PyTorch - podstawy sieci neuronowych
Podstawowa zasada działania sieci neuronowej obejmuje zbiór podstawowych elementów, czyli sztuczny neuron lub perceptron. Zawiera kilka podstawowych wejść, takich jak x1, x2… .. xn, które generują wyjście binarne, jeśli suma jest większa niż potencjał aktywacji.
Schematyczne przedstawienie neuronu próbki jest wymienione poniżej -

Wygenerowane wyjście można uznać za sumę ważoną z potencjałem aktywacji lub odchyleniem.
$$ Wyjście = \ sum_jw_jx_j + Odchylenie $$
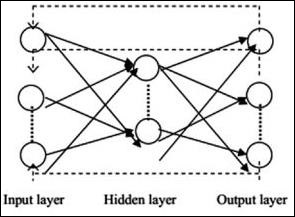
Poniżej opisano typową architekturę sieci neuronowej -

Warstwy między wejściami i wyjściami są nazywane warstwami ukrytymi, a gęstość i typ połączeń między warstwami to konfiguracja. Na przykład, w pełni połączona konfiguracja ma wszystkie neurony warstwy L połączone z neuronami L + 1. Aby uzyskać bardziej wyrazistą lokalizację, do następnej warstwy możemy podłączyć tylko lokalne sąsiedztwo, powiedzmy dziewięć neuronów. Rysunek 1-9 ilustruje dwie ukryte warstwy z gęstymi połączeniami.
Różne typy sieci neuronowych są następujące -
Sieci neuronowe z wyprzedzeniem
Sieci neuronowe typu feedforward obejmują podstawowe jednostki rodziny sieci neuronowych. Ruch danych w tego typu sieci neuronowej odbywa się z warstwy wejściowej do warstwy wyjściowej, poprzez obecne warstwy ukryte. Wyjście jednej warstwy służy jako warstwa wejściowa z ograniczeniami dotyczącymi wszelkiego rodzaju pętli w architekturze sieci.

Powtarzające się sieci neuronowe
Powtarzające się sieci neuronowe mają miejsce, gdy wzór danych zmienia się konsekwentnie w okresie. W RNN ta sama warstwa jest stosowana do akceptowania parametrów wejściowych i wyświetlania parametrów wyjściowych w określonej sieci neuronowej.
Sieci neuronowe można budować za pomocą pakietu torch.nn.

Jest to prosta sieć ze sprzężeniem zwrotnym. Pobiera dane wejściowe, przepuszcza je przez kilka warstw jedna po drugiej, a na końcu podaje dane wyjściowe.
Z pomocą PyTorch możemy wykonać następujące kroki dla typowej procedury szkoleniowej dla sieci neuronowej -
- Zdefiniuj sieć neuronową, która ma pewne parametry (lub wagi), których można się nauczyć.
- Iteruj po zbiorze danych wejściowych.
- Przetwarzanie danych przez sieć.
- Oblicz stratę (jak daleko jest do poprawności wyniku).
- Propaguj gradienty z powrotem do parametrów sieci.
- Zaktualizuj wagi sieci, zwykle za pomocą prostej aktualizacji, jak podano poniżej
rule: weight = weight -learning_rate * gradient