Algorytmy regresji - regresja liniowa
Wprowadzenie do regresji liniowej
Regresję liniową można zdefiniować jako model statystyczny, który analizuje liniową zależność między zmienną zależną a danym zestawem zmiennych niezależnych. Liniowa zależność między zmiennymi oznacza, że gdy zmieni się (wzrośnie lub zmniejszy) wartość jednej lub więcej zmiennych niezależnych, odpowiednio zmieni się również wartość zmiennej zależnej (wzrośnie lub zmniejszy).
Matematycznie zależność można przedstawić za pomocą następującego równania -
Y = mX + b
Tutaj Y jest zmienną zależną, którą próbujemy przewidzieć
X to zmienna zależna, której używamy do prognozowania.
m jest nachyleniem linii regresji, która reprezentuje wpływ X na Y
b jest stałą, znaną jako punkt przecięcia z osią Y. Jeśli X = 0, Y byłoby równe b.
Ponadto zależność liniowa może mieć charakter pozytywny lub negatywny, jak wyjaśniono poniżej -
Pozytywna relacja liniowa
Zależność liniowa będzie nazywana dodatnią, jeśli wzrośnie zarówno zmienna niezależna, jak i zależna. Można to zrozumieć za pomocą poniższego wykresu -

Negatywna relacja liniowa
Zależność liniowa będzie nazywana dodatnią, jeśli niezależne wzrosty i zależna zmienna spadną. Można to zrozumieć za pomocą poniższego wykresu -

Rodzaje regresji liniowej
Regresja liniowa ma dwa typy:
- Prosta regresja liniowa
- Wielokrotna regresja liniowa
Prosta regresja liniowa (SLR)
Jest to najbardziej podstawowa wersja regresji liniowej, która przewiduje odpowiedź przy użyciu pojedynczej cechy. W lustrzankach jednoobiektywowych założenie jest takie, że dwie zmienne są liniowo powiązane.
Implementacja Pythona
Możemy zaimplementować SLR w Pythonie na dwa sposoby, jeden to dostarczenie własnego zestawu danych, a drugi to użycie zestawu danych z biblioteki scikit-learn python.
Example 1 - W poniższym przykładzie implementacji Pythona używamy naszego własnego zestawu danych.
Najpierw zaczniemy od zaimportowania niezbędnych pakietów w następujący sposób -
%matplotlib inline
import numpy as np
import matplotlib.pyplot as pltNastępnie zdefiniuj funkcję, która obliczy ważne wartości dla lustrzanek jednoobiektywowych -
def coef_estimation(x, y):Poniższy wiersz skryptu poda liczbę obserwacji n -
n = np.size(x)Średnią z wektorów xiy można obliczyć w następujący sposób -
m_x, m_y = np.mean(x), np.mean(y)Odchylenie krzyżowe i odchylenie o x możemy znaleźć w następujący sposób -
SS_xy = np.sum(y*x) - n*m_y*m_x
SS_xx = np.sum(x*x) - n*m_x*m_xNastępnie współczynniki regresji, czyli b, można obliczyć w następujący sposób -
b_1 = SS_xy / SS_xx
b_0 = m_y - b_1*m_x
return(b_0, b_1)Następnie musimy zdefiniować funkcję, która wykreśli linię regresji, a także będzie przewidywać wektor odpowiedzi -
def plot_regression_line(x, y, b):Poniższa linia skryptu przedstawia rzeczywiste punkty jako wykres punktowy -
plt.scatter(x, y, color = "m", marker = "o", s = 30)Następująca linia skryptu przewiduje wektor odpowiedzi -
y_pred = b[0] + b[1]*xNastępujące linie skryptu wykreślą linię regresji i umieszczą na nich etykiety -
plt.plot(x, y_pred, color = "g")
plt.xlabel('x')
plt.ylabel('y')
plt.show()Na koniec musimy zdefiniować funkcję main () do dostarczania zestawu danych i wywoływania funkcji, którą zdefiniowaliśmy powyżej -
def main():
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
y = np.array([100, 300, 350, 500, 750, 800, 850, 900, 1050, 1250])
b = coef_estimation(x, y)
print("Estimated coefficients:\nb_0 = {} \nb_1 = {}".format(b[0], b[1]))
plot_regression_line(x, y, b)
if __name__ == "__main__":
main()Wynik
Estimated coefficients:
b_0 = 154.5454545454545
b_1 = 117.87878787878788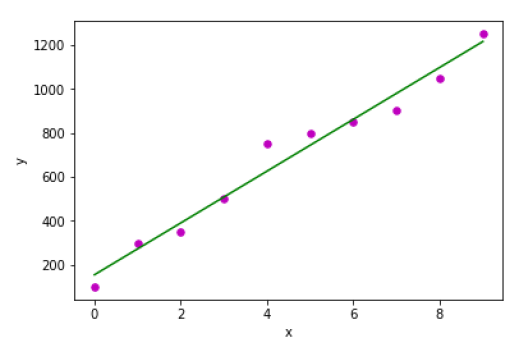
Example 2 - W poniższym przykładzie implementacji Pythona korzystamy z zestawu danych dotyczących cukrzycy ze scikit-learn.
Najpierw zaczniemy od zaimportowania niezbędnych pakietów w następujący sposób -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_scoreNastępnie załadujemy zbiór danych dotyczących cukrzycy i utworzymy jego obiekt -
diabetes = datasets.load_diabetes()Ponieważ wdrażamy lustrzankę, będziemy używać tylko jednej funkcji:
X = diabetes.data[:, np.newaxis, 2]Następnie musimy podzielić dane na zestawy uczące i testowe w następujący sposób -
X_train = X[:-30]
X_test = X[-30:]Następnie musimy podzielić cel na zestawy treningowe i testowe w następujący sposób -
y_train = diabetes.target[:-30]
y_test = diabetes.target[-30:]Teraz, aby wytrenować model, musimy utworzyć obiekt regresji liniowej w następujący sposób -
regr = linear_model.LinearRegression()Następnie wytrenuj model za pomocą zestawów uczących w następujący sposób -
regr.fit(X_train, y_train)Następnie wykonaj prognozy za pomocą zestawu testowego w następujący sposób -
y_pred = regr.predict(X_test)Następnie wydrukujemy współczynnik, taki jak MSE, wynik wariancji itp. W następujący sposób -
print('Coefficients: \n', regr.coef_)
print("Mean squared error: %.2f" % mean_squared_error(y_test, y_pred))
print('Variance score: %.2f' % r2_score(y_test, y_pred))Teraz wykreśl wyniki w następujący sposób -
plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()Wynik
Coefficients:
[941.43097333]
Mean squared error: 3035.06
Variance score: 0.41
Wielokrotna regresja liniowa (MLR)
Jest to rozszerzenie prostej regresji liniowej, która przewiduje odpowiedź przy użyciu dwóch lub więcej cech. Matematycznie możemy to wyjaśnić następująco -
Rozważmy zbiór danych zawierający n obserwacji, p cechy, tj. Zmienne niezależne i y jako jedną odpowiedź, tj. Zmienną zależną, linię regresji dla cech p można obliczyć w następujący sposób -
$$ h (x_ {i}) = b_ {0} + b_ {1} x_ {i1} + b_ {2} x_ {i2} + ... + b_ {p} x_ {ip} $$Tutaj h (x i ) to przewidywana wartość odpowiedzi, a b 0 , b 1 , b 2 …, b p to współczynniki regresji.
Wiele modeli regresji liniowej zawsze zawiera błędy w danych znane jako błąd resztkowy, który zmienia obliczenia w następujący sposób -
$$ h (x_ {i}) = b_ {0} + b_ {1} x_ {i1} + b_ {2} x_ {i2} + ... + b_ {p} x_ {ip} + e_ {i} $$Możemy również zapisać powyższe równanie w następujący sposób -
$$ y_ {i} = h (x_ {i}) + e_ {i} \: lub \: e_ {i} = y_ {i} - h (x_ {i}) $$Implementacja Pythona
w tym przykładzie będziemy używać zbioru danych mieszkaniowych w Bostonie ze scikit Learn -
Najpierw zaczniemy od zaimportowania niezbędnych pakietów w następujący sposób -
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, metricsNastępnie załaduj zestaw danych w następujący sposób -
boston = datasets.load_boston(return_X_y=False)Poniższe wiersze skryptu definiują macierz cech, X i wektor odpowiedzi, Y -
X = boston.data
y = boston.targetNastępnie podziel zbiór danych na zestawy uczące i testowe w następujący sposób -
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=1)Przykład
Teraz utwórz obiekt regresji liniowej i wytrenuj model w następujący sposób -
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
print('Coefficients: \n', reg.coef_)
print('Variance score: {}'.format(reg.score(X_test, y_test)))
plt.style.use('fivethirtyeight')
plt.scatter(reg.predict(X_train), reg.predict(X_train) - y_train,
color = "green", s = 10, label = 'Train data')
plt.scatter(reg.predict(X_test), reg.predict(X_test) - y_test,
color = "blue", s = 10, label = 'Test data')
plt.hlines(y = 0, xmin = 0, xmax = 50, linewidth = 2)
plt.legend(loc = 'upper right')
plt.title("Residual errors")
plt.show()Wynik
Coefficients:
[
-1.16358797e-01 6.44549228e-02 1.65416147e-01 1.45101654e+00
-1.77862563e+01 2.80392779e+00 4.61905315e-02 -1.13518865e+00
3.31725870e-01 -1.01196059e-02 -9.94812678e-01 9.18522056e-03
-7.92395217e-01
]
Variance score: 0.709454060230326
Założenia
Poniżej przedstawiono niektóre założenia dotyczące zbioru danych utworzonego przez model regresji liniowej -
Multi-collinearity- Model regresji liniowej zakłada, że w danych występuje bardzo mała lub żadna współliniowość. Zasadniczo multi-kolinearność występuje, gdy niezależne zmienne lub cechy mają w sobie zależność.
Auto-correlation- Kolejnym założeniem, w którym przyjęto model regresji liniowej, jest to, że w danych występuje bardzo mała autokorelacja lub jej brak. Zasadniczo autokorelacja występuje, gdy istnieje zależność między błędami resztowymi.
Relationship between variables - Model regresji liniowej zakłada, że związek między odpowiedzią a zmiennymi cech musi być liniowy.