku nie ma wystarczających zasobów, aby pomieścić wiadomość o dużym rozmiarze, wiadomość jest przechowywana i przełącznik czeka.

Ta technika została uznana za substytut przełączania obwodów. Podobnie jak w przełączaniu obwodów cała ścieżka jest zablokowana tylko dla dwóch podmiotów. Przełączanie wiadomości jest zastępowane przełączaniem pakietów. Przełączanie wiadomości ma następujące wady:
Każdy przełącznik na ścieżce przesyłania wymaga wystarczającej ilości pamięci, aby pomieścić całą wiadomość.
Ze względu na technikę „zapisz i przekaż” oraz uwzględnione oczekiwania na dostępność zasobów, przełączanie komunikatów przebiega bardzo wolno.
Przełączanie wiadomości nie było rozwiązaniem dla mediów strumieniowych i aplikacji czasu rzeczywistego.
Przełączanie pakietów
Wady przełączania wiadomości zrodziły pomysł przełączania pakietów. Cała wiadomość jest dzielona na mniejsze fragmenty zwane pakietami. Informacje o przełączaniu są dodawane w nagłówku każdego pakietu i przesyłane niezależnie.
Pośredniczącym urządzeniom sieciowym łatwiej jest przechowywać pakiety o niewielkich rozmiarach i nie zajmują one dużo zasobów ani na ścieżce nośnej, ani w wewnętrznej pamięci przełączników.

Przełączanie pakietów zwiększa wydajność linii, ponieważ pakiety z wielu aplikacji mogą być multipleksowane przez nośną. Internet wykorzystuje technikę przełączania pakietów. Przełączanie pakietów umożliwia użytkownikowi rozróżnianie strumieni danych na podstawie priorytetów. Pakiety są przechowywane i przekazywane zgodnie z ich priorytetem w celu zapewnienia jakości usług.
Warstwa łącza danych to druga warstwa modelu warstwowego OSI. Ta warstwa jest jedną z najbardziej skomplikowanych warstw i ma złożone funkcje i zobowiązania. Warstwa łącza danych ukrywa szczegóły sprzętu i przedstawia się wyższej warstwie jako medium do komunikacji.
Warstwa łącza danych działa między dwoma hostami, które są w pewnym sensie bezpośrednio połączone. To bezpośrednie połączenie może być typu punkt-punkt lub rozgłaszanie. Mówi się, że systemy w sieci rozgłoszeniowej znajdują się na tym samym łączu. Praca warstwy łącza danych staje się bardziej złożona, gdy ma do czynienia z wieloma hostami w jednej domenie kolizyjnej.
Warstwa łącza danych jest odpowiedzialna za konwersję strumienia danych na sygnały bit po bicie i wysyłanie ich przez podstawowy sprzęt. Na końcu odbiorczym warstwa łącza danych pobiera dane ze sprzętu w postaci sygnałów elektrycznych, łączy je w rozpoznawalny format ramki i przekazuje do warstwy wyższej.
Warstwa łącza danych ma dwie podwarstwy:
Logical Link Control: Zajmuje się protokołami, kontrolą przepływu i kontrolą błędów
Media Access Control: Zajmuje się faktyczną kontrolą mediów
Funkcjonalność warstwy łącza danych
Warstwa łącza danych wykonuje wiele zadań w imieniu wyższej warstwy. To są:
Framing
Warstwa łącza danych pobiera pakiety z warstwy sieci i hermetyzuje je w ramki, a następnie wysyła każdą klatkę bit po bicie do sprzętu. Po stronie odbiornika warstwa łącza danych odbiera sygnały ze sprzętu i łączy je w ramki.
Addressing
Warstwa łącza danych zapewnia sprzętowy mechanizm adresowania warstwy 2. Zakłada się, że adres sprzętowy w łączu jest unikalny. Jest zakodowany w sprzęcie w momencie produkcji.
Synchronization
Gdy ramki danych są wysyłane przez łącze, obie maszyny muszą być zsynchronizowane, aby mógł nastąpić transfer.
Error Control
Czasami sygnały mogą napotkać problem podczas przejścia i bity są odwracane, a błędy te są wykrywane i podejmowane są próby odzyskania rzeczywistych bitów danych. Zapewnia również mechanizm raportowania błędów do nadawcy.
Flow Control
Stacje na tym samym łączu mogą mieć różną prędkość lub pojemność. Warstwa łącza danych zapewnia kontrolę przepływu, która umożliwia obu maszynom wymianę danych z tą samą prędkością.
Multi-Access
Gdy host na udostępnionym łączu próbuje przesłać dane, istnieje duże prawdopodobieństwo kolizji. Warstwa łącza danych zapewnia mechanizm, taki jak CSMA / CD, umożliwiający dostęp do współdzielonych mediów między wieloma systemami.
Istnieje wiele przyczyn, takich jak szumy, przesłuchy itp., Które mogą pomóc w uszkodzeniu danych podczas transmisji. Warstwy wyższe pracują na pewnym uogólnionym spojrzeniu na architekturę sieci i nie są świadome faktycznego przetwarzania danych sprzętowych, stąd też warstwy wyższe oczekują bezbłędnej transmisji między systemami. Większość aplikacji nie działałaby zgodnie z oczekiwaniami, gdyby otrzymywały błędne dane. Aplikacje, takie jak głos i wideo, mogą nie mieć tego wpływu, a przy pewnych błędach mogą nadal działać dobrze.
Warstwa łącza danych wykorzystuje pewien mechanizm kontroli błędów, aby zapewnić, że ramki (strumienie danych) są przesyłane z pewnym poziomem dokładności. Aby jednak zrozumieć, w jaki sposób kontrolowane są błędy, należy wiedzieć, jakie rodzaje błędów mogą wystąpić.
Rodzaje błędów
Mogą występować trzy rodzaje błędów:
Single bit error

W ramce jest jednak tylko jeden bit, który jest uszkodzony.
Multiple bits error

Odebrano ramkę z więcej niż jednym bitem w stanie uszkodzonym.
Burst error

Ramka zawiera więcej niż 1 kolejnych bitów uszkodzonych.
Mechanizm kontroli błędów może obejmować dwa możliwe sposoby:
Wykrywanie błędów
Korekta błędów
Wykrywanie błędów
Błędy w odebranych ramkach są wykrywane za pomocą kontroli parzystości i cyklicznej kontroli nadmiarowej (CRC). W obu przypadkach kilka dodatkowych bitów jest wysyłanych wraz z rzeczywistymi danymi, aby potwierdzić, że bity odebrane na drugim końcu są takie same, jak zostały wysłane. Jeśli sprawdzenie na końcu odbiorcy nie powiedzie się, bity są uważane za uszkodzone.
Test zgodności
Jeden dodatkowy bit jest wysyłany wraz z oryginalnymi bitami, aby liczba jedynek była parzysta w przypadku parzystości lub nieparzysta w przypadku nieparzystej parzystości.
Nadawca podczas tworzenia ramki zlicza zawarte w niej jedynki. Na przykład, jeśli używana jest parzystość, a liczba jedynek jest parzysta, to dodawany jest jeden bit o wartości 0. W ten sposób liczba jedynek pozostaje parzysta, jeśli liczba jedynek jest nieparzysta, dodaje się bit o wartości 1, aby była parzysta.

Odbiornik po prostu liczy jedynki w ramce. Jeśli liczba 1s jest parzysta i używana jest parzystość, ramka jest uważana za nieuszkodzoną i jest akceptowana. Jeśli liczba 1 jest nieparzysta i używana jest nieparzysta parzystość, ramka nadal nie jest uszkodzona.
Jeśli pojedynczy bit przerzuca się podczas przesyłania, odbiornik może go wykryć, zliczając 1s. Ale jeśli więcej niż jeden bit jest błędny, odbiornikowi bardzo trudno jest wykryć błąd.
Cykliczna kontrola nadmiarowa (CRC)
CRC to inne podejście do wykrywania, czy odebrana ramka zawiera prawidłowe dane. Technika ta polega na binarnym dzieleniu wysyłanych bitów danych. Dzielnik jest generowany za pomocą wielomianów. Nadawca wykonuje operację dzielenia na wysyłanych bitach i oblicza pozostałą część. Przed wysłaniem rzeczywistych bitów nadawca dodaje resztę na końcu rzeczywistych bitów. Rzeczywiste bity danych plus reszta nazywane są słowem kodowym. Nadawca przesyła bity danych jako słowa kodowe.

Z drugiej strony, odbiornik wykonuje operację dzielenia na słowach kodowych przy użyciu tego samego dzielnika CRC. Jeśli reszta zawiera wszystkie zera, bity danych są akceptowane, w przeciwnym razie uważa się, że podczas przesyłania wystąpiło pewne uszkodzenie danych.
Korekta błędów
W świecie cyfrowym korekcję błędów można przeprowadzić na dwa sposoby:
Backward Error Correction Gdy odbiorca wykryje błąd w odebranych danych, zwraca się do nadawcy o ponowne przesłanie jednostki danych.
Forward Error Correction Gdy odbiornik wykryje jakiś błąd w otrzymanych danych, wykonuje kod korygujący błędy, który pomaga mu w automatycznym odzyskiwaniu i korygowaniu niektórych rodzajów błędów.
Pierwsza z nich, Backward Error Correction, jest prosta i może być skutecznie stosowana tylko wtedy, gdy retransmisja nie jest droga. Na przykład światłowody. Ale w przypadku transmisji bezprzewodowej retransmisja może kosztować zbyt dużo. W tym drugim przypadku używana jest korekcja błędów do przodu.
Aby poprawić błąd w ramce danych, odbiornik musi dokładnie wiedzieć, który bit w ramce jest uszkodzony. Aby zlokalizować bit z błędem, zbędne bity są używane jako bity parzystości do wykrywania błędów.Na przykład, bierzemy słowa ASCII (dane 7-bitowe), wtedy może być 8 rodzajów informacji, których potrzebujemy: pierwsze siedem bitów, aby powiedzieć nam, który bit jest błędem i jeszcze jednym bitem, aby powiedzieć, że nie ma błędu.
Dla m bitów danych używa się r nadmiarowych bitów. r bitów może dostarczyć 2r kombinacji informacji. W słowie kodowym bitowym m + r istnieje możliwość, że same r bitów mogą zostać uszkodzone. Zatem liczba użytych bitów r musi informować o położeniu bitów m + r plus informacja o braku błędów, tj. M + r + 1.

Warstwa łącza danych jest odpowiedzialna za implementację przepływu punkt-punkt i mechanizm kontroli błędów.
Kontrola przepływu
Gdy ramka danych (dane warstwy 2) jest przesyłana z jednego hosta do drugiego na jednym nośniku, wymagane jest, aby nadawca i odbiorca pracowali z tą samą prędkością. Oznacza to, że nadawca wysyła z szybkością, z jaką odbiorca może przetwarzać i akceptować dane. Co się stanie, jeśli prędkość (sprzęt / oprogramowanie) nadawcy lub odbiorcy różni się? Jeśli nadawca wysyła zbyt szybko, odbiornik może być przeciążony, (zapchany) i dane mogą zostać utracone.
Do kontroli przepływu można zastosować dwa rodzaje mechanizmów:
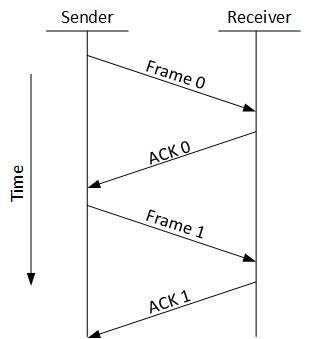
Stop and WaitTen mechanizm kontroli przepływu wymusza na nadawcy po przesłaniu ramki danych zatrzymanie się i czekanie, aż zostanie odebrane potwierdzenie wysłania ramki danych.
Sliding Window
W tym mechanizmie kontroli przepływu zarówno nadawca, jak i odbiorca uzgadniają liczbę ramek danych, po których powinno zostać wysłane potwierdzenie. Jak się dowiedzieliśmy, mechanizm kontroli przepływu zatrzymywania i czekania marnuje zasoby, protokół ten stara się maksymalnie wykorzystać zasoby bazowe.
Kontrola błędów
Kiedy ramka danych jest transmitowana, istnieje prawdopodobieństwo, że ramka danych może zostać utracona podczas przesyłania lub odebrana jest uszkodzona. W obu przypadkach odbiorca nie otrzymuje prawidłowej ramki danych, a nadawca nie wie nic o jakiejkolwiek utracie, w takim przypadku zarówno nadawca, jak i odbiorca są wyposażeni w protokoły, które pomagają im wykryć błędy przesyłu, takie jak utrata danych. rama. Stąd albo nadawca retransmituje ramkę danych, albo odbiorca może zażądać ponownego wysłania poprzedniej ramki danych.
Wymagania dotyczące mechanizmu kontroli błędów:
Error detection - Nadawca i odbiorca, obaj lub ktokolwiek, muszą upewnić się, że wystąpił jakiś błąd podczas przesyłania.
Positive ACK - Gdy odbiornik otrzyma poprawną ramkę, powinien to potwierdzić.
Negative ACK - Gdy odbiorca otrzyma uszkodzoną ramkę lub zduplikowaną ramkę, wysyła NACK z powrotem do nadawcy, a nadawca musi ponownie przesłać prawidłową ramkę.
Retransmission: Nadawca utrzymuje zegar i ustawia limit czasu. Jeżeli potwierdzenie przesłanej wcześniej ramki danych nie nadejdzie przed upływem limitu czasu, nadawca ponownie przesyła ramkę, myśląc, że ramka lub jej potwierdzenie zostały utracone podczas przesyłania.
Istnieją trzy rodzaje dostępnych technik, które warstwa łącza danych może wdrożyć w celu kontrolowania błędów za pomocą automatycznych żądań powtórzeń (ARQ):
Zatrzymaj i czekaj ARQ

W ARQ Stop-and-Wait może wystąpić następujące przejście:
- Nadawca utrzymuje licznik czasu.
- Po wysłaniu ramki nadawca uruchamia licznik czasu.
- Jeśli potwierdzenie ramki nadejdzie na czas, nadawca przesyła następną ramkę w kolejce.
- Jeśli potwierdzenie nie nadejdzie na czas, nadawca zakłada, że ramka lub jej potwierdzenie zostały utracone podczas przesyłania. Nadawca ponownie przesyła ramkę i uruchamia licznik czasu.
- Jeśli otrzymane zostanie negatywne potwierdzenie, nadawca ponownie przesyła ramkę.
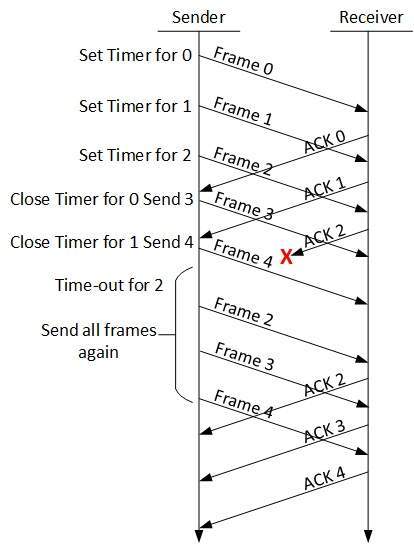
Go-Back-N ARQ
Zatrzymaj i czekaj Mechanizm ARQ nie wykorzystuje zasobów w pełni. Po otrzymaniu potwierdzenia nadawca pozostaje bezczynny i nic nie robi. W metodzie Go-Back-N ARQ zarówno nadawca, jak i odbiorca utrzymują okno.
Rozmiar okna wysyłającego umożliwia nadawcy wysyłanie wielu ramek bez otrzymywania potwierdzenia poprzednich. Okno odbiorcze umożliwia odbiornikowi odbieranie wielu ramek i potwierdzanie ich. Odbiornik śledzi numer sekwencji przychodzącej ramki.
Kiedy nadawca wysyła wszystkie ramki w oknie, sprawdza, do jakiego numeru sekwencyjnego otrzymał pozytywne potwierdzenie. Jeśli wszystkie ramki zostaną pozytywnie potwierdzone, nadawca wysyła następny zestaw ramek. Jeśli nadawca stwierdzi, że otrzymał NACK lub nie otrzymał żadnego potwierdzenia ACK dla określonej ramki, przesyła ponownie wszystkie ramki, po których nie otrzymuje żadnego pozytywnego potwierdzenia.
Selektywne powtarzanie ARQ
W Go-back-N ARQ zakłada się, że odbiornik nie ma żadnego miejsca w buforze dla swojego rozmiaru okna i musi przetwarzać każdą ramkę tak, jak nadejdzie. Wymusza to na nadawcy retransmisję wszystkich ramek, które nie zostały potwierdzone.
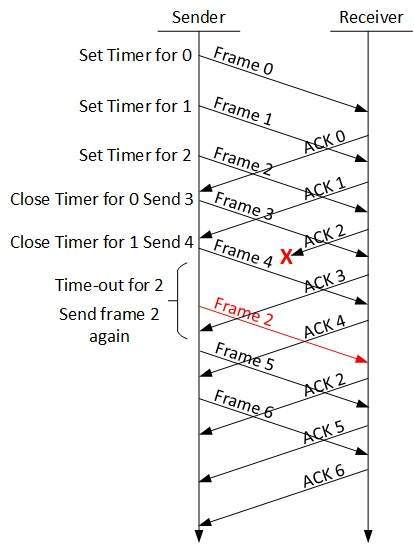
W ARQ z selektywnym powtarzaniem, odbiornik śledząc numery sekwencji, buforuje ramki w pamięci i wysyła NACK tylko dla ramki, której brakuje lub jest uszkodzona.
W tym przypadku nadawca wysyła tylko pakiet, dla którego otrzymał NACK.
Warstwa 3 w modelu OSI jest nazywana warstwą sieciową. Warstwa sieciowa zarządza opcjami dotyczącymi adresowania hostów i sieci, zarządzania podsieciami i intersieciami.
Warstwa sieciowa odpowiada za routing pakietów ze źródła do miejsca docelowego w podsieci lub poza nią. Dwie różne podsieci mogą mieć różne schematy adresowania lub niezgodne typy adresowania. Podobnie jest z protokołami, dwie różne podsieci mogą działać na różnych protokołach, które nie są ze sobą kompatybilne. Warstwa sieci jest odpowiedzialna za kierowanie pakietów od źródła do celu, mapowanie różnych schematów adresowania i protokołów.
Funkcjonalności warstwy 3
Urządzenia pracujące w warstwie sieciowej skupiają się głównie na routingu. Routing może obejmować różne zadania mające na celu osiągnięcie jednego celu. Mogą to być:
Adresowanie urządzeń i sieci.
Wypełnianie tabel routingu lub tras statycznych.
Kolejkowanie danych przychodzących i wychodzących, a następnie przekazywanie ich zgodnie z ograniczeniami jakości usług ustawionymi dla tych pakietów.
Współpraca między dwiema różnymi podsieciami.
Dostarczanie pakietów do miejsca docelowego z najlepszymi staraniami.
Zapewnia mechanizm zorientowany na połączenie i bez połączenia.
Funkcje warstwy sieciowej
Dzięki swoim standardowym funkcjom warstwa 3 może zapewniać różne funkcje, takie jak:
Zarządzanie jakością usług
Równoważenie obciążenia i zarządzanie łączami
Security
Współzależność różnych protokołów i podsieci z różnymi schematami.
Inny projekt sieci logicznej w porównaniu z projektem sieci fizycznej.
L3 VPN i tunele mogą służyć do zapewniania dedykowanej łączności typu end-to-end.
Protokół internetowy jest powszechnie szanowanym i wdrażanym protokołem warstwy sieciowej, który pomaga komunikować się z urządzeniami końcowymi przez Internet. Występuje w dwóch smakach. IPv4, który rządził światem od dziesięcioleci, ale teraz brakuje mu przestrzeni adresowej. IPv6 został stworzony, aby zastąpić IPv4 i miejmy nadzieję, złagodzi również ograniczenia IPv4.
Adresowanie sieciowe w warstwie 3 jest jednym z głównych zadań warstwy sieciowej. Adresy sieciowe są zawsze logiczne, tj. Są to adresy oparte na oprogramowaniu, które można zmienić poprzez odpowiednią konfigurację.
Adres sieciowy zawsze wskazuje na host / węzeł / serwer lub może reprezentować całą sieć. Adres sieciowy jest zawsze konfigurowany na karcie sieciowej i jest generalnie mapowany przez system z adresem MAC (adresem sprzętowym lub adresem warstwy 2) urządzenia do komunikacji w warstwie 2.
Istnieją różne rodzaje adresów sieciowych:
IP
IPX
AppleTalk
Omawiamy tutaj własność intelektualną, ponieważ jest ona jedyną, której używamy obecnie w praktyce.
Adresowanie IP zapewnia mechanizm rozróżniania hostów i sieci. Ponieważ adresy IP są przypisywane w sposób hierarchiczny, host zawsze znajduje się w określonej sieci. Host, który musi komunikować się poza swoją podsiecią, musi znać docelowy adres sieciowy, do którego ma zostać wysłany pakiet / dane.
Hosty w różnych podsieciach potrzebują mechanizmu do wzajemnej lokalizacji. To zadanie może zostać wykonane przez DNS. DNS to serwer udostępniający adres w warstwie 3 zdalnego hosta zmapowany z jego nazwą domeny lub FQDN. Gdy host uzyskuje adres warstwy 3 (adres IP) zdalnego hosta, przekazuje cały swój pakiet do swojej bramy. Brama to router wyposażony we wszystkie informacje, które prowadzą do trasowania pakietów do hosta docelowego.
Routery korzystają z tablic routingu, które zawierają następujące informacje:
Metoda dotarcia do sieci
Routery po otrzymaniu żądania przekazania przekazują pakiet do następnego przeskoku (sąsiedni router) w kierunku miejsca przeznaczenia.
Następny router na ścieżce podąża za tym samym i ostatecznie pakiet danych dociera do celu.
Adres sieciowy może być jednym z następujących:
Unicast (przeznaczone dla jednego hosta)
Multiemisja (przeznaczona do grup)
Transmisja (przeznaczona dla wszystkich)
Anycast (przeznaczony do najbliższego)
Router domyślnie nigdy nie przekazuje dalej ruchu rozgłoszeniowego. Ruch multiemisji wymaga specjalnego traktowania, ponieważ w większości jest to strumień wideo lub audio o najwyższym priorytecie. Anycast jest podobny do unicast, z wyjątkiem tego, że pakiety są dostarczane do najbliższego miejsca docelowego, gdy dostępnych jest wiele miejsc docelowych.
Gdy urządzenie ma wiele ścieżek do celu, zawsze wybiera jedną ścieżkę, preferując ją przed innymi. Ten proces selekcji nazywany jest routingiem. Routing odbywa się za pomocą specjalnych urządzeń sieciowych zwanych routerami lub może odbywać się za pomocą procesów programowych. Routery programowe mają ograniczoną funkcjonalność i ograniczony zakres.
Router jest zawsze skonfigurowany z jakąś domyślną trasą. Trasa domyślna informuje router, gdzie przekazać pakiet, jeśli nie znaleziono trasy do określonego miejsca docelowego. W przypadku, gdy istnieje wiele ścieżek prowadzących do tego samego miejsca docelowego, router może podjąć decyzję na podstawie następujących informacji:
Licznik skoków
Bandwidth
Metric
Prefix-length
Delay
Trasy mogą być konfigurowane statycznie lub dynamicznie. Jedną trasę można skonfigurować tak, aby była preferowana w stosunku do innych.
Routing emisji pojedynczej
Większość ruchu w Internecie i intranetach, znanych jako dane unicast lub ruch unicast, jest wysyłana do określonego miejsca docelowego. Routing danych unicast przez Internet nazywa się routingiem unicast. To najprostsza forma wyznaczania trasy, ponieważ cel podróży jest już znany. Dlatego router musi po prostu przeszukać tablicę routingu i przekazać pakiet do następnego przeskoku.
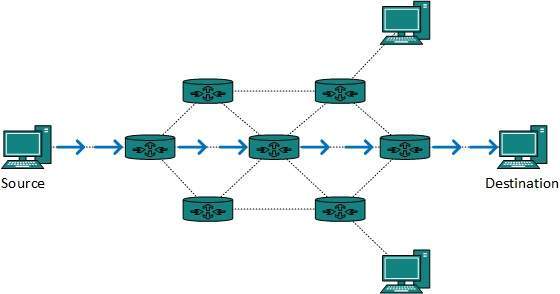
Routing transmisji
Domyślnie pakiety rozgłoszeniowe nie są trasowane ani przekazywane dalej przez routery w żadnej sieci. Routery tworzą domeny rozgłoszeniowe. Można go jednak skonfigurować tak, aby przekazywał dalej transmisje w niektórych szczególnych przypadkach. Wiadomość rozgłoszeniowa jest przeznaczona dla wszystkich urządzeń sieciowych.
Routing transmisji można wykonać na dwa sposoby (algorytm):
Router tworzy pakiet danych, a następnie wysyła go po kolei do każdego hosta. W takim przypadku router tworzy wiele kopii pojedynczego pakietu danych z różnymi adresami docelowymi. Wszystkie pakiety są wysyłane jako unicast, ale ponieważ są wysyłane do wszystkich, symuluje to tak, jakby router nadawał.
Ta metoda wymaga dużej przepustowości, a router musi mieć adres docelowy każdego węzła.
Po drugie, kiedy router odbiera pakiet, który ma być rozesłany, po prostu wyrzuca te pakiety ze wszystkich interfejsów. Wszystkie routery są konfigurowane w ten sam sposób.
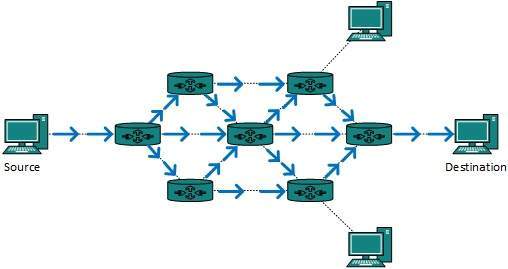
Ta metoda jest łatwa dla procesora routera, ale może powodować problem zduplikowanych pakietów odbieranych z routerów równorzędnych.
Odwrotne przekazywanie ścieżki to technika, w której router wie z wyprzedzeniem o swoim poprzedniku, skąd powinien odbierać rozgłaszanie. Ta technika służy do wykrywania i odrzucania duplikatów.
Routing multiemisji
Trasowanie multiemisji to szczególny przypadek routingu rozgłoszeniowego, w którym występują istotne różnice i wyzwania. W routingu rozgłoszeniowym pakiety są wysyłane do wszystkich węzłów, nawet jeśli tego nie chcą. Jednak w przypadku routingu multiemisji dane są wysyłane tylko do węzłów, które chcą odbierać pakiety.
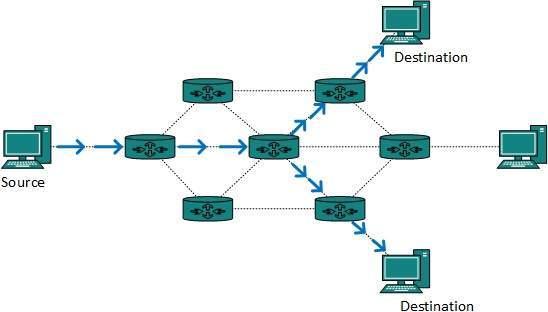
Router musi wiedzieć, że istnieją węzły, które chcą odbierać pakiety multiemisji (lub przesyłać strumieniowo), a tylko on powinien przekazywać dalej. Routing multiemisji działa w oparciu o protokół drzewa, aby uniknąć zapętlenia.
Routing multiemisji wykorzystuje również technikę przekazywania zwrotnego ścieżki w celu wykrywania i odrzucania duplikatów i pętli.
Routing Anycast
Przekazywanie pakietów anycast to mechanizm, w którym wiele hostów może mieć ten sam adres logiczny. Po odebraniu pakietu przeznaczonego na ten adres logiczny jest on wysyłany do hosta, który znajduje się najbliżej w topologii routingu.
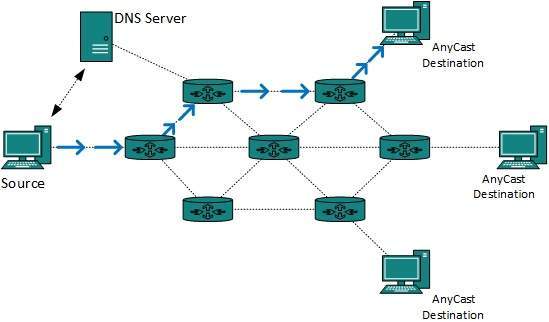
Routing Anycast odbywa się za pomocą serwera DNS. Za każdym razem, gdy odbierany jest pakiet Anycast, system DNS pyta, dokąd go wysłać. DNS dostarcza adres IP, który jest najbliższym skonfigurowanym adresem IP.
Protokoły routingu emisji pojedynczej
Istnieją dwa rodzaje protokołów routingu do trasowania pakietów emisji pojedynczej:
Protokół routingu wektora odległości
Distance Vector to prosty protokół routingu, który podejmuje decyzję o routingu na podstawie liczby przeskoków między źródłem a miejscem docelowym. Trasa z mniejszą liczbą przeskoków jest uważana za najlepszą. Każdy router ogłasza swoje najlepsze trasy innym routerom. Ostatecznie wszystkie routery budują swoją topologię sieci w oparciu o ogłoszenia swoich równorzędnych routerów,
Na przykład protokół informacji o routingu (RIP).
Protokół routingu stanu łącza
Protokół stanu łącza jest nieco skomplikowany niż protokół wektora odległości. Uwzględnia stany łączy wszystkich routerów w sieci. Ta technika pomaga trasom w tworzeniu wspólnego wykresu całej sieci. Następnie wszystkie routery obliczają najlepszą ścieżkę do celów routingu, na przykład Open Shortest Path First (OSPF) i Intermediate System to Intermediate System (ISIS).
Protokoły routingu multiemisji
Protokoły routingu emisji pojedynczej używają wykresów, podczas gdy protokoły routingu multiemisji używają drzew, tj. Drzewa opinającego, aby uniknąć pętli. Drzewo optymalne nazywane jest drzewem obejmującym najkrótszą ścieżkę.
DVMRP - Protokół routingu multiemisji wektora odległości
MOSPF - Najpierw najkrótsza ścieżka otwarta multiemisji
CBT - Drzewo oparte na rdzeniu
PIM - Multiemisja niezależna od protokołu
Obecnie powszechnie używana jest niezależna od protokołu multiemisja. Ma dwa smaki:
PIM Dense Mode
Ten tryb wykorzystuje drzewa oparte na źródłach. Jest używany w gęstym środowisku, takim jak LAN.
PIM Sparse Mode
W tym trybie używane są wspólne drzewa. Jest używany w rzadkich środowiskach, takich jak WAN.
Algorytmy routingu
Algorytmy routingu są następujące:
Powódź
Flooding to najprostsza metoda przekazywania pakietów. Po odebraniu pakietu routery wysyłają go do wszystkich interfejsów z wyjątkiem tego, na którym został odebrany. Powoduje to zbyt duże obciążenie sieci i wiele zduplikowanych pakietów wędrujących w sieci.
Time to Live (TTL) może służyć do unikania nieskończonej pętli pakietów. Istnieje inne podejście do zalewania, które nazywa się Selective Flooding w celu zmniejszenia narzutu w sieci. W tej metodzie router nie wylewa się na wszystkie interfejsy, ale selektywne.
Najkrótsza droga
Decyzje o routingu w sieci są najczęściej podejmowane na podstawie kosztów między źródłem a miejscem docelowym. Liczba chmielów odgrywa tutaj główną rolę. Najkrótsza ścieżka to technika, która wykorzystuje różne algorytmy do decydowania o ścieżce z minimalną liczbą przeskoków.
Typowe algorytmy najkrótszej ścieżki to:
Algorytm Dijkstry
Algorytm Bellmana Forda
Algorytm Floyda Warshalla
W prawdziwym świecie sieci pod tą samą administracją są na ogół rozproszone geograficznie. Może istnieć wymóg połączenia dwóch różnych sieci tego samego rodzaju, jak również różnych rodzajów. Routing między dwiema sieciami nosi nazwę intersieci.
Sieci można uznać za różne na podstawie różnych parametrów, takich jak protokół, topologia, sieć warstwy 2 i schemat adresowania.
W intersieci routery znają swoje adresy i adresy poza nimi. Mogą być skonfigurowane statycznie do pracy w innej sieci lub mogą się uczyć przy użyciu protokołu routingu międzysieciowego.
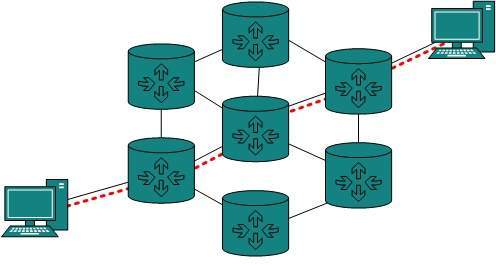
Protokoły routingu używane w organizacji lub administracji nazywane są protokołami bram wewnętrznych lub IGP. RIP, OSPF to przykłady protokołu IGP. Routing między różnymi organizacjami lub administracjami może mieć protokół Exterior Gateway, a istnieje tylko jeden EGP, tj. Border Gateway Protocol.
Tunelowanie
Jeśli są to dwie oddzielne geograficznie sieci, które chcą się ze sobą komunikować, mogą wdrożyć dedykowaną linię między nimi lub muszą przekazywać swoje dane przez sieci pośredniczące.
Tunelowanie to mechanizm, za pomocą którego dwie lub więcej takich samych sieci komunikuje się ze sobą, omijając pośrednie zawiłości sieciowe. Tunelowanie jest skonfigurowane na obu końcach.
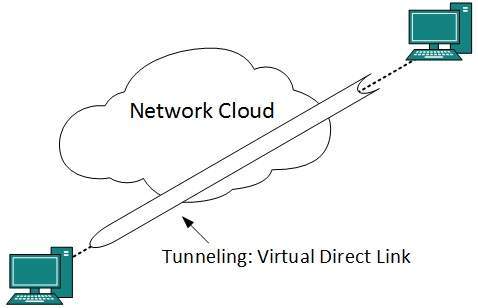
Gdy dane wchodzą z jednego końca tunelu, są oznaczane. Te oznaczone dane są następnie kierowane do sieci pośredniej lub tranzytowej, aby dotrzeć do drugiego końca tunelu. Gdy dane istnieją, Tunnel, jego tag jest usuwany i dostarczany do innej części sieci.
Oba końce wydają się być bezpośrednio połączone, a znakowanie sprawia, że dane są przesyłane przez sieć tranzytową bez żadnych modyfikacji.
Fragmentacja pakietów
Większość segmentów Ethernet ma ustaloną maksymalną jednostkę transmisji (MTU) na 1500 bajtów. Pakiet danych może mieć większą lub mniejszą długość w zależności od aplikacji. Urządzenia na ścieżce tranzytu mają również swoje możliwości sprzętowe i programowe, które mówią, jaką ilość danych może obsłużyć urządzenie i jaki rozmiar pakietu może przetworzyć.
Jeśli rozmiar pakietu danych jest mniejszy lub równy rozmiarowi pakietu, który może obsłużyć sieć tranzytowa, jest on przetwarzany neutralnie. Jeśli paczka jest większa, jest dzielona na mniejsze części, a następnie przesyłana dalej. Nazywa się to fragmentacją pakietów. Każdy fragment zawiera ten sam adres docelowy i źródłowy i jest łatwo kierowany przez ścieżkę tranzytową. Na końcu odbiorczym jest ponownie montowany.
Jeśli pakiet z bitem DF (nie fragmentuj) ustawionym na 1 dociera do routera, który nie może obsłużyć pakietu ze względu na jego długość, pakiet jest odrzucany.
Gdy pakiet jest odbierany przez router, ma ustawiony bit MF (więcej fragmentów) na 1, router wie, że jest to pofragmentowany pakiet i że części oryginalnego pakietu są w drodze.
Jeśli pakiet jest pofragmentowany za mały, narzut rośnie. Jeśli pakiet jest zbyt duży, router pośredniczący może nie być w stanie go przetworzyć i może zostać odrzucony.
Każdy komputer w sieci ma adres IP, za pomocą którego można go jednoznacznie zidentyfikować i zaadresować. Adres IP to adres logiczny warstwy 3 (warstwy sieci). Ten adres może się zmienić przy każdym ponownym uruchomieniu komputera. Komputer może mieć jeden adres IP w jednym czasie i inny w innym czasie.
Protokół rozpoznawania adresów (ARP)
Podczas komunikacji host potrzebuje adresu warstwy 2 (MAC) urządzenia docelowego, które należy do tej samej domeny rozgłoszeniowej lub sieci. Adres MAC jest fizycznie zapisywany na karcie sieciowej (NIC) urządzenia i nigdy się nie zmienia.
Z drugiej strony rzadko zmienia się adres IP w domenie publicznej. Jeśli karta sieciowa zostanie zmieniona w przypadku błędu, zmienia się również adres MAC. W ten sposób, aby miała miejsce komunikacja w warstwie 2, wymagane jest mapowanie między nimi.
Aby poznać adres MAC zdalnego hosta w domenie rozgłoszeniowej, komputer, który chce zainicjować komunikację, wysyła wiadomość rozgłoszeniową ARP z pytaniem „Kto ma ten adres IP?” Ponieważ jest to emisja, wszystkie hosty w segmencie sieci (domenie rozgłoszeniowej) odbierają ten pakiet i przetwarzają go. Pakiet ARP zawiera adres IP hosta docelowego, z którym host wysyłający chce rozmawiać. Gdy host otrzyma skierowany do niego pakiet ARP, odpowiada z własnym adresem MAC.
Gdy host otrzyma docelowy adres MAC, może komunikować się ze zdalnym hostem za pomocą protokołu łącza Layer-2. To mapowanie adresu MAC na IP jest zapisywane w pamięci podręcznej ARP hostów wysyłających i odbierających. Następnym razem, jeśli będą wymagać komunikacji, mogą bezpośrednio odwołać się do odpowiedniej pamięci podręcznej ARP.
Reverse ARP to mechanizm, w którym host zna adres MAC zdalnego hosta, ale wymaga znajomości adresu IP do komunikacji.
Internet Control Message Protocol (ICMP)
ICMP to protokół diagnostyki sieci i raportowania błędów. ICMP należy do zestawu protokołów IP i używa IP jako protokołu nośnego. Po skonstruowaniu pakietu ICMP jest on hermetyzowany w pakiecie IP. Ponieważ protokół IP sam w sobie jest niewiarygodnym protokołem, który należy wykonać, podobnie jak ICMP.
Wszelkie informacje zwrotne dotyczące sieci są odsyłane do hosta, z którego pochodzą. Jeśli wystąpi jakiś błąd w sieci, jest to zgłaszane za pomocą protokołu ICMP. ICMP zawiera dziesiątki komunikatów diagnostycznych i komunikatów o błędach.
ICMP-echo i ICMP-echo-response to najczęściej używane komunikaty ICMP do sprawdzania osiągalności hostów typu end-to-end. Kiedy host odbiera żądanie echa ICMP, jest zobowiązany do odesłania odpowiedzi echa ICMP. Jeśli wystąpi problem w sieci tranzytowej, ICMP zgłosi ten problem.
Protokół internetowy w wersji 4 (IPv4)
IPv4 to 32-bitowy schemat adresowania używany jako mechanizm adresowania hostów TCP / IP. Adresowanie IP umożliwia jednoznaczną identyfikację każdego hosta w sieci TCP / IP.
IPv4 zapewnia hierarchiczny schemat adresowania, który umożliwia podzielenie sieci na podsieci, z których każda ma dobrze zdefiniowaną liczbę hostów. Adresy IP są podzielone na wiele kategorii:
Class A - używa pierwszego oktetu do adresów sieciowych i ostatnich trzech oktetów do adresowania hostów
Class B - wykorzystuje dwa pierwsze oktety do adresów sieciowych i dwa ostatnie do adresowania hostów
Class C - używa pierwszych trzech oktetów do adresów sieciowych i ostatniego do adresowania hostów
Class D - zapewnia płaski schemat adresowania IP w przeciwieństwie do struktury hierarchicznej dla powyżej trzech.
Class E - Jest używany jako eksperymentalny.
IPv4 ma również dobrze zdefiniowane przestrzenie adresowe, które mają być używane jako adresy prywatne (bez możliwości routingu w Internecie) i adresy publiczne (dostarczane przez dostawców usług internetowych i mogą być routowane w Internecie).
Chociaż IP nie jest wiarygodne; zapewnia mechanizm „Best-Effort-Delivery”.
Protokół internetowy w wersji 6 (IPv6)
Wyczerpanie adresów IPv4 dało początek nowej generacji protokołu internetowego w wersji 6. IPv6 adresuje swoje węzły za pomocą 128-bitowego adresu, zapewniającego dużą przestrzeń adresową do wykorzystania w przyszłości na całej planecie lub poza nią.
IPv6 wprowadził adresowanie Anycast, ale usunął koncepcję rozgłaszania. Protokół IPv6 umożliwia urządzeniom samodzielne uzyskanie adresu IPv6 i komunikację w tej podsieci. Ta autokonfiguracja eliminuje niezawodność serwerów DHCP (Dynamic Host Configuration Protocol). Dzięki temu, nawet jeśli serwer DHCP w tej podsieci jest wyłączony, hosty mogą się ze sobą komunikować.
IPv6 zapewnia nową funkcję mobilności IPv6. Urządzenia mobilne wyposażone w protokół IPv6 mogą przemieszczać się bez konieczności zmiany ich adresów IP.
Protokół IPv6 wciąż znajduje się w fazie przejściowej i oczekuje się, że w nadchodzących latach całkowicie zastąpi protokół IPv4. Obecnie istnieje kilka sieci działających w oparciu o IPv6. Istnieją pewne mechanizmy przejścia dla sieci obsługujących protokół IPv6, które umożliwiają łatwe komunikowanie się i poruszanie się po różnych sieciach za pośrednictwem protokołu IPv4. To są:
- Implementacja podwójnego stosu
- Tunneling
- NAT-PT
Następna warstwa w modelu OSI jest rozpoznawana jako warstwa transportowa (warstwa-4). Wszystkie moduły i procedury dotyczące transportu danych lub strumienia danych są zaklasyfikowane do tej warstwy. Jak wszystkie inne warstwy, ta warstwa komunikuje się ze swoją równorzędną warstwą transportową zdalnego hosta.
Warstwa transportowa oferuje połączenia peer-to-peer i end-to-end między dwoma procesami na zdalnych hostach. Warstwa transportowa pobiera dane z górnej warstwy (tj. Warstwy aplikacji), a następnie dzieli je na segmenty o mniejszym rozmiarze, numeruje każdy bajt i przekazuje je do dolnej warstwy (warstwy sieciowej) w celu dostarczenia.
Funkcje
Ta warstwa jest pierwszą, która rozbija dane informacyjne dostarczane przez warstwę aplikacji na mniejsze jednostki zwane segmentami. Numeruje każdy bajt w segmencie i prowadzi ich księgowość.
Ta warstwa zapewnia, że dane muszą być odbierane w tej samej kolejności, w jakiej zostały wysłane.
Ta warstwa zapewnia kompleksowe dostarczanie danych między hostami, które mogą, ale nie muszą należeć do tej samej podsieci.
Wszystkie procesy serwera, które zamierzają komunikować się w sieci, są wyposażone w dobrze znane punkty dostępu usług transportowych (TSAP), znane również jako numery portów.
Komunikacja od końca do końca
Proces na jednym hoście identyfikuje swojego równorzędnego hosta w zdalnej sieci za pomocą TSAP, zwanych również numerami portów. Punkty TSAP są bardzo dobrze zdefiniowane, a proces, który próbuje komunikować się ze swoim rówieśnikiem, wie o tym z góry.
Na przykład, gdy klient DHCP chce komunikować się ze zdalnym serwerem DHCP, zawsze żąda na porcie numer 67. Gdy klient DNS chce komunikować się ze zdalnym serwerem DNS, zawsze żąda na porcie numer 53 (UDP).
Dwa główne protokoły warstwy transportowej to:
Transmission Control Protocol
Zapewnia niezawodną komunikację między dwoma hostami.
User Datagram Protocol
Zapewnia zawodną komunikację między dwoma hostami.
Protokół kontroli transmisji (TCP) jest jednym z najważniejszych protokołów pakietu protokołów internetowych. Jest to najczęściej używany protokół transmisji danych w sieciach komunikacyjnych, takich jak internet.
funkcje
TCP to niezawodny protokół. Oznacza to, że odbiorca zawsze wysyła do nadawcy pozytywne lub negatywne potwierdzenie pakietu danych, dzięki czemu nadawca zawsze ma jasną wskazówkę, czy pakiet danych dotarł do miejsca przeznaczenia, czy też musi go ponownie wysłać.
TCP zapewnia, że dane dotrą do celu w tej samej kolejności, w jakiej zostały wysłane.
TCP jest zorientowany na połączenie. Protokół TCP wymaga ustanowienia połączenia między dwoma zdalnymi punktami przed wysłaniem rzeczywistych danych.
Protokół TCP zapewnia mechanizm sprawdzania błędów i odzyskiwania.
TCP zapewnia komunikację typu end-to-end.
TCP zapewnia kontrolę przepływu i jakość usług.
TCP działa w trybie klient / serwer punkt-punkt.
TCP zapewnia serwer z pełnym dupleksem, tj. Może pełnić rolę zarówno odbiorcy, jak i nadawcy.
nagłówek
Długość nagłówka TCP wynosi minimum 20 bajtów i maksymalnie 60 bajtów.
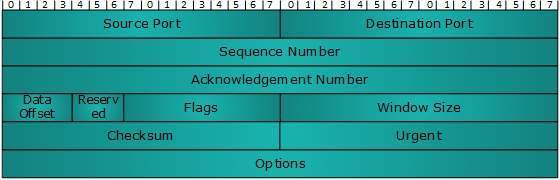
Source Port (16-bits) - Identyfikuje port źródłowy procesu aplikacji na urządzeniu wysyłającym.
Destination Port (16-bits) - Identyfikuje port docelowy procesu aplikacji na urządzeniu odbiorczym.
Sequence Number (32-bits) - Kolejna liczba bajtów danych segmentu w sesji.
Acknowledgement Number (32-bits) - Gdy ustawiona jest flaga ACK, liczba ta zawiera następny numer sekwencyjny oczekiwanego bajtu danych i działa jako potwierdzenie wcześniej odebranych danych.
Data Offset (4-bits) - To pole określa zarówno rozmiar nagłówka TCP (słowa 32-bitowe), jak i przesunięcie danych w bieżącym pakiecie w całym segmencie TCP.
Reserved (3-bits) - Zarezerwowane do użytku w przyszłości i wszystkie są domyślnie ustawione na zero.
Flags (1-bit each)
NS - Bit sumy jednorazowej jest używany przez proces sygnalizacji powiadomienia o zatorach.
CWR - Gdy host odbiera pakiet z ustawionym bitem ECE, ustawia opcję Congestion Windows Reduced na potwierdzenie odebrania ECE.
ECE -Ma dwa znaczenia:
Jeśli bit SYN ma wartość 0, wówczas ECE oznacza, że pakiet IP ma ustawiony bit CE (doświadczenie przeciążenia).
Jeśli bit SYN jest ustawiony na 1, ECE oznacza, że urządzenie obsługuje ECT.
URG - Wskazuje, że pole Urgent Pointer zawiera istotne dane i powinno zostać przetworzone.
ACK- Wskazuje, że pole potwierdzenia ma znaczenie. Jeśli ACK jest zerowane, oznacza to, że pakiet nie zawiera żadnego potwierdzenia.
PSH - Po ustawieniu jest to żądanie do stacji odbiorczej wysłania danych PUSH (gdy tylko nadejdą) do aplikacji odbierającej bez ich buforowania.
RST - Flaga resetowania ma następujące funkcje:
Służy do odrzucania połączenia przychodzącego.
Służy do odrzucania segmentu.
Służy do ponownego uruchomienia połączenia.
SYN - Ta flaga służy do ustanowienia połączenia między hostami.
FIN- Ta flaga służy do zwalniania połączenia i nie ma już więcej danych. Ponieważ pakiety z flagami SYN i FIN mają numery sekwencyjne, są przetwarzane we właściwej kolejności.
Windows Size - To pole jest używane do sterowania przepływem między dwiema stacjami i wskazuje ilość bufora (w bajtach), który odbiornik zaalokował dla segmentu, tj. Ile danych oczekuje odbiornik.
Checksum - To pole zawiera sumę kontrolną nagłówka, danych i pseudo nagłówków.
Urgent Pointer - Wskazuje na pilny bajt danych, jeśli flaga URG jest ustawiona na 1.
Options - Ułatwia dodatkowe opcje, które nie są objęte zwykłym nagłówkiem. Pole opcji jest zawsze opisane słowami 32-bitowymi. Jeśli to pole zawiera dane mniejsze niż 32-bitowe, wypełnienie jest używane do pokrycia pozostałych bitów w celu osiągnięcia granicy 32-bitowej.
Adresowanie
Komunikacja TCP między dwoma zdalnymi hostami odbywa się za pomocą numerów portów (TSAP). Numery portów mogą wynosić od 0 do 65535, które są podzielone na:
- Porty systemowe (0 - 1023)
- Porty użytkownika (1024 - 49151)
- Porty prywatne / dynamiczne (49152-65535)
Zarządzanie połączeniami
Komunikacja TCP działa w modelu serwer / klient. Klient inicjuje połączenie, a serwer je akceptuje lub odrzuca. Uzgadnianie trójetapowe służy do zarządzania połączeniami.
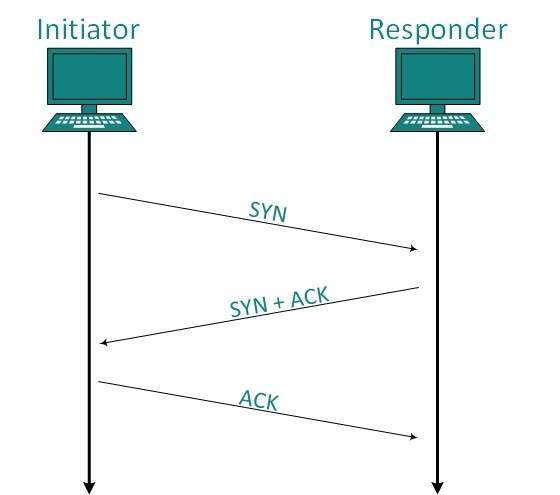
Ustanowienie
Klient inicjuje połączenie i wysyła segment z numerem sekwencji. Serwer potwierdza to swoim własnym numerem sekwencyjnym i ACK segmentu klienta, który jest o jeden większy niż numer sekwencyjny klienta. Klient po otrzymaniu ACK swojego segmentu wysyła potwierdzenie odpowiedzi serwera.
Wydanie
Zarówno serwer, jak i klient mogą wysłać segment TCP z flagą FIN ustawioną na 1. Gdy strona odbierająca odpowiada na to potwierdzając FIN, ten kierunek komunikacji TCP jest zamykany, a połączenie jest zwalniane.
Zarządzanie przepustowością
TCP wykorzystuje koncepcję rozmiaru okna, aby dostosować się do potrzeb zarządzania przepustowością. Rozmiar okna informuje nadawcę na zdalnym końcu, ile segmentów bajtów danych może odebrać odbiornik na tym końcu. Protokół TCP używa fazy powolnego startu, używając rozmiaru okna 1 i zwiększa wykładniczo rozmiar okna po każdej pomyślnej komunikacji.
Na przykład klient używa systemu Windows w rozmiarze 2 i wysyła 2 bajty danych. Po otrzymaniu potwierdzenia tego segmentu rozmiar okna jest podwojony do 4, a następnie wysłany, wysłany segment będzie miał 4 bajty danych. Po otrzymaniu potwierdzenia 4-bajtowego segmentu danych klient ustawia rozmiar okna na 8 i tak dalej.
W przypadku pominięcia potwierdzenia, tj. Utraty danych w sieci tranzytowej lub otrzymania NACK, wówczas rozmiar okna zmniejsza się do połowy i rozpoczyna się od nowa faza powolnego startu.
Kontrola błędów i kontrola przepływu
TCP używa numerów portów, aby wiedzieć, jakiego procesu aplikacji potrzebuje do przekazania segmentu danych. Oprócz tego używa numerów sekwencyjnych do synchronizacji ze zdalnym hostem. Wszystkie segmenty danych są wysyłane i odbierane z numerami sekwencyjnymi. Nadawca wie, który ostatni segment danych został odebrany przez Odbiorcę, gdy otrzyma ACK. Odbiorca wie o ostatnim segmencie wysłanym przez Nadawcę odwołując się do numeru sekwencyjnego ostatnio odebranego pakietu.
Jeśli numer kolejny ostatnio odebranego segmentu nie zgadza się z numerem sekwencyjnym, którego oczekiwał odbiorca, jest on odrzucany, a NACK jest odsyłany. Jeśli nadejdą dwa segmenty z tym samym numerem sekwencyjnym, wartość znacznika czasu TCP jest porównywana w celu podjęcia decyzji.
Multipleksowanie
Technika łączenia dwóch lub więcej strumieni danych w jednej sesji nazywa się multipleksowaniem. Kiedy klient TCP inicjuje połączenie z serwerem, zawsze odwołuje się do dobrze zdefiniowanego numeru portu, który wskazuje proces aplikacji. Sam klient używa losowo wygenerowanego numeru portu z prywatnych pul numerów portów.
Używając multipleksowania TCP, klient może komunikować się z wieloma różnymi procesami aplikacji w jednej sesji. Na przykład, klient żąda strony internetowej, która z kolei zawiera różne typy danych (HTTP, SMTP, FTP itp.), Przekroczenie limitu czasu sesji TCP zostaje zwiększone, a sesja pozostaje otwarta przez dłuższy czas, dzięki czemu można być unikanym.
Umożliwia to systemowi klienckiemu otrzymywanie wielu połączeń za pośrednictwem jednego połączenia wirtualnego. Te połączenia wirtualne nie są dobre dla serwerów, jeśli limit czasu jest zbyt długi.
Kontrola zatorów
Kiedy duża ilość danych jest dostarczana do systemu, który nie jest w stanie ich obsłużyć, pojawia się przeciążenie. TCP kontroluje przeciążenie za pomocą mechanizmu okna. TCP ustawia rozmiar okna, informując drugą stronę, ile segmentów danych ma wysłać. TCP może używać trzech algorytmów do kontroli przeciążenia:
Addytywny wzrost, multiplikatywny spadek
Powolny start
Limit czasu reakcji
Zarządzanie zegarem
TCP używa różnych typów timerów do sterowania i zarządzania różnymi zadaniami:
Licznik czasu podtrzymania życia:
Ten zegar służy do sprawdzania integralności i ważności połączenia.
Po wygaśnięciu czasu utrzymywania aktywności host wysyła sondę, aby sprawdzić, czy połączenie nadal istnieje.
Zegar retransmisji:
Ten licznik czasu utrzymuje stanową sesję wysłanych danych.
Jeżeli potwierdzenie wysłania danych nie zostanie odebrane w czasie retransmisji, segment danych jest wysyłany ponownie.
Licznik czasu trwałego:
Sesja TCP może zostać wstrzymana przez dowolny host, wysyłając Window Size 0.
Aby wznowić sesję, host musi wysłać rozmiar okna z większą wartością.
Jeśli ten odcinek nigdy nie osiągnie drugiego końca, oba końce mogą czekać na siebie przez nieskończony czas.
Po wygaśnięciu licznika czasu utrwalania host ponownie wysyła rozmiar swojego okna, aby powiadomić drugą stronę.
Persist Timer pomaga uniknąć zakleszczeń w komunikacji.
Czas oczekiwania:
Po zwolnieniu połączenia jeden z hostów czeka na czas oczekiwania na całkowite zakończenie połączenia.
Ma to na celu upewnienie się, że drugi koniec otrzymał potwierdzenie żądania zakończenia połączenia.
Limit czasu może wynosić maksymalnie 240 sekund (4 minuty).
Odzyskiwanie po awarii
TCP to bardzo niezawodny protokół. Dostarcza numer sekwencyjny do każdego bajtu wysyłanego w segmencie. Zapewnia mechanizm sprzężenia zwrotnego, tj. Gdy host odbiera pakiet, jest powiązany z potwierdzeniem ACK, który pakiet ma następny oczekiwany numer sekwencyjny (jeśli nie jest to ostatni segment).
Gdy serwer TCP ulegnie awarii w trakcie komunikacji i ponownie uruchomi swój proces, wysyła transmisję TPDU do wszystkich swoich hostów. Hosty mogą następnie wysłać ostatni segment danych, który nigdy nie był niepotwierdzony, i kontynuować.
User Datagram Protocol (UDP) jest najprostszym protokołem komunikacyjnym warstwy transportowej dostępnym w zestawie protokołów TCP / IP. Obejmuje minimalną ilość mechanizmu komunikacyjnego. Mówi się, że protokół UDP jest zawodnym protokołem transportowym, ale wykorzystuje usługi IP, które zapewniają mechanizm dostarczania z najlepszymi wysiłkami.
W UDP odbiorca nie generuje potwierdzenia odebrania pakietu, az kolei nadawca nie czeka na potwierdzenie wysłania pakietu. Ta wada sprawia, że ten protokół jest zawodny, a także łatwiejszy w przetwarzaniu.
Wymóg UDP
Może pojawić się pytanie, po co nam zawodny protokół do przesyłania danych? Wdrażamy UDP, w którym pakiety potwierdzeń współdzielą znaczną przepustowość wraz z rzeczywistymi danymi. Na przykład w przypadku przesyłania strumieniowego wideo tysiące pakietów są przekazywane do użytkowników. Potwierdzenie wszystkich pakietów jest kłopotliwe i może wiązać się z ogromną stratą przepustowości. Najlepszy mechanizm dostarczania bazowego protokołu IP zapewnia najlepsze wysiłki w celu dostarczenia pakietów, ale nawet jeśli niektóre pakiety w strumieniu wideo zostaną utracone, wpływ nie jest tragiczny i można go łatwo zignorować. Utrata kilku pakietów w ruchu wideo i głosowym czasami pozostaje niezauważona.
funkcje
UDP jest używany, gdy potwierdzenie danych nie ma żadnego znaczenia.
UDP to dobry protokół do przesyłania danych w jednym kierunku.
Protokół UDP jest prosty i odpowiedni do komunikacji opartej na zapytaniach.
UDP nie jest zorientowany na połączenie.
UDP nie zapewnia mechanizmu kontroli przeciążenia.
UDP nie gwarantuje zamówionego dostarczenia danych.
UDP jest bezpaństwowy.
UDP jest odpowiednim protokołem do aplikacji strumieniowych, takich jak VoIP, strumieniowe przesyłanie multimediów.
Nagłówek UDP
Nagłówek UDP jest tak prosty, jak jego funkcja.

Nagłówek UDP zawiera cztery główne parametry:
Source Port - Ta 16-bitowa informacja jest używana do identyfikacji portu źródłowego pakietu.
Destination Port - Ta 16-bitowa informacja służy do identyfikacji usługi na poziomie aplikacji na komputerze docelowym.
Length - Pole Długość określa całą długość pakietu UDP (łącznie z nagłówkiem). Jest to pole 16-bitowe, a minimalna wartość to 8 bajtów, czyli rozmiar samego nagłówka UDP.
Checksum - W tym polu przechowywana jest suma kontrolna wygenerowana przez nadawcę przed wysłaniem. IPv4 ma to pole jako opcjonalne, więc jeśli pole sumy kontrolnej nie zawiera żadnej wartości, przyjmuje się wartość 0, a wszystkie jego bity są ustawiane na zero.
Aplikacja UDP
Oto kilka aplikacji, w których do przesyłania danych używany jest protokół UDP:
Usługi nazw domen
Simple Network Management Protocol
Trivial File Transfer Protocol
Protokół informacji o routingu
Kerberos
Warstwa aplikacji jest najwyższą warstwą w modelu warstwowym OSI i TCP / IP. Ta warstwa istnieje w obu modelach warstwowych ze względu na jej znaczenie w interakcji z użytkownikami i aplikacjami użytkownika. Ta warstwa jest przeznaczona dla aplikacji, które są zaangażowane w system komunikacji.
Użytkownik może bezpośrednio współdziałać z aplikacjami lub nie. Warstwa aplikacji to miejsce, w którym inicjowana jest i odzwierciedla rzeczywista komunikacja. Ponieważ ta warstwa znajduje się na górze stosu warstw, nie obsługuje żadnych innych warstw. Warstwa aplikacji korzysta z transportu i wszystkich warstw pod nią, aby komunikować się lub przesyłać swoje dane do zdalnego hosta.
Gdy protokół warstwy aplikacji chce komunikować się ze swoim równorzędnym protokołem warstwy aplikacji na zdalnym hoście, przekazuje dane lub informacje do warstwy transportowej. Resztę wykonuje warstwa transportowa za pomocą wszystkich warstw pod nią.

Istnieje niejasność w rozumieniu warstwy aplikacji i jej protokołu. Nie każdą aplikację użytkownika można umieścić w warstwie aplikacji. z wyjątkiem tych aplikacji, które współdziałają z systemem komunikacyjnym. Na przykład oprogramowanie do projektowania lub edytor tekstu nie może być uważane za programy warstwy aplikacji.
Z drugiej strony, gdy używamy przeglądarki internetowej, która w rzeczywistości używa protokołu Hyper Text Transfer Protocol (HTTP) do interakcji z siecią. HTTP to protokół warstwy aplikacji.
Innym przykładem jest protokół transferu plików, który pomaga użytkownikowi przesyłać pliki tekstowe lub binarne przez sieć. Użytkownik może używać tego protokołu w dowolnym oprogramowaniu opartym na graficznym interfejsie użytkownika, takim jak FileZilla lub CuteFTP, a ten sam użytkownik może używać protokołu FTP w trybie wiersza poleceń.
Dlatego niezależnie od używanego oprogramowania jest to protokół, który jest uwzględniany w warstwie aplikacji używanej przez to oprogramowanie. DNS to protokół, który pomaga protokołom aplikacji użytkownika, takim jak HTTP, wykonywać swoje zadania.
Dwa zdalne procesy aplikacji mogą komunikować się głównie na dwa różne sposoby:
Peer-to-peer: Oba procesy zdalne działają na tym samym poziomie i wymieniają dane przy użyciu współdzielonych zasobów.
Client-Server: Jeden proces zdalny działa jako klient i żąda zasobu z innego procesu aplikacji działającego jako serwer.
W modelu klient-serwer każdy proces może działać jako serwer lub klient. To nie typ maszyny, wielkość maszyny ani jej moc obliczeniowa sprawiają, że jest ona serwerem; to zdolność obsługi żądania sprawia, że maszyna jest serwerem.
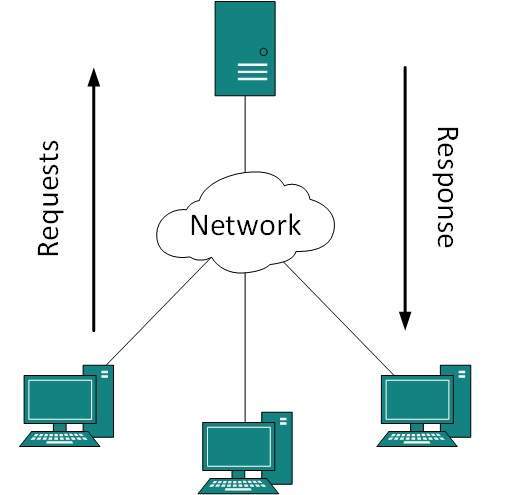
System może działać jednocześnie jako serwer i klient. Oznacza to, że jeden proces działa jako serwer, a inny jako klient. Może się również zdarzyć, że procesy klienta i serwera znajdują się na tej samej maszynie.
Komunikacja
Dwa procesy w modelu klient-serwer mogą współdziałać na różne sposoby:
Sockets
Zdalne wywołania procedur (RPC)
Gniazda
W tym paradygmacie proces działający jako serwer otwiera gniazdo przy użyciu dobrze znanego (lub znanego klientowi) portu i czeka, aż nadejdzie żądanie klienta. Drugi proces działający jako klient również otwiera gniazdo, ale zamiast czekać na przychodzące żądanie, klient przetwarza „najpierw żądania”.
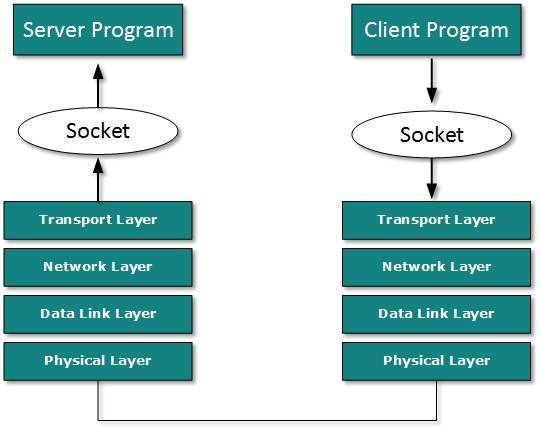
Gdy żądanie dotrze do serwera, jest obsługiwane. Może to być udostępnienie informacji lub żądanie zasobów.
Zdalne wywołanie procedury
Jest to mechanizm, w którym jeden proces współdziała z innym za pomocą wywołań procedur. Jeden proces (klient) wywołuje procedurę leżącą na zdalnym hoście. Mówi się, że proces na zdalnym hoście jest serwerem. Oba procesy mają przydzielone kody pośredniczące. Ta komunikacja odbywa się w następujący sposób:
Proces klienta wywołuje kod pośredniczący klienta. Przekazuje wszystkie parametry związane z programem lokalnym do niego.
Wszystkie parametry są następnie pakowane (organizowane) i wykonywane jest wywołanie systemowe w celu wysłania ich na drugą stronę sieci.
Kernel wysyła dane przez sieć, a drugi koniec je odbiera.
Zdalny host przekazuje dane do kodu pośredniczącego serwera, gdzie są one usuwane.
Parametry są przekazywane do procedury, a następnie procedura jest wykonywana.
Wynik odsyłany jest do klienta w ten sam sposób.
Istnieje kilka protokołów, które działają dla użytkowników w warstwie aplikacji. Protokoły warstwy aplikacji można ogólnie podzielić na dwie kategorie:
Protokoły używane przez użytkowników, na przykład e-maile.
Protokoły, które pomagają i obsługują protokoły używane przez użytkowników, na przykład DNS.
Kilka protokołów warstwy aplikacji opisano poniżej:
System nazw domen
System nazw domenowych (DNS) działa w modelu serwera klienta. Wykorzystuje protokół UDP do komunikacji w warstwie transportowej. DNS używa hierarchicznego schematu nazewnictwa opartego na domenie. Serwer DNS jest skonfigurowany przy użyciu w pełni kwalifikowanych nazw domen (FQDN) i adresów e-mail zmapowanych na ich odpowiednie adresy protokołu internetowego.
Serwer DNS jest żądany z FQDN i odpowiada z zamapowanym adresem IP. DNS używa portu UDP 53.
Prosty protokół przesyłania poczty
Prosty protokół przesyłania poczty (SMTP) służy do przesyłania poczty elektronicznej od jednego użytkownika do drugiego. Zadanie to jest wykonywane za pomocą oprogramowania klienta poczty e-mail (agentów użytkownika), z którego korzysta użytkownik. Agenty użytkownika pomagają użytkownikowi wpisać i sformatować wiadomość e-mail oraz przechowywać ją do czasu udostępnienia Internetu. Gdy wiadomość e-mail jest wysyłana do wysłania, proces wysyłania jest obsługiwany przez agenta przesyłania wiadomości, który zwykle jest wbudowany w oprogramowanie klienta poczty e-mail.
Agent przesyłania wiadomości używa SMTP do przekazywania wiadomości e-mail do innego agenta przesyłania wiadomości (po stronie serwera). Podczas gdy protokół SMTP jest używany przez użytkownika końcowego tylko do wysyłania wiadomości e-mail, serwery zwykle używają protokołu SMTP zarówno do wysyłania, jak i odbierania wiadomości e-mail. SMTP używa portów TCP o numerach 25 i 587.
Oprogramowanie klienckie do odbierania wiadomości e-mail korzysta z protokołu IMAP lub protokołu POP.
Protokół Przesyłania Plików
Protokół przesyłania plików (FTP) jest najczęściej używanym protokołem do przesyłania plików w sieci. FTP używa protokołu TCP / IP do komunikacji i działa na porcie TCP 21. FTP działa w modelu klient / serwer, w którym klient żąda pliku z serwera, a serwer wysyła żądany zasób z powrotem do klienta.
FTP używa sterowania poza pasmem, tj. FTP używa portu TCP 20 do wymiany informacji sterujących, a rzeczywiste dane są przesyłane przez port TCP 21.
Klient żąda od serwera pliku. Gdy serwer otrzyma żądanie dotyczące pliku, otwiera połączenie TCP dla klienta i przesyła plik. Po zakończeniu przesyłania serwer zamyka połączenie. W przypadku drugiego pliku klient ponownie żąda, a serwer ponownie otwiera nowe połączenie TCP.
Protokół pocztowy (POP)
Post Office Protocol w wersji 3 (POP 3) jest prostym protokołem pobierania poczty używanym przez programy użytkownika (oprogramowanie klienta poczty e-mail) do pobierania wiadomości z serwera pocztowego.
Gdy klient potrzebuje pobrać wiadomości z serwera, otwiera połączenie z serwerem na porcie TCP 110. Użytkownik może wtedy uzyskać dostęp do swoich wiadomości i pobrać je na lokalny komputer. POP3 działa w dwóch trybach. Najpopularniejszym trybem usuwania jest usuwanie wiadomości e-mail ze zdalnego serwera po ich pobraniu na komputery lokalne. Drugi tryb, tryb zachowania, nie usuwa wiadomości e-mail z serwera poczty i daje użytkownikowi możliwość późniejszego dostępu do wiadomości na serwerze pocztowym.
Hyper Text Transfer Protocol (HTTP)
Hyper Text Transfer Protocol (HTTP) to podstawa sieci World Wide Web. Hipertekst to dobrze zorganizowany system dokumentacji, który wykorzystuje hiperłącza do łączenia stron w dokumentach tekstowych. HTTP działa w modelu klient-serwer. Gdy użytkownik chce uzyskać dostęp do dowolnej strony HTTP w Internecie, komputer kliencki na końcu użytkownika inicjuje połączenie TCP z serwerem na porcie 80. Gdy serwer przyjmuje żądanie klienta, klient jest upoważniony do dostępu do stron internetowych.
Aby uzyskać dostęp do stron internetowych, klient zwykle używa przeglądarek internetowych, które są odpowiedzialne za inicjowanie, utrzymywanie i zamykanie połączeń TCP. HTTP jest protokołem bezstanowym, co oznacza, że serwer nie przechowuje żadnych informacji o wcześniejszych żądaniach klientów.
Wersje HTTP
HTTP 1.0 używa nietrwałego protokołu HTTP. W jednym połączeniu TCP można wysłać co najwyżej jeden obiekt.
HTTP 1.1 używa trwałego protokołu HTTP. W tej wersji jednym połączeniem TCP można wysłać wiele obiektów.
Systemy komputerowe i systemy komputerowe pomagają ludziom wydajnie pracować i badać to, co nie do pomyślenia. Gdy te urządzenia są połączone razem w sieć, możliwości są wielokrotnie zwiększane. Niektóre podstawowe usługi, które może zaoferować sieć komputerowa, to.
Usługi katalogowe
Usługi te mapują między nazwą a jej wartością, która może być wartością zmienną lub stałą. Ten system oprogramowania pomaga przechowywać informacje, organizować je i zapewnia różne sposoby uzyskiwania do nich dostępu.
Accounting
W organizacji wielu użytkowników ma przypisane nazwy użytkowników i hasła. Usługi katalogowe umożliwiają przechowywanie tych informacji w tajemniczej formie i udostępnianie na żądanie.
Authentication and Authorization
Poświadczenia użytkownika są sprawdzane w celu uwierzytelnienia użytkownika w momencie logowania i / lub okresowo. Konta użytkowników można ustawić w hierarchiczną strukturę, a ich dostęp do zasobów można kontrolować za pomocą schematów uprawnień.
Domain Name Services
DNS jest szeroko stosowany i jest jedną z podstawowych usług, w których działa internet. Ten system mapuje adresy IP na nazwy domen, które są łatwiejsze do zapamiętania i zapamiętania niż adresy IP. Ponieważ sieć działa z pomocą adresów IP, a ludzie mają tendencję do zapamiętywania nazw witryn internetowych, DNS dostarcza adres IP witryny internetowej, który jest mapowany na jej nazwę z zaplecza na żądanie nazwy witryny internetowej od użytkownika.
Usługi plików
Usługi plików obejmują udostępnianie i przesyłanie plików przez sieć.
File Sharing
Jednym z powodów, dla których narodziło się networking, było udostępnianie plików. Udostępnianie plików umożliwia użytkownikom udostępnianie ich danych innym użytkownikom. Użytkownik może przesłać plik na określony serwer, do którego mają dostęp wszyscy zamierzeni użytkownicy. Alternatywnie, użytkownik może udostępnić swój plik na swoim komputerze i zapewnić dostęp wybranym użytkownikom.
File Transfer
Jest to czynność polegająca na kopiowaniu lub przenoszeniu pliku z jednego komputera na inny komputer lub na wiele komputerów za pomocą podstawowej sieci. Sieć umożliwia użytkownikowi lokalizowanie innych użytkowników w sieci i przesyłanie plików.
Usługi komunikacyjne
Email
Poczta elektroniczna to metoda komunikacji, bez której użytkownik komputera nie może się obejść. To podstawa dzisiejszych funkcji internetowych. System poczty elektronicznej ma jeden lub więcej serwerów poczty elektronicznej. Wszyscy jego użytkownicy otrzymują unikalne identyfikatory. Gdy użytkownik wysyła wiadomość e-mail do innego użytkownika, w rzeczywistości jest ona przesyłana między użytkownikami za pomocą serwera poczty e-mail.
Social Networking
Najnowsze technologie sprawiły, że życie techniczne stało się społeczne. Osoby znające się na komputerach mogą znajdować inne znane osoby lub przyjaciół, mogą się z nimi kontaktować oraz udostępniać przemyślenia, zdjęcia i filmy.
Internet Chat
Czat internetowy zapewnia natychmiastowe usługi przesyłania tekstu między dwoma hostami. Dwie lub więcej osób może komunikować się ze sobą za pomocą usług tekstowego czatu internetowego. W dzisiejszych czasach czat głosowy i czat wideo są bardzo powszechne.
Discussion Boards
Tablice dyskusyjne zapewniają mechanizm łączenia wielu ludzi o tych samych zainteresowaniach, umożliwiając użytkownikom umieszczanie zapytań, pytań, sugestii itp., Które mogą być widoczne dla wszystkich innych użytkowników. Inni też mogą odpowiedzieć.
Remote Access
Ta usługa umożliwia użytkownikowi dostęp do danych znajdujących się na komputerze zdalnym. Ta funkcja jest znana jako Pulpit zdalny. Można to zrobić za pomocą zdalnego urządzenia, np. Telefonu komórkowego lub komputera domowego.
Usługi aplikacji
To nic innego jak świadczenie usług sieciowych dla użytkowników, takich jak usługi internetowe, zarządzanie bazami danych i współdzielenie zasobów.
Resource Sharing
Aby efektywnie i ekonomicznie wykorzystywać zasoby, sieć zapewnia sposób ich współdzielenia. Może to obejmować serwery, drukarki, nośniki pamięci itp.
Databases
Ta usługa aplikacji jest jedną z najważniejszych usług. Przechowuje dane i informacje, przetwarza je i umożliwia użytkownikom efektywne ich wyszukiwanie za pomocą zapytań. Bazy danych pomagają organizacjom w podejmowaniu decyzji na podstawie statystyk.
Web Services
World Wide Web stała się synonimem internetu i służy do łączenia się z Internetem oraz uzyskiwania dostępu do plików i usług informacyjnych udostępnianych przez serwery internetowe.