Algorytmy grupowania - hierarchiczne grupowanie
Wprowadzenie do klastrowania hierarchicznego
Klastrowanie hierarchiczne to kolejny nienadzorowany algorytm uczenia się, który jest używany do grupowania nieoznakowanych punktów danych o podobnych cechach. Hierarchiczne algorytmy grupowania dzielą się na dwie kategorie -
Agglomerative hierarchical algorithms- W aglomeracyjnych algorytmach hierarchicznych każdy punkt danych jest traktowany jako pojedynczy klaster, a następnie kolejno łączy lub aglomeruje (podejście oddolne) pary klastrów. Hierarchia skupień jest reprezentowana jako dendrogram lub struktura drzewiasta.
Divisive hierarchical algorithms - Z drugiej strony, w algorytmach hierarchicznych z podziałem, wszystkie punkty danych są traktowane jako jeden duży klaster, a proces grupowania polega na podzieleniu (podejście odgórne) jednego dużego klastra na różne małe klastry.
Kroki prowadzące do aglomeracyjnego klastrowania hierarchicznego
Wyjaśnimy najczęściej używane i najważniejsze hierarchiczne grupowanie, tj. Aglomeracyjne. Kroki, aby wykonać to samo, są następujące -
Step 1- Traktuj każdy punkt danych jako pojedynczy klaster. Dlatego na początku będziemy mieć, powiedzmy, klastry K. Liczba punktów danych będzie również wynosić K. na początku.
Step 2- Teraz na tym etapie musimy utworzyć duży klaster, łącząc dwa punkty danych szafy. Spowoduje to w sumie klastry K-1.
Step 3- Teraz, aby utworzyć więcej klastrów, musimy połączyć dwa klastry zamknięte. Spowoduje to w sumie klastry K-2.
Step 4 - Teraz, aby utworzyć jeden duży klaster, powtórz powyższe trzy kroki, aż K stanie się 0, tj. Nie ma więcej punktów danych do połączenia.
Step 5 - W końcu, po utworzeniu jednego dużego klastra, dendrogramy zostaną użyte do podzielenia na wiele klastrów w zależności od problemu.
Rola dendrogramów w aglomeracyjnym hierarchicznym klastrowaniu
Jak omówiliśmy w ostatnim kroku, rola dendrogramu zaczyna się po utworzeniu dużego klastra. Dendrogram zostanie użyty do podzielenia klastrów na wiele klastrów powiązanych punktów danych w zależności od naszego problemu. Można to zrozumieć na podstawie następującego przykładu -
Przykład 1
Aby to zrozumieć, zacznijmy od zaimportowania wymaganych bibliotek w następujący sposób -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as npNastępnie będziemy wykreślać punkty danych, które wzięliśmy dla tego przykładu -
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],])
labels = range(1, 11)
plt.figure(figsize=(10, 7))
plt.subplots_adjust(bottom=0.1)
plt.scatter(X[:,0],X[:,1], label='True Position')
for label, x, y in zip(labels, X[:, 0], X[:, 1]):
plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom')
plt.show()
Z powyższego diagramu bardzo łatwo można zobaczyć, że w naszych punktach danych mamy dwie klastry, ale w rzeczywistych danych mogą istnieć tysiące klastrów. Następnie będziemy wykreślać dendrogramy naszych punktów danych przy użyciu biblioteki Scipy -
from scipy.cluster.hierarchy import dendrogram, linkage
from matplotlib import pyplot as plt
linked = linkage(X, 'single')
labelList = range(1, 11)
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True)
plt.show()
Teraz, po utworzeniu dużej gromady, wybierana jest najdłuższa odległość w pionie. Następnie przechodzi przez nią pionowa linia, jak pokazano na poniższym schemacie. Gdy pozioma linia przecina niebieską linię w dwóch punktach, liczba klastrów wynosiłaby dwa.

Następnie musimy zaimportować klasę do klastrowania i wywołać jej metodę fit_predict, aby przewidzieć klaster. Importujemy klasę AgglomerativeClustering biblioteki sklearn.cluster -
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward')
cluster.fit_predict(X)Następnie wykreśl klaster za pomocą następującego kodu -
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow')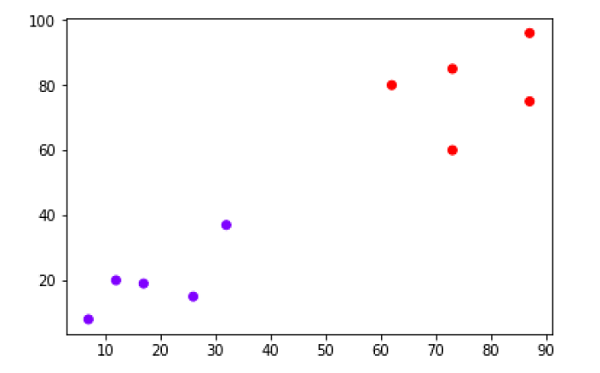
Powyższy diagram przedstawia dwie grupy z naszych punktów danych.
Przykład 2
Ponieważ zrozumieliśmy pojęcie dendrogramów z prostego przykładu omówionego powyżej, przejdźmy do innego przykładu, w którym tworzymy klastry punktu danych w zestawie danych Pima Indian Diabetes Dataset za pomocą hierarchicznego grupowania -
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
import numpy as np
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
data.shape
(768, 9)
data.head()| slno. | preg | Plas | Pres | skóra | test | masa | pedi | wiek | klasa |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0,351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Patient Dendograms")
dend = shc.dendrogram(shc.linkage(data, method='ward'))
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
cluster.fit_predict(patient_data)
plt.figure(figsize=(10, 7))
plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow')